Введение
Понятие облака неразрывно связано с двумя абстракциями — гарантированное качество ресурсов и их взаимная изоляция. Рассмотрим, как эти понятия применяются к устройству сети в облачном решении. Изолированность ресурсов подразумевает следующее:
- антиспуфинг,
- выделение приватного сегмента сети,
- фильтрация публичного сегмента для минимизации воздействий извне.
Гарантированное качество ресурсов — это QoS в общем понимании, то есть обеспечение требуемой полосы и требуемого отклика внутри сети облака. Далее — подробный разбор реализации упомянутых концепций в облачных инфраструктурах.
Управление трафиком
Оптимизация маршрутов таким образом, чтобы использовать возможности сетевых линков по-максимуму (иначе говоря, нахождение максимума cуммы min-cut [] для всех пар взаимодействующих конечных точек с учетом их весов, то есть приоритетов QoS), считается наиболее сложной задачей в распределенных сетях. IGP, призванные решать эту проблему, в общем случае являются недостаточно гибкими — трафик может быть отсортирован только на основании заранее выделенных меток QoS и о динамическом анализе и перераспределении трафика приходится не думать. Для OpenFlow, поскольку средства анализа отдельных элементов трафика являются неотъемлемой частью протокола, решить эту задачу достаточно несложно — достаточно построить корректно работающий классификатор отдельных потоков . Еще один несомненный плюс OpenFlow в этом случае — в централизованном подсчете стратегии форвардинга возможно учесть множество дополнительных параметров, которые просто не включены ни в один из стандартов IGP.
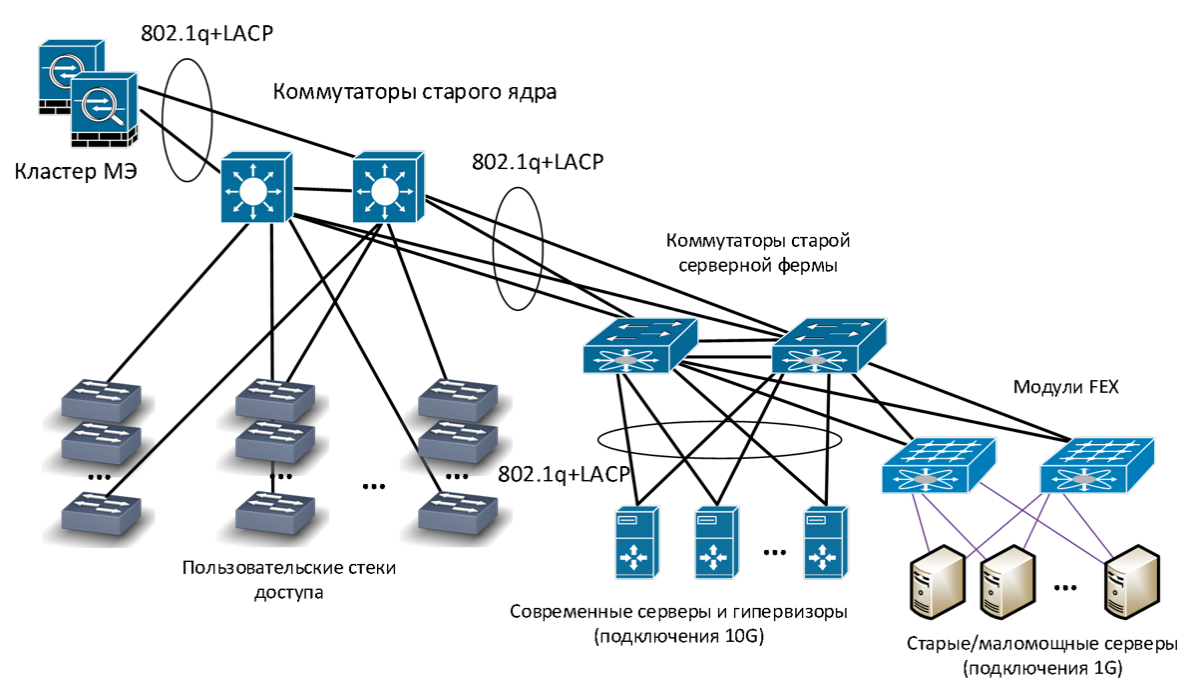
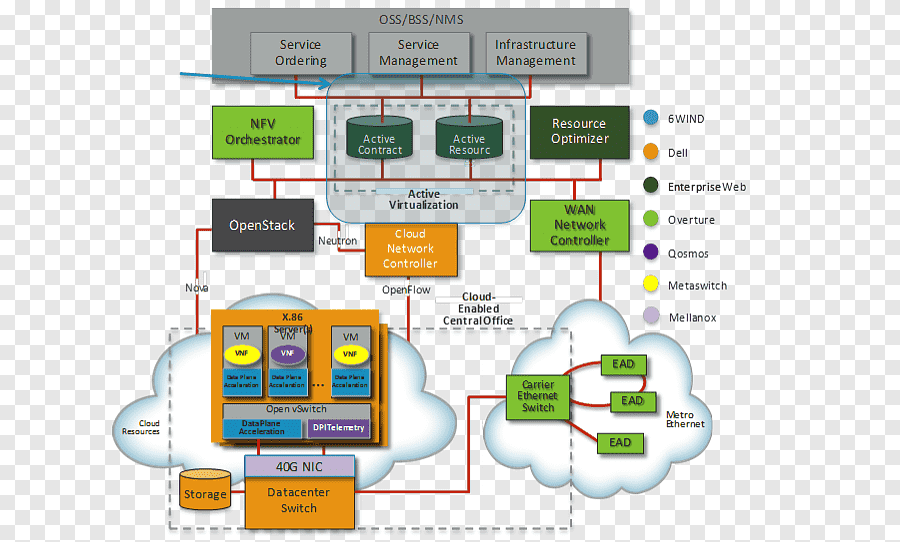
Проектирование сети даже небольшого датацентра с гетерогенным наполнением (содержание одновременно множества розничных пользоватей без физической привязки группы машин к стойке), приводит к задаче построения распределенных L2-over-L3 сетей (overlay networks) [] с помощью одного из существующих механизмов, из-за невозможности технически поместить десятки тысяч виртуальных хостов в один широковещательный сегмент обычными способами. Указанные технологии позволяют «разгрузить» логику форвардинга, поскольку оборудование теперь оперирует метками, соответствующим группам хостов вместо отдельных адресов в приватных (и, возможно, публичных) сегментах пользовательских сетей. За дешевизной и сравнительной простотой внедрения кроется привязка как минимум к производителю сетевого оборудования и конечная недетерминированность — если отвлечься от детализации, все оверлейные протоколы предоставляют обучаемый свич внутри отдельной