
Установка и начало
Чтобы упростить весь процесс, я буду использовать онлайн-интерпретатор: Корнелльского университета.
Посмотрите на скриншот. Оранжевый кружок внизу показывает простую программу, содержащую одну инструкцию, складывающую два числа, содержащихся в регистрах и , и помещающая результат в.
Регистры — это ячейки памяти внутри микропроцессора. Микропроцессор не может напрямую выполнять операции с данными, сохранёнными в памяти (ОЗУ). Он должен загрузить данные в регистр перед тем, как выполнить операцию.
С правой стороны вы можете видеть список регистров. Второй столбец, названный Register отображает имя регистра. В первом столбце мы устанавливаем начальное значение регистра. Регистры, выделенные оранжевым, регистры и устанавливаются в значения 3 и 4 соответственно.
Нажмите зелёную кнопку Run для записи программы. Она складывает регистры и и сохраняет результат в x3. Я уже запустил программу, и вы можете видеть значение 7 регистра в столбце Decimal.
Вы можете скопировать программу побольше и попробовать запустить. Входная величина помещается в регистр. Это значение, от которого счётчик начинает считать вниз. Запишите в этот регистр, например, , записав в колонку Init Value.
Вы можете видеть, как происходит счёт назад, в колонке Decimal для регистров или памяти. Обратный счёт происходит во второй колонке в памяти по адресу 0x04.
Перед запуском вы должны установить CPU на 2 Hz. При этом будет выполняться две инструкции в секунду. Если процессор будет работать быстрее, вы не сможете следить за тем, что происходит. После этого нажимаете зелёную кнопку Run. При работе программы вы можете видеть, как она печатает в окне внизу, какая строка кода исполняется.
Чтобы запустить программу заново, нажмите синюю кнопку Reset. Сейчас вы знаете основы: как вставить программу, ввести данные и запустить её. Итак, сейчас мы обсудим микропроцессор RISC-V и то, как он программируется.
Миф 4: RISC-V использует устаревшую векторную обработку вместо современных SIMD-инструкций
Некоторые люди в лагере ARM хотят создать впечатление, что дизайнеры RISC-V застряли в прошлом и не в курсе последних достижений микропроцессорной архитектуры. Дизайнеры RISC-V решили использовать векторную обработку вместо SIMD (Single Instruction Multiple Data). Ранее это было популярно в старых суперкомпьютерах Cray. Позднее SIMD были добавлены в x86-процессоры для мультимедийных приложений.
Может показаться, что SIMD — это более новая технология, но это не так. SIMD впервые появились на компьютере Lincoln TX-2, используемом для реализации первого графического интерфейса под названием Sketchpad, созданного Иваном Сазерлендом.
Векторная обработка в суперкомпьютере Cray была гораздо более продвинутым способом обработки множества элементов данных. Причина, по которой эти машины впали в немилость, заключалась в том, что суперкомпьютеры производились в штуках, и обычные ПК просто превзошли их в количестве.
SIMD были добавлены в x86-процессоры довольно хаотично, без планирования, для получения небольшого повышения скорости в работе с мультимедиа.
SIMD проще, чем набор команд для настоящей векторной обработки. Однако с расширением возможностей SIMD и увеличениями их длины мы получили нечто более сложное, чем векторная обработка. Нечто неряшливое и негибкое.
Факт, что Cray использовал векторную обработку в 1980-х годах, не означает, что векторная обработка — устаревшая технология. Это все равно, что сказать, будто колесо — это устаревшая технология, потому что оно давненько появилось.
Векторная обработка стала актуальной, потому что от нее выигрывает машинное обучение, продвинутая графика и обработка изображений. Это области, в которых нужна производительность. И ребята из RISC-V не единственные, кто это понял. ARM добавила свои собственные инструкции векторной обработки — SVE2. Если бы они были устаревшими или ненужными, пожалуй, их не добавляли бы в процессоры.
Метрологический АЦП
- 7 независимых АЦП с выходной частотой отсчетов 4/8/16 кГц (4 канала тока и 3 канала напряжения). Эти каналы образуют 3 блока для измерения параметров каждой фазы F0-F2.
- В блоке каналов F0 реализуем автоматический выбор канала тока (который имеет максимальное значение) для последующих расчетов мощностных характеристик. Если разница токов превышает 6%, то формируется прерывание. Кроме этой функции в остальном блоки F0-F2 идентичны.
- Все каналы АЦП имеют независимые калибровочные коэффициенты наклона характеристики.
- Каждый канал тока имеет независимый интегратор.
- В каждом блоке АЦП (F0-F2) независимо рассчитывается период сигнала по каналу напряжения. Количество периодов, в течение которого рассчитывается эта величина, можно задавать равным 1/2/4/8/16/32/64/128 периодам.
- В каждом блоке есть проверка на пропадание периодического сигнала в канале напряжения.
- В каждом блоке проверяется «просадка» напряжения ниже заданного уровня, а так же превышения сигнала в каналах тока и напряжения установленного лимита.
- Есть возможность скорректировать фазы сигналов в каналах напряжения с точностью до 0,02%.
- Вычисляются среднеквадратические, квадрат среднеквадратических значений токов и напряжений, а так же их независимая калибровка.
- При вычислении активной и реактивной энергии значение накопленной энергии в течение периода сохраняется в отдельных регистрах (для положительной и отрицательной энергии).
- Вычисляются полная мощность и полная энергия.
- Вычисляется сдвиг фаз по отношению к фазе 0.
Миф 3: Отсутствие условного исполнения было ошибкой
В 32-битном коде ARM (ARMv7 и более ранние) есть условные инструкции (conditional instructions). Берем обычную инструкцию вроде LDR (загрузка в регистр) или ADD и отслеживаем условие выполнения EQ для равенства или NE для неравенства — получаем соответствующие условные инструкции LDREQ и ADDNE.
Инструкция CMP устанавливает один из флагов, проверяемых при выполнении условных инструкций. Инструкции исполняются только в том случае, если условие выполнено. Если непонятно, предлагаю изучить дополнительные материалы:
-
ARM, x86 and RISC-V Microprocessors Compared — разбор уникальных особенностей каждого процессора, включая условное выполнение.
-
Conditional Execution — разбор условного выполнения на 32-разрядной архитектуре ARM (AArch32) Azeria Labs (отличные учебники ARM).
