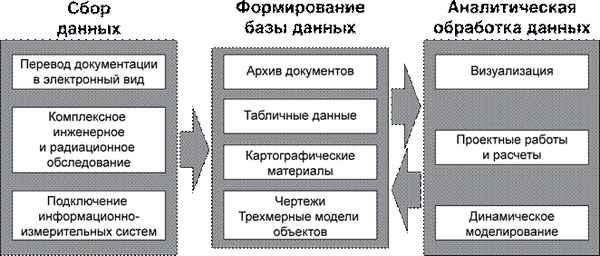
Архитектура и дизайн ИСППР
- Интерфейс
- Моделирование
- Data Mining
- Data collection
- Анализ домена (собственно, где мы будем нашу ИСППР использовать)
- Сбор данных
- Анализ данных
- Выбор моделей
- Экспертный анализ\интерпретация моделей
- Внедрение моделей
- Оценка ИСППР
- Внедрение ИСППР
- Сбор обратной свзяи (на любом этапе, на самом деле)
А где тут машинное обучение и теория игр?
Обычные нейронные сети
вот где карту оформляли туда и идитеTsadiras AK, Papadopoulos CT, O’Kelly MEJ (2013) An artificial neural network based decision support system for solving the buffer allocation problem in reliable production lines. Comput Ind Eng 66(4):1150–1162Arsene CTC, Gabrys B, Al-Dabass D (2012) Decision support system for water distribution systems based on neural networks and graphs theory for leakage detection. Expert Syst Appl 39(18):13214–13224
обучение-решение-обучение
i
TNстроить интерфейс вокруг
Теория игр
q
- Merkert, Mueller, Hubl, A Survey of the Application of Machine Learning in Decision Support Systems, University of Hoffenhaim 2015
- Tariq, Rafi,Intelligent Decision Support Systems- A Framework, India, 2011
- Sanzhez i Marre, Gibert, Evolution of Decision Support Systems, University of Catalunya, 2012
- Ltifi, Trabelsi, Ayed, Alimi, Dynamic Decision Support System Based on Bayesian Networks, University of Sfax, National School of Engineers (ENIS), 2012
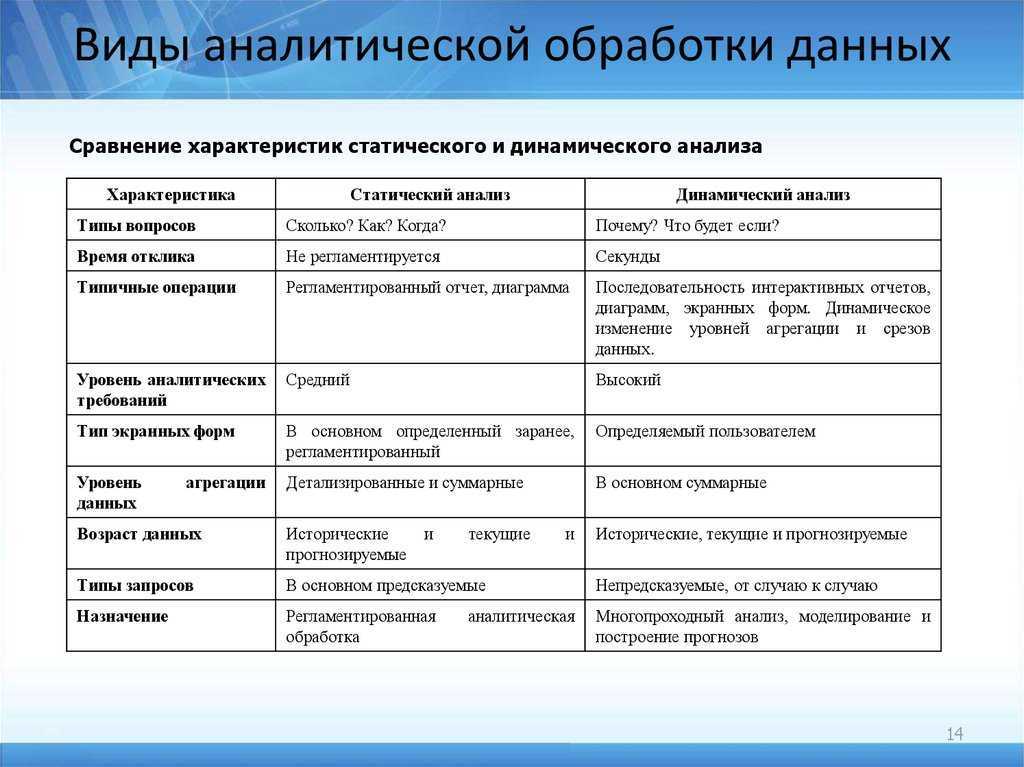
Анализ данных.
Анализ данных — широкое понятие. Сегодня существуют десятки его определений.
В самом общем смысле анализ данных — это исследования, связанные с обсчетом
многомерной системы данных, имеющей множество параметров. В процессе анализа данных исследователь производит совокупность действий с целью формирования определенных представлений о характере явления, описываемого этими данными. Как правило, для анализа данных используются различные математические методы.
