
Выбрать содержание программы: концепции, подходы, теории
Подумайте, что нужно знать участникам обучения, чтобы на рабочем месте они использовали целевые навыки, технологии, модели и делали это правильно. Что им нужно узнать, чтобы сформировались эффективные установки? Это и будет определять содержание программы. Сформулируйте темы и основные тезисы.
Содержание довольно часто подбирают под влиянием моды в конкретной теме. Например, если планируется обучение по мотивации, то очень часто включают в программу теории мотивации Герцберга и Маслоу, алгоритм постановки задачи, связывающий задачу и потребность человека. Но для изменения конкретного поведения сотрудников в реальных ситуациях это содержание может быть совершенно бесполезным, даже вредным. Отталкивайтесь от проблемы и задач.
Компонентные тесты
В микросервисной архитектуре компонентами являются сами сервисы. Здесь нужно изолировать каждый компонент (сервис) от его аналогов или коллабораторов (collaborators) и писать тесты с определенной степенью детализации. Мы можем использовать такие инструменты, как WireMock, для имитации внешней системы или других сервисов. Также мы можем использовать in-memory базы данных для имитации БД, но это создаст немного больше сложностей. В идеале нужно сымитировать все внешние зависимости и тестировать сервис в изоляции. В компонентных тестах нужно запустить сервис локально и автоматически (если у вас есть проект Reactive SpringBoot WebFlux, вы можете использовать WebTestClient и аннотацию @AutoConfigureWebTestClient, чтобы сделать это), и когда сервис запущен, обратиться к его конечной точке, чтобы проверить наши функциональные требования.
На этом уровне необходимо покрыть большинство сценариев функционального тестирования, поскольку компонентные тесты выполняются до деплоя, и если в нашем сервисе существует функциональная проблема, мы можем обнаружить ее до него. Это соответствует подходу shift-left и раннему тестированию.
Испытание I. Проворный
1. Не полагаться на документы.
В связи с не зависимым от документа, не существует больше никакой необходимости тестирования записи случаев, но вы должны нарисовать карту мышления, но вам нужна тест точка.
Хотя некоторые компании используют гибкие модели развития, они требуют тестирование и R & D персонал для записи в соответствии с документом традиционной модели, поскольку документ является очень важным, он является основой для последующего понимания проекта. Таким образом, тест случай, спрос документ, R & D дизайн документ требует в соответствии с требованиями традиционная модель осуществляется. Если он не опирается на документы, тест или разработчики были разделены, проект не может быть ясно, потому что спрос документов и различие проекта слишком велики, эти изменения в мозге разработчиков и тестеров, они Заберите после мстить.
Поэтому некоторые компании требуют ключа к документам записи. Но некоторые компании требуют других документов на свет, основные документы.
2. итерационный цикл часто.
Поскольку проект итерационный период часто, нагрузка велика, давление велико, так что вам нужно настроить себя, адаптивное выживание.
Во-первых вводятся основные понятия модульного тестирования, тестирования интеграции, тестирования системы и приемо-сдаточных испытаний.
Время, затраченное на функциональной точки четыре типа (время от менее к мульти-заказ):Тест блок <интегрированный тест <приемочного испытания = <Тестовая система
Как применить этот подход уже сегодня
Классифицируйте все задачи, пользуясь описанными выше правилами.
Подумайте о том, чтобы отправить сотни и тысячи старых задач в архив и начать с чистого листа. Не волнуйтесь, при необходимости вы достанете старые задачи из архива и классифицируете их.
Разработчики не будут ждать, пока вы классифицируете все задачи. Они начнут разбираться с багами сразу же, как только появится несколько задач данного класса.
Разработчики работают над исправлениями до полного устранения багов. НИКАКИХ ИСКЛЮЧЕНИЙ! Если нарушить это правило, подход перестанет работать. Это правило мотивирует менеджера по продукту корректно классифицировать и приоретизировать задачи.
Не позволяйте всем подряд классифицировать задачи как «баги» — получится бардак. Пусть все создают задачи, но не классифицируют их.
Классифицировать задачи должен менеджер по продукту. Возможно другие члены команды тоже захотят классифицировать задачи. В этом случае установите четкие правила и следите за порядком.
Наглядное изображение процесса работы:
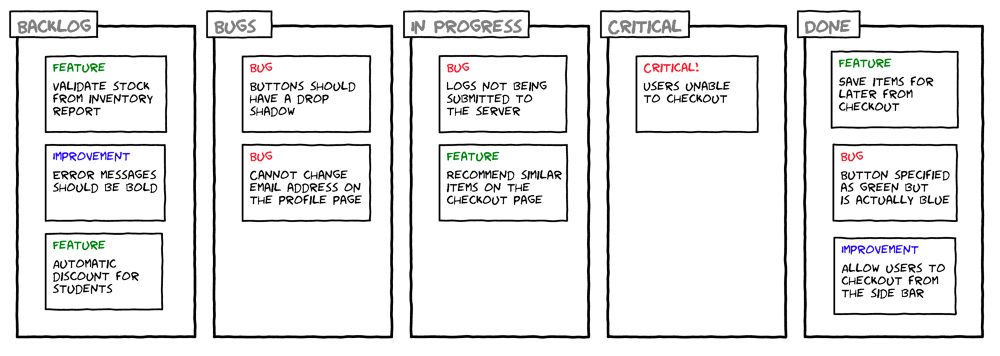
Если критичных проблем или багов несколько, можете приоретизировать их, чтобы легче пережить кризис.
