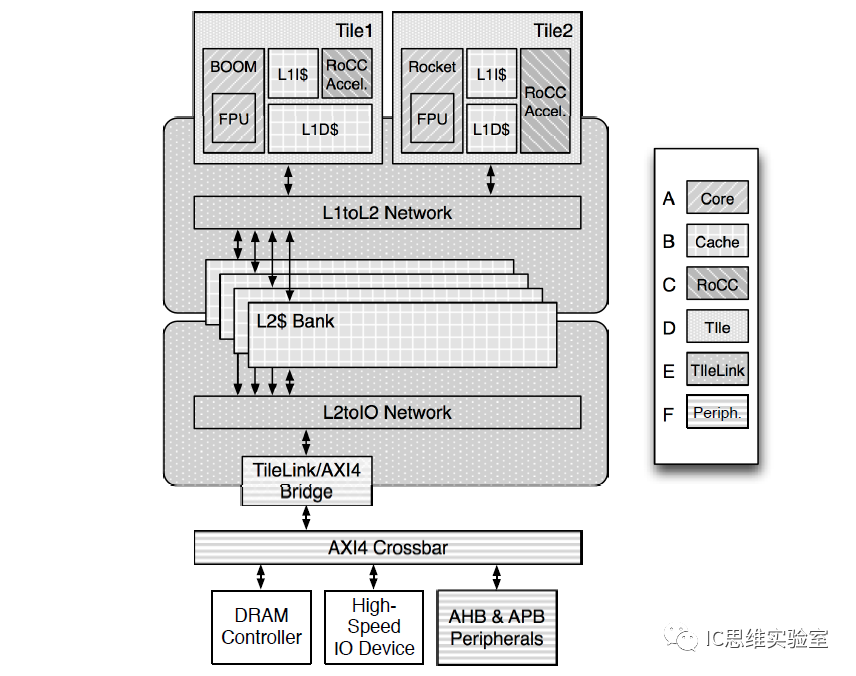
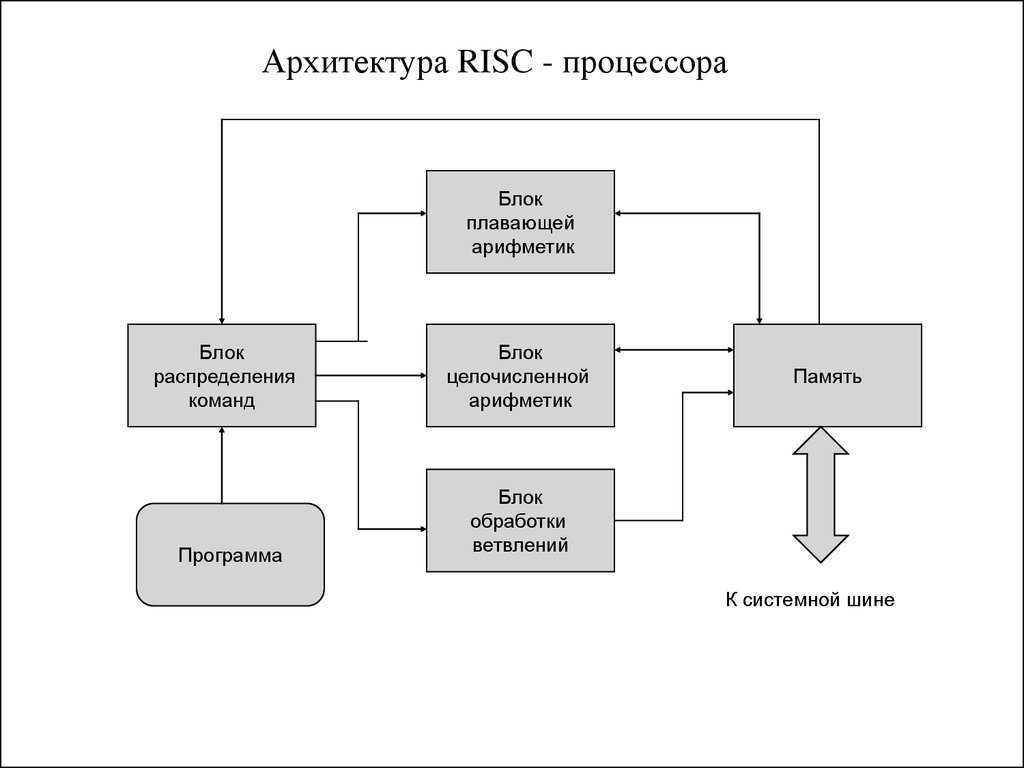
Внутреннее наполнение
Roma укомплектован экраном на 14,1 дюйма с разрешением Full HD или 1920х1080 точек. Если этой диагонали не хватит, есть порт HDMI для подключения внешнего дисплея.
Лэптоп поставляется с оперативной памятью LPDDR4/LPDDR4X объемом до 16 ГБ (сколько ОЗУ установлено в минимальной комплектации, производитель не уточняет) и флеш-накопителем вместительностью до 256 ГБ. Притом используется вовсе не полноценный SSD-накопитель – вместо него установлен довольно медленный флеш-модуль стандарта еММС.

Дактилоскоп — чуть ли не единственное, за исключением процессора, чем Roma может выделиться среди большинства современных ноутбуков
В наличии клавиатура с подсветкой, веб-камера Full HD, модули Bluetooth 5.0 и Wi-Fi 802.11ac (Wi-Fi 5). Из проводных интерфейсов у ноутбука есть SD-слот, Ethernet, а также USB-C и полноразмерные USB-A.
