В чем разница между катастрофой и катастрофой?
Определение:
Катастрофа: Катастрофа — трагическое событие, варьирующееся от крайнего несчастья до полного свержения или разорения.
Катастрофа: Катастрофа — это внезапное событие, которое приносит большие потери и разрушения.
Использование:
Катастрофа: Термин катастрофа теперь используется для описания любого события с катастрофическим концом.
Катастрофа: Термин катастрофа используется чаще, чем катастрофа.
Строгость:
Катастрофа: Иногда термин «катастрофа» подразумевает событие, которое имеет более серьезные и продолжительные негативные последствия, чем катастрофа.
Катастрофа: Бедствие может иметь менее серьезные и разрушительные последствия, чем катастрофа.
Изображение предоставлено Pixabay
Что означает бедствие?
Бедствие — это внезапное событие, которое приносит большие потери и разрушения, то есть гибель людей и разрушение собственности. Железнодорожная авария, кораблекрушение, оползень и отказ предприятия — вот лишь некоторые примеры катастроф. В онлайн-словаре Merriam-Webster стихийное бедствие определяется как «внезапное катастрофическое событие, повлекшее за собой большой ущерб, убытки или разрушение», а в Оксфордском словаре — как «внезапная авария или стихийная катастрофа, которая вызывает большой ущерб или гибель людей». Однако Словарь синонимов Мерриам-Вебстера (1984) описывает катастрофу следующим образом:
«Катастрофа — это непредвиденное происшествие или несчастье… которое случается либо из-за виновного отсутствия предвидения, либо из-за неблагоприятных внешних факторов и несет с собой разрушение или разрушение».
Согласно «Выбери правильное слово: современное руководство по синонимам» (1968), катастрофу можно использовать для описания как личной, так и общественной утраты.
По сравнению с бедствием, бедствие означает относительно небольшую или менее серьезную потерю или разрушение. Следующие примеры предложений помогут вам лучше понять значение этого слова.
Государство назначило специальную комиссию для расследования обрушения этого здания и нескольких других инженерных катастроф.
Они запустили новую программу, чтобы люди знали о возможных стихийных бедствиях.
В этой катастрофе погибло около сотни человек.
У правительства был план аварийного восстановления.

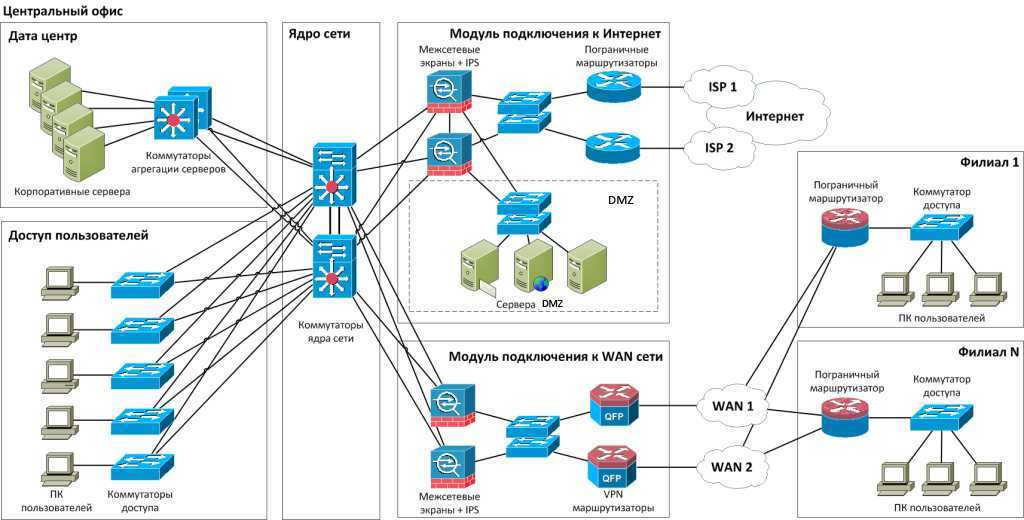
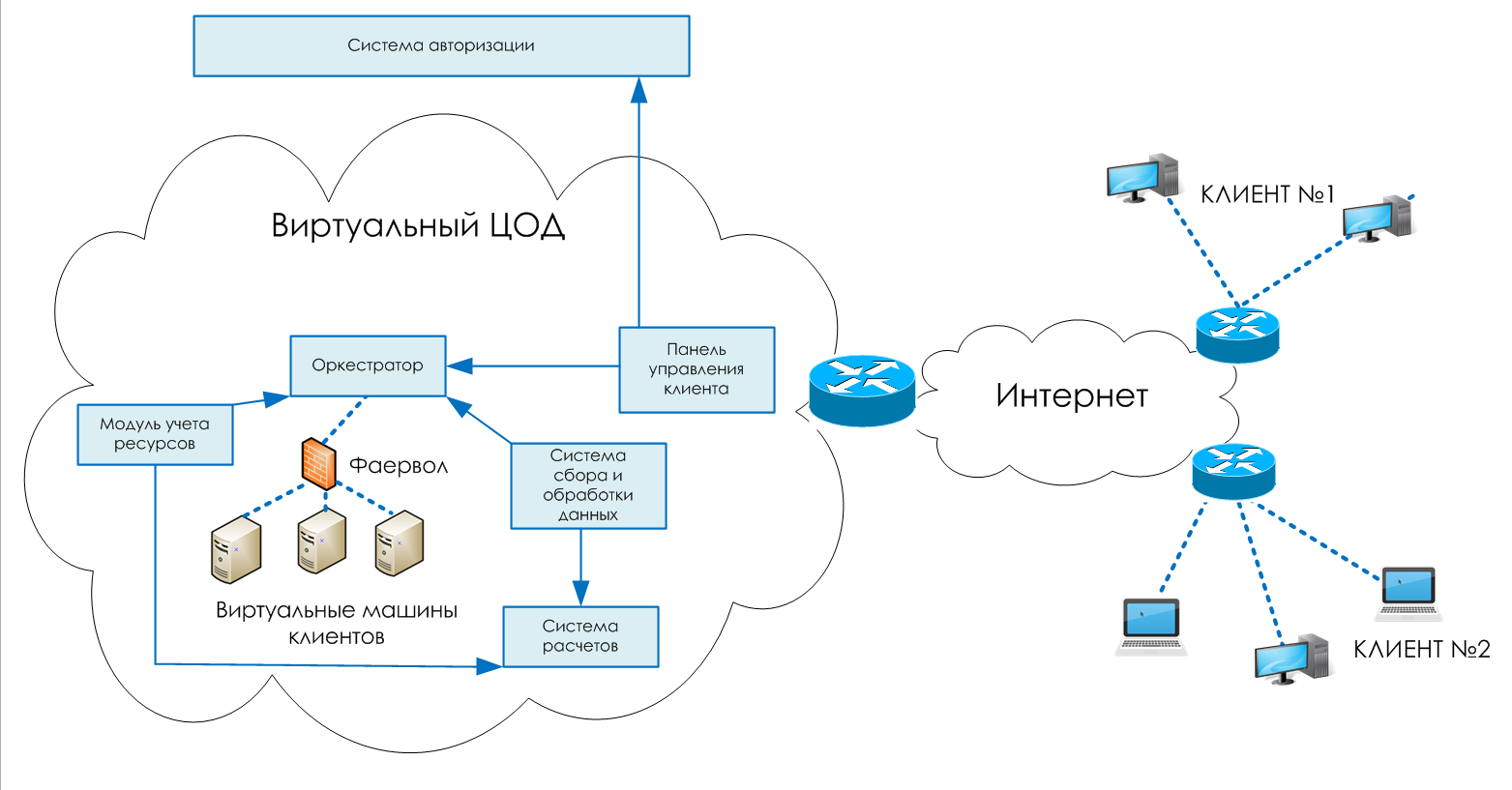
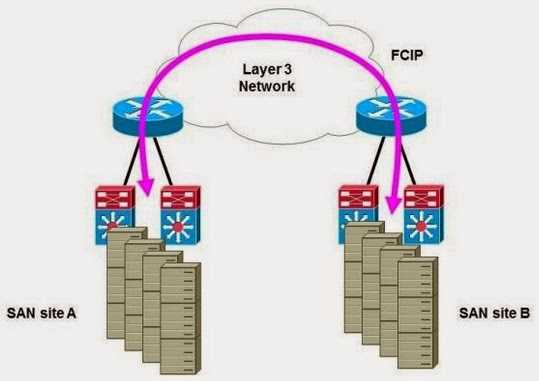
Развертывание failover-кластера
Процедуру установки кластера можно разделить на четыре этапа. На первом этапе необходимо сконфигурировать аппаратную часть, которая должна соответствовать The Microsoft Support Policy for Windows Server 2008 Failover Clusters. Все узлы кластера должны состоять из одинаковых или сходных компонентов. Все узлы кластера должны иметь доступ к хранилищу, созданному с использованием FibreChannel, iSCSI или Serial Attached SCSI. От хранилищ, работающих с Windows Server 2008, требуется поддержка persistent reservations.
