
Введение
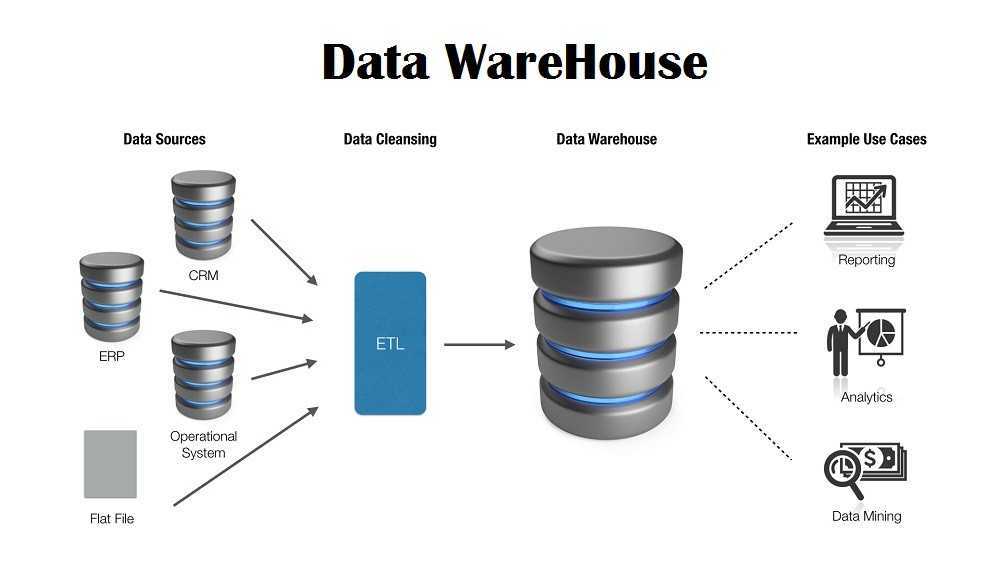
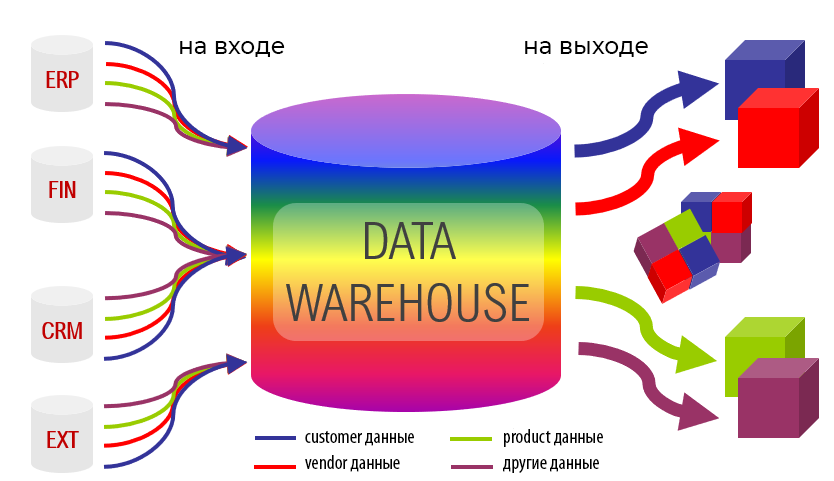
В вычислительной терминологии хранилище данных относится к системе, которая используется для анализа данных, отчетности в режиме реального времени и принятия решений. Его часто считают фундаментальной частью эффективной бизнес-аналитики. Хранилища данных используются в качестве централизованных хранилищ для интегрированных данных, происходящих из разных источников. Текущие, а также исторические данные хранятся в одном месте и используются для создания отчетов для бизнес-работников по мере необходимости.
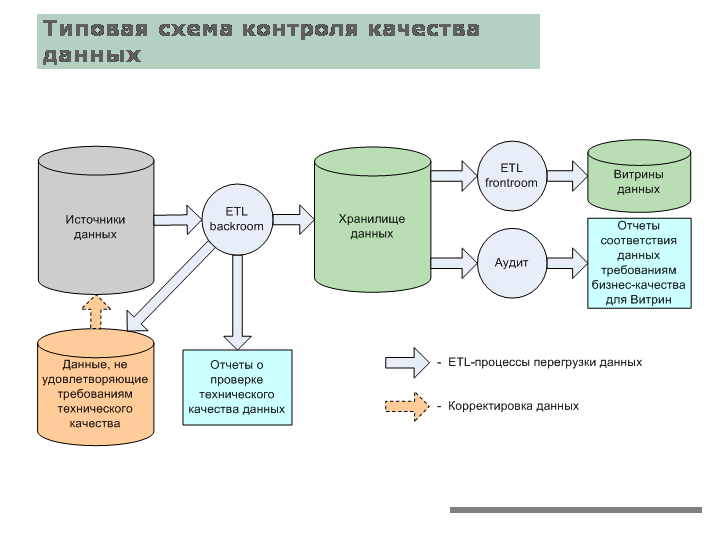
Необработанные данные, полученные от различных отделов в бизнесе, подвергаются очистке перед использованием для дополнительной обработки. Этот процесс очистки данных имеет решающее значение для обеспечения стандартного качества данных, прежде чем они будут использоваться для отчетности и других подобных целей.
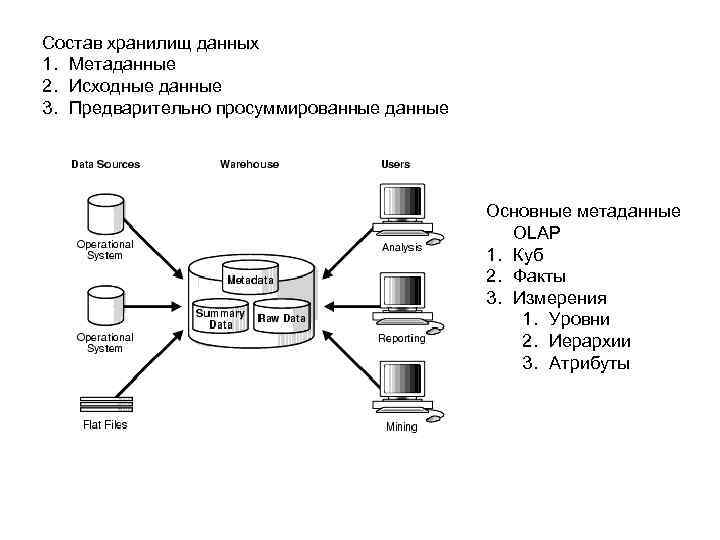
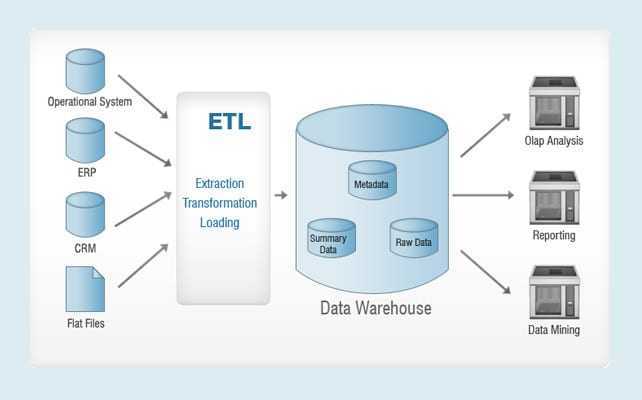
Более широкое определение хранилищ данных также включает в себя множество инструментов, используемых для бизнес-аналитики, извлечения данных и преобразования, для загрузки данных в репозиторий и для управления, а также для получения метаданных.
Создание репозитория с файлами CDH
Для эксплуатации разработанного функционала нам также требовался Spark 2.2, не входящий в парсэль CDH (там доступна первая версия данного сервиса). Для его установки требуется загрузить отдельный парсэль с данным сервисом и соответствующий manifest.json, также доступные в архиве Cloudera.
После загрузки парсэлей и manifest.json требуется перенести их в соответствующие папки нашего репозитория. Создаем отдельные папки для файлов CDH и Spark:
Переносим в созданные папки парсэли и файлы manifest.json. Чтобы сделать их доступными для установки по сети выдаем папке с парсэлями соответствующие доступы:
Можно приступать к установке CDH, о чем я расскажу в следующем посте.
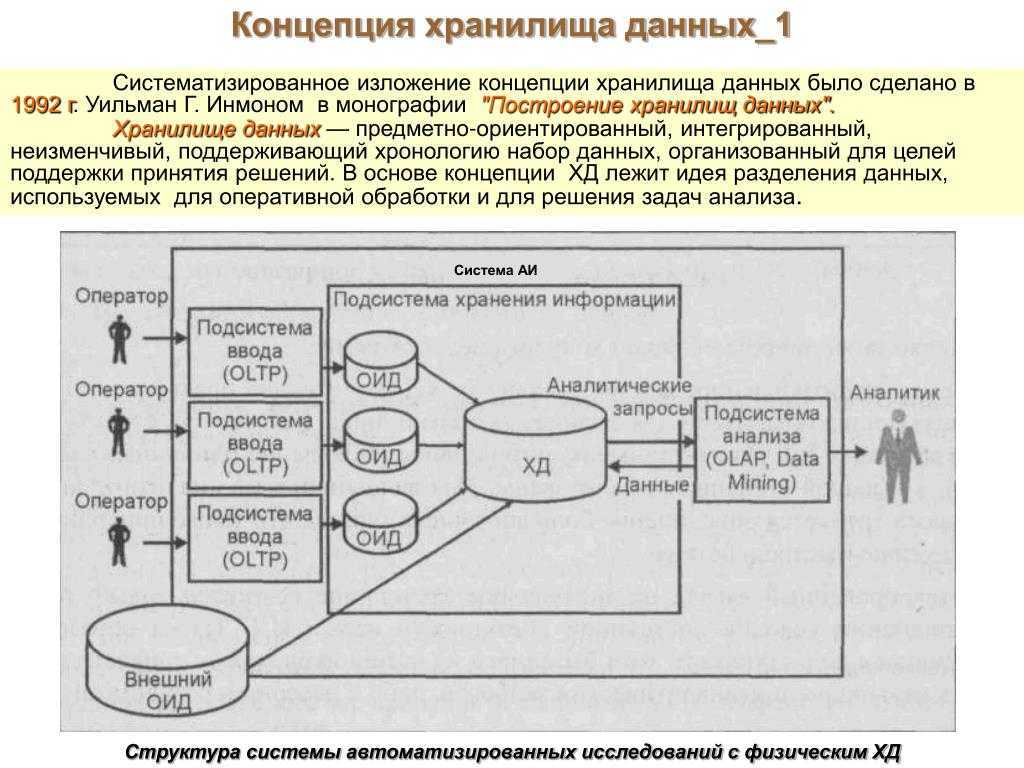
Текущая архитектура платформы данных в крупной компании
- Первое поколение: проприетарные корпоративные хранилища данных и платформы бизнес-аналитики. Это решения за большие суммы денег, которые оставили компаниям столь же большие объёмы технического долга. Технический долг в тысячах неподдерживаемых ETL джобов, таблиц и отчетов, которые понимает только небольшая группа специалистов, что приводит к недооценке положительного влияния этого функционала на бизнес.
