1 — Введение отказа на уровне ресурса, aka нехватка ресурсов.
Да, облачные технологии приучили нас к тому, что ресурсы практически неограничены, но спешу разочаровать вас: они все же не бесконечны. Экземпляр, контейнер, функция и проч. — вне зависимости от абстракции, ресурсы в конце концов заканчиваются. Выход за грани допустимого, максимальное исчерпание ресурсов называется истощением.
Нехватка ресурсов имитирует атаку типа «отказ в обслуживании», только не обычную, чтобы внедриться в намеченный сервер. Это введение отказов, возможно распространено, потому, наверное, что в применении не сложно.
Истощая ресурсы ЦПУ, памяти и ввода/вывода
Один из моих любимых инструментов — stress-ng, переписка оригинального инструмента нагрузочного тестирования, за авторством Амоса Уотерленда.
Со stress-ng можно вводить отказы, нагружая различные физические подсистемы компьютера, так же как и управляя интерфейсами ядра системы, используя стресс-тесты. Доступны следующие стресс-тесты: ЦПУ, кэш ЦПУ, устройство, ввод/вывод, прерывание, файловая система, память, сеть, ОС, конвейер, планировщик и ВМ. Man-страницы включают полное описание всех доступных стресс-тестов, а таких всего 220!
Ниже — несколько практических примеров, как использовать stress-ng:
Нагрузка на ЦПУ дает нужный микс операций с памятью, кэшем и плавающей запятой. Это, пожалуй. лучший способ хорошенько разогреть ЦПУ.
Нагрузка пишет N-байты для каждого процесса-обработчика ; по умолчанию задан 1 Гб, и он идеален для выполнения стресс-теста вводы/вывода. В этом примере я задам 80% свободного места файловой системы.
отлично подходит для стресс-тестов памяти. В этом примере stress-ng запускает 9 стресс-тестов виртуальной памяти, которые в час совокупно потребляют 90% доступной памяти. Т.о., каждый тресс-тест потребляет 10% доступной памяти.
Нехватка дискового пространства на жестких дисках
— это утилита командной строки, собранная для того, что конвертировать и копировать файлы. Однако умеет читать и/или писать из файлов особых устройств типа и для таких задач, как резервное копирование загрузочного сектора жесткого диска и получение фиксированного объема случайных данных. Т.о., ее можно использовать для введения отказов на сервере и имитации переполнения диска. У вас файлы журнала переполняли сервер и роняли приложение? Так вот, поможет — и сделает больно!
Используйте очень осторожно. Введете не ту команду — и данные на харде сотрутся, уничтожатся или перепишутся!
Подтормаживание API приложений
Производительность, устойчивость и масштабируемость API имеют большое значение. API вообще жизненно необходимы для сборки приложений и роста бизнеса.
Нагрузочное тестирование — отличный способ проверить приложение, прежде чем оно попадет в производственную среду. Также это классный метод стрессовой нагрузки, поскольку зачастую вскрывает исключения и ограничения, которые при иных обстоятельствах остались бы невидимы до встречи с реальным трафиком.
— это инструмент для сбора контрольных показателей HTTP, создающий значительную нагрузку на системы. Особенно люблю влупить проверки доступности API, особенно если речь идет о проверке работоспособности, потому что они вскрывают много чего относительно проектировочных решений на уровне кода разработчика: как настроен кэш? как реализовано ограничение скорости? отдает ли система приоритет проверкам работоспособности относительно балансировщиков нагрузки?
Вот с чего можно начать:
Эта команда запускает 12 потоков и держит открытыми 400 соединений по HTTP в течение 20 секунд.
5 — Введение отказов и инструменты оркестрации типа «все в одном»
Вполне вероятно, что вы потерялись в таком множестве инструментов. К счастью, есть парочка введений отказа и инструментов оркестрации, которые включают в себя большую их часть и ими легко пользоваться.
Chaos Toolkit
Один из моих любимых инструментов — Chaos Toolkit, платформа с открытым исходным кодом для хаос-инжиниринга, которую коммерчески поддерживает замечательная команда ChaosIQ. Вот лишь некоторые из них: Расс Майлз, Силвейн Хеллегуарх и Марк Паррьен.
