Системы высокой доступности HPE
Первый класс систем защищает данные от различных программных и аппаратных сбоев. Такие системы часто называют локальным кластером. Для таких сред на базе Linux компания HPE рекомендует использовать пакет HPE Serviceguard. Это программное обеспечение поддерживает множество различных серверов и систем хранения. При использовании операционных систем компании Microsoft рекомендуется пользоваться кластерным программным обеспечением Windows Server 2008/2012 Failover Clustering. Для систем на базе VMware vSphere предлагается использовать VMware Fault Tolerance и VMware High Availability.
Метрики
Как работают метрики в этой матрице? Это хорошо видно на примере задачи обеспечения сетевой безопасности. На входе мы вводим действующую топологию сети, чтобы на выходе получить модернизированную сеть с учётом лучших практик в сфере ИБ.
Главным SLA для данного процесса становится аптайм, стремящийся к 100% по передаче данных. Всё осуществляется при соблюдении конфиденциальности, целостности и доступности циркулирующей информации. Снижение SLA ниже допустимых значений приводит к перезапуску процесса по новой с привлечением всех необходимых в компании подразделений, определенных матрицей RACI.
Виртуализация, облака и катастрофоустойчивость
С распространением виртуализации и облачных технологий появились новые способы защиты от катастроф:
- Репликация в облако. Технологии частных и публичных облаков упростили репликацию между площадками. Процесс репликации может охватывать все виртуальные машины, конкретные базы данных или снимки данных. Кроме того, облачные технологии помогают организациям выбрать наиболее подходящий по финансовым условиям вариант DR – появилась гибкость выбора допустимого времени простоя. То есть нередко можно выбрать приемлемое время простоя и при этом вписаться в бюджет.
- Виртуализация как механизм резервного копирования/восстановления. Здесь идея проста: намного проще восстановить виртуальную машину, чем физический сервер. Можно сохранять в резервном ЦОД «снимки состояния» ВМ или зеркалировать виртуальные машины. В последнем случая получается конфигурация «активный/активный» – при отказе на основной площадке ВМ, выполняющей критичные задачи, происходит переключение на такую же ВМ на резервной площадке.
- Использование технологий программного конфигурирования (Software Defined, SD). По сути, это развитие виртуализации. Программно-конфигурируемые платформы (сетевое оборудование, системы хранения, устройство безопасности, балансировщики нагрузки и пр.) позволяют получить гибкую отказоустойчивую среду с «виртуальными устройствами» различного назначения, функционирующими как виртуальные машины на стандартных серверах. Например, если задействовать для DR механизмы балансирования нагрузки (Global Server Load Balancing, GSLB), можно автоматически переключать пользователей на резервную площадку при отказе основной. Для пользователей процесс будет прозрачным.
- IaaS (инфраструктура по требованию). Облачные платформы и среды виртуализации позволяют быстро выделять необходимые ИТ-ресурсы. Для DR важна возможность быстрого восстановления виртуальных машин и данных. Облачные технологии и виртуализация отлично подходят для этой цели. Можно создавать очень экономичные решения IaaS – «активный/активный» или «активный/пассивный». Например, задается регулярное резервное копирование ВМ и данных в ЦОД провайдера. В случае аварии развертывается новая среда – запускаются ВМ с их резервированными данными. Процесс это не мгновенный, но достаточно быстрый. В IaaS главное – гибкость. При реализации стратегии DR провайдер поможет заказчику извлечь из этой гибкости максимум.

По данным EMC, проводившей в 2014 году опрос российских компаний, лишь 6% респондентов делают ставку на режим работы «активный/активный». Эти компании реже сталкиваются с потерей данных, чем те, что полагаются на резервное копирование: 13% против 24%.
Леонид ШИШЛОВ
На мой взгляд, ключевое отличие западной индустрии от отечественной – внимание к эксплуатации и операционным вопросам. У нас за последние несколько лет было построено и введено в эксплуатацию множество ЦОД разных размеров, включая мегаЦОД
Соответственно опыт в отечественной индустрии наработан солидный. Но, к сожалению, за все эти годы основной упор делался на проектировании и строительстве объектов и экспертиза развивалась именно по этим этапам жизненного цикла ЦОД. При этом практически никто не уделял должного внимании вопросам эксплуатации и технического обслуживания. Проще говоря, мы научились неплохо строить такие объекты, но пока не научились грамотно их эксплуатировать. Именно в этом направлении необходимо перенимать успешный зарубежный опыт и изучать наработанные индустриальные стандарты.
Как мы к этому пришли?
С виду кажется, что все задачи по защите собственных и клиентских систем решаются очень просто. Но это не совсем так. На самом деле, чтобы прийти к инфраструктурному уровню ИБ, нужно постараться. В частности, мы в Oxygen сделали это за следующие три шага:
Шаг 1. Описание процессов. В качестве базовой и отправной точки мы выбрали международный стандарт по информационной безопасности ISO 27-серии, тем более что он имеет свой перевод в виде ГОСТа. В соответствии с контекстом деятельности компании мы выделили и описали основные процессы: от набора персонала до проектирования новых сервисов и вывода из эксплуатации ненужных систем. Получился достаточно объемный регламент, которым мы руководствуемся до сих пор.
Шаг 2. Описание ролей. Начали создавать планы по достижению целей информационной безопасности, а сразу после этого — реализовывать их. Матрица RACI оказалась очень полезной для визуализации: сразу стало понятно, кто участвует в каждом процессе и на каких ролях. Масштабируя процессы ИБ на структурные подразделения компании, мы сразу наглядно видим, кто и что должен сделать для достижения заданного уровня ИБ.
Шаг 3. Добавление метрик. Нам также хотелось получить ответы на вопросы и измерить эффективность тех или иных мер обеспечения ИБ. И тогда мы разработали метрики для измерения эффективности каждого процесса. В число этих метрик входит очень многое — от доли сотрудников, ознакомленных с политиками и регламентами до значения uptime подсистем обсечения безопасности и инфраструктуры в целом. Такие показатели хорошо видны на дашбордах, которыми пользуются все руководители.
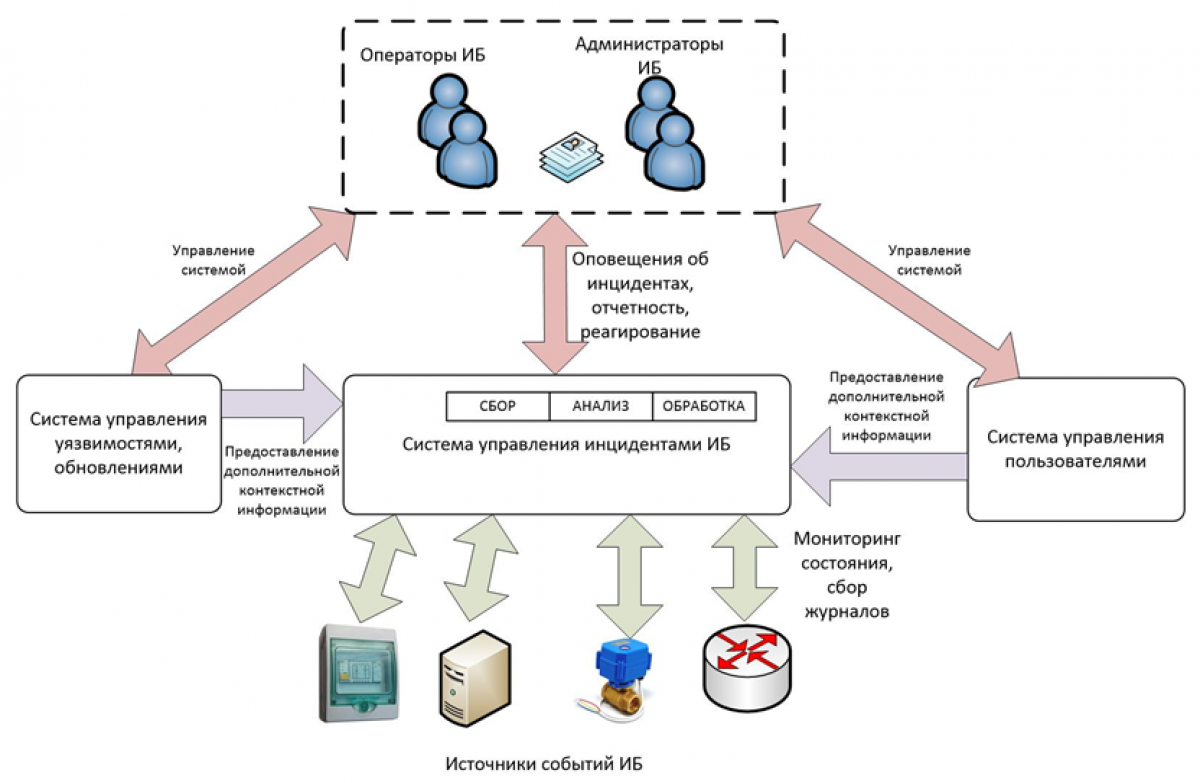
Результат: После проведения всей этой работы мы создали виртуальную модель системы информационной безопасности в дата-центре. На её основе можно прослеживать взаимосвязи между различными составляющими системы, определять зоны ответственности и разрабатывать меры оперативного противодействия атакам на инфраструктуру.
