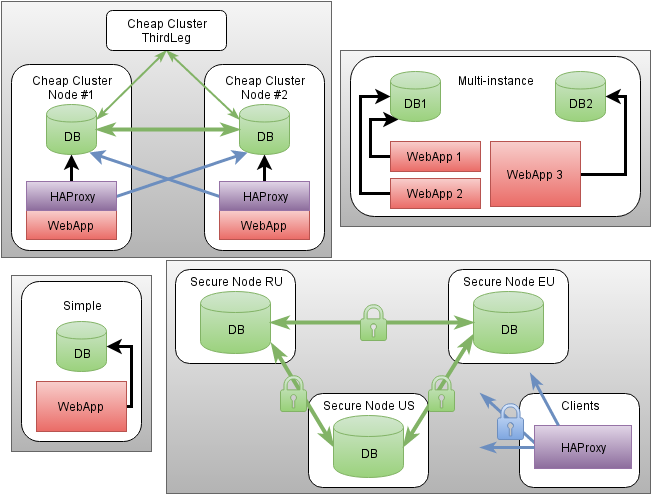
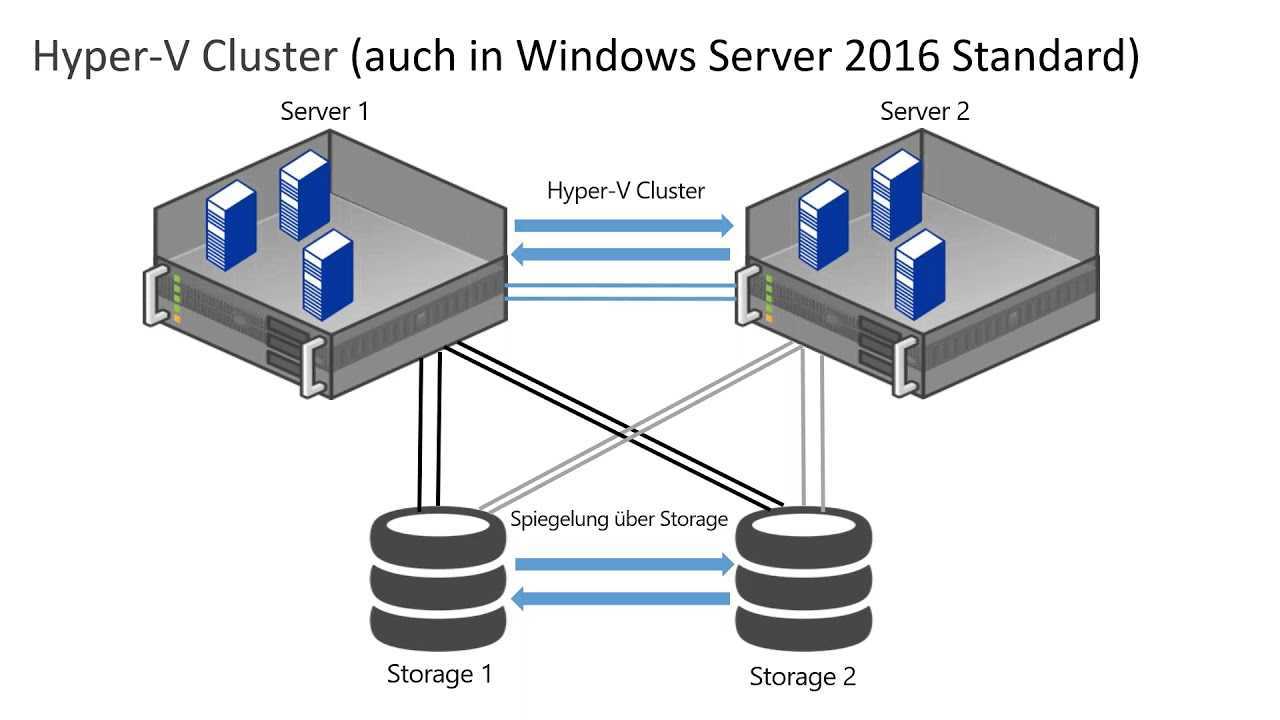
Проверка репликации данных
На одном из узлов создадим базу данных, таблицу и вставим данные в нее:
$ mysql -uroot MariaDB > create database test; Query OK, 1 row affected (0.121 sec) MariaDB > create table test.test (id INT PRIMARY KEY, name VARCHAR(32)); Query OK, 0 rows affected (0.195 sec) MariaDB > insert into test.test values(1, "name"); Query OK, 1 row affected (0.003 sec)
Убедимся, что репликация произошла на оставшиеся узлы, выполнив на каждом из них команду запроса данных:
$ mysql -uroot -e 'select * from test.test;' +----+------+ | id | name | +----+------+ | 1 | name | +----+------+
Аналогичным образом вы можете осуществить проверку и для других операций.
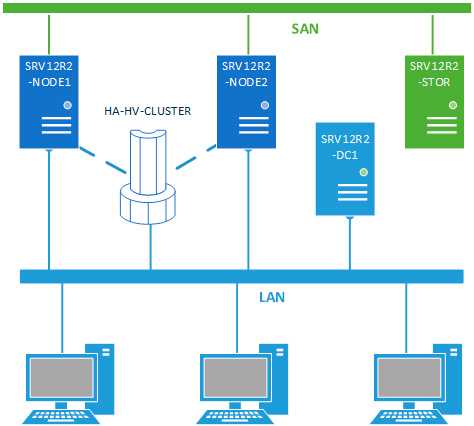
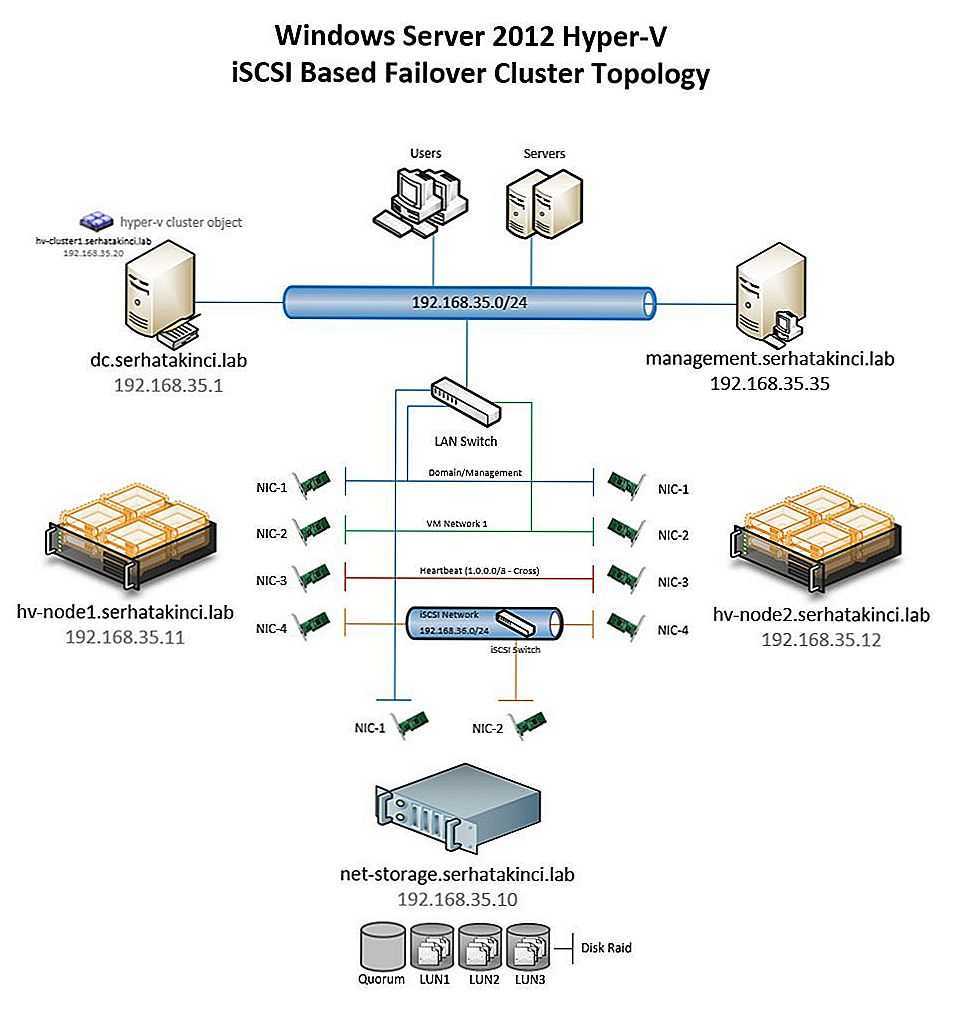
Требования к оборудованию для Hyper-V
Если вы создаете отказоустойчивый кластер с кластерными виртуальными машинами, то серверы кластера должны отвечать требованиям к оборудованию для роли Hyper-V. Для Hyper-V требуется 64-разрядный процессор, включающий следующие возможности.
- Виртуализация с использованием оборудования. Это возможно на процессорах, допускающих виртуализацию, а именно на процессорах с технологией Intel Virtualization Technology (Intel VT) или AMD Virtualization (AMD-V).
