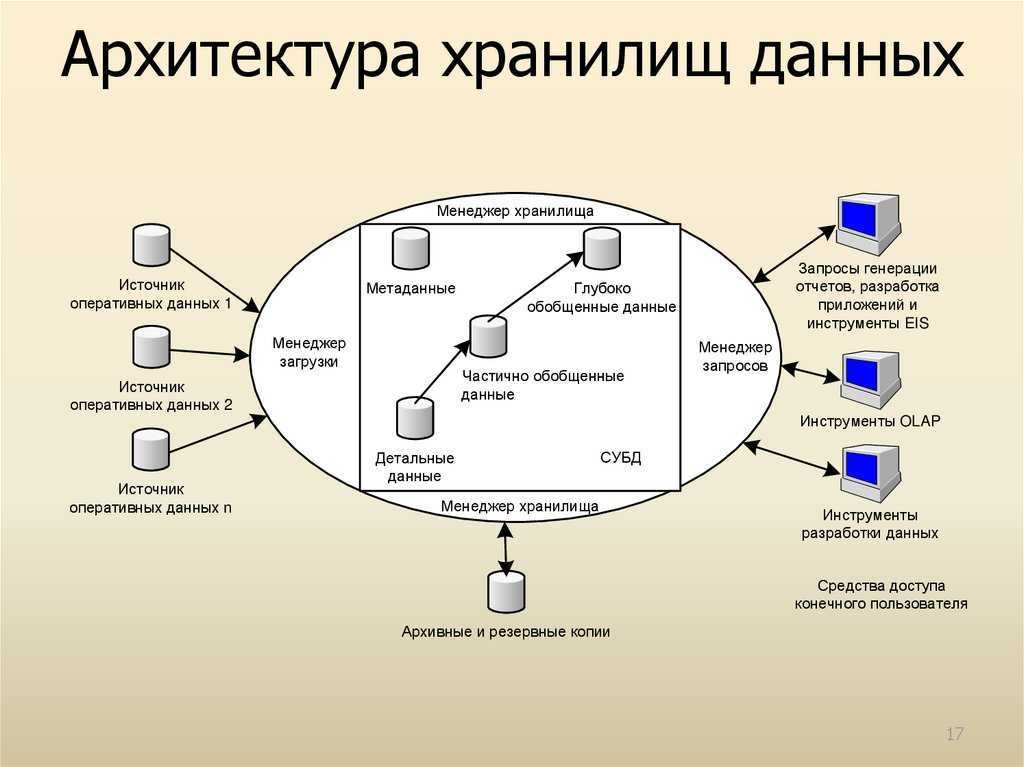
Отслеживание измененных экстентов
SQL Server использует две внутренние структуры данных для отслеживания экстентов, измененных операциями массового копирования, и экстентов, измененных с момента последней полной резервной копии. Эти структуры данных существенно ускоряют разностные резервные копии. Они также ускоряют операции записи в журнал массового копирования, если база данных использует модель восстановления с неполным протоколированием. Как и страницы GAM и SGAM, эти структуры представляют собой растровые изображения, в которых каждый бит представляет один экстент.
-
Схема разностных изменений (Differential Changed Map, DCM)
Эта схема отслеживает экстенты, которые были изменены со времени последнего выполнения инструкции . Если бит для экстента равен , экстент был изменен с момента последнего оператора. Если бит равен , экстент не был изменен.
Чтобы определить, какие экстенты были изменены, разностные резервные копии считывают только страницы DCM. Это существенно сокращает количество страниц, которые должна просмотреть разностная резервная копия. Продолжительность выполнения разностной резервной копии пропорциональна количеству экстентов, измененных с момента последней инструкции, а не общему размеру базы данных.
-
Схема массовых изменений (Bulk Changed Map, BCM)
Это отслеживает экстенты, которые были изменены операциями с неполным протоколированием с момента последнего оператора. Если бит для экстента равен , экстент был изменен операцией с неполным протоколированием после последней инструкции. Если бит равен , экстент не был изменен операциями с неполным протоколированием.
Несмотря на то, что страницы BCM существуют во всех базах данных, они соответствуют только в том случае, если база данных использует модель восстановления с неполным протоколированием. В этой модели восстановления при выполнении инструкции процесс резервного копирования проверяет схемы BCM на наличие измененных экстентов. Затем она включает в себя экстенты из резервной копии журнала. Это восстанавливает операции с неполным протоколированием, если база данных восстанавливается из резервной копии базы данных и последовательности резервных копий журналов транзакций. Страницы BCM не относятся к базе данных, использующую простую модель восстановления, так как операции массового ведения журнала не регистрируются. Они не актуальны в базе данных, использующую модель полного восстановления, так как эта модель восстановления обрабатывает операции с неполным протоколированием как полностью зарегистрированные операции.
