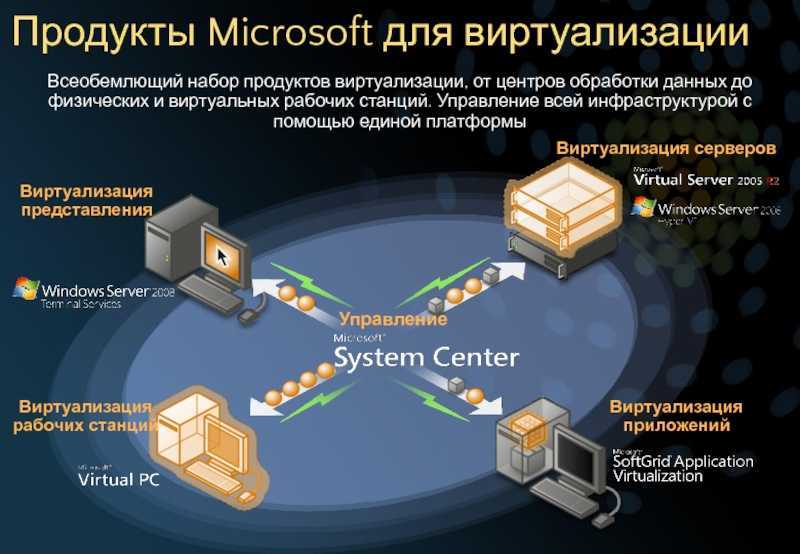
Сколько зарабатывают компьютерные лингвисты
Размер зарплаты цифрового лингвиста зависит от его опыта и компетенций, а также стремления к постоянному развитию и статуса компании, в которой он работает.
Некоторые работодатели готовы взять новичка без опыта, но с хорошей теоретической подготовкой. В среднем компании ищут специалистов с опытом работы от года.
На момент написания статьи на hh.ru компьютерному лингвисту или специалисту по обработке естественного языка предлагали оклад от 95 тыс. рублей.



В США, согласно данным Glassdoor, средний уровень зарплат начинающего компьютерного лингвиста составляет около 92 тыс. долларов в год. Специалист высокого профиля может зарабатывать до 170 тыс. долларов в год.
Как машины различают омонимы и понимают новые слова
Машины учатся различать омонимы и новые слова так же, как и человек — по контексту. Допустим, я скажу: «Налей мне, пожалуйста, бокал красностопа». По контексту понятно, что это какой-то напиток. Если в тексте написано, что мясо отлично сочетается с эндемическим красностопом Краснодарского края, — из контекста станет понятно, что это, скорее всего, сорт красного винограда.
Достаточно пары-тройки примеров словоупотребления, чтобы правильно восстановить смысл слова. На этом базируется идея: когда ты учишь язык, можно начинать смотреть фильмы или читать книги в оригинале, пока ты не начнёшь понимать, о чём говорят.
↑йНЛОЭЧРЕПМЮЪ КХМЦБХЯРХЙЮ ЙЮЙ НДМН ХГ ЮЙРСЮКЭМШУ МЮОПЮБКЕМХИ ЯНБПЕЛЕММНИ ОПХЙКЮДМНИ КХМЦБХЯРХЙХ
б ПЮЛЙЮУ МЮОПЮБКЕМХЪ ЙНЛОЭЧРЕПМЮЪ КХМЦБХЯРХЙЮ Б ЬХПНЙНЛ ЯЛШЯКЕ ЯКНБЮ НАЗЕДХМЪЧРЯЪ ЙЮЙ ЙНЛОЭЧРЕПМНЕ ЛНДЕКХПНБЮМХЕ Я ЖЕКЭЧ ОПНБЕПЙХ ЮДЕЙБЮРМНЯРХ РЕНПЕРХВЕЯЙХУ ТНПЛЮКЭМН-ЛЮРЕЛЮРХВЕЯЙХУ ЛНДЕКЕИ ЪГШЙЮ Х ЕЦН НРДЕКЭМШУ СПНБМЕИ, РЮЙ Х ОПХЛЕМЕМХЕ ПЮГКХВМШУ ЛЮРЕЛЮРХВЕЯЙХУ ЛЕРНДНБ ДКЪ ПЕЬЕМХЪ ЙНМЙПЕРМШУ ОПХЙКЮДМШУ ГЮДЮВ Б ПЮГКХВМШУ ЯХЯРЕЛЮУ НАПЮАНРЙХ ХМТНПЛЮЖХХ. яПЕДХ ЯНБПЕЛЕММШУ МЮОПЮБКЕМХИ ЙНЛОЭЧРЕПМНИ КХМЦБХЯРХЙХ ЛНФМН БШДЕКХРЭ ЯКЕДСЧЫХЕ (ЯЛ. ОПЕГЕМРЮЖХЧ ЙНЛО_КХМЦ):
лЮЬХММШИ ОЕПЕБНД
пЕВЕБШЕ РЕУМНКНЦХХ (Б ВЮЯРМНЯРХ, ЮБРНЛЮРХВЕЯЙНЕ ПЮЯОНГМЮБЮМХЕ ПЕВХ, ASR)
кХМЦБХЯРХВЕЯЙНЕ НАЕЯОЕВЕМХЕ ХМТНПЛЮЖХНММНЦН ОНЯХЙЮ
юБРНЛЮРХВЕЯЙНЕ ХГБКЕВЕМХЕ ДЮММШУ (Data Mining)
юБРНЛЮРХВЕЯЙНЕ ПЕТЕПХПНБЮМХЕ РЕЙЯРНБ
яНГДЮМХЕ ЩКЕЙРПНММШУ КЕЙЯХЙНЦПЮТХВЕЯЙХУ ПЕЯСПЯНБ (ЯКНБЮПЕИ, НМРНКНЦХИ)
йНПОСЯМЮЪ КХМЦБХЯРХЙЮ (ЯНГДЮМХЕ Х ХЯОНКЭГНБЮМХЕ ЩКЕЙРПНММШУ ЙНПОСЯНБ РЕЙЯРНБ)
ПЮГПЮАНРЙЮ БНОПНЯМН-НРБЕРМШУ ЯХЯРЕЛ
вЮЯРЭ ДЮММШУ МЮОПЮБКЕМХИ, Ю РЮЙФЕ ПЮГПЮАНРЙЮ ЯХЯРЕЛ ЮБРНЛЮРХВЕЯЙНЦН ЮМЮКХГЮ МЮ ПЮГМШУ ЪГШЙНБШУ СПНБМЪУ: ЛНПТНКНЦХВЕЯЙХУ ЮМЮКХГЮРНПНБ (ОЮПЯЕПНБ), ЯХЯРЕЛ ЮБРНЛЮРХВЕЯЙНЦН ЯХМРЮЙЯХВЕЯЙНЦН ЮМЮКХГЮ Х Р.О. ВЮЯРН БШДЕКЪЧР Б НРДЕКЭМСЧ НАКЮЯРЭ — ЮБРНЛЮРХВЕЯЙЮЪ НАПЮАНРЙЮ ЕЯРЕЯРБЕММНЦН ЪГШЙЮ (Natural Language Processing, NLP — НАЫЕЕ МЮОПЮБКЕМХЕ ХЯЙСЯЯРБЕММНЦН ХМРЕККЕЙРЮ Х ЙНЛОЭЧРЕПМНИ КХМЦБХЯРХЙХ.
Векторное представление (text embeddings)
В традиционном NLP слова рассматриваются как дискретные символы, которые далее представляются в виде one-hot векторов. Проблема со словами — дискретными символами — отсутствие определения cхожести для one-hot векторов. Поэтому альтернатива — обучиться кодировать схожесть в сами векторы.
