Начальная страница
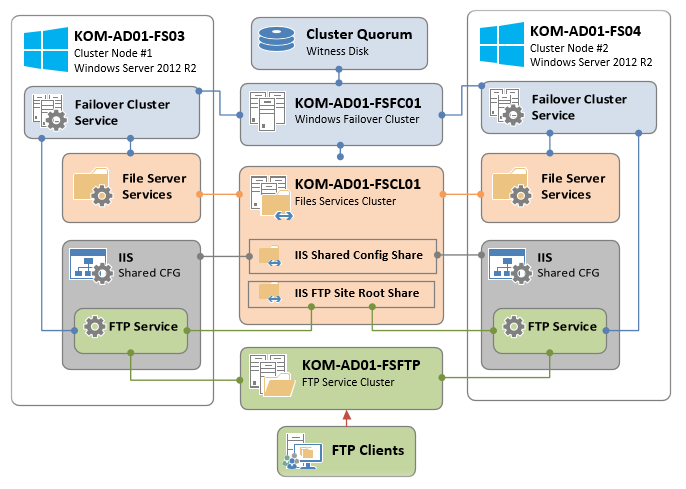
Идентификатор события 1135 указывает, что один или несколько узлов кластера были удалены из активного членства в отказоустойчивом кластере. Это может сопровождаться следующими симптомами:
- Отработка отказа кластера\nудаляется из активного членства в отказоустойчивом кластере: проблема с удаленными узлами из активного членства в отказоустойчивом кластере
- Идентификатор события 1069, идентификатор события 1069 — кластеризованная служба или доступность приложений
- Идентификатор события 1177 для события потери кворума 1177 — кворум и подключение, необходимые для кворума
- Код события 1006 для службы кластера остановлен: идентификатор события 1006 — запуск службы кластера
Проверка и сетевые тесты рекомендуется использовать в качестве одного из начальных шагов по устранению неполадок, чтобы гарантировать отсутствие проблем конфигурации, которые могут быть причиной проблем.
Проверка установки рекомендуемых исправлений
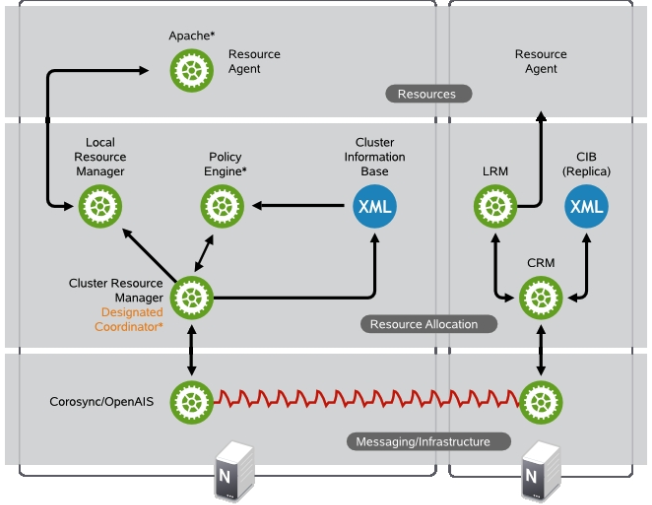
Служба кластеров — это основной программный компонент, который управляет всеми аспектами операции отказоустойчивого кластера и управляет базой данных конфигурации кластера. Если вы видите идентификатор события 1135, корпорация Майкрософт рекомендует установить исправления, упомянутые в приведенных ниже статьях базы знаний, и перезагрузить все узлы кластера, а затем наблюдать, возникает ли проблема повторно.
- Исправление для Windows Server 2012 R2
- Исправление для Windows Server 2012
- Исправление для Windows Server 2008 R2
Проверьте, запущена ли служба кластера на всех узлах.
Выполните следующую команду в соответствии с операционной системой Windows, чтобы убедиться, что служба кластера постоянно работает и доступна.
Отказоустойчивость СХД
К системам хранения данных в части обеспечения отказоустойчивости предъявляются более высокие требования, чем к серверам. Проблема неисправности сервера в большинстве случаев относительно легко решается его ремонтом или заменой. В то же время потеря данных может оказать серьёзное негативное влияние на бизнес и принести существенные убытки
Для предотвращения подобных случаев уделяется повышенное внимание обеспечению надёжности и отказоустойчивости СХД. Так, во всех СХД корпоративного класса применяется дублирование контроллеров, благодаря чему при выходе из строя одного из них доступ к данным сохраняется
Кроме того, СХД используют организацию дисков в RAID-массивы, которые позволяют восстановить данные при отказе нескольких дисков массива. Наконец, существуют кластерные конфигурации, когда несколько СХД объединяются в единую систему. Такая система состоит из нескольких контроллеров (принадлежащих разным физическим СХД), а данные могут быть распределены между различными СХД, входящими в её состав.
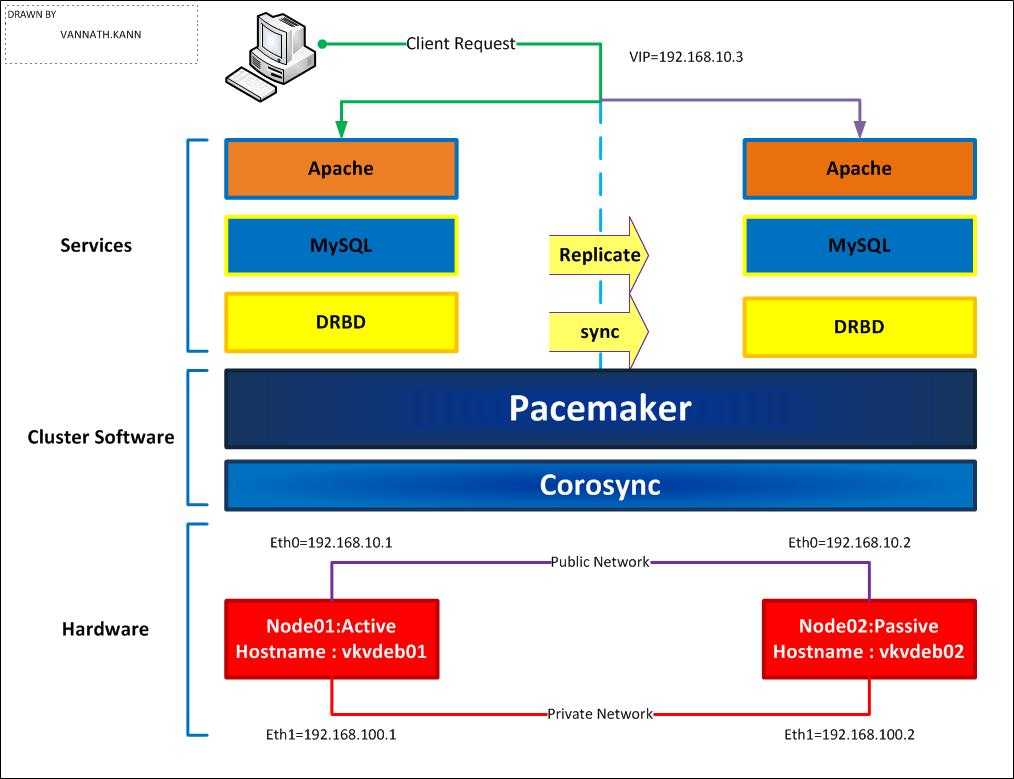
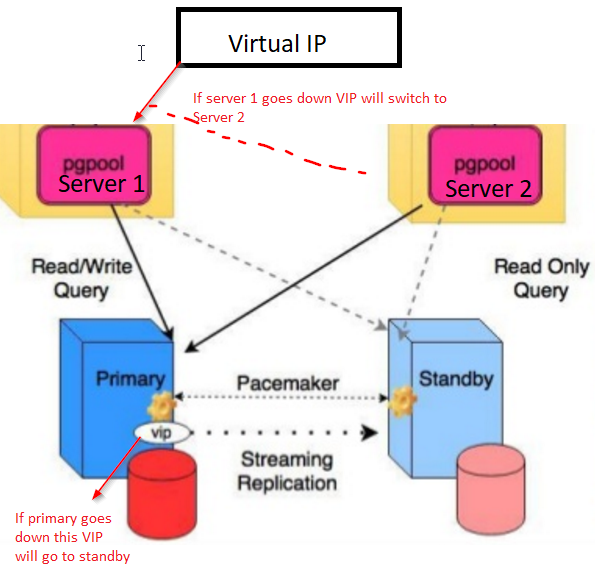
Резервирование серверов (кластеры)
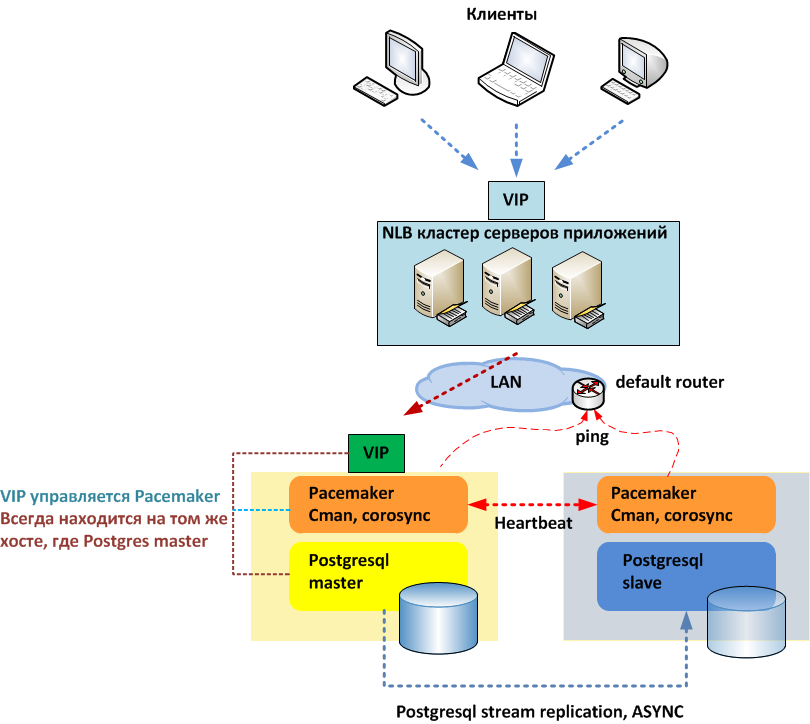
В подобных случаях применяется резервирование сервера целиком. C помощью специального программного обеспечения несколько серверов объединяются в единую систему. В случае аварии на одном из них, его нагрузка перекладывается на другие, входящие в систему. Такая организация называется кластером высокой доступности (high availability cluster, HA-кластер).