А за счет обучения персонала и знакомства сотрудников с этой картой, каждый может увидеть, что все ИБ-процессы и безопасность компании в целом — часть повседневной работы всех участников системы, а не что-то отстранённое и абстрактное.
Инженерый подход рулит
Комплексный инженерный подход показал, насколько фрагментарно обычно выстроен ИБ-процесс взаимодействия внутри компаний.
Теперь, когда мы оказываем услуги по инфобезу клиентам, (а иногда даже во время атак или после свершившегося инцидента), мы из раза в раз убеждаемся в необходимости фундамента в виде выстроенных процессов обеспечения и управления информационной безопасности.
Для того, чтобы нам самим было удобно работать, мы в Oxygen пришли к концепции трёх центров мониторинга внутри ЦОДа:
-
Мониторинг ИТ (его ещё называют NOC)
-
Мониторинг и управление подсистем ЦОД — Data Center Infrastructure Management (DCIM)
-
Мониторинг информационной безопасности – Security Operations Center (корпоративный SOC).
Все эти центры не только управляют своими системами, но непрерывно взаимодействуют друг с другом, участвуют в бизнес-процессах компании и развивают не только катастрофоустойчивость ЦОДа, но также формируют актуальную продуктовую линейку компании, достигая синергического эффекта в улучшении SLA предоставляемых услуг.
