
Презентация на тему: » Многомерная модель данных. OLAP, определение OLAP (On-Line Analytical Processing) — технология оперативной аналитической обработки данных, использующая.» — Транскрипт:
1
Многомерная модель данных

2
OLAP, определение OLAP (On-Line Analytical Processing) — технология оперативной аналитической обработки данных, использующая методы и средства для сбора, хранения и анализа многомерных данных в целях поддержки процессов принятия решений.

3
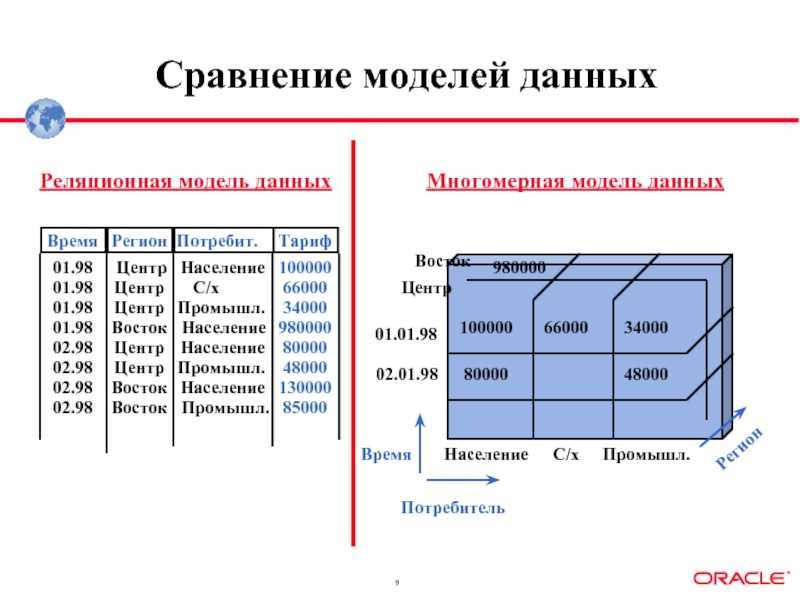
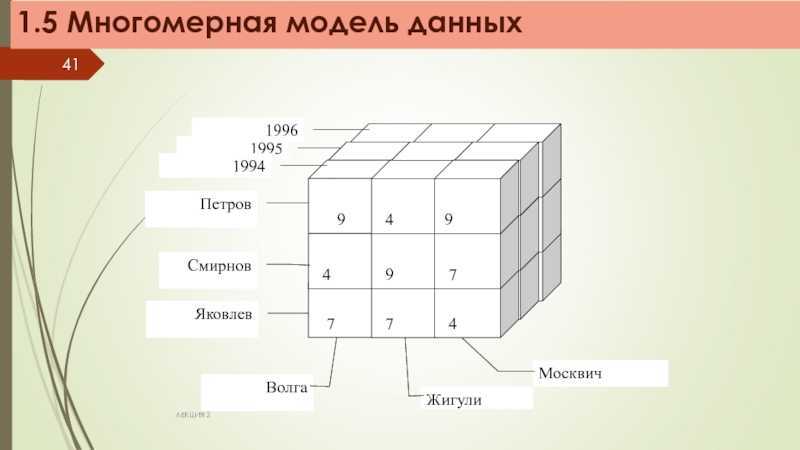
ОLАР-системы Многомерная модель данных Измерение — это последовательность значений одного из анализируемых параметров. Например, для параметра «время» это последовательность календарных дней, для параметра «реrион» это может быть список городов. По Кодду, многомерное концептуальное представление (multidimensional conceptual view) — это множественная перспектива, состоящая из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям определяется как многомерный анализ.

4
Гиперкуб

5
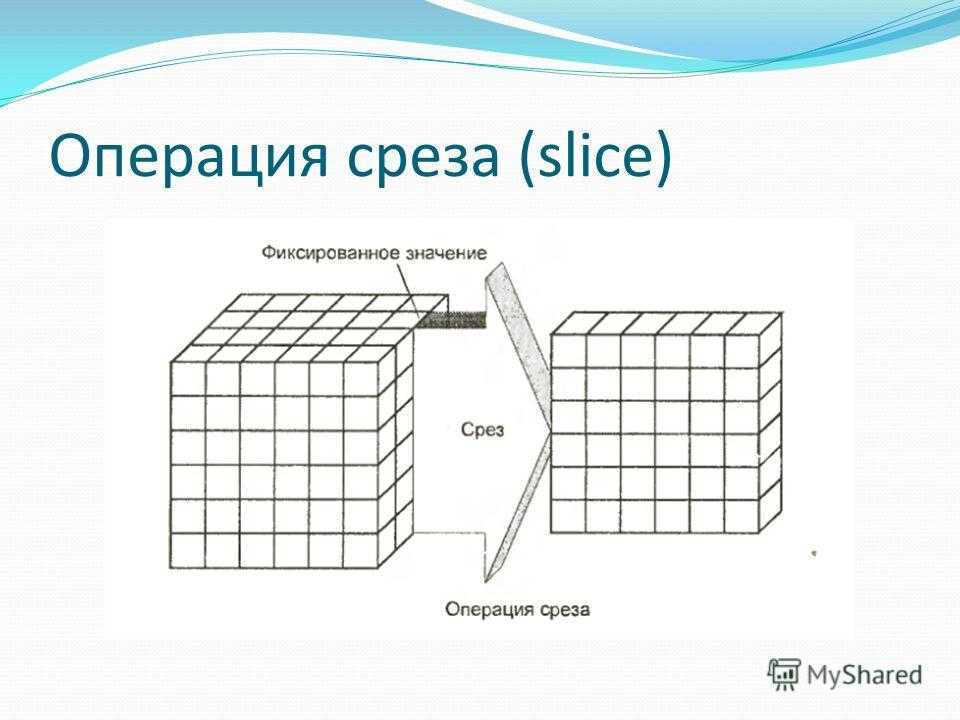
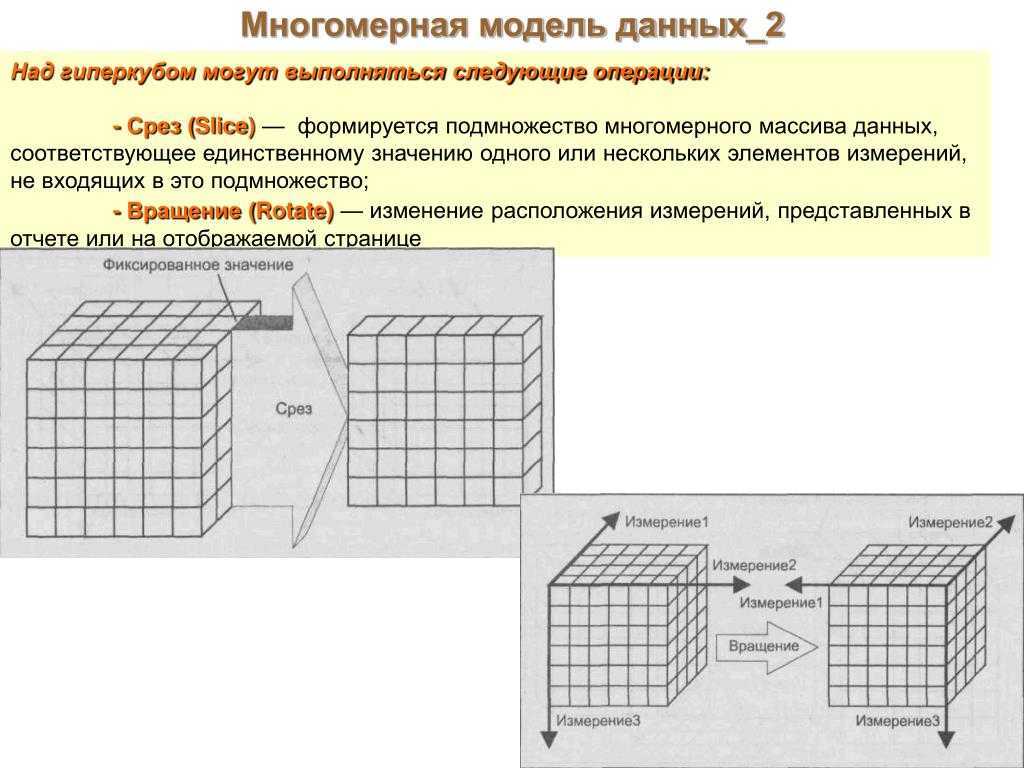
Операция среза (slice)
6
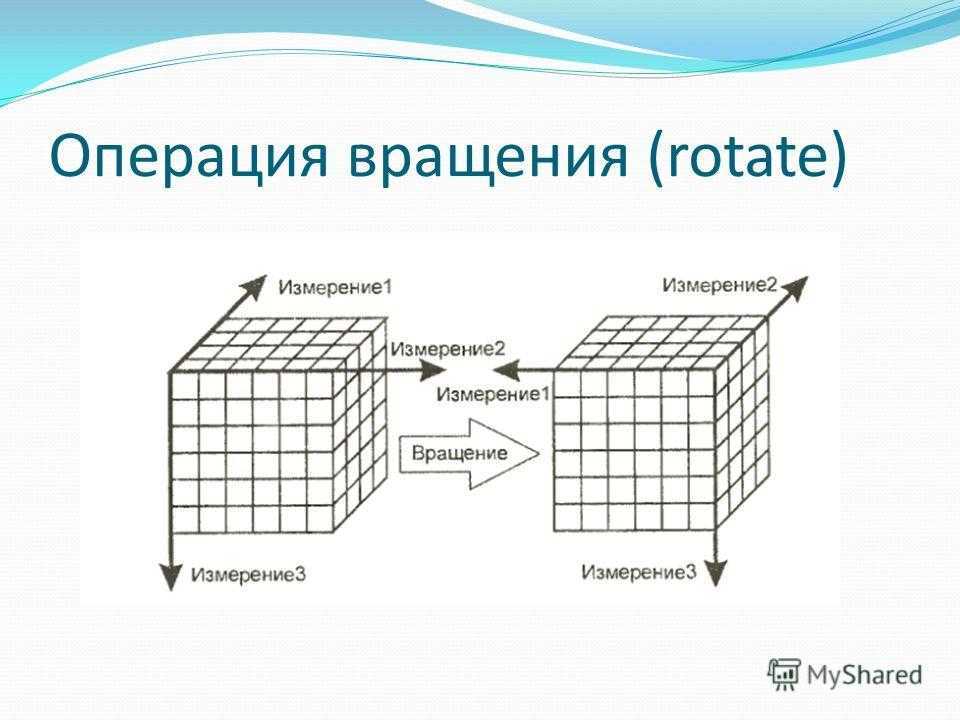
Операция вращения (rotate)
8
Двенадцать правил Кодда 1. Многомерность. 2. Прозрачность. 3. Доступность. 4. Постоянная производительность при разработке отчетов. 5. Клиент-серверная архитектура. 6. Равноправие измерений. 7. Динамическое управление разреженными матрицами. 8. Поддержка многопользовательского режима. 9. Неограниченные перекрестные операции. 10. Интуитивная манипуляция данными. 11. Гибкие возможности получения отчетов. 12. Неограниченная размерность и число уровней агрегации.