Векторное представление — метод представления строк, как векторов со значениями. Строится плотный вектор (dense vector) для каждого слова так, чтобы встречающиеся в схожих контекстах слова имели схожие вектора. Векторное представление считается стартовой точкой для большинства NLP задач и делает глубокое обучение эффективным на маленьких датасетах. Техники векторных представлений Word2vec и GloVe, созданных Google (Mikolov) Stanford (Pennington, Socher, Manning) соответственно, пользуются популярностью и часто используются для задач NLP. Давайте рассмотрим эти техники.
Word2Vec
Word2vec принимает большой корпус (corpus) текста, в котором каждое слово в фиксированном словаре представлено в виде вектора. Далее алгоритм пробегает по каждой позиции t в тексте, которая представляет собой центральное слово c и контекстное слово o. Далее используется схожесть векторов слов для c и o, чтобы рассчитать вероятность o при заданном с (или наоборот), и продолжается регулировка вектор слов для максимизации этой вероятности.
Для достижения лучшего результата Word2vec из датасета удаляются бесполезные слова (или слова с большой частотой появления, в английском языке — a,the,of,then). Это поможет улучшить точность модели и сократить время на тренировку. Кроме того, используется отрицательная выборка (negative sampling) для каждого входа, обновляя веса для всех правильных меток, но только на небольшом числе некорректных меток.
Word2vec представлен в 2 вариациях моделей:
- Skip-Gram: рассматривается контекстное окно, содержащее k последовательных слов. Далее пропускается одно слово и обучается нейронная сеть, содержащая все слова, кроме пропущенного, которое алгоритм пытается предсказать. Следовательно, если 2 слова периодически делят cхожий контекст в корпусе, эти слова будут иметь близкие векторы.
- Continuous Bag of Words: берется много предложений в корпусе. Каждый раз, когда алгоритм видим слово, берется соседнее слово. Далее на вход нейросети подается контекстные слова и предсказываем слово в центре этого контекста. В случае тысяч таких контекстных слов и центрального слова, получаем один экземпляр датасета для нашей нейросети. Нейросеть тренируется и ,наконец, выход закодированного скрытого слоя представляет вложение (embedding) для определенного слова. То же происходит, если нейросеть тренируется на большом числе предложений и словам в схожем контексте приписываются схожие вектора.
Единственная жалоба на Skip-Gram и CBOW — принадлежность к классу window-based моделей, для которых характерна низкая эффективность использования статистики совпадений в корпусе, что приводит к неоптимальным результатам.
GloVe
GloVe стремится решить эту проблему захватом значения одного word embedding со структурой всего обозримого корпуса. Чтобы сделать это, модель ищет глобальные совпадения числа слов и использует достаточно статистики, минимизирует среднеквадратичное отклонение, выдает пространство вектора слова с разумной субструктурой. Такая схема в достаточной степени позволяет отождествлять схожесть слова с векторным расстоянием.
Помимо этих двух моделей, нашли применение много недавно разработанных технологий: FastText, Poincare Embeddings, sense2vec, Skip-Thought, Adaptive Skip-Gram.
↑жЕКХ, ГЮДЮВХ Х НЯМНБМШЕ МЮОПЮБКЕМХЪ ОПХЙКЮДМНИ КХМЦБХЯРХЙХ
оПХЙКЮДМЮЪ КХМЦБХЯРХЙЮ ЙЮЙ ЯЮЛНЯРНЪРЕКЭМЮЪ МЮСВМЮЪ ДХЯЖХОКХМЮ БНГМХЙКЮ ЯПЮБМХРЕКЭМН МЕДЮБМН (ОПХАКХГХРЕКЭМН Й 1920-Л ЦНДЮЛ). нДМЮЙН ГЮДЮВХ, ЯБЪГЮММШЕ Я ОПХКНФЕМХЕЛ КХМЦБХЯРХВЕЯЙХУ ГМЮМХИ Б ПЮГКХВМШУ ЯТЕПЮУ ВЕКНБЕВЕЯЙНИ ДЕЪРЕКЭМНЯРХ, БЙКЧВЮЪ ЛНДЕКХПНБЮМХЕ ОПНЖЕЯЯЮ ОНГМЮМХЪ, НАСВЕМХЕ ЪГШЙС, ЯНГДЮМХЕ МНПЛЮРХБМШУ ЪГШЙНБШУ НОХЯЮМХИ Х Р.О. ЯРНЪКХ ОЕПЕД ЪГШЙНГМЮМХЕЛ СФЕ ДЮБМН. оНД «ЬЮОЙНИ» ДЮММНИ НАКЮЯРХ ХЯЯКЕДНБЮМХЪ НВЕМЭ ВЮЯРН НАЗЕДХМЪЧР ЛМНФЕЯРБН, МЮ ОЕПБШИ БГЦКЪД, ПЮГМНПНДМШУ МЮОПЮБКЕМХИ Х ОПХКНФЕМХИ. я НДМНИ ЯРНПНМШ, НРДЕКЭМШЕ НАКЮЯРХ ОПХЙКЮДМНИ КХМЦБХЯРХЙХ ПЮЯЯЛЮРПХБЮЧРЯЪ ЙЮЙ ВЮЯРХ ДХЯЖХОКХМ Б ПЮЛЙЮУ ЯТНПЛХПНБЮБЬЕЦНЯЪ МЕДЮБМН МЮСВМНЦН МЮОПЮБКЕМХЪ, МЮГШБЮЕЛНЦН НАЫХЛ РЕПЛХМНЛ Computer Science. я ДПСЦНИ ЯРНПНМШ, КХМЦБХЯРХВЕЯЙХЕ ЛНДЕКХ ХЯЯКЕДСЧРЯЪ Х ОПХЛЕМЪЧРЯЪ Б ЯСЦСАН ЦСЛЮМХРЮПМШУ НАКЮЯРЪУ РЮЙХУ, ЙЮЙ ОПЮЙРХЙЮ ОПЕОНДЮБЮМХЪ ЪГШЙЮ, РЕНПХХ ПЕВЕБНЦН БНГДЕИЯРБХЪ, ОНКХРХВЕЯЙНИ КХМЦБХЯРХЙЕ. яНЦКЮЯМН ю.м.аЮПЮМНБС БЯЕ ЩРХ МЮОПЮБКЕМХЪ ЛНФМН НАЗЕДХМХРЭ Б РНЛ ЯЛШЯКЕ, ВРН Б МХУ «ХГСВЮЧРЯЪ Х ПЮГПЮАЮРШБЮЧР ЯОНЯНАШ НОРХЛХГЮЖХХ ТСМЙЖХНМХПНБЮМХЪ ЪГШЙЮ».
мЕ ЯСЫЕЯРБСЕР ЕДХМНИ РНВЙХ ГПЕМХЪ МЮ ЯНЯРЮБ НЯМНБМШУ МЮОПЮБКЕМХИ ОПХЙКЮДМНИ КХМЦБХЯРХЙХ. нАШВМН БШДЕКЪЧР ЯКЕДСЧЫХЕ МЮОПЮБКЕМХЪ, ЯБЪГЮММШЕ Я ХГСВЕМХЕЛ ЪГШЙЮ:
- КЕЙЯХЙНЦПЮТХЪ — РЕНПХЪ Х ОПЮЙРХЙЮ ЯНЯРЮБКЕМХЪ ЯКНБЮПЕИ;
- КХМЦБНДХДЮЙРХЙЮ — МЮСЙЮ Н ПЮГПЮАНРЙЮУ ЛЕРНДХЙ НАСВЕМХЪ ХМНЯРПЮММНЛС ЪГШЙС;
- РЕПЛХМНБЕДЕМХЕ — МЮСЙЮ НА СОНПЪДНВЕМХХ Х ЯРЮМДЮПРХГЮЖХХ МЮСВМН-РЕУМХВЕЯЙНИ РЕПЛХМНКНЦХХ;
- ОЕПЕБНДНБЕДЕМХЕ — РЕНПХЪ ОЕПЕБНДЮ
- ЙБЮМРХРЮРХБМЮЪ КХМЦБХЯРХЙЮ (ХГСВЕМХЕ ВЮЯРНРМШУ ЯБНИЯРБ ЪГШЙНБШУ ЕДХМХЖ Х ХУ ЯБЪГЭ Я ДПСЦХЛХ ЯБНИЯРБЮЛХ, РЮЙХЛХ ЙЮЙ ТНМЕРХВЕЯЙЮЪ ЯКНФМНЯРЭ, ЛНПТНКНЦХВЕЯЙЮЪ ЯКНФМНЯРЭ, ЛМНЦНГМЮВМНЯРЭ, БНГПЮЯР).
