
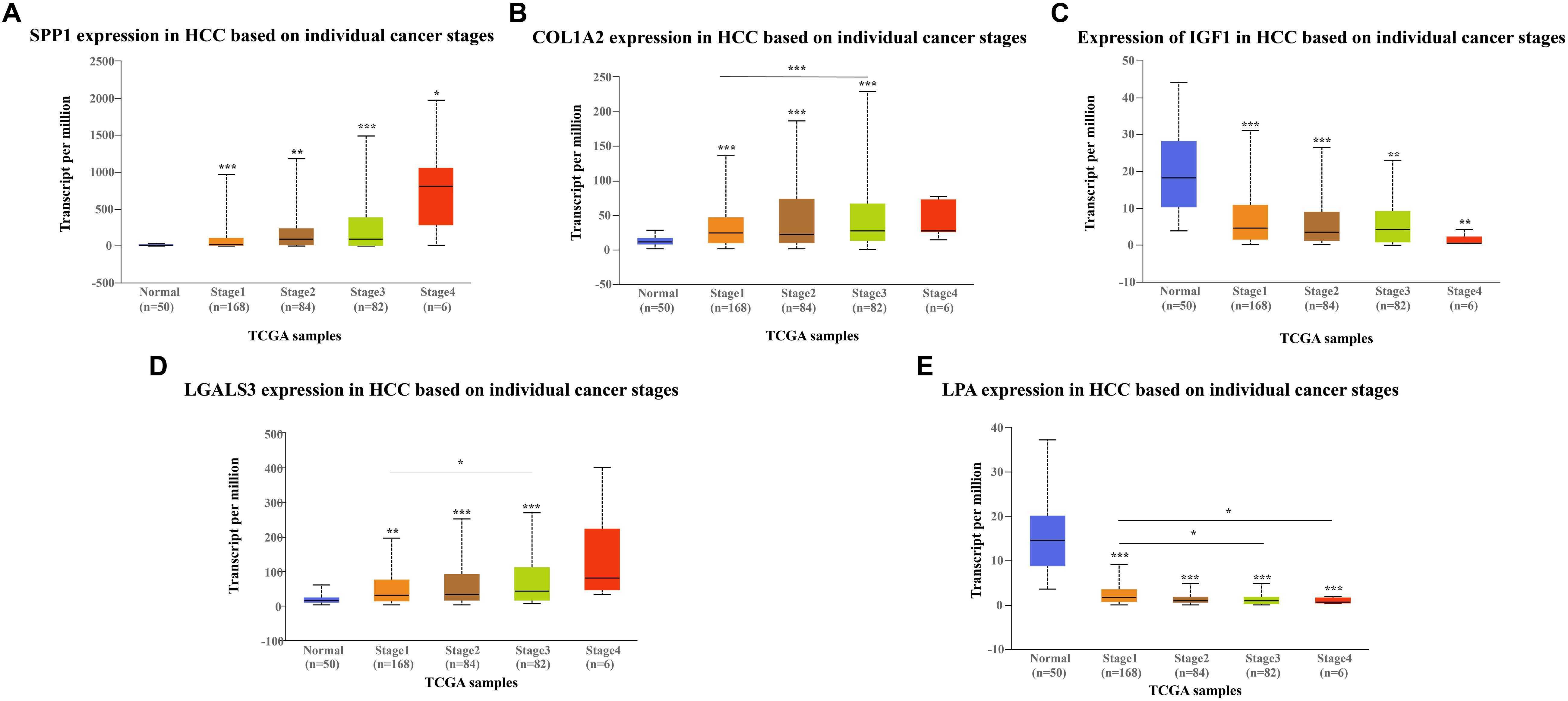
Введение или о чипах FPGA в 3-х абзацах
Микросхема FPGA (англ. field-programmable gate array), она же программируемая пользователем вентильная матрица (ПЛИС), — это интегральная микросхема (ИМС), которую можно реконфигурировать под любые сложные вычислительные задачи. В индустрии существует потребность в специализированных микросхемах (ASIC, application-specific integrated circuit, «интегральная схема специального назначения») — от управления космическими аппаратами и до расчетов по финансовым моделям. Однако до появления FPGA сильным и одновременно слабым местом специализированных ИМС была жесткая функциональность, заложенная в микросхему, а также высокая сложность проектирования и стоимость запуска в производство. Если функционал затем требовалось потом хоть чуть-чуть изменить, или на этапе проектирования произошли ошибки, то нужно было создавать по сути новую ИМС.
FPGA-ускоритель с чипом Intel Altera Arria 10 и портами 10GE
Появление на рынке FPGA-ускорителей, которые можно перепрограммировать сколь угодное число раз, причем на языке высокого уровня типа С, стало настоящим прорывом в нише высокопроизводительных вычислений. Это позволило ускорить время разработки, время выхода продуктов на рынок. Появились совершенно новые возможности для разработчиков аппаратных средств, в т.ч. работающих над программированием специализированных интегральных схем типа ASIC.
FPGA-процессоры прошли уже 2 этапа с точки зрения доступности этой технологии и сегодня активно входят в третий этап. Первые FPGA появились в 1985 году, но их программирование по-прежнему требовало знания языка низкого уровня типа ассемблера. На втором этапе, который начался примерно в 2013 году, и благодаря усилиям компании Altera, появилась возможность программирования на С-подобном языке высокого уровня. Это кардинально расширило применимость FPGA, но высокая стоимость чипов по-прежнему сдерживала расширение круга клиентов, которые могли бы себе позволить эту технологию.
