
Слово «неверный» пишется слитно
Чтобы выяснить, в каких случаях это слово пишется слитно, обратимся сначала к словообразованию.
Качественное прилагательное «верный» образует с помощью приставки не- слово с противоположным значением:
Это новое слово можно заменить синонимами без приставки — «ложный», «ошибочный».
Понаблюдаем:
Прием синонимичной замены аналогичных прилагательных, образованных с помощью приставки не-, убедит нас в их слитном написании:
- интересный — не интересный рассказ — скучный рассказ;
- легкий — не легкий труд — тяжелый труд;
- сильный — не сильный шум — слабый шум.
Как определить сложность алгоритма
Мы рассмотрели два алгоритма и увидели примеры их сложности. Но так и не поговорили о том, как эту сложность определять. Есть три основных способа.
Оценка «на глаз»
Первый и наиболее часто используемый способ. Именно так мы определяли сложность linear search и binary search. Обобщим эти примеры.
Первый случай. Есть алгоритм some_function, который выполняет действие А, а после него — действие В. На А и В нужно K и J операций соответственно.
В случае последовательного выполнения действий сложность алгоритма будет равна O(K + J), а значит, O(max (K, J)). Например, если А равно n^2, а В — n, то сложность алгоритма будет равна O(n^2 + n). Но мы уже знаем, что нас интересует только самая быстрорастущая часть. Значит, ответ будет O(n^2).
Второй случай. Посчитаем сложность действий или вызова методов в циклах. Размер массива равен n, а над каждым элементом будет выполнено действие А (n раз). А дальше всё зависит от «содержимого» A.
Посчитаем сложность бинарного поиска:
Если на каждом шаге A работает с одним элементом, то, независимо от количества операций, получим сложность O(n). Если же A обрабатывает arr целиком, то алгоритм совершит n операций n раз. Тогда получим O(n * n) = O(n^2). По такой же логике можно получить O(n * log n), O(n^3) и так далее.
Третий случай — комбо. Для закрепления соединим оба случая. Допустим, действие А требует log(n) операций, а действие В — n операций. На всякий случай напомню: в алгоритмах всегда идёт речь о двоичных логарифмах.
Добавим действие С с пятью операциями и вот что получим:
O(n * (n * log(n) + n) + 5) = O(n^2 * log(n) + n^2 + 5) = O(n^2 * log(n)).
Мы видим, что самая дорогая часть алгоритма — действие А, которое выполняется во вложенном цикле. Поэтому именно оно доминирует в функции.
Есть разновидность определения на глаз — амортизационный анализ. Это относительно редкий, но достойный упоминания гость. В двух словах его можно объяснить так: если на X «дешёвых» операций (например, с O(1)) приходится одна «дорогая» (например, с O(n)), то на большом количестве операций суммарная сложность получится неотличимой от O(1).
Частый пациент амортизационного анализа — динамический массив. Это массив, который при переполнении создаёт новый, больше оригинального в два раза. При этом элементы старого массива копируются в новый.
Практически всегда добавление элементов в такой массив «дёшево» — требует лишь одной операции. Но когда он заполняется, приходится тратить силы: создавать новый массив и копировать N старых элементов в новый. Но так как массив каждый раз увеличивается в два раза, переполнения случаются всё реже и реже, поэтому average case добавления элемента равен O(1).
Мастер-теорема
Слабое место прикидывания на глаз — рекурсия. С ней и правда приходится тяжко. Поэтому для оценки сложности рекурсивных алгоритмов широко используют мастер-теорему.
По сути, это набор правил по оценке сложности. Он учитывает, сколько новых ветвей рекурсии создаётся на каждом шаге и на сколько частей дробятся данные в каждом шаге рекурсии. Это если вкратце.
Метод Монте-Карло
Метод Монте-Карло применяют довольно редко — только если первые два применить невозможно. Особенно часто с его помощью описывают производительность систем, состоящих из множества алгоритмов.
Как поступить, если источником информации становится конкретное физическое лицо?
Бывают такие ситуации, когда источником информации становится не организация, а определённое лицо. В этих случаях необходимо узнать как можно больше сведений об этом авторе, чтобы определить, в какой степени нужно доверять информации, поступившей от него. Убедиться в достоверности данных можно путём ознакомления с иными работами автора, с его источниками (если таковые имеются), либо же выяснить, обладает ли он речевой свободой, то есть может ли предоставлять такую информацию.
Этот критерий определяется наличием у него учёной степени либо же должного опыта в определённой сфере, а также должности, которую он занимает. В противном же случае информация вполне может оказаться бесполезной и даже принести вред. Если нельзя проверить каким-либо образом достоверность сведений, они сразу же могут считаться бессмысленными. При поиске же информации в первую очередь нужно чётко сформулировать ту проблему, которая требует разрешения, что понизит возможность дезинформирования.
Если же сведения являются анонимными, то за достоверность информации ни в коем случае нельзя ручаться. Любые сведения должны иметь своего автора и подкрепляться имеющейся у него репутацией. Самыми ценными в принципе являются те данные, источником которых является человек опытный, а не случайный.
Что важно при обработке данных при цифровой трансформации?[править]
вариант 1править
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Сильная внутренняя экспертиза команды в области подхода управления с помощью данных +
Хранить данные в бумажном виде в архиве
вариант 2править
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Понимать, какой информацией располагает компания, а чего не хватает +
Хранить данные в бумажном виде в архиве
вариант 3править
Обновить техническое обеспечение компании, используя самую современную технику
Обучить всех сотрудников использовать Excel для обработки данных
Обучить всех сотрудников языкам программирования, способных запускать нейронные сети
Определить методы сбора, анализа и интерпретации результатов +
Хранить данные в бумажном виде в архиве
Как работает протокол?