Как получить ₽30 млн на вывод решения в области искусственного интеллекта на новые рынки
Поддержка ИТ-отрасли

Производитель заявляет о 10 часах работы от аккумулятора и сканере отпечатков пальцев, встроенном в тачпад. Ноутбук Roma весит 1,7 кг, что довольно много по современным меркам, располагает габаритами 325х225х18 мм в закрытом состоянии.
Без «Байкалов» не обойдется
На первых этапах продвижения «Ростехом» и Yadro отечественных компьютеров и серверов в их технике будут использоваться процессоры разработки российской компании Baikal Electronics «Байкал-М». Об этом изданию сообщил глава департамента по координации реализации национальных проектов Объединенной приборостроительной корпорации (управляющей компании холдинга «Росэлектроника» «Ростеха») Андрей Матвеенко.
Директор Ассоциации российских разработчиков и производителей электроники Иван Покровский утверждает, что 27,8 млрд руб. – это гигантские инвестиции в разработку CPU. По его подсчетам, это больше, чем было вложено в производство двух наиболее массовых процессоров серий «Эльбрус» и «Байкал» вместе взятых.
Почему всем нужен свой процессор?
Итак, сегодня, в ужесточающейся борьбе за место под солнцем между США, Китаем и Россией, очень актуальным становится технологическая независимость в цифровой сфере, как в области, куда перемещаются все инфраструктурные связи государства, бизнеса и населения. Ещё недавно можно было бы выбрать путь глобализации и влиться в мировые технологические цепочки (к сожалению, в общей своей массе единичными и бессистемными звеньями, за исключением поставки полезных ископаемых, но влиться).
Но последние мировые тенденции говорят о том, что даже Европа начала наращивать свою субъектность в микроэлектронике, разрабатывая собственные европейские процессоры (а ей-то уж зачем, но всё равно разрабатывает), не говоря уже о переносе микроэлектронных производств из Тайваня в США и Японию и вложений Китая в создание собственного независимого процессора. В общем, мировая тенденция не оставляет выбора и нам. Необходимость создания собственного российского процессора, который решал бы этот вопрос — аксиома, вне зависимости от того, есть у России сегодня такие возможности, или нет.
Теперь о возможностях. Россия может и разрабатывает процессоры и микроконтроллеры нескольких архитектур разной степени независимости. Этот этап мы завершили. Производить на территории России мы можем только те микроконтроллеры, которые не требуют технологических норм выше 90 нм. Современные процессоры общего назначения мы производить у себя сейчас не можем, поскольку у нас нет соответствующего оборудования для современных технологических норм нижн 90 нм, да и те процессоры Эльбрус-2СМ, которые производились на заводе «Микрон» в Зеленограде по нормам 90 нм не показывали желаемой производительности, поскольку оборудование было ориентировано на производство по этим нормам других продуктов.
Теоретически, в Зеленограде можно произвести процессор и по нормам 65 нм, но для этого пришлось бы использовать слишком много циклов травления, и в результате получить очень невысокий процент годных чипов. Новую фабрику по технологии 28 и 16 нм ещё только начинают строить, а НИРы на разработку оборудования были профинансированы только в прошлом году. Поэтому в ближайшие 4-5 лет ожидать чего-то своего прорывного не стоит, а технологию 6 нм, для которой сейчас разрабатывается Эльбрус-32С и Байкал-S2, можно ожидать лишь к 2030-му году. Так что печатать их будем опять же в TSMC, если нам позволят это делать американские собственники этой условно тайваньской компании.
То есть, сейчас перед нами стоит несколько очень сложных задач, которые нельзя решить сразу. Потребуется действовать в течение какого-то времени, и поступательно делать то, что возможно в каждый конкретный момент. Давайте рассмотрим процесс повышения технической независимости именно с этих позиций.
Переход к оперативке
В прошлой главе я обмолвился о сегменте .rodata, еще раньше без объяснений ввел сегмент .text. Теперь введем еще два сегмента: .data и .bss. Они оба предназначены для хранения глобальных переменных, но первый инициализируется при включении заранее заданными данными, а второй — нет. Причем с .bss есть еще некая неопределенность: в некоторых источниках его инициализировать и не надо вообще, в других — надо обязательно, причем нулями. Хотя и не хочется заниматься бесполезным копированием нулей, для совместимости с Си сделать это придется.
Итак, берем предыдущий пример и вместо .text указываем .data, но не спешим прошивать контроллер. Для начала заглянем в дизассемблерный файл res/firmware.lss чтобы убедиться что массив начинается именно из начала оперативной памяти, 0x2000’0000:
Упс, что-то пошло не так. Очевидно, ассемблер не знает где у нашего контроллера начало оперативной памяти. Чтобы ему это указать, создадим файл lib/gd32vf103cbt6.ld, в котором пропишем следующее:
То есть сначала мы указываем начало определенной памяти и ее размер, а потом принадлежность секций к той или иной памяти. Теперь этот файл нужно подсунуть компилятору (точнее, линкеру) при помощи ключа -T:
Вот теперь данные попали именно туда, куда надо:
Но прошивать полученным кодом контроллер все еще рано, ведь мы знаем, что оперативная память тем и отличается от постоянной, что может не сохраняться при отключении питания. Это значит, что перед работой основного кода нам в эту память надо сначала скопировать данные. Для этого компилятор заботливо сохранил наши константы в безымянном сегменте сразу после .text, это можно увидеть если посмотреть непосредственно res/firmware.hex файл.