Учитывая, что ИБ сегодня является одной из ключевых сфер обеспечения доступности и сохранности данных, на мой взгляд, такой подход можно считать уже проверенной практикой. Вы можете использовать его внутри своей инфраструктуры…или обратиться к нам, чтобы получить в готовом виде. Главное помнить, что профилактика всегда дешевле тушения пожаров, а процессы инфобеза проходят через всю компанию, кто бы что ни говорил по этому поводу.
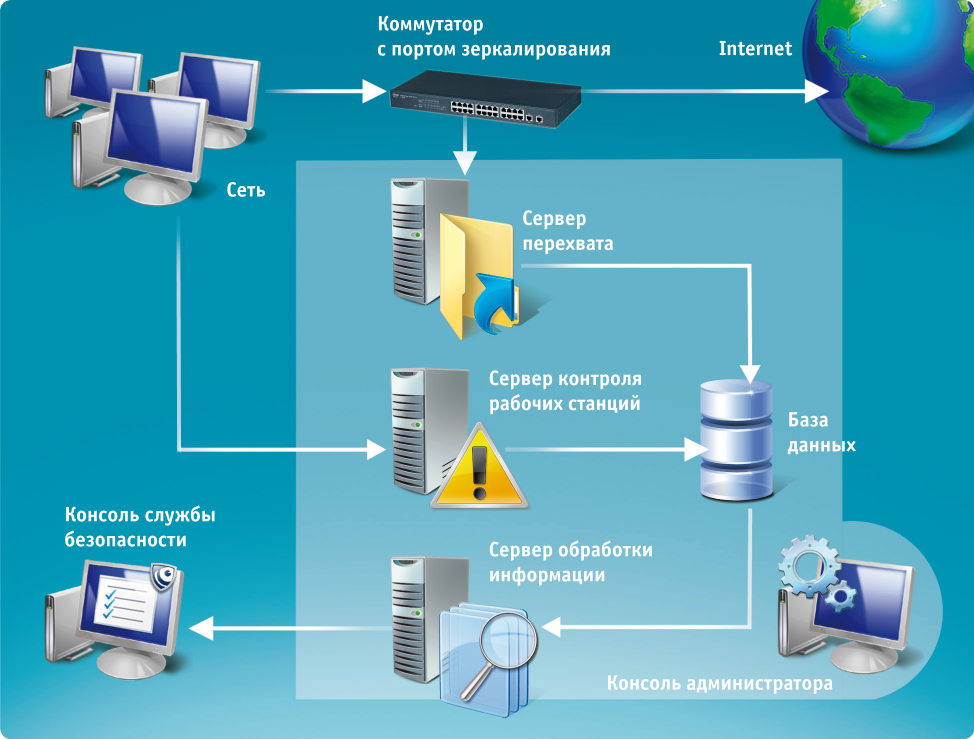
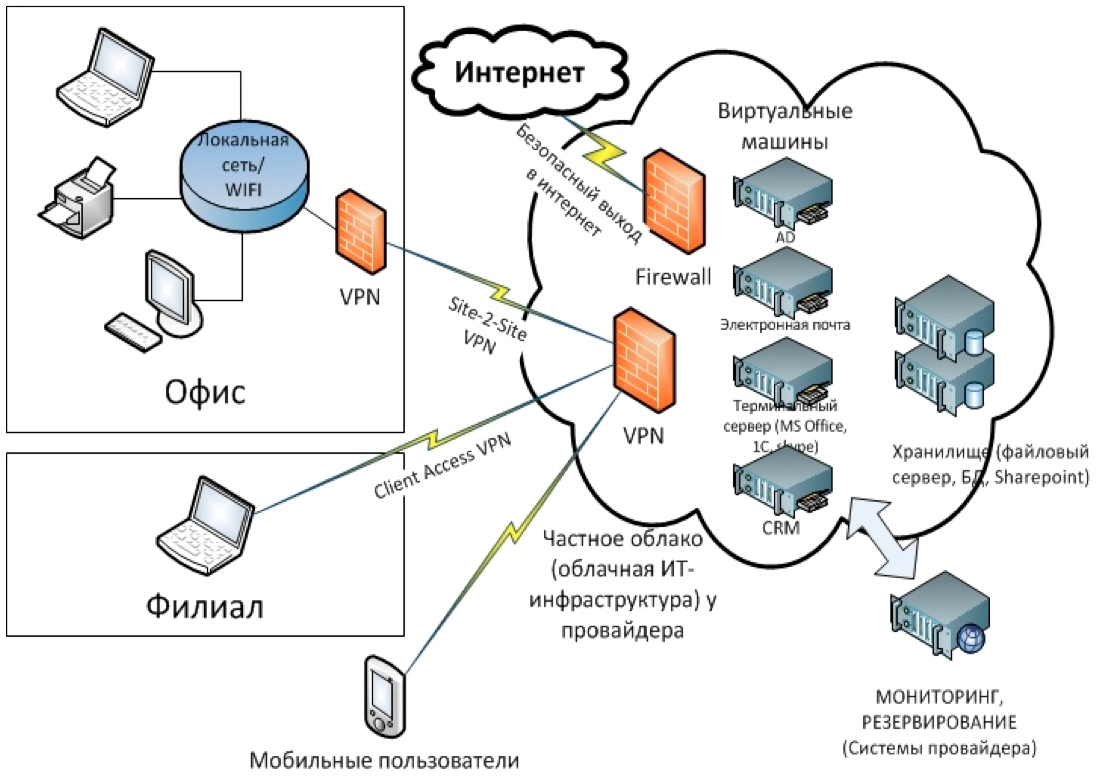
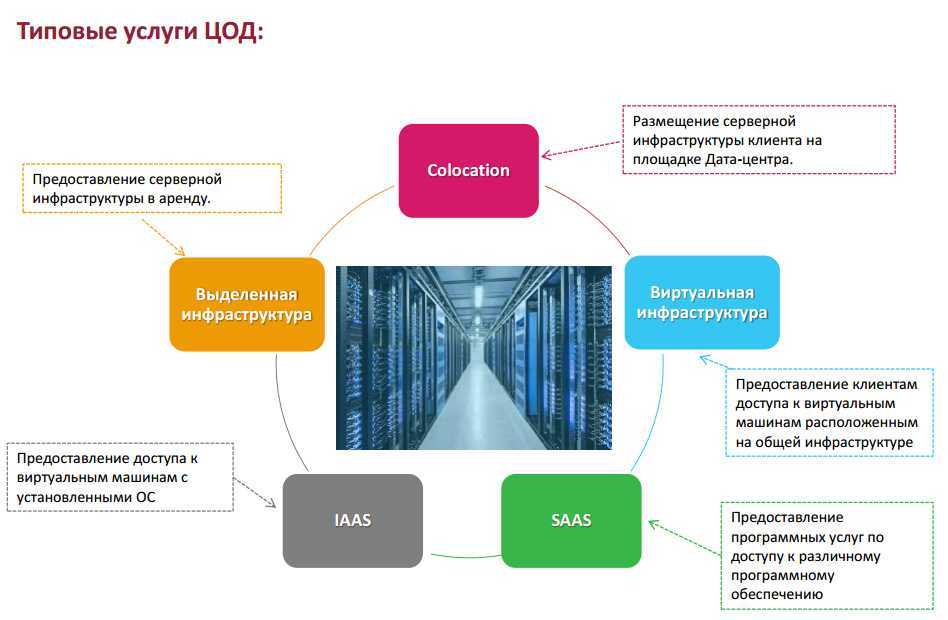
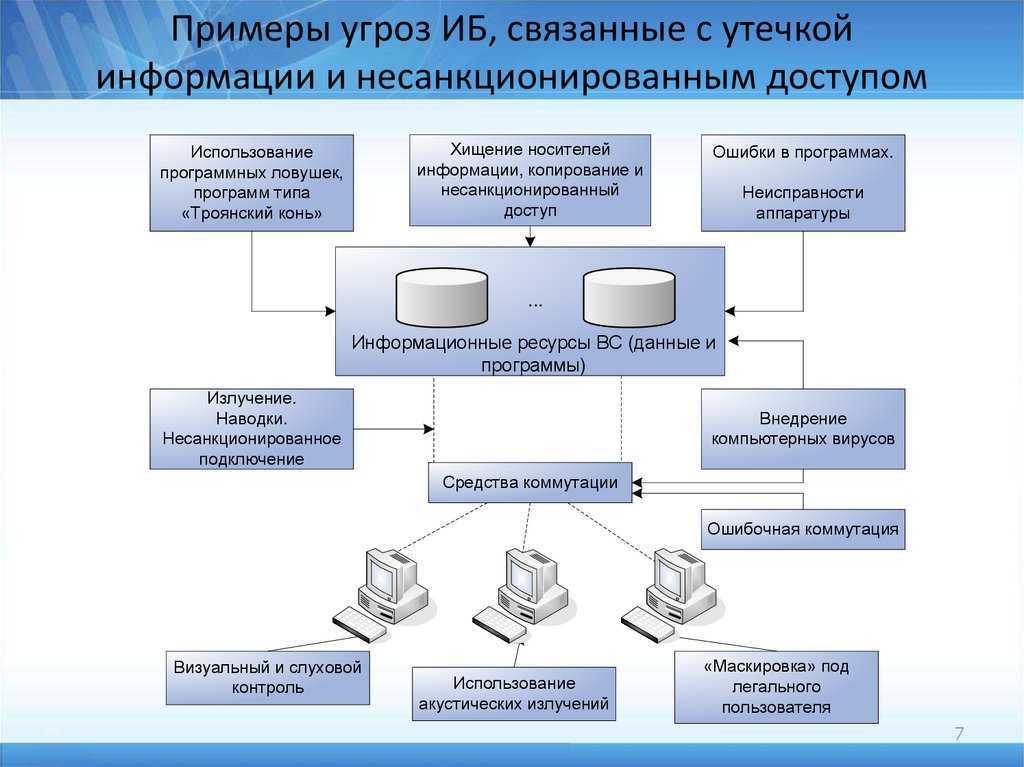
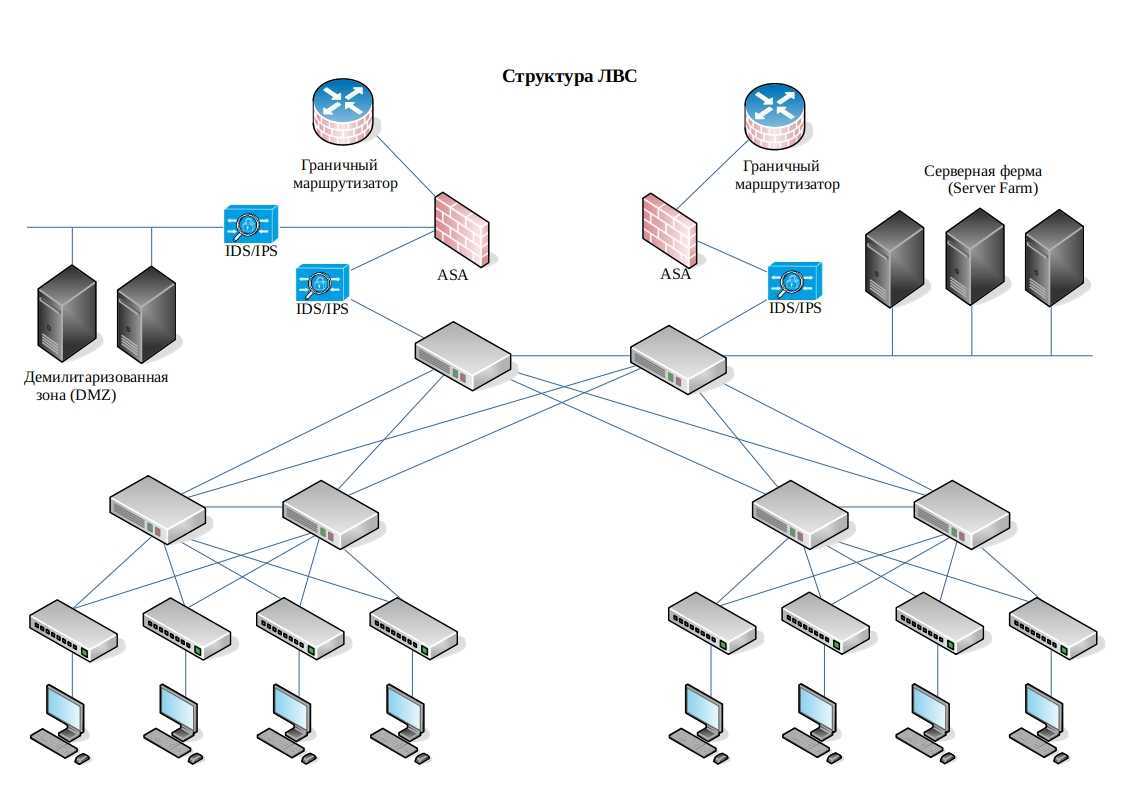
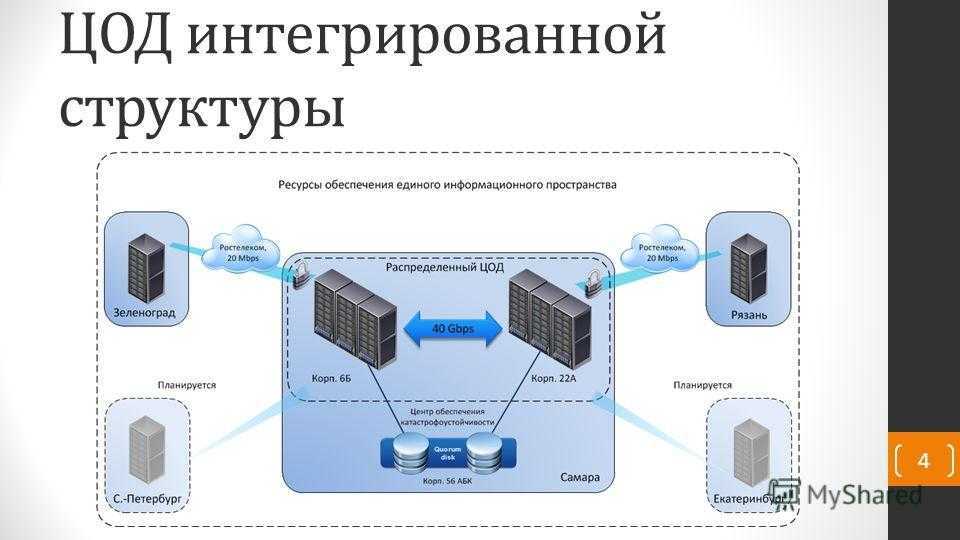
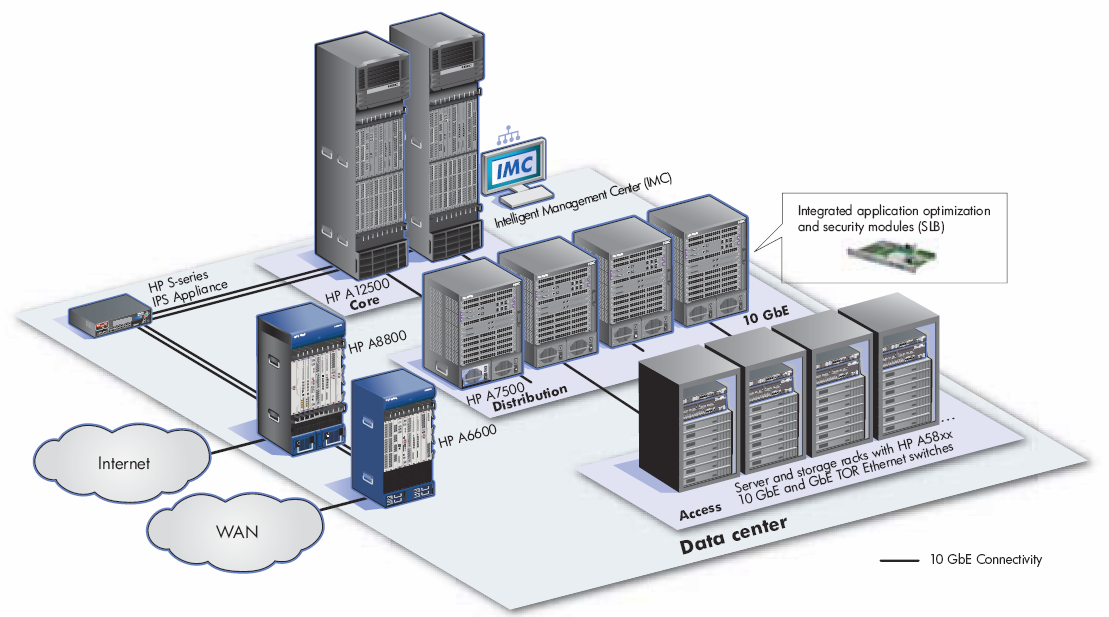
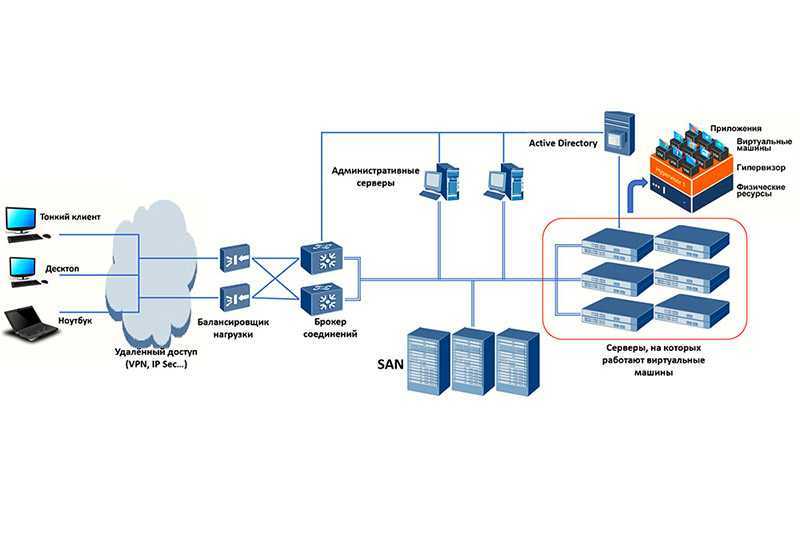
P.S. На всякий случай мы приносим извинения всем Василиям. Любые совпадения имен и лиц в этой статье — абсолютно случайны!
Почему же атаки удаются?
Неверно будет говорить, что сегодня кто-то не использует защиту. Как правило, компании задумываются об информационной безопасности: внедряют протоколы, развивают внутреннюю экспертизу или обращаются к ИБ-подрядчикам. Почему же их всё равно взламывают?
Увы, современный человек чаще всего живет в своей иллюзии безопасности. Мы придумываем разные схемы, готовимся, но в определенный момент просто “что-то идет не так”. Но реальность такова, что каждый инцидент ИБ — это набор взаимосвязанных инцидентов, один следует за другим. Как дорожка из домино.
