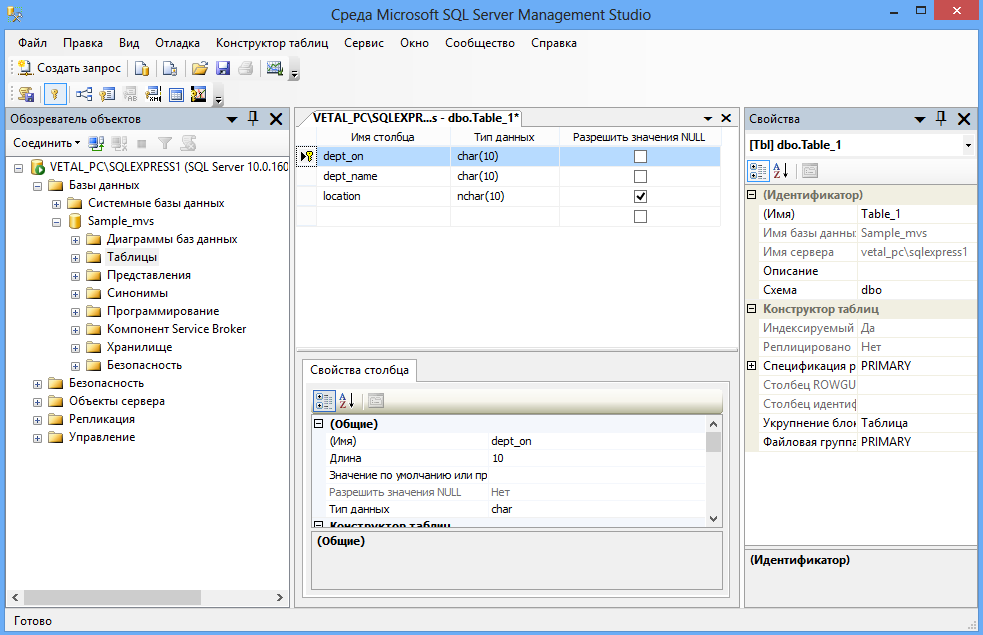
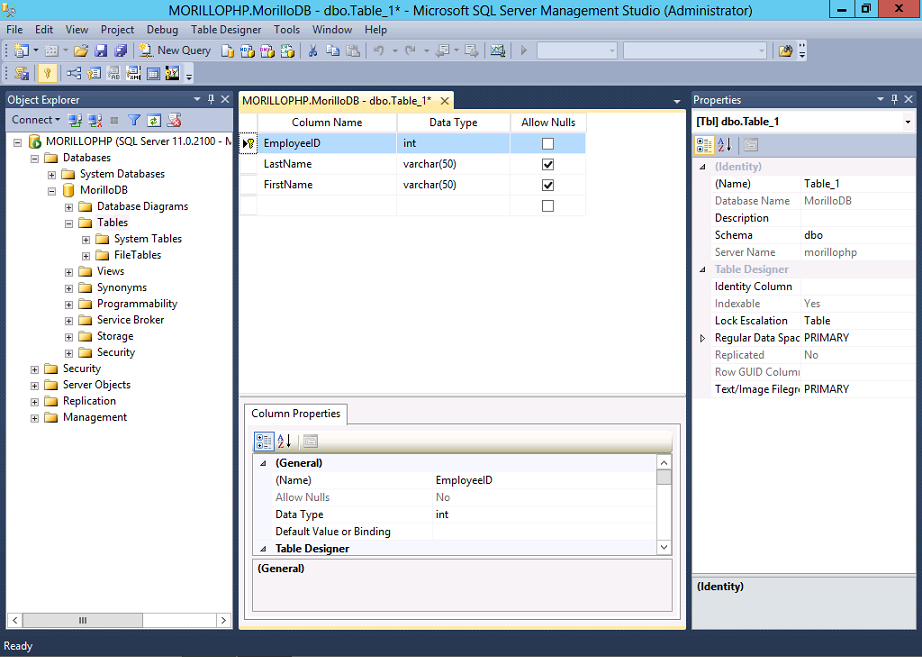
Временные таблицы
Последнее обновление: 14.08.2017
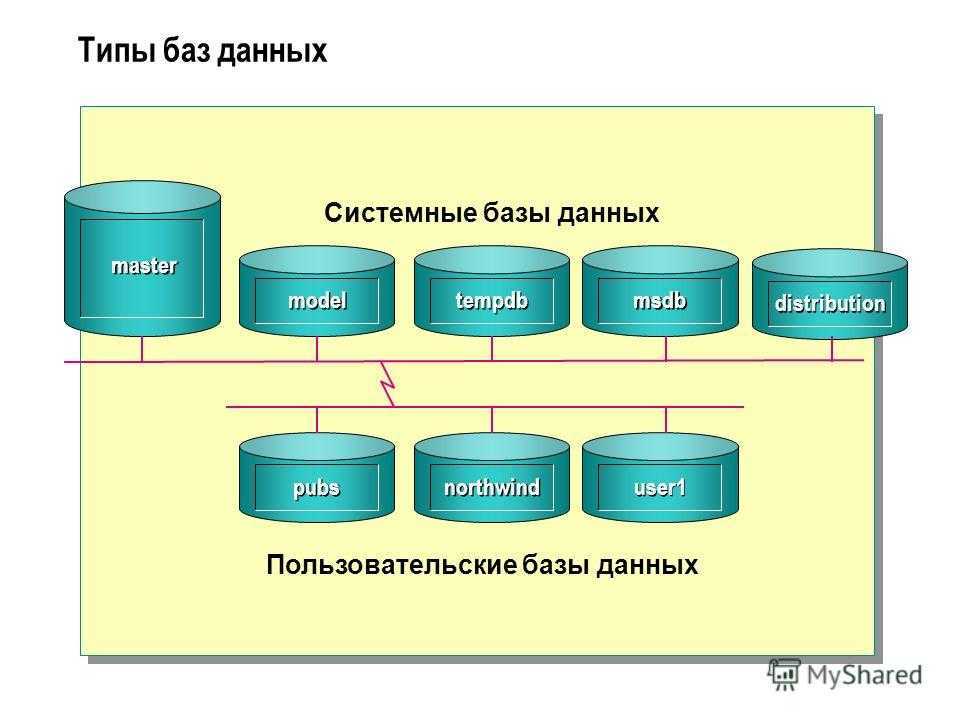
Временные локальные и глобальные таблицы
В дополнение к табличным переменным можно определять временные таблицы. Такие таблицы могут быть полезны для хранения табличных данных
внутри сложного комплексного скрипта.
Временные таблицы существуют на протяжении сессии базы данных. Если такая таблица создается в редакторе запросов (Query Editor) в SQL Server Management Studio,
то таблица будет существовать пока открыт редактор запросов. Таким образом, к временной таблице можно обращаться из разных скриптов внутри редактора запросов.
После создания все временные таблицы сохраняются в таблице tempdb, которая имеется по умолчанию в MS SQL Server.
Если необходимо удалить таблицу до завершения сессии базы данных, то для этой таблицы следует выполнить команду DROP TABLE.
Название временной таблицы начинается со знака решетки #. Если используется один знак #, то создается локальная таблица, которая доступна в течение
текущей сессии. Ели используются два знака ##, то создается глобальная временная таблица. В отличие от локальной глобальная временная таблица доступна всем открытым сессиям базы данных.
Например, создадим локальную временную таблицу:
CREATE TABLE #ProductSummary
(ProdId INT IDENTITY,
ProdName NVARCHAR(20),
Price MONEY)
INSERT INTO #ProductSummary
VALUES ('Nokia 8', 18000),
('iPhone 8', 56000)
SELECT * FROM #ProductSummary
И с этой таблицей можно работать в большей степени как и с обычной таблицей — получать данные, добавлять, изменять и удалять их. Только после закрытия
редактора запросов эта таблица перестанет существовать.
