Производительность [ править ]
Когда одновременно выполняется более одной программы, система SMP имеет значительно лучшую производительность, чем однопроцессор, поскольку разные программы могут выполняться на разных процессорах одновременно. Точно так же асимметричная многопроцессорная обработка (AMP) обычно позволяет только одному процессору запускать программу или задачу одновременно
Например, AMP можно использовать для назначения конкретных задач ЦП в зависимости от приоритета и важности выполнения задачи. AMP был создан задолго до SMP с точки зрения обработки нескольких процессоров, что объясняет отсутствие производительности на основе приведенного примера
В случаях, когда среда SMP обрабатывает много заданий, администраторы часто теряют эффективность оборудования. Программное обеспечение было разработано для планирования заданий и других функций компьютера, так что использование процессора достигает своего максимального потенциала. Хорошие программные пакеты могут реализовать этот максимальный потенциал за счет отдельного планирования каждого ЦП, а также за счет возможности интеграции нескольких SMP-машин и кластеров.
Доступ к ОЗУ сериализован; это и проблемы с согласованностью кеша приводят к небольшому отставанию производительности от количества дополнительных процессоров в системе.
Преимущества / недостатки [ править ]
В современных системах SMP все процессоры тесно связаны внутри одного блока с шиной или коммутатором; в более ранних системах SMP один процессор занимал весь шкаф. Некоторые из общих компонентов — это глобальная память, диски и устройства ввода-вывода. На всех процессорах работает только одна копия ОС, и ОС должна быть спроектирована так, чтобы использовать преимущества этой архитектуры. Некоторые из основных преимуществ включают рентабельные способы увеличения пропускной способности. Для решения различных проблем и задач SMP применяет несколько процессоров к одной задаче, известной как параллельное программирование .
Однако есть несколько ограничений масштабируемости SMP из-за согласованности кеша и общих объектов.
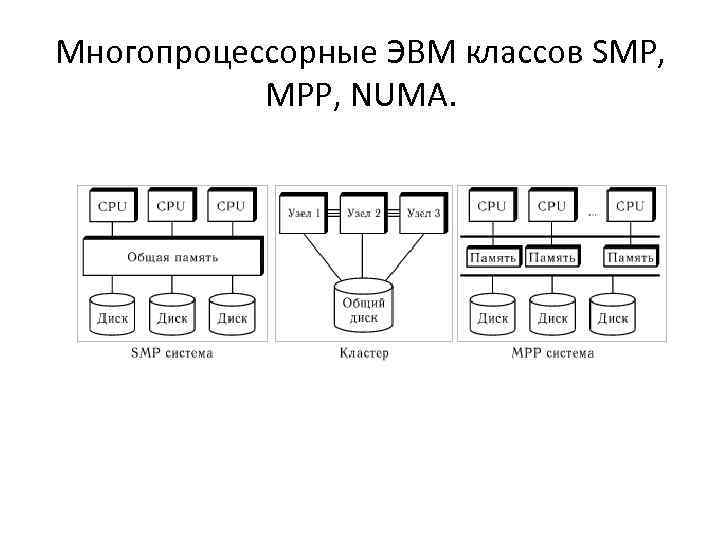
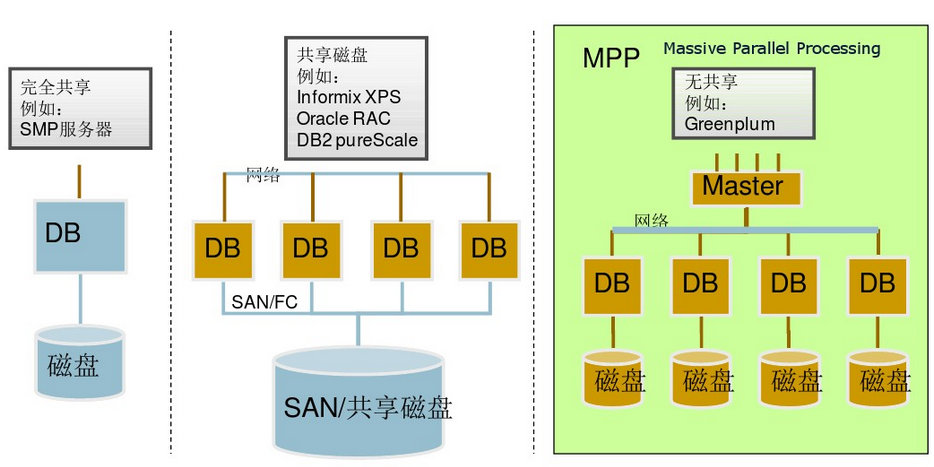
Разница между NUMA и MPP
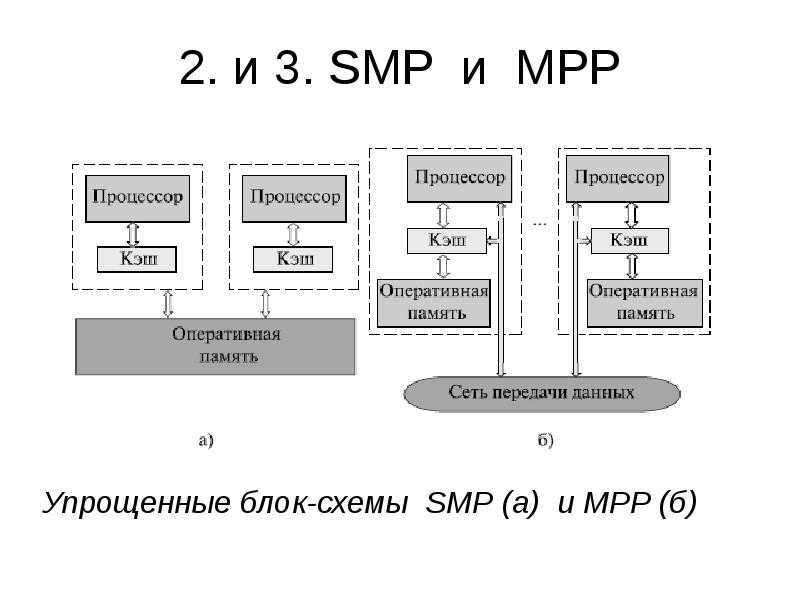
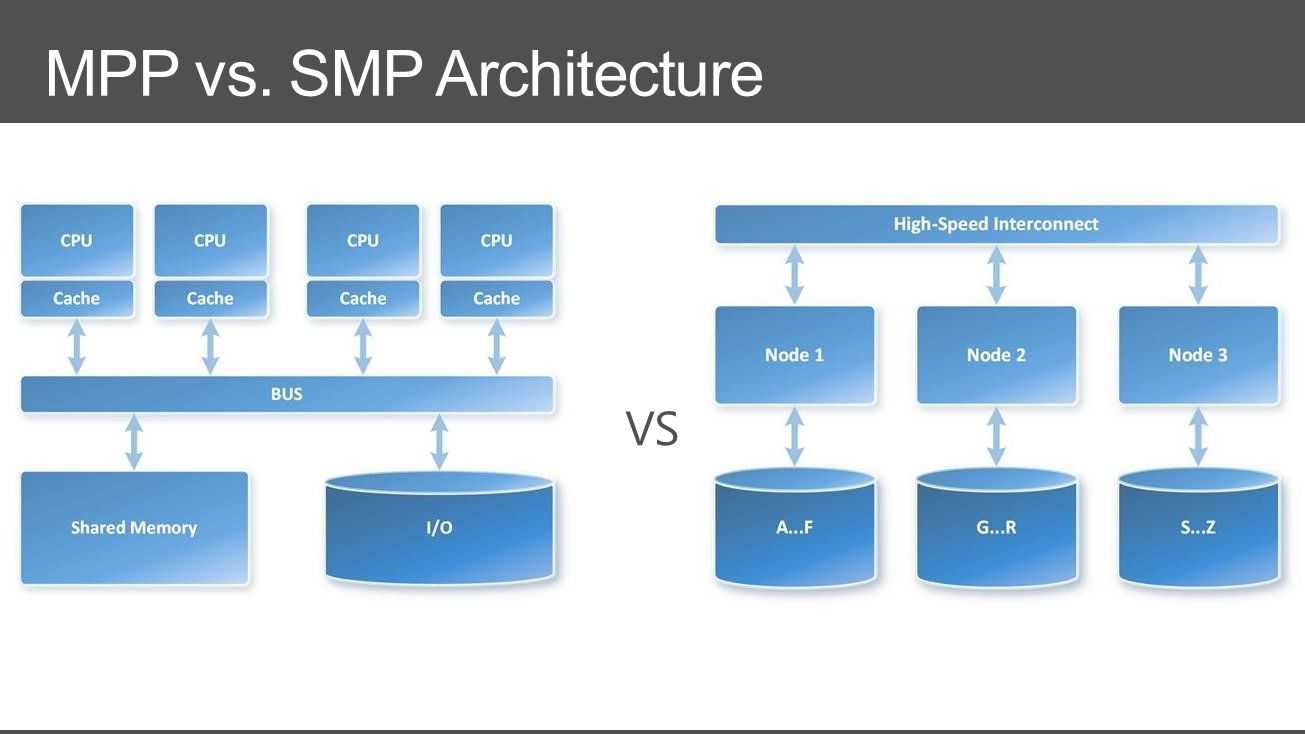
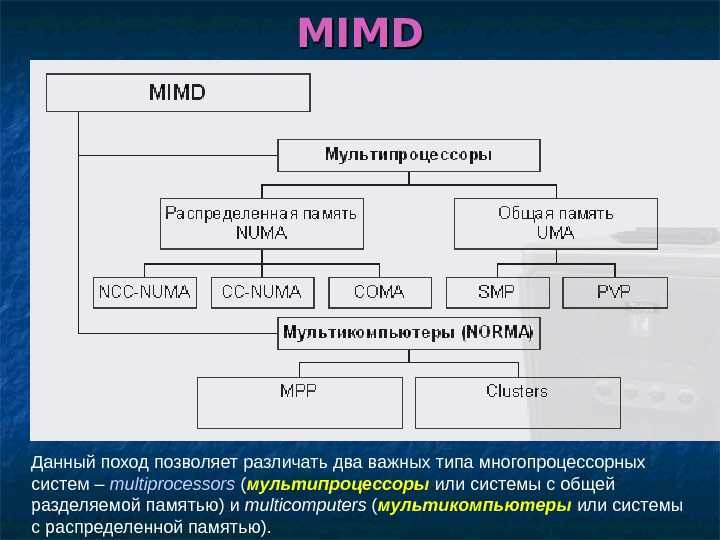
С архитектурной точки зрения NUMA и MPP имеют много общего: они состоят из нескольких узлов, каждый узел имеет свой собственный ЦП, память, ввод-вывод, а узлы могут обмениваться информацией через механизм соединения узлов. Так в чем же между ними разница? Анализируя внутреннюю структуру и принцип работы следующих серверов NUMA и MPP, нетрудно найти разницу. Во-первых, другой механизм соединения узлов. Механизм соединения узлов NUMA реализован на одном физическом сервере. Когда определенному процессору требуется удаленный доступ к памяти, он должен ждать. Это также Основная причина, по которой серверы NUMA не могут добиться линейного увеличения производительности при увеличении ЦП. Механизм соединения узлов MPP реализуется посредством ввода-вывода за пределами различных серверов SMP.Каждый узел имеет доступ только к локальной памяти и хранилищу, а обмен информацией между узлами и обработка самих узлов выполняются параллельно. Следовательно, производительность MPP может в основном достигать линейного расширения при добавлении узлов. Во-вторых, другой механизм доступа к памяти. На сервере NUMA любой ЦП может получить доступ к памяти всей системы, но производительность удаленного доступа намного ниже, чем у доступа к локальной памяти, поэтому при разработке приложений следует избегать удаленного доступа к памяти. На сервере MPP каждый узел обращается только к локальной памяти, и нет проблем с удаленным доступом к памяти.
