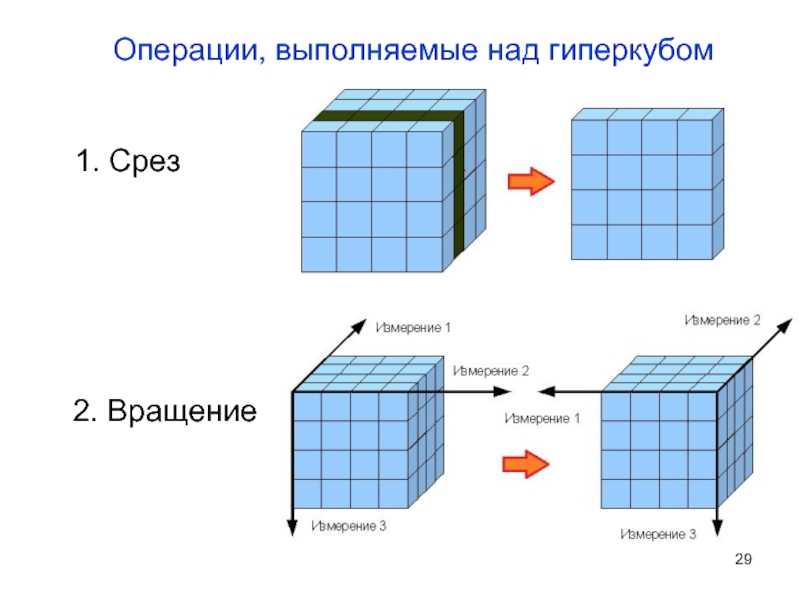
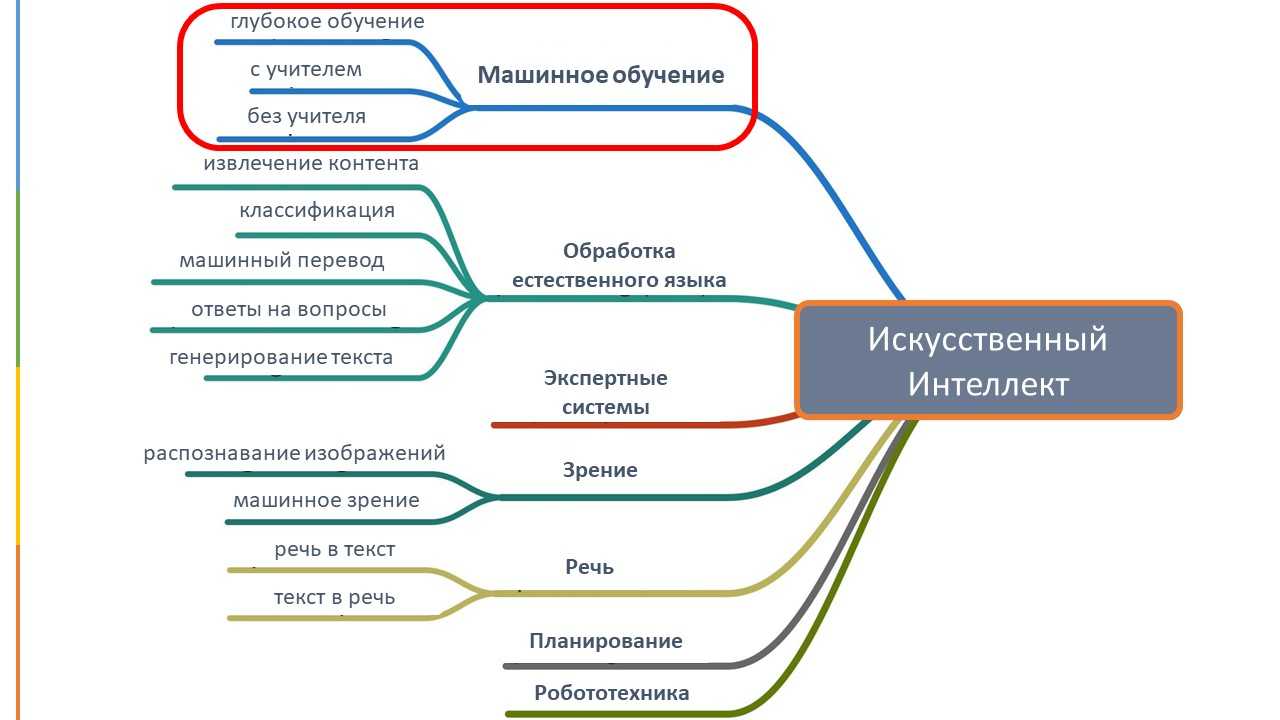
Иерархии атрибутов
Нам известно, что при разворачивании и сворачивании уровней по каждой оси значения в сводной таблице изменяются. Почему это происходит? Ответ следует искать в иерархии атрибутов.
Сверните все уровни и обратите внимание на общие итоги для каждого компонента «Группа стран» и «Календарный год». Это значение получено из объекта элемент (Все) в иерархии
Это вычисленное значение всех элементов в иерархии.
-
Значение элемента (Все) для всех групп стран и дат — $80 450 596,98
-
Значение элемента (Все) для 2008 календарного года — $16 038 062,60
-
Значение элемента (Все) для Тихоокеанского региона — $1 594 335,38
Подобные агрегаты предварительно вычисляются и заранее сохраняются. Именно поэтому службам Analysis Services свойственна высокая скорость обработки запросов.

Разверните иерархию и вы увидите самый нижний уровень. Он называется конечным элементом. У конечного элемента в иерархии нет дочерних элементов. В этом примере юго-запад является конечным элементом.
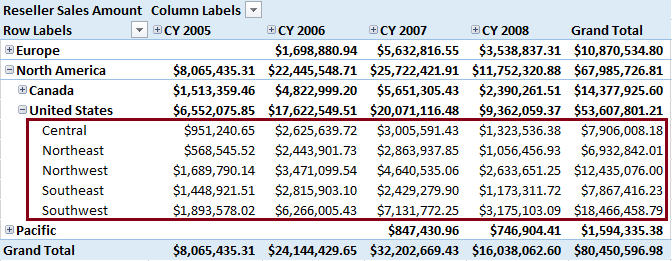
Все, что выше этого элемента, называется родительским элементом. США является родительским объектом юго-запада.