9
Дополнительные правила Кодда 1. Пакетное извлечение против интерпретации. 2. Поддержка всех моделей ОLАР-анализа. 3. Обработка ненормализованных данных. 4. Сохранение результатов OLAP: хранение их отдельно от исходных данных. 5. Исключение отсутствующих значений. 6. Обработка отсутствующих значений.

10
Тест FASMI F AST (Быстрый) ANALYSIS (Анализ) SHARED (Разделяемой) МULТIDIМЕNSIONАL (Mногомерной) INFORMAТION (Информации)

11
OLAP-серверы MOLAP — многомерный (multivаriаtе) ОLАР. Для реализации многомерной модели используют многомерные БД. ROLAP — реляционный (relаtiоnаl) OLAP. Для реализации многомерной модели используют реляционные БД. HOLAP — гибридный (hybrid) OLAP. Для реализации многомерной модели используют и многомерные, и реляционные БД.

12
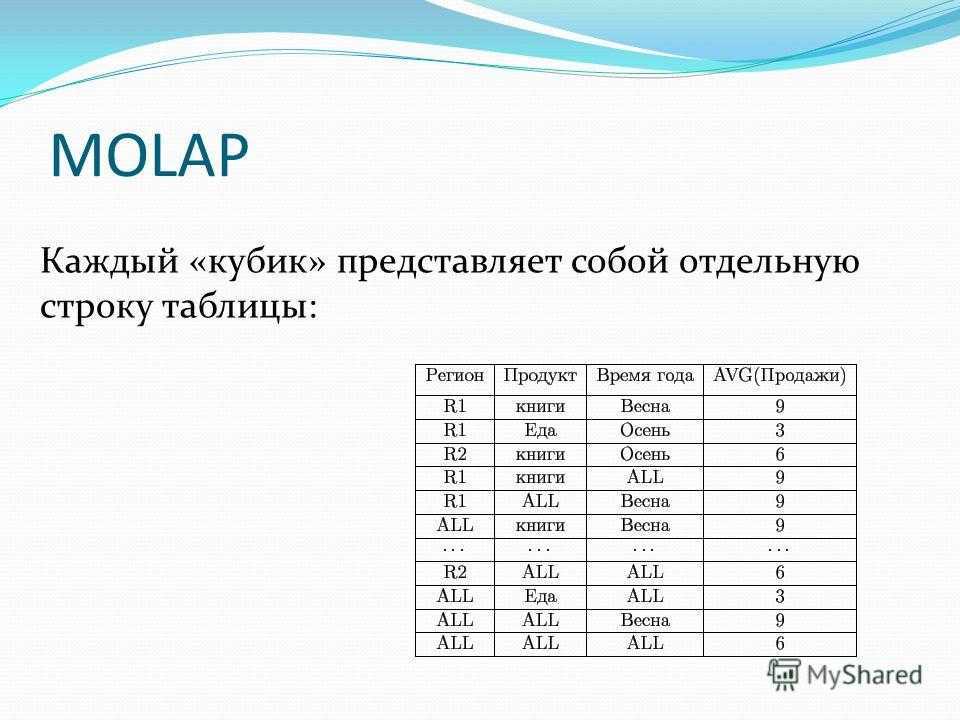
MOLAP Каждый «кубик» представляет собой отдельную строку таблицы:
13
MOLAP Преимущества: поиск и выборка данных осуществляются значительно быстрее, легко включить в информационную модель разнообразные встроенные функции. Недостатки: большой объем, сложно хранить разреженные данные, чувствительны к изменениям структуры многомерной модели.

14
MOLAP – когда использовать? объем исходных данных для анализа не слишком велик (не более нескольких гигабайт), т. е. уровень агрегации данных достаточно высок; набор информационных измерений стабилен; время ответа системы на нерегламентированные запросы является наиболее критичным параметром; требуется широкое использование сложных встроенных функций.

15
ROLAP – схема «звезда» В центре – таблица фактов, по краям – таблицы измерений
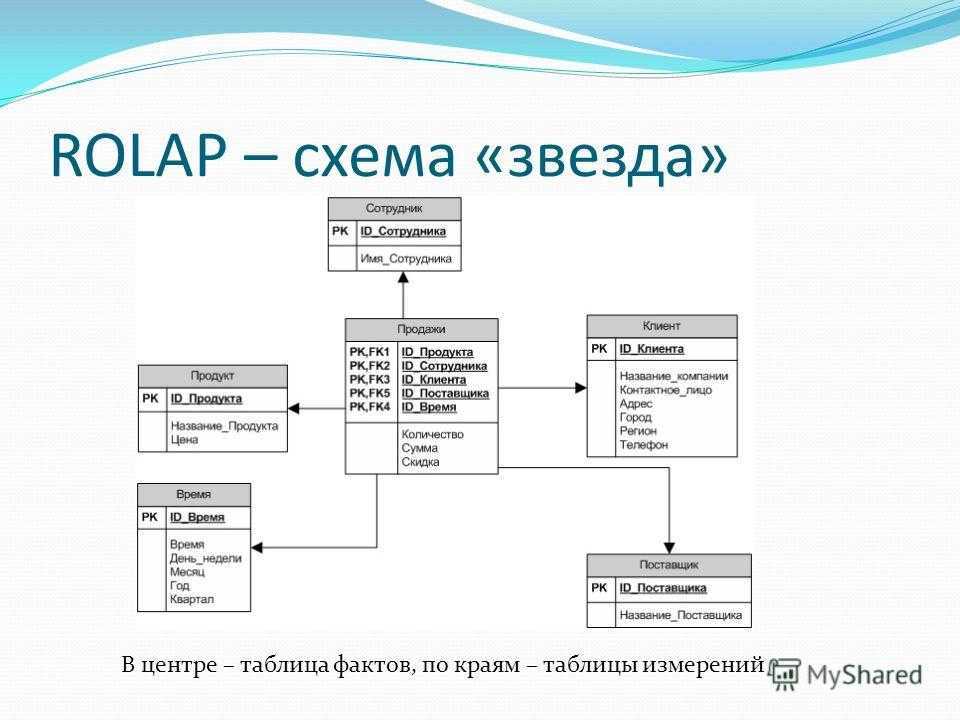
16
ROLAP – схема «снежинка»
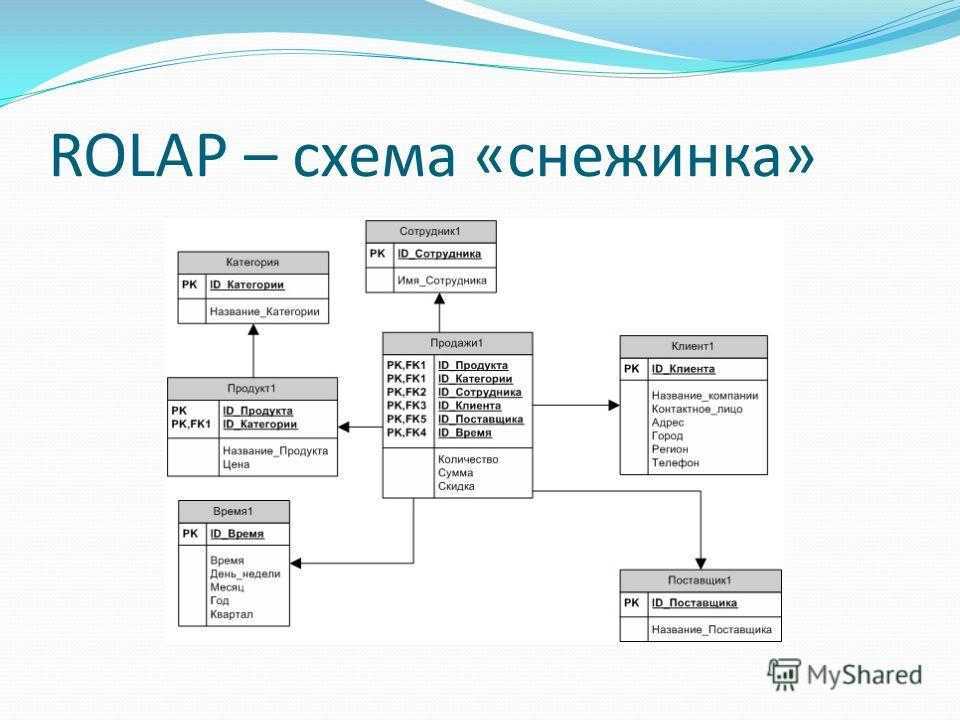
17
ROLAP Плюсы: В большинстве случаев корпоративные хранилища данных реализуются средствами реляционных СУБД и инструменты ROLAP позволяют производить анализ непосредственно над ними. В случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, RОLАР системы с динамическим представлением размерности являются оптимальным решением, т. к. В них такие модификации не требуют физической реорганизации БД. Реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа. Минусы: низкая скорость работы!




![Многомерное представление данных- ключевое требование к olap средствам [реферат №9091]](https://robotrackkursk.ru/wp-content/uploads/9/e/e/9ee9491ed4d071fb4d2d689bf0143c25.jpeg)



18
Вопросы Какие операции можно производить над гиперкубом? Поясните все составные части теста FASMI. Приведите плюсы и минусы MOLAP. Приведите плюсы и минусы ROLAP.

