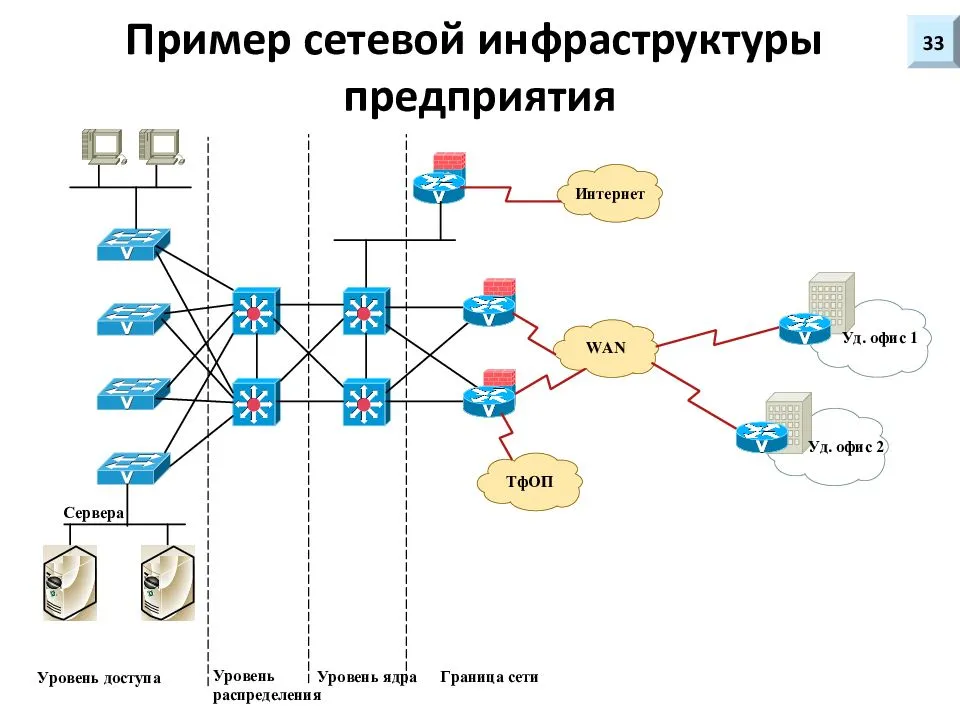
Резервирование на уровне узлов сервера
Резервирование достаточно широко применяется уже на нижнем уровне – самого устройства, то есть — в самих серверах. Многие их узлы дублируются, либо имеют такую возможность. Например, современные серверы предоставляют следующие возможности по резервированию:
Оперативная память
Серверы имеют особый режим работы памяти: Memory Mirroring или Mirrored memory protection. В этом режиме осуществляется зеркалирование каналов, то есть каналы разбиваются на пары, и в каждой паре один из каналов становится копией другого. Все банки памяти при этом должны быть сконфигурированы идентично.
Работа в этом режиме защищает от однобитовых ошибок или выхода из строя всего модуля памяти.
При работе в режиме зеркалирования памяти одни и те же данные записываются в банки системной и зеркалированной памяти, но считываются только из банков системной памяти. Если в каком-то из модулей системной памяти произошла многобитовая ошибка (или превышено допустимое количество однобитовых ошибок), то происходит переназначение банков: банки зеркалированной памяти назначаются системной памятью, а банки системной — зеркалированной. Это обеспечивает бесперебойную работу сервера за исключением случаев, когда ошибка происходит в одном и том же месте в системном и зеркалированном модулях памяти одновременно (вероятность этого крайне мала).
Недостатком такой организации является двукратное уменьшение объёма оперативной памяти. Или, иными словами, двукратное увеличение ее стоимости.
Диски
Аналогично оперативной памяти можно организовать зеркалирование дисков. Для этого каждому диску назначается дубликат, который содержит его полную копию благодаря тому, что информация одновременно записывается на диск и дублирующую его копию. В простейшем случае такая система состоит из двух одинаковых дисков.
Однако, как и в случае с зеркалированием оперативной памяти, недостатком такой организации является высокая (фактически – двойная) стоимость ресурсов. Поэтому часто используются другие варианты организации дисков в единые массивы (RAID, см. статью из Wikipedia). Существует достаточно много вариантов организации RAID-массивов, которые имеют различные параметры стоимости, скорости работы и степени отказоустойчивости.
Питание
Серверы среднего и старшего уровня имеют по два блока питания. В случае выхода из строя одного из них, сервер продолжает работать от второго. Иногда серверы оснащаются тремя и более блоками питания. В этом случае один из них остаётся резервным (так называемая схема N+1), либо БП дублируются (схема N+N). В последнем случае их число должно быть чётным.
Интерфейсы (платы расширения)
И снова самое простое, что можно сделать для обеспечения отказоустойчивости – это дублирование интерфейсных плат. Однако так как
a) современная инфраструктура имеет большое разнообразие интерфейсов разных стандартов (Ethernet, FC, Infiniband, и т.д.) и физических носителей («оптоволокно» или «медь»),
b) отказ интерфейсной платы не ведет к потере информации (он только нарушает процесс её передачи),
резервирование интерфейсных плат не входит в набор стандартных средств, которые по умолчанию предоставляются производителем оборудования. Здесь решение о резервировании остаётся на усмотрение пользователя.
Таким образом, отказоустойчивость сервера может быть повышена путем резервирования некоторых его узлов, как только что было описано. Но есть компоненты, которые задублировать невозможно. К ним относятся, в частности, RAID-контроллер и материнская плата. Выход из строя RAID-контроллера может привести к частичной или полной потере данных, а выход из строя материнской платы приведет к остановке всего сервера. Как защититься от таких неисправностей и обеспечить безотказную работу?
Роль Apache Cassandra в HyperStore
- При создании нового объекта Cassandra (первичный ключ и его соответствующие значения) он хешируется, а хэш используется для того, чтобы связать объект с определенным vNode. Система проверяет, какому хосту назначен этот vNode, а затем первая реплика объекта Cassandra хранится на диске Cassandra на этом хосте.
- Например, представим, что хост-машине назначено 96 vNodes, распределенных по нескольким дискам данных HyperStore. Объекты Cassandra, чьи значения хэша попадают в диапазоны токенов любого из этих 96 vNodes, будут записаны на диск Cassandra на этом хосте.