Компоненты иерархии атрибута
Все эти компоненты работают на формирование понятия иерархии атрибута. Иерархия атрибута представляет собой дерево элементов атрибута, содержащих следующие уровни.
-
Конечный уровень, содержащий все отдельные элементы атрибута, и все элементы конечного уровня ( конечные элементы).
-
Промежуточные уровни, если иерархия атрибута является иерархией родительских и дочерних элементов (подробнее об этом позже).
-
Элемент (Все), содержащий совокупное значение всех дочерних атрибутов. При необходимости можно скрыть или отключить уровень (Все), если он не имеет смысла для данных. Например, хотя код продукта является числовым, не имеет смысла суммировать или усреднять или иным образом агрегировать все коды продуктов.
Примечание
Разработчики бизнес-аналитики часто задают свойства в иерархии атрибута, чтобы сформировать определенное поведение в клиентских приложениях или добиться максимальной производительности. Например, можно задать AttributeHierarchyEnabled=False для атрибутов, для которых элемент (All) не имеет смысла. С другой стороны, возможно, вы просто хотите скрыть элемент (Все), поэтому должны задать AttributeHierarchyVisible = False. Дополнительные сведения о свойствах см. в разделе Dimension Attribute Properties Reference .
Читаем данные
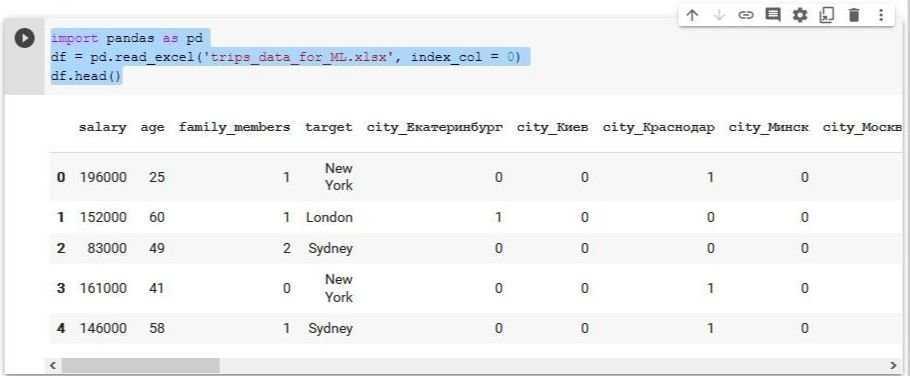
Данные нужно прочитать из файла и преобразовать в подходящий для работы формат. Для этого в колабе добавим новую кодовую ячейку с помощью кнопки «+ Код» вверху и напишем в ней:
В первой строчке мы импортировали популярную библиотеку Pandas, предназначенную для работы с табличными данными. Чтобы каждый раз в коде не писать её полное название, по сложившейся в data science традиции будем использовать для неё короткое имя pd.
Во второй строке мы создали переменную с названием df. Далее, после знака «равно», Pandas, под коротким именем pd, с помощью функции .read_excel () прочитала файл trips_data_for_ML.xlsx, который мы загрузили в наш колаб-ноутбук. Параметр index_col мы приравняли к нулю — это означает, что индексной колонкой (той, где идут номера строк) в нашей новой таблице df мы назначили колонку под номером 0 из прочитанной Excel-таблицы.
Наконец, в третьей строке мы применили к нашей переменной df метод .head ().
Подобные работы
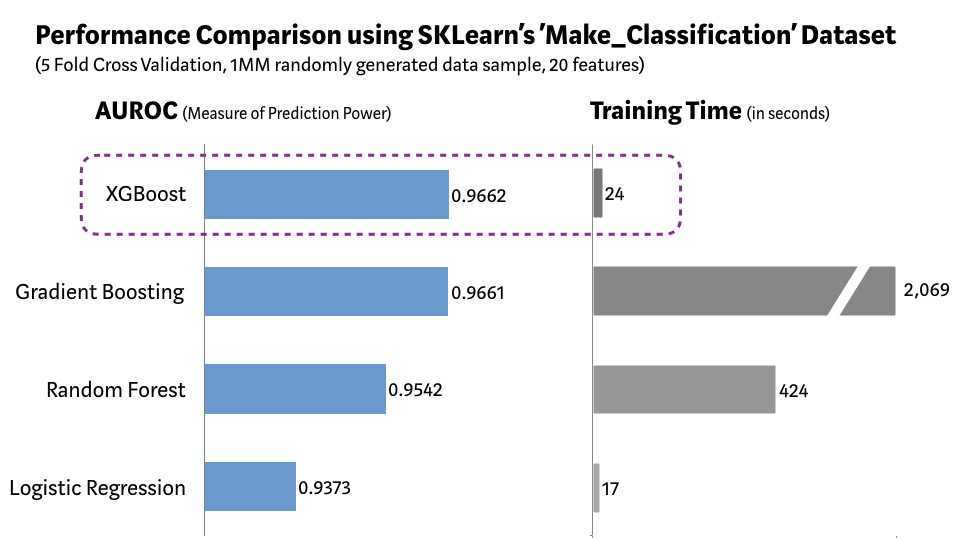
Выбор функций: выбор функций в машинном обучении, в широком смысле, означает разумный выбор подмножества функций сходства (близости) на основе их полезности для прогнозирования
Широко используемые методы, такие как прямой отбор и регуляризация LASSO , характеризуются важностью признаков, основанных на всем наборе обучающих данных, они называются глобальными методами. Выбор функции для конкретного экземпляра определяется особенностями каждого входа, изученным в путем обучения описательной модели для максимизации обобщающей способности по обратным связям выбранной функции и переменной отклика, а в с использованием структуры «субъект-критик» для имитации многообразия опорных векторов при оптимизации выбора функции
В отличие от них, TabNet использует другой набор функций, с контролируемой разреженностью (предикативностью) в сквозном обучении и единой моделью сопоставления выходных данных, которые обеспечивают в результате превосходную производительность при компактном представлении данных.
