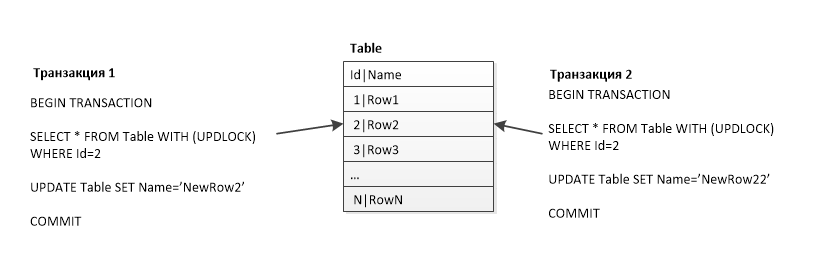
Совместимость
Инструкцию DELETE можно использовать в тексте определяемой пользователем функции, если изменяемым объектом является табличная переменная.
При удалении строки, содержащей столбец FILESTREAM, также удаляются и связанные с ней файлы файловой системы. Базовые файлы удаляются сборщиком мусора FILESTREAM. Дополнительные сведения см. в разделе Доступ к данным FILESTREAM с помощью Transact-SQL.
В инструкции DELETE, которая прямо или косвенно ссылается на представление с определенным для него триггером , не может быть указано предложение FROM. Дополнительные сведения о триггерах INSTEAD OF см. в разделе CREATE TRIGGER (Transact-SQL).
Режим блокировки
По умолчанию инструкция всегда получает монопольную блокировку намерения (IX) для объекта таблицы и страниц, которые он изменяет, монопольную блокировку (X) для строк, которые он изменяет, и удерживает эти блокировки до завершения транзакции.
Если ресурс удерживается монопольной блокировкой намерения (IX), другие транзакции не могут изменять тот же набор данных. Операции считывания будут допускаться только при наличии подсказки NOLOCK или уровня изоляции незафиксированной операции чтения. Можно переопределить поведение оптимизатора запросов по умолчанию с помощью табличных подсказок на время выполнения инструкции DELETE указанием другого способа блокировки, но использовать подсказки рекомендуется только опытным разработчикам и администраторам баз данных и только при крайней необходимости. Дополнительные сведения см. в разделе Указания по таблицам (Transact-SQL).
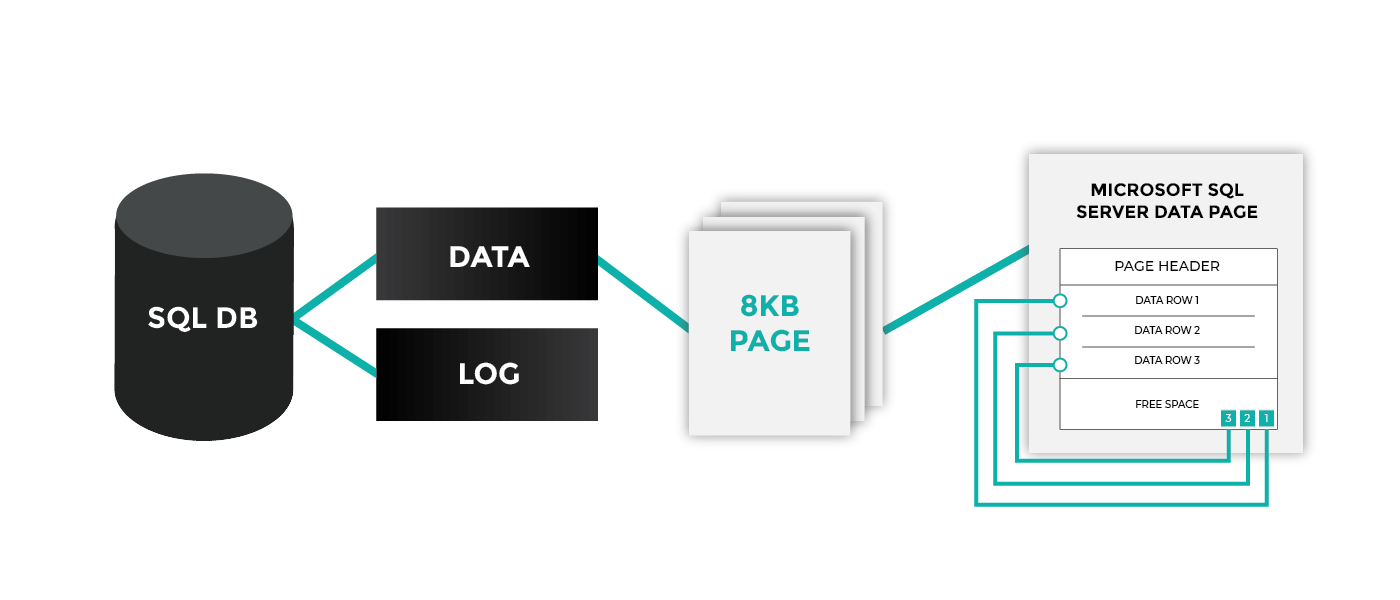
Когда строки удаляются из кучи, компонент Компонент Database Engine может использовать строку или страницу блокировки для операции. В результате пустые страницы, в которых выполняются операции удаления, остаются размещенными для кучи. Если их не освободить, занимаемое ими место не может быть использовано под другие объекты базы данных.