- Дополнительные реплики объекта Cassandra (количество реплик зависит от вашей конфигурации) связываются с vNodes со следующим порядковым номером и сохраняются на том узле, которому назначены эти vNodes, при условии, что при необходимости vNodes будут «пропущены», чтобы каждая реплика объекта Cassandra хранилась на другой хост-машине.
Что нам для этого надо?
- Я буду описывать установку на 3 ноды, но в вашем случае их может быть сколько угодно.
Вы так же можете установить OpenNebula на одну ноду, но в этом случае вы не сможете построить отказоустойчивый кластер, а вся ваша установка по этому руководству сведется лишь к установке самой OpenNebula, и например, OpenvSwitch.Кстати, еще вы можете установить CentOS на ZFS, прочитав мою предыдущую статью (не для продакшена) и настроить OpenNebula на ZFS, используя написанный мной ZFS-драйвер - Также, для функционирования Ceph, крайне желательна 10G сеть. В противном случае, вам не имеет смысла поднимать отдельный кэш-пул, так как скоростные характеристики вашей сети будут даже ниже, чем скорость записи на пул из одних только HDD.
- На всех нодах установлен CentOS 7.
- Также каждая нода содержит:
- 2SSD по 256GB — для кэш-пула
- 3HDD по 6TB — для основного пула
- Оперативной памяти, достаточной для функционирования Ceph (1GB ОЗУ на 1TB данных)
- Ну и ресурсы необходимые для самого облака, CPU и оперативная память, которые мы будем использовать для запуска виртуальных машин
- Еще хотел добавить, что установка и работа большинства компонентов требует отключенного SELINUX. Так что на всех трех нодах он отключен:
- На каждой ноде установлен EPEL-репозиторий:
DAS
Direct Attached Storage — это исторически первый вариант подключения носителей, применяемый до сих пор. Накопитель, с точки зрения компьютера, в котором он установлен, используется монопольно, обращение с накопителем происходит поблочно, обеспечивая максимальную скорость обмена данными с накопителем с минимальными задержками. Также это наиболее дешевый вариант организации системы хранения данных, однако не лишенный своих недостатков. К примеру если нужно организовать хранение данных предприятия на нескольких серверах, то такой способ организации не позволяет совместное использование дисков разных серверов между собой, так что система хранения данных будет не оптимальной: некоторые сервера будут испытывать недостаток дискового пространства, другие же — не будут полностью его утилизировать:
Конфигурации систем с единственным накопителем применяются чаще всего для нетребовательных нагрузок, обычно для домашнего применения. Для профессиональных целей, а также промышленного применения чаще всего используется несколько накопителей, объединенных в RAID-массив программно, либо с помощью аппаратной карты RAID для достижения отказоустойчивости и\или более высокой скорости работы, чем единичный накопитель. Также есть возможность организации кэширования наиболее часто используемых данных на более быстром, но менее емком твердотельном накопителе для достижения и большой емкости и большой скорости работы дисковой подсистемы компьютера.
[править] Железо
Решил брать все в одном месте. Вот какой набор получился.
| № | Наименование | Цена (на март 2012 г.) | Количество | Сумма |
|---|---|---|---|---|
| 1. | Жесткий диск 3000ГБ Hitachi «Deskstar 5K3000 HDS5C3030ALA630» 5700об./мин., 32МБ (SATA III) | 5544.82 | 3 | 16634.46 |
| 2. | Мат. плата Socket1155 ASUS «P8Z68-V LX» (iZ68, 4xDDR3, SATA III, SATA II, RAID, 2xPCI-E, D-Sub, DVI, HDMI, SB, 1Гбит LAN, USB2.0, USB3.0, ATX) | 3115.2 | 1 | 3115.2 |
| 3. | Корпус Miditower Zalman «MS1000-HS1», ATX, черный (без БП) | 4012 | 1 | 4012 |
| 4. | Кулер для процессора Socket775/115x Arctic Cooling «Alpine 11 Plus» | 328.04 | 1 | 328.04 |
| 5. | Привод BD-ROM/DVD±RW 12xBD/16x8x16xDVD/48x32x40xCD Samsung «SH-B123L/BSBP», черный (SATA) | 2185.36 | 1 | 2185.36 |
| 6. | Модуль памяти 2×2ГБ DDR3 SDRAM Kingston «ValueRAM» KVR1333D3S8N9K2/4G (PC10600, 1333МГц, CL9) | 767 | 1 | 767 |
| 7. | Процессор Intel «Core i3-2100» (3.10ГГц, 2×256КБ+3МБ, EM64T, GPU) Socket1155 | 3314.62 | 1 | 3314.62 |
| 8. | Блок питания 750Вт Corsair «TX750 V2» CMPSU-750TXV2EU ATX12V V2.3 (20/24+4/8+6/8pin, вентилятор d140мм) + кабель питания EURO (1.8м) | 3890.46 | 1 | 3890.46 |
| 9. | Жесткий диск 250ГБ Seagate «Barracuda ST250DM000» 7200об./мин., 16МБ (SATA III) | 2153.5 | 1 | 2153.5 |
Итого: 36400.64 р.
Выбор комплектующих особо не принципиален и осуществлялся на основе имеющихся в одном магазине.
Для сетевого хранилища не нужен производительный процессор, но в перспективе предполагается развертывание на нем дополнительных сервисов (Веб сервер, база данных и т.д.), поэтому был выбран Core i3-2100.
Основа массива — 3 диска Hitachi Deskstar 5K3000 (для RAID 5 нужно минимум 3 диска) емкостью 3Тб. Это «зеленые» диски и не совсем подходят для производительных решений, но выбора не было, да и получилось «задешево». Кроме того, не стояла задача по скорости — главное объем и надежность. Предполагается получить объем хранения порядка 7-8Тб.
Для установки системы предусмотрим отдельный маленький жесткий диск 250ГБ Seagate Barracuda.
Материнская плата имеет видеовыходы, которые работают в случае поддержки процессором (выбранный поддерживает). На материнской плате 4 разъема SATA3 и 2 SATA6.