Для большего удобства доступа к этим данным добавим в .ld-файл немного магии
Теперь мы можем использовать область флеш-памяти начиная с _data_load чтобы инициализировать собственно оперативку. Ах да, раз уж у нас есть внешний файл с адресами памяти, вынесем туда же стек:
Вот теперь наконец наш массив будет корректно читаться из оперативной памяти.
При создании переменных в секции .bss было бы странно присваивать им какие-то значения (хотя никто не запрещает, просто использованы они не будут). Вместо этого можно использовать директиву-заполнитель .comm arr, 10 (для переменной arr размером 10 байт). Стоит отметить, что использовать ее можно в любой секции, причем резервировать данные она будет только в .bss. Ниже приведены еще примеры объявления переменных различных размеров:
Миф 6: Современный ISA должен справляться с целочисленным переполнением
Часто критикуется факт, что RISC-V не вызывает аппаратного исключения (hardware exception) и не устанавливает никаких флагов в случае переполнения при исполнении целочисленных арифметических инструкций. Кажется, почти в любой дискуссии о RISC-V в качестве аргумента используется тезис, что дизайнеры RISC-V застряли в 1980-х годах (тогда никто не проверял на целочисленные переполнения).
Тема сложная, так что начнем с простого. Большинство компиляторов для популярных языков не вызывают переполнения по умолчанию. Примеры:
-
C/C++ и Objective-C
-
RUST (не для релиза)
-
GO
-
Java/Kotlin
-
C# (используйте checked блок)
Некоторые из них не делают этого даже в режиме отладки по умолчанию. В Java для исключений переполнения надо вызвать addExact и subtractExact. В C# надо написать код в контексте checked:
В Go надо использовать библиотеку overflow с функциями overflow.Add, overflow.Sub или варианты, вызывающие «панику» (аналог исключения), такие как overflow.Addp и overflow.Subp.
Единственный популярный компилируемый язык, вызывающий исключение при целочисленном переполнении, — это Swift. И если погуглить, обнаружится много недовольных этим людей. Так что утверждение о серьезности недостатка этой фичи в RISC-V кажется странным.
Многие языки с динамической типизацией, например Python, при переполнении изменяют размер целых чисел на более крупные типы (с 16 бит на 32, потом на 64 и так далее — прим. переводчика). Но эти языки настолько медленные, что дополнительные инструкции, необходимые на RISC-V, не имеют значения.










Немного о компании Yadro
Компания Yadro, которая поможет «Ростеху» в создании новых отечественных процессоров, была основана в 2014 г. В настоящее время она специализируется на производстве серверов, систем хранения данных (СХД), ПО и специализированных вычислительных систем. Среди ее партнеров числятся Samsung, Intel, Broadcom, Microsemi, Toshiba, Micron, Molex, MSI, Seagate, RedHat, Suse и другие компании.
Суперапп для ЦОД: что это такое и как его внедрять
ПО

Появившись как дочерняя структура «Национальной компьютерной корпорации» (НКК), в начале 2019 г. компания перешла под управление «ИКС холдинга» предпринимателя Антона Черепенникова. В сентябре 2020 г., по данным ЕГРЮЛ, он избавился от своей доли в компании. Теперь она почти на 100% принадлежит ООО «Юэсэм телеком», крупнейшая доля в котором (39,2%) числится за Алишером Усмановым.
Yadro является членом индустриальных ассоциаций OpenPOWER Foundation, OpenCAPI, SNIA, Linux Foundation, Gen-Z Consortium, PCI-SIG и др. Помимо разработки собственной продукции, с момента основания 23 октября 2014 г. компания Yadro осуществляет доверенное производство вычислительных систем, СХД и ленточных библиотек на базе технологического партнерства (OEM) с IBM. Производство ОЕМ-продукции Yadro также осуществляет на собственной производственной площадке. В 2016 г. Yadro и IBM подписали партнерское OEM-соглашение по сборке сертифицированных серверов на базе процессоров Power и производстве СХД под собственным брендом компании.
Yadro является одним из крупнейших российских производителей СХД и серверов. CNews писал, что в IV квартале 2019 г. и по итогам всего 2019 г. Yadro заняла второе место по поставкам СХД на российский рынок (в денежном выражении), уступив лишь китайской Huawei. По итогам IV квартала 2020 г. Yadro занимала 22,5% этого рынка (в деньгах; статистика IDC). Выручка компании за весь 2020 г. достигла 26 млрд руб.
В июне 2021 г. CNews сообщал, что реестре российской продукции при Минпомторге обнаружились три СХД разработки Yadro, собранные на процессорах разработки американской компании IBM. С 1 января 2021 г. это прямо противоречит действующей в России нормативной базе. Все три СХД были внесены в реестр в апреле 2021 г.
Миф 2: Инструкции переменной длины усложняют параллельное декодирование инструкций
В мире x86-инструкция в принципе может быть бесконечной длины, хотя для практических целей она ограничена 15 байтами. Это усложняет разработку суперскалярных процессоров, которые параллельно декодируют несколько команд. Почему? Потому что, когда вы получили, скажем, 32 байта кода, вы не знаете, где начинается каждая отдельная инструкция. Решение этой проблемы требует использования сложных методов, которые часто требуют больше циклов для декодирования.