Традиционно маршрут проектирования и верификации ПЛИС крайне трудоемок и требует высокой специализации, по своей сложности маршрут приближается к проектированию ASIC. Это ограничивает использование ПЛИС разработчиками. Особенно это касается вычислительных приложений, где участники процесса, — программист, математик, алгоритмист, — желают сфокусироваться на своей задаче, а не на ее аппаратной реализации. Решая эту проблему, компания Altera в 2013 году вывела на рынок для своих ПЛИС поддержку открытого стандарта программирования гетерогенных вычислительных платформ OpenCL, что расширило возможность применения аппаратуры разработчиками вычислительных приложений, не знакомых (малознакомых) с аппаратурой ПЛИС, языками HDL, маршрутом проектирования и верификации. Но, осталась проблема – дорогостоящая аппаратура и средства проектирования.
И, наконец, где-то с 2016 года можно говорить о третьем этапе, который ознаменовался доступностью для широкого круга клиентов полностью готовых серверов (физических и виртуальных) с FPGA-процессорами в облаках крупнейших дата-центров — Amazon Web Services (AWS), Cloud Alibaba и Huawei Cloud. В России впервые выделенные серверы с FPGA-процессорами стали доступны в дата-центре Selectel с 2017 года.
Обзор
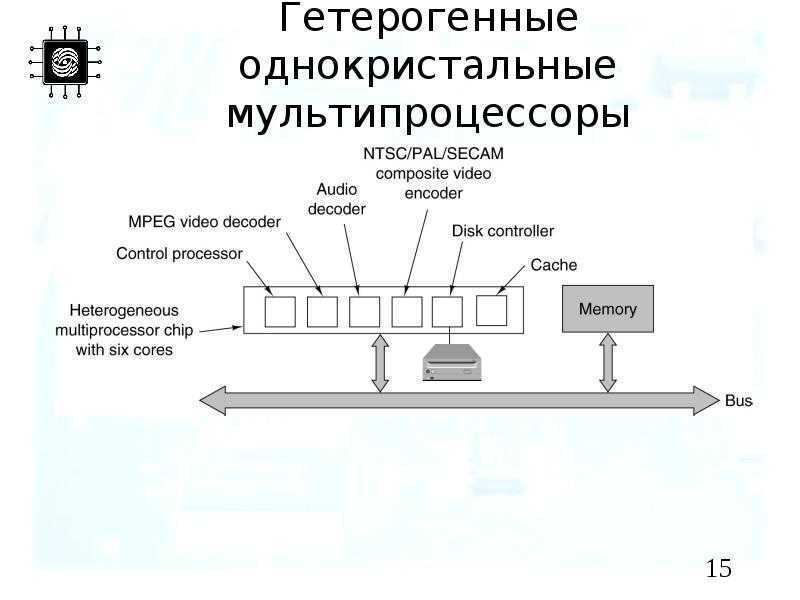
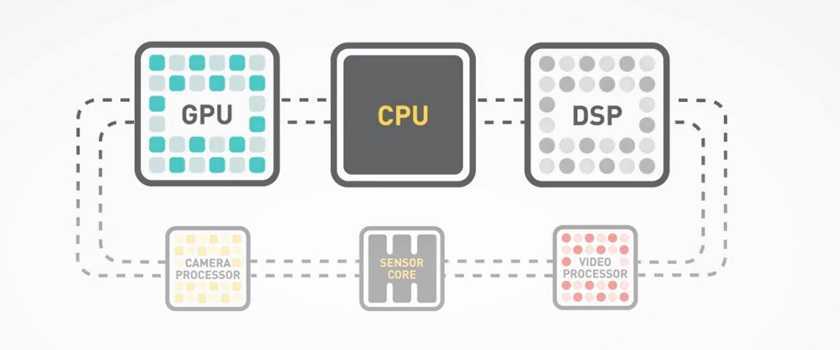
Первоначально представленный встроенные системы такой как Ячейка широкополосного доступа совместное использование системной памяти напрямую между несколькими участниками системы делает гетерогенные вычисления более распространенными. Сами по себе гетерогенные вычисления относятся к системам, которые содержат несколько процессоров: центральные процессоры (Процессоры), графические процессоры (Графические процессоры), цифровые сигнальные процессоры (DSP) или любого типа специализированные интегральные схемы (ASIC). Архитектура системы позволяет использовать любой ускоритель, например графический процессор, чтобы работать на том же уровне обработки, что и ЦП системы.
Среди своих основных характеристик HSA определяет унифицированный виртуальное адресное пространство для вычислительных устройств: там, где графические процессоры традиционно имеют собственную память, отдельную от основной (ЦП) памяти, HSA требует, чтобы эти устройства совместно использовали таблицы страниц чтобы устройства могли обмениваться данными путем совместного использования указатели. Это должно поддерживаться заказным блоки управления памятью.:6–7 Для обеспечения возможности взаимодействия, а также для облегчения различных аспектов программирования, HSA предназначен для ЭТО -агностика как для процессоров, так и для ускорителей, а также для поддержки языков программирования высокого уровня.