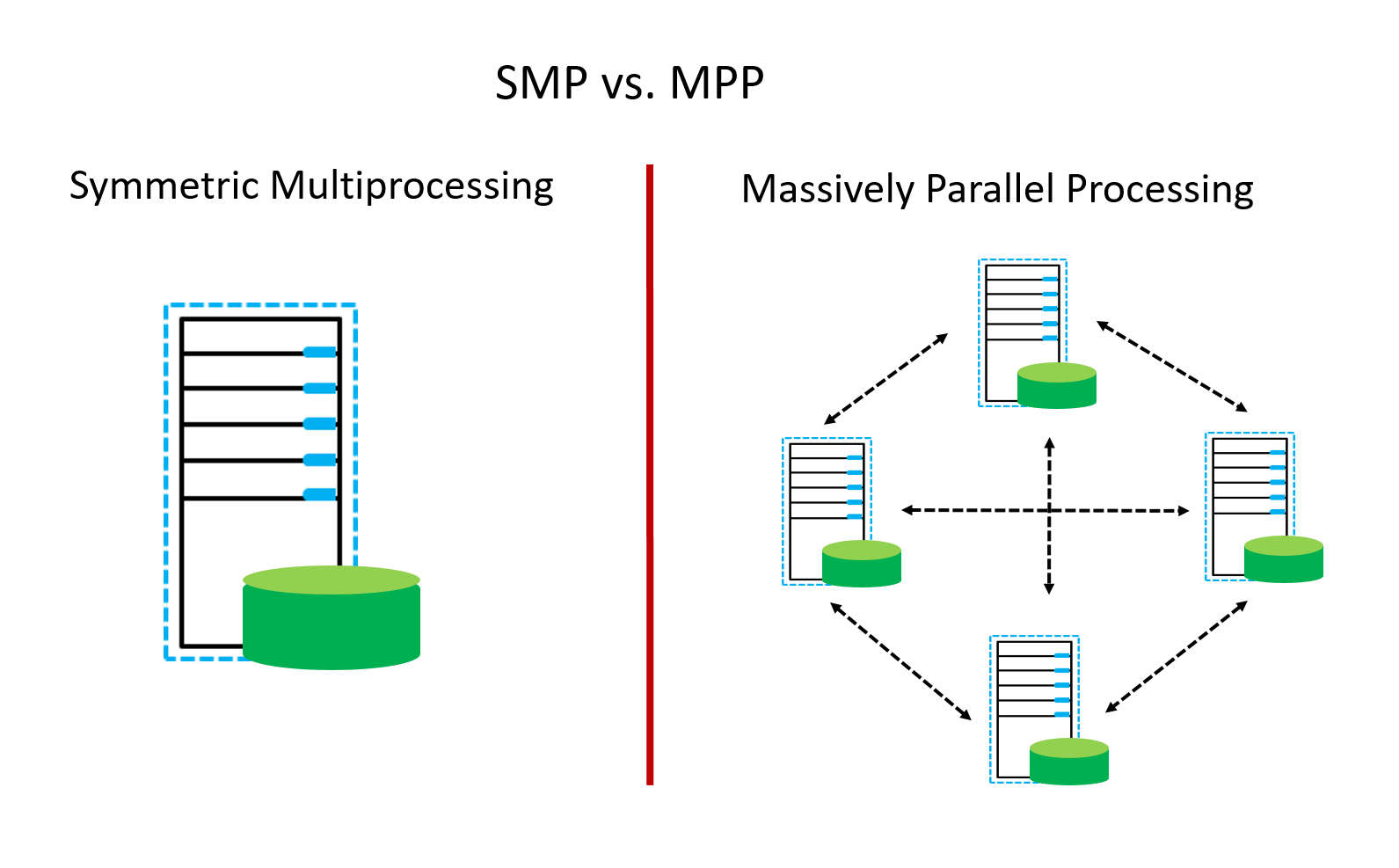
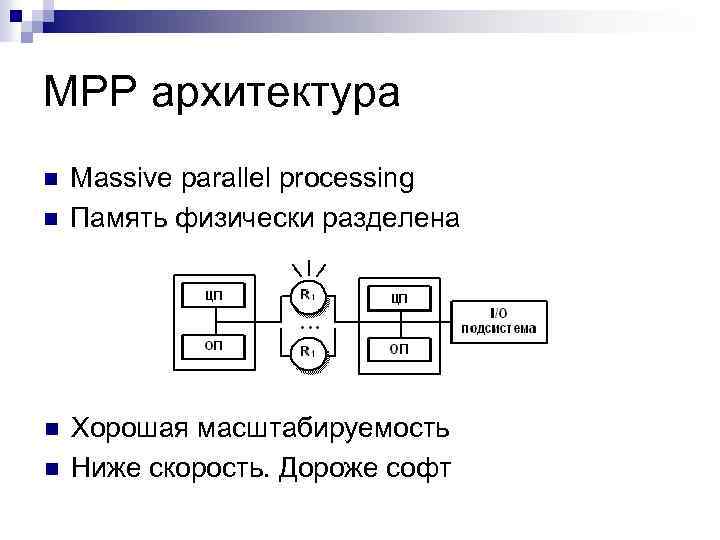
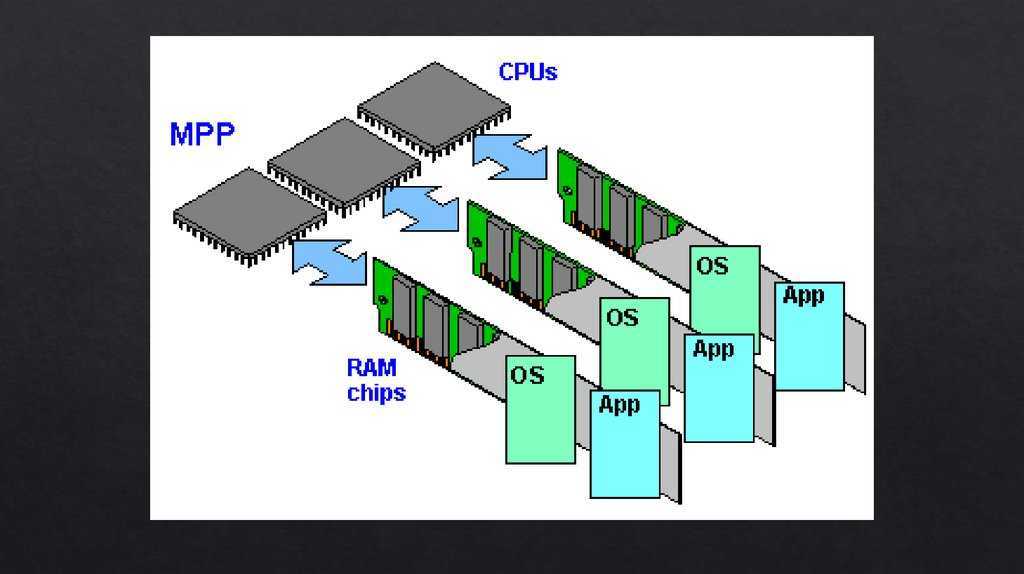
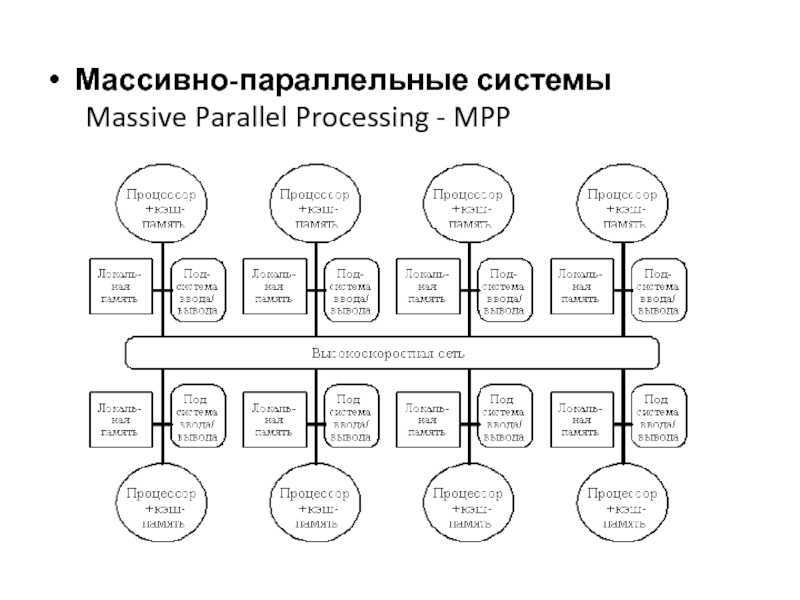
MPP(Massive Parallel Processing)
В отличие от NUMA, MPP предоставляет другой способ расширения системы. Он состоит из нескольких серверов SMP, соединенных через определенную сеть межсетевого взаимодействия узлов, работающих вместе для выполнения одних и тех же задач, и с точки зрения пользователя это серверная система. Его основная особенность заключается в том, что несколько SMP-серверов (каждый SMP-сервер называется узлом) подключены через сеть межсетевого взаимодействия узлов. Каждый узел получает доступ только к своим собственным локальным ресурсам (памяти, хранилищу и т. Д.), Которые являются полностью общими (Share Nothing). ) Структура, поэтому возможности расширения являются наилучшими. Теоретически ее расширение не ограничено. Текущая технология может реализовать соединение 512 узлов и тысяч процессоров. В настоящее время в отрасли нет стандартов для сетей межсетевого взаимодействия узлов, таких как Bynet от NCR и SPSwitch от IBM. Все они используют различные механизмы внутренней реализации. Однако Интернет узла используется только внутренним сервером MPP и прозрачен для пользователей. В системе MPP каждый узел SMP также может запускать свою собственную операционную систему, базу данных и т. д. Но в отличие от NUMA у него нет проблемы удаленного доступа к памяти. Другими словами, ЦП в каждом узле не может получить доступ к памяти другого узла. Обмен информацией между узлами осуществляется через сеть взаимосвязей узлов, и этот процесс обычно называется перераспределением данных. Но серверу MPP необходим сложный механизм для планирования и балансировки нагрузки каждого узла и параллельной обработки. В настоящее время некоторые серверы, основанные на технологии MPP, часто используют программное обеспечение системного уровня (например, базы данных) для защиты от этой сложности. Например, Teradata от NCR — это программное обеспечение для реляционной базы данных, основанное на технологии MPP. При разработке приложений на основе этой базы данных, независимо от того, из скольких узлов состоит внутренний сервер, разработчики сталкиваются с одной и той же системой баз данных без необходимости Подумайте, как запланировать загрузку определенных узлов.
Ссылки [ править ]
- ^ Джон Кубятович. Введение в параллельные архитектуры и потоки . 2013 Краткий курс по параллельному программированию.
- ^ Дэвид Каллер ; Джасвиндер Пал Сингх; Ануп Гупта (1999). Параллельная компьютерная архитектура: аппаратно-программный подход . Морган Кауфманн . п. 47. ISBN 978-1558603431.
- ^ Лина Дж. Карам, Исмаил Аль-Камал, Алан Гатерер, Джин А. Франц, Дэвид В. Андерсон, Брайан Л. Эванс (2009). «Тенденции в многоядерных платформах DSP» . Журнал обработки сигналов IEEE . 26 (6): 38–49. Bibcode2009ISPM … 26 … 38K . DOI10.1109 / MSP.2009.934113 . S2CID 9429714 .
- ↑ Грегори В. Уилсон (октябрь 1994 г.). «История развития параллельных вычислений» .
- ↑ Мартин Х. Вейк (январь 1964 г.). «Четвертый обзор отечественных электронных цифровых вычислительных систем» . Лаборатории баллистических исследований , Абердинский полигон . Берроуз D825.
- ^ Функциональные характеристики IBM System / 360 Model 65 . Четвертый выпуск. IBM. Сентябрь 1968 года. A22-6884-3.
- ^ Функциональные характеристики IBM System / 360 Model 67 . Третье издание. IBM. Февраль 1972 года. GA27-2719-2.
- ^ M65MP: эксперимент в многопроцессорности OS / 360
- ^ Program Logic Manual, OS I / O Supervisor Logic, Release 21 (R21.7) (Десятое изд.). IBM. Апрель 1973 года. GY28-6616-9.
- ^ Программы управления разделением времени Майком Александером (май 1971) содержат информацию о MTS, TSS, CP / 67 и Multics.
- ^ Системное руководство GE-635 . General Electric . Июль 1964 г.
- ^ Системное руководство GE-645 . General Electric. Январь 1968 г.