Интервал между DCM- и BCM-страницами равен интервалу между GAM- и SGAM-страницами — 64 000 экстентов. Страницы DCM и BCM находятся за страницами GAM и SGAM в физическом файле следующим образом:
Использование секционированных таблиц для управления данными и повышения производительности запросов
Индексы columnstore поддерживают секционирование, что является хорошим способом управления данными и их архивации. Секционирование также повышает производительность выполнения запросов путем ограничения операций одной или несколькими секциями.
Упрощение управления данными с помощью секций
В больших таблицах практичнее всего управлять диапазонами данных с помощью секций. Преимущества использования секций для таблиц rowstore также относятся к индексам columnstore.
Например, при использовании секций в таблицах rowstore и columnstore можно получить следующие преимущества:
- Управление размером добавочных резервных копий. Вы можете создавать резервные копии секций в разных файловых группах и помечать их как доступные только для чтения. При этом во время архивации файловые группы только для чтения будут пропускаться.
- Снижение затрат на хранение за счет перемещения старых секций в экономичное хранилище. Например, можно выполнить переключение секций, чтобы переместить секцию в экономичное хранилище.
- Эффективное выполнение операций путем их ограничения одной секцией. Например, для обслуживания индекса вы можете назначить только фрагментированные секции.
Кроме того, при использовании секционирования индекса columnstore можно добиться следующего:
Экономия 30 % затрат на хранение. Вы можете выполнить сжатие старых секций с помощью параметров сжатия COLUMNSTORE_ARCHIVE. Производительность выполнения запроса к данным снизится, что допустимо, если секция редко запрашивается.
Повышение производительности запросов с помощью секций
Используя секции, вы можете ограничить запросы на сканирование только определенных секций, что ограничивает количество строк для сканирования. Например, если индекс секционируется по годам, а запрос выполняет анализ прошлогодних данных, запросу нужно просканировать данные всего в одной секции.
Использование нескольких секций для индекса columnstore
Когда объем данных не слишком большой, индекс columnstore позволяет эффективно работать с меньшим количеством секций, чем обычно используется для индекса rowstore. Если у вас нет хотя бы миллиона строк на секцию, большинство строк могут отправляться в дельта-хранилище, где они не получают преимуществ высокой производительности и сжатия, обеспечиваемых индексом columnstore. Например, если загрузить миллион строк в таблицу с 10 секциями по 100 000 строк на каждую, все строки перейдут в разностные группы строк.
Пример
- Загрузите 1 000 000 строк в одну секцию или в несекционированную таблицу. Вы получите одну сжатую группу строк с 1 000 000 строк. Это удобно для высокого уровня сжатия данных и высокой производительности запросов.
- Загрузите 1 000 000 строк с равномерным распределением по 10 секциям. Каждая секция получает по 100 000 строк. Это значение ниже минимального порога для сжатия columnstore. В результате индекс columnstore может иметь 10 разностных групп строк с 100 000 строк в каждой. Вы можете принудительно передать разностные группы строк в индекс columnstore. Тем не менее, если это единственные строки в индексе columnstore, сжатые группы строк будут слишком малы для максимального сжатия и максимальной производительности запросов.
Дополнительные сведения о секционировании см. в записи блога Сунила Агарвала (Sunil Agarwal) Should I partition my columnstore index? (Следует ли секционировать индекс columnstore?).
Планирование ресурсов для tempdb в SQL Server
Определение требуемого размера в рабочей среде SQL Server зависит от многих факторов. Как описано выше, эти факторы включают текущую рабочую нагрузку и используемые функции SQL Server. Рекомендуется проанализировать текущую рабочую нагрузку, выполнив следующие задачи в среде тестирования SQL Server:
- Включите автоувеличение для .
- Запускайте отдельные запросы или файлы трассировки рабочей нагрузки и следите за использованием диска базой данных .
- Выполняйте операции обслуживания индексов, например перестроение индексов, и следите за использованием диска базой данных .
- Используйте значения используемого пространства на диске из предыдущих шагов для прогнозирования общей рабочей нагрузки. Скорректируйте полученное значение с учетом предполагаемой параллельной обработки и задайте соответствующий размер .