Команда должна постоянно и следовать правилам классификации и приоретизации. При таком подходе разработку будет идти быстро и в соответствии со стандартами качества.
Автоматизация тестирования сайтов, мобильных и веб- приложений: когда делать и какими инструментами
Команды разработки и тестирования стремятся автоматизировать UI-тесты по нескольким причинам. К наиболее примечательным относятся:
- Время. Ручное тестирование движется медленно и не успевает за релизами в полном объеме.
- Стоимость. Ручное тестирование требует значительных ресурсов и затрат.
- Точность. Ручное тестирование склонно к большему количеству ошибок при выполнении повторяющихся задач. Автоматизация снижает вероятность этих ошибок.
- Масштаб. Сложно полагаться на надежность ручного тестирования при выполнении сложных итераций.
- Тренд. Большинство организаций осознали пользу, которую могут извлечь из автоматизированного тестирования.
Таблица сравнения ручного и автоматического тестирования
Разбираем в каких случаях применять автоматическое тестирование.
| Критерий | Ручное тестирование | Автоматическое тестирование |
|---|---|---|
| Скорость | Низкая | Высокая |
| Точность | Низкая | Высокая |
| Масштабируемость | Низкая | Высокая |
| Рентабельность инвестиций в краткосрочное тестирование | Высокая | Высокая |
| Рентабельность инвестиций в долгосрочное тестирование | Низкая | Высокая |
| Возможность повторного использования теста | Низкая | Высокая |
| Покрытие тестов | Низкая | Высокая |
| Порог входа | Легко освоить | Требуется постараться |
| Прозрачность | Скорее низкая | Скорее высокая |
| Адаптивность | Высокая | Требуется постараться |
| Лучше всего подходит для: | Юзабилити-тестирование;Исследовательское тестирование;Ранние стадии разработки; Тестирование пользовательского интерфейса;Ad-hoc тесты; | Сквозное тестирование;Регрессионное тестирование;Тестирование стабильных версий пользовательского интерфейса; |
Ребята из SimbirSoft сделали классный обзор инструментов для тестирования и подобрали подходящие инструменты для тестирования.
Инструмент для тестирования iOS- и Android-приложений
Для покрытия тестами основных пользовательских сценариев выбрали Appium по следующим причинам:
- кроссплатформенность, возможность частично переиспользовать код
- подходит для end-to-end тестов, может работать с веб
- наличие в команде специалистов, хорошо знающих Selenium, который служит оболочкой данного фреймворка.
Appium помог успешно провести тесты для iOS и Android. При этом следует учитывать, что подобные end-to-end тесты с Appium не проводятся на каждом merge request, поскольку это занимает много времени. Подробнее →
Инструмент для тестирования веб-приложений и сайтов
Для тестирования веб-приложений и сайтов ребята применяют WebDriver (в связке с Selenium и протоколом автоматизации DevTools). Однажды они нашли статью с исследованием от Giovanni Rago – автора серии полезных материалов о тестировании – и перевели его статью «Puppeteer vs Selenium vs Playwright: сравнение скорости» (Puppeteer vs Selenium vs Playwright, a speed comparison). В итоге решили опробовать новые инструменты, такие как Puppeteer и Playwright. Подробнее →
В каких случаях MBT оправдывает себя?
Есть аргумента за и против использования тестирования на основе моделей. Его самое очевидное преимущество заключается в том, что после создания тестируемой модели можно сгенерировать тестовые сценарии простым щелчком кнопки. Более того, тот факт, что модель должна быть заранее формализована, позволяет на ранних этапах обнаруживать несоответствия требованиям и помогает группам быстрее приходить к общему согласию по ожидаемому поведению. Заметьте: когда тестовые сценарии пишутся вручную, «модель» все равно присутствует, но она не формализована и существует лишь в уме тестера. MBT заставляет группу тестирования четко выражать ожидания в терминах поведения системы и записывать их с использованием четко определенной структуры.
Еще одно явное преимущество — меньшие издержки сопровождения проекта. Изменения в поведении системы или добавление новых средств может быть отражено обновлением модели, что обычно куда проще, чем вручную модифицировать тестовые сценарии — один за другим. Одна идентификация тестовых сценариев, которые нужно изменить, иногда требует очень много времени
Также примите во внимание, что модель создается независимо от реализации или собственно тестирования. То есть члены группы могут параллельно работать над разными задачами
Недостатком является то, что зачастую требуется перестройка образа мышления. По-видимому, это одна из самых главных проблем в этой методике. К общеизвестной проблеме, которая заключается в том, что у специалистов в ИТ-индустрии нет времени экспериментировать с новыми инструментами, добавляется и другая: быстро обучиться использованию этой методике вряд ли удастся. В зависимости от конкретной группы, применение MBT может потребовать некоторых изменений в процессе, что тоже отчасти вызывает неприятие этой методики.