Обучение на основе деревьев: модели на основе деревьев являются наиболее распространенным подходом к изучению на табличных данных
Важной и сильной стороной древовидных моделей является их эффективность в выборе глобальных характеристик с наибольшим статистическим объемом информации . Чтобы улучшить производительность стандартных древовидных моделей за счет уменьшения остаточной дисперсии модели, одним из распространенных подходов является ансамблевый (агрегирование)
Среди методов агрегирования – случайные леса , использующие случайные подмножества данных со случайно выбранными объектами для генерации и эволюции деревьев. XGBoost и LightGBM — два недавних подхода к дереву решений ансамбля, которые доминируют в использовании и исследовании в науке о данных (Data Science). Наши экспериментальные результаты для различных наборов данных показывают, что эффективность древовидных моделей может быть превзойдена, если улучшить способность к глубокому обучению при сохранении свойств функции, предсказательной способности.
Интеграция DNN в деревья решений: представление деревьев решений с помощью канонических элементов ГНС, как в , приводит к избыточности представления и неэффективному обучению. Предлагаются гибкие (нейронные) деревья решений с дифференцируемыми функциями принятия решений вместо не дифференцируемых
Однако при отказе от деревьев теряется их способность автоматического выбора функций, что важно для табличных данных. В функцией мягкого связывания предлагается моделировать деревья решений в ГНС, но она при перечислении всевозможных решений является неэффективной
В предлагается ГНС-архитектура, явно использующая объясняющие способности комбинаций функций, но обучение основано на передаче знаний с помощью дерева решений с градиентным бустингом, есть ограничения по улучшению производительности. В предлагается ГНС-архитектура адаптивного роста от базовой системы «примитивов обучения» (вершин, ребер), с помощью функций маршрутизации до конечных узлов дерева решений. TabNet отличается от этих методов тем, что включает в себя гибкую функцию возможности выбора с контролируемой разреженностью за счет последовательных переоценок.
Модели преобразования таблиц в тексты: таблично-текстовые модели извлекают текстовую информацию из табличных данных, для чего в последних работах предлагается последовательный механизм контроля внимания на уровне полей. В отличие от них, мы демонстрируем применение обучения с учителем или самообучения вместо сопоставления табличных данных с другим типом данных.
Самообучение: обучение без учителя показывает, что полезно для самообучения, особенно на небольших выборках данных . Недавняя работа с данными по языку и изображению показала значительные достижения — особенно важен тщательный выбор цели обучения без учителя и архитектуры глубокого обучения без учителя.
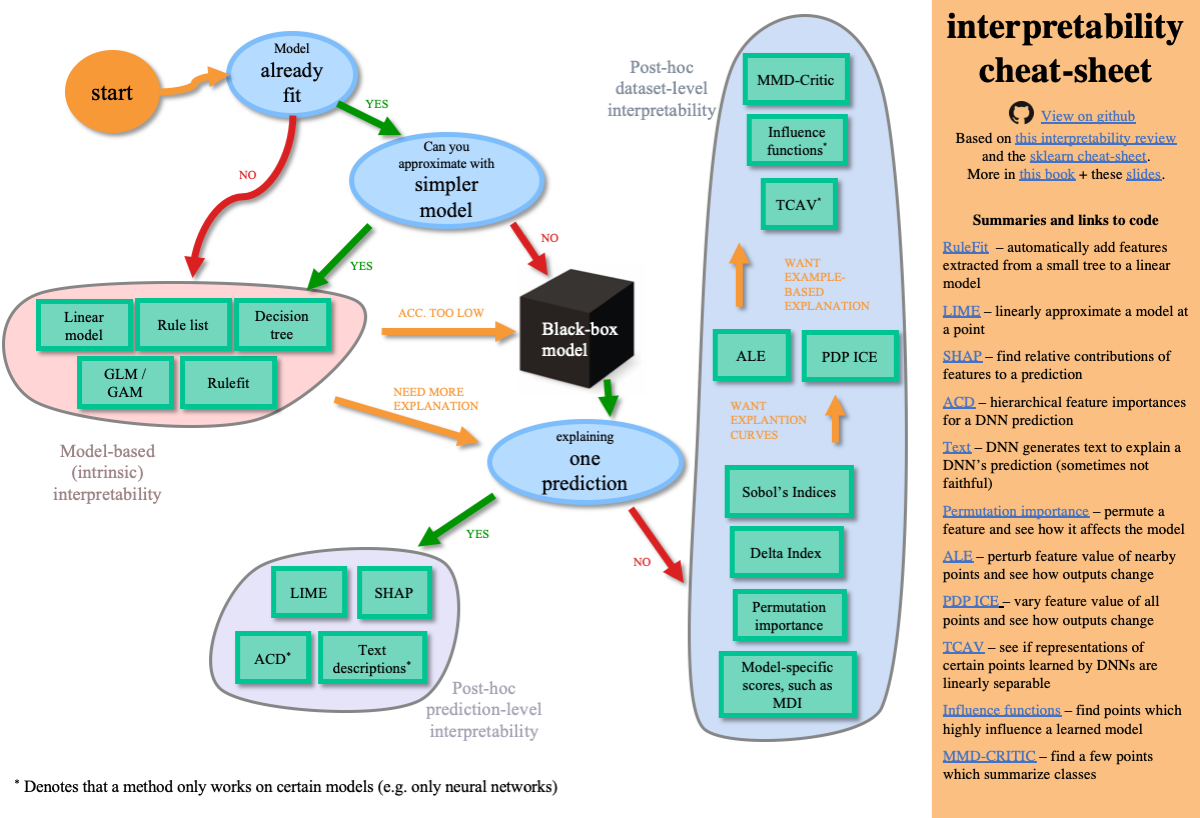
Рисунок 3. Иллюстрация древовидной классификации решений с использованием обычных блоков ГНС (слева) и соответствующего многообразия решений (справа). Соответствующие объекты выбираются с помощью мультипликативных разреженных масок на входных данных. Выбранные объекты линейно преобразуются, и после добавления смещения (для представления, учета границ) ReLU выполняет выбор области путем обнуления областей, находящихся на отрицательной стороне градиента границы. Агрегация нескольких кластеров основана по аддитивному принципу. По мере увеличения C1 и C2, граница решения становится более резкой из-за функции Softmax (значения классифицирующей логистической функции).
Как смоделировать бизнес-процесс самостоятельно
Покажем, как описать и смоделировать бизнес-процесс, на примере обработки заявки учебного центра. Использовать конструкторы не будем — все модели из примера построим в графическом редакторе.