На втором этапе на каждый узел требуется добавить компонент Failover Clustering — например, через Server Manager. Эту задачу можно выполнять с использованием учетной записи, обладающей административными правами на каждом узле. Серверы должны принадлежать к одному домену. Желательно, чтобы все узлы кластера были с одинаковой ролью, причем лучше использовать роль member server, так как роль domain controller чревата возможными проблемами с DNS и Exchange.
Третий не обязательный, но желательный этап заключается в проверке конфигурации. Проверка запускается через оснастку Failover Cluster Management. Если для проверки конфигурации указан только один узел, то часть проверок будет пропущена.
На четвертом этапе создается кластер. Для этого из Failover Cluster Management запускается мастер Create Cluster, в котором указываются серверы, включаемые в кластер, имя кластера и дополнительные настройки IP-адреса. Если серверы подключены к сетям, которые не будут использоваться для общения в рамках кластера (например, подключение только для обмена данными с хранилищем), то в свойствах этой сети в Failover Cluster Management необходимо установить параметр «Do not allow the cluster to use this network».
После этого можно приступить к настройке приложения, которое требуется сконфигурировать для обеспечения его высокой доступности.
Для этого необходимо запустить High Availability Wizard, который можно найти в Services and Applications оснастки Failover Cluster Management.
Гиперкуб
Стандартная ситуация для адаптивной архитектуры — превращение бывших фабрик, водонапорных башен и даже религиозных сооружений в жилые или общественные здания. Но более современный подход – не приспосабливать уже готовое здание, а заложить соответствующие решения в новые постройки ещё на этапе проектирования.
— При таком подходе анализируются модели развития здания и закладывается возможность для его трансформации в будущем, — отмечают специалисты. — Такой метод может применяться при создании самых разных объектов — от выставочных павильонов и стадионов до многоквартирных домов.
Адаптивная архитектура более мобильна, она реагирует на изменения численности населения города, экологические условия и даже погоду. Существуют особые биометаллы, которые трансформируются при нагреве или охлаждении.


Гиперкуб архитектора Бориса Бернаскони. Фото bernasconi.com
Одним из наиболее ярких примеров современной адаптивной архитектуры в России является «Гиперкуб» в «Сколково» построенный по проекту Бориса Бернаскони. В здании учтены принципы «4Э»: энергоэффективность, экологичность, эргономичность, экономичность. Куб может обеспечивать себя энергией и очищать воду, бетонный экзокаркас позволяет менять фасад, а внутреннее пространство легко трансформируется под новые задачи.
Вообще уровень адаптивности архитектуры определяется не только ее приспособлением к реалиям, но и способностью с наименьшими затратами менять функции при изменении внешних условий.
Адаптироваться во что бы то ни стало
— Адаптивная архитектура подразумевает проектирование конструкций и зданий, которые взаимодействуют с окружающей средой, подстраиваются под новые условия и при необходимости могут трансформироваться, — считают эксперты. — Основные фишки адаптивной архитектуры — гибкость, многофункциональность и способность обновляться.