- Второе поколение: экосистемы больших данных (Big Data) с Data Lake в качестве серебряной пули. Сложная экосистема больших данных и долго отрабатывающие batch джобы, поддерживаемые центральной командой узко-специализированных data-инженеров. В лучшем случае используется для R&D аналитики.
- использования облачных сервисов для хранения и обработки данных и облачных Machine Learning платформ.
Рисунок 1: Три поколения платформ данных
Централизованное и монолитное
Рисунок 2: Вид с высоты 10 000 метров на монолитную платформу данных
- Сбор (to ingest) данных со всей организации от транзакционных систем, отвечающих за операционную поддержку бизнеса, до данных от внешних поставщиков. Например, в сфере потокового мультимедиа платформа данных обеспечивает загрузку таких данных, как: производительность медиа плееров; особенности пользовательского взаимодействия с плеерами; прослушиваемые песни; артисты, на которых пользователи подписаны; финансовые транзакции с поставщиками контента и данные исследования рынка внешними компаниями (демографическая информация о клиентах и т.п.).
- Очистка, обогащение и преобразование данных, загруженных из источников в тот формат достоверных данных, которые могут использовать различные группы потребителей. В нашем примере, одним из таких процессов трансформации данных могло бы быть преобразование отдельных кликов пользовательского взаимодействия в пользовательские сессии, обогащённые данными о пользователях — чтобы представить пользовательский опыт в виде агрегированных представлений.
- Предоставление доступа (to serve) к наборам данным конечным пользователям. Реализация пользовательских потребностей в интервале от аналитики и machine learning до BI отчетов. В нашем примере потокового мультимедиа, это может быть предоставление доступа в режиме реального времени к информации о дефектах и качестве работы медиа плееров по всему миру. Работать такой доступ может через распределённые интерфейсы, такие как Kafka.
Рисунок 3: Централизованная платформа данных без чётких границ между данными разных бизнес-доменов. И без владения соответствующими данными со стороны бизнес-домена
- Большое количество источников и большие объёмы данных. Чем больше данных становятся доступными повсеместно, тем меньше наши способности собирать, согласовывать и контролировать их в рамках одной платформы. К примеру, касательно клиентской информации появляется всё больше источников внутри и за пределами организаций. Они предоставляют разнообразную информацию о существующих и потенциальных клиентах. Подход, при котором нам нужно собирать и хранить данные в одном месте, чтобы получить ценность из интеграции различных источников, ограничит нашу способность реагировать на появление новых источников данных. Поймите меня правильно, я осознаю потребность аналитиков и data scientists обрабатывать разнообразные наборы данных с минимальными издержками и с возможностью интеграции их. Также понятно, что данные наших информационных систем (обслуживающие операционные потребности бизнеса) следует отделять от данных, используемых в аналитических целях. Но я предполагаю, что существующие решения централизованных хранилищ данных – не самый оптимальных вариант для крупных предприятий с большим количеством бизнес-доменов и постоянно появляющимися новыми источниками данных.
- Потребности организаций в инновациях. Необходимость в быстрой проверке гипотез и частых экспериментах ведёт к большому количеству вариантов использования данных. Это подразумевает постоянно растущее количество трансформаций в данных, которые необходимо реализовывать на наших централизованных платформах данных. Долгое время реализации потребностей пользователей исторически являлось точкой организационных трений и остаётся таковым при текущей архитектуре платформы данных.
.1 Работа с сервером отчетов Reporting Services
Необходимые отчеты можно получать по средствам Reporting Services. Данное
средство позволяет получать отчеты в удобной пользователю web-форме. Для получения отчетов с помощью
сервера отчетов необходим web-браузер.
Для начала работы необходимо пройти по адресу сервера отчетов и
произвести вход на сервер (ввести логин, пароль). После пользователь получает
список доступных его учетной записи отчетов (см. рисунок 3.1). После выбора
отчета происходит его посторенние, что занимает несколько секунд и вывод в виде
html страницы.
Рисунок 3.1 — Окно выбора отчетов.
Существует следующий список отчетов:
— Год рождения (см. рисунок 3.2) — отчет группирует студентов
по году рождения и учебному заведению которое они окончили, и выводит их
количество;
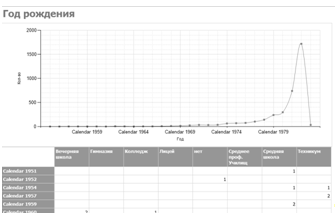
Рисунок 3.2 — Отчет «Год рождения».
— Место жительства (см. рисунок 3.3) — отчет группирует
студентов по месту жительства и строит диаграммы;
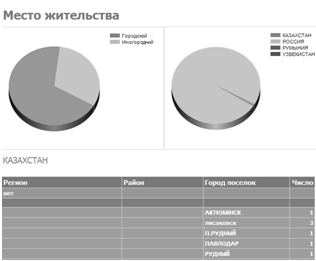
Рисунок 3.3 — Отчет «Место жительства».
— Списки зачисления (см. рисунок 3.4) — отчет формирует списки
зачисленных на каждом факультете, специальности;
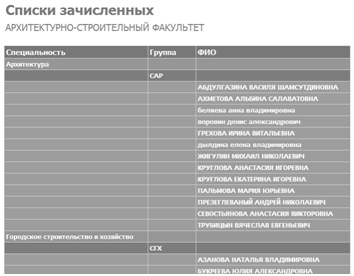
Рисунок 3.4 — Отчет «Списки зачисления».
— Доп. образование (см. рисунок 3.5) — отчет группирует
студентов по дополнительным курсам на базе высшего учебного заведения в связи с
местом их учебы и выводит их количество;
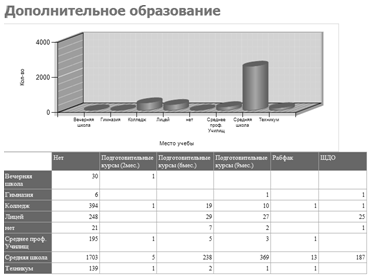
Рисунок. 3.5 — Отчет «Доп. образование».
— Образование (см. рисунок 3.6) — отчет группирует студентов по
факультетам и специальностям в связи с их текущим образованием и выводит их
количество;
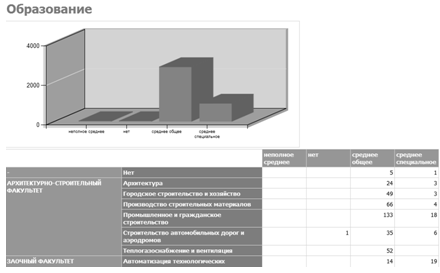
Рисунок. 3.6 — Отчет «Образование».
— Языкознание (см. рисунок 3.7) — отчет группирует студентов
изучаемому иностранному языку в связи с их текущим образованием и выводит их
количество;
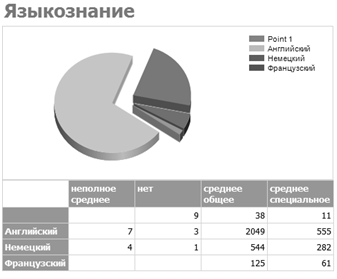
Рисунок. 3.7 — Отчет «Языкознание».
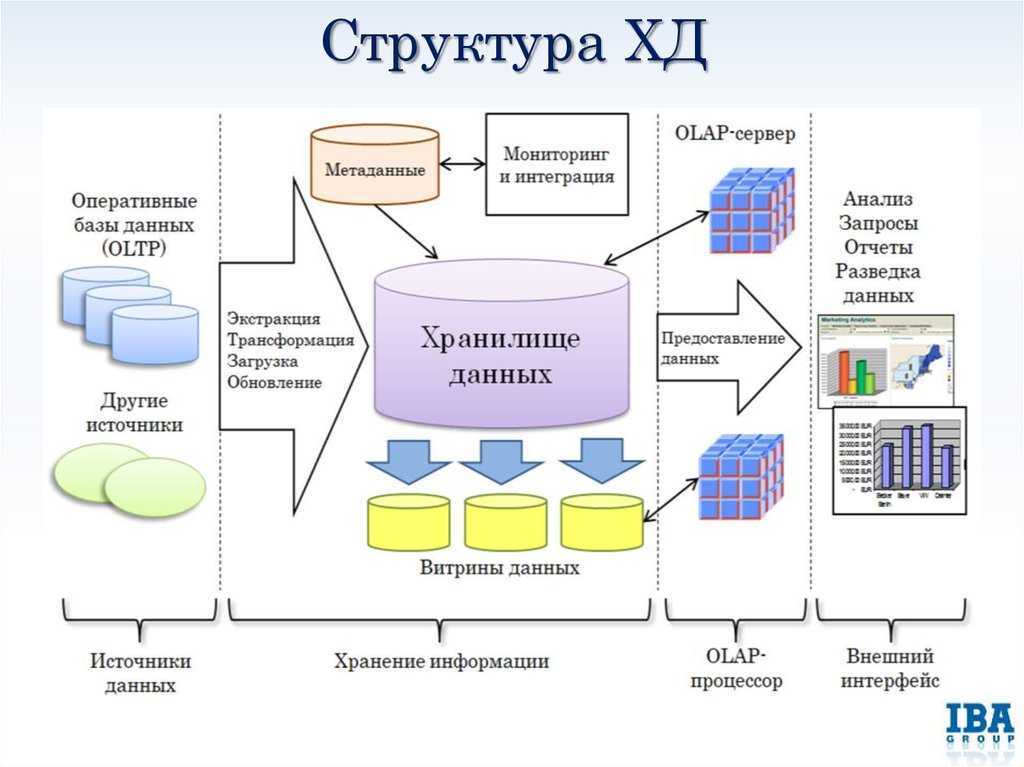
— Зачисленные (см. рисунок 3.8) — отчет выводит информацию о
количестве зачисленных и не зачисленных студентов по специальностям;
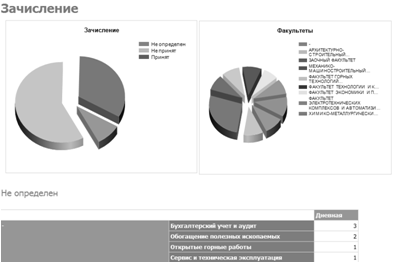
Рисунок 3.8 — Отчет «Зачисленные».