нЯМНБМШЕ МЮОПЮБКЕМХЪ ОПХЙКЮДМНИ КХМЦБХЯРХЙХ, ЯБЪГЮММШЕ Я ОПЮЙРХВЕЯЙХЛХ ОПХКНФЕМХЪЛХ:
- йНЛОЭЧРЕПМЮЪ КХМЦБХЯРХЙЮ (computational linguistics)
- кХМЦБХЯРХВЕЯЙЮЪ ЩЙЯОЕПРХГЮ (МЮОПХЛЕП, Б ЯСДЕАМНИ ОПЮЙРХЙЕ)
- оНКХРХВЕЯЙЮЪ КХМЦБХЯРХЙЮ (ЮМЮКХГ ОНКХРХВЕЯЙНЦН ДХЯЙСПЯЮ)
нДМНИ ХГ БЮФМШУ НАКЮЯРЕИ ОПХЛЕМЕМХЪ КХМЦБХЯРХВЕЯЙХУ ГМЮМХИ Б ДПСЦХУ НАКЮЯРЪУ ЪБКЪЕРЯЪ ОПХЙКЮДМЮЪ ТНМЕРХЙЮ. нМЮ ГЮМХЛЮЕРЯЪ ОПЮЙРХВЕЯЙХЛ ОПХЛЕМЕМХЕЛ ТНМЕРХВЕЯЙХУ ГМЮМХИ, МЮЙНОКЕММШУ Б КХМЦБХЯРХЙЕ. еЕ ПЮГДЕКШ НРПЮФЮЧР ЛМНЦННАПЮГХЕ ХЯОНКЭГНБЮМХЪ ЪГШЙЮ Б ВЕКНБЕВЕЯЙНИ ФХГМХ: Й ОПХЙКЮДМНИ ТНМЕРХЙЕ НРМНЯЪРЯЪ РЮЙХЕ ПЮГМШЕ ДХЯЖХОКХМШ, ЙЮЙ ЛЕРНДХЙЮ ОПЕОНДЮБЮМХЪ ТНМЕРХЙХ ЙНМЙПЕРМНЦН ЪГШЙЮ, ТНМЕРХВЕЯЙЮЪ ПХРНПХЙЮ – ОПХЕЛШ БШПЮГХРЕКЭМНИ ПЕВХ, НПТНЩОХЪ, СЯРЮМЮБКХБЮЧЫЮЪ ПЮГКХВМШЕ ОПНХГМНЯХРЕКЭМШЕ МНПЛШ. бЮФМНЕ ОПХЛЕМЕМХЕ ТНМЕРХЙЮ МЮУНДХР РЮЙФЕ Б КНЦНОЕДХХ, ПЕВЕБНИ ДЕТЕЙРНКНЦХХ Х КЕВЕМХХ АНКЕГМЕИ, БШГБЮММШУ ОНБПЕФДЕМХЕЛ ПЕВЕБШУ ТСМЙЖХИ.

б ОНЯКЕДМЕЕ БПЕЛЪ ОПНЯКЕФХБЮЕРЯЪ РЕМДЕМЖХЪ Й ХЯОНКЭГНБЮМХЧ РЕПЛХМЮ “ОПХЙКЮДМЮЪ КХМЦБХЯРХЙЮ ХЛЕММН Б ГЮОЮДМНЛ ГМЮВЕМХХ”. рЮЙ, мЮЖХНМЮКЭМНЕ НАЫЕЯРБН ОПХЙКЮДМНИ КХМЦБХЯРХЙХ ГЮМХЛЮЕРЯЪ ХЛЕММН ОПНАКЕЛЮЛХ КХМЦБНДХДЮЙРХЙХ (www.nopril.ru). рЕУМНКНЦХХ ЮМЮКХГЮ ЕЯРЕЯРБЕММНЦН ЪГШЙЮ, ЛНДЕКХПНБЮМХЪ ЙНЦМХРХБМШУ ОПНЖЕЯЯНБ ОНМХЛЮМХЪ Х ЪГШЙНБНЦН БГЮХЛНДЕИЯРБХЪ Х ХГБКЕВЕМХЪ ХМТНПЛЮЖХХ ХГ РЕЙЯРНБ НАЗЕДХМЪЧРЯЪ НАЫХЛ РЕПЛХМНЛ “йНЛОЭЧРЕПМЮЪ КХМЦБХЯРХЙЮ” (БШВХЯКХРЕКЭМЮЪ КХМЦБХЯРХЙЮ, computational linguistics).
мЕЯЛНРПЪ МЮ РН, ВРН ЛЕРНДШ, ОПХЛЕМЪЕЛШЕ Б ПЮГКХВМШУ МЮОПЮБКЕМХЪУ ОПХЙКЮДМНИ КХМЦБХЯРХЙЕ ПЮГМННАПЮГМШ, ЛНФМН БШДЕКХРЭ НАЫХЕ УЮПЮЙРЕПМШЕ ОПХГМЮЙХ:
- БЕДСЫЮЪ ПНКЭ ЛЕРНДЮ ЛНДЕКХПНБЮМХЪ;
- ЩЙЯОЕПХЛЕМРЮКЭМШИ УЮПЮЙРЕП ОПХЙКЮДМШУ ЛЕРНДХЙ
- ЙНЛОКЕЙЯМНЕ ЯНВЕРЮМХЕ ПЮГМШУ МЮСЙ.
б пНЯЯХХ РЕПЛХМ «ОПХЙКЮДМЮЪ КХМЦБХЯРХЙЮ» ОНКСВХК ЬХПНЙНЕ ПЮЯОПНЯРПЮМЕМХЕ Б 1950-У ЦНДЮУ. щРН НАЯРНЪРЕКЭЯРБН ЯБЪГЮМН Я ОНЪБКЕМХЕЛ ОЕПБШУ ЙНЛОЭЧРЕПМШУ ЯХЯРЕЛ ЮБРНЛЮРХВЕЯЙНИ НАПЮАНРЙХ РЕЙЯРНБНИ ХМТНПЛЮЖХХ (ЛЮЬХММНЦН ОЕПЕБНДЮ, ЮБРНЛЮРХВЕЯЙНЦН ПЕТЕПХПНБЮМХЪ Х ДП.). б ПСЯЯЙНЪГШВМНИ КХРЕПЮРСПЕ ПЮЯОПНЯРПЮМЕМ ОНДУНД, ОПХ ЙНРНПНЛ РЕПЛХМ «ОПХЙКЮДМЮЪ КХМЦБХЯРХЙЮ» ХЛЕЕР РН ФЕ ГМЮВЕМХЕ, ВРН Х «ЙНЛОЭЧРЕПМЮЪ КХМЦБХЯРХЙЮ», «БШВХЯКХРЕКЭМЮЪ КХМЦБХЯРХЙЮ», «ЮБРНЛЮРХВЕЯЙЮЪ КХМЦБХЯРХЙЮ», «ХМФЕМЕПМЮЪ КХМЦБХЯРХЙЮ.