В прикрепленной статье я также объясняю, почему ребята из RISC-V отказались от условного исполнения
Она значительно затрудняет реализацию Out-of-Order Execution (OoOE), а это очень важно для создания высокопроизводительных чипов. На самом деле современные 64-разрядные процессоры ARM (ARMv8 и выше) не имеют условного исполнения по этой же причине
В них есть только инструкции по условному отбору (CSEL, CSINC), но они выполняются безусловно.
Подробнее: Conditional select instructions in ARM AArch64
С другой стороны, в лагере ARM отсутствие условных инструкций убивает производительность даже на простых микропроцессорах без OoOE (многие 32-разрядные ARM). Предполагается, что в процессоре с малым количеством транзисторов не реализовать достаточно сложный предсказатель ветвлений, способный избежать потери производительности из-за ошибок ветвлений (miss-prediction).
Но у ребят из RISC-V снова есть решение. Если вы посмотрите на ядра серии SiFive 7, они фактически реализовали МОС, чтобы справиться с этим. Короткие ветви из одной инструкции могут быть объединены в одну ARM-подобную условную инструкцию. Рассмотрим код:
Поскольку переход к done — это одна инструкция, чип серии SiFive 7 может распознать этот шаблон и объединить в одну инструкцию. В псевдокоде это будет:
Эта функция называется . Подчеркну, что инструкции ADDNE нет — это просто способ пояснить происходящее. Преимущество такого МОС в том, что мы избавляемся от ветвления. И значит, мы избавляемся от затрат на ошибки предсказания ветвления (вызывающее сброс конвейера инструкций). Вот что пишут SiFive в патентной заявке:
В лагере ARM могут возразить, что полагаться на МОС плохо, потому что это добавляет сложности и транзисторов. Однако ARM обычно использует МОС для объединения CMP с инструкциями ветвления типа BEQ или BNE. В RISC-V условные переходы выполняются в одну инструкцию, и только около 15% кода — это инструкции ветвления.
Таким образом, RISC-V имеет большее преимущество. ARM может поспорить с этим преимуществом, используя МОС. Но раз macro-op fusion — честная игра для ARM, то RISC-V тоже может пользоваться этим инструментом.
Миф 8: Целочисленное переполнение дешево в реализации
Получение и хранение бита переполнения недорого только в сферическом вакууме. Это все равно что сказать, будто функция мутации в программировании недорогая с точки зрения памяти или циклов процессора. Но сейчас не об этом.
Один из аргументов, за который топят адвокаты чистых функций (non-mutating) в программировании, в том, что их легче выполнять параллельно, чем мутирующие c общим состоянием. То же самое относится и к out-of-order суперскалярным процессорам. Суперскалярные процессоры выполняют множество команд параллельно. Выполнение инструкций параллельно проще, если инструкции не имеют общего состояния.
Регистры статуса вводят общее состояние и, следовательно, зависимости между инструкциями. Вот почему RISC-V был разработан так, чтобы не иметь никаких регистров статуса. Инструкции ветвления в RISC-V, например, сравнивают два регистра напрямую, а не читают регистр статуса.
Для поддержки регистров статуса в суперскалярном процессоре, где инструкции выполняются не по порядку, вам нужен более сложный учет. Речь идет не просто о добавлении пары триггеров для хранения бита.