Чтобы удалить из кучи строки и освободить страницы, воспользуйтесь одним из следующих методов.
-
Задайте указания TABLOCK в инструкции DELETE. Использование TABLOCK приведет к тому, что при выполнении операции удаления будет установлена блокировка IX объекта, а не блокировка строки или страницы. что позволит освободить страницы. Дополнительные сведения об указании TABLOCK см. в разделе Табличные указания (Transact-SQL).
-
Если из таблицы удаляются все строки, пользуйтесь инструкцией .
-
Перед удалением строк создайте в куче кластеризованный индекс. Потом его можно будет удалить. Этот метод потребует больше времени и потребляет больше временных ресурсов.
Примечание
Пустые страницы можно удалить из кучи в любое время с помощью инструкции .
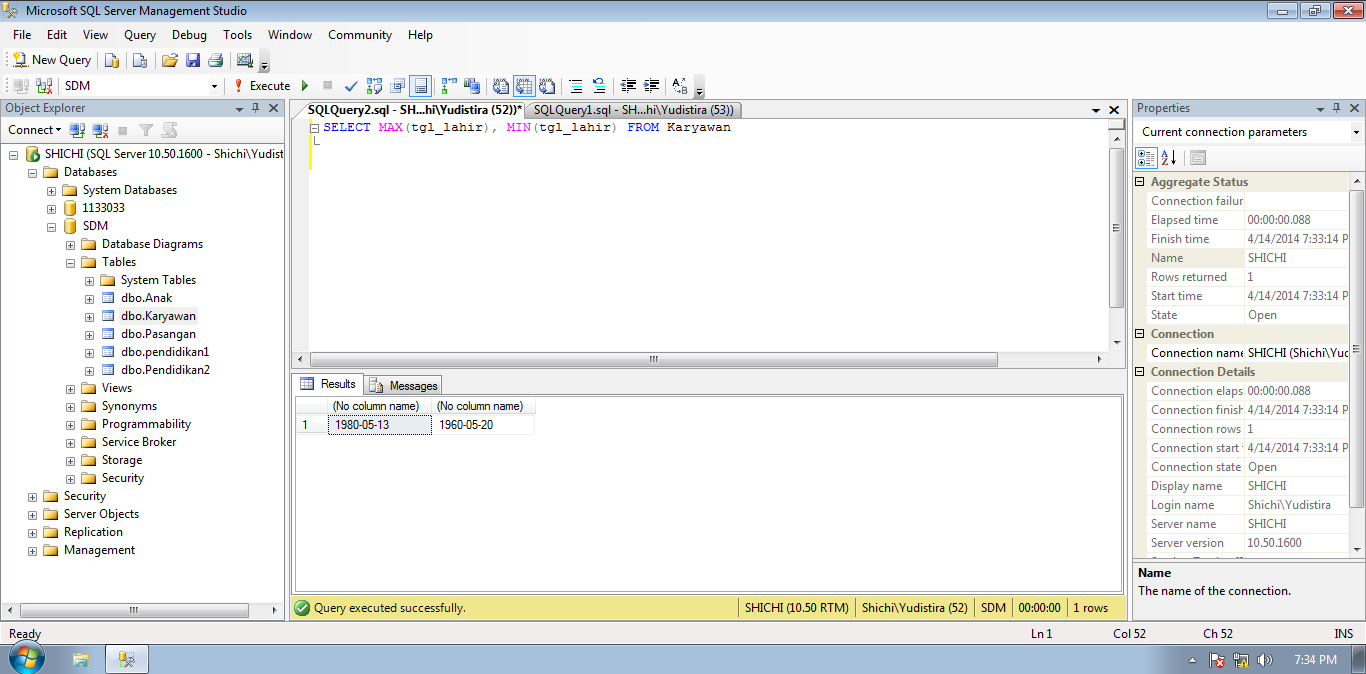
Как нормализовать набор данных без преобразования столбцов в массив?