— Семья (см. рисунок 3.9) — отчет группирует родственников по
связям с абитуриентом.
Рисунок 3.9 — Отчет «Семья».
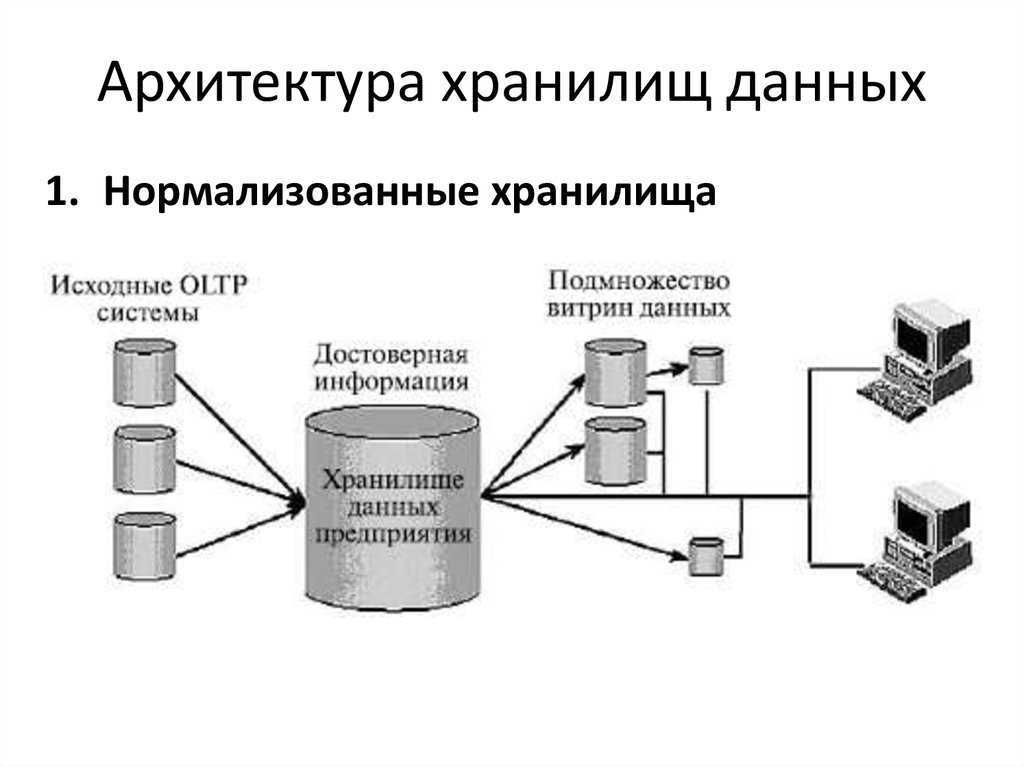
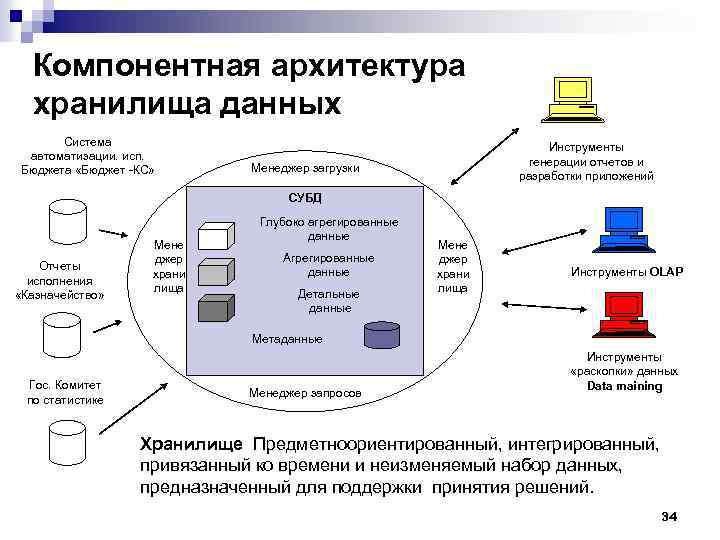
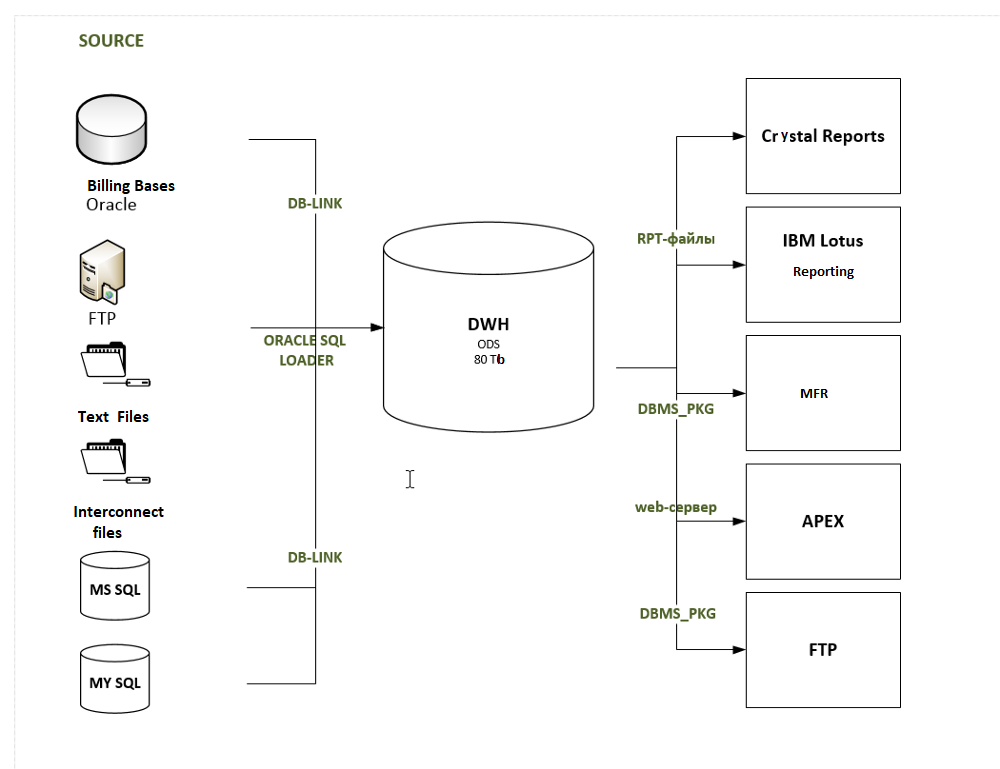
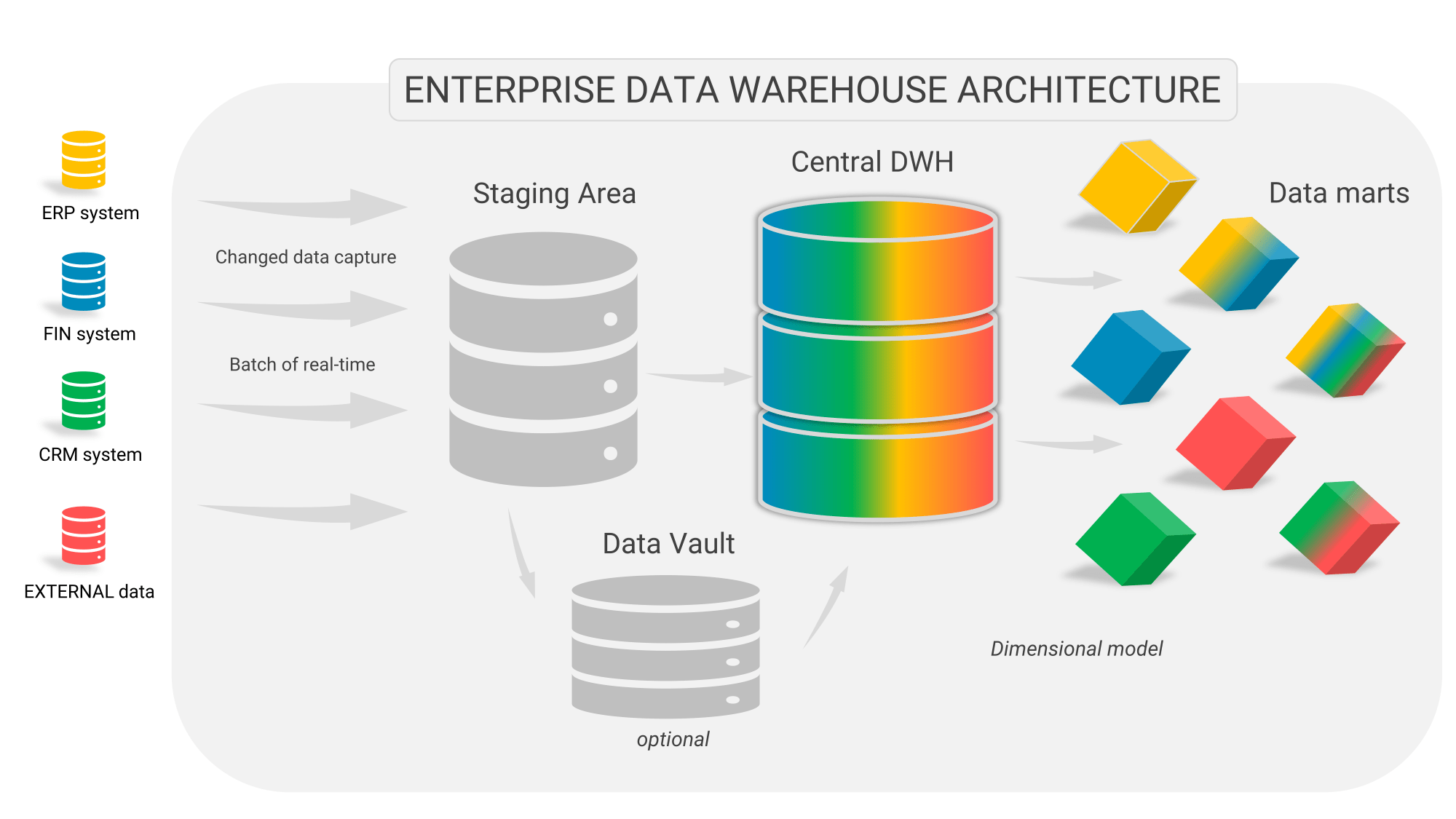
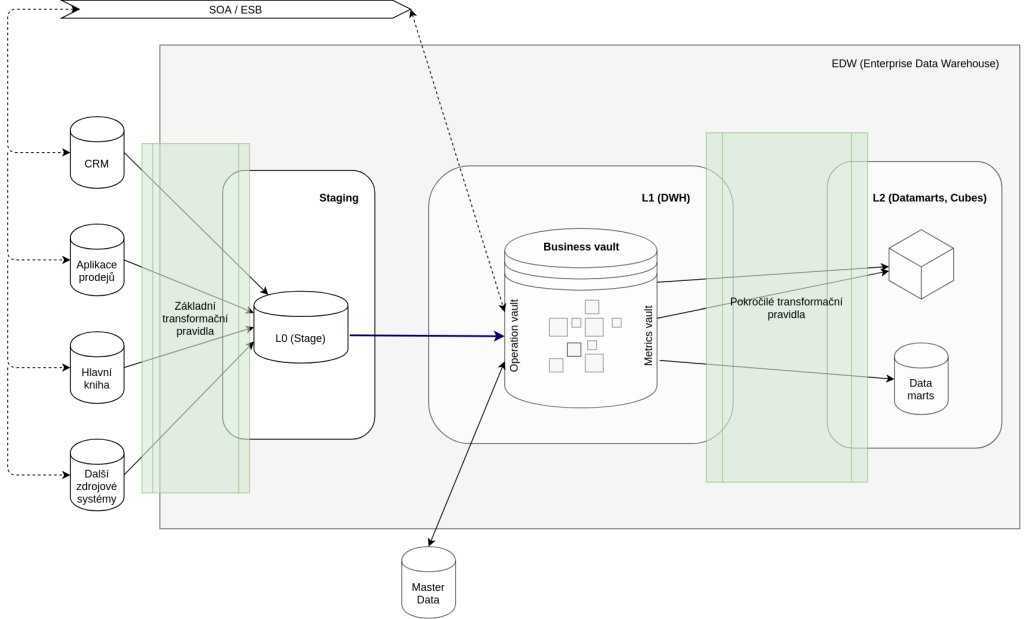
Архитектура корпоративного хранилища данных
конвейер данных
- Слой «сырых» данных (источников данных)
- Хранилище и её экосистему
- Интерфейс пользователя (инструменты аналитики)
ETL
Одноуровневая архитектура
одноуровневую архитектуру
Слой отчётности соединён напрямую со всей базой данных EDW
- Традиционно считается, что накопитель становится хранилищем, начиная со 100 ГБ данных. Если работать с ними напрямую, это может привести к неаккуратным результатам запросов, а также низкой скорости обработки.
