
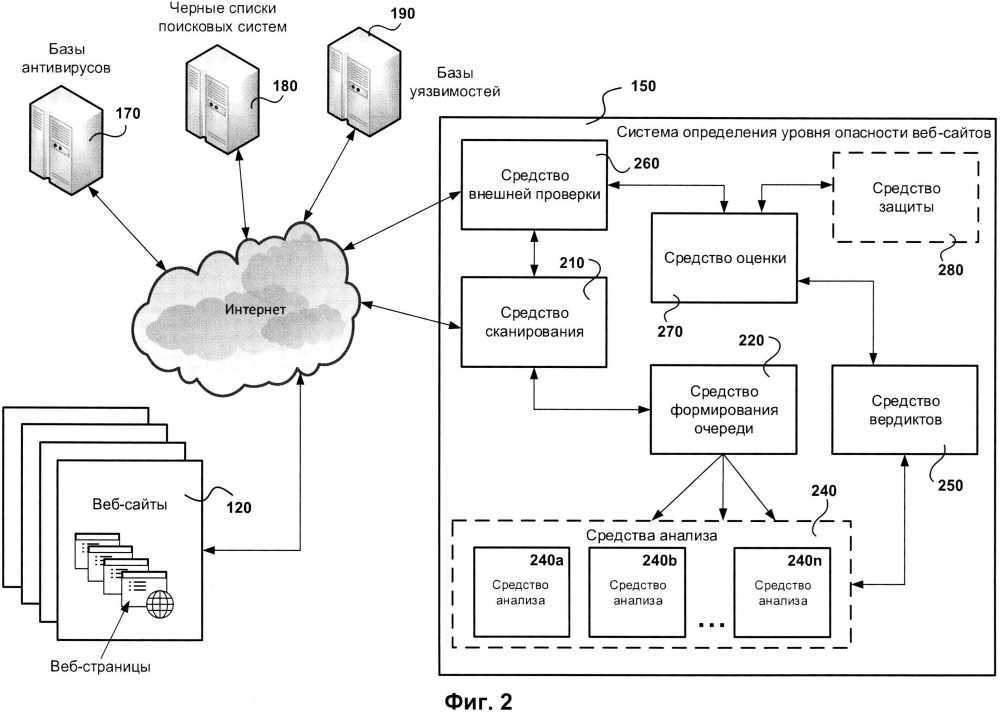
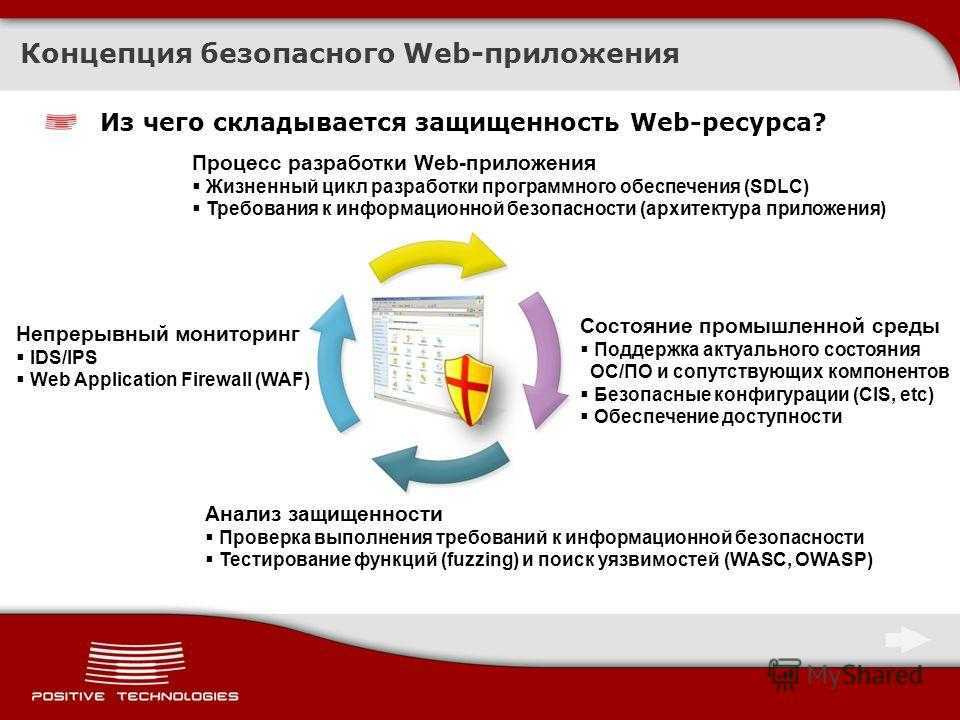
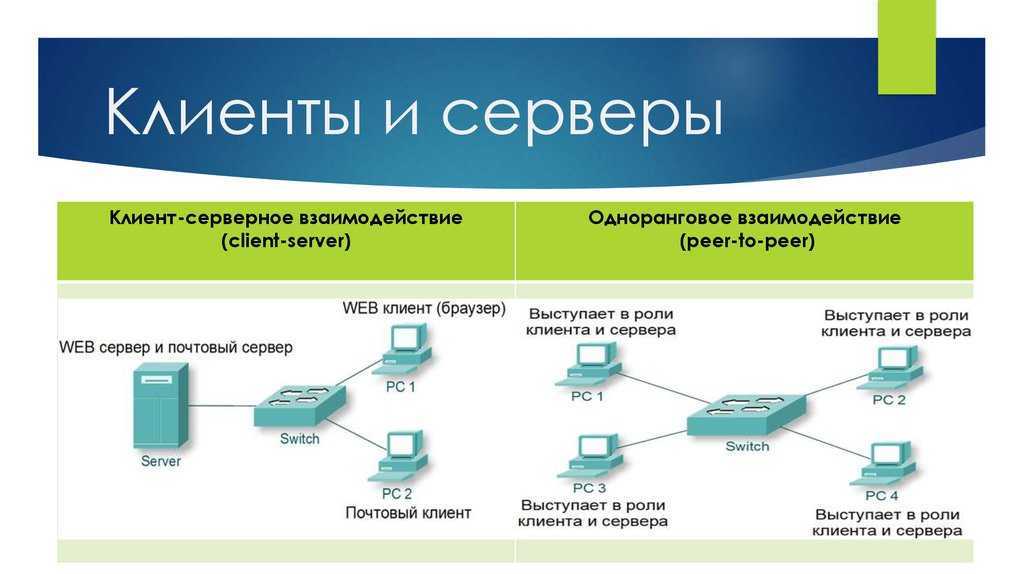
Введение
В июле 2018 года Федеральная служба по техническому и экспортному контролю (далее — ФСТЭК России) представила приказ №131 об утверждении «Требований по безопасности информации, устанавливающих уровни доверия (далее — УД) к средствам технической защиты информации и средствам обеспечения безопасности информационных технологий». В соответствии с новым перечнем требований для средств защиты информации (далее — СЗИ) устанавливаются УД, характеризующие безопасность их применения для обработки и защиты информации, содержащей государственную тайну, конфиденциальные сведения или данные ограниченного доступа. По новым правилам в отношении СЗИ всех уровней доверия должны проводиться исследования по выявлению уязвимостей и недекларированных возможностей (далее — НДВ) в соответствии с методикой, разработанной в дополнение к приказу №131 и утвержденной ФСТЭК России в феврале 2019 года.