- Должна быть доступна и включена технология аппаратного предотвращения выполнения данных (DEP). То есть необходимо включить атрибут Intel XD (атрибут отключения выполнения) или AMD NX (атрибут запрета выполнения).
Дополнительные сведения о роли Hyper-V см. в статье Обзор Hyper-V.
Рекомендации
Ознакомьтесь с заметками о выпуске за SQL Server 2019 и SQL Server 2022 г.
Обязательное программное обеспечение для установки. Перед запуском программы установки для установки или обновления установите следующие компоненты, чтобы сократить время установки. Можно установить обязательное программное обеспечение на каждом узле отказоустойчивого кластера, а затем один раз перезапустить узлы перед началом работы программы установки.
-
Windows PowerShell больше не устанавливается программой установки SQL Server . Windows PowerShell является необходимым условием для установки компонентов ядра СУБД SQL Server и SQL Server Management Studio. Если Windows PowerShell отсутствует на компьютере, его можно включить, следуя инструкциям на странице Windows Management Framework.
-
платформа .NET Framework 3.5 с пакетом обновления 1 (SP1) больше не устанавливается программой установки SQL Server, но может потребоваться при установке SQL Server в более старых операционных системах Windows. Дополнительные сведения см. в статье Требования к оборудованию и программному обеспечению для SQL Server 2019.
-
пакет обновления Майкрософт. Чтобы избежать перезагрузки компьютера из-за установки платформа .NET Framework 4 во время установки, SQL Server программа установки требует установки Майкрософт обновления на компьютере. Для SQL Server 2014 (12.x) и более поздних версий, устанавливаемых в поддерживаемых версиях Windows, это обновление уже включено. Если вы устанавливаете в более ранней версии операционной системы Windows, скачайте ее из Майкрософт обновления для платформа .NET Framework 4.0 в Windows Vista и Windows Server 2008.
-
.NET Framework 4. Программа установки устанавливает платформу .NET Framework 4 в кластеризованной операционной системе. Чтобы сократить время установки, перед запуском программы установки рекомендуется установить .NET Framework 4.
-
SQL Server Настройка файлов поддержки. Эти файлы можно установить, запустив файл SqlSupport.msi, который находится на установочном носителе.
Убедитесь, что антивирусная программа не установлена в кластере WSFC. Дополнительные сведения см. в статье Microsoft Базы знаний Майкрософт, Antivirus software may cause problems with cluster services.
В имени кластерной группы при установке отказоустойчивого кластера нельзя использовать следующие символы:
-
Оператор «меньше» ()
-
оператор «больше» ();
-
Двойная кавычка ()
-
Одна кавычка ()
-
амперсанд ().
Кроме того, убедитесь, что существующие имена групп кластеров не содержат неподдерживаемых символов.
Необходимо, чтобы все узлы кластера имели одинаковую конфигурацию, в т.ч. COM+, буквы разделов диска и пользователей в группе администраторов.
Убедитесь, что вы очистили системные журналы на всех узлах и снова просмотрели системные журналы. Прежде чем продолжить, убедитесь в том, что в журналах нет сообщений об ошибках.
Перед установкой или обновлением отказоустойчивого кластера SQL Server отключите все приложения и все службы, которые могут использовать компоненты SQL Server в ходе установки. Дисковые ресурсы необходимо оставить в режиме «в сети».
SQL Server автоматически задает зависимости между кластерной группой SQL Server и дисками, которые будут находиться в отказоустойчивом кластере. Не устанавливайте зависимости для дисков перед установкой.
-
При установке отказоустойчивого кластера SQL Server создается объект компьютера (учетные записи Active Directory) для имени сетевого ресурса SQL Server . В кластере Windows Server 2008 учетная запись имени кластера (учетная запись компьютера для самого кластера) должна иметь разрешение на создание объектов компьютера. Дополнительные сведения см. в статье Настройка учетных записей в Active Directory.
-
Если вы используете общую папку SMB в качестве хранилища, учетная запись установки SQL Server должна иметь seSecurityPrivilege на файловом сервере. Для этого с помощью консоли локальной политики безопасности на файловом сервере добавьте учетную запись установки SQL Server в раздел Управление правами аудита и журнала безопасности.
Удаление кластера
Рассмотрим процесс удаления нод из кластера и самого кластера. Данные действия не могут быть выполнены из веб-консоли — все операции делаем в командной строке.
Подключаемся по SSH к одной из нод кластера. Смотрим все узлы, которые присоединены к нему:
pvecm nodes
Мы получим список нод — удалим все, кроме локальной, например:
pvecm delnode pve2
pvecm delnode pve3
* в данном примере мы удалили ноды pve2 и pve3.
Необходимо подождать, минут 5, чтобы прошла репликация между нодами. После останавливаем следующие службы:
systemctl stop pvestatd pvedaemon pve-cluster corosync
Подключаемся к базе sqlite для кластера PVE:
sqlite3 /var/lib/pve-cluster/config.db
Удаляем из таблицы tree все записи, поле name в которых равно corosync.conf:
> DELETE FROM tree WHERE name = ‘corosync.conf’;
Отключаемся от базы:
> .quit
Удаляем файл блокировки:
rm -f /var/lib/pve-cluster/.pmxcfs.lockfile
Удаляем файлы, имеющие отношение к настройке кластера:
rm /etc/pve/corosync.conf
rm /etc/corosync/*
rm /var/lib/corosync/*
Запускаем ранее погашенные службы:
systemctl start pvestatd pvedaemon pve-cluster corosync
Кластер удален.
Файлы моментального снимка базы данных
Вид файла, используемый для хранения копируемых во время записи данных моментального снимка базы данных, зависит от того, создается ли моментальный снимок пользователем или используется внутренними механизмами.
- Данные моментального снимка базы данных, созданного пользователем, хранятся в одном или нескольких разреженных файлах. Технология разреженных файлов является свойством файловой системы NTFS. Изначально разреженный файл не содержит данных пользователя, и место на диске под него не выделяется. Общие сведения об использовании разреженных файлов в моментальных снимках базы данных и о том, как растут моментальные снимки базы данных, см. в разделе Просмотр размера разреженного файла моментального снимка базы данных.
- Моментальные снимки базы данных могут использоваться внутренними механизмами при выполнении определенных команд DBCC. Эти команды включают DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC и DBCC CHECKFILEGROUP. Внутренним моментальным снимком базы данных используются разреженные дополнительные потоки данных исходных файлов базы данных. Подобно разреженным файлам, дополнительные потоки данных являются свойством файловой системы NTFS. Использование разреженных дополнительных потоков данных позволяет связать несколько расположений данных с одним файлом или папкой, не затрагивая при этом размер файла или статистику тома.
На практике
Настала пора реализовать намеченные задачи. Я в своем примере использовал дистрибутив Red Hat Enterprise Linux 7. Ты можешь взять любой другой Linux, принципы построения кластера будут те же.
Для начала установим пакеты, которые требуются для нормальной работы ПО на обеих нодах (ставим пакеты на обе ноды).
Следующую команду тоже нужно исполнять с правами рута, но если использовать , то скрипт установщика отработает неверно и не создастся пользователь hacluster.
Проверяем пользователя hacluster (Pacemaker) и меняем пароль:
hacluster:x:189:189:cluster user:/home/hacluster:/sbin/nologin
Авторизуемся на нодах под именем пользователя hacluster. Если выходит ошибка доступа к ноде (), то, скорее всего, из-под Linux-УЗ наложены запреты на использование удаленных оболочек. Необходимо снять ограничение на время установки.
Когда увидишь следующее, можешь двигаться дальше:
User may run the following commands on ha-node1:
(ALL) NOPASSWD: ALL
Теперь проверяем на обеих нодах установленные пакеты corosync, pacemaker и pcs, добавляем в автозагрузку и запускаем службу конфигурации pacemaker.
Авторизуемся на нодах под пользователем hacluster:
Создаем кластер из двух нод:
Включаем и запускаем все кластеры на всех нодах:
При использовании двух нод включаем stonith. Он нужен для «добивания» серверов, которые не смогли полностью завершить рабочие процессы. Игнорируем кворум.
Запрашиваем статус на обеих нодах () и видим:
Cluster name: HACLUSTER
Stack: corosync
Current DC: ha-node2 (version 1.1.18-11.el7_5.3-2b07d5c5a9) — partition with quorum
Last updated: Wed Oct 17 13:12:00 2018
Last change: Wed Oct 17 13:10:47 2018 by root via cibadmin on ha-node1
2 nodes configured
0 resources configured
Online:
No resources
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Добавляем виртуальный сетевой адрес и nginx как ресурсы (надеюсь, ты помнишь про тайм-аут в 30 секунд) и запрашиваем статус кластера.
Full list of resources:
virtual_ip (ocf::heartbeat:IPaddr2): Started ha-node1
nginx (ocf::heartbeat:nginx): Started ha-node1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Выключаем первую ноду на несколько минут. Запрашиваем статус второй ноды, чтобы убедиться, что первая недоступна.
Full list of resources:
virtual_ip (ocf::heartbeat:IPaddr2): Started ha-node2
nginx (ocf::heartbeat:nginx): Started ha-node2
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Как только первая нода будет доступна, вручную переключаем на нее виртуальный IP и nginx командой
Осталось запросить статус кластера и убедиться, что адрес присвоен первой ноде.
virtual_ip (ocf::heartbeat:IPaddr2): Started ha-node1
Список всех поддерживаемых сервисов можно посмотреть c помощью команды .