Chaos Toolkit определяет декларативный и расширяемый API для удобного проведения эксперимента по хаос-инжинирингу. Он включает драйверы для AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humino, Prometheus и Gremlin.
Расширения — это набор проверок и действий, используемых для экспериментов так: останавливаем случайно выбранный инстанс в конкретной зоне доступности, если содержит значение .
Провести вышеупомянутый эксперимент просто:
Сила Chaos Toolkit в том, что, во-первых, он с открытым исходным кодом и его можно подстроить под ваши нужды. Во-вторых, он прекрасно вписывается в конвейер CI/CD и поддерживает непрерывный хаос-тестинг.
Минус Chaos Toolkit в том, что на его освоение требуется время. Более того, в нем нет готовых экспериментов, так что придется писать их самому. Впрочем, я знаком с командой в ChaosIQ, которая работает не покладая рук, разбираясь с этой задачей.
Gremlin
Еще один мой любимчик — Gremlin. Вмещает в себя исчерпывающий набор режимов введения отказов в несложном инструменте с интуитивным пользовательским интерфейсом. Такая себе «Хаос-как-услуга».
Gremlin поддерживает введение отказов на уровне , позволяя быстро экспериментировать со всей системой, в т.ч. с «железом», различными облачными провайдерами, контейнеризированными средами, включая Kubernetes, приложениями и — в некоторой степени — бессерверными приложениями.
Плюс бонус — ребята из Gremlin большие молодцы, пишут отличный контент для блога и всегда готовы помочь! Вот некоторые из них: Мэтью, Колтон, Тэмми, Рич, Ана и HML.
В использовании Gremlin проще некуда:
Сперва войдите в приложение Gremlin и выберите «Create Attack».
Назначьте цель — инстанс.
Выберите тип отказа, который хотите ввести, и да начнется хаос!
Должен признать, что Gremlin всегда мне нравился: с ним эксперименты по хаос-инжинирингу интуитивно просты.
Минус в ценовой политике — требуется лицензия для работы, что может не подойти для начинающих пользователей или разовых работ. Однако недавно добавили его бесплатную версию. Более того, Gremlin-клиент и daemon нужно устанавливать в инстансы, которые надо атаковать, а это не всем по душе.






Run Command от AWS System Manager
Приложение Run command для работы с EC2, представленное в 2015 году, сделано для простого и безопасного администрирования инстансов. Сегодня оно позволяет удаленно и безопасно управлять конфигурацией ваших инстансов — не только ЕС2, но и конфигурированные в вашей гибридной среде. Это включает локальные серверы и виртуальные машины, и даже ВМ в других облачных средах, используемых с Systems Manager.
Run Command позволяет автоматизировать задачи DevOps или выполнять ad-hoc обновления конфигурации, вне зависимости от размера вашего парка.
В то время, как Run Command по большей части используется для задач типа установки и первоначального развертывания приложений, получения журналов или подключения инстансов к домену Windows, он также хорошо подходит для проведения хаос-экспериментов.
У меня есть статья на тему введения хаоса с использованием AWS System Manager и множества готовых введений отказов с открытым исходным кодом. Попробуйте — прикольно!