Подробнее: Decoding x86: From P6 to Core 2 — Part 1
Есть мнение, что методы, используемые в Intel и AMD, основаны на грубом методе проб и ошибок, когда просто делаются многочисленные предположения о том, где инструкции начинаются и заканчиваются.
Однако дополнительная сложность сжатых инструкций для RISC-V тривиальна. Выбранные инструкции всегда будут выровнены по 16 бит. Это значит, что каждый 16-битный блок — это либо начало 16/32-битной инструкции, либо конец 32-битной инструкции.
Этот простой факт можно использовать для разработки различных способов параллельного декодирования инструкций RISC-V. Я уже не дизайнер чипов, но даже я могу придумать схему для достижения этого. Например, мог бы связать декодеры с каждым 16-битным блоком, как показано на диаграмме ниже.
Затем каждый декодер получит свой первый вход из связанного 16-битного блока. Таким образом, первая часть инструкции для декодера D2 будет взята из блока команд B2. А вторая часть — из B3, если у нас 32-битная инструкция.
При декодировании декодер определяет, 16-битная или 32-битная инструкция перед ним, и решает, использовать ли второй входной поток из следующего блока Важное замечание: каждый декодер решает, использовать ли второй 16-битный блок данных инструкций, независимо от других декодеров. Значит, это можно делать параллельно
Для сравнения, я понятия не имею, как бы я декодировал x86-инструкции, которые могут быть длиной от 1 до 15 байт. Выглядит это как значительно более сложная задачка.
В любом случае, создатели RISC-V говорят, что это не сложная проблема. То, что я описал, — попытка объяснить, почему это несложно, с точки зрения не профессионала. Только не зацикливайтесь на предложенном решении — очевидно, что ему не хватает деталей. Например, вам точно понадобится какая-то логика для переключения мультиплексоров.
RISC-V покоряет мир ноутбуков
В мире появился уникальный ноутбук на базе процессора с архитектурой RISC-V. Как пишет портал Liliputing, его создали китайские компании DeepComputing и Xcalibyte. За счет выбора архитектуры CPU аналогов у него на момент выхода материала не существовало.
Свой лэптоп разработчики назвали Roma. В настоящее время DeepComputing и Xcalibyte принимают предварительные заказы на него, не уточняя, когда намереваются выпустить хотя первую партию этих лэптопов. По информации издания The Register, первые образцы Roma сойдут с конвейера в сентябре 2022 г., но разработчики не подтверждают это.
Авторы проекта также не раскрывают стоимость Roma. Известно лишь, что он будет выпущен ограниченным тиражом, что всегда негативно отражается и на конечной цене, и на итоговой доступности. С другой стороны, разработчики отказались от первоначальных планов по распространению Roma исключительно в Китае. Теперь они нацелились на глобальный релиз.
В процессорах для ноутбуков чаще всего используется архитектура х86. Для создания CPU ее применяют компании AMD и Intel, основные игроки этого рынка. Минимальное количество ноутбуков снабжаются ARM-процессорами.
Roma выполнен по современным канонам «ноутбукостроения». Тонкий корпус, строгий дизайн, множество интерфейсов
Однако и ARM, и х86 являются закрытыми архитектурами, в отличие от открытой и не требующей лицензионных выплат RISC-V. За счет этого она пользуется высоким спросом среди разработчиков микросхем во всем мире. Поддержка и развитие RISC-V осуществляется некоммерческой организацией RISC-V International, в которую входят более 1000 членов в 50 странах. Процессоры RISC-V широко применяются в микроконтроллерах. К примеру, компания Western Digital ежегодно поставляет более 2 млрд контроллеров RISC-V в своих накопителях.
Подробности о процессорах
По планам компаний, на которые ссылаются «Ведомости», к 2025 г. новые чипы должны работать в компьютерной технике в структурах госкорпорации, а также в подведомственных учреждениях Минобрнауки, Минпросвещения и Минздрава. Также в планы партнеров входит реализация в 2025 г. 60 тыс. серверов и ПК на новых процессорах на сумму 7 млрд руб.
По данным CNews, новый чип будет выпускаться по 12-нанометровому техпроцессу. В России фабрик, оснащенных оборудованием для такого производства, нет, в связи с чем «Ростеху» потребуется помощь иностранных производителей.
Создаваемый CPU получит восемь ядер с частотой 2 ГГц. Прочие его характеристики, включая объем кэш-памяти, уровень тепловыделения (TDP) и т. д., пока не установлены.
0,5. Как можно обойтись без небольшого извращения?
Совместимость с stm32f103 по выводам и части периферии дает некую надежду на возможность портирования кода оттуда без полной переработки. И действительно, простая периферия вроде SPI или DMA (без прерываний!) вполне успешно запустилась после небольших танцев с бубном.
В работе с регистрами стоит отметить, что GigaDevice предпочитают использовать макросы, в отличие от STMicroelectronics, которые использовали структуры. Плюс нумерация с нуля вместо единицы. Приведу пару примеров:
| GD32VF103 | STM32F103 |
|---|---|
| RCU_APB2EN |= RCU_APB2EN_SPI0EN; | RCC->APB2ENR |= RCC_APB2ENR_SPI1EN; |
| SPI_DATA(SPI_NAME) = data; | SPI1->DR = data; |
| DMA_CHCNT(LCD_DMA, LCD_DMA_CHAN) = size; | DMA1_Channel3->CNDTR = size; |
Здесь сразу бросается в глаза что в RISCV регистр SPI_DATA представлен макросом, в который можно подставить номер используемого модуля SPI. И это очень классно! Можно где-нибудь в заголовочнике объявить что используем SPI0, что он висит на DMA0 на канале 2 и препроцессор сам все подставит без всяких накладных расходов.
