
Считывание строк пакета
Если в коде используется источник данных SQL Server (), рекомендуется использовать параметр rowsPerRead, чтобы указать размер пакета. Этот параметр определяет количество строк, которые запрашиваются и затем отправляются во внешний скрипт для обработки. Во время выполнения алгоритм видит только указанное число строк в каждом пакете.
Возможность управлять объемом данных, обрабатываемых за один раз, может помочь при решении или предотвращении проблем. Например, если входной набор данных является слишком обширным (имеет много столбцов) или набор данных содержит несколько крупных столбцов (например, произвольный текст), можно уменьшить размер пакета, чтобы избежать нехватки памяти при разбивке на страницы.
По умолчанию для этого параметра задано значение 50 000, чтобы гарантировать хорошую производительность даже на компьютерах с недостаточным объемом памяти. Если на сервере достаточно памяти, увеличение этого значения до 500 000 или даже до миллиона может помочь повысить производительность, особенно для больших таблиц.
Преимущества увеличения размера пакета становятся очевидными для большого набора данных и для задачи, которая может выполняться в нескольких процессах. Однако увеличение этого значения не всегда дает наилучшие результаты. Для определения оптимального значения рекомендуется поэкспериментировать с данными и алгоритмом.
Оптимизация алгоритма машинного обучения
В этом разделе приведены различные советы и ресурсы, относящиеся к RevoScaleR и другим возможностям в Microsoft R.
Совет
Общее обсуждение оптимизации R выходит за рамки этой статьи. Тем не менее, если необходимо ускорить выполнение кода, мы рекомендуем ознакомиться с популярной статьей The R Inferno. В ней подробно описаны программные конструкции в R и распространенные ловушки, а также представлено множество примеров методов программирования R.
Оптимизации для RevoScaleR
Множество алгоритмов RevoScaleR поддерживают параметры управления созданием обученной модели. Хотя точность и правильность модели имеет большое значение, производительность алгоритма не менее важна. Чтобы должным образом сбалансировать точность и время обучения, можно изменить параметры для повышения скорости вычислений. Во многих случаях это позволяет повысить производительность, не снижая точность и правильность.
поддерживает параметр , управляющий глубиной дерева принятия решений
По мере увеличения значения возможно снижение производительности, поэтому важно проанализировать преимущества увеличения глубины в зависимости от негативного влияния на производительность.
Можно сбалансировать временную сложность и точность прогнозирования, настроив такие параметры, как , , и. Если увеличить глубину до 10 или 15, стоимость вычислений сильно увеличится.
Попробуйте использовать аргумент , если первая зависимая переменная в формуле является факторной.
Если для параметра задано значение , регрессия выполняется с применением обратного секционирования
При этом операция может выполняться быстрее, а также потреблять меньше памяти, чем при стандартной регрессии. Если в формуле используется много переменных, производительность может существенно повыситься.
Используйте аргумент , если первая зависимая переменная является факторной.
Если для задано значение , алгоритм использует обратное секционирование, что может ускорить выполнение и снизить использование памяти. Если в формуле используется много переменных, производительность может существенно повыситься.
Подробные сведения об оптимизации RevoScaleR см. в следующих статьях:
-
Статья о поддержке: Варианты настройки производительности для rxDForest и rxDTree
-
Методы управления подгонкой модели в модели с усиленным деревом: Оценка моделей с помощью стохастического градиентного усиления
-
Общие сведения о том, как RevoScaleR перемещает и обрабатывает данные: Написание пользовательских алгоритмов фрагментации в ScaleR
-
Модель программирования для RevoScaleR: Управление потоками в RevoScaleR
-
Справочник по функциям для rxDForest
-
Справочник по функциям для rxBTrees
Использование MicrosoftML
Также рекомендуется изучить новый пакет MicrosoftML, который предоставляет масштабируемые алгоритмы машинного обучения, которые могут использовать контексты вычислений и преобразования, предоставляемые RevoScaleR.
Изменение версии среды выполнения R
Если вы установили одно из приведенных выше накопительных обновлений для SQL Server 2016 или 2017, в экземпляре SQL может быть несколько версий R. Каждая версия содержится во вложенной папке экземпляра с именем <major> . <minor> (папка из исходной установки может не иметь номера версии, добавленного к имени папки).
При установке пакета CU, содержащего R 3.5, создается папка :
- SQL Server 2016: .
- SQL Server 2017: .
Каждый экземпляр SQL использует одну из этих версий в качестве стандартной версии R. Стандартную версию можно изменить с помощью служебной программы командной строки RegisterRext.exe. Эта программа находится в папке R в каждом экземпляре SQL:
<путь_к_экземпляру_SQL> \R_SERVICES.n.n\library\RevoScaleR\rxLibs\x64\RegisterRext.exe
Примечание
Возможности, описываемые в этой статье, доступны только с копией RegisterRext.exe, включенной в пакеты CU для SQL. Не используйте копию, поставляемую с исходной установкой SQL.
Чтобы изменить версию среды выполнения R, передайте следующие аргументы командной строки в RegisterRext.exe:
-
— обязательный аргумент, который указывает, что вы настраиваете стандартную версию R.
-
<имя_экземпляра> — необязательно, экземпляр, который нужно настроить. Если он не указан, настраивает экземпляр, заданный по умолчанию.
-
<путь_к_папке_R_SERVICES> — необязательно, путь к папке версии среды выполнения, которую вы хотите задать в качестве стандартной версии R.