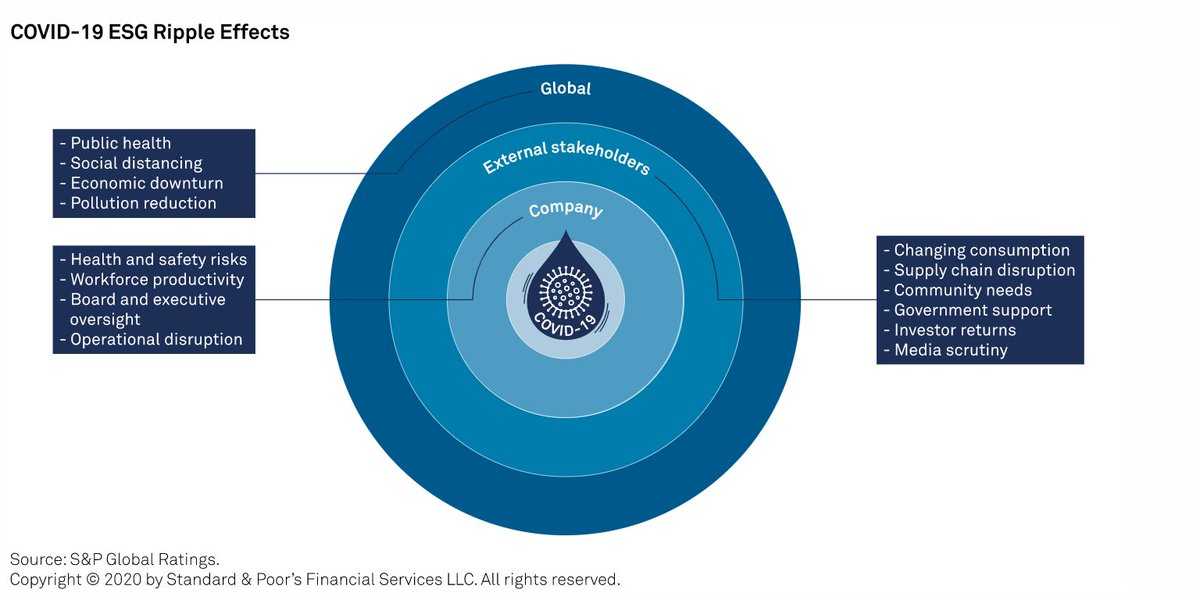
Виды тестов на уровни антител при COVID-19 – от чего зависит интерпретация результатов анализов
Чтобы диагностировать COVID-19, используются разные виды тестов – генетические и антигенные, требующие мазка из носоглотки и анализы крови на наличие антител.
- Генетическое тестирование. Основано на методах молекулярной биологии, поэтому наиболее чувствительно. То есть COVID-положительные результаты обычно являются истинными (достоверными).
- Антигенные тесты. Это популярные кассетные тесты на SARS-CoV-2. Они менее чувствительны, но просты в использовании и результат получается быстро. Результат теста на COVID может быть положительным (была инфекция), отрицательным (вирус не обнаружен) или неубедительным (тест нужно повторить).
- Анализы на антитела. Обнаруживают COVID-специфические антитела IgG и антитела IgM. Это могут быть качественные тесты, т.е. оценка того, существуют ли вообще данные антитела. При интерпретации результатов тестов IgG и IgM результаты интерпретируются с использованием готовых, простых для понимания инструкций. Также доступны количественные тесты. В них уровень антител к COVID определяется числовым значением, выраженным в единице BAU/ml.
Внедрение неисправностей на уровне сети и зависимостей
Eight Fallacies of Distributed Computing
- Сеть надёжна.
- Задержка равна нулю.
- Пропускная способность безгранична.
- Сеть безопасна.
- Топология не меняется.
- Есть только один администратор.
- Транспортировка всегда происходит без проблем.
- Сеть гомогенна.
Внедрение задержек, потерь и повреждений сети
(traffic control)— Внедряем задержку в 100 мс:
— Внедряем задержку в 100 мс с дельтой в 50 мс:
— Имитируем повреждение 5 % сетевых пакетов:
— Имитируем потерю 7 % пакетов с корреляцией в 25 %:
Примечание: 7 % позволяют сохранить работоспособность TCP.
IP-адреса— Блокируем доступ к API DynamoDB из экземпляра EC2:
— Блокируем доступ экземпляра EC2 к API EC2:
Я мог бы рассказать анекдот про DNS…
Идёт обновление кэша DNS…DDoS-атака на Dynотчёту ThousandEyes Global DNS PerformanceDDoS-атакамиblackholingслужбы DNSiptables
Внесение неисправностей с помощью Toxiproxy
ToxiproxyToxiproxyинженерной командой ShopifyСлайд из выступления Simon’а Eskildsen’а, главы команды production-разработки, Shopifyтоксиков()этой записи в блоге
Закругляюсь!