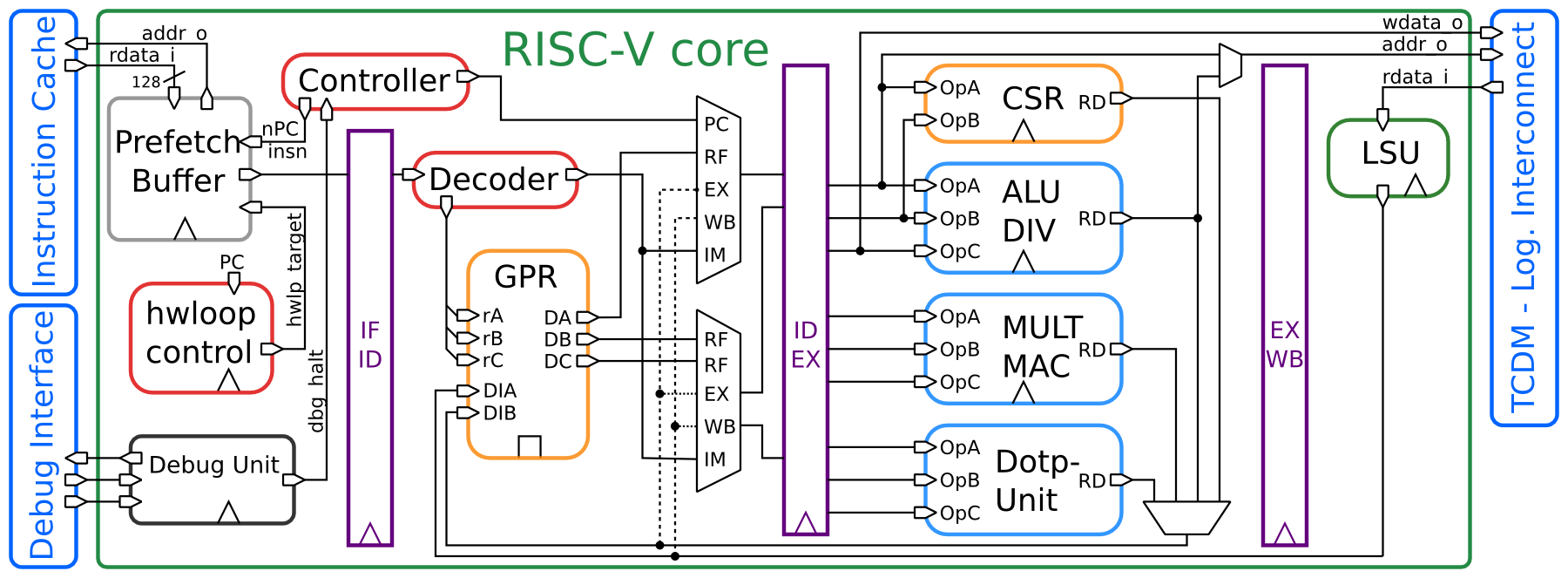
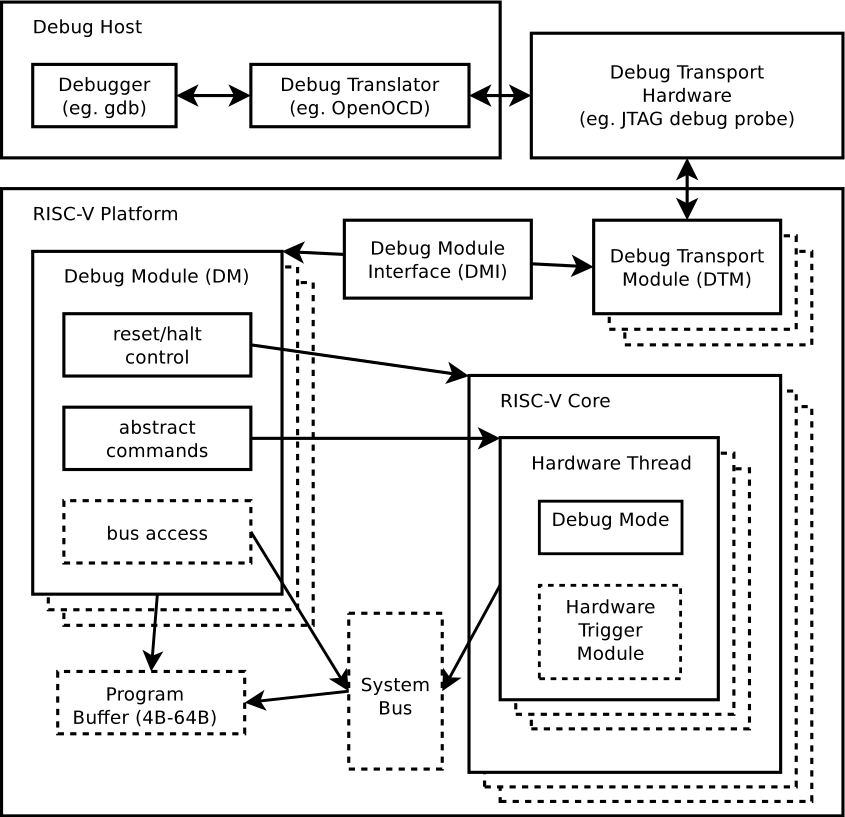
Отладка, но теперь по-настоящему
Пытаясь отладить простую программу C на процессоре RISC-V, мы решили множество проблем. Сначала с помощью и нашли нашу память в виртуальной машине RISC-V. Затем использовали эту информацию для ручного управления размещением памяти в нашей версии дефолтного скрипта компоновщика , что позволило точно определить символ . Затем использовали этот символ в собственной версии , которая настраивает наш стек и глобальные указатели и, наконец, вызвали функцию . Теперь можно достичь поставленной цели и запустить отладку нашей простой программы в GDB.
Напомним, вот сама программа на C:
Компилирование и компоновка:
Тут мы указали гораздо больше флагов, чем в прошлый раз, поэтому давайте пройдёмся по тем, которые не описали раньше.
— разделённый запятыми список флагов для передачи компоновщику (). Здесь означает «секции сбора мусора», а получает указание удалить неиспользуемые секции после компоновки. Флаги , и сообщают компоновщику не обрабатывать стандартные системные файлы запуска (например, дефолтный ), стандартные реализации системной stdlib и стандартные системные дефолтные связываемые библиотеки
У нас свой скрипт и компоновщик, поэтому важно передать эти флаги, чтобы значения по умолчанию не конфликтовали с нашей пользовательской настройкой
указывает путь к нашему скрипту компоновщика, который в нашем случае просто . Наконец, мы указываем файлы, которые хотим скомпилировать, собрать и скомпоновать: и . Как и раньше, в результате получается полноценный и готовый к запуску файл под названием .
Теперь запустим наш красивенький новенький исполняемый файл в :
Теперь запустите , не забудьте загрузить символы отладки для , указав его последним аргументом:
Затем подключим наш клиент к серверу , который мы запустили как часть команды :
Установим точку останова в main:
И начнём выполнение программы:
Из приведённого выдачи понятно, что мы успешно попали в точку останова на строке 2! Это видно и в текстовом интерфейсе, наконец-то у нас правильная строка , значение равно , а — . Если вы делали всё как в статье, то выдача будет примерно такой:
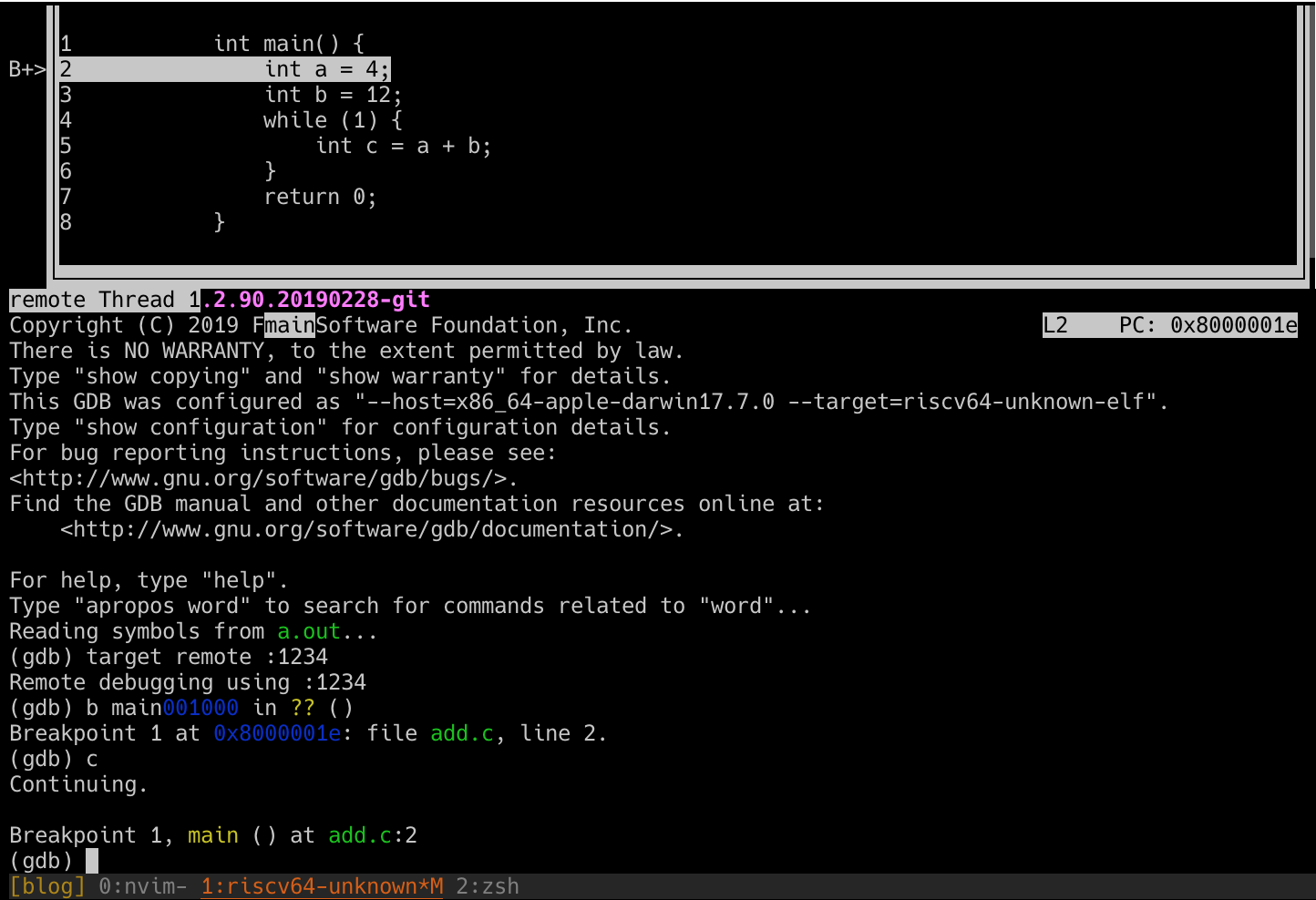
С этого момента можно использовать как обычно: для перехода к следующей инструкции, для проверки значений внутри регистров по мере выполнения программы и т. д. Экспериментируйте в своё удовольствие… мы, конечно, немало поработали ради этого!
Настройка программного окружения
Разработчики данного контроллера предлагают скачать с их сайта некую IDE. Но мы этого делать не будем: только консоль, текстовый редактор и хардкор.
Вот краткий список используемого софта. Что приятно, весь софт присутствует в репозитории, ничего качать с сайта GigaDevice не пришлось.
| софт | описание |
|---|---|
| gcc-riscv64-unknown-elf | компилятор |
| stm32flash, dfu-util | Прошивальщики через bootloader |
| kicad | Трассировка плат |
| screen | Отладка по UART |
Отдельно остановлюсь на прошивке контроллера. Основных способов три:
(1). JTAG — теоретически, самый правильный способ. Вот только подобрать правильное заклинание для него мне так и не удалось