Я подключил их следующим образом: 1 SATA3 к приводу BD-ROM/DVD±RW, 3 к корзине из 3-х дисков с возможностью hot-swap (это особенность корпуса — в нем установлена корзина на 3 диска), 1 SATA6 к нашему системному диску и 1 SATA6 к внешнему eSATA.
В перспективе наш NAS может быть модернизирован добавлением второй сетевой карты для объединение их в единый пул. Для добавления дисков необходима отдельная плата с необходимым количеством портов SATA (PCI или PCI-1x,4x,16x), т.к. на данный момент портов SATA не осталось.
Выглядеть это будет так.
Дверца снизу закрывает корзину на 3 диска.
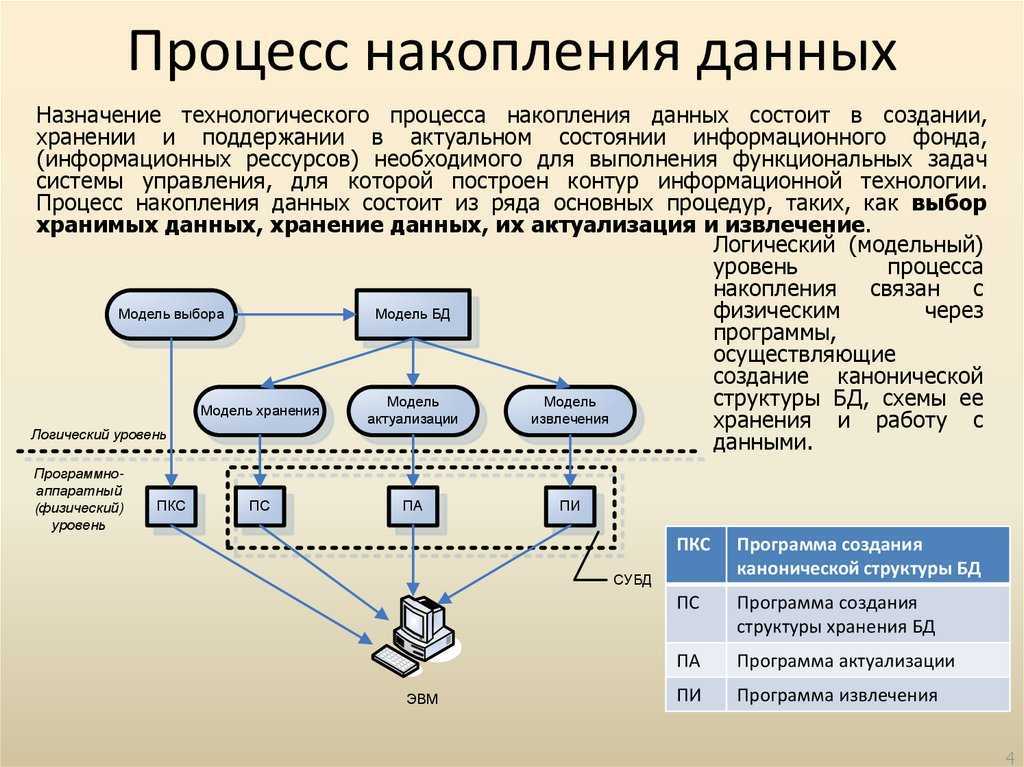
Проектирование хранилища объектов
Практически любому приложению нужно хранилище, но требования к этому компоненту системы могут сильно различаться. Возьмем для примера хранилище документов: возможно, на начальных этапах работы ему не придется обслуживать большое количество запросов на чтение, но впоследствии может понадобиться масштабирование. Другое приложение (такое как, например, галерея изображений) уже с момента запуска должно уметь и быстро обслуживать большое количество запросов, и масштабироваться по мере необходимости.
Эти тонкости осложняют процесс организации хранилища. Но все не так плохо: c приходом хранилища объектов (object storage) в качестве стандартного способа хранения неструктурированных данных (во многом за счет необходимости использования HTTP) начался процесс стандартизации работы приложения с хранилищем.
Но вопрос все еще остается: как организовать заточенное под ваше приложение и в то же время гибкое хранилище объектов?
Поскольку работа с хранилищем объектов подразумевает использование HTTP-серверов и клиентов, для обслуживания HTTP-трафика необходимо выбрать подходящий веб-сервер (например, не нуждающийся в представлении NGINX). В качестве бэкэнда можно использовать легковесный и хорошо масштабируемый сервер хранилища объектов. На эту роль отлично подходит Minio. Гибкость подобной системы является ключевым фактором при создании сервиса корпоративного уровня.
С помощью NGINX Plus администраторы могут не только настроить балансировку входящего трафика, но и кэширование, дросселирование (throttling), завершение SSL/TLS и даже фильтрацию трафика на основе различных параметров. Minio, с другой стороны, предлагает легковесное хранилище объектов, совместимое с Amazon S3.
Minio создан для размещения неструктурированных данных, таких как фотографии, видеозаписи, файлы журналов, резервные копии, а также образы виртуальных машин и контейнеров. Небольшой размер позволяет включать его в состав стека приложений, аналогичного Node.js, Redis и MySQL. В minio также поддерживается распределенный режим (distributed mode), который предоставляет возможность подключения к одному серверу хранения объектов множества дисков, в том числе расположенных на разных машинах.
В этой статье мы рассмотрим несколько сценариев использования NGINX Plus в сочетании с Minio, которые позволяют настроить хорошо масштабируемое, отказоустойчивое и стабильное хранилище объектов корпоративного класса.
Облака и эфемерные хранилища
Логическим продолжением перехода на виртуализацию является запуск сервисов в облаках. В предельном случае сервисы разбиваются на функции, запускаемые по требованию (бессерверные вычисления, serverless)
Важной особенностью тут является отсутствие состояния, то есть сервисы запускаются по требованию и потенциально могут быть запущены столько экземпляров приложения, сколько требуется для текущей нагрузки. Большинство поставщиков (GCP, Azure, Amazon и прочие) облачных решений предлагают также и доступ к хранилищам, включая файловые и блочные, а также объектные
Некоторые предлагают дополнительно облачные базы, так что приложение, рассчитанное на запуск в таком облаке, легко может работать с подобными системами хранения данных. Для того, чтобы все работало, достаточно оплатить вовремя эти услуги, для небольших приложений поставщики вообще предлагают бесплатное использование ресурсов в течение некоторого срока, либо вообще навсегда.