Рекомендации по применению приказа №131 касаются только тех разработчиков, кто специализируется на программных решениях для защиты инфраструктур и систем, содержащих информацию, доступ к которой должен быть ограничен или защищен. Однако любое программное обеспечение (далее — ПО), разрабатываемое и используемое в системах, где хранятся и обрабатываются данные, имеет встроенные программные алгоритмы для защиты информации (например, проверки полномочий доступа к данным или к системе в целом), которые также могут нуждаться в проверке на безопасность.
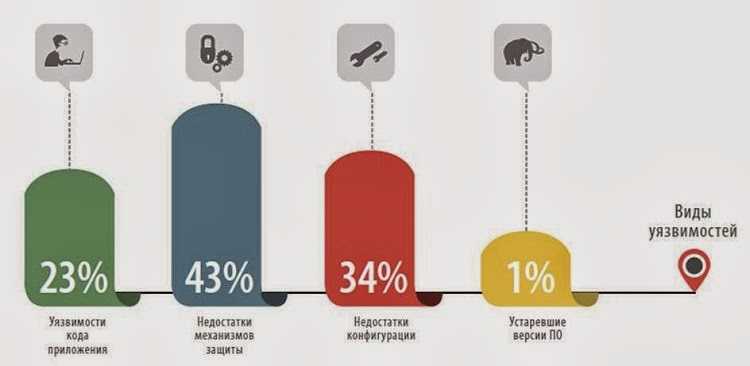
Основной причиной инцидентов в области ИБ чаще всего становятся ошибки кодирования, приводящие к уязвимостям программ и систем. В связи с этим для предотвращения нарастающих угроз в информационной сфере всем разработчикам программных продуктов рекомендуется принимать меры по выпуску защищенного ПО и придерживаться требований ГОСТ и приказов ФСТЭК России, касающихся безопасной разработки кода.
Объекты исследования
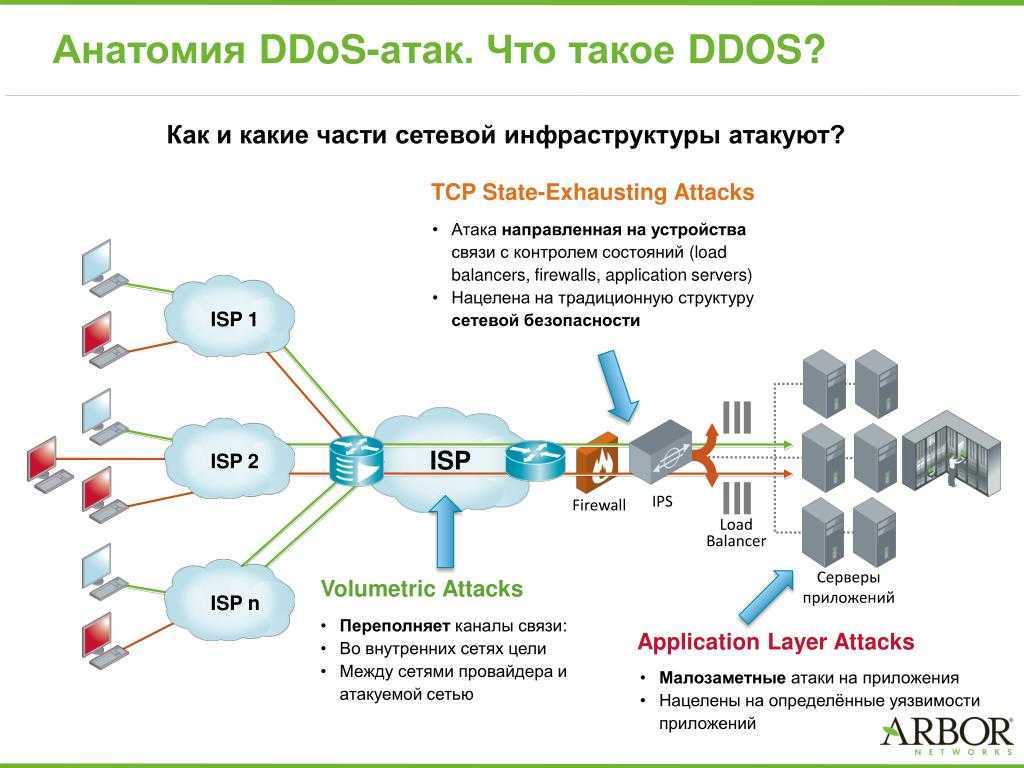
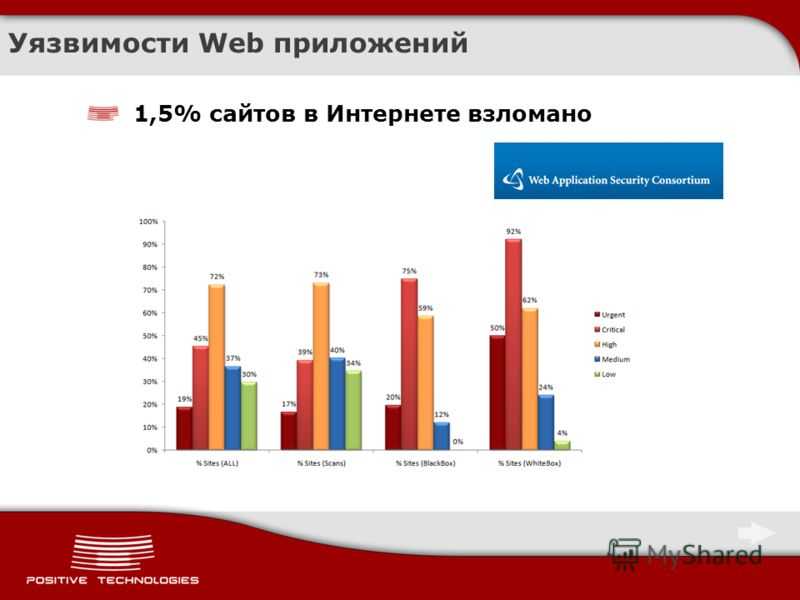
Рис.1. Распределение исследованных продуктов по типам(СЗИ от НСД – средство защиты от несанкционированного доступа; ППО с СЗИ – прикладное программное обеспечение со встроенными средствами защиты информации; МЭ – межсетевой экран; САВЗ – средство антивирусной защиты; СУБД – системы управления базами данных; ОС – операционная система; СОВ – система обнаружения вторжений)Рис.2. Распределение исследованных продуктов в зависимости от доступа к исходным текстамРезультаты исследованийРис.3. Распределение выявленных уязвимостей в зависимости от степени критичностиРис.4. Распределение выявленных уязвимостей в зависимости от типа
исследованного ПО
- межсайтовое выполнение скриптов (CAPEC-63);
- межсайтовая подделка запросов (CAPEC-62);
- повышение привилегий, связанное с обходом функций безопасности (CAPEC-233);
- атаки, направленные на отказ в обслуживании (CAPEC-2);
- раскрытие критичной информации ПО в сообщениях об ошибках (CAPEC-54);
- инъекция SQL-кода (CAPEC-66).