Еще один недостаток в том, что вам придется проделывать больше подготовительной работы, поэтому на то, чтобы увидеть первый сгенерированный тестовый сценарий, уйдет больше времени по сравнению с использованием традиционных, создаваемых вручную тестовых сценариев. Кроме того, сложность тестируемого проекта должна быть достаточно высокой, чтобы оправдать эти усилия.
К счастью, несколько эмпирических правил, на наш взгляд, помогают понять, когда MBT принесет реальную пользу. Наличие бесконечного набора системных состояний с требованиями, которые вы можете охватить разными способами, — это первый признак. Реагирующая или распределенная система либо система с асинхронными или недетерминированными взаимодействиями — другой признак. Наличие методов с множеством сложных параметров также может указывать в направлении MBT.
Когда эти условия выполняются, MBT может дать значительную экономию в усилиях, затрачиваемых на тестирование. Пример тому — Microsoft Blueline, проект, где в рамках инициативы соответствия стандартам протоколов Windows проверялись сотни протоколов. В этом проекте мы использовали Spec Explorer для проверки точности технической документации протоколов относительно реального поведения этих протоколов. На это потребовались гигантские усилия, и Microsoft потратила на тестирование порядка 250 человеко-лет. Microsoft Research провела статистическое исследование, которое показало, что применение MBT сэкономило Microsoft 50 человеко-лет работы тестеров, или примерно 40% усилий по сравнению с традиционным подходом к тестированию.
Тестирование на основе моделей — мощная методика, которая добавляет методологию систематизации в традиционные методики. Spec Explorer является зрелым инструментом, который использует концепции MBT в тесно интегрированной, современной среде разработки, и представляет собой бесплатный Visual Studio Power Tool.
Юминь Чоу (Yiming Cao) — старший руководитель разработок в группе Microsoft Interop and Tools, работает над Protocol Engineering Framework (в том числе Microsoft Message Analyzer) и Spec Explorer. До перехода в Microsoft работал в IBM Corp., потом в начинающей компании, занимающейся технологиями потоковой передачи медийной информации.





Серхио Мера (Sergio Mera) — старший менеджер программ в группе Microsoft Interop and Tools, работает над Protocol Engineering Framework (в том числе Microsoft Message Analyzer) и Spec Explorer. До перехода в Microsoft был научным сотрудником и лектором на факультете компьютерных наук Университета Буэнос-Айреса, работал над модальной логикой и машинным доказательством теорем.
Возможности доработки выгрузки из 1С в Битрикс
В статье собраны некоторые полезные и интересные примеры доработок выгрузки из 1С на сайты на платформе Битрикс (Возможно, что-то подойдёт и для WordPress и других платформ, принимающих типовую выгрузку на сайт из 1С). Доработки рассмотрены без привязки к конкретным конфигурациям, примеры кода взяты в основном из доработок УТ 10 и 11. Некоторые доработки требуют изменений на стороне Битрикса, некоторые укладываются в типовой функционал.
Примеры взяты из личного опыта, возможно, описание где-то не полное, т.к. доработки делались в разное время. Если материал будет интересен или будут аналогичные актуальные задачи, буду стараться дополнять статью более подробным описанием и примерами.
Пример создания карты тест-кейсов для UI-тестирования
Вокруг формы минимум 13 тест-кейсов. Сделаем разметку от TC-1 до TC-13 и выполним тестирование пользовательского интерфейса:
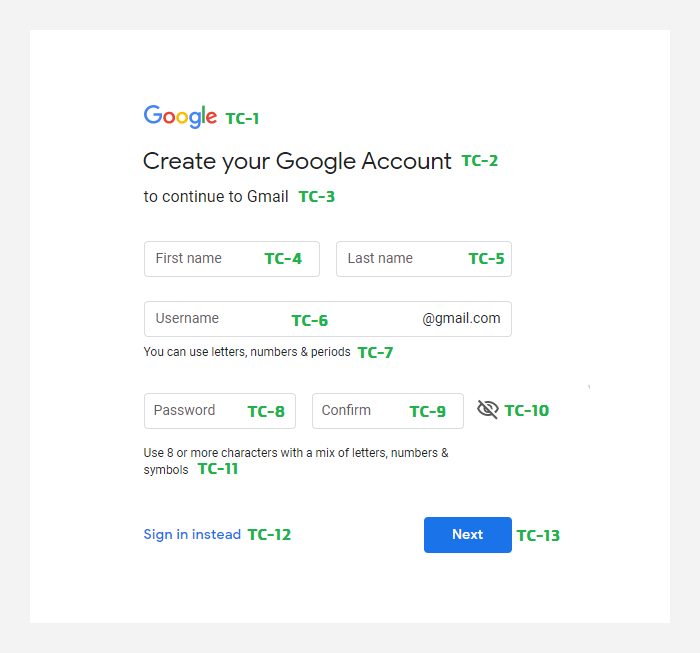 Пример покрытия тестами формы авторизации.
Пример покрытия тестами формы авторизации.
ТC-1
Проверить логотип, его положение и шрифт страницы.