Пока что спецификации HSA охватывают:
Промежуточный уровень HSA
Промежуточный уровень HSA (HSAIL), a набор виртуальных инструкций для параллельных программ
- похожий к Промежуточное представление LLVM и SPIR (использован OpenCL и Вулкан )
- доработанный до конкретной инструкции, установленной JIT-компилятор
- поздно принимать решения, на каком ядре (ах) следует запустить задачу
- явно параллельный
- поддерживает исключения, виртуальные функции и другие высокоуровневые функции
- поддержка отладки
Модель памяти HSA
- совместим с C ++ 11, OpenCL, Ява и .СЕТЬ модели памяти
- расслабленная последовательность
- разработан для поддержки как управляемых языков (например, Java), так и неуправляемых языков (например, C )
- значительно упростит разработку сторонних компиляторов для широкого спектра разнородных продуктов, запрограммированных на Фортран, C ++, C ++ AMP, Java и др.
Диспетчер HSA и время выполнения
- разработан для обеспечения гетерогенной организации очереди задач: рабочая очередь на ядро, распределение работы по очередям, балансировка нагрузки путем кражи работы
- любое ядро может планировать работу для любого другого, включая себя
- значительное сокращение накладных расходов на планирование работы ядра
Мобильные устройства являются одной из областей применения HSA, в которой он обеспечивает повышенную энергоэффективность.
Блок-схемы
На приведенных ниже блок-схемах представлены общие иллюстрации того, как работает HSA, и его сравнение с традиционными архитектурами.
Обзор
Среди своих основных функций HSA определяет единое виртуальное адресное пространство для вычислительных устройств: там, где графические процессоры традиционно имеют свою собственную память, отдельную от основной (ЦП) памяти, HSA требует, чтобы эти устройства совместно использовать таблицы страниц, чтобы устройства могли обмениваться данными, разделяя указатели. Это должно поддерживаться пользовательскими модулями управления памятью. Для обеспечения возможности взаимодействия, а также для облегчения различных аспектов программирования, HSA предназначен для ISA -агностики как для процессоров, так и для ускорителей, а также для поддержки языков программирования высокого уровня.
На данный момент спецификации HSA охватывают:
Промежуточный уровень HSA
Промежуточный уровень HSA (HSAIL), набор виртуальных команд для параллельных программ
- аналогично Промежуточное представление LLVM и SPIR (используется OpenCL и Vulkan )
- , завершено до определенного набора инструкций Компилятор JIT
- поздно принимает решение о том, какое ядро (а) должно запускать задачу
- явно параллельную
- поддерживает исключения, виртуальные функции и другие высокоуровневые функции
- отладка поддержка
модели памяти HSA
- , совместимой с C ++ 11, OpenCL, Java и .NET моделями памяти
- ослаблены согласованность
- разработана для поддержки как управляемых языков (например, Java), так и неуправляемых языков (например, C )
- значительно упростит разработку сторонних компиляторов для широкого спектра разнородных продуктов, запрограммированных на Fortran, C ++, C ++ AMP, Java и др.
Диспетчер HSA и среда выполнения
- разработаны для включения гетерогенной организации очереди задач: рабочая очередь на ядро, распределение работы по очередям, балансировка нагрузки путем кражи работы
- любое ядро может планировать работу для любого другого, включая само
- значительное сокращение накладных расходов планирования работы для ядра
Мобильные устройства являются одной из областей применения HSA, в которой он обеспечивает повышенную энергоэффективность.
Блок-схемы
Блок-схемы ниже представляют собой общие иллюстрации о том, как работает HSA и как он соотносится с традиционными архитектурами.
Открытый стандарт и аппаратная независимость
Мы уже говорили о том, что HSA — это открытая платформа. API и спецификации предоставляются разработчиком бесплатно, а сама HSA не зависит от набора инструкций CPU или GPU.
Для обеспечения совместимости аппаратных решений различных вендоров был создан свой набор ISA: HSAIL (HSA Intermediate Layer), обеспечивающий работу ПО вне зависимости от того, что находится внутри HSA-решения. Сам же Intermediate Layer поддерживает работу с исключениями, виртуальными функциями, моделями памяти современных языков, так что никаких проблем с поддержкой C++, Java и .Net не предвидится, при этом разработчики могут как обращаться к «железу» напрямую, так и задействовать готовые библиотеки оптимизации HSA, которые будут самостоятельно распределять задачи и упорядочивать общение с железом, упрощая работу программиста.

Поддержка программного обеспечения
Графические процессоры AMD содержат определенные дополнительные функциональные блоки, предназначенные для использования в рамках HSA. В Linux драйвер ядра amdkfd обеспечивает необходимую поддержку.
Некоторые из специфических для HSA функций, реализованных в оборудовании, должны поддерживаться ядром операционной системы и конкретными драйверами устройств. Например, поддержка видеокарт AMD Radeon и AMD FirePro, а также APU на базе Graphics Core Next (GCN) была объединена с версией 3.19 основной линии ядра Linux, выпущенной 8 февраля 2015 года. Программы не взаимодействуют напрямую с amdkfd, но ставят свои задания в очередь, используя среду выполнения HSA. Эта самая первая реализация, известная как amdkfd, ориентирована на APU или «Berlin» и работает вместе с существующим графическим драйвером ядра Radeon.