В результате на основе вот этого проекта (https://habr.com/ru/post/496046/ исходный код тут: https://github.com/COKPOWEHEU/stm32f103_ili9341_models3D) получилась такая демка:
Исходный код тут: https://github.com/COKPOWEHEU/RISCV-ili9341-3D
Почему именно RISC-V
«Ростех» пока не раскрывает истинные причины выбора RISC-V в качестве архитектуры своих будущих процессоров. Сама по себе эта архитектура имеет открытую систему команд для микроконтроллеров и микропроцессоров, а все ее спецификации находятся в открытом доступе.
Выбор RISC-V мог быть продиктован именно этим фактором. Для примера, создание процессора на архитектуре ARM начинается с покупки у одноименной британской компании соответствующей лицензии.
«Эта открытая архитектура обладает быстрорастущей экосистемой – о переходе на RISC-V в собственных разработках уже объявили , Samsung, Huawei, Nvidia, Western Digital, Qualcomm, Alibaba и многие другие. В ряде стран ЕС, в Индии, Китае и Израиле уже запущены национальные программы по поддержке разработки на базе RISC-V», – сообщил изданию представитель Yadro.
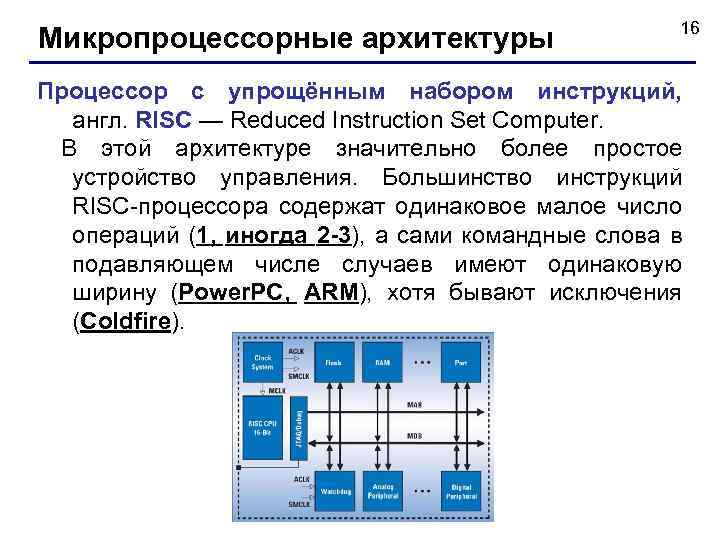



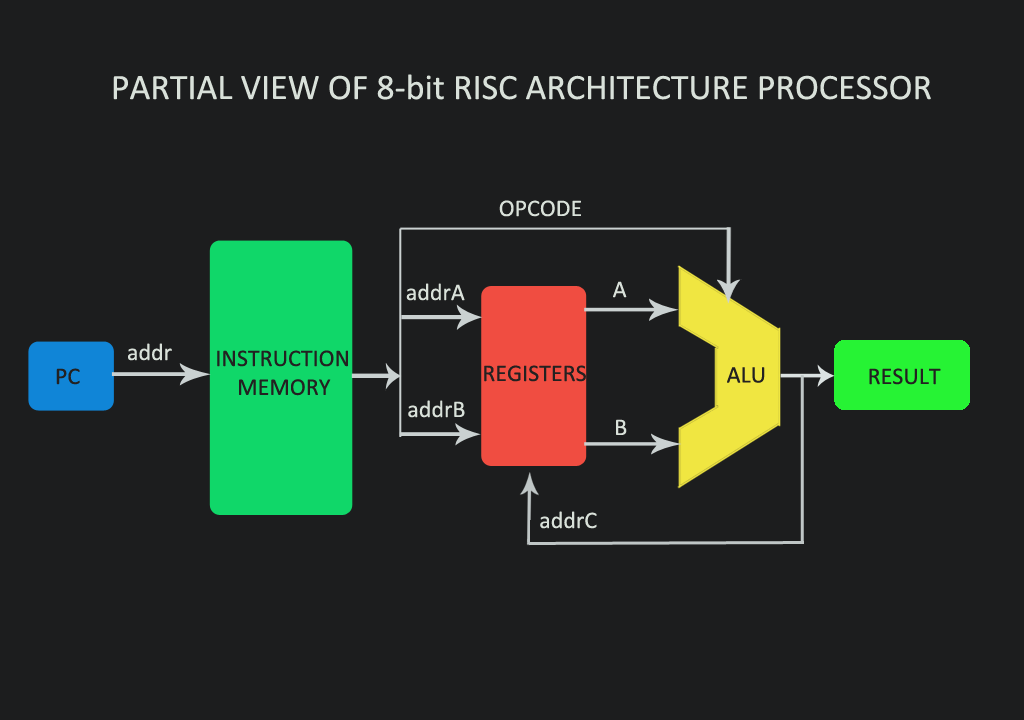
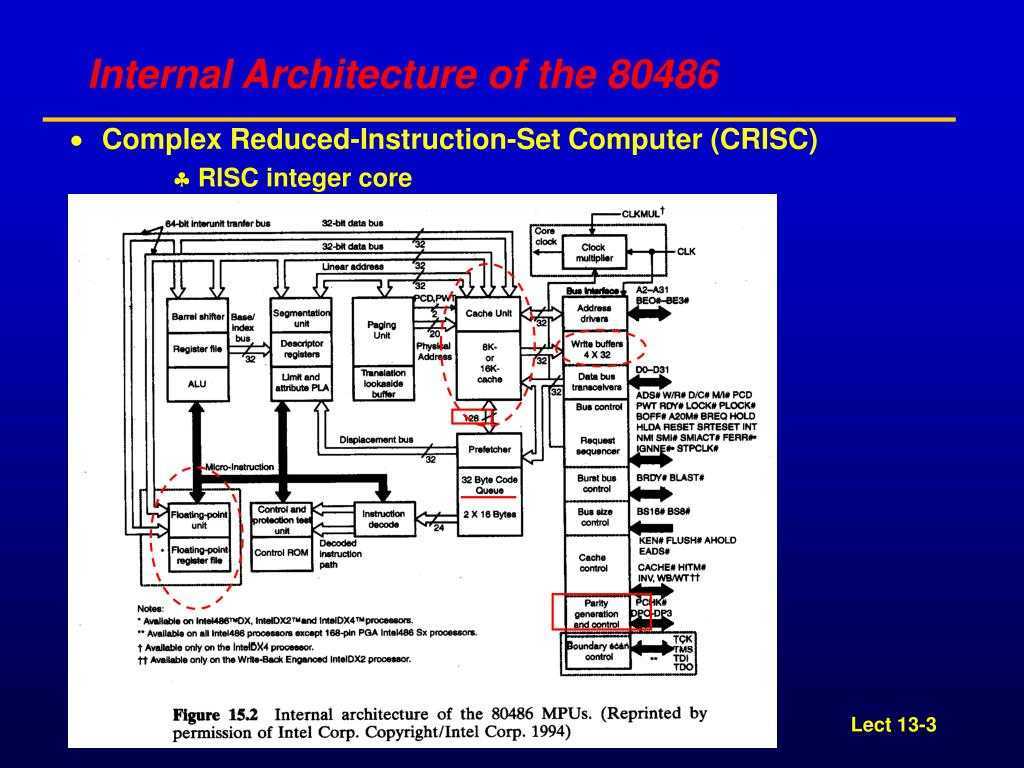



Не исключено, что при создании чипов будут использоваться наработки основанной в 2015 г. российской компании Syntacore – разработчика микропроцессорных ядер. Она является одним из лидеров экосистемы RISC-V и лицензирует микропроцессорные технологии собственной разработки на базе архитектуры RISC-V клиентам в России и за рубежом.
Цифровизация выездного урегулирования задолженности: как технологии помогают банкам больше зарабатывать
ИТ в банках
Продукты на базе процессорных технологий Syntacore разрабатываются по проектным нормам от 180 до 7 нм. Как сообщал CNews, в ноябре 2019 г. Yadro выкупила 51-процентную долю в ней. Следует отметить, что у Syntacore есть офисы не только в России, но и на Кипре. К тому же, она является резидентом «Сколково».