Впервые сам термин «адаптивная архитектура» стал использовать в конце 1960-х годов американский информатик Николас Негропонте. Но идеи адаптивности возникли задолго до этого.
Так, в античных сооружениях для гладиаторских боев и иных ристалищ уже существовали трансформируемые конструкции, которые защищали от солнца и улучшали акустику. Средневековье отметилось подъёмными мостами замков.
Позже хрустальный дворец Всемирной выставки 1851 года в Лондоне сделали разборным и по окончании эвента разобрали и перенесли в другой район города. Много потрудились на этой ниве советские конструктивисты 1920-1930 годов — Татлин, Эль Лисицкий, Мельников. Работа последнего — здание газеты «Ленинградская правда» — оказала существенное влияние на современную архитектуру.

Проект Московского отделения здания газеты «Ленинградская правда». Архитектор Константин Мельников
С развитием архитектуры происходит адаптация жилых помещений под различные нужды при помощи перегородок, трансформируемых спальных мест. Эту тенденцию мы можем наблюдать в проектах Ле Корбюзье, Геррита Ритвельда. Последний спроектировал знаменитый дом Шредер в Голландии. Это единый объем, не замкнутый сам на себе, а органично взаимодействующий с окружающим миром. Архитектор отказался от традиционных стен. Второй этаж — пространство с трансформируемыми перегородками, которые при желании можно убрать. Это яркий пример адаптивной архитектуры, в соответствии с шестнадцатью пунктами «пластичной архитектуры» нидерландского художника, архитектора и философа Тео ван Дусбурга. Согласно им каждый отдельный элемент интерьера, будучи пространственной проекцией, должен быть открытым со всех точек «как кристалл, растворенный в универсальном пространстве».

«Дом без стен» архитектора Геррита Ритвельда. Фото magazindomov.ru
И если под это подогнана теория, то время катастроф может оказаться временем изящных решений – смесь нужды и художественного вкуса дают широкий простор для архитектурных решений в духе времени.
Извержение индонезийского супервулкана Тоба
 В массовой культуре сильно распиарен супервулкан Йеллоустоун, находящийся в США. Его название фигурирует чуть ли не в каждом топе самых опасных для человечества угроз. Однако он является только одним из многих вулканов, представляющих реальную опасность.
В массовой культуре сильно распиарен супервулкан Йеллоустоун, находящийся в США. Его название фигурирует чуть ли не в каждом топе самых опасных для человечества угроз. Однако он является только одним из многих вулканов, представляющих реальную опасность.
Супервулкан Тоба на индонезийском острове Суматра в последний раз извергался около 75 тысяч лет назад во время последней ледниковой эпохи, после чего на планете похолодало ещё сильнее. К слову, мощность того извержения была примерно в 20 раз выше мощности извержения вулкана Тамбора в 1815 году, из-за которого температура на планете снизилась настолько, что наступил Год без лета. По мнению учёных, извержение супервулкана Тоба 75 тысяч лет назад и последующее сильное похолодание могло сократить популяцию людей всего до десяти тысяч человек.
И он снова может начать извергаться, что, по разным оценкам, превышает угрозу извержения Йеллоустоуна. В этом случае могут пострадать не только более 50 миллионов человек, проживающих на густонаселённом острове Суматра, но и ещё десятки миллионов из-за катастрофических цунами, которые произойдут после начала извержения.
Этот вулкан попал в список потенциальных угроз из-за того, что ещё с 2015 года в районе, где он расположен, наблюдаются вулканические газы и нагрев земли, что является одним из показателей того, что гигант вскоре может проснуться.
Какой метод кластеризации выбирать?
Если сравнивать частоту использования K-means, иерархической кластеризации и DBSCAN, то на первом месте, бесспорно, будет K-means, а второе место будут делить иерархический подход и DBSCAN. Иерархическая кластеризация — более известный и простой в понимании метод, чем DBSCAN, но довольно редко отрабатывающий качественно. Частая проблема иерархической кластеризации — раннее образование одного гигантского кластера и ряда очень небольших, что приводит к сильной несбалансированности количества объектов в итоговых кластерах. В то же время DBSCAN — менее широко известный подход, но, когда его можно применить, качество, как правило, получается выше, чем в K-means или иерархической кластеризации.
Краш-тест
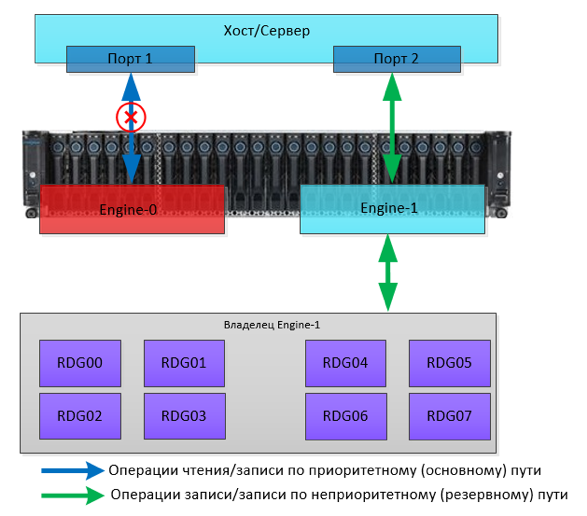
Краш-тест в нашем случае будет достаточно простой и быстрый, поскольку функционал репликации (переключение, консистентность и пр.) был рассмотрен в прошлой статье. Поэтому для испытания надежности именно метрокластера нам достаточно проверить автоматизацию обнаружения аварии, переключения и отсутствие потерь при записи (остановки ввода-вывода).
Для этого мы эмулируем полный отказ одной из СХД, физически выключив оба её контроллера, запустив предварительно копирование большого файла на LUN, который должен активироваться на другой СХД.
Отключаем одну СХД. На второй СХД видим алерты и сообщения в логах о том, что пропала связь с соседней системой. Если настроены оповещения по SMTP или SNMP мониторинг, то админу придут соответствующие оповещения.