Кроме того, amdkfd поддерживает гетерогенную организацию очередей (HQ), цель которой — упростить распределение вычислительных заданий между несколькими процессорами и графическими процессорами с точки зрения программиста. Поддержка управления гетерогенной памятью ( HMM ), подходящая только для графического оборудования с версией 2 IOMMU AMD, была принята в основную версию ядра Linux 4.14.
Интегрированная поддержка платформ HSA была объявлена для Sumatra-версии OpenJDK, которая должна выйти в 2015 году.
AMD APP SDK — это проприетарный комплект разработки программного обеспечения AMD, предназначенный для параллельных вычислений, доступный для Microsoft Windows и Linux. Bolt — это библиотека шаблонов C ++, оптимизированная для гетерогенных вычислений.
GPUOpen включает в себя несколько других программных инструментов, связанных с HSA. CodeXL версии 2.0 включает профилировщик HSA.
Пример оборудования
Гетерогенное вычислительное оборудование можно найти во всех областях вычислений — от высокопроизводительных серверов и высокопроизводительных вычислительных машин до встроенных устройств с низким энергопотреблением, включая мобильные телефоны и планшеты.
- Высокопроизводительные вычисления
- Cray XD1
- Компьютеры SRC SRC-6 и SRC-7
- Встроенные системы (DSP и мобильные платформы)
- Инструменты Техаса OMAP
- Аналоговые устройства Blackfin
- Qualcomm Львиный зев
- Nvidia Тегра
- Samsung Exynos
- яблоко
- Movidius Myriad Блоки обработки зрения, который включает в себя несколько симметричных процессоров, дополненных фиксированные функциональные блоки, и пара SPARC на базе контроллеров.
- HiSilicon Кирин SoC
- MediaTek SoC
- Системы дизайна Cadence DSP Tensilica
- Реконфигурируемые вычисления
- Xilinx Программируемая вентильная матрица (FPGA; например, Virtex-II Pro, Virtex 4 FX, Virtex 5 FXT) и и Платформы
- Intel «Стеллартон» (Атом + Альтера FPGA )
- Сети
- Сетевые процессоры Intel IXP
- Нетроном Сетевые процессоры NFP
- Универсальные вычислительные, игровые и развлекательные устройства
- Intel Процессоры Sandy Bridge, Ivy Bridge и Haswell
- AMD Экскаватор и Райзен ВСУ
-
IBM Ячейка, найденный в Игровая приставка 3
SpursEngine, вариант процессора IBM Cell
- Двигатель эмоций, найденный в PlayStation 2
-
РУКА big.LITTLE / DynamIQ
Почти все поставщики ARM предлагают разнородные решения; ARM, Qualcomm, Nvidia, Apple, Samsung, HiSilicon, MediaTek и др.
Архитектура процессора
Пример оборудования
Гетерогенное вычислительное оборудование можно найти во всех областях вычислений — от высокопроизводительных серверов и высокопроизводительных вычислительных машин до встроенных устройств с низким энергопотреблением, включая мобильные телефоны и планшеты.
- Высокопроизводительные вычисления
- Cray XD1
- Компьютеры SRC SRC-6 и SRC-7
- Встроенные системы (DSP и мобильные платформы)
- Инструменты Техаса OMAP
- Аналоговые устройства Blackfin
- Qualcomm Львиный зев
- Nvidia Тегра
- Samsung Exynos
- яблоко
- Movidius Myriad Блоки обработки зрения, который включает в себя несколько симметричных процессоров, дополненных фиксированные функциональные блоки, и пара SPARC на базе контроллеров.
- HiSilicon Кирин SoC
- MediaTek SoC
- Системы дизайна Cadence DSP Tensilica
- Реконфигурируемые вычисления
- Xilinx Программируемая вентильная матрица (FPGA; например, Virtex-II Pro, Virtex 4 FX, Virtex 5 FXT) и и Платформы
- Intel «Стеллартон» (Атом + Альтера FPGA )
- Сети
- Сетевые процессоры Intel IXP
- Нетроном Сетевые процессоры NFP
- Универсальные вычислительные, игровые и развлекательные устройства
- Intel Процессоры Sandy Bridge, Ivy Bridge и Haswell
- AMD Экскаватор и Райзен ВСУ
-
IBM Ячейка, найденный в Игровая приставка 3
SpursEngine, вариант процессора IBM Cell
- Двигатель эмоций, найденный в PlayStation 2
-
РУКА big.LITTLE / DynamIQ
Почти все поставщики ARM предлагают разнородные решения; ARM, Qualcomm, Nvidia, Apple, Samsung, HiSilicon, MediaTek и др.
Архитектура процессора
Гетерогенная многоядерность не лишена проблем
Есть две довольно специфические «проблемы» с разнородными многоядерными процессорами на такой платформе, как ПК. Первый связан с Overclocking , поскольку, если каждый кластер ядер работает со скоростью и с другим множителем, мы не сможем разогнать весь процессор как таковой, а просто определенную группу ядер (кластер). Хотя это правда, что Intel и AMD пока не раскрывают технических данных по этому поводу. В любом случае логично думать, что в лучшем случае можно будет разогнать только определенные кластеры ядер, а не все, поскольку они неоднородны.
