
Вступление
Вероятно, вы знаете, что компания Splunk всерьез и, возможно, надолго ушла с рынка этой страны. Но мы продолжаем работать со Splunk, я этим занимаюсь больше 5 лет, а Аня, @manabanana — второй год. Мы обросли практикой, рецептами, фишками и ощущениями от этой системы. (Факты и цифры, оставленные в этом абзаце и других местах текста без изменений следует воспринимать как актуальные по состоянию на 2019 год, когда был прочитан данный доклад. С тех пор многое изменилось, профессиональные интересы докладчиков, принявших в прошлом челленж Splunk, связаны в настоящее время с рядом других систем и сфер IT, подробности можно узнать в наших профилях или в личном диалоге.)
Я расскажу, как у нас устроен Splunk, а Аня поделится предельно конкретным кейсом по мониторингу нашей системы мониторинга, который она решила благодаря ее всепроникающей логике и изобретательности. Если конкретно — кейс будет про жизненный цикл данных внутри поискового индекса, как за этим можно смотреть, чем нас удивил мониторинг процессов и где в итоге мы нашли зацепку.
Думаю, что многие пошли в IT-сферу, исходя из кайфа, который испытываешь, когда напишешь офигенный код, построишь удачную архитектуру, и это всё здорово и эффективно работает. В дополнение вы покрываете свои системы тестами, и работа составляющих их звеньев становится абсолютно прозрачной и понятной.
Наша мотивация и цель сегодня такая же — поделиться ощущением от эксплуатации сложных систем. Тем удовольствием и кайфом, которые мы испытываем, когда такая система — с множеством степеней свободы, движущихся частей и параметров настройки — из неуправляемого хаотического нечто становится послушной, понятной и предсказуемой. Это очень приятное ощущение.
О визуализации
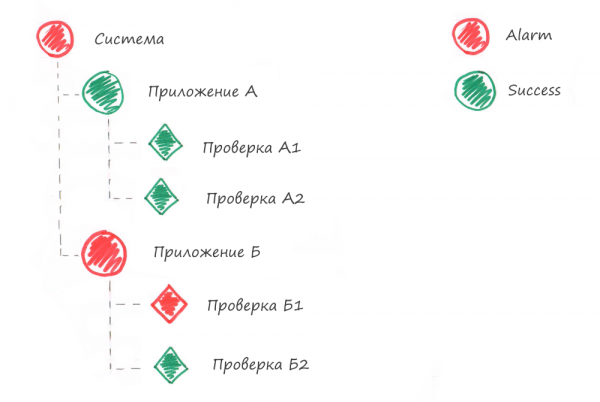
Подобно тому, как метрики делились на уровни, аналогично разделяется и визуализация:
Уровень площадки – самый высокий уровень визуализации, с которого, после получения алерта, пользователю мониторинга стоит начинать работать. Дашборд(ы) здесь представляют собой набор логически разделенных индикаторов «всё хорошо/что-то сломалось»
Например, каждая панель показывает состояние какой-либо группы приложений – Nginx`ы, Apache`и, Службы виртуализации; при наличии проблемы с любой из сущностей группы панель переходит из состояния «всё хорошо» в состояние «что-то сломалось», привлекая внимание
Уровень группы – следующий уровень, к которому переходит пользователь; должен быть доступен по drilldown-ссылке с предыдущего дашборда. Если ранее мы подсветили, с какой группой возникла проблема, здесь мы должны ответить на вопрос «с каким именно объектом группы?»
Продолжая начатый выше пример, здесь отображаются все Nginx на вашей площадке, по которым выведены ключевые показатели – состояния процессов, состояния соединений с БД, количество ошибок и так далее. Тут не стоит сильно вдаваться в детали, пяти-шести панелей на объект наблюдений будет достаточно
Уровень объекта – конечная точка движения нашего пользователя в большинстве случаев. На этом уровне детально визуализируются метрики конкретного приложения/процесса/другого подвергнутого принудительному мониторингу объекта. Здесь пользователь должен найти для себя ответ на такой вопрос – «что же именно сломалось?». Начиная с этого уровня, переходы между дашбордами должны наследовать контекст – если пользователь на уровне группы кликнул по панели процесса nginx_01 хоста proxy.local, метрики именно этого приложения на этом хосте и должны отображаться
Уровень фрагмента объекта – формально, продолжение предыдущего уровня, но введен вот зачем: если какая-либо часть нашего объекта имеет слишком много метрик и достойна того, чтобы рассматриваться отдельно, под неё заводится персональный дашборд. Например, у нашего Nginx есть апстримы со своими метриками; дабы не усложнять уровень объекта и не перегружать его, мы заводим под апстрим персональный дашборд, а на предыдущем оставляем только кликабельные индикаторы с состоянием апстрима «онлайн/частично онлайн/оффлайн». И вновь, переходы должны наследовать контекст, чтобы облегчить пользователю навигацию
Уровень инфраструктуры – самый низкий уровень визуализации и отправная точка в сборе метрик. Тут отображаются показатели хост-системы и окружающего «железа». Хорошим ходом будет разбить на разные дашборды метрики разных частей – состояние CPU, RAM, дисков и т.д., организовав возможность горизонтального перехода между ними. Переход же на этот уровень можно создать с двух предыдущих, снова с учётом ранее установленного контекста; если пользователь смотрел на метрики приложения на хосте proxy.local, этого хоста метрики и должны отображаться
Подводя итог написанному выше, у нас получается такая диаграмма уровней, демонстрирующая путь пользователя:
Пользователь мониторинга двигается сверху вниз, разбирая инцидент
Общие рекомендации:
-
Делайте ваши дашборды шаблонными, с возможностью установки контекста через переменные. Мысль достаточно очевидная, согласен, но, тем не менее, мне приходилось встречать хардкод хостов и приложений, порождающий ворох из копий одних и тех же дашборд, что выливалось в неподдерживаемый хаос
-
Также, стоит выносить в переменные различные потенциально изменяемые вещи – имя базы данных с метриками, вручную составленные словари «число-значение» и т.п.