Если не указать /rhome, будет указан путь, по которому располагается RegisterRext.exe.
Изменение версии среды выполнения R в SQL Server 2016
Например, чтобы настроить R 3.5 в качестве стандартной версии R для экземпляра MSSQLSERVER01 в SQL Server 2016, сделайте следующее:
Изменение версии среды выполнения R в SQL Server 2017
Например, чтобы настроить R 3.5 в качестве стандартной версии R для экземпляра MSSQLSERVER01 в SQL Server 2017, сделайте следующее:
В этих примерах не нужно включать аргумент , так как вы указываете ту же папку, в которой расположена служебная программа RegisterRext.exe.
Начало работы
Начните с установки, добавьте двоичные файлы в свое любимое средство разработки и напишите свой первый скрипт.
Шаг 1. Установите программное обеспечение
Установите одну из следующих версий:
- Machine Learning Server (изолированный) в SQL Server 2017
- R Server (изолированный) в SQL Server 2016 — только R
Шаг 2. Настройте среду разработки
На изолированном сервере часто работают локально с использованием среды разработки, установленной на том же компьютере.
- Настройка средств R
- Настройка средств Python
Шаг 3. Написание первого скрипта
Напишите скрипт R или Python, используя функции из RevoScaleR и revoscalepy, а также алгоритмы машинного обучения.
-
Обзор R и RevoScaleR в 25 функциях. Начните с базовых команд R, а затем перейдите к распространяемым аналитическим функциям RevoScaleR, которые обеспечивают высокую производительность и масштабирование решений R. Она содержит параллелизуемые версии многих популярных пакетов моделирования для R, например кластеризацию методом К-средних, деревья и леса принятия решений, а также средства для работы с данными.
-
Краткое руководство. Пример двоичной классификации с использованием пакета Python microsoftml. Создайте модель двоичной классификации с помощью функций из пакета microsoftml и хорошо известного набора данных по раку груди.
-
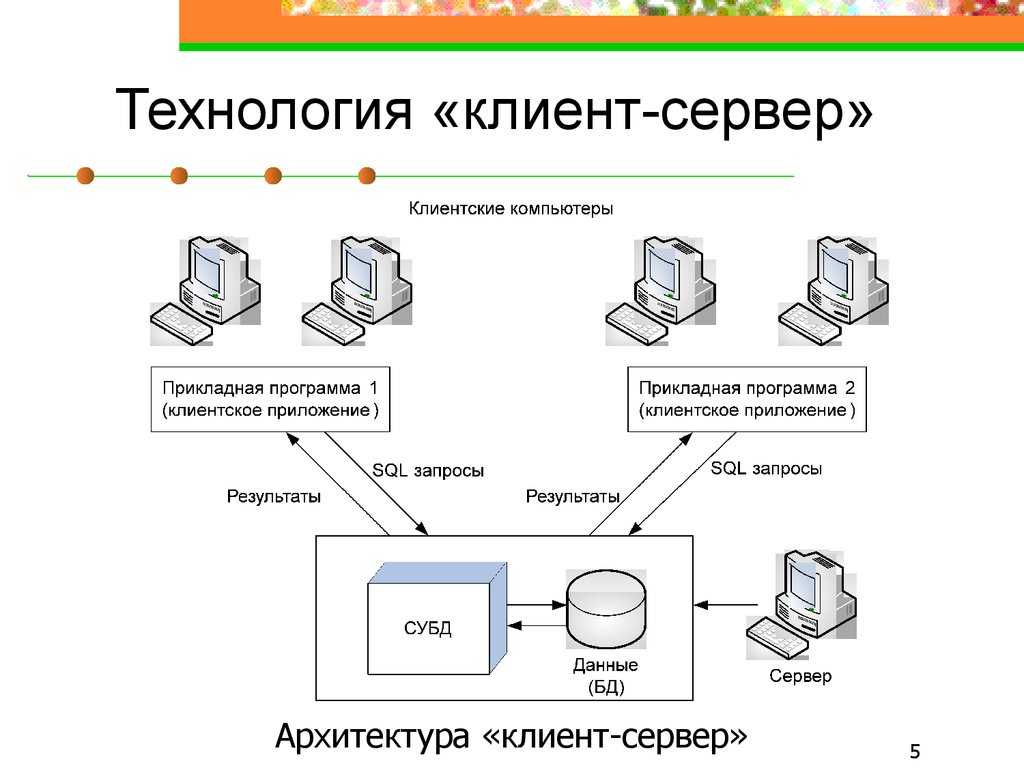
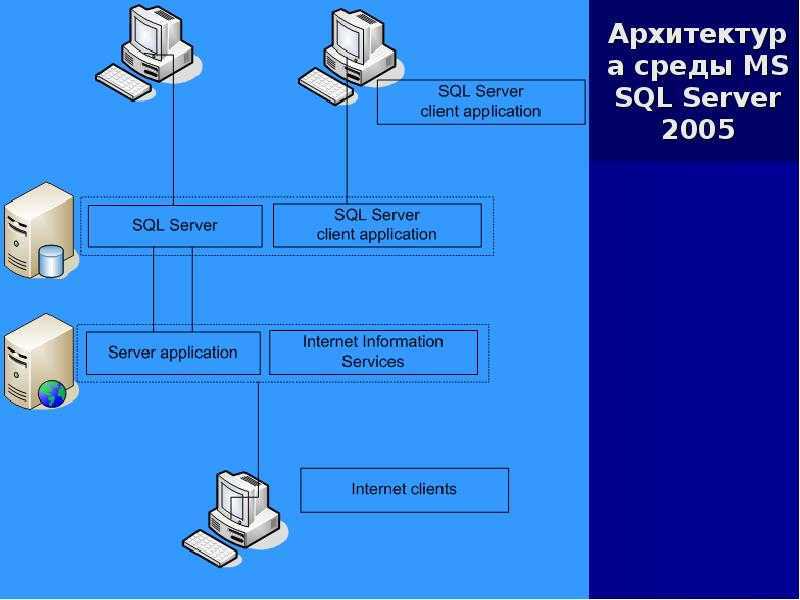