Какие задачи решает компьютерный лингвист
Компьютерный, или цифровой лингвист — это специалист, который разрабатывает алгоритмы и программы, способные воспроизводить когнитивную языковую деятельность человека: умение читать, понимать на слух, говорить, участвовать в диалоге и переводить с одного языка на другой.
Что делает компьютерный лингвист:
- разрабатывает алгоритмы и методы машинного перевода;
- программирует системы извлечения и поиска информации, распознавания речи и других продуктов;
- работает с генераторами текстов;
- объединяет похожие тексты в группы;
- разрабатывает вопросно-ответные системы;
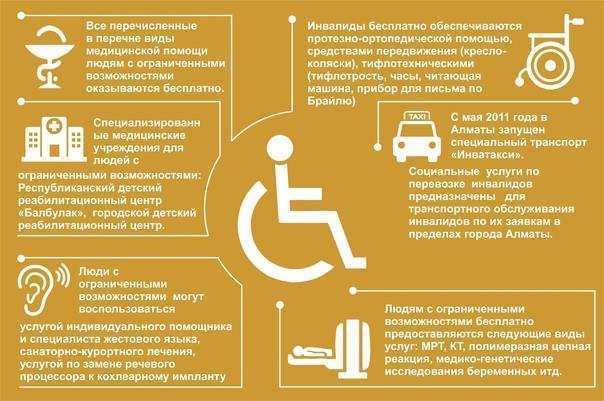
- создаёт программы, которые облегчают коммуникацию людям с ограниченными возможностями.
Помимо этого, цифровой лингвист анализирует, насколько хорошо работают программы по автоматической обработке текста: системы проверки правописания, машинные переводчики или измерители сходства текстов.
Подготовка компьютерных лингвистов
Профессия лингвиста очень востребована (с сайта ВШЭ):
-
В компаниях-гигантах IT, так или иначе связанных с задачами текстового поиска и анализа, таких как:
- Google,
- Яндекс,
- Mail.ru,
- ABBYY,
- Samsung,
- Лаборатория Касперского и других.
-
В стартапах, разрабатывающих новые лингвистические технологии –
например, для создания роботов, говорящих на естественном языке …
или для автоматического распознавания эмоций в текстах пользователей социальных сетей. -
В компаниях и институтах, занимающихся прикладными лингвистическими задачами и их современными решениями:
— для разработки электронных словарей и тезаурусов;- для разработки инновационных методик обучению языку;
- для разработки компьютерных моделей естественного языка.
-
В компаниях, не занимающихся лингвистикой, но нуждающихся в профессионале для обработки
больших объемов неструктурированных текстовых данных, например:- в рекрутинге;
- в биржевой аналитике;
- в юридической поддержке;
- в маркетинге.
Где готовят компьютерных лингвистов и вообще хороших лингвистов-теоретиков:
- Москва, Академия МИД
- Москва (с филиалом в Н.Новгороде), Высшая школа экономики,
Факультет филологии ВШЭ (магистерская программа «Компьютерная лингвистика») - Москва, МГИМО
- Москва, Филфак МГУ им. Ломоносова
- Московский лингвистический университет (МГЛУ им. Мориса Тореза)
-
Москва, МФТИ, Факультет инноваций и высоких технологий,
кафедра распознавания изображений и обработки текста
(направления «Интеллектуальные системы» и «Методы машинного обучения»). - Санкт-Петербург, Инъяз РГПУ им. А. И. Герцена
-
Санкт-Петербург, СПбГУ, Гуманитарный факультет,
кафедра информационных систем в искусстве и гуманитарных науках
(программа «Инженерия гуманитарных знаний»). - Новосибирский лингвистический университет (НГЛУ им. Добролюбова)
- Пятигорский лингвистический институт
Почему «Алиса» не понимает собеседника
Здесь может быть много проблем проблем, например:
- человек странно сформулировал мысль;
- в процессе перевода его слов в текст произошла какая-то ошибка, например был слишком сильный фоновый шум;
- человек говорит с акцентом;
- говорит тихо или слишком громко.
А ещё бывает так, что «Алиса» не может выполнить то, что хочет человек. Например, ты думал, что голосовой интерфейс может заказать цветы онлайн, а он не может. В этих моментах можно самому открыть поиск и набрать нужное вручную.
При этом у «Алисы» есть режим болталки. Когда ты произносишь «Давай поговорим», в разговор включается искусственная нейронная сеть. Она пытается сгенерировать фразу, которую считает наиболее подходящим ответом человеку-собеседнику.
У подобного общения есть проблема — ей сложно поддерживать длительный и осмысленный разговор. «Алиса» не помнит того, что ей сказали час назад
Чтобы это стало возможным, ей надо как-то выбирать из потока текста что-то важное и неважное и где-то это хранить. Есть целое направление, где люди бьются над созданием искусственных нейронных сетей, обладающих памятью, — но пока безрезультатно
Компьютерная лингвистика решает задачи, связанные с обработкой естественного языка
Компьютерная лингвистика — это область знаний, которая занимается компьютерным моделированием владения естественным языком и решением прикладных задач автоматической обработки текстов и речи.
История компьютерной лингвистики начинается в 1950-х годах с исследований известного американского лингвиста, публициста и философа Ноама Хомского по формализации структуры естественного языка, а также с пробных экспериментов по машинному переводу и первых ИИ-программ понимания естественного языка.
Можно сказать, что компьютерная лингвистика зародилась в январе 1954 года, когда в Джорджтаунском университете (США) был проведён первый в мире публичный эксперимент по машинному переводу. Инженерам удалось перевести более 60 предложений с русского языка на английский в полностью автоматическом режиме.
В конце 1980-х годов с развитием интернета объём доступных в электронном виде текстов резко увеличился, что привело к качественному скачку в технологиях информационного поиска. Возникли совершенно новые задачи для обработки текстов на естественном языке. Тогда же были созданы первые алгоритмы машинного обучения и системы статистического машинного перевода.
Прорыв в области обработки языка пришёлся на 2010-е годы, когда стали развиваться алгоритмы глубокого обучения. С тех пор появилось и продолжает появляться множество разработок для решения задач компьютерной лингвистики.