Чтобы такая череда инцидентов не приводила к неприятным последствиям, важно развивать навык по выявлению и быстрой реакции на разные виды атак. Сегодня мало грамотно расставить “сигнальные флажки”
В реальной жизни требуется быстрая и грамотная реакция, а это уже навык, который нужно тренировать и развивать у команды ИБшников.
В общем, в вопросах ИБ профилактика – это лучшее лечение. А для профилактики нужно очень много всего, прямо как в кабинете дорогостоящего терапевта элитной медицинской клиники:
-
На уровне сети — изоляция сегментов и выявление сетевых аномалий с помощью NGFW и сетевых детекторов, защита инфраструктур от DDOS;
-
Для аудита уязвимостей — использование сканеров, тесты на проникновения и ручное проверка тактик и техник взлома;
-
На уровне WEB-ресурсов — применение межсетевых экранов уровня приложений, анализ логики приложений;
-
Для людей (чтобы исключить социальную инженерию, человеческий фактор в атаках) — повышение осведомленности и проведение киберучений;
-
На рабочих местах и серверах (защита конечных точек) — целый набор решений от классических антивирусов до продвинутой защиты от таргетированных атак и атак нулевого дня.
-
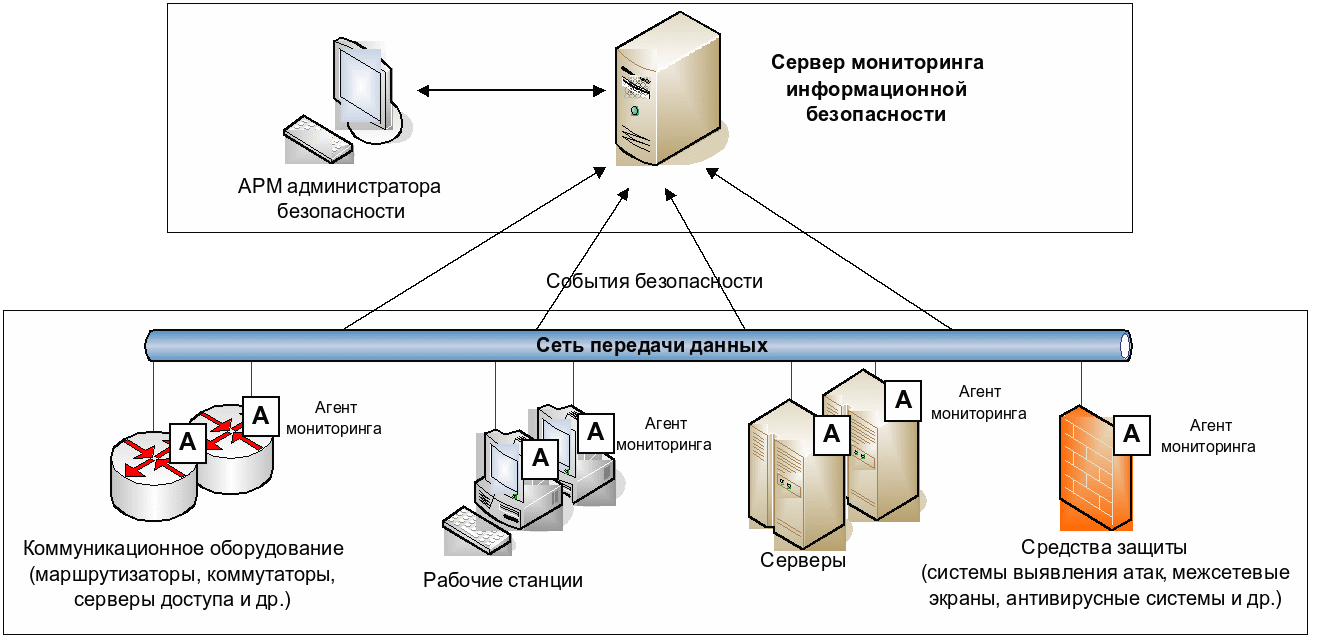
В целом — оперативное реагирование на изменения в инфраструктуре и мониторинг поведения подсистем с помощью SIEM.