ТC-2
- Проверить правильность заголовка страницы.
- Проверить шрифт
ТC-3
- Проверить фокус курсора на поле по умолчанию.
- Проверить обязательные поля, нажав кнопку «Далее», пока форма пуста.
- Проверить положение и выравнивание текстового поля.
- Проверить ввод как допустимых, так и недопустимых символов в метках полей.
ТC-4
- Проверить положение и выравнивание текстового поля.
- Проверить метки полей, убедитесь, что принимаются как допустимые, так и недопустимые символы.
ТC-5
- Проверить положение и выравнивание текстового поля.
- Проверить метки полей, убедитесь, что принимаются как допустимые, так и недопустимые символы.
ТC-6
- Проверить сообщение об ошибке, введя разрешенные и запрещенные символы.
- Проверить правильность сообщения об ошибке.
ТC-7
Проверить всплывающие окна и гиперссылки.
ТC-8
- Проверьте метки полей, убедитесь, что принимаются как допустимые, так и недопустимые символы.
- Проверьте положение и выравнивание текстового поля.
ТC-9
- Сохраните неподходящий пароль.
- Проверьте метки полей, убедитесь, что принимаются как допустимые, так и недопустимые символы.
- Проверьте положение и выравнивание текстового поля.
ТC-10
- Проверьте положение значка.
- Проверьте значок, показывает или скрывает пароль пользователя.
- Проверить качество изображения.
ТC-11
- Проверьте сообщение об ошибке, введя разрешенные и запрещенные символы.
- Проверьте правильность сообщения об ошибке.
ТC-12
Протестируйте всплывающие окна и гиперссылки.
ТC-13
- Протестируйте отправку данных.
- Проверьте положение и ясность кнопки.
Подход на основе тестовых данных
Одной из самых больших проблем в тестировании и автоматизированных тестах являются тестовые данные. Предлагаю следующие рекомендации:
-
Хорошо бы иметь службы генерации тестовых данных и вызывать эндпоинты этих служб, чтобы получить свежесозданные тестовые данные для использования в тестах.
-
Если нет возможности создать тестовые данные автоматически, лучше провести анализ требований к тестовым данным и создать тестовые данные вручную или обратиться за помощью к соответствующей команде для их получения.
-
В тестовых и промежуточных средах я рекомендую маскировать критические тестовые данные.
Собеседование в Яндекс: театр абсурда :/ +591
- 02.04.21 05:00
•
kesn
•
#550088
•
Хабрахабр
•
•
205000
Управление персоналом, Карьера в IT-индустрии, Python
Рекомендация: подборка платных и бесплатных курсов 3D-моделирования — https://katalog-kursov.ru/
Привет, хабр!
Напомню, что в той статье я рассказывал, каким я вижу идеальное собеседование и что я нашёл компанию, которая так и делает — и я туда прошёл, хотя это был адский отбор. Я, довольный как слон, везде отметил, что я не ищу работу, отовсюду удалился и стал работать работу.
Как вы думаете, что делают рекрутеры, когда видят «Alexandr, NOT OPEN FOR WORK»? Правильно, пишут «Алексей, рассматриваете вариант работать в X?» Я обычно игнорирую это, но тут мне предложили попытать счастья с Яндекс.Лавкой, и я не смог пройти мимо — интересно было, смогу ли я устроиться куда-нибудь, когда введут великий российский файерволл. К тому же за последние 3 года я проходил только два интервью, и мне показалось, что я не в теме, что нынче требуется индустрии. Блин, я оказался и вправду не в теме. И вы, скорей всего, тоже — об этом и статья.
Короче, я согласился — буду продавать дошики и похмелье!
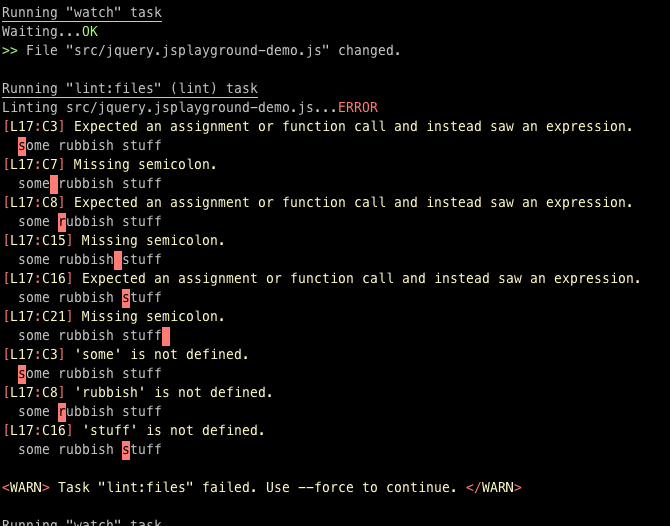
Мне назначили дату интервью, и также прислали методичку, чтобы я понимал, что меня ждёт и как готовиться. Чтобы ничего не заспойлерить, я замазал квадратиками важную информацию.
Вы тоже заметили «вопросы на C++» в методичке для питониста? Не то чтобы я знал C++, но в институте проходили, авось что-нибудь да вспомню на интервью.