Давайте посмотрим, что произойдет, когда мы попытаемся нормализовать набор данных без преобразования функций в массивы для обработки.
from sklearn import preprocessing
import pandas as pd
housing = pd.read_csv("/content/sample_data/california_housing_train.csv")
d = preprocessing.normalize(housing)
scaled_df = pd.DataFrame(d, columns=names)
scaled_df.head()
Вывод :

Здесь значения нормализованы по строкам, что может быть очень неинтуитивно. Нормализация по строкам означает, что нормализуется каждая отдельная выборка, а не признаки.
Однако вы можете указать ось при вызове метода для нормализации по элементу (столбцу).
Значение параметра оси по умолчанию установлено на 1. Если мы изменим значение на 0, процесс нормализации произойдет по столбцу.
from sklearn import preprocessing
import pandas as pd
housing = pd.read_csv("/content/sample_data/california_housing_train.csv")
d = preprocessing.normalize(housing, axis=0)
scaled_df = pd.DataFrame(d, columns=names)
scaled_df.head()
Вывод :

Вы можете видеть, что столбец для total_bedrooms в выходных данных совпадает с тем, который мы получили выше после преобразования его в массив и последующей нормализации.
Обработка ошибок
Для DELETE можно реализовать обработку ошибок, заключив инструкцию в конструкцию .
При выполнении инструкции может возникнуть ошибка, если инструкция нарушает триггер или пытается удалить строку, на которую ссылаются данные в другой таблице с помощью ограничения . Если удаляет несколько строк, и одна из удаленных строк нарушает триггер или ограничение, эта инструкция отменяется, возвращается ошибка и строки не удаляются.
В случае арифметической ошибки (переполнение, деление на ноль или выход за пределы допустимых значений), возникающей в ходе вычисления выражения при выполнении инструкции DELETE, Компонент Database Engine будет обрабатывать эти ошибки, как если бы для было задано значение ON. Оставшаяся часть пакетной операции отменяется и возвращается сообщение об ошибке.
Объединение реляционных данных и данных JSON
SQL Server предоставляет гибридную модель для хранения и обработки реляционных данных и данных JSON с использованием стандартного языка Transact-SQL. Вы можете формировать коллекции документов JSON в таблицах, устанавливать отношения между ними, комбинировать строго типизированные скалярные столбцы, которые хранятся в таблицах с гибкими парами «ключ —значение», хранящимися в столбцах JSON, и запрашивать скалярные значения и значения JSON в одной таблице или нескольких с использованием полного Transact-SQL.
Текст JSON обычно хранится в столбцах или и индексируется как обычный текст. Любая функция или компонент SQL Server, которые поддерживают текст, поддерживают и JSON, поэтому в обмене данных между JSON и другими компонентами SQL Server нет практически никаких ограничений. JSON можно хранить во временных таблицах или в таблицах в памяти, применять к тексту JSON предикаты безопасности на уровне строк и т. д.
Рассмотрим несколько способов применения встроенной поддержки JSON в SQL Server.
Метод 7. Использование метода z-оценки
Следующий метод, который мы хотим обсудить, — это метод z-оценки. Он преобразует информацию в распределение. Метод z-оценки вычисляет среднее значение каждого столбца, затем вычитает его из каждого столбца и, наконец, делит на стандартное отклонение. Таким образом мы получаем данные, нормализованные между -1 и 1.
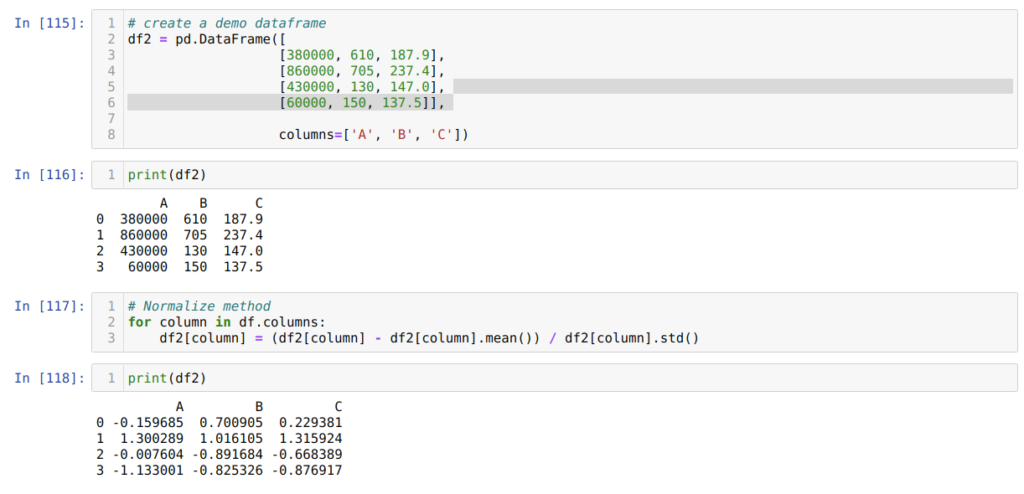
В ячейке номер мы создаем фрейм фиктивных данных и выводим его.
