Oracle 12с
Oracle 12с — это система управления реляционными базами данных, разработанная и управляемая корпорацией Oracle. В настоящее время онa поддерживает несколько моделей данных, таких как документ, график, реляционные и ключевые значения в одной БД. Последние версии переориентированы на облачные вычисления. Лицензирование Oracle database engine полностью запатентовано, доступны как бесплатные, так и платные опции. Наравне с SQL СУБД использует процедурное расширение под названием PL/SQL, а также язык Java.Плюсы Oracle 12с1) Инновации для ежедневного рабочего процесса. Начиная с выпуска Oracle 12c, когда программное обеспечение вступило в эру гибридных облаков, регулярно появлялись новые технологии облачных вычислений
С каждым новым выпуском Oracle старается идти в ногу с инновационными тенденциями, уделяя особое внимание информационной безопасности, включая активную защиту данных, разделение, улучшенное резервное копирование и восстановление.2) Сильная техническая поддержка и документация. Oracle обеспечивает достойную поддержку клиентов и предоставляет полную техническую документацию по нескольким ресурсам
Таким образом, найти решения любых возникающих проблем достаточно легко. Можно рассчитывать на некоторую поддержку сообщества.3) Большая вместимость. Многомодельное решение Oracle позволяет размещать и обрабатывать огромное количество данных. В сочетании с возможностями обработки данных в памяти создается мощный механизм для синхронной обработки данных.Минусы Oracle 12с1) Высокая стоимость. Хотя эта СУБД имеет бесплатные версии, они очень ограничены по функциональности. Стандартная версия стоит более 1 миллиона рублей, корпоративная — более 3 миллионов рублей.2) Ресурсоемкая технология. СУБД Oracle нуждается в мощной инфраструктуре. Установка не только требует много места на диске, но и постоянную модернизацию аппаратной части.3) Высокий порог вхождения. Быстро обучиться эксплуатации не получится. Для запуска лучше приглашать сертифицированных инженеров Oracle DB. Документация Oracle, хотя и охватывает множество вопросов, иногда может привести в тупик.Учитывая все эти преимущества и недостатки, вы можете рассматривать Oracle 12с как разумное решение для онлайн-OLTP, хранилища данных и даже смешанного (OLTP и DW) приложения для баз данных. Если имеется миллиард записей для хранения и управления и достаточный бюджет для его поддержки – программное обеспечение Oracle hybrid cloud является хорошим вариантом выбора.
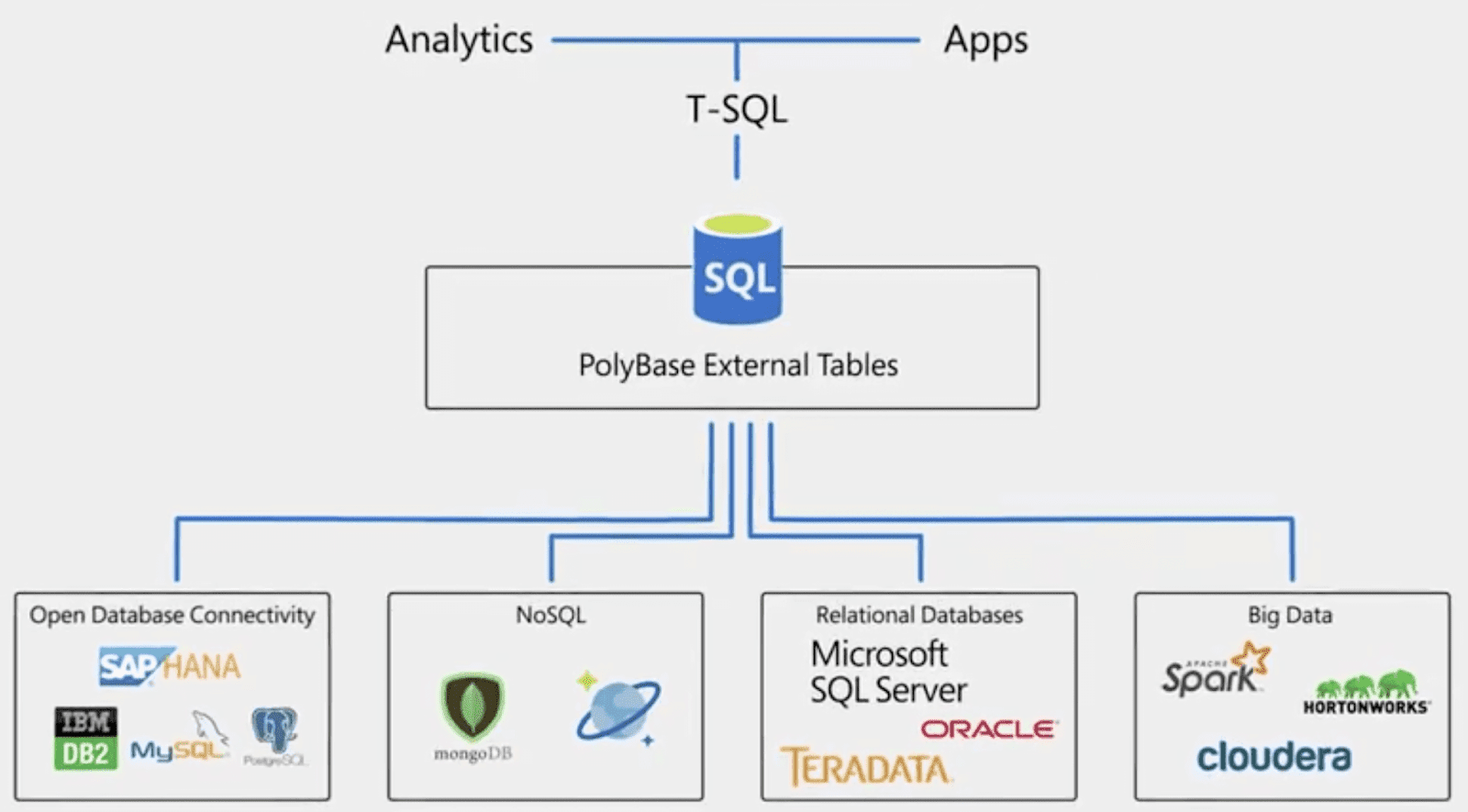
Ограничения реляционных СУБД
Реляционные СУБД просты, удобны и предсказуемы. А их рынок один из самых консервативных в IT-отрасли. Поэтому даже при появлении множества NoSQL реляционные базы остаются самым востребованным инструментом в очень разных отраслях.