- Для запросов данных непосредственно из хранилища могут потребоваться чёткие формулировки, чтобы система могла отфильтровывать их от нерелевантных данных. Это усложняет работу с инструментами представления.
- Имеются ограниченные возможности обеспечения гибкости и аналитики.
Двухуровневая архитектура (архитектура витрин данных)
двухуровневой архитектуревитрин данных
В двухуровневой архитектуре EDW дополняется витринами данных, предоставляющими данные, относящиеся к конкретной предметной области
Трёхуровневая архитектура (аналитическая онлайн-обработка)
аналитической онлайн-обработки (OLAP)
Слой OLAP-кубов может получать информацию из распределённых витрин или напрямую из EDW
OLAP-куб, демонстрирующий многомерные данные продажoreilly.comдокументацию Microsoft
Архитектура следующего поколения платформы данных
Рисунок 6: Сдвиг парадигмы построения платформы данных следующего поколения.
Данные и распределённая domain driven архитектура
Рисунок 8: Распределённые конвейеры обработки данных, реализованные внутри своих доменов
Данные и продуктовое мышление
Кросс функциональная data-команда бизнес-домена
Рисунок 10: Кросс функциональная доменная data-команда
- Масштабируемое хранения данных в разных форматах
- Шифрование данных (тут же хэширование, обезличивание и т.д.)
- Версионирование data-продуктов
- Хранение схемы данных data-продукта
- Контроль доступа к данным
- Журналирование
- Оркестровка потоков/процессов по обработке данных
- Кэширование данных в памяти
- Хранение метаданных и data lineage
- Мониторинг, оповещения, логгирование
- Расчёт метрик качества data-продуктов
- Ведение каталога данных
- Стандартизация и политики, возможность контроля соответствия
- Адресация data-продуктов
- CI/CD pipelines для data-продуктов
Возможные заблуждения и рекомендации по их разрешению
1. Хранилище данных — это OLAP.
OLAP является аналитическим инструментом и одним,
но далеко не единственным средством анализа
данных в хранилище.
Важно
отметить,
что средства
OLAP могут быть использованы
и вне хранилища. OLAP-анализ данных, находящихся
в своих источниках, может быть произведен без
их извлечения
и
загрузки в хранилище.
Однако эффективность
многомерного
анализа при наличии хранилища данных резко
возрастает
Во избежание разночтений полезно провести демонстрацию
конкретного OLAP-средства и на концептуальном
уровне представить архитектуру
хранилища данных.
Обычно это позволяет определить единые понятия,
необходимые для дальнейшего развития
проекта.
2. Построение хранилища данных — задача только
информационных технологий.
Хранилище данных можно построить исключительно
в тесном контакте ИТ- и бизнес-подразделений.
Дело в том, что
ИТ-специалисты компетентны в вопросах
структуры источников
данных и методов доступа к ним, а представители
основных
подразделений лучше понимают
потребности бизнеса.
Необходимо, чтобы конкретный заказчик
внутри банка обладал достаточными полномочиями
для поддержки проекта. Рекомендуется
сформировать
рабочую (проектную) группу
или комитет, ответственный за создание
и развитие хранилища данных.
3. Загрузка данных — это просто.
Недооценка сложности процедур загрузки
данных приводит к провалу большей
части проектов,
которые банки
начинают делать
самостоятельно.
Существует возможность минимизировать
риски, связанные с загрузкой данных,
за счет четкой
формализации
целей и задач
проекта и
исследования информационных
источников на предмет достаточности
и согласованности данных для решения
поставленных
задач. Благодаря этому можно с
самого начала
выявить потенциальные трудности,
связанные с исходными
данными, и скорректировать
потребности бизнеса,
а также произвести нужные доработки
в информационных системах.
4. Сначала загрузим все в хранилище,
а уж затем определим цели.
Загрузка данных — достаточно
сложный процесс. Проведение
его без определения
целей анализа
может привести
либо к неполной востребованности
хранилища
данных, либо к необходимости
в дальнейшем его серьезной
переработки.
Перед началом проекта следует
провести исследование потребностей
бизнеса.
Основная цель такого
исследования — определение
согласованных с руководством
потребностей
бизнеса в анализе
В итоге
очень важно получить скоординированный
с руководством
заказчика
документ, описывающий задачи
анализа информации в порядке
убывания их приоритета, а
также результаты,
которые может принести решение
данных задач бизнесу. Это
позволит осуществить
декомпозицию задач анализа
и
разбить их решение
на этапы
Следующим важным
шагом должно стать исследование
информационных
источников,
призванное
гарантировать
выполнение работ в поставленные
сроки.
5. Хранилище данных — это
готовая программа.


Построение хранилища данных
— проект, требующий серьезной
проработки
и усилий со стороны
бизнеса и поставщика
информационных технологий.
Наиболее эффективным
подходом здесь будет
совместный проект банка и компании,
специализирующейся в
этой области.
Общемировая практика
показывает, что хранилища
данных создаются
под конкретного
заказчика.
Серьезным преимуществом
является
наличие квалифицированного
персонала, типовых
витрин данных для бизнес-заказчиков,
а также
отраслевой модели данных.
6. Хранилище данных
можно построить за
пару недель.
Цикл создания хранилища
данных и решения
первой значимой
для бизнеса задачи
не превышает трех
месяцев. Сроки
можно и сократить,
но качество
при этом
заметно
ухудшится. Хотя
хранилище развивается итерационно,
уже на первом
этапе надо заложить
серьезный фундамент
не
только для решения
первой задачи,
но и для
развития аналитики
в стратегической
перспективе.
7. Централизованное
хранение метаданных
решит все
проблемы.
При построении
хранилища данных
необходимо
использовать
принцип централизации
метаданных,
но при этом важно
понимать,
что
на нынешнем
этапе развития
информационных
технологий
централизовать хранение
метаданных
довольно сложно. Например,
в технических
метаданных
должны содержаться
информация
об источниках и
их структуре,
описание потоков
данных и
процессов
перегрузки.
Если первые два набора
обычно поставляются
вместе с информационной
системой, то
вторые, как
правило, формируются в
рамках проекта
по созданию
хранилища и
размещаются на сервере перегрузки
данных
Настройка вспомогательного софта
Настало время сконфигурировать PostgreSQL и создать базы данных для наших будущих сервисов. Данные настройки актуальны для версии CDH 5.12.1, при установке других версий дистрибутива рекомендуется ознакомиться с разделом «Cloudera Manager and Managed Service Datastores» официального сайта.
Для начала произведем инициализации базы данных:
/var/lib/pgsql/data/pg_hba.conf
Затем внесем некоторые коррективы в файл /var/lib/pgsql/data/postgres.conf (приведу только те строки, которые надо изменить или проверить на соответствие:
После окончания конфигурации требуется создать базы данных (для тех, кому ближе терминология Oracle – схемы) для сервисов, которые будем устанавливать. В нашем случае были установлены следующие сервисы: Cloudera Management Service, HDFS, Hive, Hue, Impala, Oozie, Yarn и ZooKeeper. Из них Hive, Hue и Oozie нуждаются в базах, а также 2 базы потребуются для нужд сервисов Cloudera – одна для сервера Cloudera Manager, другая для менеджера отчетов, входящего в Cloudera Management Service. Запустим и PostgreSQL и добавим его в автозагрузку:
Теперь мы можем подключиться и создать нужные базы:
Для других сервисов базы данных создаются аналогично.
