
Дважды отмерь и один раз отрежь (Measure Twice and Cut Once)
Некачественно выполненный этап написания требований обычно приводит к более чем 50% проблем в разработке. Поэтому подготовьтесь, разработав системный подход к процессу программирования.
Дважды проверьте все требования проекта, чтобы убедиться, что вы ничего не упускаете и не добавляете лишнего в свой код. После этого сделайте наброски, которые будут направлять весь процесс для получения высококачественного кода. Всегда тестируйте свой проект с самых основ, чтобы убедиться, что все в порядке.
Этот принцип дает гораздо более предсказуемые результаты, особенно если стоимость проекта уже высока. Вы избавите себя от головной боли, связанной с удалением или добавлением строк кода в соответствии с требованиями.
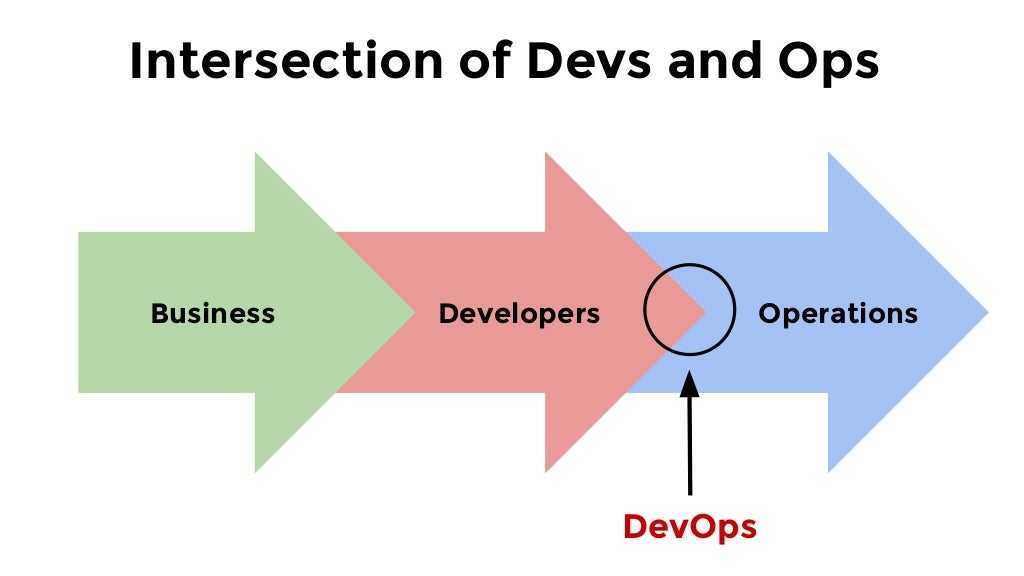
Принцип 10. Dev-Prod Parity
В статье с двенадцатью факторами предлагается минимизировать разницу между средой разработки и производственной средой. Это снижает вероятность появления ошибок в конкретной среде.
Разработчики должны стремиться использовать одни и те же сторонние сервисы в процессе разработки и производства. Чтобы минимизировать различия между разработкой и производством, команды, работающие над проектом, должны использовать одни и те же операционные системы, службы поддержки и зависимости. В результате непрерывное развертывание занимает меньше времени. Это также способствует идее быстрой разработки приложений (RAD).
Процесс непрерывного развертывания становится беспроблемным, когда разработчики сокращают количество различий между стадиями разработки и производства.
S.O.L.I.D
Эта аббревиатура обозначает пять принципов объектно-ориентированного программирования и дизайна.
S — Single Responsibility Principle (SRP) — Принцип единой ответственности.
O — Open/Closed Principle (OCP) — Принцип открытия / закрытия.
L — Liskov Substitution Principle — Принцип замещения Лисков.
I — Interface Segregation Principle — Принцип разделения интерфейса.
D — Dependency Inversion Principle — Принцип инверсии зависимостей.
Давайте кратко рассмотрим каждый из этих принципов
Принцип единой ответственности (SRP)
Это принцип разработки программного обеспечения, который гласит, что класс должен иметь только одну причину для изменения. Другими словами, у него должна быть только одна ответственность.
Здесь мы говорим о связанности. Все элементы в структурах или модулях данного класса должны иметь функциональное родство друг с другом. Чётко определив ответственность своего класса, вы повысите его связанность.
Принцип открытости / закрытости (OCP)
Принцип гласит, что вы должны иметь возможность изменять поведение класса, не изменяя сам класс.
Следовательно, вы можете расширить поведение класса за счет композиции, интерфейса и наследования. Однако вы не можете открыть класс для незначительных изменений.
Принцип замещения Лисков (LSP)
В своей исследовательской работе 1988 года Барбара Лисков заявила, что производные классы должны быть спроектированы так, чтобы их при необходимости можно было заменить своими базовыми классами без потери обратной совместимости
Таким образом, вам нужно проявлять осторожность при использовании наследования в проекте
Хотя наследование выгодно, рекомендуется использовать его в контексте и умеренно. Принцип направлен на предотвращение случаев, когда классы расширяются только за счет общих вещей.
Перед выполнением наследования необходимо учитывать предварительные условия класса.
Принцип разделения интерфейса (ISP)
ISP предпочитает много конкретных интерфейсов одному общему. Цель состоит в том, чтобы иметь гранулярные и специфичные для клиента интерфейсы.
Вам необходимо повысить связанность в интерфейсах и разработать бережливые модули — с минимально возможным поведением.
Интерфейсы с множеством поведений сложно поддерживать и развивать. Так что вам следует избегать их.
Принцип инверсии зависимостей (DIP)
Принцип утверждает, что программисты должны полагаться на абстракции, а не на конкретные классы. Мы можем разбить это на две части:
Модули высокого уровня должны быть независимыми от модулей низкого уровня. И те, и другие должны зависеть от абстракций
Абстракции не должны зависеть от деталей реализации. Детали должны зависеть от абстракций.
Итак, в чем причина этого принципа? Ответ состоит в том, что абстракции мало меняются. Следовательно, вы можете легко изменить поведение вашего приватного или публичного кода. Таким образом, вы ускорите его дальнейшую эволюцию.
Заключение
У каждого профессионала должны быть руководящие принципы. Подобные принципы способствуют единству среди профессионалов в обслуживании своих клиентов. Как благородная область деятельности, разработка программного обеспечения не должна оставаться в стороне.