По данным DB-Engines за февраль 2021 года, мировая доля реляционных СУБД составляет 74% от всех:

Однако реляционные БД не лишены недостатков.
Масштабируемость
Реляционную базу данных трудно масштабировать горизонтально, то есть распределять таблицы по разным серверам. В этом случае очень сложно строить запросы и связывать таблицы.
Поэтому растущую базу приходится помещать на более мощный и дорогой сервер, то есть масштабировать вертикально.
Но возможности даже самой мощной машины ограничены, поэтому реляционные базы плохо приспособлены для хранения действительно больших данных.
Сложность
Из-за нормализации реляционная база данных имеет сложную структуру. А скорость обработки запроса зависит от числа таблиц, к которым запрос обращается.
Представьте себе, что таблиц 100, 200, 1000, — СУБД будет работать медленно, а код запроса будет очень громоздким.
Как начать работу с MongoDB
- Скачать MongoDB на официальном сайте проекта, где компания представляет СУБД и другие решения, в том числе коммерческие. Можно воспользоваться официальным репозиторием MongoDB на GitHub или пакетным менеджером. В macOS это brew, в Linux — apt-get и другие.
- Скачать MongoShell — шелл-оболочку, которая позволяет отдавать команды. Она скачивается отдельно и тоже есть на официальном сайте.
- Установить MongoDB и шелл-оболочку на сервер, где будет храниться база. В реальных проектах обычно это арендованные на хостингах мощности. Создать тестовую базу данных для тренировки можно и на собственном устройстве.
Взаимодействие с базой обычно происходит через терминал. Можно подключить модули для поддержки разных языков программирования, но по умолчанию язык запросов для MongoDB — это JavaScript. Операторы, с помощью которых управляют базой данных MongoDB, основаны на нем.
Какие реляционные БД популярны в веб-разработке
MySQL
Это открытая СУБД, купленная Oracle в придачу к Sun Microsystems. С ней работают более половины (55,6%) всех разработчиков (по опроса, который в 2020 году провёл сайт StackOverflow.com среди 65 тысяч респондентов).
Главные её преимущества — бесплатность и высокая скорость работы с данными. MySQL создавалась для обработки огромных массивов информации в промышленных масштабах, но благодаря доступности и быстродействию оккупировала Всемирную паутину, заслужив звание «СУБД всея интернета». И сегодня MySQL всё ещё самая удобная СУБД для работы с интернет-страницами и веб-приложениями.
MySQL пользуется мощной поддержкой у создателей языков программирования: практически во всех популярных языках есть интерфейс для работы с ней.
SQLite
Эта СУБД использует большую часть стандартного языка SQL.
Главное преимущество SQlight — встраиваемость. Это объясняется тем, что SQlight не приложение типа «клиент-сервер» (в отличие от других реляционных СУБД), а библиотека, которую подключают непосредственно к программе.
И она тоже весьма популярна: достаточно сказать, что SQLite есть в каждом смартфоне. Например, в смартфонах на Android там хранятся контакты и медиа, а в iOS её используют многие приложения.
PostgreSQL
Её можно назвать самой продвинутой. Это не просто реляционная, а объектно-реляционная свободная СУБД.
PostgreSQL поддерживает не только типы данных, которые есть в других реляционных СУБД. Помимо числовых, текстовых, булевых и других стандартных типов, в ней можно хранить и обрабатывать геометрические и денежные данные, сетевые адреса, JSON, XML, массивы, а также создавать собственные типы данных.
Особенности реляционных баз данных
Что же делает реляционную БД именно реляционной?
Схема БД. В нее входят набор таблиц, их атрибуты и отношения между ними. Также здесь есть Primary Key, Foreign Key и т.д



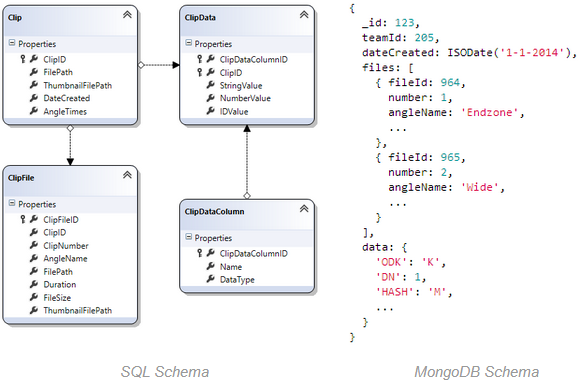



Эту схему важно знать заранее, потому что без этого невозможно положить в БД какие-либо данные.
Нормальные формы. Если сделать базу данных как одну огромную таблицу со всеми данными, то это будет работать очень плохо
Данные нужно разбить на меньшие таблицы и создать связи между ними. Для этого и есть обычные формы. На них строятся реляционные базы данных.
ACID-транзакции. Осмелюсь сказать, что это самое важное в описанном типе баз данных. Название ACID происходит от Atomicity (атомарность), Consistency (последовательность), Isolation (отделенность) и Durability (долговечность). В реляционной системе БД существует транзакционный механизм, в результате которого набор запросов или набор операций по БД по истечении сохранит все эти данные. При этом только тогда все данные будут согласованы между собой, а доступ к ним будет даже при падении всей системы.