Далее, в ячейке , мы вычисляем среднее значение столбцов и вычитаем его из каждого столбца. Затем делим значение столбца на стандартное отклонение.
В итоге, в ячейке номер мы получаем и выводим на экран данные, нормализованные в диапазоне от -1 до 1.
Проверка встроенной поддержки JSON с образцом базы данных AdventureWorks
Чтобы получить образец базы данных AdventureWorks, скачайте по крайней мере файл базы данных и примеры сценариев с GitHub.
После восстановления образца базы данных в экземпляре SQL Server распакуйте файлы образца и откройте файл JSON Sample Queries procedures views and indexes.sql в папке JSON. Выполните сценарии в этом файле, чтобы переформатировать некоторые данные как данные JSON, протестируйте образцы запросов и отчеты по данным JSON, индексируйте данные JSON, а затем импортируйте и экспортируйте JSON.
Вот, что делать с помощью скриптов, включенных в файл.
-
Выполнить денормализацию существующей схемы для создания столбцов данных JSON.
-
Сохранить информацию из , , , и других таблиц, содержащих информацию о заказах на продажу, в столбцах JSON в таблице .
-
-
Создайте процедуры и представления для запроса данных JSON.
-
Проиндексируйте данные JSON. Создайте индексы свойств JSON и полнотекстовые индексы.
-
-
Импортируйте и экспортируйте JSON. Создать и запустить процедуры для экспорта содержимого таблиц и в качестве результатов в формате JSON, а затем импортировать и обновить таблицы и , используя входные данные JSON.
-
Выполните примеры запросов. Выполните несколько запросов, вызывающих хранимые процедуры и представления, которые были созданы при выполнении шагов 2 и 4.
-
Очистите скрипты. Не выполняйте это действие, если хотите оставить хранимые процедуры и представления, которые были созданы при выполнении шагов 2 и 4.
Разделители нулевой длины
Если разделитель, переданный в String # split , является строкой нулевой длины или регулярным выражением, тогда Разделение строки # будет действовать немного иначе. Он ничего не удалит из исходной строки и разделит на каждый символ. По сути, это превращает строку в массив равной длины, содержащий только односимвольные строки, по одной для каждого символа в строке.
Это может быть полезно для итерации над строкой и использовался в версиях до 1.9.x и до 1.8.7 (которые поддерживали ряд функций из 1.9.x) для перебора символов в строке, не беспокоясь о разбиении многобайтовых символов Unicode. Однако, если вы действительно хотите перебирать строку и используете 1.8.7 или 1.9.x, вам, вероятно, следует вместо этого использовать String # each_char .
#!/usr/bin/env ruby str = "Она превратила меня в тритона!" str.split ('' ). каждый do | c | помещает c end
Сопоставление перечислений
LINQ to SQL поддерживает два способа для сопоставления типа CLR System.Enum с типами SQL Server.
-
Сопоставление с числовыми типами SQL (, , , ).
При сопоставлении типа System.Enum среды CLR с числовым типом SQL, выполняется сопоставление базового целочисленного значения CLR System.Enum со значением в столбце базы данных SQL Server. Например, если объект System.Enum с именем содержит элемент с именем , базовое целочисленное значение для которого равно 3, то этому элементу сопоставляется значение 3 в базе данных.
-
Сопоставление с текстовыми типами SQL (, , , ).
При сопоставлении типа CLR System.Enum с текстовым типом SQL выполняется сопоставление значения в базе данных SQL с именами элементов перечисления CLR System.Enum. Например, если объект System.Enum с именем содержит элемент с именем , базовое целочисленное значение для которого равно 3, то этому элементу сопоставляется значение в базе данных.
Примечание
При сопоставлении текстовых типов SQL с типом CLR System.Enum в сопоставляемый столбец SQL включаются только имена элементов Enum. Прочие значения в столбце SQL, сопоставленном с Enum, не поддерживаются.
Реляционный конструктор объектов и программа командной строки SQLMetal не выполняют автоматическое сопоставление типа SQL с классом CLR Enum. Такое сопоставление необходимо настроить вручную, изменив DBML-файл для использования реляционным конструктором объектов и программой SQLMetal. дополнительные сведения о сопоставлении настраиваемых типов см. в статье сопоставления настраиваемых типов SQL-CLR.