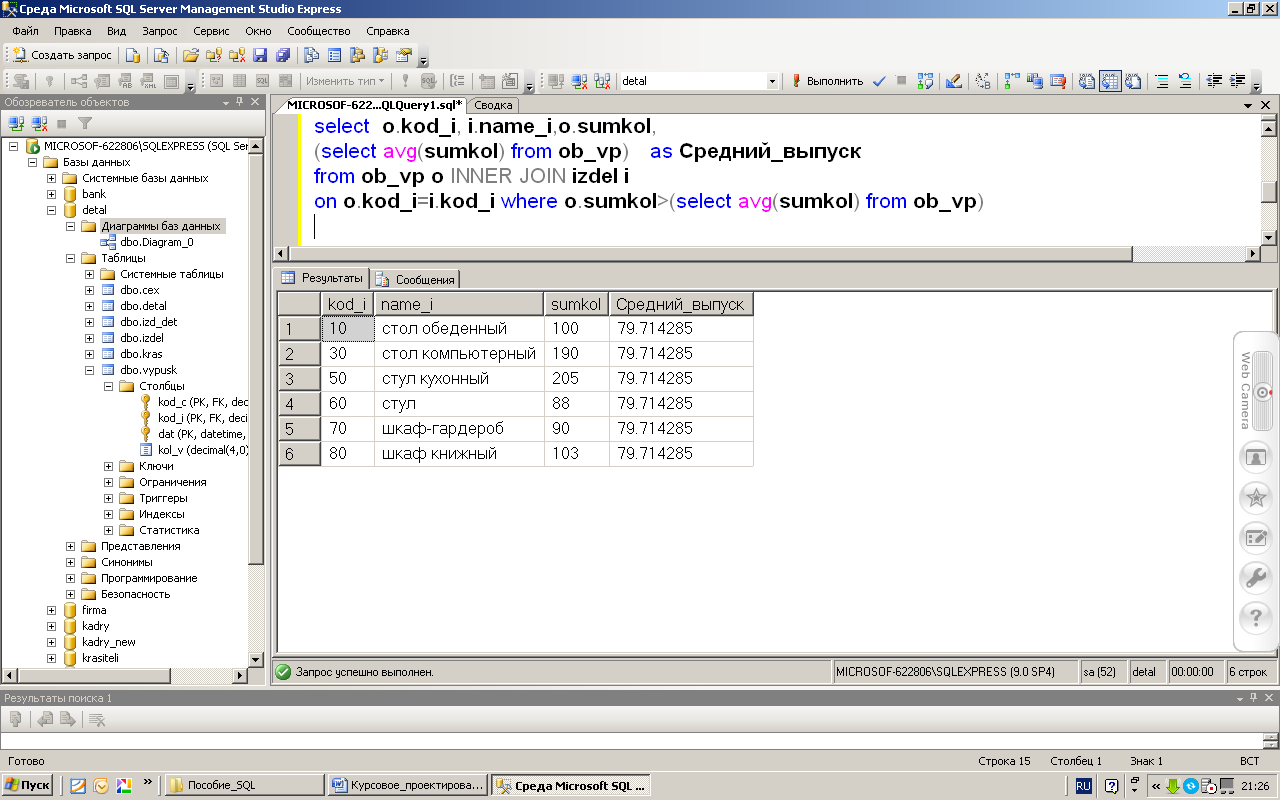
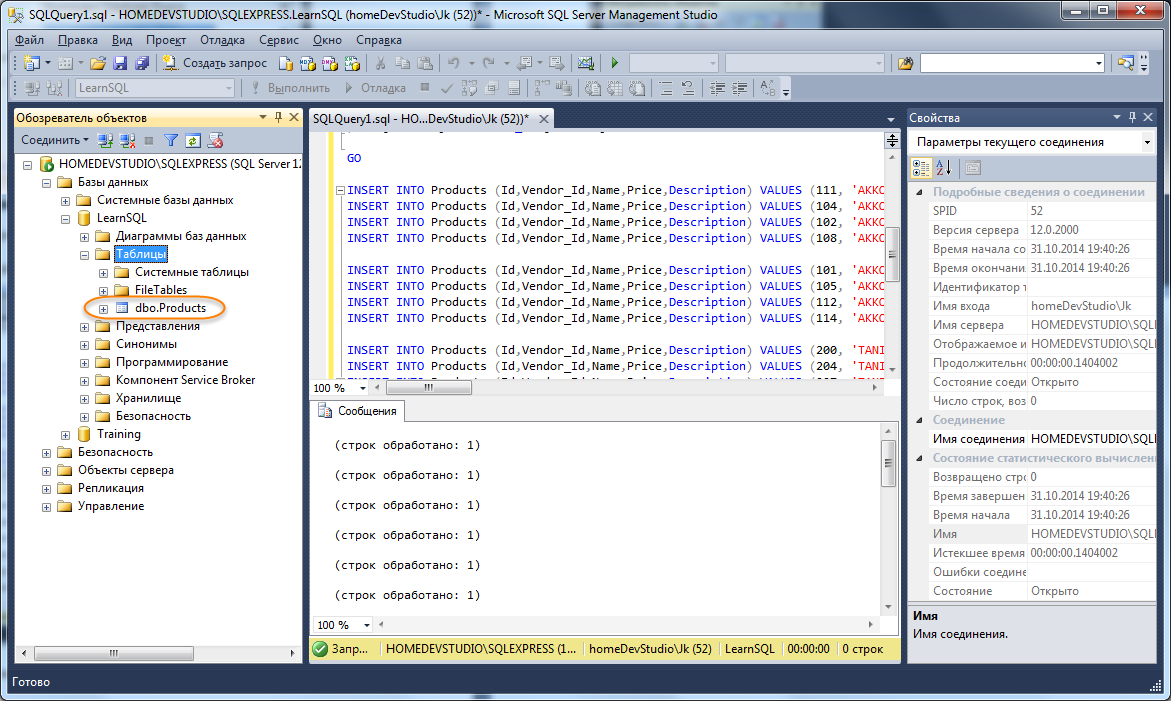
Подобные таблицы удобны для каких-то временных промежуточных данных. Например, пусть у нас есть три таблицы:
CREATE TABLE Products
(
Id INT IDENTITY PRIMARY KEY,
ProductName NVARCHAR(30) NOT NULL,
Manufacturer NVARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price MONEY NOT NULL
);
CREATE TABLE Customers
(
Id INT IDENTITY PRIMARY KEY,
FirstName NVARCHAR(30) NOT NULL
);
CREATE TABLE Orders
(
Id INT IDENTITY PRIMARY KEY,
ProductId INT NOT NULL REFERENCES Products(Id) ON DELETE CASCADE,
CustomerId INT NOT NULL REFERENCES Customers(Id) ON DELETE CASCADE,
CreatedAt DATE NOT NULL,
ProductCount INT DEFAULT 1,
Price MONEY NOT NULL
);
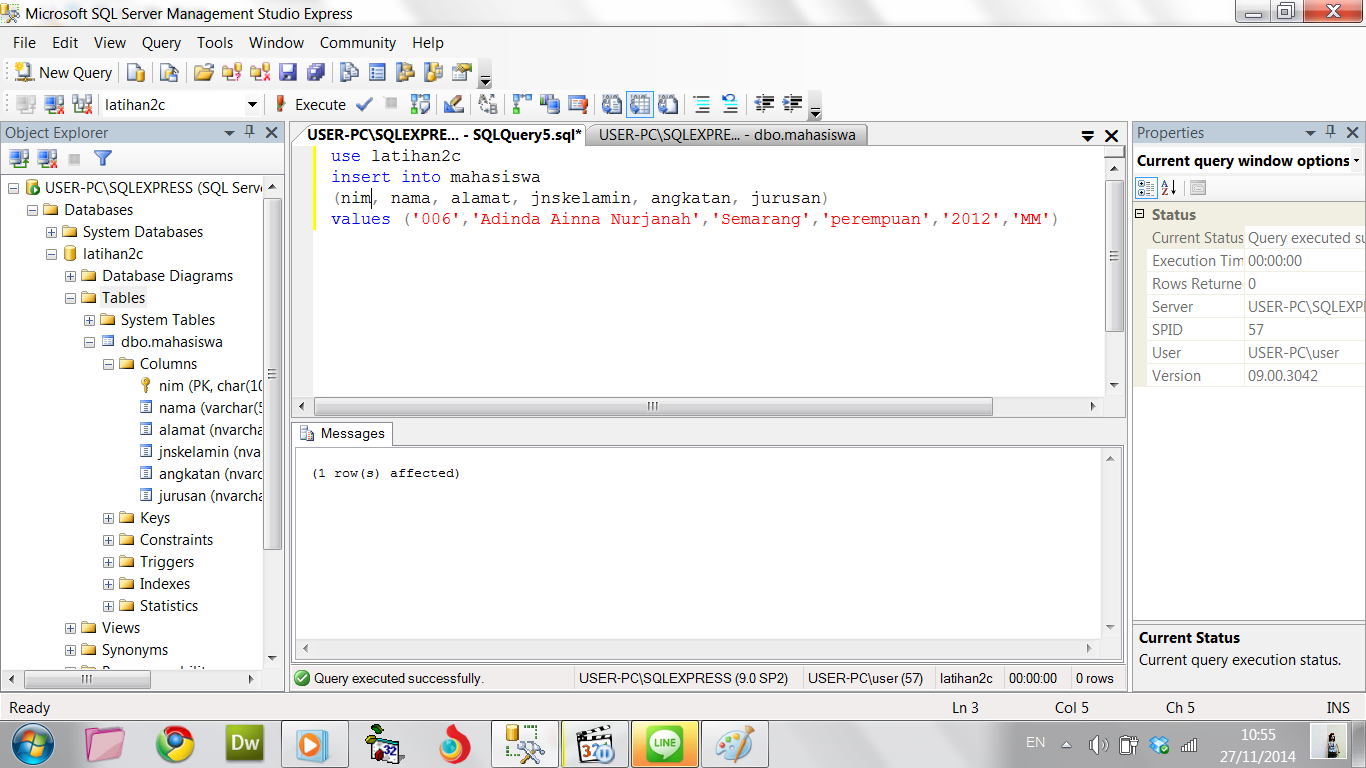
Выведем во временную таблицу промежуточные данные из таблицы Orders:
SELECT ProductId, SUM(ProductCount) AS TotalCount, SUM(ProductCount * Price) AS TotalSum INTO #OrdersSummary FROM Orders GROUP BY ProductId SELECT Products.ProductName, #OrdersSummary.TotalCount, #OrdersSummary.TotalSum FROM Products JOIN #OrdersSummary ON Products.Id = #OrdersSummary.ProductId
Здесь вначале извлекаются данные во временную таблицу #OrdersSummary. Причем так как данные в нее извлекаются с помощью выражения SELECT INTO, то
предварительно таблицу не надо создавать. И эта таблица будет содержать id товара, общее количество проданного товара и на какую сумму был продан товар.