Эти принципы помогают хорошо организовать работу с базами данных, сделать ее проще и понятнее. Именно поэтому реляционные базы данных так популярны.
Хранилище данных объектов
Хранилища данных объектов оптимизированы для хранения и извлечения больших двоичных объектов, например изображений, текстовых файлов, видео- и аудиопотоков, объектов данных и документов приложений большого размера, образы дисков виртуальных машин. Объект состоит из сохраненных данных, метаданных и уникального идентификатора доступа к объекту. Хранилища объектов поддерживают отдельные большие файлы, а также позволяют управлять всеми файлами за счет внушительного общего объема хранилища.
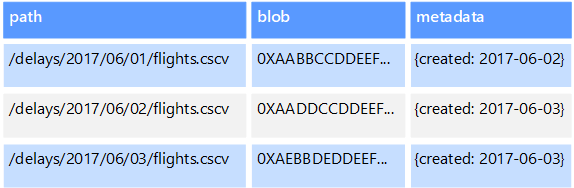
Некоторые хранилища данных объектов реплицируют определенный большой двоичный объект между несколькими узлами кластера, что обеспечивает быстрое параллельное чтение. Этот процесс, в свою очередь, позволяет реализовать масштабируемую архитектуру запроса данных, хранящихся в больших файлах, так как несколько процессов, обычно выполняющихся на разных серверах, могут одновременно запрашивать большие файлы данных.
Часто хранилища данных объектов используют как сетевые общие папки. Доступ к файлам, хранящимся в этих папках, можно получить через компьютерную сеть с использованием стандартных сетевых протоколов, например SMB. Если созданы необходимые механизмы поддержки безопасности и одновременного доступа, такое совместное использование данных позволяет распределенным службам с высокой степенью масштабируемости предоставлять доступ к данным для базовых низкоуровневых операций, то есть для простых запросов на чтение и запись.
Соответствующие службы Azure:
- Хранилище BLOB-объектов Azure
- Azure Data Lake Storage
- Хранилище файлов Azure
NuoDB
Создатели NuoDB решили сделать развертывание кластера в облаке приятным и необременительным занятием. Кажется, удалось это им не очень. Зато уровень рекламного буллшита в документации зашкаливает. Это проприетарная СУБД, написанная преимущественно на Java. Первый релиз состоялся в январе 2013-го. Начнем с типов узлов, точнее, типов процессов, которые запускаются в кластере (в терминологии NuoDB — домене). Есть один брокер — основной процесс, который собирает домен в единое целое. К нему клиент подключается в первую очередь и узнает о конфигурации домена. На каждом узле запущены агенты, которые общаются с брокером и докладывают о состоянии узлов. База данных создается через брокер, в нее входит один или более движков транзакций (Transaction Engine) и один или более менеджеров хранения (Storage Manager). К первому подключаются клиенты для выполнения запросов, второй отвечает за хранение данных. При создании БД задается, сколько именно должно быть создано движков и менеджеров и на каких именно узлах домена они должны быть расположены.
 Распределение ролей в кластере NuoDB
Распределение ролей в кластере NuoDB
Все это можно настроить через довольно удобную веб‑админку, с красивым логотипом в виде зеленой птички. Однако на практике не все так просто. Это единственная БД в обзоре, которой понадобился корректно работающий DNS (или правильные /etc/hosts). Узел идентифицирует себя по доменному имени, другие узлы должны иметь возможность подключиться к нему по этому имени.
Внезапно — шардинга здесь нет. Хоть репликация есть, и на том спасибо. Все данные в БД дублируются на все менеджеры хранения данной БД. Утверждается, что БД остается частично работоспособной при падениях брокера, агента и даже движков транзакций и менеджера хранения. В качестве разнообразия можно настроить хранение данных в хадуповой HDFS (ну хоть тут появляется какой‑то шардинг).
Никакой совместимости на уровне протокола нет, JDBC-драйвер — свой уникальный. Было бы понятно, если бы это была какая‑то консолька по развертыванию кластера обычных СУБД (вроде Amazon RDS). А так, в чем смысл существования NuoDB? Несмотря ни на что, в NuoDB нормальная реализация транзакций: база поддерживает уровни изоляции от read committed до serializable (по умолчанию repeatable read), обеспечивает атомарность многопроцедурных транзакций.
Нет шардированных таблиц — нет проблем с ограничениями уникальности и ссылочной целостности. Присутствуют все привычные для реляционных баз констрейнты. В целом все как у людей — разграничение прав доступа, оптимизатор запросов на основе статистики, B-tree индексы. Обычный SQL двадцатилетней давности. Непонятно, что здесь нового.
Архивация данных
Чаще всего при архивации данных применяются NoSQL хранилища, поскольку известно, что не потребуются нормализация или соответствие требованиям ACID.
Выбор СУБД для анализа данных зависит от множества факторов, например, от типа данных, которые вы анализируете, от их количества и необходимой скорости доступа.
Например, реляционная база данных лучше всего подходит для приложений вроде анализа поведения пользователей. Если данные помещаются в электронную таблицу, то все еще лучше выбрать реляционную базу данных, такую как Postgres или BigQuery. Выбор объясняется тем, что реляционные СУБД хорошо анализируют данные в строках и столбцах.
Простая транзакция
- Блокируем альбом по ключу.
- Создаем запись в таблице фотографий.
- Если у фотографии публичный статус, то накручиваем в альбоме счетчик публичных фотографий, обновляем запись и коммитим транзакцию.
ACIDEventual Consistency
- При отказе дата-центра должны быть доступны и чтение, и запись в новое хранилище.