Не забываем прогнать скрипт для подготовки базы сервера Cloudera Manager, передав ему на вход данные для подключения к созданной для него базе:
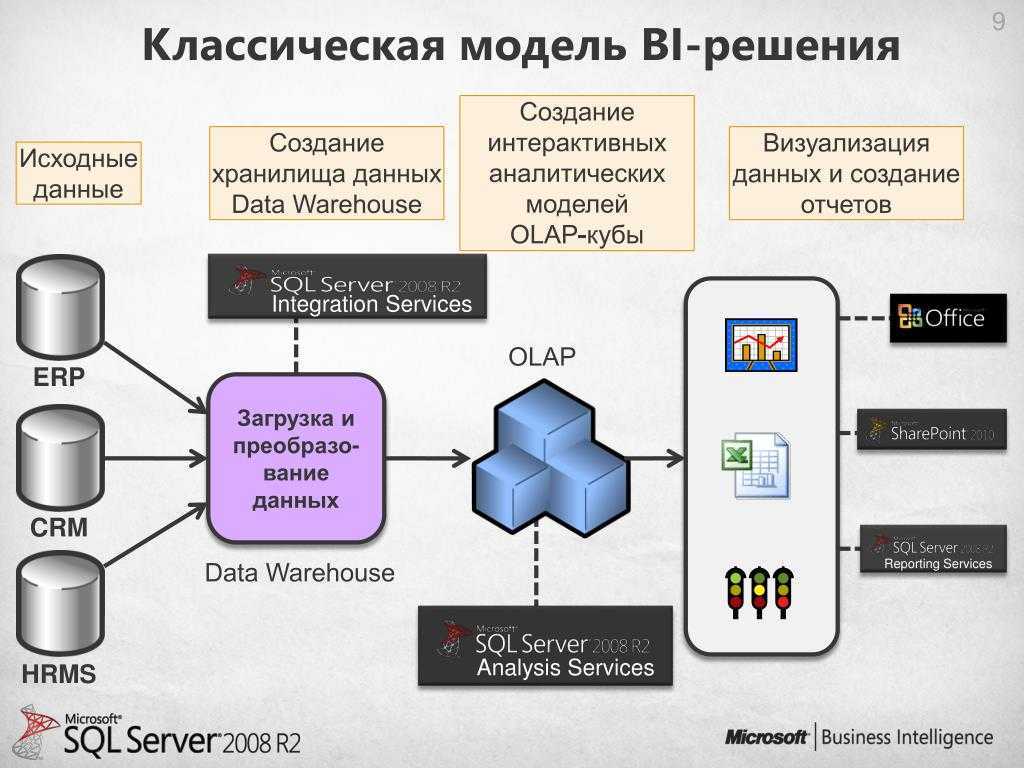
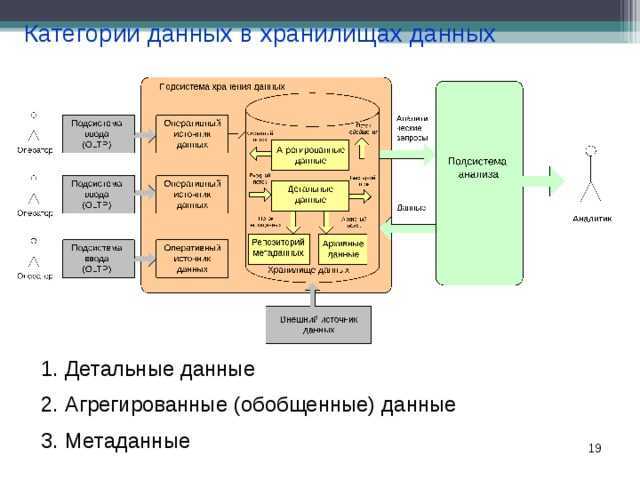
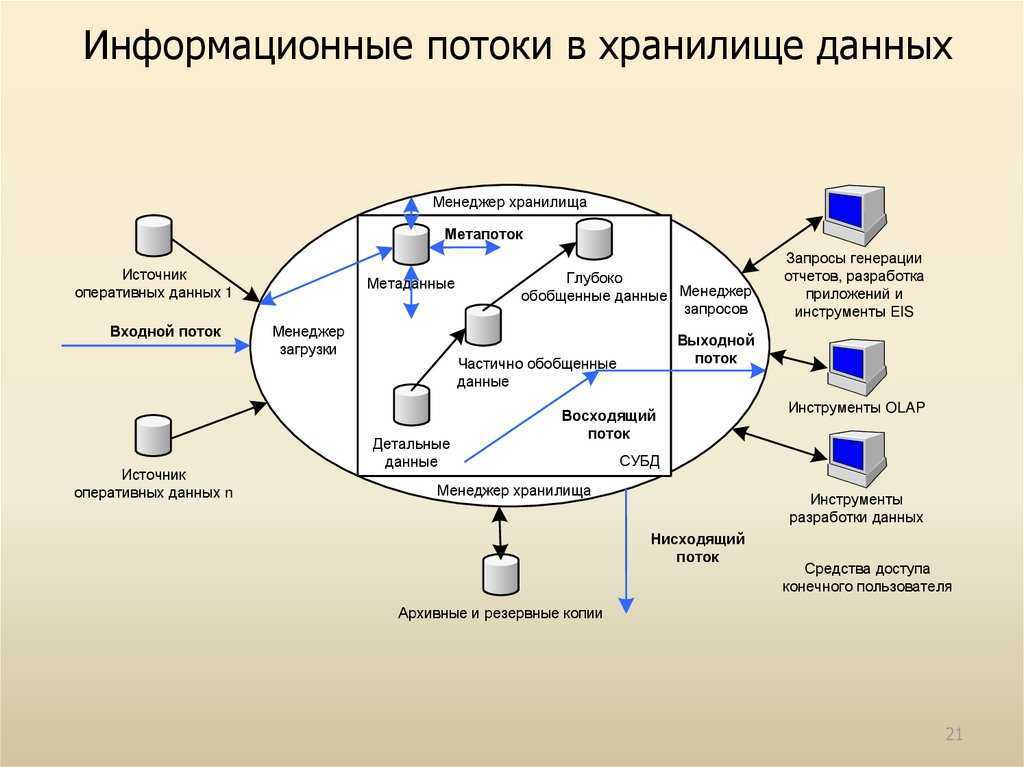
Как связаны аналитические системы и хранилище данных
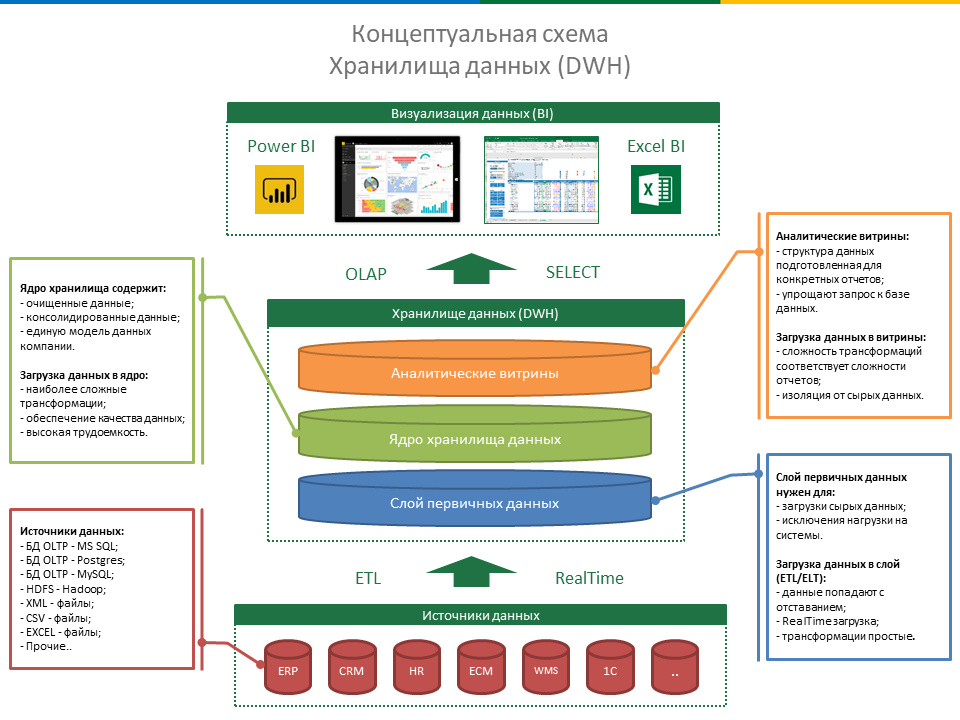
Хранилище данных (ХД) является основой и ядром аналитической системы. Стоит отметить, что это не просто некая база данных, хранящая данные на постоянной или временной основе и используемая в процессе подготовки аналитических материалов (что часто соответствует интуитивному и несколько вульгарному представлению о сущности ХД), а информационная система, обладающая определенными свойствами.
ХД — важнейшая часть процесса принятия управленческих решений — и это еще раз говорит о том, что аналитическая система нацелена на высокоуровневый обзор состояния компании.
ХД является предметно-ориентированной системой: данные организуются в объектную модель, отвечающую предметной области конкретной компании.
ХД интегрирует данные, что означает, что данные собираются из разных источников, но в ХД они очищаются и приводятся к «единому общему знаменателю» сущностей объектной модели, поэтому говорят о том, что ХД — это интегрированная система.
ХД неволатильно, то есть всегда достаточно статично и организовано таким образом, что обновление данных происходит за счет отслеживания изменений, произошедших в информационных системах-источниках. Например, данный принцип запрещает полную перезаливку данных при обновлении, что порой встречается на хранилищах небольшого объема. Такой подход хоть и быстрее в реализации, но приводит к проблемам в долгосрочной перспективе. В ХД должны быть предусмотрены механизмы инкрементальной загрузки данных.
ХД хранит всю истории деятельности компании. Это означает, что хранятся все данные, загруженные из любых источников. Переход с одной производственной системы на другую, архивация данных и изменение горизонта хранения данных в исходной системе не должны влиять на базовый принцип хранения данных в ХД за все время.
Важным моментом являются надежность и адаптивность ХД. Оно должно быть построено таким образом, чтобы гибко реагировать на структурные изменения в системах-источниках. ХД должно быть робастным, что означает, что изменения входящих данных определенного масштаба должны приводить к изменениям в хранилище такого же или меньшего масштаба, например, изменение или удаление какого-то поля одной таблицы не должно приводить к остановке обновления всего хранилища. Появление нового источника данных должно укладываться в существующую архитектуру, а не приводить к запуску нового проекта по переделке хранилища, а то и построению новой системы рядом со старой.
В силу того, что ХД объединяет данные всей компании, инициативы по ее внедрению должны координироваться между всеми отделами — потенциальными пользователями системы, то есть принято бизнес-средой. Каждое из подразделений, поставляющих данные в ХД и планирующее использовать результаты внедрения системы, должно быть активно вовлечено в проект развития ХД, проверять качество данных, принимать результаты на всех этапах проекта. В противном случае, легко может произойти ситуация, когда после завершения проекта результаты не используются в должной мере из-за их несогласованности с потребностями конкретных бизнес-пользователей. Здесь мы видим еще одно принципиальное различие между оперативными и аналитическими системами. Развитие первых – в первую очередь зона ответственности ИТ-отдела, вторые инициируются и развиваются как мероприятие стратегического уровня с зоной курирования топ менеджментом компании.
Таким образом, ХД решает задачу предоставления консолидированного набора данных (собранных из разных источников) о состоянии компании, дает согласованную «картину мира» в заданной временной отрезок. Это устойчивый фундамент, на основании которого можно строить и развивать аналитические системы компании, «взращивая» их в ходе эволюции управленческих процессов.