Затем эта таблица может использоваться в выражениях INNER JOIN.
Подобным образом определяются глобальные временные таблицы, единственное, что их имя начинается с двух знаков ##:
CREATE TABLE ##OrderDetails (ProductId INT, TotalCount INT, TotalSum MONEY) INSERT INTO ##OrderDetails SELECT ProductId, SUM(ProductCount), SUM(ProductCount * Price) FROM Orders GROUP BY ProductId SELECT * FROM ##OrderDetails
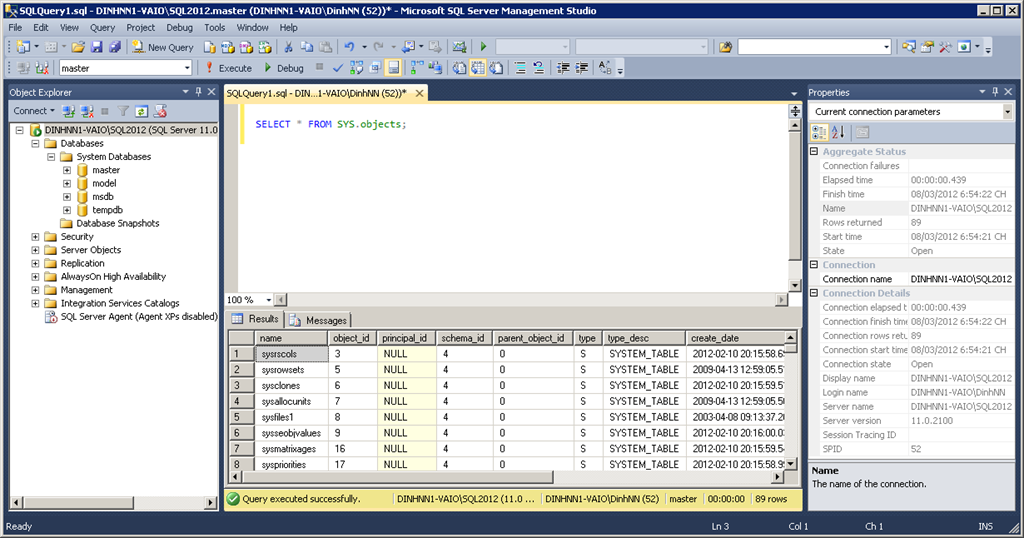
Обобщенные табличные выражения
Кроме временных таблиц MS SQL Server позволяет создавать обобщенные табличные выражения (common table expression или CTE),
которые являются производными от обычного запроса и в плане производительности являются более эффективным решением, чем временные.
Обобщенное табличное выражение задается с помощью ключевого слова WITH:
WITH OrdersInfo AS ( SELECT ProductId, SUM(ProductCount) AS TotalCount, SUM(ProductCount * Price) AS TotalSum FROM Orders GROUP BY ProductId ) SELECT * FROM OrdersInfo -- здесь нормально SELECT * FROM OrdersInfo -- здесь ошибка SELECT * FROM OrdersInfo -- здесь ошибка
В отличие от временных таблиц табличные выполнения хранятся в оперативной памяти и существуют только во время первого выполнения запроса, который представляет это табличное выражение.
НазадВперед
Шаг 2. Регулярный запуск рабочей нагрузки
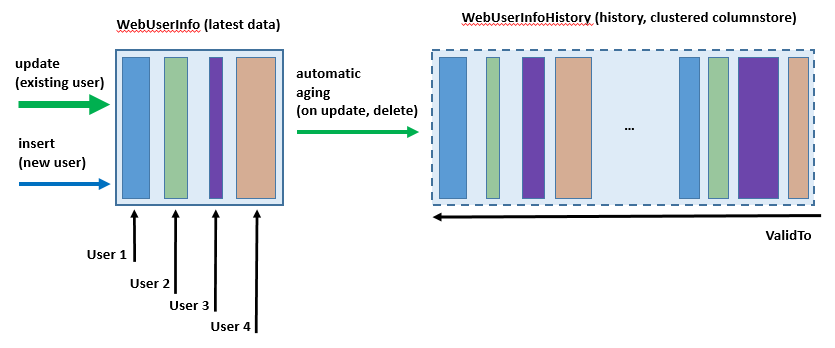
Главное преимущество темпоральных таблиц — то, что для отслеживания изменений вам не нужно каким-либо образом изменять или настраивать веб-сайт. После создания темпоральных таблиц в них прозрачно сохраняются предыдущие версии строк каждый раз, когда вы вносите изменения в данные.
Чтобы использовать автоматическое отслеживание изменений в этой конкретной ситуации, мы просто будем изменять столбец PagesVisited каждый раз, когда пользователь будет завершать сеанс посещения веб-сайта.
Важно отметить, что запросу на обновление не нужно знать точное время самой операции или то, как будут сохранены данные журнала для последующего анализа. Оба аспекта автоматически обрабатываются Базой данных SQL Azure и Управляемым экземпляром Azure SQL
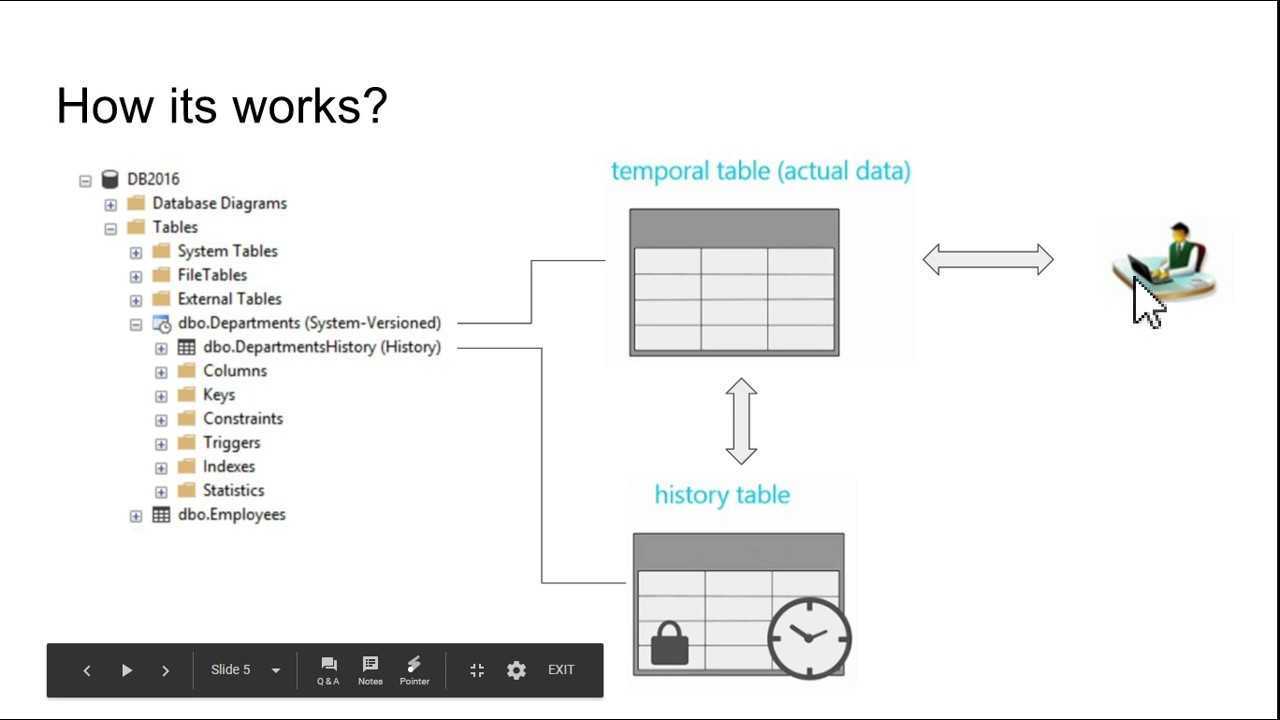
Следующая схема иллюстрирует, как при каждом обновлении создаются данные журнала.
Шаг 1. Настройка таблиц в качестве временных
В зависимости от того, начинаете вы разработку новых приложений или обновляете существующее приложение, вы создадите временные таблицы или измените существующие, добавляя в них временные атрибуты. В общем случае может потребоваться сделать и то, и другое. Используйте SQL Server Management Studio (SSMS), SQL Server Data Tools (SSDT), Azure Data Studio или любое другое средство для разработки Transact-SQL.
Важно!