(2). Bootloader.UART — замыкаем вывод Boot0 на питание, ресетим контроллер (можно по питанию, можно вывести кнопку), после чего через stm32flash (да, прошивать можно утилитой, предназначенной для другого семейства!) прошиваем
Ну и наконец притягиваем Boot0 обратно к земле, снова ресетим и смотрим как работает (или как именно не работает) программа
(3). Bootloader.USB — аналогичный предыдущему вариант, только вместо stm32flash используется dfu-util:
Только надо помнить, что для USB важна стабильность тактовой частоты, поэтому если для наших первых опытов хватит встроенного RC-генератора, для USB придется поставить внешний кварц.
Внимательный читатель может заметить, что утилите dfu-util передается некий адрес. Он соответствует началу реальной флеш-памяти контроллера. В нормальном режиме работы этот адрес отображается также и на нулевой адрес, и оттуда же начинается выполнение кода. Если же замкнуть Boot0 на питание, то на тот же нулевой адрес отображается либо Bootloader, либо оперативная память в зависимости от Boot1. В результате работать с контроллером можно вообще не задействуя его флеш, только из оперативки.
Переход к оперативке
В прошлой главе я обмолвился о сегменте .rodata, еще раньше без объяснений ввел сегмент .text. Теперь введем еще два сегмента: .data и .bss. Они оба предназначены для хранения глобальных переменных, но первый инициализируется при включении заранее заданными данными, а второй — нет. Причем с .bss есть еще некая неопределенность: в некоторых источниках его инициализировать и не надо вообще, в других — надо обязательно, причем нулями. Хотя и не хочется заниматься бесполезным копированием нулей, для совместимости с Си сделать это придется.
Итак, берем предыдущий пример и вместо .text указываем .data, но не спешим прошивать контроллер. Для начала заглянем в дизассемблерный файл res/firmware.lss чтобы убедиться что массив начинается именно из начала оперативной памяти, 0x2000’0000:
Упс, что-то пошло не так. Очевидно, ассемблер не знает где у нашего контроллера начало оперативной памяти. Чтобы ему это указать, создадим файл lib/gd32vf103cbt6.ld, в котором пропишем следующее:
То есть сначала мы указываем начало определенной памяти и ее размер, а потом принадлежность секций к той или иной памяти. Теперь этот файл нужно подсунуть компилятору (точнее, линкеру) при помощи ключа -T:
Вот теперь данные попали именно туда, куда надо:
Но прошивать полученным кодом контроллер все еще рано, ведь мы знаем, что оперативная память тем и отличается от постоянной, что может не сохраняться при отключении питания. Это значит, что перед работой основного кода нам в эту память надо сначала скопировать данные. Для этого компилятор заботливо сохранил наши константы в безымянном сегменте сразу после .text, это можно увидеть если посмотреть непосредственно res/firmware.hex файл.
Для большего удобства доступа к этим данным добавим в .ld-файл немного магии
Теперь мы можем использовать область флеш-памяти начиная с _data_load чтобы инициализировать собственно оперативку. Ах да, раз уж у нас есть внешний файл с адресами памяти, вынесем туда же стек:
Вот теперь наконец наш массив будет корректно читаться из оперативной памяти.