↑жЕКХ, ГЮДЮВХ Х НЯМНБМШЕ МЮОПЮБКЕМХЪ ОПХЙКЮДМНИ КХМЦБХЯРХЙХ
оПХЙКЮДМЮЪ КХМЦБХЯРХЙЮ ЙЮЙ ЯЮЛНЯРНЪРЕКЭМЮЪ МЮСВМЮЪ ДХЯЖХОКХМЮ БНГМХЙКЮ ЯПЮБМХРЕКЭМН МЕДЮБМН (ОПХАКХГХРЕКЭМН Й 1920-Л ЦНДЮЛ). нДМЮЙН ГЮДЮВХ, ЯБЪГЮММШЕ Я ОПХКНФЕМХЕЛ КХМЦБХЯРХВЕЯЙХУ ГМЮМХИ Б ПЮГКХВМШУ ЯТЕПЮУ ВЕКНБЕВЕЯЙНИ ДЕЪРЕКЭМНЯРХ, БЙКЧВЮЪ ЛНДЕКХПНБЮМХЕ ОПНЖЕЯЯЮ ОНГМЮМХЪ, НАСВЕМХЕ ЪГШЙС, ЯНГДЮМХЕ МНПЛЮРХБМШУ ЪГШЙНБШУ НОХЯЮМХИ Х Р.О. ЯРНЪКХ ОЕПЕД ЪГШЙНГМЮМХЕЛ СФЕ ДЮБМН. оНД «ЬЮОЙНИ» ДЮММНИ НАКЮЯРХ ХЯЯКЕДНБЮМХЪ НВЕМЭ ВЮЯРН НАЗЕДХМЪЧР ЛМНФЕЯРБН, МЮ ОЕПБШИ БГЦКЪД, ПЮГМНПНДМШУ МЮОПЮБКЕМХИ Х ОПХКНФЕМХИ. я НДМНИ ЯРНПНМШ, НРДЕКЭМШЕ НАКЮЯРХ ОПХЙКЮДМНИ КХМЦБХЯРХЙХ ПЮЯЯЛЮРПХБЮЧРЯЪ ЙЮЙ ВЮЯРХ ДХЯЖХОКХМ Б ПЮЛЙЮУ ЯТНПЛХПНБЮБЬЕЦНЯЪ МЕДЮБМН МЮСВМНЦН МЮОПЮБКЕМХЪ, МЮГШБЮЕЛНЦН НАЫХЛ РЕПЛХМНЛ Computer Science. я ДПСЦНИ ЯРНПНМШ, КХМЦБХЯРХВЕЯЙХЕ ЛНДЕКХ ХЯЯКЕДСЧРЯЪ Х ОПХЛЕМЪЧРЯЪ Б ЯСЦСАН ЦСЛЮМХРЮПМШУ НАКЮЯРЪУ РЮЙХУ, ЙЮЙ ОПЮЙРХЙЮ ОПЕОНДЮБЮМХЪ ЪГШЙЮ, РЕНПХХ ПЕВЕБНЦН БНГДЕИЯРБХЪ, ОНКХРХВЕЯЙНИ КХМЦБХЯРХЙЕ. яНЦКЮЯМН ю.м.аЮПЮМНБС БЯЕ ЩРХ МЮОПЮБКЕМХЪ ЛНФМН НАЗЕДХМХРЭ Б РНЛ ЯЛШЯКЕ, ВРН Б МХУ «ХГСВЮЧРЯЪ Х ПЮГПЮАЮРШБЮЧР ЯОНЯНАШ НОРХЛХГЮЖХХ ТСМЙЖХНМХПНБЮМХЪ ЪГШЙЮ».
мЕ ЯСЫЕЯРБСЕР ЕДХМНИ РНВЙХ ГПЕМХЪ МЮ ЯНЯРЮБ НЯМНБМШУ МЮОПЮБКЕМХИ ОПХЙКЮДМНИ КХМЦБХЯРХЙХ. нАШВМН БШДЕКЪЧР ЯКЕДСЧЫХЕ МЮОПЮБКЕМХЪ, ЯБЪГЮММШЕ Я ХГСВЕМХЕЛ ЪГШЙЮ:
КЕЙЯХЙНЦПЮТХЪ — РЕНПХЪ Х ОПЮЙРХЙЮ ЯНЯРЮБКЕМХЪ ЯКНБЮПЕИ;
КХМЦБНДХДЮЙРХЙЮ — МЮСЙЮ Н ПЮГПЮАНРЙЮУ ЛЕРНДХЙ НАСВЕМХЪ ХМНЯРПЮММНЛС ЪГШЙС;
РЕПЛХМНБЕДЕМХЕ — МЮСЙЮ НА СОНПЪДНВЕМХХ Х ЯРЮМДЮПРХГЮЖХХ МЮСВМН-РЕУМХВЕЯЙНИ РЕПЛХМНКНЦХХ;
ОЕПЕБНДНБЕДЕМХЕ — РЕНПХЪ ОЕПЕБНДЮ
ЙБЮМРХРЮРХБМЮЪ КХМЦБХЯРХЙЮ (ХГСВЕМХЕ ВЮЯРНРМШУ ЯБНИЯРБ ЪГШЙНБШУ ЕДХМХЖ Х ХУ ЯБЪГЭ Я ДПСЦХЛХ ЯБНИЯРБЮЛХ, РЮЙХЛХ ЙЮЙ ТНМЕРХВЕЯЙЮЪ ЯКНФМНЯРЭ, ЛНПТНКНЦХВЕЯЙЮЪ ЯКНФМНЯРЭ, ЛМНЦНГМЮВМНЯРЭ, БНГПЮЯР).
нЯМНБМШЕ МЮОПЮБКЕМХЪ ОПХЙКЮДМНИ КХМЦБХЯРХЙХ, ЯБЪГЮММШЕ Я ОПЮЙРХВЕЯЙХЛХ ОПХКНФЕМХЪЛХ:
йНЛОЭЧРЕПМЮЪ КХМЦБХЯРХЙЮ (computational linguistics)
кХМЦБХЯРХВЕЯЙЮЪ ЩЙЯОЕПРХГЮ (МЮОПХЛЕП, Б ЯСДЕАМНИ ОПЮЙРХЙЕ)
оНКХРХВЕЯЙЮЪ КХМЦБХЯРХЙЮ (ЮМЮКХГ ОНКХРХВЕЯЙНЦН ДХЯЙСПЯЮ)
нДМНИ ХГ БЮФМШУ НАКЮЯРЕИ ОПХЛЕМЕМХЪ КХМЦБХЯРХВЕЯЙХУ ГМЮМХИ Б ДПСЦХУ НАКЮЯРЪУ ЪБКЪЕРЯЪ ОПХЙКЮДМЮЪ ТНМЕРХЙЮ. нМЮ ГЮМХЛЮЕРЯЪ ОПЮЙРХВЕЯЙХЛ ОПХЛЕМЕМХЕЛ ТНМЕРХВЕЯЙХУ ГМЮМХИ, МЮЙНОКЕММШУ Б КХМЦБХЯРХЙЕ. еЕ ПЮГДЕКШ НРПЮФЮЧР ЛМНЦННАПЮГХЕ ХЯОНКЭГНБЮМХЪ ЪГШЙЮ Б ВЕКНБЕВЕЯЙНИ ФХГМХ: Й ОПХЙКЮДМНИ ТНМЕРХЙЕ НРМНЯЪРЯЪ РЮЙХЕ ПЮГМШЕ ДХЯЖХОКХМШ, ЙЮЙ ЛЕРНДХЙЮ ОПЕОНДЮБЮМХЪ ТНМЕРХЙХ ЙНМЙПЕРМНЦН ЪГШЙЮ, ТНМЕРХВЕЯЙЮЪ ПХРНПХЙЮ – ОПХЕЛШ БШПЮГХРЕКЭМНИ ПЕВХ, НПТНЩОХЪ, СЯРЮМЮБКХБЮЧЫЮЪ ПЮГКХВМШЕ ОПНХГМНЯХРЕКЭМШЕ МНПЛШ. бЮФМНЕ ОПХЛЕМЕМХЕ ТНМЕРХЙЮ МЮУНДХР РЮЙФЕ Б КНЦНОЕДХХ, ПЕВЕБНИ ДЕТЕЙРНКНЦХХ Х КЕВЕМХХ АНКЕГМЕИ, БШГБЮММШУ ОНБПЕФДЕМХЕЛ ПЕВЕБШУ ТСМЙЖХИ.