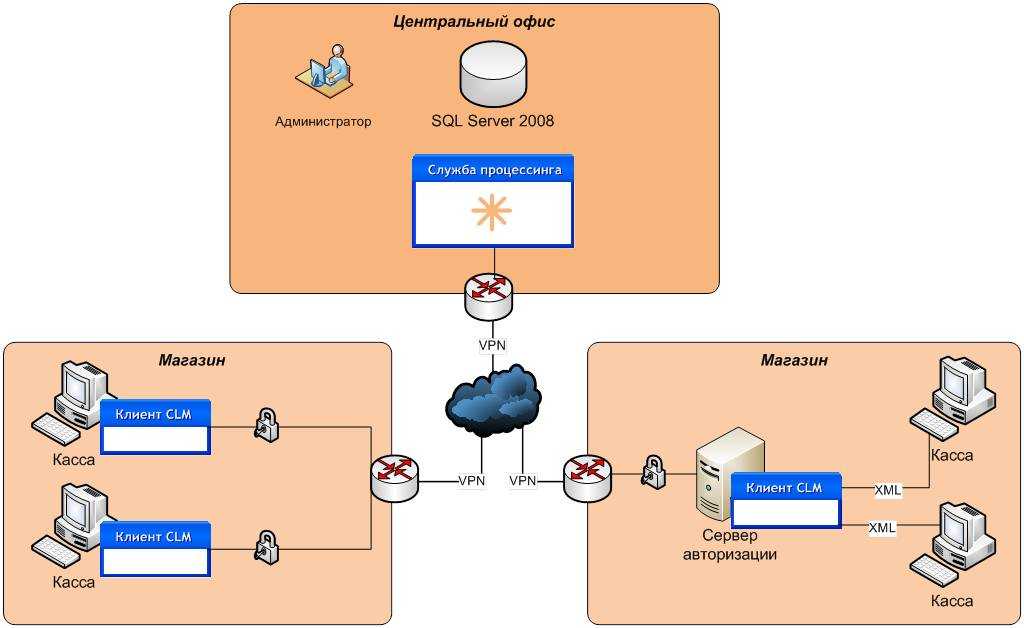
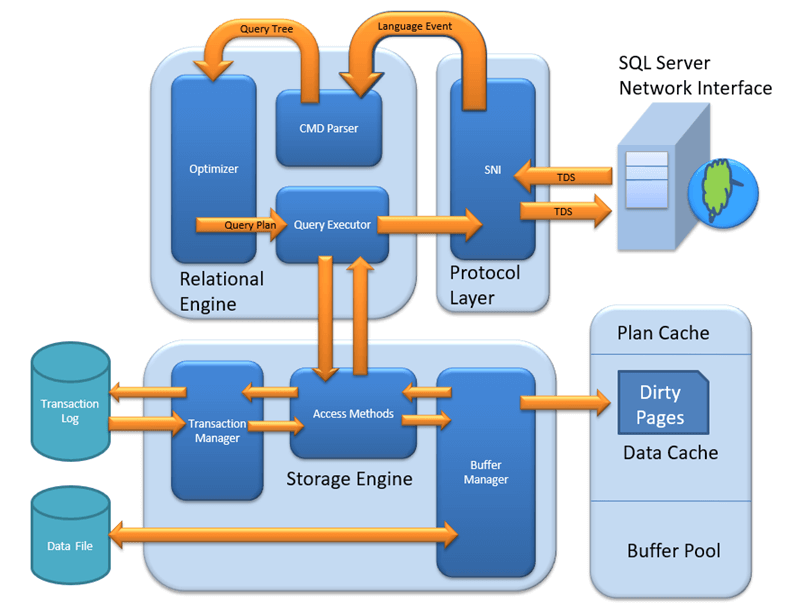
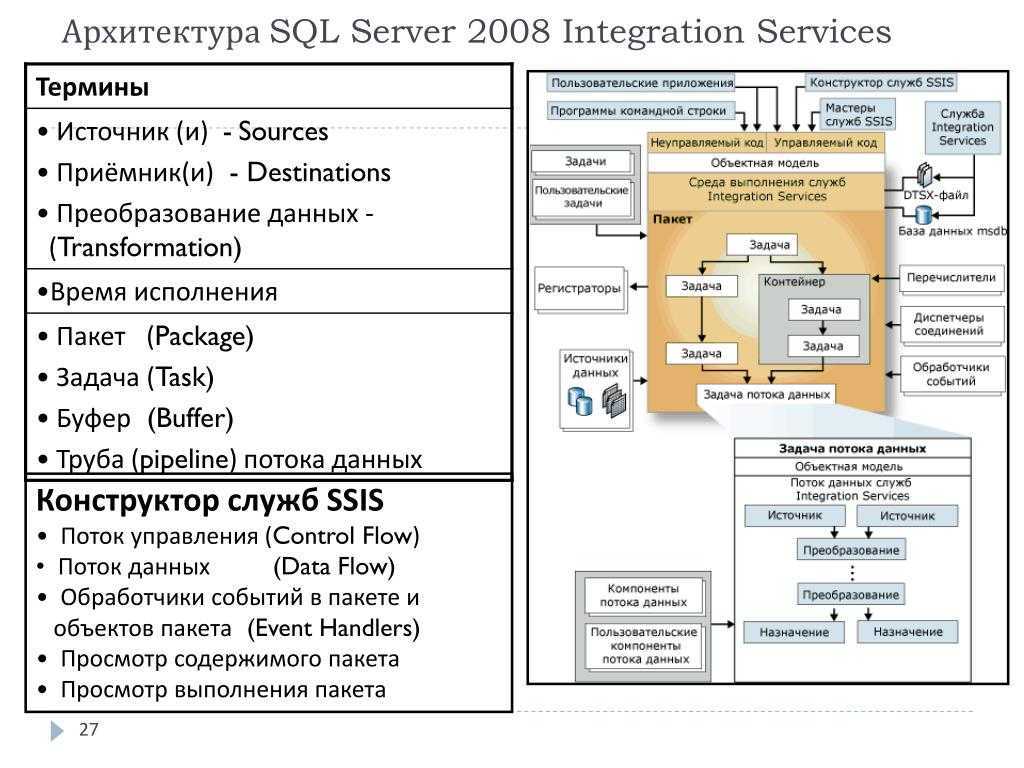
Выберите оптимальный язык для задачи. R лучше всего подходит для статистических вычислений, проведение которых с помощью SQL может вызывать трудности. Для достижения максимальной производительности операций на основе наборов данных используйте возможности SQL Server. Для очень быстрых вычислений на основе столбцов используйте выполняющееся в памяти ядро СУБД.
Шаг 4. Ввод решения в эксплуатацию
Изолированные серверы могут использовать функцию ввода в эксплуатацию сервера Microsoft Machine Learning Server, не зависящего от языка SQL. Настройка изолированного сервера для ввода в эксплуатацию дает следующие преимущества: развертывание и размещение кода как веб-служб, проведение диагностики и проверка емкости веб-служб.
Шаг 5. Обслуживание сервера
Для SQL Server регулярно выпускаются накопительные пакеты обновления. Их применение повышает безопасность и расширяет функциональные возможности существующей установки.
Описание новых возможностей и изменений см. в статье Загружаемые файлы CAB, а также на веб-страницах накопительных пакетов обновления для SQL Server 2016 и SQL Server 2017.
Дополнительные сведения о применении обновлений к существующему экземпляру см. в разделе инструкций по установке.
Часть 2. Настройка регулятора ресурсов
- Создайте пулы ресурсов.
CREATE RESOURCE POOL MarketingPool
- Создайте группы рабочих нагрузок.
USING SalesPool
USING MarketingPool
GO
-
Создайте функцию-классификатор, которая будет активироваться при подключении пользователя. Функция связывает подключение с определенной группой рабочих
нагрузок с учетом имени входа пользователя, устанавливающего подключение
(то есть определяется, относится имя входа к отделу продаж или отделу маркетинга).
RETURNS SYSNAME WITH SCHEMABINDING
BEGIN
DECLARE @val varchar(32)
IF ‘Sales’ = SUSER_SNAME()
SET @val = ‘SalesGroup’;
ELSE IF ‘Marketing’ = SUSER_SNAME()