Из недостатков: могут заблокировать аккаунт, на котором все работает, что может привести к простоям в работе. Также могут быть проблемы со связностью и\или доступностью таких сервисов по сети, поскольку такие хранилища полностью зависят от корректной и правильной работы глобальной сети.
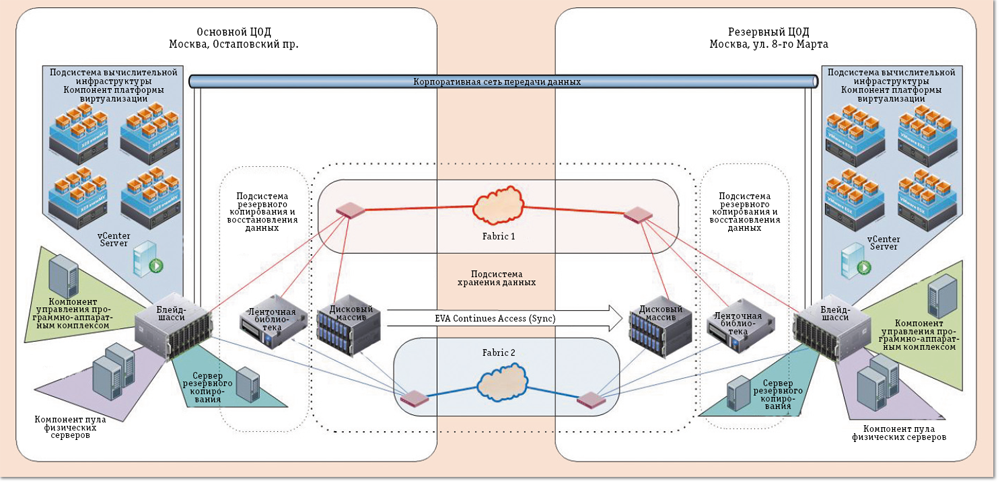
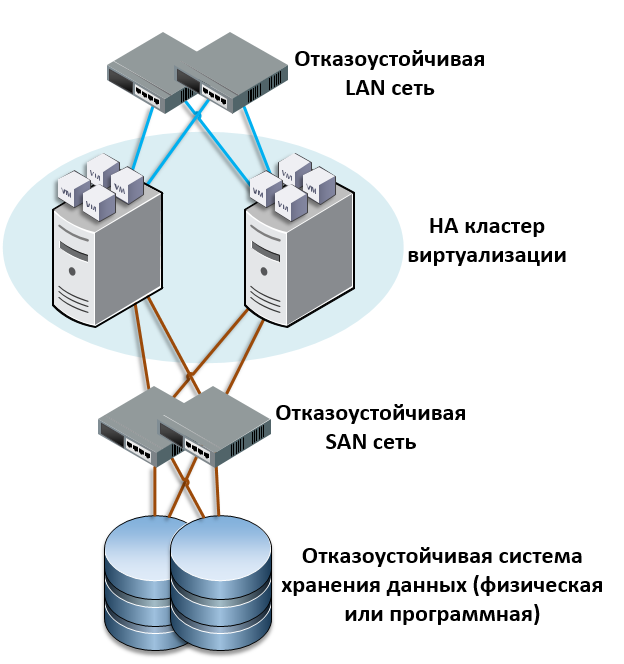
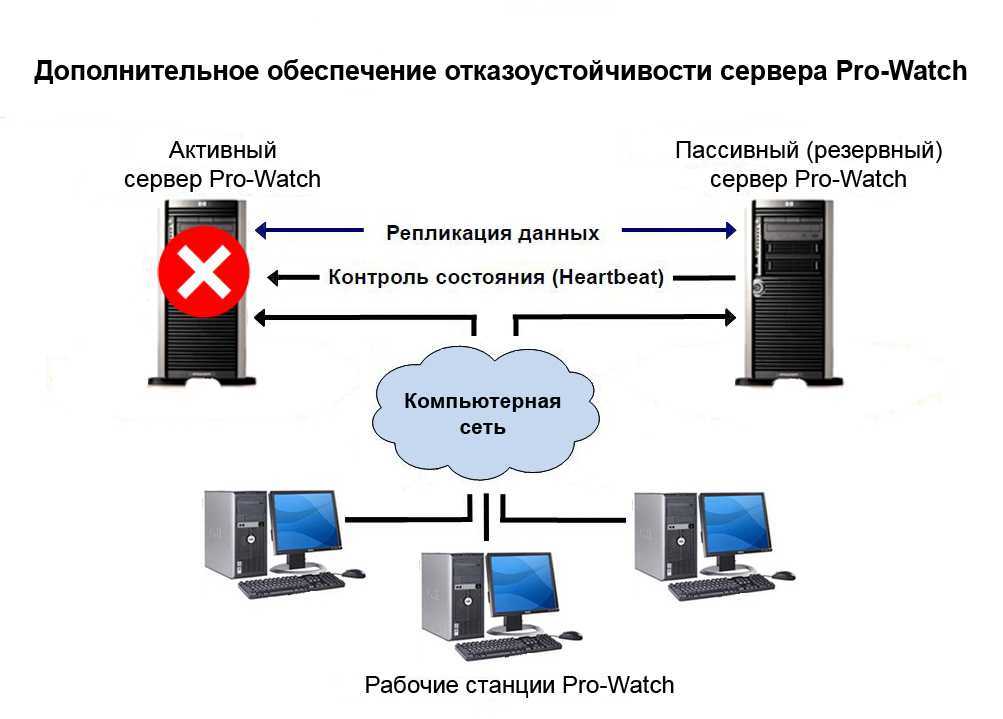
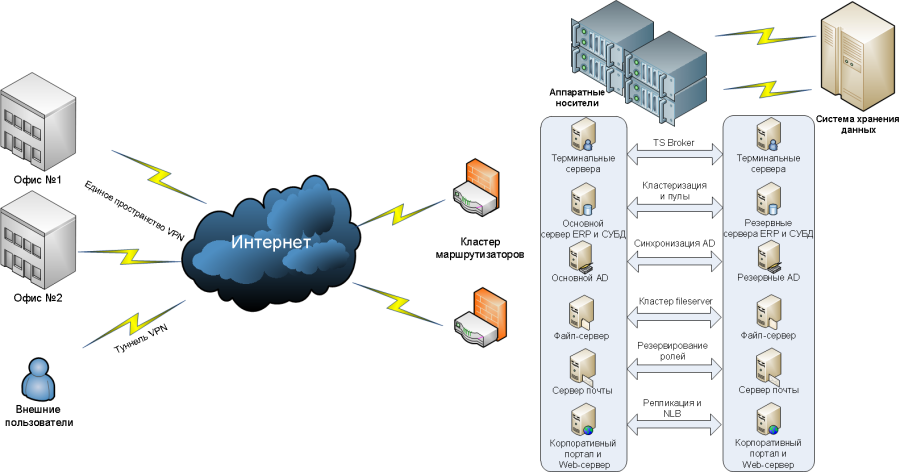
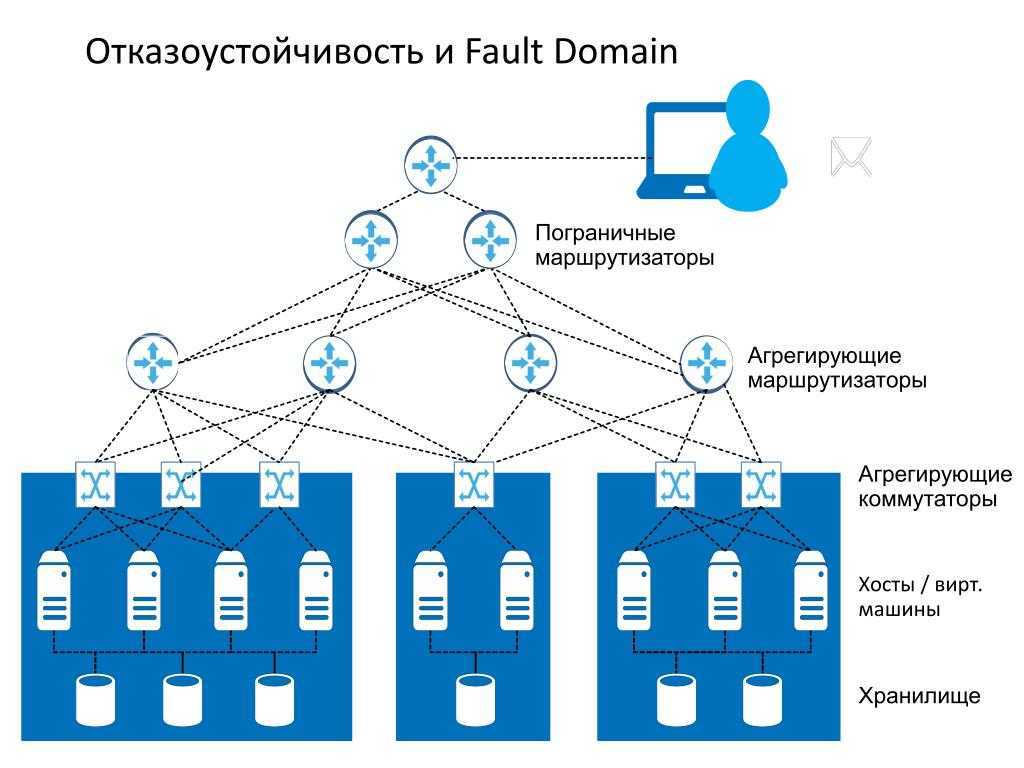
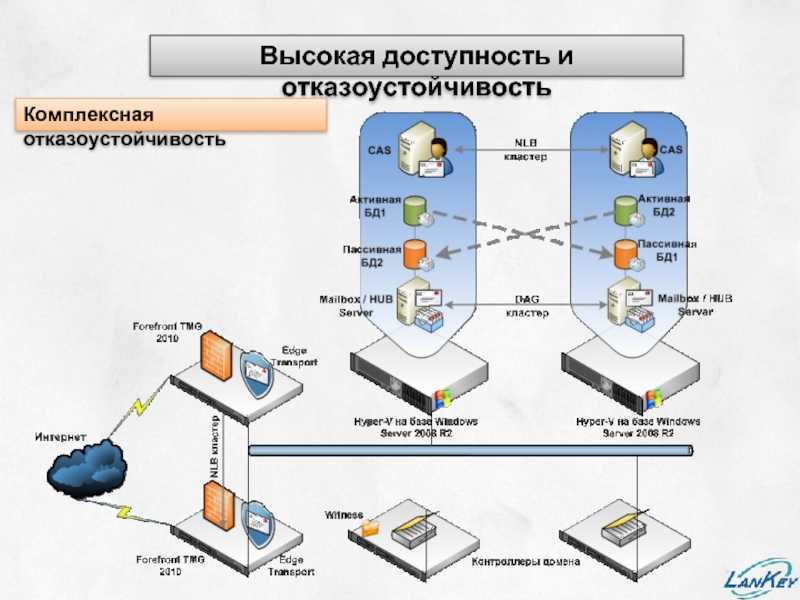
Резервирование серверов (кластеры)
В подобных случаях применяется резервирование сервера целиком. C помощью специального программного обеспечения несколько серверов объединяются в единую систему. В случае аварии на одном из них, его нагрузка перекладывается на другие, входящие в систему. Такая организация называется кластером высокой доступности (high availability cluster, HA-кластер).
В простейшем и самом распространённом случае система состоит из двух серверов (так называемый двухузловой кластер), один из которых является основным, а другой —дублирующим, резервным (конфигурация active/passive). Все вычисления производятся на основном сервере, а дублирующий сервер включается в работу в случае аварии на основном. Такая конфигурация является затратной, так как каждый узел дублируется. На схеме ниже показана конфигурация active/passive, состоящая из нескольких (N) серверов.
Конфигурация Active/Passive
В другом варианте построения кластера серверы (два или больше) могут иметь равноценный статус, то есть работать одновременно (конфигурация active/active). В такой конфигурации нагрузка вышедшего из строя сервера распределяется по остальным серверам кластера. Если серверов в кластере немного, то скорее всего произойдёт снижение производительности, так как нагрузка на оставшиеся в кластере серверы возрастёт.