Тут что-то написано про leetcode, но я человек ответственный, поэтому к интервью не готовлюсь. Это кстати я не шуткую, реально: если вы ответственный человек, то вы, когда предстаёте перед компанией, отвечаете за то, что вы заявляете как ваши умения. Можно выучить типовые вопросы и даже казаться умнее и опытнее, чем есть, но по факту это переобучение на тестовых заданиях/вопросах. Ребята из ml поймут. Поэтому я гол как сокол и чист как стёклышко или что там ещё блин, если что-то знаю — скажу, что-то не знаю — скажу что не знаю. Таким образом работодатель знает, что он покупает и сколько ещё нужно вложить в меня средств на обучение. Все счастливы.
Пирамида фронтенд-тестирования
Kent C. DoddsТрофей тестирования
- Основа трофея — это множество статических проверок: ESLint, Prettier, TypeScript.
- К статическим проверкам мы пишем много интеграционных тестов.
- Там, где мы не можем писать интеграционные тесты, допустимы Unit-тесты.
- E2E тесты следует писать для критичных и важных сценариев.
Универсальная формула тестирования
Универсальная формула тестирования.
- Стоимость написания, запуска и поддержка тестов зависят от компетенций разработчиков в проекте и от технологического стека проекта
- Уверенность в работе кода, покрытого тестами у всех разная. Одному разработчику достаточно написать тесты, покрывающие основные сценарии, в то время как другой разработчик не успокоится пока не напишет пару десятков тестов, покрывающих все ситуации.
Модель вообще не нужна
Мы как-то строили модель, предсказывающую крепость пива после дображивания (на самом деле, это было не пиво и вообще не алкоголь, но суть похожа). Задача ставилась так: понять, как параметры, задаваемые в начале брожения, влияют на крепость финального пива, и научиться лучше управлять ей. Задача казалась весёлой и перспективной, и мы потратили не одну сотню человеко-часов на неё, прежде чем выяснили, что на самом-то деле финальная крепость не так уж и важна заказчику. Например, когда пиво получается 7.6% вместо требуемых 8%, он просто смешивает его с более крепким, чтобы добиться нужного градуса. То есть, даже если бы мы построили идеальную модель, это принесло бы прибыли примерно нисколько.
Эта ситуация звучит довольно глупо, но на самом деле случается сплошь и рядом. Руководители инициируют machine learning проекты, «потому что интересно», или просто чтобы быть в тренде. Осознание, что это не очень-то и нужно, может прийти далеко не сразу, а потом долго отвергаться. Мало кому приятно признаваться, что время было потрачено впустую. К счастью, есть относительно простой способ избегать таких провалов: перед началом любого проекта оценивать эффект от идеальной предсказательной модели. Если бы вам предложили оракула, который в точности знает будущее наперёд, сколько бы были бы готовы за него заплатить? Если потери от брака и так составляют небольшую сумму, то, возможно, строить сложную систему для минимизации доли брака нет необходимости.
Как-то раз команде по кредитному скорингу предложили новый источник данных: чеки крупной сети продуктовых магазинов. Это выглядело очень заманчиво: «скажи мне, что ты покупаешь, и я скажу, кто ты». Но вскоре оказалось, что идентифицировать личность покупателя было возможно, только если он использовал карту лояльности. Доля таких покупателей оказалась невелика, а в пересечении с клиентами банка они составляли меньше 5% от входящих заявок на кредиты. Более того, это были лучшие 5%: почти все заявки одобрялись, и доля «дефолтных» среди них была близка к нулю. Даже если бы мы смогли отказывать все «плохие» заявки среди них, это сократило бы кредитные потери на совсем небольшую сумму. Она бы вряд ли окупила затраты на построение модели, её внедрение, и интеграцию с базой данных магазинов в реальном времени. Поэтому с чеками поигрались недельку, и передали их в отдел вторичных продаж: там от таких данных будет больше пользы.
Зато пивную модель мы всё-таки достроили и внедрили. Оказалось, что она не даёт экономии на сокращении брака, но зато позволяет снизить трудозатраты за счёт автоматизации части процесса. Но поняли мы это только после долгих дискуссий с заказчиком. И, если честно, нам просто повезло.
Тестовые двойники
Помощниками в тестировании выступают «тестовые двойники» (test doubles). Их выделяют 5 видов.






Пустышка (Dummy). Такой двойник не содержит поведения и используется в качестве заполнителя параметров. Никогда реально не вызывается.
Подделка (Fake). Это реально написанная реализация, которая имеет более простую логику, чем реальный аналог.
Есть ещё три вида похожих между собой тестовых двойников. Но есть и различия.
Заглушка (Stub) — имеет заранее подготовленные ответы на вызовы методов. Практически не имеет логики.
Шпион (Spy). Более сложная система. Это гибрид реального объекта и мока. Он имеет поведение реального объекта, но может записывать определенную информацию о вызове его методов. Также можно переопределить поведение некоторых методов.
Мок (Mock). Самый сложный из тестовых двойников, но дающий наибольший контроль. Может иметь сложную логику ответов, зависящих от параметров вызовов, их количества, генерировать исключения при вызове методов с неопределенным поведением и имеет другой, полезный для тестирования функционал.