-
Добавляйте описание к всем панелям. Если отображаемая на панели информация кажется хоть немного неочевидной, не поленитесь дать ей описание – буквально одно-два предложения сильно облегчат работу пользователей и помогут вам же, когда возникнет необходимость вернуться к работе с дашбордом
В качестве средства визуализации сейчас лидирует небезызвестная Grafana, в которой есть функционал переменных, внутренних и внешних ссылок c шаблонизацией, комментариев к панелям и еще всякое-всякое.
Свежие новости и статьи

Статьи
10 ноября 2022
Как мы на Яндекс Почту мигрировали: кейс ALP ITSM
ALP ITSM обеспечивает IT-поддержку компаниям разного масштаба — от небольших офисов с 20 сотрудниками до международных фастфуд-гигантов. Мы помогаем нашим клиентам находить выгодные IT-решения, подбираем и устанавливаем оптимальные сервисы. Но недавно мы сами оказались в ситуации, когда нужно было отказываться от привычных решений и искать новые варианты. Рассказываем, как наша компания численностью 120 сотрудников переходила на отечественный почтовый продукт и что из этого вышло.
Статьи
5 сентября 2022
Импортозамещение и локализация ИТ-инфраструктуры. Что общего? И в чем отличия?
В чем разница между импортозамещением и локализацией ИТ? Для каких компаний подходят эти две стратегии? Значит ли их реализация, что от иностранного софта и оборудования нужно будет отказаться полностью? Разобраться в теме помог Сергей Идиятов, руководитель направления консалтинга ALP ITSM.

Статьи
22 августа 2022
Топ-5 рекомендаций для CEO: как локализовать IT-инфраструктуру?
Для компаний с центральным офисом в зарубежных странах санкционный кризис стал серьезным испытанием. При сохранении бизнеса в России нужно выделить IT-инфраструктуру локального офиса и сделать ее независимой и автономной от глобальной компании, объявившей об уходе из РФ. Этот «развод по-итальянски» требует четкого плана, ресурсов и крепких нервов. Как минимизировать риски, рассказывает Сергей Идиятов, руководитель направления консалтинга ALP ITSM, сервисной IT-компании холдинга ALP Group.

Статьи
11 мая 2022
Не можно, а нужно: рассказываем, как безболезненно перенести IT-инфраструктуру компании в российское облако. Кейс ALP ITSM
За последние два месяца российские компании столкнулись с различными сложностями, в том числе по части IT. Среди них — остановка продажи нового ПО, невозможность оплаты услуг западных сервисов, повышение цен на оборудование и всевозможные блокировки. ALP ITSM помогает клиентам найти решения, чтобы обезопасить IT-инфраструктуру в нынешних условиях. Делимся опытом миграции из зарубежных облаков в российские.
Статьи
1 апреля 2022
Автоматизируй это! Четыре бизнес-процесса, где нельзя обойтись без Service Desk.
Когда компания растет, увеличивается и количество запросов от пользователей. Однажды это превращается в «снежный ком»: техподдержка не справляется с потоком, заявки теряются, время обработки обращений все дольше, пользователи недовольны. Знакомая ситуация? Тогда нужно срочно внедрять ServiceDesk. Разбираемся, чем может помочь эта система, и какие направления стоит автоматизировать в первую очередь.
Настройка Монитора основных показателей
В правом окне формы настройки флажками отметьте те показатели, которые анализируете в отчете.