1. Задаём точки входа и выхода. Вход — первое событие в процессе, выход — результат. Так обозначают границы, чтобы потом наполнить процесс действиями. Нужно определить:
- Когда начинается процесс. В нашем примере это момент получения заявки от клиента. Если компания использует CRM, точкой входа будет попадание заявки в систему.
- Когда процесс закончится. Это момент успешной реализации сделки: клиент оплатил счёт, а продавец и логист организовали доставку.
Можно придумать несколько вариантов точек входа и выхода — для разных вариантов развития события.
Задаём границы бизнес-процессаИнфографика: Майя Мальгина для Skillbox Media
2. Описываем элементы. При составлении схемы перед глазами нужно держать основную информацию о процессе, чтобы ничего не забыть. Для этого в любом файле подробно описываем:


- зачем нужен процесс;
- из каких шагов и действий он состоит;
- кто исполнители;
- есть ли ограничения по срокам — сколько времени должен занимать весь процесс и его отдельные шаги;
- какие события сопровождают действия исполнителей — например, обмен документами, информацией, денежные переводы;
- какого результата нужно достичь — например, нужны подготовленные документы или оплата по счёту;
- перечень ресурсов — что исполнителю нужно для реализации процесса;
- показатели эффективности — по каким параметрам отслеживать, достигнута цель процесса или нет;
- детали и особенности отдельных этапов.
Здесь лежит шаблон текстового описания процесса.
3. Выделяем основные этапы процесса. На основе описанного в предыдущем пункте процесса составляем блок-схему. В графическом редакторе рисуем каркас — основные этапы в пределах границ входа и выхода.
Рисуем каркас — основные этапы процессаИнфографика: Майя Мальгина для Skillbox Media
4. Добавляем детали. Наполняем каркас «мясом» — основными событиями по процессу и действиями исполнителя по алгоритму.
Добавляем детали — основные события процесса и действия исполнителяИнфографика: Майя Мальгина для Skillbox Media
5. Задаём роли. В процессе может быть несколько исполнительских ролей. Их может выполнять один или несколько сотрудников. Обычно роли обезличены, без уточнения фамилий, — только должности.
6. Наполняем схему ресурсами. Отмечаем на схеме источники ресурсов, которые будут использовать в бизнес-процессе. Например, какие документы кто кому и на каком этапе отправит, какие базы и системы для этого будет использовать.
В нашей «ручной» схеме — это просто дополнительные элементы в алгоритме. Если для моделирования используется специальный софт, к схеме можно прикрепить ссылки.
Фрагмент процессной модели бизнес-процесса: основные действия менеджера по продажамИнфографика: Майя Мальгина для Skillbox Media
Блок-схема готова. Если таких схем несколько, их процессы можно связать друг с другом на одной карте.
Что такое финансовая модель
Финансовая модель — таблица, в которой объединяют показатели доходов, расходов, прибыли компании и показывают связи между ними.
Финансовая модель помогает:
- увидеть, какую прибыль получит компания при текущем уровне доходов и расходов;
- увидеть, за счёт чего можно увеличить прибыль;
- оценить, как изменится финансовый результат компании, если изменить некоторые показатели — например, снизить себестоимость продукции на 5%;
- принимать управленческие решения на основе этих данных.
При этом решения могут быть разными: от воплощения финансовой модели в жизнь до закрытия компании. Закрытие возможно, если модель показывает неудовлетворительный финансовый результат и нет никаких способов сделать его приемлемым.
Финансовые модели могут быть любой сложности. Их используют как для глобальных расчётов, так и для отдельных проектов. Например, бюджет компании на несколько лет вперёд — пример глобального применения финансовых моделей. Пример отдельного проекта — расчёт чистой прибыли от новой услуги компании или изменения прибыли после увеличения цен на продукт.
Как строят финансовые модели? Обычно финансовые модели собирают в Microsoft Excel или «Google Таблицах». Некоторые компании используют для этого специализированные программы. Как правило, эти программы заточены под одну цель.
Ключевые атрибуты
Модели представляют собой наборы связанных объектов, которые для создания ассоциаций используют ключи и индексы. Модели служб Analysis Services не отличаются друг от друга. Для каждого измерения (напомним, что оно эквивалентно таблице в реляционной модели) существует ключевой атрибут. Ключевой атрибут используется в отношениях внешнего ключа к таблице фактов (группе мер). Все неключевые атрибуты в измерении связаны (прямую или косвенно) с ключевым атрибутом.
Часто, но не всегда, ключевой атрибут может быть атрибутом гранулярности. Гранулярность — это уровень детализации или точности в данных. Общий пример является самым быстрым способом понять все значения. Рассмотрим следующие значения данных. Для ежедневных продаж требуются значения дат, заданные для дня. Для квот достаточно указать квартал. Но если аналитические данные содержат результаты состязания из спортивного мероприятия, гран следует указать в миллисекундах. Гран будет представлять уровень точности в значениях данных.
Валюта является еще одним примером: финансовое приложение может отслеживать денежные значения до многих десятичных разрядов, в то время как сбор средств местного учебного заведения может нуждаться только в значениях до ближайшего доллара
Чтобы избежать хранения ненужных данных, очень важно понимать смысл грана. Исключение миллисекунд из отметки времени или копеек из суммы объема продаж может сэкономить пространство хранения и время обработки, если подобный уровень детализации не имеет отношения к выполняемому анализу
Чтобы задать атрибут гранулярности, воспользуйтесь вкладкой «Использование измерений» в конструкторе кубов в SQL Server Data Tools. В примере модели AdventureWorks ключевым атрибутом измерения «Дата» является ключ «Дата». Для компонента «Заказы на продажу» атрибут гранулярности эквивалентен ключевому атрибуту. Для компонента «Цели продаж» уровнем гранулярности является квартал, поэтому атрибуту гранулярности задано значение «Календарный квартал».

Примечание
Если атрибут гранулярности отличается от ключевого атрибута, все неключевые атрибуты должны быть напрямую или косвенно связаны атрибутом гранулярности. Внутри куба атрибут гранулярности определяет гранулярность измерения.
Область запроса (пространство куба)
Область запроса определяется границами, в пределах которых происходит выбор данных. Ее размеры могут варьироваться от куба целиком (куб является крупнейшим объектом запроса) до ячейки.
Пространство куба — это совокупность элементов иерархий атрибутов куба с мерами куба.