Анализ данных нельзя рассматривать только как обработку информации после
ее сбора. Анализ данных — это прежде всего средство проверки гипотез и решения задач исследователя.
Известное противоречие между ограниченными познавательными способностями
человека и бесконечностью Вселенной заставляет нас использовать модели и моделирование, тем самым упрощая изучение интересующих объектов, явлений и систем.
Слово «модель» (лат. modelium) означает «мера», «способ», «сходство с какой-
то вещью».
Построение моделей — универсальный способ изучения окружающего мира, позволяющий обнаруживать зависимости, прогнозировать, разбивать на группы и решать множество других задач. Основная цель моделирования в том, что модель должна достаточно хорошо отображать функционирование моделируемой системы.
2.1. Двенадцать правил Кодда
1. Многомерность — OLAP-система на концептуальном уровне должна представлять данные в виде многомерной модели, так как это сильно упрощает процессы восприятия и анализа информации.
2. Прозрачность — OLAP-система должна скрывать от пользователя реальную реализацию многомерной модели, способ организации, источники, средства обработки и хранения.
3. Доступность — OLAP-система должна предоставлять пользователю единую, согласованную и целостную модель данных, обеспечивая доступ к данным независимо от места и способа их хранения.
4. Постоянная производительность при разработке отчетов — производительность OLAP-систем не должна значительно уменьшаться при увеличении количества измерений, по которым выполняется анализ.
5. Клиент-серверная архитектура — OLAP-система должна быть способна работать в среде «клиент-сервер», т. к. большинство данных, которые требуется подвергать оперативной аналитической обработке, хранятся распределено. Главной идеей является то, что серверный компонент инструмента OLAP должен быть достаточно интеллектуальным и позволять строить общую концептуальную схему на основе консолидации и обобщения различных физических и логических схем корпоративных БД для обеспечения эффекта прозрачности.
6. Равноправие измерений — OLAP-система должна поддерживать многомерную модель, в которой все измерения равноправны. При необходимости дополнительные характеристики могут быть предоставлены отдельным измерениям, но такая возможность должна быть предоставлена любому измерению.
7. Динамическое управление разреженными матрицами — OLAP-система должна обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной величиной для моделей, имеющих разное число измерений и различную степень разреженности данных.
8. Поддержка многопользовательского режима — OLAP-система должна предоставлять возможность работать нескольким пользователям совместно с одной аналитической моделью или создавать для них различные модели из единых данных. Из-за возможности чтения и записи данных, система должна обеспечивать целостность и безопасность информации.
9. Неограниченные перекрестные операции — OLAP-система должна обеспечивать сохранение функциональных отношений, описанных с помощью определенного формального языка между ячейками гиперкуба при выполнении любых из возможных четырех операций: среза, вращения, консолидации или детализации. Система должна самостоятельно выполнять преобразование установленных отношений, не требуя от пользователя их переопределения.
10. Интуитивная манипуляция данными — OLAP-система должна предоставлять способ выполнения операций среза, вращения, консолидации и детализации над гиперкубом без необходимости пользователю совершать множество действий с интерфейсом. Измерения, определенные в аналитической модели, должны содержать всю необходимую информацию для выполнения всех возможных операций над гиперкубом.
11. Гибкие возможности получения отчетов — OLAP-система должна поддерживать различные способы визуализации данных, т. е. отчеты должны представляться в любой возможной ориентации. Средства формирования отчетов должны представлять синтезируемые данные или информацию, следующую из модели данных в ее любой возможной ориентации.
12. Неограниченная размерность и число уровней агрегации — исследование о возможном числе необходимых измерений, требующихся в аналитической модели, показало, что одновременно может использоваться до девятнадцать измерений. Отсюда вытекает настоятельная рекомендация, чтобы аналитический инструмент мог одновременно предоставить не меньше пятнадцати измерений, а предпочтительнее двадцати измерений. Более того, каждое из общих измерений не должно быть ограничено по числу определяемых пользователем-аналитиком уровней агрегации и путей консолидации1.
Оперативная аналитическая обработка данных.
В основе концепции OLAP лежит принцип многомерного представления данных. В 1993 году E. F. Codd рассмотрел недостатки реляционной модели, в первую очередь, указав на невозможность «объединять, просматривать и анализировать данные с точки зрения множественности измерений, то есть самым понятным для корпоративных аналитиков способом», и определил общие требования к системам OLAP, расширяющим функциональность реляционных СУБД и включающим многомерный анализ как одну из своих характеристик.
По Кодду, многомерное концептуальное представление данных (multi-dimensional conceptual view) представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных.
Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению.