- Сохранение текущей скорости разработки. То есть при работе с новым хранилищем количество кода должно быть приблизительно тем же самым, не должно появляться необходимости дописывать что-то в хранилище, разрабатывать алгоритмы разрешения конфликтов, поддержания вторичных индексов и т.п.
- Скорость работы нового хранилища должна быть достаточно высокой, как при чтении данных, так и при обработке транзакций, что эффективно означало неприменимость академически строгих, универсальных, но медленных решений, как, например, двухфазных коммитов.
- Автоматическое масштабирование на лету.
- Использование обычных дешёвых серверов, без необходимости покупки экзотических железяк.
- Возможность развития хранилища силами разработчиков компании. Иными словами, приоритет отдавался своим или основанным на открытом коде решениям, желательно на Java.
А что там внутри. Пример нормализации
Разберём устройство реляционной БД подробнее на примере. Позже это поможет нам понимать и сравнивать базы разных типов.
Допустим, у нас есть база данных, в которой всего одна таблица — Messages. В ней хранится информация о телефонных разговорах клиентов и операторов компании по ремонту техники.
Каждая строка этой таблицы содержит данные о звонке клиента по его проблеме и ответ оператора, а также дату обращения.
Телефон у компании многоканальный. Поэтому одному и тому же оператору могут звонить разные клиенты, а один и тот же клиент может попадать на разных операторов с разными вопросами.
Список использованных источников
- https://works.doklad.ru/view/4aUsIAPwaFE.html#:~:text=%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0%20%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5%20%D0%B1%D0%B0%D0%B7%D0%B0%D0%BC%D0%B8%20%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85%20(%D0%A1%D0%A3%D0%91%D0%94,%D1%80%D0%B0%D0%B7%D0%BB%D0%B8%D1%87%D0%B0%D1%8E%D1%82%20%D0%BF%D0%BE%20%D0%B8%D1%81%D0%BF%D0%BE%D0%BB%D1%8C%D0%B7%D1%83%D0%B5%D0%BC%D0%BE%D0%B9%20%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D0%B8%20%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
- https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B1%D0%B0%D0%B7%D0%B0%D0%BC%D0%B8_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
- http://www.bseu.by/it/tohod/lekcii5_3.htm
- https://works.doklad.ru/view/ypE_dGE0e-k.html
- https://works.doklad.ru/view/NXW7YhSUk1k.html
- https://xreferat.com/33/2525-1-sistema-upravleniya-bazami-dannyh.html
- Политика безопасности в сетях и Интернет.
- 3D принтеры
- Искусство ведения переговоров
- Операции с документами. Офисный софт.
- Особенности перевода текстов официально-делового и научного стилей
- Объект графического дизайна
- Компьютерный вирус
- Административно-правовые гарантии прав граждан
- Источники административного права
- Иллюстрации и их значение в книжном издании
- Линейное и тоновое изображение трехмерных геометрических тел
- Лидерами рождаются или становятся
Столбчатые хранилища данных
Столбчатое хранилище данных или хранилище семейств столбцов упорядочивает данные по столбцам и строкам. Столбчатое хранилище данных в простейшей форме почти неотличимо от реляционной базы данных, по крайней мере организационно. Настоящее преимущество столбчатого хранилища данных заключается в способности денормализованно структурировать разреженные данные, что связано со столбцово-ориентированным методом хранения данных.


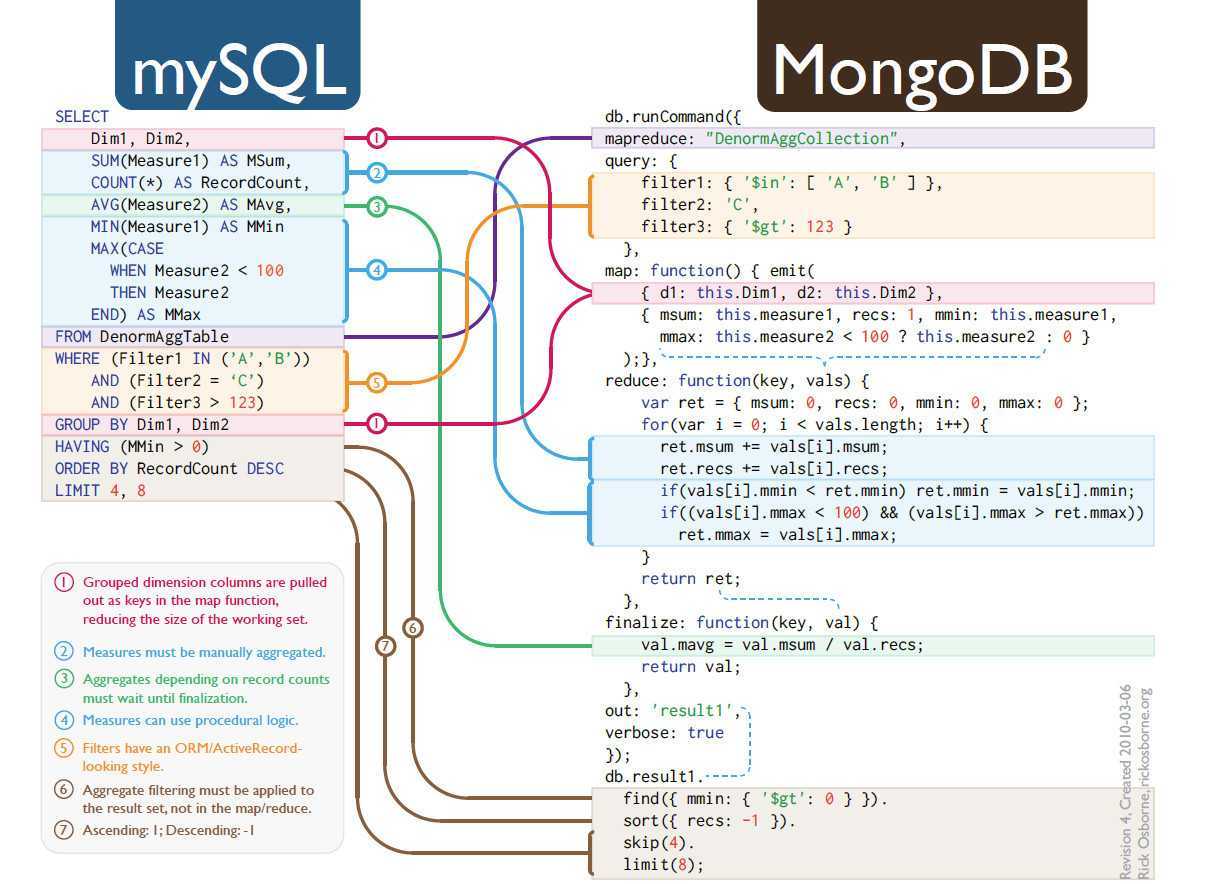





Столбчатое хранилище данных можно представить как набор табличных данных со строками и столбцами, в которых столбцы разделяются на определенные группы или семейства столбцов. Каждое семейство столбцов включает набор логически связанных столбцов, которые обычно извлекаются или управляются как единое целое. Другие данные, которые используются в других процессах, хранятся отдельно в других семействах столбцов. В семейство столбцов можно динамически добавить новые столбцы, а строки могут быть разреженными (то есть строки не обязаны иметь значение для каждого столбца).