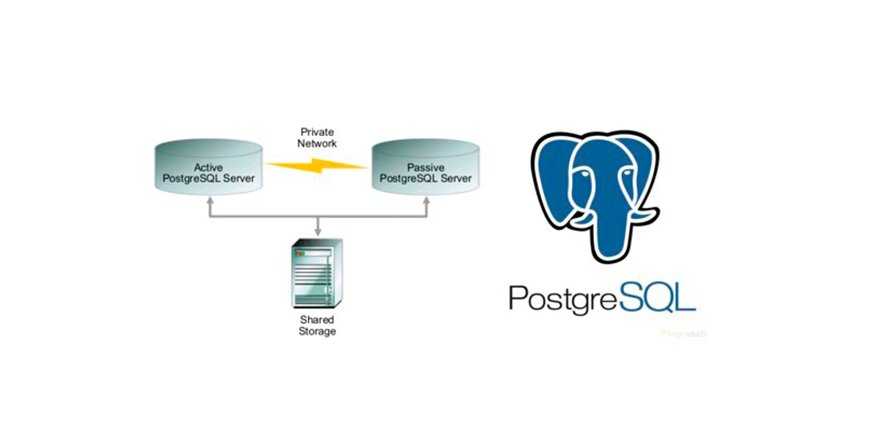
В простейшем и самом распространённом случае система состоит из двух серверов (так называемый двухузловой кластер), один из которых является основным, а другой —дублирующим, резервным (конфигурация active/passive). Все вычисления производятся на основном сервере, а дублирующий сервер включается в работу в случае аварии на основном. Такая конфигурация является затратной, так как каждый узел дублируется. На схеме ниже показана конфигурация active/passive, состоящая из нескольких (N) серверов.
Конфигурация Active/Passive
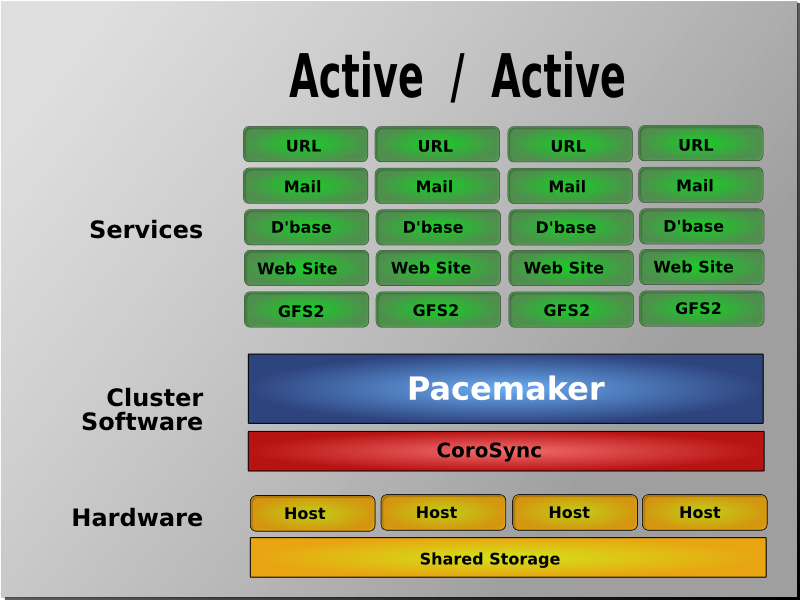
В другом варианте построения кластера серверы (два или больше) могут иметь равноценный статус, то есть работать одновременно (конфигурация active/active). В такой конфигурации нагрузка вышедшего из строя сервера распределяется по остальным серверам кластера. Если серверов в кластере немного, то скорее всего произойдёт снижение производительности, так как нагрузка на оставшиеся в кластере серверы возрастёт.
Конфигурация Active/Active
Здесь стоит заметить, что в конфигурации active/passive (которая имеет полное резервирование каждого узла) такого снижения не будет. Однако этот вариант стоит дороже, так как каждый узел дублируется. Фактически, за отказоустойчивость и отсутствие потери производительности всегда приходится платить двойную цену.
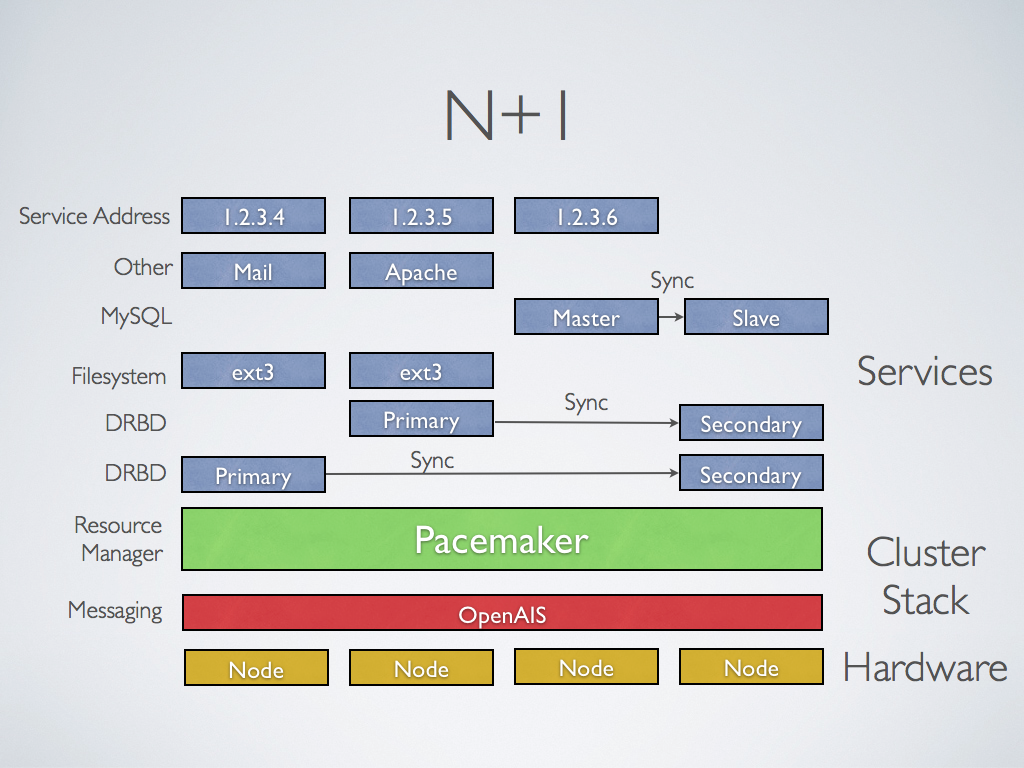
Третьим, альтернативным вариантом, который позволяет избежать как высоких расходов, так и потери производительности кластера при отказе одного из узлов, является конфигурация N+1. В этой конфигурации кластер имеет один полноценный резервный сервер, который при работе в обычном режиме не несёт на себе никакой нагрузки, а включается в работу только в случае отказа одного из активных серверов.
