Как найти риски проекта и оценить их
Самый эффективный способ найти риски — мозговой штурм с командой проекта. Так каждый сможет предложить свои идеи. Лучше, если в мозговом штурме будут участвовать люди, занимающие разные роли в проекте, имеющие разный бэкграунд. Люди с разным опытом и набором навыков помогут найти риски, о которых руководитель не догадывается.
Некоторые члены команды участвовали в нескольких проектах внутри компании. Они поделятся информацией об опасностях, с которыми столкнулись коллеги. Новичок может рассказать об опыте команд, в которых он работал раньше.
Чтобы структурировать информацию, полученную во время мозгового штурма, используйте диаграмму Исикавы. Диаграмма, известная как «рыбьи кости», наглядно показывает причинно-следственные связи.
В «голову» рыбы помещают риск, который нужно проанализировать. На «костях» пишут причины, которые могут привести к негативному событию. К ним могут вести «кости» поменьше — причины второго порядка. Иногда добавляют третий, четвёртый и даже пятый уровни.
Вот диаграмма Исикавы, составленная для анализа проблемы — у компании низкие продажи.
Так выглядит диаграмма Исикавы с тремя уровнями факторов. Пока она не заполнена до концаИнфографика: Майя Мальгина для Skillbox Media
Например, есть риск, что поставщики вовремя не доставят товар. На диаграмму поместят следующие причины:
- нет инструментов отслеживания;
- государство может ввести ограничения;
- нет человека, который отвечает за доставку товара.
Может оказаться, что список рисков слишком большой. Это нормальный результат для такого анализа. Нужно будет выбрать самые важные риски, на которых сосредоточится команда.
Для оценки рисков используйте матрицу вероятности и последствий. С помощью неё вы поймёте, о каких рисках нужно помнить в первую очередь.
Инфографика: Майя Мальгина для Skillbox Media
Сначала проанализируйте, какие последствия могут быть, если риск превратится в проблему. Используйте шкалу:
- Сильный эффект — если проблема может сорвать проект или существенно его изменить.
- Средний — если событие может повлиять на проект, но это можно поправить.
- Слабый — если риск незначительно повлияет на проект, но точно его не сорвёт.
Потом оцените вероятность того, что риск возникнет:
- Высокий — высокая вероятность риска.
- Средний — риск есть.
- Низкий — скорее всего, риска нет.
Затем нужно собрать оценки вероятности и силы последствий на одной шкале и разбить риски на несколько групп.
- Если вероятность низкая, а последствия дадут слабый эффект, то об этом риске не стоит беспокоиться. Просто имейте в виду, что он есть.
- Если вероятность высокая и последствия дадут сильный эффект, о защите от этого риска нужно позаботиться в первую очередь.
Несколько незначительных рисков обычно меньше влияют на проект, чем один риск высокого уровня. Последние чаще приводят к тому, что проект срывается. Поэтому работайте сначала с проблемами высокого и среднего уровня.
Требования
Модель кластеризации должна содержать ключевой столбец и входные столбцы. Входные столбцы также можно определить как прогнозируемые. Столбцы, для которых задано значение Predict Only , для построения кластеров не используются. Их распределения в кластерах вычисляются после построения кластеров.
Входные и прогнозируемые столбцы
Алгоритм кластеризации Майкрософт поддерживает определенные входные столбцы и прогнозируемые столбцы, перечисленные в следующей таблице. Дополнительные сведения о том, что означают типы контента при использовании в модели интеллектуального анализа данных, см. в разделе «Типы контента (интеллектуальный анализ данных)».
| Столбец | Типы содержимого |
|---|---|
| Входной атрибут | Непрерывные, циклические, дискретные, дискретизированные, ключевые, табличные и упорядоченные |
| Прогнозируемый атрибут | Continuous, Cyclical, Discrete, Discretized, Table, Ordered |
Примечание
Типы содержимого Cyclical и Ordered поддерживаются, но алгоритм обрабатывает их как дискретные величины и не производит их особой обработки.
Лимиты ошибок
Концепция лимитов ошибок довольно подробно освещена в книге SRE, но и здесь следует ее упомянуть. SR-инженеры Google используют лимиты ошибок, чтобы сбалансировать надежность и темпы внедрения обновлений. Этот лимит определяет допустимый уровень отказа для сервиса в течение некоторого периода времени (обычно — месяц). Лимит ошибок — это просто 1 минус SLO сервиса, поэтому ранее обсуждавшаяся 99,99-процентно доступная служба имеет 0,01% «лимита» на ненадежность. До тех пор, пока сервис не израсходовал свой лимит ошибок в течение месяца, команда разработчиков свободна (в пределах разумного) запускать новые функции, обновления и т. д.
Если лимит ошибок израсходован, внесение изменений в сервис приостанавливается (за исключением срочных исправлений безопасности и изменений, направленных на то, что вызвало нарушение в первую очередь), пока служба не восполнит запас в лимите ошибок или пока не сменится месяц. Многие сервисы в Google используют метод скользящего окна для SLO, чтобы лимит ошибок восстанавливался постепенно. Для серьёзных сервисов с SLO более 99,99%, целесообразно применять ежеквартальное, а не ежемесячное обнуление лимита, поскольку количество допустимых простоев у них невелико.
Лимиты ошибок устраняют напряженность в отношениях между отделами, которая в противном случае могла бы возникнуть между SR-инженерами и разработчиками продукта, предоставляя им общий, основанный на данных механизм оценки риска запуска продукта. Они также дают и SR-инженерам, и командам разработки общую цель развития методов и технологий, которые позволят внедрять нововведения быстрее и запускать продукты без «раздувания бюджета».
Группа барьеров «Финансы»; Группа барьеров «Персонал»; Группа барьеров «Законодательство».
К группе барьеров «Финансы» относят барьеры, вызывающие излишние финансовые затраты на проведение изменений бизнес-процессов. К данным затратам относя расходы, которые предприятие понесет в текущем периоде, а также возможные инвестиции в новые технологии и средства.
К группе барьеров «Персонал» относятся барьеры, когда возникают силы сопротивления изменениям, которые обычно наблюдаются со стороны сотрудников. На преодоление этих сил также потребуются и финансовые ресурсы. В общем случае при их устранении могут возникнуть необратимые отрицательные последствия для предприятия — уход ценных сотрудников, снижение морально-психологического климата и как следствие снижение производительности труда и прочее.
К группе барьеров «Законодательство» относят барьеры, мешающие проведению изменений, которые возникают со стороны законодательства. Рассмотрение этих барьеров актуально в случае, если при оптимизации бизнес-процессов планируется перераспределение ответственности между сотрудниками организации или изменение принципов и схем мотивации, либо сокращение персонала.
Для конкретных предприятии в конкретных условиях могут быть и другие специфичные группы барьеров, мешающих проведению изменений. Эти группы также нужно идентифицировать, перечислить основные барьеры, входящие в их состав.
После определения основных барьеров по каждому выделенному бизнес-процессу нужно ранжировать величину каждого барьера по шкале от 1 до 5. После этого по каждому бизнес-процессу нужно рассчитать суммарную величину сил всех барьеров, которые могут помешать проведению изменений в нем (см. табл. 2.5). Суммарная величина всех барьеров может достигать величины нескольких десятков, поэтому необходимо провести нормирование, приведя к диапазону от 1 до 5 для всех бизнес-процессов. Полученное значение называется степенью возможности проведения изменений в бизнес-процессе.
Сдвигающая ИС (усиливающая).
Определенные группы западных фирм получают поддержку своей производственно-хозяйственной деятельности от использования ИТ, но полностью не зависят от них при достижении производственных целей. Разработка соответствующих приложений, безусловно, необходима, чтобы облегчить фирме достижение ее стратегических целей.
Это, как правило, быстрорастущие фирмы обрабатывающей промышленности
Информационные системы, используемые в производстве и учете, хотя и важны, но не играют жизненно важной роли для повышения эффективности. Тем не менее, быстрый рост номенклатуры продукции, мест размещения производства, численности персонала и т.п., внутренних и внешних установок фирм оказывает сильное влияние на их операции, на управленческий контроль и процессы разработки новых продуктов
Новые приложения ИС были направлены на то, чтобы облегчить выявление и внедрение новых продуктов, модернизировать и интегрировать операции и перестроить управленческий контроль.