При создании переменных в секции .bss было бы странно присваивать им какие-то значения (хотя никто не запрещает, просто использованы они не будут). Вместо этого можно использовать директиву-заполнитель .comm arr, 10 (для переменной arr размером 10 байт). Стоит отметить, что использовать ее можно в любой секции, причем резервировать данные она будет только в .bss. Ниже приведены еще примеры объявления переменных различных размеров:
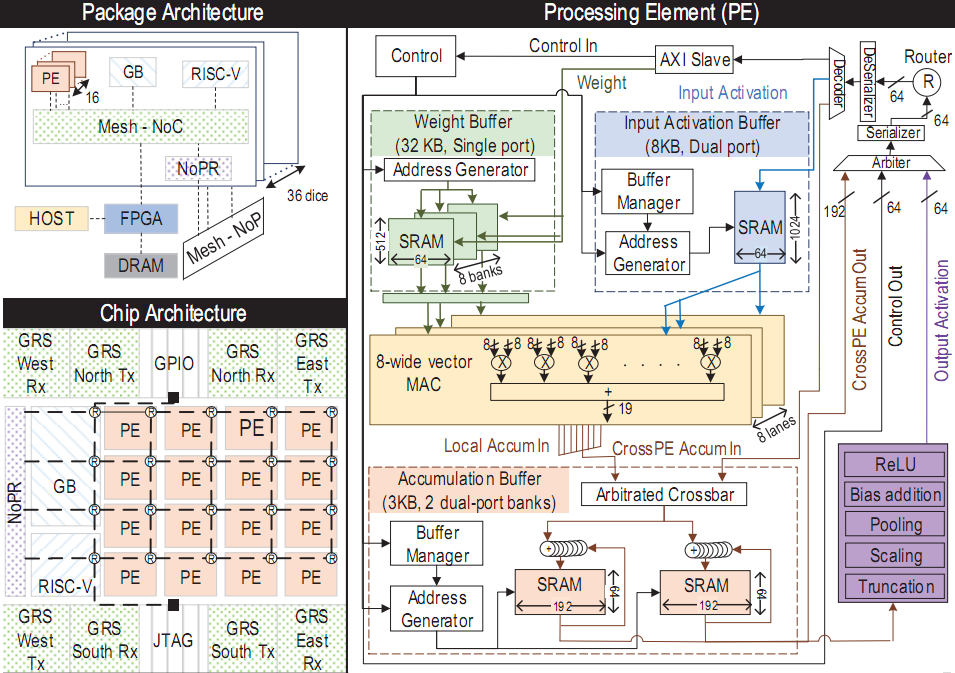
Ядра RISC-V запущенные в 2020 году
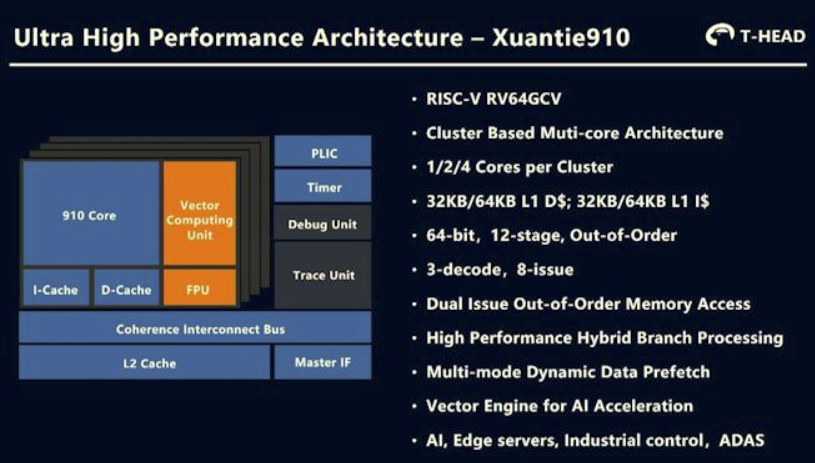 Alibaba XT910
Alibaba XT910
Слишком много ядер RISC-V, чтобы перечислить их все здесь, остановимся на некоторых из наиболее заметных анонсов — 64-разрядное ядро RISC-V Alibaba XT910, компания Andes добавила кеш-памяти второго уровня в его 32-разрядные и 64-разрядные RISC- V-ядра, а также многоядерная поддержка семейства 45-й серии. Если мы не ошибаемся, SiFive не выпускала новые ядра в 2020 году, но выпуск SiFive Core IP 20G1 улучшил существующие ядра RISC-V компании за счет улучшения производительности, повышения эффективности и уменьшения занимаемой площади.
Одна из замечательных особенностей RISC-V заключается в том, что он открыт, поэтому он отлично подходит для студентов, которые могут создавать программные ядра RISC-V, работающие на платформах FPGA, и в этом году Университет Китайской академии наук (UCAS) разработал NutShell, 64-разрядный SoC, который работает на частоте до 200 МГц и может работать под управлением Linux. RISC-V international мог бы даже продвигать RISC-V ISA как подходящий для 13-летних детей, поскольку молодой Николас Шарки участвовал в семинаре и сумел создать собственное ядро RISC-V …
Кому это нужно
Процессоры Ventana, как ожидается, заинтересуют глобальных облачных провайдеров и крупных участников ИТ-рынка, которые испытывают потребность в специализированном «железе».
Архитектура RISC-V является открытой и расширяемой, за ее использование не нужно платить. При необходимости клиент Ventana сможет разработать специализированный ускоритель в виде чиплета, а также дополнительные инструкции RISC-V для управления им.
К примеру, поясняет The Register, если клиенту необходим процессор, который способен ускорить сжатие или распаковку данных, то вся логика, реализующая данные операции переносится на «железо», в виде чиплета.
Когда приложению необходима процедура сжатия/распаковки, оно выполняет инструкцию, также предусмотренную клиентом и «зашитую» внутрь CPU. Далее ядро CPU, выполняющее код приложения «видит» данную инструкцию и отдает соответствующую команду специализированной микросхеме на соседнем чиплете, а затем получает результат и возвращает его обратно в программу.
Важно, что и расширенные инструкции, и связанная с ней функциональность при таком подходе остаются доступными исключительно заказчику. Как отмечает The Register, ARM в подобном случае оставляет за собой право использовать заказанные клиентами модификации как ей заблагорассудится
Например, она может без спроса дать доступ к ним всем своим клиентам, что не очень-то и устраивает крупных игроков.