Конфигурация N+1
Краткое сравнение конфигураций сведено в таблицу ниже. Стоит отметить, что кроме описанных трех, бывают и другие, более сложные конфигурации отказоустойчивых кластеров. Например, N+M – когда для обеспечения более высокого уровня отказоустойчивости в состав кластера включается не один, а несколько резервных серверов.
|
Active/Active |
Active/Passive |
N+1 |
|
|
Стоимость решения |
Нормальная (суммарная стоимость всех узлов; все узлы кластера работают) |
Высокая (фактически – двойная, т.к. дублируются все узлы кластера) |
Нормальная + 1 (суммарная стоимость всех узлов + 1 резервный узел) |
|
Производи-тельность при отказе |
Снижение производительности |
Нет снижения производительности |
Нет снижения производительности |
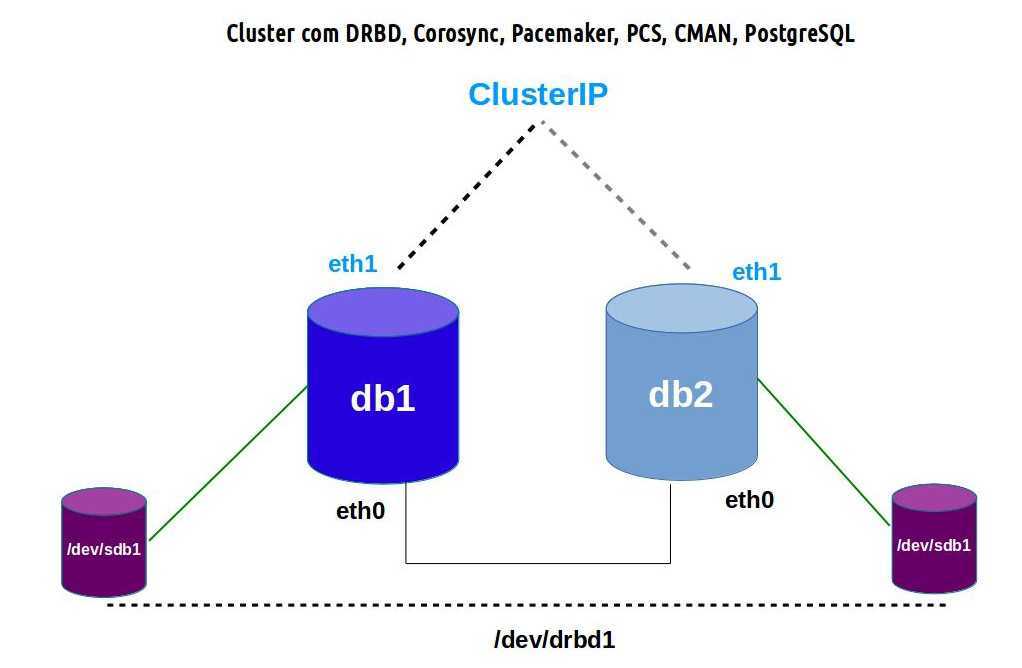
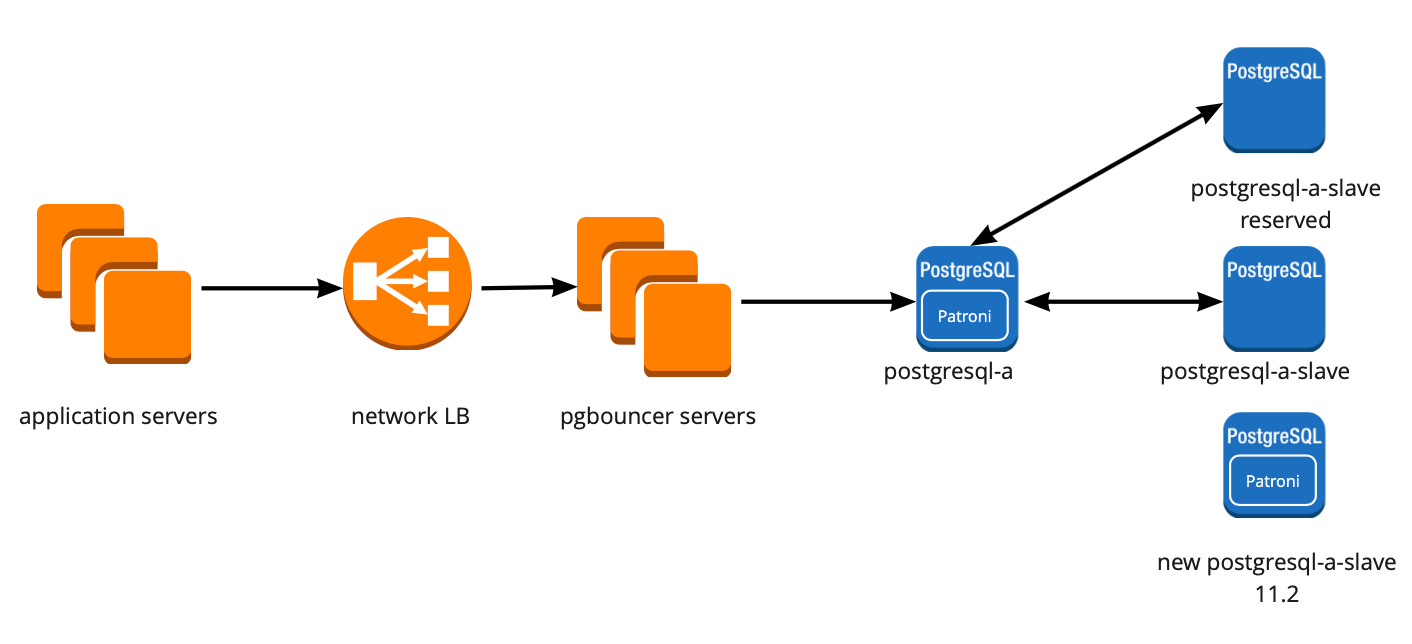
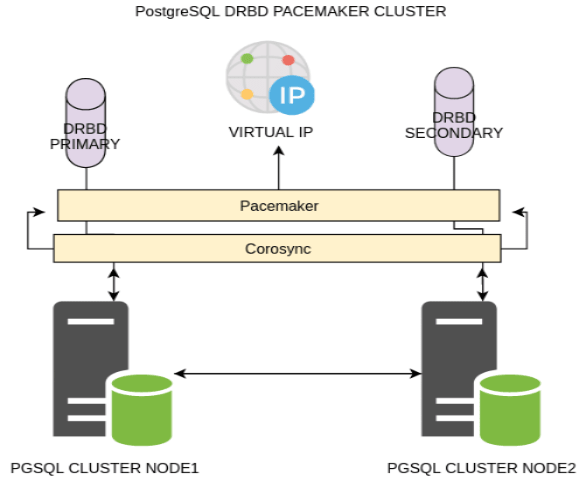
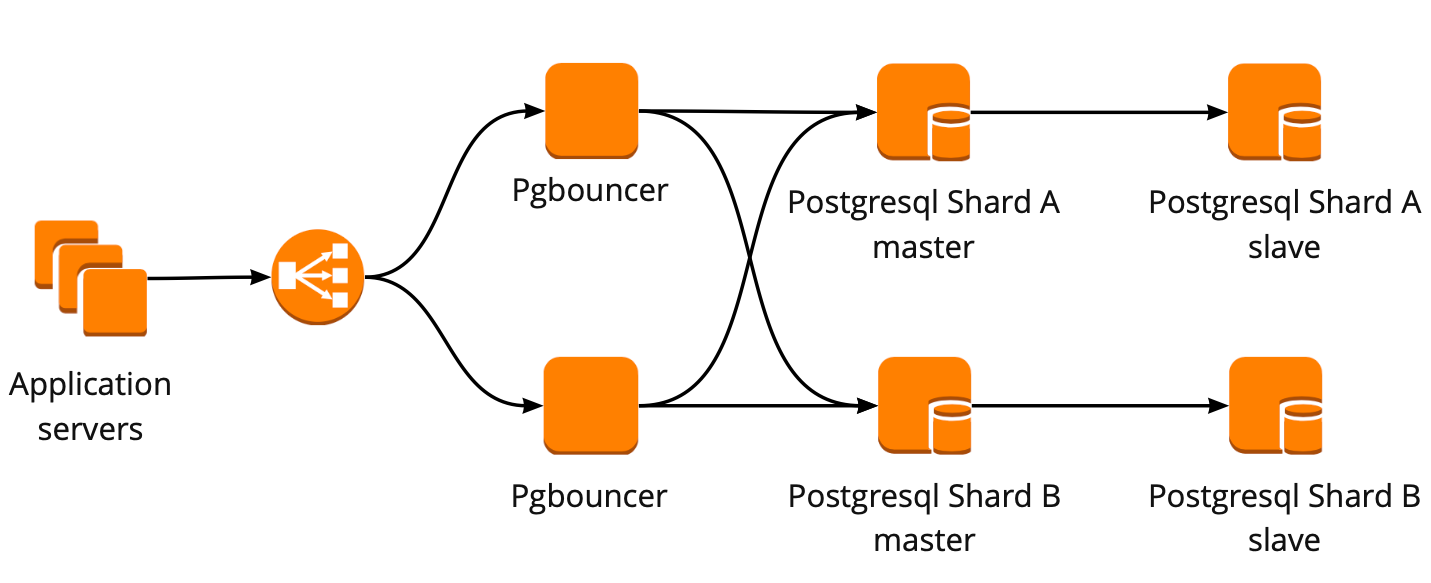