Все тестовые двойники, за исключением fake, в основном создаются с помощью фреймворков, с которыми мы часто работаем. Для Java это Mockito, для Kotlin – MockK, для других языков такие фреймворки тоже есть.
Описать целевое поведение в терминах инструментов, технологий, алгоритмов
Это значит ответить на вопрос: что нужно уметь делать сотрудникам, чтобы демонстрировать эффективное поведение на рабочем месте? Например, продавцы, объясняя высокую цену, должны уметь подбирать убедительные для клиентов аргументы
Ещё им важно сохранять эмоциональный штиль в случае агрессивного давления клиента.. Важно формулировать цели на языке, понятном заказчику обучения, в его терминологии.
Важно формулировать цели на языке, понятном заказчику обучения, в его терминологии.
Часто инструменты и алгоритмы можно найти в различных источниках (публикациях, книгах). Но бывает, что готовые не подходят или их нет. В этом случае алгоритмы придётся изобрести. Или превратить в алгоритм поведение тех, кто добился успеха в похожих условиях.
Создать план тренировки знаний
Теперь пора оценить глубину теоретических знаний, которые нужно сформировать у участников обучения. Теория должна быть достаточной для формирования умений, чтобы сотрудники понимали, почему они должны поступать в тех или иных ситуациях так, а не иначе.
- Отталкиваясь от плана формирования умений, вы избегаете перегрузки теоретической программы знаниями, которые на практике не пригодятся. Этим часто невольно грешат эксперты в теме обучения — им кажется важным всё, хотя для конкретных целей обучения можно обойтись без такого глубокого погружения.
- Такой план действий позволяет избежать и другой крайности — классической ловушки эксперта. Это когда специалист не объясняет какие-то нюансы, важные для формирования нужных умений у новичков, потому что из-за его погружённости в тему они кажутся ему и так очевидными.
Третий подход – конструкторы сайтов

Весь остальной мир пока что живет тут. Пока что 90% интернета сделано на MPA, причем, при помощи конструкторов. Кстати, конструкторы достаточно крутые. Тут есть Tilda, Webflow, Bitrix, Readymag. Что-то из этого – конструктор, что-то – CMS. Сейчас эта грань путается. Дальше я немного про них поговорю. Это, в принципе, то, с чем работают нормальные люди, WiseAdvice в том числе.
90% потребностей можно решить с помощью обычных MPA.

Наверное, аудитория знает, что работать с Tilda – очень просто. Любой нормальный человек, который владеет компьютером, это все осваивает минут за 15. Ничего хитрого, готовые блоки, лендинг. Это все делается быстро, профессионально, красиво и вообще без лишних заморочек. Сели и сделали сайт. И он выглядит, как 90% интернета. Это круто. Если не знали об этом – надо знать.
Если вы не уложились в Tilda, попробуйте Webflow. Он похож на продукты Adobe. Если вы раньше работали с Photoshop, Illustrator, Corel Draw – там интерфейс очень похожий. Вы можете двигать мышкой, добавлять элементы. Потратив 2-3 часа на освоение вы сможете сделать красивый сайт практически на коленке, не понимая ничего ни в HTML, ни в CSS. Верстка там, конечно, не идеальная, но выглядит очень хорошо. Остается только сделать обработку определенных событий, определенных постов – формочек, HTML для сайта.
Если вам нужно веб-приложение, которое не будет интегрироваться с 1С – конструкторов вам хватит.
Гиперпараметрическая оптимизация модели
что такое гиперпараметры и чем они отличаются от обычных параметров
- Гиперпараметры модели можно считать настройками алгоритма, которые мы задаём до начала его обучения. Например, гиперпараметром является количество деревьев в «случайном лесе», или количество соседей в методе k-ближайших соседей.
- Параметры модели — то, что она узнаёт в ходе обучения, например, веса в линейной регрессии.
недообучением и переобучением высокое смещение высокая дисперсия TPOT генетическое программирование
Случайный поиск с перекрёстной проверкой
- — методика выбора гиперпараметров. Мы определяем сетку, а потом из неё случайно выбираем различные комбинации, в отличие от сеточного поиска (grid search), при котором мы последовательно пробуем каждую комбинацию. Кстати, случайный поиск работает почти так же хорошо, как и сеточный, но гораздо быстрее.
- Перекрёстной проверкой называется способ оценки выбранной комбинации гиперпараметров. Вместо разделения данных на обучающий и тестовый наборы, что уменьшает количество доступных для обучения данных, мы воспользуемся k-блочной перекрёстной проверкой (K-Fold Cross Validation). Для этого мы разделим обучающие данные на k блоков, а затем прогоним итеративный процесс, в ходе которого сначала обучим модель на k-1 блоках, а затем сравним результат при обучении на k-ом блоке. Будем повторять процесс k раз, и в конце получим среднее значение ошибки для каждой итерации. Это и будет финальная оценка.
- Задаём сетку гиперпараметров.
- Случайно выбираем комбинацию гиперпараметров.
- Создаём модель с использованием этой комбинации.
- Оцениваем результат работы модели с помощью k-блочной перекрёстной проверки.