Расширения RISC-V
Как только у нас будет базовый набор, мы можем добавить к нему расширения, чтобы определить точные характеристики ядра (замороженные расширения — по состоянию на август 2019 г. — выделены жирным шрифтом ):
- M — стандартное расширение для целочисленного умножения и деления
- A — стандартное расширение для атомарных инструкций
- F — стандартное расширение для плавающей точки одинарной точности
- D — стандартное расширение для плавающей точки двойной точности
- G — сокращение для базовых и вышеуказанных расширений
- Q — стандартное расширение для Quad-Precision с плавающей точкой
- L — стандартное расширение для десятичной плавающей запятой
- C — стандартное расширение для сжатых инструкций
- B — стандартное расширение для управления битами
- J — стандартное расширение для динамически переводимых языков, таких как C #, Go, Haskell, Java, JavaScript, OCaml, PHP, Python, R, Ruby, Scala или WebAssembly
- T — стандартное расширение для транзакционной памяти
- P — стандартное расширение для SIMD-операций
- V — стандартное расширение для векторных операций
- N — стандартное расширение для прерываний на уровне пользователя
- H — стандартное расширение для гипервизора
Первое замечание заключается в том, что многие расширения все еще находятся в стадии доработки, и, если мы правильно понимаем, поддержка таких функций, как прерывания на уровне пользователя, SIMD-операций и поддержка гипервизора, все еще разрабатывается.
Информационная безопасность
О порядке предоставления доступа к минимальному набору функций интеллектуальных систем учета электрической энергии (мощности)» (вместе с «Правилами предоставления доступа к минимальному набору функций интеллектуальных систем учета электрической энергии (мощности)»)требования ФСБ к средствам криптографической зашиты информации для некорректируемых регистраторов (СКЗИ НР)
5.1. Криптография
- Блоки сопроцессоров для поддержки блочных шифров «Кузнечик», «Магма» и AES;
- Блок генератора случайных чисел;
- Блок вычисления CRC по произвольному полиному;
- Блок специальной энергозависимой памяти ключевой информации с батарейным питанием
- Однократно программируемая ПЗУ первоначального загрузчика, в которой реализуется уникальная идентификация каждой микросхемы.
5.2. Инженерная защита
- 3 вывода для детекторов проникновения (электронные пломбы)
- Блок детектора изменения тактовой частоты
- Блок детектора изменения напряжения питания
- Блок оптического детектора
- Блок генерации шума в цепи питания
- Защитная экранная сетка
- Защита от несанкционированного считывания памяти
можно почитать тут
Храним данные на флешке
Использование стека отлично подходит для локальных переменных, которые не будут сохраняться между вызовами функций. Но иногда возникает необходимость использовать глобальные переменные и константы, доступные любой функции.
Начнем с простого — хранения массива констант. Для этого используется та же флеш-память, что и для исполняемого кода. Для удобства ее иногда выделяют в отдельный сегмент .rodata, но пока мы этим заниматься не будем. Просто объявим в конце нашей программы массив из 4 значений:
Директива .short означает, что элемент памяти — короткое целое размером 2 байта. О других директивах резервирования места я расскажу чуть позже.
Ну и заменяем предыдущую рекурсивную мигалку на последовательное чтение из этого массива с выводом на светодиоды:
Здесь стоит отметить две вещи. Во-первых, замена lw на lh при работе с GPIOB_OCTL. Поскольку элементы данных в массиве 2-байтные, как и регистр GPIOB_OCTL, старшие байты вполне можно не писать, это немного сэкономит память. Во-вторых, увеличение адреса в массиве не на 1, а на размер элемента. Если бы мы использовали 32-битные константы, увеличивать пришлось бы на 4 байта, а если байтовые — то на 1.
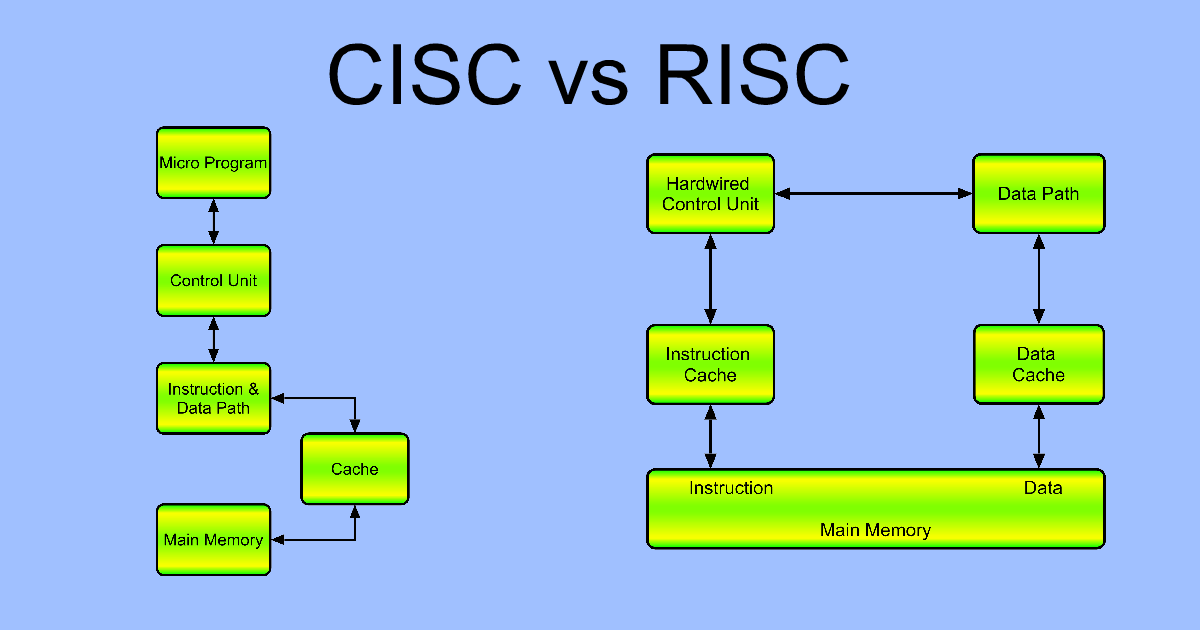
RISC
RISC-архитектура (Reduced Instruction Set Computer) относится к процессорам с сокращённым набором команд. В ней быстродействие увеличивается посредством упрощения инструкций: за счёт того, что их декодирование становится проще, уменьшается время исполнения. Изначально RISC-процессоры не обладали инструкциями деления и умножения и не могли работать с числами, имеющими плавающую запятую. Их появление связано с тем, что в CISC достаточно много способов адресации и команд использовались крайне редко.