Файловые группы
- Эта файловая группа содержит первичный файл данных и все вторичные файлы, не входящие в другие файловые группы.
- Пользовательские файловые группы могут создаваться для удобства администрирования, распределения и размещения данных.
Например, , и могут быть созданы на трех дисках соответственно и отнесены к файловой группе . В этом случае можно создать таблицу на основе файловой группы . Запросы данных из таблицы будут распределены по трем дискам, и это улучшит производительность. Подобного улучшения производительности можно достичь и с помощью одного файла, созданного на чередующемся наборе дискового массива RAID. Тем не менее файлы и файловые группы позволяют без труда добавлять новые файлы на новые диски.
Все файлы данных хранятся в файловых группах, перечисленных в следующей таблице.
| Файловая группа | Описание |
|---|---|
| Первичная | Файловая группа, содержащая первичный файл. Все системные таблицы являются частью первичной файловой группы. |
| Данные, оптимизированные для памяти | В основе оптимизированной для памяти файловой группы лежит файловая группа файлового потока. |
| Файловый поток | |
| Определяемые пользователем маршруты | Любая файловая группа, созданная пользователем при создании или изменении базы данных. |
Файловая группа по умолчанию (первичная)
Если в базе данных создаются объекты без указания файловой группы, к которой они относятся, они назначаются файловой группе по умолчанию. В любом случае только одна файловая группа создается как файловая группа по умолчанию. Файлы в файловой группе по умолчанию должны быть достаточно большими, чтобы вмещать новые объекты, не назначенные другим файловым группам.
Файловая группа PRIMARY является группой по умолчанию, если только она не была изменена инструкцией ALTER DATABASE. Системные объекты и таблицы распределяются внутри первичной файловой группы, а не новой файловой группой по умолчанию.
Файловая группа данных, оптимизированных для памяти
Дополнительные сведения об оптимизированных для памяти файловых группах см. в разделе Оптимизированные для памяти файловые группы.
Файловая группа файлового потока
Дополнительные сведения о файловых группах файлового потока см. в статьях и Создание базы данных с поддержкой FILESTREAM.
Пример файлов и файловых групп
В следующем примере создается база данных на основе экземпляра SQL Server. База данных содержит первичный файл данных, пользовательскую файловую группу и файл журнала. Первичный файл данных входит в состав первичной файловой группы, а пользовательская файловая группа состоит из двух вторичных файлов данных. Инструкция ALTER DATABASE придает пользовательской файловой группе статус файловой группы по умолчанию. Затем создается таблица, определяющая пользовательскую файловую группу. (В этом примере используется универсальный путь к , чтобы не указывать версию SQL Server.)
Данная иллюстрация обобщает все вышесказанное (кроме данных файлового потока).

Шаг 1. Подготовка CNO в AD DS
Перед началом работы убедитесь, что знаете следующее:
- Имя, которое требуется назначить кластеру
- Имя учетной записи пользователя или группы, которой требуется предоставить права на создание кластера.
Мы рекомендуем создать подразделение для кластерных объектов. Если подразделение, которое вы хотите использовать, уже существует, для завершения этого шага требуется членство в группе Операторы учета. Если подразделение для кластерных объектов необходимо создать, для завершения этого шага требуется членство в группе Администраторы домена или аналогичной группе.
Примечание
Если вы создали CNO в контейнере компьютеров по умолчанию, а не в подразделении, вам не нужно выполнять шаг 3 этого раздела. В этом сценарии администратор кластера может создать до 10 VCO без какой-либо дополнительной настройки.
Предварительная подготовка CNO в AD DS
-
На компьютере с установленными средствами AD DS из средств удаленного администрирования сервера или на контроллере домена откройте Пользователи и компьютеры Active Directory. Для этого на сервере запустите диспетчер сервера, а затем в меню «Сервис» выберите Пользователи и компьютеры Active Directory.
-
Чтобы создать подразделение для объектов компьютера кластера, щелкните правой кнопкой мыши доменное имя или существующее подразделение, наведите указатель мыши на «Создать» и выберите подразделение. В поле «Имя» введите имя подразделения и нажмите кнопку «ОК».
-
В дереве консоли щелкните правой кнопкой мыши подразделение, в котором нужно создать CNO, наведите указатель мыши на «Создать» и выберите » Компьютер».
-
В поле «Имя компьютера » введите имя, которое будет использоваться для отказоустойчивого кластера, а затем нажмите кнопку «ОК».
Примечание
Это имя кластера, которое пользователь, создающий кластер, укажет в мастере создания кластеров на странице Точка доступа для администрирования кластера или укажет как значение параметра –Name для командлета New-Cluster Windows PowerShell.
-
Рекомендуется щелкнуть правой кнопкой мыши только что созданную учетную запись компьютера, выбрать пункт «Свойства» и выбрать вкладку «Объект «. На вкладке «Объект» установите флажок «Защитить объект от случайного удаления » и нажмите кнопку «ОК».
-
Щелкните правой кнопкой мыши только что созданную учетную запись компьютера и выберите команду «Отключить учетную запись». Нажмите кнопку «Да «, чтобы подтвердить, а затем нажмите кнопку «ОК».
Примечание
Учетную запись необходимо отключить, чтобы во время создания кластера соответствующий процесс подтвердил, что учетная запись не используется в данный момент существующим компьютером или кластером в домене.
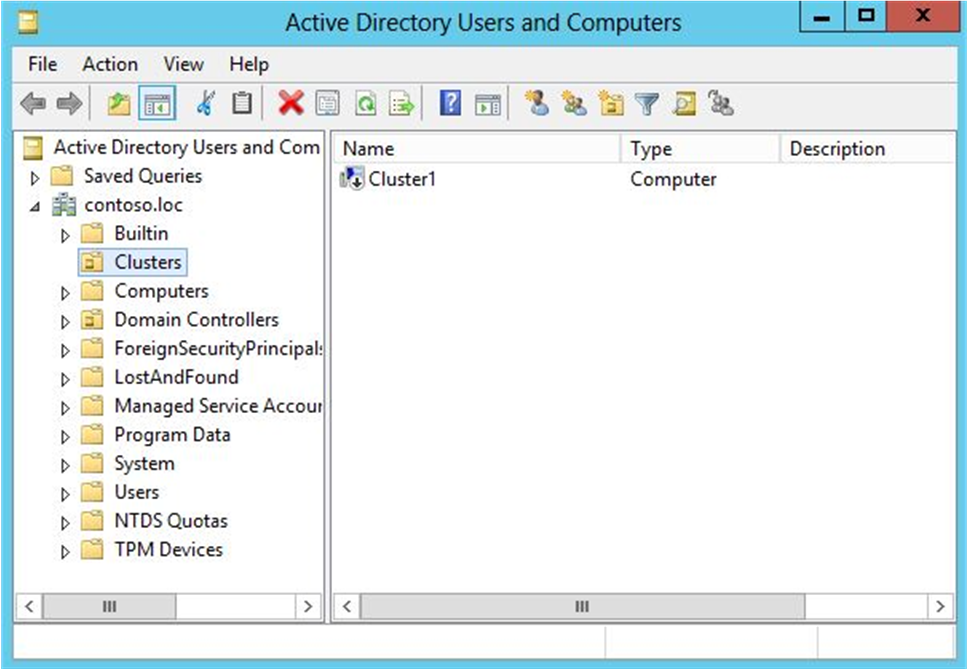
Рис. 1. Отключенный CNO в примере подразделения кластеров
Режимы кворума для отказоустойчивого кластера Windows
В предыдущем разделе я рассмотрел инструмент Windows Cluster Quorum. Основываясь на информации, мы можем установить следующую формулу для большинства в кластере.
Quorum = FLOOR (N/2+1)
Где N = количество узлов. Предположим, у нас есть четыре узла кластера, и на каждом узле кластера работает экземпляр SQL Server.
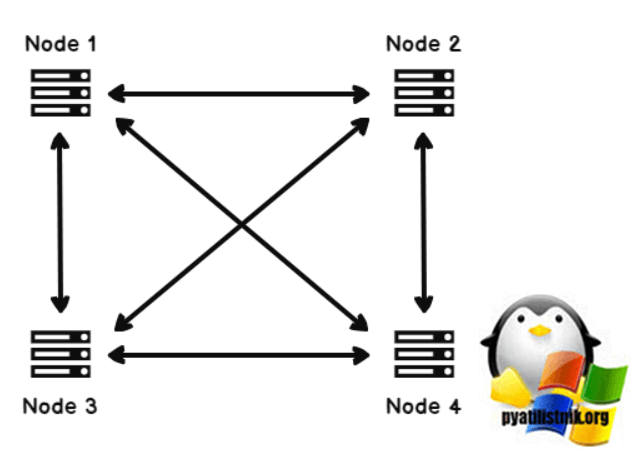
Согласно приведенной выше формуле, нам нужно три голоса, чтобы кластер оставался в сети.
Кворум=4/2+1=3
А теперь представьте сценарий
- Узел 1 и узел 2 не могут обмениваться данными между узлом 3 и узлом 4. Узел 1 и узел 2 могут обмениваться данными друг с другом.