Чтобы обеспечить синхронизацию с обновлениями Базы данных SQL Azure и Управляемого экземпляра SQL Azure, рекомендуется всегда использовать последнюю версию Management Studio. Обновите среду SQL Server Management Studio.
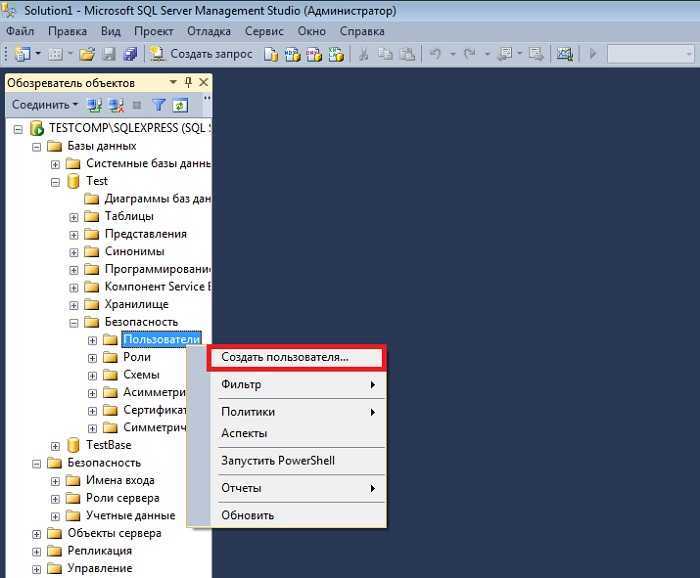



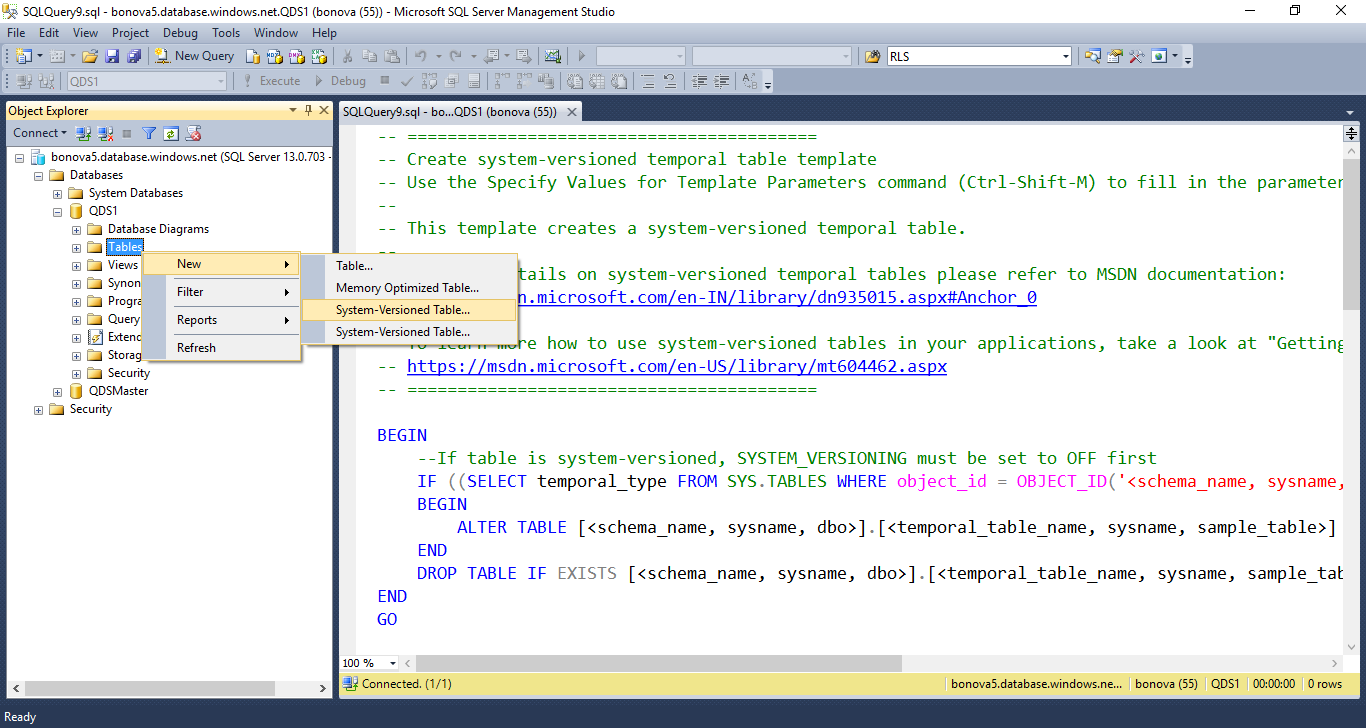
Создание новой таблицы
Используйте пункт контекстного меню «New System-Versioned Table» (Новая таблица с системным управлением версиями) в обозревателе объектов SSMS, чтобы открыть редактор запросов с шаблоном сценария временной таблицы, а затем щелкните «Указать значения для параметров шаблона» (Ctrl+Shift+M) для заполнения шаблона:
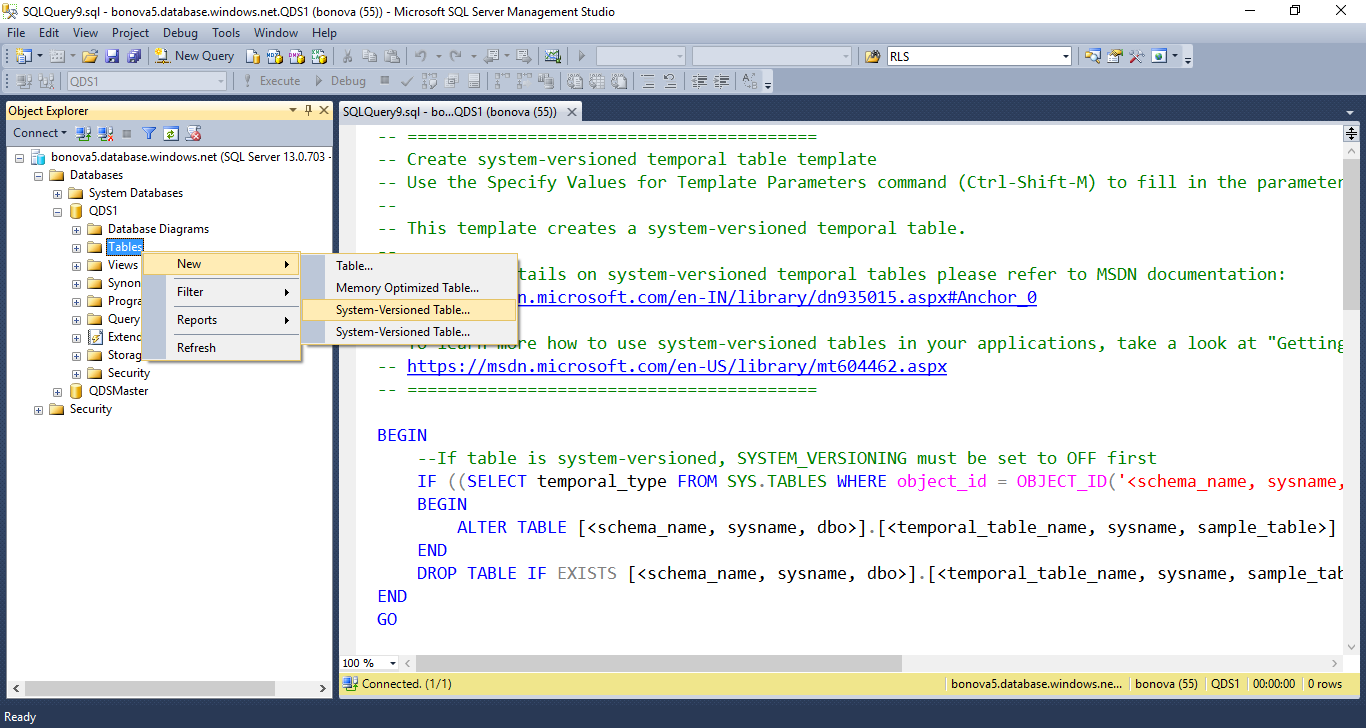
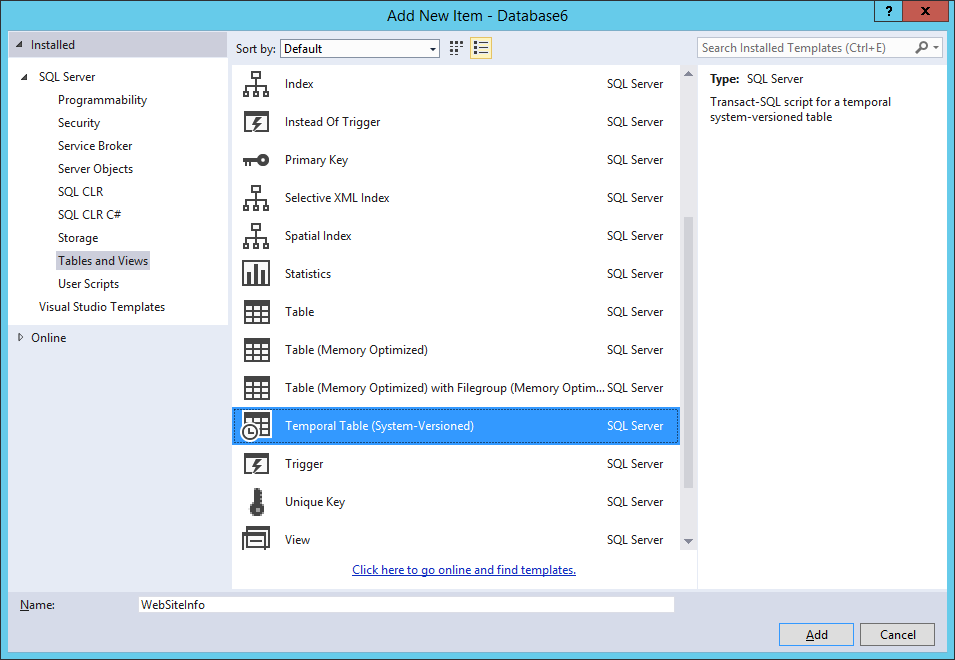
В SSDT при добавлении новых элементов в проект базы данных выберите шаблон «Темпоральная таблица (с системным управлением версиями)». Откроется конструктор таблиц, в котором вы сможете легко указать макет таблицы.