Инженеры-программисты сделают себе одолжение, придерживаясь вышеуказанных принципов разработки и проектирования программного обеспечения. Таким образом вы сможете более эффективно обслуживать своих клиентов и сотрудничать с другими инженерами.
Для вас подготовил перевод Никита Ульшин, Team Lead & JS-разработчик, веду блог ulshin.me и ТГ-канал @ulshinblog.
Комментарии, пожелания и конструктивная критика приветствуются ![]()
Источники
-
1cloud.ru. Справочная: что такое Continuous Delivery (2019)
-
Martin Fowler. ContinuousDelivery (2013)
-
Jez Humble. The Case for Continuous Delivery (2014)
-
B. Alanna, N. Forsgren, J. Humble et al. State of DevOps Report (2016)
-
Chen, Lianping. Continuous Delivery: Huge Benefits, but Challenges Too (2015)
-
Leppänen, M.; Mäkinen, S.; Pagels, M.; Eloranta, V. P.; Itkonen, J.; Mäntylä, M. V.; Männistö, T. The Highways and Country Roads to Continuous Deployment (2015)
-
A. Häkli, D. Taibi, K. Systä. Towards Cloud Native Continuous Delivery: An Industrial Experience Report (2018)
-
Г. А. Минашин. Переключатели функциональности (feature toggles): виды, преимущества и работа с ними в .NET (2019)
-
Как «продать» технические задачи бизнесу (2021)
Определение возможностей для улучшения
Команды ищут возможность повысить эффективность каждого шага, последовательно сокращая Total Lead Time. Это включает в себя определение Process Time, а также качества каждого шага с помощью метрики %C&A. Чем выше это число, тем меньше требуется доработок, и тем быстрее работа движется по системе.
Как показано на рисунке 6, Delay Time (время между шагами) часто является наиболее значительным начальным фактором. Время задержки представляет собой передачу, ожидание и другие непроизводительные затраты времени, не связанные с добавленной стоимостью.
Процесс на рисунке 6 имеет две значительные задержки и значительный объем доработок на первом этапе процесса развертывания. Сокращение задержек, как правило, является самым быстрым и простым способом снижения Total Lead Time. Еще одной приоритетной областью для улучшения является любой шаг с низкими показателями %C&A (большим процентом доработок), поскольку сокращение переделок позволяет ART сосредоточиться на создании ценности (например, для программного решения вместо исправления ошибок команда может сосредоточиться на новых фичах).






Последующие возможности для улучшения сосредоточены на уменьшении размера партии и применении методов DevOps, определенных в каждой из последующих статей, описывающих конвейер непрерывной поставки.
Рисунок 6. Визуализация потока выявляет основные ”бутылочные горлышки” поставки
Топологии DevOps
Способы применения DevOps сильно зависят от конкретной организации. По словам Мэттью Скелтона (Matthew Skelton) и Мануэля Пайса (Manuel Pais), чтобы внедрение DevOps проходило успешно, компании применяют разные типы топологий или командных структур. Скелтон и Пайс выделяют девять типов топологий.
Сотрудничество Dev- и Ops-команд
Это идеальная командная структура для DevOps. В ней Dev- и Ops-группы тесно взаимодействуют друг с другом:
- Разработчики серьёзно относятся к задачам команд поддержки и прислушиваются к Ops-коллегам, если это необходимо.
- Члены команд поддержки отлично понимают, чем занимаются разработчики.
Распределённые операционные обязанности
Такая топология применяется в Facebook и Netflix. Она состоит из команд разработчиков, в которые вплетены команды поддержки. Dev и Ops при этом почти не различаются.
Лучше всего подходит для компаний с отдельными веб-приложениями.
Ops в качестве «инфраструктуры как услуги»
Эта топология подходит для организаций с различными/несколькими службами, расположенными на облачных платформах, но с традиционным IT-отделом, реструктурировать который не планируется. При таком подходе Ops-группа — это, по сути, «инфраструктура как услуга» (Infrastructure as a Service, IaaS).
DevOps как внешний сервис
Некоторые организации не обладают достаточным опытом или не могут себе позволить организацию отдельной Ops-команды. В таком случае они могут поручить управление операционными аспектами ПО внешнему провайдеру.
DevOps-команды «по требованию»
Dev- и Ops-команды временно объединяются, чтобы достичь какой-то конкретной цели. Как только задача выполнена, команду распускают.
Команда DevOps advocacy
Такая топология подходит для слабо сплочённых команд. DevOps-адвокаты помогают и разработчикам, и группе поддержки, рассказывают им о DevOps-практиках и вовлекают в работу.
SRE-команда
Эту топологию придумали в Google. В такой структуре есть группа, которая занимается «проектированием надёжности сайта» (Site Reliability Engineering, SRE). Разработчики доказывают сотрудникам этой команды, что их ПО соответствует стандартам. SRE могут откатить изменения, если не согласны с ними.
Сотрудничество на основе контейнеров
При контейнеризации требования к развёртыванию и времени выполнения переносятся на слой контейнеров. Это убирает часть взаимозависимостей между Dev- и Ops-командами.
Такая структура подходит для организаций с хорошо развитой инженерной культурой.
Воссоздать стратегию обновления
Стратегия обновления «воссоздать» — это процесс «все или ничего», который позволяет обновлять все аспекты системы одновременно с коротким периодом простоя.
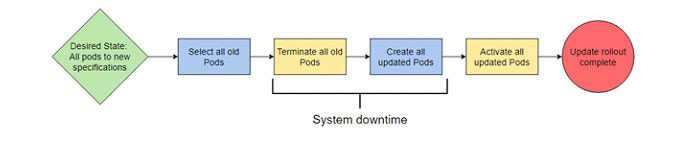
В этой стратегии развертывание выбирает все устаревшие модули и сразу деактивирует их.
После деактивации всех старых модулей развертывание создает обновленные модули для всей системы. Система не работает, начиная с деактивации старого модуля и заканчивая созданием последнего обновленного модуля.
Стратегия воссоздания используется для систем, которые не могут функционировать в частично обновленном состоянии или если вы предпочитаете простои, чем предоставлять пользователям меньшее удобство. Чем больше размер обновления, тем больше вероятность того, что последовательное обновление вызовет ошибку.
Следовательно, воссоздать стратегию лучше для крупных обновлений и капитальных ремонтов.