Смысл хаос-инжиниринга не в том, чтобы ломать что-то в production. Это целое путешествие. Путешествие к знанию, получаемому путем проведения экспериментов в контролируемой среде — любой среде, будь то локальное окружение для разработки, beta, staging или production. Это путешествие может начаться где угодно! Об этом прекрасно сказала Olga Hall:
Прежде чем внести неисправность, помните, что необходимо иметь наготове соответствующие мониторинг и алерты
Без них вы не сможете оценить влияние экспериментов с хаосом или измерить радиус поражения — два критически важных компонента в практике хаос-инжиниринга.
Некоторые из описанных методов могут нанести серьёзный урон, поэтому соблюдайте осторожность и проводите начальные испытания на тестовых экземплярах, от падения которых не пострадают реальные клиенты.
Наконец, тестируйте, пробуйте, испытывайте, а затем повторяйте всё снова. Помните, что цель хаос-инжиниринга — выработать уверенность в способности вашего приложения (и инструментов) пережить турбулентные условия эксплуатации.
(на Medium — прим. перев.)
Всем доброго времени суток! С вами AsaQr и сегодня я расскажу вам о том, как проходить Путь Героя максимально далеко, не прибегая к излишним покупкам и непредвиденным тратам.
А также покажу что выгоднее всего покупать в Магазине Пути Героя и за Монеты и за Сертификат.
Подписывайтесь, если ещё не подписаны, и мы начинаем! ![]()
Путь героя представляет из себя временное событие, которое проходит каждый месяц и длится чуть меньше месяца (например, в сентябре 2022 года это 25 дней).
Каждый день вам предстоит выполнять различные рутинные задания, чтобы повышать уровень в общем прогрессе и соответственно получать самые вкусные награды.
На картинке выше представлен список заданий по дням именно в Сентябре 2022. Имейте ввиду, что каждый месяц список заданий и наград обновляется. Все актуальные изображения по предстоящим Путям Героя вы можете посмотреть у меня в телеграм-канале.
Сразу отвечу на вопрос «А стоит ли покупать Золотой пропуск? И если да, то какой?» Ответ: Да, однозначно стоит, но только Стандарт. Дополнительные награды в «Премиум» и «Премиум +» оооочень мизерные. Аватарки, конечно, дело такое.
Разница в наградах без пропуска и с золотым пропуском действительно ощутима и купить его куда выгоднее, чем купить слот на х4 изумрудов по этой же стоимости.
Поэтому наша самая главная цель — дойти до 65 уровня и получить Сертификат Пути Героя.
Задания, необходимые для выполнения с целью получения очков, которые конвертируются в уровень — меняются каждый день.
Наше самое главное преимущество — мы знаем когда и какое задание нам предстоит сделать, поэтому наш главный инструмент для максимального результата — ПОДГОТОВКА.
Модель ядра хранилища и корпоративная модель данных
Миф 1.На самом деле.Миф 2.На самом деле.Миф 3.На самом деле.Разработка модели данных – это не процесс изобретения и придумывания чего-то нового. Фактически, модель данных в компании уже существует. И процесс ее проектирования скорее похож на «раскопки». Модель аккуратно и тщательно извлекается на свет из «грунта» корпоративных данных и облекается в структурированную форму.Миф 4.На самом деле.Миф 5.На самом деле.Миф 6.На самом деле.
Слой первичных данных (или историзируемый staging или операционный слой)
очищаемый
- возможность ошибиться (в структурах, в алгоритмах трансформации, в гранулярности ведения истории) – имея полностью историзируемые первичные данные в зоне доступности для хранилища, мы всегда можем сделать перезагрузку наших таблиц;
- возможность подумать – мы можем не торопиться с проработкой большого фрагмента ядра именно в этой итерации развития хранилища, т.к. в нашем стейджинге в любом случае будут, причем с ровным временным горизонтом (точка «отсчета истории» будет одна);
- возможность анализа – мы сохраним даже те данные, которых уже нет в источнике – они могли там затереться, уехать в архив и т.д. – у нас же они остаются доступными для анализа;
- возможность информационного аудита – благодаря максимально подробной первичной информации мы сможем потом разбираться – как у нас работала загрузка, что мы в итоге получили такие цифры (для этого нужно еще иметь маркировку мета-атрибутами и соответствующие метаданные, по которым работает загрузка – это решается на сервисном слое).