Утилита md5sum, предназначенная для хеширования данных заданного файла по алгоритму MD5, возвращает строку. Она состоит из 32 цифр в шестнадцатеричной системе счисления (016f8e458c8f89ef75fa7a78265a0025).
То есть хеш, полученный от функции, работа которой основана на этом алгоритме, выдает строку в 16 байт (128) бит. И эта строка включает в себя 16 шестнадцатеричных чисел. При этом изменение хотя бы одного ее символа приведет к последующему бесповоротному изменению значений всех остальных битов строки.
В данном алгоритме предполагается наличие 5 шагов, а именно:
-
Выравнивание потока
-
Добавление длины сообщения
-
Инициализация буфера
-
Вычисление в цикле
-
Результат вычислений
На первом шаге “Выравнивание потока” сначала дописывают единичный бит в конец потока, затем необходимое число нулевых бит. Входные данные выравниваются так, чтобы их новый размер был сравним с 448 по модулю 512. Выравнивание происходит, даже если длина уже сравнима с 448.




На втором шаге в оставшиеся 64 бита дописывают 64-битное представление длины данных до выравнивания. Сначала записывают младшие 4 байта. Если длина превосходит то дописывают только младшие биты. После этого длина потока станет кратной 512. Вычисления будут основываться на представлении этого потока данных в виде массива слов по 512 бит.
На третьем для вычислений используются четыре переменные размером 32 бита и задаются начальные значения в 16-ричном виде. В этих переменных будут храниться результаты промежуточных вычислений.
Во время 4-го шага “Вычисление в цикле” происходит 4 раунда, в которых сохраняются значения, оставшиеся после операций над предыдущими блоками. После всех операций суммируются результаты двух последних циклов. Раундов в MD5 стало 4 вместо 3 в MD4. Добавилась новая константа для того, чтобы свести к минимуму влияние входного сообщения. В каждом раунде на каждом шаге и каждый раз константа разная. Она суммируется с результатом и блоком данных. Результат каждого шага складывается с результатом предыдущего шага. Из-за этого происходит более быстрое изменение результата. Изменился порядок работы с входными словами в раундах 2 и 3.
В итоге на 5-ом шаге мы получим результат вычислений, который находится в буфере это и есть хеш. Если выводить побайтово, начиная с младшего байта первой переменной и закончив старшим байтом последней, то мы получим MD5-хеш.
Назовите три шага по созданию концепции цифровой трансформации?[править]
Анализ инфраструктуры – Создание технологического видения – Временная оценка преобразований, исходя из динамики изменения внешней среды
Диагностика текущего состояния – Формирование целевого состояние – Разработка дорожной карты преобразования +
Определение состояния продуктов и процессов – Создание стратегического видения – Временная оценка преобразований, исходя из текущего состояния организации
Изучение кадрового потенциала и культуры – Создание бизнес-архитектуры – Определение вех цифровой трансформации
Извлечение данных – Трансформация данных – Загрузка данных
Компетентные и некомпетентные
Помимо подразделения на достоверные и недостоверные, источники также могут быть компетентными и некомпетентными.
Наиболее широко представлены такие источники информации, как уполномоченные официальных структур власти. В первую очередь государственные учреждения должны снабжать граждан самой объективной и точной информацией. Однако даже сведения пресс-службы правительства могут быть подделаны, и нет гарантии, что из государственного источника не может просочиться информация, не являющаяся достоверной. Именно поэтому получить информацию – не означает доверять ей безоговорочно.
Первые шаги устранения ошибки установки соединения
Рассмотрим основные причины ошибки установки соединения с базой данных и способы их устранения.
Только до25 декабря
Пройди опрос иполучи обновленный курс от Geekbrains
Дарим курс по digital-профессиям
и быстрому вхождения в IT-сферу
Чтобы получить подарок, заполните информацию в открывшемся окне
Перейти
Скачать файл
Прежде всего, настоятельно рекомендуем создать резервную копию всей важной информации и обновлять ее после каждого значимого изменения. Тогда вы гарантированно не потеряете данные
А в случае серьезной ошибки и восстановления базы данных, не столкнетесь с необходимостью создания сайта с нуля. Для создания резервной копии используются плагины Duplicator или All-in-One WP Migration.
Есть много программных модулей для резервного копирования, но они не смогут вам помочь при отсутствии доступа в админку.
В такой ситуации нужен плагин ISPmanager или другой модуль, который поможет, управляя хостингом, сделать полное резервное копирование сайта.
 Первые шаги устранения ошибки установки соединения
Первые шаги устранения ошибки установки соединения
При возникновении сложностей стоит воспользоваться технической поддержкой, которая есть на всех платных хостингах. Здесь вам окажут квалифицированную помощь с созданием резервной копии.
Удалить кеш DNS
DNS действует как книга записей, в которой хранятся все доменные имена, соответствующие их IP-адресам. Но если эти данные устареют или будут повреждены, браузер не сможет установить успешное соединение с Интернетом. Поэтому рекомендуется удалить временные кэшированные данные.
Вот шаги, чтобы очистить кеш DNS в ОС Windows:
- Откройте меню «Пуск» и найдите CMD.
- Запустите командную строку как администратор.
- Теперь введите ipconfig / flushdns и нажмите Enter.
Это приведет к удалению кеша DNS, и, надеюсь, этот паршивый запрос решит проблему.
Очистка DNS может задержать загрузку веб-сайта при следующем их посещении. Однако это всего лишь одноразовая задержка, и она будет исправлена, как только данные кэша будут повторно заполнены.
Отключить расширение браузера
Большая часть проблем при доступе к браузеру обычно возникает из-за установленных нами расширений. Даже я столкнулся с проблемой, когда веб-сайт не загружался должным образом, и обнаружил, что виноваты расширения. Я думаю, что эти расширения браузера могут приводить к неправильным или неправильным запросам.