Типы дисков виртуальной машины
Вы можете выбирать уровень производительности для своих дисков. Типы управляемых дисков, доступных в качестве базового хранилища (перечислены в порядке увеличения производительности): жесткие диски (HDD) категории «Стандартный», твердотельные накопители (SSD) категории «Стандартный», SSD категории «Премиум» и диски категории «Ультра».
Производительность диска увеличивается с увеличением емкости, сгруппированной по , от P1 с 4 ГиБ пространства и 120 операциями ввода-вывода в секунду до P80 с 32 ТиБ хранилища и 20 000 операций ввода-вывода в секунду. Хранилище категории «Премиум» поддерживает кеш хранилища, который помогает повысить производительность операций чтения и записи для некоторых рабочих нагрузок. Дополнительные сведения см. в статье Обзор управляемых дисков.
Существует также три основных , которые рекомендуется рассматривать для SQL Server на виртуальной машине Azure: диск ОС, временный диск и ваши диски данных. Тщательно выбирайте, что должно храниться на диске операционной системы и временном диске .
Диск операционной системы
Диск операционной системы — это виртуальный жесткий диск, который может быть использован как загрузочный и подключен в качестве рабочей версии операционной системы. Отмечается как диск . Когда вы создаете виртуальную машину Azure, платформа подключает к ней как минимум один диск в качестве диска операционной системы. Диск — это место по умолчанию для установки приложений и конфигурации файлов.
В рабочих средах SQL Server не используйте диск операционной системы для файлов данных, файлов журналов и журналов ошибок.
Временный диск
Многие виртуальные машины Azure содержат диск другого типа, так называемый временный диск (отмеченный как диск ). Емкость этого диска может различается в зависимости от серии и размера виртуальной машины. Временный диск — это означает, что дисковое хранилище пересоздается (в том смысле, что оно освобождается и выделяется снова) при перезапуске виртуальной машины или перемещении на другой узел (например, для восстановления службы).
Диск временного хранилища не сохраняется в удаленном хранилище и, следовательно, на нем не должны храниться файлы пользовательской базы данных, файлы журнала транзакций или что-либо, что необходимо сохранить.
Поместите на локальный временный SSD-диск для SQL Server рабочих нагрузок, если только не вызывает озабоченность потребление локального кэша. Если вы используете виртуальную машину без временного диска , рекомендуется разместить ее на отдельном изолированном диске или в пуле носителей с кэшированием только для чтения. Дополнительные сведения см. в разделе .
Диски данных
Диски данных — это диски удаленного хранилища, которые часто создаются в пулах носителей, чтобы увеличить емкость и производительность каждого отдельного диска для виртуальной машины.
Подключайте минимальное количество дисков, способное удовлетворить требования вашей рабочей нагрузки к количеству операций ввода-вывода в секунду, пропускной способности и емкости. Не превышайте максимальное количество дисков данных самой маленькой виртуальной машины, размер которой вы планируете изменить.
Размещайте файлы данных и журналов на дисках данных, подготовленных в соответствии с требованиями к производительности.
Отформатируйте диск данных, чтобы он использовал размер единицы размещения 64 КБ для всех файлов данных, размещенных на дисках, кроме временного диска (который имеет значение по умолчанию 4 КБ). Виртуальные машины SQL Server, развернутые через Azure Marketplace, поставляются с дисками данных, отформатированными с размером единицы размещения и чередованием для пула носителей, равным 64 КБ.
Примечание
Файлы баз данных SQL Server также можно размещать непосредственно в хранилище BLOB-файлов Azure или в хранилище SMB например в файловой папке Azure категории «Премиум», но мы рекомендуем использовать управляемые диски Azure для максимальной производительности, надежности и доступности функций.