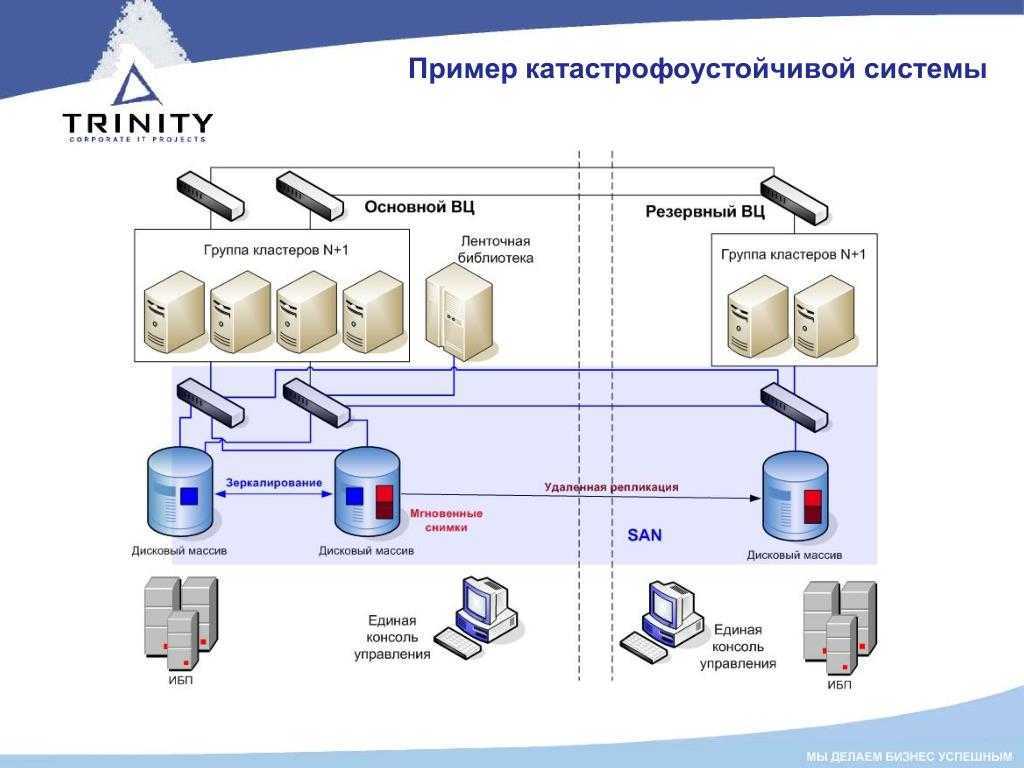
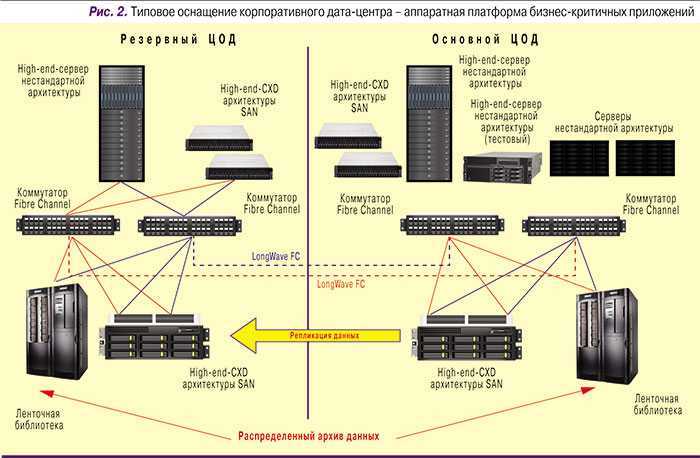
Катастрофоустойчивая конфигурация как ИТ-инструмент
Обычно, если речь заходит о катастрофоустойчивой конфигурации ЦОДа, ИТ-сервиса, зданий и сооружений, сразу представляется нечто циклопическое, дорогое и недоступное – в большинстве случаев из-за того, что не каждый бизнес может четко сформулировать необходимые и достаточные требования к надежности ИТ и зачастую играет «по полной», доводя решение задачи до абсолюта, а порой и абсурда – применяет двух- и более кратное резервирование систем, строит собственный ЦОД и т. п. Тогда как перед принятием решения о необходимости обеспечения катастрофоустойчивости ИТ-менеджерам следовало бы уточнить ряд вопросов:
- насколько необходимо применение ресурсоемких технологий высокой доступности в конкретной бизнес-среде;
- может быть, недоступность того или иного ИТ-сервиса не стоит потраченных на обеспечение его катастрофоустойчивости средств;
- какова стоимость минуты простоя ИТ-сервиса.
Со стороны бизнеса тоже неплохо бы получить ответ на другие вопросы:
- что является катастрофой для бизнеса;
- имеет ли к этому отношение служба ИТ;
- готов ли бизнес обеспечить ресурсами, кадрами и сервисом катастрофоустойчивое решение.
По итогам анализа подобных вопросов и должно быть принято осознанное и подкрепленное доброй волей руководителей решение. Если бизнес готов взять на себя эту «ношу», можно двигаться дальше и рассматривать подходы к решению задач обеспечения высокой доступности ИТ.
Системы с полным резервированием HPE
Второй тип систем – системы с полным резервированием кроме защиты от сбоев позволяют свести к минимуму простои в случае выхода из строя одного из дата-центров, где размещены элементы вычислительной системы. Такой вид вычислительных систем как правило реализуется с помощью кампусного кластера или метрокластера. Основная разница в способах синхронной репликации. При построении метрокластера в среде Linux рекомендуется средства HPE Serviceguard и HPE Metrocluster, они синхронизируют кластер с функциями репликации. В средах Microsoft Windows для этих целей используется Microsoft Windows Server 2008/2012 Failover Clustering с приложением HPE Cluster Extension (CLX) for Windows.
Системы хранения позволяют организовать устойчивое распределенное хранилище для вычислительных систем с полным резервированием. Благодаря этому есть конфигурации вычислительных систем, которые позволяют избежать простоев даже если одна из площадок размещения полностью выйдет из строя.
Такие конфигурации систем находят применение на распределенных фермах виртуальных машин и кроме высокой отказоустойчивости позволяют сбалансированно распределять нагрузку между ЦОД, перемещая виртуальные машины между площадками. Компания HPE предлагает несколько семеств массивов, с помощью которых можно построить такие конфигурации: HPE 3PAR StoreServ, HPE StoreVirtual, HPE XP7.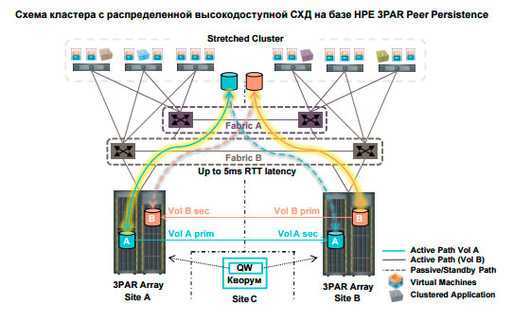
При использовании массивов HPE 3PAR StoreServ для построении конфигурации с высокой доступностью нужно иметь лиценции HPE 3PAR Remote Copy и HPE 3PAR Peer Persistence.
Функционал HPE 3PAR Peer Persistence может использоваться для Microsoft Windows Server 2008/2012 R2, VMware vSphere 5.x/6.x, Red Hat Enterprise Linux 6.x.
3PAR Peer Persistence обеспечивает высокую доступность следующим образом:
-
-
-
- хосты получают доступ к массивам с помощью фабрик fc, iscsi или fcoe;
- благодаря репликации hpe 3par remote copy поддерживается синхронность данных;
- тома экспортируются в режиме r/w с одинаковым идентификатором с обоих массивов, поэтому для хостов это выглядит как одна схд;
- пути к логическому тому массива, где хранится первичная копия данных находятся в активном режиме, а пути к тому на втором массива – в режиме ожидания;
- оба массива могут содержать активные и пассивные тома;
- в качестве кворумного механизма для автоматической обработки неполадок используется quorum witness.
-
-
Для построения конфигурации с высокой доступностью на массивах HPE XP7 нужна лицензия High Availability Software. Этот функционал базируется на поддержке двух синхронных активных копий, хранящихся физически на разных СХД, распределенных между двумя площадками. Любой том доступен для чтения и записи одновременно с двух массивов. Эта конфигурация поддерживается Microsoft Windows Server 2008/2012, Red Hat Enterprise Linux 5.x/6.x, IBM AIX 6.1/7.1, HP-UX 11iv2/11iv3, VMware vSphere 5.x/6.x, Oracle Solaris 10/11.1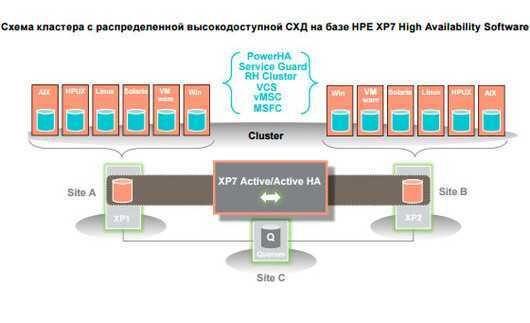
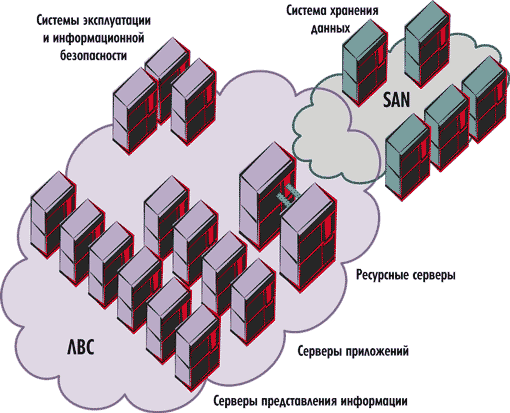
Массивы HPE StoreVirtual не требуют специальных дополнительных лицензий для построения высокодоступных конфигураций, поэтому они намного выгоднее. Но они предназначены для работы в iSCSI сетях хранения данных. Их можно использовать в следущих окружениях Microsoft Windows Server 2008/2012, VMware vSphere 5.x/6.x, Red Hat Enterprise Linux 6.x.