так как столбец SQL, предназначенный для перечисления, будет иметь тот же тип, что и другие числовые и текстовые столбцы; эти средства не будут распознавать намерения и по умолчанию для сопоставления, как описано в следующих разделах и сопоставления. Дополнительные сведения о создании кода с помощью файла DBML см. в разделе Создание кода в LINQ to SQL.
Метод DataContext.CreateDatabase создает столбец SQL числового типа в соответствии с типом CLR System.Enum.
Расширенная проверка Transact-SQL
Важно!
Функция расширенной проверки Transact-SQL будет удалена из следующей версии SQL Server Data Tools и следующей основной версии Visual Studio.
Расширенная проверка Transact-SQL — это средство системы проекта базы данных, которое позволяет разработчикам передавать свои проекты базы данных в службу Transact-SQL Compiler Service во время сборки для проверки их кода с помощью синтаксического анализатора и интерпретатора ядра SQL Server.
Служба Transact-SQL Compiler Service
Служба Transact-SQL — это компонент, основанный на ядре СУБД Microsoft SQL Server 2012. Эта служба позволяет проверять синтаксис и семантику инструкций DDL с той же достоверностью, что и ядро СУБД Microsoft SQL Server 2012. Это автоматически означает, что служба компилятора не поддерживает синтаксические конструкции или функции, которые стали устаревшими в Microsoft SQL Server 2012. Дополнительные сведения об устаревших функциях см. в разделе Неподдерживаемые функциональные возможности ядра СУБД в SQL Server 2012.
В целях проверки проекта базы данных служба Compiler Service создает частично автономную базу данных и имитирует выполнение инструкций DDL применительно к этой базе данных. Дополнительные сведения см. в разделе Частично автономные базы данных.
На службу Compiler Service распространяются ограничения двух категорий.
Средства, которые зависят от конфигурации базы данных или экземпляра, включая следующие:
-
ссылки на трех- или четырехкомпонентные объекты
-
Таблицы FileTable
-
Отслеживание изменений
-
Функции набора строк — OPENROWSET, OPENQUERY, OPENDATASOURCE
-
Полнотекстовый семантический поиск
Средства, которые в настоящее время не поддерживаются для проверки, включая следующие:
-
Компонент Service Broker
-
Секционированные схемы с определяемыми пользователем группами FileGroups
-
Параметры сортировки метаданных SQL Azure (в службах Compiler Service используются параметры сортировки метаданных частично автономных баз данных SQL Server 2012 — Latin1_General_100_CI_AS_KS_WS_SC)
Включение и отключение расширенной проверки
Расширенная проверка Transact-SQL включена по умолчанию в проекте базы данных, который создан непосредственно из Базы данных SQL Azure, или в проекте, для которого в качестве целевой платформы задана SQL Azure. Рекомендуется использовать расширенную проверку при разработке для SQL Azure или при создании базы данных уровня приложения, предназначенной для SQL Server 2012. Дополнительные сведения о базах данных уровня приложения см. в разделе Частично автономные базы данных.
Функцию расширенной проверки можно также использовать при разработке базы данных уровня приложения для SQL Server 2008/R2 в целях достижения совместимости с Microsoft SQL Server 2012 и SQL Azure.
Включение или отключение расширенной проверки на уровне проекта
-
В обозревателе решений щелкните правой кнопкой мыши файл проекта и выберите Свойства.
-
В окне Параметры проекта, в разделе Целевая платформа установите или снимите флажок Включить расширенную проверку Transact-SQL для общих объектов.
Включение расширенной проверки на уровне файлов
-
Дважды щелкните правой кнопкой мыши SQL-файл в обозревателе решений.
Примечание
Чтобы отключить средства расширенной проверки Transact-SQL на уровне файлов, задайте для свойства Действие сборки значение Сборка.
-
В окне Свойства измените значение свойства Расширенная проверка T-SQL на False.
Дополнительные сведения о параметрах сортировки в частично автономных базах данных см. в разделе Параметры сортировки в автономной базе данных.


Возврат данных из таблицы SQL Server в формате JSON
Если у вас есть веб-служба, которая получает данные с уровня базы данных и возвращает их в формате JSON, либо платформы или библиотеки JavaScript, которые принимают данные в формате JSON, вы можете отформатировать выходные данные JSON прямо в запросе SQL. Вместо написания кода или включения библиотеки для преобразования результатов табличных запросов и последующей сериализации объектов в формате JSON вы можете делегировать форматирование в SQL Server с помощью FOR JSON.