метки, что может вызвать затруднения при оптимизации трафика внутри оверлейного сегмента, из-за «развязанности» протоколов маршрутизации третьего уровня и механизмов самого оверлея. Выбирая OpenFlow, мы сводим все управление трафиком к одному уровню принятия решений — сетевому контроллеру. Оверлеи или замещающий их собственный механизм, безусловно, могут выполнять ту же роль по уменьшению объема правил в свичах-аггрегаторах (spine на картинке ниже), а оптимизация направления трафика на ToR свичах (leaf) будет происходить, базируясь на произвольном наборе метрик, в отличие от простой балансировки (как, к примеру, в ECMP).
Двухуровневый spine-leaf
Список источников
-
Лурджан,
М.Б. Исследование возможностей внедрения алгоритмов маршрутизации в
программно-конфигурируемых сетях (SDN) / М.Б. Лурджан, А.А. Воропаева,
Г.В. Ступак // Наукові праці Донецького національного технічного
університету. Серія: Обчислювальна техніка та автоматизація.
– Красноармійськ, ДонНТУ, 2015. Випуск 1 (28). – С.
81 – 89. -
Лурджан,
М.Б. ВИКОРИСТАННЯ ПРОГРАМНО-КОНФІГУРОВАНИХ МЕРЕЖ ДЛЯ БАЛАНСУВАННЯ
НАВАНТАЖЕННЯ В ТРАНСПОРТНИХ МЕРЕЖАХ
ОПЕРАТОРІВ ЗВ’ЯЗКУ / М.Б. Лурджан, А.А. Воропаева // Наукові
праці Донецького національного технічного університету. Серія:
Обчислювальна техніка та автоматизація. – Красноармійськ,
ДонНТУ, 2016. Випуск 1 (28). – С. 87 – 95. -
Tkachova
O. Software-Defined Network controllers in the cloud: performance and
fault tolerance evaluation / Tkachova O., Yevsieieva O. // Proceedings
of 2015 1st International Conference on Advanced Information and
Communication Technologies. – Lviv, Ukraine, 2015.
– P.24 – 28. -
SDN,
облака и интеллектуальные транспортные сети .
– Режим доступа: http://www.ip-news.ru/?cat=articles&key=71 -
Р.Л
Смелянский Технологии SDN и NFV: новые
возможности для телекоммуникаций .
– Режим доступа: http://arccn.ru/media/1132 -
Решения
SDN .
– Режим доступа: http://rusteletech.ru/resheniya-sdn -
Міночкін
Д.А. Використання
програмно-визначених мереж для модернізації IT-інфраструктури
мобільного зв’язку / Міночкін Д.А. // Десята міжнародна
науково-технічна конференція “ПРОБЛЕМИ
ТЕЛЕКОМУНІКАЦІЙ”
– Киів,Україна, 2016. – с. 158 – 161. -
Марціленко
С.В. Застосування
програмно-визначуваних мереж (SDN) в технології 5G / Марціленко С.В.,
Глоба Л.С. // Десята міжнародна науково-технічна конференція
“ПРОБЛЕМИ ТЕЛЕКОМУНІКАЦІЙ” –
Киів,Україна, 2016.
– с. 191 – 194. -
Роговой
В.П. Центры обработки данных на базе
технологии SDN / Роговой В.П. // Десята міжнародна науково-технічна
конференція “ПРОБЛЕМИ ТЕЛЕКОМУНІКАЦІЙ” –
Киів,Україна, 2016. – с. 182 – 185.