Другие фирмы включаются в эту же категорию из-за систематических «недовложений» средств в разработку ИТ, до того момента или периода, пока существующие системы безнадежно не устареют. Такие фирмы продолжают использовать технику, которую продавец уже перестает продавать.
Проекты разработки приложений, связанные с перестройкой систем нужно рассматривать как вопрос приоритетов в компании. Отсутствие равновесия в системных операциях приводит к дисбалансу управления, но не угрожает жизнеспособности предприятия.
Во многих фирмах по различным причинам ИС не несут полной нагрузки, но и остановка системы на короткое время не нанесет сильного урона такой организации. Примером такой организации может служить ЦЕРН (Европейский центр ядерных исследований, CERN – фр.). Фактически, ЦЕРН является совокупностью большого числа различных проектов, объединенных единой управленческой системой. Общая организация построена на принципе распределенных технологий и общего электронного документооборота.
Резервирование на уровне узлов сервера
Резервирование достаточно широко применяется уже на нижнем уровне – самого устройства, то есть — в самих серверах. Многие их узлы дублируются, либо имеют такую возможность. Например, современные серверы предоставляют следующие возможности по резервированию:
Оперативная память
Серверы имеют особый режим работы памяти: Memory Mirroring или Mirrored memory protection. В этом режиме осуществляется зеркалирование каналов, то есть каналы разбиваются на пары, и в каждой паре один из каналов становится копией другого. Все банки памяти при этом должны быть сконфигурированы идентично.
Работа в этом режиме защищает от однобитовых ошибок или выхода из строя всего модуля памяти.
При работе в режиме зеркалирования памяти одни и те же данные записываются в банки системной и зеркалированной памяти, но считываются только из банков системной памяти. Если в каком-то из модулей системной памяти произошла многобитовая ошибка (или превышено допустимое количество однобитовых ошибок), то происходит переназначение банков: банки зеркалированной памяти назначаются системной памятью, а банки системной — зеркалированной. Это обеспечивает бесперебойную работу сервера за исключением случаев, когда ошибка происходит в одном и том же месте в системном и зеркалированном модулях памяти одновременно (вероятность этого крайне мала).
Недостатком такой организации является двукратное уменьшение объёма оперативной памяти. Или, иными словами, двукратное увеличение ее стоимости.
Диски
Аналогично оперативной памяти можно организовать зеркалирование дисков. Для этого каждому диску назначается дубликат, который содержит его полную копию благодаря тому, что информация одновременно записывается на диск и дублирующую его копию. В простейшем случае такая система состоит из двух одинаковых дисков.

![Сетевая инфраструктура предприятия,её защита [курсовая №72746]](https://robotrackkursk.ru/wp-content/uploads/a/c/d/acd64339106a2b0798f699044f1b7447.jpeg)
Однако, как и в случае с зеркалированием оперативной памяти, недостатком такой организации является высокая (фактически – двойная) стоимость ресурсов. Поэтому часто используются другие варианты организации дисков в единые массивы (RAID, см. статью из Wikipedia). Существует достаточно много вариантов организации RAID-массивов, которые имеют различные параметры стоимости, скорости работы и степени отказоустойчивости.
Питание
Серверы среднего и старшего уровня имеют по два блока питания. В случае выхода из строя одного из них, сервер продолжает работать от второго. Иногда серверы оснащаются тремя и более блоками питания. В этом случае один из них остаётся резервным (так называемая схема N+1), либо БП дублируются (схема N+N). В последнем случае их число должно быть чётным.
Интерфейсы (платы расширения)
И снова самое простое, что можно сделать для обеспечения отказоустойчивости – это дублирование интерфейсных плат. Однако так как
a) современная инфраструктура имеет большое разнообразие интерфейсов разных стандартов (Ethernet, FC, Infiniband, и т.д.) и физических носителей («оптоволокно» или «медь»),
b) отказ интерфейсной платы не ведет к потере информации (он только нарушает процесс её передачи),
резервирование интерфейсных плат не входит в набор стандартных средств, которые по умолчанию предоставляются производителем оборудования. Здесь решение о резервировании остаётся на усмотрение пользователя.
Таким образом, отказоустойчивость сервера может быть повышена путем резервирования некоторых его узлов, как только что было описано. Но есть компоненты, которые задублировать невозможно. К ним относятся, в частности, RAID-контроллер и материнская плата. Выход из строя RAID-контроллера может привести к частичной или полной потере данных, а выход из строя материнской платы приведет к остановке всего сервера. Как защититься от таких неисправностей и обеспечить безотказную работу?
Практическое применение
Давайте рассмотрим пример сервиса с целевой надежностью в 99,99% и проработаем требования как к его компонентам, так и к работе с его сбоями.
Цифры
Предположим, что ваш 99,99-процентно доступный сервис имеет следующие характеристики:
Одно крупное отключение и три незначительных отключения в год
Это звучит пугающе, но обратите внимание, что целевой уровень надежности в 99,99% подразумевает один 20-30-минутный масштабный простой и несколько коротких частичных отключений в год. (Математика указывает, что: а) отказ одного сегмента не считается отказом всей системы с точки зрения SLO и б) общая надежность вычисляется суммой надежности сегментов.)
Пять критических компонентов в виде других независимых сервисов с надежностью 99,999%.
Пять независимых сегментов, которые не могут отказать друг за другом.
Все изменения проводятся постепенно, по одному сегменту за раз.
Математический расчет надежности будет выглядеть следующим образом:
Требования к компонентам
- Суммарный лимит ошибок за год составляет 0,01 процента от 525 600 минут в год, или 53 минуты (на основе 365-дневного года, при наихудшем сценарии).
- Лимит, выделяемый на отключения критических компонентов, составляет пять независимых критических компонентов с лимитом 0,001% каждый = 0,005%; 0,005% от 525 600 минут в год, или 26 минут.
- Оставшийся лимит ошибок вашего сервиса составляет 53-26=27 минут.
Требования к реагированию на отключения
- Ожидаемое количество простоев: 4 (1 полное отключение и 3 отключения, затрагивающие только один сегмент)
- Совокупное воздействие ожидаемых отключений: (1×100%) + (3×20%) = 1.6
- Время обнаружения сбоя и восстановления после него: 27/1.6 = 17 минут
- Время, выделенное мониторингу на обнаружение сбоя и оповещение о нем: 2 минуты
- Время, данное дежурному специалисту чтобы начать анализировать оповещение: 5 минут. (Система мониторинга должна отслеживать нарушения SLO и посылать сигнал на пейджер дежурному каждый раз, когда в системе происходит сбой. Многие сервисы Google находятся на поддержке посменных дежурных SR-инженеров, которые реагируют на срочные вопросы.)
- Оставшееся время для эффективной минимизации отрицательных последствий: 10 минут
Так что же за удивительный инструмент создал этот удивительный топ менеджер?
Научное определение Ключевых Факторов Успеха гласит: КФУ – это ограниченное число областей деятельности, достижение положительных результатов в которых гарантирует успех в конкурентной борьбе компании, подразделению или человеку
То есть это те области, или факторы, на которых следует фокусировать внимание, чтобы добиться успеха
«Ключевые Факторы Успеха – это те немногие области, в которых все должно обязательно идти без сбоев, чтобы гарантировать успех менеджеру или компании
Следовательно, это те сферы управленческой деятельности или работы компании, которым следует уделять особое и постоянное внимание, добиваясь в них максимальных результатов. КФУ – это не только сферы, жизненно важные для нынешнего процветания компании, но и для ее будущих успехов», — считают Боенлон и Змуд, авторы статьи «Исследование Ключевых Факторов Успеха»
Они также обращают внимание на то, что есть разница между факторами успеха компании, то есть тем, что может способствовать процветанию компании в будущем, и КФУ, ограниченным числом факторов, требующих постоянного внимания руководителей.
Раз уж мы заговорили о том, что с чем не следует путать, давайте отделим Ключевые Факторы Успеха (CSF) от Ключевых Показателей Эффективности (KPI). КПЭ являются единицами измерения успеха, а КФУ – это то, что способствует успеху. Например:
- КПЭ – количество новых клиентов компании должно быть не менее 10 в неделю.
- КФУ – создание нового колл-центра, предоставляющего услуги клиентам на более высоком уровне, за счет чего, собственно, и будут достигнуты показатели КПЭ.
Уточнение «Правила дополнительных девяток» для вложенных компонентов
Случайный читатель может сделать вывод, что каждое дополнительное звено в цепочке зависимостей требует дополнительных девяток, так что для зависимостей второго порядка требуется две дополнительные девятки, для зависимостей третьего порядка — три дополнительные девятки и т. д.
Это неверный вывод. Он основан на наивной модели иерархии компонентов в виде дерева с постоянным разветвлением на каждом уровне. В такой модели, как показано на рис. 1, имеется 10 уникальных компонентов первого порядка, 100 уникальных компонентов второго порядка, 1 000 уникальных компонентов третьего порядка и т. д., что приводит к созданию в общей сложности 1 111 уникальных сервисов, даже если архитектура ограничена четырьмя слоями. Экосистема высоконадежных сервисов с таким количеством независимых критических компонентов явно нереалистична.
Рис. 1 — Иерархия компонентов: Неверная модель
Критический компонент сам по себе может вызвать сбой всего сервиса (или сегмента сервиса) независимо от того, где он находится в дереве зависимостей. Поэтому, если данный компонент X отображается как зависимость нескольких компонентов первого порядка, X следует считать только один раз, так как его сбой в конечном итоге приведет к сбою службы независимо от того, сколько промежуточных сервисов будут также затронуты.
Корректное прочтение правила выглядит следующим образом:
- Если сервис имеет N уникальных критических компонентов, то каждый из них вносит 1/N в ненадежность всего сервиса, вызванную этим компонентом, невзирая на то, как низко он расположен в иерархии компонентов.
- Каждый компонент должен учитываться только один раз, даже если он несколько раз появляется в иерархии компонентов (другими словами, учитываются только уникальные компоненты). Например, при подсчете компонентов Сервиса А на рис. 2, Сервис Б следует учитывать только раз.
Рис. 2 — Компоненты в иерархии
Например, рассмотрим гипотетический сервис A с лимитом ошибок 0,01 процента. Владельцы сервиса готовы потратить половину этого лимита на собственные ошибки и потери, а половину — на критические компоненты. Если сервис имеет N таких компонентов, то каждый из них получает 1/N оставшегося лимита ошибок. Типичные сервисы часто имеют от 5 до 10 критических компонентов, и поэтому каждый из них может отказать только в одной десятой или одной двадцатой степени от лимита ошибок Сервиса A. Следовательно, как правило, критические части сервиса должны иметь одну дополнительную девятку надежности.
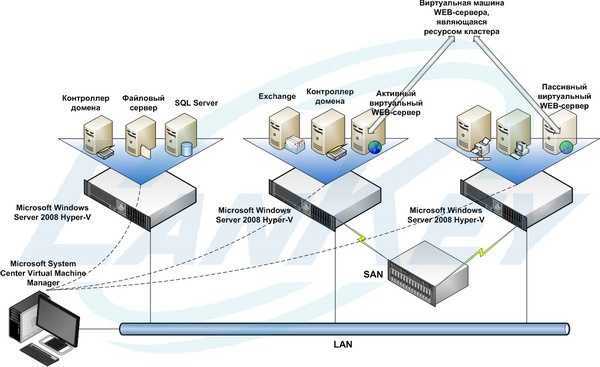
Возможности Win2k3
Вообще говоря, одни кластеры предназначены для повышения доступности данных,
другие — для обеспечения максимальной производительности. В контексте статьи нас
будут интересовать MPP (Massive Parallel Processing) — кластеры, в
которых однотипные приложения выполняются на нескольких компьютерах, обеспечивая
масштабируемость сервисов. Существует несколько технологий, позволяющих
распределять нагрузку между несколькими серверами: перенаправление трафика,трансляция адресов, DNS Round Robin, использование специальных
программ, работающих на прикладном уровне, вроде веб-акселераторов. В
Win2k3, в отличие от Win2k, поддержка кластеризации заложена изначально и
поддерживается два типа кластеров, отличающихся приложениями и спецификой
данных:
1. Кластеры NLB (Network Load Balancing) — обеспечивают
масштабируемость и высокую доступность служб и приложений на базе протоколов TCP
и UDP, объединяя в один кластер до 32 серверов с одинаковым набором данных, на
которых выполняются одни и те же приложения. Каждый запрос выполняется как
отдельная транзакция. Применяются для работы с наборами редко изменяющихся
данных, вроде WWW, ISA, службами терминалов и другими подобными сервисами.
2. Кластеры серверов – могут объединять до восьми узлов, их главная
задача — обеспечение доступности приложений при сбое. Состоят из активных и
пассивных узлов. Пассивный узел большую часть времени простаивает, играя роль
резерва основного узла. Для отдельных приложений есть возможность настроить
несколько активных серверов, распределяя нагрузку между ними. Оба узла
подключены к единому хранилищу данных. Кластер серверов используется для работы
с большими объемами часто изменяющихся данных (почтовые, файловые и
SQL-серверы). Причем такой кластер не может состоять из узлов, работающих под
управлением различных вариантов Win2k3: Enterprise или Datacenter (версии Web и
Standart кластеры серверов не поддерживают).
В Microsoft Application Center 2000 (и только) имелся еще один вид
кластера — CLB (Component Load Balancing), предоставляющий возможность
распределения приложений COM+ между несколькими серверами.
NLB-кластеры
При использовании балансировки нагрузки на каждом из хостов создается
виртуальный сетевой адаптер со своим независимым от реального IP и МАС-адресом.
Этот виртуальный интерфейс представляет кластер как единый узел, клиенты
обращаются к нему именно по виртуальному адресу. Все запросы получаются каждым
узлом кластера, но обрабатываются только одним. На всех узлах запускается
служба балансировки сетевой нагрузки (Network Load Balancing Service),
которая, используя специальный алгоритм, не требующий обмена данными между
узлами, принимает решение, нужно ли тому или иному узлу обрабатывать запрос или
нет. Узлы обмениваются heartbeat-сообщениями, показывающими их
доступность. Если хост прекращает выдачу heartbeat или появляется новый узел,
остальные узлы начинают процесс схождения (convergence), заново
перераспределяя нагрузку. Балансировка может быть реализована в одном из двух
режимов:
1) unicast – одноадресная рассылка, когда вместо физического МАС
используется МАС виртуального адаптера кластера. В этом случае узлы кластера не
могут обмениваться между собой данными, используя МАС-адреса, только через IP
(или второй адаптер, не связанный с кластером);
2) multicast – многоадресная рассылка, МАС-адрес кластера назначается
физическому адресу, но не затирая его. Для реализации этого метода
маршрутизаторы должны поддерживать групповые МАС-адреса.
В пределах одного кластера следует использовать только один из этих режимов.
Можно настроить несколько NLB-кластеров на одном сетевом адаптере,
указав конкретные правила для портов. Такие кластеры называют виртуальными. Их
применение дает возможность задать для каждого приложения, узла или IP-адреса
конкретные компьютеры в составе первичного кластера, или блокировать трафик для
некоторого приложения, не затрагивая трафик для других программ, выполняющихся
на этом узле. Или, наоборот, NLB-компонент может быть привязан к нескольким
сетевым адаптерам, что позволит настроить ряд независимых кластеров на каждом
узле. Также следует знать, что настройка кластеров серверов и NLB на одном узле
невозможна, поскольку они по-разному работают с сетевыми устройствами.
![Ключевые факторы успеха (группа барьеров «финансы»; группа барьеров «персонал»; группа барьеров «законодательство».) [реферат №2540]](https://robotrackkursk.ru/wp-content/uploads/2/5/9/259e53994b9d7862fc9391937fe2459e.png)
Администратор может сделать некую гибридную конфигурацию, обладающую
достоинствами обоих методов, например, создав NLB-кластер и настроив репликацию
данных между узлами. Но репликация выполняется не постоянно, а время от времени,
поэтому информация на разных узлах некоторое время будет отличаться.
С теорией на этом закончим, хотя о построении кластеров можно рассказывать
еще долго, перечисляя возможности и пути наращивания, давая различные
рекомендации и варианты конкретной реализации. Все эти тонкости и нюансы оставим
для самостоятельного изучения и перейдем к практической части.
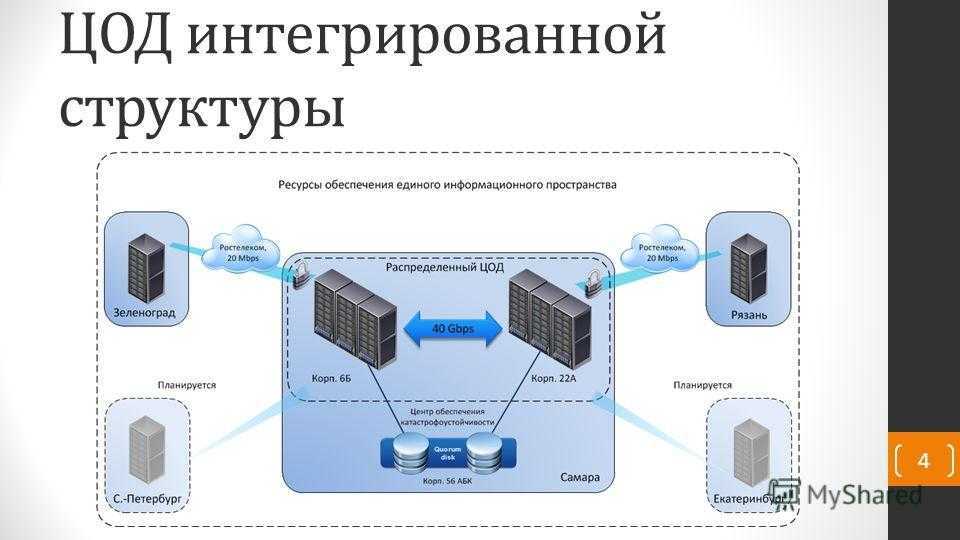
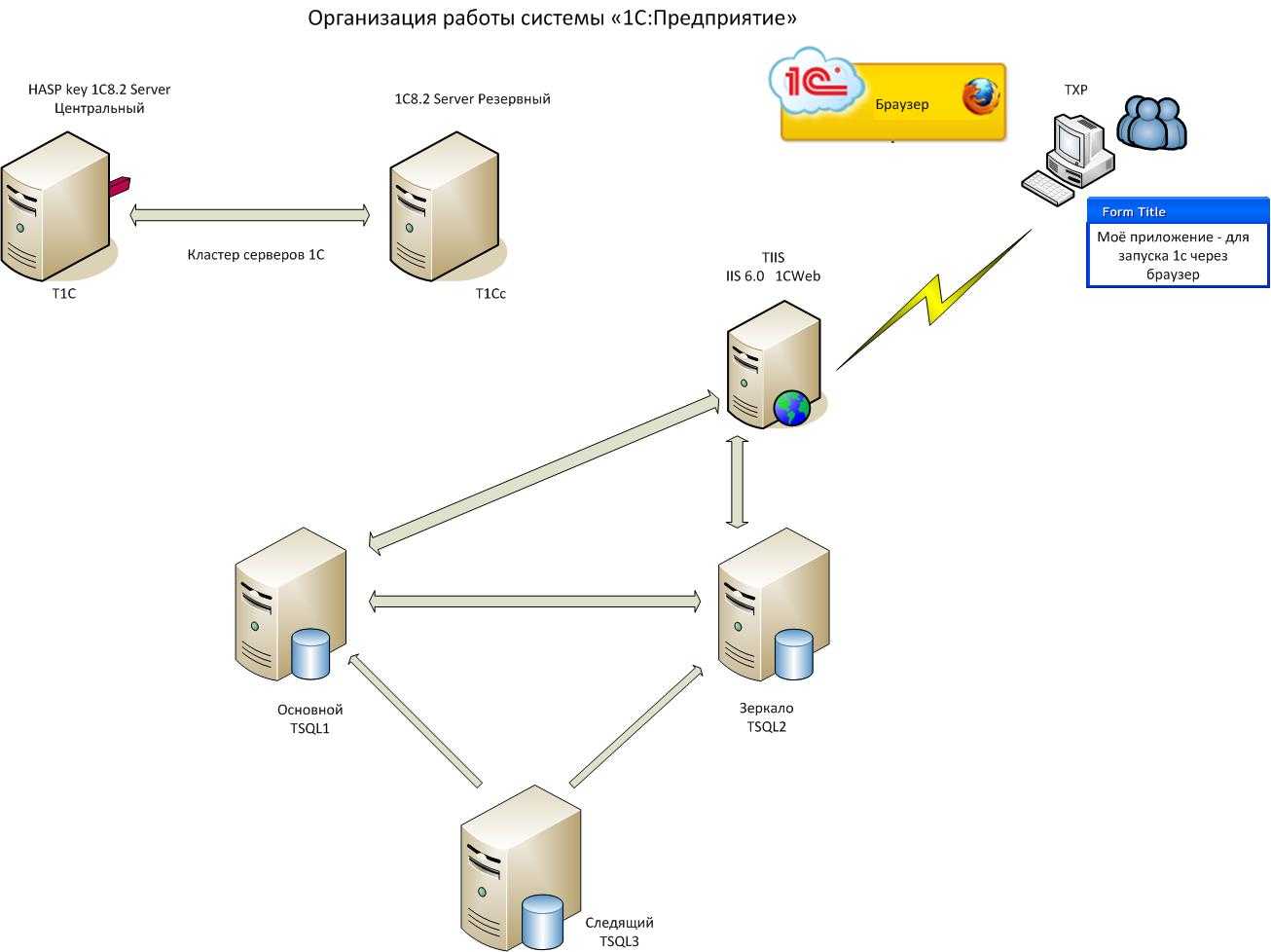
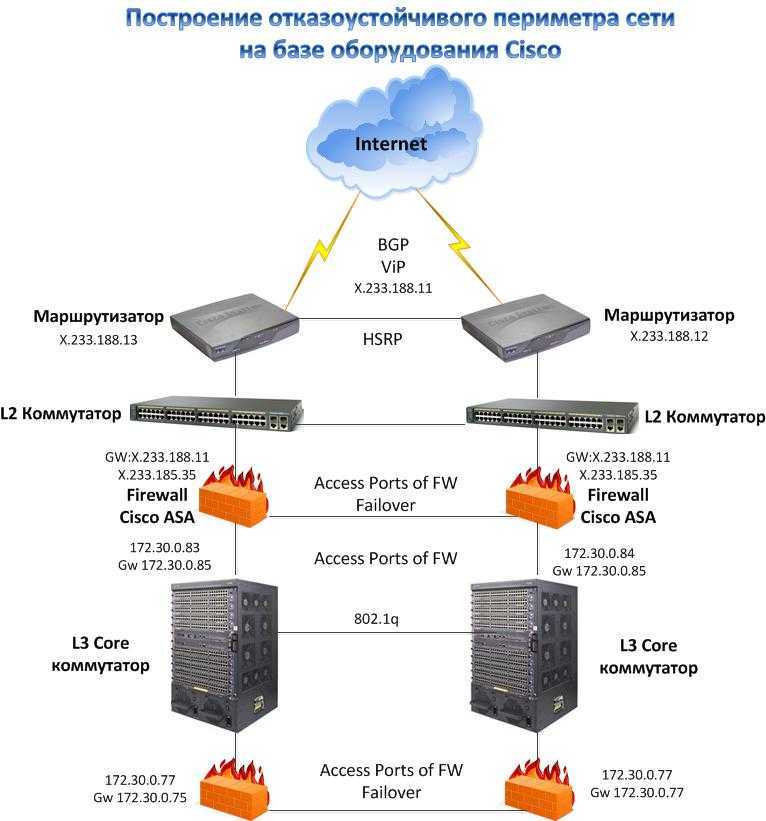
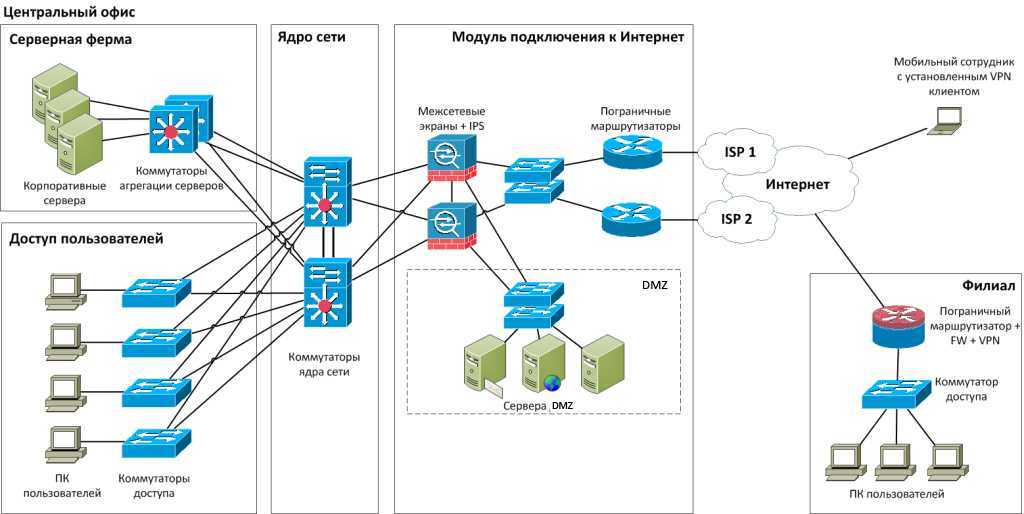
Вопросы, которые решает ИТ-инфраструктура
Сегодня от ИТ-инфраструктуры зависит многое: насколько ваш бизнес будет успешен, какой он будет приносить доход, как продуктивно будет работать ваша организация. Поэтому данная система должна быть надёжна, стабильна и конечно же безопасна. Можно сказать, это самый важный актив организации.
При проектировании IT-структуры предприятия следует помнить, что она должна соответствовать конкретной компании её спросам. Компьютерная сеть обязана быть правильно организована. Нужно следить за обновлениями программ и вовремя поправлять все неисправности. Не забывайте, что компьютерная сеть помогает вашему предприятию получать прибыль.
Чем бы ни занималась компания, основными задачами в работе с потоком клиентов являются:
- Быстрое решение всех возникающих проблем, анализ рисков, бесперебойное функционирование всех бизнес-процессов.
- Стандартизация всех процессов, увеличение производства продукции и наращивание торговли.
- Обязательное сохранение максимального показателя безопасности и обеспечение безопасности материалов.
- Способность быстро информировать обо всех новшествах в работе.
- Комфортность управления.
- Уменьшение расходов на разработку и эксплуатацию фондов.
Принципы создания ИТ-инфраструктуры предприятия
Есть много направлений разработки IT-инфраструктуры предприятия, среди которых выделяются максимально перспективные: создание IT с нуля, усовершенствование уже имеющейся инфраструктуры, преобразование инфраструктуры под определенные бизнес-процессы (продвижение новых услуг для заказчиков, улучшение качества обслуживания).
Для создания оптимальной, оперативной инфраструктуры требуется привлечь к работе грамотных специалистов, а для этого требуются серьезные материальные затраты.
Чаще всего разработку проекта, его продвижение, подбор всего компьютерного оборудования, программного обеспечения, разработку исполнительной документации доверяют компании, которая специализируется именно на этом. Хорошо, если она же сможет заняться и ИТ-аутсорингом.
Для бесперебойной работы системы необходимо детально изучить организационную структуру и техническую документацию предприятия, дающую подробную информацию о функциональном предназначении и возможности дальнейшего роста о действующих бизнес-процессах.
Эта информация пригодится для формирования необходимого резерва, функционального его использования и при необходимости возможность проводить проверку.
Одна из наиболее распространенных ошибок — желание сэкономить на затратах и создать максимально простую ИТ-инфраструктуру. Часто бывает так, что на предприятии начинают внедрять ERP систему, и после становится, очевидно, что ИТ-инфраструктура к этому абсолютно не готова.
Распространенной ошибкой может быть и эксперимент по сотрудничеству с различными серверными бизнес-приложениями для всего предприятия, при этом отказываясь от разработки структуры стабилизационного фонда.
ТОП-30 IT-профессий 2022 года с доходом от 200 000 ₽
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности
и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились
с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:
Александр Сагун
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2022
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 16880
Когда всё сделано правильно продвижение бизнес-процессов будет проходить без проблем. Если всё же происходит какой-либо сбой в работе системы, это легко можно решить с помощью копирования или соединить системы в единый сектор.
Для того чтобы привести к общему знаменателю ошибки и повреждённые данные, нужно сформировать механизм резервного копирования и реабилитации.
Принципы создания ИТ-инфраструктуры предприятия
В период планирования обязательно должны учитываться опция ввода новых пользователей и воплощение функционального развития бизнес-процессов в небольшой период времени.
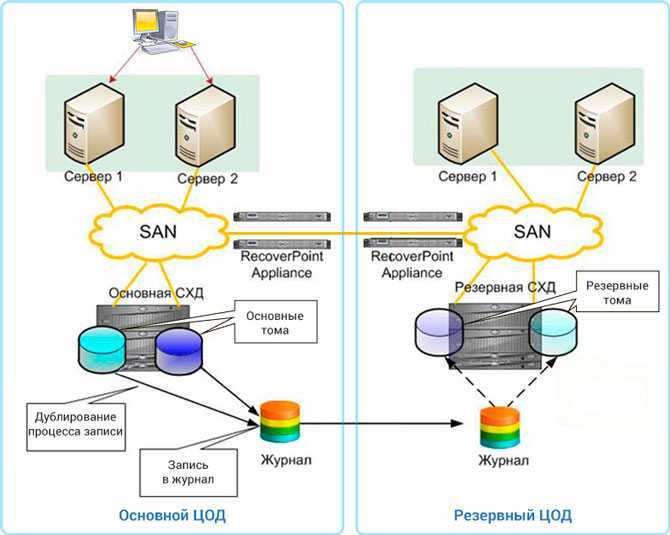
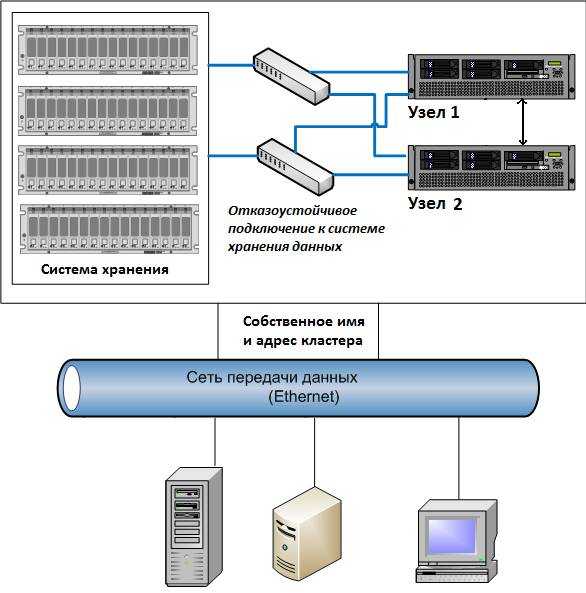
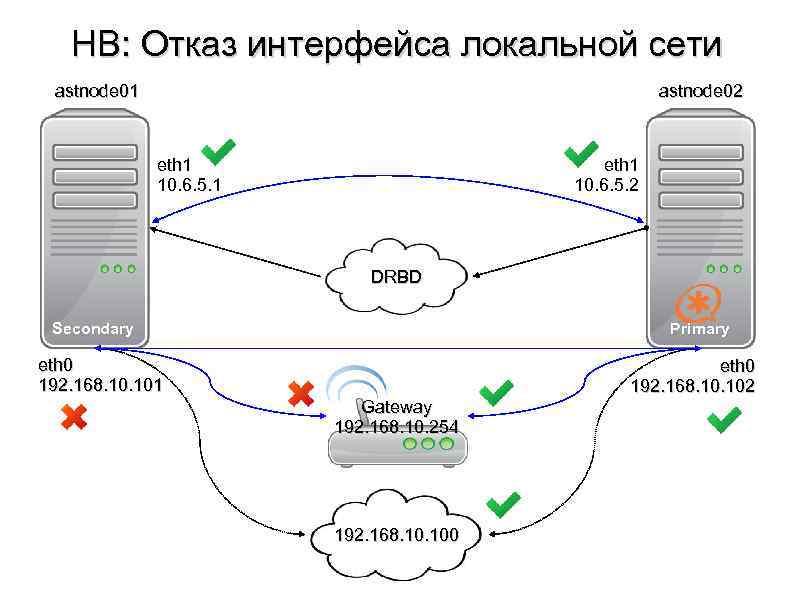
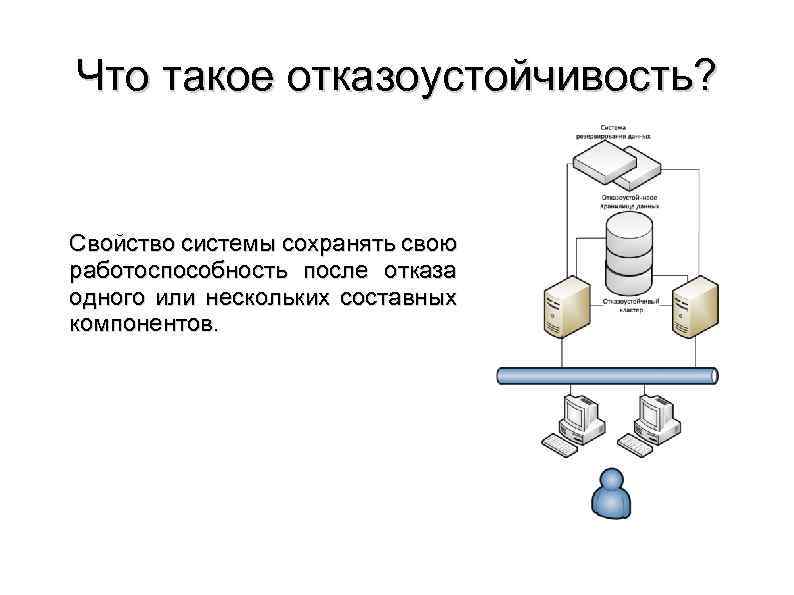
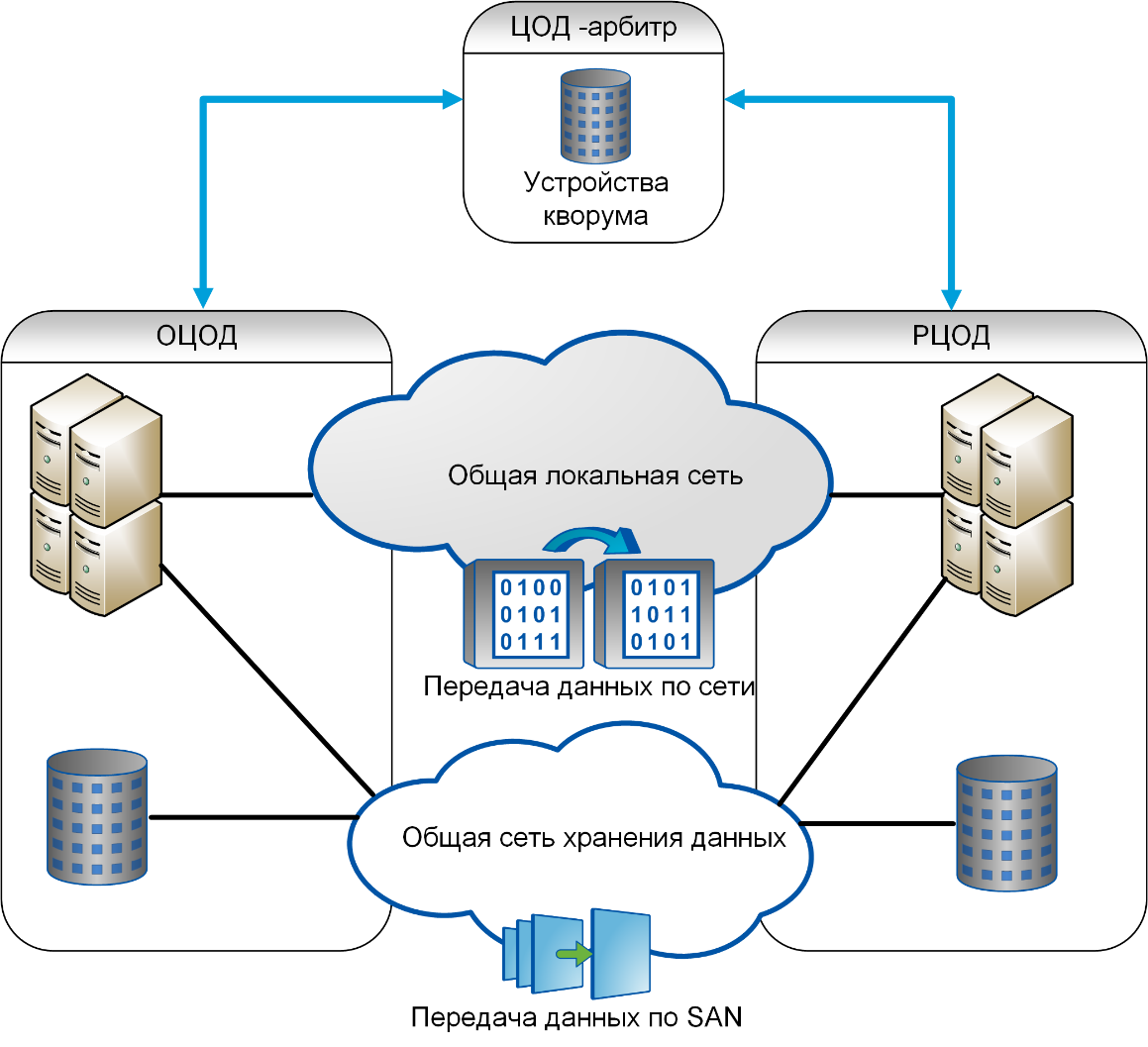
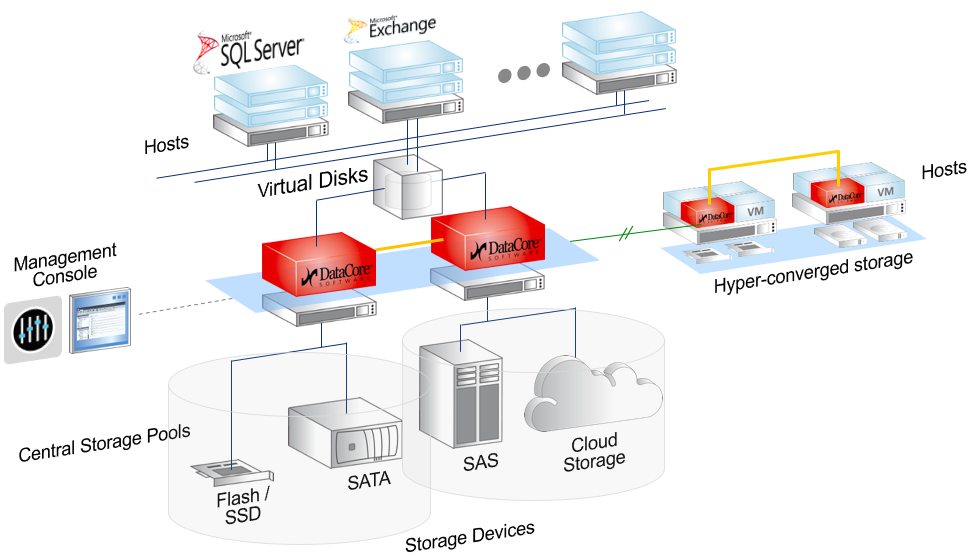
Отказоустойчивость СХД
К системам хранения данных в части обеспечения отказоустойчивости предъявляются более высокие требования, чем к серверам. Проблема неисправности сервера в большинстве случаев относительно легко решается его ремонтом или заменой. В то же время потеря данных может оказать серьёзное негативное влияние на бизнес и принести существенные убытки
Для предотвращения подобных случаев уделяется повышенное внимание обеспечению надёжности и отказоустойчивости СХД. Так, во всех СХД корпоративного класса применяется дублирование контроллеров, благодаря чему при выходе из строя одного из них доступ к данным сохраняется
Кроме того, СХД используют организацию дисков в RAID-массивы, которые позволяют восстановить данные при отказе нескольких дисков массива. Наконец, существуют кластерные конфигурации, когда несколько СХД объединяются в единую систему. Такая система состоит из нескольких контроллеров (принадлежащих разным физическим СХД), а данные могут быть распределены между различными СХД, входящими в её состав.
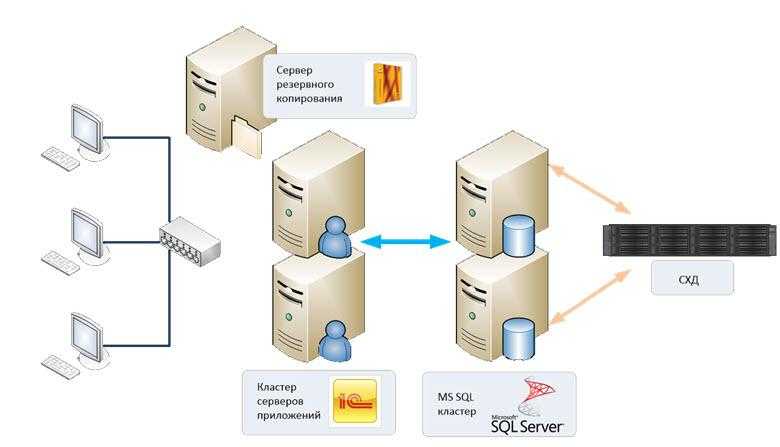
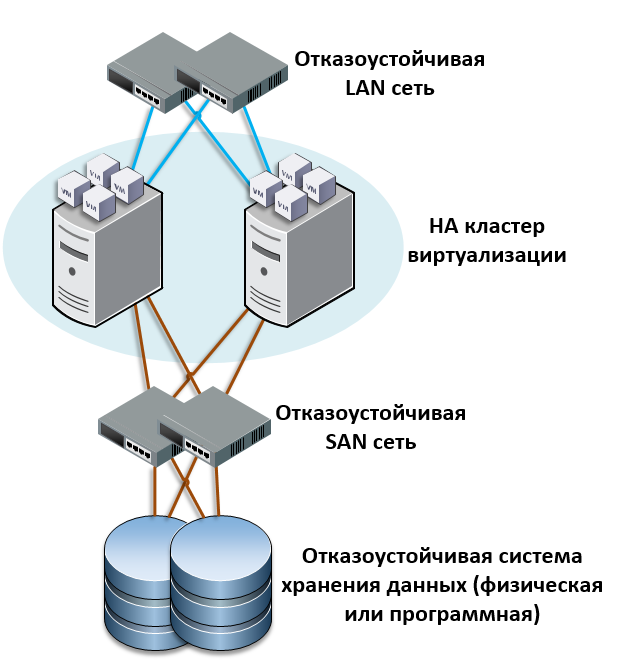
Резервирование серверов (кластеры)
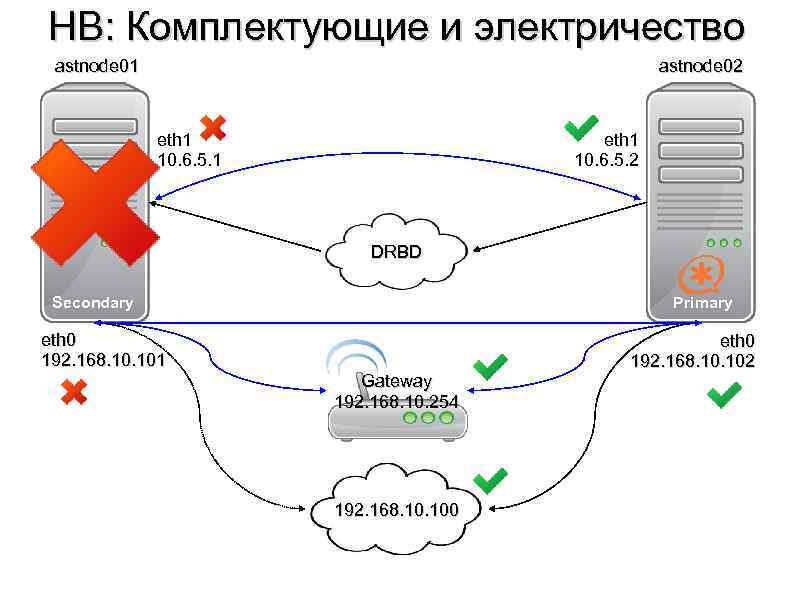
В подобных случаях применяется резервирование сервера целиком. C помощью специального программного обеспечения несколько серверов объединяются в единую систему. В случае аварии на одном из них, его нагрузка перекладывается на другие, входящие в систему. Такая организация называется кластером высокой доступности (high availability cluster, HA-кластер).
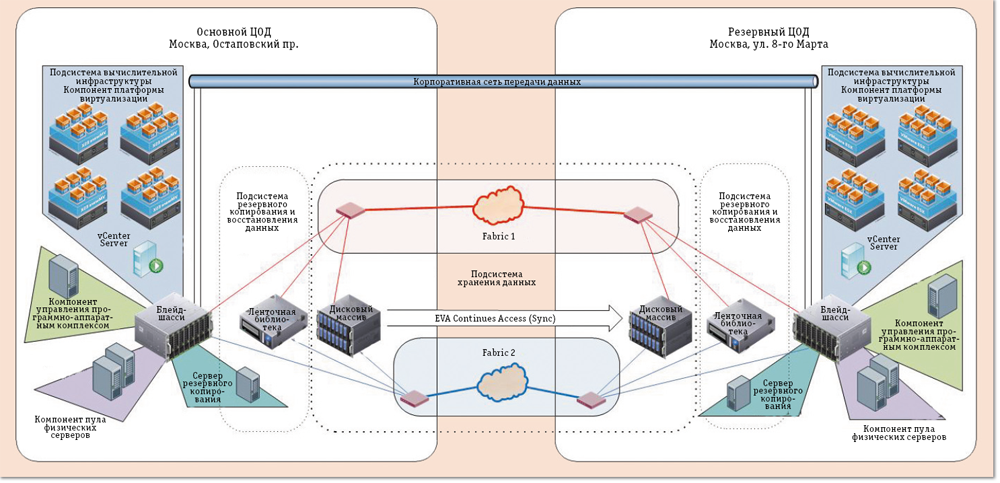
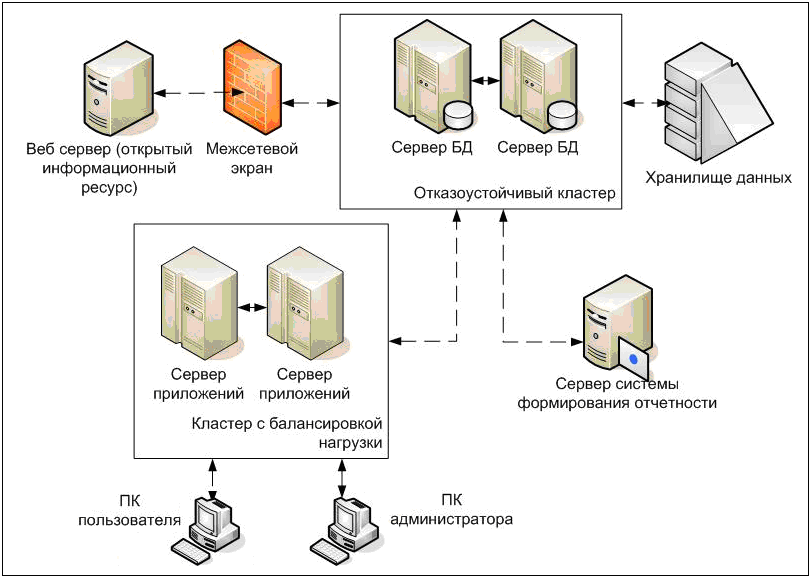
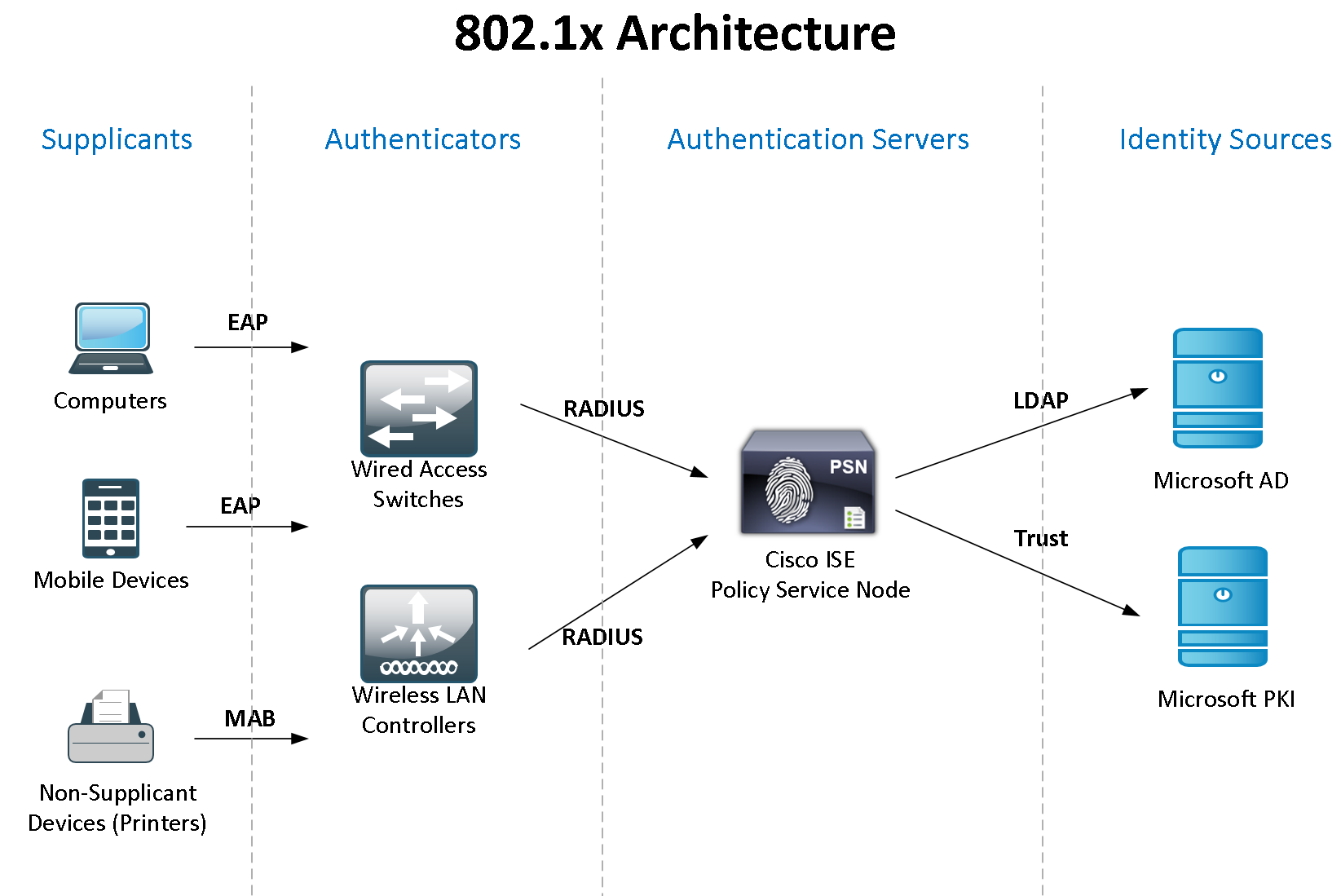
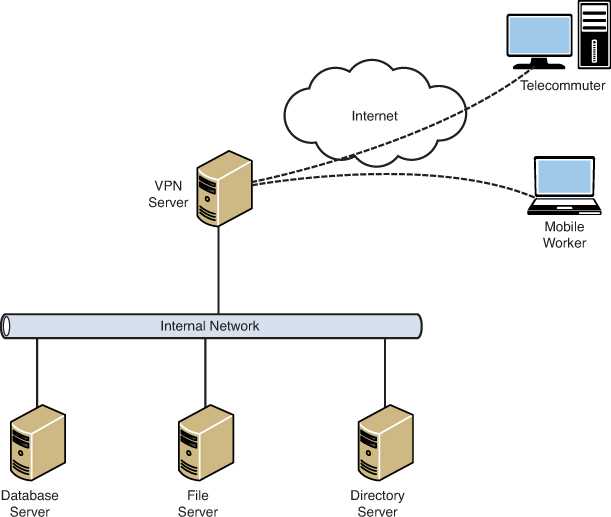
В простейшем и самом распространённом случае система состоит из двух серверов (так называемый двухузловой кластер), один из которых является основным, а другой —дублирующим, резервным (конфигурация active/passive). Все вычисления производятся на основном сервере, а дублирующий сервер включается в работу в случае аварии на основном. Такая конфигурация является затратной, так как каждый узел дублируется. На схеме ниже показана конфигурация active/passive, состоящая из нескольких (N) серверов.
Конфигурация Active/Passive
В другом варианте построения кластера серверы (два или больше) могут иметь равноценный статус, то есть работать одновременно (конфигурация active/active). В такой конфигурации нагрузка вышедшего из строя сервера распределяется по остальным серверам кластера. Если серверов в кластере немного, то скорее всего произойдёт снижение производительности, так как нагрузка на оставшиеся в кластере серверы возрастёт.
Конфигурация Active/Active
Здесь стоит заметить, что в конфигурации active/passive (которая имеет полное резервирование каждого узла) такого снижения не будет. Однако этот вариант стоит дороже, так как каждый узел дублируется. Фактически, за отказоустойчивость и отсутствие потери производительности всегда приходится платить двойную цену.
Третьим, альтернативным вариантом, который позволяет избежать как высоких расходов, так и потери производительности кластера при отказе одного из узлов, является конфигурация N+1. В этой конфигурации кластер имеет один полноценный резервный сервер, который при работе в обычном режиме не несёт на себе никакой нагрузки, а включается в работу только в случае отказа одного из активных серверов.
Конфигурация N+1
Краткое сравнение конфигураций сведено в таблицу ниже. Стоит отметить, что кроме описанных трех, бывают и другие, более сложные конфигурации отказоустойчивых кластеров. Например, N+M – когда для обеспечения более высокого уровня отказоустойчивости в состав кластера включается не один, а несколько резервных серверов.
|
Active/Active |
Active/Passive |
N+1 |
|
|
Стоимость решения |
Нормальная (суммарная стоимость всех узлов; все узлы кластера работают) |
Высокая (фактически – двойная, т.к. дублируются все узлы кластера) |
Нормальная + 1 (суммарная стоимость всех узлов + 1 резервный узел) |
|
Производи-тельность при отказе |
Снижение производительности |
Нет снижения производительности |
Нет снижения производительности |
Вывод: рычаги для увеличения надежности сервиса
Стоит внимательно посмотреть на представленные цифры, потому что они подчеркивают фундаментальный момент: есть три основных рычага, для увеличения надежности сервиса.
- Сократите частоту отключений — за счет политик выпуска, тестирования, периодических оценок структуры проекта и т.д.
- Уменьшите уровень среднего простоя — с помощью сегментирования, географического изолирования, постепенной деградации, или изолирования клиентов.
- Сократите время восстановления — с помощью мониторинга, спасательных действий «одной кнопкой» (например, откат к предыдущему состоянию или добавление резервной мощности), практики оперативной готовности и т. д.
Вы можете балансировать между этими тремя методами для упрощения реализации отказоустойчивости. Например, если трудно достичь 17-минутного MTTR, сосредоточьте свои усилия на сокращении времени среднего простоя. Стратегии минимизации отрицательных последствий и смягчения влияния критических компонентов рассматриваются более подробно далее в этой статье.