Конфигурация Active/Active
Здесь стоит заметить, что в конфигурации active/passive (которая имеет полное резервирование каждого узла) такого снижения не будет. Однако этот вариант стоит дороже, так как каждый узел дублируется. Фактически, за отказоустойчивость и отсутствие потери производительности всегда приходится платить двойную цену.
Третьим, альтернативным вариантом, который позволяет избежать как высоких расходов, так и потери производительности кластера при отказе одного из узлов, является конфигурация N+1. В этой конфигурации кластер имеет один полноценный резервный сервер, который при работе в обычном режиме не несёт на себе никакой нагрузки, а включается в работу только в случае отказа одного из активных серверов.
Конфигурация N+1
Краткое сравнение конфигураций сведено в таблицу ниже. Стоит отметить, что кроме описанных трех, бывают и другие, более сложные конфигурации отказоустойчивых кластеров. Например, N+M – когда для обеспечения более высокого уровня отказоустойчивости в состав кластера включается не один, а несколько резервных серверов.
|
Active/Active |
Active/Passive |
N+1 |
|
|
Стоимость решения |
Нормальная (суммарная стоимость всех узлов; все узлы кластера работают) |
Высокая (фактически – двойная, т.к. дублируются все узлы кластера) |
Нормальная + 1 (суммарная стоимость всех узлов + 1 резервный узел) |
|
Производи-тельность при отказе |
Снижение производительности |
Нет снижения производительности |
Нет снижения производительности |
Почему пандемия стала стимулом
Эксперты весьма оптимистично смотрят на перспективы развития рынка облачных решений. Облака были одним из самых активно развивающихся сегментов ИТ еще до 2020 года. Однако пандемия дополнительно стимулировала этот сегмент. Прежде всего, это было связано с переходом к гибридному формату работы, который до этого в большинстве компаний был скорее исключением. Столь глобальные изменения привели к росту спроса на виртуальные рабочие столы и инфраструктуру, на которой они функционируют (VDI). Благодаря этому, облачные сервисы для организации удаленной работы развивались очень быстрыми темпами в течение всех 2020-2021 гг.
Остальные сегменты облачного рынка сохранили прежние темпы роста, так как большая часть отраслей бизнеса по-прежнему нуждается в облачных решениях и не сокращает свои инвестиции в это направление. Исключениями стали отрасли, наиболее сильно пострадавшие от последствий пандемии, например, туризм. Но в то же время промышленность, финансовый сектор, ритейл продолжают наращивать объемы потребляемых облачных услуг. Пандемия ускорила процессы цифровизации в этих отраслях, прежде всего развитие дистанционных каналов обслуживания.
Сценарии незаменимости
Незаменимый характер катастрофоустойчивого облака отлично демонстрируют все типичные случаи сбоев в работе ИТ-систем. Сбои могут спровоцировать совершенно разные факторы — от поломки конкретной единицы оборудования до природного катаклизма.
Эксперт DataLine Михаил Соловьев перечислил следующие сценарии:
- Сложная поломка оборудования, например, отказ СХД или кластера SDS (программно-определяемого хранилища);
- Воздействие воды на оборудование вследствие прорыва систем отопления, водоснабжения и канализации, возможно, в результате наводнения;
- Пожар в серверной комнате или в дата-центре – в результате этого восстановление данных невозможно;
- Изъятие или кража сервера.
Немаловажно, что DataLine как опытный и квалифицированный провайдер предлагает комплексную поддержку заказчикам. Качество сервиса гарантируется строгими условиями соглашений о предоставлении услуг
|
Мы строго соблюдаем параметры SLA в рамках сервиса катастрофоустойчивого облака, особенно время переключения при аварии. В состав SLA входят: доступность сервиса, производительность систем хранения, быстродействие процессоров, круглосуточная техподдержка, время реагирования на инцидент и так далее. Основные показатели решения: гарантированная доступность, RTO (допустимое время восстановления данных), гарантированная производительность дисковой системы, скорость процессора, — заключает Михаил Соловьев. |
Внедрение стратегии
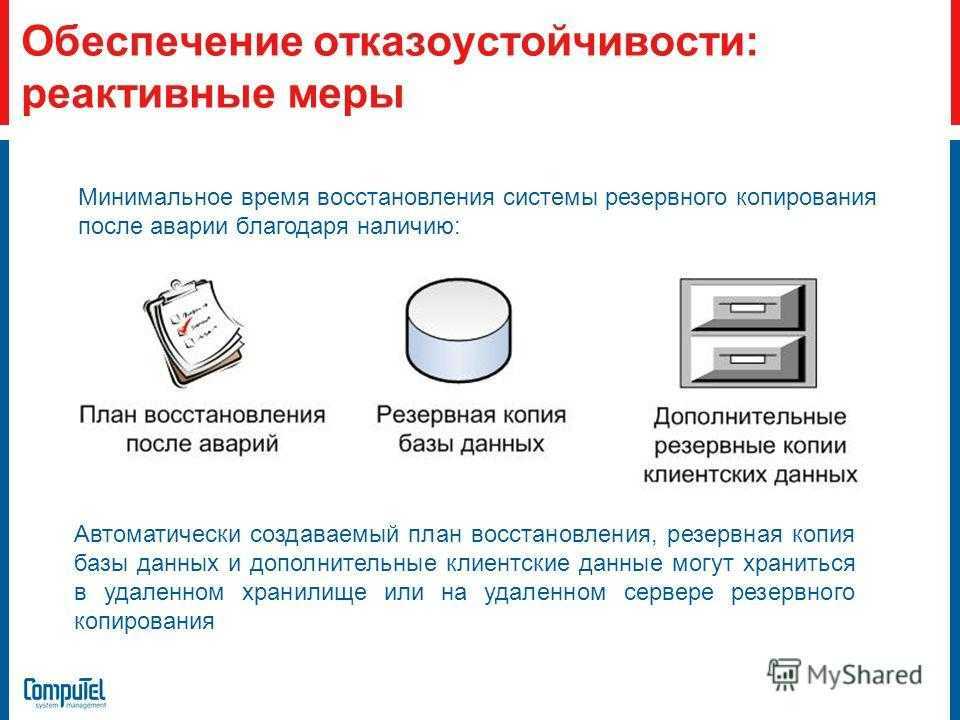
После разработки плана, настало время для реализации вашей стратегии. В зависимости от этого может потребоваться помощь стороннего провайдера, который предоставит вам необходимые ресурсы для размещения баз. Также вы можете использовать собственные серверы, однако такой вариант резервирования является не самым безопасным и надежным.