История
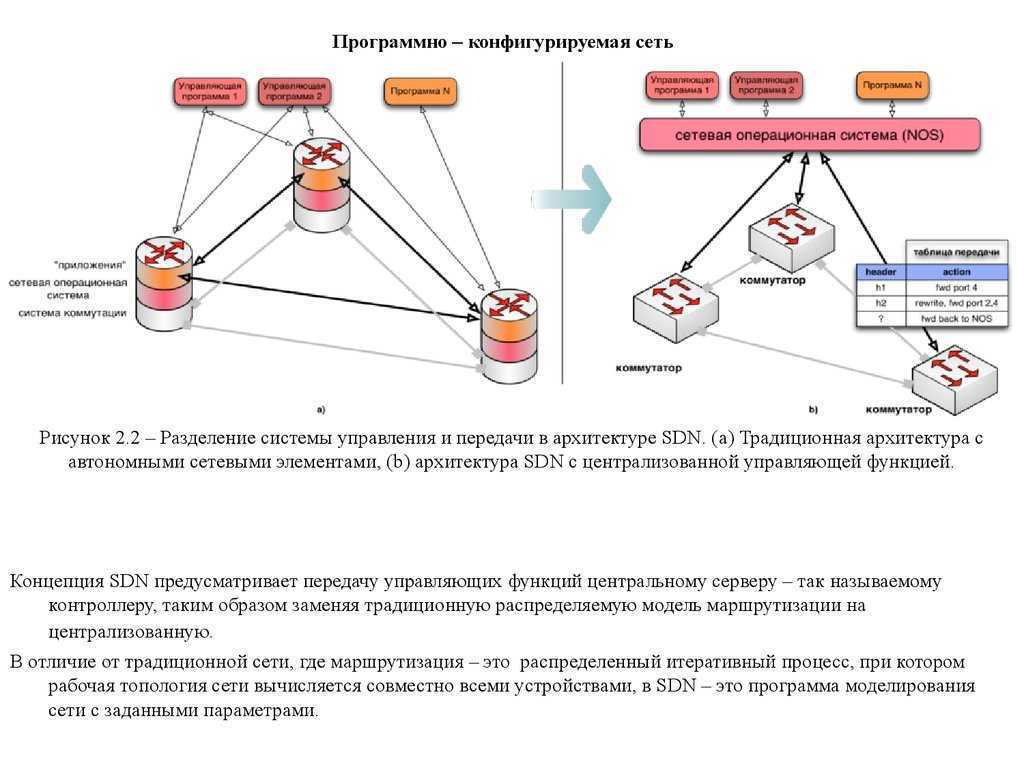
История принципов SDN может быть прослежена до разделения плоскости управления и данных, впервые использованной в коммутируемой телефонной сети общего пользования как способ упростить предоставление ресурсов и управление задолго до того, как эта архитектура начала применяться. используется в сетях передачи данных.
Инженерная группа Интернета (IETF) начала рассматривать различные способы разделения функций управления и пересылки в предлагаемом стандарте интерфейса, опубликованном в 2004 г. и получившем соответствующее название «Разделение элементов управления и пересылки» (ForCES). Рабочая группа ForCES также предложила сопутствующую архитектуру SoftRouter. Дополнительные ранние стандарты IETF, которые преследовали цель отделения управления от данных, включают Linux Netlink как протокол IP Services и архитектуру на основе элемента вычисления пути (PCE).
Эти первые попытки не увенчались успехом по двум причинам. Во-первых, многие в интернет-сообществе считали, что разделение управления и данных рискованно, особенно из-за возможности сбоя в плоскости управления. Во-вторых, производители были обеспокоены тем, что создание стандартных интерфейсов прикладного программирования (API) между плоскостями управления и данных приведет к усилению конкуренции.
Использование программного обеспечения с открытым исходным кодом в архитектурах разделенного управления / плоскости данных уходит своими корнями в проект Ethane в Стэнфордском отделе компьютерных наук. Простая конструкция переключателя Ethane привела к созданию OpenFlow. API для OpenFlow был впервые создан в 2008 году. В этом же году была создана NOX — операционная система для сетей.
Работа над OpenFlow продолжалась в Стэнфорде, в том числе с созданием испытательных стендов для оценки использования протокол в одной сети университетского городка, а также через глобальную сеть в качестве магистрали для соединения нескольких кампусов. В академической среде было несколько исследовательских и производственных сетей, основанных на переключателях OpenFlow от NEC и Hewlett-Packard ; а также на основе белых ящиков Quanta Computer, начиная примерно с 2009 года.
Помимо академических кругов, Nicira в 2010 году впервые внедрила OVS для управления OVS от Onix, co. -разработано в NTT и Google. Заметным развертыванием было внедрение B4 в 2012 году. Позже Google признал свой первый OpenFlow с развертыванием Onix в своих центрах обработки данных одновременно. Еще одно известное крупное развертывание — China Mobile.
Open Networking Foundation было основано в 2011 году для продвижения SDN и OpenFlow.