Когда вы обдумываете стратегию воссоздания, спросите себя:
- Будет ли у моих пользователей больше впечатлений от простоев или временного снижения производительности?
- Может ли моя система работать во время непрерывного обновления?
- Могу ли я обновить систему, не затрагивая значительное количество пользователей?
Воссоздать реализацию обновления
Эта реализация очень похожа на стратегию скользящего обновления.
Как видите, единственная разница между реализацией скользящего обновления и воссоздания заключается в строке 12, где мы заменили strategy.type: RollingUpdateна strategy.type: Recreate.
Как и в прошлый раз, мы развернем развертывание через командную строку, используя:
Стратегия обновления канарейки
Стратегия канареечного обновления — это процесс частичного обновления, который позволяет вам протестировать новую версию программы на реальной пользовательской базе без обязательства полного развертывания.
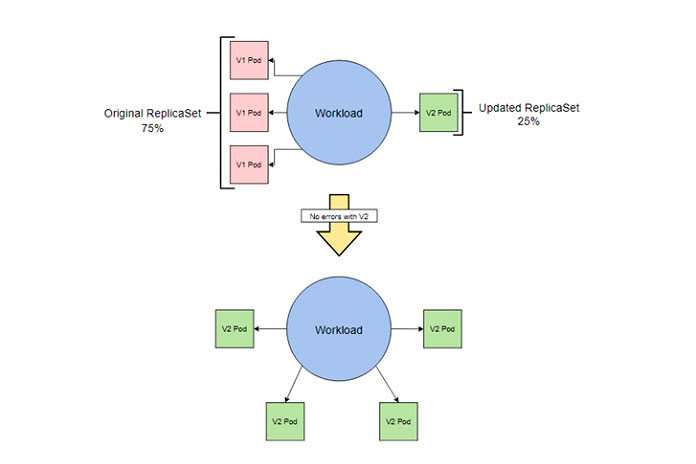
В этой стратегии развертывание создает несколько новых модулей, в то время как большинство модулей остается в предыдущей версии, обычно в соотношении 1: 4.
Большинство пользователей по-прежнему используют предыдущую версию, но небольшая группа пользователей, не осознавая этого, использует новую версию в качестве тестировщиков.
Если мы не обнаружим никаких ошибок из этого подмножества, мы можем масштабировать обновленный ReplicaSet, чтобы произвести полное развертывание.
Если мы действительно обнаружим ошибку, мы можем легко откатить несколько обновленных модулей, пока не исправим ошибку.
Преимущество канареечной стратегии обновления заключается в том, что она позволяет протестировать новую версию без риска полного сбоя системы.