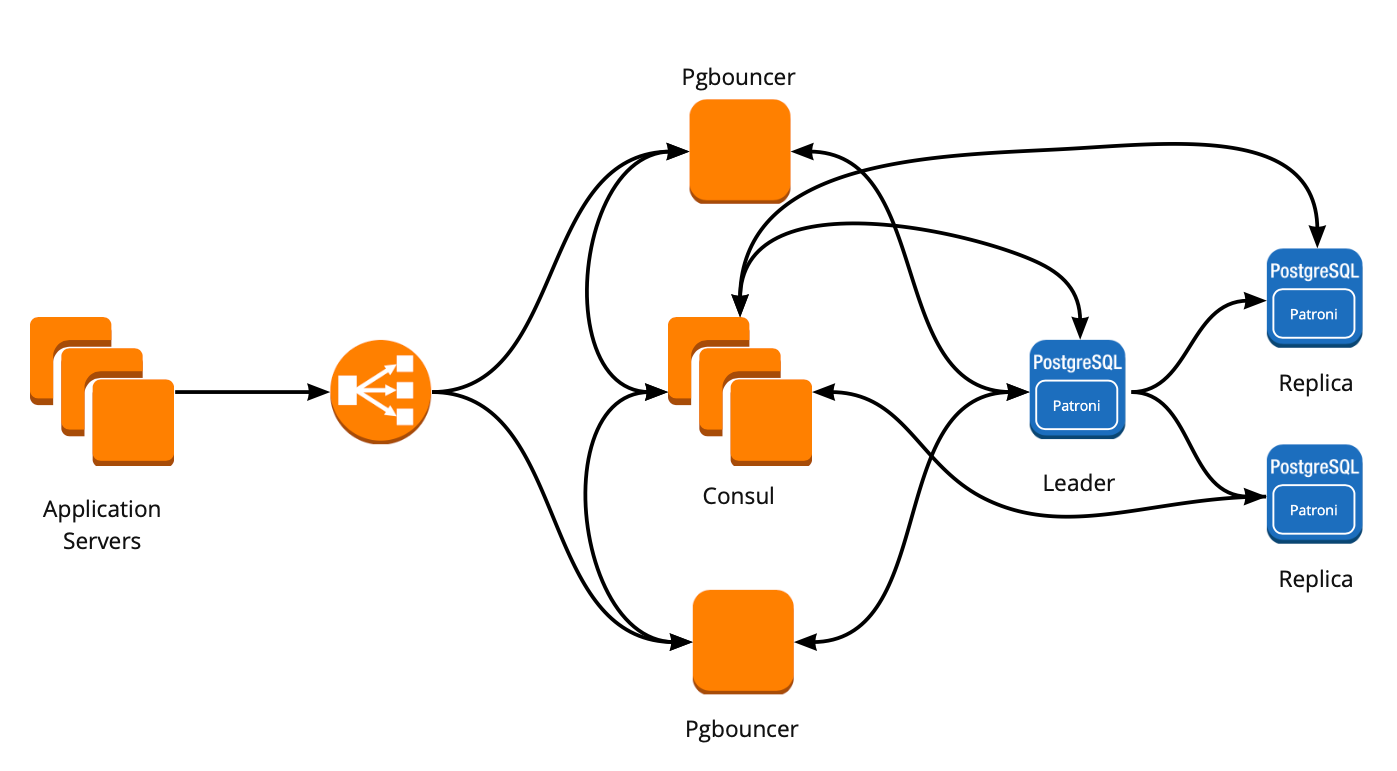
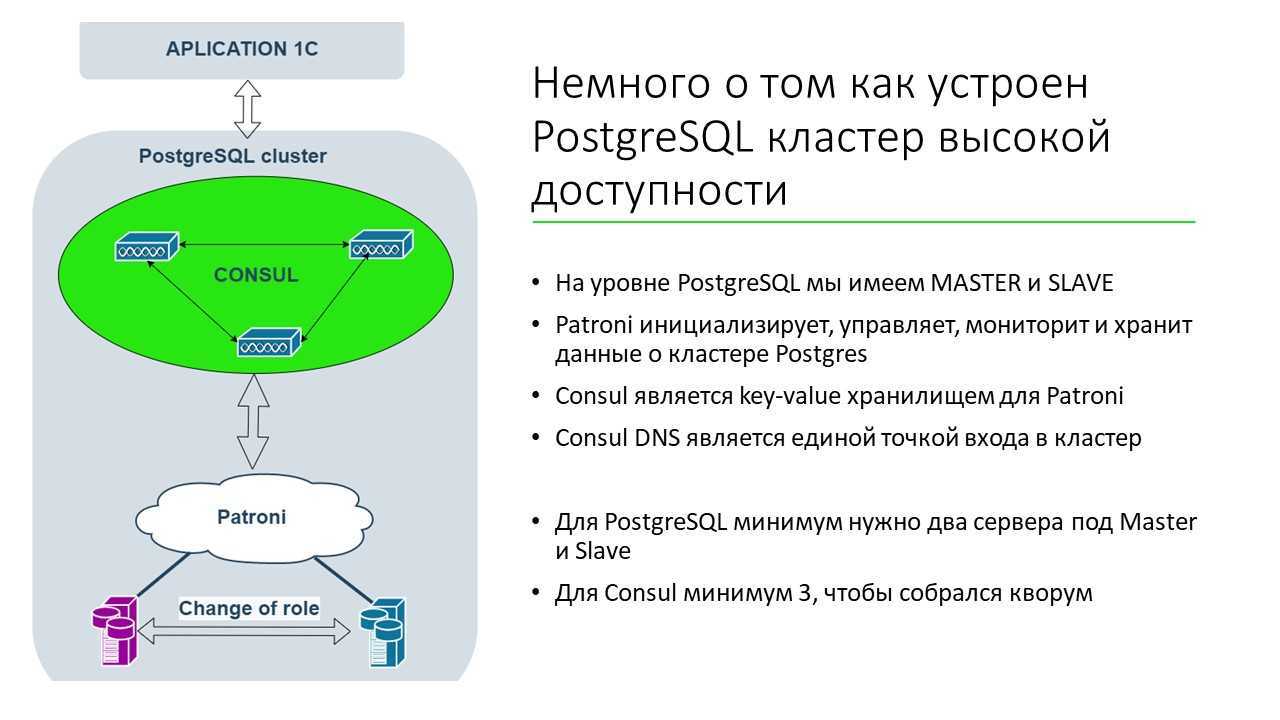
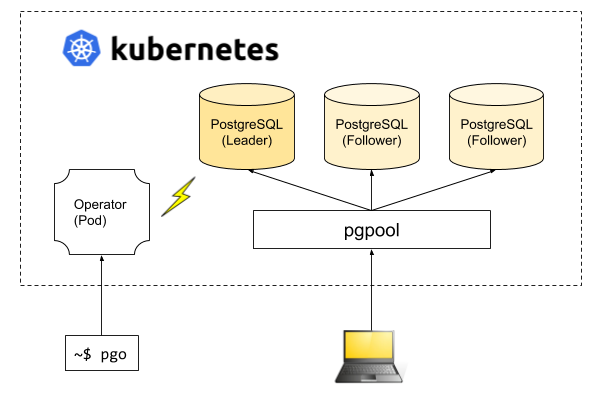
Создание отказоустойчивого кластера PostgreSQL
Самописные скрипты
- Мастер мог не умереть, вместо этого мог произойти сетевой сбой. Failover, не зная об этом, продвинет реплику до мастера, а старый мастер будет продолжать работать. В результате мы получим два сервера в роли master и не будем знать, на каком из них последние актуальные данные. Такую ситуацию называют ещё split-brain;
- Мы остались без реплики. В нашей конфигурации мастер и одна реплика, после переключения реплика продвигается до мастера и у нас больше нет реплик, поэтому приходится в ручном режиме добавлять новую реплику;
- Нужен дополнительный мониторинг работы failover, при этом у нас 12 шардов PostgreSQL, а значит мы должны мониторить 12 кластеров. При увеличении количества шардов надо ещё не забыть обновить failover.