Вот быстрые шаги по отключению расширений браузера в Chrome:
- Запустите на компьютере браузер Google Chrome.
- Посетите страницы расширений Chrome по адресу chrome: // extensions / address.
- Переключите кнопку, чтобы отключить расширение.
- Теперь отключите каждое из расширений по одному, пока ошибка не будет исправлена.
Более того, рекомендуется сразу удалить расширения, которые вызывают расширение.
Хотя эти надстройки, как правило, добавляют браузеру больше функций, иногда они могут приводить к некоторым проблемам. Когда это произойдет, лучше попрощаться с этим расширением.
Бинарный поиск
Следующая остановка — binary search, он же бинарный, или двоичный, поиск.
В чём отличие бинарного поиска от уже знакомого линейного? Чтобы его применить, массив arr должен быть отсортирован. В нашем случае — по возрастанию.
Часто binary search объясняют на примере с телефонным справочником. Возможно, многие читатели никогда не видели такую приблуду — это большая книга со списками телефонных номеров, отсортированных по фамилиям и именам жителей. Для простоты забудем об именах.
Итак, есть огромный справочник на тысячу страниц с десятками тысяч пар «фамилия — номер», отсортированных по фамилиям. Допустим, мы хотим найти номер человека по фамилии Жила. Как бы мы действовали в случае с линейным поиском? Открыли бы книгу и начали её перебирать, строчку за строчкой, страницу за страницей: Астафьев… Безье… Варнава… Ги… До товарища Жилы он дошёл бы за пару часов, а вот господин Янтарный заставил бы алгоритм попотеть ещё дольше.
Бинарный поиск мудрее и хитрее. Он открывает книгу ровно посередине и смотрит на фамилию, например Мельник — буква «М». Книга отсортирована по фамилиям, и алгоритм знает, что буква «Ж» идёт перед «М».
Алгоритм «разрывает» книгу пополам и выкидывает часть с буквами, которые идут после «М»: «Н», «О», «П»… «Я». Затем открывает оставшуюся половинку посередине — на этот раз на фамилии Ежов. Уже близко, но Ежов не Жила, а ещё буква «Ж» идёт после буквы «Е». Разрываем книгу пополам, а левую половину с буквами от «А» до «Е» выбрасываем. Алгоритм продолжает рвать книгу пополам до тех пор, пока не останется единственная измятая страничка с заветной фамилией и номером.
Перенесём этот принцип на массивы. У нас есть отсортированный массив arr и число 7, которое нужно найти. Почему поиск называется бинарным? Дело в том, что алгоритм на каждом шаге уменьшает проблему в два раза. Он буквально отрезает на каждом шаге половину arr, в которой гарантированно нет искомого числа.
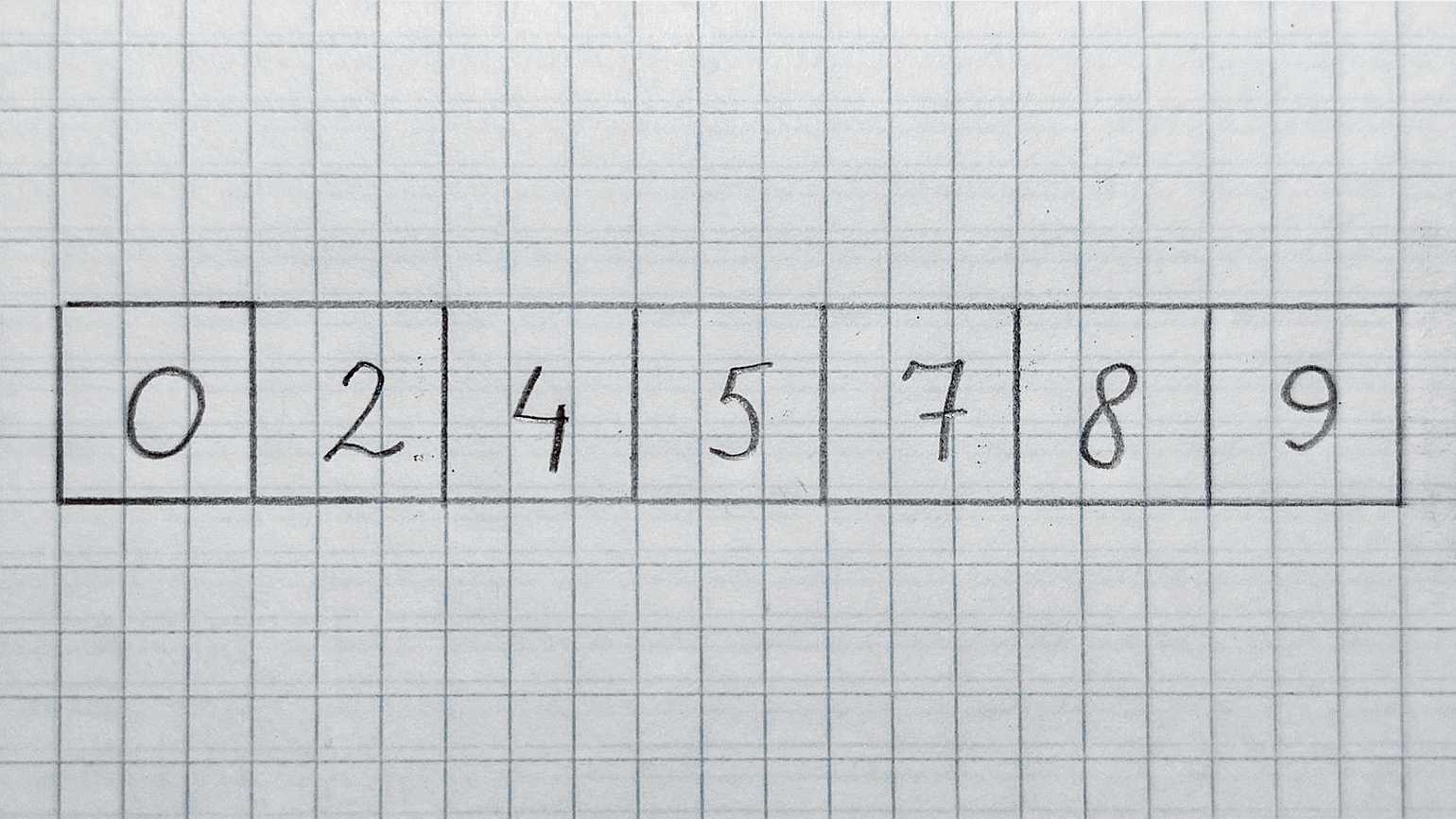
Фото: Валерий Жила для Skillbox Media
На каждом шаге мы проверяем только середину. При этом есть три варианта развития событий:
- попадаем в 7 — тогда проблема решена;
- нашли число меньше 7 — отрезаем левую половину и ищем в правой половине;
- нашли число больше 7 — отрезаем правую половину и ищем в левой половине.