- ^ Ричард Shetron (5 мая 1998). «Страх многопроцессорной обработки?» . Группа новостейalt.folklore.computers . Usenet: .
- ^ DEC 1077 и SMP
- ^ Руководство по продажам продукции VAX, страницы 1-23 и 1-24 : VAX-11/782 описывается как асимметричная многопроцессорная система в 1982 г.
- ^ VAX 8820/8830/8840 Руководство пользователя системного оборудования : к 1988 г. операционная система VAX была SMP
- ^ Хокни, RW; Джесшоп, CR (1988). Параллельные компьютеры 2: архитектура, программирование и алгоритмы . Тейлор и Фрэнсис. п. 46. ISBN 0-85274-811-6.
- ↑ Хоули, Джон Альфред (июнь 1975 г.). «MUNIX, версия UNIX для многопроцессорной обработки» . core.ac.uk . Проверено 11 ноября 2018 .
- ^ Variable SMP — многоядерная архитектура ЦП с низким энергопотреблением и высокой производительностью. NVIDIA. 2011 г.
Использует
Системы с разделением времени и серверные системы часто могут использовать SMP без изменения приложений, поскольку в них может быть несколько процессов, работающих параллельно, а система с несколькими запущенными процессами может запускать разные процессы на разных процессорах.
На персональных компьютерах SMP менее полезен для приложений, которые не были изменены. Если система редко запускает более одного процесса одновременно, SMP полезен только для приложений, которые были модифицированы для многопоточной (многозадачной) обработки. Программное обеспечение, запрограммированное на заказ, может быть написано или изменено для использования нескольких потоков, так что оно может использовать несколько процессоров.
Многопоточные программы также могут использоваться в системах с разделением времени и в серверных системах, которые поддерживают многопоточность, что позволяет им более эффективно использовать несколько процессоров.
Переменный SMP [ править ]
| Нейтральность этого раздела оспаривается . Соответствующее обсуждение можно найти на странице обсуждения . Не удаляйте это сообщение, пока не будут выполнены соответствующие условия . ( Август 2017 г. ) ( Узнайте, как и когда удалить этот шаблон сообщения ) |
Переменная симметричная многопроцессорная обработка (vSMP) — это особая технология мобильного использования, инициированная NVIDIA. Эта технология включает в себя дополнительное пятое ядро в четырехъядерном устройстве, называемое ядром Companion, созданное специально для выполнения задач на более низкой частоте во время активного режима ожидания мобильного устройства, воспроизведения видео и музыки.
Проект Kal-El ( Tegra 3 ) , запатентованный NVIDIA, был первым SoC (System on Chip), в котором реализована эта новая технология vSMP. Эта технология не только снижает энергопотребление мобильного устройства в активном режиме ожидания, но также максимизирует производительность четырехъядерного процессора во время активного использования для интенсивных мобильных приложений. В целом эта технология удовлетворяет потребность в увеличении времени автономной работы при активном и резервном использовании за счет снижения энергопотребления мобильных процессоров.
В отличие от текущих архитектур SMP, ядро vSMP Companion прозрачно для ОС, что означает, что операционная система и запущенные приложения совершенно не знают об этом дополнительном ядре, но все же могут использовать его преимущества. Некоторые из преимуществ архитектуры vSMP включают согласованность кэша, эффективность ОС и оптимизацию энергопотребления. Преимущества этой архитектуры объясняются ниже:
- Когерентность кэша: нет никаких последствий для синхронизации кешей между ядрами, работающими на разных частотах, поскольку vSMP не позволяет ядру Companion и основным ядрам работать одновременно.
- Эффективность ОС: это неэффективно, когда несколько ядер ЦП работают на разных асинхронных частотах, потому что это может привести к возможным проблемам с планированием. [ как? ] При использовании vSMP активные ядра ЦП будут работать с одинаковой частотой для оптимизации планирования ОС.