Например, можно сформировать выходные данные JSON, совместимые со спецификацией OData. Веб-служба ожидает запрос и ответ в указанном ниже формате.
-
Запрос:
-
Ответ:
URL-адрес OData представляет запрос столбцов ProductID и ProductName для продукта с 1. FOR JSON можно использовать для форматирования выходных данных для SQL Server.
Выходные данные этого запроса — текст JSON, который полностью соответствует спецификации OData. Форматирование и экранирование выполняются SQL Server. SQL Server может также выдать результаты запроса в любом формате, таком как OData JSON или GeoJSON.
Наблюдение за процессом
Наблюдение за процессом отслеживания измененных данных позволяет определить, правильно ли записываются изменения и насколько приемлема задержка при записи в таблицы изменений. Наблюдение также помогает выявить возможные ошибки. SQL Server включает два динамических представления управления, которые помогают отслеживать фиксацию измененных данных: sys.dm_cdc_log_scan_sessions и sys.dm_cdc_errors.
Выявление сеансов с пустыми результирующими наборами
Каждая строка в административном представлении sys.dm_cdc_log_scan_sessions представляет сеанс просмотра журнала (за исключением строки с идентификатором 1). Сеанс просмотра журнала является эквивалентом одного выполнения хранимой процедуры sp_cdc_scan. Во время сеанса просмотр может возвратить изменения или пустой результат. Если результирующий набор пуст, то для столбца empty_scan_count в представлении sys.dm_cdc_log_scan_sessions устанавливается значение 1. Если пустые результирующие наборы встречаются последовательно (например, при непрерывном выполнении задания отслеживания), то счетчик empty_scan_count в последней существующей строке увеличивается. Например, если в представлении sys.dm_cdc_log_scan_sessions уже существует 10 строк просмотров, возвративших данные об изменениях, и пять результатов подряд были пусты, то в представлении будет содержаться 11 строк. В столбце empty_scan_count последней строки содержится значение 5. Чтобы определить сеансы, возвратившие пустой результирующий набор, выполните следующий запрос.
Определение задержки
В административное представление включен столбец, записывающий задержку для каждого сеанса отслеживания. Задержка представляет собой время, прошедшее между фиксацией транзакции в исходной таблице и фиксацией последней отслеженной транзакции в таблицу изменений. Столбец задержки заполняется только для активных сеансов. У сеансов, значение в столбце empty_scan_count для которых больше 0, для столбца задержки устанавливается значение 0. Следующий запрос возвращает среднее время задержки для наиболее новых сеансов.
Данные о задержках можно использовать для определения того, насколько быстро или медленно процесс отслеживания обрабатывает транзакции. Эти данные наиболее полезны в том случае, если процесс отслеживания выполняется непрерывно. Если процесс отслеживания выполняется по расписанию, то задержка может быть высокой, ввиду запаздывания между фиксацией транзакций в исходной таблице и выполнением процесса отслеживания по его расписанию.
Еще одним важным показателем эффективности процесса отслеживания является пропускная способность. Это среднее число команд в секунду, обрабатываемых в каждом сеансе. Для определения пропускной способности сеанса следует разделить значение в столбце command_count column на значение в столбце продолжительности. Следующий запрос возвращает среднюю пропускную способность для наиболее новых сеансов.
Получение выборки данных с помощью сборщика данных
Сборщик данных SQL Server позволяет осуществлять сбор моментальных снимков из любой таблицы или динамического административного представления и создать хранилище данных о производительности. Если для базы данных активирована система отслеживания измененных данных, то полезно создавать снимки представлений sys.dm_cdc_log_scan_sessions и sys.dm_cdc_errors с регулярными интервалами для последующего анализа. Следующая процедура настраивает сборщик данных на сбор образцов данных из административного представления sys.dm_cdc_log_scan_sessions.
Настройка сбора данных
-
Включите сборщик данных и настройте хранилище данных управления. Дополнительные сведения см. в разделе Управление сбором данных.
-
Выполните следующий код для создания пользовательского сборщика для отслеживания измененных данных.
-
В среде SQL Server Management Studioразверните вкладку Управление, затем вкладку Сбор данных. Щелкните правой кнопкой мыши пункт Сборщик данных о производительности CDC, затем пункт Запустить набор сбора данных.
-
В хранилище данных, которое было настроено в шаге 1, найдите таблицу custom_snapshots.cdc_log_scan_data. В данной таблице предоставлен архивный моментальный снимок данных из сеансов просмотра журнала. Эти данные могут быть использованы для анализа задержки, пропускной способности и других показателей производительности во времени.