SET @val = ‘MarketingGroup’;
RETURN @val;
END
GO
ALTER RESOURCE GOVERNOR
GO
-
Теперь активируем регулятор ресурсов.
GO
Пример использования изоляции рабочих нагрузок
Обоим отделам необходима прогнозируемая производительность запросов. Отделу продаж необходим постоянный доступ к нужным ресурсам, в идеале этот отдел должен работать в изоляции, всегда имея доступ к 100 процентам выделенной ему мощности ЦП. Однако в то
Ваша задача — обеспечить в этой среде изоляцию рабочих нагрузок, прогнозируемую производительность и прогнозируемое выставление счетов.
Примечание
Следующее пошаговое руководство можно рассматривать как обучающую инструкцию. Чтобы выполнить его самостоятельно, запустите компьютер или виртуальную машину (на которую установлен выпуск SQL Server 2012 Enterprise, Evaluation или Developer), имеющую два ядра ЦП.
Применение обновлений
Мы рекомендуем применить последнее накопительное обновление к компонентам ядра СУБД и машинного обучения. Накопительные обновления устанавливаются с помощью программы установки.
На устройствах, подключенных к Интернету, можно скачать самораспаковывающийся исполняемый файл. При применении обновления для ядра СУБД автоматически запрашиваются накопительные обновления для существующих функций R и Python.
На отключенных серверах требуются дополнительные действия. Необходимо получить накопительный пакет обновления для ядра СУБД, а также CAB-файлы для функций машинного обучения. Все файлы должны быть переданы на изолированный сервер и применены вручную.
- Начните с базового экземпляра. Накопительные обновления можно применять только к существующим установкам:
- Сервер машинного обучения (изолированный) из начального выпуска SQL Server 2019
- Сервер машинного обучения (изолированный) из начального выпуска SQL Server 2017
- Сервер R Server (изолированный) из начального выпуска SQL Server 2016, SQL Server 2016 1 или SQL Server 2016 SP 2
Закройте все открытые сеансы R или Python и завершите все процессы, запущенные в системе.