- было бы удобно выставить требования к транзакционной целостности этого слоя, но практика показывает, что это трудно достижимо (это означает то, что в этой области мы не гарантируем ссылочную целостность родительских и дочерних таблиц) – выравнивание целостности происходит на последующих слоях;
- данный слой содержит очень большие объемы (самый объемный на хранилище — несмотря на всю избыточность аналитических структур) – и надо уметь обращаться с такими объемами – как с точки зрения загрузки, так и с точки зрения запросов (иначе можно серьезно деградировать производительность всего хранилища).
Сервисный слой
- область метаданных – используется для механизма управления загрузкой данных;
- область качества данных – для реализации офф-лайн проверок качества данных (т.е. тех, что не встроены непосредственно в ETL-процессы).
управляющий процесс
Проектирование и ведение моделей данных хранилища
проектировать«сущность-связь»многомерная модель
- задача построение концептуальной (логической) модели ядра — системный и бизнес анализ — исследование предметной области, углубление в детали и учет нюансов «живых данных» и их использования в бизнесе;
- задача построения модели анализа – и далее концептуальной (логической) модели витрин;
- задача построения физических моделей – управление избыточностью данных, оптимизация с учетом особенностей СУБД под запросы и загрузку данных.
- Модель данных – это не набор «красивых картинок», а процесс ее проектирования – это не процесс их рисования. Модель отражает наше понимание предметной области. А процесс ее составления – это процесс ее изучения и исследования. Вот на это тратится время. А вовсе не на то, чтобы «нарисовать и раскрасить».
- Модель данных – это проектный артефакт, способ обмена информацией в структурированном виде между участниками команды. Для этого она должна быть всем понятна (это обеспечивается нотацией и пояснением) и доступна (опубликована).
- Модель данных не создается единожды и замораживается, а создается и развивается в процессе развития системы. Мы сами задаем правила ее развития. И можем их менять, если видим – как сделать лучше, проще, эффективнее.
- Модель данных (физическая) позволяет консолидировать и использовать набор лучших практик, направленных на оптимизацию – т.е. использовать те приемы, которые уже сработали для данной СУБД.
Chaos Monkey
Chaos Monkey – это инструмент, используемый для проверки устойчивости облачных систем путем преднамеренного создания сбоев в этих системах, чтобы понять их реакцию.
Netflix создал его для тестирования отказоустойчивости и возможности восстановления инфраструктуры AWS.
Он был назван Chaos Monkey, потому что он создает разрушения, как дикая вооруженная обезьяна, чтобы проверить ошибки.
Также именно Chaos Monkey положила начало новой инженерной практике Chaos Engineering.
Он был создан по принципу, что лучше тестировать сбои неоднократно, чтобы избежать внезапного серьезного отказа.
Эпидемиология и клиническое значение
Частота лекарственного взаимодействия напрямую связана с количеством используемых лекарств, т. е. полипрагмазией. Чем больше лекарств принимает пациент, тем выше риск клинически значимых лекарственных взаимодействий, включая побочные эффекты.



Связь между количеством используемых лекарств и частотой взаимодействий между ними выражается в виде факториала (обозначается символом «!»). Например, если пациент принимает 5 препаратов, то теоретически возможное количество вариантов взаимодействия лекарств равно 5!, То есть 1x2x3x4x5 = 120. С другой стороны, многие теоретически возможные лекарственные взаимодействия не имеют большого клинического значения. Частота значительных лекарственных взаимодействий варьируется на несколько процентов.
В группу самого высокого риска входят пожилые пациенты, которые обычно страдают различными заболеваниями и принимают множество лекарств (в том числе безрецептурных) и пищевых добавок. Ученые рассчитали, что на каждого такого больного приходится в среднем 7 лекарственных препаратов. Наиболее частые патологии, требующие лечения у пожилых людей, артериальная гипертензия, дислипидемия и диабет. Сердечно-сосудистые препараты используются более чем у 80% обследованных пациентов.
Пожилая пациентка принимает множество лекарств
В возрасте 46–50 лет до 74% пациентов принимают 3 или более препаратов. Среди всех причин госпитализации, госпитализация из-за лекарственного взаимодействия колеблется от 2 до 7%.