Вложенный куб — это подмножество куба, представляющее отфильтрованное представление куба. Вложенные кубы можно определить в инструкции SCOPE в скрипте вычисления MDX, или в предложении SUBSELECT, или в запросе MDX, или как куб сеанса.
Ячейка — это пространство на пересечении элемента измерения мер и элемента из каждой иерархии атрибута в кубе.
Как изображают бизнес-процессы
Чаще всего бизнес-процессы моделируют графически, в виде карт и схем, как мы показывали выше. Иногда описывают текстом — в виде пошаговой инструкции с уточнениями, кто и что делает. Также используют таблицы: в строках пишут действия, а в столбцах — исполнителей и этапы.
На мой взгляд, графическое моделирование — наиболее удобное и наглядное. Изобразить бизнес-процессы можно двумя способами: в специальных программах для моделирования и в обычных графических редакторах.
В специальных программах. Это способ для профессионалов в моделировании.
Специальный софт удобен тем, что шаблоны нотаций уже вшиты в него, — не нужно изучать правила иллюстрирования дополнительно. Но придётся разбираться в функциональности программ.
Вот четыре конструктора, которые я использовал в своей практике для моделирования процессов:
- Microsoft Visio 2010 — векторный графический редактор для создания разных видов схем: блок-схем, схем технологических процессов, моделей бизнес-процессов, планов зданий и этажей, трёхмерных карт и так далее. Платный.
- Bizagi Process Modeler — программа для моделирования процессов по нотации BPMN с возможностью совместной работы. Бесплатная.
- ARIS Express — программа для моделирования бизнес-процессов и оргструктуры с нотациями eEPC или BPMN. Бесплатная.
- Business Studio — система, в которой можно описать, оптимизировать и регламентировать бизнес-процессы предприятия. Платная.
Фрагмент бизнес-модели с процессом обработки заявки в Business StudioСкриншот: личный архив Александра Завьялова
Как правило, у всех платных конструкторов есть демоверсии, которых хватает, чтобы смоделировать простой процесс. Но повторюсь, специальное ПО — вариант для профессионалов. Не нужно тратить на него время, если вы не планируете моделировать бизнес-процессы постоянно.
В графических редакторах. Этот способ подойдёт для новичков, которые только знакомятся с моделированием бизнес-процессов. Проще всего взять обычный графический редактор — например, Microsoft Paint, Figma или Adobe Photoshop — и самостоятельно нарисовать интуитивно понятную схему процесса.
Также для изображения бизнес-процессов используют сервисы для создания ментальных карт. На мой взгляд, самые удачные из них — XMind, Diagrams и MindManager.
Моделирование ситуаций
ОПИСАНИЕ ЗАДАЧИ
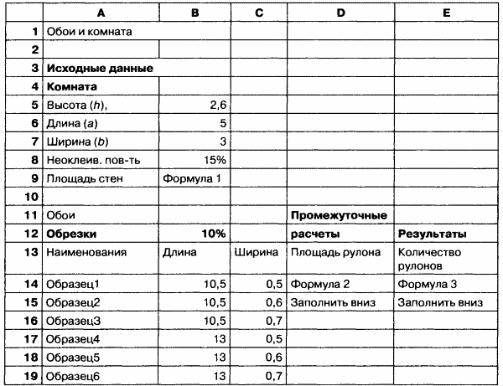
В магазине продаются обои. Наименования, длина и ширина рулона известны. Для удобства обслуживания надо составить таблицу, которая позволит определить необходимое количество рулонов для оклейки любой комнаты.
Формализуем задачу в виде поиска ответов на вопросы.


ИНФОРМАЦИОННАЯ МОДЕЛЬ
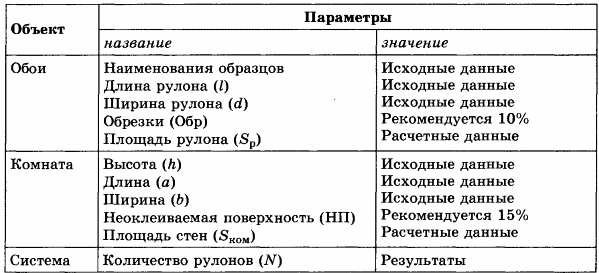
Дополним информационную модель в табличной форме математической моделью.
При расчете фактической площади рулона, которая пойдет на оклейку помещения, надо отбросить обрезки. Формула имеет вид:
В прямоугольной комнате две стены площадью ah и две стены площадью bh. При расчете фактической площади стен учитывается неоклеиваемая площадь окон и дверей
![]()
Необходимо также учесть, что количество рулонов должно быть целым числом, но не меньшим, чем значение N.
Количество рулонов, необходимых для оклейки комнаты, вычисляется по формуле
Примечание. Значения, указанные в исходных данных в процентах — Обр и НП, — используются в расчетных формулах в виде числа, получаемого делением процентного значения на 100. При выполнении расчетов в электронных таблицах делить на 100 не надо, так как тип данных Процент воспринимается средой именно как такое число.