Если вы включили возможность запуска в качестве веб-узлов и узлов вычислений для развертывания веб-служб, создайте резервную копию файла AppSettings.json в качестве меры предосторожности. Применение SQL Server 2017 CU13 или более поздней версии изменяет этот файл, поэтому для сохранения исходной версии может потребоваться резервная копия.
На компьютере с подключением к Интернету скачайте самый свежий накопительный пакет обновлений для используемой версии со страницы Последние обновления для Microsoft SQL Server.
Загрузите последнее накопительное обновление
Это исполняемый файл.
На устройстве, подключенном к Интернету, дважды щелкните EXE-файл, чтобы запустить программу установки, и выполняйте шаги мастера, чтобы принять условия лицензионного соглашения, просмотреть затронутые функции и отслеживать ход выполнения до завершения.
На сервере без подключения к Интернету:
Получите соответствующие CAB-файлы для R и Python. Ссылки для загрузки см. в разделе CAB-загрузки для накопительных обновлений в экземплярах SQL Server с аналитикой в базе данных.
Перенесите все файлы, основные исполняемые и CAB-файлы в папку на автономном компьютере.
Дважды щелкните EXE-файл, чтобы запустить программу установки. При установке накопительного обновления на сервере без подключения к Интернету вам будет предложено выбрать расположение CAB-файлов для R и Python.
После установки войдите на сервер, для которого вы включили развертывание с веб-узлами и узлами вычислений, и отредактируйте файл AppSettings.json, добавив запись «MMLResourcePath» непосредственно под «MMLNativePath». Пример:
Запустите служебную программу CLI с правами администратора для перезапуска веб-узлов и узлов вычислений. Инструкции и синтаксис см. в разделе Отслеживание, запуск и остановка веб-узлов и узлов вычислений.
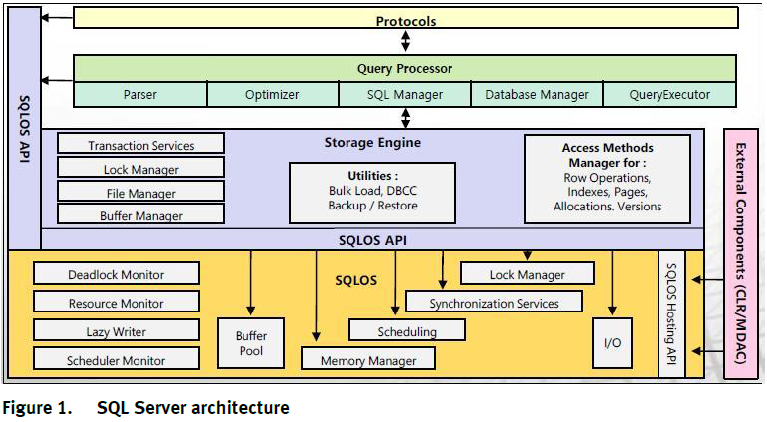
Что такое службы R?
SQL Server R Services позволяют выполнять скрипты R в базе данных. С их помощью можно подготавливать и очищать данные, выполнять проектирование признаков, а также обучать, оценивать и развертывать модели машинного обучения в базе данных. Этот компонент выполняет скрипты там, где хранятся данные, и устраняет необходимость перемещения данных по сети на другой сервер.
Базовые распределения R включены в службы R Services. Вы можете использовать пакеты и платформы с открытым кодом в дополнение к пакетам Microsoft RevoScaleR, MicrosoftML, ../r/ref-r-olapr.md) и sqlrutils для R.
R Services используют платформу расширяемости для выполнения скриптов R на SQL Server. Дополнительные сведения о том, как это работает:
- Платформа расширяемости
- Расширение R
Контрольный список перед установкой
-
Необходим экземпляр ядра СУБД. Вы не можете установить только R, хотя его можно добавить в существующий экземпляр добавочным образом.
-
Для обеспечения непрерывности бизнес-процессов группы доступности Always On поддерживаются для служб R Services. Необходимо установить службы R Services и настроить пакеты на каждом узле.
-
Не устанавливайте службы R Services на экземпляр отказоустойчивого кластера (FCI) SQL Server Always On. Механизм безопасности, используемый для изолирования процессов R, несовместим со средой с экземпляром отказоустойчивого кластера (FCI) SQL Server Always On.
-
Не устанавливайте R Services на контроллер домена. Этап установки служб R Services завершится с ошибкой.
-
-
Не устанавливайте Общие компоненты>R Server (изолированный) на том же компьютере, где работает экземпляр для выполнения в базе данных.
-
Параллельная установка с другими версиями R поддерживается, но не рекомендуется. Она поддерживается, так как экземпляр SQL Server использует собственные копии дистрибутива R с открытым кодом. Однако выполнение кода, использующего R, на компьютере SQL Server за пределами SQL Server может привести к различным проблемам:
- Вы используете другую библиотеку и другой исполняемый файл и получаете результаты, отличающиеся от результатов при работе в SQL Server.
- Скриптами R, выполняемыми во внешних библиотеках, невозможно управлять с помощью SQL Server, так как это приведет к состязанию за ресурсы.