Почему это работает? Вспомните про требование к отсортированности массива, и всё встанет на свои места.
Итак, смотрим в середину. Карандаш будет служить нам указателем.
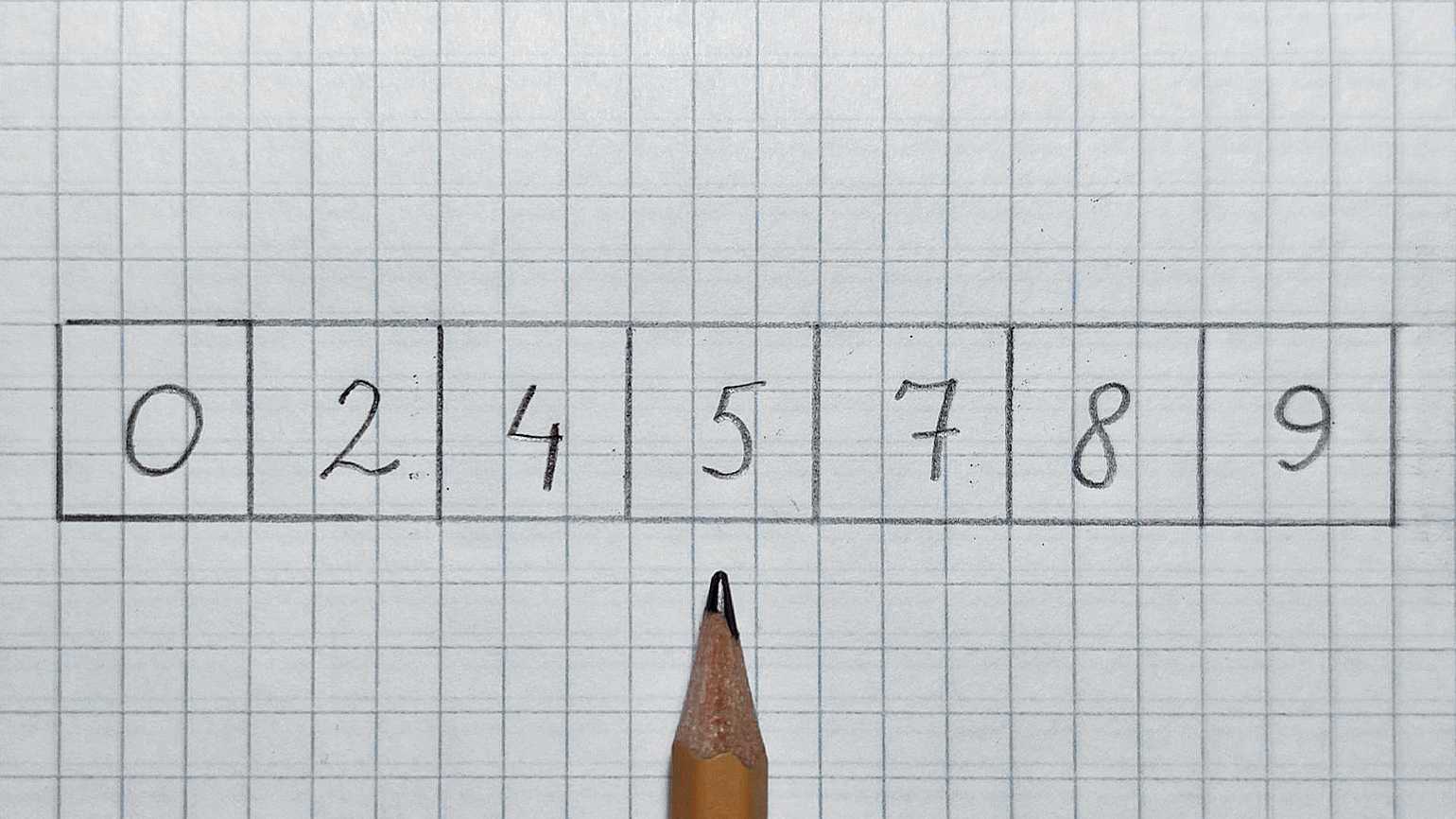
Фото: Валерий Жила для Skillbox Media
В середине находится число 5, оно меньше 7. Значит, отрезаем левую половину и проверенное число. Смотрим в середину оставшегося массива:
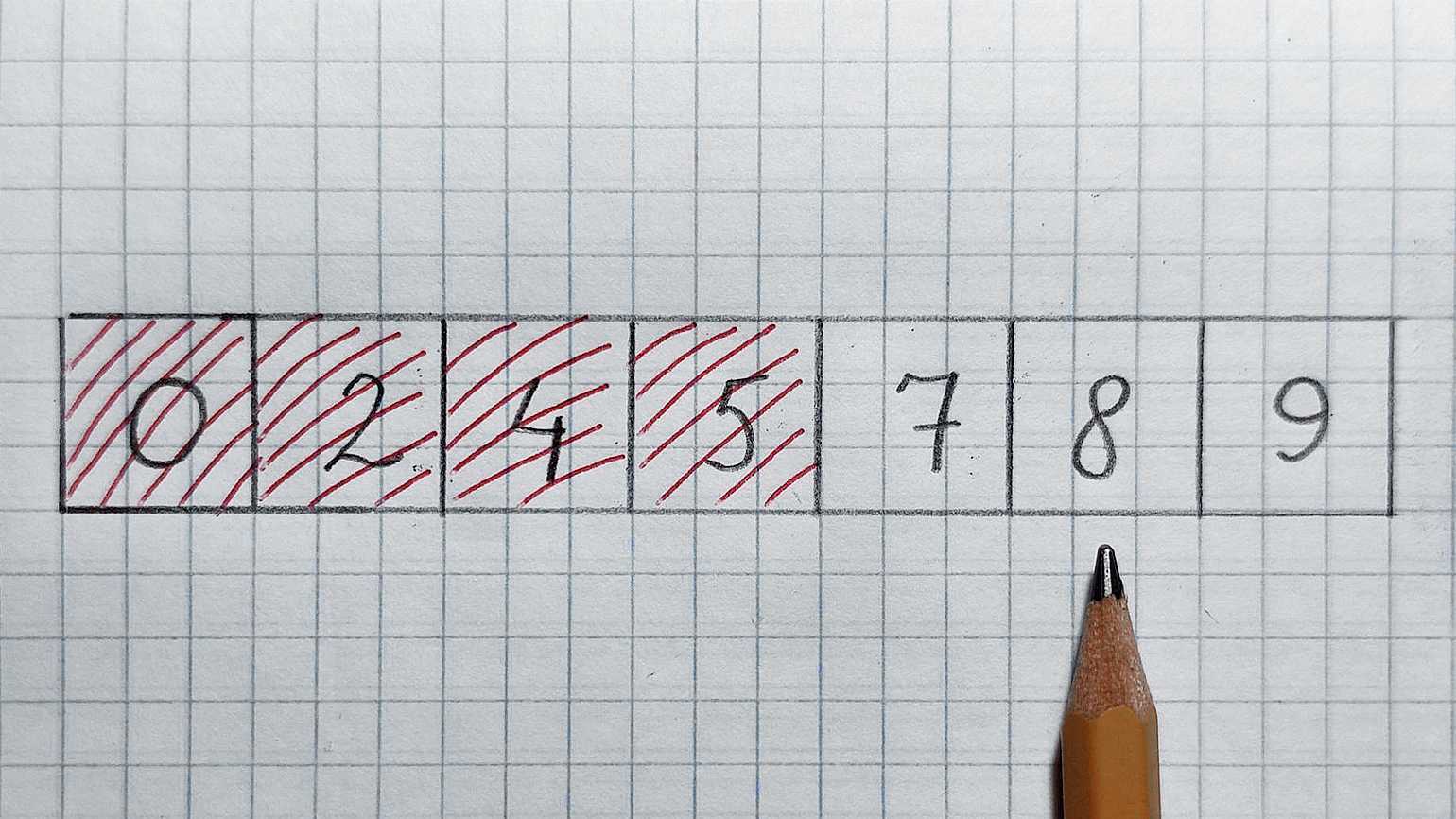
Фото: Валерий Жила для Skillbox Media
В середине число 8, оно больше 7. Значит, отрезаем правую половинку и проверенное число. Остаётся число 7 — как раз его мы и искали. Поздравляю!
Фото: Валерий Жила для Skillbox Media
Теперь давайте попробуем записать это в виде красивого псевдокода. Как обычно, назовём середину mid и будем перемещать «окно наблюдения», ограниченное двумя индексами — low (левая граница) и high (правая граница).








Алгоритм организован рекурсивно, то есть вызывает сам себя на строках 7 и 9. Есть итеративный вариант с циклом, без рекурсии, но он кажется мне уродливым. Если не находим искомый элемент, возвращаем -1. В начале работы алгоритма значение low совпадает с началом массива, а high — с его концом. И они бегут навстречу друг другу…
Чтобы запускать алгоритм, не задумываясь о начальных значениях индексов low и high, можно написать такую функцию-обёртку:
Посчитаем сложность бинарного поиска:
Best case. Как и у линейного поиска, лучший случай равен O(1), ведь искомое число может находиться в середине массива, и тогда мы найдём его с первой попытки.
Worst case. Чтобы найти худший случай, нужно ответить на вопрос: «Сколько раз нужно разделить массив на 2, чтобы в нём остался один элемент?» Или найти минимальное число k, при котором справедливо 2^k ≥ n.
Надеюсь, что большинство читателей смогут вычислить k. Но на всякий случай подскажу решение: k = log n по основанию 2 (в алгоритмах практически все логарифмы двоичные). Поэтому worst case бинарного поиска — O(log n).
Раскрытие конфиденциальных данных
Этот тип проблем безопасности веб-приложений связан с раскрытием конфиденциальной информации клиентов, такой как номера телефонов, информация об учетной записи, номера кредитных карт и т.д. Уязвимость, связанная с раскрытием данных, является тревожным сигналом для компаний, поскольку она может привести к более серьезным последствиям. такие как нарушенная аутентификация, инъекция, атаки посредника или другие типы атак.
Профилактика
Улучшенная защита данных
Крайне важно зашифровать как хранимые, так и передаваемые данные с помощью современных методов шифрования. Протоколы безопасности
Вся входящая информация должна поступать через расширенные протоколы безопасности, такие как HTTPS, SSL и TSL.