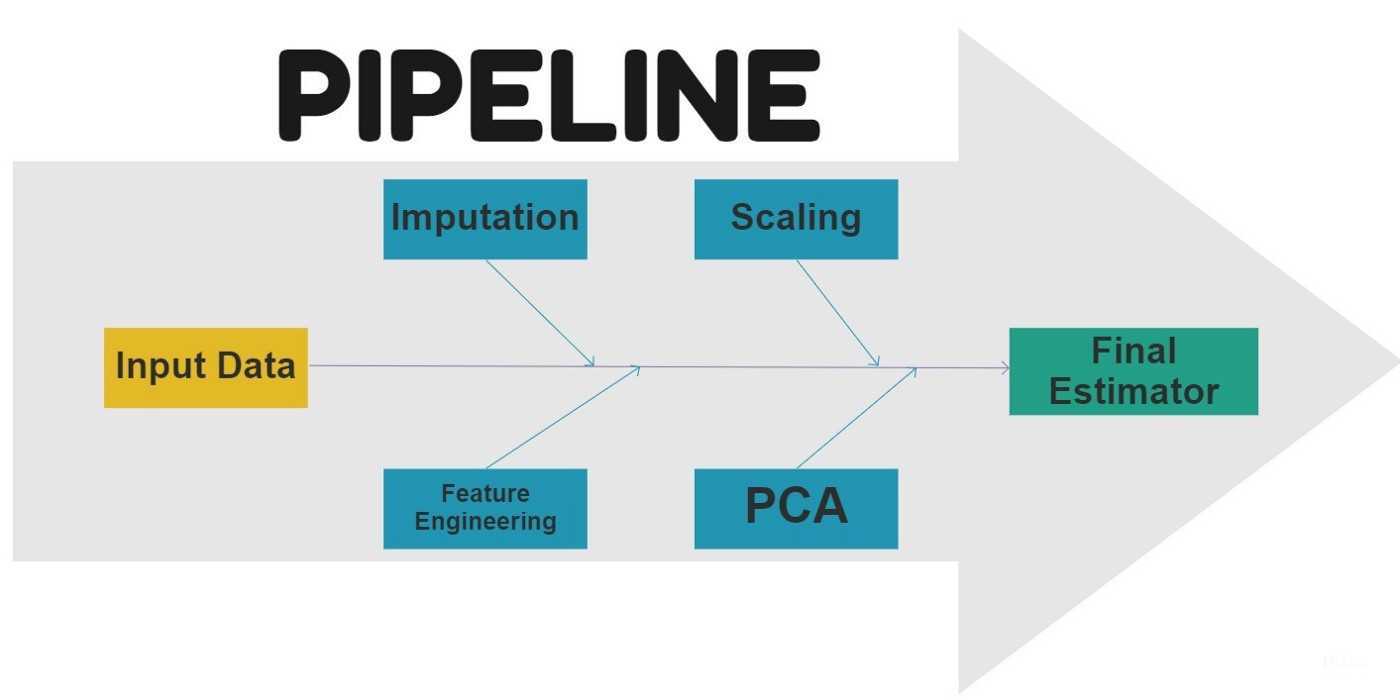
КОМПЬЮТЕРНАЯ МОДЕЛЬ
Для моделирования выберем среду табличного процессора. В этой среде информационная и математическая модели объединяются в таблицу, которая содержит три области:
исходные данные;
промежуточные расчеты;
результаты.
Заполните по образцу расчетную таблицу.
Введите формулы в расчетные ячейки.
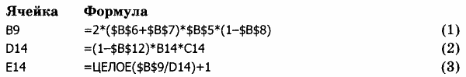
Примечание. Функция ЦЕЛОЕ() округляет до ближайшего целого числа, меньшего, чем заданное. Но поскольку количество рулонов нельзя округлять в меньшую сторону, то к значению функции прибавляем 1 для округления в большую сторону и получаем 1 запасной рулон.
ТЕСТИРОВАНИЕ
Провести тестовый расчет компьютерной модели по данным, приведенным в таблице.
ЭКСПЕРИМЕНТ 1
Провести расчет количества рулонов обоев для помещений вашей квартиры.
ЭКСПЕРИМЕНТ 2
Изменить данные некоторых образцов обоев и проследить за пересчетом результатов.
ЭКСПЕРИМЕНТ 3
Добавить строки с образцами и дополнить модель расчетом по новым образцам.
ПРОВЕДЕНИЕ ИССЛЕДОВАНИЯ
1. Введите в таблицу тестовые данные и сравните результаты тестового расчета с результатами, приведенными в таблице.
2. Поочередно введите размеры комнат вашей квартиры и результаты расчетов скопируйте в текстовый редактор.
3. Составьте отчет.
4. Проведите другие виды расчетов согласно плану.
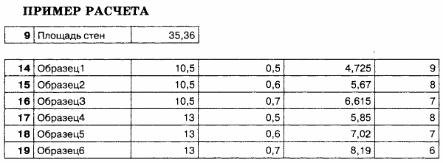
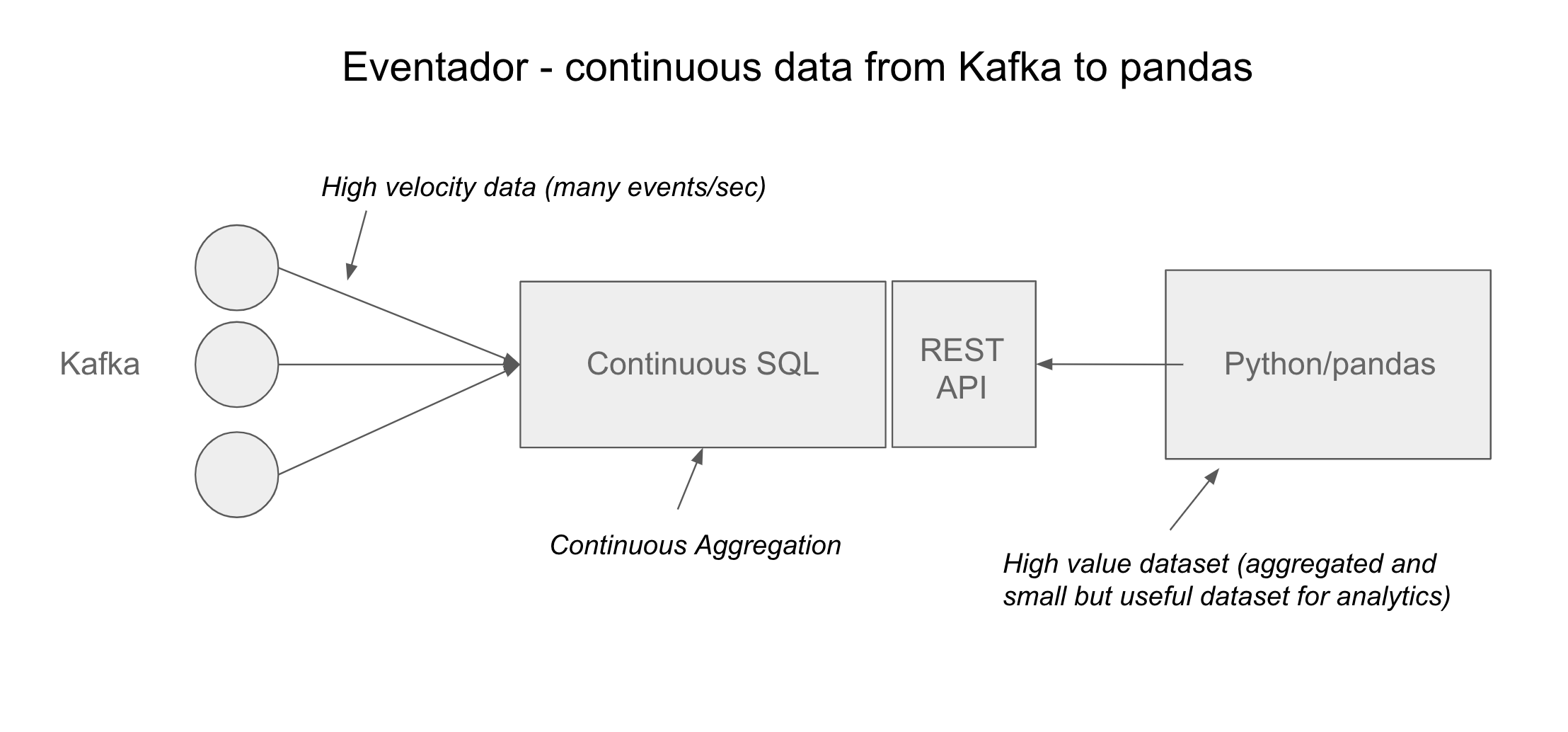
Меры и измерения
Куб служб Analysis Services состоит из мер, измерений и атрибутов измерений, которые присутствуют в сводной таблице.