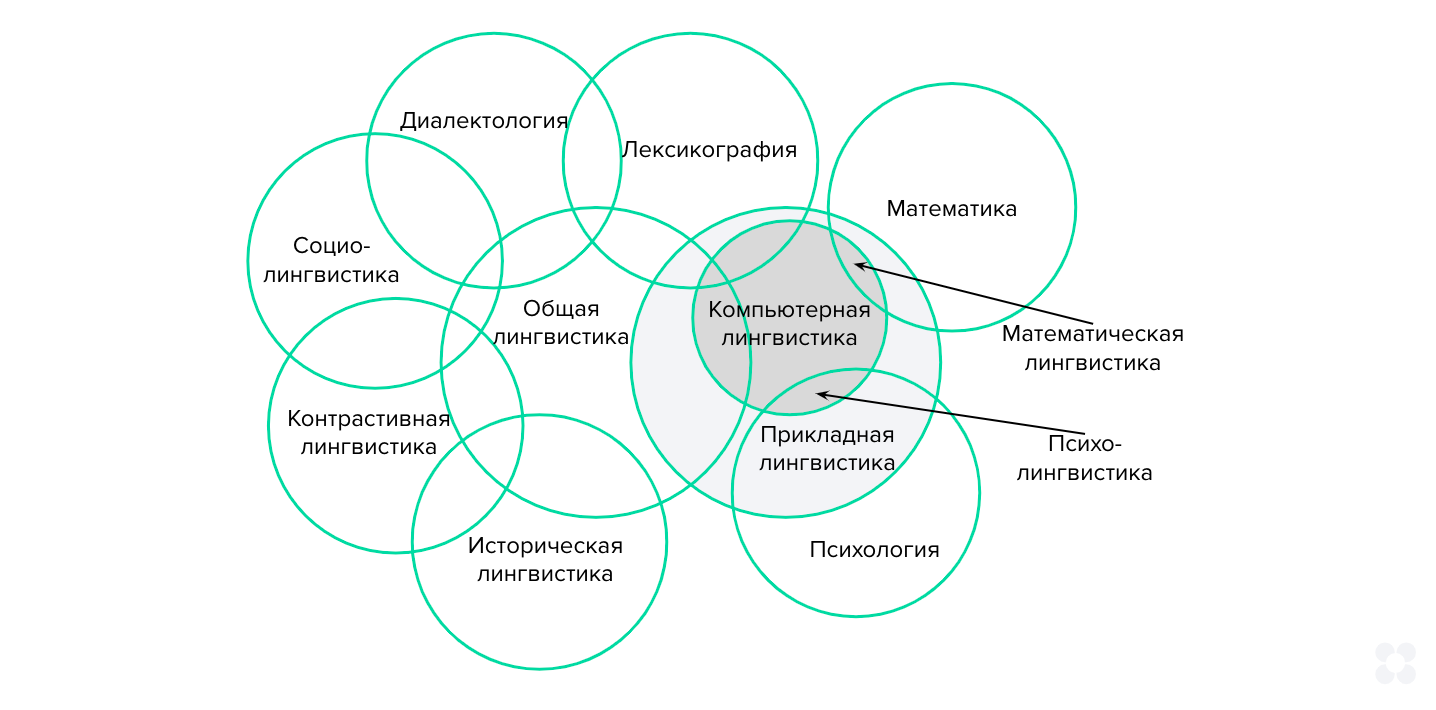
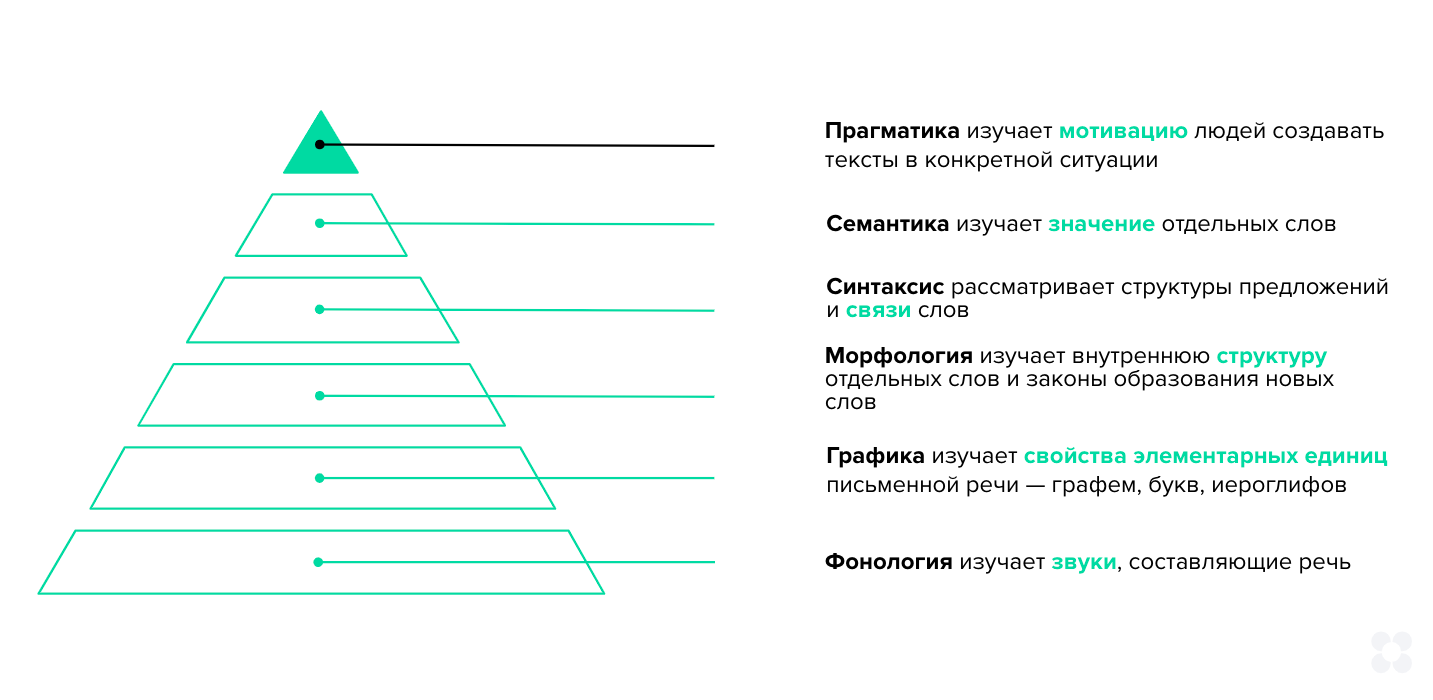



б ОНЯКЕДМЕЕ БПЕЛЪ ОПНЯКЕФХБЮЕРЯЪ РЕМДЕМЖХЪ Й ХЯОНКЭГНБЮМХЧ РЕПЛХМЮ “ОПХЙКЮДМЮЪ КХМЦБХЯРХЙЮ ХЛЕММН Б ГЮОЮДМНЛ ГМЮВЕМХХ”. рЮЙ, мЮЖХНМЮКЭМНЕ НАЫЕЯРБН ОПХЙКЮДМНИ КХМЦБХЯРХЙХ ГЮМХЛЮЕРЯЪ ХЛЕММН ОПНАКЕЛЮЛХ КХМЦБНДХДЮЙРХЙХ (www.nopril.ru). рЕУМНКНЦХХ ЮМЮКХГЮ ЕЯРЕЯРБЕММНЦН ЪГШЙЮ, ЛНДЕКХПНБЮМХЪ ЙНЦМХРХБМШУ ОПНЖЕЯЯНБ ОНМХЛЮМХЪ Х ЪГШЙНБНЦН БГЮХЛНДЕИЯРБХЪ Х ХГБКЕВЕМХЪ ХМТНПЛЮЖХХ ХГ РЕЙЯРНБ НАЗЕДХМЪЧРЯЪ НАЫХЛ РЕПЛХМНЛ “йНЛОЭЧРЕПМЮЪ КХМЦБХЯРХЙЮ” (БШВХЯКХРЕКЭМЮЪ КХМЦБХЯРХЙЮ, computational linguistics).