Большой толковый словарь
НЕВЕРНЫЙ, -ая, -ое; -рен, -рна, -рно. 1. Не соответствующий истине, действительности; неправильный. Н-ая мысль. Н-ые сведения. Слухи неверны. 2. Неточный, ошибочный. Н-ые вычисления. Сделать в шахматах н. ход. Н. расчёт. Н. глаз, слух (допускающий ошибку в восприятии чего-л.). Взять неверную ноту (фальшиво воспроизвести её). Один н. шаг — и всё пропало. Любое н-ое движение — гибель. 3. Такой, которому нельзя верить, доверять; изменяющий своему долгу, обязательствам; вероломный. Н. друг, союзник. Н-ая жена; н. муж (нарушающие супружескую верность). 4. Слабый, тусклый, дрожащий (о свете, лучах и т.п.). Н. свет луны. Н-ое мерцание звёзд. ◊ Фома неверный. О человеке, которого трудно заставить поверить чему-л., убедить в чём-л. (из евангельского сказания об апостоле Фоме, не поверившем сообщению о воскресении Христа). Неверно, нареч. Н. записать телефон. Спеть мотив н. Свет горит н. Неверный, -ого; м.; Неверная, -ой; ж. Устар. О человеке, исповедующем чужую, по сравнению с чьей-л., веру, религию; об иноверце. Неверность, -и; ж. Упрекать в неверности кого-л.
Теперь пришло время одноключевых КА.
DES
- ECB (англ. electronic code book) — режим «электронной кодовой книги» (простая замена);
- CBC (англ. cipher block chaining) — режим сцепления блоков;
- CFB (англ. cipher feed back) — режим обратной связи по шифротексту;
- OFB (англ. output feed back) — режим обратной связи по выходу.
- Прямым развитием DES в настоящее время является алгоритм Triple DES (3DES). В 3DES шифрование/расшифровка выполняются путём троекратного выполнения алгоритма DES.
RC4
- высокая скорость работы;
- переменный размер ключа.
- используются не случайные или связанные ключи;
- один ключевой поток используется дважды.
Illivion
Blowfish
- скорость (шифрование на 32-битных процессорах происходит за 26 тактов);
- простота (за счёт использования простых операций, уменьшающих вероятность ошибки реализации алгоритма);
- компактность (возможность работать в менее, чем 5 Кбайт памяти);
- настраиваемая безопасность (изменяемая длина ключа).
Twofish
- 128-битный блочный симметричный шифр
- Длина ключей 128, 192 и 256 бит
- Отсутствие слабых ключей
- Эффективная программная (в первую очередь на 32-битных процессорах) и аппаратная реализация
- Гибкость (возможность использования дополнительных длин ключа, использование в поточном шифровании, хэш-функциях и т. д.).
- Простота алгоритма — для возможности его эффективного анализа.
Skipjack
Принимая во внимание, что стоимость вычислительных мощностей уменьшается вдвое каждые 18 месяцев, лишь через 36 лет стоимость взлома Skipjack полным перебором сравняется со стоимостью взлома DES сегодня.
Риск взлома шифра с помощью более быстрых способов, включая дифференциальный криптоанализ, незначителен. Алгоритм не имеет слабых ключей и свойства комплементарности.
Устойчивость Skipjack к криптоанализу не зависит от секретности самого алгоритма.
Mars
- простейшие операции (сложение, вычитание, исключающее или)
- подстановки с использованием таблицы замен
- фиксированный циклический сдвиг
- зависимый от данных циклический сдвиг
- умножение по модулю 232
- ключевое забеливание
Idea
- сложение по модулю
- умножение по модулю
- побитовое исключающее ИЛИ (XOR).
- никакие две из них не удовлетворяют дистрибутивному закону
- никакие две из них не удовлетворяют ассоциативному закону
Что не является трендом в области ГосТех?[править]
вариант 1править
Адаптивная безопасность
Мультиканальное вовлечение граждан
Повсеместное использование аналитики
Создание множества независимых систем по учету трудовых ресурсов в каждом регионе
Цифровая идентификация граждан +
вариант 2править
Адаптивная безопасность
Мультиканальное вовлечение граждан
Рабочая сила в цифровом формате
Уменьшение количества использования аналитических отчетах на всех этапах государственного управления
Цифровая идентификация граждан +
вариант 3править
Мультиканальное вовлечение граждан
Повсеместное использование аналитики
Рабочая сила в цифровом формате
Создание неизменяющегося подхода для противодействия киберугрозам
Цифровая идентификация граждан +
«Неверный» или «не верный»: слитно или раздельно?
1. Пишутся слитно прилагательные с «не», если они приобретают противоположное значение с «не». В таких случаях, как правило, их можно заменить синонимом без «не». Например: неверный — ошибочный.
2. Пишется раздельно, если имеется или подразумевается противопоставление.
3. Пишется раздельно, если есть пояснительные слова отрицательных местоимений и наречий (начинающихся с «ни») или сочетаний «далеко не», «вовсе не», «отнюдь не».
Примечание 1. Иногда пишется раздельно, если слово «не верный» с зависимыми словами стоит после определяемого существительного:
4. Пишется слитно, если в качестве пояснительного слова выступает наречие меры и степени («весьма», «крайне», «очень», «почти», наречное выражение «в высшей степени» и т. п.)
Его подход оказался в высшей степени неверным.
Примечание 2. При наличии в качестве пояснительного слова наречия «совсем» возможно как слитное, так и раздельное написание, что связано с двумя значениями, в которых употребляется указанное наречие: 1) «совершенно, очень»; 2) «отнюдь», «никоим образом»;
Совсем не верное решение. (Никоим образом не истинное).
Двоякое толкование допускает и наречие «вовсе»: 1) «отнюдь»; 2) «совсем, совершенно» — в разговорном стиле речи;
Он часто ошибался, и иногда вовсе предлагал неверные решения. (Совсем неверные).
