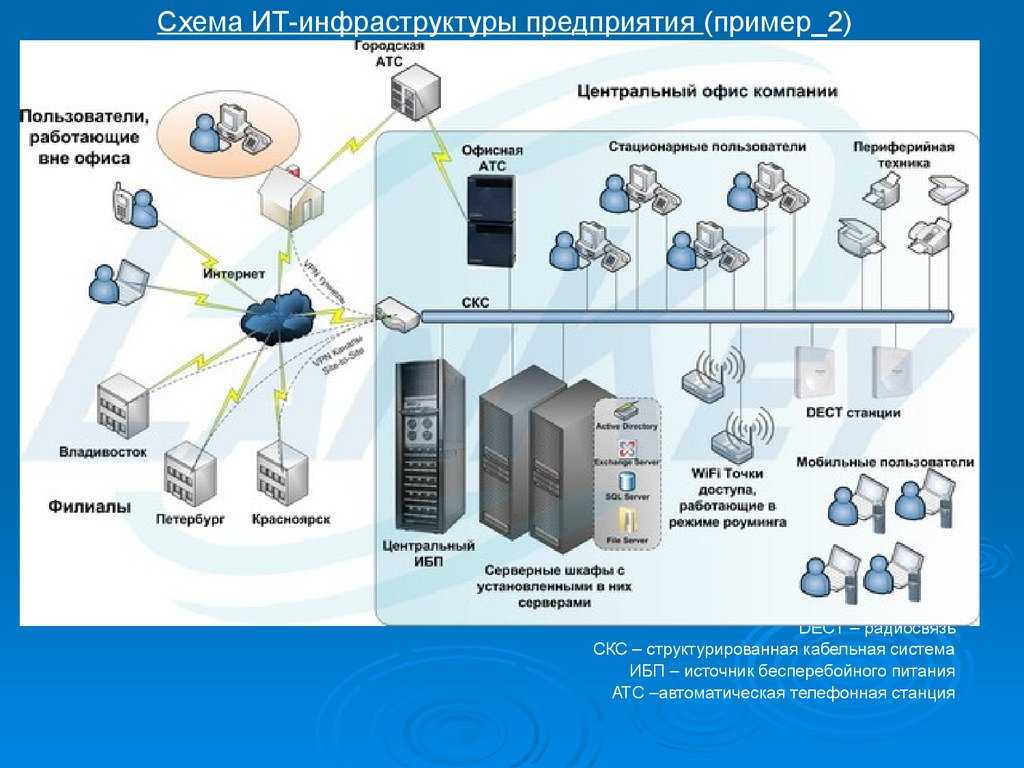
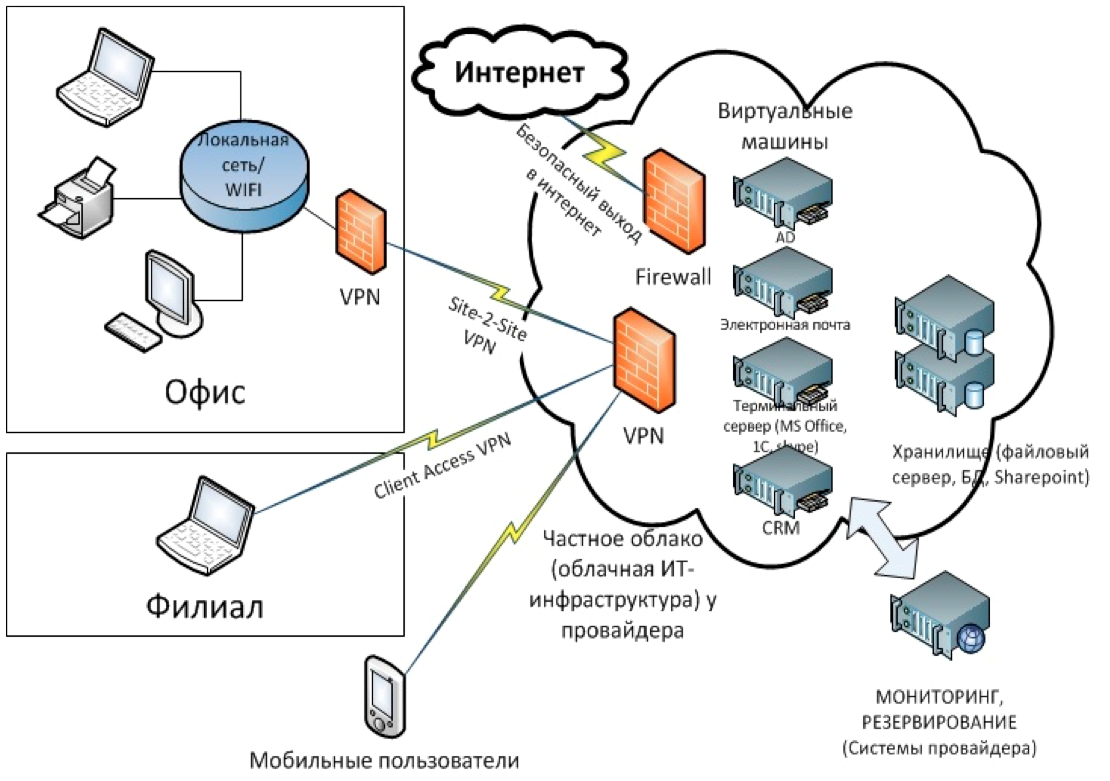
Оптимизация числа бекендов
Идентичность серверов, обеспечивающих работу основного приложения позволяет применить активное резервирование. То есть, в обработке запросов задействуются все бекенды, без резерва. Как только один из них сбоит, он автоматически «выпадает» из списка, а фронтенд перестает подавать на него запросы. Однако такая последовательность грозит повышением нагрузки на остальные серверы.
Чтобы гарантировать повышение отказоустойчивости, следует рассчитывать количество бекендов исходя из предпосылки, что в любую секунду под угрозой может оказаться 25% их числа.
Назначение нескольких серверов с целью обработки fastcgi-запросов при помощи upstream происходит с участием Nginx. Распределение запросов между серверами производится в автоматическом режиме.
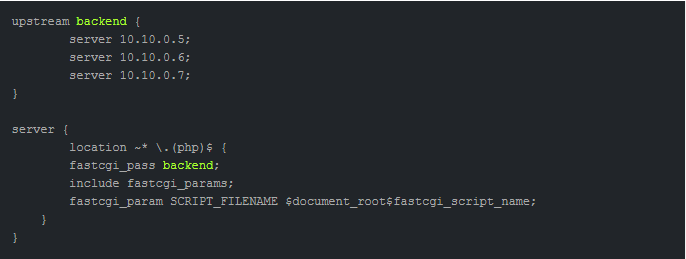
Также Nginx анализирует ошибки, содержащиеся в ответах бекендов, в реальном времени. Если ошибка обнаружена — отправка запросов на вышедший из строя бекенд приостанавливается. Тайминг и число попыток настраиваются.
Почему важен план обеспечения непрерывности бизнеса?