Рис.5. Распределение выявленных уязвимостей в зависимости от типа вектора атаки
- неверное использование данных, полученных из недоверенного источника, для генерации HTML-страницы (CWE-79);
- использование аутентификационных данных (данные cookie) для авторизации запроса (CWE-352);
- неверное использование данных, полученных из недоверенного источника, при выполнении функций безопасности (CWE-807);
- отсутствие авторизации при выполнении критичных операций (CWE-862);
- неверное использование данных, полученных из недоверенного источника, для генерации запроса к СУБД (CWE-89);
- неверная генерация сообщений об ошибках (CWE-209).
Рис.6. Распределение выявленных уязвимостей в зависимости от ошибки (недостатка) ПОРис.7. Распределение выявленных уязвимостей в зависимости от метода формирования перечня потенциальных уязвимостей
Yasca
Сайт: www.yasca.org
Лицензия: Open Source
Платформа: Unix, Windows
Языки: С++, Java, .NET, ASP, Perl, PHP, Python и другие.
Yasca так же, как и RATS не нуждается в установке, при этом имеет не
только консольный интерфейс, но и простенький GUI. Разработчики рекомендуют
запускать утилиту через консоль — мол, так возможностей больше. Забавно, что
движок Yasca написан на PHP 5.2.5, причем интерпретатор (в самом урезанном
варианте) лежит в одной из подпапок архива с программой. Вся программа логически
состоит из фронт-енда, набора сканирующих плагинов, генератора отчета и
собственно движка, который заставляет все шестеренки вращаться вместе. Плагины
свалены в директорию plugins — туда же нужно устанавливать и дополнительные
аддоны. Важный момент! Трое из стандартных плагинов, которые входят в состав
Yasca, имеют неприятные зависимости. JLint, который сканирует Java’овские
.class-файлы, требует наличия jlint.exe в директории resource/utility. Второй
плагин — antiC, используемый для анализа сорцов Java и C/C++, требует antic.exe
в той же директории. А для работы PMD, который обрабатывает Java-код, необходима
установленная в системе Java JRE 1.4 или выше. Проверить правильность установки
можно, набрав команду «yasca ./resources/test/». Как выглядит сканирование?
Обработав скормленные программе сорцы, Yasca выдает результат в виде
специального отчета. Например, один из стандартных плагинов GREP позволяет с
помощью паттернов, описанных в .grep файлах, указать уязвимые конструкции и
легко выявлять целый ряд уязвимостей. Набор таких паттернов уже включен в
программу: для поиска слабого шифрования, авторизации по «пароль равен логину»,
возможные SQL-инъекции и много чего еще. Когда же в отчете захочется увидеть
более детальную информации, не поленись установить дополнительные плагины. Чего
стоит одно то, что с их помощью можно дополнительно просканировать код на на
.NET (VB.NET, C#, ASP.NET), PHP, ColdFusion, COBOL, HTML, JavaScript, CSS,
Visual Basic, ASP, Python, Perl.
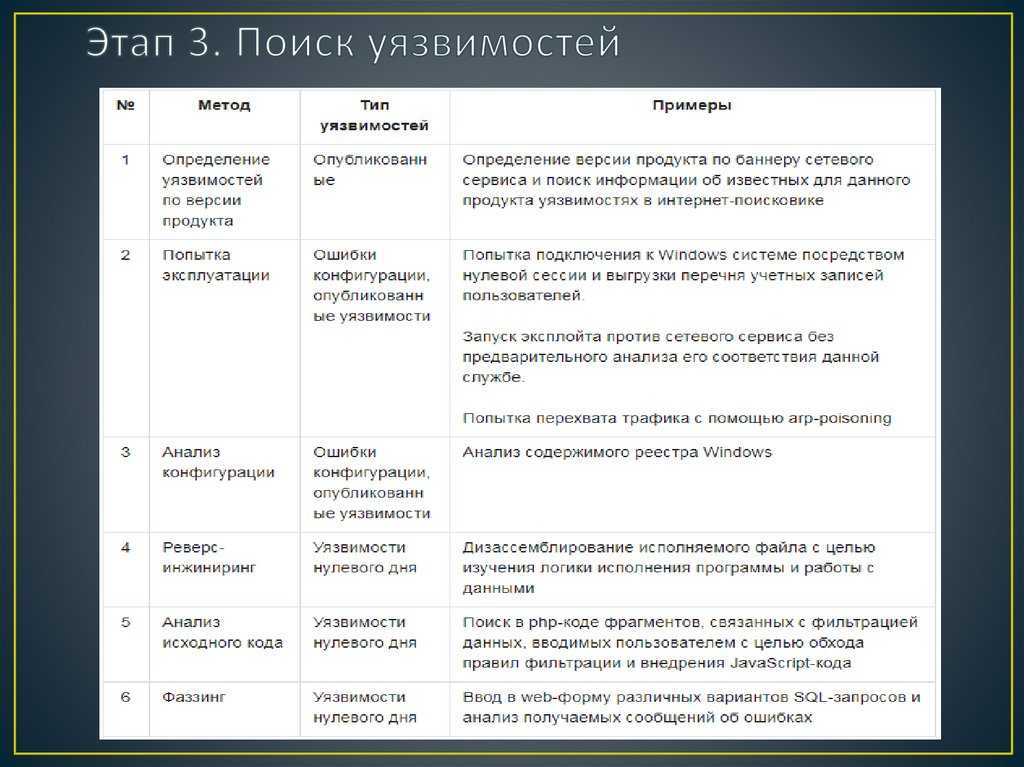
Технологии выявления
Практически все доступные на текущий момент статические анализаторы используют в том или ином виде следующие технологии выявления уязвимостей в коде:
Задача выявления уязвимостей в коде не является полностью алгоритмизированной и автоматизируемой, в связи с чем для проведения внешнего аудита безопасности кода должны привлекаться эксперты. Соответственно облачная платформа для внешнего аудита кода должна обеспечивать удобные механизмы для взаимодействия эксперта и разработчика.
- структурный анализ текстов программ – основывается на задании правил построения законченных и семантически целостных фрагментов кода, на соответствие которым оцениваются исходные тексты программ. Для задания указанного множества правил используются контекстно-свободные грамматики, БНФ-нотация, и другие формальные методы описания языков программирования. Данный метод обладает наивысшим уровнем абстракции и может использоваться для выявления широкого спектра уязвимостей. Его недостатком является относительно высокая вероятность ошибок классификации, включая ошибки первого (пропуск уязвимости) и второго (ложные выявления уязвимостей) рода;
- структурная оценка сложности исходных текстов основывается на построении моделей покрытия кода, относительно которых могут оцениваться, например, межмодульная связность (маршруты, связывающие функциональные объекты по данным, по управлению), сложность покрытия кода (например, на основе оценки цикломатического числа в графе покрытия кода). Метод может использоваться для оценки качества кода в целом (то есть качества кодирования алгоритмов);
- сигнатурный анализ кода – основывается на ранее имевшемся опыте выявления уязвимостей, сведенном в базу сигнатур уязвимостей. Сигнатура определятся заданием минимального множества фрагмента кода, по которым может быть идентифицирована уязвимость. Для описания сигнатур уязвимостей используются параметризованные шаблоны (например, регулярные выражения). Достоинство сигнатурного метода состоит в его относительно высокой точности.