![Технологии оперативного анализа данных [реферат №3037]](https://robotrackkursk.ru/wp-content/uploads/7/5/1/75183f254c60f0be9710560354dac48b.jpeg)
![Оперативный и интеллектуальный анализ данных [реферат №306]](https://robotrackkursk.ru/wp-content/uploads/1/e/2/1e21bf87a01553e8907c96ee3f862080.jpeg)



Так, измерение Исполнитель может определяться направлением консолидации, состоящим из уровней обобщения «предприятие — подразделение — отдел — служащий». Измерение Время может даже включать два направления консолидации — «год — квартал — месяц — день» и «неделя — день», поскольку счет времени по месяцам и по неделям несовместим. В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений.
Операция спуска (drilling down) соответствует движению от высших ступеней консолидации к низшим; напротив, операция подъема (rolling up) означает движение от низших уровней к высшим.
Какая информация может использоваться аналитической системой?
 Аналитическая обработка информации OLAP основана на данных, источником которых могут быть:
Аналитическая обработка информации OLAP основана на данных, источником которых могут быть:
- Базы данных организации, ERP и CRM-системы для учета продаж, процессов производства, привлечения целевой аудитории и поставщиков, а также работа с сотрудниками.
- Хранилища данных: системы, где собрана вся информация, с которой работает компания. Такое хранилище может генерировать информацию из разносторонних баз, CRM-систем или напрямую с устройств, в частности через снятие показаний с соответствующих датчиков.
В структуре хранилищ данных выделяются определенные «зоны», так называемые витрины. Это пласт сведений из хранилища, куда поступает вся информация по тематическим рубрикам. Относиться это может как к конкретному подразделению компании, так и к другому направлению деятельности. Речь идет о данных, указанных в описании маркетинговых исследований, уровне продаж или финансовых показателях и пр. К данным из этой зоны проще получить доступ к определенному отделу компании или отправить туда запросы.
Платформы типа Mail.ru Cloud Solutions используют технологии аналитической обработки данных под управлением Arenadata DB на основе многомерной базы данных Greenplum. Она предназначена для хранения и обработки больших массивов информации, а также на предоставление откликов на различные аналитические запросы. Все это позволяет делать максимально точные прогнозы, своевременно сносить корректировки в рабочие стратегии, что положительно скажется на качестве предоставляемых услуг и уровне дохода. А все потому, что аналитический метод обработки данных позволяет взаимодействовать с различными источниками информации путем выполнения анализа в режиме реального времени с последующим построением прогнозируемой модели.
Чтобы реализовать все это на практике, требуется обладать глубокими практическими знаниям в данной области, иметь в собственном распоряжении соответствующее оборудование и программное обеспечение. Если с данными работами возникнут сложности, потребуются дополнительные профессиональны консультации или помощь специалистов, обратитесь в компанию «Xelent». Связаться с нами можно по телефону или воспользовавшись одним из онлайн-сервисов.
Популярные услуги
Виртуальная инфраструктура IaaS
IaaS – решение, которое позволяет отказаться от использования физического оборудования и значительно сократить расходы компании.
Гибридные облака
Гибридное облако (hybridcloud) – отдельная IT-инфраструктура, представляющая собой объединение виртуального приватного облака (VPC) и выделенных серверов. Использование гибридных решений позволяет компании решить нехватку собственных ресурсов за счет мощностей облачного провайдера.
Облако для бизнеса
Облака в бизнесе применяются для хранения и обработки информации. Такие решения пользуются спросом среди малого, среднего и крупного бизнеса. Небольшие организации переносят в облако почтовые сервисы, бухгалтерию, приложения для обмены данными.
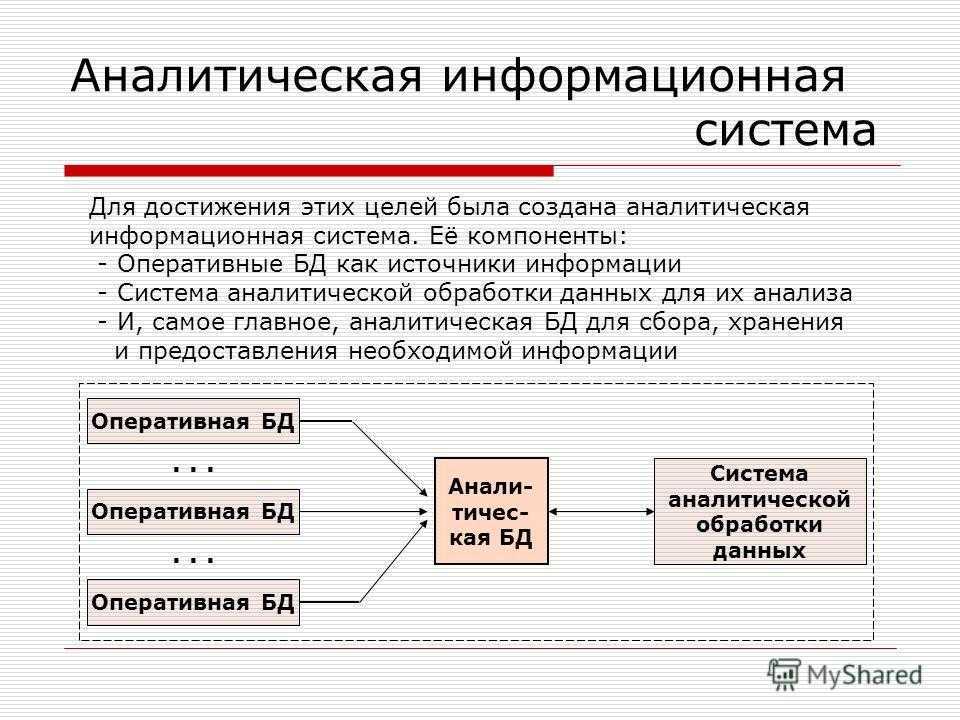
Интеллектуальный анализ данных
интеллектуальный анализ данных (ИАД) обычно определяют, как метод поддержки принятия решений, основанный на анализе зависимостей между данными. В рамках такой общей формулировки обычный анализ отчетов, построенных по базе данных, также может рассматриваться как разновидность ИАД. Чтобы перейти к рассмотрению более продвинутых технологий ИАД, посмотрим, как можно автоматизировать поиск зависимостей между данными.