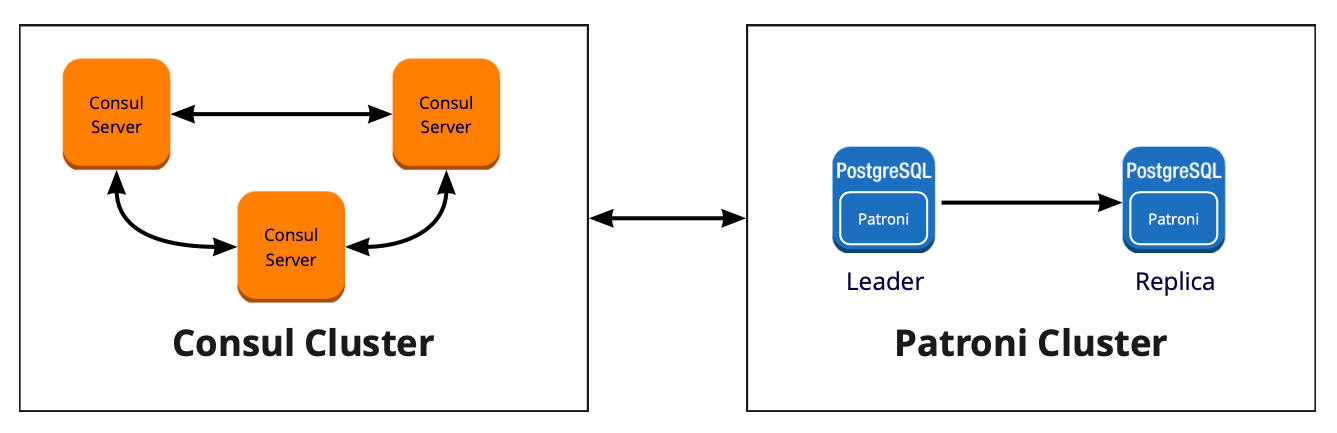
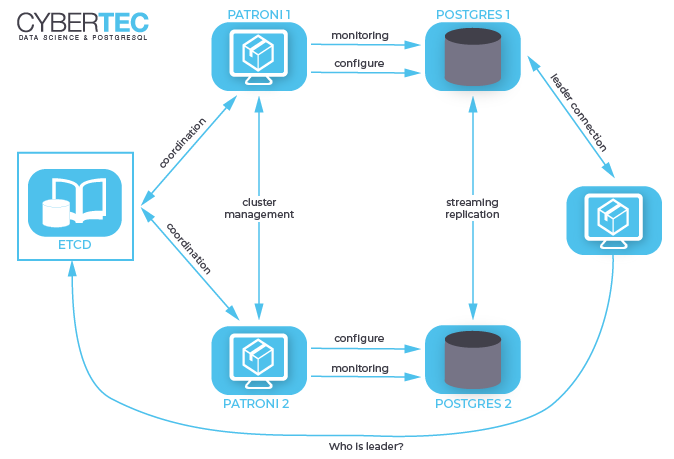
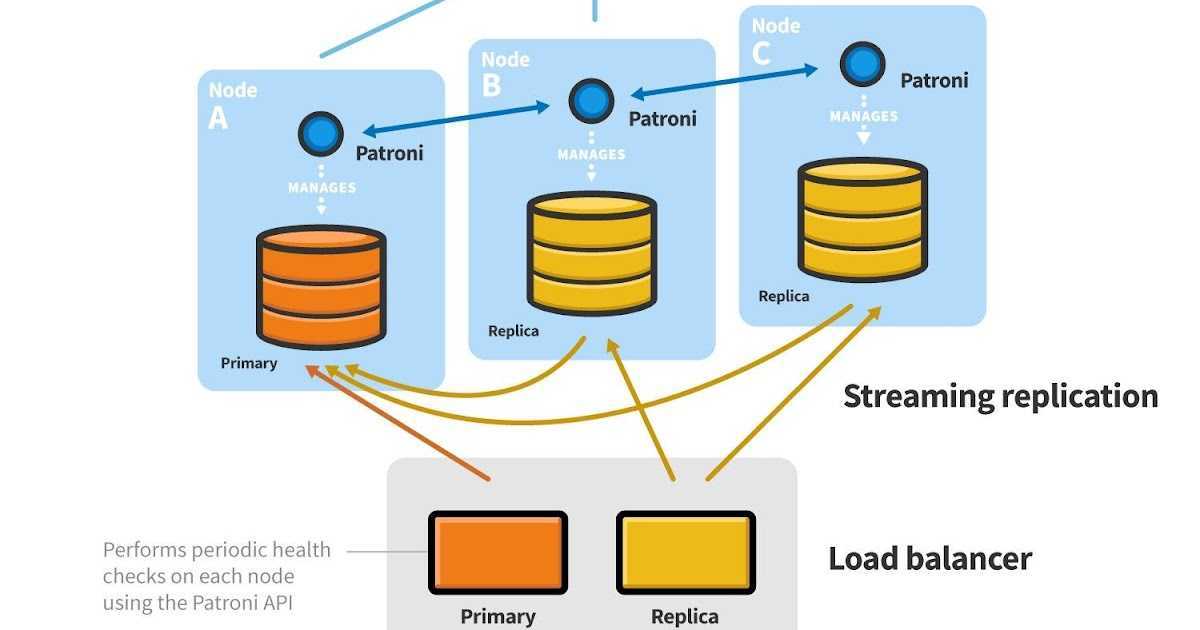
Patroni
- Расписан каждый параметр конфигурации, понятно как что работает;
- Автоматический failover работает из коробки;
- Написан на python, а так как мы сами много пишем на python, то нам будет проще разбираться с проблемами и, возможно, даже помочь развитию проекта;
- Полностью управляет PostgreSQL, позволяет менять конфигурацию сразу на всех нодах кластера, а если для применения новой конфигурации требуется перезапуск кластера, то это можно сделать опять же с помощью Patroni.
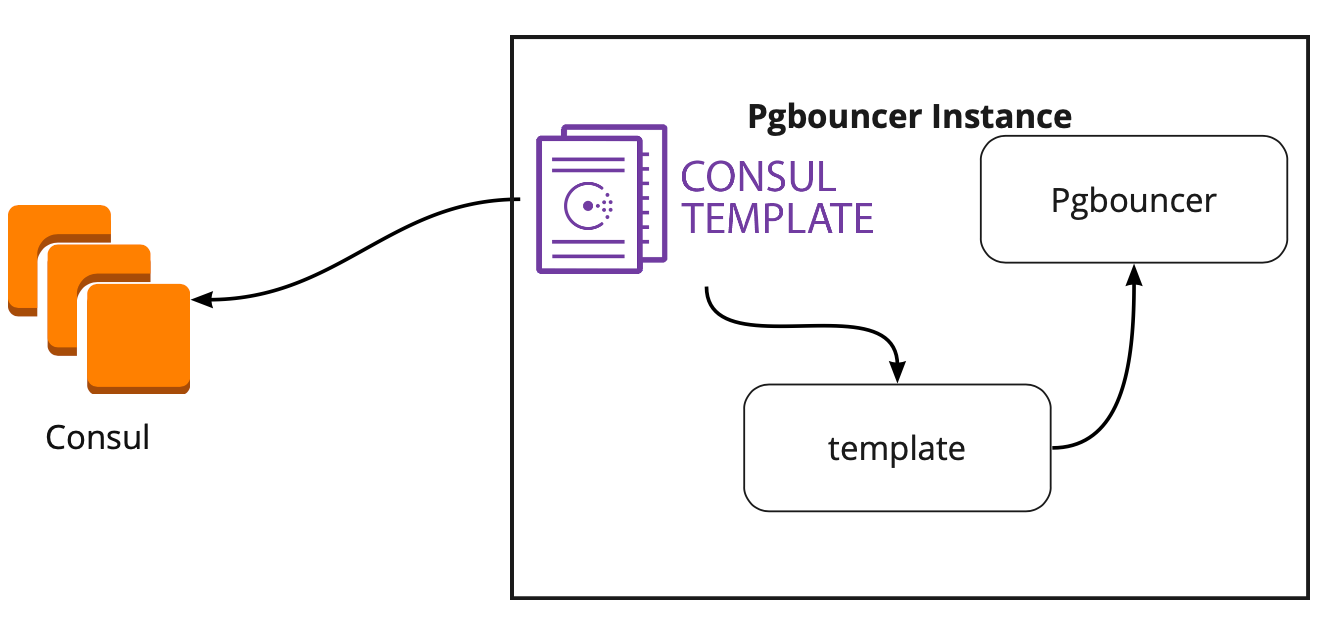
- Из документации непонятно, как правильно работать с PgBouncer. Хотя минусом это назвать сложно, потому что задача Patroni — управлять PostgreSQL, а как будут ходить подключения к Patroni — уже наша проблема;
- Мало примеров внедрения Patroni на больших объёмах, при этом много примеров внедрения с нуля.
Виды кластеров
Кластер — это группа независимых компьютеров (так называемых узлов или нодов), к которой можно получить доступ как к единой системе. Кластеры могут быть предназначены для решения одной или нескольких задач. Традиционно выделяют три типа кластеров:
- Кластеры высокой готовности или отказоустойчивые кластеры (high-availability clusters или failover clusters) используют избыточные узлы для обеспечения работы в случае отказа одного из узлов.