Непрерывность бизнеса имеет решающее значение в то время, когда простои недопустимы. Время простоя может происходить из множества мест. Некоторые опасности, такие как кибератаки и экстремальные погодные условия, похоже, усугубляются
Крайне важно иметь план BC, учитывающий любые возможные сбои в работе
Во время кризисСтратегия должна позволять организации функционировать с минимальными затратами. Непрерывность бизнеса способствует устойчивости организации, позволяя ей быстро реагировать на сбои. Strong BC экономит деньги, время и репутацию компании. Длительное отключение представляет финансовую, личную и репутационную опасность.
Непрерывность бизнеса требует, чтобы бизнес смотрел на себя, анализировал потенциальные слабые места и собирал важную информацию, такую как списки контактов и технические схемы системы, которые могут быть полезны вне сценариев катастроф. Организация может укрепить свою связь, технологии и отказоустойчивость за счет внедрения планирования обеспечения непрерывности бизнеса.
Вам также может потребоваться план BC по юридическим или нормативным причинам
Крайне важно понимать, какие правила применяются к конкретной организации, особенно в эпоху растущего регулирования
Основные элементы плана обеспечения непрерывности бизнеса
Стратегия обеспечения непрерывности бизнеса состоит из трех основных компонентов: устойчивости, восстановления и непредвиденных обстоятельств.
№1. Устойчивость
Вы можете повысить устойчивость организации, разрабатывая жизненно важные службы и инфраструктуры с учетом нескольких аварийных сценариев, таких как ротация персонала, избыточность данных и поддержание избыточной емкости. Обеспечение устойчивости к различным непредвиденным обстоятельствам также может помочь компаниям в непрерывном предоставлении основных услуг на месте и за его пределами.
№ 2. Восстановление
Крайне важно быстро восстановиться после аварии, чтобы возобновить работу компании. Установка целевого времени восстановления для различных систем, сетей или приложений может помочь расставить приоритеты, какие части должны быть восстановлены в первую очередь
Другой тактика восстановления включают запасы ресурсов, соглашения с третьими сторонами о принятии на себя корпоративной деятельности и использование адаптированных помещений для критически важных функций.
№3. непредвиденные обстоятельства
План на случай непредвиденных обстоятельств включает в себя процедуры для ряда внешних событий, а также цепочку подчинения, которая распределяет обязанности внутри компании. Эти обязательства могут включать замену оборудования, аренду офисных помещений на случай чрезвычайной ситуации, оценку ущерба и привлечение сторонних поставщиков для оказания помощи.
Аварийное восстановление и непрерывность бизнеса
Планирование аварийного восстановления, как и планирование непрерывности бизнеса, определяет запланированную тактику организации для процессов после сбоя. План аварийного восстановления, с другой стороны, является просто подмножеством планирования обеспечения непрерывности бизнеса.
Планы аварийного восстановления в основном ориентированы на данные и сосредоточены на хранении данных в такой форме, которая обеспечивает более быстрый доступ к ним после аварии. Непрерывность бизнеса учитывает это, но также фокусируется на управлении рисками, надзоре и планировании, необходимых для того, чтобы бренд продолжал функционировать во время перерыва.
Примеры
Отказоустойчивость оборудования иногда требует, чтобы сломанные части были удалены и заменены новыми частями, пока система все еще находится в рабочем состоянии (в вычислительной технике, известной как горячая замена ). Такая система, реализованная с одним резервным копированием, известна как одноточечная устойчивость и представляет собой подавляющее большинство отказоустойчивых систем. В таких системах среднее время наработки на отказ должно быть достаточно большим, чтобы операторы успели починить неисправные устройства (среднее время ремонта ) до того, как резервное копирование также выйдет из строя. Это помогает, если время наработки на отказ как можно больше, но это не требуется специально для отказоустойчивой системы.
Отказоустойчивость особенно успешна в компьютерных приложениях. Tandem Computers построили весь свой бизнес на таких машинах, которые использовали одноточечный допуск для создания своих систем NonStop с временем безотказной работы, измеряемым годами.
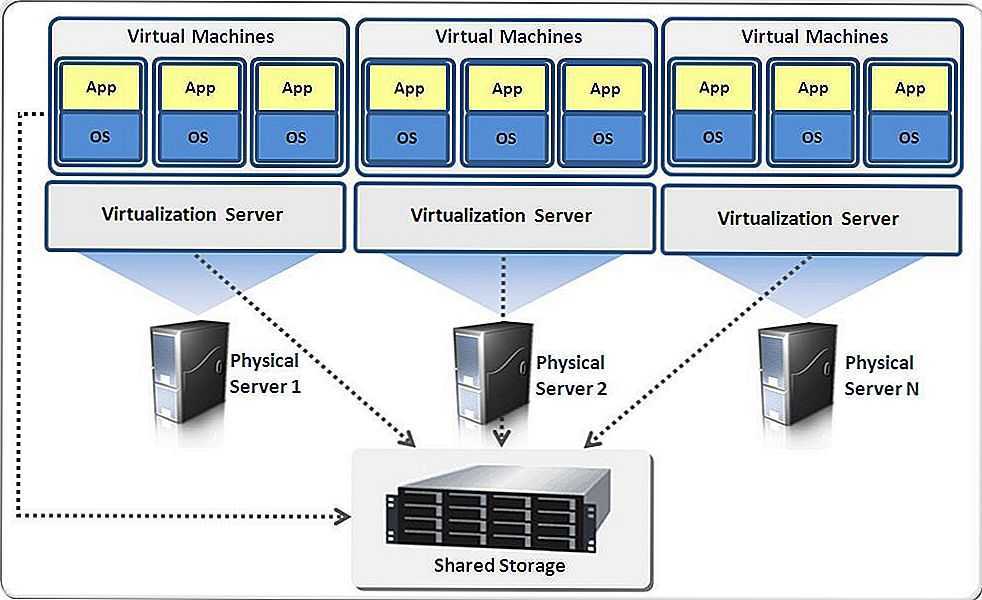
Отказоустойчивые архитектуры могут включать в себя также компьютерное программное обеспечение, например, с помощью процесса репликации.
Форматы данных также могут быть разработаны для постепенного ухудшения качества. HTML, например, разработан с учетом прямой совместимости, что позволяет игнорировать новые HTML-объекты веб-браузерами, которые их не понимают, не вызывая при этом документ непригодный для использования.
Технологии резервирования
Как вы понимаете, для обеспечения непрерывности всех процессов обязательным является наличие резервной площадки для размещения серверов
То есть при возникновении любого форс-мажора важно развернуть инфраструктуру на новых мощностях, поэтому наличие запасного «железа» на резервной площадке окажется очень кстати.. Может использоваться несколько типов резерва:
Может использоваться несколько типов резерва:
Холодный резерв. В этом случае потребуется наличие серверной с запасным оборудованием. Также может планироваться закупка дополнительного оборудования или хранение «железа» на складе. Основная трудность будет связана с быстрым запуском аппаратуры, особенно, в случае его закупки или аренды сразу после возникновения катастрофы. Процедура потребует времени, поэтому возможны простои в работе компании. Помимо склада с оборудованием, наиболее редкие серверы и ПК могут храниться на складах поставщиков. Восстановление инфраструктуры в таком случае может занять от нескольких дней до нескольких недель, однако такой вариант является самым дешевым.