Вторая проблема с гетерогенными архитектурами: поддержка программного обеспечения , поскольку, в конце концов, операционная система должна поддерживать этот тип реализации, чтобы назначить рабочую нагрузку правильным ядрам. В случае Linux ядро, есть модули, которые отвечают за управление тактовой частотой процессора или активацию и деактивацию ядер соответственно, но проблема с этими модулями заключается в том, что они работают независимо и могут создавать конфликты между ними, снижая эффективность в некоторых случаях или снижая производительность в других.
Очевидно, что этому типу архитектуры суждено рано или поздно стать популярным (вспомним Intel Lakefield и то, что AMD тоже «играет» с ним), поэтому, учитывая, что наиболее используемая операционная система — это Microsoft Windowsнам придется подождать, пока Microsoft «поставит батарейки», чтобы принять этот тип архитектуры, и посмотреть, как она в конечном итоге будет работать.
Поддержка программного обеспечения
Графические процессоры AMD содержат определенные дополнительные функциональные блоки, предназначенные для использования в рамках HSA. В Linux драйвер ядра amdkfd обеспечивает необходимую поддержку.






Некоторые из специфических для HSA функций, реализованных в оборудовании, должны поддерживаться ядро операционной системы и конкретные драйверы устройств. Например, поддержка AMD Radeon и AMD FirePro видеокарты и ВСУ на основе Графическое ядро Next (GCN) был объединен с версией 3.19 Основная линия ядра Linux, выпущенный 8 февраля 2015 года. Программы не взаимодействуют напрямую с amdkfd, но ставят свои задания в очередь, используя среду выполнения HSA. Эта самая первая реализация, известная как amdkfd, фокусируется на или «Berlin» APU и работает вместе с существующим графическим драйвером ядра Radeon.
Кроме того, amdkfd поддерживает неоднородная организация очередей (HQ), цель которого — упростить распределение вычислительных заданий между несколькими процессорами и графическими процессорами с точки зрения программиста. Поддержка для управление неоднородной памятью (ХМ), подходит только для графического оборудования с версией 2 AMD IOMMU, был принят в основную версию ядра Linux 4.14.
Интегрированная поддержка платформ HSA была объявлена для выпуска Sumatra. OpenJDK, срок погашения в 2015 году.
AMD APP SDK это проприетарный комплект для разработки программного обеспечения AMD, предназначенный для параллельных вычислений, доступный для Microsoft Windows и Linux. Bolt — это библиотека шаблонов C ++, оптимизированная для гетерогенных вычислений.
GPUOpen понимает пару других программных инструментов, связанных с HSA. CodeXL версия 2.0 включает профилировщик HSA.
Вызовы
Гетерогенные вычислительные системы создают новые проблемы, которых нет в типичных однородных системах. Наличие нескольких элементов обработки поднимает все проблемы, связанные с однородными системами параллельной обработки, в то время как уровень неоднородности в системе может внести неоднородность в разработку системы, методы программирования и общие возможности системы. Области неоднородности могут включать:
- ISA или архитектура набора команд
Вычислительные элементы могут иметь разную архитектуру набора команд, что ведет к двоичной несовместимости.
- ABI или двоичный интерфейс приложения
Вычислительные элементы могут интерпретировать память по-разному. Это может включать как порядок байтов, соглашение о вызовах, и макет памяти, и зависит как от архитектуры, так и от компилятор использовался.
-
API или интерфейс прикладного программирования
Услуги библиотеки и ОС могут быть доступны не для всех вычислительных элементов.
- Низкоуровневая реализация языковых функций
- Интерфейс памяти и Иерархия
Вычислительные элементы могут иметь разные тайник конструкции, согласованность кеша протоколы, а доступ к памяти может быть равномерным или неоднородным доступом к памяти (NUMA ). Различия также можно найти в способности читать данные произвольной длины, поскольку некоторые процессоры / блоки могут выполнять только байтовый, словарный или пакетный доступ.
- Соединить
- Спектакль
- Разделение данных
Неоднородность
Обычно неоднородность в контексте вычислений называется к разным архитектуры с набором команд (ISA), где у основного процессора есть один, а у других процессоров есть другая — обычно очень другая — архитектура (может быть, более одного), а не просто другая микроархитектура (плавающая точка обработка номеров является частным случаем этого — обычно не называется гетерогенной).
В прошлом гетерогенные вычисления означали, что разные ISA нужно было обрабатывать по-разному, а в современном примере Гетерогенная системная архитектура (HSA) системы устранить разницу (для пользователя) при использовании нескольких типов процессоров (обычно Процессоры и GPU), обычно на одном Интегральная схема, чтобы обеспечить лучшее из обоих миров: общую обработку графического процессора (помимо хорошо известных возможностей рендеринга трехмерной графики графического процессора, он также может выполнять математически интенсивные вычисления на очень больших наборах данных), в то время как процессоры могут запускать операционную систему и выполнять традиционные серийные задания.
Уровень неоднородности современных вычислительных систем постепенно увеличивается, поскольку дальнейшее масштабирование производственных технологий позволяет ранее дискретным компонентам стать интегрированными частями система на кристалле, или SoC.[нужна цитата ] Например, многие новые процессоры теперь включают встроенную логику для взаимодействия с другими устройствами (SATA, PCI, Ethernet, USB, RFID, радио, UART, и контроллеры памяти ), а также программируемые функциональные блоки и аппаратные ускорители (GPU, криптография сопроцессоры, программируемые сетевые процессоры, A / V кодеры / декодеры и т. д.).