Запрос вложенных иерархических подмассивов JSON
Вы можете использовать несколько вызовов для запроса вложенных структур JSON. В документе JSON, используемом в этом примере, есть вложенный массив с именем , каждый дочерний элемент которого имеет вложенный массив . Следующий запрос будет анализировать дочерние элементы из каждого документа, возвращать каждый объект массива в виде строки, а затем анализировать массив :
Первый вызов вернет фрагмент массива с помощью предложения AS JSON. Этот фрагмент массива будет передан во вторую функцию , которая вернет , каждого дочернего элемента, а также массив . Массив будет передан в третью функцию , которая вернет значение для домашнего животного.
Результаты этого запроса показаны в приведенной ниже таблице.
| familyName | childGivenName | childFirstName | petName |
|---|---|---|---|
| AndersenFamily | Jesse | Merriam | Goofy |
| AndersenFamily | Jesse | Merriam | Shadow |
| AndersenFamily | Lisa | Miller |
Корневой документ объединяется с двумя строками , возвращаемыми при первом вызове , в результате чего получаются две строки (или два кортежа). Затем каждая строка объединяется с новыми строками, созданными функцией , с помощью оператора . У Jesse два домашних животных, поэтому объединяется с двумя строками, созданными для Goofy и Shadow. У Лизы нет домашних животных, поэтому для этого кортежа не возвращаются строки. Однако, так как используется оператор , в столбце будет значение . Если использовать вместо , Lisa не будет возвращаться в результатах из-за отсутствия строк домашних животных, которые можно было бы объединить с этим кортежем.
Remarks
Параметр путь_json, который используется в качестве второго аргумента инструкции OPENJSON или в предложении_with, может начинаться с ключевого слова lax или strict.
- В нестрогом режиме OPENJSON не выдает ошибку, если не удалось найти объект или значение по указанному пути. Если не удается найти путь, OPENJSON возвращает пустой результирующий набор или значение NULL.
- В строгом режиме OPENJSON возвращает ошибку, если путь не найден.
В некоторых примерах на этой странице явно указывается режим пути: нестрогий или строгий режим. Режим пути является необязательным. Если режим пути не указан явно, по умолчанию используется нестрогий режим. Дополнительные сведения о режиме пути и выражениях пути см. в статье Выражения пути JSON (SQL Server).
Имена столбцов в предложении_with сопоставляются с ключами в тексте JSON. Если указать имя столбца , он сопоставляется с ключом . Если требуется сослаться на вложенный ключ в объекте , нужно указать путь в пути столбца.
Путь_json может содержать ключи с буквенно-цифровые символами. Если в ключах используются специальные символы, экранируйте имя ключа в пути_json двойными кавычками. Например, соответствует значению 1 в следующем тексте JSON:
Выражения
Выражения — это выражение формулы в исходном коде. Выражение может иметь побочные эффекты: например, при вызове функции внутри выражения функция может что-то напечатать. В типичном языке программирования есть как минимум следующие типы выражений:
- Доступ к переменной (variable access): например,
- Литерал (literal): например, или
- Унарный оператор (unary operator): например,
- Бинарный оператор (binary operator): например, или
- Разные бинарные операторы обычно имеют разный приоритет и могут группироваться скобками, но в функциональных языках (LISP, Haskell) операторы бывают неотличимы от функций
- Типовой набор операторов: арифметические, логические, сравнения; такой набор уже позволяет создавать полноценные программы
- Вызов функции (function call): например,
Восходящий разбор методом свёртки (LL, LR, SLR, LALR)
Если вы используете табличный недетерминированный конечный автомат со стеком для восходящего разбора методом свёртки, то вы можете следовать нескольким правилам:
- добавляйте действия по созданию AST в список действий при свёртке в рамках атрибутивной грамматики
- на каждое правило грамматики создавайте узлы AST с помощью оператора
- сохраняйте указатели на узлы в ячейку стека парсера, соответствующую результату свёртки текущего правила
- извлекайте из соответствующих ячеек стека результаты свёртки предыдущих правил
Пример декларативного описания правила грамматики с конструированием AST (для генератора парсеров Lemon):
Обработка готового AST
Путём обработки готового AST можно
- во фронтенде компилятора или интерпретатора: проверять семантические правила языка
- в компиляторе: выполнять генерацию промежуточного или машинного кода
- в компиляторе или интерпретаторе: генерировать код виртуальной машины
- в интерпретаторе: выполнять программу непосредственно
- для отладки: печатать AST, полученный из парсера
Реализация рекомендаций по настройке
Рекомендации помощника по настройке ядра СУБД можно реализовать вручную или автоматически в качестве компонента текущего сеанса. Для изучения результатов настройки перед их реализацией пользуйтесь графическим интерфейсом пользователя помощника по настройке ядра СУБД. Затем можно использовать SQL Server Management Studio для выполнения скриптов Transact-SQL, которые помощник по настройке ядра СУБД создаются в результате анализа рабочей нагрузки для реализации рекомендаций. Если не нужно проверять результаты перед их реализацией, укажите параметр -a в программе командной строки dta . Этот параметр передает программе указание автоматически применить рекомендации по настройке после проведения анализа рабочей загрузки. Следующие процедуры иллюстрируют, как использовать оба интерфейса помощника по настройке ядра СУБД для реализации его рекомендаций.