- Узел 3 и узел 4 не могут обмениваться данными между узлом 1 и узлом 2. Узел 3 и узел 4 могут обмениваться данными друг с другом.
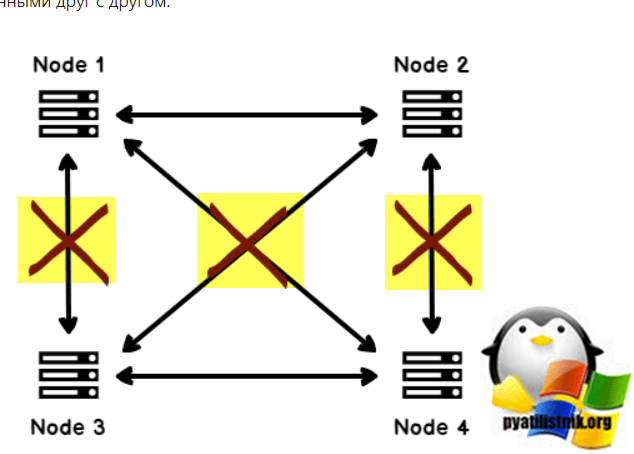
В этом сценарии Узел 1 и Узел 2 пытается перевести в оперативный режим ресурсы, принадлежащие Узлу 3 и Узлу 4. Аналогичным образом, Узел 3 и Узел 4 пытается перевести в оперативный режим ресурсы, принадлежащие Узлу 1 и Узлу 2. Чтобы избежать этих сценариев, у нас есть различные конфигурации кворума, и мы должны тщательно настраивать конфигурацию кворума. Давайте обсудим эти режимы конфигурации кворума.
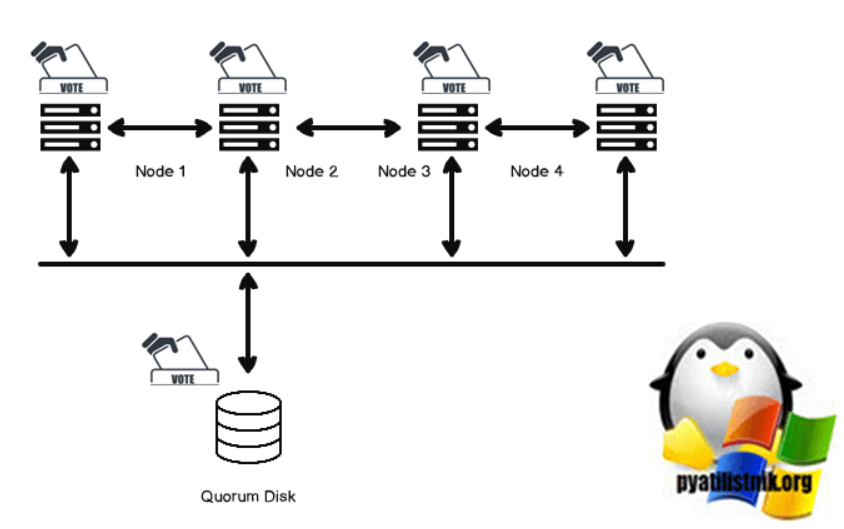
Режим настройки кворума большинства узлов и дисков в отказоустойчивом кластере Windows
В этом режиме конфигурации кворума каждый узел кластера получает один голос, и, кроме того, один голос поступает от кластерного диска (кворумного диска). Этот диск может быть диском небольшого размера с высокой доступностью и должен входить в группу кластера. Подходит для кластера с четными узлами. Диск кворума также хранит данные конфигурации кластера. Обычно администраторы Windows устанавливают размер диска кворума равным 1 ГБ.
Допустим, узел 1 и узел 2 не работают. У нас все еще есть три голоса, чтобы запустить кластерные сервисы.
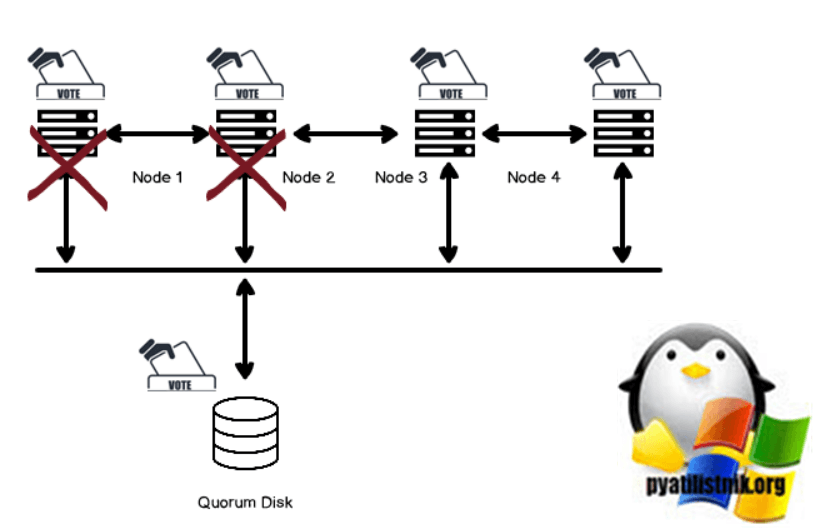
Если еще один узел также выходит из строя, и у нас есть только один узел и один диск кворума для голосования, службы кластера в этом случае отключены.