Примечание. В некоторых случаях возможно двоякое толкование и, поэтому, двоякое написание:
Решение не верное. (Отрицается правильность).
5. Пишется слитно, если есть наречия меры и степени: «весьма», «очень», «крайне», «почти», наречное выражение «в высшей степени» и т. п.
6. Пишется раздельно в вопросительном предложении, если подчеркивается отрицание:
Примечание. Но пишется слитно, если отрицание не подчеркивается:
Источник статьи: http://gramatik.ru/nevernyj-ili-ne-vernyj-slitno-ili-razdelno/
Неверная конфигурация безопасности
Неправильная конфигурация безопасности — одна из распространенных проблем веб-приложений. Это проблема, связанная с отсутствием реализации контроля безопасности или проблемами, вызванными ошибками безопасности. Большинство приложений имеют эту уязвимость из-за неполных конфигураций, конфигураций по умолчанию, которые оставались неизменными в течение долгого времени, незашифрованных файлов, ненужных запущенных служб и т. Д. Неправильная конфигурация безопасности может привести к серьезным утечкам данных, которые запятнают репутацию компании и приведут к значительным финансовым потерям.









Nissan North American — одна из недавних жертв хакерской атаки, вызванной уязвимостью неправильной конфигурации. Серьезная утечка данных произошла из-за неправильно настроенного сервера Git компании, который был защищен учетными данными по умолчанию (имя пользователя и пароль) admin / admin.
Профилактика
Последовательное сканирование уязвимостей
Чтобы избежать неправильной конфигурации системы безопасности, крайне важно проводить регулярное сканирование вашей системы, чтобы обнаружить любые недостатки, которые могут стать легкой мишенью. Обновления
Веб-приложение требует регулярных обновлений для устранения киберугроз и защиты информации о клиентах.
Ошибки «Invalid CSR» при генерации сертификата из панели управления облачного провайдера
В процессе активации сертификата можно столкнуться с ошибкой «Invalid CSR». Такая ошибка возникает по следующим причинам:
- Неправильное имя FQDN (полное имя домена) в качестве Common Name (в некоторых панелях управления это поле может также называться Host Name или Domain Name). В этом поле должно быть указано полное доменное имя вида domain.com или subdomain.domain.com (для субдоменов). Имя домена указывается без https://. В качестве данного значения нельзя использовать интранет-имена (text.local). В запросе для wildcard-сертификатов доменное имя необходимо указывать как *.domain.com.
- В CSR или пароле есть не латинские буквы и цифры. В CSR поддерживаются только латинские буквы и цифры – спецсимволы использовать запрещено. Это правило распространяется и на пароли для пары CSR/RSA: они не должны содержать спецсимволов.
- Неверно указан код страны. Код страны должен быть двухбуквенным ISO 3166-1 кодом (к примеру, RU, US и т.д.). Он указывается в виде двух заглавных букв.
- В управляющей строке не хватает символов. CSR-запрос должен начинаться с управляющей строки ——BEGIN CERTIFICATE REQUEST—— и заканчиваться управляющей строкой ——END CERTIFICATE REQUEST——. С каждой стороны этих строк должно быть по 5 дефисов.
- В конце или начале строки CSR есть пробелы. Пробелы на концах строк в CSR не допускаются.
- Длина ключа меньше 2048 бит. Длина ключа должна быть не менее 2048 бит.
- В CRS-коде для сертификата для одного доменного имени есть SAN-имя. В CSR-коде для сертификата, предназначенного защитить одно доменное имя, не должно быть SAN (Subject Alternative Names). SAN-имена указываются для мультидоменных (UCC) сертификатов.
- При перевыпуске или продлении сертификата изменилось поле Common Name. Это поле не должно меняться.
Способы проверки
Поскольку достоверными являются только те сведения, которые соотносятся с действительностью, очень важным является навык проверки полученных данных и определения степени их достоверности. Если овладеть таким умением, то можно избежать разного рода дезинформационных ловушек. Для этого нужно в первую очередь выявить, какой смысловой нагрузкой обладают полученные сведения: факторной либо оценочной.
Контроль достоверности информации крайне важен. Факты являются тем, с чем сталкивается человек в первую очередь, когда получает какую-либо новую для него информацию. Они именуют уже проверенные на достоверность сведения. Если же информация не была проверена либо же это невозможно сделать, то фактов в себе она не содержит. К ним относятся числа, события, имена, даты. Также фактом является то, что можно измерить, подтвердить, потрогать или перечислить. Чаще всего возможность их представления имеется у социологических и научно-исследовательских институтов, агентств, специализирующихся на статистике, и т. д. Главным признаком, различающим факт и оценку достоверности информации, является объективность первого. Оценка же всегда является отражением чьего-либо субъективного взгляда или эмоционального отношения, а также призывает к определённым действиям.
Вспомним про хеш
Хеш-функция — функция, осуществляющая преобразование массива входных данных произвольной длины в выходную битовую строку установленной длины, выполняемое определенным алгоритмом. Преобразование, производимое хеш-функцией, называется хешированием. Результат преобразования называется хешем.
Хеш-функции применяются в следующих случаях:
-
При построении ассоциативных массивов.
-
При поиске дубликатов в последовательностях наборов данных.
-
При построении уникальных идентификаторов для наборов данных.
-
При вычислении контрольных сумм от данных для последующего обнаружения в них ошибок, возникающих при хранении и передаче данных.
-
При сохранении паролей в системах защиты в виде хеш-кода (для восстановления пароля по хеш-коду требуется функция, являющаяся обратной по отношению к использованной хеш-функции).
-
При выработке электронной подписи (на практике часто подписывается не само сообщение, а его хеш-образ).