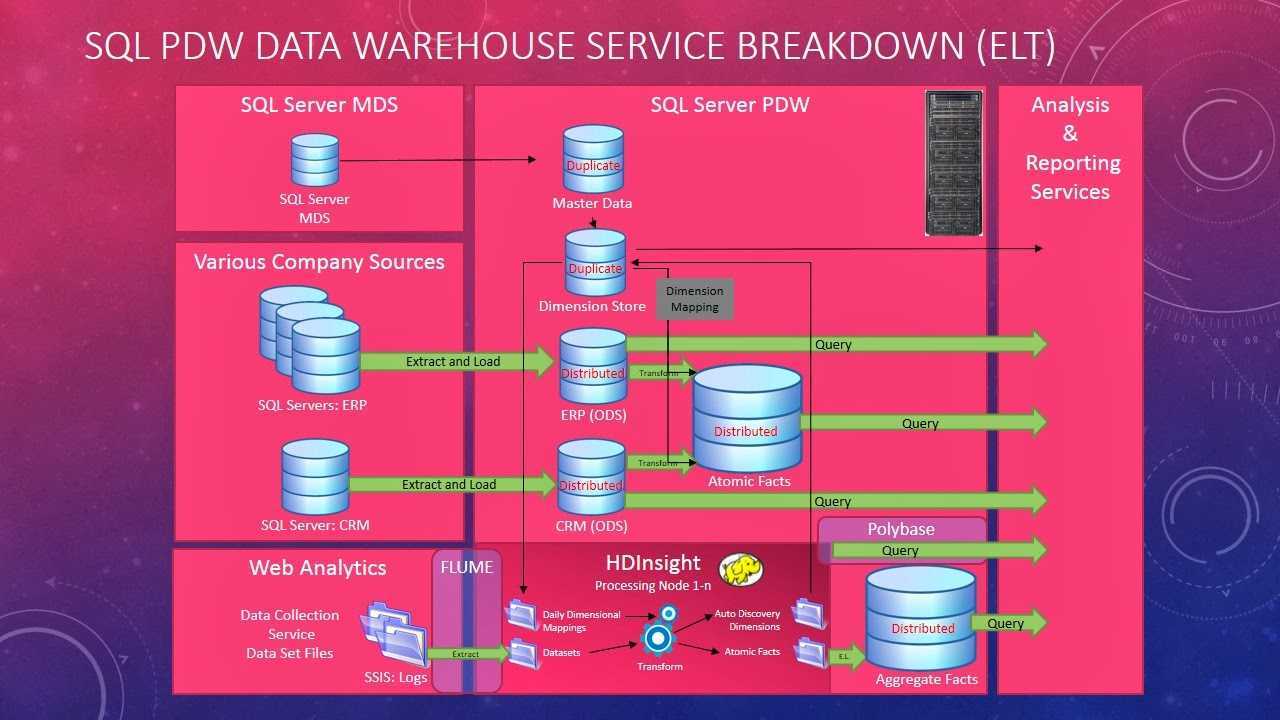
Важно!
После установки обязательно выполните действия после конфигурации, описанные в этой статье. В их число входят включение SQL Server для использования внешних скриптов и добавление учетных записей, необходимых для того, чтобы SQL Server выполнял задания R от вашего имени. Изменения в конфигурации обычно требуют перезапуска экземпляра или службы панели элементов.
Предлагаемые оптимизации
Также может потребоваться оптимизировать сервер для поддержки машинного обучения с использованием R или установки предварительно обученных моделей.
Добавление рабочих учетных записей
Если вы предполагаете, что будете интенсивно использовать среду R или множество пользователей будут одновременно выполнять скрипты, вы можете увеличить количество рабочих учетных записей, назначенных службе панели запуска. Дополнительные сведения см. в разделе Масштабирование параллельного выполнения внешних сценариев в SQL Server службы машинного обучения.
Оптимизация сервера для выполнения внешних скриптов
Параметры по умолчанию для программы установки SQL Server призваны оптимизировать выполнение на сервере различных служб, поддерживаемых ядром СУБД, включая процессы извлечения, преобразования и загрузки, ведение отчетности, аудит и приложения, использующие данные SQL Server. Поэтому при использовании параметров по умолчанию ресурсы для машинного обучения могут быть ограничены или регулироваться, особенно в случае с операциями с интенсивным использованием памяти.
Чтобы задачам машинного обучения назначались соответствующие приоритеты и выделялись необходимые ресурсы, рекомендуем использовать Resource Governor SQL Server для настройки внешнего пула ресурсов. Кроме того, можно изменить размер памяти, выделяемой ядру СУБД SQL Server, или увеличить количество учетных записей в службе Панель запуска SQL Server.
-
Сведения о настройке пула ресурсов для управления внешними ресурсами см. в разделе Создание внешнего пула ресурсов.
-
Сведения об изменении объема памяти, выделяемой для базы данных, см. в разделе Параметры конфигурации памяти сервера.
-
Чтобы изменить число учетных записей R, которые могут быть запущены Панель запуска SQL Server, см. раздел масштабирование параллельного выполнения внешних сценариев в SQL Server службы машинного обучения.
Если у вас установлен выпуск Standard Edition, но отсутствует Resource Governor, вы можете использовать для управления ресурсами сервера, используемыми R, динамические административные представления и расширенные события, а также мониторинг событий Windows.
Установка дополнительных пакетов R
Решения на R, создаваемые для SQL Server, могут вызывать базовые функции R, функции из собственных пакетов, установленных с SQL Server, а также сторонних пакетов R, совместимых с версией R с открытым исходным кодом, установленной SQL Server.