Теплый резерв. Этот вариант подразумевает наличие запасной площадки, на которой имеется базовая вычислительная инфраструктура, а также настроена сеть и WAN-каналы. То есть подключено базовое оборудования, что позволит сразу можно перенаправить необходимые нагрузки. По вычислительным мощностям теплый резерв будут уступать основной площадке, но зато позволит запустить систему в течение одного дня. Такое решение можно назвать самым популярным, так как оно сочетает низкую стоимость и приемлемое время ввода в эксплуатацию.
Горячий резерв. Именно такой вариант обеспечивает наилучшую катастрофоустойчивость информационных систем. Предполагается, что у компании имеется резервная площадка, которая по производительности и мощности не уступает основной. Все данные инфраструктуры постоянно реплицируются и копируются, поэтому в запасном ЦОД хранятся актуальные копии данных. Площадка имеет готовую инфраструктуру с настроенными каналами и готова к мгновенному использованию
Этот вариант подойдет для крупных организаций, которым критически важно избежать даже минутных простоев бизнес-процессов. Минус подобного решения – простой оборудования
По сути, вам придется оплачивать сразу две площадки со всей инфраструктурой, из-за чего расходы могут значительно возрасти.
Вариант 2. Достаточно крупная организация, время восстановления критично для обеспечения непрерывности процессов
Отказоустойчивость в этом случае может быть реализована как через разделяемые диски, так и с помощью потоковой репликации в зависимости от наличия/отсутствия системы хранения данных, при этом по-прежнему необходимо резервирование ВМ и БД. Сравнение вариантов отказоустойчивости приведено в таблице ниже.
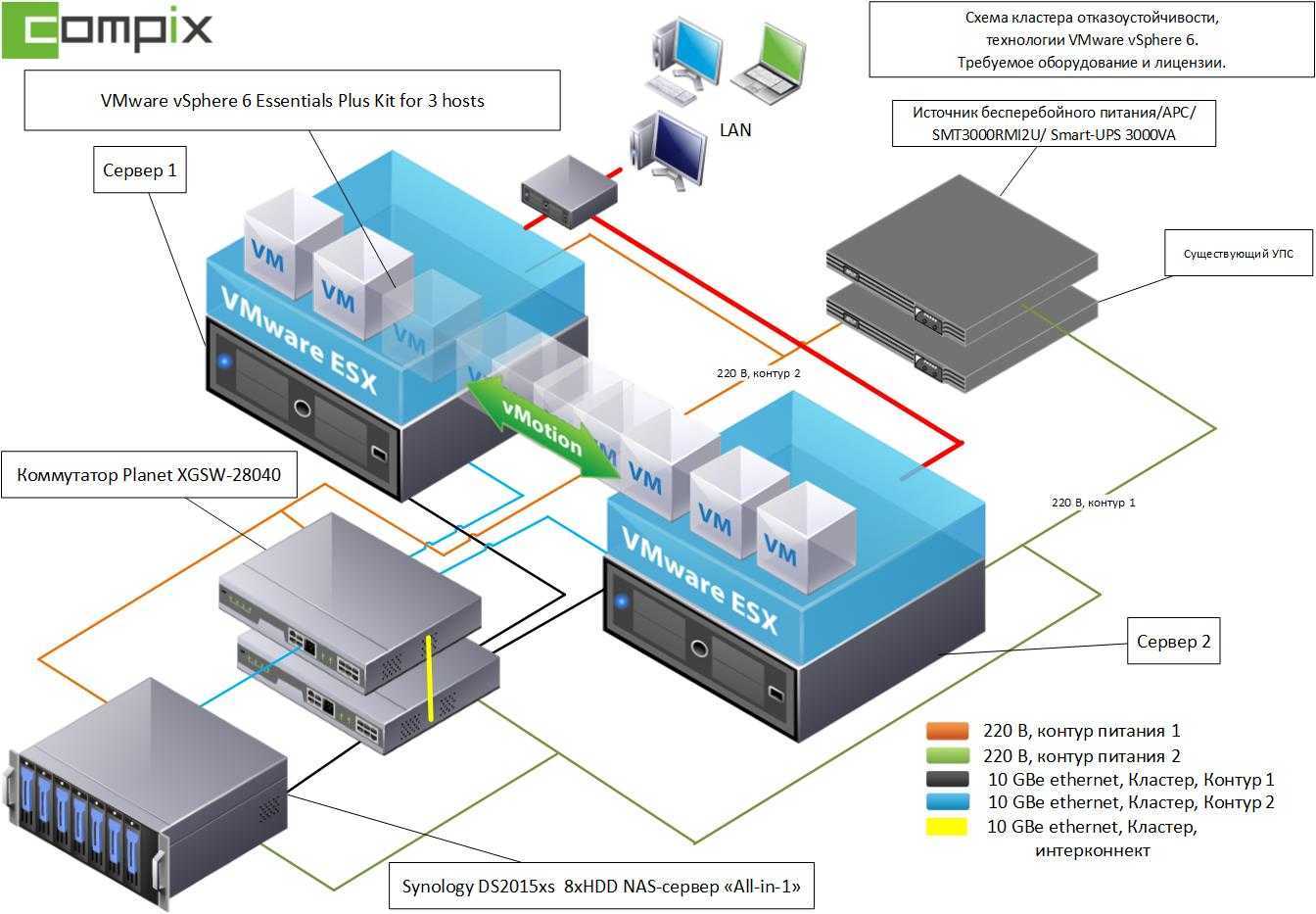
В качестве СУБД возможен вариант использования как бесплатной версии PostgreSQL, так и использование коммерческой версии дистрибутива, например, PostgresPRO.
Поддержка версии PostgreSQL может осуществляться как хостинг-провайдерами в случае размещения СУБД в «облаке», так и сторонними организациями.
Как итог можно подобрать оптимальное решение между стоимостью поддержки, отсутствием необходимости лицензировать СУБД и отказоустойчивостью решения в целом.
Эффективность данных
Гарантия HyperEfficient (в рамках гарантии HPE SimpliVity HyperGuarantee) предусматривает экономию емкости на уровне 90 % по сравнению с традиционными решениями. Это связано с тем, что HPE SimpliVity сжимает и оптимизирует все данные на этапе записи в реальном времени, устраняя ненужную обработку данных и повышая производительность приложений.
По сути, когда виртуальная машина записывает некоторые данные, прежде чем они будут записаны на какой-либо диск, в ходе записи выполняется дедупликация всех данных в кластере, а затем происходит их сжатие, что позволяет оптимизировать данные на протяжении всего жизненного цикла на платформе. Это может значительно уменьшить количество операций, которые обычно создают наибольшую задержку в ходе работы с хранилищем. После того, как данные уже были записаны один раз, и влечет за собой дополнительные накладные расходы на вычисления на платформе, поскольку они повторно считываются, дедуплицируются/сжимаются и снова записываются.
Что это все значит для удаленных площадок? Это позволяет вам хранить больше данных при меньшем объеме хранилища, уменьшая занимаемую площадь и экономя деньги, поскольку вам не нужно покупать хранилище, которое вам не нужно. Это улучшает общую производительность системы и оптимизирует хранение данных.