На следующей диаграмме представлен пример таблицы с двумя семействами столбцов: и . Данные одной сущности имеют одинаковые ключи строк во всех семействах столбцов
Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории хранилищ. Семейства столбцов очень хорошо подходят для хранения данных с различными схемами

В отличие от хранилища пар «ключ — значение» и баз данных документов, большинство столбчатых баз данных упорядочивают хранимые данные с помощью самих значений ключей, а не хэш-кодов от них. Ключ строки рассматривается как первичный индекс и обеспечивает доступ на основе определенного ключа или их диапазона. Некоторые реализации позволяют создавать вторичные индексы по определенным столбцам в семействе столбцов. Вторичные индексы позволяют получать данные по значениям столбцов, а не ключам строки.
Все столбцы одного семейства хранятся на диске в одном файле. Каждый файл содержит определенное число строк. При использовании больших наборов данных этот подход позволяет повысить производительность за счет снижения объема данных, которые необходимо считывать с диска, когда отправляется запрос на получение нескольких столбцов за раз.
Чтение и запись строки из одного семейства столбцов — это обычно атомарные операции. Однако некоторые реализации поддерживают атомарность всей строки, распределенной по нескольким семействам столбцов.
Соответствующие службы Azure:
- Azure Cosmos DB для Apache Cassandra
- Использование HBase в HDInsight
Хранилища данных внешних индексов
Хранилища данных внешних индексов позволяют искать информацию, содержащуюся в других хранилищах данных и службах. Внешний индекс выступает в роли вторичного индекса любого хранилища данных. Кроме того, с его помощью можно индексировать большие объемы данных и предоставлять доступ к этим индексам почти в реальном времени.
Например, в файловой системе могут храниться текстовые файлы. По пути файл можно найти быстро, но поиск на основе содержимого выполняется медленно, так как сканируются все файлы. Внешний индекс позволяет создавать вторичные индексы, а затем быстро искать путь к файлам, соответствующим заданным условиям. Рассмотрим еще один пример использования внешнего индекса. Предположим, что хранилища пар «ключ — значение» поддерживают индексирование только по ключу. Вы можете создать вторичный индекс на основе значений данных и быстро найти ключ, однозначно определяющий каждый соответствующий элемент.

Индексы создаются в процессе индексирования, который может выполняться по модели извлечения, то есть по требованию хранилища данных, или по модели передачи, то есть по команде из кода приложения. В некоторых системах поддерживаются многомерные индексы и полнотекстовый поиск по большим объемам текстовых данных.
Часто хранилища данных внешних индексов используют для реализации полнотекстового поиска и поиска в Интернете. В этих случаях поддерживается точный или нечеткий поиск. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором. Некоторые внешние индексы также поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, при поиске по запросу «собаки» соответствием считается «питомцы») и морфологии (например, при поиске по запросу «бег» соответствием считается «бегущий»).