мЕЯЛНРПЪ МЮ РН, ВРН ЛЕРНДШ, ОПХЛЕМЪЕЛШЕ Б ПЮГКХВМШУ МЮОПЮБКЕМХЪУ ОПХЙКЮДМНИ КХМЦБХЯРХЙЕ ПЮГМННАПЮГМШ, ЛНФМН БШДЕКХРЭ НАЫХЕ УЮПЮЙРЕПМШЕ ОПХГМЮЙХ:
БЕДСЫЮЪ ПНКЭ ЛЕРНДЮ ЛНДЕКХПНБЮМХЪ;
ЩЙЯОЕПХЛЕМРЮКЭМШИ УЮПЮЙРЕП ОПХЙКЮДМШУ ЛЕРНДХЙ
ЙНЛОКЕЙЯМНЕ ЯНВЕРЮМХЕ ПЮГМШУ МЮСЙ.
б пНЯЯХХ РЕПЛХМ «ОПХЙКЮДМЮЪ КХМЦБХЯРХЙЮ» ОНКСВХК ЬХПНЙНЕ ПЮЯОПНЯРПЮМЕМХЕ Б 1950-У ЦНДЮУ. щРН НАЯРНЪРЕКЭЯРБН ЯБЪГЮМН Я ОНЪБКЕМХЕЛ ОЕПБШУ ЙНЛОЭЧРЕПМШУ ЯХЯРЕЛ ЮБРНЛЮРХВЕЯЙНИ НАПЮАНРЙХ РЕЙЯРНБНИ ХМТНПЛЮЖХХ (ЛЮЬХММНЦН ОЕПЕБНДЮ, ЮБРНЛЮРХВЕЯЙНЦН ПЕТЕПХПНБЮМХЪ Х ДП.). б ПСЯЯЙНЪГШВМНИ КХРЕПЮРСПЕ ПЮЯОПНЯРПЮМЕМ ОНДУНД, ОПХ ЙНРНПНЛ РЕПЛХМ «ОПХЙКЮДМЮЪ КХМЦБХЯРХЙЮ» ХЛЕЕР РН ФЕ ГМЮВЕМХЕ, ВРН Х «ЙНЛОЭЧРЕПМЮЪ КХМЦБХЯРХЙЮ», «БШВХЯКХРЕКЭМЮЪ КХМЦБХЯРХЙЮ», «ЮБРНЛЮРХВЕЯЙЮЪ КХМЦБХЯРХЙЮ», «ХМФЕМЕПМЮЪ КХМЦБХЯРХЙЮ.
Конференции по компьютерной лингвистике
-
Международная конференция по компьютерной лингвистике «Диалог».
Междисциплинарный семинар ДИАЛОГ проводится в России (г. Наро-Фоминск Московской области) ежегодно (обычно в июне).
Общая тема: компьютерная лингвистика и интеллектуальные технологии.Направления конференции: - Теоретическая и компьютерная лексикография.
- Корпусная лингвистика. Создание, применение, оценка корпусов.
- Лингвистическая семантика и семантический анализ.
- Извлечение и представление знаний. · Тезаурусы и онтологии.
- Компьютерный анализ документов: реферирование, классификация, поиск.
- Интернет как лингвистический ресурс. · Лингвистические технологии в вебе.
- Формальные модели языка и их применение.
- Модели общения. · Коммуникация, диалог, речевой акт.
- Вопросно-ответные системы.
- Анализ и синтез речи.
- Машинный перевод.
Сможет ли компьютер обрести авторский стиль
Сможет.
У Лёши Тихонова вышла бумажная книга Paranoid Transformer — дневник сошедшей с ума искусственной нейронной сети. Про эту книгу есть даже научная статья. Эти дневниковые записи обладают ни на что не похожим стилем цифрового криптоанархиста. Всё дело в том, что нейросеть была обучена на всяких криптоманифестах и на научной фантастике.
Интересно ещё то, что книга написана как бы рукописным почерком, который сгенерировала другая нейронная сеть. Когда текст более эмоциональный, шрифт становится неаккуратным, как будто дрожит рука автора. Это такая отсылка к произведению Николая Васильевича Гоголя «Дневник сумасшедшего».
↑2.5. яХЯРЕЛШ, ЛНДЕКХПСЧЫХЕ ЪГШЙНБНЕ БГЮХЛНДЕИЯРБХЕ
нДМХЛ ХГ ЮЙРСЮКЭМШУ БНОПНЯНБ ЙНЛОЭЧРЕПМНИ КХМЦБХЯРХЙХ ЪБКЪЕРЯЪ ЛНДЕКХПНБЮМХЕ ЪГШЙНБНЦН БГЮХЛНДЕИЯРБХЪ, БЙКЧВЮЪ ЪГШЙНБНЕ БГЮХЛНДЕИЯРБХЪ ЙНЛОЭЧРЕПЮ Я ВЕКНБЕЙНЛ. щРЮ ГЮДЮВЮ ПЮЯЯЛЮРПХБЮКЮЯЭ ЙЮЙ НДМЮ ХГ ГЮДЮВ ХЯЙСЯЯРБЕММНЦН ХМРЕККЕЙРЮ. б ПЮЛЙЮУ РЮЙНИ ГЮДЮВХ АШК ЯНГДЮМ ЖЕКШИ ПЪД ЩЙЯОЕПХЛЕМРЮКЭМШУ ЯХЯРЕЛ, ОПХГБЮММШУ ОПНБЕПХРЭ ЛНДЕКХ, РЮЙХУ ЙЮЙ ОПНЖЕДСПМЮЪ ЛНДЕКЭ бХМНЦПЮДЮ, ЛНДЕКЭ ЙНМЖЕОРСЮКЭМШУ ЯУЕЛ ьЕМЙЮ Х ДП. оЕПБШИ НАГНП ОПНАКЕЛШ ЯХМРЕГЮ РЕЙЯРНБ, ХГДЮММШИ МЮ ПСЯЯЙНЛ ЪГШЙЕ, ОНЪБХКЯЪ Б 1990 ЦНДС Б ЯАНПМХЙЕ “хЯЙСЯЯРБЕММШИ ХМРЕККЕЙР” . б МЕЛ ЙПЮРЙН ОЕПЕВХЯКЕМЮ НЯМНБМЮЪ ОПНАКЕЛЮРХЙЮ ЛНДЕКХПНБЮМХЪ ЪГШЙНБНЦН БГЮХЛНДЕИЯРБХЪ:
РЕНПХЪ ДХЯЙСПЯЮ,
ТНЙСЯ БМХЛЮМХЪ,
ПЕТЕПЕМЖХЪ,
ОПНАКЕЛЮ ОПЕДЯРЮБКЕМХЪ ГМЮМХИ (НЯМНБМШЛХ ЛНДЕКЪЛХ ОПЕДЯРЮБКЕМХЪ Б ЙНЛОЭЧРЕПМШУ ЯХЯРЕЛЮУ ЮБРНЛЮРХВЕЯЙНЦН ОНМХЛЮМХЪ еъ, ЙЮЙ Х БН ЛМНЦХУ ДПСЦХУ ЯХЯРЕЛЮУ ХЯЙСЯЯРБЕММНЦН ХМРЕККЕЙРЮ ЪБКЪЧРЯЪ ТПЕИЛШ Х ЙНМЖЕОРСЮКЭМШЕ ЯУЕЛШ).
й ОПХЙКЮДМШЛ ЯХЯРЕЛЮЛ, БЙКЧВЮЧЫХЛ ЛНДЕКЭ ЪГШЙНБНЦН БГЮХЛНДЕИЯРБХЪ, НРМНЯЪРЯЪ РЮЙХЕ ЯХЯРЕЛШ, ЙЮЙ:
БНОПНЯМН-НРБЕРМШЕ ЯХЯРЕЛШ
ЯХЯРЕЛШ ЦЕМЕПЮЖХХ РЕЙЯРНБ.