-
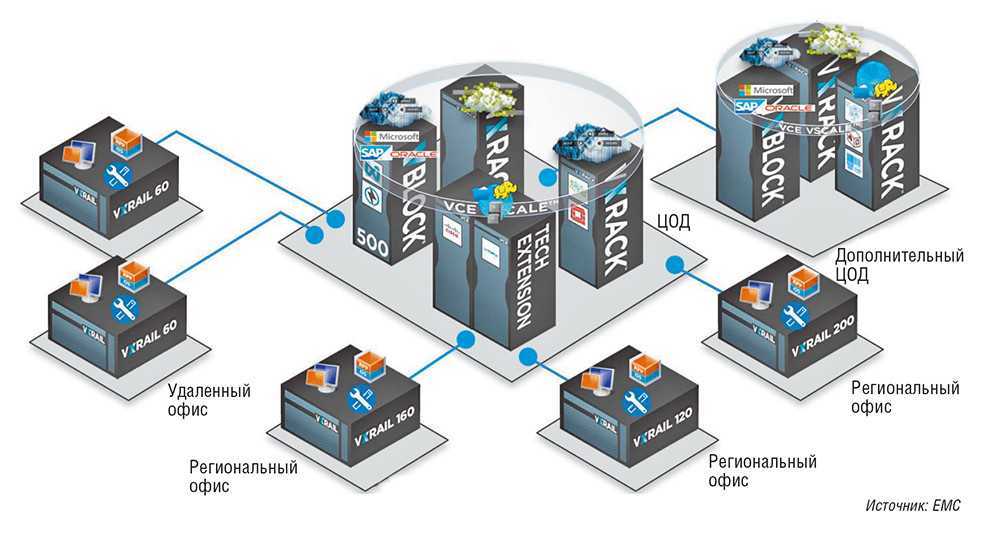
Гиперконвергентная инфраструктура для периферийных вычислений, часть 1. Проблемы удаленных офисов и филиалов.
-
Гиперконвергентная инфраструктура для периферийных вычислений, часть 2. Управление несколькими удаленными площадками.
Подробнее о понятиях
IT-инфраструктура строится с учетом возможных сбоев в работе. В идеале любые критические ситуации система должна переживать с минимальными потерями или вовсе без них. И под сбоями понимаются не только аппаратные или программные неполадки, но и ураганы, пожары и любые другие стихийные бедствия, а также человеческий фактор. По сути список возможных угроз можно продолжать бесконечно.
ИТ-инфраструктура должна быть спроектирована с учетом, если не всех, то хотя бы большинства возможных угроз. Основная задача – чтобы система пережила возможные опасности и осталась в рабочем состоянии. Именно в связи с этим и звучат два термина – отказоустойчивость и катастрофоустойчивость. Рассмотрим подробнее каждый из них.
Отказоустойчивость – это определенное свойство системы сохранять свою работоспособность после отказа одного или нескольких компонентов. С его помощью удается продолжить выполнение бизнес-задач без сбоев и простоя. Это свойство характеризует два технических момента инфраструктуры, а именно – коэффициент готовности и показатели надежности. В первом случае речь идет о времени от всего срока эксплуатации системы, в котором она находится в рабочем состоянии. Второй показатель определяет вероятность безотказной работы инфраструктуры за определенный период.
Катастрофоустойчивость же определяется как способность системы продолжать запущенные задачи при выходе всего ЦОДа из строя. Например, это может потребоваться при отключении электричества или различных природных явлениях, которые влияют на работу оборудования.