Многомерные OLAP -системы
В многомерных СУБД данные организованы не в виде реляционных таблиц, а упорядоченных многомерных массивов или гиперкубов, когда все хранимые данные должны иметь одинаковую размерность, что означает необходимость образовывать максимально полный базис измерений. Данные могут быть организованы в виде поликубов , в этом варианте значения каждого показателя хранятся с собственным набором измерений, обработка данных производится собственным инструментом системы.
Достоинствами MOLAP являются:
— более быстрое, чем при ROLAP получение ответов на запросы -з атрачиваемое время на один-два порядка меньше;
Прогнозирования являются стержнем любой торговой системы, поэтому профессионально составленные прогнозы Forex могут сделать Вас ужасно богатым.
— из-за ограничений SQL затрудняется реализация многих встроенных функций.
К ограничениям MOLAP относятся:
— сравнительно небольшие размеры баз данных — предел десятки Гигабайт;
— за счёт денормализации и предварительной агрегации многомерные массивы используют в 2,5-100 раз больше памяти, чем исходные данные;
— отсутствуют стандарты на интерфейс и средства манипулирования данными;
— имеются ограничения при загрузке данных.
Требования к OLAP-системам. FASMI
Ключевое требование, предъявляемое к OLAP-системам — скорость, позволяющая использовать их в процессе интерактивной работы аналитика с информацией. В этом смысле OLAP-системы противопоставляются, во-первых, традиционным РСУБД, выборки из которых с типовыми для аналитиков запросами, использующими группировку и агрегирование данных, обычно затратны по времени ожидания и загрузке РСУБД, поэтому интерактивная работа с ними при сколько-нибудь значительных объемах данных сложна. Во-вторых, OLAP-системы противопоставляются и обычному плоскофайловому представлению данных, например, в виде часто используемых традиционных электронных таблиц, представление многомерных данных в которых сложно и не интуитивно, а операции по смене среза — точки зрения на данные — также требуют временных затрат и усложняют интерактивную работу с данными.
Fast (быстрый) в отражает упомянутое выше требование к скорости реакции системы. По Пендсу, интервалы с момента инициации запроса до получения результата должен измеряться секундами
Важность этого требования возрастает при использовании таких систем в качестве инструмента оперативного представления данных для аналитика, так как длительное время ожидания может пагубно влиять на цепочку рассуждений аналитика.
Analysis (анализ) предполагает приспособленность системы к использованию в релевантной для задачи и пользователя бизнес-логике с сохранением доступной «обычному» пользователю легкости оперирования данными без использования низкоуровневого специального инструментария.
Shared (доступность, общедоступность) описывает очевидное требование к возможности одновременного многопользовательского доступа к информации с интегрированной системой разграничения прав доступа вплоть до уровня конкретной ячейки данных.
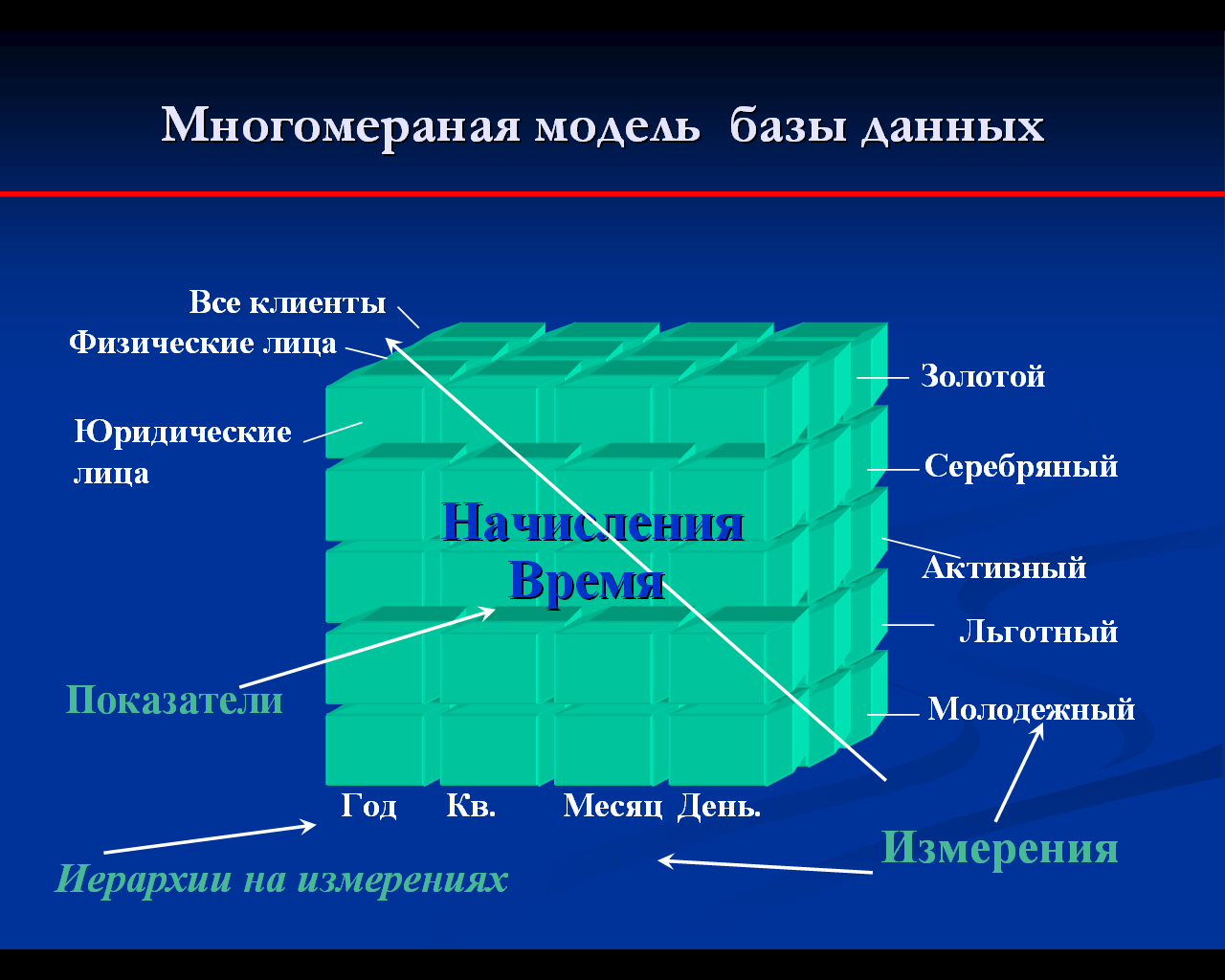
Многомерность в рамках OLAP предполагает концептуальное представление данных в виде многомерной структуры данных — гиперкуба (OLAP-куба), рёбрами в котором выступают измерения(dimension), а данные (facts — факты; measures — меры, показатели) расположены на пересечении осей измерений.
При этом измерение обычно представляет собой плоский или иерархический список. Например, измерение «Партнёры» может включать список партнёров компании, измерение «Время» — список филиалов с географической группировкой (регион мира, страна, регион, город, филиал). Если в качестве меры определён объём продаж, то на срезе по измерениям «Партнёры» и «Время» будем иметь таблицу с данными об изменении объема продажа по партнёрам во времени, в качестве заголовков строк и столбцов которой будут выступать наши измерения — «Время» и «Партнёры», а в ячейках на пересечении строк и столбцов будут расположены значений меры, т. е. данные об объеме продаж в конкретный период времени для конкретного партнёра.
Information (информация) — это все релевантные целям пользователя данные, при этом наличие «лишних» данных негативно сказывается на требовании к скорости реакции системы.
История OLAP
Возникновение систем OLAP было спровоцировано развитием систем поддержки принятия решений (DSS — Decision Support Systems). Первой в своём роде стала IBM System 360 – масштабная система корпоративного менеджмента, появившаяся в 1965 году. До её появления такой масштаб системы данных казался несбыточной мечтой, подкрепленной нереальностью финансовых затрат на проектирование и содержание, даже будь эта мечта реализованной. Первые системы информационного менеджмента, MIS — management information systems, имели цель оповещения руководителей упорядоченными массивами данных о жизнедеятельности предприятия.
К началу 70-ых годов системы поддержки принятия решений оказались на волне популярности, а продукты этой отрасли уже насчитывали сотни наименований. Дальше – больше. Так, к середине 70-ых годов проблемам поддержки принятия решений в лице компьютерных технологий посвящались форумы и собрания, академические исследования и научные конференции.
К концу 70-ых выделились критерии оценки систем, разрабатываемых на основе технологии DSS. В ту пору и стали выделяться первые интерактивные компьютерные приложения, способные структурировать небольшие массивы данных для решения информационных задач.
Лишь к началу 90-ых годов интерактивные терминалы стали сменяться персональными компьютерами. В итоге, изменение архитектуры DSS-систем произошло, как говориться, в корне. Системы перестали быть сервер-ориентированными, вместо чего появились решения типа «клиент-сервер».
Следующему ключевому событию в истории технологии OLAP суждено было случиться в 1993 году. В это время Эдгар Кодд предложил 12 критериев соответствия приложения технологии OLAP. Немногим позже, критерии были сформированы в тест, получивший название FASMI.
Хранилища данных (место OLAP в информационной структуре предприятия)
Термин «OLAP» неразрывно связан с термином «хранилище данных» (Data Warehouse).
Приведем определение, сформулированное «отцом-основателем» хранилищ данных Биллом Инмоном: «Хранилище данных — это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений».
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Зачем строить хранилища данных — ведь они содержат заведомо избыточную информацию, которая и так «живет» в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами, в том числе разрозненностью данных, хранением их в форматах различных СУБД и в разных «уголках» корпоративной сети. Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах. Автор имеет достаточно печальный опыт попыток «накормить» голодных аналитиков «сырыми» данными из оперативных систем — им это оказалось «не по зубам».
Таким образом, задача хранилища — предоставить «сырье» для анализа в одном месте и в простой, понятной структуре. Ральф Кимбалл в предисловии к своей книге «The Data Warehouse Toolkit» пишет, что если по прочтении всей книги читатель поймет только одну вещь, а именно: структура хранилища должна быть простой, — автор будет считать свою задачу выполненной.
Есть и еще одна причина, оправдывающая появление отдельного хранилища — сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
На мой взгляд, под хранилищем можно понимать не обязательно гигантское скопление данных — главное, чтобы оно было удобно для анализа. Вообще говоря, для маленьких хранилищ предназначается отдельный термин — Data Marts (киоски данных), но в нашей российской практике его не часто услышишь.
Технические аспекты многомерного хранения данных
Как уже говорилось выше, средства OLAP-анализа могут извлекать данные и непосредственно из реляционных систем. Такой подход был более привлекательным в те времена, когда OLAP-серверы отсутствовали в прайс-листах ведущих производителей СУБД. Но сегодня и Oracle, и Informix, и Microsoft предлагают полноценные OLAP-серверы, и даже те IT-менеджеры, которые не любят разводить в своих сетях «зоопарк» из ПО разных производителей, могут купить (точнее, обратиться с соответствующей просьбой к руководству компании) OLAP-сервер той же марки, что и основной сервер баз данных.

OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные по-разному
Прежде чем рассмотреть эти способы, нам нужно поговорить о таком важном аспекте, как хранение агрегатов. Дело в том, что в любом хранилище данных — и в обычном, и в многомерном — наряду с детальными данными, извлекаемыми из оперативных систем, хранятся и суммарные показатели (агрегированные показатели, агрегаты), такие, как суммы объемов продаж по месяцам, по категориям товаров и т
п. Агрегаты хранятся в явном виде с единственной целью — ускорить выполнение запросов. Ведь, с одной стороны, в хранилище накапливается, как правило, очень большой объем данных, а с другой — аналитиков в большинстве случаев интересуют не детальные, а обобщенные показатели. И если каждый раз для вычисления суммы продаж за год пришлось бы суммировать миллионы индивидуальных продаж, скорость, скорее всего, была бы неприемлемой. Поэтому при загрузке данных в многомерную БД вычисляются и сохраняются все суммарные показатели или их часть.
Но, как известно, за все надо платить. И за скорость обработки запросов к суммарным данным приходится платить увеличением объемов данных и времени на их загрузку. Причем увеличение объема может стать буквально катастрофическим — в одном из опубликованных стандартных тестов полный подсчет агрегатов для 10 Мб исходных данных потребовал 2,4 Гб, т. е. данные выросли в 240 раз! Степень «разбухания» данных при вычислении агрегатов зависит от количества измерений куба и структуры этих измерений, т. е. соотношения количества «отцов» и «детей» на разных уровнях измерения. Для решения проблемы хранения агрегатов применяются подчас сложные схемы, позволяющие при вычислении далеко не всех возможных агрегатов достигать значительного повышения производительности выполнения запросов.
Теперь о различных вариантах хранения информации. Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо в многомерных структурах. Многомерное хранение позволяет обращаться с данными как с многомерным массивом, благодаря чему обеспечиваются одинаково быстрые вычисления суммарных показателей и различные многомерные преобразования по любому из измерений. Некоторое время назад OLAP-продукты поддерживали либо реляционное, либо многомерное хранение. Сегодня, как правило, один и тот же продукт обеспечивает оба этих вида хранения, а также третий вид — смешанный. Применяются следующие термины:
- MOLAP (Multidimensional OLAP) — и детальные данные, и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
- ROLAP (Relational OLAP) — детальные данные остаются там, где они «жили» изначально — в реляционной БД; агрегаты хранятся в той же БД в специально созданных служебных таблицах.
- HOLAP (Hybrid OLAP) — детальные данные остаются на месте (в реляционной БД), а агрегаты хранятся в многомерной БД.