Временную таблицу также можно создать, непосредственно указав инструкции Transact-SQL, как показано в следующем примере
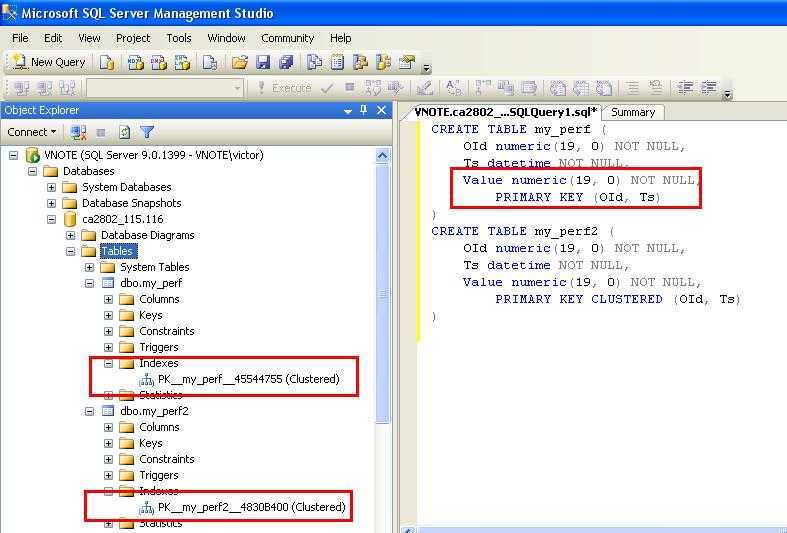
Обратите внимание, что обязательными элементами каждой временной таблицы являются определение PERIOD и предложение SYSTEM_VERSIONING со ссылкой на другую таблицу пользователя, в которой будут храниться исторические версии строк
При создании временной таблицы с системным управлением версиями автоматически создается сопутствующая таблица журнала с конфигурацией по умолчанию. Таблица журнала по умолчанию содержит кластеризованный индекс сбалансированного дерева в столбцах периода (конец и начало) с включенным сжатием страниц. Эта конфигурация оптимальна для большинства сценариев, в которых используются временные таблицы, особенно для .
В данном случае наша цель — выполнить анализ тенденций с учетом времени, используя журнал данных за длительный период и большие наборы данных, поэтому в качестве хранилища для таблицы журнала выбран кластеризованный индекс columnstore. Кластеризованный индекс columnstore обеспечивает очень хорошее сжатие и производительность аналитических запросов. Темпоральные таблицы обеспечивают гибкость, позволяя настроить индексы для текущих и темпоральных таблиц полностью независимо друг от друга.
Примечание
Индексы columnstore доступны на уровнях «Критически важный для бизнеса», «Общего назначения» и «Премиум», а также на стандартном уровне (S3 и выше).
В следующем сценарии показано, как индекс по умолчанию в таблице журнала можно изменить на кластеризованный индекс columnstore.
В обозревателе объектов темпоральные таблицы представлены специальным значком, чтобы их было удобней отличать, а таблица журнала отображается как дочерний узел.
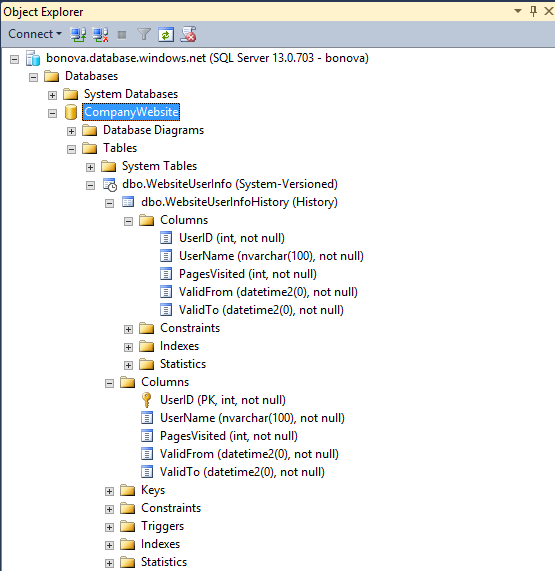
Преобразование существующей таблицы во временную
Рассмотрим альтернативный сценарий, в котором таблица WebsiteUserInfo уже существует, но не была предназначена для хранения журнала изменений. В этом случае можно просто расширить существующую таблицу, превратив ее во временную, как показано в следующем примере.
Управление периодом удержания данных журнала
При использовании временных таблиц с системным управлением версиями таблица журнала может увеличить размер базы данных значительнее, чем обычные таблицы. Большой и постоянно растущий объем таблицы журнала может стать проблемой не только из-за затрат на хранение. Кроме этого, он может повлиять на производительность при выполнении темпоральных запросов. Таким образом, разработка политики хранения данных для управления данными в таблице журнала является важным аспектом планирования и управления жизненным циклом всех темпоральных таблиц. При использовании Базы данных SQL Azure и Управляемого экземпляра SQL Azure доступны следующие подходы для управления данными журнала в темпоральной таблице:
Для чего нужно журналировать изменения данных?
Очень часто бывает, что в организации пользователи могут, выполняют действия после которых что-то с данными становится не так и потом узнать, кто это сделал просто не реально, так как все будут говорить, что это не они, они ничего не меняли, а если и меняли, то только что-то не важное. Также бывает необходимо узнать, когда конкретно вносилось, то или иное изменение, и какие конкретно данные изменялись, т.е
допустим какое значение было и на какое оно поменялось в тот или иной промежуток времени. Как уже говорилось выше, одним из самых распространенных способов вести такой аудит данных является использование триггеров, но, он будет отслеживать все изменения над этой таблицей. А нам, допустим, необходимо знать только то, что изменялось во время выполнения определенной процедуры, а все остальные изменения, которые происходили, без участия этой процедуры, нам не важны. Так как, например именно этой процедурой пользуются пользователи, чтобы изменить данные. Именно такую задачу мне недавно необходимо было решить. И сейчас я расскажу, как я это сделал.
Задача.
Необходимо отслеживать изменения при выполнении одной процедуры, и записывать их в отдельную таблицу. В которой необходимо хранить следующие данные: кто обновлял или добавлял данные, когда, какие данные были до этого и какие данные стали.
Решение.
В эту процедуру необходимо встроить процесс журналирования, а именно написать процедуру для получения данных в виде строки, всех полей одной записи таблицы, по уникальному идентификатору (при правильном планирование структуры базы данных такой идентификатор всегда создается) с динамическим изменением количества полей (так как в дальнейшем может осуществляться добавление колонок в таблицу), для того чтобы отслеживать данные, какие были и какие стали. Создать таблицу для журналирования. Вставлять в нее данные по всем изменениям, путем простого insert. Написать функцию, которая парсила строку с данными для оперативного и удобного просмотра этих самых данных. Вот и все.
Как читать чужой код? Часть 3. Разбор и доработка запросов
Во всех вакансиях есть требование — умение читать чужой код. Но ни на одних курсах специально этому не учат.
Чтобы устранить это противоречие, пишу данную статью. Рассмотрю случаи, в которых нам необходимо разбирать чужой код, поймём, чей код мы пытаемся разобрать, зачем и, главное, как. В статье описан личный опыт длиною в 18 лет начиная с версии платформы 7.7. Статья будет большой, набираемся терпения). Статья содержит в себе описание сценариев разбора кода, т.е. набор шагов. В статье не получится показать это на практике. Для этого планирую сделать онлайн или оффлайн курс, где на примерах будет показан разбор незнакомого кода. Статья разбита на 4 публикации для удобства изучения.
Добавление данных
При добавлении новых данных необходимо учитывать столбцы периодов ( PERIOD ), если они не скрыты ( HIDDEN). С темпоральными таблицами с системным управлением версиями также можно использовать переключение секций.