Независимо от выбранного типа резервного копирования БД, вам потребуется описать план восстановления. Он должен содержать следующее:
- Описывать особенности восстановления копий. В том числе, методы могут включать мгновенное воссоздание, репликацию или непрерывную защиту с последующим восстановлением.
- Обозначить сроки и объем БД для восстановления. Эти параметры должны рассчитываться с учетом реальных критериев и объемов. Наиболее практичным считается многоуровневое восстановление.
- Описать особенности аварийного восстановления. Это потребуется для восстановления работоспособности вашей компании после аварии.
Еще один немаловажный момент при внедрении стратегии – обучение сотрудников. Оно позволит работникам понять стратегию резервирования и свою роль в этом процессе. Лица, ответственные за восстановление данных, должны четко понимать всю последовательность действий в случае критической ситуации и то, каким образом будет выполняться восстановление копий.
Если у вас возникли трудности с выбором подходящей стратегии резервирования данных, то специалисты дата-центра Xelent всегда готовы помочь. Мы проанализируем потребности вашей компании и подберет максимально эффективный и надежный вариант.
Популярные услуги
Удаленные рабочие места (VDI)
Переведите офис на удаленную работу в течение 1 дня. Облако с площадками в Санкт-Петербурге, Москве, Алма-Ате и Минске.
Частное облако с управлением через vCloudDirector
Простая, удобная и надежная интеграция облачной инфраструктуры в IT-инфраструктуру компании с глубокими индивидуальными настройками.
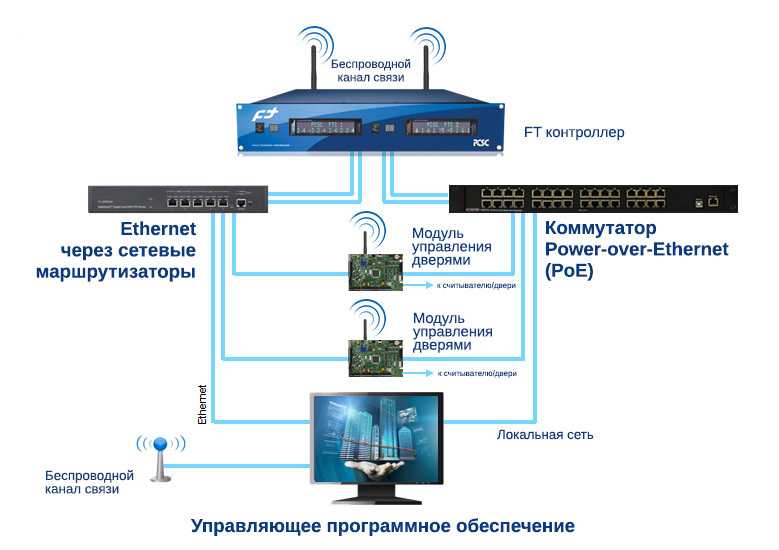
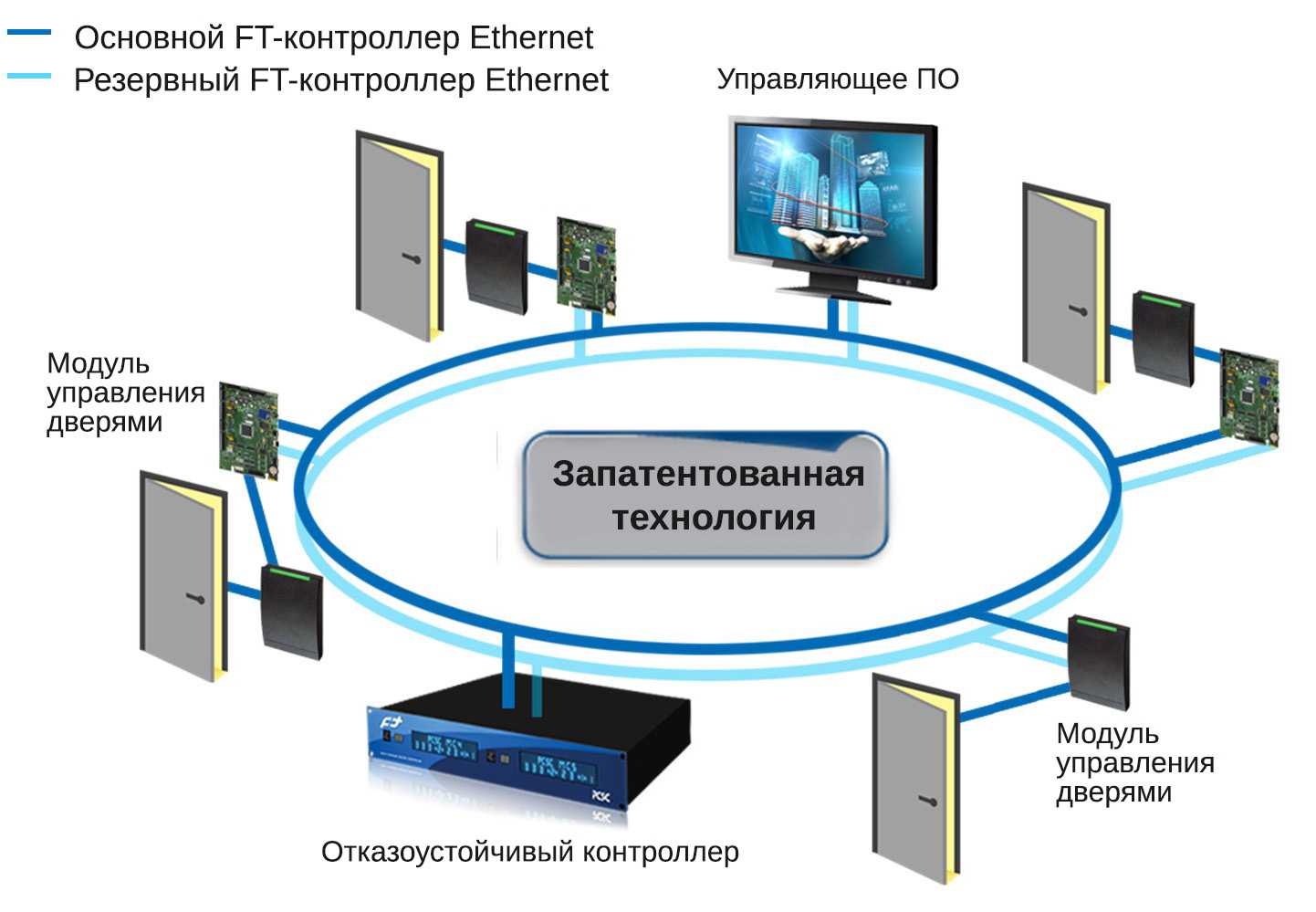
Отказоустойчивое облако Xelent
Каждый элемент в отказоустойчивом облаке подключен к двум независимым линиям питания. Система АВР позволяет корректно переключать нагрузку между основным и резервным питанием.