- Оптимизация мощности: в архитектуре на основе асинхронной синхронизации каждое ядро находится на отдельной плоскости питания, чтобы обрабатывать регулировку напряжения для разных рабочих частот. В результате это может повлиять на производительность. [ как? ] Технология vSMP может динамически включать и отключать определенные ядра для активного и резервного использования, снижая общее энергопотребление.
Эти преимущества приводят к тому, что архитектура vSMP значительно выигрывает [ термин павлина ] по сравнению с другими архитектурами, использующими технологии асинхронной синхронизации.
5.5. Параллельная архитектура PVP с векторными процессорами
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гбайт/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP-архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дорого стоят, эти машины не могут быть общедоступными.
Наиболее популярны три машины PVP-архитектуры:
1. CRAY X1, SMP-архитектура (рис. 5.8). Пиковая производительность системы в стандартной конфигурации может составлять десятки терафлопс.
2. NEC SX-6, NUMA-архитектура. Пиковая производительность системы может достигать 8 Тфлопс, производительность одного процессора составляет 9,6 Гфлопс. Система масштабируется с единым образом операционной системы до 512 процессоров.
3. Fujitsu-VPP5000 (vector parallel processing), MPP-архитектура (рис. 5.9). Производительность одного процессора составляет 9.6 Гфлопс, пиковая производительность системы может достигать 1249 Гфлопс, максимальная емкость памяти – 8 Тбайт. Система масштабируется до 512 процессоров.
Парадигма программирования на PVP-системах предусматривает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
За счет большой физической памяти (доли терабайта) даже плохо векторизуемые задачи на PVP-системах решаются быстрее на машинах со скалярными процессорами.
|
Рисунок 5.8 – CRAY SV-2 |
Рисунок 5.9 – Fujitsu-VPP5000 |
Дизайн [ править ]
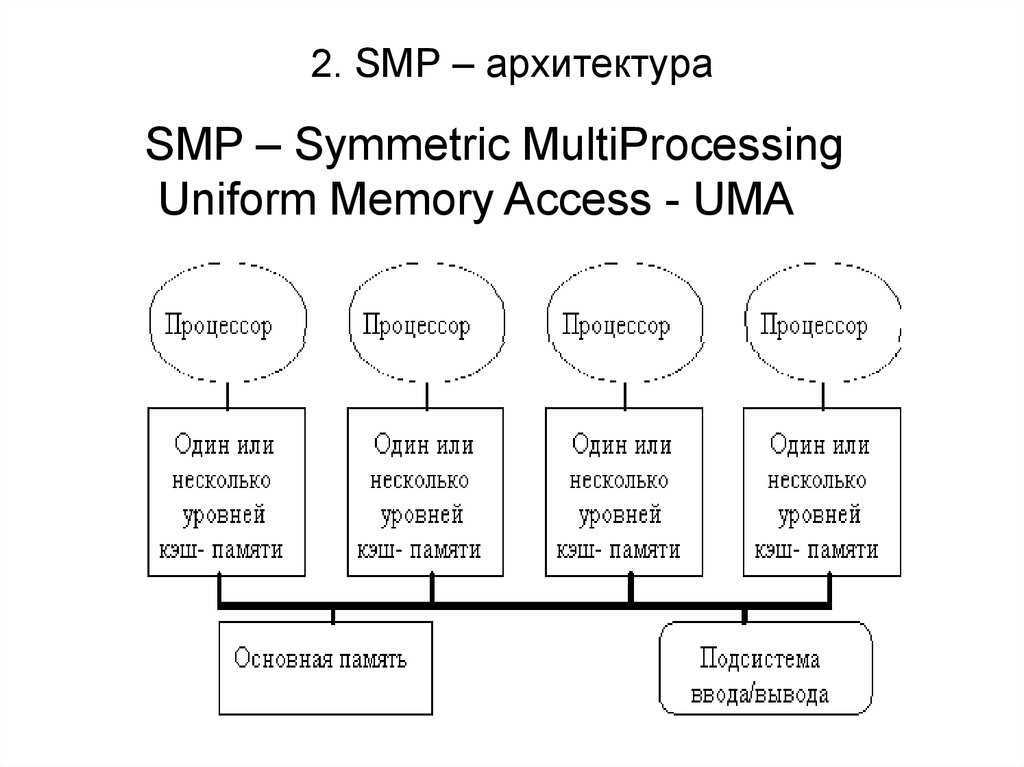
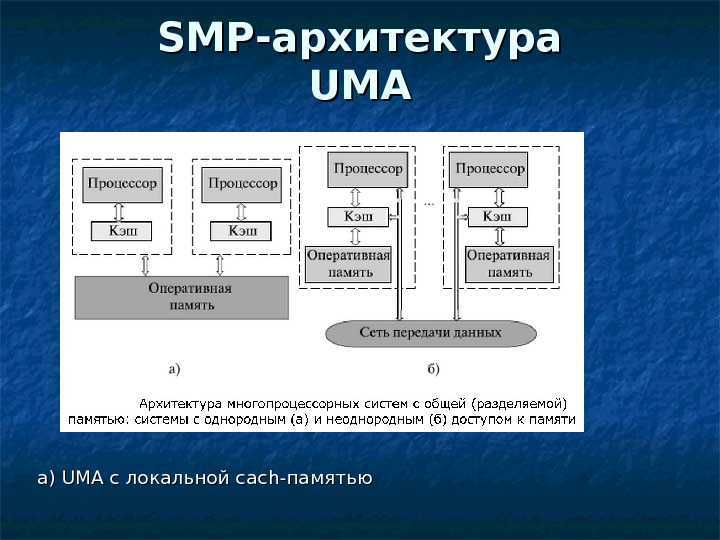
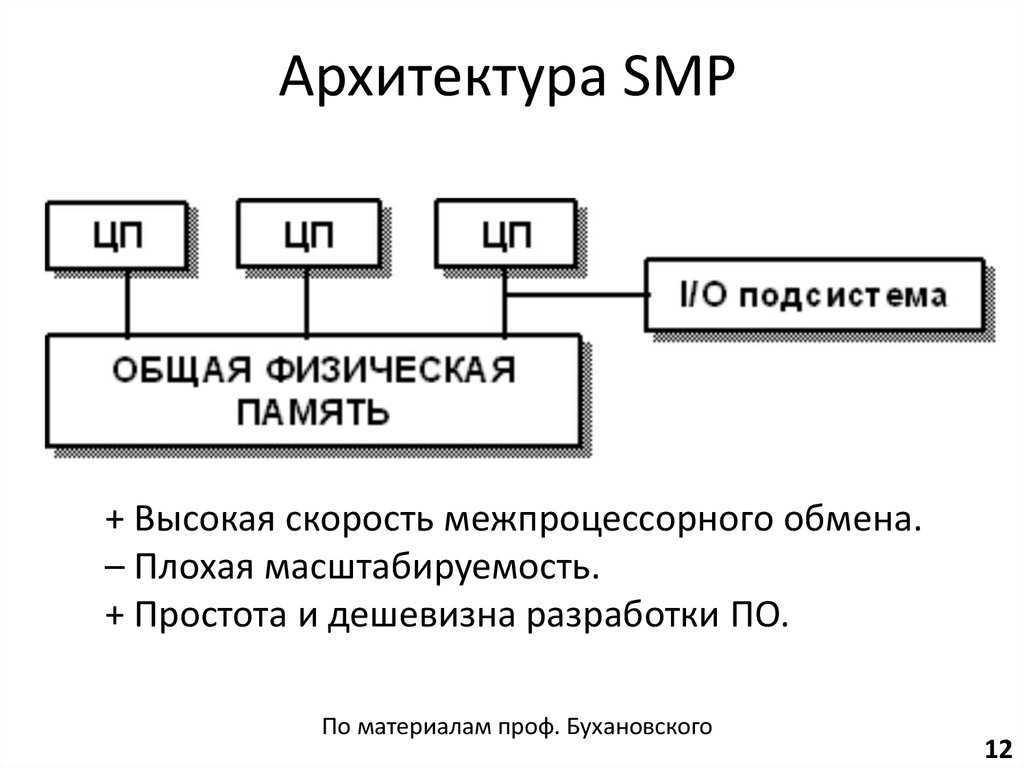
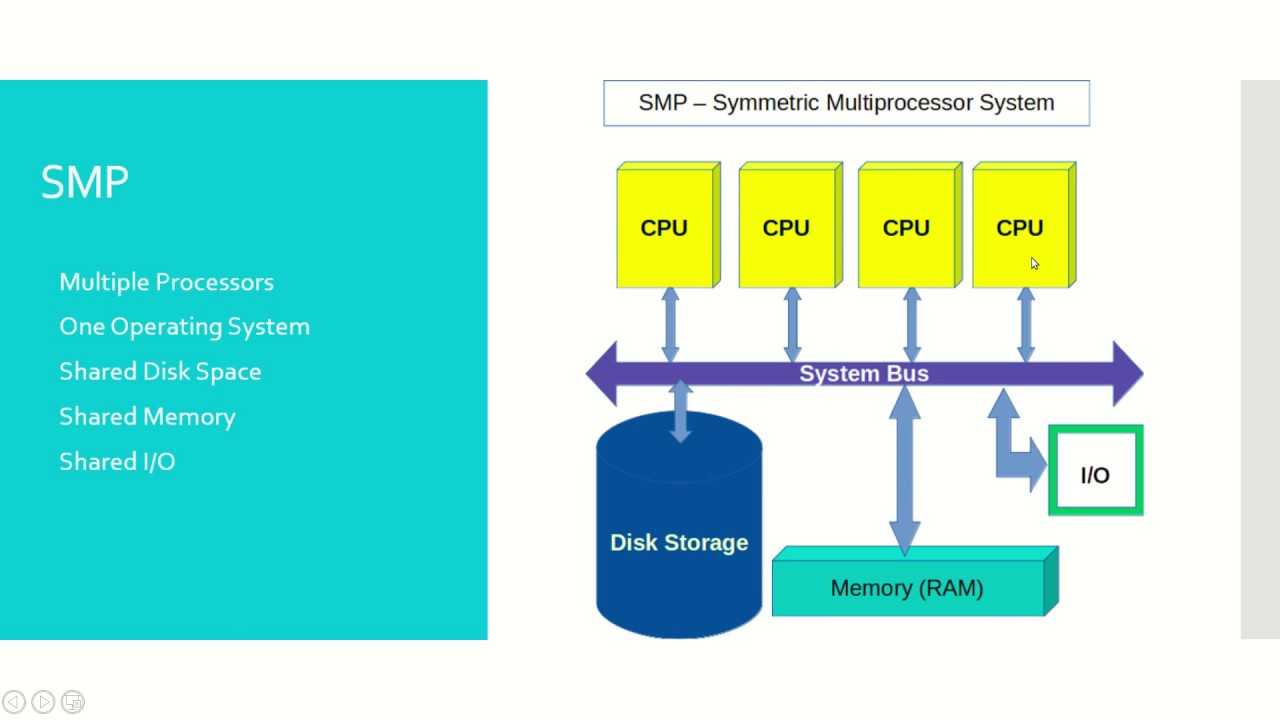
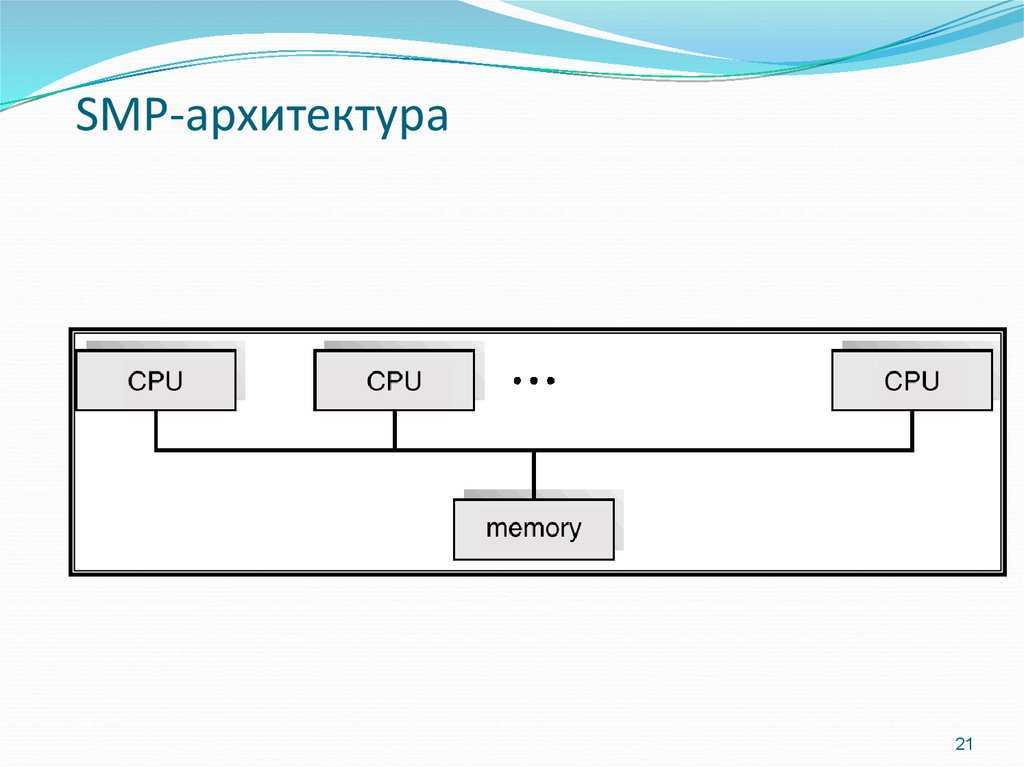
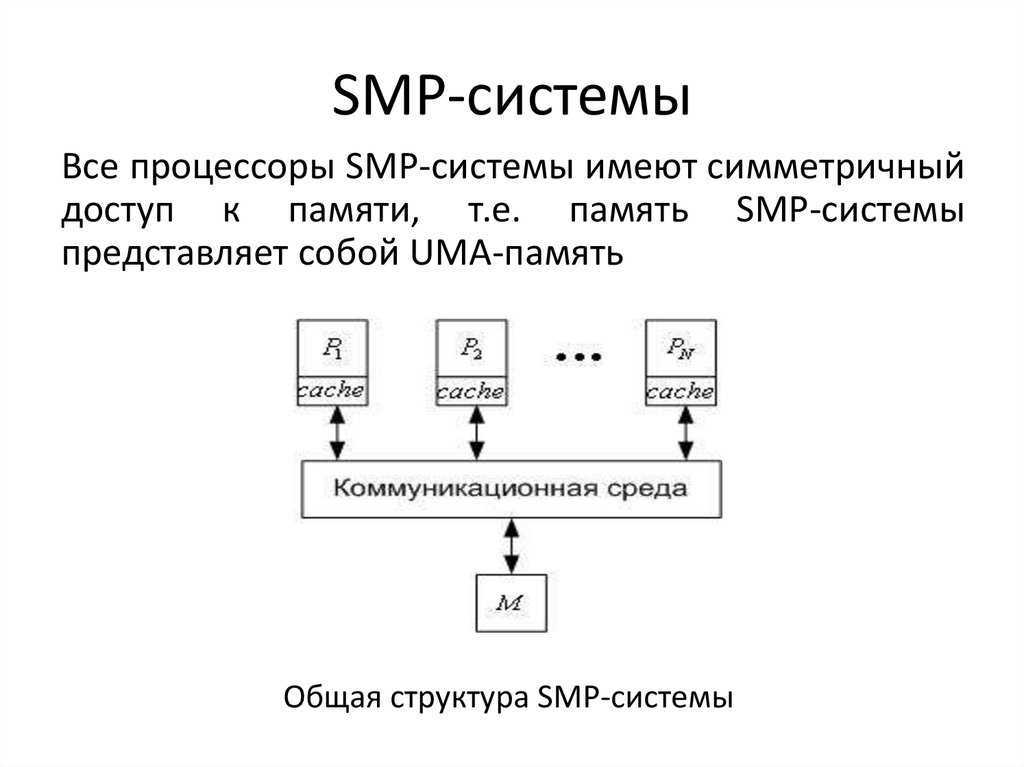
Системы SMP имеют централизованную разделяемую память, называемую основной памятью (MM), работающую под управлением одной операционной системы с двумя или более однородными процессорами. Обычно каждый процессор имеет связанную частную высокоскоростную память, известную как кэш-память (или кэш), для ускорения доступа к данным основной памяти и уменьшения трафика системной шины.