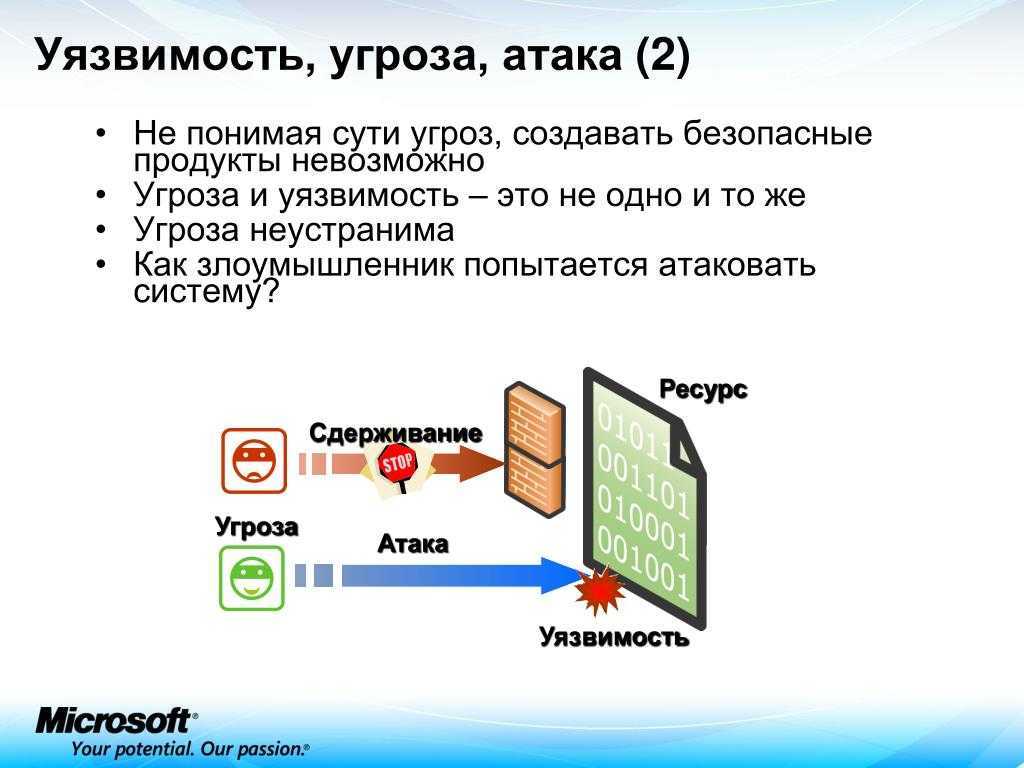
Выявление уязвимостей программного обеспечения
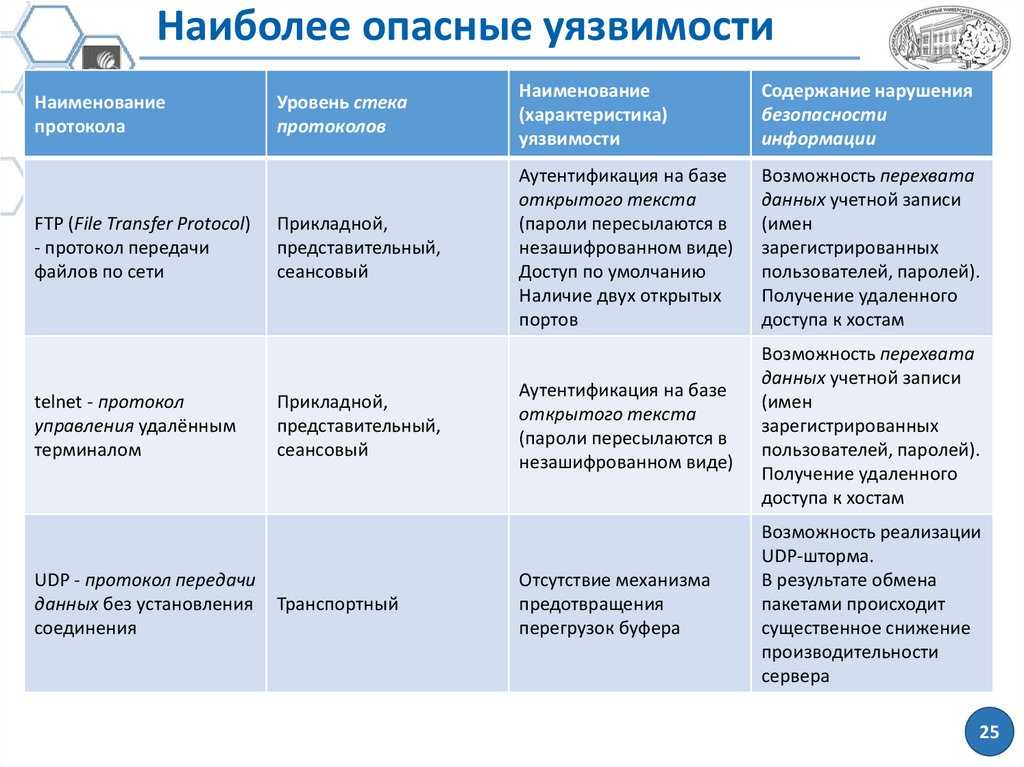
Руководящий документ по не декларированным возможностям был сформирован в девяностые годы прошлого века с целью решения задачи контроля над продаваемым в Российскую Федерацию зарубежным программным обеспечением и тогда, естественно, имел очень важное значение. Методики, которые были определены в этом руководящем документе, опирались на теорию надежности функционирования программных продуктов, поэтому проблемы защиты непосредственно программного кода были представлены в документе в недостаточно явной форме
Согласно этому документу главными видами проверок, которые обязаны проводить испытательные лаборатории, считаются структурный статический и динамический анализ исходных текстов (структуры программы, формирования и прохождения всех ее путей).
К числу достоинств документа можно причислить:
- требование предоставить исходный программный код и документацию;
- требование выполнять контроль избыточности, которое может позволить исключить определенные закладные компоненты;
- требование присутствия определения полномасштабного тестирования.
Последнее требование при наличии необходимого мониторинга и аудита работы способно позволить выявить практически все уязвимости несложных программ, но касательно сложного программного обеспечения это будет весьма проблематичным.
Но имеется также у руководящего документа и отдельные недостатки. Прежде всего это существенная вычислительная сложность статического и динамического анализа. Практически, при возрастании сложности программного обеспечения динамический анализ превращается в неразрешимую задачу, и становится формальной процедурой, отнимающей большое количество времени и ресурсов у специалистов.
Также следует отметить отсутствие или недостаточность проверок, которые напрямую связаны с безопасностью программного продукта. К примеру, не упомянут сигнатурный анализ в требованиях к проверке программ ниже второго уровня контроля, то есть, программ, которые обрабатывают секретные и конфиденциальные информационные данные. Не задействованы требования к содержимому базы потенциально опасных конструкций, что может сделать неэффективными методики сигнатурного анализа.
На сегодняшний день используются следующие основные подходы к определению уязвимостей кода:
- Подход, который состоит в использовании структурного статического и динамического анализа исходного программного кода и регламентируется руководящим документом.
- Подход, который заключается в использовании сигнатурно-эвристического анализа потенциально опасных операций. Он выполняет сканирование программного кода на наличие таких операций, и далее осуществляется ручной или автоматический анализ фрагмента кода для определения реальной угрозы для программного обеспечения.