Россия на прицеле
Вы можете сказать: “Да ваши примеры все из США!”. И будете правы. Но, к сожалению, в России такие сценарии тоже возможны. Хорошо, что никто не взломал элементы критической инфраструктуры как в США, но зато компании регулярно теряют деньги из-за атак.
По данным открытой статистики, в 2022 году организации на территории РФ уже подверглись массированным DDoS-атакам. Осуществлялись крупные кражи баз данных. При этом основным мотивом выступала не финансовая выгода злоумышленника, а дестабилизация работы российских компаний — то есть хакеры часто не ставили даже цели монетизировать свои действия.
И ЦОДы, естественно, становятся одними из первых, кто должен держать удар.
Стандартизация в облаках
Сначала маленькое, но важное уточнение про внутренние и невидимые клиентам процессы облака.
Облачный провайдер обеспечивает приемлемую для клиентов стоимость услуг за счет максимально возможной унификации и стандартизации своей деятельности.
-
Провайдер закупает много оборудования, которое, по возможности, должно быть однотипным, позволяющим с минимальной перенастройкой заменить вышедший из строя узел новым.
-
Однотипность оборудования также позволяет и планировать его обслуживание, и иметь склад гарантированно подходящих запчастей (или даже подменных серверов). Это положительно влияет на время доступности облака.
-
Сервисы предоставляются с использованием множества копий одного и того же программного обеспечения, обслуживание которого осуществляется по единым процессам. Это позволяет существенно упрощать развитие сервиса и улучшать срок его предоставления клиентам.
-
В стандартах управления информационной безопасностью, таких как ISO 27001, Cloud security alliance или ГОСТ Р 57580.1-2017 есть требование о разработке стандартов документации и регламентировании деятельности. Это еще одна причина, заставляющая провайдеров делать экземпляры своих сервисов как можно более похожими друг на друга, а в идеале – идентичными.
При запуске новой услуги, провайдер доводит ее до блеска и до максимально возможной автоматизации. Это позволяет эффективно оказывать быструю поддержку с применением сравнительно небольшого количества персонала.
Обратной стороной этого подхода является то, что чем специфичнее услуга, чем меньше она представлена у конкретного провайдера, и чем сильнее она отличается от других копий подобной услуги — тем тяжелее (дольше и дороже) провайдеру ее оказывать.
Еще одним следствием унификации и централизации является то, что доступ ко всем служебным компонентам облака и автоматизация деятельности происходит из единых на все облако (или как минимум на существенную его часть) серверов управления. А управление облаком – это как раз то, что защищает провайдер в своей зоне ответственности.
Провайдер имеет возможность оказывать и нестандартные услуги с помощью создания частного облака. Частное облако – это облако, собранное на отдельном наборе оборудования (серверов, СХД, сетевого оборудования), и полностью отделенное от общего облака. Оно отдельно управляется и может отвечать каким-то иным, относительно стандартного облака, требованиям: как в части безопасности, так и в части применяемых ИТ-решений. Естественно, такое облако получается дороже, чем стандартное, а процесс его создания занимает некоторое время.