- Кластеры балансировки нагрузки (load-balancing clusters) служат для распределения запросов от клиентов по нескольким серверам, образующим кластер.
- Вычислительные кластеры (compute clusters), как следует из названия, используются в вычислительных целях, когда задачу можно разделить на несколько подзадач, каждая из которых может выполняться на отдельном узле. Отдельно выделяют высокопроизводительные кластеры (HPC — high performance computing clusters), которые составляют около 82% систем в рейтинге суперкомпьютеров Top500.
Системы распределенных вычислений (gird) иногда относят к отдельному типу кластеров, который может состоять из территориально разнесенных серверов с отличающимися операционными системами и аппаратной конфигурацией. В случае грид-вычислений взаимодействия между узлами происходят значительно реже, чем в вычислительных кластерах. В грид-системах могут быть объединены HPC-кластеры, обычные рабочие станции и другие устройства.
Такую систему можно рассматривать как обобщение понятия «кластер». ластеры могут быть сконфигурированы в режиме работы active/active, в этом случае все узлы обрабатывают запросы пользователей и ни один из них не простаивает в режиме ожидания, как это происходит в варианте active/passive.
Oracle RAC и Network Load Balancing являются примерами active/ active кластера. Failover Cluster в Windows Server служит примером active/passive кластера. Для организации active/active кластера требуются более изощренные механизмы, которые позволяют нескольким узлам обращаться к одному ресурсу и синхронизовать изменения между всеми узлами. Для организации кластера требуется, чтобы узлы были объединены в сеть, для чего наиболее часто используется либо традиционный Ethernet, либо InfiniBand.
Программные решения могут быть довольно чувствительны к задержкам — так, например, для Oracle RAC задержки не должны превышать 15 мс. В качестве технологий хранения могут выступать Fibre Channel, iSCSI или NFS файловые сервера. Однако оставим аппаратные технологии за рамками статьи и перейдем к рассмотрению решений на уровне операционной системы (на примере Windows Server 2008 R2) и технологиям, которые позволяют организовать кластер для конкретной базы данных (OracleDatabase 11g), но на любой поддерживаемой ОС.
Oracle Grid Infrastructure
Для работы Oracle RAC требуется Oracle Clusterware (или стороннее ПО) для объединения серверов в кластер. Для более гибкого управления ресурсами узлы такого кластера могут быть организованы в пулы (с версии 11g R2 поддерживается два варианта управления — на основании политик для пулов или, в случае их отсутствия, администратором).
Во втором релизе 11g Oracle Clusterware был объединен с ASM под общим названием Oracle Grid Infrastructure, хотя оба компонента и продолжают устанавливаться по различным путям.
Automatic Storage Management (ASM) — менеджер томов и файловая система, которые могут работать как в кластере, так и с singleinstance базой данных. ASM разбивает файлы на ASM Allocation Unit.
Размер Allocation Unit определяется параметром AU_SIZE, который задается на уровне дисковой группы и составляет 1, 2, 4, 8, 16, 32 или 64 MB. Далее Allocation Units распределяются по ASM-дискам для балансировки нагрузки или зеркалирования. Избыточность может быть реализована, как средствами ASM, так и аппаратно.
ASM-диски могут быть объединены в Failure Group (то есть группу дисков, которые могут выйти из строя одновременно — например, диски, подсоединенные к одному контролеру), при этом зеркалирование осуществляется на диски, принадлежащие разным Failure Group. При добавлении или удалении дисков ASM автоматически осуществляет разбалансировку, скорость которой задается администратором.
На ASM могут помещаться только файлы, относящиеся к базе данных Oracle, такие как управляющие и журнальные файлы, файлы данных или резервные копии RMAN. Экземпляр базы данных не может взаимодействовать напрямую с файлами, которые размещены на ASM. Для обеспечения доступа к данным дисковая группа должна быть предварительно смонтирована локальным ASM-экземпляром.
Oracle рекомендует использовать ASM в качестве решения для управления хранением данных вместо традиционных менеджеров томов, файловых систем или RAW-устройств.
Резервирование на уровне узлов сервера
Резервирование достаточно широко применяется уже на нижнем уровне – самого устройства, то есть — в самих серверах. Многие их узлы дублируются, либо имеют такую возможность. Например, современные серверы предоставляют следующие возможности по резервированию:
Оперативная память
Серверы имеют особый режим работы памяти: Memory Mirroring или Mirrored memory protection. В этом режиме осуществляется зеркалирование каналов, то есть каналы разбиваются на пары, и в каждой паре один из каналов становится копией другого. Все банки памяти при этом должны быть сконфигурированы идентично.
Работа в этом режиме защищает от однобитовых ошибок или выхода из строя всего модуля памяти.
При работе в режиме зеркалирования памяти одни и те же данные записываются в банки системной и зеркалированной памяти, но считываются только из банков системной памяти. Если в каком-то из модулей системной памяти произошла многобитовая ошибка (или превышено допустимое количество однобитовых ошибок), то происходит переназначение банков: банки зеркалированной памяти назначаются системной памятью, а банки системной — зеркалированной. Это обеспечивает бесперебойную работу сервера за исключением случаев, когда ошибка происходит в одном и том же месте в системном и зеркалированном модулях памяти одновременно (вероятность этого крайне мала).
Недостатком такой организации является двукратное уменьшение объёма оперативной памяти. Или, иными словами, двукратное увеличение ее стоимости.
Диски
Аналогично оперативной памяти можно организовать зеркалирование дисков. Для этого каждому диску назначается дубликат, который содержит его полную копию благодаря тому, что информация одновременно записывается на диск и дублирующую его копию. В простейшем случае такая система состоит из двух одинаковых дисков.
Однако, как и в случае с зеркалированием оперативной памяти, недостатком такой организации является высокая (фактически – двойная) стоимость ресурсов. Поэтому часто используются другие варианты организации дисков в единые массивы (RAID, см. статью из Wikipedia). Существует достаточно много вариантов организации RAID-массивов, которые имеют различные параметры стоимости, скорости работы и степени отказоустойчивости.
Питание
Серверы среднего и старшего уровня имеют по два блока питания. В случае выхода из строя одного из них, сервер продолжает работать от второго. Иногда серверы оснащаются тремя и более блоками питания. В этом случае один из них остаётся резервным (так называемая схема N+1), либо БП дублируются (схема N+N). В последнем случае их число должно быть чётным.
Интерфейсы (платы расширения)
И снова самое простое, что можно сделать для обеспечения отказоустойчивости – это дублирование интерфейсных плат. Однако так как
a) современная инфраструктура имеет большое разнообразие интерфейсов разных стандартов (Ethernet, FC, Infiniband, и т.д.) и физических носителей («оптоволокно» или «медь»),
b) отказ интерфейсной платы не ведет к потере информации (он только нарушает процесс её передачи),
резервирование интерфейсных плат не входит в набор стандартных средств, которые по умолчанию предоставляются производителем оборудования. Здесь решение о резервировании остаётся на усмотрение пользователя.
Таким образом, отказоустойчивость сервера может быть повышена путем резервирования некоторых его узлов, как только что было описано. Но есть компоненты, которые задублировать невозможно. К ним относятся, в частности, RAID-контроллер и материнская плата. Выход из строя RAID-контроллера может привести к частичной или полной потере данных, а выход из строя материнской платы приведет к остановке всего сервера. Как защититься от таких неисправностей и обеспечить безотказную работу?