Ровно через 10 секунд (видно на обоих скриншотах) репликационная связь METRO (та, что была Primary на упавшей СХД) автоматически стала Primary на работающей СХД. Задействовав существующий мапинг, LUN TEST остался доступен хосту, запись немного просела (в пределах обещанных 10 процентов), но не прервалась.
Тест завершен успешно.
Сценарий сбоя Ceph
начинается самое интересное
- Нормальная работа примерно до 70 секунды;
- Провал на минуту примерно до 130 секунды;
- Плато, которое заметно выше, чем работа в нормальном режиме — это работа кластеров degraded;
- Затем мы включаем отсутствующий узел — это учебный кластер, там всего 3 сервера и 15 SSD. Пускаем сервер в работу где-то в районе 260 секунды.
- Сервер включился, вошел в кластер — IOPS’ы упали.
Внутреннее поведение Ceph
первоначальная синхронизация данных
- OSD считывает имеющиеся версии, имеющуюся историю (pg_log — для определения текущих версий объектов).
- После чего определяет, на каких OSD лежат последние версии деградировавших объектов (missing_loc), а на каких отставшие.
- Там, где хранятся отставшие версии нужно провести синхронизацию, а новые версии могут быть использованы в качестве опорных для чтения и записи данных.
Для сравнения:
- чем больше объектов, тем больше история missing_loc;
- чем больше PG — тем больше pg_log и OSD map;
- чем больше размер дисков;
- чем выше плотность размещения (количество дисков в каждом сервере);
- чем выше нагрузка на кластер и чем быстрее ваш кластер;
- чем дольше OSD находится дауне (в состоянии Offline);
чем более крутой кластер мы построили, и чем дольше часть кластера не отвечала — тем больше оперативной памяти потребуется при старте
Почему важен план обеспечения непрерывности бизнеса?
Непрерывность бизнеса имеет решающее значение в то время, когда простои недопустимы. Время простоя может происходить из множества мест. Некоторые опасности, такие как кибератаки и экстремальные погодные условия, похоже, усугубляются
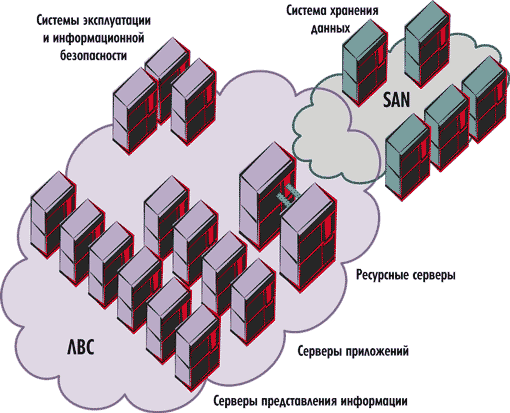



Крайне важно иметь план BC, учитывающий любые возможные сбои в работе
Во время кризисСтратегия должна позволять организации функционировать с минимальными затратами. Непрерывность бизнеса способствует устойчивости организации, позволяя ей быстро реагировать на сбои. Strong BC экономит деньги, время и репутацию компании. Длительное отключение представляет финансовую, личную и репутационную опасность.
Непрерывность бизнеса требует, чтобы бизнес смотрел на себя, анализировал потенциальные слабые места и собирал важную информацию, такую как списки контактов и технические схемы системы, которые могут быть полезны вне сценариев катастроф. Организация может укрепить свою связь, технологии и отказоустойчивость за счет внедрения планирования обеспечения непрерывности бизнеса.
Вам также может потребоваться план BC по юридическим или нормативным причинам
Крайне важно понимать, какие правила применяются к конкретной организации, особенно в эпоху растущего регулирования
Основные элементы плана обеспечения непрерывности бизнеса
Стратегия обеспечения непрерывности бизнеса состоит из трех основных компонентов: устойчивости, восстановления и непредвиденных обстоятельств.
№1. Устойчивость
Вы можете повысить устойчивость организации, разрабатывая жизненно важные службы и инфраструктуры с учетом нескольких аварийных сценариев, таких как ротация персонала, избыточность данных и поддержание избыточной емкости. Обеспечение устойчивости к различным непредвиденным обстоятельствам также может помочь компаниям в непрерывном предоставлении основных услуг на месте и за его пределами.
№ 2. Восстановление
Крайне важно быстро восстановиться после аварии, чтобы возобновить работу компании. Установка целевого времени восстановления для различных систем, сетей или приложений может помочь расставить приоритеты, какие части должны быть восстановлены в первую очередь
Другой тактика восстановления включают запасы ресурсов, соглашения с третьими сторонами о принятии на себя корпоративной деятельности и использование адаптированных помещений для критически важных функций.
№3. непредвиденные обстоятельства
План на случай непредвиденных обстоятельств включает в себя процедуры для ряда внешних событий, а также цепочку подчинения, которая распределяет обязанности внутри компании. Эти обязательства могут включать замену оборудования, аренду офисных помещений на случай чрезвычайной ситуации, оценку ущерба и привлечение сторонних поставщиков для оказания помощи.
Аварийное восстановление и непрерывность бизнеса
Планирование аварийного восстановления, как и планирование непрерывности бизнеса, определяет запланированную тактику организации для процессов после сбоя. План аварийного восстановления, с другой стороны, является просто подмножеством планирования обеспечения непрерывности бизнеса.
Планы аварийного восстановления в основном ориентированы на данные и сосредоточены на хранении данных в такой форме, которая обеспечивает более быстрый доступ к ним после аварии. Непрерывность бизнеса учитывает это, но также фокусируется на управлении рисками, надзоре и планировании, необходимых для того, чтобы бренд продолжал функционировать во время перерыва.
Windows Clustering
У Microsoft существуют решения для реализации каждого из трех типов кластеров. В состав Windows Server 2008 R2 входят две технологии: Network Load Balancing (NLB) Cluster и Failover Cluster. Существует отдельная редакция Windows Server 2008 HPC Edition для организации высокопроизводительных вычислительных сред. Эта редакция лицензируется только для запуска HPC-приложений, то есть на таком сервере нельзя запускать базы данных, web- или почтовые сервера.