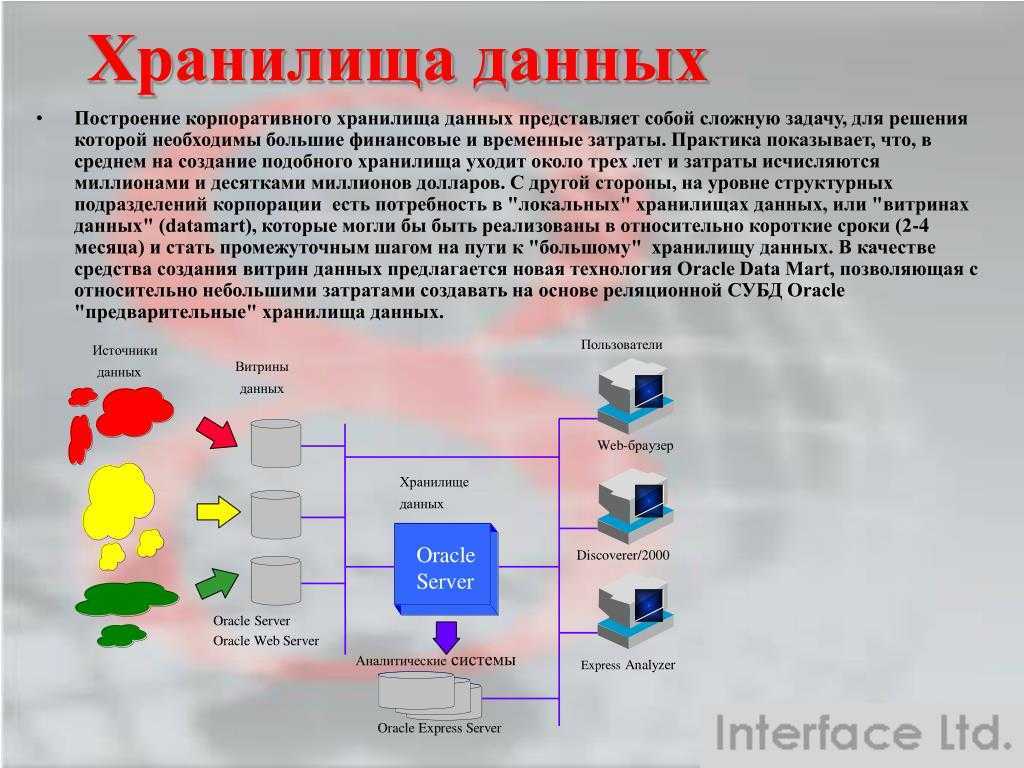
Витрины данных (Data Marts)
Витрины данных являются объектами хранения аналитической информации, нацеленными на поддержку конкретных бизнес-функций, конкретных подразделений компании. На уровне базы данных витрины обычно реализуются по схеме «звезда» или «снежинка» и содержат данные из области детальных данных (System of records). Также могут быть реализованы в виде многомерного OLAP-куба. Витрины данных являются основой, обеспечивающей возможность проведения многомерного анализа (OLAP) данных.
Ниже представлены основные принципы проектирования витрин данных.
- Витрины данных ориентированы на бизнес и при их проектировании необходимо учесть все измерения, показатели и иерархии, необходимые пользователям.
- При проектировании витрин данных необходимо учитывать особенности BI-приложения, используемого на проекте. Например, в Oracle Discoverer нет возможности создавать несбалансированные иерархии и это нужно учитывать.
Шаг 1: Определение целей деятельности
Рассматриваемая компания находится на подъеме. Для дальнейшего
быстрого роста ей понадобится смешанная команда, состоящая из
администраторов, торговых представителей, производственников и
сотрудников поддерживающих подразделений. Первые лица компании хотят
знать, приносит ли все ускоряющийся рост численности компании
должную отдачу организации. Компания совершенствует технологию
продаж и пробует различные режимы торговли. В силу этого ключевым
сотрудникам, отвечающим за принимаемые решения, необходимо получать
сведения об эффективности различных режимов продаж. Внешние причины,
действующие на рынке, меняют баланс между национальным и
региональными факторами. Руководству компании необходимо понимать
степень влияния этих факторов на их бизнес.
Для ответа на вопросы лиц, принимающих решения, проектировщикам
пришлось разобраться в том, что определяет успех этого вида бизнеса.
Компанией руководят владелец, президент и четыре ключевых менеджера.
Эти руководители следят за центрами прибыли и отвечают за
прибыльность подконтрольных им территорий. Они совместно используют
ресурсы, контакты, возможности продаж и персонал. Менеджеры
анализируют различные факторы, чтобы сделать заключение о
благополучности и росте своих сегментов. Всех членов этой группы
интересует общая прибыль компании. Но для принятия обоснованных
решений о том, что именно вносит наибольший вклад в ее получение,
система должна учитывать влияние значительного числа факторов.
Например, небольшой контракт требует почти таких же накладных
расходов на его администрирование, как и большой контракт. Поэтому
множество небольших контрактов могут дать при равном доходе
существенно меньшую прибыль, чем несколько больших контрактов.
Отслеживание размера контракта становится важным при выяснении
факторов, приводящих к получению больших контрактов.
В ходе работы с руководящей командой проектировщики выяснили
количественные показатели бизнес-активности, которыми пользуются
лица, принимающие решения, для оценки работы организации. Эти
показатели являются ключевыми индикаторами, численным выражением
оценки деятельности компании. К ним относятся: количество проданных
единиц изделий, общая прибыль, чистая прибыль, затраченное время,
число обученных студентов, количество заявок на повторное обучение.
Все эти ключевые индикаторы деятельности компании были собраны в
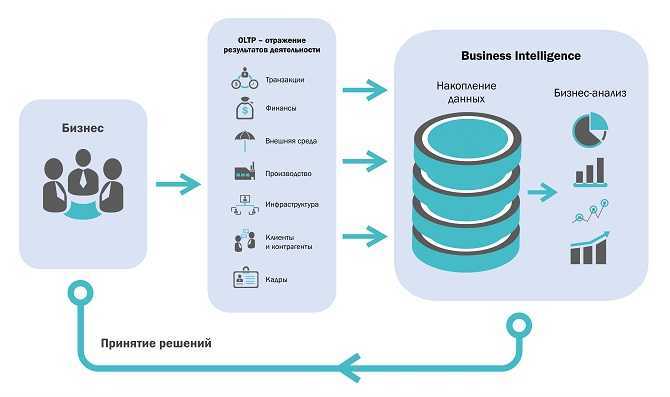
Что такое аналитические системы
Прежде всего хотелось бы рассказать про категоризацию ИТ-систем в целом. Они делятся на два больших класса — оперативные системы (OLTP) и аналитические системы (BI).
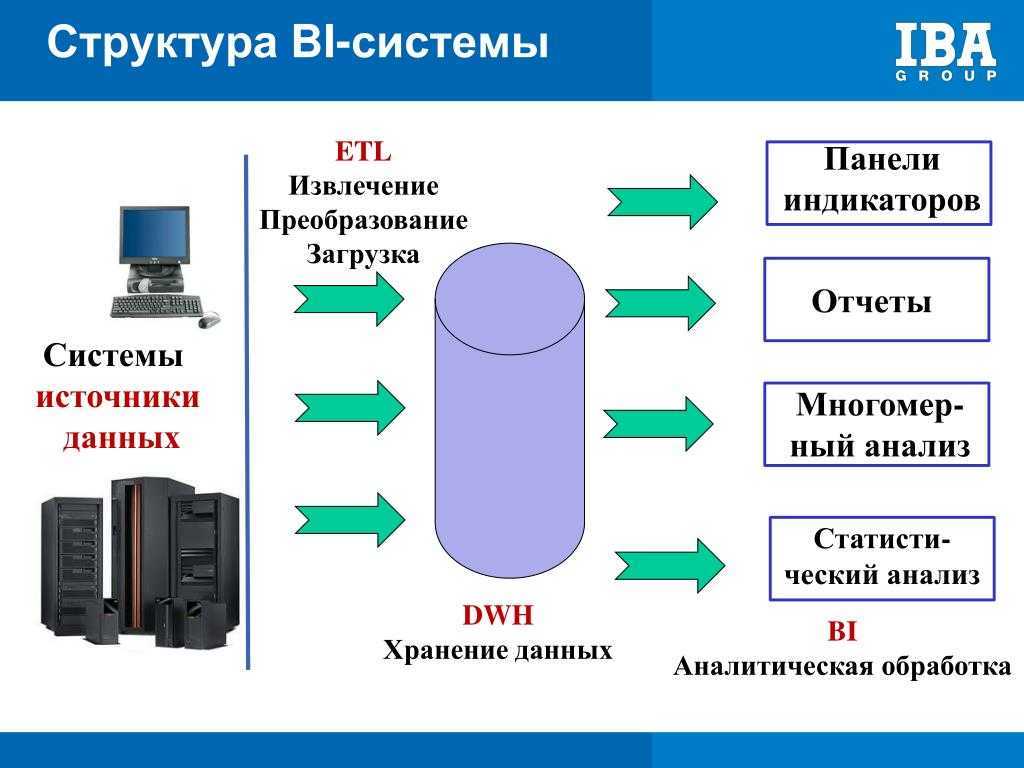
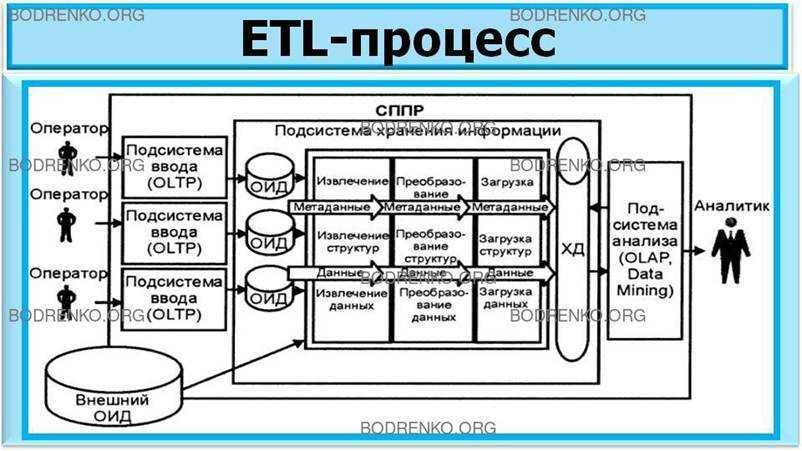
BI-системы, с другой стороны, позволяют наблюдать и анализировать результаты бизнес- процессов — следят «за вращением колес». Они не столь критичны для проведения ежедневных операций, но их значение проявляется на уровнях выше — тактическом и стратегическом. Менеджмент, вооруженный качественной и эффективной аналитической системой, может видеть как текущее состояние компании и проводить исторический анализ, так и заглядывать в будущее, делать прогнозы по развитию организации, принимать обоснованные управленческие решения.