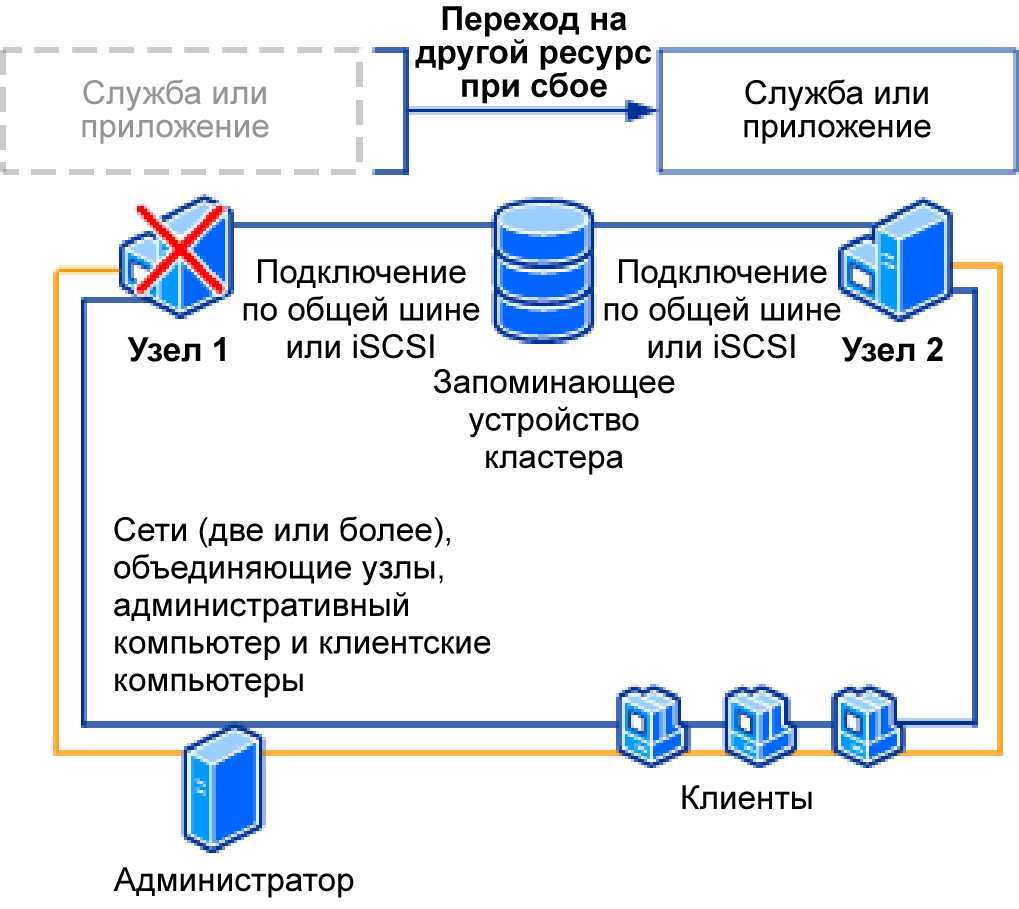
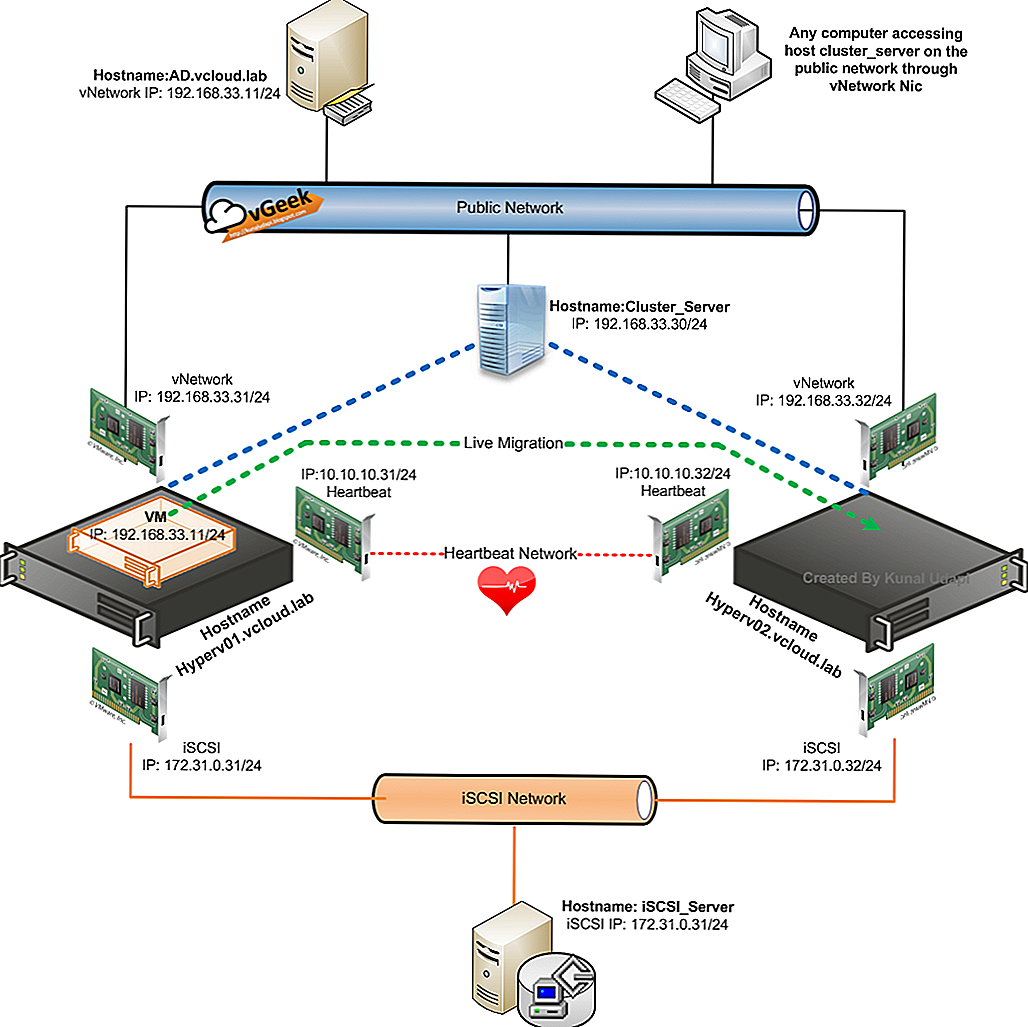
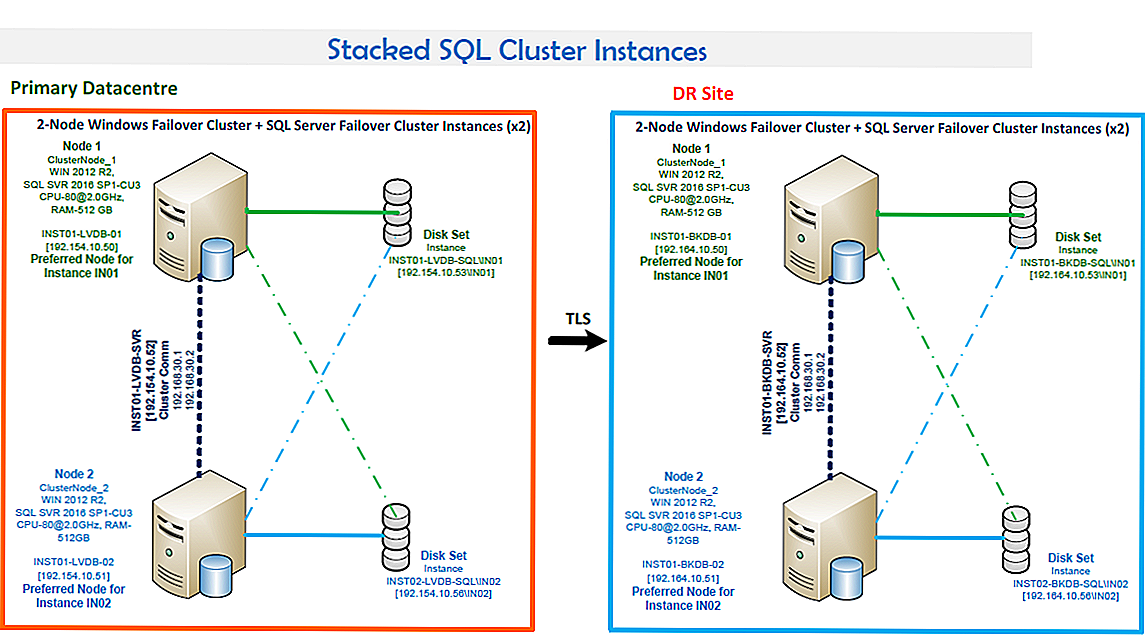
Технологии SQL Server AlwaysOn и WSFC
SQL Server AlwaysOn — это решение высокого уровня доступности и аварийного восстановления с использованием WSFC. Компоненты AlwaysOn представляют собой интегрированные, гибкие решения, повышающие доступность приложений, окупаемость вложений в оборудование и упрощающее развертывание систем высокого уровня доступности и управление ими.
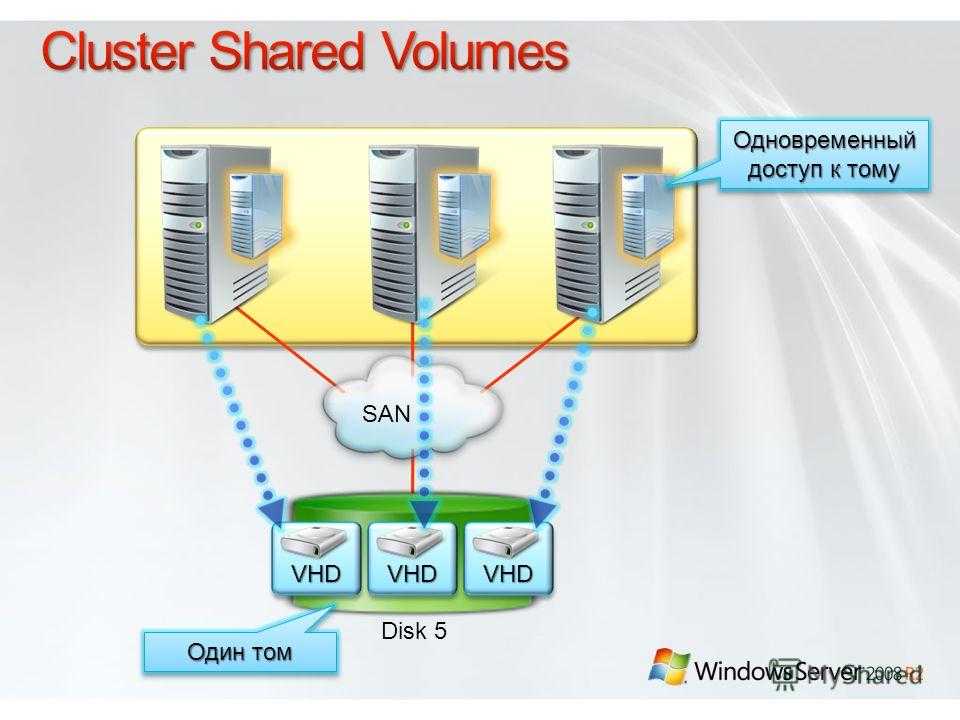
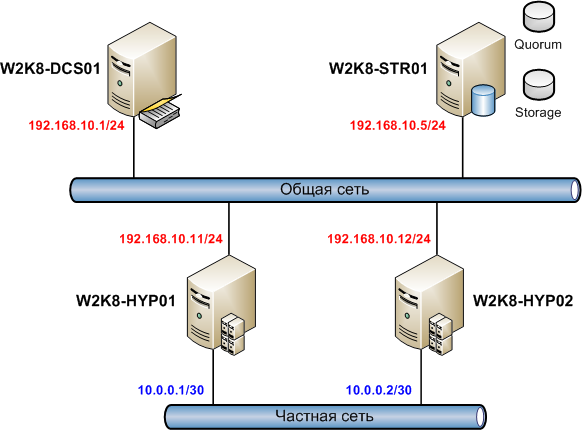
Экземпляры Группы доступности AlwaysOn и экземпляры отказоустойчивого кластера AlwaysOn используют технологию платформы WSFC и регистрируют компоненты в качестве ресурсов кластера WSFC. Связанные ресурсы объединяются в роль, которую можно сделать зависимой от других ресурсов кластера WSFC. Затем кластер WSFC сможет выявлять необходимость в перезапуске экземпляра SQL Server (и сигнализировать об этой необходимости), а также автоматически выполнять отработку отказа с переходом на другой серверный узел в кластере WSFC.
Важно!
Чтобы воспользоваться всеми возможностями технологий SQL Server AlwaysOn, вам следует выполнить несколько связанных с WSFC предварительных требований.
Дополнительные сведения см. в разделе Предварительные требования, ограничения и рекомендации для групп доступности Always On (SQL Server).