В худшем случае все пользователи из тестовой подгруппы сталкиваются с критическими ошибками, в то время как 75% или более пользовательской базы продолжают работу без перебоев.
Процесс отката также намного быстрее, чем стратегия скользящего обновления, потому что вам нужно откатить только часть модулей, а не всю систему.
Обратной стороной является то, что для обновленных модулей потребуется отдельное развертывание, которым может быть сложно управлять в масштабе. Кроме того, канареечная стратегия приводит к более медленному развертыванию из-за периода ожидания после развертывания в нашем первоначальном подмножестве и завершения полного развертывания.
Обдумывая канареечную стратегию, спросите себя:
- Каков наихудший сценарий, если это обновление не удастся?
- Как скоро мне нужно будет завершить полное развертывание?
- Сколько я провел внутреннего тестирования?
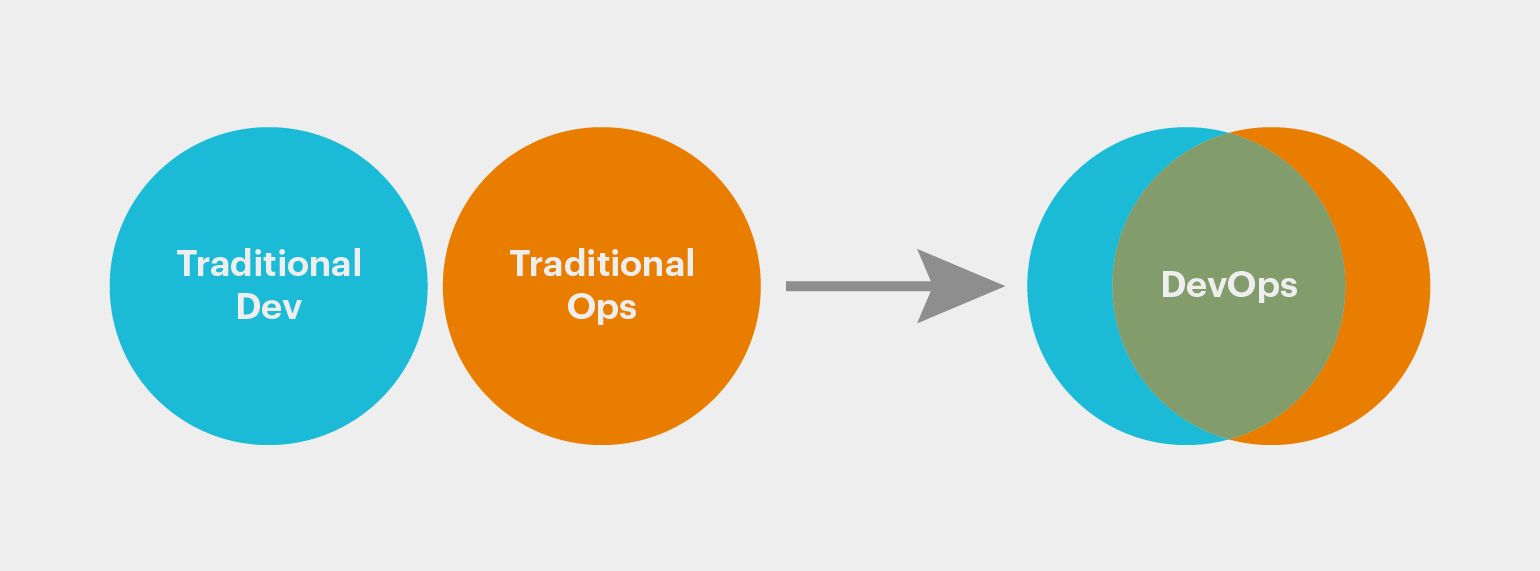
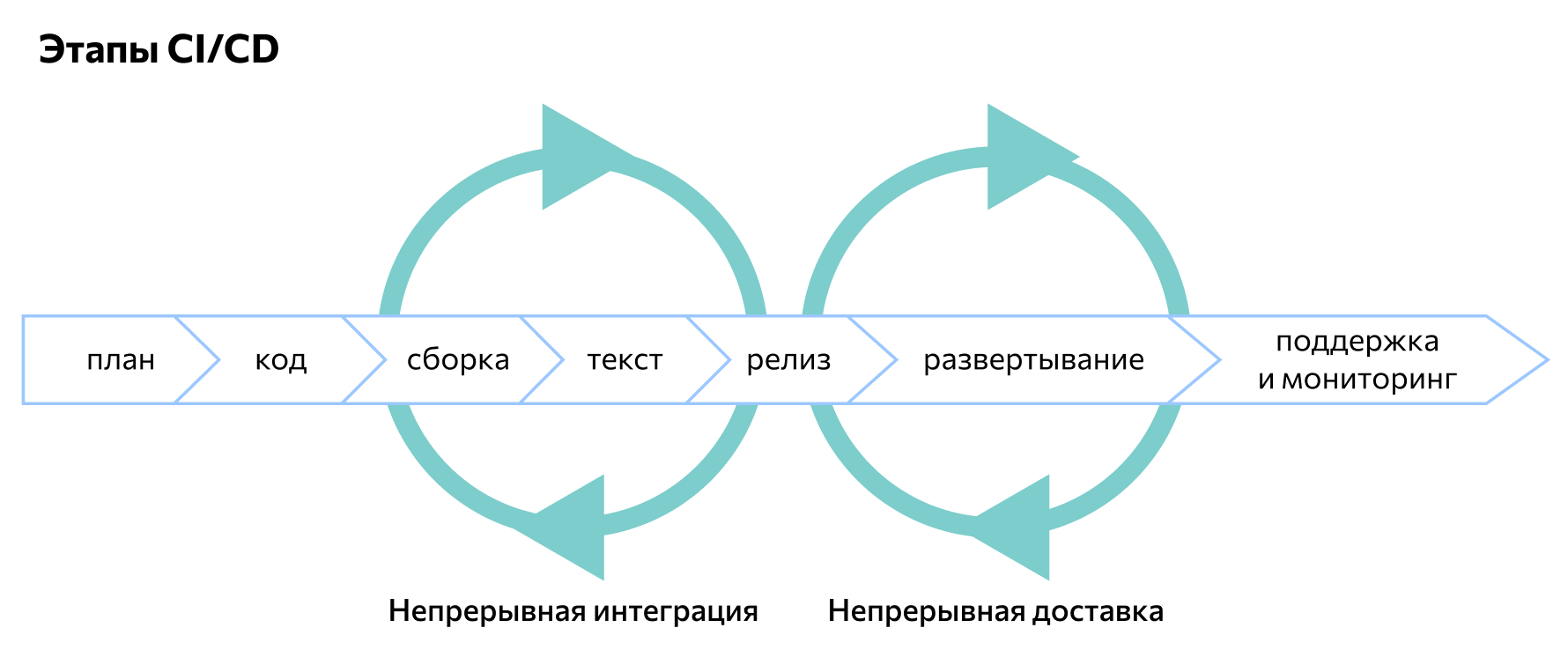
Этапы CI/CD
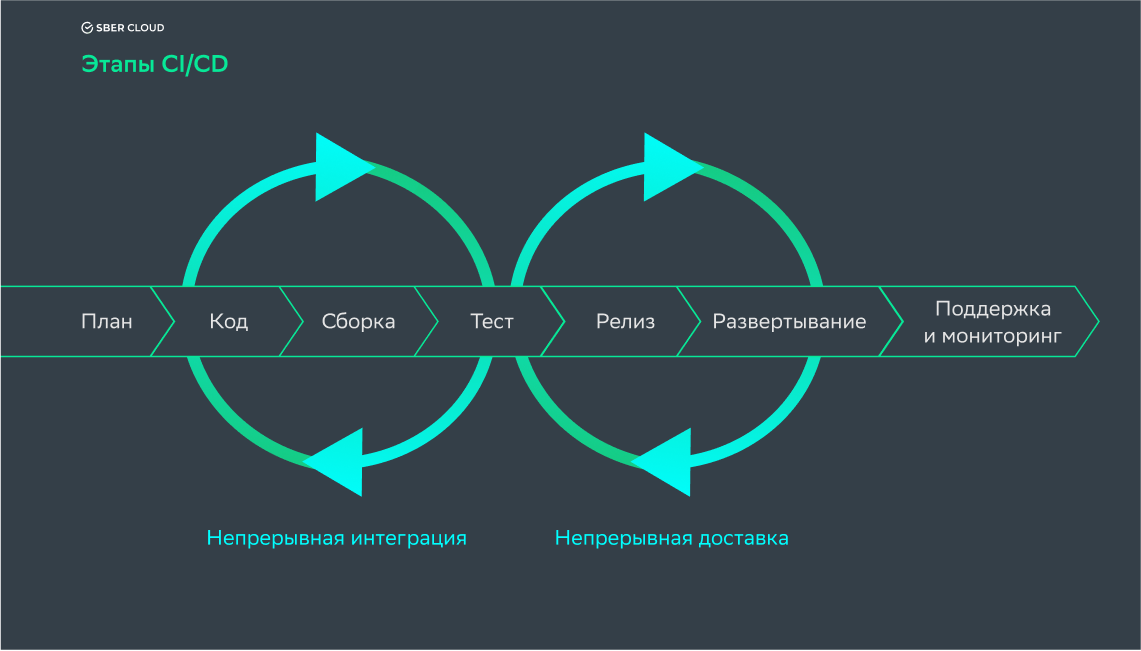
Методология CI/CD подразумевает разделение процесса разработки на семь этапов:
- Написание кода. Разработчики пишут код своего модуля и проводят тестирование в ручном режиме. После этого результат работы соединяется в главной ветке с текущей версией проекта. После того, как в главной ветке публикуются все коды модулей, начинается второй этап.
- Сборка. Выбранная система контроля версий инициирует автоматическую сборку и последующее тестирование проекта. Триггеры для активации сборки могут быть настроены самостоятельно. Для автоматизации сборки применяется Jenkins или другой инструмент.