Помимо количества используемых лекарств, возраста пациента и заболевания (особенно печени и почек) факторы риска взаимодействия включают конкретные группы лекарств, например, комбинацию ингибиторов АПФ и НПВП, фармакогенетические причины и так далее.
Принцип планирования рабочего дня
Это, пожалуй, наиболее индивидуальный принцип. Я стараюсь правильно распределять задачи в течение дня с учётом моих личных особенностей. Вот мои правила:
-
Самое ценное для меня время — это первые три часа рабочего дня. В эти часы я стараюсь решать самые сложные задачи.
-
Если выполнять задачи короткими интенсивными интервалами по 2–3 часа, то результаты будут лучше.
-
Нужно периодически менять вид деятельности.
-
Задачи, на решение которых нужно меньше 5 минут, я предпочитаю выполнять немедленно.
Понимаю, что эти правила подойдут не всем. Например, если вы классическая «сова» и с трудом просыпаетесь по утрам, то первое правило — совсем не для вас. Тут важен принцип — главное, последить за собой, за своей эффективностью в течение рабочего дня и попытаться сформулировать свои собственные правила распределения задач во времени.
Отказы в мире бессерверных приложений
Введение отказа может стать настоящим вызовом, если вы используете бессерверные компоненты, поскольку бессерверно управляемые сервисы типа AWS Lambda нативно не поддерживают введение отказов.
Введение отказов в функции Lambda
Чтобы разобраться в этой проблеме, я написал небольшую библиотеку python и прослойку lambda — для введения отказов в AWS Lambda. В настоящий момент и то, и то поддерживает задержку, ошибки, исключения и введение кода ошибки НТТР. Введение отказа достигается путем настройки AWS SSM Parameter Store следующим образом:
Можно добавить декоратор python в функцию handler, чтобы ввести отказ.
— сгенерировать исключение:
— ввести код ошибки «неверный НТТР»:
— ввести задержку:
Жмакните здесь, чтобы узнать больше об этой библиотеке питон.
Введение отказа в исполнение Lambda через ограничение параллелизма
Lambda по умолчанию использует в целях безопасности регулировку параллельных исполнений всех функций в определеннном регионе, на аккаунт. Параллельные исполнения относятся к нескольким исполнениям кода функции, происходящих в любой отдельно взятый момент времени. Они используются для масштабирования вызов функции к входящему запросу. Но оно может служить и для обратной цели: остановки исполнения Lambda.
Эта команда снизит параллелизм до нуля, провоцируя отказы запросов с ошибкой типа «торможение» — код неисправности .
Thundra — трассировка бессерверных передач
Thundra — это инструмент наблюдения за бессерверными приложениями, имеющий встроенную способность вводить отказы в бессерверные приложения. Он делает обработчики-обертки для введения отказов типа «отсутствие обработчика ошибок» — для операций с DynamoDB, «отсутствие нейтрализации ошибок» — для источника данных, или «отсутствие тайм-аута в исходящих НТТР-запросах». Я сам его не пробовал, но в этом посте за авторством Янь Чуи и в этом великолепном видео Марши Вильяльба процесс неплохо описывается. Выглядит многообещающе.
И в заключении раздела о бессерверных приложениях скажу, что о трудностях хаос-инжиниринга применительно к бессерверным приложениям у Янь Чуи есть отличная статья. Всем рекомендую к прочтению.
Как проверить уровень иммунитета при COVID-19?
Метод мониторинга уровня иммунитета, полученного после COVID-19 или после вакцинации против SARS-COV-2 — измерение концентрации антител против SARS-CoV-2. Известно, что иммунитет пропорционален концентрации антител.
Некоторые тесты адаптированы для измерения антител, особенно важных в механизмах противовирусного гуморального иммунитета – антител, нейтрализующих IgG anti-S. Результат теста выражается в BAU/мл. Измерение концентрации антител дважды позволяет уловить скорость изменения концентрации с течением времени.
Сроки измерений антител жестко не фиксированы, но их однозначно не следует делать в первые 2 недели после вакцинации. Лучше дождаться второй бустерной дозы и сдать анализы через пару недель.