Теперь вернемся к сложным запросам, которые могут возникнуть у клиентов облака. Понятно, что чем сложнее запрос, тем труднее его предугадать. Поэтому я скорее опишу некоторые предсказуемые случаи и ситуации, возникающие из-за необходимости соблюдать несколько стандартов одновременно.
С теорией закончили, теперь практика
Настраивать реплику мы будем в нашей лабе. В лабораторных условиях мы эмулировали два ЦОДа (на самом деле, две рядом стоящие стойки, которые как будто стоят в разных зданиях). Стенд состоит из двух СХД Engine N2, которые соединены между собой оптическими кабелями. К обеим СХД подключен физический сервер с ОС Windows Server 2016 используя 10Gb Ethernet. Стенд довольно простой, но сути это не меняет.
Схематично он выглядит так:
Логически репликация организована следующим образом:
Теперь разберем функциональные возможности репликации, которые у нас есть сейчас.
Поддерживается два режима: асинхронный и синхронный. Логично, что синхронный режим ограничен расстоянием и каналом связи. В частности, для синхронного режима требуется использовать оптоволокно в качестве физики и 10 гигабитный Ethernet (или выше).
Поддерживаемое расстояние для синхронной репликации – 40 километров, значение задержек канала оптики между ЦОДами до 2 миллисекунд. Вообще работать будет и с большими задержками, но тогда будут сильные тормоза при записи (что тоже логично), поэтому если вы задумали синхронную репликацию между ЦОД-ами, следует проверить качество оптики и задержки.
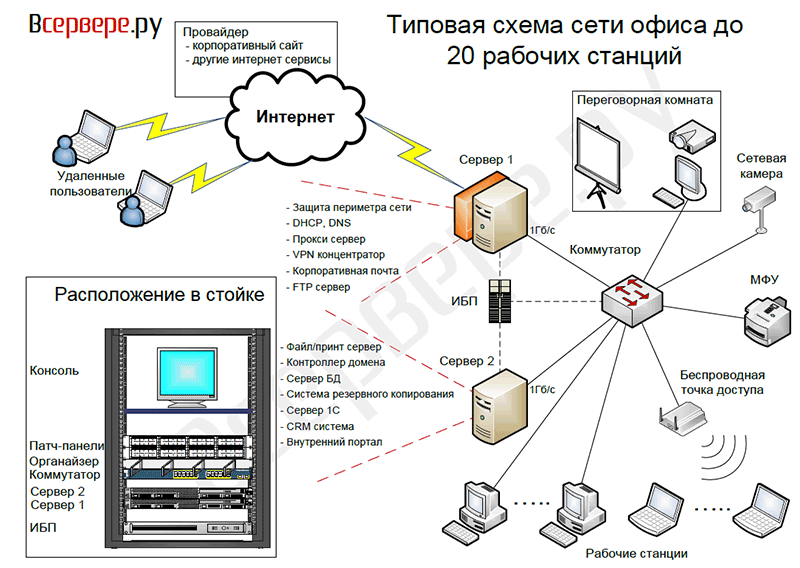
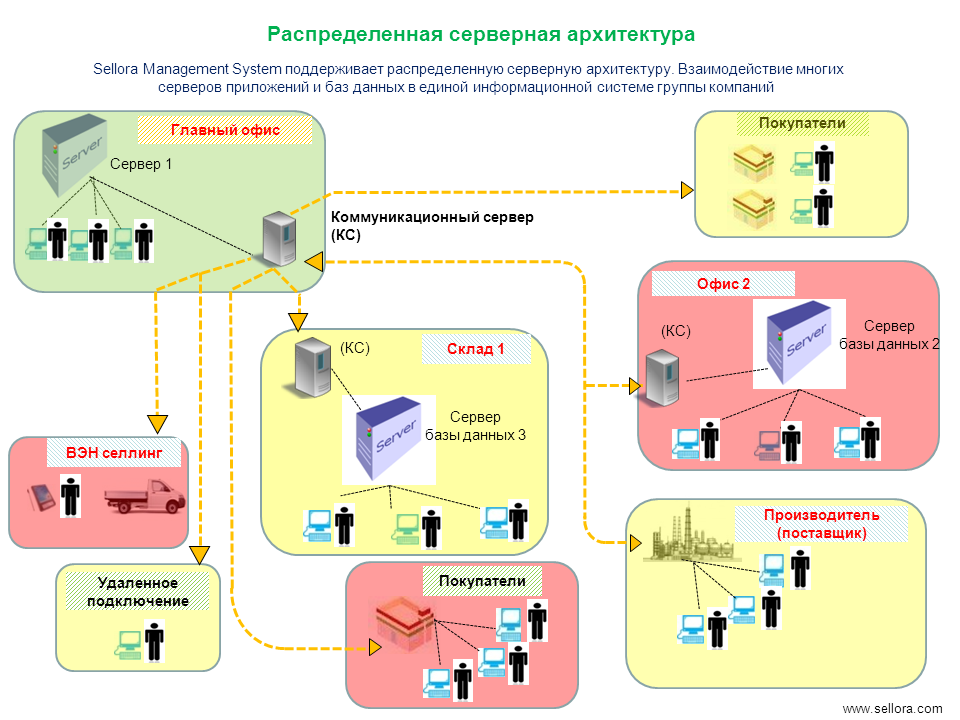
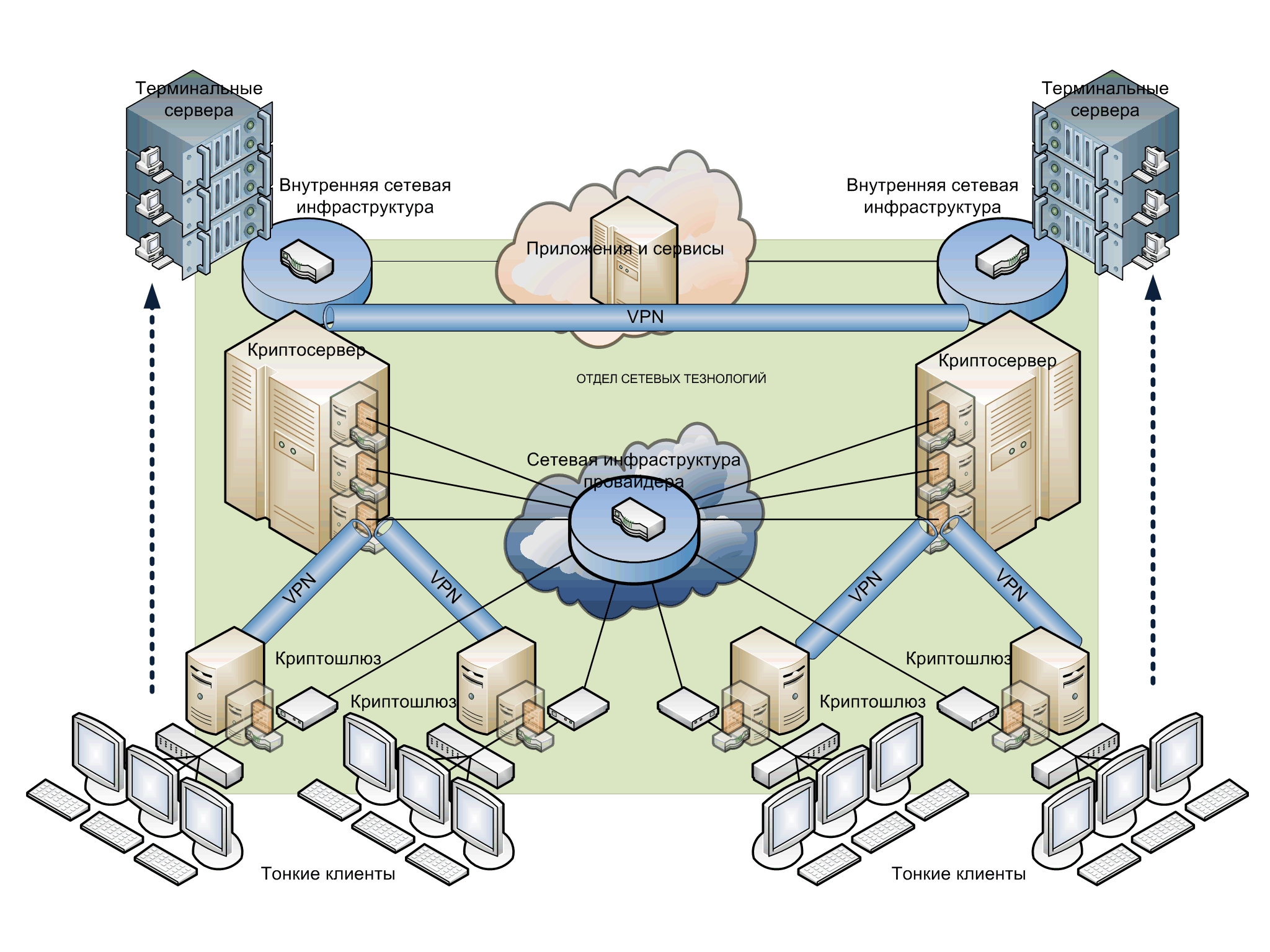
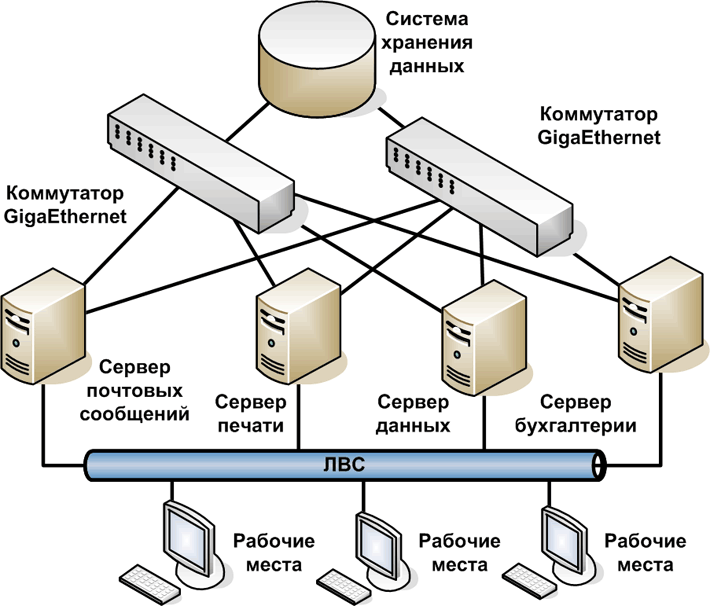

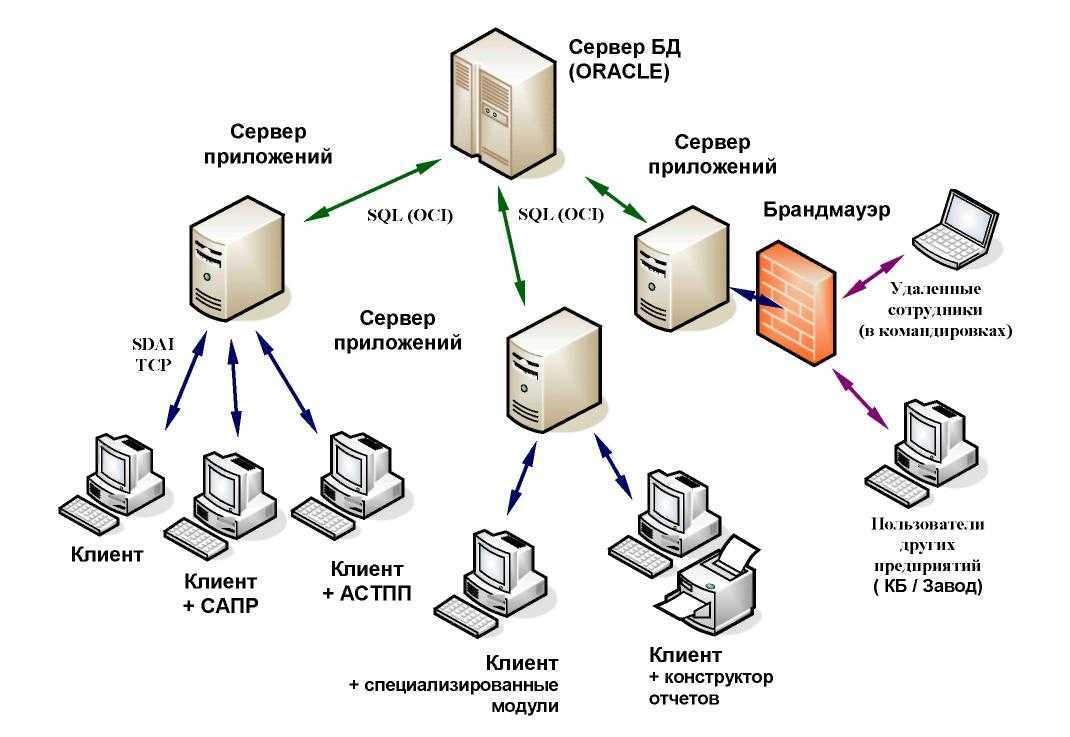
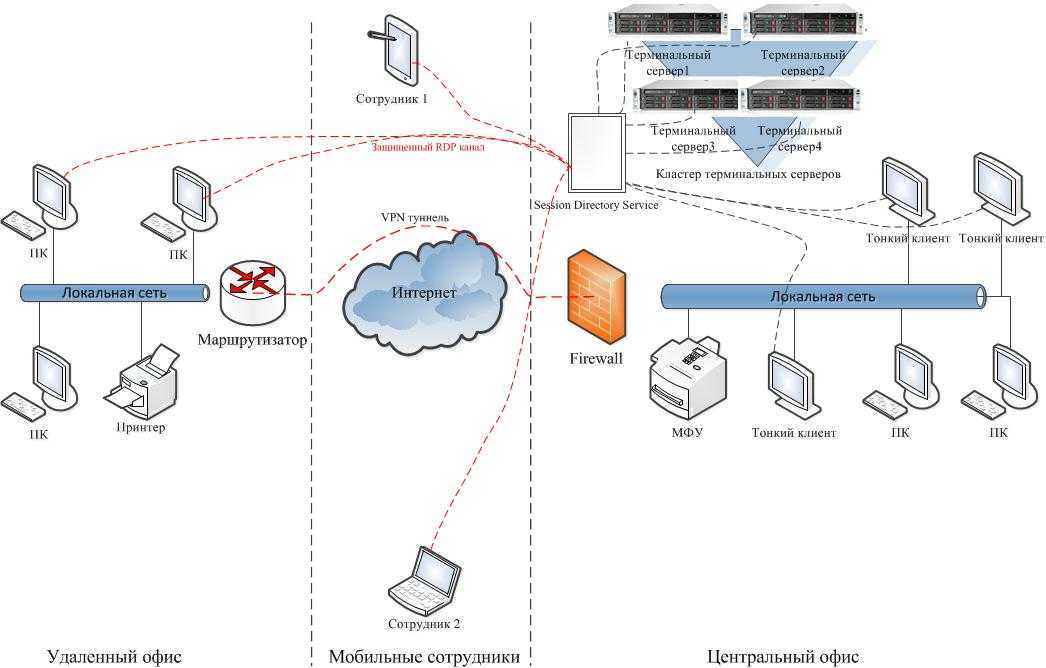
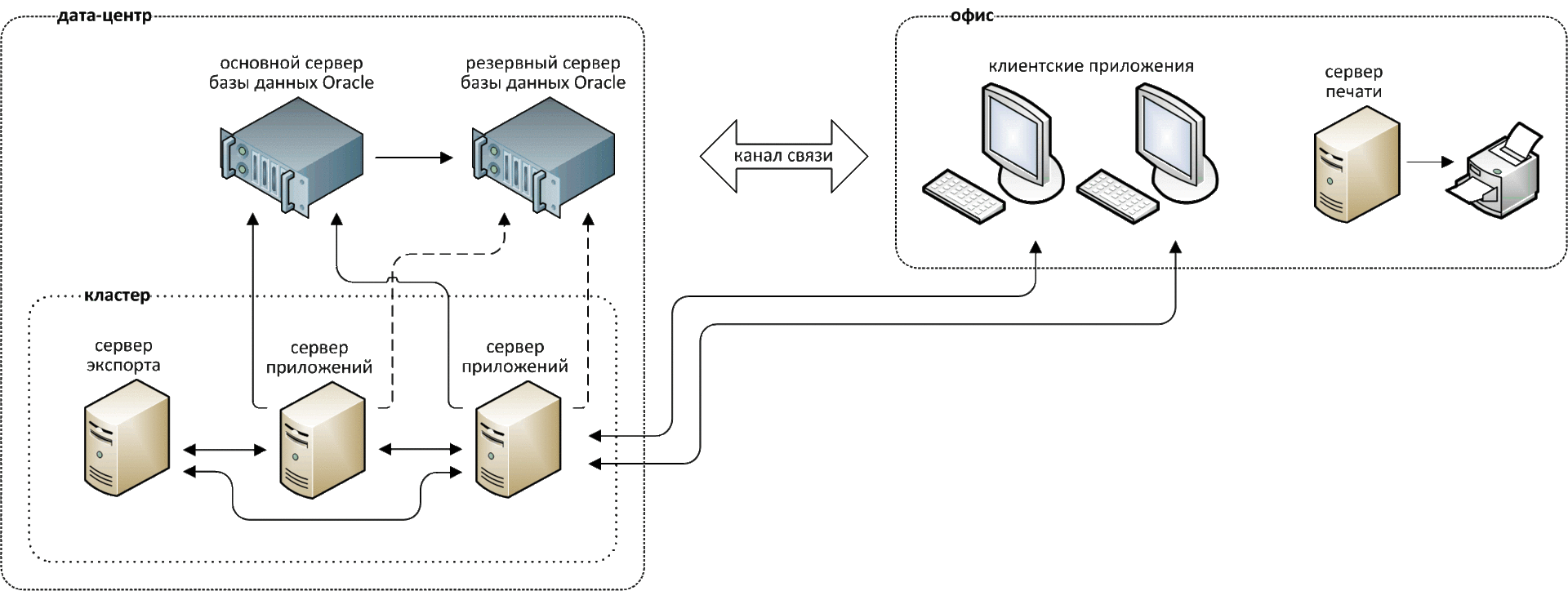
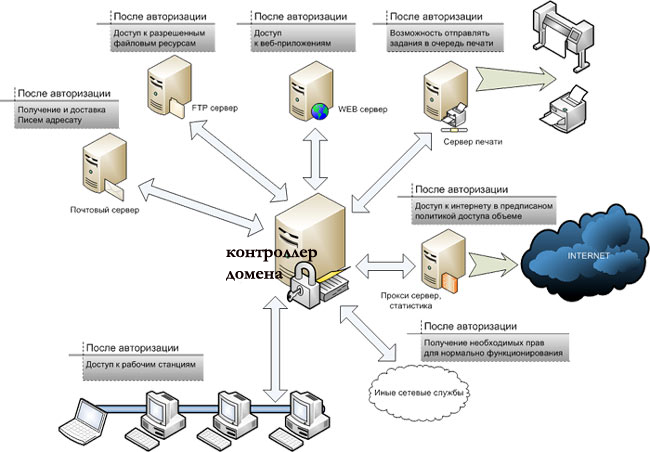
К асинхронной репликации требования не такие серьезные. Точнее, их нет совсем. Подойдет любое работающее соединение по Ethernet.
На текущий момент в СХД AERODISK ENGINE поддерживается репликация для блочных устройств (LUNов) по протоколу Ethernet (по меди или по оптике). Для проектов, где обязательно требуется репликация через SAN-фабрику по Fibre Channel, мы сейчас дописываем соответствующее решение, но пока оно не готово, поэтому в нашем случае – только Ethernet.
Репликация может работать между любыми СХД серии ENGINE (N1, N2, N4) с младших систем на старшие и наоборот.
Функционал обоих режимов репликации полностью идентичен. Ниже подробнее о том, что есть:
- Репликация «one to one» или «один к одному», то есть классический вариант с двумя ЦОД-ами, основным и резервным
- Репликация «one to many» или «один к многим», т.е. один LUN можно реплицировать на несколько СХД сразу
- Активация, деактивация и «разворот» репликации, соответственно, для включения, выключения или изменения направления репликации
- Репликация доступна как для пулов RDG (Raid Distributed Group), так и для DDP (Dynamic Disk Pool). При этом LUN пула RDG можно реплицировать только в другой RDG. C DDP аналогично.