Недавние результаты показывают, что мультипроцессор с гетерогенной микросхемой ISA, использующий разнообразие, предлагаемое несколькими ISA, может превзойти лучшую однородную архитектуру с той же самой ISA на целых 21% при 23% экономии энергии и 32% сокращении затрат. Продукт задержки энергии (EDP). Объявление AMD в 2014 году о своих совместимых по выводам процессорах ARM и x86 под кодовым названием Project Skybridge,предложил мультипроцессор на базе гетерогенного ISA (ARM + x86).[нужна цитата ]
Гетерогенная топология ЦП
Система с гетерогенная топология ЦП это система, в которой используется один и тот же ISA, но сами ядра разные по скорости. Настройка больше похожа на симметричный мультипроцессор. (Хотя такие системы технически асимметричные мультипроцессоры, ядра не различаются по ролям или доступу к устройствам.)
Обычно такая топология используется для повышения энергоэффективности мобильных SoC. ARM большой.LITTLE это типичный случай, когда более быстрые ядра с высокой мощностью сочетаются с более медленными ядрами с низким энергопотреблением.Apple Кремний произвел ядра ARM с аналогичной организацией. Intel также выпустила гибридные ядра x86 под кодовым названием Lakefield, хотя и не без серьезных ограничений в поддержке набора команд.
Майнинг bitcoin
В качестве награды за работу по отслеживанию и защите транзакций майнеры зарабатывают биткойны, практически – за каждый успешно обработанный блок. В Bitcoin основатели установили лимит 21 млн Bitcoins, доступного для добычи, поэтому стоимость криптовалюты постоянно растет, как и число желающих их заполучить.
Потенциальным майнерам нужно сначала узнать про GPU и что это в компьютере, а потом уже разбираться в блокчейнах и криптовалютах. Хорошо понимать, что такое RAM и CPU в компьютере, а потом двигаться дальше.
Печальная правда заключается в том, что в настоящее время только те, у кого есть специализированное, мощное оборудование, могут выгодно добывать биткойны. Хотя их добыча по-прежнему теоретически и технически возможна для всех. Однако, те, у кого недостаточно мощные устройства, рано или поздно обнаружат, что на электроэнергию тратится больше денег, чем на добычу биткоинов.
Принципиально работа майнеров заключается в подборе одной-единственной из многих миллионов комбинаций хэша, подходящего ко всем вновь созданным транзакциям и сгенерированному секретному ключу. Ясно, что только самое производительное оборудование способно обеспечить майнеру конкурентное преимущество и обеспечит получение награды.
Другие виды графики
Из истории видно, что первоначально графика была дискретной — отдельная плата, на которой распаяны графический процессор и видеопамять. Де-факто — компьютер в компьютере. И на данный момент этот вид остаётся самым производительным и одновременно дорогим.
Следом появилась iGPU, графика с разделяемой памятью. Примеры: Intel 740 и Intel HD Graphics и Vega от AMD. Собственной видеопамяти в таких графических адаптерах как правило нет, вместо этого используется RAM. Популярное решение для компактных и офисных ПК, ноутбуков, а также для игровых приставок.
А что интересного есть ещё?
Инженеры — люди увлеченные и зачастую творческие, поэтому разрабатывали и другие виды графики. Толчком к реализации новых идей стало появление шины PCIe в 2002 году.
Nvidia, в команде с другими вендорами, разработала стандарт MXM (Mobile PCI Express Module), который должен был решить проблему модификации графической части ноутбуков. Модули MXM можно менять по мере необходимости без полного разбора устройства — это некая разновидность привычных нам дискретных видеокарт, но без собственного активного охлаждения.
Ещё одной интересной технологией является гибридная графика. Так как APU начали набирать всё большую популярность, во многих ПК графические ядра простаивают без дела — всю нагрузку на себя берёт видеокарта. Из-за этого даже стали появляться удешевлённые версии CPU без iGPU, например процессоры Intel с литерой “F”. Однако есть способы задействовать одновременно видеокарту и интегрированную графику. Например, AMD на своём сайте заявляет, что: “Двойная графика AMD Radeon представляет собой инновационную технологию, используемую только на платформах AMD, благодаря которой гибридные процессоры AMD и определенные дискретные графические карты AMD Radeon могут работать вместе. Благодаря такому сочетанию платформа обеспечивает потрясающее качество и производительность, лучшие чем у каждого из устройств по отдельности”.
Похожая технология есть и у Nvidia, называется она — Optimus. Когда нагрузка низкая, используется iGPU в процессоре, когда нагрузка высокая, в работу включается дискретная графика со словами: “Сейчас батя разберётся”.
Конечно, у двойной графики от AMD и Nvidia есть множество нюансов и компромиссов, но получить и производительность и увеличенное время автономной работы с их помощью можно.
Ещё одна технология, заслуживающая внимания, это внешняя видеокарта или eGPU (External Graphics Processing Unit).
Ноутбуки на заре своего появления не могли похвастаться мощной графикой. Это сейчас можно приобрести игрового монстра с RTX 3080 на борту, но раньше на лэптопах преимущественно работали с нетребовательными офисными приложениями. Но потом стало очевидно, что PCIe позволяет создать интерфейс для подключения внешней графики, решающей эту проблему.