Если же говорить кратко, то принцип отказоустойчивости направлен на устранение возможных точек отказа инфраструктуры, тогда как катастрофоустойчивость позволяет поддержать работоспособность системы даже после серьезной аварии.
Аренда выделенного
сервера
Разместим оборудование
в собственном дата-центре
уровня TIER III.
Конфигуратор сервера
Подбор оборудования для решения Ваших задач и экономии бюджета IT
Запросить КП
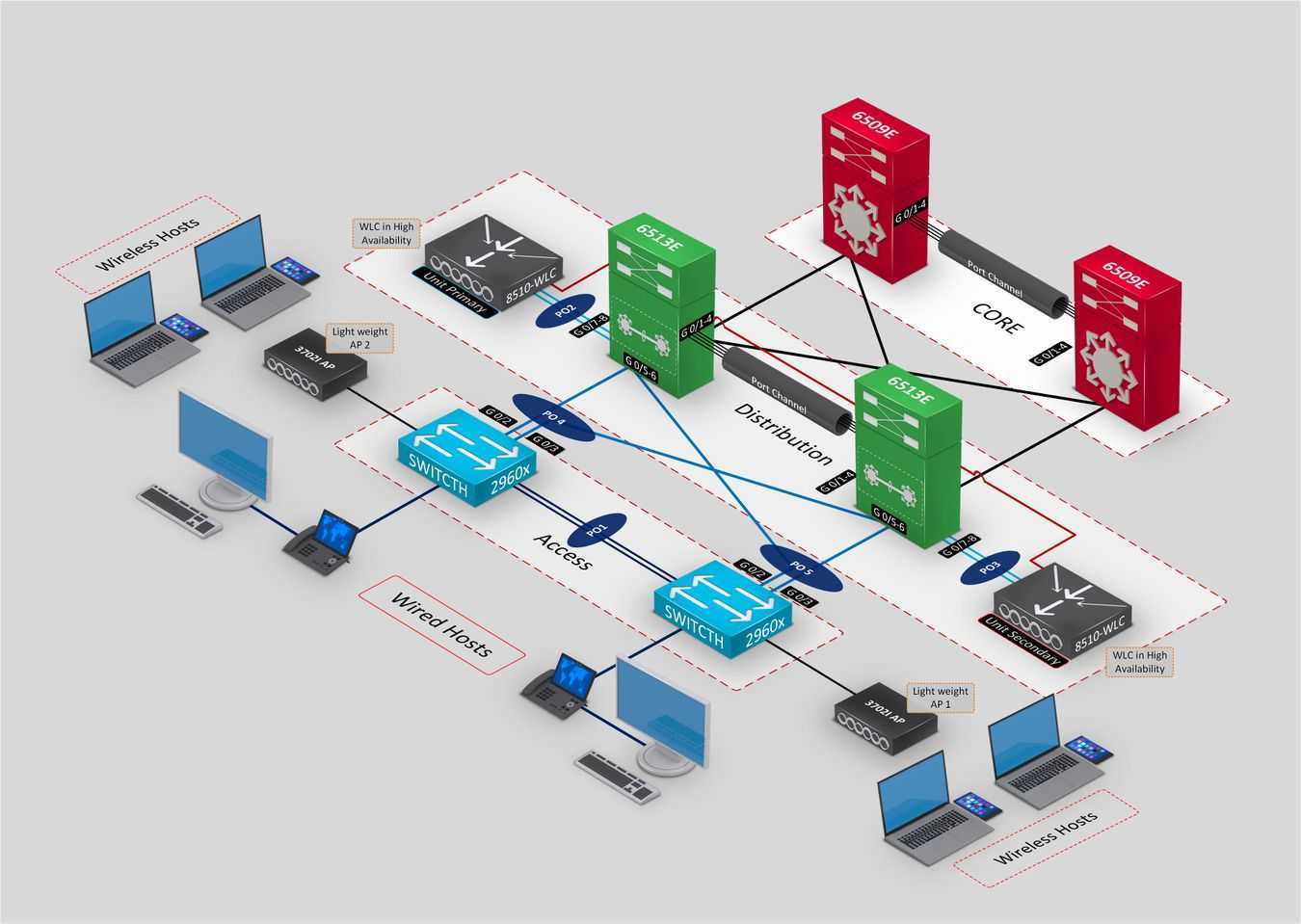
Факторы, влияющие на функционирование ИТ-системы
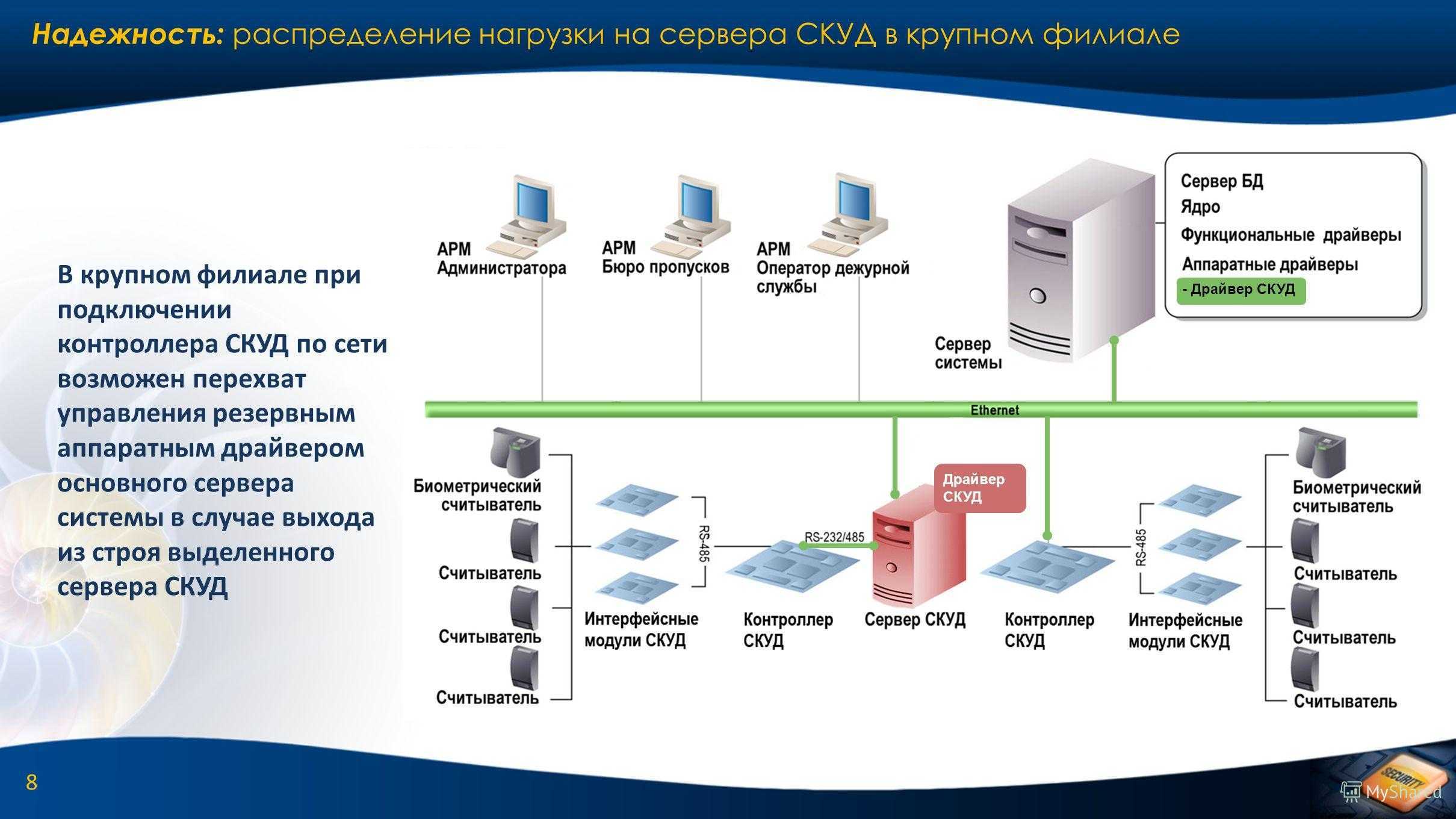
Ключевой фактор — отсутствие единой точки отказа — это узел или объект системы, выход из строя которого приведет к сбою всей системы. Сложность современных приложений растет, становится все больше элементов системы, следовательно потенциальных точек отказа. К тому же, они могут находиться на разных уровнях архитектуры. Потенциально любая часть ИТ-инфраструктуры может стать точкой отказа, например, сервер, СХД, брандмауэр, источник питания или сетевой кабель.
К другим возможным сбоям относятся:
- отключение питания;
- скачок напряжения;
- несанкционированный доступ;
- вирусы и киберугрозы;
- перегрузка сети.
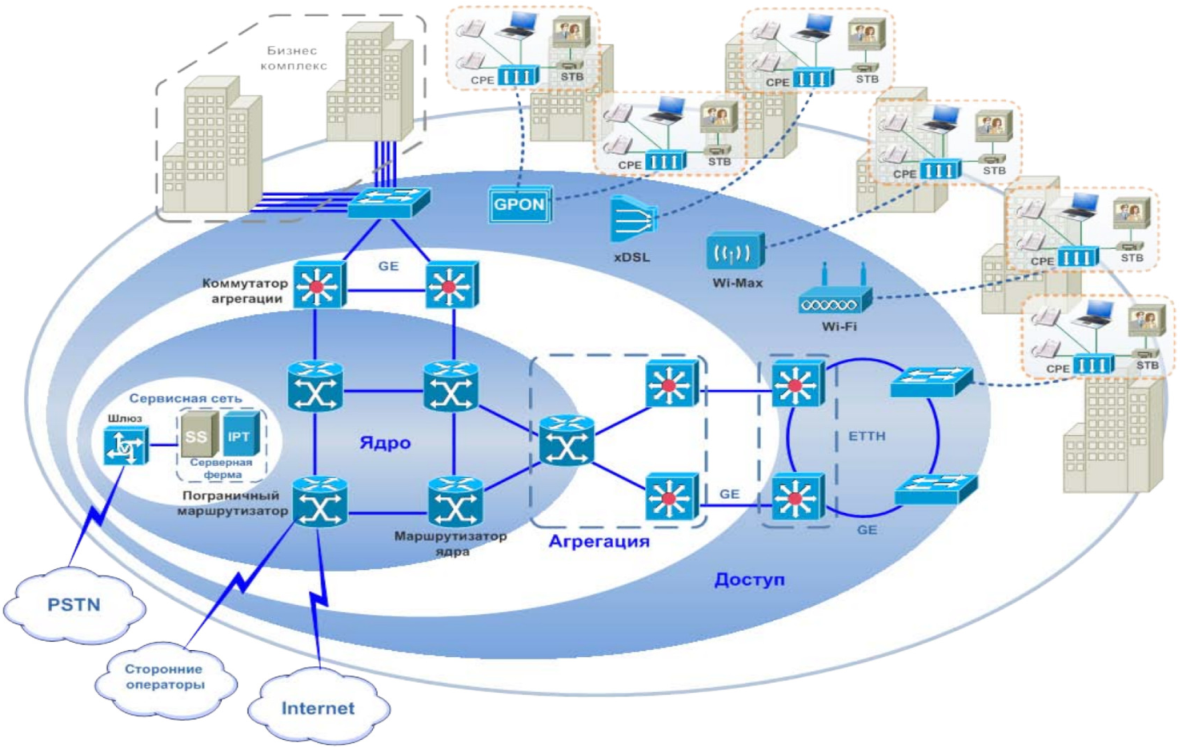
Инженерные системы ЦОД
Обеспечить бесперебойную работу поможет провайдер, для чего поставщик услуг проводит резервирование сетевых каналов, средств БП и обслуживание дата-центра. В зону ответственности провайдера входит постоянный мониторинг системы, плановое обслуживание, контроль доступа к ЦОД. На случай кризисной ситуации существует прописанная модель действий.