Пакеты, которыми вы хотите пользоваться из SQL Server, должны быть установлены в библиотеке по умолчанию, используемой экземпляром. При наличии отдельной установки R на компьютере, а также если вы установили пакеты в библиотеки пользователей, вы не сможете использовать их из T-SQL.
Процесс установки пакетов R и управления ими в SQL Server 2016 и SQL Server 2017 отличается. В SQL Server 2016 администратор базы данных должен установить пакеты R, необходимые пользователям. В SQL Server 2017 можно настроить группы пользователей для совместного использования пакетов на уровне базы данных или настроить роли базы данных, чтобы разрешить пользователям устанавливать собственные пакеты. Дополнительные сведения см. в статье Установка пакетов с помощью средств R.
Известные проблемы
В этом разделе перечислены известные проблемы, связанные с использованием служебной программы SqlBindR.exe, а также обновлениями Machine Learning Server, которые могут повлиять на экземпляры SQL Server.
Восстановление ранее установленных пакетов
Если вы выполнили обновление до Microsoft R Server 9.0.1, SqlBindR.exe для этой версии не удастся полностью восстановить первоначальные пакеты или компоненты R. Следует восстановить SQL Server на экземпляре и применить все служебные выпуски. Перезапустите экземпляр.
Более поздняя версия SqlBindR автоматически восстанавливает первоначальные компоненты R, устраняя необходимость в их переустановке или повторном исправлении сервера. Однако необходимо установить все обновления пакетов R, которые могли быть добавлены после первоначальной установки.
Используйте команды R для синхронизации установленных пакетов с файловой системой с помощью записей в базе данных. Дополнительные сведения см. в разделе Управление пакетами R для SQL Server.
Проблемы с перезаписью файла sqlbinr.ini в SQL Server
Сценарий: Эта проблема возникает при привязке Machine Learning Server 9.4.7 к SQL Server 2017. При обновлении и привязке Python или при обновлении до нового cu-файла он не понимает, что Python привязан, и перезаписывает файлы. С R подобных проблем не выявлено.
В качестве обходного решения создайте файл в каталоге PYTHON_SERVICES, который не является пустым. Содержимое не влияет на работу файла.
Создайте файл , содержащий 9.4.7.82, и сохраните его в следующее расположение:
Проблемы с несколькими обновлениями от SQL Server
Сценарий: экземпляр служб SQL Server 2016 R Services ранее обновлен до версии 9.0.1. Выполнен новый установщик для Microsoft R Server 9.1.0. Установщик показывает список всех допустимых экземпляров.
По умолчанию установщик выбирает ранее привязанные экземпляры. Если продолжить, для ранее привязанных экземпляров будет отменена привязка. В результате предыдущая установка 9.0.1 удаляется, в том числе все связанные пакеты, но новая версия Microsoft R Server (9.1.0) не устанавливается.
В качестве обходного решения можно изменить имеющуюся установку R Server следующим образом:
- На панели управления и откройте элемент Установка и удаление программ.
- Найдите Microsoft R Server и нажмите Изменить.
- При запуске установщика выберите экземпляры, которые необходимо привязать к 9.1.0.
Microsoft Machine Learning Server 9.2.1 и 9.3 не имеют этой проблемы.
Привязка или отмена привязки оставляет несколько временных папок
Удалите временные папки после завершения установки.
Примечание
Не забудьте дождаться завершения установки. Удаление библиотек R, связанных с одной версией, и добавление новых библиотек R может занять много времени. По завершении операции временные папки удаляются.
Шаг 2. Преобразование или переупаковка кода
Объем необходимых изменений в коде зависит от того, планируете ли вы отправлять код с удаленного клиента для выполнения в контексте вычислений SQL Server или хотите развернуть код в составе хранимой процедуры. Второй способ позволяет повысить производительность и безопасность данных, хотя он и накладывает некоторые дополнительные требования.
-
Чтобы избежать перемещения данных, по возможности определяйте в качестве первичных входных данных SQL-запрос.
-
При выполнении кода в хранимой процедуры вы можете передать несколько наборов скалярных входных данных. Для всех параметров, которые требуется использовать в выходных данных, добавьте ключевое слово OUTPUT.
Например, следующий скалярный вход содержит имя модели, которое также позже изменяется с помощью скрипта R и включается в выходные данные в отдельном столбце:
-
Все переменные, передаваемые в качестве параметров хранимой процедуры sp_execute_external_script, должны быть сопоставлены с переменными в коде. По умолчанию переменные сопоставляются по имени. Все столбцы во входном наборе данных также должны быть сопоставлены с переменными в скрипте.
Предположим, что скрипт R содержит следующую формулу:
Если входной набор данных не содержит столбцы с именами ArrDelay, CRSDepTime, DayOfWeek, CRSDepHour и DayOfWeek, возникает ошибка.
-
В некоторых случаях необходимо заранее определить схему выходных данных для результатов.
Например, чтобы вставить данные в таблицу, необходимо использовать инструкцию WITH RESULT SET для определения схемы.
Схема выходных данных также требуется, если скрипт использует аргумент . Дело в том, что SQL Server может распределить запрос между несколькими параллельными процессами и собирать результаты в конце. Поэтому схему вывода необходимо подготовить до того, как могут быть созданы параллельные процессы.
В других случаях схему результатов можно опустить, указав параметр WITH RESULT SETS UNDEFINED. Эта инструкция возвращает набор данных из скрипта, не присваивая имена столбцам и не определяя типы данных SQL.