Включение быстрого анализа
Свойство быстрого анализа необходимо установить для каждого столбца источника или преобразования, использующего этот анализ. Для установки этого свойства используется расширенный редактор источника «Неструктурированный файл» и преобразование «Преобразование данных».
-
Щелкните правой кнопкой источник «Неструктурированный файл» или преобразование «Преобразование данных» и выберите Показать расширенный редактор.
-
В диалоговом окне Расширенный редактор перейдите на вкладку Свойства входов и выходов .
-
На панели Входы и выходы щелкните столбец, для которого нужно включить быстрый анализ.
-
В окне «Свойства» разверните узел Пользовательские свойства и задайте свойству FastParse значение True.
-
Нажмите кнопку ОК.
Метод join()
Теперь, когда вы знаете, как разбить строку на подстроки, пора научиться использовать метод join() для формирования строки из подстрок.
Синтаксис метода Python join() следующий:
Здесь – любой итерируемый объект Python, содержащий подстроки. Это может быть, например, список или кортеж. – это разделитель, с помощью которого вы хотите объединить подстроки.
По сути, метод join() объединяет все элементы в , используя в качестве разделителя.
А теперь пора примеров!
Примеры использования метода join() в Python
В предыдущем разделе мы разбивали строку по запятым и получали в итоге список подстрок. Назовем этот список .

Теперь давайте сформируем строку, объединив элементы этого списка при помощи метода join(). Все элементы в – это названия фруктов.
my_list = my_string.split(",")
# после разделения my_string мы получаем my_list:
#
Обратите внимание, что разделитель для присоединения должен быть указан именно в виде строки. В противном случае вы столкнетесь с синтаксическими ошибками
Чтобы объединить элементы в с использованием запятой в качестве разделителя, используйте а не просто . Это показано во фрагменте кода ниже.
", ".join(my_list) # Output: Apples, Oranges, Pears, Bananas, Berries
Здесь элементы объединяются в одну строку с помощью запятых, за которыми следуют пробелы.
Разделитель может быть любым.
Давайте для примера используем в качестве разделителя 3 символа подчеркивания .
"___".join(my_list) # Output: Apples___Oranges___Pears___Bananas___Berries
Элементы в теперь объединены в одну строку и отделены друг от друга тремя подчеркиваниями .
Теперь вы знаете, как сформировать одну строку из нескольких подстрок с помощью метода join().
6.3.7. Создание полиномиальных признаков
Часто бывает полезно усложнить модель, учитывая нелинейные особенности входных данных. Простой и распространенный метод использования — это полиномиальные функции, которые могут получить термины высокого порядка и взаимодействия функций. Реализован в :
>>> import numpy as np
>>> from sklearn.preprocessing import PolynomialFeatures
>>> X = np.arange(6).reshape(3, 2)
>>> X
array(,
,
])
>>> poly = PolynomialFeatures(2)
>>> poly.fit_transform(X)
array(,
,
])
Особенности X были преобразованы из $(X_1, X_2)$ к $(1, X_1, X_2, X_1^2, X_1X_2, X_2^2)$.
В некоторых случаях требуются только условия взаимодействия между функциями, и это можно получить с помощью настройки :
>>> X = np.arange(9).reshape(3, 3)
>>> X
array(,
,
])
>>> poly = PolynomialFeatures(degree=3, interaction_only=True)
>>> poly.fit_transform(X)
array(,
,
])
Особенности $X$ были преобразованы из $(X_1, X_2, X_3)$ к $(1, X_1, X_2, X_3, X_1X_2, X_1X_3, X_2X_3, X_1X_2X_3)$.
Обратите внимание , что полиномиальные функции используются неявно в методах ядра (например, , ) при использовании полиномиальных . См
Раздел Полиномиальная интерполяция для регрессии Риджа с использованием созданных полиномиальных функций
См. Раздел Полиномиальная интерполяция для регрессии Риджа с использованием созданных полиномиальных функций.