Можно считать очевидным, что второй подход не имеет недостатков избыточной структуризации всего программного обеспечения и очень большого объема полноформатного тестирования. Так как количество потенциально опасных операций обычно не превышает примерно десяти процентов объема всего программного обеспечения, то примерно в десять (иногда и в двадцать) раз может быть снижено время ручного анализа исходного текста.
Касательно статического и динамического анализа необходимо заметить, что итоговые результаты статического анализа по сложности интерпретации могут быть сопоставимыми с исходными текстами, а динамический анализ может дополнительно потребовать формирования и исполнения соответствующих тестов маршрутов. Это означает, что сигнатурно-эвристический анализ способен сократить затраты времени на поиск не декларированных возможностей в десятки раз. Практика показывает, что практически все выявленные на этапе сертификационных испытаний уязвимости кода, были найдены за счет применения именно второго подхода.
Замечание 1
Следует подчеркнуть, что для выявления уязвимостей программного обеспечения нужно использовать комплексный подход.
Burp Suite Pro
решение
Proxy — прокси-сервер, который перехватывает трафик, проходящий по протоколу HTTP(S), в режиме man-in-the-middle. Находясь между браузером и целевым веб-приложением, эта утилита позволяет перехватывать, изучать и изменять трафик, идущий в обоих направлениях.
Spider — веб-паук, который в автоматическом режиме собирает информацию о содержимом и функционале приложения (веб-ресурса).
Scanner (только в Burp Suite Pro) — сканер для автоматического поиска уязвимостей в веб-приложениях.
Intruder — гибкая утилита, позволяющая в автоматическом режиме производить атаки различного вида




Например, перебор идентификаторов, сбор важной информации и прочее.
Repeater — инструмент для ручного изменения и повторной отсылки отдельных HTTP-запросов, а также для анализа ответов приложения.
Sequencer — утилита для анализа случайных данных приложения на возможность предсказания алгоритма их генерации.
Decoder — утилита для ручного или автоматического кодирования и декодирования данных приложения.
Comparer — инструмент для поиска визуальных различий между двумя вариациями данных.
Extender — инструмент для добавления расширений в Burp Suite