Целью интеллектуального анализа данных (англ. Datamining, другие варианты перевода — «добыча данных», «раскопка данных») является обнаружение неявных закономерностей в наборах данных. Как научное направление он стал активно развиваться в 90-х годах XXвека, что было вызвано широким распространением технологий автоматизированной обработки информации и накоплением в компьютерных системах больших объемов данных . И хотя существующие технологии позволяли, например, быстро найти в базе данных нужную информацию, этого во многих случаях было уже недостаточно. Возникла потребность поиска взаимосвязей между отдельными событиями среди больших объемов данных, для чего понадобились методы математической статистики, теории баз данных, теории искусственного интеллекта и ряда других областей.
Классическим считается определение, данное одним из основателей направления Григорием Пясецким-Шапиро : DataMining — исследование и обнаружение «машиной» (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интерпретации.
Учитывая разнообразие форм представления данных, используемых алгоритмов и сфер применения, интеллектуальный анализ данных может проводиться с помощью программных продуктов следующих классов:
· специализированных «коробочных» программных продуктов для интеллектуального анализа;
· математических пакетов;
· электронных таблиц (и различного рода надстроек над ними);
· средств, интегрированных в системы управления базами данных (СУБД);
· других программных продуктов.
В качестве примера можно привести СУБД MicrosoftSQLServer и входящие в ее состав службы AnalysisServices, обеспечивающие пользователей средствами аналитической обработки данных в режиме on-line (OLAP)и интеллектуального анализа данных, которые впервые появились в MSSQLServer 2000.
Не только Microsoft, но и другие ведущие разработчики СУБД имеют в своем арсенале средства интеллектуального анализа данных.
В ходе проведения интеллектуального анализа данных проводится исследование множества объектов (или вариантов). В большинстве случаев его можно представить в виде таблицы, каждая строка которой соответствует одному из вариантов, а в столбцах содержатся значения параметров, его характеризующих. Зависимая переменная — параметр, значение которого рассматриваем как зависящее от других параметров (независимых переменных). Собственно, эту зависимость и необходимо определить, используя методы интеллектуального анализа данных.
АРХИТЕКТУРА OLAP-СИСТЕМ
Многомерность в OLAP-приложениях представляют в виде трех уровней:
- Многомерное представление данных — средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными; слой многомерного представления абстрагирован от физической структуры данных и воспринимает данные как многомерные.
- Многомерная обработка — средство (язык) формулирования многомерных запросов (традиционный реляционный язык SQL здесь оказывается непригодным) и процессор, умеющий обработать и выполнить такой запрос.
- Многомерное хранение — средства физической организации данных, обеспечивающие эффективное выполнение многомерных запросов.
Во всех OLAP-системах первые два уровня присутствуют обязательно, а третий уровень не обязательно присутствует в них, хотя и является широко распространенным, так как данные для многомерного представления могут извлекаться и из обычных реляционных структур, и тогда процессор многомерных запросов будет транслировать многомерные запросы в SQL-запросы, которые выполняются реляционной СУБД.
OLAP-продукты, чаще всего, представляют собой OLAP-сервер, многомерную серверную СУБД (такую как, Microsoft OLAP Services или Oracle Express Server) или же OLAP-клиент, средство многомерного представления данных (такое как, Pivot Tables в Excel 2000 фирмы Microsoft или ProClarity фирмы Knosys)1.
OLAP-сервер обеспечивает хранение данных, выполнение над ними необходимых операций и формирование многомерной модели на концептуальном уровне.
OLAP-клиент обеспечивает пользователю возможность удобно манипулировать данными для выполнения задач анализа, представляя пользователю интерфейс к многомерной модели данных2.
Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но так же этот слой может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы Microsoft.
OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные по-разному. В любом ХД как в обычном так и в многомерном вместе с детальными данными, извлекаемыми из оперативных систем, хранятся и суммарные показатели (агрегированные показатели, агрегаты), такие, как суммы объемов продаж по месяцам, по категориям товаров и т. п. Агрегаты хранятся в явном виде с единственной целью — ускорить выполнение запросов.
Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо в многомерных структурах. Многомерное хранение позволяет обращаться с данными как с многомерным массивом, благодаря чему обеспечиваются одинаково быстрые вычисления суммарных показателей и различные многомерные преобразования по любому из измерений. Некоторое время назад OLAP-продукты поддерживали либо реляционное, либо многомерное хранение. Сегодня, как правило, один и тот же продукт обеспечивает оба этих вида хранения, а также третий вид — смешанный. Способ реализации хранения данных очень важен, т. к. от него зависят такие характеристики, как занимаемые ресурсы и в следствии производительность. Выделяют три основных способа реализации:
- MOLAP (Multidimensional OLAP) — детальные данные и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
- ROLAP (Relational OLAP) — детальные данные остаются в реляционной БД; агрегаты хранятся в той же БД в специально созданных служебных таблицах.
- HOLAP (Hybrid OLAP) — детальные данные остаются в реляционной БД, а агрегаты хранятся в многомерной БД.
Каждый из этих способов имеет свои преимущества и недостатки и должен применяться в зависимости от различных условий — объема данных, мощности реляционной СУБД и т. д.
При хранении данных в многомерных структурах возникает потенциальная проблема «разбухания» за счет хранения пустых значений. Если в многомерном массиве зарезервировано место под все возможные комбинации меток измерений, а реально заполнена лишь малая часть, то большая часть куба будет пустовать, хотя место будет занято. Современные OLAP-продукты умеют справляться с этой проблемой.
СПИСОК ЛИТЕРАТУРЫ
СПИСОК СОКРАЩЕНИЙ
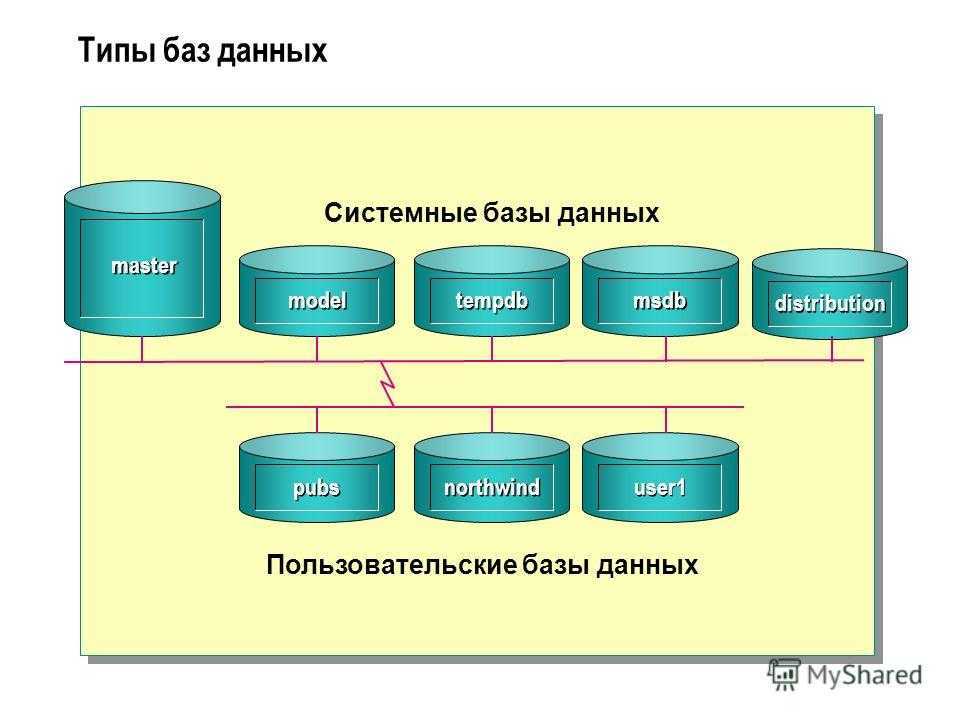
- БД – Базы данных
- СППР – Системами поддержки принятия решений
- СУБД – Системы управления базами данных
- ХД – Хранилища данных
- Виды рисков в менеджменте
- Коммуникативные стратегии и тактики в рекламе и связях с общественностью (Коммуникативные стратегии и языковые способы их реализации как интегральная основа модели)
- Коммуникативные стратегии и тактики в рекламе и связях с общественностью
- визуальные коммуникации — реферат
- Ритуальная коммуникация в рекламе, связях с общественностью
- Ритуальная коммуникация в рекламе и связях с общественностью
- Технологии оперативного анализа данных
- Технология электронного документооборота
- ЭЛЕКТРОННАЯ ЦИФРОВАЯ ПОДПИСЬ (Электронная цифровая подпись: понятие, составляющие, назначение)
- Электронная цифровая подпись
- Технологии интеллектуального анализа данных. Введение в анализ данных
- Особенности спроса на общественные блага (Классификация экономических благ)
Многообразие СППР
классификации
По области применения
- Бизнес и менеджмент (прайсинг, рабочая сила, продукты, стратегия и т.п.)