Зная уровень ранних антител – IgM и поздних – IgG можно оценить эффективность иммунной системы, т.е. справилась ли она с коронавирусом SARS CoV-2 после заражения или после вакцинации. Тестирование уровня антител к COVID-19 также позволяет оценить время, прошедшее с момента заражения или последнего контакта с вирусом.
Принцип буферного листа
Я предпочитаю вести заметки по задаче на отдельном листе. Я записываю туда всю справочную и полезную информацию по задаче: названия переменных, куски алгоритма, определения, формулы. Тут же, например, можно записать имена и контакты сотрудников, которым можно задать вопросы по задаче. Этот лист подходит также для записи дополнительно возникающих дочерних задач.
При этом все заметки по задаче хранятся в одном месте, их легко окинуть взглядом и найти нужную информацию — она всегда перед глазами. Кстати, это не обязательно должен быть лист бумаги. Можно использовать любое приложение для ведения заметок. Главное, чтобы всё было в одном месте. После завершения работы над задачей лист можно будет отсканировать и сохранить.
Сбои на уровне ресурсов или «исчерпание ресурсов»
(resource exhaustion)DoS-атака
Исчерпание ресурсов CPU, памяти и ввода/вывода
stress-ngоригинальной утилиты(stressors)Страницы руководстваstress-ng
- Стресс-тест CPU — — предлагает отличное сочетание операций с памятью, кэшем и с плавающей запятой. Пожалуй, является лучшим способом «поджарить» CPU.
- Стресс-тест пишет N байтов для каждого процесса-worker’а iomix. Значение N по умолчанию равно 1 Гб и идеально подходит для стресс-теста ввода/вывода. В этом примере я указываю 80 % свободного пространства в файловой системе:
- идеально подходит для проведения стресс-тестов памяти. В данном примере stress-ng запускает 9 стрессоров виртуальной памяти. Вместе они «съедают» 90 % доступной памяти на один час (каждый стрессор использует 10 % доступной памяти):
Исчерпание места на жестких дисках
Используйте dd чрезвычайно осторожно! Ошибка в команде может стереть, уничтожить или перезаписать данные на жёстком диске!
Клонировать и исследовать репозиторий
Нам нужно развернуть демонстрационное приложение, которое мы подготовили ниже. Мы собираемся клонировать репозиторий, vfarcic/go-demo-8созданный Виктором Фарчичем.
Далее мы заходим в каталог, в котором клонировали репозиторий.
Теперь создайте пространство имен с именем go-demo-8.
Теперь давайте кратко рассмотрим приложение, которое мы собираемся развернуть, расположенное в terminate-podsкаталоге в файле с именем pod.yaml.




Это приложение определяется как один модуль с одним контейнером go-demo-8. Он включает в себя другие ресурсы, такие как livenessProbeи readinessProbe.
Применение определения к кластеру
Теперь мы применяем это определение к нашему кластеру внутри go-demo-8пространства имен. Это заставит наше приложение работать как Pod.
Пришло время нанести урон и уничтожить наше приложение!
Установите плагин Chaos Toolkit Kubernetes
Чтобы проводить эксперименты с хаосом в нашем приложении, мы можем использовать плагин Chaos Toolkit для Kubernetes. Этот инструментарий не поддерживает Kubernetes из коробки. Нам нужен плагин для функций, выходящих за рамки базовых готовых функций. Давайте установим плагин Kubernetes, используя pip.
Примечание. Изучите плагин Chaos Toolkit с помощью discoverкоманды, чтобы увидеть все его функции, параметры и аргументы.
Как работает иммунитет к COVID-19 у выздоровевших людей?
Чтобы получить ответ на этот вопрос, рассмотрим механизм иммунитета к коронавирусу. Иммунитет, защищающий организм от заражения COVID-19, связан с наличием в организме антител, специфичных к вирусу SARS-CoV-2 и специализированных клеток иммунной системы. Они запрограммированы на уничтожение вируса при новом контакте.
Антитела – это специфические белки, выработка которых обусловлена клетками иммунной системы. Антитела распознают отдельные структурные элементы патогенов, вызвавших их образование. Они имеют общие фрагменты и небольшие «центры», отвечающие за специфическую реакцию. По общей структурной схеме антитела, присутствующие в организме, делятся на классы.