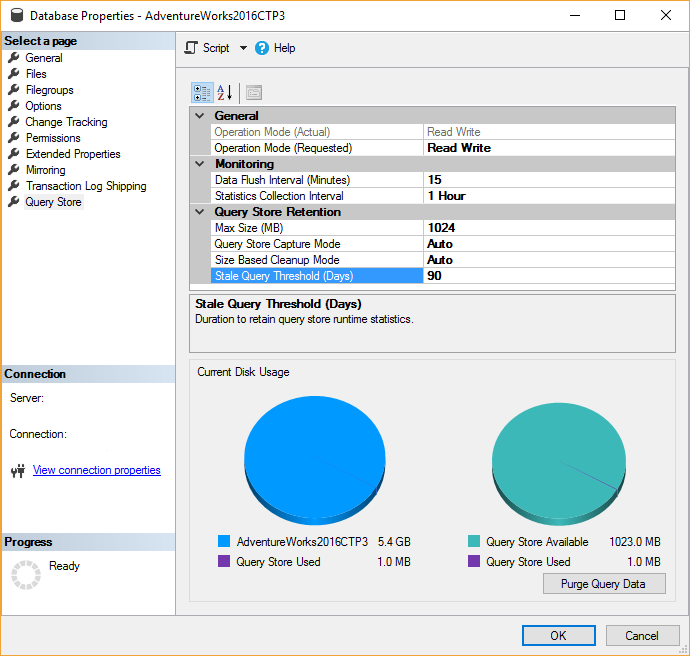
Установка оптимального режима записи для хранилища запросов
Наиболее важные данные следует хранить в хранилище запросов. В приведенной ниже таблице описаны типичные сценарии для каждого режима записи в хранилище запросов.
Режим записи хранилища запросов
Сценарий
все
Тщательно анализируйте рабочую нагрузку на основе форм всех запросов и частоты их выполнения, а также других статистических данных.Выявление новых запросов в рабочей нагрузке.Обнаруживайте, используются ли динамические запросы для определения возможностей для пользовательской или автоматической параметризации.Примечание
Это режим записи по умолчанию в версиях SQL Server 2016 (13.x); и SQL Server 2017 (14.x);.
Автоматически
Сосредоточьте внимание на важных и действенных запросах
Примерами могут служить запросы, которые выполняются регулярно или потребляют ресурсы в значительных объемах.Примечание
Начиная с версии SQL Server 2019 (15.x) это режим записи по умолчанию.
None
Вы уже записали набор запросов, который хотите отслеживать в среде выполнения, и хотите исключить отвлекающие факторы, которые могут быть внесены другими запросами.Значение None подходит для тестовых сред и сред тестирования производительности.Кроме того, значение None подходит для поставщиков программного обеспечения, поставляющих конфигурацию хранилища запросов, настроенную для наблюдения за рабочей нагрузкой приложений.Значение None следует использовать с осторожностью, поскольку можно упустить возможность отслеживания и оптимизации важных новых запросов. Старайтесь не использовать None, если этого не требуется в конкретном сценарии.
Custom
SQL Server 2019 (15.x) появился пользовательский режим записи с помощью команды
Хотя параметр Auto используется по умолчанию и рекомендуется, если по-прежнему возникают проблемы с издержками, которые могут возникнуть хранилище запросов, администраторы баз данных могут использовать пользовательские политики записи для дальнейшей настройки поведения записи хранилище запросов. Дополнительные сведения и рекомендации см. в разделе далее в этой статье. Дополнительные сведения об этом синтаксисе см. в разделе .
Примечание
Курсоры, запросы в хранимых процедурах и скомпилированные в собственном коде запросы всегда записываются, если задан режим записи в хранилище запросов All, Auto или Custom. Чтобы записывать скомпилированные в собственном коде запросы, включите сбор статистики на уровне запроса с помощью хранимой процедуры sys.sp_xtp_control_query_exec_stats.
Рекомендации по повышению производительности FILESTREAM
Функция SQL Server FILESTREAM позволяет хранить двоичные данные больших объектов varbinary(max) в виде файлов в файловой системе. При наличии большого количества строк в контейнерах FILESTREAM, которые являются базовым хранилищем для столбцов FILESTREAM и FileTable, можно создать том файловой системы, содержащий большое количество файлов
Чтобы обеспечить оптимальную производительность при обработке интегрированных данных из базы данных и файловой системы, важно обеспечить оптимальную настройку файловой системы. Ниже приведены некоторые доступные параметры настройки файловой системы
-
Проверка высоты для драйвера фильтра FILESTREAM SQL Server . Оцените все драйверы фильтров, загруженные для стека хранилища, связанного с томом, в котором компонент FILESTREAM хранит файлы, и убедитесь, что драйвер RsFx находится в нижней части стека. Для перечисления драйверов фильтров для определенного тома можно использовать программу управления FLTMC.EXE. Ниже приведен пример выходных данных служебной программы FLTMC: фильтры
Имя фильтра Число экземпляров Высота над уровнем моря Frame Sftredir 1 406000 MpFilter 9 328000 luafv 1 135000 FileInfo 9 45000 RsFx0103 1 41001.03 -
Убедитесь, что для этих файлов свойство «Время последнего доступа» отключено на сервере. Этот атрибут файловой системы поддерживается в реестре:
Имя ключа:
Имя: NtfsDisableLastAccessUpdate
Тип: REG_DWORD
Значение: 1 -
Убедитесь, что на сервере отключена нотация 8.3. Этот атрибут файловой системы поддерживается в реестре:
Имя ключа:
Имя: NtfsDisable8dot3NameCreation
Тип: REG_DWORD
Значение: 1 -
Убедитесь, что в контейнерах каталога FILESTREAM не включено шифрование или сжатие файловой системы, так как это может приводить к некоторым задержкам при доступе к этим файлам.