- Ручное тестирование. После проверки CI-системой работоспособности тестовой версии код передается для ручного исследования.
- Релиз.После ручного тестирования в сборку вносятся исправления. Следом проходит релиз версии кода для клиентов.
- Развертывание. На этом этапе текущая (рабочая) версия кода размещается на production-серверах разработчика. Клиент может взаимодействовать с программой и изучать ее функции.
- Поддержка и мониторинг. Продукт начинает использоваться конечными пользователями. При этом разработчики продолжают его поддерживать и проводят анализ пользовательского опыта.
- Планирование. Исходя из пользовательского опыта разрабатывается новый функционал и готовится план доработок. После этого разработчик начинает написание кода — и цикл замыкается.
 Этапы CI/CD
Этапы CI/CD
Время, необходимое для реализации каждого из этапов, зависит от сложности продукта. При этом по мере обновления и усложнения продукта на прохождение цикла будет требоваться все больше времени.
DevOps-практики
Конечно же, в основе DevOps лежит не только общение и сотрудничество. Выпускать как можно более качественное ПО и как можно чаще помогает множество практик DevOps. DevOps нацелена на высокую эффективность, поэтому призывает применять средства автоматизации рутинных задач.
А теперь подробнее об этих практиках и инструментах.
Непрерывная интеграция (Continuous Integration, CI)
Обычно разработчики вручную обновляли свой код, а затем вручную же его тестировали.
При непрерывной интеграции разработчики часто заливают изменения кода в центральный репозиторий. После внесения изменений происходит автоматическая сборка и для неё запускаются автоматизированные тесты.
Эта практика помогает быстрее выявлять ошибки и повышает качество ПО.
Непрерывная поставка и развёртывание (Continuous Delivery и Continuous Deployment)
Это продолжение непрерывной интеграции. После сборки все изменения кода автоматически развёртываются в тестовой среде. После этого развёрнутый код прогоняют через автоматические тесты, и запускается развёртывание в производственной среде. И только неудачный тест может предотвратить запуск обновления сборки. Так разработчики могут быстрее обнаруживать и исправлять ошибки.
Все эти задачи помогают выполнять Jenkins, Bamboo, Travis, TeamCity и другие CI- и CD-утилиты.
Непрерывное тестирование (Continuous Testing)
Практика непрерывного тестирования помогает как можно раньше выявлять возможные риски на всех стадиях разработки ПО — чтобы ошибки не повлияли на конечных пользователей.
Например, когда код развёртывается на серверах сборки, запускаются автоматические модульные тесты для выявления любых ошибок. Если какие-то тесты не проходят, сборка отклоняется, а разработчик получает уведомление о том, что код нужно перепроверить.
Таким образом, код будет развёрнут в среде контроля качества (QA environment) для функционального тестирования, только если успешно пройдёт все модульные тесты.
Примечание переводчика
Функциональные тесты (ФТ) проверяют работу приложения снаружи, как если бы это делал пользователь, а модульные тесты (МТ, юнит-тесты) — изнутри, с точки зрения разработчика.
ФТ помогают создать приложение, которое делает ровно то, чего хочет клиент. Они гарантируют, что вы никогда не сломаете логику работы. МТ помогают писать чистый код без ошибок — надёжный, производительный, не вызывающий утечек памяти, расширяемый и так далее.
Согласно ISTQB, модульное тестирование может проверять и функциональность — в том случае, если компонент (модуль, программу, функцию, объект, класс и так далее) можно тестировать отдельно от других.
В числе популярных инструментов для непрерывного тестирования — Selenium, Travis и Appium.
Непрерывное наблюдение (Continuous Monitoring)
Предполагается, что приложение, инфраструктура, промежуточное ПО и сети постоянно мониторятся на предмет производительности, ошибок, безопасности и соответствия требованиям.
Большинство компаний следят за такими показателями:
- использование CPU и памяти;
- использование дискового пространства;
- действия клиентов;
- политики безопасности.
Применяя непрерывный мониторинг, вы всегда будете в курсе любых проблем на контурах: от тестирования до продакшена. Это поможет вам обеспечить высокую доступность продукта.

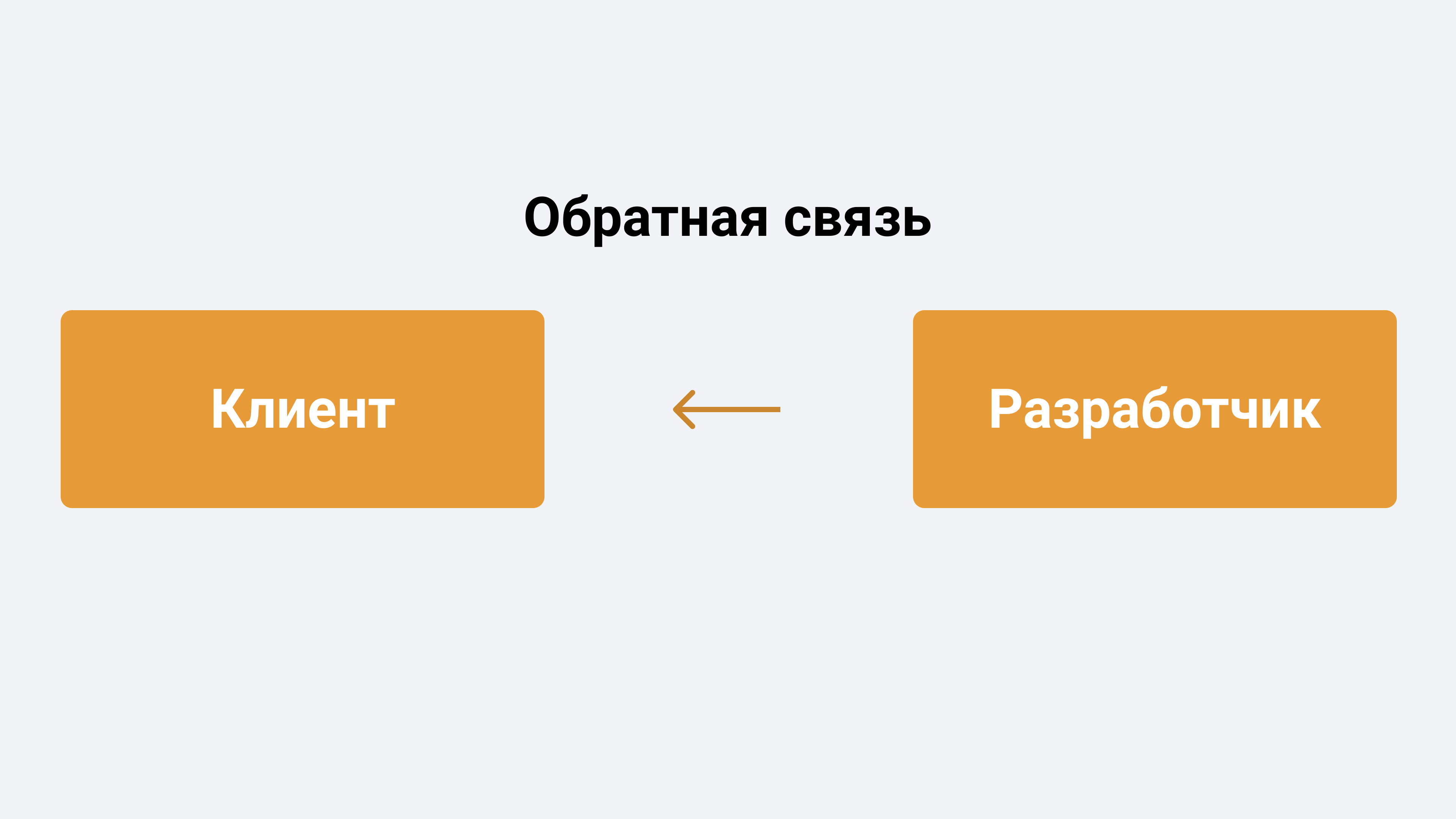


Популярные инструменты непрерывного мониторинга: Nagios, Sensu, Prometheus.