Соответствующие службы Azure:
Поиск Azure
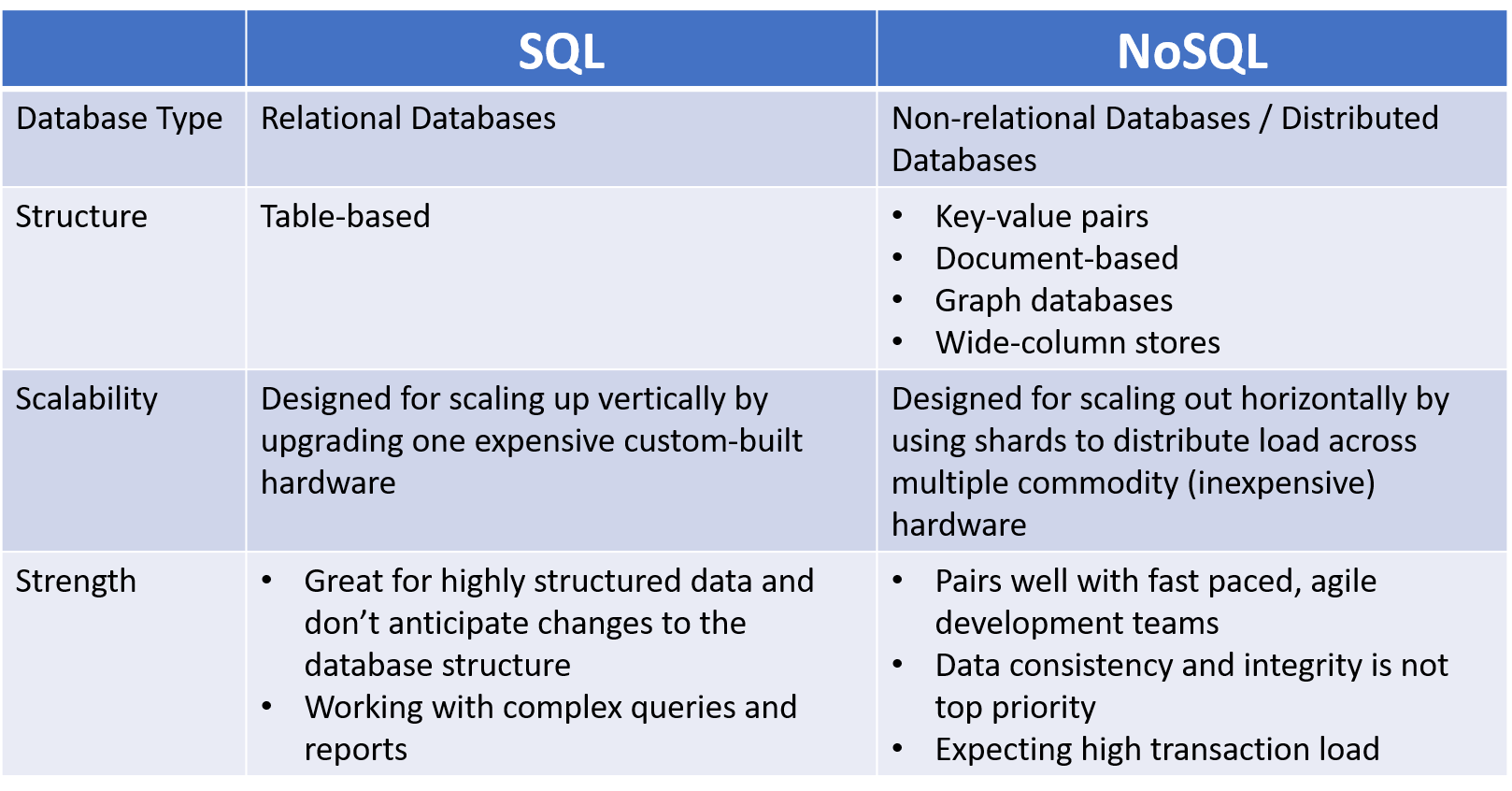
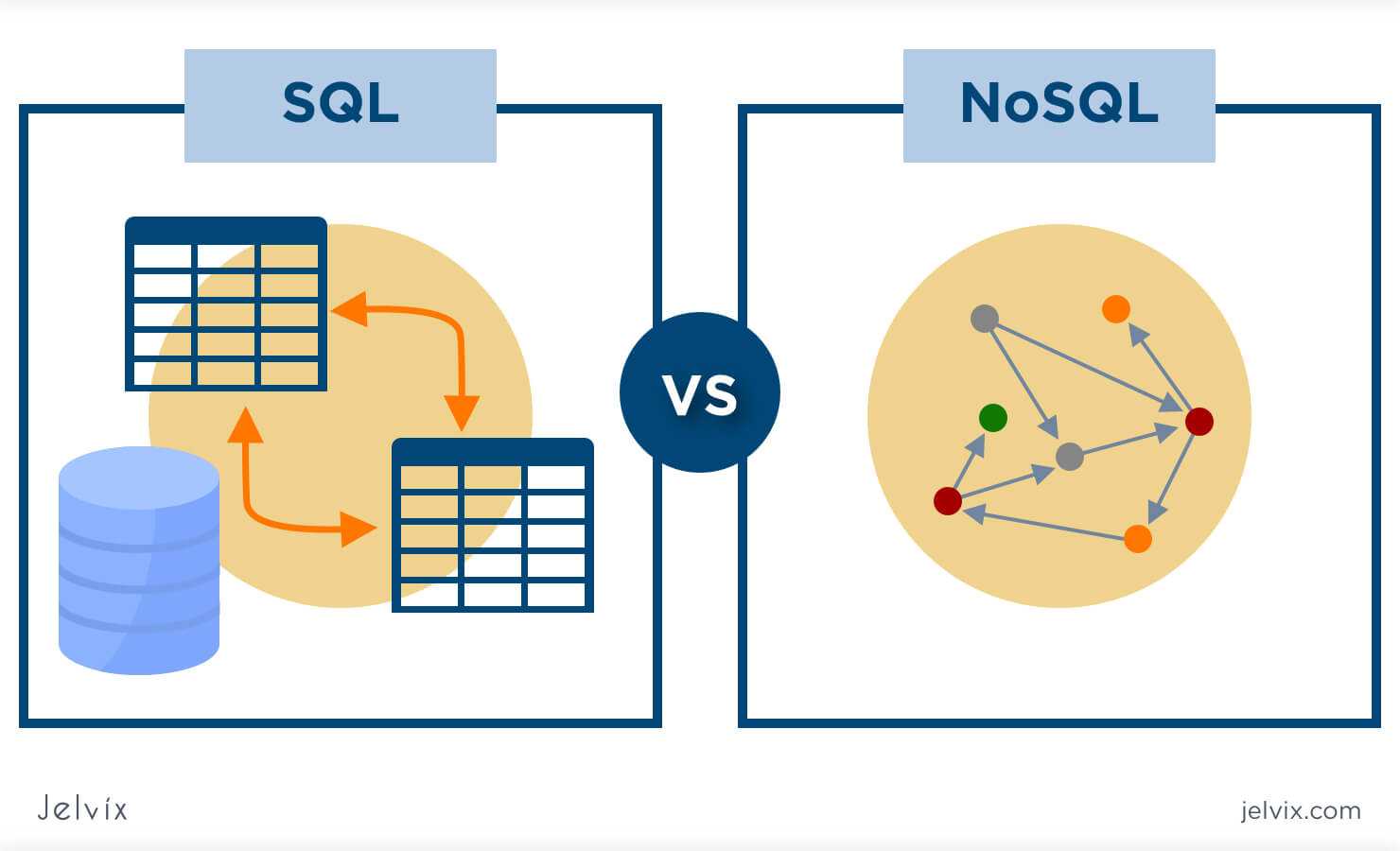
Подводим итоги: сравниваем реляционную и нереляционную БД
 Чтобы понять, какой вид технологии предоставляет больше возможностей для бизнеса, выполним некоторое сравнение баз данных на основе реляционных и нереляционных систем:
Чтобы понять, какой вид технологии предоставляет больше возможностей для бизнеса, выполним некоторое сравнение баз данных на основе реляционных и нереляционных систем:
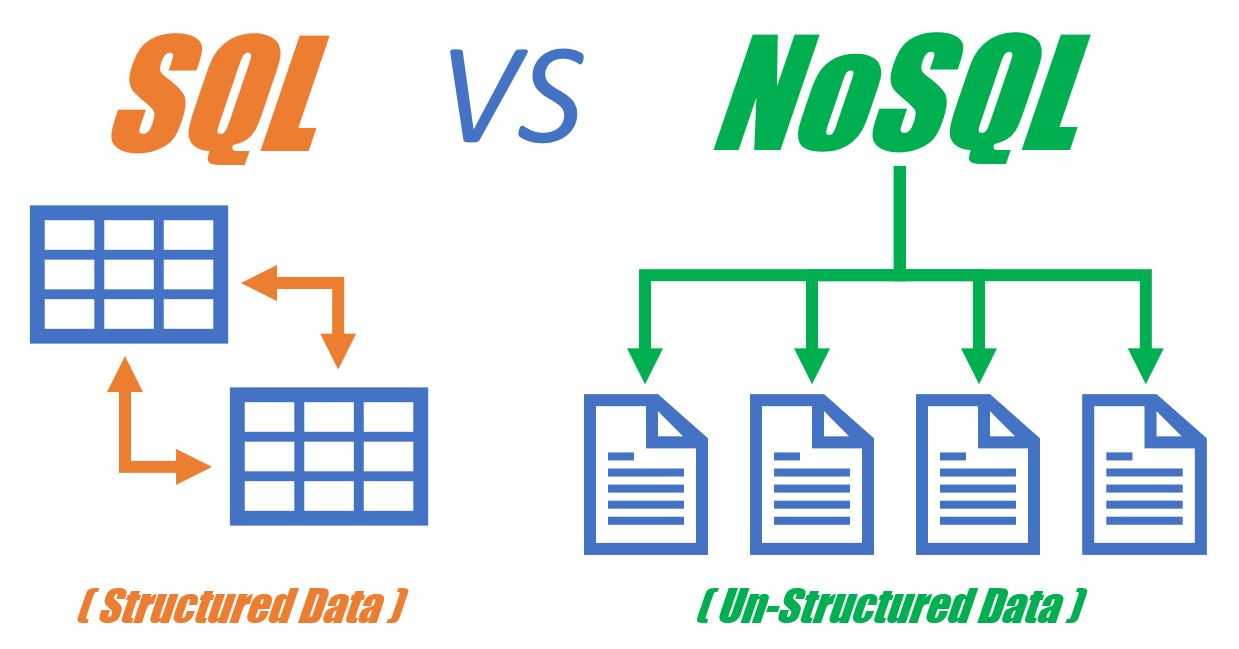
- Структура и тип данных. SQL требует жесткой структуризации на основании шаблонов. В NoSQL по отношению к структуре не предъявляется никаких требований.
- Масштабируемость. В SQL предусмотрено вертикальное масштабирование. В NoSQL можно использовать и вертикальное, и горизонтальное. Но второй вариант более простой и практичный.
- Запросы. В реляционных системах получить данные можно при помощи языка SQL. А вот в каждой NoSQL-базе предусмотрен свой алгоритм работы.
- Надежность. SQL более простые и удобные в последующей работе благодаря своей структуризации. NoSQL имеет высокую защиту от хакерских атак.
- Работа с данными сложных структур. Здесь первенство у реляционных БД, что также связано с наличием строгой структуры.