- Решаем, какие гиперпараметры дают лучший результат.
Вернёмся к гиперпараметрической настройке
- : минимизация функции потерь;
- : количество используемых слабых деревьев решений (decision trees);
- : максимальная глубина каждого дерева решений;
- : минимальное количество примеров, которые должны быть в «листовом» (leaf) узле дерева решений;
- : минимальное количество примеров, которые нужны для разделения узла дерева решений;
- : максимальное количество признаков, которые используются для разделения узлов.
закон убывания доходности применительно к машинному обучению здесь говорит о переобучении уменьшения сложности модели с помощью гиперпараметров
Несколько разделений на поезда
Мы можем повторить процесс разбиения временного ряда на обучающие и тестовые наборы несколько раз.
Это потребует обучения и оценки нескольких моделей, но эти дополнительные вычислительные затраты обеспечат более надежную оценку ожидаемой производительности выбранного метода и конфигурации на невидимых данных.
Мы могли бы сделать это вручную, повторив процесс, описанный в предыдущем разделе, с разными точками разделения.
С другой стороны, библиотека Scikit-Learn предоставляет нам эту возможность вTimeSeriesSplitобъект.
Вы должны указать количество разделений для создания иTimeSeriesSplitвозвращать индексы поезда и тестировать наблюдения для каждого запрошенного разделения.
Общее количество обучающих и тестовых наблюдений рассчитывается для каждой итерации (я) следующее:
кудаn_samplesобщее количество наблюдений иn_splitsэто общее количество расколов.
Давайте сделаем это на примере. Предположим, у нас есть 100 наблюдений, и мы хотим создать 2 разделения.
Для первого разделения размеры поезда и теста будут рассчитываться как:
Или первые 33 записи используются для обучения, а следующие 33 записи используются для тестирования.
Второй сплит рассчитывается следующим образом:
Или, первые 67 записей используются для обучения, а остальные 33 записи используются для тестирования.
Вы можете видеть, что размер теста остается неизменным. Это означает, что статистика эффективности, рассчитанная на основе прогнозов каждой обученной модели, будет согласованной и может быть объединена и сравнена. Это обеспечивает сравнение яблок с яблоками.
Что отличается, так это количество записей, используемых для обучения модели каждого разделения, предлагая большую и большую историю для работы. Это может сделать интересный аспект анализа результатов. С другой стороны, это также можно контролировать, поддерживая согласованность количества наблюдений, использованных для обучения модели, и используя только одно и то же количество самых последних (последних) наблюдений в наборе обучающих данных, каждый разделенный для обучения модели, 33 в этом надуманном примере.






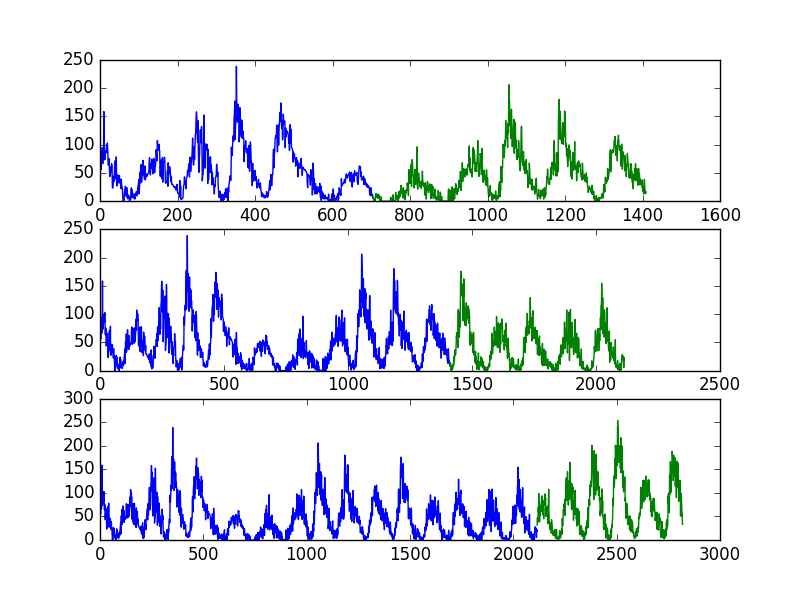
Давайте посмотрим, как мы можем применить TimeSeriesSplit к нашим данным солнечных пятен.
Набор данных имеет 2820 наблюдений. Давайте создадим 3 разбиения для набора данных. Используя ту же арифметику, что и выше, мы ожидаем, что будут созданы следующие разделение на поезда и тесты:
- Сплит 1: 705 поезд, 705 тест
- Сплит 2: 1410 поезд, 705 тест
- Сплит 3: 2115 поезд, 705 тест
Как и в предыдущем примере, мы построим поезд и тестовые наблюдения, используя разные цвета. В этом случае у нас будет 3 разбиения, так что будет 3 отдельных участка данных.
При выполнении примера печатается число и размер поезда и наборов тестов для каждого разделения.
Мы можем видеть, что количество наблюдений в каждом из наборов поездов и тестов для каждого разбиения соответствует ожиданиям, рассчитанным с использованием простой арифметики выше.