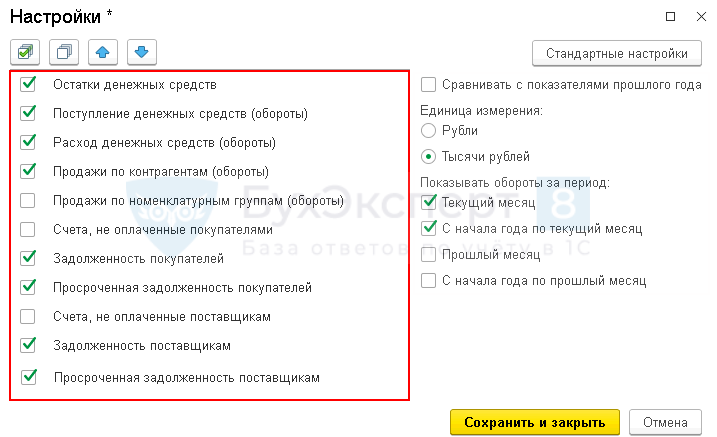
Используя кнопки командной панели, меняйте расположение показателей в списке.
Для удобства работы в командную панель показателей добавлены кнопки:
- установка флажков по всем показателям отчета;
- сброс всех установленных флажков.
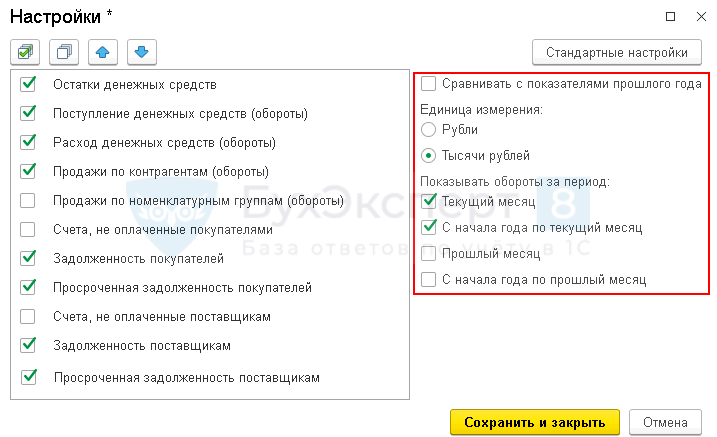
В правом окне настройки отчета установите дополнительные условия: например, сравнить данные с аналогичным периодом прошлого года или вывести единицы измерения в рублях или тысячах рублей.
Отчет по умолчанию отображает итоговые данные. Детальную расшифровку по любому показателю можно получить, нажав в сформированном отчете на наименование выбранного показателя.









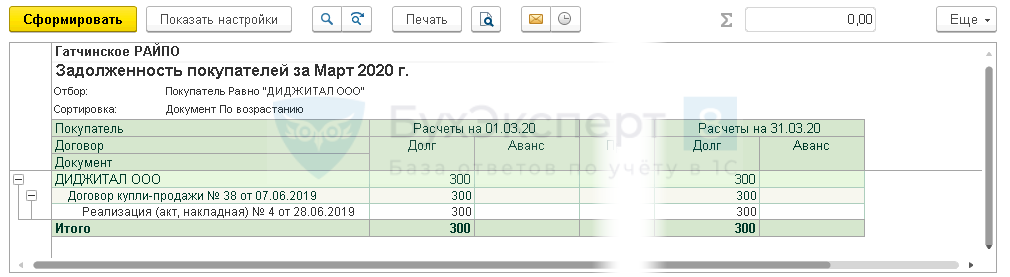
Вернуть стандартные настройки отчета можно по кнопке Настройки — Стандартные настройки.

Стандартные настройки включают показатели:
- Остатки денежных средств
- Поступление денежных средств (обороты)
- Расход денежных средств (обороты)
- Продажи по контрагентам (обороты)
- Задолженность покупателей
- Задолженность поставщикам
Профилирование
Ещё одно эффективное средство, которое есть в CLR – API профилирования. Его (в основном) используют сторонние инструменты для подключения к среде выполнения на низком уровне. Подробнее про API можно узнать из этого обзора, но на высоком уровне с его помощью можно выполнять обратные вызовы, которые активируются, если:
- происходят события, связанные со сборщиком мусора;
- выбрасываются исключения;
- загружаются/выгружаются сборки;
- и многое другое.
Изображение со страницы BOTR Profiling API – Overview
Кроме того, у него есть другие эффективные функции. Во-первых, вы можете установить обработчики, которые вызываются каждый раз, когда выполняется метод .NET, будь то в самой среде или из пользовательского кода. Эти обратные вызовы известны как обработчики Enter/Leave. Вот здесь есть хороший пример, как их использовать. Однако для этого нужно понять конвенции вызовов для разных ОС и архитектур центрального процессора, что не всегда просто. Также не забывайте, что API профилирования это COM-компонент, доступ к которому можно получить только из кода C/C++, но не из C#/F#/VB.NET.
Во-вторых, профилировщик может переписать IL-код любого .NET-метода перед JIT-компиляцией с помощью SetILFunctionBody() API. Этот API действительно эффективен. Он лежит в основе многих инструментов APM .NET. Подробнее о его использовании можно узнать из моего поста How to mock sealed classes and static methods и сопутствующего кода.