на Дне взаимодействия и технологий 2014 года, программное обеспечение- определенная сеть была продемонстрирована компанией Avaya с использованием моста кратчайшего пути (IEEE 802.1aq ) и OpenStack в качестве автоматизированного кампуса, расширяющего автоматизацию от центра обработки данных до конечного устройства
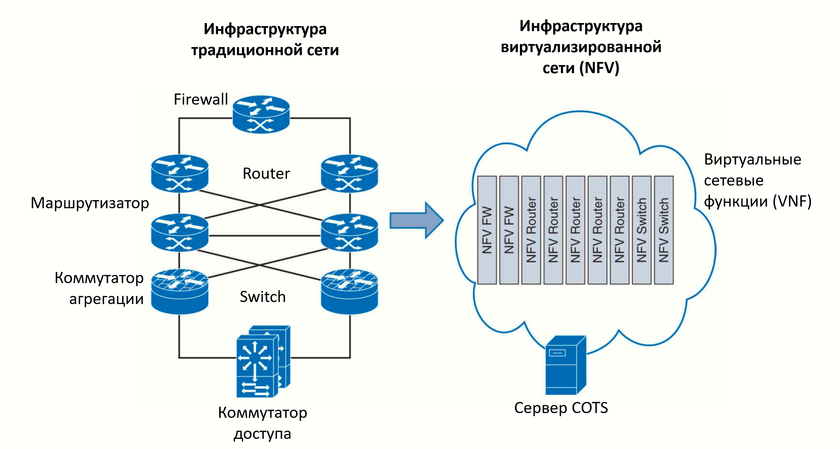
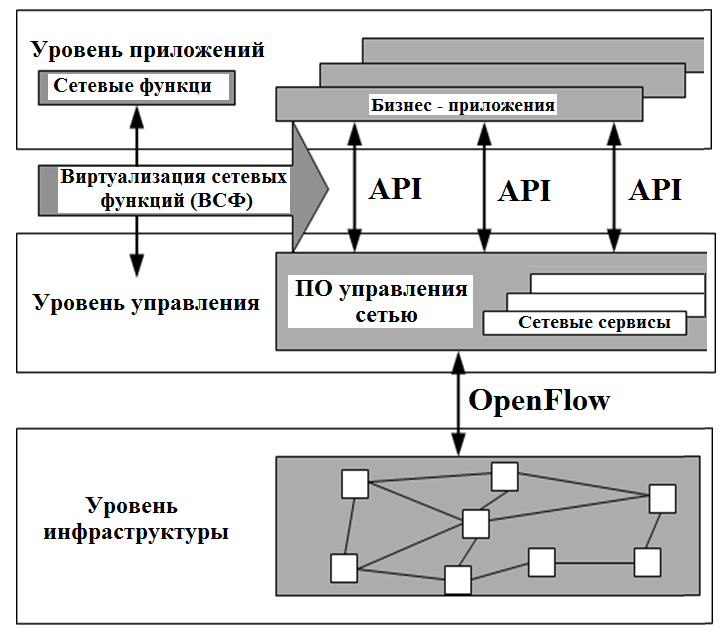
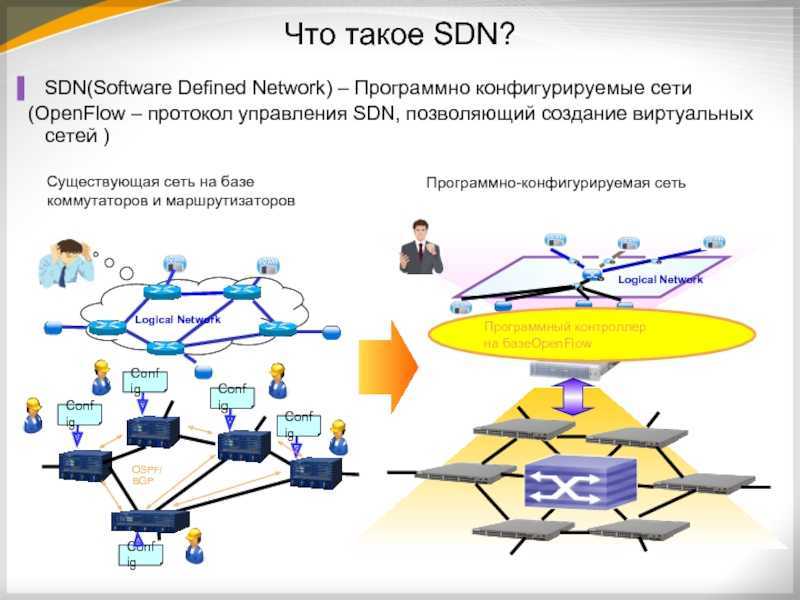
Реализации SDN-подхода
На сегодняшний день есть три способа реализации SDN-подхода: Способ 1.
На базе виртуальных коммутаторов по технологии Overlay (протоколы
VXLAN, NVGRE и пр.), т. е. когда на серверах, на которых
«крутятся» виртуальные машины, настраивается
коммутация виртуальных портов между собой и отображение виртуальных
портов на физические, после этого уже физические порты связываем между
собой туннелями. Программирование самого виртуального коммутатора
происходит с помощью специально выделенного ресурса, который называется
«программно-конфигурируемый контроллер». По
существу это операционная система, которая управляет, распределяет,
контролирует и мониторит ресурсы сети. Надо подчеркнуть, что при этом
способе в качестве среды передачи данных используется традиционная IP
сеть.
Способ 2. На базе серверов агрегации трафика. В этом случае выделяется
специальный сервер, на который с помощью туннелирования заводятся
соответствующие каналы передачи данных, далее через механизм
туннелирования этот сервер под управлением SDN-контроллера осуществляет
коммутацию и передачу данных. Здесь также используется в качестве среды
передачи данных традиционная IP сеть.
Следует отметить, что перечисленные способы – это
программно-реализованные методы разделения со всеми вытекающими
последствиями, которые, прежде всего, сказываются на скорости передачи
данных.
Способ 3. В этом способе сеть передачи данных строится на базе
специальных коммутаторов, для управления которыми используют протоколы
Openflow, XMPP и пр. SDN сеть состоит из OpenFlow-коммутаторов и
SDN-контроллеров. SDN-коммутатор реализует только функции передачи
данных. Поэтому это очень простое программируемое устройство, умеющее
выполнять несколько простых команд. Как следствие простоты, он
существенно дешевле существующих маршрутизаторов и коммутаторов. Работа
SDN-коммутатора состоит в том, чтобы выделить из поступающего пакета
данных заголовок; если коммутатор «знаком» с тем,
как обрабатывать пакеты с такими заголовками, то он действует по
заранее загруженной в него программе. Иначе по защищенному
OpenFlow-каналу отправляет запрос на контроллер. В ответ контроллер по
OpenFlow-каналу загружает программу обработки пакетов с такими
заголовками.