Детальные данные (System of records)
Данная область является основной хранилища данных. В этой области хранятся преобразованные и очищенные детальные данные, полученные из систем-источников, и основные классификаторы. Хорошо спроектированная модель данной области является залогом дальнейшего успешного функционирования базы данных и BI-приложения.
Данная область содержит следующие типы сущностей:
- справочники и классификаторы;
- сущности, содержащие фактические значения;
- сущности, описывающие связи.
Справочники и классификаторы определяют:
- участников основных бизнес-процессов – клиентов, поставщиков, филиалы, услуги, продукты и т.п.
- базовые справочники – дата и время, валюта, страны и т.п.
- прочие справочники – отражающие потребности бизнеса в необходимой аналитике данных, определяющие в разрезе каких справочников необходимо анализировать фактические данные.
Сущности, содержащие фактические значения, – транзакционные данные из систем источников. Например, информация о совершенных телефонных звонках, выставленных счетах, проводках, проданных товарах и т.п.
Сущности, содержащие связи, определяют взаимосвязи между остальными сущностями. Например, Клиент-Услуга.
Область детальных данных не содержит никаких агрегатов. Только детальные, очищенные и структурированные в соответствии с моделью данные.
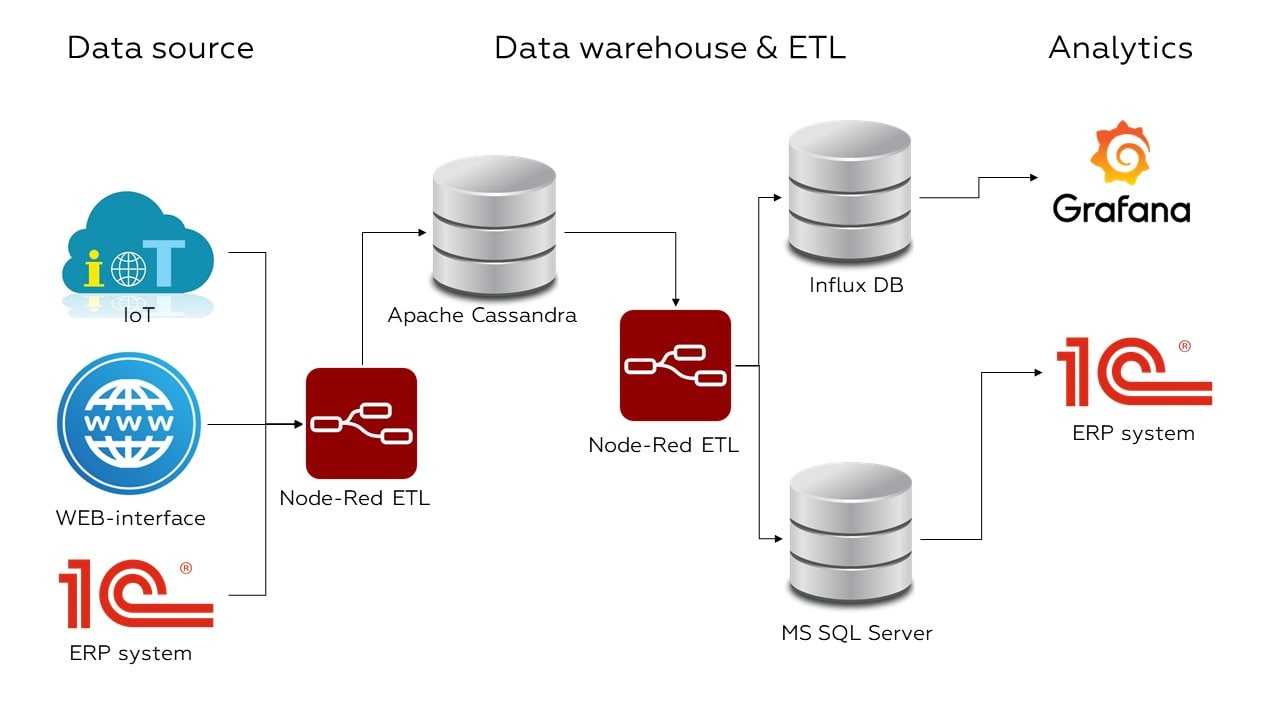
Типы корпоративных хранилищ данных
Хранилище данных внутри компании
Хранилище данных на внутренних мощностях компанииинструменты интеграции данных
- дорогостоящая технологическая инфраструктура (и аппаратная, и программная)
- необходимость найма команды дата-инженеров и специалистов DevOps для создания и поддержки всей платформы данных.
Когда использовать
Виртуальное хранилище данных
Виртуальное хранилище данныхнесколько виртуально соединённых баз данных
Схема связей между абстракцией виртуального хранилища данных и исходными базами данных
- Необходимы постоянное обслуживание ПО и оборудования разных баз данных, а также затраты на них.
- Данным, хранящимся в виртуальном хранилище, всё равно нужно ПО преобразования, чтобы сделать их удобоваримыми для конечных пользователей и инструментов отчётности.
- Сложные запросы данных могут занимать слишком много времени, поскольку все необходимые элементы данных могут располагаться в двух отдельных базах данных.
Когда использовать
Построение логической модели данных
После согласования концептуальной модели с функциональными специалистами Заказчика специалист по модели данных приступает к разработке логической модели. Логическая модель расширяет концептуальную путем определения для сущностей их атрибутов, описания и ограничений. Более точно определяются состав сущностей и взаимосвязи между ними.
Процесс формирования логической модели включает в себя следующие работы:
- определение атрибутов (Attributes);
- уточнение состава сущностей области хранения детальных данных (System of Records);
- сопоставление данных систем-источников атрибутам сущностей логической модели данных;
- определение иерархий (Hierarchy);
- определение состава и типов медленно меняющихся измерений (SCD);
- определение основных бизнес-запросов (Business Queries) — групп запросов пользователей к определенному набору данных;
- проведение GAP-анализа:
- анализ логической модели (с учетом имеющихся данных в системах-источниках) на предмет выявления требований, которые не могут быть удовлетворены;
- принятие решений по требованиям, которые не могут быть удовлетворены;
- определение состава и структуры агрегатов (Summary Area), витрин данных (Data Marts);
- определение состава значений (Domains) для измерений и иерархий;
- формирование рабочего документа с описанием логической модели;
- проведение внешнего аудита модели — сопоставление логической модели и требований на уровне показателей;
- согласование логической модели с функциональными специалистами Заказчика.
Проектирование хранилища данных
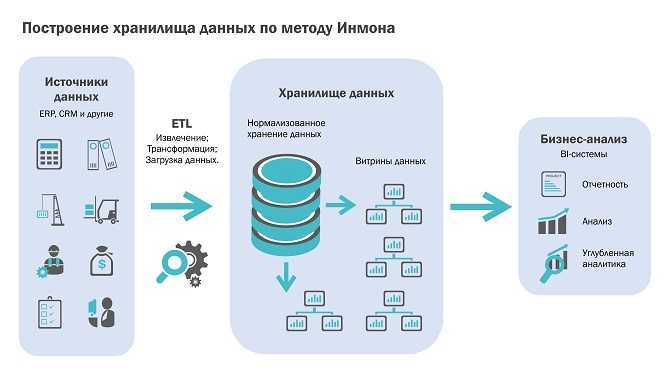
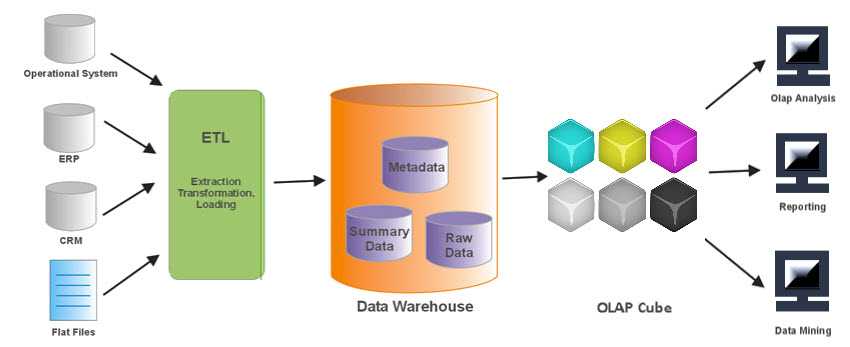
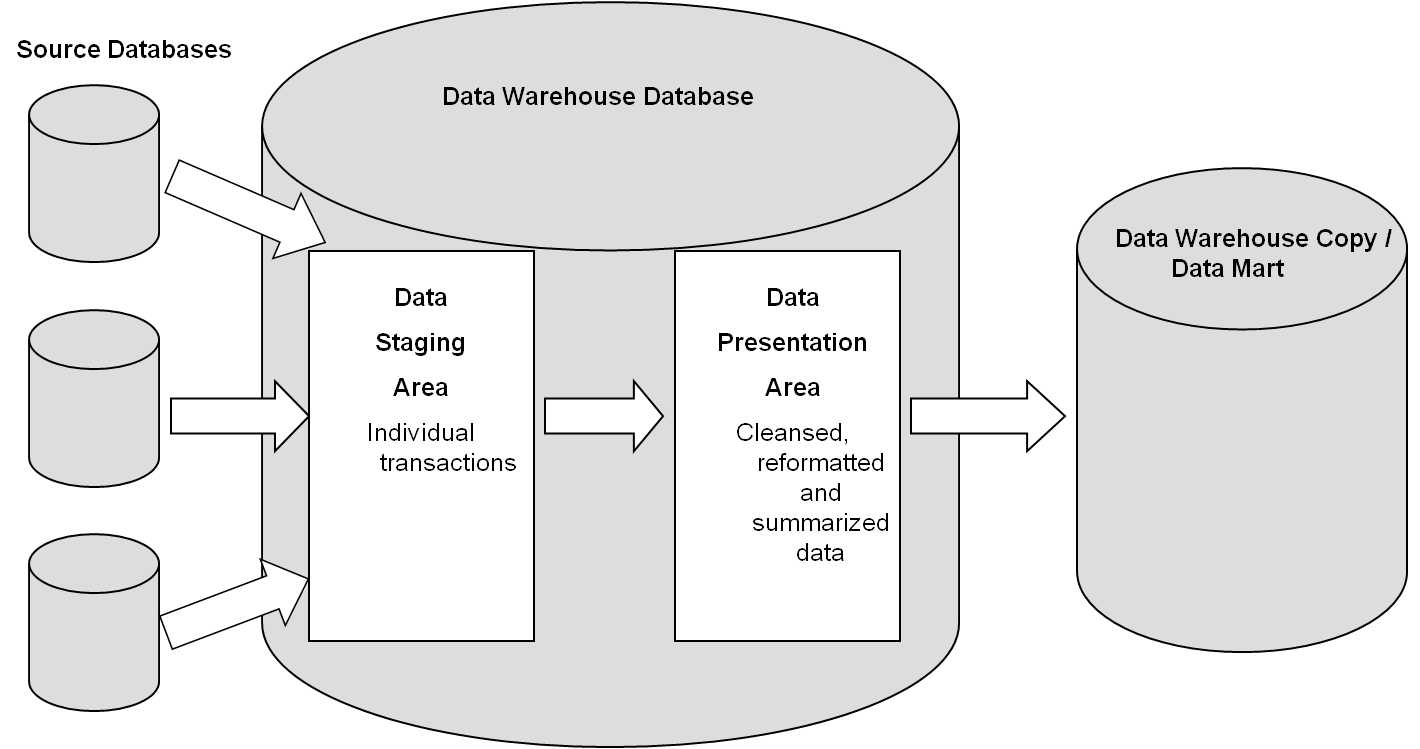
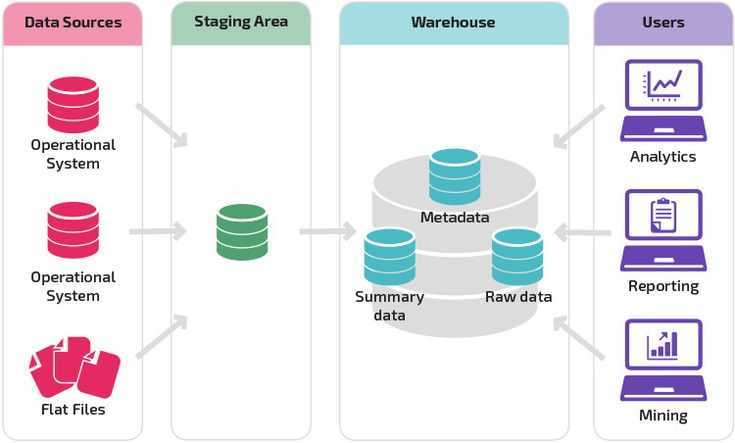
Хранилища данных помогают принимать бизнес-решения на основе исторических данных, собранных в течение определенного периода времени. Однако бизнес-данные обычно распределяются между несколькими базами данных и приложениями, расположенными в разных географических зонах. Теперь представьте, что вы компилируете эти данные, а затем используете Big Data Analytics для повышения удовлетворенности клиентов, упрощения затрат и поиска новых возможностей для роста. Хорошо спроектированное хранилище данных может помочь вам в этом.