ICorProfiler API
Оказывается, чтобы API профилирования работал, в среде выполнения должны быть всяческие ухищрения. Просто посмотрите на обсуждение на странице Allow rejit on attach (подробную информацию о ReJIT см. в ReJIT: A How-To Guide).
Полное определение всех интерфейсов и обратных вызовов API профилирования можно найти в \vm\inc\corprof.idl (см. Interface description language). Оно разбивается на 2 логические части. Одна часть – это интерфейс Профилировщик -> Среда выполнения (EE), известный как :
Это реализуется в следующих файлах:
- \vm\proftoeeinterfaceimpl.h
- \vm\proftoeeinterfaceimpl.inl
- \vm\proftoeeinterfaceimpl.cpp
Другая основная часть – обратные вызовы Среда выполнения -> Профилировщик, которые группируются под интерфейсом :
Эти обратные вызовы реализуются в следующих файлах:
- vm\eetoprofinterfaceimpl.h
- vm\eetoprofinterfaceimpl.inl
- vm\eetoprofinterfaceimpl.cpp
- vm\eetoprofinterfacewrapper.inl
Наконец, стоит заметить, что API профилирования могут не работать на всех ОС и архитектурах, на которых работает .NET Core. Вот один из примеров: ELT call stub issues on Linux. Подробную информацию см. в Status of CoreCLR Profiler APIs.
Profiling v. Debugging
В качестве небольшого отступления нужно сказать, что профилирование и отладка всё-таки немного пересекаются. Поэтому полезно понимать, что предоставляют различные API в контексте .NET Runtime (взято из CLR Debugging vs. CLR Profiling).
Разница между отладкой и профилированием в CLR
| Отладка | Профилирование |
|---|---|
| Предназначена для поиска проблем с корректностью кода | Предназначено для диагностики и поиска проблем с производительностью |
| Может иметь очень высокий уровень вмешательства | Как правило, имеет низкий уровень вмешательства. Хотя профилировщик поддерживает изменение IL-кода или установку обработчиков enter/leave, всё это предназначено для инструментирования, а не для радикального изменения кода. |
| Основная задача – полный контроль цели. Это включает инспекцию, контроль выполнения (например команда set-next-statement) и внесение модификаций (функция Edit-and-Continue). | Основная задача – инспекция цели. Для этого предусмотрено инструментирование (изменение IL-кода, установка обработчиков enter/leave) |
| Обширный API и толстая модель объекта, заполненная абстракциями. | Небольшой API. Абстракций мало или отсутствуют. |
| Высокий уровень интерактивности: действия отладчика контролируются пользователем (или алгоритмом). Фактически редакторы и отладчики часто интегрированы (IDE). | Интерактивность отсутствует: данные обычно собираются без вмешательства пользователя, после чего анализируются. |
| Небольшое количество критических изменений, если нужна обратная совместимость. Мы думаем, что миграция с версии 1.1 на версию 2.0 отладчика, будет простой или не очень сложной задачей. | Большое количество критических изменений, если нужна обратная совместимость. Мы думаем, что миграция с версии 1.1 на версию 2.0 отладчика, будет тяжёлой задачей, идентичной его полному переписыванию. |
Управление графиком реализации проекта
Вы должны смотреть на график реализации проекта с разных сторон, чтобы выявить проблемы и решить, что с ними делать. Сначала сравните текущий график с вашим базовым планом. Простая диаграмма Ганта поможет вам увидеть, опережаете ли вы график, отстаете или идете по расписанию. Например, вы можете показать свое базовое расписание с полосами одного цвета, а текущее расписание другим цветом. С другой стороны, значения дисперсии сообщают вам точную разницу между вашим базовым планом и вашим текущим графиком.
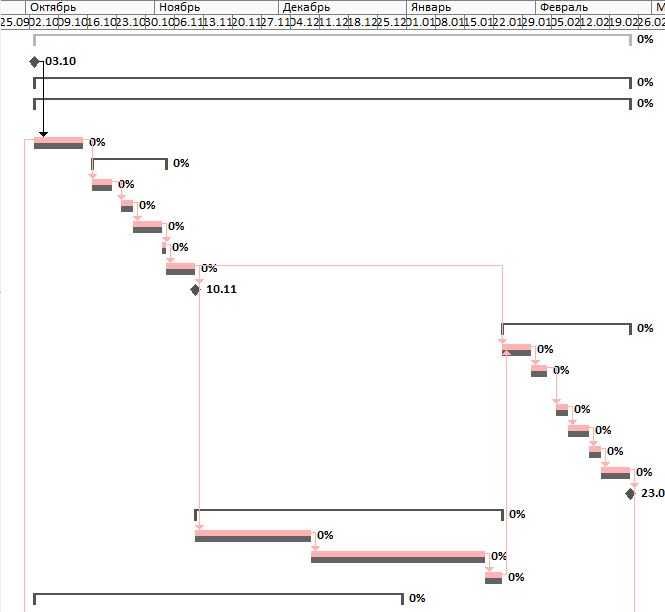
Выявление проблемных задач помогает определить, где вам нужно внести изменения, чтобы не нарушать график. Если вы используете программу планирования, часто есть фильтры и предустановки, которые обеспечивают ранее предупреждение о задержках. Например, незавершенные задачи, которые выполняются с опозданием, задачи, которые должны были начаться, но не завершились, или задачи, которые не выполнили столько работы, как планировалось.