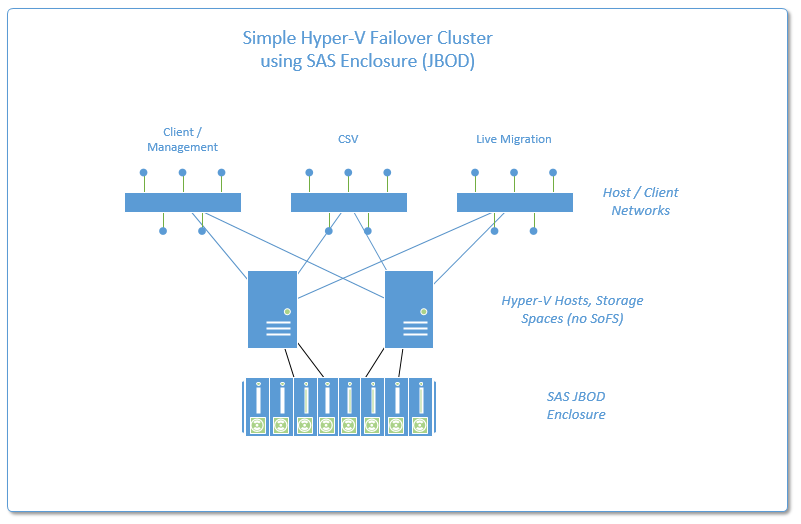
Экземпляр отказоустойчивого кластера AlwaysOn представляет собой экземпляр SQL Server, установленный на нескольких узлах в кластере WSFC. Этот тип экземпляра зависит от ресурсов для хранения и имени виртуальной сети. Хранилище может использовать общее дисковое пространство на базе Fibre Channel, iSCSI, FCoE или SAS либо локально подключенное хранилище на основе локальных дисковых пространств (S2D). Ресурс имени виртуальной сети зависит от одного или нескольких виртуальных IP-адресов, которые расположены в разных подсетях. Служба SQL Server и служба агента SQL Server также являются ресурсами, и обе они зависят от ресурсов хранилища и имени виртуальной сети.
В случае отработки отказа служба WSFC переносит владение ресурсов экземпляра на указанный узел отработки отказа. Затем экземпляр SQL Server перезапускается на узле отработки отказа и выполняется обычное восстановление баз данных. В любой момент времени FCI и базовые ресурсы могут размещаться только на одном узле в кластере.
Примечание
Экземпляру отказоустойчивого кластера Always On требуется симметричное общее дисковое хранилище, например сеть хранения данных (SAN) или общая папка SMB. Тома общего дискового хранилища должны быть доступны всем потенциальным узлам отработки отказа в кластере WSFC.
Дополнительные сведения см. в статье Экземпляры отказоустойчивого кластера групп доступности Always On (SQL Server).
Высокий уровень доступности на уровне баз данных с Группы доступности AlwaysOn
Группа доступности AlwaysOn — это одна или несколько пользовательских баз данных, для которых отработка отказа выполняется одновременно. Группа доступности состоит из первичной реплики доступности и от одной до четырех вторичных реплик, которые поддерживаются за счет перемещения данных на основании журнала SQL Server для обеспечения защиты данных, не требующей общего хранилища. Каждая реплика размещается в экземпляре SQL Server в отдельном узле кластера WSFC. Группа доступности и соответствующее имя виртуальной сети регистрируются как ресурсы в кластере WSFC.
Прослушиватель группы доступности на узле первичной реплики отвечает на входящие клиентские запросы на подключение к имени виртуальной сети и в зависимости от атрибутов в строке подключения перенаправляет каждый запрос в соответствующий экземпляр SQL Server .
При отработке отказа вместо переноса владения общих физических ресурсов на другой узел WSFC используется для перенастройки вторичной реплики на другом экземпляре SQL Server в первичную реплику группы доступности. Затем ресурс виртуального сетевого имени группы доступности переводится на этот экземпляр.
Первичная реплика баз данных группы доступности одновременно может размещаться только на одном экземпляре SQL Server , все связанные вторичные реплики должны находиться на отдельном экземпляре, и каждый экземпляр должен находиться на отдельном физическом узле.
Примечание
Группы доступности AlwaysOn не требует развертывать экземпляр отказоустойчивого кластера или использовать симметричное общее хранилище (SAN или SMB).
Экземпляр отказоустойчивого кластера (FCI) может использоваться совместно с группой доступности для повышения доступности реплики доступности. Однако во избежание соперничества в кластере WSFC автоматический переход на другой ресурс группы доступности не поддерживается для реплики доступности, размещенной в FCI.
Дополнительные сведения см. в статье Обзор групп доступности AlwaysOn SQL Server)
Добавление диска в том CSV в отказоустойчивом кластере
Компонент CSV по умолчанию включен в отказоустойчивом кластере. Чтобы добавить диск в CSV, необходимо добавить его в группу Доступное хранилище кластера (если он еще не добавлен), а затем добавить его в том CSV в кластере. для выполнения этих процедур можно использовать диспетчер отказоустойчивости кластеров или отказоустойчивые кластеры Windows PowerShell командлеты.
добавление диска к доступному служба хранилища
-
В диспетчере отказоустойчивости кластеров в дереве консоли разверните имя кластера, а затем разверните элемент Хранилище.
-
Щелкните правой кнопкой мыши дискии выберите команду Добавить диск. Появится список дисков, которые можно добавить для использования в отказоустойчивом кластере.
-
Выберите диск или диски, которые требуется добавить, а затем нажмите кнопку ОК.
Диски будут добавлены в группу Доступное хранилище.
Windows PowerShell эквивалентные команды (добавить диск в доступный служба хранилища)
Следующие командлеты Windows PowerShell выполняют ту же функцию, что и предыдущая процедура. Вводите каждый командлет в одной строке, несмотря на то, что здесь они могут отображаться разбитыми на несколько строк из-за ограничений форматирования.
В приведенном ниже примере определяются диски, готовые к добавлению в кластер, после чего они добавляются в группу Доступное хранилище.
добавление диска в доступную служба хранилища в CSV
-
в диспетчер отказоустойчивости кластеров в дереве консоли разверните узел имя кластера, разверните служба хранилища, а затем выберите диски.
-
выберите один или несколько дисков, назначенных доступному служба хранилища, щелкните выделенный фрагмент правой кнопкой мыши и выберите добавить в общие тома кластера.
Диски будут добавлены в группу Общий том кластера в кластере. Диски отображаются для каждого узла кластера в виде нумерованных томов (точек подключения) в папке% SystemDrive% ClusterStorage. Тома имеют файловую систему CSVFS.
Примечание
Тома CSV можно переименовать в папке% SystemDrive% ClusterStorage.
Windows PowerShell эквивалентные команды (добавить диск в CSV-файл)
Следующие командлеты Windows PowerShell выполняют ту же функцию, что и предыдущая процедура. Вводите каждый командлет в одной строке, несмотря на то, что здесь они могут отображаться разбитыми на несколько строк из-за ограничений форматирования.
В приведенном ниже примере диск Cluster Disk 1, включенный в группу Доступное хранилище, добавляется в том CSV в локальном кластере.
Создание кластерных ролей
После создания отказоустойчивого кластера можно создать кластерные роли для размещения кластерных рабочих нагрузок.
Примечание
Для кластерных ролей, требующих точки доступа клиента, в доменных службах Active Directory создается виртуальный объект-компьютер (VCO). По умолчанию все объекты VCO для кластера создаются в том же контейнере или подразделении, что и объект CNO. Имейте в виду, что после создания кластера объект CNO можно переместить в любое подразделение.
Вот как можно создать кластерную роль:
-
Чтобы на каждом узле отказоустойчивого кластера установить роль или компонент, необходимый для кластерной роли, используйте диспетчер сервера или Windows PowerShell. Например, чтобы создать кластерный файловый сервер, установите роль файлового сервера на всех узлах кластера.
В таблице ниже приведены кластерные роли, которые можно настроить в мастере высокой доступности, и соответствующие роли или компоненты сервера, которые необходимо установить.
Кластерная роль Необходимая роль или компонент Сервер пространства имен Пространства имен (часть роли файлового сервера) Сервер пространства имен DFS Роль DHCP-сервера Координатор распределенных транзакций (DTC) Нет Файловый сервер Роль файлового сервера Универсальное приложение Неприменимо Универсальный сценарий Неприменимо Универсальная служба Неприменимо Брокер реплики Hyper-V Роль Hyper-V Целевой сервер iSCSI Сервер цели iSCSI (часть роли файлового сервера) iSNS-сервер Компоненты службы iSNS-сервера служба очередей сообщений Компонент службы очереди сообщений Другой сервер Нет Виртуальная машина Роль Hyper-V WINS-сервер Компонент WINS-сервера -
В диспетчер отказоустойчивости кластеров разверните узел имя кластера, щелкните правой кнопкой мыши элемент ролии выберите пункт настроить роль.
-
Для создания кластерной роли выполните последовательность действий, предлагаемую мастером высокой доступности.
-
Чтобы проверить, создана ли кластерная роль, на панели Роли убедитесь в том, что роль имеет состояние Выполняется. На панели «Роли» также указан узел владельца. Чтобы протестировать отработку отказа, щелкните правой кнопкой мыши роль, выберите пункт переместить, а затем выберите пункт выбрать узел. В диалоговом окне Перемещение кластерной роли выберите нужный узел кластера и нажмите кнопку ОК. В столбце Узел владельца убедитесь в том, что узел владельца изменился.