Меры — это находящиеся в ячейках числовые значения данных, выраженные в виде сумм, количеств, процентов, минимальных значений, максимальных значений, средних значений. Значения мер являются динамичными, вычисляются в режиме реального времени согласно переходам пользователя по таблице и работе с ней. В этом примере в ячейках показаны суммы продаж торговых посредников, которые увеличиваются или уменьшаются в зависимости от того, разворачиваются оси или сворачиваются. Для любой комбинации даты (год, квартал, месяц или дата) и территории продаж (группа стран, страна, регион) можно получить значение суммы продаж торговых посредников, вычисленной для данной конкретной ситуации. Другие термины, которые являются синонимами мер, — это факты (в хранилищах данных) и вычисляемые поля (в табличной модели и модели данных Excel).
Измерения находятся на осях столбцов и строк сводной таблицы и определяют значение меры. Измерения аналогичны таблицам в реляционной модели данных. Распространенные примеры измерения — время, география, продукты, клиенты, сотрудники и т. д. В этом примере существует два измерения — «Территория продаж» в строках и «Дата» в верхней части. Однако вы можете легко перетаскивать другие измерения, связанные с компонентом «Продажи торгового посредника», такие как «Рекламные акции» или «Продукты», чтобы просматривать эффективность продаж по этим измерениям. Возможность изучения данных интересными способами зависит от создаваемых измерений и от того, будут ли они связаны с таблицами фактов в источнике данных.
Атрибуты измерения — это именованные элементы в измерении, схожие со столбцами в таблице. В этом примере используются следующие атрибуты измерения «Территория продаж»: «Группа стран» (Европа, Северная Америка, Тихоокеанский регион), «Страна» (Канада, США) и «Регион» (центральный, северо-восточный, северо-западный, юго-восточный и юго-западный).
Каждый атрибут имеет связанный с ним набор значений данных или элементов. В этом примере элементами атрибута «Группа стран» являются Европа, Северная Америка и Тихоокеанский регион. Элементы — это реальные значения данных, принадлежащие атрибуту.
Примечание
Одним из аспектов моделирования данных является оформление шаблонов и отношений, уже существующих в данных. При работе с данными, входящими в естественную иерархию, как в случае со странами-регионами-городами, это отношение можно оформить путем создания связи атрибутов. Связь атрибутов — это связь «один ко многим» между атрибутами, например связь между государством и городом — государство имеет много городов, но город принадлежит только одному штату. Создание связей атрибутов в модели ускоряет производительность запросов, поэтому рекомендуется создавать их, если данные поддерживают его. Связь атрибутов создается в конструкторе измерений в SQL Server Data Tools. См. Define Attribute Relationships.
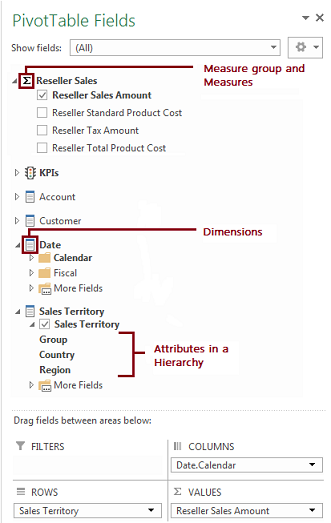
В приложении Excel модель метаданных отображается в списке полей сводной таблицы. Сравните приведенную выше сводную таблицу с расположенным ниже списком полей
Обратите внимание, что список полей содержит компоненты «Территория продаж», «Группа», «Страна», «Регион» (метаданные), тогда как в сводной таблице находятся только элементы (значения данных). Зная, как выглядит значок, можно без труда соотнести части многомерной модели со сводной таблицей в Excel
Как разработать хорошую финмодель: главные рекомендации
Как мы говорили , финансовая модель может понадобиться не только собственникам или менеджерам компании, но и внешним пользователям. Они также должны ориентироваться в ней без проблем.
Поэтому важно сделать так, чтобы финмодель была понятна всем заинтересованным лицам. Вот несколько рекомендаций, как организовать структуру модели, сделать её читаемой и простой в восприятии
Структура финансовой модели
- Чётко обозначьте, где входные данные, где расчёты, а где выводы. Для этого в электронных таблицах удобно использовать разные листы и разноцветные ярлыки для них.
- Внутри блока делайте отдельные разделы для каждой области вводных или расчётов. Например, выручку лучше считать не в том же разделе, в котором считали расходы.
- Не используйте одну и ту же строку модели для разных данных. По возможности соблюдайте принцип: «одна строка — одна формула». Это позволит растягивать формулы на любые периоды.
- Если под данные каждого месяца отводится отдельный лист, используйте одну структуру колонок для всех листов. Один и тот же показатель на разных листах должен находиться в одном и том же столбце. Это также упростит расчёты в следующих периодах.
Читаемость
- Все строки и столбцы должны быть подписаны. Любой пользователь должен понимать, о чём идёт речь в каждом блоке.