Инфраструктура как код (Infrastructure as Code, IaC)
Инфраструктура как код (Infrastructure as Code, IaC) — это модель, при которой инфраструктура — виртуальные машины, балансировщики нагрузки, сети и так далее — настраивается и управляется программно, а не вручную. Такая инфраструктура стала необходимым компонентом DevOps в организациях, которые специально перешли на облачные платформы.
Например, Amazon Web Services (AWS) предоставляет API для программного взаимодействия со своей облачной инфраструктурой. Использование программного кода для определения конфигурации помогает сделать процесс стандартным и быстро развёртывать ресурсы в облаке.
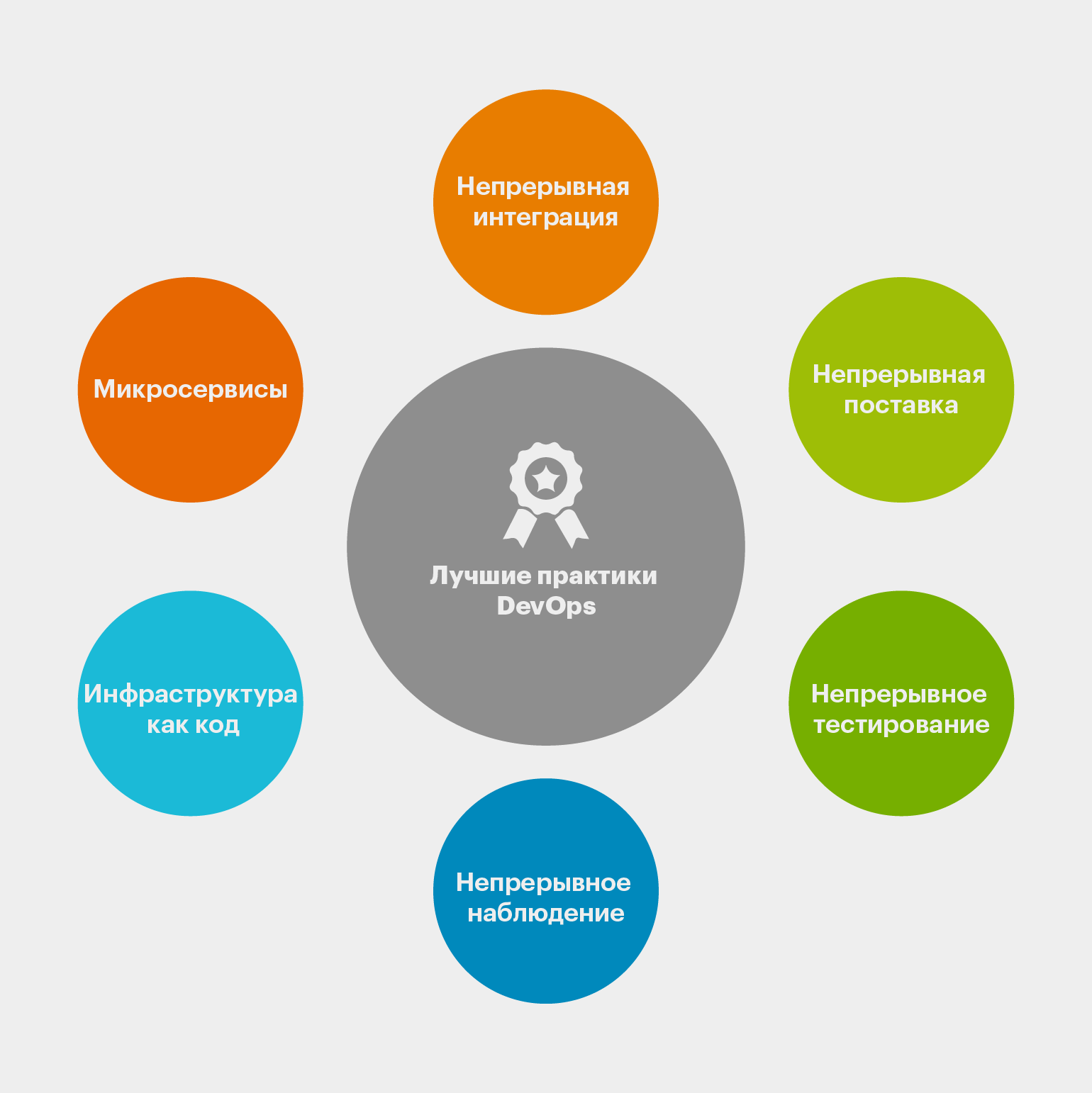
Микросервисы (Microservices)
В отличие от традиционного монолита, приложение в микросервисной архитектуре состоит из множества маленьких сервисов или компонентов. Каждый сервис отвечает за свою функциональность, а взаимодействуют они через легковесный интерфейс или API.