- Инжиниринг (дизайн продукта, контроль качества…)
- Финансы (кредитование и займы)
- Медицина (лекарства, виды лечения, диагностика)
- Окружающая среда
По соотношению данные\модели (методика Стивена Альтера)
- FDS (File Drawer Systems — системы предоставления доступа к нужным данным)
- DAS (Data Analysis Systems — системы для быстрого манипулирования данными)
- AIS (Analysis Information Systems — системы доступа к данным по типу необходимого решения)
- AFM(s) (Accounting & Financial models (systems) — системы рассчета финансовых последствий)
- RM(s) (Representation models (systems) — системы симуляции, AnyLogic как пример)
- OM(s) (Optimization models (systems) — системы, решающие задачи оптимизации)
- SM(s) (Suggestion models (systems) — системы построения логических выводов на основе правил)
По типу использумого инструментария
- Model Driven — в основе лежат классические модели (линейные модели, модели управления запасами, транспортные, финансовые и т.п.)
- Data Driven — на основе исторических данных
- Communication Driven — системы на оснвое группового принятия решений экспертами (системы фасилитации обмена мнениями и подсчета средних экспертных значений)
- Document Driven — по сути проиндексированное (часто — многомерное) хранилище документов
- Knowledge Driven — внезапно, на основе знаний. При чем знаний как экспертных, так и выводимых машинно
2.3. Тест FASMI
Определенные ранее особенности распространены. Более известен тест FASMI (Fast of Shared Multidimensional Information), созданный в 1995 г. Ричардом Критом и Найджелом Пендсом на основе анализа правил Кодда. В данном контексте акцент сделан на скорость обработки, наличие средств статистического анализа, многопользовательский доступ, многомерность и релевантность информации, т. е. представление анализируемых фактов как функций от большого числа их характеризующих параметров. Они определили OLAP следующими пятью ключевыми словами: Fast (Быстрый), Analysis (Анализ), Shared (Разделяемой), Multidimensional (Многомерной), Information (Информации).
Fast (Быстрый) — OLAP-система должна обеспечивать выдачу большинства ответов пользователям в пределах приблизительно пяти секунд. При этом самые простые запросы обрабатываются в течение одной секунды, и очень немногие более двадцати секунд. Конечные пользователи воспринимают процесс неудачным, если результаты не получены на протяжении тридцати секунд. Они способны нажать комбинацию клавиш + +





![Технологии оперативного анализа данных [реферат №3037]](https://robotrackkursk.ru/wp-content/uploads/5/1/9/519436f86ccb7220f9b57a780292e015.jpeg)
![Оперативный и интеллектуальный анализ данных [реферат №306]](https://robotrackkursk.ru/wp-content/uploads/c/f/6/cf614f1599347024847eb0dca7d80b5d.jpeg)
Analysis (Анализ) — OLAP-система должна справляться с любым логическим и статистическим анализом, характерным для данного приложения, и обеспечивать его сохранение в виде, доступном для конечного пользователя. Система должна позволять пользователю определять новые специальные вычисления как часть анализа и формировать отчеты любым желаемым способом без необходимости программирования. Все требуемые функциональные возможности анализа должны обеспечиваться понятным для конечных пользователей способом.
Shared (Разделяемой) — OLAP-система должна выполнять все требования защиты конфиденциальности. Если множественный доступ для записи необходим, обеспечивается блокировка модификаций на соответствующем уровне. Обработка множественных модификаций должна выполняться своевременно и безопасным способом.
Multidimensional (Многомерной) — OLAP-система должна обеспечить многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий, обеспечивающих наиболее логичный способ анализа. Это требование не устанавливает минимальное число измерений, которые должны быть обработаны, поскольку этот показатель зависит от приложения. Оно также не определяет используемую технологию БД, если пользователь действительно получает многомерное концептуальное представление информации.
Information (Информации) — OLAP-система должна обеспечивать получение необходимой информации в условиях реального приложения. Мощность различных систем измеряется не объемом хранимой информации, а количеством входных данных, которые они могут обработать. В этом смысле мощность продуктов сильно различается. Большие OLAP-системы могут оперировать в тысячу раз большим количеством данных по сравнению с простыми версиями OLAP-систем. При этом следует учитывать множество факторов, включая дублирование данных, использование дискового пространства, эксплуатационные показатели, требуемую оперативную память, интеграцию с информационными хранилищами и т. п.
Типы многомерных OLAP систем.
В рамках OLAP -технологий на основе того, что многомерное представление данных может быть организовано как средствами реляционных СУБД, так многомерных специализированных средств, различают три типа многомерных OLAP -систем:
— многомерный (Multidimensional) OLAP- MOLAP
-реляционный (Relation) OLAP — ROLAP
-смешанныйилигибридный ( Hibrid ) OLAP — HOLAP
Выше по существу изложены существо и различия между многомерной и реляционной моделью OLAP -систем. Сущность смешанной OLAP -системы заключается в возможности использования многомерного и реляционного подхода в зависимости от ситуации: размерности информационных массивов, их структуры, частности обращений к тем или иным записям, вида запросов и т.д.