Процессоры могут быть соединены между собой с помощью шин, перекрестных переключателей или ячеистых сетей на кристалле. Узким местом масштабируемости SMP с использованием шин или перекрестных переключателей является пропускная способность и потребляемая мощность межсоединения между различными процессорами, памятью и дисковыми массивами. Сеточные архитектуры избегают этих узких мест и обеспечивают почти линейную масштабируемость для гораздо большего количества процессоров в ущерб программируемости:
Системы SMP позволяют любому процессору работать над любой задачей независимо от того, где данные для этой задачи расположены в памяти, при условии, что каждая задача в системе не выполняется на двух или более процессорах одновременно. При надлежащей поддержке операционной системы системы SMP могут легко перемещать задачи между процессорами, чтобы эффективно сбалансировать рабочую нагрузку.
Внешние ссылки [ править ]
- История мультиобработки
- Linux и многопроцессорность
- AMD
| vтеПараллельные вычисления | |
|---|---|
| Общий |
|
| Уровни |
|
| Многопоточность |
|
| Теория |
|
| Элементы |
|
| Координация |
|
| Программирование |
|
| Аппаратное обеспечение |
|
| API |
|
| Проблемы |
|
Программирование [ править ]
Однопроцессорные системы и системы SMP требуют различных методов программирования для достижения максимальной производительности. Программы, работающие в системах SMP, могут увеличивать производительность, даже если они были написаны для однопроцессорных систем. Это связано с тем, что аппаратные прерывания обычно приостанавливают выполнение программы, в то время как ядро, которое их обрабатывает, может вместо этого выполняться на простаивающем процессоре. Эффект в большинстве приложений (например, игр) заключается не столько в увеличении производительности, сколько в том, что программа работает более плавно. Некоторые приложения, в частности, программное обеспечение для сборки и некоторые распределенные вычисления.проекты, выполняются быстрее (почти) из-за количества дополнительных процессоров. (Компиляторы сами по себе являются однопоточными, но при создании программного проекта с несколькими модулями компиляции, если каждый модуль компиляции обрабатывается независимо, это создает неприятно параллельную ситуацию во всем проекте с несколькими модулями компиляции, что позволяет практически линейное масштабирование компиляции. время. Проекты распределенных вычислений изначально параллельны.)