Изоляция трафика
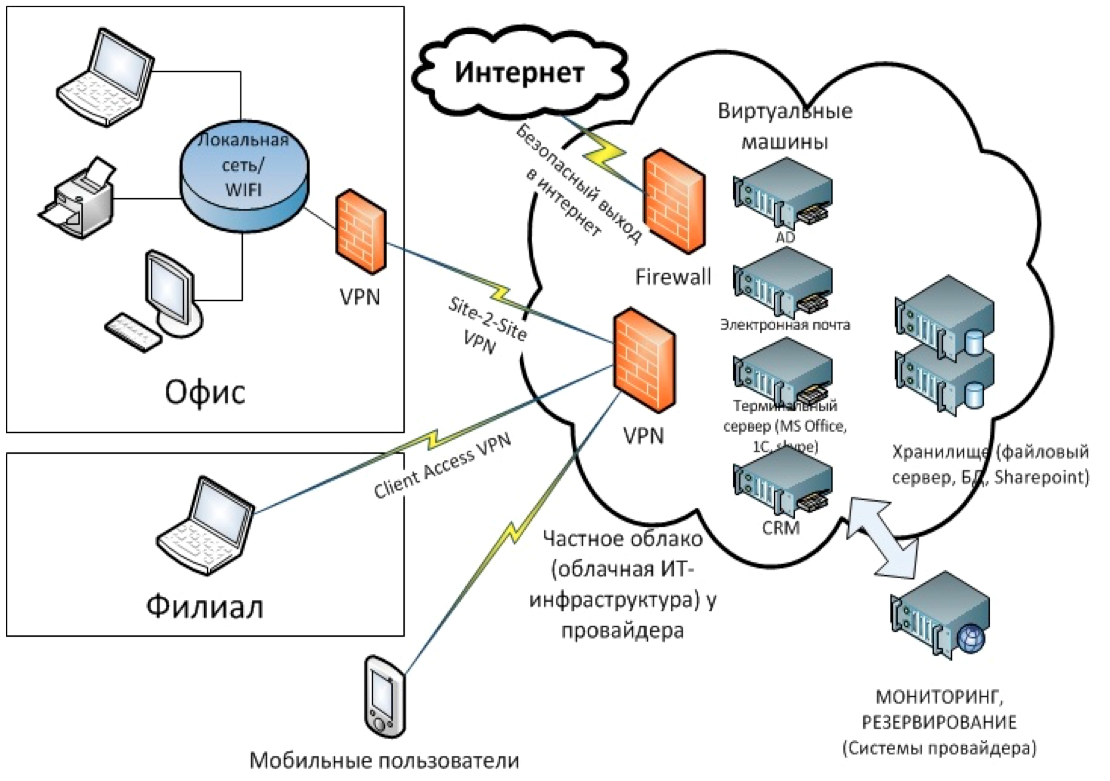
- Антиспуфинг с помощью iptables/ebtables или статических правил в OpenVSwitch: максимально дешевое решение, но на практике неудобно — если для linux bridge правила создаются с помощью механизма nwfilter в libvirt и автоматически подтягиваются при запуске виртуальной машины, для ovs оркестровке придется отслеживать момент старта и проверять или обновлять соответствующие правила в свиче. Добавление или удаление адреса или миграция виртуальной машины превращаются в обоих случаях в нетривиальную задачу, перекладываемую на логику оркестровки. В момент запуска нашего сервиса в публичное использование мы применяли именно nwfilter [], но были вынуждены перейти на OpenFlow 1.0 из-за недостаточной гибкости решения в целом. Также стоит упомянуть довольно экзотический метод фильтрации исходящего трафика с помощью netlink для технологий, работающих в обход сетевого стека хоста (macvtap/vf), который в свое время не был принят в ядро, несмотря на высокую коммерческую востребованность.
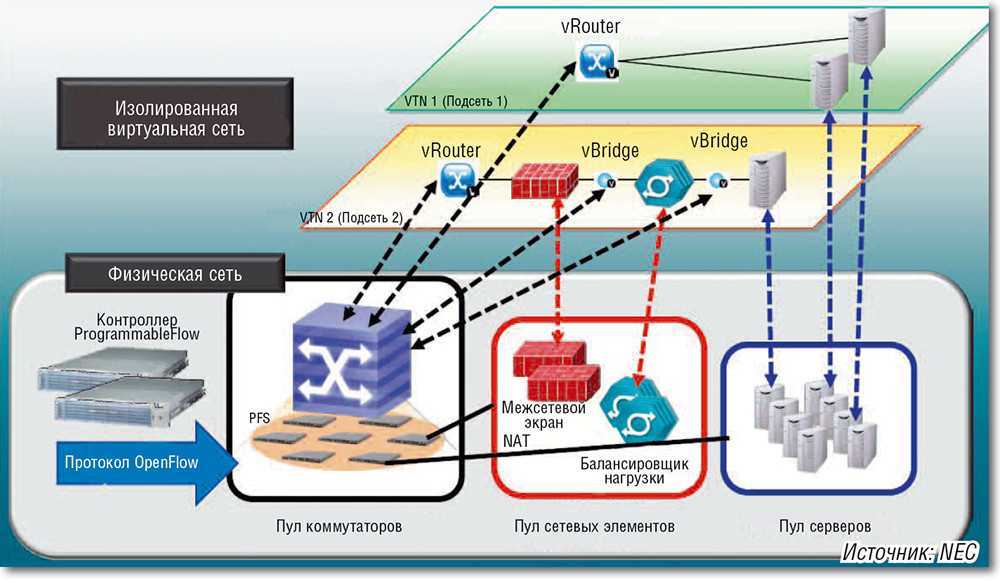
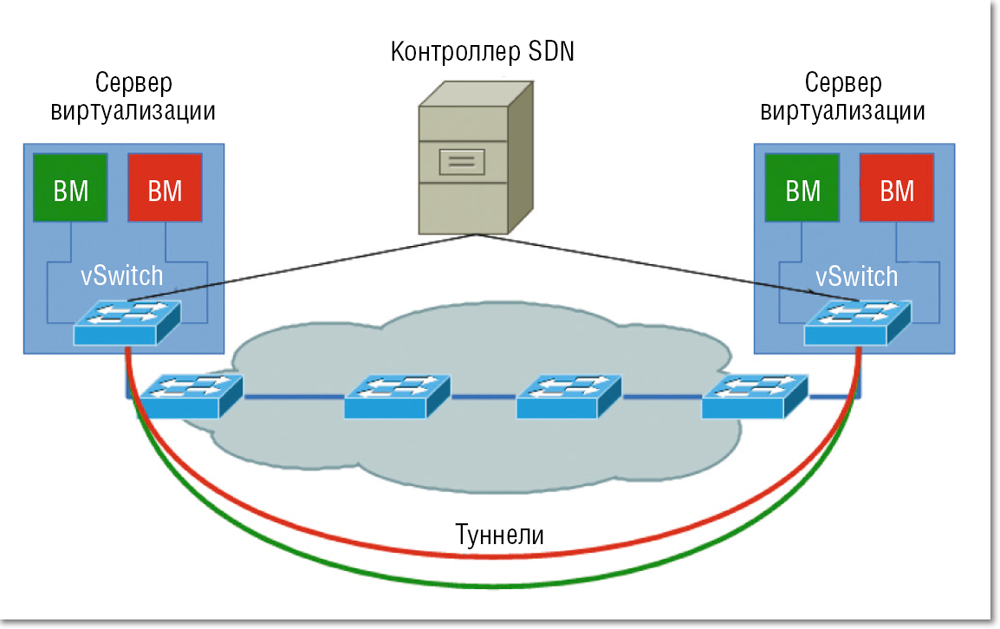
- Антиспуфинг с помощью правил в свиче уровня стойки (ToR switch) при переносе в него портов виртуальных машин с помощью одного из механизмов туннелирования трафика непосредственно от интерфейсов виртуальных машин (см. картинку ниже). В качестве плюсов такого решения можно отметить сосредоточение логики на свиче == отсутствие необходимости ее «размазывания» по программным свичам вычислительных нод. Маршрут трафика между машинами одной вычислительной ноды всегда будет проходить через свич, что может быть не всегда удобно.