Работа компонентов LINSTOR
Есть два основных сервиса:
-
linstor-controller — запускается в одном экземпляре и представляет собой центральное API и шедулер ресурсов;
-
linstor-satellite — миньоны LINSTOR’а, устанавливаются на всех storage- и compute-узлах, используются для взаимодействия с менеджером логических томов и настройки DRBD.
Когда мы обращаемся к LINSTOR, чтобы создать том определенного размера, LINSTOR автоматически сканирует все узлы в кластере и выбирает наиболее подходящие. После этого linstor-satellite создает том, конфигурационный файл для DRBD и выполняет команду с названием ресурса:
У DRBD есть собственный набор утилит, которые используются для взаимодействия с конфигурацией и ядром:
-
drbdadm (требует наличия конфигурационного файла) читает конфигурацию ресурса, после чего выполняет все команды через более низкоуровневую утилиту drbdsetup;
-
drbdsetup — общается напрямую с ядром для настройки DRBD, позволяя добавлять или изменять специфические свойства для каждого устройства.
Работа с DRBD
Копнём ещё чуть глубже и рассмотрим, как DRBD взаимодействуют друг с другом, как выполняется репликация и какие состояния могут быть у наших ресурсов*.
* Обычным пользователям LINSTOR’а эта информация не нужна. Но она крайне полезна для понимания механизмов его работы и при отладке в случае сложных проблем.
Посмотрим на содержимое конфигурационного файла , который сгенерировал LINSTOR и поместил его для каждого узла отдельно в :
-
— название ресурса;
-
— опции хранения ресурса, из которых видно, что включен кворум;
-
— конфигурация каждого из узлов;
-
— ID, который назначается каждому узлу;
-
— имя backing-устройства, которое используется для хранения данных; здесь можно увидеть, что на node1 мы используем LVM-том, когда как на node3 значение указывает на diskless-устройство;
-
— номер устройства в ядре, определяющий его имя ()
Также можем выполнить команду для просмотра состояния устройства. Пример для первого узла:
В данном случае мы видим, что реплика находится в , т.е. содержит актуальные данные, а также «видит» состояние двух других реплик в кластере.


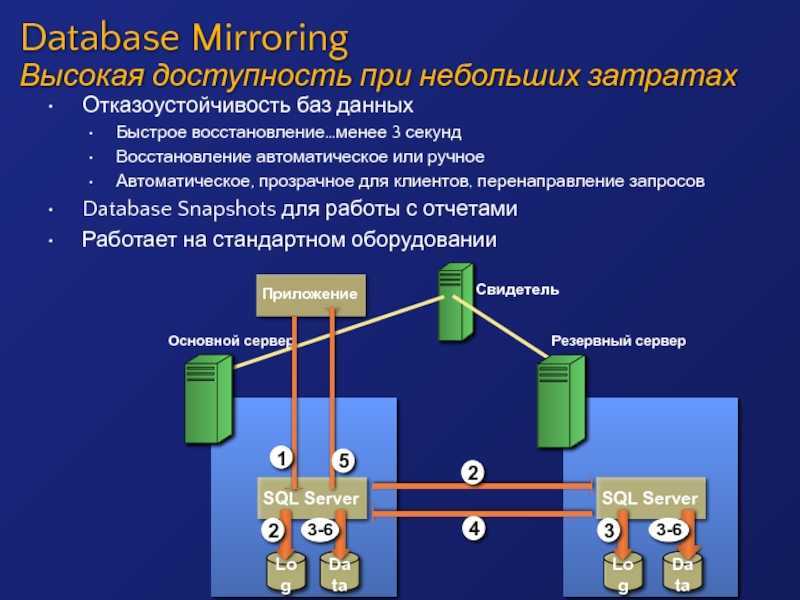
Использование созданного ресурса
Начиная с девятой версии ресурс автоматически переводится в режим primary при монтировании или открытии устройства в эксклюзивном режиме.
У DRBD нет как таковой master/slave-репликации. Поэтому даже diskless-узел может быть primary. В таком случае он будет ответственнен за репликацию данных на два других storage-узла, то есть будет читать и писать сразу на оба.
Про взаимодействие с DRBD и split-brain
На данном моменте я предлагаю остановиться, так как объём статьи и так уже выходит за рамки разумного предела. Если вам всё же интересно, как осуществляется взаимодействие с DRBD на низком уровне, предлагаю посмотреть интерактивную презентацию в моем докладе.
Наличие кворума в DRBD позволяет сильно сократить возможность возникновения split-brain. Но рано или поздно вы всё-таки можете столкнуться с такой ситуацией. Split-brain означает, что в кластере есть два независимых состояния и вам нужно выбрать одно из них, чтобы восстановить кластер
Важно понимать, как работает DRBD, чтобы с легкостью диагностировать такие проблемы
Подробно о том, как работать с DRBD и как «вылечить» split-brain, я рассказываю в докладе и к статье про отладку DRBD9 в LINSTOR.