- Не забывайте оформлять блок расчётов. Чаще всего внешние пользователи изучают только блоки входа и выхода. Но в некоторых случаях — например, при выдаче кредитов или долгосрочном финансировании — пользователей может заинтересовать, каким образом компания пришла к таким цифрам. В этом случае блок расчётов будет для них самым интересным, поэтому все данные в нём должны быть также подписаны.
- Указывайте единицы измерения каждой величины. Хотя бы там, где могут возникнуть сомнения.
- Числа в модели должны иметь 3–4 значащие цифры — остальное лучше убрать с экрана. Для этого используйте форматирование ячеек — не нужно менять значения ячейки вручную или с помощью формул.
- Визуально отделяйте блоки друг от друга заголовками и «подсвечивайте» важные строки отдельными цветами. Лучше всего использовать для этого стили отображения таблиц.
Ментальный подход в моделировании бизнес-процессов
Это вариант моделирования «для себя». Его используют, чтобы структурировать общие представления о бизнес-процессе, но не раскладывать его на этапы и не составлять алгоритмов.
При ментальном подходе на процесс смотрят не как на последовательность результатов или действий, а как на набор связанных друг с другом понятий. Обычно их собирают на интеллект-карте: в центре «чёрный ящик» с процессом, на орбите — связанные с ним идеи и элементы. Жёстких рамок и нотаций нет — карты рисуют в произвольной форме.
Такая визуализация помогает найти решение, как сделать процесс эффективнее. Дальше это решение воплощают на основе : забирают в основную модель главные элементы, а ненужные отбрасывают.
Ниже дан пример ментальной карты процесса снабжения предприятия. На карте собраны понятия, которые связаны между собой внутри процесса. Но по этапам они не распределены.
Занятия
| Дата | № занятия | Темы | Материалы | Задания |
|---|---|---|---|---|
| 9 сентября 2019 | 1 | Предисловие | — | Проверить доступ к стенду |
| Введение в бизнес-анализ данных. SQL и его роль в анализе данных | — | |||
| Моделирование предметной области | — | |||
| Информация о курсе | ||||
| — | 2 | Основы | ||
| — | 3 | Фильтрация (WHERE), сортировка, удаление дубликатов | ||
| — | 4 | Подзапросы, группирование (GROUP BY) | ||
| — | 5 | JOIN | ||
| — | 6 | Подзапросы | ||
| — | 7 | Advanced Pandas 1 | ||
| — | 8 | Advanced Pandas 2 | ||
| — | 9 | Оконные функции | Задачи на последних слайдах | |
| — | 10 | Модели данных | ||
| — | 11 | Проектная работа | ||
| — | 12 | Проектная работа | Задание на слайдах | |
| — | 13 | Проектная работа | Задание на слайдах | |
| — | 14 | Проектная работа и подведение итогов |
Аннотация курса
В наши дни автоматизация и оптимизация многих видов деятельности невозможна без сбора и последующего анализа больших объёмов информации. При этом со временем стало ясно, что некоторые способы хранить и читать данные — модели данных — особенно удобны для людей. Именно такие модели стали универсальным языком общения людей с самыми разными технологиями. В этом смысле широчайшее распространение получила реляционная модель, а одним из самых широкоупотребительных языков оказался SQL, и сегодня самые разные технологии (совсем не только реляционные) позволяют его использовать.
В ходе занятий мы будем осваивать именно само мышление, принятое в отрасли обработки и анализа данных. Речь не о конкретных технологиях или продуктах. В курсе на практических примерах будут даваться знания и отрабатываться навыки, которые понадобятся практически любому аналитику при работе с источниками данных. Акцент делается именно на аналитической деятельности: аналитик пользуется системами сбора и хранения данных, но не собирается администрировать их.
Занятия предполагают интерактивное выполнение заданий на реальных БД. Студентам рекомендуется приходить с ноутбуками.
Специальной предварительной подготовки не требуется. Любой студент ВМК обладает достаточными навыками для участия в курсе.
Итого
-
Необходимо различать модель данных предметной области и модель данных приложения.
-
Концептуальная модель данных — всегда для предметной области, физическая модель данных — всегда для приложения, логическая модель данных — может быть как для предметной области, так и для приложения.
-
Логическая модель данных приложения зависит от типа СУБД (например, реляционная СУБД и документная СУБД), но не от конкретной СУБД (для PostgreSQL и для Oracle может использоваться одна модель). Физическая модель данных приложения зависит и от типа СУБД, и от конкретной СУБД.
-
В зависимости от специфики проекта может составляться различный набор моделей данных.
-
Почти всегда должны составляться: концептуальная модель данных предметной области и одна из логических моделей данных (предметной области или приложения).
Мой личный набор, который я использую в большинстве проектов — концептуальная модель данных предметной области и логическая модель данных приложения.
В моих конкретных условиях он оказался оптимальным по отношения «полученная польза / затраченные усилия».
А какие виды моделей данных составляете вы в своих проектах?
P.S. Дополнение 4. Модель данных микросервиса
Модель данных предметной области никак не зависит архитектуры, в том числе наличия или отсутствия микросервисов. Но как организован переход от логической модели к физической в случае микросервисной архитектуре?
Как это было у нас. На этапе сбора требований «по классике» были составлены концептуальная и логическая модели данных предметной области.
После того, как на этапе проектирования были выделены микросервисы и определены зоны их ответственности, была сделана «нарезка» логической модели предметной области — какой микросервис будет хранить какие сущности. Это нужно для того, чтобы передать этот кусок модели (вместе с иными требованиями) той подкоманде, которая будет заниматься микросервисом. Приложение было большим, подкоманд много, некоторые из них субподрядные. Давать всем общую модель было избыточно.
Одна и та же сущность предметной области при «нарезке» могла попасть сразу в несколько микросервисов: например, сведения об организациях были нужны практически во всех микросервисах (с разным реквизитным составом).
Как назвать эту модель? С одной стороны, она остаётся логической моделью предметной области — сущности это понятия предметной области, а не таблицы, уровень детализации соответствует логической модели. С другой стороны, она уже частично привязана к реализации — то есть определён микросервис, в котором эта сущность будет имплементирована.
Таким образом, между логической моделью предметной области и моделью данных приложения (неважно, логической или физической) может существовать еще один промежуточный этап — «логическая модель данных предметной области, планируемая к реализации в рамках компонента архитектуры приложения»