ToR filtering networkheresy
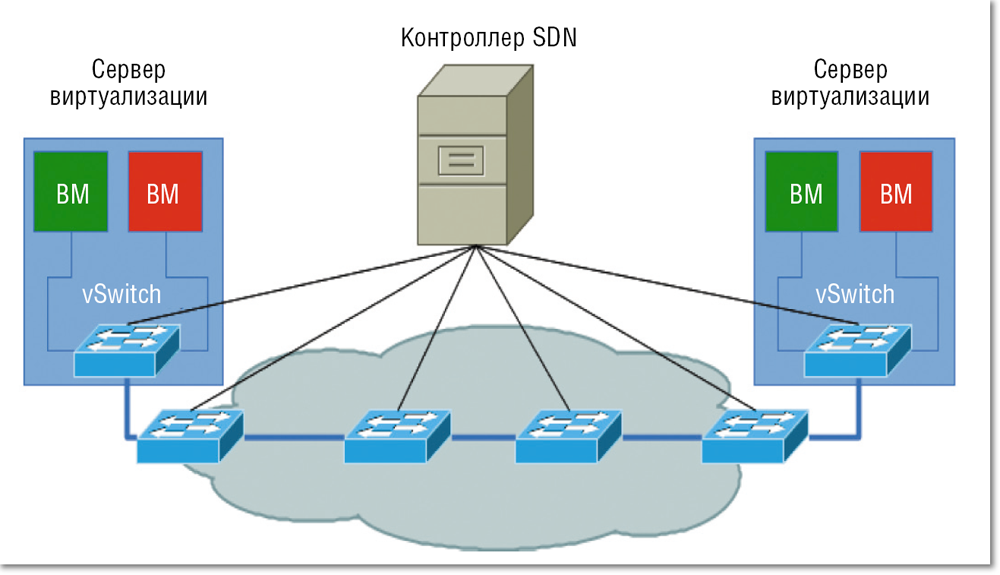
- Антиспуфинг при проверке полей в OpenFlow сети — когда все свичи, физические и виртуальные, подключены к группе контроллеров, обеспечивающих, помимо перенаправления и трансформации полей трафика повсюду, его очистку на уровне программного свича вычислительной (compute) ноды. Это самый сложный и самый гибкий из возможных вариантов, поскольку абсолютно вся логика, начиная от пересылки датаграмм внутри обычного свича, будет вынесена в контроллер. Неполные или неконсистентные правила могут привести либо к нарушению связности, либо к нарушению изоляции, поэтому системы с большим процентом реактивных (задающихся динамически по запросу от свича) правил следует тестировать с помощью, фреймворков наподобие NICE [].
- Выделение сегмента сети — решение, практикуемых в крупных гомогенных структурах, при этом за группой виртуальных машин закрепляется либо привязка к физическим машинам (и портам физического свича), либо к тегу инкапсуляции любого типа (vlan/vxlan/gre). Граница фильтрации находится на стыке L2 сегмента, иначе говоря, сегменту выделяется подсеть или набор подсетей и невозможность их подмены обуславливается роутингом в вышестоящей инфраструктуре, пример — OpenStack Neutron без гибридного драйвера Nova []. Глубокого теоретического интереса этот подход не представляет, но имеет широкую практическую распространенность, унаследованную от до-виртуализационной эпохи.