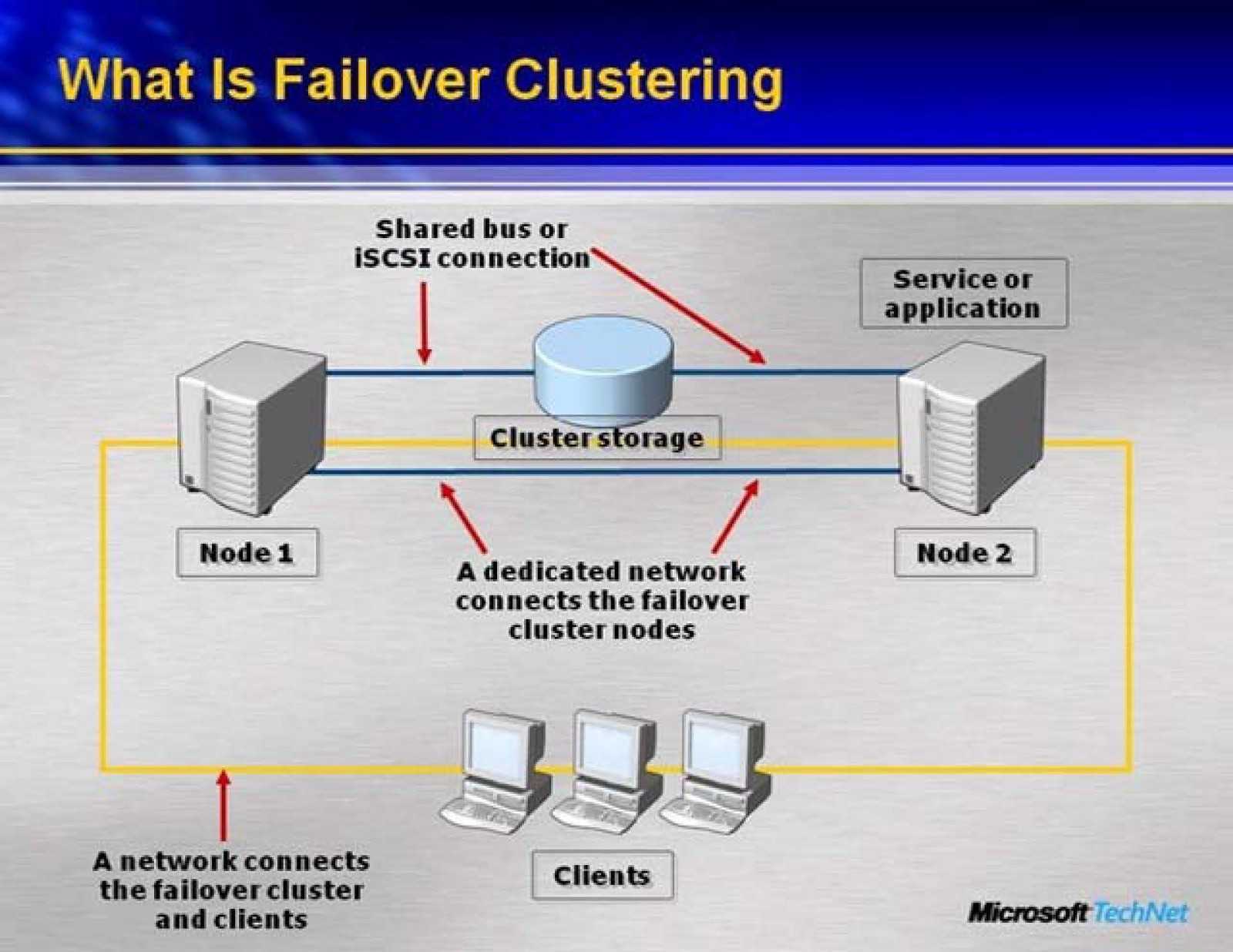
Отказоустойчивый кластер
Настроим автоматический перезапуск виртуальных машин на рабочих нодах, если выйдет из строя сервер.
Для настройки отказоустойчивости (High Availability или HA) нам нужно:
- Минимум 3 ноды в кластере. Сам кластер может состоять из двух нод и более, но для точного определения живых/не живых узлов нужно большинство голосов (кворумов), то есть на стороне рабочих нод должно быть больше одного голоса. Это необходимо для того, чтобы избежать ситуации 2-я активными узлами, когда связь между серверами прерывается и каждый из них считает себя единственным рабочим и начинает запускать у себя все виртуальные машины. Именно по этой причине HA требует 3 узла и выше.
- Общее хранилище для виртуальных машин. Все ноды кластера должны быть подключены к общей системе хранения данных — это может быть СХД, подключенная по FC или iSCSI, NFS или распределенное хранилище Ceph или GlusterFS.
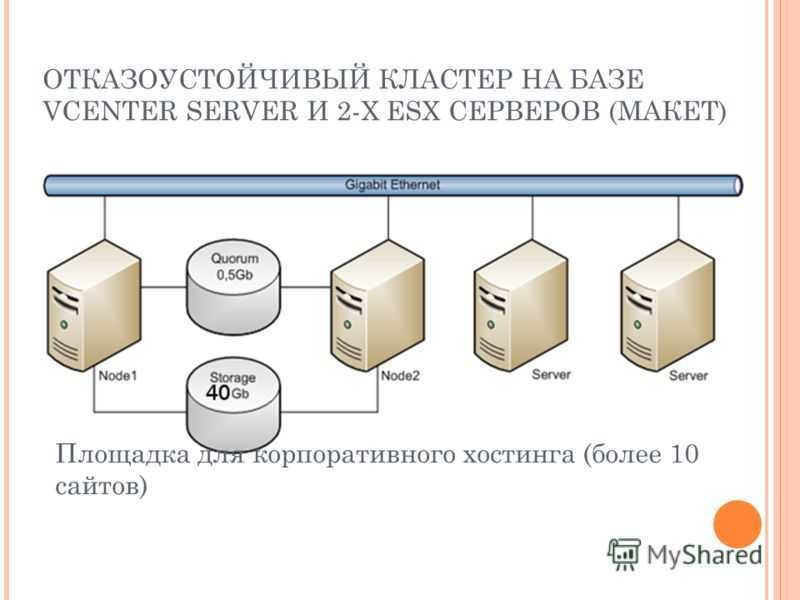
1. Подготовка кластера
Процесс добавления 3-о узла аналогичен процессу, — на одной из нод, уже работающей в кластере, мы копируем данные присоединения; в панели управления третьего сервера переходим к настройке кластера и присоединяем узел.
2. Добавление хранилища
Подробное описание процесса настройки самого хранилища выходит за рамки данной инструкции. В данном примере мы разберем пример и использованием СХД, подключенное по iSCSI.
Если наша СХД настроена на проверку инициаторов, на каждой ноде смотрим командой:
cat /etc/iscsi/initiatorname.iscsi
… IQN инициаторов. Пример ответа:
…
InitiatorName=iqn.1993-08.org.debian:01:4640b8a1c6f
* где iqn.1993-08.org.debian:01:4640b8a1c6f — IQN, который нужно добавить в настройках СХД.
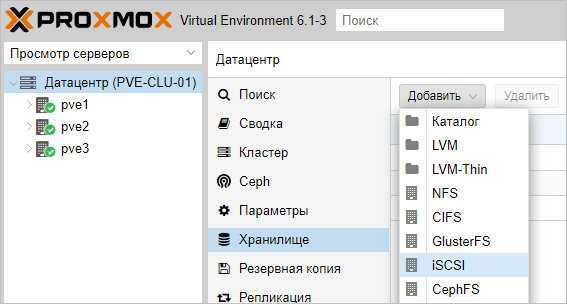
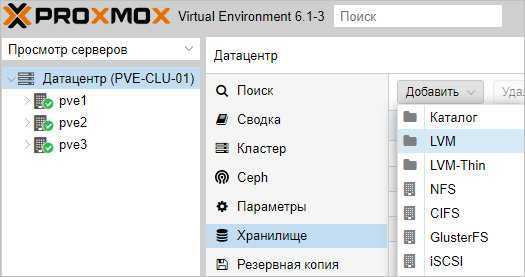
После настройки СХД, в панели управления Proxmox переходим в Датацентр — Хранилище. Кликаем Добавить и выбираем тип (в нашем случае, iSCSI):
В открывшемся окне указываем настройки для подключения к хранилке:
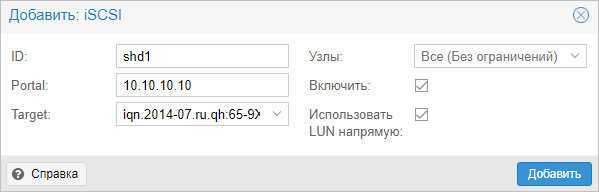
* где ID — произвольный идентификатор для удобства; Portal — адрес, по которому iSCSI отдает диски; Target — идентификатор таргета, по которому СХД отдает нужный нам LUN.