Системные программисты должны встроить поддержку SMP в операционную систему , в противном случае дополнительные процессоры останутся простаивающими, а система будет функционировать как однопроцессорная.
Системы SMP также могут усложнять наборы инструкций. Однородная процессорная система обычно требует дополнительных регистров для «специальных инструкций», таких как SIMD (MMX, SSE и т. Д.), В то время как гетерогенная система может реализовывать различные типы оборудования для разных инструкций / использования.
История [ править ]
Самой ранней производственной системой с несколькими идентичными процессорами была Burroughs B5000 , которая работала около 1961 года. Однако во время выполнения это было : один процессор ограничивался прикладными программами, а другой процессор в основном обрабатывал операционную систему и аппаратные прерывания. В Burroughs D825 впервые был реализован SMP в 1962 году.
![Симметричная многопроцессорная обработкасодержание а также дизайн [ править ]](https://robotrackkursk.ru/wp-content/uploads/5/0/e/50edd30e35e1da21949c9e737426aa26.jpeg)
![Симметричная многопроцессорная обработкасодержание а также дизайн [ править ]](https://robotrackkursk.ru/wp-content/uploads/5/e/f/5ef8f6f810d36fd5c5782bb04dce0725.jpeg)
![Симметричная многопроцессорная обработкасодержание а также дизайн [ править ]](https://robotrackkursk.ru/wp-content/uploads/7/a/6/7a68c60918cd244f384a46755dc478ef.png)
![Симметричная многопроцессорная обработкасодержание а также дизайн [ править ]](https://robotrackkursk.ru/wp-content/uploads/8/0/d/80defd8d9aade94b9a6778c100dddfbd.jpeg)
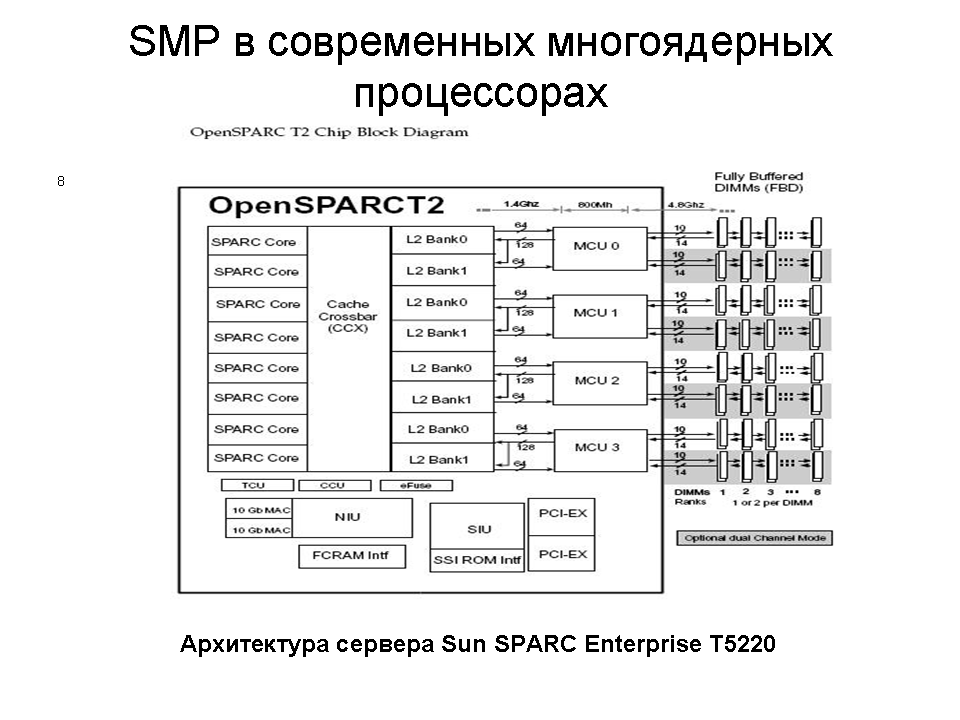
IBM предложила двухпроцессорные компьютерные системы на основе своей System / 360 Model 65 и родственной Model 67 и 67–2. На этих машинах работали операционные системы OS / 360 M65MP и TSS / 360 . Другое программное обеспечение, разработанное в университетах, особенно Michigan Terminal System (MTS), использовало оба процессора. Оба процессора могут получать доступ к каналам данных и инициировать ввод-вывод. В OS / 360 M65MP периферийные устройства обычно могут быть подключены к любому процессору, поскольку ядро операционной системы работает на обоих процессорах (хотя и с «большой блокировкой» вокруг обработчика ввода-вывода). Супервизор MTS (UMMPS) может работать на обоих ЦП модели IBM System / 360 67–2. Блокировки супервизора были небольшими и использовались для защиты отдельных общих структур данных, к которым можно было получить доступ одновременно с любого процессора.
Другие мэйнфреймы, поддерживающие SMP, включали UNIVAC 1108 II , выпущенный в 1965 году, который поддерживал до трех процессоров, а также GE-635 и GE-645 , , хотя GECOS на многопроцессорных системах GE-635 выполнялся в главном устройстве. -slave асимметричный режим, в отличие от Multics в многопроцессорных системах GE-645, который работал в симметричном режиме.
Начиная с версии 7.0 (1972 г.), операционная система TOPS-10 от Digital Equipment Corporation реализовывала функцию SMP, самой ранней системой, работающей с SMP, была система с двумя процессорами DECSystem 1077 с двумя процессорами KI10. Позже система KL10 могла объединять до 8 процессоров в режиме SMP. В противоположность этому , РИК первый многопроцессорной VAX системы, VAX-11/782 был асимметричным, , но позже VAX многопроцессорные системы были SMP.
Ранние коммерческие реализации SMP для Unix включали Sequent Computer Systems Balance 8000 (выпущенный в 1984 году) и Balance 21000 (выпущенный в 1986 году). Обе модели были основаны на процессорах National Semiconductor NS32032 с тактовой частотой 10 МГц , каждая из которых имела небольшой кэш со сквозной записью, подключенный к общей памяти для формирования общей памяти.система. Другой ранней коммерческой реализацией SMP для Unix была система Honeywell Information Systems Italy XPS-100 на базе NUMA, разработанная Дэном Гиланом из VAST Corporation в 1985 году. Ее конструкция поддерживала до 14 процессоров, но из-за электрических ограничений самой крупной продаваемой версией была двухпроцессорная система. . Операционная система была получена и перенесена корпорацией VAST на основе кода AT&T 3B20 Unix SysVr3, используемого внутри компании AT&T.
Ранее существовали некоммерческие многопроцессорные порты UNIX, в том числе порт под названием MUNIX, созданный в Морской аспирантуре к 1975 году .