Welcome to the Overlay Networks. The software instead of hardware is the solution
Until now we learned that if we stick with the underlay, it can restrict us in multiple ways. In order to get transport independence, overlays can come to our rescue.
Overlays are software-based and not dependent on transport. It’s like a virtual network ( virtual links) on top of the physical network. This virtual network needs to have underlay created first.
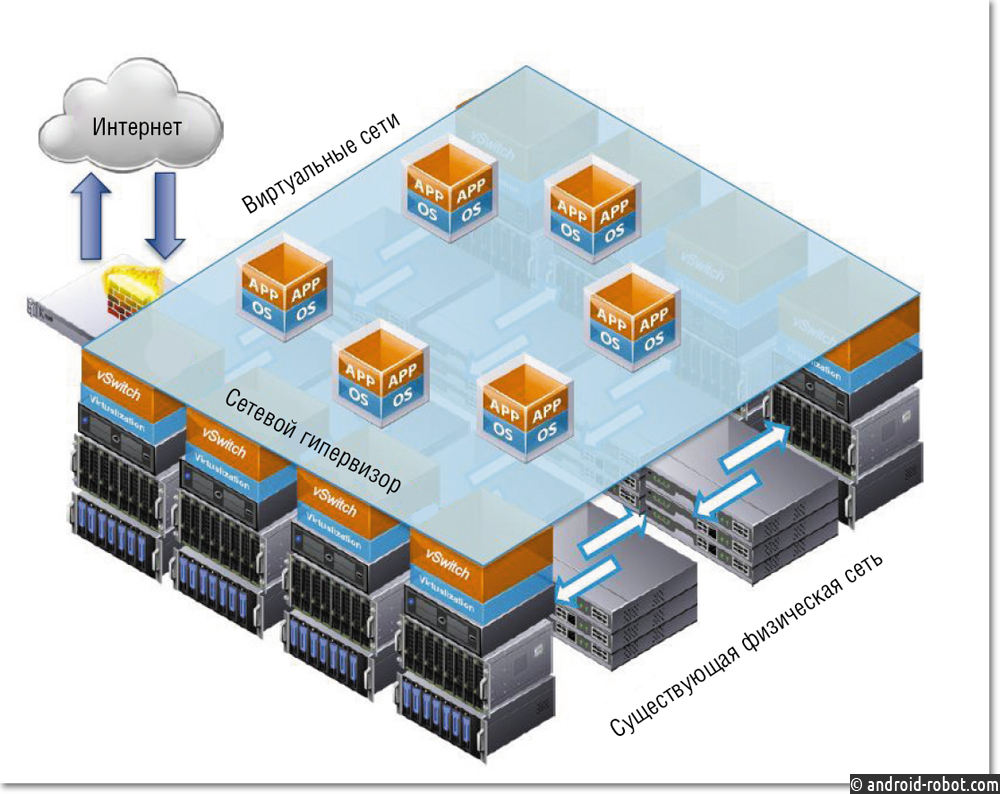
The trick is simple. Create an underlay once and forget it. Now create overlays on top of it and since they are software-based. changing the configurations is super easy and friendly. Underlay is a pipe on which overlays run. The intelligence is all in the overlay.
However, to have overlays in SD-WAN, we will need a special CPE called SD-WAN edge device. These overlay nodes are installed at all the sites.
overlay vs underlay in SD-WAN
Актуальность темы
Перед тем как рассматривать новые подходы и решения для оптимизации и
управления сетями, следует отметить целый ряд проблем, повлиявших на
необходимость изменения инфраструктуры мобильных операторов. Среди
них:
• Изменение модели
вычислений
• Взрывной рост
мобильности
• Быстрый рост трафика
(к 2016г. объем увеличился в 6 раз)
• Изменение структуры
трафика (2016г. 90% — видеотрафик)
• Несоответствие
темпов роста трафика и доходов оператора
Высокий темп развития сервисов,
масштабов их охвата, а так же рост
количества и вариативности
контента привели к
изменению концепции
орга-низации
вычислений — место устаревшей
клиент-серверной
архитектуры заняли центры обработки
данных (ЦОД) и облака. В то же время, сетями хранения
данных стали файловые системы и
базы данных. Рост показателей нагрузки усложнился возникающими
проблемами в управлении сетями, причем на фоне повышения требований к
безопасности и надежности
Еще одной немаловажной проблемой является
постоянное обновление программного обеспечения и аппаратных средств,
что влечет за собой приобретение дополнительного оборудования и
привлечение специалистов, которые будут занимаются настройкой и
поддержкой этого оборудования. Построение сети на базе постоянно
усложняющихся устройств, подразумевает использование большого
количества протоколов маршрутизации (на сегодняшний
день количество применяемых протоколов и их
версий достигло 600)
Все они отличаются своими принципами
работы, типами и алгоритмами. Как результат — невозможность провайдера
вводить новые сервисы, вдобавок, производители сетевого оборудования не
успевают модернизировать свои устройства для удовлетворения требований
заказчиков. Одним из возможных вариантов решения большинства
вышеперечисленных проблем может стать применение технологии SDN, что
позволит изменить представление и существенно повлиять на подход к
построению сетей связи.