Каждый из этих способов имеет свои преимущества и недостатки и должен применяться в зависимости от условий — объема данных, мощности реляционной СУБД и т. д.
При хранении данных в многомерных структурах возникает потенциальная проблема «разбухания» за счет хранения пустых значений. Ведь если в многомерном массиве зарезервировано место под все возможные комбинации меток измерений, а реально заполнена лишь малая часть (например, ряд продуктов продается только в небольшом числе регионов), то бо/льшая часть куба будет пустовать, хотя место будет занято. Современные OLAP-продукты умеют справляться с этой проблемой.
Продолжение следует. В дальнейшем мы поговорим о конкретных OLAP-продуктах, выпускаемых ведущими производителями.
С автором статьи можно связаться по адресу: alperovich@digdes.com
Размещено с разрешения редакции PC Week/RE
| Обсудить на форуме | Написать вебмастеру |
2001 Interface Ltd
Особенности
В СУБД, основанных на многомерном представлении данных, данные организованы не в форме реляционных таблиц, а в виде упорядоченных многомерных массивов: гиперкубов (все хранимые в базе данных ячейки должны иметь одинаковую мерность, то есть находиться в максимально полном базисе измерений) и/или витрин данных, представляющих собой предметно-ориентированные подмножества хранилища данных, спроектированные для удовлетворения нужд отдельной группы (сообщества) пользователей и удовлетворяющие требованиям защиты от несанкционированного доступа в организации; они обеспечивают более быструю реакцию на запросы сведений за счет того, что обращения поступают к относительно небольшим блокам данных, необходимых для конкретной группы пользователей. Для достижения сравнимой производительности реляционные системы требуют тщательной проработки схемы базы данных, определения способов индексации и специальной настройки. В случае многомерных баз данных, как правило, не требуется даже указание на то, по каким реквизитам (группам реквизитов) требуется индексация данных. Ограничения SQL остаются реальностью, что не позволяет реализовать в реляционных СУБД многие встроенные функции, легко обеспечиваемые в системах основанных на многомерном представлении данных. Вместе с тем, реляционные СУБД обеспечивают качественно более высокий уровень защиты данных и разграничения прав доступа, а также имеют более развитые средства администрирования и реальный опыт работы с большими и сверхбольшими базами данных. В то время, как для многомерных баз данных, в настоящее время отсутствуют единые стандарты на интерфейс, языки описания и манипулирования данными. Многомерные СУБД не поддерживают репликацию данных, наиболее часто используемую в качестве механизма загрузки.
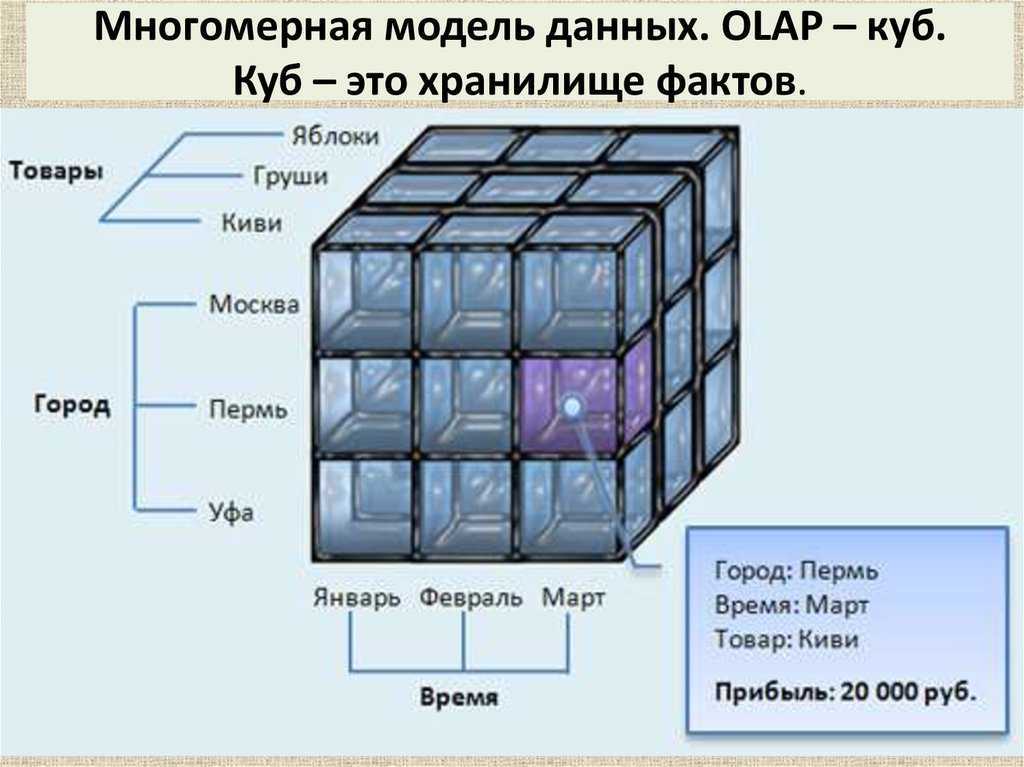