Управляя расписанием, вы также будете тратить время на управление ресурсами и всеми контрактами, которые вы подписали для их получения. Например, возможно, ресурс будет недоступен в день, когда должно начаться выполнение его задачи, что может привести к различного рода штрафам со стороны поставщика ресурса.
Изучение графика реализации проекта поможет вам увидеть, есть ли у вашего проекта проблемы, и определить возможные решения, если это так.
NTA и NBA
У вас уже скорее всего есть SIEM, который получает агрегированные данные трафика в форматах NetFlow, sFlow, jFlow, Packeteer или сам создаёт такие агрегаты из копии трафика. Их основные данные – информация L3 и L4 OSI. Также, у вас скорее всего внедрён IDS/IPS, который не записывает трафик, но анализирует его полную копию от L2 до L7, насколько позволяет шифрование.
Если эти средства не решили ваши задачи, можно дополнить систему мониторинга с помощью Network Traffic Analysis. Это решение производит запись трафика для его последующего исследования. При планировании стоит учесть гораздо больший по сравнению с LM/SIEM объем хранилища и необходимость предварительной расшифровки данных.
Трафик объединяет в себе и информацию, и факт её передачи. В отличие от событий, генерация которых избирательна, он полностью описывает, что произошло между двумя взаимодействующими системами, и его нельзя удалить или сфабриковать. События собираются в LM или SIEM с некоторой задержкой, если это не Syslog, в случае которого возможен спуфинг. А если успеть очистить журнал источника – действие, подозрительное само по себе – что точно случилось узнать будет трудно.
Также можно использовать решения класса Network Behavior Analysis – аналог U(E)BA для сети со всеми его преимуществами и недостатками, но с парой особенностей. Во-первых, эти решения гораздо чаще выпускаются в виде обособленных продуктов. Во-вторых, как мы уже говорили в части 6, основных сетевых протоколов несколько десятков, что делает решение «из коробки» довольно эффективным.
Результат использования NTA и NBA – у вас есть аналоги SIEM и U(E)BA, позволяющие использовать все особенности трафика.
Мониторинг и контроль рисков
Когда вы разрабатывали свой план управления рисками, вы определили риски, которые нужно отслеживать, и ответные меры, которые вы будете использовать для их устранения (мы писали об этом в одной из предыдущих частей). Теперь, когда проект находится в стадии реализации, вы должны внимательно следить за тем, чтобы риски стали реальностью. Если это происходит, то вы приступаете к ответным мерам.







В Плане управления рисками каждому риску, который вы решили отслеживать, назначен владелец. Работа этого человека – следить за назначенным ему риском и регулярно обновлять его статус. Давайте подробно рассмотрим, что означает наличие риска.
- Внедрите упреждающие меры реагирования на риски. Это означает, что вы предпринимаете шаги, чтобы избежать, смягчить, перенести или запланировать непредвиденные обстоятельства для риска до того, как он произойдет.
- Следите за признаками возникновения высокоприоритетных рисков. Также следите за событиями, которые запускают план действий в чрезвычайных ситуациях. Если возникает риск, начните реагировать в соответствии с вашим планом. Затем проследите за результатами ответных действий.
- Регулярно сообщайте о статусе рисков и обновляйте журнал рисков и подробные сведения, т.е. повышение или понижение вероятности риска или воздействия в случае изменения ситуации. Иногда риски исчезают по мере продвижения проекта, и вы можете их вычеркнуть из своего плана.
Не забывайте о менее приоритетных рисках. Изменения в проекте могут увеличить их вероятность или влияние. Как команда проекта, время от времени проверяйте их, чтобы увидеть, нужно ли их отслеживать. Также следите за возможными новыми рисками, которые возникли из-за изменений в проекте.