NLB-кластер используется для фильтрации и распределения TCP/IPтрафика между узлами. Такой тип кластера предназначен для работы с сетевыми приложениями — например, IIS, VPN или межсетевым экраном.
Могут возникать сложности с приложениями, которые полага ются на сессионные данные, при перенаправлении клиента на другой узел, на котором этих данных нет. В NLB-кластер можно включать до тридцати двух узлов на x64-редакциях, и до шестнадцати — на x86.
Failoverclustering — это кластеризации с переходом по отказу, хотя довольно часто термин переводят как «отказоустойчивые кластеры».
Узлы кластера объединены программно и физически с помощью LAN- или WAN-сети, для multi-site кластера в Windows Server 2008 убрано требование к общей задержке 500 мс, и добавлена возможность гибко настраивать heartbeat. В случае сбоя или планового отключения сервера кластеризованные ресурсы переносятся на другой узел. В Enterprise edition в кластер можно объединять до шестнадцати узлов, при этом пятнадцать из них будут простаивать до тех пор, пока не произойдет сбой. Приложения без поддержки кластеров (cluster-unaware) не взаимодействуют со службами кластера и могут быть переключены на другой узел только в случае аппаратного сбоя.
Приложения с поддержкой кластеров (cluster-aware), разработанные с использованием ClusterAPI, могут быть защищены от программных и аппаратных сбоев.
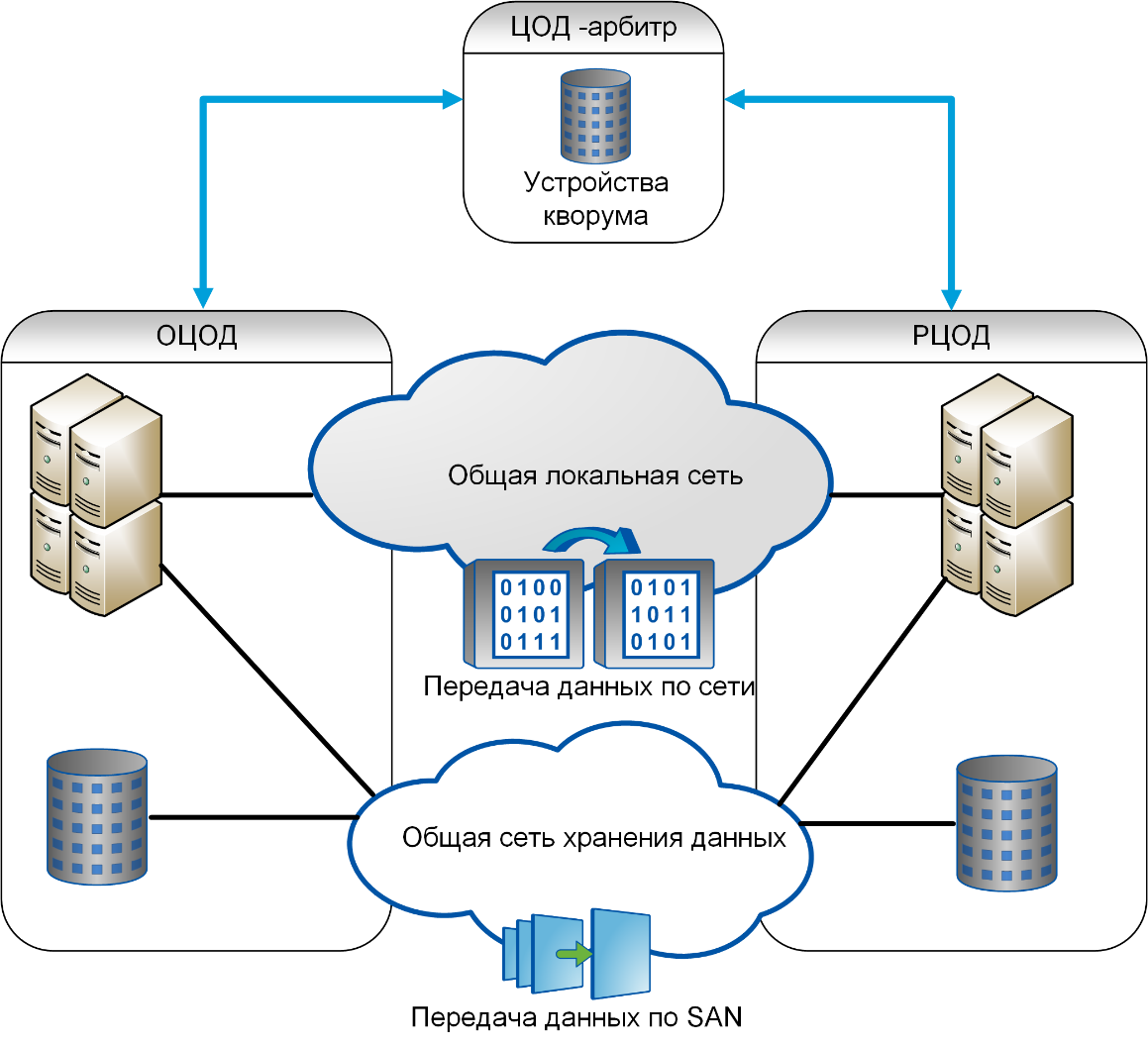
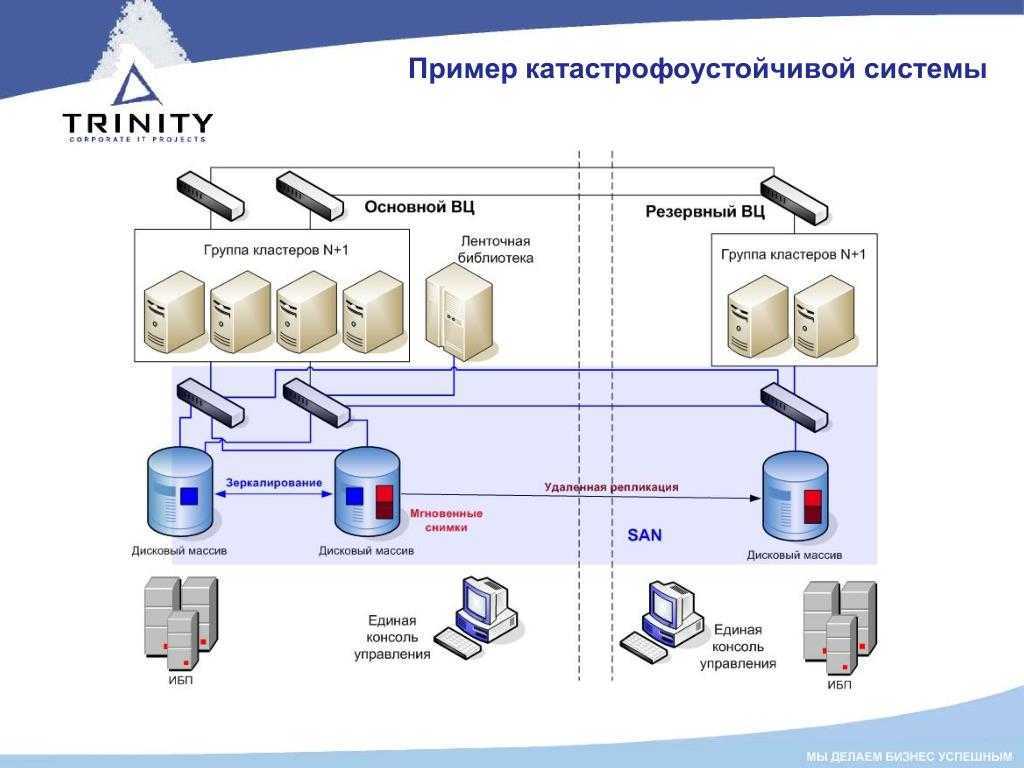
Технологии резервирования
Как вы понимаете, для обеспечения непрерывности всех процессов обязательным является наличие резервной площадки для размещения серверов
То есть при возникновении любого форс-мажора важно развернуть инфраструктуру на новых мощностях, поэтому наличие запасного «железа» на резервной площадке окажется очень кстати.. Может использоваться несколько типов резерва:
Может использоваться несколько типов резерва:
Холодный резерв. В этом случае потребуется наличие серверной с запасным оборудованием. Также может планироваться закупка дополнительного оборудования или хранение «железа» на складе. Основная трудность будет связана с быстрым запуском аппаратуры, особенно, в случае его закупки или аренды сразу после возникновения катастрофы. Процедура потребует времени, поэтому возможны простои в работе компании. Помимо склада с оборудованием, наиболее редкие серверы и ПК могут храниться на складах поставщиков. Восстановление инфраструктуры в таком случае может занять от нескольких дней до нескольких недель, однако такой вариант является самым дешевым.
Теплый резерв. Этот вариант подразумевает наличие запасной площадки, на которой имеется базовая вычислительная инфраструктура, а также настроена сеть и WAN-каналы. То есть подключено базовое оборудования, что позволит сразу можно перенаправить необходимые нагрузки. По вычислительным мощностям теплый резерв будут уступать основной площадке, но зато позволит запустить систему в течение одного дня. Такое решение можно назвать самым популярным, так как оно сочетает низкую стоимость и приемлемое время ввода в эксплуатацию.
Горячий резерв. Именно такой вариант обеспечивает наилучшую катастрофоустойчивость информационных систем. Предполагается, что у компании имеется резервная площадка, которая по производительности и мощности не уступает основной. Все данные инфраструктуры постоянно реплицируются и копируются, поэтому в запасном ЦОД хранятся актуальные копии данных. Площадка имеет готовую инфраструктуру с настроенными каналами и готова к мгновенному использованию
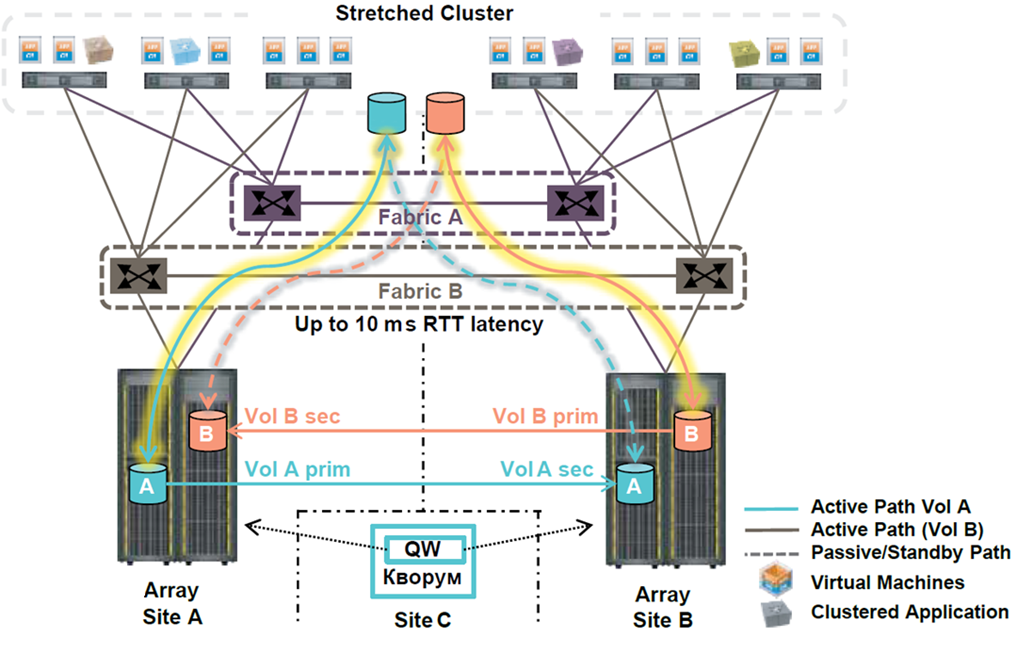