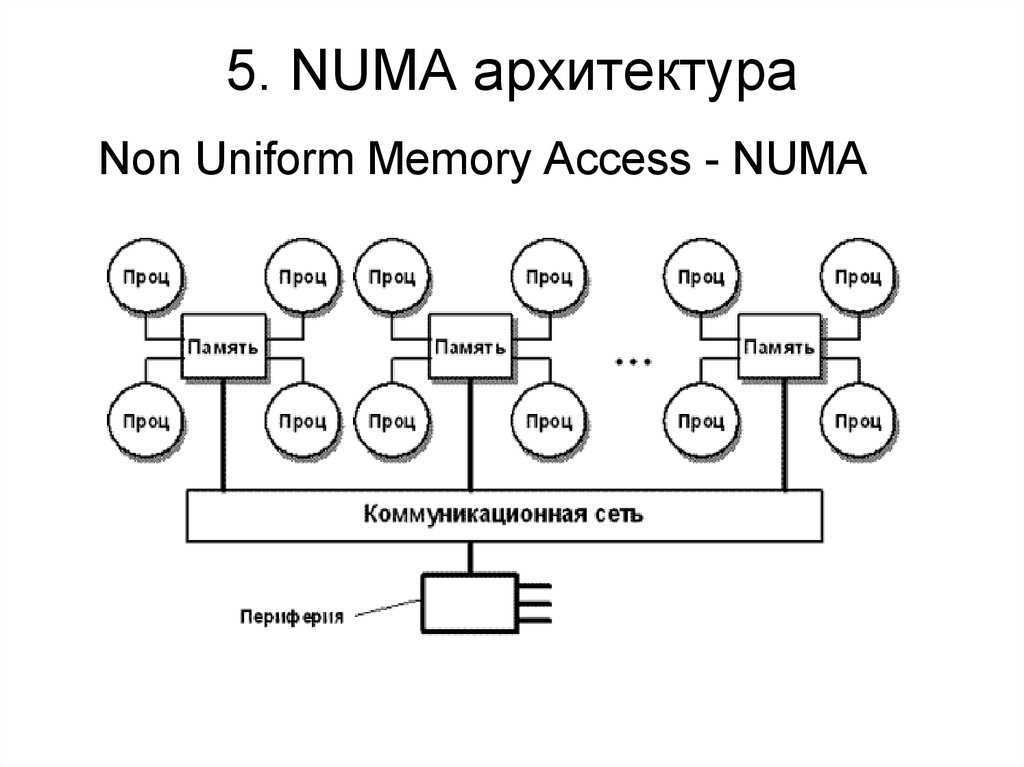
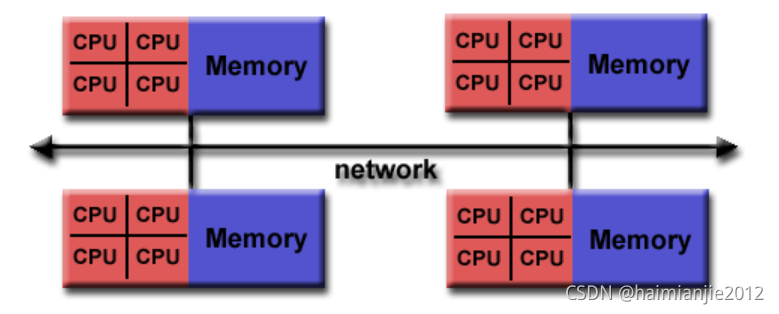
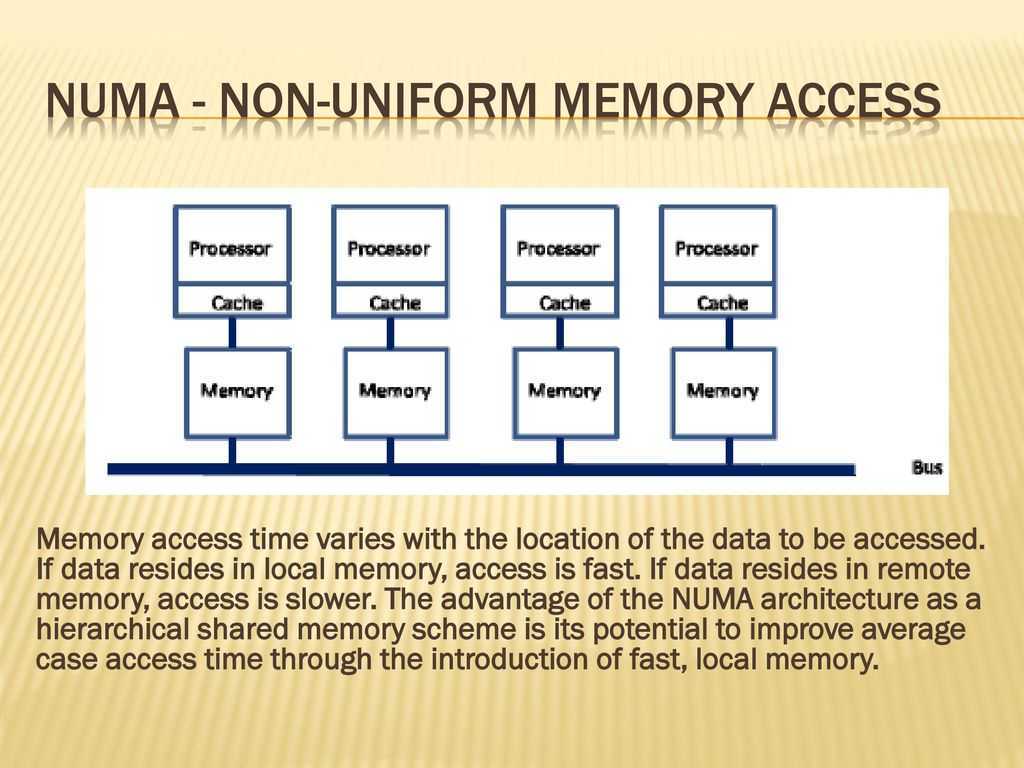
5.4. Гибридная архитектура NUMA
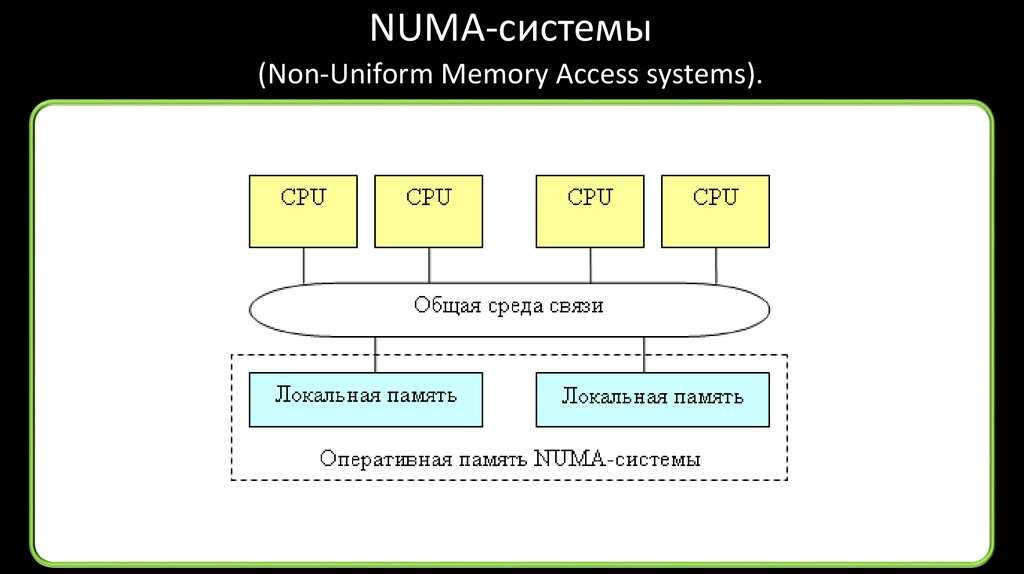
Главная особенность гибридной архитектуры NUMA (nonuniform memory access) – неоднородный доступ к памяти.
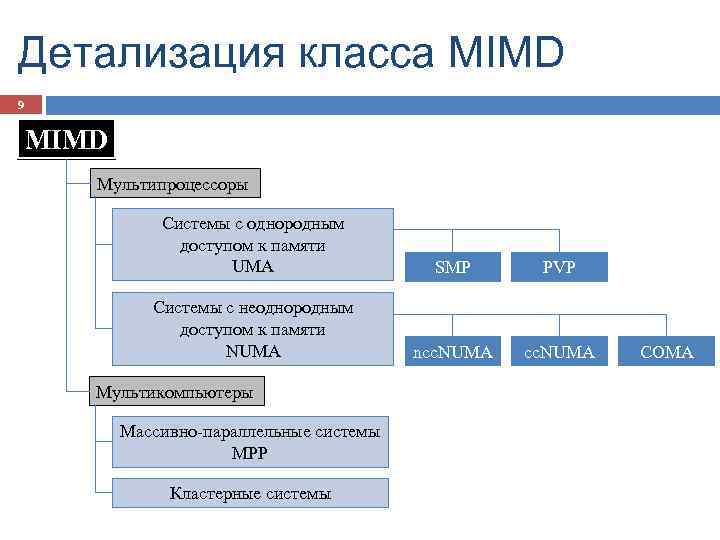
Суть этой архитектуры – в особой организации памяти, а именно: память физически распределена по различным частям системы, но логически она является общей, так что пользователь видит единое адресное пространство. Система построена из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной. По существу, архитектура NUMA является MPP (массивно-параллельной) архитектурой, где в качестве отдельных вычислительных элементов берутся SMP (симметричная многопроцессорная архитектура) узлы. Доступ к памяти и обмен данными внутри одного SMP-узла осуществляется через локальную память узла и происходит очень быстро, а к процессорам другого SMP-узла тоже есть доступ, но более медленный и через более сложную систему адресации.
Гибридная архитектура совмещает достоинства систем с общей памятью и относительную дешевизну систем с раздельной памятью.
В структурной схеме компьютера с гибридной сетью (рис. 5.7) три процессора связываются между собой при помощи общей оперативной памяти в рамках одного SMP-узла. Узлы связаны сетью типа «бабочка» (Butterfly).
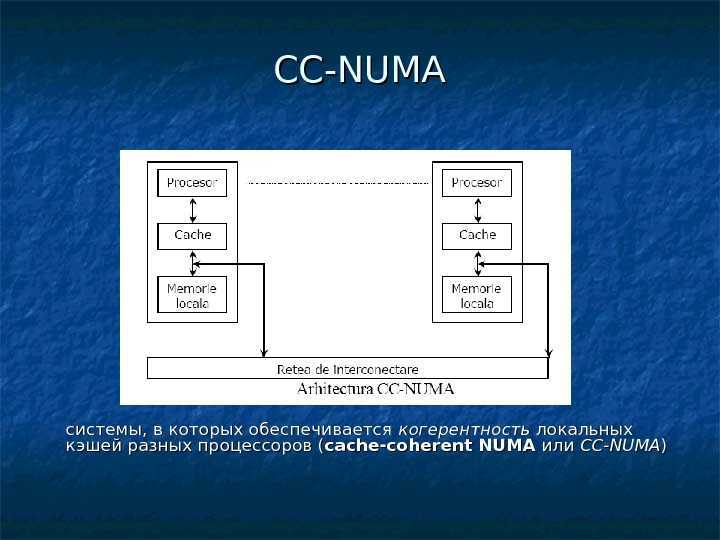
Впервые идею гибридной архитектуры предложил Стив Воллох, он воплотил ее в системах серии Exemplar. Вариант Воллоха – система, состоящая из восьми SMP-узлов. Фирма HP купила идею и реализовала на суперкомпьютерах серии SPP. Идею подхватил Сеймур Крей (Seymour R. Cray) и добавил новый элемент – когерентный кэш, создав так называемую архитектуру cc-NUMA (Cache Coherent Non-Uniform Memory Access), которая расшифровывается как «неоднородный доступ к памяти с обеспечением когерентности кэшей». Он ее реализовал на системах типа Origin.