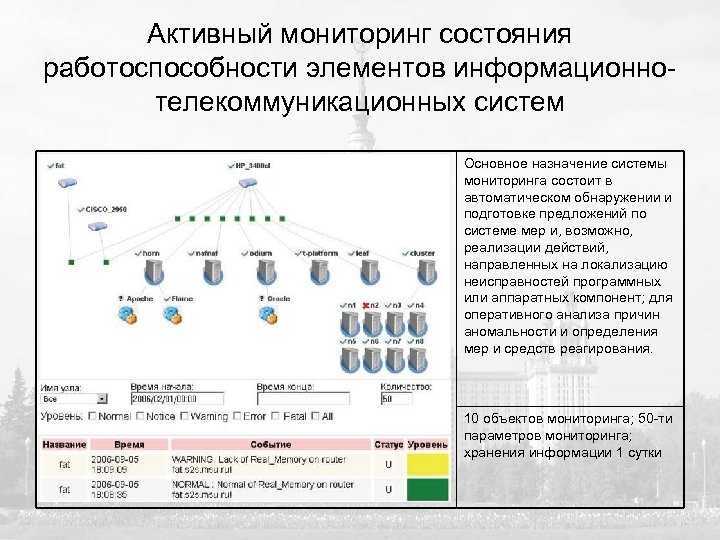
О мониторинге в контексте метрик
Если спросить среднестатистического технаря-инженера, с чем у него ассоциируется мониторинг, то скорее всего вам ответят – «метрики приложения», и подразумеваться будет их сбор и некоторая визуализация. Причем, о изнанке этого процесса, как показал мой опыт, многие даже не задумываются – в понимании большинства «оно просто показывается в Grafana/Kibana/Zabbix/подставьте нужное».
Ответ этот, замечу, всё же не полный, поскольку одними лишь метриками всё не ограничивается. Точнее даже так: мониторинг — это не только о том, чтобы метрики собрать и вывести на дашборд. И вот с этого момента давайте поподробнее.
Из чего же сделан мониторинг?
Со временем, я для себя вывел следующие аспекты:
-
Сбор метрик из различных источников – приложения, показатели хоста, «железной» части площадки; различия в pull и push моделях пока не затрагиваем, об этом чуть позже
-
Запись и дальнейшее их (метрик) хранение в базе данных с учетом особенностей самой БД и использования собранных данных
-
Визуализация метрик, которая должна балансировать между возможностями выбранного технологического стека, удобством использования дашборд и «хотелками» тех, кому с этим всем предстоит работать
-
Отслеживание показаний метрик по заданным правилам и отправка алертов
-
В случае продвинутого мониторинга сюда можно добавить еще один пункт — выявление аномалий и проактивное информирование о деградации наблюдаемой системы на основе ML.
Монитор целевых показателей
Монитор целевых показателей — это результат работы организации на сегодняшний момент. Все целевые показатели компании отображаются в мониторинге, сведения в котором предоставлены в форме отчетности. Применение отчета по монитору целевых показателей помогает провести анализ большего их процента, отображенного на одной странице.
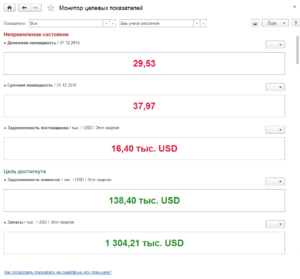
Отчет может предоставляться как в бумажном виде, так и на электронных носителях. По каждому целевому показателю необходимо провести детальный отчет, который в дальнейшем будет передан собственнику или учредителю компании. Он может содержать сведения о поставленных целях, фактические запросы и параметры и пр.
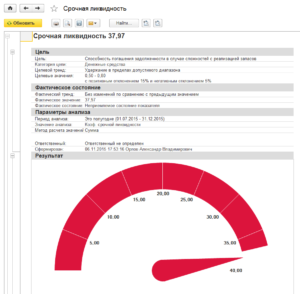
Также необходимо обеспечить автоматическую рассылку монитора целевых показателей топ-менеджерам и руководителям компании. Данная рассылка должна реализоваться в соответствии с предварительно настроенным расписанием. Применение такого подхода позволяет своевременно информировать сотрудников о целевых показателях организации.
В роли адресатов или получателей сведений о целевых показателях могут выступать работники компании, ее партнеры и контрагенты, а также физические лица, прошедшие регистрацию в информационной базе предприятия. Руководящий состав может получать сведения о состоянии текущей деятельности фирмы по электронной почте с включением базовых показателей эффективности бизнеса.
Диагностика
Для начала взглянем на диагностическую информацию, которой нас обеспечивает CLR. Традиционно для этого используется отслеживание событий для Windows (ETW).
Событий, о которых CLR предоставляет информацию, достаточно много. Они связаны со:
- сбором мусора (GC);
- JIT-компиляцией;
- модулями и доменами приложений;
- работой с тредами и конфликтами при блокировках;
- а также многим другим.
Например, здесь возникает событие во время загрузки в AppDomain, здесь событие связано с выбросом исключения, а здесь с циклом выделения памяти сборщиком мусора.
Perf View
Если вы хотите увидеть события в системе трассировки (ETW), связанные с вашими .NET приложениями, я рекомендую использовать великолепный инструмент PerfView и начать с этих обучающих видео или этой презентации PerfView: The Ultimate .NET Performance Tool. PerfView получил широкое признание за предоставляемую бесценную информацию. Например, инженеры Microsoft регулярно используют его для анализа производительности.