Несмотря на все перспективы RISC-V как архитектуры, она процессоров общего назначения, созданных с ее использованием, на массовом рынке пока нет, утверждает руководитель направления импортозамещения оборудования компании «Крок» Наталия Софронова. «Наиболее массовое применение она пока нашла только в микроконтроллерах и устройствах интернета вещей», – сказала она «Ведомостям.
Миф 8: Целочисленное переполнение дешево в реализации
Получение и хранение бита переполнения недорого только в сферическом вакууме. Это все равно что сказать, будто функция мутации в программировании недорогая с точки зрения памяти или циклов процессора. Но сейчас не об этом.
Один из аргументов, за который топят адвокаты чистых функций (non-mutating) в программировании, в том, что их легче выполнять параллельно, чем мутирующие c общим состоянием. То же самое относится и к out-of-order суперскалярным процессорам. Суперскалярные процессоры выполняют множество команд параллельно. Выполнение инструкций параллельно проще, если инструкции не имеют общего состояния.
Регистры статуса вводят общее состояние и, следовательно, зависимости между инструкциями. Вот почему RISC-V был разработан так, чтобы не иметь никаких регистров статуса. Инструкции ветвления в RISC-V, например, сравнивают два регистра напрямую, а не читают регистр статуса.
Для поддержки регистров статуса в суперскалярном процессоре, где инструкции выполняются не по порядку, вам нужен более сложный учет. Речь идет не просто о добавлении пары триггеров для хранения бита.
За что такие деньги
Судя по всему, высокая стоимость ноутбука – это следствие исключительно наличия у него процессора RISC-V. Все прочие его характеристики самые обыкновенные по современным меркам, к тому же, в нем нет дискретной видеокарты. Привычная всем ОС Windows ему, к слову, тоже не досталась.
На наборе интерфейсов разработчики экономить не стали
Чтобы получить возможность пользоваться Roma, нужно не только заплатить как минимум $1500. Для этого потребуется изучить операционную систему OpenAnolis. Подавляющее большинство потенциальных покупателей данного лэптопа о ней, вероятнее всего, никогда не слышали.