Ну и закончим на гении китайской инженерной мысли.
Встречайте — база ZA-KB1650 от Zeal-All со встроенной дискретной (простите за каламбур) видеокартой GeForce GTX 1650. На кой чёрт они распаяли дискретную видеокарту прямо на материнской плате, мы никогда не узнаем. Но это явно продукт под определённую задачу.
Общая архитектура SoC
Независимо от того, о каком типе SoC мы говорим, все они имеют ряд общих элементов в отношении их организации. Что мы под этим подразумеваем? Организация или архитектура — это способ, которым компоненты процессора взаимосвязаны друг с другом внутри интегрированного чипа.

В SoC все элементы имеют общий доступ к одной и той же памяти, это означает, что во всех SoC доступ к памяти осуществляется через один компонент. Во всех архитектурах это северный мост или северный мост, который связывает все компоненты ЦП между ними и с Оперативная память Память.
Северный мост на самом деле не запускает никаких программ, но он действительно организует отправку и получение данных, поэтому внутренне SoC непрерывно обрабатывает большой объем данных и является наиболее важной частью при проектировании. SoC
Среди пользователей существует миф о том, что создание SoC — это склеивание различных частей вместе. На самом деле все обстоит иначе, поскольку взаимосвязь между компонентами требует построения определенной инфраструктуры взаимодействия, которая различается для каждой SoC.
Майнинг других криптовалют
Начинающим крипто-претендентам следует взяться за какую-то из самых простых и новых монет, чтобы реально их добыть. В 2019-м году это:
- Monero,
- Aeon,
- DogeCoin,
- Vertcoin,
- ByteCoin,
- Steem,
- Electroneum…

Monero, признанный самой передовой монетой конфиденциальности, основан на алгоритме хеширования с проверкой работоспособности, известном как CryptoNight. Вы можете легко добывать Monero на обычном компьютере просто путем загрузки и установки программного обеспечения Monero добычи. Поэтому эта новая криптовалюта считается одним из лучших вариантов майнинга с GPU, по сравнению с другими.
Читайте так же “Облачный майнинг”
Архитектура DSP
Специфика решаемых задач оказывает существенное влияние на архитектуру и системное ПО для DSP. По словам Jennifer Eyre, аналитика исследовательского центра BDTI, “архитектура DSP формируется теми задачами, которые на них считаются” (“Architecture of DSP is molded by algorithms”, из “Evolution of DSP Processors”). Перечислим особенности таких задач:
-
Практически бесконечный параллелизм уровня команд (ILP, Instruction Level Parallelism)
-
Большинство алгоритмов (свертка, быстрое преобразование Фурье, вычисления с комплексными числами) сводятся к выполнению операций сложения и умножения над плотными массивами данных
-
Вычисление производятся на встроенных системах, с жёсткими требованиями по энергопотреблению
Таким образом, основными целями являются максимальное использование присущего задачам параллелизма и снижение энергопотребления при выполнении циклов.
Для использования ILP используются различные техники:
-
Векторные инструкции (SIMD, Single Instruction Multiple Data)
-
Сложные инструкции (CISC, Complex Instruction Set Computer):
-
Составные математические операции (умножение и вычитание с накоплением, гистограммы, спецфункции, комплексные вычисления)
-
Операции умножения со сдвигом (для арифметики с фиксированной точкой)
-
Широкий набор режимов адресации (с шагом, с пре- и пост-инкрементом, циклическим обходом и пр.)
-
Алгоритмо-специфические операции (например подсчёт контрольных сумм сетевых пакетов, криптография, аудио-видео декодеры)
-
Расширяемые системы команд (в IP-продуктах Ceva и Tensillica)
-
-
Сильно расслоенная память (для выдачи нескольких параллельных загрузок за такт или индексных обращений в память типа scatter/gather)
-
Избавление от задержек, вызываемых ветвлениями:
-
Поддержка предикатного выполнения для всех команд процессора (или подавляющего большинства)
-
Процессорные хинты (специальные инструкции для предзагрузки данных)
-
Слоты задержки
-
Быстрые циклы (zero-overhead loops)
-
-
Вынесение наиболее вычислительно-ёмких алгоритмов (алгоритм Витерби, БПФ, QR-разложение, нейросетевые вычисления) на встроенные ускорители (т.н. fixed function units)
-
Ускорение продолжительных операций с памятью с помощью специальных блоков прямого доступа в память (DMA), с поддержкой произвольных 2D/3D-шагов
Для снижения же энергопотребления используются
-
Переход от действительных чисел на арифметику с фиксированной точкой
-
Нестандартные типы данных (например 20- и 40-битные целые)
-
Упорядоченные (in-order) вычисления, отсутствие спекулятивности (speculation) и внеочередного выполнения (out-of-order)
-
Явное формирование параллельно исполняемых пакетов инструкций компилятором (VLIW)
-
Отсутствие отслеживания процессором зависимостей между инструкциями и перенос ответственности за точное планирование инструкций на компилятор (exposed pipeline)
-
Отсутствие кэшей
-
Прямое обращение в глобальную DRAM-память приведёт к остановке процессора для выполнения транзакции
-
Вместо instruction- и data-кэшей используется небольшая (до 1 Мбайта) быстрая SRAM-память, т.н. scratchpad или Tightly Coupled Memory, загрузками в которую явно управляет программист
-
-
Для упрощения таких загрузок часто используются оверлеи – специальный механизм разбиения программы на независимые участки, которые могут по требованию динамически подгружаться в TCM, вытесняя друг друга
-
-
Вместо таблиц предсказания ветвлений (branch target buffer, BTB) в DSP используются различные техники для амортизации ветвлений (слоты задержки, хинты, быстрые циклы)
-
Кластерные регистровые файлы (т.е. разбиение регистрового файла на блоки, регистры которых не могут использоваться вместе в одной инструкции)

В процессорах общего назначения каждое из указанных решений привело бы к фатальному ухудшению производительности и удобства работы, но в случае DSP особенности применения снимают эту проблему.