php.testsparker.com premium.bgabank.com H: Cross-site scripting (reflected)M: SSL cookie without secure flag set
M: SSL certificate (not trusted or expired)L: Cookie without HttpOnly flag set
L: Password field with autocomplete enabled
L: Strict transport security not enforcedЕсли для веб-пентеста вы часто используете Burp Suiteэта утилита отлично впишется в ваш арсенал
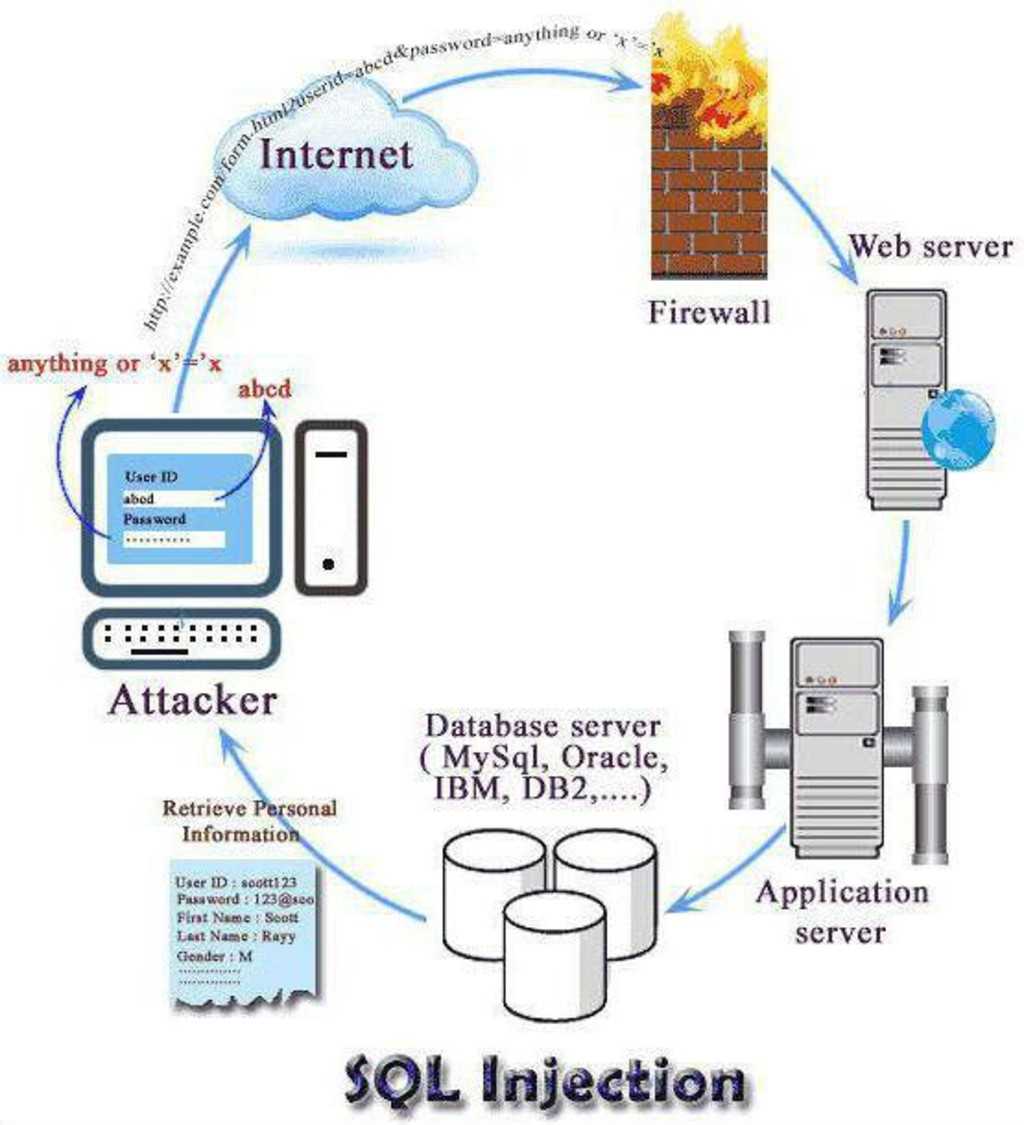
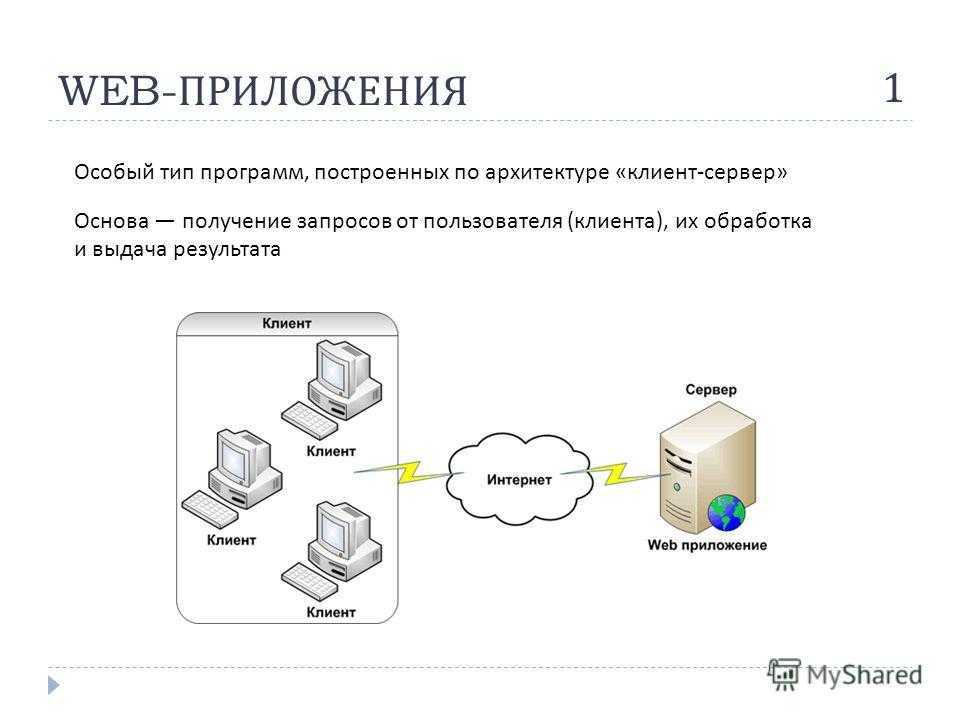
SQL and Code injection
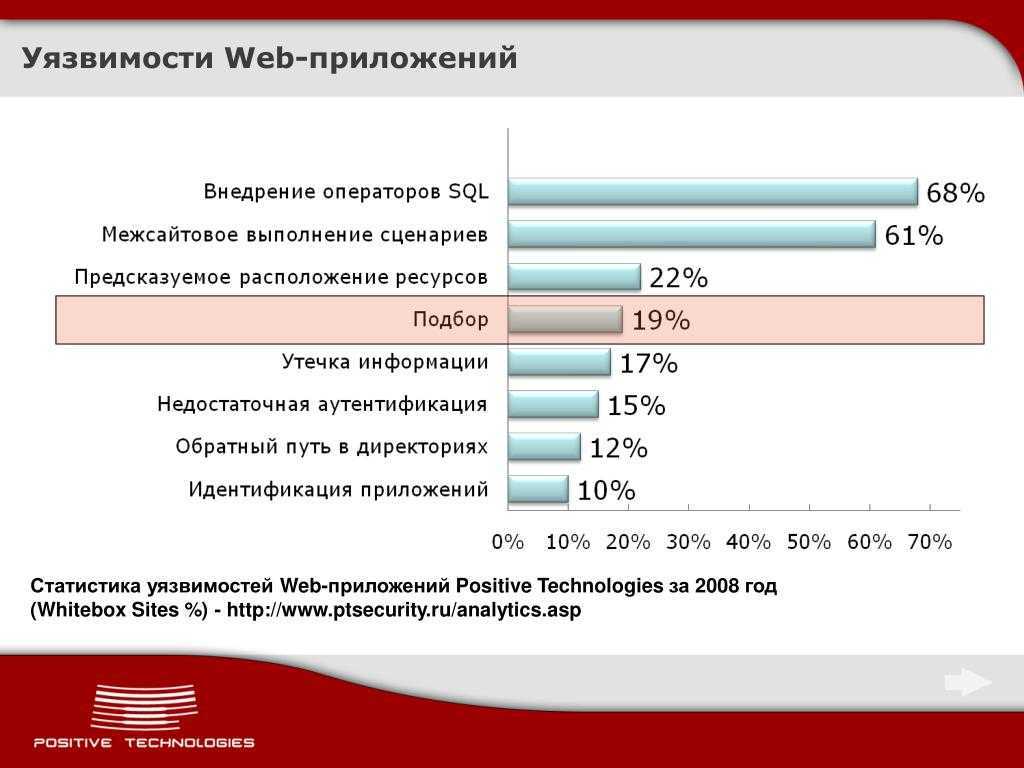
Пожалуй, сейчас это самый распространенный способ взлома сайтов и программ, работающих с базами данных, основанный на внедрении в запрос произвольного SQL-кода.
Внедрение SQL, в зависимости от типа используемой СУБД и условий внедрения, может дать возможность атакующему выполнить произвольный запрос к базе данных (например, прочитать содержимое любых таблиц, удалить, изменить или добавить данные), получить возможность чтения и/или записи локальных файлов и выполнения произвольных команд на атакуемом сервере.
В общих чертах поиск уязвимости с помощью SQL инъекций будет выглядеть следующим образом:
Форма входа в систему имеет 2 поля — имя и пароль. Обработка происходит в базе данных через выполнение SQL запроса:
Следует ввести корректное имя ’tester’, а в поле пароль ввести строку:
В итоге, если поле не имеет соответствующих валидаций или обработчиков данных, может вскрыться уязвимость, позволяющая войти в защищенную паролем систему, т.к. SQL запрос примет следующий вид:
Условие ‘1’ = ‘1’ всегда будет истинным и поэтому SQL запрос всегда будет возвращать много значений.
Как было сказано ранее, SQL Injection — один из самых популярных подходов, как раз благодаря ему в 2019 году в украинской платформе по управлению IPTV/OTT-проектами Ministra TV обнаружена критическая уязвимость. Эксперты из CheckPoint нашли логическую уязвимость в функции авторизации платформы Ministra, которая выражается в неспособности подтверждения запроса, что позволяет удаленному злоумышленнику обойти авторизацию и выполнить SQL-инъекцию через отдельную уязвимость, которую в противном случае мог бы использовать лишь злоумышленник, прошедший авторизацию (полную версию можно посмотреть https://www.youtube.com/watch?v=jqXPePSefss).