Новые правила аккредитации и получения налоговых льгот для ИТ-компаний: что важно знать
Поддержка ИТ-отрасли
OpenAnolis – детище холдинга Alibaba. По сути, это еще один из нескольких десятков дистрибутивов Linux, но один из тех, кому еще очень далеко до всемирной известности. Изучение столь непопулярной системы может стать для многих проблемой, поэтому, вероятно, самым верным решением будет ее полное удаление из памяти Roma. Заменить OpenAnolis можно будет, к примеру, на Ubuntu. Это как раз самый популярный в мире Linux-дистрибутив. В августе 2022 г. разработчики встроили в него полноценную поддержку процессоров RISC-V.
Немного о новостях
Недавно «Ведомости» со ссылкой на «Ростех» сообщили о разработке в России процессора, основанного на открытой архитектуре RISC-V:
На программу потратят 27,8 млрд рублей. 18 млрд выделят «Ростех» и его дочернее предприятие «Национальные технологии», а на 9,8 млрд проект будет профинансирован напрямую из бюджета.
Это больше, чем сумма всех инвестиций, вложенных государством и частными компаниями в производство процессоров «Эльбрус» и «Байкал» в рамках программы импортозамещения.
Процессор получит 8 ядер, работающих с тактовой частотой 2 ГГц. Разработчики «Ростеха» и Yadro планируют создать несколько вариаций новых процессоров для серверов и настольных компьютеров.
Миф 1: RISC-V «раздувает» размер программ
Инструкция RISC-V в среднем делает меньше работы, чем ARM. В ARM есть инструкция LDR для загрузки данных из памяти в регистр. Она создана для выполнения типичного кода C/C++, например:
Например, мы хотим загрузить данные из массива xs по индексу i. Можно перевести код в ARM, где регистр x1 содержит стартовый адрес массива xs, а регистр x2 — индекс i. Нам надо посчитать сдвиг в байтах от начального адреса x1. Для массива 32-bit целых это соответствует умножению индекса i на 4 для получения сдвига в байтах. Для ARM то же самое можно сделать двойным сдвигом регистра x2 влево.
mem соответствует основной памяти. Мы используем x1, x2 и сдвиги 2, 4 или 8 для получения исходного адреса. Целиком инструкция будет выглядеть так:
В RISC-V эквивалент потребует целых три инструкции (# отмечает комментарии):
Выглядит это как огромное преимущество ARM: код плотнее в 3 раза. Вы получаете меньшее использование кэша и большую производительность конвейера команд.
Сжатые инструкции спешат на помощь!
Однако RISC-V поддерживает сжатые инструкции добавлением всего 400 логических вентилей (AND, OR, NAND) к чипу. Таким образом, две инструкции (из наиболее частотных) могут поместиться в 32-битное слово. Круче всего, что сжатие не добавляет задержек — это не zip-декомпрессия. Декомпрессия выполняется в процессе обычного декодирования инструкций, поэтому она «мгновенная».
Сжатые инструкции следуют закону Парето:
20% инструкций используются 80% времени.
Не воспринимайте это буквально. Создатели RISC-V тщательно отобрали инструкции и сделали их частью сжатого набора команд.
Таким образом RISC-V легко превосходит ARM в плотности кода.
На самом деле современные ARM-чипы могут работать в двух режимах: либо в 32-битном режиме (AArch32) для обратной совместимости, либо в 64-битном режиме (AArch64). В 32-битном режиме чипы ARM поддерживают сжатые инструкции Thumb.
Уточнение: Не путайте 64-битный режим с длиной инструкции. Инструкции в 64-битном режиме по-прежнему имеют ширину 32 бита. Смысл 64-разрядного ARM заключается в возможности работать с 64-разрядными регистрами общего назначения. Для 64-разрядного режима ARM полностью переработал набор команд, поэтому нам надо четко понимать, о каком наборе команд мы говорим.
Такое различие менее важно для RISC-V, где 32-битный набор команд (RV32I) и 64-битный набор команд (RV64I) почти идентичны. Это связано с тем, что дизайнеры RISC-V думали о 32-разрядных, 64-разрядных и даже 128-разрядных архитектурах при разработке RISC-V ISA
Вернемся к сжатым инструкциям RISC-V. Хотя меньшее потребление памяти инструкциями хорошо для кэша, это не решает всех проблем. У нас все еще больше инструкций для декодирования, выполнения и записи результатов. Однако это можно решить с помощью макро-оперативного слияния (macro-op fusion, МОС).










Уменьшаем количество инструкций макро-оп слиянием (МОС)
МОС превращает несколько инструкций в одну. Создатели RISC-V , которые компиляторы должны выдавать, чтобы помочь проектировщикам чипов RISC-V добиться МОС. Одно из требований состоит в том, чтобы у операций был один и тот же регистр назначения (место, куда сохраняется результат). В нашем примере обе инструкции ADD и LW сохраняют результат в регистр x1, мы можем соединить их в одну операцию в декодере инструкций.
Это правило позволяет избежать одного из возражений против МОС: поддержка сохранения результатов в нескольких регистрах в соединенных инструкциях превращается в головняк. Нет, это не потому, что каждая инструкция должна использовать один и тот же регистр назначения, чтобы она была соединена. Наоборот, по этой причине объединенную инструкцию не нужно записывать в несколько регистров.