Рисунок 5.7 – Структурная схема компьютера с гибридной сетью
Организация когерентности многоуровневой иерархической памяти
Понятие когерентности кэшей описывает тот факт, что все центральные процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Действительно, поскольку кэш-память принадлежит отдельному компьютеру, а не всей многопроцессорной системе в целом, данные, попадающие в кэш одного компьютера, могут быть недоступны другому. Чтобы этого избежать, следует провести синхронизацию информации, хранящейся в кэш-памяти процессоров.
Для обеспечения когерентности кэшей существует несколько возможностей:
— использовать механизм отслеживания шинных запросов (snoopy bus protocol), в котором кэши отслеживают переменные, передаваемые к любому из центральных процессоров и при необходимости модифицируют собственные копии таких переменных;
— выделять специальную часть памяти, отвечающую за отслеживание достоверности всех используемых копий переменных.
Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях, SGI Origin3000, Sun HPC 15000, IBM/Sequent NUMA-Q 2000. На сегодня максимальное число процессоров в cc-NUMA-системах может превышать 1000 (серия Origin3000). Обычно вся система работает под управлением единой ОС, как в SMP. Возможны также варианты динамического «подразделения» системы, когда отдельные «разделы» системы работают под управлением разных ОС. При работе с NUMA-системами, так же, как с SMP, используют так называемую парадигму программирования с общей памятью (shared memory paradigm).
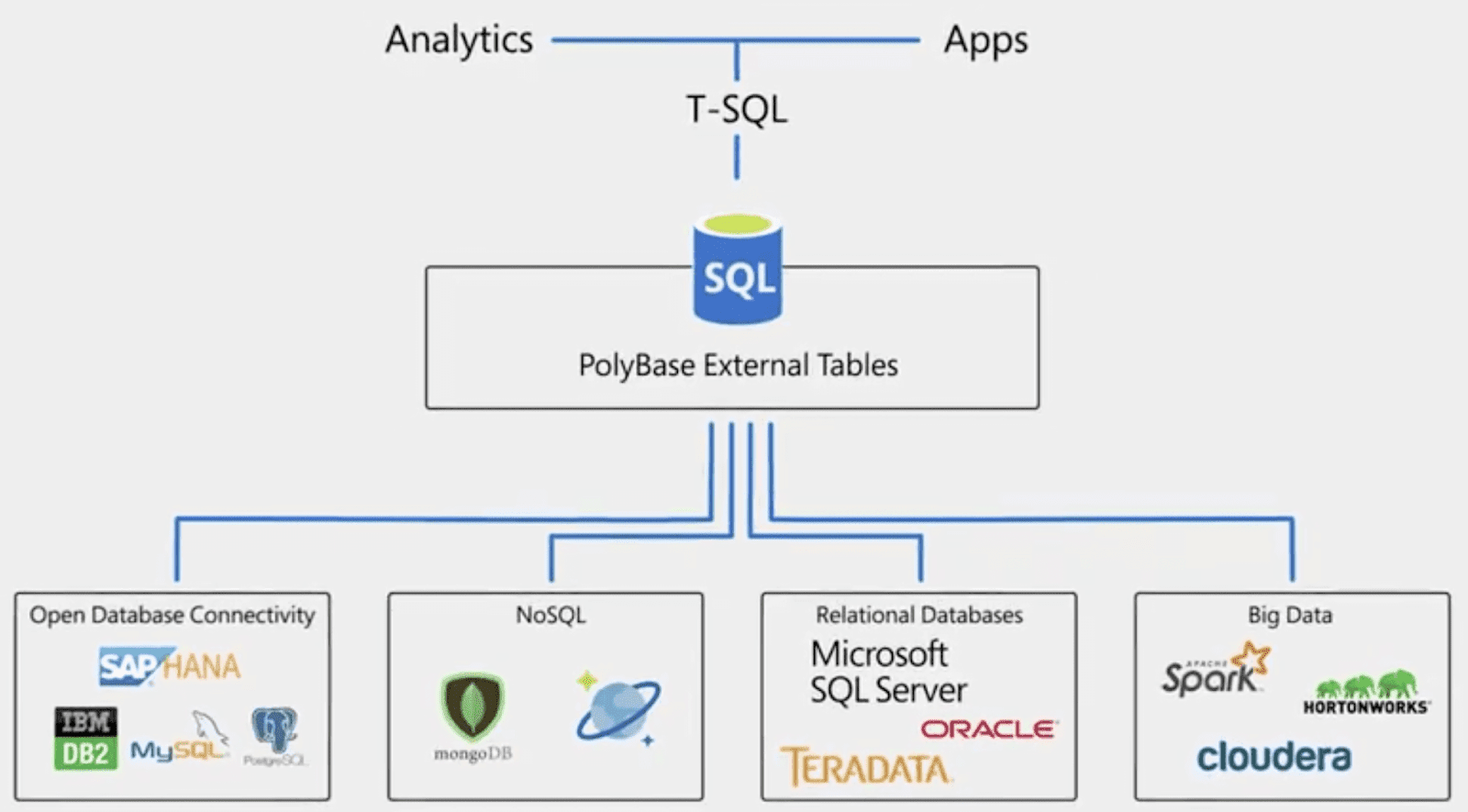
Выбор хранилища данных
Какой сервер больше подходит для среды хранилища данных? Это необходимо начать с нагрузочных характеристик самой среды хранилища данных. Как мы все знаем, типичная среда хранилища данных требует большого количества сложных операций обработки и всестороннего анализа, требующих, чтобы система имела высокую способность обработки ввода-вывода, а система хранения должна обеспечивать достаточную полосу пропускания ввода-вывода, чтобы соответствовать этому. Типичная OLTP-система ориентирована на онлайн-обработку транзакций, и каждая транзакция включает в себя не так много данных, что требует, чтобы система имела высокие возможности обработки транзакций и могла обрабатывать как можно больше транзакций за единицу времени. Очевидно, что нагрузочные характеристики этих двух прикладных сред полностью различаются. С точки зрения архитектуры NUMA, он может интегрировать множество процессоров в физический сервер, так что система имеет более высокую способность обработки транзакций. Поскольку задержка удаленного доступа к памяти намного больше, чем доступ к локальной памяти, Следовательно, необходимо минимизировать взаимодействие данных между различными модулями ЦП. Очевидно, что архитектура NUMA больше подходит для среды обработки транзакций OLTP.При использовании в среде хранилища данных большой объем сложной обработки данных неизбежно приведет к большому объему взаимодействия данных, что значительно снизит загрузку ЦП. Относительно возможности параллельной обработки архитектуры сервера MPP превосходят, и она больше подходит для сложных сред комплексного анализа и обработки данных. Конечно, необходимо использовать систему реляционной базы данных, которая поддерживает технологию MPP, чтобы защитить сложность балансировки нагрузки и планирования между узлами. Кроме того, эта возможность параллельной обработки имеет прямое отношение к сети взаимосвязи узлов. Очевидно, что производительность ввода-вывода сети межсетевого взаимодействия узлов сервера MPP, адаптированная к среде хранилища данных, должна быть очень заметной, чтобы дать полную возможность производительности всей системы.
Трансфер из:https://www.cnblogs.com/carl-angela/p/5407236.html OF: geek3 Верить в то, что мечты являются источником ценности, что видение определяет все в будущем, что вера в успех важнее самого успеха, что в жизни бывают неудачи без неудач и что качество жизни зависит от бескомпромиссности вера! —— Я компьютерщик!
Альтернативы [ править ]
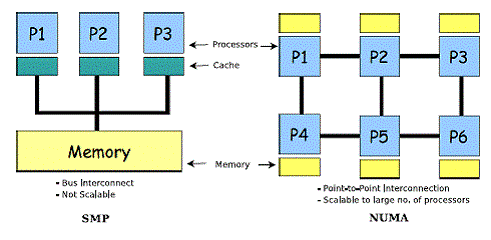
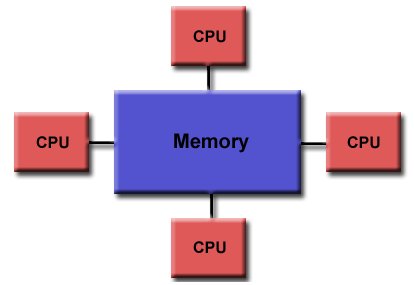
Схема типичной SMP-системы. Три процессора подключены к одному модулю памяти через системную шину или кроссбарный переключатель.
SMP использует единую общую системную шину, которая представляет собой один из самых ранних стилей архитектур многопроцессорных машин, обычно используемый для создания небольших компьютеров с 8 процессорами.
В более крупных компьютерных системах могут использоваться более новые архитектуры, такие как NUMA (неоднородный доступ к памяти), которая выделяет разные банки памяти для разных процессоров. В архитектуре NUMA процессоры могут обращаться к локальной памяти быстрее, а к удаленной — медленнее. Это может значительно улучшить пропускную способность памяти, если данные локализованы для определенных процессов (и, следовательно, процессоров). С другой стороны, NUMA удорожает перемещение данных от одного процессора к другому, как при балансировке рабочей нагрузки. Преимущества NUMA ограничены определенными рабочими нагрузками, особенно на серверах, где данные часто прочно связаны с определенными задачами или пользователями.
Наконец, есть компьютерная кластерная многопроцессорная обработка (например, Beowulf ), в которой не вся память доступна для всех процессоров. Методы кластеризации довольно широко используются для создания очень больших суперкомпьютеров.