Структура OLAP-куба
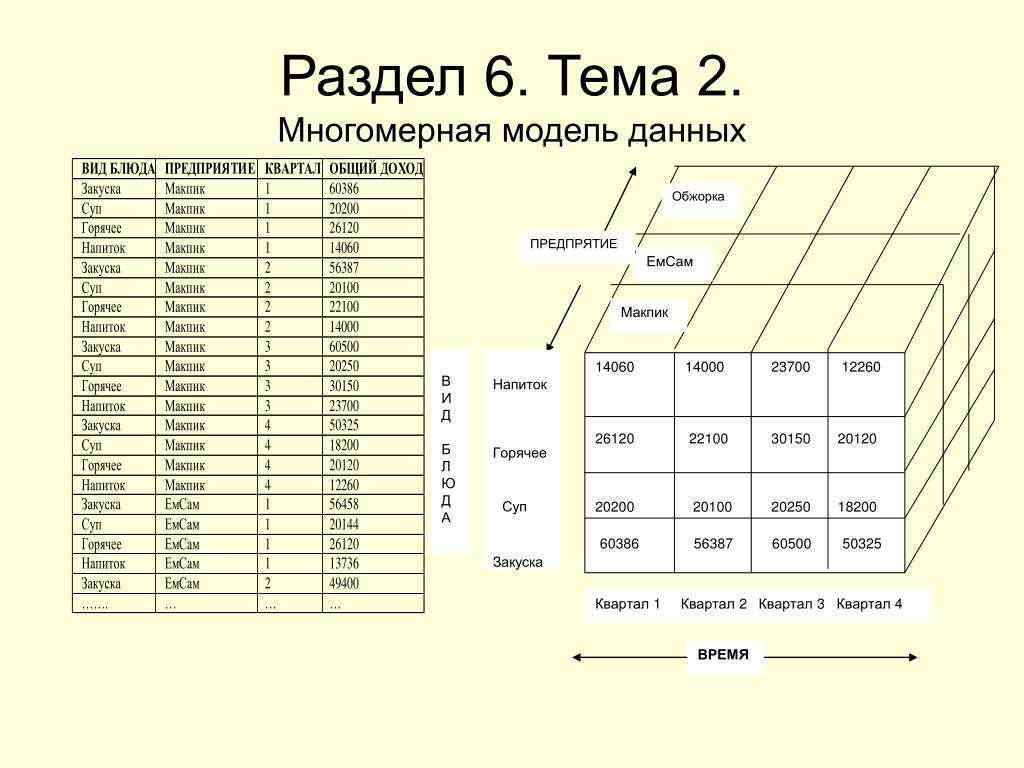
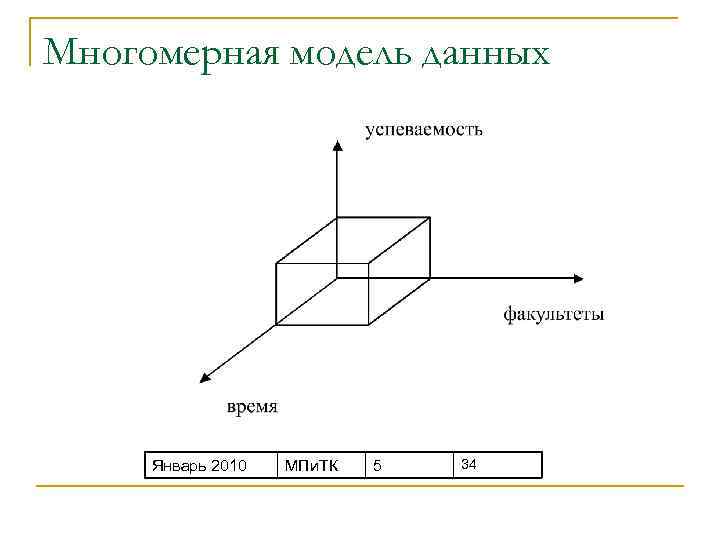
В процессе анализа данных часто возникает необходимость построения зависимостей между различными параметрами, число которых может быть значительным.
Под измерением будем понимать последовательность значений одного из анализируемых параметров. Например, для параметра «время» это — последовательность дней, месяцев, кварталов, лет.
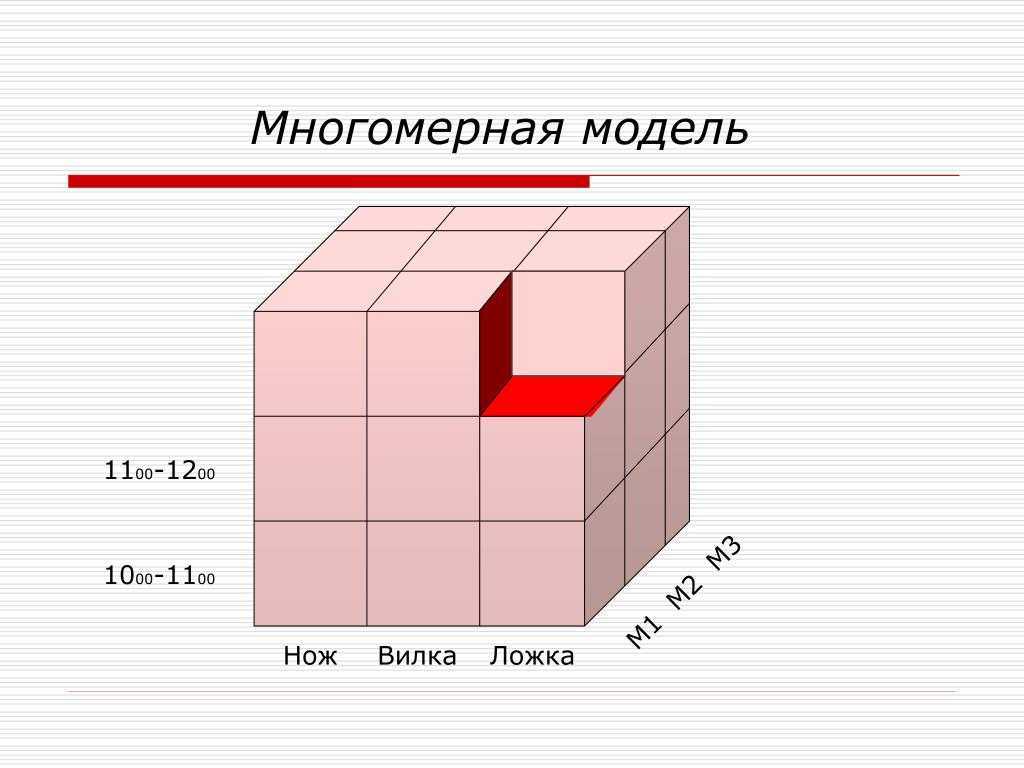
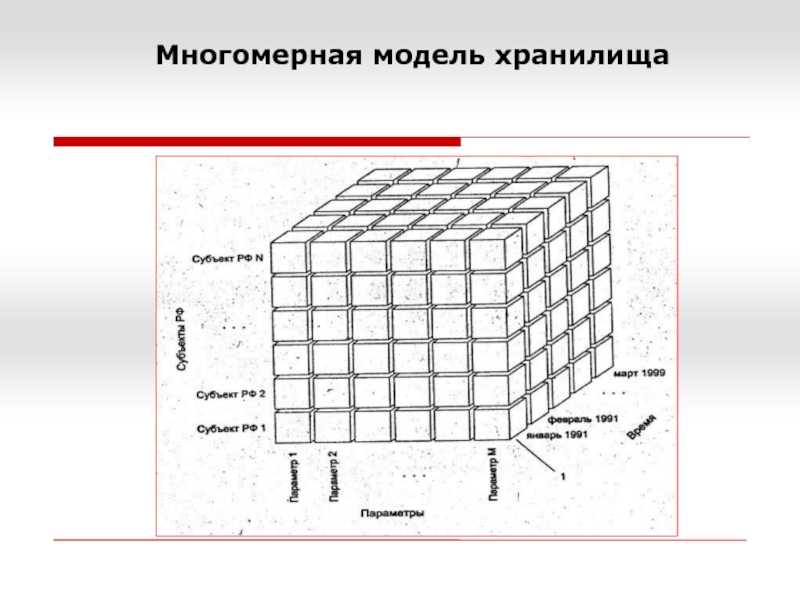
Возможность анализа зависимостей между различными параметрами предполагает возможность представления данных в виде многомерной модели — гиперкуба (рисунок 1), или OLAP-куба.
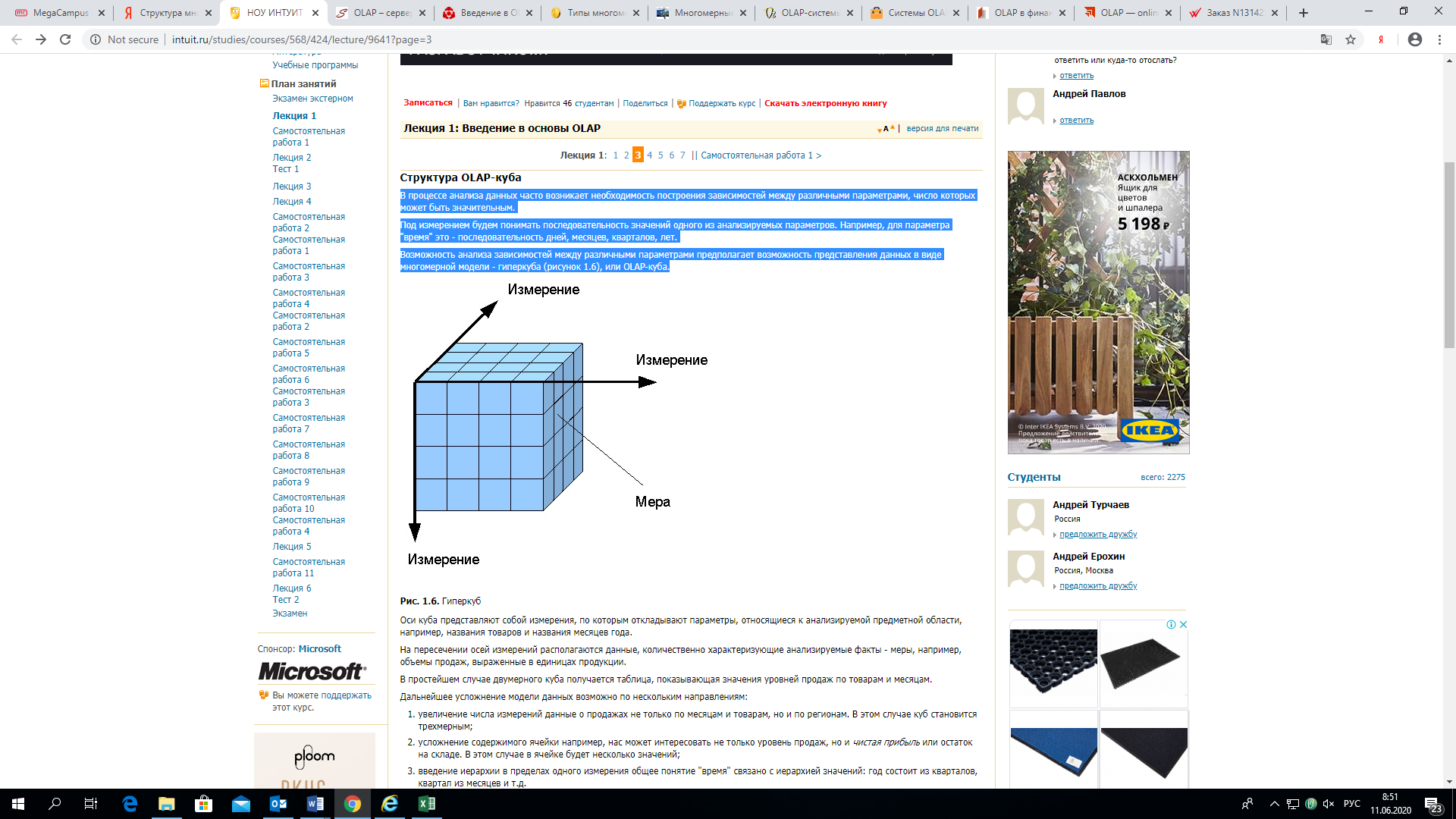 рис 1
рис 1
Оси куба представляют собой измерения, по которым откладывают параметры, относящиеся к анализируемой предметной области, например, названия товаров и названия месяцев года.
На пересечении осей измерений располагаются данные, количественно характеризующие анализируемые факты — меры, например, объемы продаж, выраженные в единицах продукции.
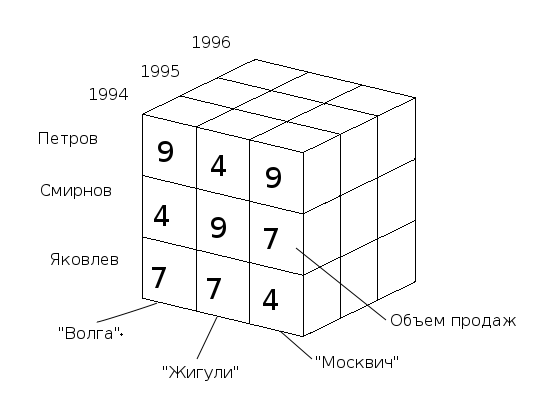
В простейшем случае двумерного куба получается таблица, показывающая значения уровней продаж по товарам и месяцам.
Дальнейшее усложнение модели данных возможно по нескольким направлениям:
— увеличение числа измерений данные о продажах не только по месяцам и товарам, но и по регионам. В этом случае куб становится трехмерным;
— усложнение содержимого ячейки например, нас может интересовать не только уровень продаж, но и чистая прибыль или остаток на складе. В этом случае в ячейке будет несколько значений;
— введение иерархии в пределах одного измерения общее понятие «время» связано с иерархией значений: год состоит из кварталов, квартал из месяцев и т.д.
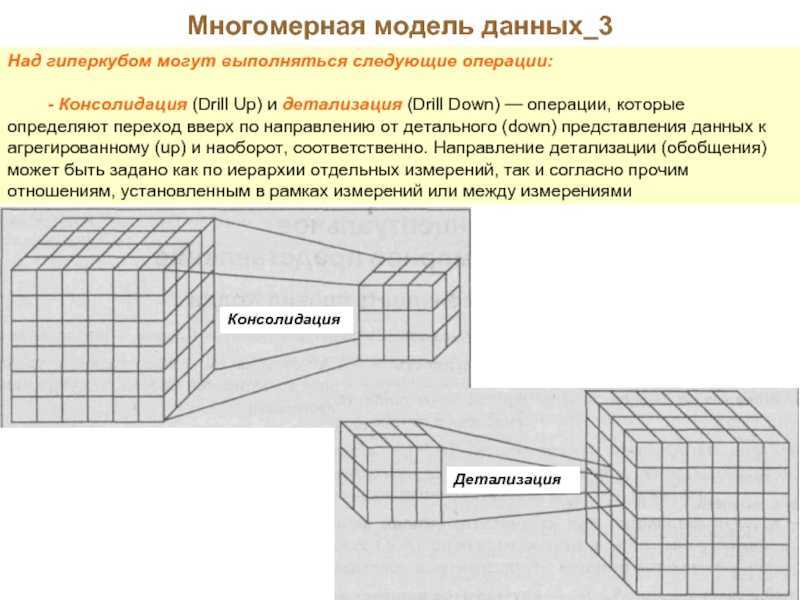
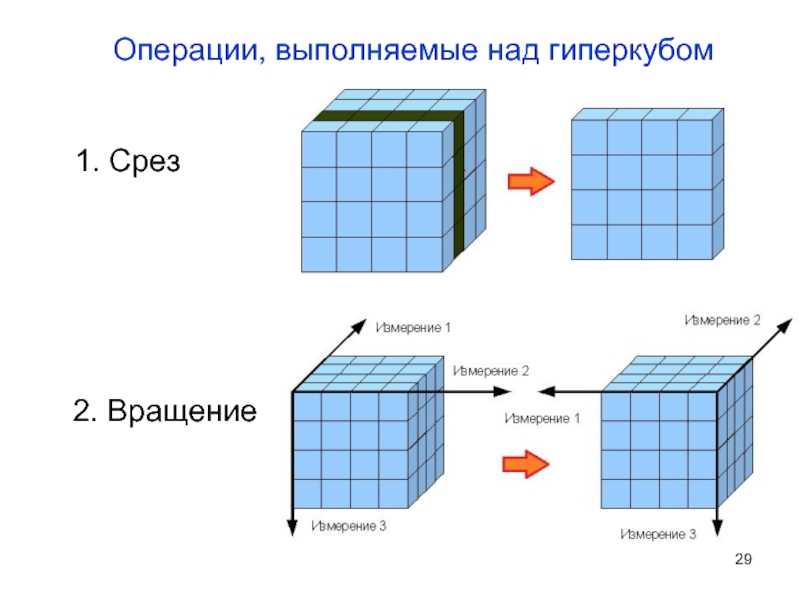
Над гиперкубом могут выполняться следующие операции:
- Срез (рисунок 2) — формируется подмножество многомерного массива данных, соответствующее единственному значению одного или нескольких элементов измерений, не входящих в это подмножество.
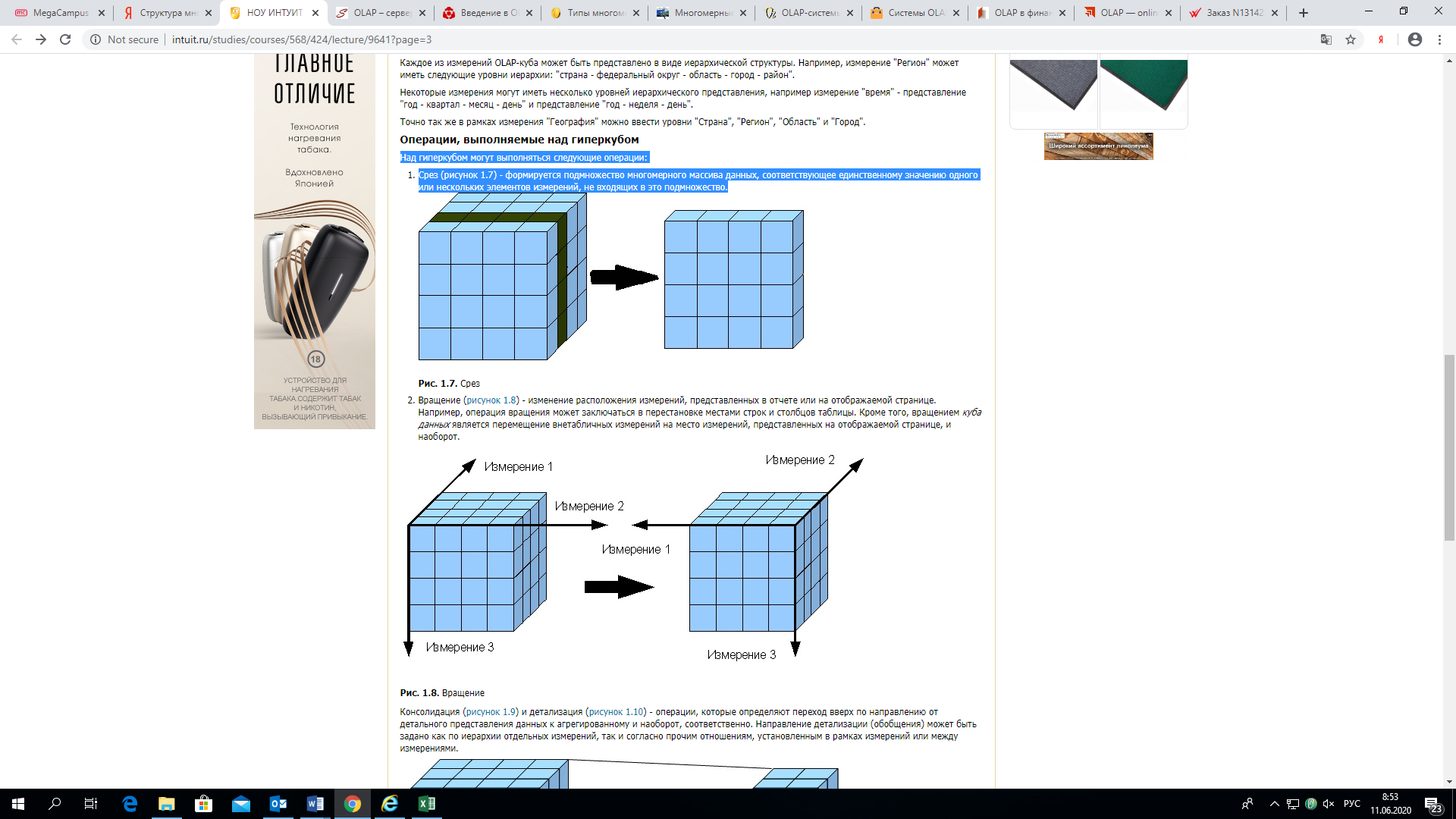 рис 2
рис 2
- Вращение (рисунок 3) — изменение расположения измерений, представленных в отчете или на отображаемой странице. Например, операция вращения может заключаться в перестановке местами строк и столбцов таблицы. Кроме того, вращением куба данных является перемещение внетабличных измерений на место измерений, представленных на отображаемой странице, и наоборот.
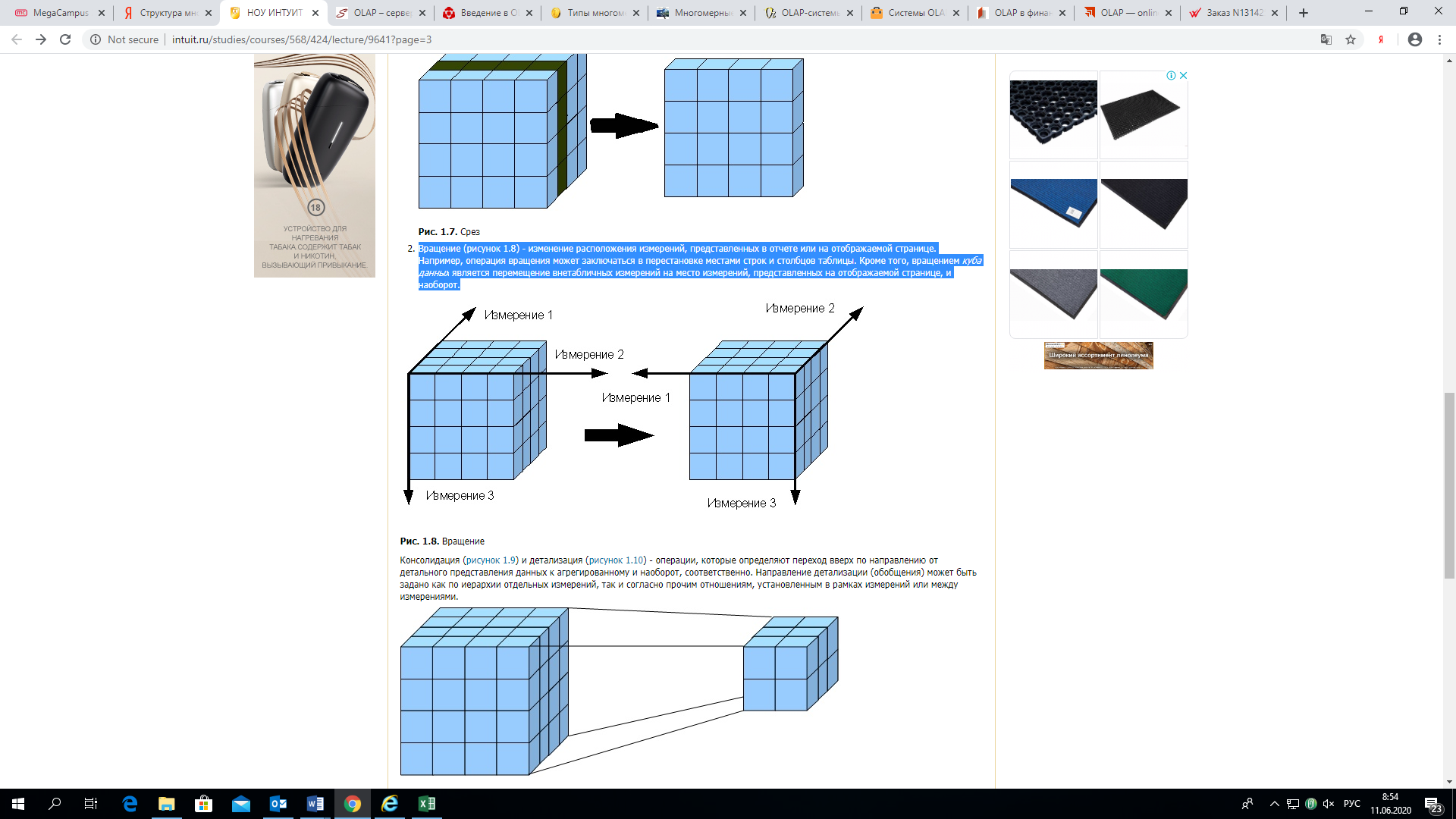 рис 3
рис 3
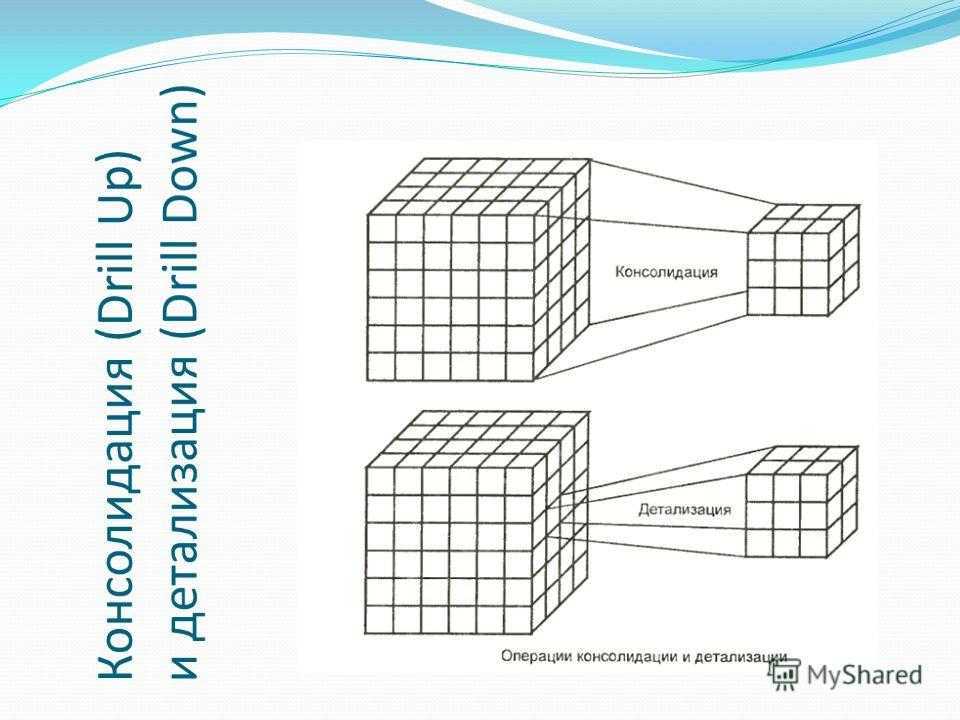