Я уже писал более подробные статьи на эту тему:
Замечание о МОС
МОС — это не бесплатный обед. Вам нужно добавить больше транзисторов в декодеры для поддержки МОС. Вам также придется работать с разработчиками компиляторов, чтобы они генерировали шаблоны кода, которые создают шаблоны инструкций, которые можно слить. Разработчики RISC-V как раз занимаются этим в данный момент. Иногда МОС просто не сработает, например, из-за границ линии кэша (cache-line). Однако эти проблемы актуальны и для x86 с их инструкциями произвольной длины.
Миф 4: RISC-V использует устаревшую векторную обработку вместо современных SIMD-инструкций
Некоторые люди в лагере ARM хотят создать впечатление, что дизайнеры RISC-V застряли в прошлом и не в курсе последних достижений микропроцессорной архитектуры. Дизайнеры RISC-V решили использовать векторную обработку вместо SIMD (Single Instruction Multiple Data). Ранее это было популярно в старых суперкомпьютерах Cray. Позднее SIMD были добавлены в x86-процессоры для мультимедийных приложений.
Может показаться, что SIMD — это более новая технология, но это не так. SIMD впервые появились на компьютере Lincoln TX-2, используемом для реализации первого графического интерфейса под названием Sketchpad, созданного Иваном Сазерлендом.
Векторная обработка в суперкомпьютере Cray была гораздо более продвинутым способом обработки множества элементов данных. Причина, по которой эти машины впали в немилость, заключалась в том, что суперкомпьютеры производились в штуках, и обычные ПК просто превзошли их в количестве.
SIMD были добавлены в x86-процессоры довольно хаотично, без планирования, для получения небольшого повышения скорости в работе с мультимедиа.
SIMD проще, чем набор команд для настоящей векторной обработки. Однако с расширением возможностей SIMD и увеличениями их длины мы получили нечто более сложное, чем векторная обработка. Нечто неряшливое и негибкое.
Факт, что Cray использовал векторную обработку в 1980-х годах, не означает, что векторная обработка — устаревшая технология. Это все равно, что сказать, будто колесо — это устаревшая технология, потому что оно давненько появилось.
Векторная обработка стала актуальной, потому что от нее выигрывает машинное обучение, продвинутая графика и обработка изображений. Это области, в которых нужна производительность. И ребята из RISC-V не единственные, кто это понял. ARM добавила свои собственные инструкции векторной обработки — SVE2. Если бы они были устаревшими или ненужными, пожалуй, их не добавляли бы в процессоры.
Храним данные на флешке
Использование стека отлично подходит для локальных переменных, которые не будут сохраняться между вызовами функций. Но иногда возникает необходимость использовать глобальные переменные и константы, доступные любой функции.
Начнем с простого — хранения массива констант. Для этого используется та же флеш-память, что и для исполняемого кода. Для удобства ее иногда выделяют в отдельный сегмент .rodata, но пока мы этим заниматься не будем. Просто объявим в конце нашей программы массив из 4 значений:
Директива .short означает, что элемент памяти — короткое целое размером 2 байта. О других директивах резервирования места я расскажу чуть позже.
Ну и заменяем предыдущую рекурсивную мигалку на последовательное чтение из этого массива с выводом на светодиоды:
Здесь стоит отметить две вещи. Во-первых, замена lw на lh при работе с GPIOB_OCTL. Поскольку элементы данных в массиве 2-байтные, как и регистр GPIOB_OCTL, старшие байты вполне можно не писать, это немного сэкономит память. Во-вторых, увеличение адреса в массиве не на 1, а на размер элемента. Если бы мы использовали 32-битные константы, увеличивать пришлось бы на 4 байта, а если байтовые — то на 1.
Заключение
В общем, я не вижу никаких серьёзных опасностей в использовании RISC-V в ситуации, когда свою архитектуру схожей простоты и производительности мы так и не придумали (хотя хотелось бы), а архитектура процессора Эльбрус в ближайшей перспективе не сулит особых успехов на рынке десктопов. Да, проблемы Эльбруса решаемы, но сопряжены с неудобными побочными эффектами, которые никуда не денутся, хотя их влияние, несомненно, будет нивелировано.
Оппоненты могут возразить, дескать RISC-V ещё слабо развита, применяется только в микроконтроллерах и не предназначена для рабочих станций и серверов, и ещё неизвестно, как она там себя поведёт. Но на это можно возразить, что RISC-V — всего лишь небольшая система команд, а предназначение процессора будет определяться набором расширений этой системы и её аппаратной реализацией. И то и то можно сделать какими угодно, в отличие от уже жёстких особенностей архитектуры Эльбруса, из которых проистекают не только преимущества в отдельных областях применений, но и основные проблемы с контекстом, объёмом кода, скоростью компиляции и т.п.
Резюмируя, я предлагаю огульно ничего не охаивать и не поддаваться на эмоциональный хайп и фейки по поводу той или иной архитектуры, а подходить к осмыслению нашего пути трезво. Думаю, что нужно сконцентрировать усилия на двух направлениях — это архитектура Эльбрус, потому что это, как минимум, интересно с научной точки зрения, и архитектура RISC-V, потому что в ней содержится больше актуальных для нас преимуществ, в том числе и потенциальных. Одновременно следует начать поиск других вариантов системы команд, которые лучше легли бы на аппаратные возможности транзисторной (а может и не только транзисторной) логики, что дало бы повышение эффективности вычислений.
Что касается Байкала, то он сам способен занять свою нишу благодаря простейшей модели бизнеса и хорошей бизнес-хватке его топ-менеджмента. Но и риски от использования лицензий ARM нужно всегда иметь ввиду.