-
В командной строке с повышенными привилегиями запустите экземпляры FLTMC и убедитесь, что к тому, на котором вы пытаетесь выполнить восстановление, не подключены драйверы фильтров.
-
Убедитесь, что в контейнерах каталога FILESTREAM находится не более 300 000 файлов. Сведения из представления каталога можно использовать, чтобы выяснить, какие каталоги в файловой системе содержат файлы . Такую ситуацию можно предотвратить с помощью нескольких контейнеров. (Дополнительные сведения см. в следующем элементе маркированного списка.)
-
При наличии только одной файловой группы FILESTREAM все файлы данных создаются в одной и той же папке. На создание очень большого количества файлов могут повлиять большие индексы NTFS, что также может привести к фрагментации.
-
Использование нескольких файловых групп обычно помогает решить эту проблему (приложение использует секционирование или содержит несколько таблиц, каждая из которых находится в собственной файловой группе).
-
При использовании SQL Server 2012 и более поздних версий в файловой группе FILESTREAM можно использовать несколько контейнеров или файлов, а также будет применяться схема распределения с циклическим перебором. Таким образом, количество файлов NTFS на каталог будет меньше.
-
-
-
Резервное копирование и восстановление можно ускорить с помощью нескольких контейнеров FILESTREAM, если для хранения контейнеров используются несколько томов.
SQL Server 2012 поддерживает несколько контейнеров для каждой файловой группы и может значительно упростить работу. Для управления большим числом файлов не требуются сложные схемы секционирования.
-
Если в экземпляре SQL существует очень большое количество контейнеров FILESTREAM, запуск баз данных с большим количеством контейнеров FILESTREAM может занять много времени, чтобы зарегистрировать их в драйвере фильтра FILESTREAM. Распространение их в нескольких разных томах поможет улучшить время запуска базы данных.
-
Файл MFT файловой системы NTFS может стать фрагментированным, что может вызвать проблемы с производительностью. Зарезервированный размер MFT зависит от размера тома, поэтому вы можете и не столкнуться с этой проблемой.
-
Можно проверить фрагментацию MFT с помощью (измените C: на фактическое имя тома).
-
Можно зарезервировать дополнительное пространство MFT с помощью команды fsutil behavior set mftzone 2.
-
Файлы данных FILESTREAM должны быть исключены из проверки антивирусным ПО.
Примечание
Windows Server 2016 автоматически включает Защитник Windows. Убедитесь, что Защитник Windows настроен для исключения файлов FILESTREAM. Невыполнение этого действия может привести к снижению производительности операций резервного копирования и восстановления.
Дополнительные сведения см. в разделе Настройка и проверка исключений для проверок антивирусной программой «Защитник Windows».
-
Write-Ahead ведения журнала (WAL)
Протокол терминов — отличный способ описать WAL. Это конкретный и определенный набор шагов реализации, необходимых для правильного хранения и обмена данными и их восстановления до известного состояния в случае сбоя. Так же как сеть содержит определенный протокол для согласованного и защищенного обмена данными, wal также описывает протокол для защиты данных.
Документ ARIES определяет WAL следующим образом:
Протокол WAL утверждает, что записи журнала, представляющие изменения некоторых данных, должны уже находиться в стабильном хранилище, прежде чем измененным данным будет разрешено заменить предыдущую версию данных в неизменяемом хранилище. То есть системе не разрешено записывать обновленную страницу в неизменяемую версию хранилища страницы, пока по крайней мере части записей журнала, описывающих обновления страницы, не будут записаны в стабильное хранилище.
Дополнительные сведения о ведении журнала упреждающей записи см. в разделе журнала транзакций с упреждающей записью в SQL Server электронной документации.