Таблица 1. Классы антител
| IgG | IgM | IgA | IgD | IgE |
Специфические физиологические функции связаны с классом антител. Антитела — часть механизма приобретенного, т.е. адаптивного иммунитета.
Для эффективной борьбы с коронавирусом организму необходим именно адаптивный иммунитет, поскольку он позволяет вырабатывать таргетные антитела и Т-лимфоциты, атакующие клетки, инфицированные вирусом. Если адаптивная реакция достаточно сильна, она оставляет постоянную память об инфекции в организме, обеспечивая защиту от вируса в будущем.
Обработка и хранение информации
Всю информацию нужно разбирать и решать, что с ней делать. Какую-то нужно тупо проигнорировать и забыть навсегда. Если задача актуальна и имеет смысл, тогда для её выполнения выделяется время в календаре и ставится напоминание для фокусировки на нем. Если приходит идея/мысль того, что нужно сделать по текущему проекту — она записывается там где хранится вся инфа по нему, если это идея нового проекта, покупки, статьи которую хочется прочитать, того что хочется изучить, книги которую хочется прочитать — она записывается в соответствующий раздел и ждет того момента, когда на неё появится время. Для этого я использую Evernote.
Список того, что хотелось бы сделать
Таким образом получается два списка дел: один для актуальных другой для потенциальных. А почему нельзя хранить это всё в одном месте? А потому, что это приводит к перегрузке, потому что становится сложно отличить актуальные от потенциальных. Потенциальные дела со временем теряют значимость (они кажутся важными только в момент возникновения в голове и добавления в список), потому по завершению текущих дел мы смотрим на список потенциальных и отбираем и назначаем действительно актуальные.
Почему нам нужен беспорядок?
Теперь, когда картинка о человеке с идеальным порядком уже не кажется такой радостной, есть пара хороших новостей для тех, кому сложно организовать свой быт так, чтобы сделать его похожим на серию картинок из блога про интерьер.
Более того, и самое важное, винить себя за беспорядок — бессмысленно и в корне неправильно. Эрик Абрахамсон и Дэвид Фридман, авторы научного бестселлера «Эффективный беспорядок» пишут: «Беспорядок — это не обязательно признак бессистемности
За столом, на котором все разбросано, можно работать эффективнее, чем за чистым».
Авторы считают, что умеренный беспорядок на самом деле самая эффективная система организации где бы то ни было: в доме, на работе, при создании бизнеса
Важно лишь установить ту грань беспорядка, которая позволит вам не выдвигать себе укоров и переломить стереотип, что нагроможденный рабочий стол делает вас безответственным. Все многочисленные эксперименты, которые проводились с той целью, чтобы выявить зависимость порядка и продуктивности приводили только к той мысли, что куда более важным считается умение расставлять приоритеты в жизни, а не папки на столе
Одним из преимуществ эффективного и допустимого вами беспорядка является то, что такую систему гораздо сложнее нарушить, а также она адаптивна к разного рода условиям. Поэтому, если сегодня ваш организм просит вас лечь спать пораньше, лучше делать это безо всякого чувства вины за невымытый пол и страха неэффективности.
Вывод: Chaos Engineering — принципы, примеры и инструменты
Со временем хаос-инжиниринг перерос в собственную полноценную индустрию. В настоящее время существует множество инструментов с открытым исходным кодом и коммерческих инструментов, таких как Litmus Chaos, Gremlin, Chaos Mesh и многих других, которые организации могут использовать. Создание устойчивых систем предназначено не только для технологических компаний. Распределенные системы стали более сложными, что означает, что сбои труднее предсказать. Кроме того, из-за различных проблем с регулированием и соответствием банкам, государственным учреждениям, фармацевтическим компаниям, образовательным учреждениям и т. Д. Необходимо регулярно тестировать свои системы и услуги, чтобы убедиться, что они соответствуют деловым и критически важным требованиям. Тестирование производительности и тестирование хаоса являются проактивными подходами к обучению созданию устойчивых систем путем наблюдения за сбоями.