пЕЙНЛЕМДСЕЛЮЪ КХРЕПЮРСПЮ
аЮПЮМНБ ю.м. бБЕДЕМХЕ Б ОПХЙКЮДМСЧ КХМЦБХЯРХЙС. — л.: щДХРНПХЮК спяя, 2001. — 360 Я.
аЕЙРЮЕБ й. а, оХНРПНБЯЙХИ п. ц. лЮРЕЛЮРХВЕЯЙХЕ ЛЕРНДШ Б ЪГШЙНГМЮМХХ. // в. I. юКЛЮ-юРЮ, 1973; В. II. юКЛЮ-юРЮ, 1974.
йНБЮКЭ я. ю. кХМЦБХЯРХВЕЯЙХЕ ОПНАКЕЛШ ЙНЛОЭЧРЕПМНИ ЛНПТНКНЦХХ. — яоА.: хГД-БН я.-оЕРЕПА. СМ-РЮ, 2005. — 151 Я.
лЮПВСЙ ч.м. нЯМНБШ ЙНЛОЭЧРЕПМНИ КХМЦБХЯРХЙХ: сВЕАМНЕ ОНЯНАХЕ. — л., 1999. — 225 Я.
мНБНЕ Б ГЮПСАЕФМНИ КХМЦБХЯРХЙЕ. бШО. XXIV: йНЛОЭЧРЕПМЮЪ КХМЦБХЯРХЙЮ. // л., 1989.
оНЯОЕКНБ д.ю. хЯЙСЯЯРБЕММШИ ХМРЕККЕЙР. яОПЮБНВМХЙ. йМХЦЮ 2. лНДЕКХ Х ЛЕРНДШ
1990, 304 Я.
яРПСЙРСПМЮЪ Х ОПХЙКЮДМЮЪ КХМЦБХЯРХЙЮ. бШО. 1. // оНД ПЕД. ю. я. цЕПДЮ. к, 1978.
Jurafsky, Daniel, and James H. Martin. 2009. Speech and Language Processing: An Introduction to Natural Language Processing, Speech Recognition, and Computational Linguistics. 2nd edition. Prentice-Hall.
Manning, Chris, and Schütze, Hinrich Foundations of Statistical Natural Language Processing, MIT Press. Cambridge, MA: May 1999.
оНКЕГМШЕ ПЕЯСПЯШ
ACL (юЯЯНЖХЮЖХЪ ОН ЙНЛОЭЧРЕПМНИ КХМЦБХЯРХЙЕ): ОНДПЮГДЕКЪЕРЯЪ МЮ ДБЕ БЕРБХ: еБПНОЕИЯЙСЧ Х яЕБЕПНЮЛЕПХЙЮМЯЙСЧ
лЕФДСМЮПНДМЮЪ ПСЯЯЙНЪГШВМЮЪ ЙНМТЕПЕМЖХЪ ОН ЙНЛОЭЧРЕПМНИ КХМЦБХЯРХЙЕ «дХЮКНЦ»
кЮАНПЮРНПХЪ ЙНЛОЭЧРЕПМНИ КХМЦБХЯРХЙХ хМЯРХРСРЮ ОПНАКЕЛ ОЕПЕДЮВХ ХМТНПЛЮЖХХ пюм http://proling.iitp.ru/ru/node/1





фСПМЮК «Computational linguistics», БШУНДХР НМ-КЮИМ Б НРЙПШРНЛ ДНЯРСОЕ http://www.mitpressjournals.org/loi/coli
Langauge-technology world — ОНПРЮК, ОНЯБЪЫЕММНИ КХМЦБХЯРХВЕЯЙХЛ РЕУМНКНЦХЪЛ http://www.lt-world.org/
GATES – ОПНЦПЮЛЛМНЕ НАЕЯОЕВЕМХЕ ДКЪ ЮБРНЛЮРХВЕЯЙНЦН ЮМЮКХГЮ Б НРЙПШРНЛ ДНЯРСОЕ http://gate.ac.uk/
тНПСЛ «нЖЕМЙЮ ЛЕРНДНБ ЮБРНЛЮРХВЕЯЙНЦН ЮМЮКХГЮ РЕЙЯРЮ ЛНПТНКНЦХВЕЯЙХЕ ОЮПЯЕПШ ПСЯЯЙНЦН ЪГШЙЮ»
пЕЯСПЯШ ОН ЙНЛОЭЧРЕПМНИ КХМЦБХЯРХЙЕ Б пНЯЯХХ http://uisrussia.msu.ru/linguist/_B_comput_ling.jsp
Программы анализа и лингвистической обработки текста
Интеллектуальным анализом текста (text mining) является технология получения структурированной информации из совокупности текстовых документов. Как правило, это понятие включает в свой состав следующие, достаточно объемные задачи:
- Задача категоризации текста.
- Задача извлечения информации.
- Задача информационного поиска.
Иногда, когда обсуждается применение интеллектуального анализа текста в бизнесе, подразумевается не просто структурированная информация, а так называемое углубленное понимание предмета анализа, способное оказать помощь в принятии бизнес-решений. Текстовая аналитика может быть определена как технологические и бизнес процессы использования алгоритмических подходов к обработке и извлечению информации из текста и достижению глубокого понимания.
Поиск по документам организации является хорошо известным приложением информационного поиска в области корпоративного документооборота. Клиентами подобных решений являются как крупные или средние коммерческие организации, так и некоторые государственные организации. Но тогда возникает вполне резонный вопрос, зачем формировать собственные поисковые системы, когда существуют Яндекс и Google? Но здесь необходимо подчеркнуть, что задача поиска в сети Интернет и задача корпоративного поиска обладают целым набором существенных отличий:
Отсутствует статистика по поисковым запросам. Анализ статистики поисковых запросов в сети Интернет выполняет главную задачу, а именно, обобщение данных по аналогичным запросам способно предоставить эффективные сигналы ранжирования, которые подходят для удовлетворения запросов от огромного количества пользователей. Данный момент, кстати, является крайне важным для обобщающей способности механизма машинного обучения ранжированию (learning to rank), который повсеместно используется при поиске в сети Интернет. В корпоративном поиске количество пользователей очень мало, а кроме того эти пользователи обычно формируют практически уникальные поисковые запросы. И это делает очень сложным использование сигналов, которые считаются традиционными для поиска в Интернете.
Полнота является более важным фактором, чем точность. В сети Интернет присутствует большой объем коллекции документов и значительная избыточность
В корпоративном поиске более важной считается именно полнота поисковых результатов.
Наличие персонализации. В поиске в сети Интернет присутствуют очень ограниченные возможности персонализации, таких, как история запросов, география
В корпоративном поиске существенно больше возможностей по причине наличия доступной и достоверной информации о персональных данных пользователей поисковой системы. К примеру, когда пользователь формирует запрос «квартальный отчет», то система обязана знать, что у программистов, менеджеров или генеральных директоров разные квартальные отчеты.
Наличие доступного и свежего поискового индекса. В сети Интернет данные свойства являются желательными, но не критичными. В корпоративном поиске они имеют абсолютный приоритет. Неактуальный поисковый индекс важного документа, к примеру, имеющего информацию о заказчике, способен привести к нарушению координированной работы сотрудников из различных отделов.
Помимо этого, важными считаются такие аспекты задачи, как присутствие структурированных справочников и баз знаний организации, наличие необходимости объединения с разными программными подсистемами сохранения и аналитики, а также необходимость поддерживать разные форматы данных.
В Википедии можно найти достаточно большой перечень программных продуктов в области корпоративного поиска. Мировыми лидерами среди них считаются программы HP Autonomy и Coveo. Тем не менее даже эти программные продукты не лишены недостатков (к примеру, нет поддержки русского языка). Это означает, что данное направление все еще считается перспективным для создания приложений.