Микросервисная архитектура — распространённое решение в DevOps-культуре. И это не случайно. Она:
Проблемы внедрения TQM
Концепция TQM выглядит понятно и логично, но многие компании сталкиваются с трудностями внедрения, и такие трудности часто работают не на пользу компании.
Ожидание быстрого результата
Часто сотрудники гонятся за получением быстрого краткосрочного результата не оглядываясь на качество. Руководители должны взять на себя ответственность за курс компании и ориентировать сотрудников на длительный и стабильный рост. Иногда для достижения значительно улучшения качества приходится ждать и работать не один год.
Отсутствие стратегии
Когда в компании нет долгосрочных последовательно реализуемых целей, сотрудники могут испытывать неуверенность в карьерном и личностном росте. Это подрывает лояльность компании и сказывается на вовлеченности сотрудников в процессы. Компании должны имеет реализуемый стратегический план развития, в котором учтены вопросы повышения качества.
Текучка кадров
Текучка кадров всегда сказывается негативно на все деятельности компании
Частично улучшить эту ситуацию поможет устранение вышеописанных проблем, однако и сами руководители должны способствовать созданию такой атмосферы, где сотрудники чувствуют себя важной частью компании и одной командой
Принцип 8. Параллелизм
В зависимости от требований каждый процесс в вашем приложении должен иметь возможность масштабирования, перезапуска или клонирования. Это может улучшить масштабируемость.
Вместо того, чтобы делать один процесс еще больше, разработчики могут создавать несколько процессов, а затем распределять нагрузку своих приложений между этими процессами. Используя этот подход, разработчики могут создавать приложения, которые могут обрабатывать различные рабочие нагрузки, назначая каждую рабочую нагрузку типу процесса. Например, можно делегировать HTTP-запросы веб-процессу, а длительные фоновые задачи — рабочему процессу.
Немного теории
Метод «развёртывания политики» применяется для формирования стратегических направлений деятельности организации. Эта методология применяется для планирования, постановки до исполнителей целей организации и оперативного анализа ее работы, который обеспечивает координацию всех действий, направленных на достижение правильно сформулированных стратегических целей. Если сказать проще, то человек видит стратегические цели компании, увязывает их со своими целями, достижение которых способствует реализации стратегии всей компании. Таким образом, этот метод помогает связать макро и микроуровни компании. Необходимо отметить, что как и любой другой инструмент производственной системы, метод основывается на здравом смысле и, как следствие, цикле PDCA-Plan-Do-Check-Act (рис 1).
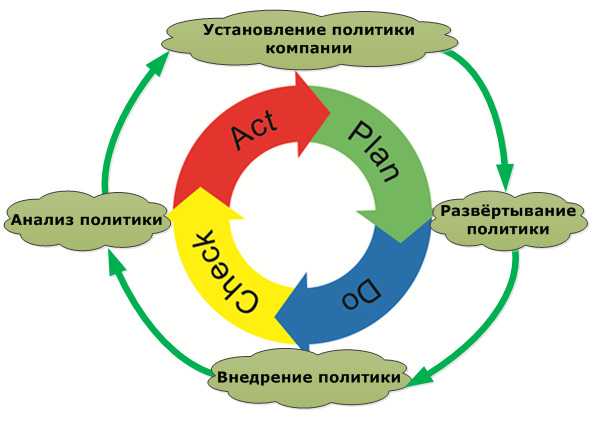
Рис. 1. Цикл развёртывания политики
Немного расшифруем рисунок, приведённый выше. После того как высший менеджмент определит годовые цели, они «развёртываются» вниз по управленческой иерархии. Цели, сформулированные руководством в абстрактной форме, по мере развертывания на более низких уровнях организационной структуры обретают все более конкретное выражение. Не стоит забывать, что если цели, определенные высшим менеджментом, не будут реализованы на практике менеджерами нижнего звена, то в них не будет никакого смысла. Как ни прекрасны проекты высокого руководства, они часто остаются всего лишь «воздушными замками».
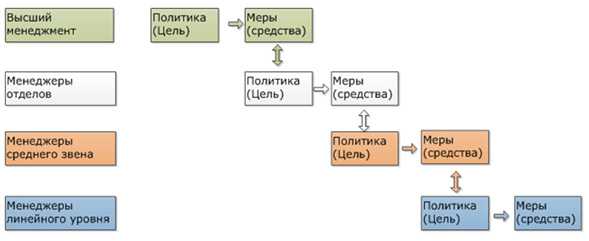
Рис. 2. Цели при развёртывании политики
Важный аспект «развертывания политики» — установка приоритетов, а это задача диаграммы «Парето», которую мы используем при построении «дерева потерь и затрат» (об этом чуть позже)
Важность установки приоритетов связана с тем, что доступные ресурсы всегда ограничены. Парето позволяет нам фокусироваться на действительно важном
Делать акцент на аспектах, вносящих наибольший вклад в достижение целей, и не распылять энергию предприятия на действия, не добавляющих ценность. После того как это сделано, на нижних управленческих уровнях развертывается все более детальный и четкий, по мере движения вниз, план действий, представляющий собой перечень конкретных мер и действий. В нашей организации мы называем его «Тактический план внедрения» (или просто TIP от английского Tactical Implementation Plan).
Откуда взялась философия Total Quality Management
Начнем с философии TQM — всеобщее управление качеством (ВУК). Это общеорганизационный метод непрерывного повышения качества организационных процессов:
-
Всеобщее — все сотрудники должны быть вовлечены в процесс.
-
Управление — организация процессов, разделенных на этапы, такие как планирование, контроль, руководство, персонал и т.д.
-
Качеством — предоставление клиенту продукта, который максимально соответствует его требованиям.
Первичную идеологию TQM разработали ученые Уолтер Шухарт и Уильям Эдвардс Деминг. После них тему подхватили Джозеф Джуран и Каору Исикава.
Начнем с Уолтера Шухарта
Он обратил внимание на постоянство процесса улучшения качества за счет уменьшения изменчивости процесса. Уолтер разработал концепцию производственного контроля и в качестве инструмента использовал контрольные карты, которые помогли улучшить качество изделий за счет максимального сокращения количества вариаций
Для увеличения показателей качества он применил разработанный цикл, или план Do, Check, Act, Plan.