Добавление новых данных с видимыми столбцами периодов
Чтобы принять в расчет новые столбцы PERIOD , создать инструкцию INSERT при наличии видимых столбцов PERIOD можно так:
-
При указании списка столбцов в инструкции INSERT столбцы PERIOD можно опустить, так как система создает для них значения автоматически.
-
Если в инструкцииINSERT вы все же указываете столбцы PERIOD в списке столбцов, в качестве их значения необходимо указать DEFAULT.
-
Если вы не указываете в инструкции INSERT список столбцов, укажите для столбцов PERIOD значение DEFAULT .
Добавление данных в таблицу со скрытыми столбцами периодов
Если столбцы PERIOD скрыты, вам нужно указать значения только для видимых столбцов (при условии, что вы добавляете данные, не указывая список столбцов). В инструкции INSERT не нужно учитывать новые столбцы PERIOD . Это гарантирует, что устаревшие приложения будут и дальше работать после включения системного управления версиями в таблицах, для которых версионирование может пойти на пользу.

Добавление данных с использованием переключения секций
Если текущая таблица секционирована, переключение секций можно использовать как эффективный механизм загрузки данных в одну или несколько секций одновременно.
Для промежуточной таблицы, которая указана в инструкции PARTITION SWITCH IN с темпоральной таблицей с системным управлением версиями, необходимо определить период SYSTEM_TIME PERIOD , но промежуточная таблица не обязательно должна быть темпоральной с системным управлением версиями.
Это гарантирует выполнение проверок темпоральной согласованности: 1) во время добавления данных в промежуточную таблицу; 2) во время добавления периода SYSTEM_TIME в предварительно заполненную промежуточную таблицу.
Если вы попытаетесь переключить секции из таблицы, в которой период не определен, появится сообщение об ошибке:
Использование пользовательского сценария очистки
В тех случаях, когда подход Stretch Database или секционирование таблиц неприемлемо, можно применить третий способ удаления данных из таблицы журнала с помощью пользовательского сценария очистки. Удаление данных из таблицы журнала возможно, только если SYSTEM_VERSIONING = OFF. Чтобы избежать несогласованности данных, необходимо выполнять очистку в течение периода обслуживания (когда рабочие нагрузки, изменяющие данные, неактивны) или в рамках одной транзакции (на время которой блокируются другие рабочие нагрузки). Для выполнения этой операции требуется разрешение CONTROL для текущей таблицы и таблицы журнала.
При выполнении сценария очистки внутри транзакции удаляйте данные небольшими фрагментами с задержкой, чтобы не создавать помеху для работы обычных приложений и запросов пользователей. Не существует единой рекомендации по оптимальному размеру фрагмента удаляемых данных для всех сценариев, но в любом случае удаление более чем 10 000 строк в одной транзакции может оказать существенное влияние на работу.
Для всех темпоральных таблиц используется одна и та же логика очистки. Поэтому можно сравнительно легко автоматизировать весь процесс с помощью универсальной хранимой процедуры, запускаемой периодически для каждой темпоральной таблицы, для которой требуется ограничить данные журнала.
На следующей схеме показано, как должна быть организована логика очистки для одиночной таблицы, чтобы снизить влияние на выполнение рабочих нагрузок.
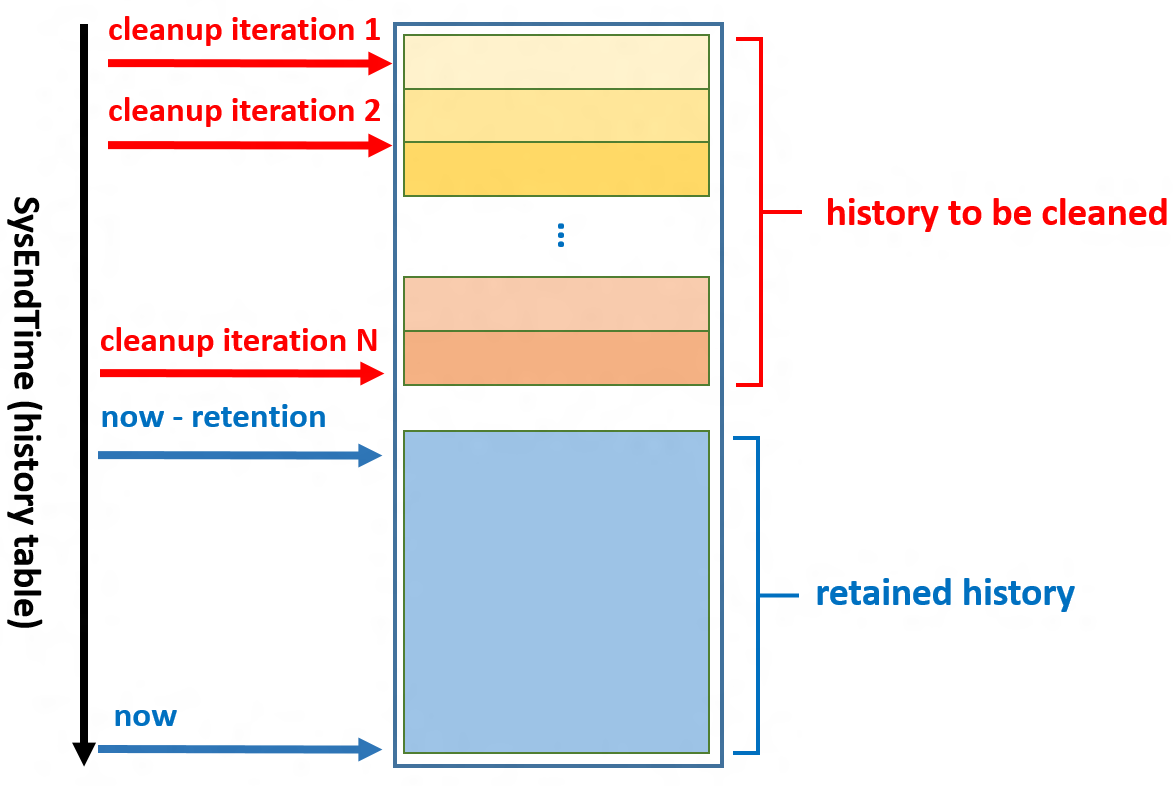
Ниже приведены общие рекомендации по реализации процесса. Составьте план ежедневного выполнения очистки с перебором всех темпоральных таблиц, для которых требуется очистка данных. Для планирования этого процесса используйте Агент SQL Server или другое средство:
- Удаляйте данные журнала из каждой темпоральной таблицы, начиная с самой старой строки и до последней, в несколько итераций небольшими фрагментами. Не удаляйте все строки в одной транзакции. Процесс показан на рисунке, приведенном выше.
- Реализуйте каждую итерацию как вызов универсальной хранимой процедуры, удаляющей часть данных из таблицы журнала. (См. пример кода для выполнения этой процедуры ниже.)
- Подсчитайте, сколько строк необходимо удалять из одной темпоральной таблицы при каждом запуске процесса. Зная это число и требуемое количество итераций, динамически определите точки разбиения для каждого вызова процедуры.
- Задайте периоды задержки между итерациями по одной таблице, чтобы уменьшить помеху для работы приложений, обращающихся к этой темпоральной таблице.
Пример хранимой процедуры, удаляющей данные из одной темпоральной таблицы, приведен в следующем фрагменте кода. (Внимательно просмотрите этот код и внесите необходимые поправки прежде, чем применять его в вашей среде.)