- Поддержка. БД SQL существуют намного дольше нереляционных аналогов, пользуются повышенной популярностью. То есть получить их поддержку достаточно просто. А вот NoSQL пока не в таком почете, особенно работают в сложных структурах.
Выводы
NoSQL БД разделились на две группы: быстрые и медленные. Быстрыми, как, собственно, и ожидалось, оказались key-value БД. Aerospike и Couchbase сильно опережают соперников.
Aerospike действительно очень быстрая БД. И нам почти получилось дойти до миллиона операций в секунду (на данных в памяти). Aerospike весьма неплохо работает и на SSD, особенно если учитывать, что Aerospike в этом режиме не использует кеширование данных в памяти, а на каждый запрос обращается к диску. Значит, в Aerospike действительно можно поместить большое количество данных (пока хватит дисков, а не ОЗУ).
Couchbase быстр, но быстр только на операциях в памяти. На графиках с тестами SSD показана скорость работы Couchbase на объеме данных лишь чуть больше объема ОЗУ — всего 200 миллионов записей. Это заметно меньше 500 миллионов, с которыми тестировались другие БД. В Couchbase просто не удалось вставить больше записей, он отказывался вытеснять кеш данных из памяти на диск и прекращал запись (операции записи завершались с ошибками). Это хороший кеш, но лишь для данных, помещающихся в ОЗУ.