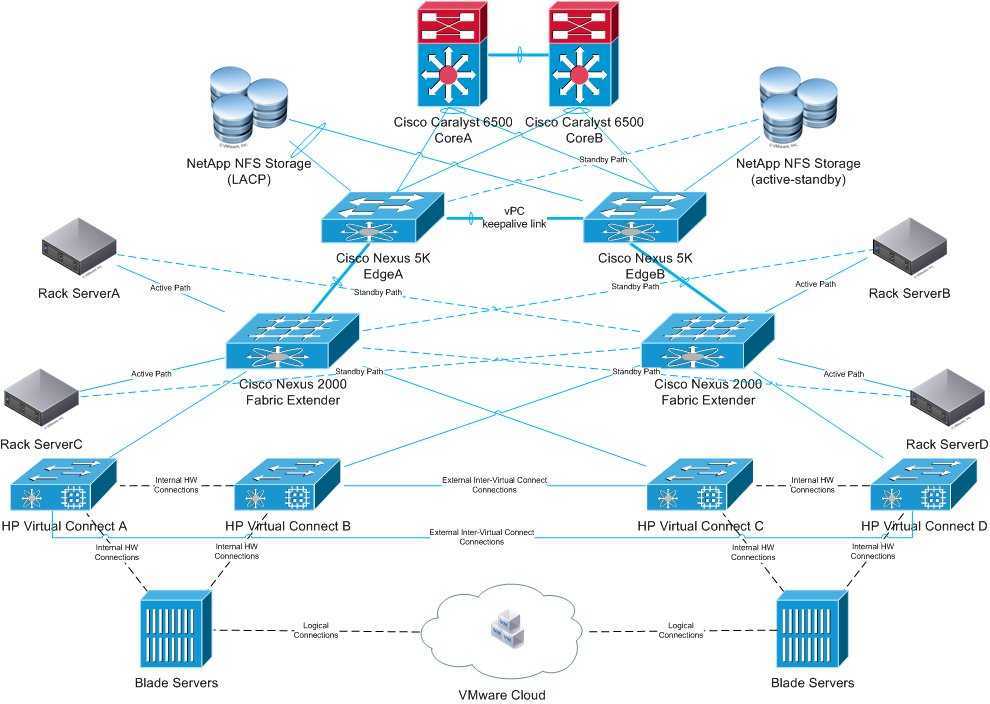
Схема избыточности переносится в масштаб дата-центра, когда на двух разных площадках строятся аналогичные инфраструктуры, связанные в единую сеть. Важный фактор отказоустойчивости ЦОД — географическая распределенность. Независимые друг от друга дата-центры ITGLOBAL.COM находятся в России, Казахстане и Нидерландах.
Аппаратная часть
Главный метод для построения аппаратной части отказоустойчивой архитектуры — резервирование, которое происходит на уровне логических модулей или оборудования. Например, СХД состоит из дублирующих элементов: контроллеры, сетевые адаптеры, БД. Если один выходит из строя, нагрузка перенаправляется на второй. Для корректной работы оборудование должно быть с аналогичными характеристиками.
Отказоустойчивые системы автоматически обнаруживают сбой процессора, материнской платы, носителя данных, подсистемы ввода-вывода или сетевого железа. Система немедленно выявляет точку отказа, ее заменяет резервный компонент.
При реализации отказоустойчивости организации используют избыточный массив независимых дисков (RAID). Технология RAID обеспечивает запись данных на несколько жестких дисков, что позволяет сбалансировать операции ввода-вывода и повысить общую производительность системы.
Программная часть
Отказоустойчивый кластер состоит из нескольких физических систем, которые совместно используют одну копию ОС. Программы выполняются на обоих системах.
Балансировщик нагрузки помогает распределять нагрузку таким образом, чтобы не было единой точки отказа. Также он обеспечивает репликацию — данные записываются на несколько машин, если сервер выходит из строя, система переключается на резервный. Кластер в режиме реального времени определяет, где находятся данные, и продолжает их использовать.
Другое необходимое для отказоустойчивой системы ПО — брокер сообщений — диспетчер, выступающий посредником между протоколами. Брокер преобразует сообщение одного протокола от приложения-источника (продюсера) в сообщение протокола принимающего приложения (консьюмера) и обеспечивает репликацию данных.
ОС для управления СХД ONTAP от вендора NetAPP обладает встроенной функциональностью для реализации резервной ИТ-площадки. Входящий в ONTAP инструмент SnapMirror — это средство асинхронной репликации данных между двумя физическими системами хранения. ПО позволяет реплицировать на резервную площадку все данные и настройки СХД.
Также NetAPP разработал продукт MetroCluster, который полностью резервирует все компоненты ЦОД на удаленной площадке. Даже если полностью отключится один из дата-центров, второй полностью восстановится в течение нескольких секунд.
Средства безопасности
Безопасность должна быть частью проектирования отказоустойчивой системы для предотвращения несанкционированного доступа и кибератак. Для этого применяются антивирусные инструменты, проверка обновлений, системы контроля и управления доступом — для построения отказоустойчивой системы необходимы все известные средства безопасности.
Наличие катастрофоустойчивого решения
Катастрофоустойчивый тип резервирования осуществляется только для критически важных систем, так как связан с большими финансовыми затратами.
Катастрофоустойчивость позволяет продолжать работу ЦОД после природных катаклизмов, аварий или любых других чрезвычайных ситуаций. Для этого строится географически распределенный дата-центр, объединенный в одну сеть. В случае ЧС данные будут сохранены, а система сохранит работоспособность.
High Availability и Disaster Recovery в облаке провайдера
Важно понимать, что поддержка отказоустойчивости корпоративной инфраструктуры и развертывание локальных резервных мощностей для аварийного восстановления доступны лишь очень крупным корпорациям. Причина — высокая стоимость таких решений.. С другой стороны, масштабируемость, географическая избыточность, а также SLA на уровне 99,99 и выше — это стандартные характеристики публичных облаков
Клиентам облачного провайдера не нужно ломать голову, где взять мощности для обеспечения отказоустойчивости. Масштабируемые ресурсы предоставляются по запросу в нужное время и в нужном объеме, а избыточность инфраструктуры заложена еще на стадии проектирования. Кроме того, облачные провайдеры предоставляют свои мощности и готовые решения (DRaaS) для аварийного восстановления. Поэтому для большинства организаций миграция в облако — это недорогое и подходящее решение для повышения отказоустойчивости своей IT-инфраструктуры.