Рассмотрим подробнее достоинства и недостатки приведённых разновидностей OLAP -систем.
Многомерные OLAP -системы
В многомерных СУБД данные организованы не в виде реляционных таблиц, а упорядоченных многомерных массивов или гиперкубов, когда все хранимые данные должны иметь одинаковую размерность, что означает необходимость образовывать максимально полный базис измерений. Данные могут быть организованы в виде поли кубов, в этом варианте значения каждого показателя хранятся с собственным набором измерений, обработка данных производится собственным инструментом системы.
Достоинствами MOLAP являются:
— более быстрое, чем при ROLAP получение ответов на запросы -затрачиваемое время на один-два порядка меньше;
— из-за ограничений SQL затрудняется реализация многих встроенных функций.
К ограничениям MOLAP относятся:
— сравнительно небольшие размеры баз данных — предел десятки Гигабайт;
— за счёт деморализации и предварительной агрегации многомерные массивы используют в 2,5-100 раз больше памяти, чем исходные данные;
— отсутствуют стандарты на интерфейс и средства манипулирования данными;
— имеются ограничения при загрузке данных.
Реляционные OLAP -системы
В настоящее время в массовых средствах, обеспечивающих аналитическую работу, преобладает использование инструментов на основе реляционного подхода.
Достоинствами ROLAP- систем являются:
— возможность оперативного анализа непосредственно содержащихся в хранилище данных, так как большинство исходных баз данных реляционного типа;
— при переменной размерности задачи выигрывают ROLAP, так как не требуется физическая реорганизация базы данных;
— ROLAP — системы могут использовать менее мощные клиентские станции и серверы, причём на серверы ложится основная нагрузка по обработке сложных SQL -запросов;
— уровень защиты информации и разграничения прав доступа в реляционных СУБД несравненно выше, чем в многомерных.
Недостатком ROLAP — систем является меньшая производительность, необходимость тщательной проработки схем базы данных, специальная настройка индексов, анализ статистики запросов и учёт выводов анализа при доработках схем баз данных, что приводит к значительным дополнительным трудозатратам.
Выполнение же этих условий позволяет при использовании ROLAP -систем добиться схожих с MOLAP -системами показателей в отношении времени доступа и даже превзойти в экономии памяти.
Гибридные OLAP -системы
Представляют собой сочетание инструментов, реализующих реляционную и многомерную модель данных. При таком подходе используются достоинства первых двух подходов и компенсируются их недостатки. В наиболее развитых программных продуктах такого назначения реализован именно этот принцип.
Использование гибридной архитектуры в OLAP -системах — это наиболее приемлемый путь решения проблем в применении программных инструментальных средств в многомерном анализе.
- Стандарты текстовой информации в ИС (текстовые редакторы)
- Технологии больших данных (Big Data)
- Реорганизация общества и его ликвидация: краткая характеристика и этапы процедур (Понятие и виды ликвидации)
- Отличительные особенности англо-американской модели корпоративного управления: ее преимущества и недостатки (Англо-американская модель корпоративного управления)
- Защитные механизмы OC Windows 8.1
- Активные и интерактивные технологии обучения
- Language and Literacy.
- KPI в контексте BPM
- Системы оперативного анализа данных OLAP
- Средства аутентификации по отпечаткам пальцев (Биометрические системы аутентификации.)
- Технологии больших данных (Big Data) (Большие данные.)
- Анимация и видео
Место OLAP в информационной структуре предприятие.
Термин «OLAP» неразрывно связан с термином «хранилище данных» (Data Warehouse).
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например, статистических отчетов.