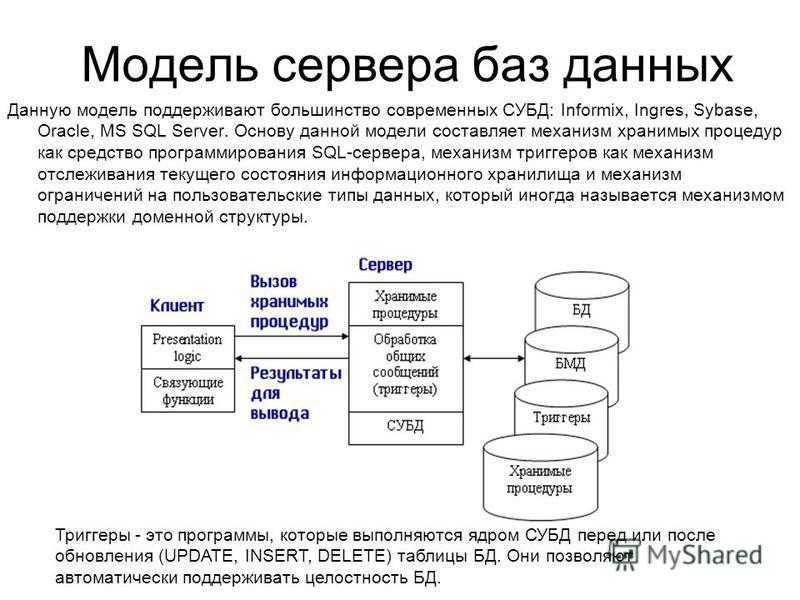
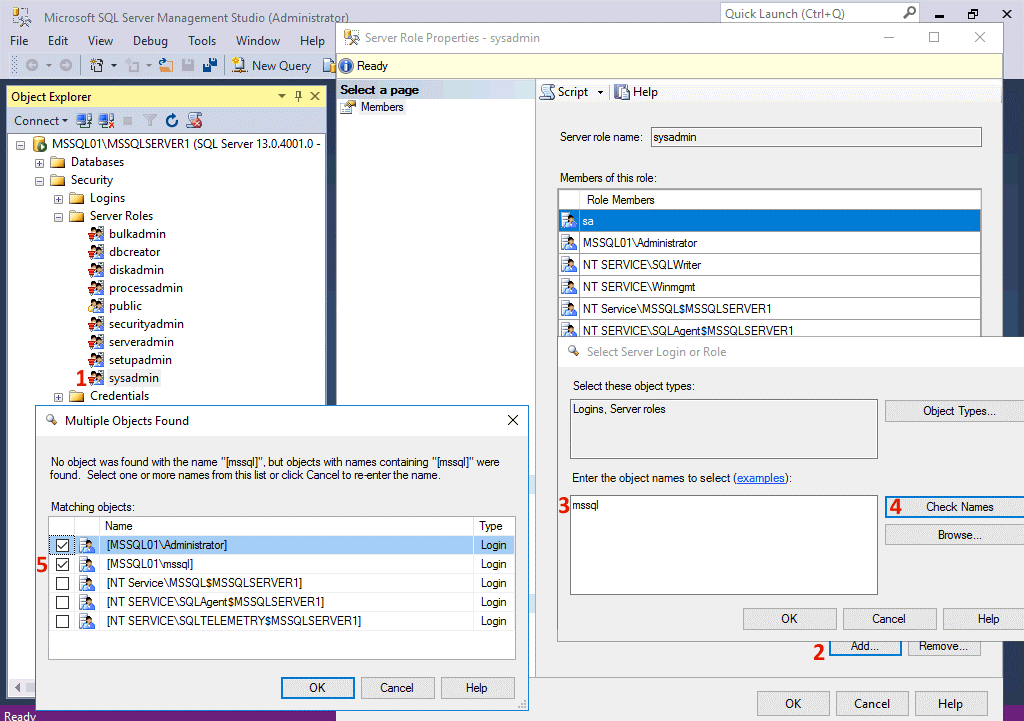
Высокий уровень доступности
Одна из общих задач при развертывании SQL Server заключается в том, чтобы обеспечить доступность всех критически важных экземпляров SQL Server и баз данных в них для организации и конечных пользователей согласно их потребностям. Доступность является ключевым компонентом платформы SQL Server, и SQL Server 2019 (15.x) представляет множество новых функций и усовершенствований, позволяющих компаниям обеспечить высокую доступность сред баз данных.
Группы доступности
| Новые функции или обновления | Сведения |
|---|---|
| До пяти синхронных реплик | В SQL Server 2019 (15.x) максимальное количество синхронных реплик увеличено до пяти, по сравнению с тремя в SQL Server 2017 (14.x);. Вы можете настроить эту группу из пяти реплик для автоматического перехода на другой ресурс в пределах группы. Предоставляется одна первичная реплика и четыре синхронные вторичные реплики. |
| Перенаправление подключения от вторичной реплики к первичной | Позволяет направлять подключения клиентских приложений к первичной реплике независимо от целевого сервера, указанного в строке подключения. Дополнительные сведения см. в статье Перенаправление подключения с правами на чтение и запись с вторичной на первичную реплику (группы доступности AlwaysOn). |
| Преимущества HADR | Каждый клиент Software Assurance SQL Server сможет использовать три улучшенных преимущества для любого выпуска SQL Server, который в настоящее время поддерживается корпорацией Майкрософт. Дополнительные сведения см. в нашем объявлении. |
Восстановление
| Новые функции или обновления | Сведения |
|---|---|
| Ускоренное восстановление базы данных | Сокращает время восстановления после перезапуска или длительного отката транзакций с помощью ускоренного восстановления базы данных (ADR). См. раздел . |
Возобновляемые операции
| Новые функции или обновления | Сведения |
|---|---|
| Сборка и перестроение кластеризованных индексов columnstore в режиме «в сети» | См. раздел Выполнение операций с индексами в режиме «в сети». |
| Возобновляемая сборка индексов rowstore в режиме «в сети» | См. раздел Выполнение операций с индексами в режиме «в сети». |
| Приостановка и возобновление начального сканирования прозрачного шифрования данных (TDE) | См. раздел . |
Сведения о реализации
Следующие факты о темпоральных таблицах с системным управлением версиями и оптимизированными для памяти таблицами необходимо учитывать при создании таблицы с системным управлением версиями, оптимизированной для операций в памяти. Варианты синтаксиса и пример см. в разделе CREATE TABLE (Transact-SQL).
- Только долговечные, оптимизированные для памяти таблицы могут поддерживать системное управление версиями (DURABILITY = SCHEMA_AND_DATA).
- Таблица журнала для оптимизированной для памяти таблицы с системным управлением версиями должна размещаться на диске независимо от того, была ли она создана конечным пользователем или системой.
- Запросы, относящиеся только к текущей таблице (в памяти), можно использовать в модулях, скомпилированных в T-SQL. Темпоральные запросы, использующие предложение FOR SYSTEM TIME, не поддерживаются в модулях, скомпилированных в собственном коде. Использование предложения FOR SYSTEM TIME поддерживается с оптимизированными для памяти таблицами в нерегламентированных запросах и в модулях с несобственным кодом.
- Если SYSTEM_VERSIONING = ON, внутренняя промежуточная таблица, оптимизированная для памяти, создается автоматически для принятия последних изменений с системным управлением версиями, которые являются результатами операций обновления и удаления в текущей таблице, оптимизированной для памяти.
- Данные из этой внутренней промежуточной таблицы регулярно перемещаются в таблицу журнала на диске асинхронной задачей сброса данных. Цель этого механизма — сохранить размер внутренних буферов памяти на уровне менее 10 % от потребляемой памяти родительских объектов. Вы можете отслеживать общее потребление памяти для темпоральной таблицы, оптимизированной для памяти, путем запроса sys.dm_db_xtp_memory_consumers (Transact-SQL) и сводки данных для внутренней промежуточной таблицы, оптимизированной для памяти, и текущей темпоральной таблицы.
- Вы можете принудительно выполнить сброс данных, вызвав sp_xtp_flush_temporal_history.
- Если SYSTEM_VERSIONING = OFF или схема таблицы с системным управлением версиями изменяется (столбцы добавляются, удаляются или изменяются), все содержимое промежуточного внутреннего буфера перемещается в таблицу журнала на диске.
- Запрос данных журнала выполняется на уровне изоляции моментального снимка и всегда возвращает объединение промежуточного буфера в памяти и дисковой таблицы без дубликатов.
- ОперацииALTER TABLE , которые изменяют схему таблицы внутренне, должны выполнить сброс данных, что может увеличить время выполнения операции.
Временные таблицы
В языке запросов временный таблицы являются промежуточным звеном для получения данных и обработки данных.
Общая концепция использования
- Данные , полученные любым способом, помещаются в некую таблицу с указанным именем
- Далее возможно обращение и выборка из данной таблицы по этому имени
- Обращение может быть многократным
- Таблицу можно уничтожить после применения
- Можно использовать позднее через объект менеджер временных таблиц
- Можно помещать несколько временных таблиц, но имена должны отличаться (перезаписи нет)
Использование в конструкторе запросов
Для создания или уничтожения предназначена вкладка «Дополнительно» 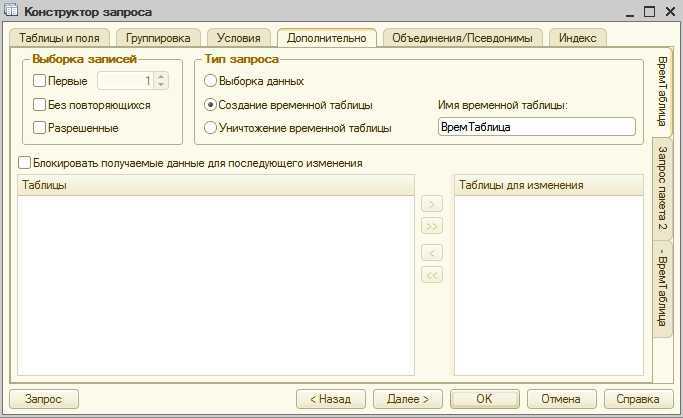
Далее такая таблица появляется в дереве «Таблицы/Базы данных»:
У временной таблицы своя особая иконка таблицы.
Для временных таблиц доступна вкладка Индексы, использование которых может ускорить обработку данных временной таблицы.