- Консолидация (рисунок 4) и детализация (рисунок 5) — операции, которые определяют переход вверх по направлению от детального представления данных к агрегированному и наоборот, соответственно. Направление детализации (обобщения) может быть задано как по иерархии отдельных измерений, так и согласно прочим отношениям, установленным в рамках измерений или между измерениями.
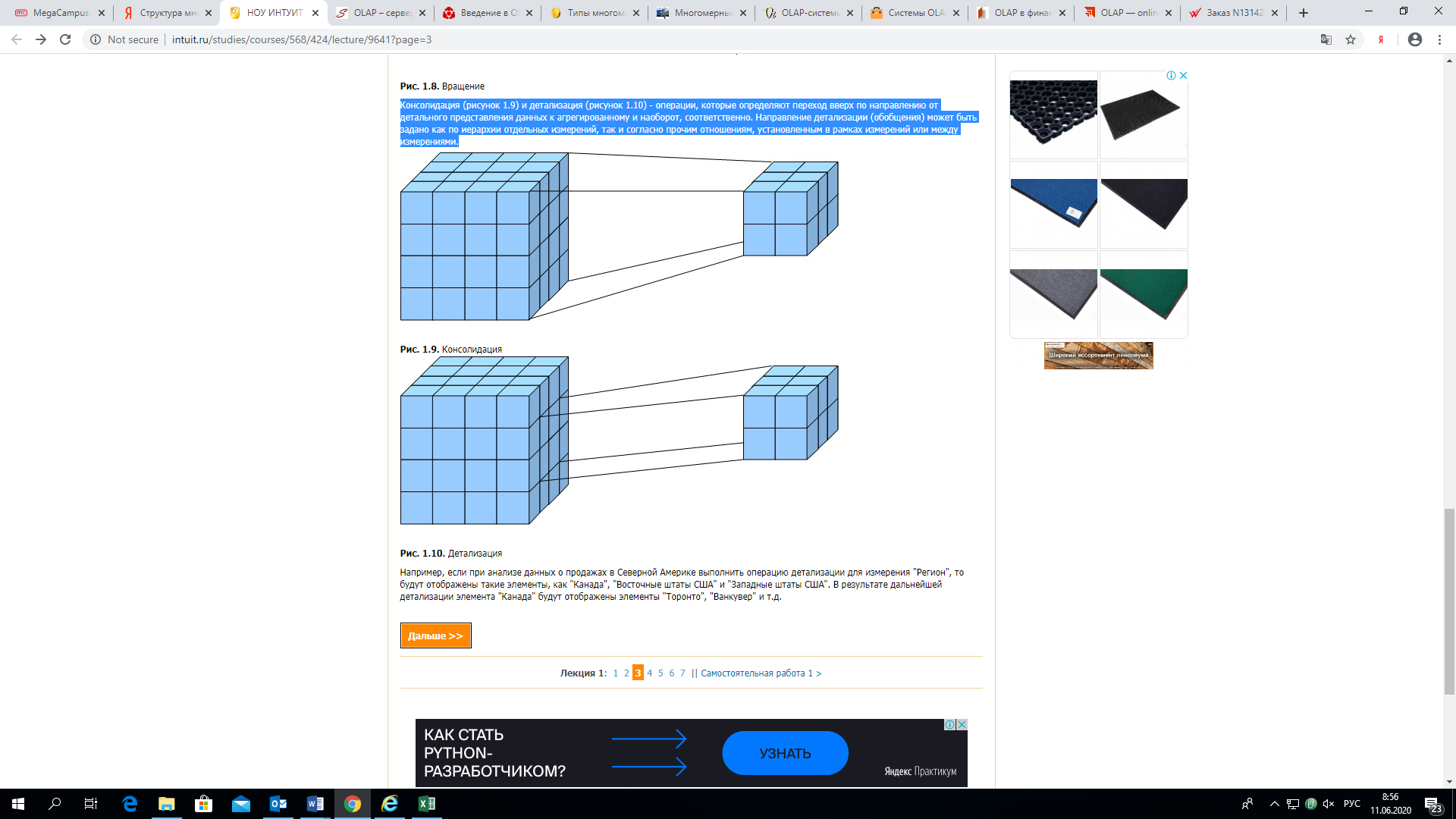 рис 4
рис 4
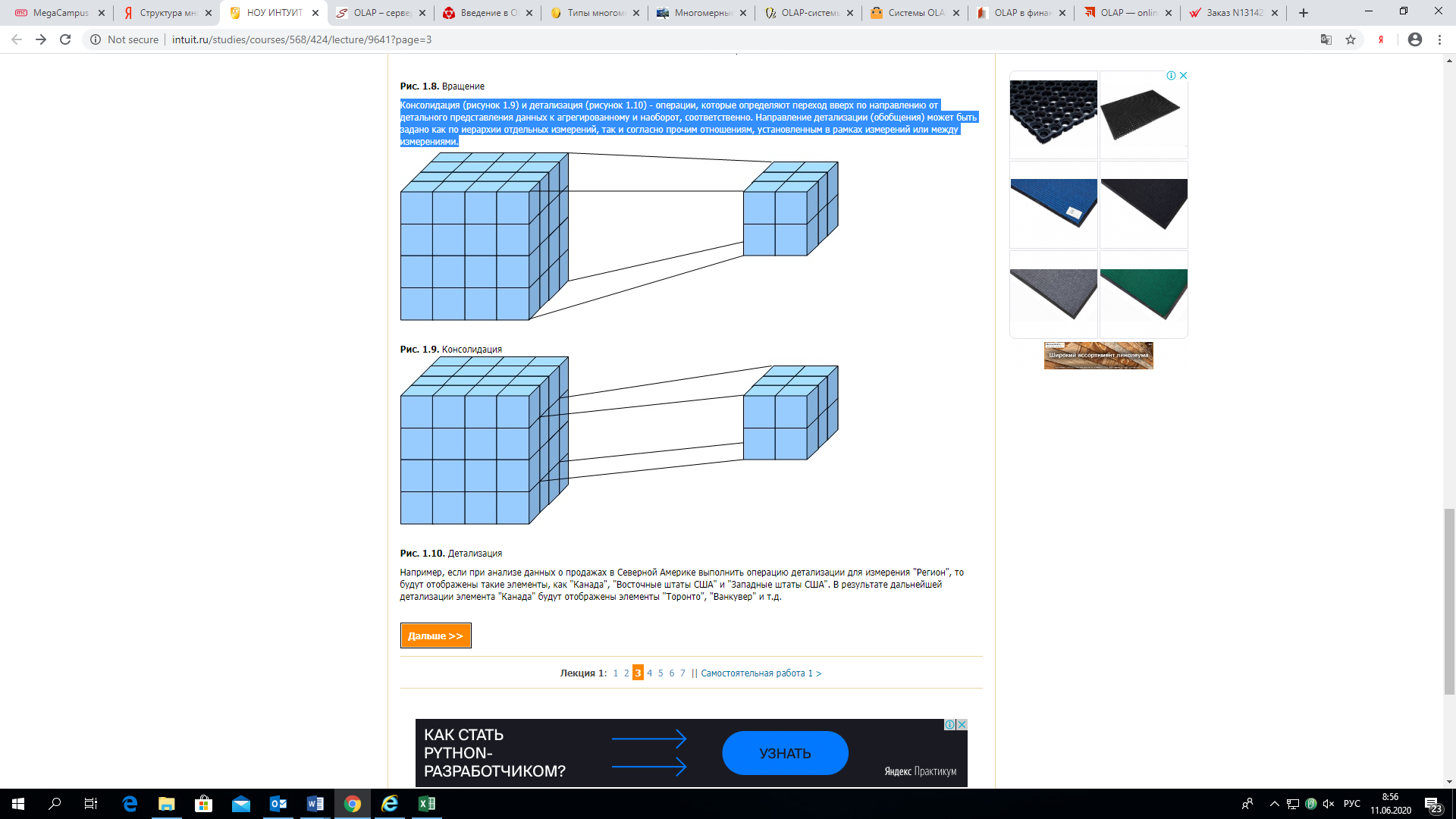 рис 5
рис 5
Prisma
Prisma.PostgreSQLMySQLSQLiteJavaScriptTypeScript
- Определите ваши типы данных на уровне приложений с помощью SDL схемы Prisma.
- На основе созданной схемы сформируйте высокоидиоматический код для выбранного вами языка.
- Займитесь созданием API REST, API GraphQL и всего остального, что вы хотите создать.
Примечательные особенности
- Клиент Prisma позволяет задать нужные вам типы данных с помощью специализированного SDL схемы, генерирующего для вас код. Даже информация о подключении для вашей базы данных исчезает из вашего кода приложения и переходит в генерируемый код.
- Функциональность Prisma Migrate позволяет задавать миграции БД декларативно (а не императивно, как в SQL). Лишние подробности того, как БД переходит из состояния A в состояние Б, скрываются.
- Prisma Studio — визуальный редактор, главным образом обеспечивающий графический интерфейс пользователя для взаимодействия с другими инструментами Prisma.
DSL схемы PrismaActiveRecordEctoProtocol BuffersThriftКстати, отдельная благодарность Prisma за прекрасную документацию. Мы однозначно считаем это важным отличием, и если ваша документация
Тест FASMI
Fast (Быстрый) — анализ должен производиться одинаково быстро по всем аспектам информации. Приемлемое время отклика — 5 с или менее.
Analysis (Анализ) — должна быть возможность осуществлять основные типы числового и статистического анализа, предопределенного разработчиком приложения или произвольно определяемого пользователем.
Shared (Разделяемой) — множество пользователей должно иметь доступ к данным, при этом необходимо контролировать доступ к конфиденциальной информации.
Multidimensional (Многомерной) — это основная, наиболее существенная характеристика OLAP.
Information (Информации) — приложение должно иметь возможность обращаться к любой нужной информации, независимо от ее объема и места хранения.
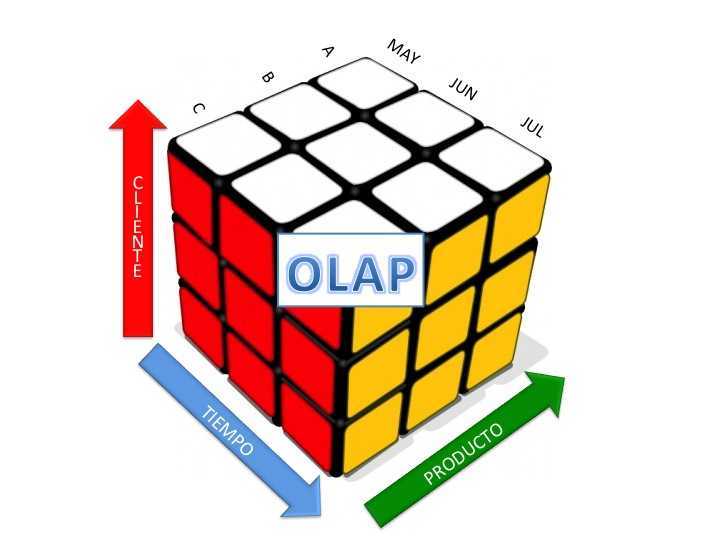
OLAP = многомерное представление = Куб
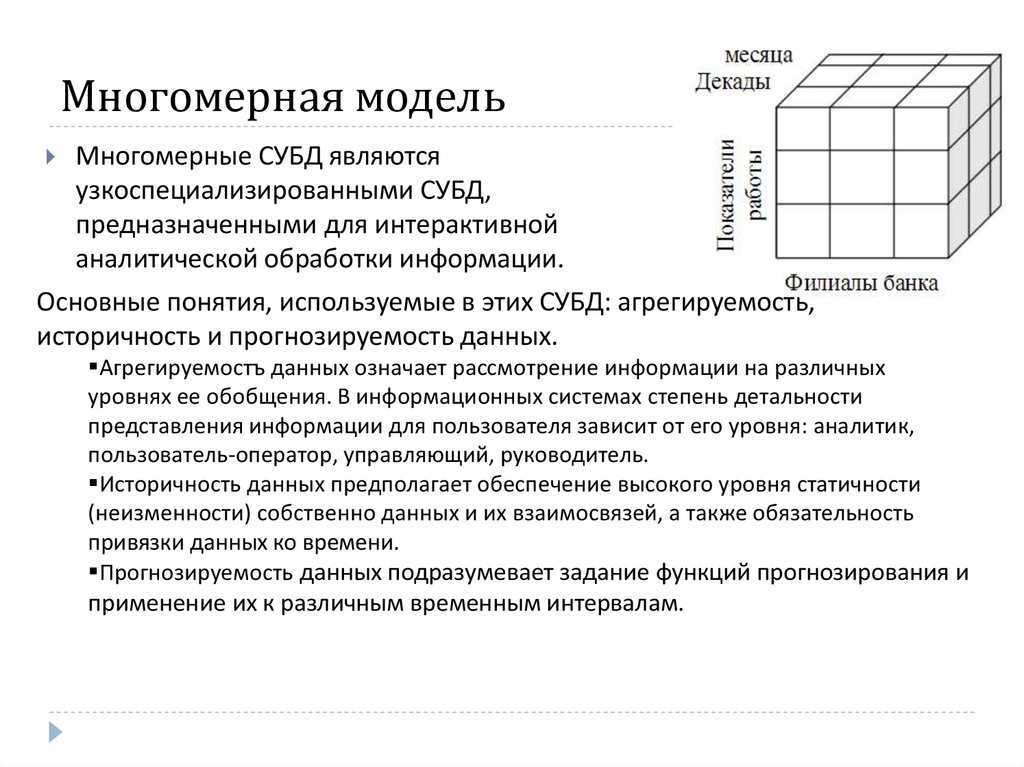
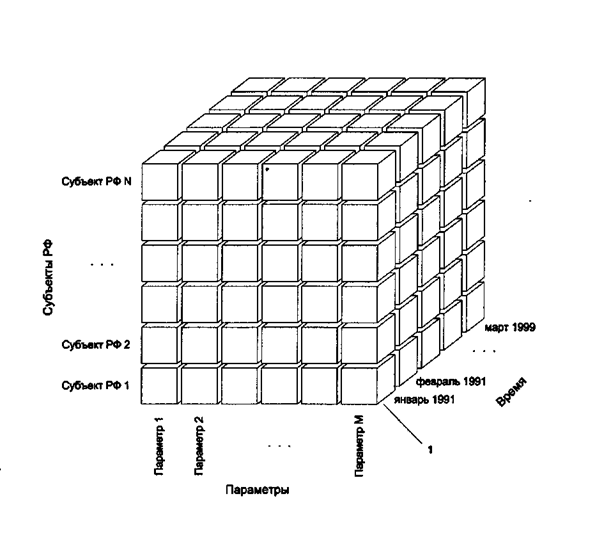
OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации. Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей — измерений (Dimensions) — находятся данные, количественно характеризующие процесс — меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п. Пользователь, анализирующий информацию, может «разрезать» куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.