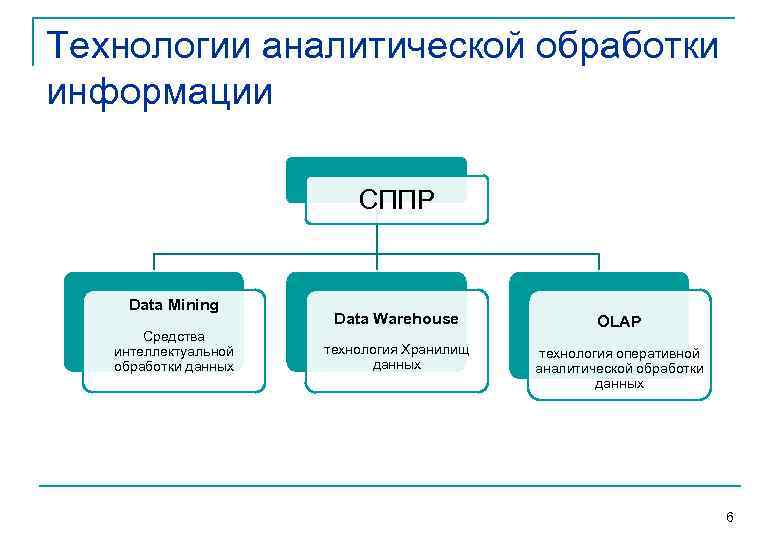
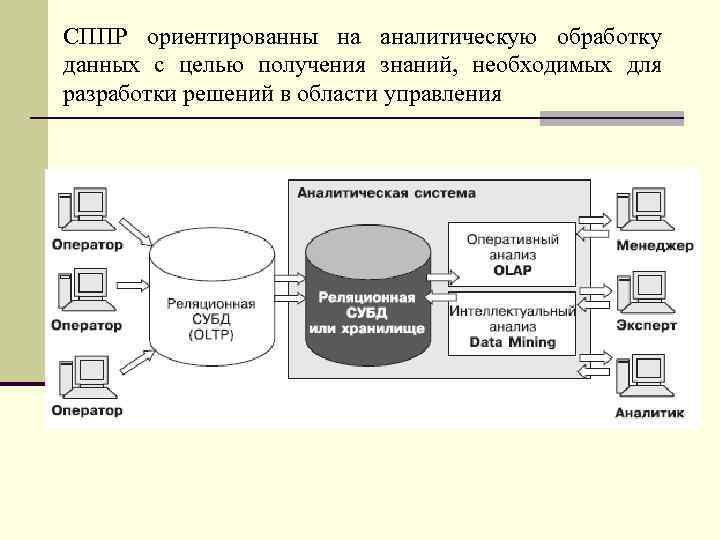


Задача хранилища — предоставить «сырье» для анализа в одном месте и в простой, понятной структуре.
Есть и еще одна причина, оправдывающая появление отдельного хранилища — сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
Под хранилищем можно понимать не обязательно гигантское скопление данных — главное, чтобы оно было удобно для анализа.
Централизация и удобное структурирование — это далеко не все, что нужно аналитику. Ему ведь еще требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого хранилища, лишены одного — гибкости. Их нельзя «покрутить», «развернуть» или «свернуть», чтобы получить желаемое представление данных. Вот бы ему такой инструмент, который позволил бы разворачивать и сворачивать данные просто и удобно! В качестве такого инструмента и выступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Подытоживая, можно определить OLAP как совокупность средств многомерного анализа данных, накопленных в хранилище.
2.2. Дополнительные правила Кодда
Набор этих требований, послуживших де-факто определением OLAP, достаточно часто вызывает различные нарекания, например, правила 1, 2, 3, 6 являются требованиями, а правила 10, 11 — неформализованными пожеланиями. Таким образом, перечисленные 12 требований Кодда не позволяют точно определить OLAP. В 1995 г. Кодд добавил еще шесть правил:
13. Пакетное извлечение против интерпретации — OLAP-система должна в равной степени эффективно обеспечивать доступ как к собственным, так и к внешним данным.
14. Поддержка всех моделей OLAP-анализа — OLAP-система должна поддерживать все четыре модели анализа данных, определенные Коддом: толковательную, стереотипную, категориальную и умозрительную.
15. Обработка ненормализованных данных — OLAP-система должна быть интегрирована с ненормализованными источниками данных. Модификации данных, выполненные в среде OLAP, не должны приводить к изменениям данных, хранимых в исходных внешних системах.
16. Сохранение результатов OLAP: хранение их отдельно от исходных данных — OLAP-система, работающая в режиме чтения-записи, после модификации исходных данных должна сохранять результаты отдельно друг от друга, т.е. обеспечивать безопасность всех исходных данных.
17. Исключение отсутствующих значений — OLAP-система, представляя данные пользователю, должна отбрасывать все отсутствующие значения, т.е. они должны отличаться от нулевых значений.
18. Обработка отсутствующих значений — OLAP-система должна игнорировать все отсутствующие значения без учета их источника. Эта особенность связана с 17-м правилом.
Кроме того, Кодд разбил все восемнадцать правил на четыре группы, и назвал их особенностями. Группы получили названия: В, S, R и D.
Основные особенности (В) включают следующие правила:
- многомерное концептуальное представление данных (правило 1);
- интуитивное манипулирование данными (правило 10);
- доступность (правило 3);
- пакетное извлечение против интерпретации (правило 13);
- поддержка всех моделей OLAP-анализа (правило 14);
- архитектура «клиент-сервер» (правило 5);
- прозрачность (правило 2);
- многопользовательская поддержка (правило 8).
Специальные особенности (S):
- обработка ненормализованных данных (правило 15);
- сохранение результатов OLAP: хранение их отдельно от исходных данных (правило 16);
- исключение отсутствующих значений (правило 17);
- обработка отсутствующих значений (правило 18).
Особенности представления отчетов (R):
- гибкость формирования отчетов (правило 11);
- стандартная производительность отчетов (правило 4);
- автоматическая настройка физического уровня (измененное оригинальное правило 7).
Управление измерениями (D):
- универсальность измерений (правило 6);
- неограниченное число измерений и уровней агрегации (правило 12);
- неограниченные операции между размерностями (правило 9).