С другой стороны, масштабируемость, географическая избыточность, а также SLA на уровне 99,99 и выше — это стандартные характеристики публичных облаков. Клиентам облачного провайдера не нужно ломать голову, где взять мощности для обеспечения отказоустойчивости. Масштабируемые ресурсы предоставляются по запросу в нужное время и в нужном объеме, а избыточность инфраструктуры заложена еще на стадии проектирования. Кроме того, облачные провайдеры предоставляют свои мощности и готовые решения (DRaaS) для аварийного восстановления. Поэтому для большинства организаций миграция в облако — это недорогое и подходящее решение для повышения отказоустойчивости своей IT-инфраструктуры.
Заказать DRaaS
Подробнее
Особенности катастрофоустойчивости
Второй подход к построению ИТ-инфраструктуры – это катастрофоустойчивость, или Disaster Tolerance. Он необходим для того, чтобы спасти важные компоненты системы и сохранить ее работоспособность при серьезной аварии. Например, такая ситуация может возникнуть при пожаре, наводнении или любом другом событии, которое приведет к массовому выходу оборудования из строя.
Главный принцип обеспечения катастрофоустойчивости заключается в использовании кластерной конфигурации. Серверы геораспределяются, то есть размещаются в разных местах, при этом поддерживается единство сети хранения данных. Создается основная и резервная площадки, которые используют единую систему.
Для защиты от природных и техногенных катастроф используется резервирование основных систем размещения и обработки данных. То есть, по сути это еще одно проявление геораспределенной системы. Наличие резервного дата-центра позволяет обеспечить работу инфраструктуры в том случае, если пострадает главное здание ЦОДа.
Нередко к катастрофоустойчивости относят и такое понятие, как Disaster Recovery, или DT. Однако формально этот термин обозначает аварийное восстановление системы. Оно требуется для поддержания работоспособности корпоративной инфраструктуры после масштабного сбоя в работе.
Термин «катастрофоустойчивость» тесно связан с двумя факторами – RTO и RPO. Разберемся, что они обозначают:
- RTO – это целевое время. То есть, это тот период, за который система должна вернуться к рабочему состоянию. Для критически важных компонентов инфраструктуры RTO определяется в секундах, тогда как другие системы могут восстанавливаться в течение часов и даже дней.
- RPO – это точка восстановления. Такой параметр отображает допустимый объем потерянных данных после аварии, который измеряется во времени. Суть в том, что некоторые системы могут потерять данные за день, тогда как другие – за несколько секунд.
Внедрение стратегии
После разработки плана, настало время для реализации вашей стратегии. В зависимости от этого может потребоваться помощь стороннего провайдера, который предоставит вам необходимые ресурсы для размещения баз. Также вы можете использовать собственные серверы, однако такой вариант резервирования является не самым безопасным и надежным.
Независимо от выбранного типа резервного копирования БД, вам потребуется описать план восстановления. Он должен содержать следующее:
- Описывать особенности восстановления копий. В том числе, методы могут включать мгновенное воссоздание, репликацию или непрерывную защиту с последующим восстановлением.
- Обозначить сроки и объем БД для восстановления. Эти параметры должны рассчитываться с учетом реальных критериев и объемов. Наиболее практичным считается многоуровневое восстановление.
- Описать особенности аварийного восстановления. Это потребуется для восстановления работоспособности вашей компании после аварии.
Еще один немаловажный момент при внедрении стратегии – обучение сотрудников. Оно позволит работникам понять стратегию резервирования и свою роль в этом процессе. Лица, ответственные за восстановление данных, должны четко понимать всю последовательность действий в случае критической ситуации и то, каким образом будет выполняться восстановление копий.
Если у вас возникли трудности с выбором подходящей стратегии резервирования данных, то специалисты дата-центра Xelent всегда готовы помочь. Мы проанализируем потребности вашей компании и подберет максимально эффективный и надежный вариант.
Популярные услуги
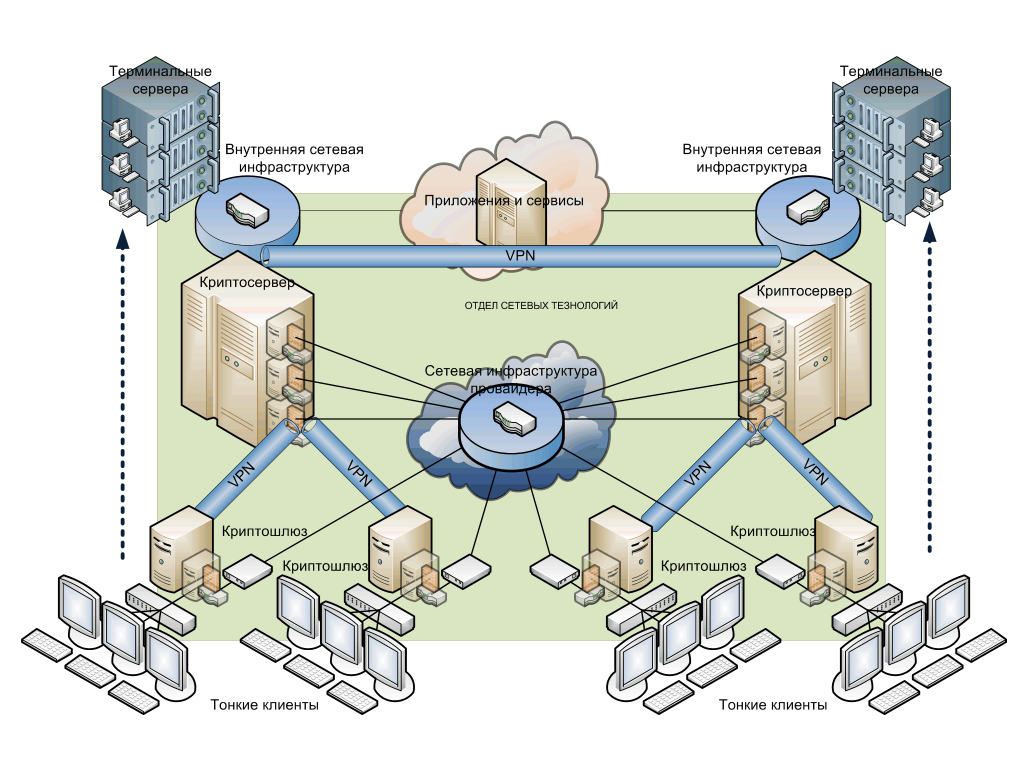
Удаленные рабочие места (VDI)
Переведите офис на удаленную работу в течение 1 дня. Облако с площадками в Санкт-Петербурге, Москве, Алма-Ате и Минске.
Частное облако с управлением через vCloudDirector
Простая, удобная и надежная интеграция облачной инфраструктуры в IT-инфраструктуру компании с глубокими индивидуальными настройками.
Отказоустойчивое облако Xelent
Каждый элемент в отказоустойчивом облаке подключен к двум независимым линиям питания. Система АВР позволяет корректно переключать нагрузку между основным и резервным питанием.
Резервирование на уровне узлов сервера
Резервирование достаточно широко применяется уже на нижнем уровне – самого устройства, то есть — в самих серверах. Многие их узлы дублируются, либо имеют такую возможность. Например, современные серверы предоставляют следующие возможности по резервированию:
Оперативная память
Серверы имеют особый режим работы памяти: Memory Mirroring или Mirrored memory protection. В этом режиме осуществляется зеркалирование каналов, то есть каналы разбиваются на пары, и в каждой паре один из каналов становится копией другого. Все банки памяти при этом должны быть сконфигурированы идентично.