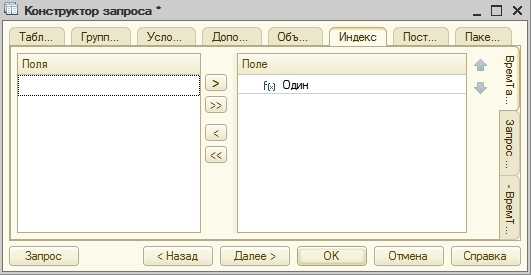
Получится такой запрос:
ИНДЕКСИРОВАТЬ ПО Один ;
Использование менеджера временных таблиц
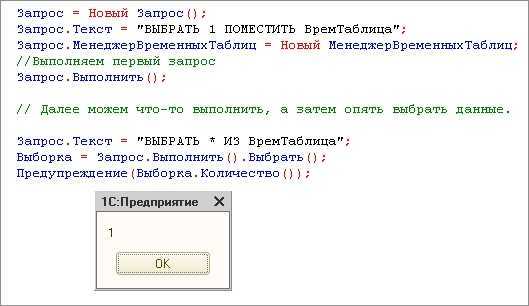
// Далее можем что-то выполнить, а затем опять выбрать данные. Запрос . Текст = «ВЫБРАТЬ * ИЗ ВремТаблица» ; Выборка = Запрос . Выполнить ( ) . Выбрать ( ) ; Предупреждение ( Выборка . Количество ( ) ) ;
Особенности
- Нельзя использовать в запросах динамического списка.
- Можно использовать в СКД.
- Временные таблицы особенно индексирование занимает некоторое время, но обычно их использование ускоряет запросы.
- Индексировать доступно только при наличии ПОМЕСТИТЬ, иначе будет вот такая ошибка «Синтаксическая ошибка индексировать ПО» (система не ожидает эту команду в данном месте)
- Допустимо использовать в соединениях
- Появились в платформе 8.1, далее оптимизировалось их использование, синтаксис не менялся.
Обзор
Темпоральные таблицы с системным управлением версиями автоматически сохраняют полный журнал изменений данных и предоставляют удобные расширения Transact-SQL для анализа на момент времени. В типичном сценарии журнал данных хранится в течение длительного времени (несколько месяцев и даже лет) несмотря на то, что они не запрашиваются регулярно.
Аудит и анализ данных на основе времени можно запросить в различных средах, особенно в системах OLTP, которые обрабатывают очень много запросов и используют технологию In-Memory OLTP. Однако использование таблиц, оптимизированных для памяти, в темпоральных сценариях весьма сложно, поскольку огромный объем созданных данных журнала обычно превышает доступный объем ОЗУ. В то же время неоптимально использовать ОЗУ для хранения журнала данных только для чтения, доступ к которым осуществляется все реже по мере их старения.
Темпоральные таблицы с системным управлением версиями для таблиц, оптимизированных для памяти, обеспечивают высокую скорость обработки транзакций, параллелизм без блокировки и в то же время позволяют хранить большой объем данных журнала с помощью таблиц в памяти для хранения текущих данных (темпоральная таблица) и таблиц на диске — для данных журнала. Влияние на операции DML сводится к минимуму за счет использования внутренней, автоматически созданной промежуточной таблицы, оптимизированной для памяти, в которой хранится журнал последних действий и которая позволяет выполнять DML из собственного кода.
На следующей схеме показана эта архитектура. 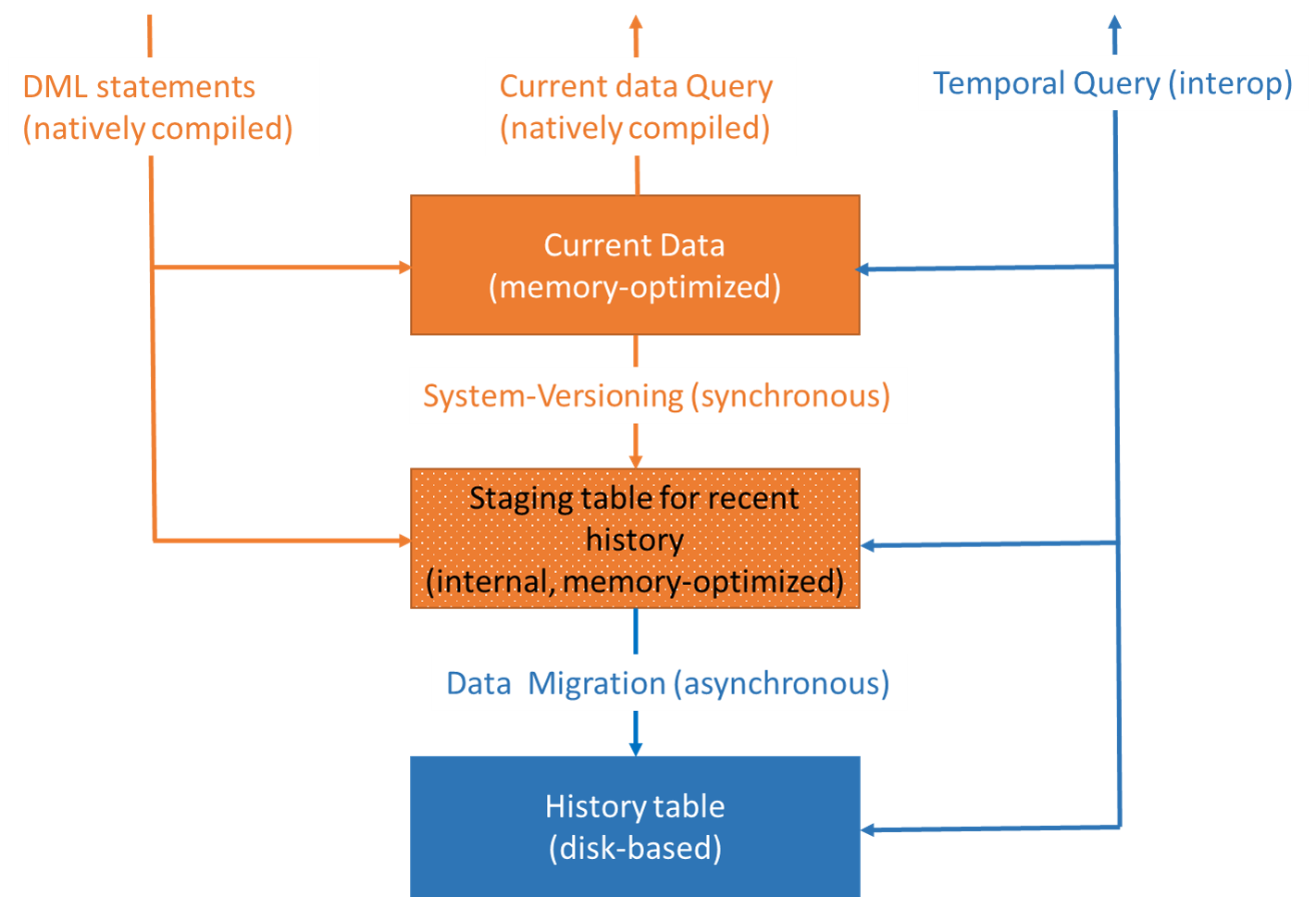
Временные таблицы в конструкторе запросов
Рассмотрим создание временных таблиц при помощи конструктора запросов. Рассмотрим несколько ситуаций.
Как поместить результат запроса во временную таблицу
Создадим с помощью конструктора вот такой простейший запрос: Соответственно текст запроса будет выглядеть следующим образом:
Но мы хотим поместить результат запроса во временную таблицу, которую назовем ВТ_Товары, то есть привести наш запрос вот к такому виду
Для этого нам необходимо перейти на закладку Дополнительно, установить тип запроса в положение Создание временной таблицы и заполнить поле с именем таблицы
Как прочитать временную таблицу из другого запроса
Очень часто при проектировании запросов большого объема возникает необходимость передавать временные таблицы из одного запроса в другой с использованием объекта МенеджерВременныхТаблиц. То есть вот такая ситуация:
Чтобы выбрать данные из временной таблицы, необходимо на закладке Таблицы и поля нажать на кнопку Создать описание временной таблицы и в открывшейся форме заполнить наименование таблицы и ее поля:
Как создать временную таблицу из параметра запроса
А теперь представим, что мы хотим выбрать данные во временную таблицу без использования менеджера временных таблиц — из внешнего источника данных, например, из таблицы значений. Такая ситуация уже рассматривалась ранее в статье о том как правильно поместить таблицу значений во временную. Применительно к текущей статье текст запроса выглядит вот так:

В этом случае нам надо сначала создать описание временной таблицы. А затем прописать ее имя на закладке Дополнительно. То есть получается комбинация двух предудущих методов. Причем знак амперсанта можно также проставить в поле с именем таблицы:
Версии расчетных таблиц в циклах

Расчетные таблицы в циклах могут иметь несколько версий. Поля в версиях не зависят от аналогичных полей в других версиях этой таблицы. Версия может быть создана на основе существующей версии, но далее они изменяются независимо друг от друга.
Каждый цикл содержит информацию о версиях расчетных таблиц использующихся в нем. Это позволяет поступательно редактировать логику в циклах, а также использовать разную логику в разных циклах одной таблицы циклов.
При создании цикла он создается с версиями таблиц, отмеченных по умолчанию.
При дублировании цикла он дублируется с сохранением версий циклов, но вы можете использовать , чтобы переключать на необходимые версии по условиям.
Версии управляются через две системные таблицы: