
Введение
В
современном мире, где информация
и способы ее обработки имеют
решающее значение важно обеспечить
отказоустойчивость систем хранения информации. Вместе
с серверным комплексом система
хранения данных является главной составной
частью любого вычислительного центра,
а потому следует подумать и об
её отказоустойчивости
Систему хранения
следует рассматривать не только
как дисковые массивы для хранения
данных, но и более широко – как комплекс,
включающий еще и транспорт ввода/вывода
(I/O), методы размещения данных, программное
обеспечение для оптимизации транспорта,
обеспечения гарантированной доставки,
размещения и хранения данных и т.д
Вместе
с серверным комплексом система
хранения данных является главной составной
частью любого вычислительного центра,
а потому следует подумать и об
её отказоустойчивости. Систему хранения
следует рассматривать не только
как дисковые массивы для хранения
данных, но и более широко – как комплекс,
включающий еще и транспорт ввода/вывода
(I/O), методы размещения данных, программное
обеспечение для оптимизации транспорта,
обеспечения гарантированной доставки,
размещения и хранения данных и т.д.
Спектр
методов повышения отказоустойчивости
систем хранения широк: это и дублирование
компонентов оборудования, и выбор
уровня RAID, и размещение данных с
точки зрения файловой системы, и
обеспечение надежности транспорта
для передачи данных, и встроенные
средства приложений.
Как
правило, сбои технического характера
происходят из-за нарушения функционирования
какого-либо компонента центра обработки
данных. Несмотря на самое тщательное
тестирование оборудования всегда есть
вероятность выхода его из строя.
Сбои логического характера случаются
по причинам нарушения целостности информации
вследствие ошибок системного программного
обеспечения или из-за неправильных действий
персонала.
Рекомендации для отказоустойчивого облака
 При развертывании облачной инфраструктуры в облаке стоит учитывать ряд факторов, которые позволят добиться высокой отказоустойчивости:
При развертывании облачной инфраструктуры в облаке стоит учитывать ряд факторов, которые позволят добиться высокой отказоустойчивости:
- Рассчитывать объем ресурсов, которые потребуются для отказоустойчивости. Многие упускают момент резервирования ресурсов как минимум в размере одного хоста, что в случае непредвиденных ситуаций отрицательно сказывается на отказоустойчивости среды.
- Учитывать максимальную загрузку серверов и систем хранения. Серверы архитектуры не стоит загружать более чем на 70-80%, но это правило часто игнорируется. Большая нагрузка может привести к просадке производительности и временным простоям в работе сервисов.
- Заранее рассчитать издержки на масштабирование. Стоит закладывать определенный резерв на случай роста вашей инфраструктуры. Конечно, облако предоставляет возможности масштабирования, но рост можно предсказать заранее и к нужному времени спланировать необходимые ресурсы.
- Учитывать особенности используемого ПО. Некорректное программное обеспечение и приложения не могут напрямую повлиять на безопасность и отказоустойчивость облачного сервиса, однако они могут привести к замедлению работы и различным сбоям. Поэтому перед построением cloud-инфраструктуры стоит заранее понять, подойдет ли сервер для работы с определенным ПО.
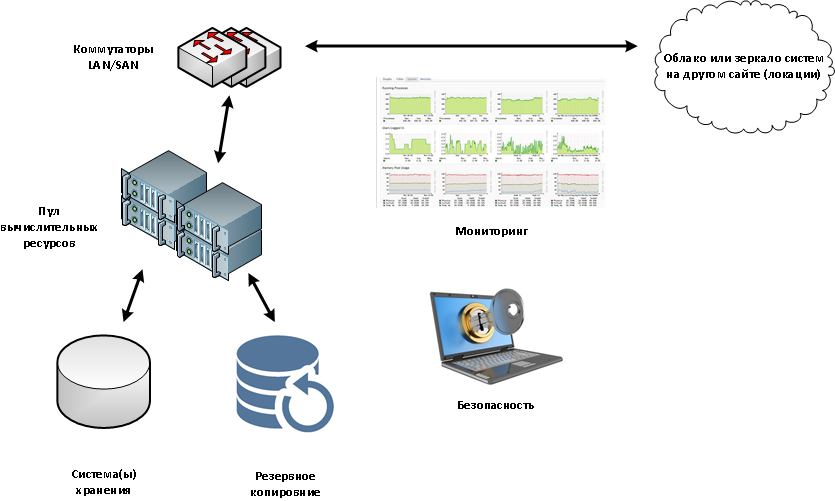
Резервирование на уровне узлов сервера
Резервирование достаточно широко применяется уже на нижнем уровне – самого устройства, то есть — в самих серверах. Многие их узлы дублируются, либо имеют такую возможность. Например, современные серверы предоставляют следующие возможности по резервированию:
Оперативная память
Серверы имеют особый режим работы памяти: Memory Mirroring или Mirrored memory protection. В этом режиме осуществляется зеркалирование каналов, то есть каналы разбиваются на пары, и в каждой паре один из каналов становится копией другого. Все банки памяти при этом должны быть сконфигурированы идентично.
Работа в этом режиме защищает от однобитовых ошибок или выхода из строя всего модуля памяти.
При работе в режиме зеркалирования памяти одни и те же данные записываются в банки системной и зеркалированной памяти, но считываются только из банков системной памяти. Если в каком-то из модулей системной памяти произошла многобитовая ошибка (или превышено допустимое количество однобитовых ошибок), то происходит переназначение банков: банки зеркалированной памяти назначаются системной памятью, а банки системной — зеркалированной. Это обеспечивает бесперебойную работу сервера за исключением случаев, когда ошибка происходит в одном и том же месте в системном и зеркалированном модулях памяти одновременно (вероятность этого крайне мала).
Недостатком такой организации является двукратное уменьшение объёма оперативной памяти. Или, иными словами, двукратное увеличение ее стоимости.
Диски
Аналогично оперативной памяти можно организовать зеркалирование дисков. Для этого каждому диску назначается дубликат, который содержит его полную копию благодаря тому, что информация одновременно записывается на диск и дублирующую его копию. В простейшем случае такая система состоит из двух одинаковых дисков.
Однако, как и в случае с зеркалированием оперативной памяти, недостатком такой организации является высокая (фактически – двойная) стоимость ресурсов. Поэтому часто используются другие варианты организации дисков в единые массивы (RAID, см. статью из Wikipedia). Существует достаточно много вариантов организации RAID-массивов, которые имеют различные параметры стоимости, скорости работы и степени отказоустойчивости.
Питание
Серверы среднего и старшего уровня имеют по два блока питания. В случае выхода из строя одного из них, сервер продолжает работать от второго. Иногда серверы оснащаются тремя и более блоками питания. В этом случае один из них остаётся резервным (так называемая схема N+1), либо БП дублируются (схема N+N). В последнем случае их число должно быть чётным.
Интерфейсы (платы расширения)
И снова самое простое, что можно сделать для обеспечения отказоустойчивости – это дублирование интерфейсных плат. Однако так как
a) современная инфраструктура имеет большое разнообразие интерфейсов разных стандартов (Ethernet, FC, Infiniband, и т.д.) и физических носителей («оптоволокно» или «медь»),
b) отказ интерфейсной платы не ведет к потере информации (он только нарушает процесс её передачи),
резервирование интерфейсных плат не входит в набор стандартных средств, которые по умолчанию предоставляются производителем оборудования. Здесь решение о резервировании остаётся на усмотрение пользователя.
Таким образом, отказоустойчивость сервера может быть повышена путем резервирования некоторых его узлов, как только что было описано. Но есть компоненты, которые задублировать невозможно. К ним относятся, в частности, RAID-контроллер и материнская плата. Выход из строя RAID-контроллера может привести к частичной или полной потере данных, а выход из строя материнской платы приведет к остановке всего сервера. Как защититься от таких неисправностей и обеспечить безотказную работу?
Настраиваем отказоустойчивый DHCP-сервис
Даже в небольших сетях для раздачи IP-адресов и прочих сетевых настроек
клиентам на порядок удобнее использовать DHCP-сервер, чем просто прописывать
адреса в настройках каждой системы вручную (и затем бороться с конфликтами).
Управление IP-адресами из одного места экономит кучу времени. Проблема в том,
что теперь клиенты зависимы от работоспособности DHCP-сервера, и в случае выхода
его из строя не смогут получить IP-адрес, соответственно, не смогут
воспользоваться ресурсами локальной и глобальной сетей. Возможно несколько
вариантов выхода. Самый очевидный — это создание кластера, в этом случае при
отказе одного сервера второй возьмет на себя всю нагрузку. Вопрос построения
отказоустойчивого кластера для файлового сервера был рассмотрен в статье «Безотказный
файлообменник», опубликованной воктябрьском номере Х
за
2008 год; многие моменты по настройке пересекаются с созданием кластера для
DHCP.
Сервер Win2k8R2 поддерживает протокол
DHCP Failover, использование которого позволяет двум серверам
синхронизировать данные об аренде адресов между собой, но на DHCP-запросы
отвечает только основной сервер. Резервный подключается, когда недоступен
первый. Учитывая, что он «знает» все, что выдал основной сервер, переход на
резервный полностью прозрачен. Установка роли DHCP-сервера стандартна. Выбираем
Add Roles в Server Manager, отмечаем «DHCP Server» в списке ролей. Далее следуют
настройки работы сервера. Вводим настройки DNS-сервера (домен и IP-адрес), затем
адрес WINS-сервера, если такая служба будет использоваться. На шаге «DHCP Scope»
задаем диапазон IP, которым будет рулить наш сервер. Просто нажимаем Add и
вводим: произвольное название, начальный и конечный IP, тип (беспроводная,
проводная), адрес шлюза и маску сети. По окончании активируем область, установив
флажок «Activate this scope». Определяемся, будем ли раздавать адреса IPv6; если
нет, переключаем на шаге «IPv6 stateless mode» флажок с Enable на Disable.
Проверяем и подтверждаем установки, щелкаем Install. Далее настраиваем Failover
Cluster, как описано в статье «Безотказный файлообменник».
Очевидно, такой подход имеет преимущества в больших сетях, где серверы
обслуживают большое количество запросов. В небольших компаниях, чтобы
организовать резервирование DHCP, часто используют второй, как правило, несильно
загруженный сервер, выполняющий другую работу. В этом случае IP-адреса между
серверами распределяются по схеме 80/20 (так советует Microsoft и многие
источники, хотя это не догма, можно 70/30 или 50/50), то есть основной сервер
берет на себя 80% адресов, оставшиеся 20 достаются второму серверу.
Рассмотрим сеть класса «С»: сервер DHCP1 берет на себя 192.168.1.1-200,
сервер DHCP2 — 192.168.1.201-254. Во избежание конфликтов на обоих серверах
настраиваются исключаемые адреса (Excluded Adresses), в которые прописываются
IP-адреса, выдаваемые другим сервером. Если основной сервер выйдет из строя,
резервный сможет отвечать на запросы клиентов и обслуживать их аренду. При
необходимости второй сервер можно легко перестроить на полный диапазон.
Осталось добавить, что при наличии в сети контроллера домена роль
DHCP-сервера обычно возлагают именно на него. Хорошей практикой является
использование двух контроллеров домена; при выходе из строя одного из них,
второй будет выполнять все возложенные задачи (восстановление и резервирование
КД описано в статье «Лови
момент» июльского
номера Х за
2008 год).
Отказоустойчивость СХД
К системам хранения данных в части обеспечения отказоустойчивости предъявляются более высокие требования, чем к серверам. Проблема неисправности сервера в большинстве случаев относительно легко решается его ремонтом или заменой. В то же время потеря данных может оказать серьёзное негативное влияние на бизнес и принести существенные убытки
Для предотвращения подобных случаев уделяется повышенное внимание обеспечению надёжности и отказоустойчивости СХД. Так, во всех СХД корпоративного класса применяется дублирование контроллеров, благодаря чему при выходе из строя одного из них доступ к данным сохраняется
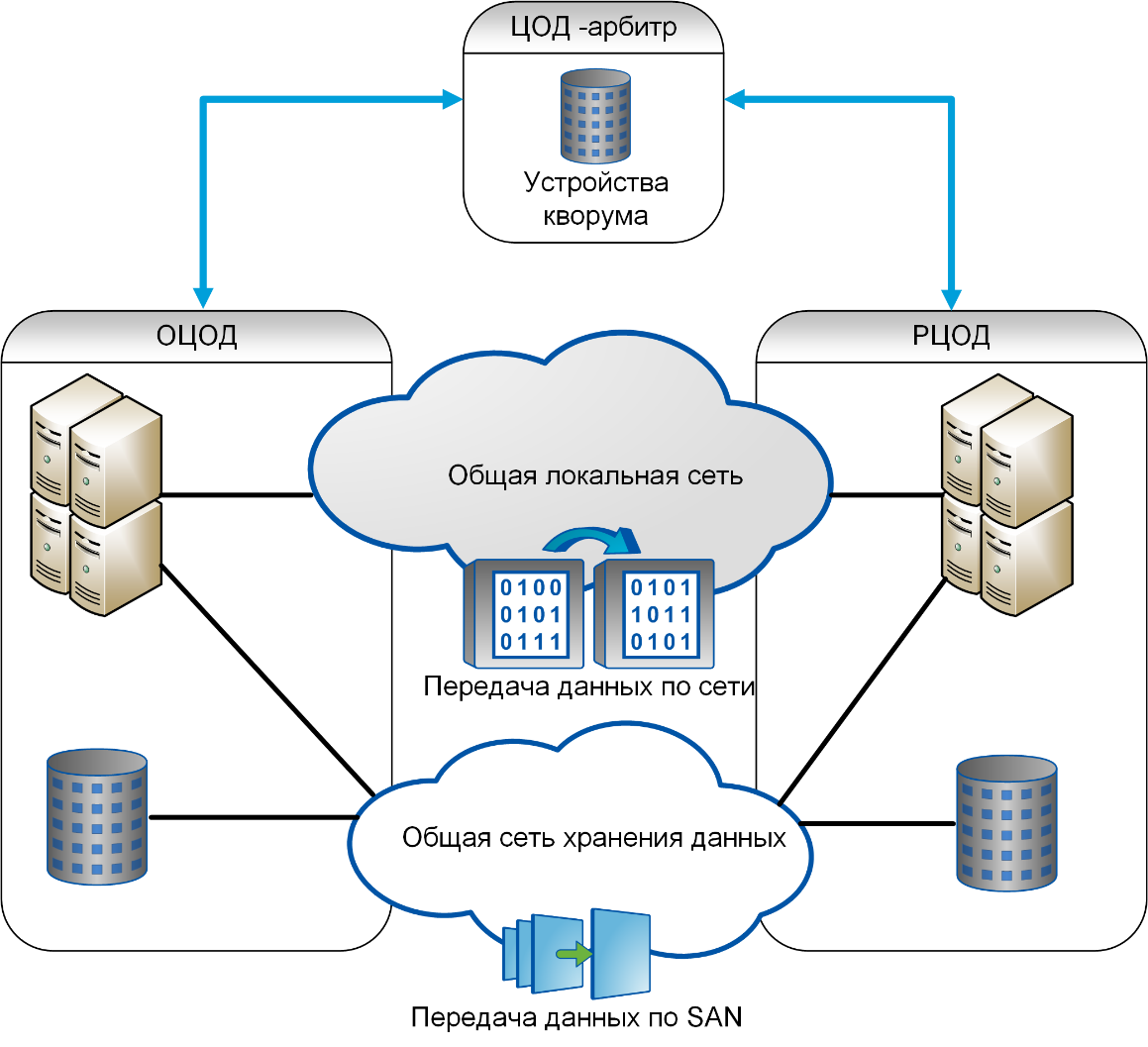
Кроме того, СХД используют организацию дисков в RAID-массивы, которые позволяют восстановить данные при отказе нескольких дисков массива. Наконец, существуют кластерные конфигурации, когда несколько СХД объединяются в единую систему. Такая система состоит из нескольких контроллеров (принадлежащих разным физическим СХД), а данные могут быть распределены между различными СХД, входящими в её состав.
Отказоустойчивость на уровне инфраструктуры
Как было показано выше, основным способом повышения отказоустойчивости является дублирование узлов. Рассмотрим этот процесс на нескольких примерах. Для начала возьмём простую (и довольно часто встречающуюся) топологию инфраструктуры небольшой компании:
В конфигурации на этом рисунке мы защищены от потери данных на СХД (т.к. СХД имеет два контроллера), но не защищены от простоя в случае, если выйдет из строя коммутатор. Поэтому для повышения отказоустойчивости нам нужно добавить второй коммутатор, и подключить к нему остальное оборудование:
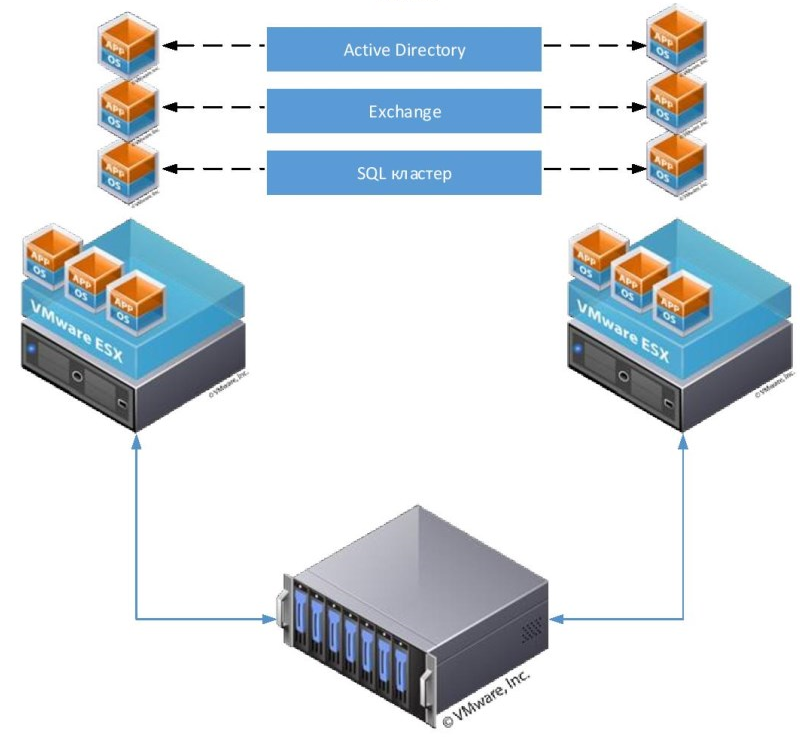

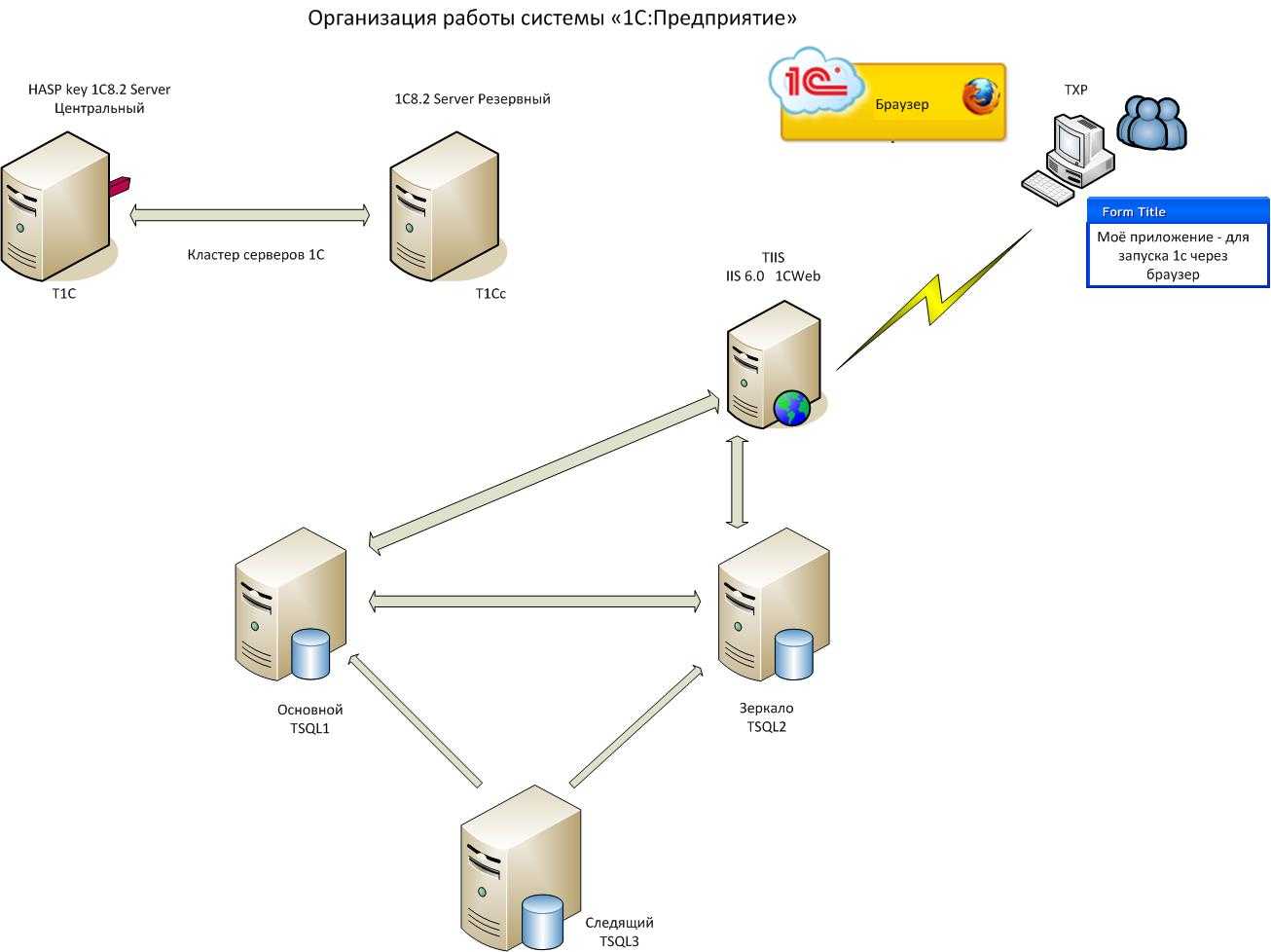
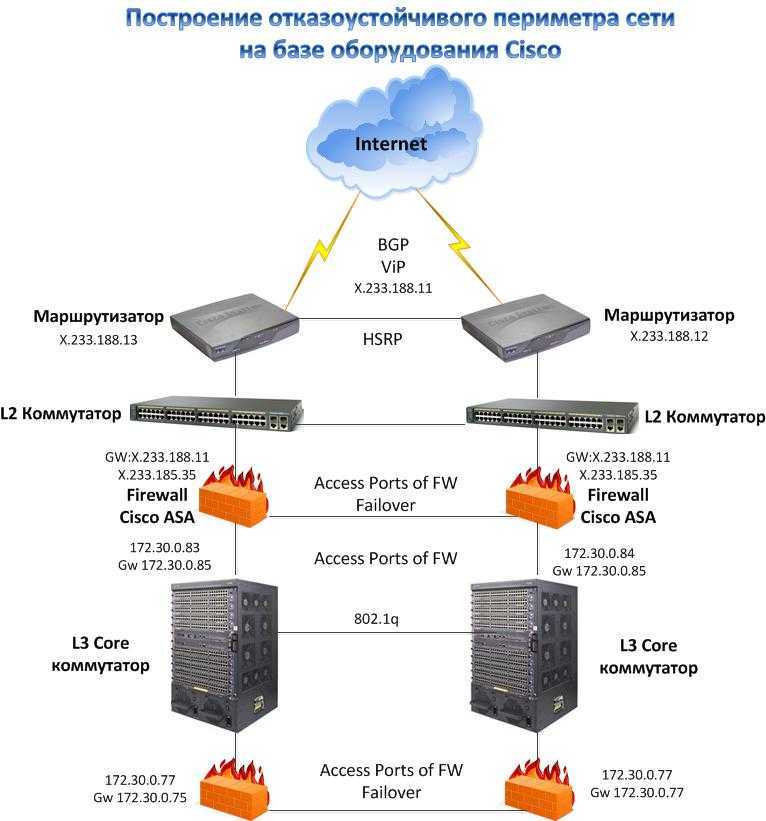
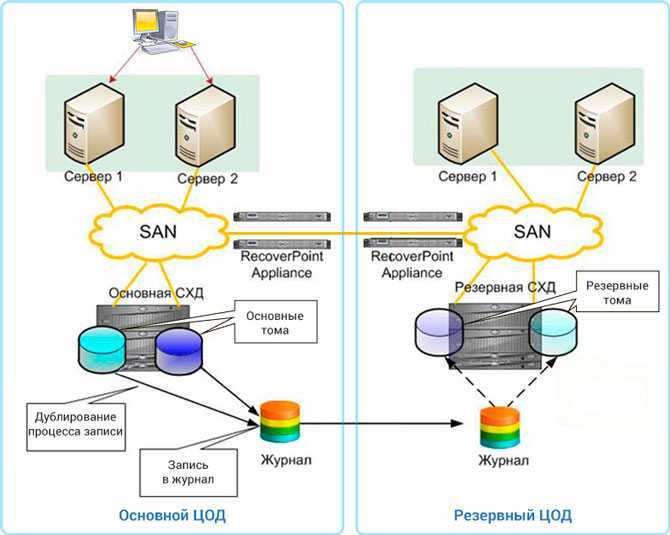
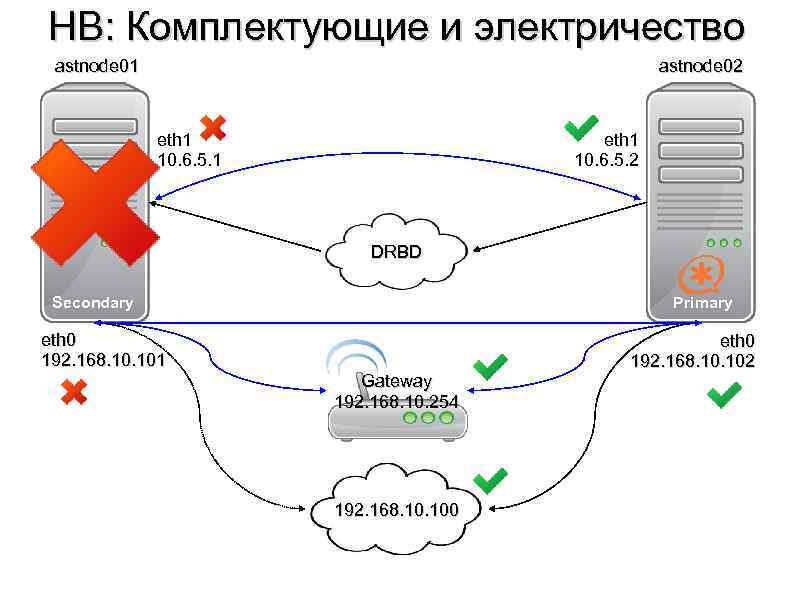
Теперь мы защищены от неполадок как со стороны СХД, так и со стороны коммутатора. Но что будет, если выйдет из строя сетевой адаптер сервера? Этот сервер потеряет доступ к сети и СХД. Поэтому нужно задублировать также и сетевые адаптеры:
Кажется, теперь мы задублировали всё, что можно. Остаются только сами серверы. Их можно объединить в отказоустойчивый кластер, как было описано ранее:
Как поддерживается отказоустойчивость
Чаще всего для повышения эффективности облачного хранения применяется многоуровневая система. Этот подход предполагает, что далеко не все данные одинаково востребованы в текущий момент. Следовательно, необходимо варьировать активность доступа и хранить файлы на разных уровнях.
За счет создания иерархии данных можно добиться значительной экономии ресурсов. Для малоактивных и невостребованных файлов могут применяться более дешевые ресурсы. А информация, которая с большой вероятностью потребуется в ближайшее время, будет храниться на более производительном уровне. При необходимости можно автоматически или вручную настраивать доступность файлов и тем самым распределять нагрузку на облачные сервисы.
Такой подход в большинстве случаев является более рациональным, чем размещение баз данных на физическом оборудовании. Дополнительная отказоустойчивость облачных серверов достигается за счет катастрофоустойчивости. Этот термин означает, что облако продолжит выполнять свои функции даже при выходе из строя всего ЦОДа. Но, как правило, катаклизмы случаются крайне редко, поэтому подобный сценарий можно назвать маловероятным.
Кроме этого, дополнительная отказоустойчивость облачных хранилищ достигается благодаря новейшим технологиям репликации. За счет этого обеспечивается мобильность данных, а также возможность переноса ресурсов с одного сервера на другой без прекращения фактического доступа.
Если облака для вас
не просто теория
Широкий спектр услуг
по выделенным северам
и мультиклауд-решениям
Конфигурация VPS и бесплатный тест уже через 2 минуты
Сконфигурировать VPS
Организация вашей IT-инфраструктуры на основе мультиклауд-решения
Запросить КП
Чаще всего облако базируется на нескольких серверах дата-центра уровня Tier III. Уровень Tier III позволяет обеспечить практически полную отказоустойчивость физической инфраструктуры, а это в свою очередь повышает доступность облачного хранилища.
Дополнительно может применяться принцип географической распределенности облака. В этом случае хранилище базируется на двух независимых площадках, которые находятся на расстоянии друг от друга. Например, это могут быть дата-центры одного поставщика в разных городах. На базе ЦОДов развертывается геораспределительный кластер.
В дата-центре присутствуют точки провайдеров связи, благодаря чему обеспечивается наилучшее качество соединения. Такой подход удобен и тем, что в случае отключения связи одним провайдером, всегда есть возможность быстро перестроить маршрутизацию и подключиться к сети через других провайдеров.
Дополнительные функциональные возможности
Имеется возможность установки дополнительных функций, дополняющих службы роли файловых служб, включая перечисленные ниже функции.
Система архивации данных Windows Server
Архивация данных Windows Server позволяет надежно архивировать и восстанавливать операционную систему, определенные приложения, а также файлы и папки, которые хранятся на сервере. В этой функциональной возможности представлены новые технологии архивирования и восстановления, которые заменяют предыдущие функции архивирования, доступные в более ранних версиях Windows.
Дополнительные сведения см. в справке по архивации Windows Server. Можно просмотреть содержимое локальной справки, введя в командной строке следующую команду: hh backup.chm.
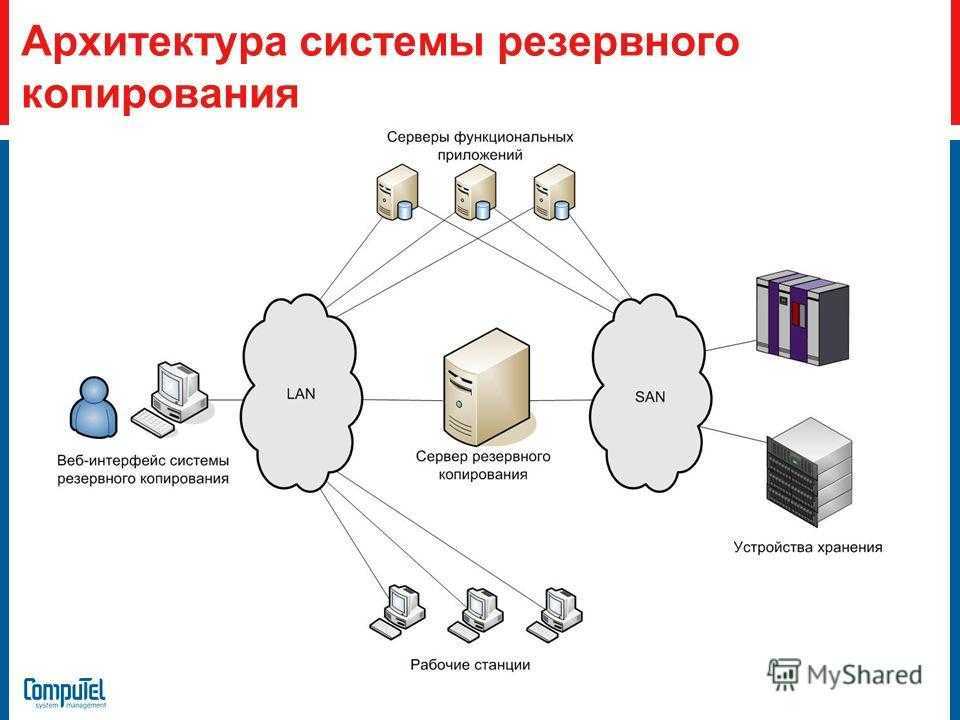
Диспетчер хранилища для сетей SAN
Диспетчер хранилища для сетей SAN позволяет обеспечить хранилище одним или несколькими оптоволоконными каналами или подсистемами хранилища iSCSI в сети SAN (Storage Area Network).
Дополнительные сведения см. в справке по диспетчеру хранилища для сетей SAN. Можно просмотреть содержимое локальной справки, введя в командной строке следующую команду: hh sanmgr.chm.
Средство отказоустойчивости кластеров
Средство отказоустойчивости кластеров обеспечивает взаимодействие нескольких серверов с целью повышения доступности служб и приложений. Кластерные серверы (называемые узлами) соединены с помощью кабелей и подключены друг к другу посредством программного обеспечения. При возникновении сбоя на одном из узлов кластера его функции немедленно передаются другому узлу (перемещение при сбое).
Дополнительные сведения см. в документации по отказоустойчивому кластеру на веб-сайте (https://go.microsoft.com/fwlink/?LinkId=62911) (может быть на английском языке).
Многопутевой ввод-вывод
Multipath I/O предоставляет поддержку различных путей данных с файлового сервера на устройство хранения. С помощью Multipath I/O можно увеличить доступность данных путем предоставления избыточных подключений к подсистемам хранения. Использование режима Multipath позволяет балансировать загрузку трафика ввода-вывода, что улучшает производительность системы и приложений.
Дополнительные сведения см. в документе, посвященном Multipath I/O на веб-сайте (https://go.microsoft.com/fwlink/?LinkId=81020) (может быть на английском языке).
Развертывание сетей хранения данных с отказоустойчивыми кластерами
При развертывании сети хранения данных (SAN) с отказоустойчивым кластером руководствуйтесь следующими рекомендациями.
Подтвердите совместимость хранилища. Обратитесь к производителям и поставщикам, чтобы подтвердить, что хранилище, включая драйверы, встроенное ПО и ПО, используемое для хранилища, совместимо с отказоустойчивыми кластерами в используемой версии Windows Server.
Изолируйте запоминающие устройства по одному кластеру на устройство: серверы из различных кластеров не должны иметь доступа к одним и тем же запоминающим устройствам. В большинстве случаев LUN, используемый для одного набора серверов кластера, должен быть изолирован от всех остальных серверов с помощью маски или зонирования LUN.
Рассмотрите использование ПО многоканального ввода-вывода или сетевых адаптеров с поддержкой совместной работы: в архитектуре хранилищ с высокой доступностью можно развернуть отказоустойчивые кластеры с несколькими адаптерами шины, используя ПО многоканального ввода-вывода или сетевых адаптеров с поддержкой совместной работы (что также называется отказоустойчивой балансировкой нагрузки — LBFO). Это обеспечивает максимальный уровень резервирования и доступности. для Windows Server 2012 R2 или Windows Server 2012 решение multipath должно быть основано на Microsoft Multipath I/O (MPIO)
Поставщики оборудования обычно предоставляют модуль MPIO для конкретного устройства (DSM), но в комплект поставки операционной системы Windows Server также входят один или несколько модулей DSM.
Важно!
Некоторые адаптеры шины и программное обеспечение многоканального ввода-вывода сильно зависят от версий. При реализации многоканального решения для кластера следует проконсультироваться с поставщиком оборудования, чтобы выбрать правильные адаптеры, встроенное программное обеспечение и программное обеспечение для используемой версии Windows Server.
рассмотрите возможность использования дисковые пространства
если планируется развертывание кластеризованного хранилища serial attached SCSI (SAS), настроенного с помощью дисковые пространства, см. раздел развертывание кластерных дисковые пространства для требований.
Избыточность, и как ее достичь
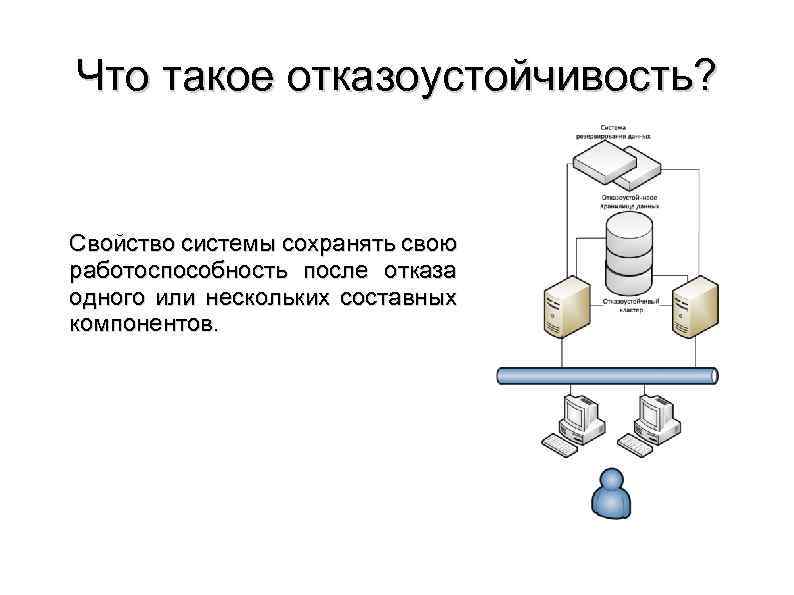
Единственный способ избежать отказа системы — избавиться от «единых» точек отказа» (SPOF). Практика управления инфраструктурами всех уровней и масштабов доказывает, что избыточность — единственный путь к такому решению, поскольку обеспечивает резервирование абсолютно всех компонентов. Логично, ведь вероятность одновременного сбоя 2-х серверов намного меньше, чем одного.
При этом резервы должны в мельчайших деталях копировать конфигурации основных компонентов (количество «оперативки», функциональные характеристики процессоров и прочее).
Какие подходы практикуются для резервирования веб-компонентов:
- Дублирование NS-записей.
- Резервирование фронтендов.
- Оптимизация числа бекендов.
- Резервирование баз данных.
Резервирование баз данных
Эта задача считается наиболее сложной в рамках повышения отказоустойчивости сети. Обычно для этого применяется репликация, в ходе которой выделяется главный сервер для БД (Мастер), отвечающий за модификацию данных. Вспомогательный сервер (Слейв) копирует все изменения, которые происходят на мастер-сервере и отвечает за их чтение.
Основной особенностью таких реплик является работа в пассивном режиме, без обработки запросов от приложений. Задача реплики — хранение актуальной копии БД с Мастера.
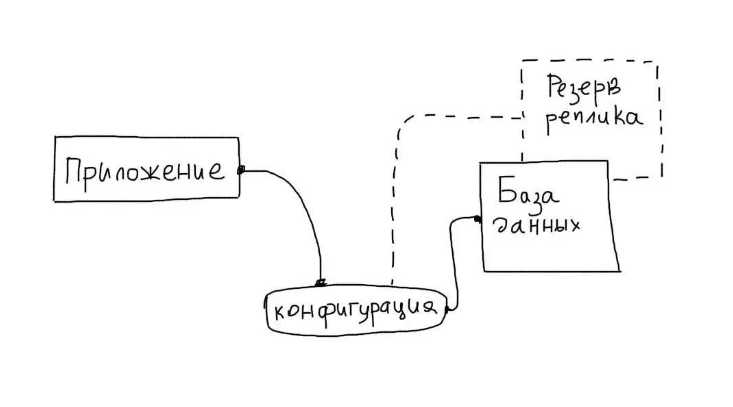
Преимуществом подхода является удобная автоматизация процессов отслеживания состояния БД. Если обнаруживается ошибка, приложение автоматически изменяет настройки и «подключает» к работе сервер-репликант.
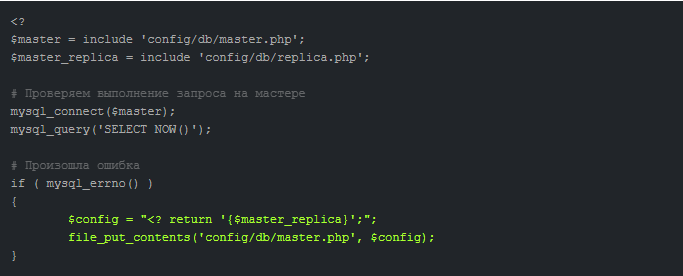
Восстановление вышедшего из строя сервера происходит следующим образом:
- Сервер отключается.
- Производится восстановление на физическом уровне.
- Проводится настройка и синхронизация реплики с дублирующего сервера.
- В приложении прописывается конфигурация рабочего дубль-сервера.
Слейв-сервер настраивается с Мастер-сервера при участии утилиты Xtrabackup.
Затем бывший Слейв переходит в статус Мастера, а восстановленный сервер превращается в резервный (Слейв).
Сетевые принтеры
Управление сетевыми принтерами — дело весьма хлопотное: стоит выйти из строя
одному, как админы вынуждены будут разбираться с недовольными менеджерами и
другими представителями офисной фауны. Часто упростить себе жизнь можно,
сгруппировав несколько идентичных принтеров (имеется в виду, что принтеры должны
иметь одного производителя, одинаковые модели, одинаковое количество памяти и
использовать одинаковые драйвера, — Прим.ред.) в пул. В этом случае клиентские
системы отсылают задания на одно логическое устройство печати, а сервер уже
самостоятельно перенаправляет их первому доступному физическому принтеру. Такой
подход позволит не только повысить доступность, но и равномернее распределить
нагрузку на принтеры, увеличить отклик, а значит, и производительность (пулинг
не допустит ситуации, когда один принтер простаивает, а второй завален
заданиями). Хотя не следует бездумно включать эту опцию, необходимо учитывать и
физическое расположение принтеров. Вряд ли пользователи будут в восторге, что
нужно бегать по этажам в поисках своих распечаток. Кроме того, весьма
нежелательно, чтобы ценные документы попадали на глаза тем лицам, для которых
они не предназначены.
Сгруппировать принтеры в пул достаточно просто. Для этого следует перейти во
вкладку «Устройства и Принтеры» (Devices and Printers), расположенную в «Панели
управления» (Control Center), вызвать окно свойств одного из принтеров, которые
будут добавлены в пул, и перейти во вкладку «Ports». Здесь требуется установить
флажок «Enable printer pooling» и отметить устройства, которые будут завязаны в
пул.
Еще одна ремарка от редактора: пулинг обеспечивает высокую доступность и
отказоустойчивость для принтеров, но не для сервера печати, поэтому при
необходимости можно настроить кластер печати по аналогии с тем, что
рассказывается в упомянутой выше статье «Безотказный файлообменник».
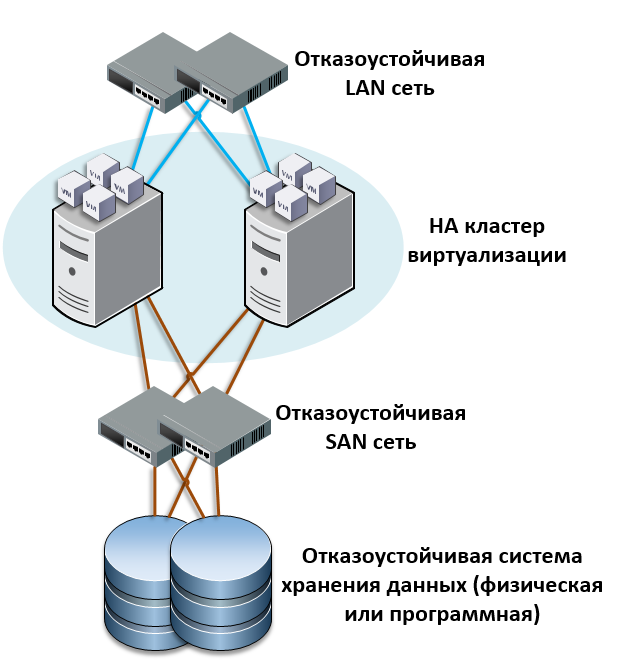
Требования к сетевой инфраструктуре и учетным записям домена
Вам потребуется следующая сетевая инфраструктура для отказоустойчивого кластера с двумя узлами и учетной записи администратора со следующими разрешениями домена:
-
Параметры сети и IP-адреса: При использовании идентичных сетевых адаптеров для сети также используются идентичные параметры связи для этих адаптеров (например, скорость, дуплексный режим, Flow управление и тип носителя). Кроме того, сравните параметры на сетевом адаптере и коммутаторе, к которому он подключается, и убедитесь в том, что они не конфликтуют.
Если есть частные сети, которые не маршрутизируются в остальную часть сетевой инфраструктуры, убедитесь, что для каждой из этих частных сетей используется уникальная подсеть. Это необходимо даже в том случае, если каждому сетевому адаптеру присвоен уникальный IP-адрес. Например, если в центральном офисе есть узел кластера, использующий одну физическую сеть, а в филиале есть другой узел, использующий отдельную физическую сеть, не указывайте адрес 10.0.0.0/24 для обеих сетей, даже если каждому адаптеру присвоен уникальный IP-адрес.
Дополнительные сведения о сетевых адаптерах см. в разделе «Требования к оборудованию» для отказоустойчивого кластера с двумя узлами ранее в этом руководстве.
-
DNS: Серверы в кластере должны использовать систему доменных имен (DNS) для разрешения имен. Можно использовать протокол динамического обновления DNS.
-
Роль домена: Все серверы в кластере должны находиться в одном домене Active Directory. Мы рекомендуем, чтобы все кластерные серверы имели одинаковую роль домена (рядовой сервер или контроллер домена). Рекомендованная роль — рядовой сервер.
-
Контроллер домена: Рекомендуется, чтобы кластеризованные серверы были членами. Если это так, вам потребуется дополнительный сервер, который выступает в качестве контроллера домена в домене, который содержит отказоустойчивый кластер.
-
Клиентов: При необходимости для тестирования можно подключить один или несколько сетевых клиентов к создаваемому отказоустойчивом кластеру и наблюдать за эффектом на клиенте при перемещении или отработки отказа кластеризованного файлового сервера с одного узла кластера на другой.
-
Учетная запись для администрирования кластера: При первом создании кластера или добавлении в него серверов необходимо войти в домен с помощью учетной записи с правами администратора и разрешениями на всех серверах в этом кластере. Она не обязательно должна входить в группу «Администраторы домена». Например, это может быть учетная запись пользователя домена, входящая в группу «Администраторы» на каждом кластерном сервере. Кроме того, если учетная запись не является учетной записью администратора домена, то учетной записи (или группе, членом которой является учетная запись) должны быть предоставлены разрешения на создание объектов компьютера и разрешение на чтение всех свойств в подразделении домена, в котором будет находиться подразделение домена.
2 Отказоустойчивость средствами ОС
Некоторые
проблемы из-за сбоя оборудования могут
быть решены на уровне операционной системы
или специализированного программного
обеспечения «Программными» решениями
повышения отказоустойчивости часто пытаются
заменить дорогостоящее аппаратное дублирование
– в результате решение удается значительно
удешевить, но снижается производительность,
появляются скрытые затраты на администрирование
и поддержку.
Файловая
система обычно является частью операционной
системы и тесно интегрирована со средствами
повышения отказоустойчивости. Которые
в свою очередь обеспечивают безотказность
транспорта на всем пути от сервера до
диска (начиная от адаптеров, коммутационных
кабелей, коммутационного оборудования,
ввода/вывода массива хранения данных,
контроллера RAID и заканчивая внутренней
разводкой от контроллера RAID до самих
дисков) только при наличии работоспособной
аналогичной цепочки. Большинство из них
умеет организовывать виртуальные массивы
RAID с избыточностью записи, части которого
физически находятся на разных массивах.
Существует
большое количество различных файловых
систем, которые делятся на ряд различных
групп по их применению. Рассмотрим некоторые
из них.
Дисковые
файловые системы обычно являются поток-ориентироваными.
Файлы в поток-ориентированых файловых
системах представляются последовательностью
битов, часто предоставляющие такие функции,
как чтение, запись, изменение данных и
произвольный доступ. Среди дисковых файловых
систем можно выделить ряд отказоустойчивых
систем, таких как журналируемые файловые
системы, это класс файловых систем, характерная
черта которых — ведение журнала, хранящего
список изменений, в той или иной степени
помогающего сохранить целостность файловой
системы. Представителями журналируемых
файловых систем являются: ReiserFS — файловая
система разработанная специально для
Linux, JFS — журналируемая файловая система
первоначально разработанная IBM и др.
Предложение от Xelent
Как видите, поддержание отказоустойчивости в облаке требует многоуровневого подхода к безопасности и надежности данных. Необходимо продумать как физический, так и аппаратный уровень отказоустойчивости, чтобы избежать простоя инфраструктуры и предотвратить потерю данных.
Если вам требуется создание надежной облачной ИТ-инфраструктуры, то наша компания Xelent готово предложить ряд решений. Выбирая наш дата-центр, вы получаете следующее:
- Непрерывность бизнес-процессов за счет подключения каждого хоста к нескольким системам хранения данных.
- Резервное копирование без затрат ресурсов клиента.
- Доступность 24/7 за счет использования коммутаторов, подключенных к разным маршрутизаторам.
- Круглосуточная техподдержка и помощь с настройкой облачной инфраструктуры.
Если у вас остались вопросы об услуге, то задавайте их нашему нашему менеджеру. Оставляйте заявку на сайте или звоните по указанным номерам!
Популярные услуги
Отказоустойчивая инфраструктура
Отказоустойчивая инфраструктура – это комплекс решений, направленных на поддержание постоянной работоспособности оборудования: компьютеров, комплектующих, ПО и локальной сети.
Публичное облако
Публичное облако позволяет быстро расширить ИТ-инфраструктуру без значительных вложений в модернизацию оборудования.
Миграция инфраструктуры в облако Xelent
Миграция в облако Xelent – технология, позволяющая адаптировать инфраструктуру к высоким нагрузкам. Понятное управление и администрирование позволяет уменьшать или наоборот увеличивать количество ресурсов, которые вам необходимы в тот или иной момент.
Оптимизация числа бекендов
Идентичность серверов, обеспечивающих работу основного приложения позволяет применить активное резервирование. То есть, в обработке запросов задействуются все бекенды, без резерва. Как только один из них сбоит, он автоматически «выпадает» из списка, а фронтенд перестает подавать на него запросы. Однако такая последовательность грозит повышением нагрузки на остальные серверы.
Чтобы гарантировать повышение отказоустойчивости, следует рассчитывать количество бекендов исходя из предпосылки, что в любую секунду под угрозой может оказаться 25% их числа.
Назначение нескольких серверов с целью обработки fastcgi-запросов при помощи upstream происходит с участием Nginx. Распределение запросов между серверами производится в автоматическом режиме.
Также Nginx анализирует ошибки, содержащиеся в ответах бекендов, в реальном времени. Если ошибка обнаружена — отправка запросов на вышедший из строя бекенд приостанавливается. Тайминг и число попыток настраиваются.
Резервирование фронтендов
Сбои и неполадки на линии серверов, которые обеспечивают получение клиентских запросов и ответы на них, грозят недоступностью веб-приложения целиком.
Чтобы избежать этого проводят резервирование фронтендов при участии виртуальных IP-адресов UCARP. Вследствие процедуры один из серверов получает виртуальный АйПи с привязанным к нему доменом. При неполадках на основном сервере дублирующий АйПи-адрес привязывается к резервной машине.
Автоматизация отслеживания состояний и переключения IP-адреса позволит ежесекундно опрашивать основной ресурс и выявлять степень корректности его действий (так называемый heartbeat). При отсутствии корректной реакции, IP-адрес делегируется фронтенду.
Упрощенный мониторинг доступности и отказоустойчивости сервера UCARP обеспечивает самостоятельно.
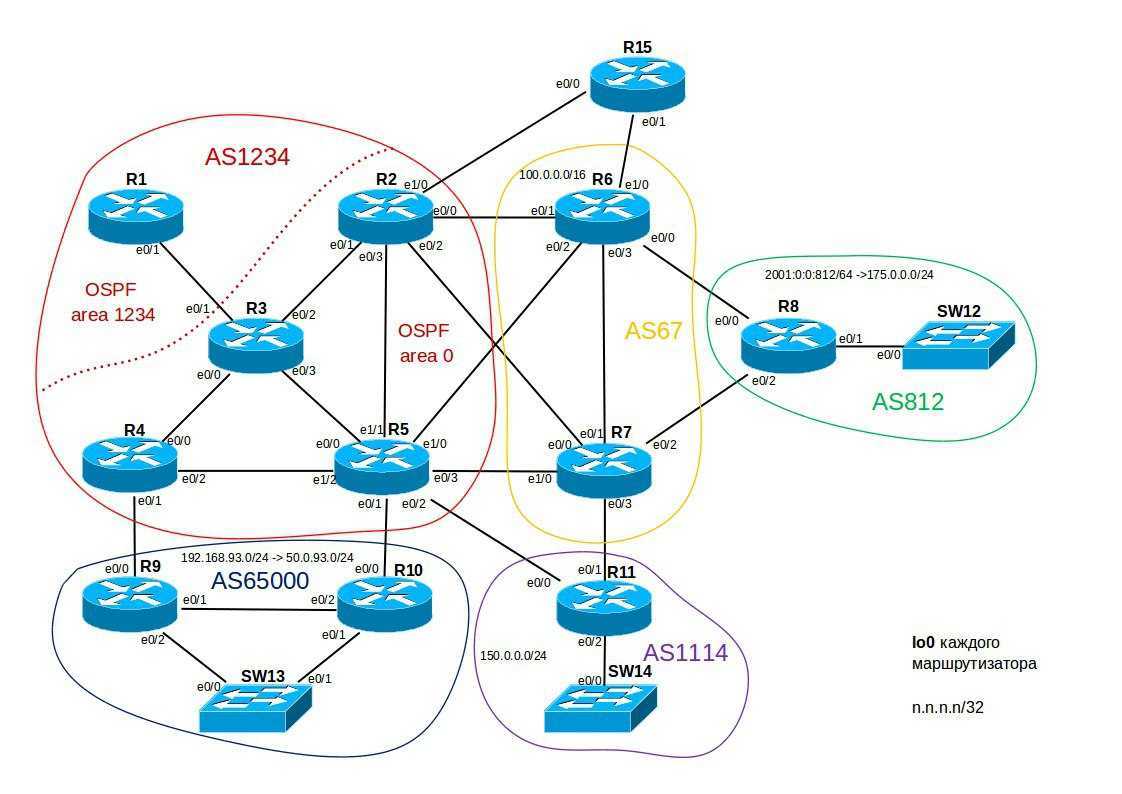
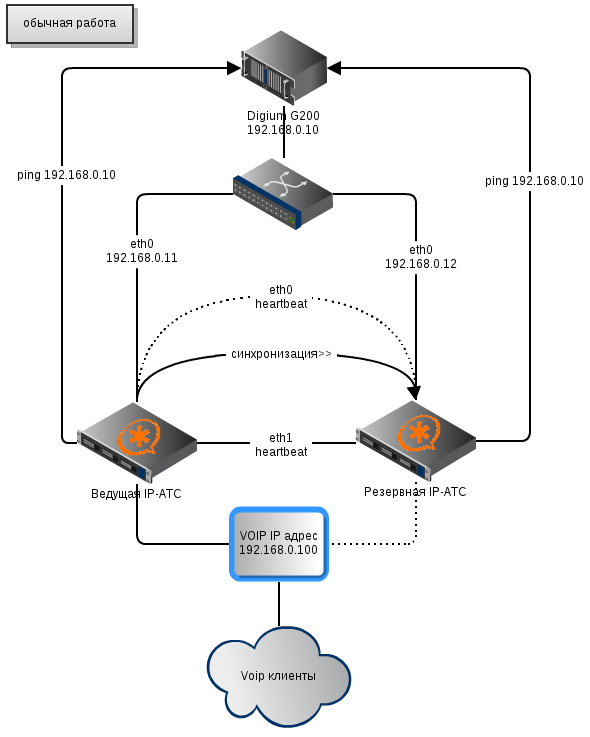
Резервирование серверов (кластеры)
В подобных случаях применяется резервирование сервера целиком. C помощью специального программного обеспечения несколько серверов объединяются в единую систему. В случае аварии на одном из них, его нагрузка перекладывается на другие, входящие в систему. Такая организация называется кластером высокой доступности (high availability cluster, HA-кластер).
В простейшем и самом распространённом случае система состоит из двух серверов (так называемый двухузловой кластер), один из которых является основным, а другой —дублирующим, резервным (конфигурация active/passive). Все вычисления производятся на основном сервере, а дублирующий сервер включается в работу в случае аварии на основном. Такая конфигурация является затратной, так как каждый узел дублируется. На схеме ниже показана конфигурация active/passive, состоящая из нескольких (N) серверов.
Конфигурация Active/Passive
В другом варианте построения кластера серверы (два или больше) могут иметь равноценный статус, то есть работать одновременно (конфигурация active/active). В такой конфигурации нагрузка вышедшего из строя сервера распределяется по остальным серверам кластера. Если серверов в кластере немного, то скорее всего произойдёт снижение производительности, так как нагрузка на оставшиеся в кластере серверы возрастёт.
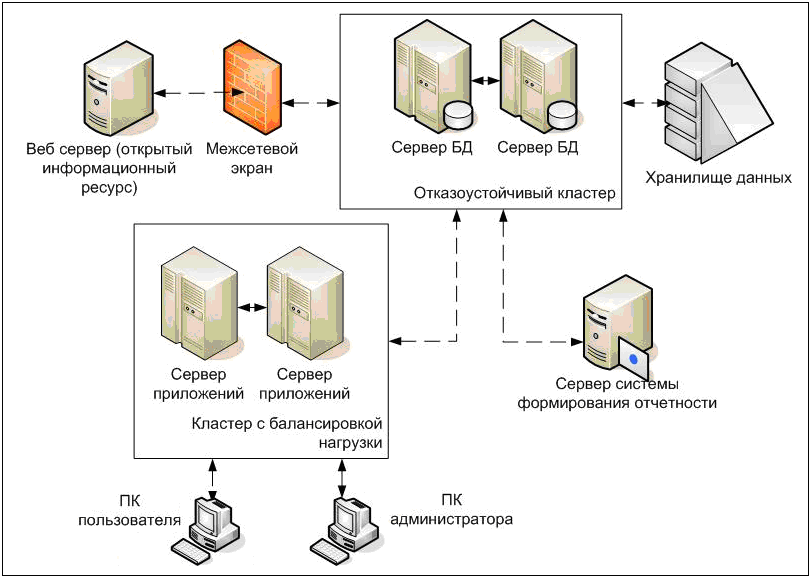
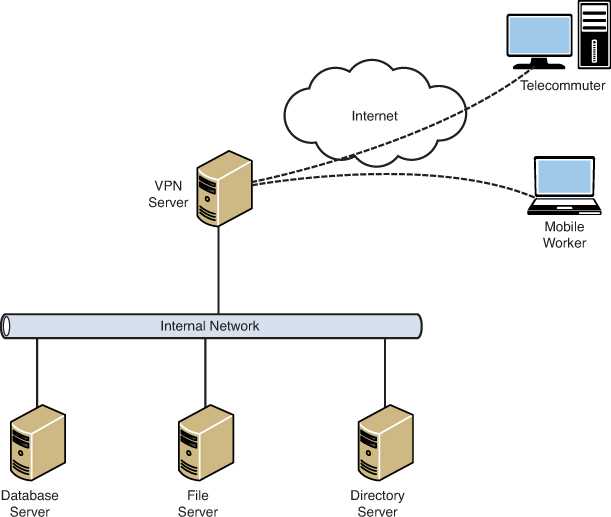
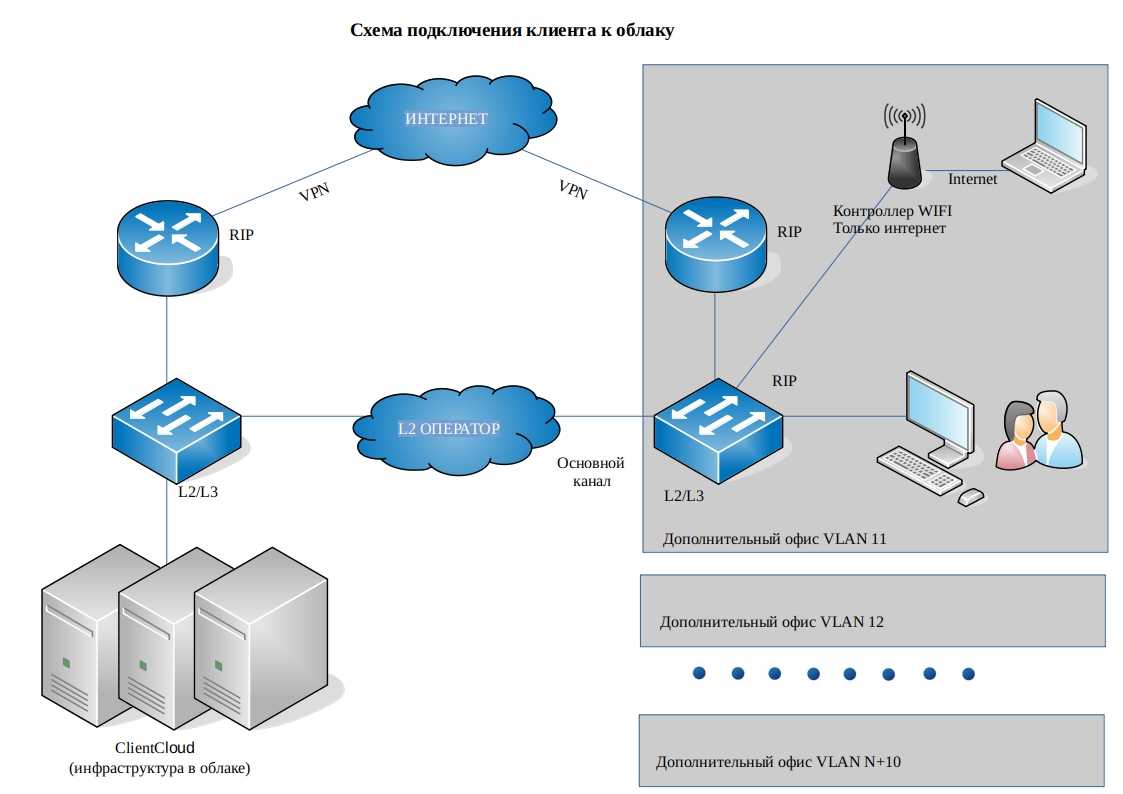
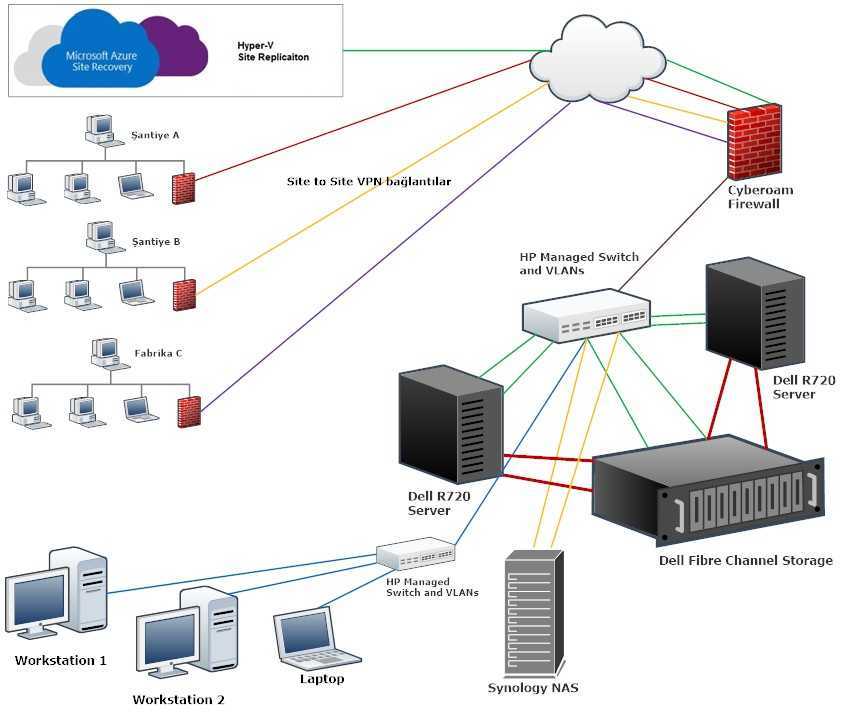
Конфигурация Active/Active
Здесь стоит заметить, что в конфигурации active/passive (которая имеет полное резервирование каждого узла) такого снижения не будет. Однако этот вариант стоит дороже, так как каждый узел дублируется. Фактически, за отказоустойчивость и отсутствие потери производительности всегда приходится платить двойную цену.
Третьим, альтернативным вариантом, который позволяет избежать как высоких расходов, так и потери производительности кластера при отказе одного из узлов, является конфигурация N+1. В этой конфигурации кластер имеет один полноценный резервный сервер, который при работе в обычном режиме не несёт на себе никакой нагрузки, а включается в работу только в случае отказа одного из активных серверов.
Конфигурация N+1
Краткое сравнение конфигураций сведено в таблицу ниже. Стоит отметить, что кроме описанных трех, бывают и другие, более сложные конфигурации отказоустойчивых кластеров. Например, N+M – когда для обеспечения более высокого уровня отказоустойчивости в состав кластера включается не один, а несколько резервных серверов.
|
Active/Active |
Active/Passive |
N+1 |
|
|
Стоимость решения |
Нормальная (суммарная стоимость всех узлов; все узлы кластера работают) |
Высокая (фактически – двойная, т.к. дублируются все узлы кластера) |
Нормальная + 1 (суммарная стоимость всех узлов + 1 резервный узел) |
|
Производи-тельность при отказе |
Снижение производительности |
Нет снижения производительности |
Нет снижения производительности |