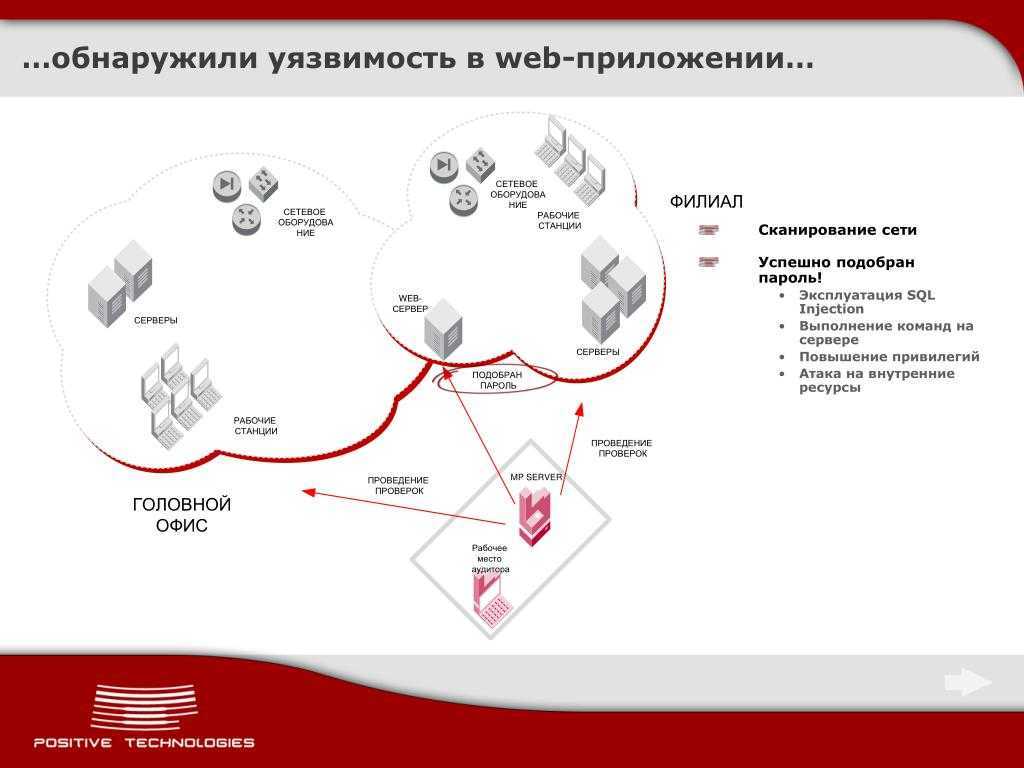
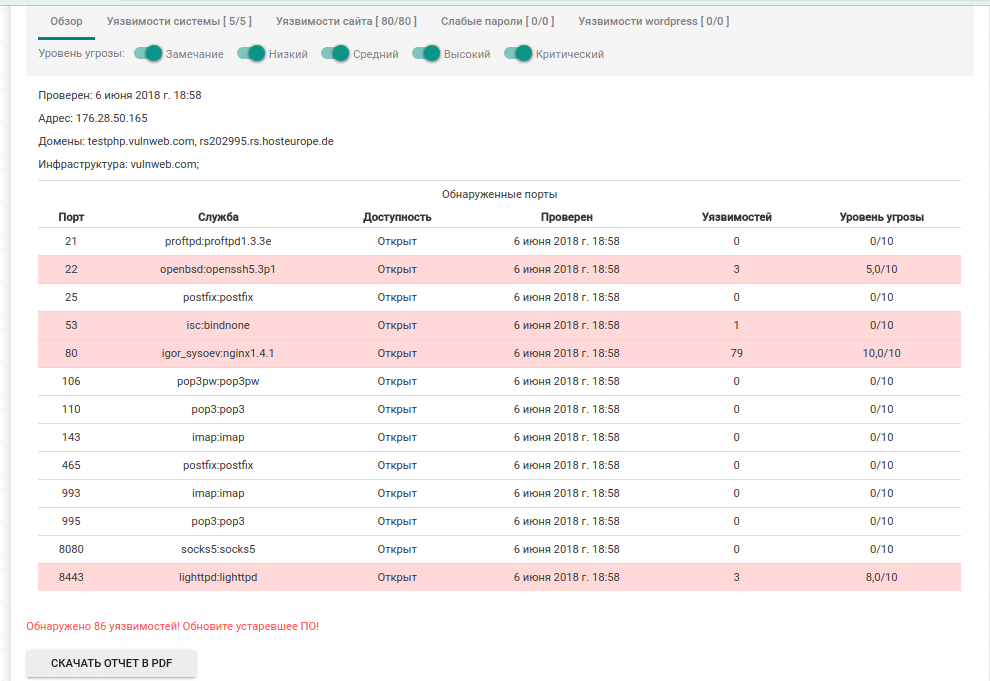
Виды сканирования
Сканирование на уязвимости — это один из начальных этапов задачи тестирования на проникновение (пентест). Сканирование на уязвимости, как пентест или любое тестирование делится на несколько видов. Рассмотрим каждый через призму сканера на уязвимости:
WhiteBox. Сканер запускается внутри исследуемой сети, что позволяет более полно и комплексно изучать уязвимости, отпадает необходимость «угадывания» типа сервиса или ОС. Плюс метода в полном и комплексном подходе к исследованию, а минус в том, что это менее приближено к ситуации реальной атаки злоумышленника.
BlackBox. «Чёрный ящик». Сканер запускается извне исследуемой сети, что приводит к необходимости работы через общедоступные интерфейсы. Приложению необходимо провести анализ открытых портов, «угадать» службы и сервисы, и провести выявление уязвимостей на основании полученной информации. Такой вариант максимально приближен к реальной ситуации: в качестве первоначальных данных у сканера есть только IP или доменное имя для проверки. Из минусов можно упомянуть, что уязвимости приложений, используемых в DMZ, так и останутся не найденными.
Разумеется, можно долго спорить о плюсах и минусах разных видов сканирования, но вряд ли кто-то будет оспаривать необходимость проведения тестирования. А практика показывает, что совмещение обоих методов позволяет получить наилучшие результаты. Мне кажется, разумнее сначала провести BlackBox сканирование, а затем WhiteBox. Кстати, сейчас мы работаем над созданием сервиса для клиентов, который позволит с помощью BlackBox-сканирования проверять инфраструктуру, расположенную в ЦОД Cloud4Y. Сервис убережёт от неприятных случайностей, когда из-за человеческого фактора не были закрыты порты или оставлены другие потенциально опасные «дыры».
Что дальше
Преобразование ассемблерного кода в промежуточное представление, на котором можно проводить анализ. Можно использовать различные байткоды. Для C-языков хорошим выбором кажется LLVM. LLVM активно поддерживается и разрабатывается сообществом, инфраструктура, в том числе полезная для статического анализа, на данный момент внушительно развита
На этом этапе есть огромное количество деталей, на которые нужно обратить внимание. Например, нужно детектировать, какие переменные адресуются в стеке, чтобы не множить сущности в полученном представлении
Нужно настроить оптимальное отображение наборов инструкций ассемблера в инструкции байткода.
Восстановление конструкций высокого уровня (например, циклов, ветвлений). Чем точнее получится восстановить исходные конструкции из ассемблерного кода, тем лучше будет качество анализа. Восстановление таких конструкций происходит с помощью применения элементов теории графов на CFG (графе потока управления) и некоторых других графических представлений программы.
Проведение алгоритмов статического анализа. Тут есть подробности
В целом, не очень важно, получили мы внутреннее представление из исходника или из бинарника — мы все также должны построить CFG, применить алгоритмы анализа потока данных и другие алгоритмы, свойственные статике. Есть некоторые особенности при анализе представления, полученного из бинарника, но они скорее технические.
Бонус
Мало кто задумывается, что письма — это HTML-код. Например, есть такое письмо от Trello:
В письмо тоже подтягиваются пользовательские значения, возможно, там есть XSS. Но письма мы смотрим в почтовых клиентах (обычно Mail.ru, Яндекс) и, разумеется, XSS в письме ведет к XSS в почтовом клиенте, а это уже другой скоуп, который никак не влияет на организацию, которая послала это письмо.
Пейлоад выглядит так:
Примерно как пейлоад для поиска XSS, но здесь мы не вызываем функцию JS, а встраиваем наши HTML-теги в шаблон письма. Также здесь есть ${77}{{77}}, как для AngularJS, только AngularJS рендерится на клиентской стороне, а этот пейлоад призван проверять возможность рендера клиентского значения через шаблонизаторы.
Пример уязвимого шаблона:
На первый взгляд — обычное письмо. Но если посмотреть на тему, то можно увидеть, что там есть HTML-теги, гиперссылка и HTML-коммент.

Идея в том, что мы добавляем нашу вредоносную гиперссылку, комментим оригинальное письмо и отправляем это письмо кому угодно.