-
-
Рассмотрите возможность создания данных времени и отслеживания с использованием T-SQL вместо R/Python.
Например, для передачи системного времени или других сведений, используемых при аудите и хранении, можно добавить вызов T-SQL, который передается в результаты, чтобы не создавать аналогичные данные в скрипте.
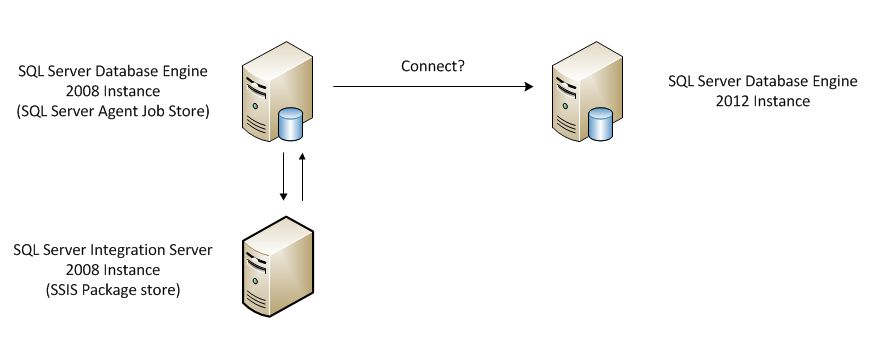
Повышение производительности и безопасности
-
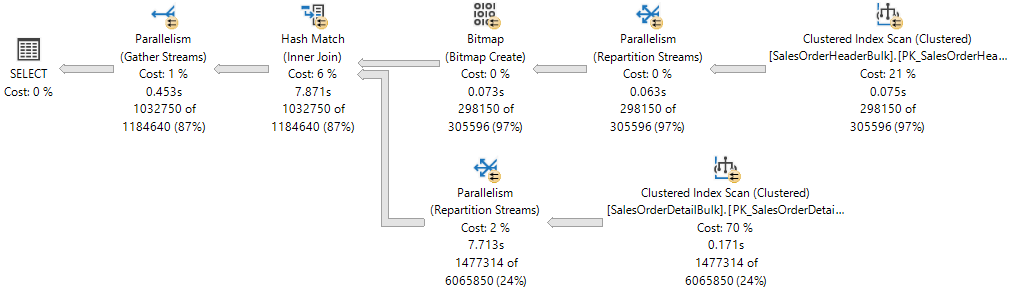
Выполняйте все запросы заранее и используйте планы запросов SQL Server для определения задач, которые могут выполняться параллельно.
Если входной запрос может выполняться параллельно, задайте параметр как часть аргументов процедуры sp_execute_external_script.
Параллельная обработка с использованием этого параметра обычно поддерживается, если SQL Server может работать с секционированными таблицами или распределять запрос между несколькими процессами и выполнять статистическую обработку результатов в конце. Параллельная обработка с использованием этого флага обычно не поддерживается, если для обучения моделей применяются алгоритмы, требующие считывания всех данных, или если вам нужно создать агрегаты.
-
Определите, нет ли в коде действий, которые можно выполнять отдельно или более эффективно с помощью вызова отдельной хранимой процедуры. Например, вы можете повысить производительность, конструируя или извлекая признаки отдельно и сохраняя значения в таблице.
-
Найдите способы выполнения вычислений на основе наборов с использованием кода T-SQL, а не R/Python.
Например, это решение R демонстрирует, как пользовательские функции T-SQL и R могут выполнять одинаковую задачу по формированию признаков: Пошаговое руководство по обработке и анализу данных.
-
Вместе с разработчиком базы данных определите способы повышения производительности с помощью таких компонентов SQL Server, как таблицы, оптимизированные для памяти, или, если вы используете выпуск Enterprise, Resource Governor.
-
Если вы используете R, по возможности замените обычные функции R функциями RevoScaleR, которые поддерживают распределенное выполнение. Дополнительные сведения см. в статье Сравнение функций Base R и RevoScaleR.
Что такое привязка?
Привязка — это процесс установки, который изменяет содержимое папок R_SERVICES и PYTHON_SERVICES на более новые исполняемые файлы, библиотеки и инструменты с Microsoft Machine Learning Server.
Передаваемые компоненты в составе модели обслуживания изменились. Обновления службы выполняются по графику поддержки Microsoft R Server и Machine Learning Server согласно политике современного жизненного цикла.
Привязка не изменяет основные принципы установки, за исключением версий компонентов и служебных обновлений:
- Интеграция Python и R по-прежнему является частью экземпляра ядра СУБД.
- Лицензирование остается неизменным (привязка не влечет никаких дополнительных затрат).
- Политики поддержки SQL Server сохраняются для ядра СУБД.
В оставшейся части этой статьи объясняется механизм привязки и принципы его работы для каждой версии SQL Server.
Примечание
Привязка применяется только к экземплярам в базе данных, связанным с экземплярами SQL Server. В этом случае для автономной установки не требуется привязка.
Рекомендации по привязке для SQL Server 2016
Для клиентов служб SQL Server 2016 R привязка предоставляет такие преимущества:
- Обновленные пакеты R.
- Новые пакеты не входят в исходную установку (Microsoft ML).
- Предварительно обученные модели машинного обучения для анализа тональности и обнаружения изображений.
Все привязки могут быть дополнительно обновлены при выходе нового главного и второстепенного выпуска Microsoft Machine Learning Server.