На графике также показаны 3 разделения и растущее число общих наблюдений на каждом последующем графике.
Использование нескольких разделений тест-поезда приведет к обучению большего количества моделей и, в свою очередь, к более точной оценке эффективности моделей на невидимых данных.
Ограничение подхода разделения поезда-теста состоит в том, что обученные модели остаются фиксированными, так как они оцениваются при каждой оценке в наборе тестов.
Это может быть нереалистичным, поскольку модели могут быть переобучены по мере появления новых ежедневных или ежемесячных наблюдений. Эта проблема рассматривается в следующем разделе.
Интервью 4
Честно говоря, вот тут я потерялся, потому что я всё жду, когда начнётся собеседование, ну, человеческое собеседование имеется в виду, а пока вместо этого я превращаюсь в алгоритмэна.
По собственным ощущениям я добрался до какого-то мини-босса и на предстоящем интервью у меня должна была пройти какая-то битва на более общие вопросы. А рекрутер мне пишет: знаете, Яндекс настоятельно советует потренироваться на задачках с leetcode. А там опять алгоритмы. Ох, не к добру это…
Ну тут уж я сломился и решил таки глянуть, что там за задачки, раз мне так настойчиво намекают. Вообще там есть сложные, и над ними было прикольно подумать и порешать в уме, но я так и не понял, как это поможет в интервью
Задачек слишком много и, что более важно, они, блин, разные, и решив одну, я не решаю класс задач — я решаю одну задачу. Соответственно либо я решаю их все и зачем мне тогда ваш Яндекс после такого, либо..
короче, я опять не готовился. Ответственный человек, помните?
Кстати, где-то в этот момент я узнал, что я юзаю что-то вроде тора, но для собеседований: я общаюсь с рекрутером, мой рекрутер общается с рекрутером Яндекса, а рекрутер Яндекса общается с собеседователями, а может цепочка ещё больше. Меня это поразило прям: вы меня тут дерёте за O(n^2) в решениях, так может я у вас посчитаю длину цепочки от кандидата до собственно интервьюера и спрошу «а можно оптимальнее?!»
Итак, началась четвёртое (да, ей-Богу) интервью. Интервьюер спрашивает, на каком языке я буду решать задачки. На йоптаскрипте, разумеется. Кстати, по косвенным признакам я понял, что интервьюер больше в C, чем в питон, и это тоже здорово. Итак: после того как компания решила нанять сеньор питон разраба за 200к и сношала его 3 часа на долбанных задачках, она отправляет на собеседование сишника и спрашивает, на каком языке кандидат будет сношаться с долбанными задачками. Л — логика!
Итак, вот задачка от мини-босса:
Задание 9
Погодите, да это же… Ну ок, хотят проверить знание каких-то базовых вещей. Сссссуууу…пер.
Если вы хотите решить задачу не так, как хотел интервьюер, то смотрите:
Внимательный читатель может заметить, что, по-моему, это даже на приведённом примере не работает ![]() , хотя пофиксить несложно. Так или иначе, вот такие вещи как я написал лично мне тяжело гонять в голове, и интервьюеру тоже; интервьюер принял это как решение, прогнав несколько тестов в уме. Если хотите возвести это в абсолют, то пишите сразу на brainfucke и с умным видом объясняйте, почему оно будет работать. А вообще я просто тонко намекаю, что всё-таки компилятор/интерпретатор под рукой нужен.
, хотя пофиксить несложно. Так или иначе, вот такие вещи как я написал лично мне тяжело гонять в голове, и интервьюеру тоже; интервьюер принял это как решение, прогнав несколько тестов в уме. Если хотите возвести это в абсолют, то пишите сразу на brainfucke и с умным видом объясняйте, почему оно будет работать. А вообще я просто тонко намекаю, что всё-таки компилятор/интерпретатор под рукой нужен.
Задание 10
Осталось совсем немного времени, и вот в довершение пара реально сложных заданий на понимание многопоточности и gil в python:
А теперь все вместе хором: НУ ОК, ХОТЯТ ПРОВЕРИТЬ ЗНАНИЕ КАКИХ-ТО БАЗОВЫХ ВЕЩЕЙ. Вы восхитительны. Спасибо.
Здесь я уже не успевал по времени и озвучил идею: мы бежим по списку и сохраняем в память значения сумм для всех range до этого элемета. Иными словами, для каждого элемента мы пробуем делать ranges, которые кончаются на этом элементе, и смотрим на их сумму элементов.
Не угадал, конечно — «а можно чтобы быстрее?». Но тут, к счастью, время вышло, и мой мозг не успел придумать ничего лучше.
>> Сейчас я нахожусь здесь <<
Прелесть ситуации в том, что я ещё не получил фидбек, то есть я кандидат Шрёдингера — я и прошёл (формально я все задачи решил), и не прошёл (== не всё угадал, где-то баги), и суперпозиция сколлапсирует, когда ответ пройдёт через всю цепочку рекрутеров ко мне. А пока я полностью беспристрастен, ведь 1) меня не отшили, то есть это не пост обиженного на компанию человека, и 2) мне плевать на результат, потому что мне и на текущей работе офигенно.