Plan — это поиск проблемы и планирование действий для ее решения. После планирования идет реализация, то есть к Do. Затем проверка — Check, где план сверяют с результатом и корректируют дальнейшие шаги. После этапа проверки следует стандартизация.
Об этом инструменте мы поговорим немного позже, а сейчас расскажем о вкладе Уильяма Эдвардса Деминга в философию управления качеством.
Уильям вывел три аксиомы, которые работали на повышение качества труда:
-
Любая деятельность может рассматриваться как технологический процесс. А, значит, может быть улучшена.
-
Для эффективной работы нужны фундаментальные изменения в процессе жизненного цикла изделия.
-
Руководители предприятия должны принимать на себя ответственность за свою деятельность.
На основе этих трех аксиом Деминг разработал 14 постулатов качества для правильной организации работы производства. Основная их суть:
-
Можно добиться снижения затрат и улучшения качества продукции если соблюдается высокая степень ответственности руководства.
-
Улучшение качества товаров ведется постоянно.
-
Не допускаются несоответствия стандартам.
-
Обучение сотрудников ведется непрерывно.
Эти труды подхватил Джозеф Джуран. Он предложил использовать разработанную им же спираль качества, которая позволила перейти на новый уровень, — от стабильности к изменениям в лучшую сторону. Джуран предлагал не контролировать брак на конечном уровне, а снимать метрики всех этапов производства.
Вот как выглядит спираль качества Джозефа Джурана:
-
Исследование рынка.
-
Проектное задание.
-
Научно-исследовательские и опытно-конструкторские работы.
-
Составление технических условий.
-
Технология и подготовка производства.
-
Материально-техническое снабжение.
-
Изготовление инструмента.
-
Производство.
-
Контроль производства.
-
Контроль готовой продукции.
-
Испытание продукции.
-
Сбыт.
-
Техническое обслуживание.
-
Исследование рынка.
Следующим эстафету усовершенствований подхватил Каору Исикава. Он предложил концепцию всеобщего контроля качества — CWQC (Company WideQuality Control). Она заключается в управлении качеством в масштабах компании и подключении конечного потребителя. Исикава также разработал методику развертывания функций качества, или QFD. Он сформулировал «Семь инструментов качества» и методики в области обучения кадров.








Концепция TQM
Сама концепция TQM была оформлена в начале 1990-х годов, когда появился международный стандарт ISO 8402.
TQM — это подход к управлению организацией, нацеленной на качество, основанный на участии всех ее членов и направленный на достижение долговременного успеха путем удовлетворения потребителя и выводы для организации и общества.
Это повторяет аксиому Деминга, но важно понимать, что TQM — это не теория или методика, — это набор принципов, методов, средств и форм управления качеством для постоянного усовершенствования.
В основе TQM лежит осознание, что брак появляется не в конце производства, а в процессе. Поэтому, чтобы обеспечить производство качественного продукта, процессы перестраиваются таким образом, чтобы формировать качество на уровне основных этапов и процессов, а не только констатировать “это брак” в самом его конце.
Например, в разработке частично за качество конечного продукта отвечает каждый специалист, который над ним работает. Мы рекомендуем включать контроль качества на всех этапах: валидации технического задания, подготовки макетов, тестирования верстки, Backend-а, интеграции, Frontend-а, верстки и релиза. С валидацией может справиться автотест: это улучшит общий процесс и сократит трудозатраты.
Этапы CI/CD
Написание кода. Каждый разработчик создает код отведенного ему модуля и тестирует его в ручном режиме. Затем разработанный и проверенный программный блок интегрируется в основной ветке с текущей версией продукта. Как только все модули будут опубликованы в главной ветке, команда переходит к следующему этапу.
Сборка. Заранее подобранная система контроля версий запускает автоматизированную сборку и тестирование всего продукта. Триггеры могут быть настроены автоматически или вручную. Автоматическая сборка выполняется с помощью Jenkins или другого сервера непрерывной интеграции.
Ручное тестирование. Как только CI-сервер закончит автоматизированную сборку продукта, он передается тестировщикам на проверку. Они используют различные методики тестирования для выявления и устранения ошибок и уязвимостей программы.
Релиз. После исправления ошибок вычищенный и отлаженный код переходит на этап релиза для клиентов. Его проверяет заказчик, возможно, с привлечением своих специалистов или ограниченной группы пользователей. По результатам проверки код отправляется на доработку или согласуется.
Развертывание. Текущая версия программы размещается на продакшн-серверах разработчика. Заказчик может работать с программой, исследовать ее функции, искать уязвимости.
Поддержка и отслеживание. После развертывания приложение становится доступным конечным пользователям. Параллельно этому разработчики выполняют его поддержку и одновременно мониторят реакцию пользователей, анализируют их опыт взаимодействия с программой.
Планирование. На основании данных, полученных при изучении пользовательского опыта, разработчик подготавливает план доработок, включающий новые функции, исправление ошибок и т.д. После этого он вносит все корректировки в продукт — и цикл разработки начинается снова.
Таким образом, рабочий процесс по методологии CI/CD включает как последовательные, так и параллельные этапы. Именно для распараллеливания в рабочем пространстве создается побочная ветка — в ней проще вести работу, не вмешиваясь в основной код до тех пор, пока программируемый модуль не будет готов к интеграции. Условно рабочий процесс по методологии CI/CD можно представить в виде следующей схемы:
Общий принцип CI/CD-разработкиОбщий принцип CI/CD-разработки
Итог
Внедряя TQM, компании усиливают уровень удовлетворенности клиентов, повышают лояльность, формируют положительный имидж, улучшают производительность труда и увеличивают прибыль.
Все эти преимущества можно проиллюстрировать примером индийских производителей подшипников для автомобилей и железнодорожной промышленности National Engineering Industrial — они как раз использовали TQM. Компания экспортирует продукцию в 21 страну. Ее подшипниками пользуются Honda и Suzuki. В компании есть свой исследовательский центр, который регулярно улучшает качество продукции. Текущий показатель дефектов составляет 100 единиц на миллион, а в планах — сократить брак до 50 единиц в течении трех лет, и впоследствии — до 10 единиц на миллион.