Система команд в RISC состоит из малого числа часто применяемых команд одного формата, которые можно выполнить за единичный такт центрального процессора. Более сложные и редко применяемые команды выполняются на программном уровне. При этом, благодаря значительному увеличению скорости реализации команд, средняя производительность RISC-процессоров выше, чем у CISC.
Современные RISC-процессоры выполняют порядка сотни команд с закреплённым форматом длиной 4 байта, используя небольшое количество простых способов адресации (индексную, регистровую и другие). Чтобы сократить число обращений к внешней оперативной памяти, в RISC применяются сотни регистров общего назначения (РОН), в то время как в CISC их всего 8-16. В RISC-процессорах обращение к памяти используется только при загрузке данных в РОН либо пересылке результатов в память.

Благодаря сокращению аппаратных средств, используемых для декодирования и реализации сложных команд, достигается значительное упрощение и снижение стоимости интегральных схем. В то же время возрастает производительность и снижается энергопотребление, что особенно актуально для мобильного сегмента. Эти же достоинства служат причиной использования во многих современных CISC-процессорах, например в последних моделях К7 и Pentium, RISC-ядра. Сложные CISC-команды заранее преобразуются в набор простых RISC-операций, которые оперативно выполняются RISC-ядром.
Характерными примерами RISC-архитектур являются:
- PowerPC;
- DEC Alpha;
- ARC;
- AMD Am29000;
- серия архитектур ARM;
- Atmel AVR;
- Intel i860 и i960;
- BlackFin;
- MIPS;
- PA-RISC;
- Motorola 88000;
- SuperH;
- RISC-V;
- SPARC.
RISC быстрее CISC, и даже при условии выполнения системой RISC четырёх или пяти команд вместо единственной, выполняемой CISC, RISC выигрывает в скорости, поскольку его команды выполняются в разы оперативнее. Однако CISC продолжает использоваться. Это связано с совместимостью: x86_64 продолжает лидировать в десктоп-сегменте, а поскольку старые программы могут функционировать только на x86, то и новые десктоп-системы должны быть x86(_64), чтобы дать возможность старым программам работать на новых устройствах.
Для Open Source это не проблема, ведь пользователь может найти в сети версию программы, подходящую для другой архитектуры. Однако создать версию проприетарной программы для другой архитектуры получится только у владельца исходного кода.
Новые процессоры на RISC-V
Американский стартап Ventana Micro Systems ведет разработку высокопроизводительных «модульных» процессоров на базе открытой архитектуры RISC-V.
Особенностью новых процессоров станет так называемая чиплетная компоновка, то есть каждое устройство будет состоять из нескольких (до шести) блоков или модулей, размещенных на общей подложке. Причем каждый из них может быть выполнен «в кремнии» с применением наиболее подходящих технологических норм. Подобный подход, по заявлению специалистов Ventana, позволяет значительно снизить затраты на разработку и ускорить данный процесс.
В единой упаковке, как пишет The Register, могут находиться вычислительные ядра, кэш-память, интерфейсы ввода-вывода и взаимодействия с памятью, а также кастомный ускоритель (например, для нагрузок, связанных с машинным обучением).
Отдельные чиплеты будут объединены за счет кэш-когерентной шины, разработанной Ventana. Она, как утверждают разработчики, способна обеспечить задержку на уровне 8 нс и скорость передачи данных в 16 Гбит/сек на линию.
Чиплетная архитектура Ventana (пример)
Разработанные Ventana вычислительные модули (CPU) включают по 16 ядер архитектуры RISC-V и, по словам разработчиков, опережают любые другие существующие реализации RV64 и, как минимум, не уступают чипам ARM Neoverse, которые предназначены для дата-центров. Выпускать CPU-блоки планируется на фабриках тайваньской TSMC с использованием 5-нанометрового техпроцесса.
Ventana по просьбе клиента готова упаковать в единый корпус вместе с собственными ядрами специализированные вычислительные блоки, дизайн которых разработан заказчиком. Он может быть практически любым, главное, чтобы соответствовал стандарту ODSA (Open Domain-Specific Architecture), то есть мог быть физически подключен к шине устройства.
В Ventana рассчитывают продемонстрировать первые образцы новых 64-битных RISC-V-процессоров клиентам во второй половине 2022 г. Старт серийного производства намечен на первое полугодие 2023 г.
Вектора переменной длины в ARM
В ARM вы не устанавливаете длину вектора явным образом. Вместо этого вы устанавливаете длину вектора косвенно, используя предикатные регистры. Они являются битовыми масками, которыми вы включаете и выключаете элементы в векторном регистре. Регистры предикатов также существуют в RISC-V, но не имеют центральной роли, как в ARM.
Чтобы получить эквивалент на ARM , используйте команду , что является сокращением от While Less Than:
Довольно сложно объяснить словами, что делает эта команда, и я использую псевдокод, чтобы объяснить её работу.
Концептуально, мы переворачиваем биты в регистре предиката в зависимости от того, меньше ли ,чем . В данном случае содержит длину вектора. Если выглядит так, то длину вектора можно считать равной 3.
То есть вектор переменной длины реализуется за счёт того, что все операции используют предикат. Рассмотрим эту операцию сложения. Представьте, что извлекает из только те элементы, для которых истинно.
Итак, мы сделали некоторое вступление. Сейчас рассмотрим более полный пример кода, чтобы увидеть, как эти наборы команд работают на практике.