Некоторые из указанных подходов можно видеть ниже на примере кода для процессора Texas Instruments:
В частности можно видеть
-
инструкцию быстрого цикла , сочетающую в себе декремент индекса цикла, сравнение с 0 и условный переход
-
явное указание пареллелизма с помощью лексемы
-
явные задержки инструкций с помощью
-
использование слотов задержки
Понятие образа в технологии FPGA
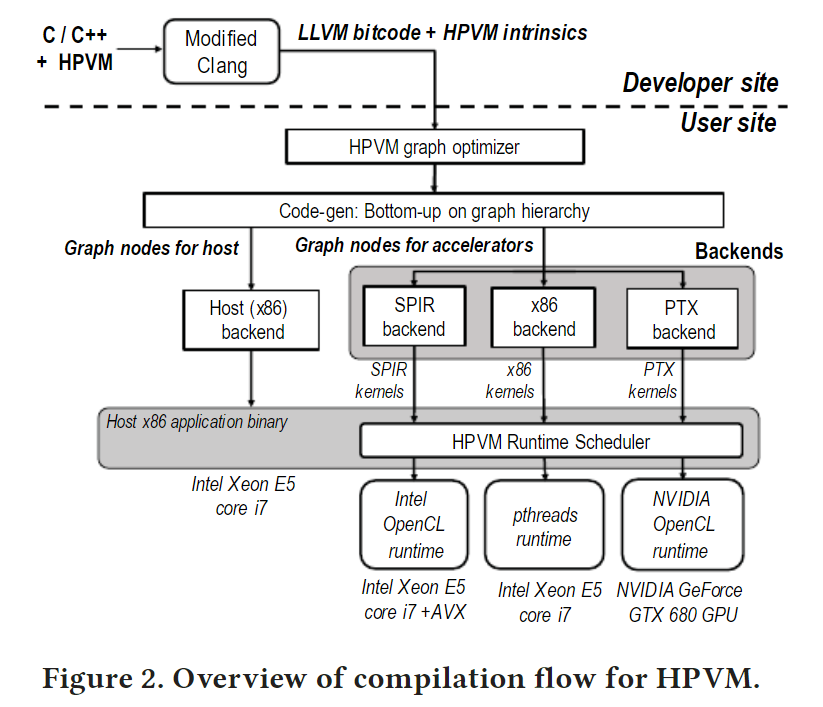
Выше мы перечислили популярные на сегодня серии чипов FPGA от Intel, — но чтобы их использовать в серверах, потребуется приобрести платы FPGA-ускорителей и осуществить программирование логики чипов на адаптере под конкретную прикладную задачу. Платы адаптеров доступны у партнеров Intel, входящих в сообщество FPGA Design Solutions Network. В частности, в России таким партнером является ООО «Алмаз-СП» (также участвует в Эйлер проджект), поставляющее как оригинальные адаптеры Intel, так и платы собственной разработки с чипами FPGA последних поколений.
Демонстрация сервера с FPGA-ускорителем «Алмаз-СП» на SelectelTechDay #2
Демо-зона аппаратных новинок на SelectelTechDay #2 (FPGA — первый стенд слева)
Если надо абстрагироваться от маршрута проектирования и сфокусироваться на вычислительной задаче, можно воспользоваться OpenCL и Intel FPGA SDK for OpenCL. Для этого потребуется пакет поддержки платы BSP, который позволит абстрагироваться от сложностей построения системы на кристалле (контроллеры памяти, PCIe, интерфейсы, тактовые домены, временные ограничения, частичная реконфигурация и т.д.) и сфокусироваться на вычислительной задаче. Такой пакет предоставляется, если для платы заявлена поддержка OpenCL (OpenCL BSP). Имея подобный пакет поддержки, можно получить «среду разработчика ПО» — где есть модель платформы, функция для ускорения, библиотека поддержки времени выполнения, модель памяти, а также специальные расширения для увеличения пропускной способности. Затем приступают к написанию кода, профилированию, оптимизации.
В результате использования SDK и BSP получается единый файл конфигурации (битстрим), которым конфигурируется ПЛИС и получается законченная система на кристалле под конкретную вычислительную задачу. Результатом программирования является микропрограмма, решающая конкретную прикладную задачу (например, расчет матрицы уравнений, преобразование видео-форматов и т.д.). Такая микропрограмма называется FPGA-образом (FPGA Image). Достаточно часто вместо термина «образ» используется термин «IP-ядро».