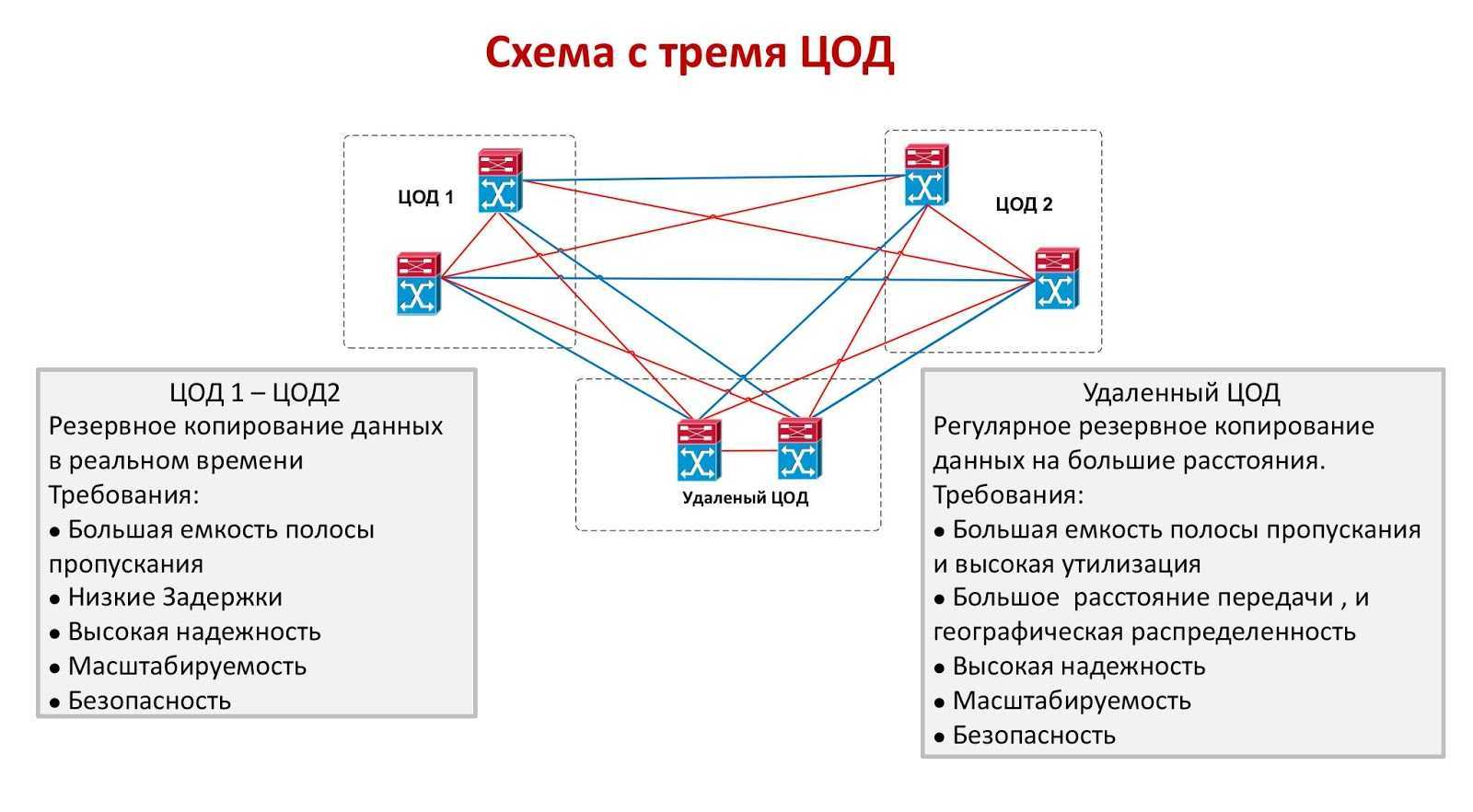
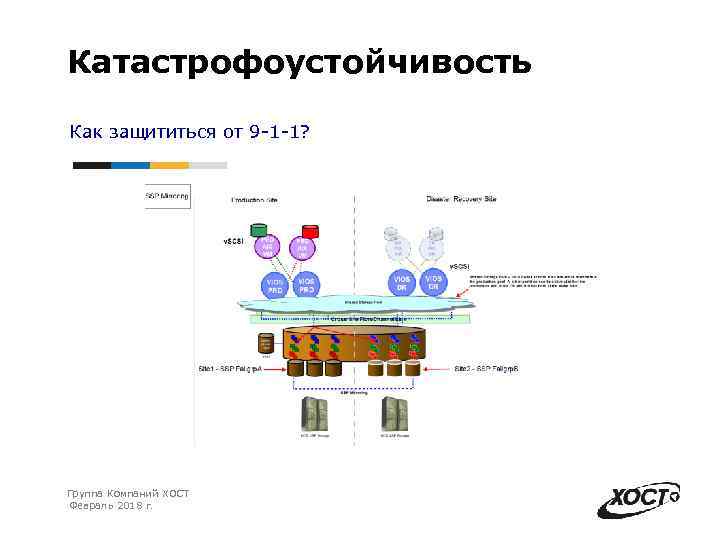
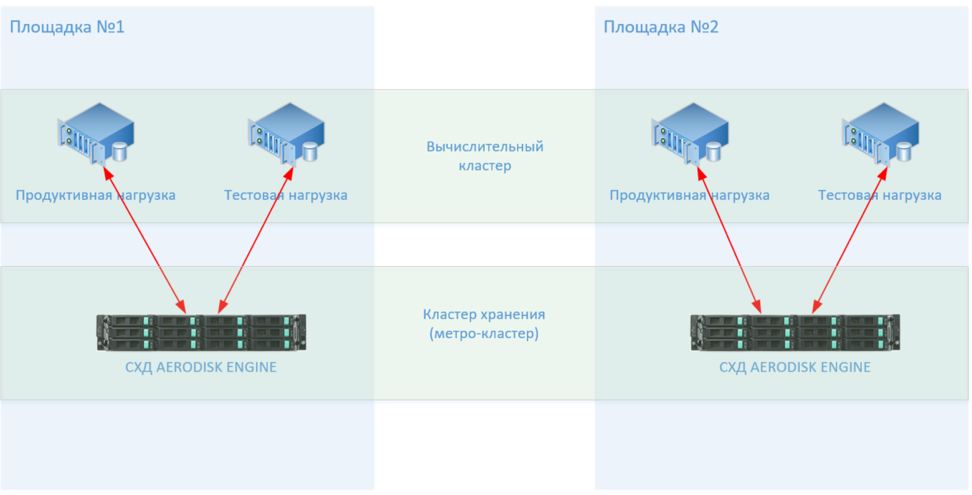
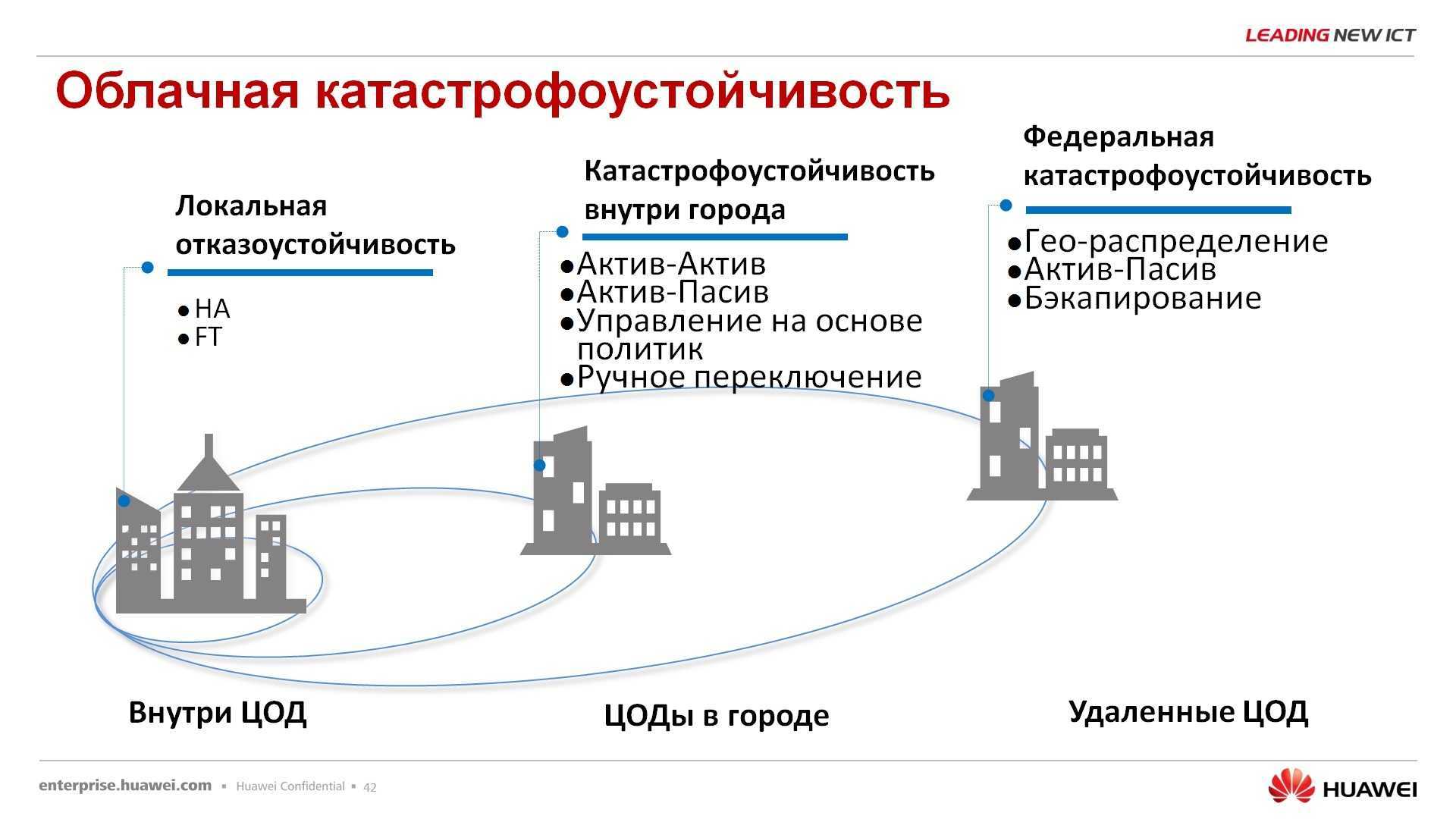
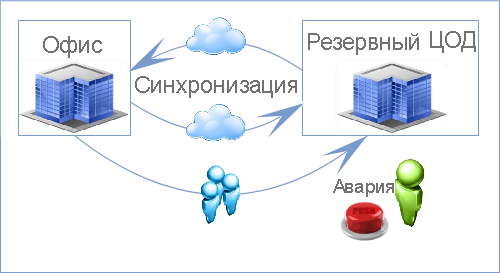
Этот вариант подойдет для крупных организаций, которым критически важно избежать даже минутных простоев бизнес-процессов. Минус подобного решения – простой оборудования
По сути, вам придется оплачивать сразу две площадки со всей инфраструктурой, из-за чего расходы могут значительно возрасти.
Не Ноев ковчег
Архитектура, устойчивая к погоде, пандемиям, антропогенному вреду вплоть до военно-политических кризисов может стать мейнстримом в ближайшие годы. В непростые времена люди психологически хотят чувствовать себя максимально защищенными. В этих условиях, а также по привычке, выработанной пандемией, социальные контакты снижаются, а дом становится новым видом ковчега, набитым уже сверхсовременными системами обороны и адаптации.
Будет ли такая парадигма спасением и не захочется ли человеку вернуться к простым радостям максимально эмоционального и человечного общения – вот вопрос.
Подготовил Даниил МАЦЕЙКО
(на фото вверху — пример устойчивой архитектры от бюро «Брусника»)