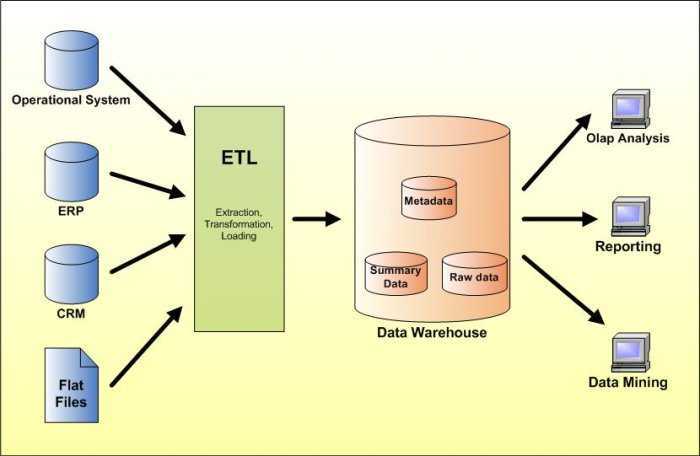
Большинство компаний, которые утверждают, что у них есть хранилище данных, не понимают, что это понятие не связано с построением “свалки” для таблиц. Вместо этого хорошее хранилище превращает необработанные данные в нечто очищенное, организованное, обобщенное и дополненное. Существует множество стандартных конструкций, которые вы можете попытаться построить. Например, стандартное хранилище данных с извлечением, преобразованием и загрузкой (ETL) использует уровни продвижения, интеграции и доступа к данным для поддержания основных функций:
- В промежуточной базе данных хранятся необработанные данные, извлеченные из нескольких источников системы данных.
- Затем уровень интеграции объединяет различные наборы данных и преобразует их из более раннего уровня и сохраняет эти преобразованные данные в базе данных хранилищ операционных данных (ODS). После процесса интеграции данные снова перемещаются в базу данных хранилища, где они сортируются по иерархии и сохраняются как факты, так и агрегированные факты.
- Третий уровень, уровень доступа, — это то, где пользователи могут извлекать данные по мере необходимости.
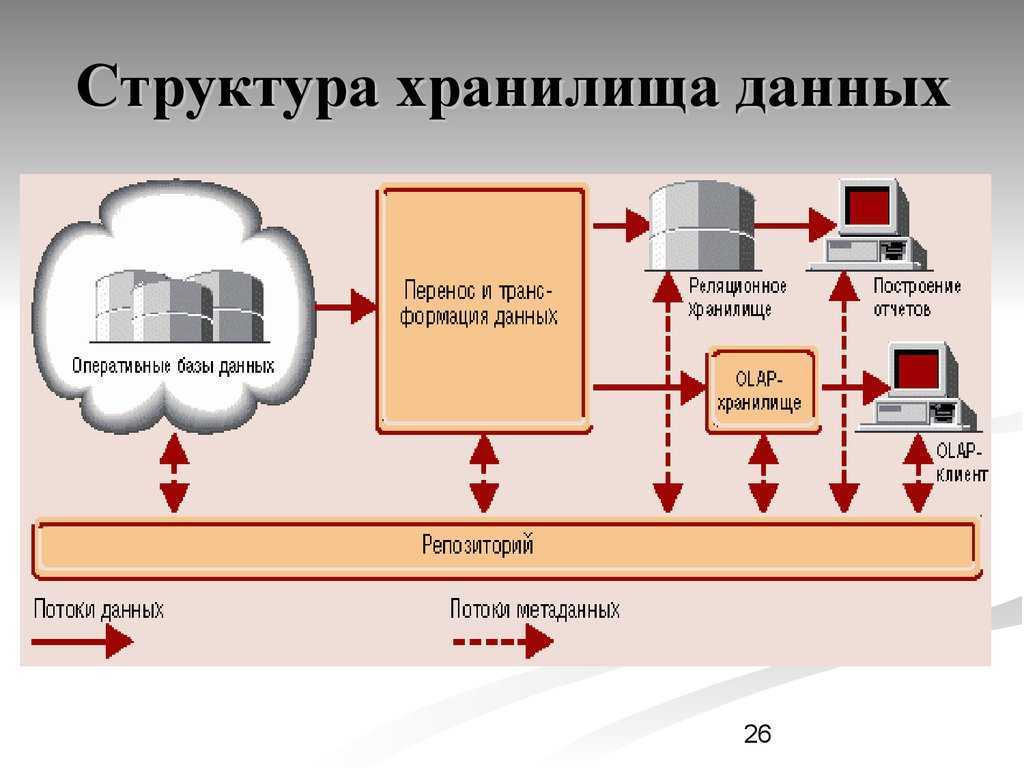
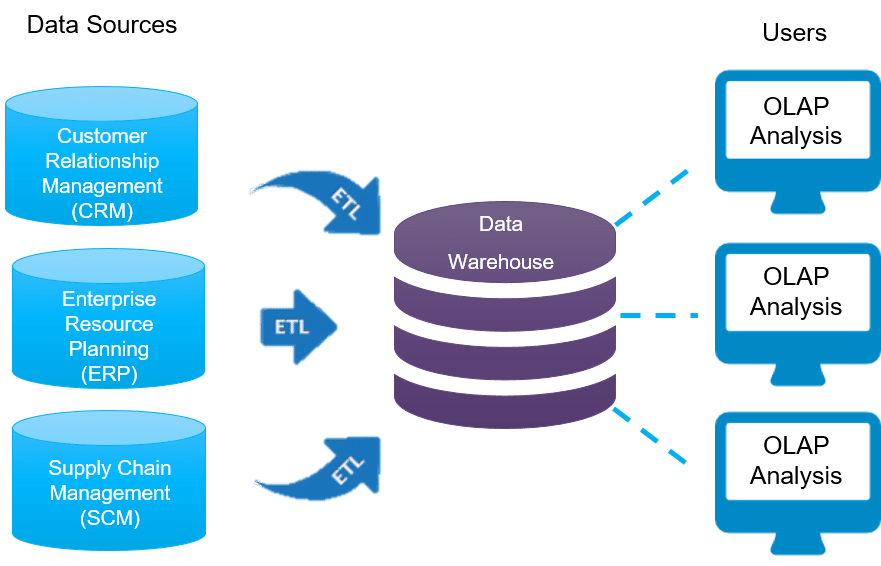
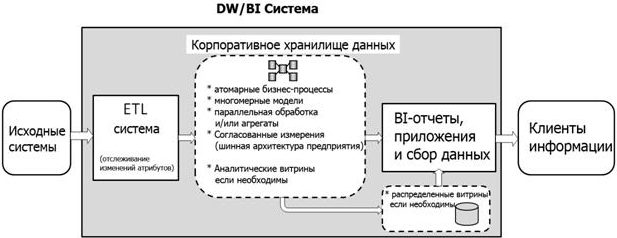
Традиционная архитектура хранилища данных
Трехуровневая архитектура
- Нижний уровень: этот уровень содержит сервер базы данных, используемый для извлечения данных из множества различных источников, например, из транзакционных баз данных, используемых для интерфейсных приложений.
- Средний уровень: средний уровень содержит сервер OLAP, который преобразует данные в структуру, лучше подходящую для анализа и сложных запросов. Сервер OLAP может работать двумя способами: либо в качестве расширенной системы управления реляционными базами данных, которая отображает операции над многомерными данными в стандартные реляционные операции (Relational OLAP), либо с использованием многомерной модели OLAP, которая непосредственно реализует многомерные данные и операции.
- Верхний уровень: верхний уровень — это уровень клиента. Этот уровень содержит инструменты, используемые для высокоуровневого анализа данных, создания отчетов и анализа данных.
Модели хранилищ данных
- Виртуальное хранилище данных — это набор отдельных баз данных, которые можно использовать совместно, чтобы пользователь мог эффективно получать доступ ко всем данным, как если бы они хранились в одном хранилище данных;
- Модель витрины данных используется для отчетности и анализа конкретных бизнес-линий. В этой модели хранилища – агрегированные данные из ряда исходных систем, относящихся к конкретной бизнес-сфере, такой как продажи или финансы;
- Модель корпоративного хранилища данных предполагает хранение агрегированных данных, охватывающих всю организацию. Эта модель рассматривает хранилище данных как сердце информационной системы предприятия с интегрированными данными всех бизнес-единиц