Нажимаем добавить, немного ждем — на всех хостах кластера должно появиться хранилище с указанным идентификатором. Чтобы использовать его для хранения виртуальных машин, еще раз добавляем хранилище, только выбираем LVM:
Задаем настройки для тома LVM:
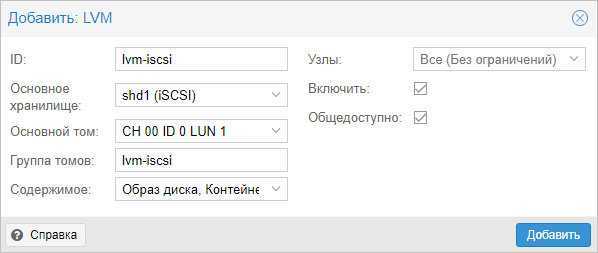
* где было настроено:
- ID — произвольный идентификатор. Будет служить как имя хранилища.
- Основное хранилище — выбираем добавленное устройство iSCSI.
- Основное том — выбираем LUN, который анонсируется таргетом.
- Группа томов — указываем название для группы томов. В данном примере указано таким же, как ID.
- Общедоступно — ставим галочку, чтобы устройство было доступно для всех нод нашего кластера.
Нажимаем Добавить — мы должны увидеть новое устройство для хранения виртуальных машин.
Для продолжения настройки отказоустойчивого кластера создаем виртуальную машину на общем хранилище.
3. Настройка отказоустойчивости
Создание группы
Для начала, определяется с необходимостью групп. Они нужны в случае, если у нас в кластере много серверов, но мы хотим перемещать виртуальную машину между определенными нодами. Если нам нужны группы, переходим в Датацентр — HA — Группы. Кликаем по кнопке Создать:
Вносим настройки для группы и выбираем галочками участников группы:
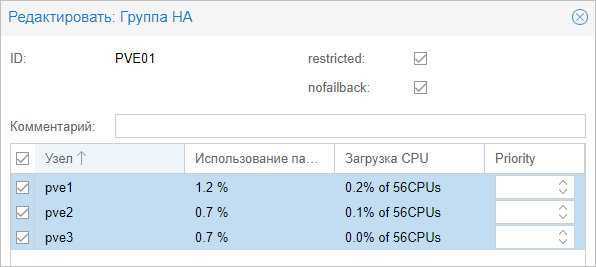
* где:
- ID — название для группы.
- restricted — определяет жесткое требование перемещения виртуальной машины внутри группы. Если в составе группы не окажется рабочих серверов, то виртуальная машина будет выключена.
- nofailback — в случае восстановления ноды, виртуальная машина не будет на нее возвращена, если галочка установлена.
Также мы можем задать приоритеты для серверов, если отдаем каким-то из них предпочтение.
Нажимаем OK — группа должна появиться в общем списке.
Настраиваем отказоустойчивость для виртуальной машины
Переходим в Датацентр — HA. Кликаем по кнопке Добавить:
В открывшемся окне выбираем виртуальную машину и группу:
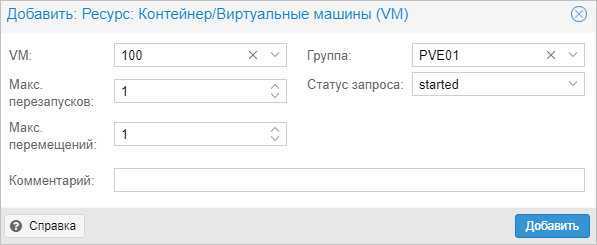
… и нажимаем Добавить.
4. Проверка отказоустойчивости
После выполнения всех действий, необходимо проверить, что наша отказоустойчивость работает. Для чистоты эксперимента, можно выключиться сервер, на котором создана виртуальная машина, добавленная в HA.
Важно учесть, что перезагрузка ноды не приведет к перемещению виртуальной машины. В данном случае кластер отправляет сигнал, что он скоро будет доступен, а ресурсы, добавленные в HA останутся на своих местах
Для выключения ноды можно ввести команду:
systemctl poweroff
Виртуальная машина должна переместиться в течение 1 — 2 минут.
Режим конфигурации кворума большинства узлов и общих файловых ресурсов в отказоустойчивом кластере Windows
Большинство узлов и общих файловых ресурсов аналогичны предыдущим режимам кворума большинства узлов и дисков. В этом случае мы заменяем диск кворума файловым хранилищем-свидетелем (FSW). FSW также подает единый голос, аналогичный диску кворума.
У нас может быть кластер Windows в разных регионах, и у нас может не быть общего хранилища между ними. Файловый ресурс-свидетель — это файловый ресурс, и мы можем настроить его на любом сервере, присутствующем в активном каталоге, и все узлы кластера должны иметь доступ к этому сетевому ресурсу. Он не содержит никаких данных конфигурации. Активный узел кластера блокирует общий файловый ресурс, а свидетель файлового ресурса-свидетеля содержит информацию о владельце.
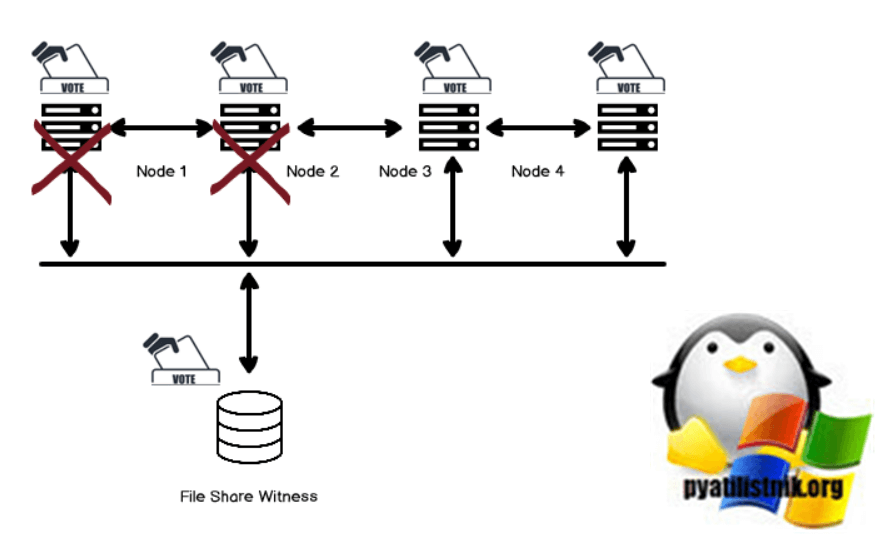
Если файловый ресурс-свидетель недоступен, кластер остается в сети из-за большинства голосов.
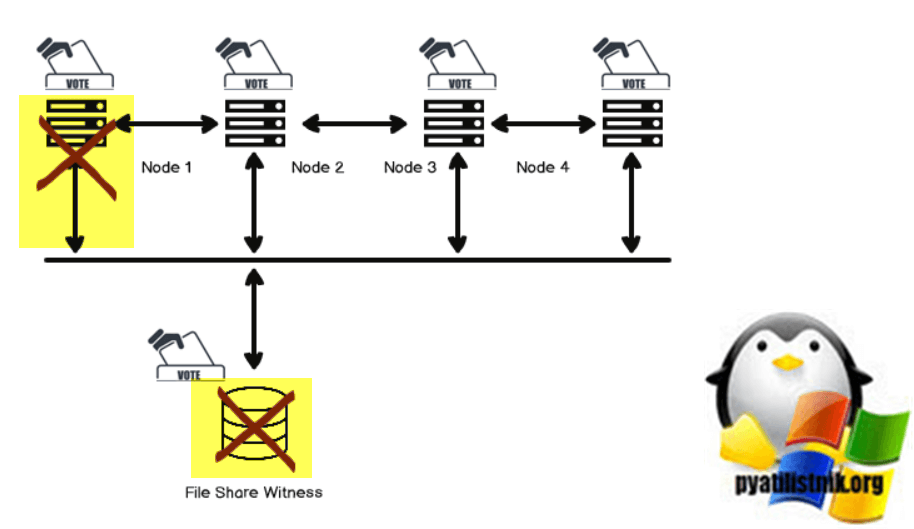
Общие сведения о кворуме кластера
В приведенной ниже таблице приведен обзор результатов кворума кластера для каждого сценария:
| Узлы сервера | Может пережить один сбой узла сервера | Может пережить один сбой узла сервера, а затем другой | Может пережить два одновременных сбоя узла сервера |
|---|---|---|---|
| 2 | 50/50 | Нет | Нет |
| 2 + свидетель | Да | Нет | Нет |
| 3 | Да | 50/50 | Нет |
| 3 + свидетель | Да | Да | Нет |
| 4 | Да | Да | 50/50 |
| 4 + свидетель | Да | Да | Да |
| 5 и выше | Да | Да | Да |
Рекомендации по кворуму кластера
- Если у вас есть два узла, требуется следящий сервер.
- Если у вас есть три или четыре узла, настоятельно рекомендуется использовать следящий сервер.
- Если у вас есть пять узлов или более, следящий сервер не нужен и не обеспечивает дополнительную устойчивость.
- Если у вас есть доступ к Интернету, используйте облачный свидетель.
- Если вы находитесь в ИТ-среде с другими компьютерами и общими папками, используйте файловый ресурс-свидетель.