Индексы
Если окажется, что ваши запросы часто выполняют в документах поиск по определенному свойству (например, по свойству в документе JSON), добавьте к свойству классический индекс NONCLUSTERED, чтобы ускорить обработку запросов.
Вы можете создать вычисляемый столбец, который предоставляет значения JSON из столбцов JSON по заданному пути (то есть, по пути ), и создать стандартный индекс в этом столбце. Пример:
Используемый в этом примере вычисляемый столбец является несохраняемым или виртуальным столбцом, который не добавляет дополнительное место в таблицу. Индекс использует его для повышения производительности запросов, как показано в следующем примере.
Важное свойство этого индекса — учет параметров сортировки. Если исходный столбец NVARCHAR имеет свойство COLLATION (например, для учета регистра или японского языка), индекс расставляется в соответствии с правилами языка или правилами учета регистра, связанными со столбцом NVARCHAR
Такой учет параметров сортировки может оказаться важным при разработке приложений для международного рынка, в которых нужно использовать особые языковые правила при обработке JSON-документов.
Оптимизированные для памяти метаданные tempdb
Состязание метаданных всегда было узким местом для масштабируемости многих рабочих нагрузок, выполняющихся в SQL Server. В SQL Server 2019 (15.x) появилась новая функция оптимизированных для памяти метаданных tempdb, входящая в семейство функций выполняющейся в памяти базы данных.
Она эффективно устраняет существующее узкое место и открывает новый уровень масштабируемости для рабочих нагрузок, активно использующих tempdb. В SQL Server 2019 (15.x) системные таблицы, связанные с управлением метаданными временных таблиц, можно переместить в неустойчивые таблицы без кратковременной блокировки, оптимизированные для памяти.
Примечание
Сейчас функция оптимизированных для памяти метаданных tempdb недоступна для Базы данных SQL Azure и Управляемых экземпляров SQL Azure.
Просмотрите это 7-минутное видео, чтобы узнать, как и когда следует использовать метаданные tempdb, оптимизированные для памяти:
Настройка и использование метаданных оптимизированной для памяти базы данных tempdb
Чтобы согласиться на применение этой новой функции, используйте следующий скрипт:
Чтобы это изменение конфигурации вступило в силу, нужно перезапустить службу.
Вы можете проверить, является ли оптимизированной для памяти, используя следующую команду T-SQL:
Если по какой-то причине не удается запустить сервер после включения оптимизированных для памяти метаданных , можно обойти эту функцию, запустив экземпляр SQL Server в минимальной конфигурации с помощью параметра запуска -f. После этого вы можете отключить функцию и перезапустить SQL Server в нормальном режиме.
Чтобы защитить сервер от потенциальных состояний нехватки памяти, можно привязать к пулу ресурсов. В этом случае вместо действий, которые обычно выполняются при привязке пула ресурсов к базе данных, следует использовать команду .
Кроме того, даже если метаданные оптимизированной для памяти базы данных tempdb уже включены, чтобы это изменение вступило в силу, требуется перезагрузка.
Ограничения оптимизированной для памяти базы данных tempdb
-
Включение и отключение функции не является динамическим. Из-за внутренних изменений, которые необходимо внести в структуру , для включения или отключения этой функции требуется перезапуск.
-
Отдельная транзакция не может обратиться к таблицам, оптимизированным для памяти, в более чем одной базе данных. Все транзакции, связанные с таблицей, оптимизированной для памяти, в пользовательской базе данных, не смогут обратиться к системным представлениям в той же транзакции. Если вы попытаетесь обратиться к системным представлениям в транзакции с участием таблицы, оптимизированной для памяти, в пользовательской базе данных, возникнет следующая ошибка:
Пример.
-
Запросы к таблицам, оптимизированным для памяти, не поддерживают указания блокировки и изоляции, поэтому запросы к представлениям каталога оптимизированной для памяти не будут учитывать указания блокировки и изоляции. Как и в случае с другими системными представлениями каталога в SQL Server, все транзакции для системных представлений будут находиться в изоляции (или в нашем случае).
-
Если оптимизированные для памяти метаданные включены, индексы columnstore нельзя создавать во временных таблицах.
-
В связи с ограничением на индексы columnstore использование системной хранимой процедуры с параметром сжатия данных или не поддерживается, если включены оптимизированные для памяти метаданные .
Примечание
Эти ограничения применяются только при создании ссылок на системные представления . При необходимости вы сможете создать временную таблицу в той же транзакции, где обращаетесь к таблице, оптимизированной для памяти, в пользовательской базе данных.