![Многомерное представление данных- ключевое требование к olap средствам [реферат №9091]](https://robotrackkursk.ru/wp-content/uploads/2/a/4/2a4ed666fc03181ef342ca232093f140.jpeg)

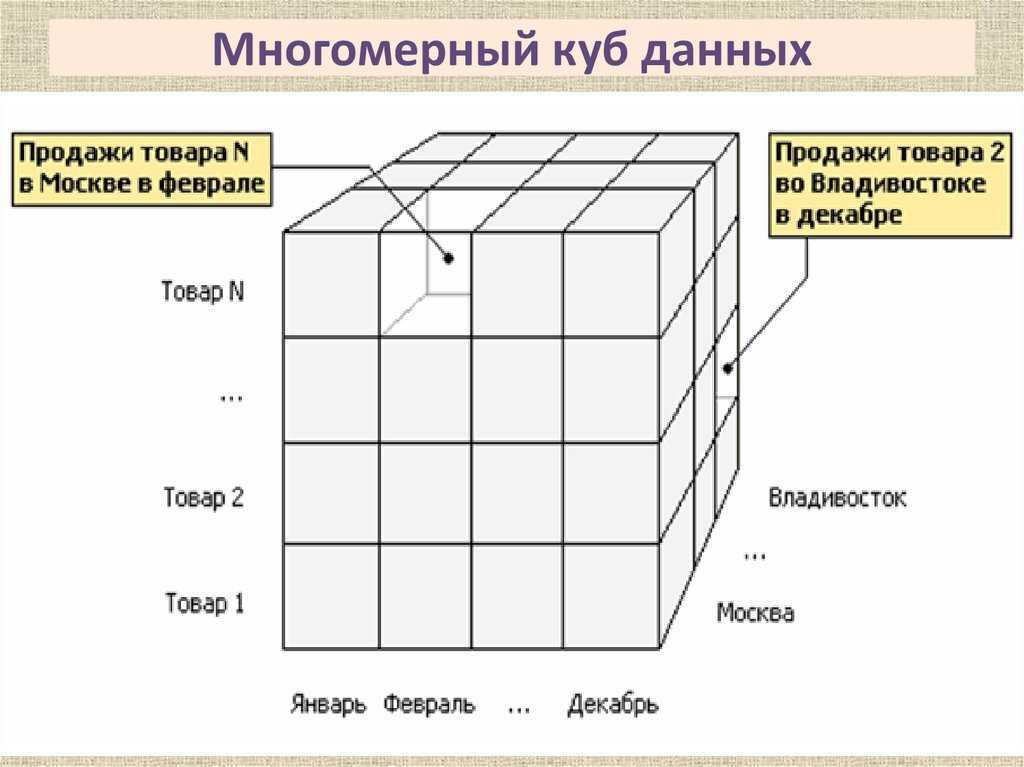

В качестве мер в трехмерном кубе, изображенном на рис. 2, использованы суммы продаж, а в качестве измерений — время, товар и магазин. Измерения представлены на определенных уровнях группировки: товары группируются по категориям, магазины — по странам, а данные о времени совершения операций — по месяцам. Чуть позже мы рассмотрим уровни группировки (иерархии) подробнее.
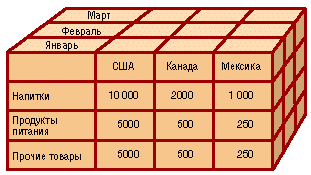 Рис. 2. Пример куба
Рис. 2. Пример куба
Схемы организации данных
В МСУБД существует 2 основные схемы организации данных: гиперкубическая и поликубическая.
Определение 8
Гиперкубическая схема предполагает использование показателей, все из которых определены одним и тем же набором измерений.
Другими словами, если БД содержит несколько гиперкубов, то все они одинаковой размерности и с совпадающими измерениями. Очевидным является то, что в некоторых случаях БД может содержать избыточную информацию (в случае обязательного заполнения ячеек).
Определение 9
Поликубическая схема предполагает наличие в БД нескольких гиперкубов с разной размерностью и разными измерениями в качестве граней.
Сервер Oracle Express Server является системой, которая поддерживает поликубическую схему БД.
Использованные источники
- OLAP.Ru
- https://it-konsultant.ru/blog/olap-online-analytical-processing/
- https://businessman.ru/sistemyi-olap—eto-chto-takoe.html
- А.О.Горбенко « Информационные системы в экономике»
- К.А. Хайдаров «Теория и практика обработки информации»
- http://www.market-pages.ru/ias/23.html
- http://sci-article.ru/stat.php?i=1443355210
- В.В. Полубояров «Использование MS SQL Server Analysis Services 2008 для построения хранилищ данных»
- Принцип работы 3D монитора
- Информационная безопасность и защита информации
- Информационная система управления взаимоотношения с клиентами — CRM
- Информационные технологии в менеджменте
- Типы ЭВМ по принципу действия
- Причины государственного регулирования экономики.
- Интеллектуальные технологии и системы
- Облачные ЕСМ-системы
- Формы занятий физическими упражнениями
- Экономическая сущность финансов предприятия (ФУНКЦИИ ФИНАНСОВ ПРЕДПРИЯТИЯ)
- What technologies cause harm to the environment, Earth’s population and the oceans?
- Правовой режим безналичных денег как объекта гражданских прав
Заключение
Пользователь найдет OLAP в большинстве бизнес-приложений в разных отраслях. Используется анализ не только бизнесом, но и другими заинтересованными сторонами.
Некоторые из его наиболее распространенных приложений включают в себя:
— Маркетинговый OLAP-анализ данных.
— Финансовую отчетность, которая охватывает продажи и расходы, составление бюджета и финансовое планирование.
— Управление бизнес-процессами.
— Анализ продаж.
— Маркетинг баз данных.
Отрасли продолжают расти, а это означает, что вскоре пользователи увидят больше приложений OLAP. Многомерная адаптированная обработка обеспечивает более динамический анализ. Именно по этой причине эти OLAP-системы и технологии используются для оценки сценариев «что, если» и альтернативных бизнес-сценариев.
OLAP – это инструмент, жизненно необходимый бизнесу.