Cassandra — единственная БД, которая пишет быстрее, чем читает :). Это оттого, что запись в ней успешно завершается (в самом быстром варианте) сразу после записи в журнал (на диске). А вот чтение требует проверок, нескольких чтений с диска, выбора самой свежей записи. Cassandra — это надежный и довольно быстрый масштабируемый архив данных.
MongoDB довольно медленна на запись, но относительно быстра на чтение. Если данные (а точнее, то, что называют working set — набор актуальных данных, к которым постоянно идет обращение) не помещаются в память, она сильно замедляется (а это именно то, что происходит при тестировании YCSB). Также нужно помнить, что у MongoDB существует глобальная блокировка на чтение/запись, что может доставить проблем при очень высокой нагрузке. В целом же MongoDB — хорошая БД для веба.
Заключение и рекомендации
Существует большое количество СУБД, не вошедших в настоящий обзор ввиду его ограниченного объема. В частности, есть СУБД с впечатляющими техническими характеристиками отечественной разработки, которые не вошли в данную статью, т.к. не являются популярными в глобальном плане. Статья является сравнительным обзором самых часто используемых реляционных СУБД, нереляционные планируется описать в следующей работе. Каждая СУБД по-своему хороша, но имеет и некоторые недостатки.


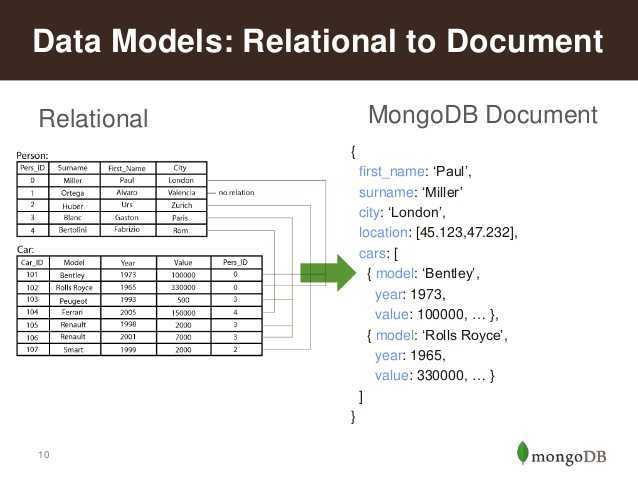

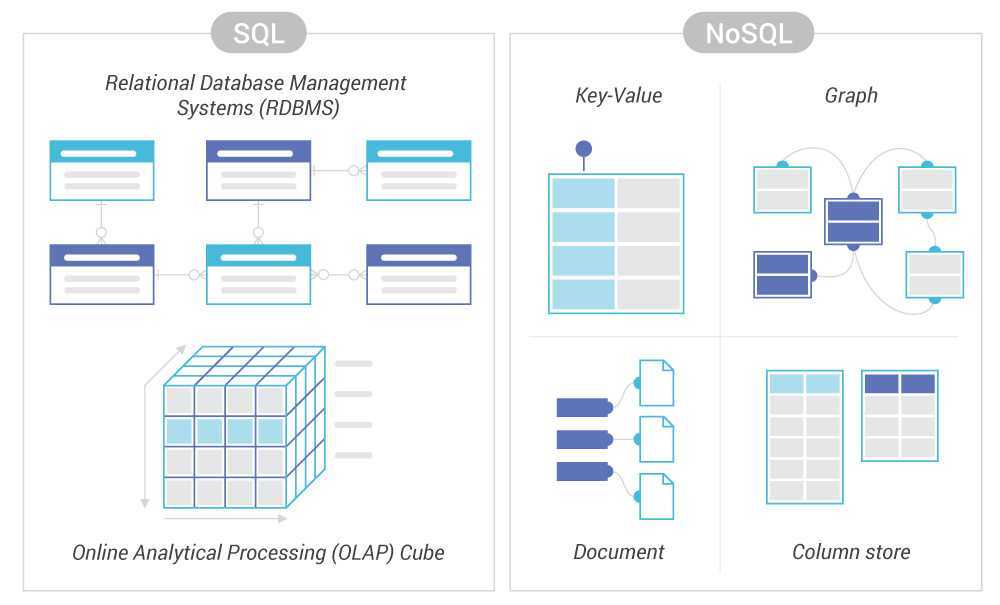
Однозначно посоветовать правильный выбор для новых проектов или для будущего перехода не представляется возможным. Попробуем в общих чертах дать рекомендации по выбору.Если открывается новый ресурс электронной коммерции, СУБД, такие как MySQL, могут стать разумной отправной точкой, которые хорошо зарекомендовали себя для веб-сайтов, веб-сервисов и систем OLTP.
В дополнение к области применения приложений для хранения данных, MSSQL также заслуживает упоминания, особенно для компаний, привыкших работать в экосистеме Microsoft. С точки зрения создания OLTP-решения и приложений для хранения данных, СУБД Oracle также является оправданным выбором.
Конечно, есть и другие СУБД, которые следует рассмотреть. Все зависит от бизнес-модели и бизнес-потребностей.
Вполне возможно, лучшей рекомендацией будет следующая: в общем случае, выбирайте ту СУБД, которую вы лучше всего знаете, и с которой наиболее приятно работать.
Существует и немного иная точка зрения. Выбор СУБД зависит в том числе и от того, что за приложение планируется разработать. То есть, грубо говоря, систему управления базами данных выбирают не разработчики, а сам продукт.
Если необходимо преодолеть технические ограничения реляционных СУБД, следует обратить внимание на нереляционные — об этом будет рассказано в следующей статье.