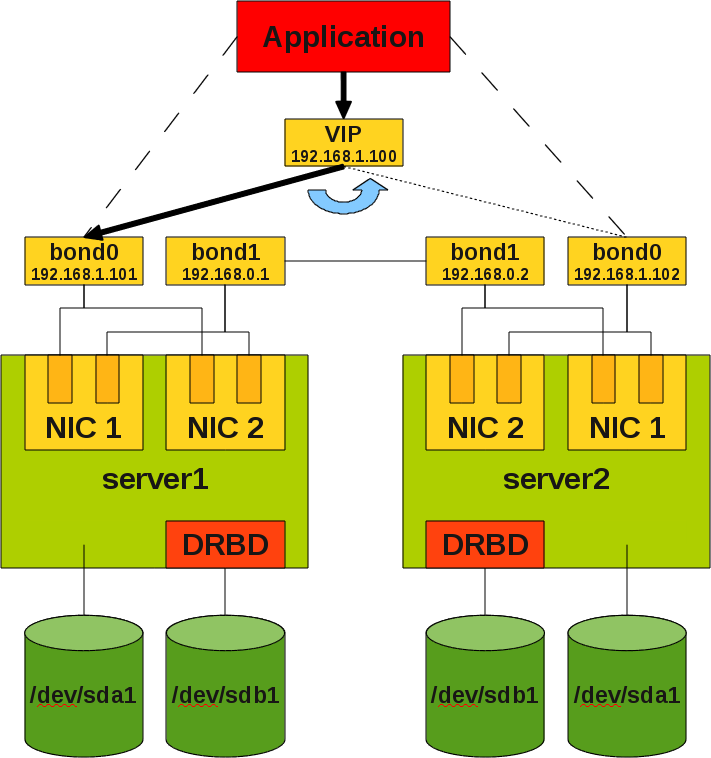
Отказоустойчивость на уровне инфраструктуры
Как было показано выше, основным способом повышения отказоустойчивости является дублирование узлов. Рассмотрим этот процесс на нескольких примерах. Для начала возьмём простую (и довольно часто встречающуюся) топологию инфраструктуры небольшой компании:
В конфигурации на этом рисунке мы защищены от потери данных на СХД (т.к. СХД имеет два контроллера), но не защищены от простоя в случае, если выйдет из строя коммутатор. Поэтому для повышения отказоустойчивости нам нужно добавить второй коммутатор, и подключить к нему остальное оборудование:
Теперь мы защищены от неполадок как со стороны СХД, так и со стороны коммутатора. Но что будет, если выйдет из строя сетевой адаптер сервера? Этот сервер потеряет доступ к сети и СХД. Поэтому нужно задублировать также и сетевые адаптеры:
Кажется, теперь мы задублировали всё, что можно. Остаются только сами серверы. Их можно объединить в отказоустойчивый кластер, как было описано ранее:
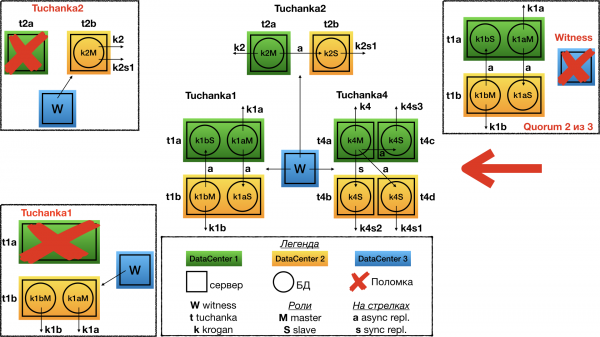
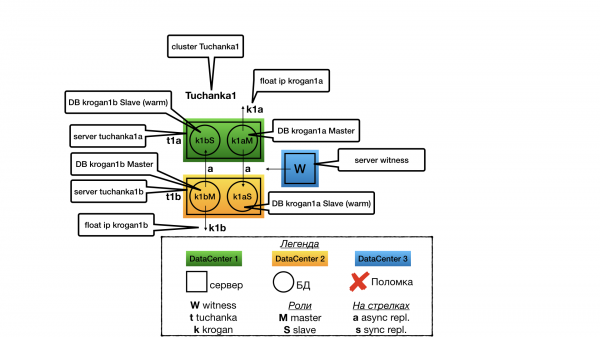
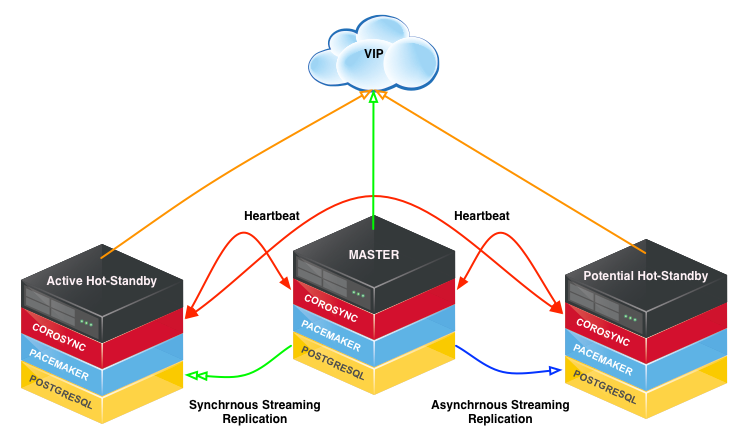
Tuchanka2 (классическая)
Структура
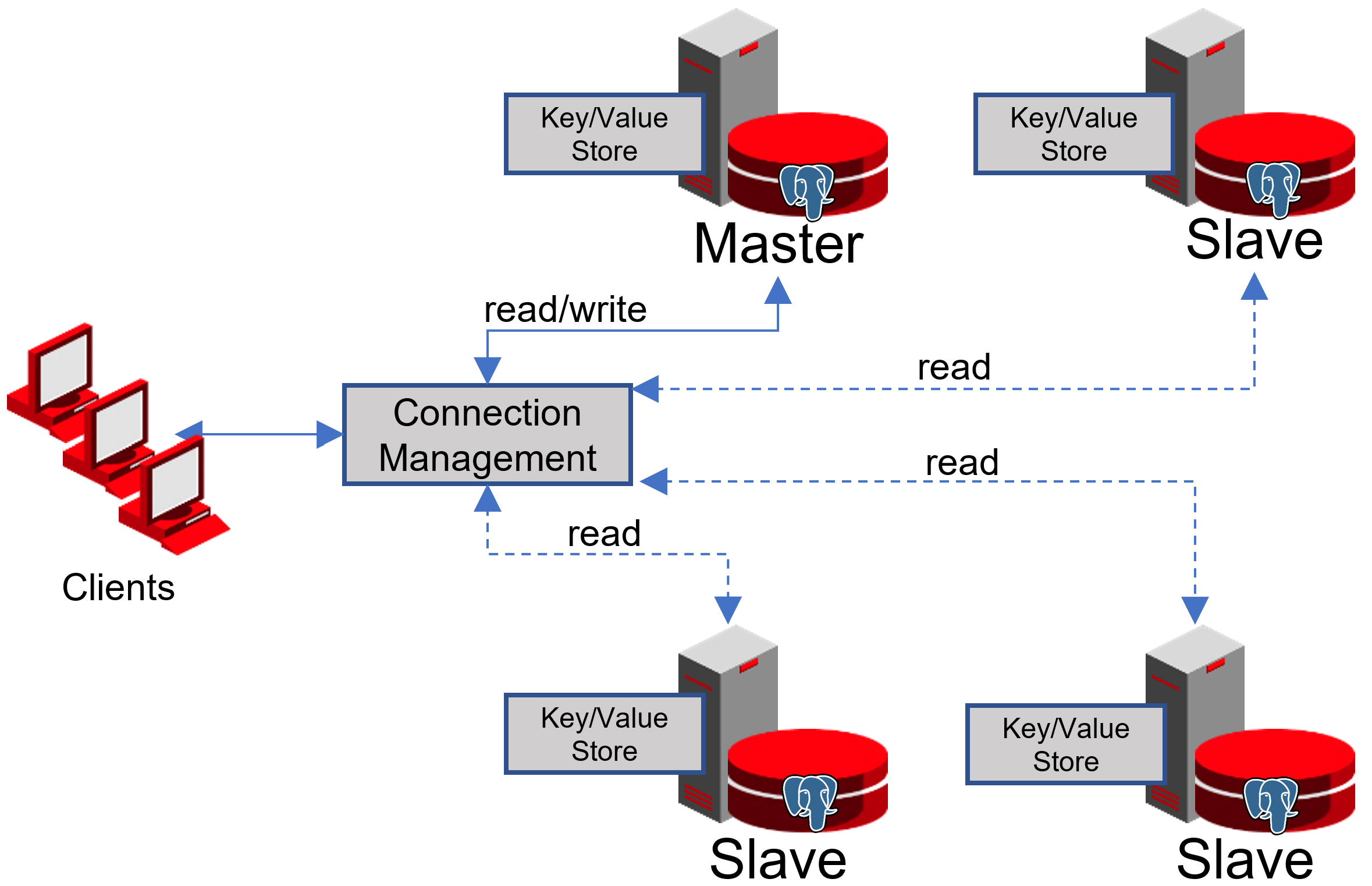
Классическая схема из двух узлов. На одном работает мастер, на втором раб. Оба могут выполнять запросы (раб только read only), поэтому на обоих указывают float IP: krogan2 — на мастер, krogan2s1 — на раба. Отказоустойчивость будет и у мастера, и у раба.
В случае с двумя узлами отказоустойчивость возможна только при асинхронной репликации, потому что при синхронной отказ раба приведёт к остановке мастера.
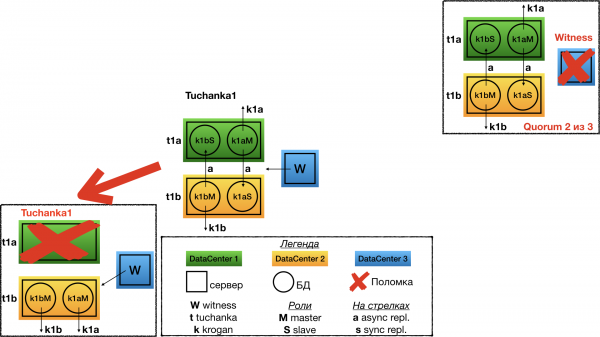
Отказ Tuchanka2
При отказе одного из дата-центров witness голосует за второй. На единственном работающем дата-центре будет поднят мастер, и на него будут указывать оба float IP: мастерский и рабский. Разумеется, инстанс должен быть настроен таким образом, чтобы у него хватило ресурсов (лимитов под connection и т.д.) одновременно принимать все подключения и запросы от мастерского и рабского float IP. То есть при нормальной работе у него должен быть достаточный запас по лимитам.