Приложение: описания использованных директив ассемблера и его инструкций
| директива | аргументы | описание |
|---|---|---|
| .align | N | выравнивание по 2^N. Например, .align 9 это выравнивание на 2^9 = 512 байт |
| .bss | секция нулевых данных в ОЗУ | |
| .data | секция ОЗУ | |
| .equ | name, val | присвоить макроконстанте name значение val. Например, .equ RLED, 5 заменит везде в тексте RLED на 5 |
| .global | name | глобально видимое имя для стыковки с другими модулями |
| .macro / .endm | name | создание макроса по имени name |
| .section | name | войти в подсекцию name |
| .short | N] | объявить одну или несколько переменных размером 2 байта с заданными значениями |
| .text | секция кода | |
| .weak | name | “слабое” имя, которое может быть перекрыто другим |
| .word | N] | см. .short, только размер 4 байта |
| инструкция | аргументы | описание |
|---|---|---|
| add | rd, r1, r2 | rd = r1 + r2 |
| addi | rd, r1, N | rd = r1 + N |
| and | rd, r1, r2 | rd = r1 & r2 |
| andi | rd, r1, N | rd = r1 & N |
| beq | r1, r2, addr | if(r1==r2)goto addr |
| beqz | r1, addr | if(r1==0)goto addr |
| bgeu | r1, r2, addr | if(r1>=r2)goto addr |
| bgtu | r1, r2, addr | if(r1> r2)goto addr |
| bltu | r1, r2, addr | if(r1< r2)goto addr |
| bne | r1, r2, addr | if(r1!=r2)goto addr |
| bnez | r1, addr | if(r1!=0)goto addr |
| call | func | вызов функции func |
| csrr | rd, csr | rd = csr |
| csrrs | rd, csr, N | rd = csr; csr |= N, атомарно |
| csrs | scr, rs | csr |= rs |
| csrs | scr, N | csr |= N |
| csrw | csr, rs | csr = rs |
| ecall | провоцирование исключения для входа в ловушку | |
| j | addr | goto addr |
| la | rd, addr | rd = addr |
| lb | rd, N(r1) | считать 1 байт по адресу r1+N |
| lh | rd, N(r1) | считать 2 байта по адресу r1+N |
| li | rd, N | rd = N |
| lw | rd, N(r1) | считать 4 байта по адресу r1+N |
| mret | возврат из обработчика исключения | |
| mv | rd, rs | rd = rs |
| or | rd, r1, r2 | rd = r1 | r2 |
| ori | rd, r1, N | rd = r1 | N |
| ret | возврат из функции | |
| sb | rs, N(r1) | записать 1 байт по адресу r1+N |
| sh | rs, N(r1) | записать 2 байта по адресу r1+N |
| slli | rd, r1, N | rd = r1 << N |
| srli | rd, r1, N | rd = r1 >> N |
| sw | rs, N(r1) | записать 4 байта по адресу r1+N |
| xor | rd, r1, r2 | rd = r1 ^ r2 |
| xori | rd, r1, N | rd = r1 ^ N |
Architecture
The RISC-V ISA has fixed-length 32-bit instructions aligned on their natural boundaries, but is designed to encode variable-length instructions.
The base ISA operates on a little-endian memory system, but non-standard extensions may add support for big-endian or bi-endian.
Hardware Threads
The RISC-V ISA specifies hardware threads, called harts. A hart is defined by its own instruction fetch unit.
A processor may contain multiple harts, at least one.
Each hart has an ID associated with it.
Exceptions, Traps and Interrupts
In RISC-V the term Exception refers to an unusual condition at run-time associated with an instruction in the current hardware thread.
A Trap is a synchronous transfer of control to a trap handler and is caused by an exceptional condition within a RISC-V thread. The trap handlers usually execute in a more privileged environment.
An external event that occurs asynchronously to the current thread will cause an Interrupt. When an interrupt occurs, some instruction is selected to experience a trap.
Privileges
The spec defines 4 priviledge modes, of which a valid combination has to be implemented. The modes are:
| Debug | Mode for complete control, for debuggers |
| Machine | Mode with nearly full control, no debug registers (think firmware), not optional |
| Hypervisor | VM-Hypervisor |
| Supervisor | OS-level |
| User | Application-level, lowest privilege |
Possible Combinations
Valid combinations of privilege levels are:
- One level: Machine mode only for embedded systems
- Two levels: Machine and User mode, small systems
- Three levels: Machine, Supervisor and User mode, Complex systems able to run Unix-like operating systems
Базовые наборы RISC-V
В настоящее время существует четыре базовых набора ISA:
- RV32I — Базовый набор целочисленных инструкций, 32-разрядный. В настоящее время версия 2.1
- RV32E — Базовый набор целочисленных инструкций (встроенный), 32-разрядный, 16 регистров с меньшим набором команд. Текущая версия 1.9, но еще не заморожена
- RV64I — Базовый набор целочисленных команд, 64-разрядный. В настоящее время версия 2.0
- RV128I — Базовый набор целочисленных инструкций, 128-битный. В настоящее время версия 1.7, но еще не заморожена.
Если информация в Википедии верна, мы, скорее всего, увидим проекты RV32I и RV64I, поскольку спецификации RV32E и RV128I еще не определены.
Миф 6: Современный ISA должен справляться с целочисленным переполнением
Часто критикуется факт, что RISC-V не вызывает аппаратного исключения (hardware exception) и не устанавливает никаких флагов в случае переполнения при исполнении целочисленных арифметических инструкций. Кажется, почти в любой дискуссии о RISC-V в качестве аргумента используется тезис, что дизайнеры RISC-V застряли в 1980-х годах (тогда никто не проверял на целочисленные переполнения).
Тема сложная, так что начнем с простого. Большинство компиляторов для популярных языков не вызывают переполнения по умолчанию. Примеры:
-
C/C++ и Objective-C
-
RUST (не для релиза)
-
GO
-
Java/Kotlin
-
C# (используйте checked блок)
Некоторые из них не делают этого даже в режиме отладки по умолчанию. В Java для исключений переполнения надо вызвать addExact и subtractExact. В C# надо написать код в контексте checked:
В Go надо использовать библиотеку overflow с функциями overflow.Add, overflow.Sub или варианты, вызывающие «панику» (аналог исключения), такие как overflow.Addp и overflow.Subp.
Единственный популярный компилируемый язык, вызывающий исключение при целочисленном переполнении, — это Swift. И если погуглить, обнаружится много недовольных этим людей. Так что утверждение о серьезности недостатка этой фичи в RISC-V кажется странным.
Многие языки с динамической типизацией, например Python, при переполнении изменяют размер целых чисел на более крупные типы (с 16 бит на 32, потом на 64 и так далее — прим. переводчика). Но эти языки настолько медленные, что дополнительные инструкции, необходимые на RISC-V, не имеют значения.