Общая инфраструктура
Если вдруг непонятно из названия, трассировка событий в ETW доступна только под Windows, что не очень вписывается в кроссплатформенный мир .NET Core. Можно использовать PerfView для анализа производительности под Linux (с помощью LTTng). Однако этот инструмент с командной строкой, под названием PerfCollect, только собирает данные. Возможности анализа и богатый пользовательский интерфейс (в том числе flamegraphs) в настоящий момент доступны только в решениях для Windows.
Но если вы всё-таки хотите проанализировать производительность .NET под Linux, есть и другие подходы:
- Getting Stacks for LTTng Events with .NET Core on Linux
- Linux performance problem
Вторая ссылка сверху ведёт на обсуждение новой инфраструктуры EventPipe, над которой работают в .NET Core (помимо EventSources & EventListeners). Цели её разработки можно посмотреть в документе Cross-Platform Performance Monitoring Design. На высоком уровне эта инфраструктура позволит создать единое место, куда CLR будет отсылать события, связанные с диагностикой и производительностью. Затем эти события будут перенаправляться к одному или более логерам, которые, например, могут включать ETW, LTTng и BPF. Необходимый логер будет определяться, в зависимости от ОС или платформы, на которой запущена CLR. Подробное объяснение плюсов и минусов различных технологий логирования см. в .NET Cross-Plat Performance and Eventing Design.
Ход работы по EventPipes отслеживается в рамках проекта Performance Monitoring и связанных с ним ‘EventPipe’ Issues.
Планы на будущее
Наконец, существуют планы по созданию контроллера профилирования производительности Performance Profiling Controller, перед которым стоят следующие задачи:
Контроллер должен управлять инфраструктурой профилирования и представлять данные о производительности, созданные компонентами .NET, отвечающими за диагностику рабочих характеристик, в простом и кроссплатформенном виде.
Согласно замыслу контроллер должен обеспечивать следующие функциональные возможности через HTTP-сервер, получая все необходимые данные из инфраструктуры EventPipes:
REST APIs
- Принцип 1: простое профилирование: профилировать среду выполнения в течение периода времени X и возвращать трассировку.
- Принцип 1: продвинутое профилирование: начинать отслеживание (вместе с конфигурацией)
- Принцип 1: продвинутое профилирование: завершать отслеживание (ответом на этот вызов будет сама трассировка).
- Принцип 2: получать статистику, связанную со всеми счётчиками EventCounters или определённым EventCounter.
HTML-страницы, просматриваемые через браузер
- Принцип 1: текстовое представление всех стеков управляемого кода в процессе.
- Принцип 2: отображение текущего состояния (возможно с историей) счётчиков EventCounters.
- Обеспечивает обзор существующих счётчиков и их значений.
- НЕРЕШЁННАЯ ПРОБЛЕМА: не думаю, что существуют нужные публичные API, чтобы подсчитывать EventCounters.
Я очень хочу увидеть, что в итоге получится с контроллером профилирования производительности (КПП?). Думаю, если его встроят в CLR, он принесёт много пользы .NET. Такой функционал есть в других средах выполнения.






Анализ освоенного объема
Анализ освоенного объема (earned value analysis, EVA) позволяет оценить, как базовый план исполнения соотносится с фактическими показателями исполнения расписания и стоимости. Другими словами, как проект получает ценность, выполняя работу. Данный анализ полезен, потому что основные показатели проекта могут быть обманчивыми.
Предположим, что сделано 50% работы, рассчитанной в вашем проекте и 50% бюджета израсходовано. Похоже, что все идет хорошо. Однако если выполнено только 25% работы, тогда возникает проблема. Вы должны завершить 75% работы, но с оставшимися только 50% времени и 50% средств.
Анализ освоенного объема может выявить подобные проблемы, потому что он смотрит на работу и затраты по отношению ко времени. Он рассматривает ваш график и бюджет в денежном выражении. Это означает, что вы видите все аспекты эффективности вашего проекта в одном блоке. Конечно, затраты уже указаны в денежном выражении, но вы также измеряете работу в денежном выражении, подсчитывая, сколько стоит человеческий труд.
Анализ освоенного объема основан на трех измерениях:
- Во-первых, вы измеряете плановую стоимость. Это то, сколько вы планируете потратить на завершение работы, запланированной до определенной даты. Это еще называется бюджетной стоимостью запланированных работ. Предположим, вы оценили, что потратите 50000 рублей на работу над задачей до 12 января. Плановая стоимость 50000 рублей.
- Во-вторых, заработанная стоимость – это сумма средств, которую вы заработали, выполнив работу. Ее еще называют бюджетной стоимостью выполненных работ. Если запланированные затраты на рабочую силу за часы, которые ваша команда проработала до 12 января, составляют 30000 рублей, заработанная стоимость составляет 30000 рублей.
- Третьим ключевым показателем является фактическая стоимость выполненных работ. Например, предположим, что вам нужно было ввести более дорогой ресурс, поэтому затраты на рабочую силу фактически составляют 35000 рублей. Это ваша реальная стоимость.