Подробнее о понятиях
IT-инфраструктура строится с учетом возможных сбоев в работе. В идеале любые критические ситуации система должна переживать с минимальными потерями или вовсе без них. И под сбоями понимаются не только аппаратные или программные неполадки, но и ураганы, пожары и любые другие стихийные бедствия, а также человеческий фактор. По сути список возможных угроз можно продолжать бесконечно.
ИТ-инфраструктура должна быть спроектирована с учетом, если не всех, то хотя бы большинства возможных угроз. Основная задача – чтобы система пережила возможные опасности и осталась в рабочем состоянии. Именно в связи с этим и звучат два термина – отказоустойчивость и катастрофоустойчивость. Рассмотрим подробнее каждый из них.
Отказоустойчивость – это определенное свойство системы сохранять свою работоспособность после отказа одного или нескольких компонентов. С его помощью удается продолжить выполнение бизнес-задач без сбоев и простоя. Это свойство характеризует два технических момента инфраструктуры, а именно – коэффициент готовности и показатели надежности. В первом случае речь идет о времени от всего срока эксплуатации системы, в котором она находится в рабочем состоянии. Второй показатель определяет вероятность безотказной работы инфраструктуры за определенный период.
Катастрофоустойчивость же определяется как способность системы продолжать запущенные задачи при выходе всего ЦОДа из строя. Например, это может потребоваться при отключении электричества или различных природных явлениях, которые влияют на работу оборудования.
Если же говорить кратко, то принцип отказоустойчивости направлен на устранение возможных точек отказа инфраструктуры, тогда как катастрофоустойчивость позволяет поддержать работоспособность системы даже после серьезной аварии.
Аренда выделенного
сервера
Разместим оборудование
в собственном дата-центре
уровня TIER III.
Конфигуратор сервера
Подбор оборудования для решения Ваших задач и экономии бюджета IT
Запросить КП
Перспективы развития
Сейчас IB-коммутатор задублирован обычным гигабитным Ethernet-коммутатором. Это необходимо для того, чтобы кластер не потерял связность при выходе основного коммутатора из строя. На подхвате стоит резервный IB-коммутатор, но переключать на него узлы кластера придется в случае неполадки вручную. После сбоя система продолжит работать с деградацией производительности на 5-10 минут. Это время необходимо для физического переключения на резервный IB-коммутатор.
Планируем полностью задублировать IB-коммутатор, чтобы при выхода из строя основного второй мгновенно взял всю нагрузку на себя. Это не так просто, как кажется — необходимо в каждый сервер установить вторую HCA-карту. Не на всех нодах есть дополнительный PCI-E, поэтому некоторые придется заменять целиком. Можно поставить одну двухпортовую карту, но такое решение не спасает от выхода из строя самой карты.
Также планируем развивать кластер в ширину — ноды рано или поздно заполнятся, а для подключения новых нод портов почти не осталось. Необходимо добавить ещё один IB-коммутатор и соединять с имеющимся последовательно.
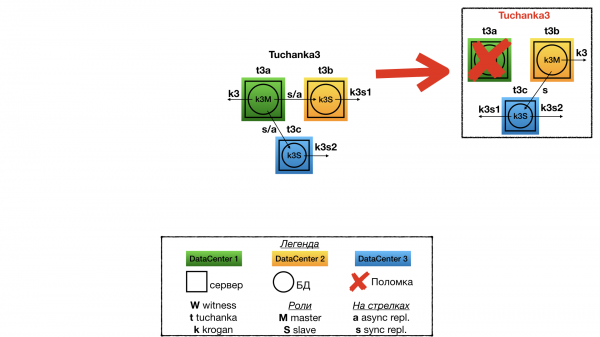
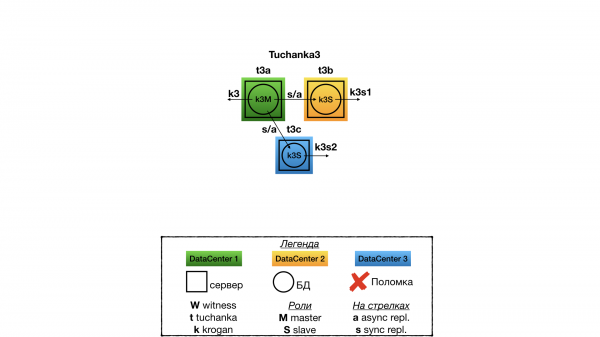
Tuchanka4 (много рабов)
Структура
Уже другая крайность. Бывают БД, на которые идет очень много запросов read-only (типичный случай высоконагруженного сайта). Tuchanka4 — это ситуация, когда рабов может быть три или больше для обработки таких запросов, но всё же не слишком много. При очень большом количестве рабов надо будет изобретать иерархическую систему реплицирования. В минимальном случае (на картинке) в каждом из двух дата-центров находится по два сервера, на каждом из которых по инстансу PostgreSQL.
Еще одной особенностью этой схемы является то, что здесь уже можно организовать одну синхронную репликацию. Она настроена так, чтобы реплицировать, по возможности, в другой дата-центр, а не на реплику в том же дата-центре, где и мастер. На мастер и на каждый раб указывает float IP. По хорошему, между рабами надо будет делать балансировку запросов каким-нибудь sql proxy, например, на стороне клиента. Разному типу клиентов может требоваться разный тип sql proxy, и только разработчики клиентов знают, кому какой нужен. Эта функциональность может быть реализована как внешним демоном, так и библиотекой клиента (connection pool), и т.д. Всё это выходит за рамки темы отказоустойчивого кластера БД (отказоустойчивость SQL proxy можно будет реализовать независимо, вместе с отказоустойчивостью клиента).
Отказ Tuchanka4
При отказе одного дата-центра (т.е. двух серверов) witness голосует за второй. В результате во втором дата-центре работают два сервера: на одном работает мастер, и на него указывает мастерский float IP (для приема read-write запросов); а на втором сервере работает раб с синхронной репликацией, и на него указывает один из рабских float IP (для read only-запросов).
Первое, что надо отметить: рабочими рабский float IP будут не все, а только один. И для корректной работы с ним нужно будет, чтобы sql proxy перенаправлял все запросы на единственно оставшийся float IP; а если sql proxy нет, то можно перечислить все float IP рабов через запятую в URL для подключения. В таком случае с libpq подключение будет к первому рабочему IP, так сделано в системе автоматического тестирования. Возможно, в других библиотеках, например, JDBC, так работать не будет и необходим sql proxy. Так сделано потому, что у float IP для рабов стоит запрет одновременно подниматься на одном сервере, чтобы они равномерно распределялись по рабским серверам, если их работает несколько.
Второе: даже в случае отказа дата-центра будет сохраняться синхронная репликация. И даже если произойдёт вторичный отказ, то есть в оставшемся дата-центре выйдет из строя один из двух серверов, кластер хоть и перестанет оказывать услуги, но всё же сохранит информацию обо всех закоммиченных транзакциях, на которые он дал подтверждение о коммите (не будет потери информации при вторичном отказе).
Сценарий сбоя Ceph
начинается самое интересное
- Нормальная работа примерно до 70 секунды;
- Провал на минуту примерно до 130 секунды;
- Плато, которое заметно выше, чем работа в нормальном режиме — это работа кластеров degraded;
- Затем мы включаем отсутствующий узел — это учебный кластер, там всего 3 сервера и 15 SSD. Пускаем сервер в работу где-то в районе 260 секунды.
- Сервер включился, вошел в кластер — IOPS’ы упали.
Внутреннее поведение Ceph
первоначальная синхронизация данных
- OSD считывает имеющиеся версии, имеющуюся историю (pg_log — для определения текущих версий объектов).
- После чего определяет, на каких OSD лежат последние версии деградировавших объектов (missing_loc), а на каких отставшие.
- Там, где хранятся отставшие версии нужно провести синхронизацию, а новые версии могут быть использованы в качестве опорных для чтения и записи данных.
Для сравнения:
- чем больше объектов, тем больше история missing_loc;
- чем больше PG — тем больше pg_log и OSD map;
- чем больше размер дисков;
- чем выше плотность размещения (количество дисков в каждом сервере);
- чем выше нагрузка на кластер и чем быстрее ваш кластер;
- чем дольше OSD находится дауне (в состоянии Offline);
чем более крутой кластер мы построили, и чем дольше часть кластера не отвечала — тем больше оперативной памяти потребуется при старте