Так как мы можем контролировать гиперссылку и контекст, мы можем зафишить кого-то невнимательного, потому что ссылка будет вести на левый сайт.
Недавно мне пришло такое письмо:
Кто-то пытался эксплуатировать абсолютно то же самое: приглашали присоединиться к организации. Разумеется, это фишинг.
Если ${7*7} -> 49 считается не на клиентской стороне, а на серверной, то это будет уязвимость, которая называется SSTI (Server Side Template Injection). Ее суть в том, что разработчики используют какие-то шаблонизаторы, потом они через эти шаблонизаторы прогоняют свои HTML-шаблоны и, если там есть что-то похожее на template expression language, они это рендерят.
Я покажу еще один пример из Bug Bounty. Это был RCE (remote code execution) через инъекцию шаблона во FreeMarker.
Это приложение позволяет создавать свои события, свою кампанию отсылки имейлов.
Имейлы здесь кастомные. Предоставляем HTML, который нужно разослать. Уязвимость была уже в том, что можно послать любой HTML с официального адреса этой компании кому угодно.
Но была еще более серьезная уязвимость. Она заключалась в том, что, если загрузить туда ${77} или #{77}, при превью этого шаблона у нас выведется 49:
Путем недолгих ковыряний я понял, что используется шаблон FreeMarker. А у шаблонизаторов FreeMarker есть такие штуки:
${cmd(‘id’)}
Достаточно вызвать, использовать его и передать ему в качестве параметра какую-то shell-команду, например, id.
И действительно показывает, что root:
Выбираем статический анализатор
Статических анализаторов для Java много: есть и проекты в опенсорс, и коммерческие продукты. Нужно определиться с требованиями к инструменту. Вот такие пожелания сформулировали мы:
- Первое очевидно: поддержка тех технологий, которые мы используем. В Одноклассниках мы пишем на Java, у нас есть JavaScript и TypeScript, а ещё мы хотим сканировать мобильные приложения, поэтому нужна поддержка Android-а.
- Второе: мы однозначно хотим taint analysis. Как мы только что выяснили, эта штука нужна, чтобы находить инъекции и подобные им баги, а они составляют значительную часть всех проблем.
- Мы поняли, что не ограничимся набором стандартных правил, потому что в нашем коде есть конструкции, которые статический анализатор «из коробки» не понимает, возможность кастомизации правил нам важна.
- Хотим, чтобы у разработчиков была единая «точка правды» про наш статический анализ: чтобы все использовали одну и ту же версию правил, знали статус сканирования на данный момент, видели какие из найденных ошибок являются ложными срабатываниями, а какие настоящими багами. В общем, нам нужен collaboration сервер.
- Наконец, мы хотим, чтобы добавление двух строчек кода в наш проект не повлекло необходимость переделывать всё. Если мы уже разобрали результаты сканирования на настоящие баги и ложные срабатывания, то следующее сканирование с небольшими изменениями позволяло бы переиспользовать предыдущие результаты.
В открытом доступе можно найти исследования, сравнивающие различные статические анализаторы. Посмотрим на одно из них, сделанное проектом OWASP (Open Web Application Security Project) в 2016-м (https://github.com/OWASP/benchmark). OWASP написал бенчмарк — приложение на Java с уязвимостями в заранее известных местах и просканировал его несколькими сканерами. Результат ниже:
Диаграмму не назвать интуитивно понятной, но разберёмся, что здесь изображено. Красная пунктирная линия — это результат, соответствующий случайному угадыванию. Все, что выше этой линии — лучше.
Также диаграмме можно заметить взаимосвязь между полнотой (сколько из всех багов было найдено) и точностью (сколько из найденного действительно является багами) анализатора. Сканеры с меньшим количеством ложных срабатываний пропускали больше багов.
Если это учесть, то мы видим, что все инструменты дают примерно одинаковый результат, нет явного лидера. У всех по-разному настроен баланс между настоящими уязвимостями и ложными срабатываниями, а в целом соотношение примерно одинаковое. Явного лидера нет, и коммерческие сканеры не показывают принципиально другие результаты по сравнению с опенсорсными.
Также OWASP протестировал один и тот же сканер Find Security Bugs с разными наборами правил, и в этом случае видно, что чем больше правил, тем больше уязвимостей обнаруживается. То есть добавление правил очевидно приносит результат.
Какой вывод мы можем сделать? Вероятно, выбор движка в статическом анализаторе не так важен для нас, как мощность набора правил и возможность дописывать детекторы под свои нужды.
Мы решили использовать опенсорсный Find Security Bugs. Это плагин для всем известного статического анализатора для Java, который раньше назывался FindBugs, а теперь называется SpotBugs. Find Security Bugs добавляет разнообразные детекторы, связанные с безопасностью, в том числе и для Android.
Также это единственный опенсорсный анализатор для Java, позволяющий добавлять свои правила taint analysis.
Всё, что связано с коллаборацией, с работой внутри команды и с серверной частью нашего инструмента, отдано SonarQube. У Find Security Bugs есть плагин для SonarQube, позволяющий загружать отчеты на сервер и управлять результатами сканирования.
Возможности современных сканеров
Основными требованиями к программе-сканеру, обеспечивающей проверку системы и её отдельных узлов на уязвимости, являются:
- Кроссплатформенность или поддержка нескольких операционных систем. При наличии такой особенности можно выполнять проверку сети, состоящей из компьютеров с разными платформами. Например, с несколькими версиями Windows или даже с системами типа UNIX.
- Возможность сканировать одновременно несколько портов – такая функция заметно уменьшает время на проверку.
- Сканирование всех видов ПО, которые обычно подвержены атакам со стороны хакеров. К такому программному обеспечению относят продукцию компании Adobe и Microsoft (например, пакет офисных приложений MS Office).
- Проверку сети в целом и отдельных её элементов без необходимости запускать сканирование для каждого узла системы.
Большинство современных сканирующих программ имеют интуитивно понятное меню и достаточно легко настраиваются в соответствии с выполняемыми задачами.
Так, практически каждый такой сканер позволяет составить список проверяемых узлов и программ, указать приложения, для которых будут автоматически устанавливаться обновления при обнаружении уязвимостей, и задать периодичность сканирования и создания отчётов.
После получения отчётов сканер позволяет администратору запускать исправление угроз.
Выводы
Если вы разрабатываете приложение, работаете над архитектурой приложения, то всегда надо иметь в виду, что интернет — это небезопасное место.
Нужно всегда помнить, что нельзя доверять пользовательскому вводу. Рассматривайте место, где пользователь вам что-то посылает, как потенциально вредоносное.
Нужно проверять свое приложение, потому что даже самый внимательный разработчик все равно когда-то ошибется, допустит у себя уязвимость, и проверка необходима — чем чаще, тем лучше.
Используйте универсальный пейлоад, помещайте его во все поля, в каждый input. Рано или поздно это сработает, потом уже научитесь раскручивать, успешно находить еще больше XSS, может быть, придумаете свои векторы атаки.
В любом приложении всегда есть уязвимости, в том числе XSS. Если вы ищете баги безопасности, вы не можете быть уверены, что их там нет. Возможно, вы просто не можете их найти, но они там есть. Используя такое убеждение, можно найти еще больше багов.