Есть ещё множество мелких особенностей, но перечислять их нет особого смысла, их мы будем упоминать по ходу настройки.
Особенности построения отказоустойчивости
High Availability, или HA, как мы уже отметили, нацелена на избавление от отдельных точек отказа. Следовательно эта концепция подразумевает резервирование различных сведений и избыточность. Резервирование производится в области программного обеспечения, «железа» и окружения. Это требуется для того, чтобы бизнес-процессы не прерывались при выходе из строя отдельного компонента ИТ-системы.
Одним из первых способов для высокой доступности в вычислениях стали средства аппаратного резервирования. Именно их часто применяли внутри локальной сети, до использования облачных приложений. Однако только при помощи аппаратного резервирования решить проблему отказоустойчивости не удалось, поэтому дополнительно стали использоваться следующие решения:
- резервирование питания за счет подключения нескольких источников – помогло решить проблему отключения физических серверов в случае сбоя на одном из них;
- резервирование отдельных хранилищ с применением RAID – позволило устранить возможную потерю данных;
- резервирование сети при помощи подключения контроллеров – решило проблему отключения сервера от сети в случае сбоев;
- устранение ошибок системы для предотвращения повреждения файловой системы.
В дальнейшем была доработана и избыточность ПО. Многие разработчики стали учитывать этот фактор при разработке приложений, для того чтобы предотвратить ошибки в работе при аппаратных сбоях или проблемах конфигурации. Для обеспечения избыточности используются следующие средства:
- внедрение специальных технологий для масштабируемости системы;
- использование технологии кластеризации и распределение нагрузки по серверам;
- обеспечение доступности;
- мониторинг работы программ и приложений;
- использование систем, имеющих способность самовосстанавливаться.
Развитие облачных технологий подняло отказоустойчивость системы на новый уровень. Появилась концепция избыточности окружения, которая характеризуется аппаратной избыточностью в стойке. Ее цель – равномерное распределение нагрузок для устранения точек отказа.
Используемые меры позволяют решить основную проблему инфраструктуры – точки отказа. За счет этого провайдеры могут гарантировать клиентам доступность всех используемых сервисов. Доступность системы фиксируется в SLA, уровень отказоустойчивости обозначается в процентном соотношении. Он отражает время доступности системы и гарантирует максимальную длительность простоя в год. Например, при показателях 99,99% время простоя в течение календарного года не может превышать 52,6 минут.
Высокая доступность системы является результатом тщательного планирования. То есть, если какие-то факторы не будут учтены на стадии разработки инфраструктуры, то добиться полной отказоустойчивости будет практически невозможно. Обязательным является создание «сценария катастрофы», который помогает учесть последствия любых разрушительных событий и понять, как будет работать система в чрезвычайных ситуациях.