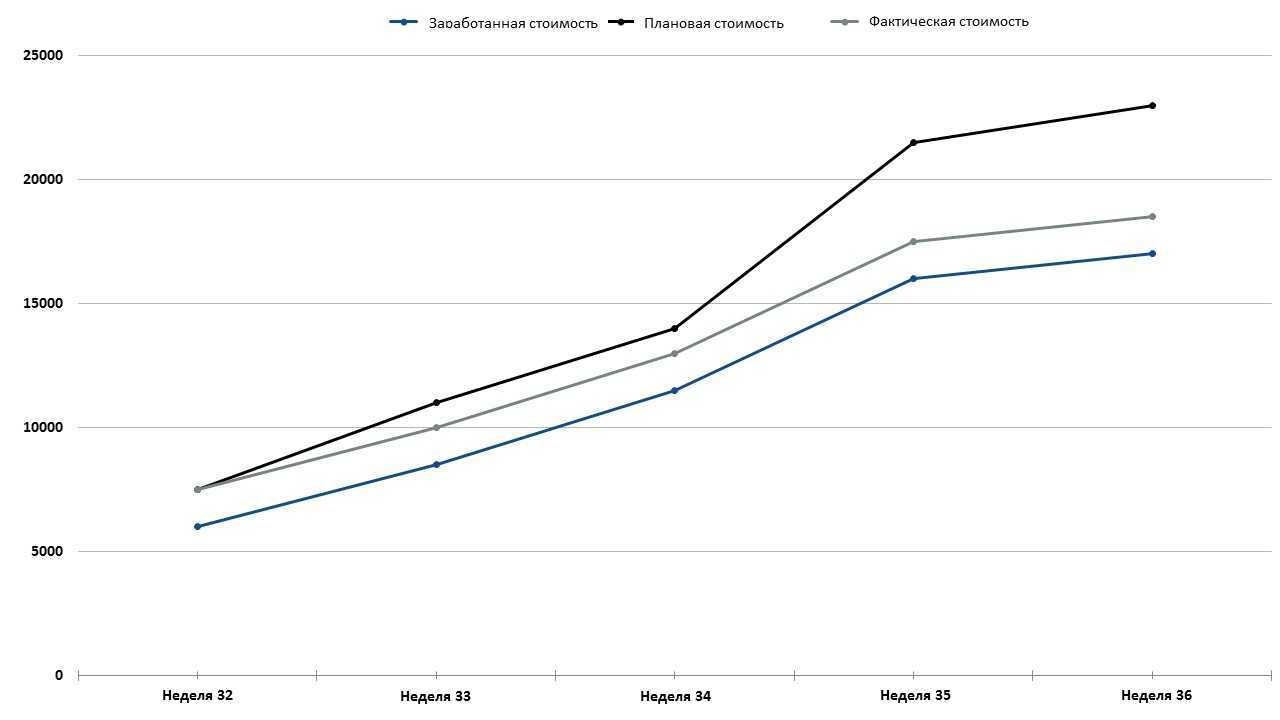
Глядя на эти значения на графике, легко увидеть, соответствует ли ваш проект графику и бюджету. Вот как вы читаете график освоенного объема:
- Во-первых, время находиться на горизонтальной оси, а стоимость – на вертикальной.
- Во-вторых, вы хотите, чтобы освоенная стоимость превышала плановую. Это означает, что вы выполнили больше работы, чем планировали. Другими словами, задача или проект опережают график. В этом примере освоенная стоимость ниже плановой стоимости, поэтому этот проект отстает от графика.
- В-третьих, вы хотите видеть фактическую стоимость ниже освоенной стоимости. Это означает, что вы фактически потратили на выполненную работу меньше, чем предполагали. В этом проекте фактическая стоимость превышает освоенную стоимость, поэтому проект также превышает бюджет.
Если вы заинтересованы в использовании показателей освоенной стоимости в своих проектах, вы можете изучить этот инструмент более подробно.
Что такое мониторинг программ[править]
Если подходить к программе как к деятельности, направленной на достижение определенной цели за ограниченное время при использовании заранее определенных ресурсов, то нельзя забывать, что важным элементом разработки программы является планирование процесса её выполнения. Для осуществления программы необходимы ресурсы, под которыми можно понимать материалы, людей, технологии и.т.д. Каждой программе для нормального функционирования требуется отслеживание и анализ полученных результатов. Мониторингом программ является функция отслеживания хода и результатов работы программы.
Демонстрационный режим
Чтобы увидеть наглядно на примере возможности мониторинга целевых показателей без обязательного введения точных данных широко используется демонстрационный режим. Он востребован в следующих ситуациях:
- начало внедрения системы при условии недостаточного объема информационных параметров, необходимых для отображения данных, но при необходимости принять решение о применении подсистемы целевых показателей;
- разработка шаблонов расчета и проектирования структуры мониторинга целевых показателей (внешний вид отображения информации согласуется с менеджерами до этапа окончательного создания шаблонов);
- освоение настроек анализа, изучение его типов и визуализации целевых показателей.