Работа в этом режиме защищает от однобитовых ошибок или выхода из строя всего модуля памяти.
При работе в режиме зеркалирования памяти одни и те же данные записываются в банки системной и зеркалированной памяти, но считываются только из банков системной памяти. Если в каком-то из модулей системной памяти произошла многобитовая ошибка (или превышено допустимое количество однобитовых ошибок), то происходит переназначение банков: банки зеркалированной памяти назначаются системной памятью, а банки системной — зеркалированной. Это обеспечивает бесперебойную работу сервера за исключением случаев, когда ошибка происходит в одном и том же месте в системном и зеркалированном модулях памяти одновременно (вероятность этого крайне мала).
Недостатком такой организации является двукратное уменьшение объёма оперативной памяти. Или, иными словами, двукратное увеличение ее стоимости.
Диски
Аналогично оперативной памяти можно организовать зеркалирование дисков. Для этого каждому диску назначается дубликат, который содержит его полную копию благодаря тому, что информация одновременно записывается на диск и дублирующую его копию. В простейшем случае такая система состоит из двух одинаковых дисков.
Однако, как и в случае с зеркалированием оперативной памяти, недостатком такой организации является высокая (фактически – двойная) стоимость ресурсов. Поэтому часто используются другие варианты организации дисков в единые массивы (RAID, см. статью из Wikipedia). Существует достаточно много вариантов организации RAID-массивов, которые имеют различные параметры стоимости, скорости работы и степени отказоустойчивости.
Питание
Серверы среднего и старшего уровня имеют по два блока питания. В случае выхода из строя одного из них, сервер продолжает работать от второго. Иногда серверы оснащаются тремя и более блоками питания. В этом случае один из них остаётся резервным (так называемая схема N+1), либо БП дублируются (схема N+N). В последнем случае их число должно быть чётным.
Интерфейсы (платы расширения)
И снова самое простое, что можно сделать для обеспечения отказоустойчивости – это дублирование интерфейсных плат. Однако так как
a) современная инфраструктура имеет большое разнообразие интерфейсов разных стандартов (Ethernet, FC, Infiniband, и т.д.) и физических носителей («оптоволокно» или «медь»),
b) отказ интерфейсной платы не ведет к потере информации (он только нарушает процесс её передачи),
резервирование интерфейсных плат не входит в набор стандартных средств, которые по умолчанию предоставляются производителем оборудования. Здесь решение о резервировании остаётся на усмотрение пользователя.
Таким образом, отказоустойчивость сервера может быть повышена путем резервирования некоторых его узлов, как только что было описано. Но есть компоненты, которые задублировать невозможно. К ним относятся, в частности, RAID-контроллер и материнская плата. Выход из строя RAID-контроллера может привести к частичной или полной потере данных, а выход из строя материнской платы приведет к остановке всего сервера. Как защититься от таких неисправностей и обеспечить безотказную работу?
Ответ за одну секунду — это быстро?
Здесь мы говорим о скорости работы
Нам важно понять, «быстро» — это как? Ответ зависит от того, что именно ожидают наши пользователи
Например, на веб-сайте пользователь готов ждать загрузки страницы максимум пару секунд. После этого он либо уйдет, либо потеряет фокус, и конверсия в любом случае снизится. А вот подбора билетов на самолет пользователь готов ждать даже дольше 10 секунд, и для него это все равно будет быстро.
Плюс при оценке скорости отклика важно понимать, где именно мы ее оцениваем. Обычно у нас есть API, за ним стоит балансер нагрузки, например, Ingress, и уже за ним клиент
И время отклика везде будет разное:
Поэтому то время ответа, которое вы видите на стороне сервера — далеко не показатель. Вам нужно попытаться «надеть тапки» пользователя и посмотреть на систему его глазами.
Для примера, случай из практики. Есть два графика:
Сверху у нас клиентский опыт ошибок, снизу – серверный. Как видите, на сервере ошибок нет вообще, а вот у клиента их достаточно. И если бы мониторинга алертов на клиентской стороне не было, ошибок мы бы просто не заметили. Ведь на сервере все работает идеально.
Избыточность, и как ее достичь
Единственный способ избежать отказа системы — избавиться от «единых» точек отказа» (SPOF). Практика управления инфраструктурами всех уровней и масштабов доказывает, что избыточность — единственный путь к такому решению, поскольку обеспечивает резервирование абсолютно всех компонентов. Логично, ведь вероятность одновременного сбоя 2-х серверов намного меньше, чем одного.
При этом резервы должны в мельчайших деталях копировать конфигурации основных компонентов (количество «оперативки», функциональные характеристики процессоров и прочее).
Какие подходы практикуются для резервирования веб-компонентов:
- Дублирование NS-записей.
- Резервирование фронтендов.
- Оптимизация числа бекендов.
- Резервирование баз данных.
Оптимизация консенсуса
Казалось бы, что тут можно оптимизировать? Ведь мы с Raft достигаем минимально возможного времени исполнения — 1 RTT. На самом деле можно быстрее — за 0 RTT.
Для этого вспомним, что помимо самого консенсуса требуется еще 1 RTT для отсылки запроса от клиента до лидера и получение ответа. Т.е. для удаленной группы консенсуса требуется в этом случае 2 RTT, что мы и видим в двухфазном коммите на 2-х примерах: отсылка и коммит на координаторе, отсылка и коммит на участниках. Итого сразу 4 RTT, и еще 1 RTT — на коммит второй фазы на координаторе.
Понятно, что консенсус на основе лидера для удаленного клиента никак не может быть быстрее 2 RTT. В самом деле, сначала нам требуется доставить сообщение до лидера, а затем лидер обязан уже переслать участникам группы и получить от них ответ. Без вариантов.
Единственный вариант — это избавиться от слабого звена — лидера. Действительно, мало того, что все записи должны проходить через него, так и в случае его падения группа становится недоступной достаточно продолжительное время. Лидер консенсуса есть самое слабое звено, и восстановление лидера — самая хрупкая и нетривиальная часть консенсуса. Поэтому надо просто от него избавиться.
Определение. Броадкаст сообщения — это посылка одного и того же сообщения всем участникам группы.
Для этого возьмем широко известный в узких кругах консенсус без мастера. Основная идея заключается в том, чтобы броадкастами добиться одинакового состояния на участниках. Для этого достаточно сделать 2 броадкаста, т.е. как раз 1 RTT. Первый броадкаст до участников системы может сделать сам клиент. Ответные броадкасты от участников могут дойти и до клиента. Если клиент видит одинаковое состояние (а он это увидит это в случае, например, отсутствия конкурентных запросов), то он на анализе содержимого ответных броадкастов сможет понять, что его запрос будет закоммичен рано или поздно. По факту, используя такой алгоритм, все участники консенсуса, включая клиента, одновременно осознают, что запрос был закоммичен. И это произойдет после 2 броадкастов, т.е. 1 RTT. Т.к. клиент все равно должен потратить 1 RTT на отсылку сообщения группе и получения ответа, то мы имеем парадоксальный вывод, что консенсус эффективно произошел за 0 RTT.