Multipart Request
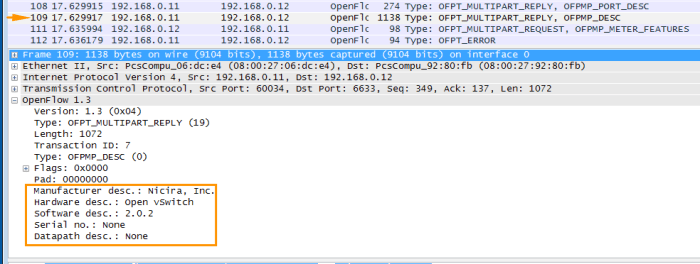
Multipart messages are used to encode request or reply that could potentially carry are large amounts of data, which may not fit into a single message. Normal messages are limited to 64KB. Multipart messages are encoded in sequence. These types of messages are primarily used to request statistics or state information.
In our packet capture we can see this exchange of information. Looking at the packet we can see attributes such as the manufacturer and hardware/software versions.
In the message you’ll see information about the switch ports sent to the controller. Anything from type, to status, to speed is included in this message. In this case, the switch port is still down.
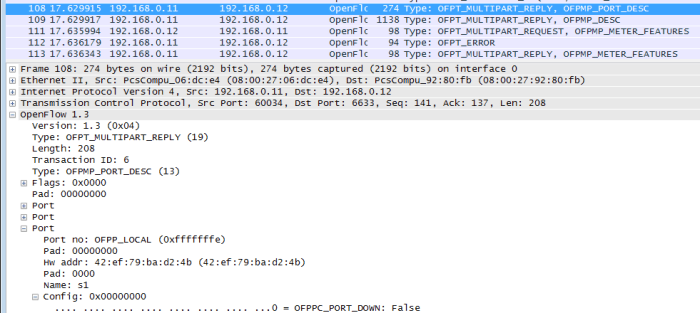
Reserved Ports
The OpenFlow reserved ports specify generic forwarding actions such as sending to the controller, flooding, or forwarding using non-OpenFlow methods, such as “normal” switch processing.
There are several flavors of required reserved ports: , , , , , , . The port represents the OpenFlow Channel used for communication between the switch and controller.
In hybrid environments, you’ll also see and ports to allow interaction between the OpenFlow pipeline and the hardware pipeline of the switch.
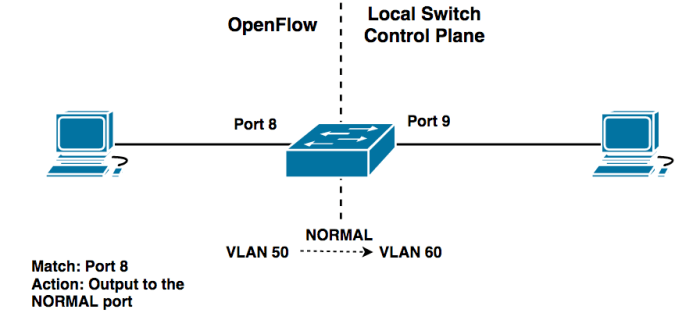
OpenFlow-only Switches vs. OpenFlow-hybrid switches
There are two types of OpenFlow switches: OpenFlow-only, and OpenFlow-hybrid.
OpenFlow-only switches are “dumb switches” having only a data/forwarding plane and no way of making local decisions. All packets are processed by the OpenFlow pipeline, and can not be processed otherwise.
OpenFlow-hybrid switches support both OpenFlow operation and normal Ethernet switching operation. This means you can use traditional L2 Ethernet switching, VLAN isolation, L3 routing, ACLs and QoS processing via the switch’s local control plane while interacting with the OpenFlow pipeline using various classification mechanisms.
You could have a switch with half of its ports using traditional routing and switching, while the other half is configured for OpenFlow. The OpenFlow half would be managed by an OpenFlow controller, and the other half by the local switch control plane. Passing traffic between these pipelines would require the use of a NORMAL or FLOOD reserved port.
OpenFlow Messages
OpenFlow Protocol supports 3 message types, each with their own setup of sub-types:
- Controller-to-switch
- Asynchronous
- Symmetric
How Overlays are formed?
The following example shows a GRE tunnel formed by SD-WAN Edge Device. The edge device adds a GRE tunnel header with a new IP header and masks the inner IP header from the MPLS domain, the MPLS forwards based on the outer IP header.
Once the packet reaches its destination, the SD-WAN edge removes the outer IP header and the Tunnel header and what we get is the original IP packet. During all this process the overlay is not aware of the underlay.
The same process can be done for the internet underlay but with the addition of encryption using IPSec. All this can be done seamlessly using the same SD-WAN Edge box.
The overlay is formed once encapsulation happens at the left SD-WAN box and ends when the header is removed at the destination. The overlay is not aware of the underlay on which it is riding. The underlay here is MPLS but it can be any other type of transport.
What problems underlays cannot solve?
While the above shows a simple example of a Layer 3 underlay. Things have changed beyond the use of just “MPLS” for transport. Think of it! internet is everywhere. High-speed data is cheaper than before. Exploiting the use of the internet for carrier transport is just a natural evolution then.
To understand the concept of overlay, I introduced two more networks. A broadband network and the 4G network. The need is to use these “low cost” transport networks to offload some of the data from the MPLS network ( if not all)
There are some issues here :
Traditional underlay
Issue 1: The Internet cannot be used as an underlay for private traffic
The first issue is that internet medium natively is insecure so it cannot be used as an underlay for private traffic. To protect it we will need to use security protocols like IPsec. IPsec is a tunneling protocol. Which is an overlay. ( but we wanted to solve the issue with underlay, isn’t it? )
Issue 3: Multi-Path forwarding
The customer wants load balancing by combining underlays of different types.
However, it is very complex ( if not impossible) to use multiple underlays which are of different types, simultaneously to forward traffic from source to destination.