MD5 — алгоритм хеширования, разработанный профессором Рональдом Л. Ривестом из Массачусетского технологического института в 1991 году. Предназначен для создания контрольных сумм или «отпечатков» сообщения произвольной длины и последующей проверки их подлинности. Алгоритм MD5 основан на алгоритме MD4.
Что дальше?
Эта статья охватывает очень много областей и не очень глубоко. Однако я надеюсь, что она поможет понять набор взаимосвязанных процессов в рамках простой структуры, которая поможет вам внедрить некоторые из основных концепций DI в корпоративный контекст. Я искренне надеюсь, что другие люди, стремящиеся объединить некоторые из этих идей в единую и консолидированную область DI, смогут воспользоваться этой работой, чтобы вдохновиться — даже если эта структура будет отброшена/переделана/адаптирована. Лично я буду внимательно наблюдать за этой областью и смотреть, как мы превращаем DI в «готовую к производству» практику, отвечающую вызовам нашего общего будущего.
Как ещё оценивают сложность алгоритмов
На протяжении всей статьи мы говорили про Big O Notation. А теперь сюрприз: это только одна из пяти существующих нотаций. Вот они слева направо: Намджун, Чонгук, Чингачгук… простите, не удержался. Сверху вниз: Small o, Big O, Big Theta, Big Omega, Small omega. f — это реальная функция сложности нашего алгоритма, а g — асимптотическая.
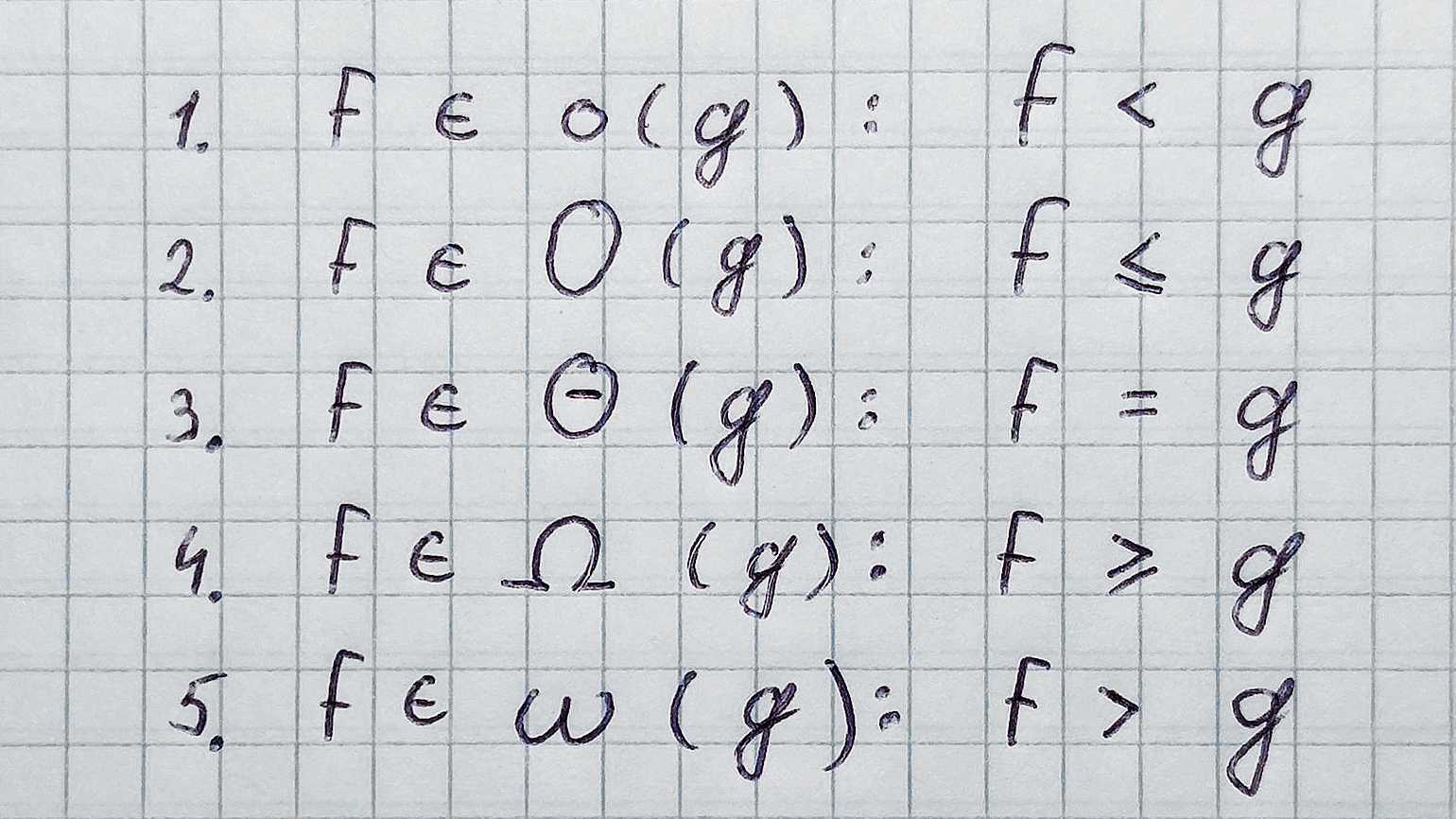
Пять нотаций в математическом представлении. Фото: Валерий Жила для Skillbox Media
Несколько слов об этой весёлой компании:
- Big O обозначает верхнюю границу сложности алгоритма. Это идеальный инструмент для поиска worst case.
- Big Omega (которая пишется как подкова) обозначает нижнюю границу сложности, и её правильнее использовать для поиска best case.
- Big Theta (пишется как О с чёрточкой) располагается между О и омегой и показывает точную функцию сложности алгоритма. С её помощью правильнее искать average case.
- Small o и Small omega находятся по краям этой иерархии и используются в основном для сравнения алгоритмов между собой.
«Правильнее» в данном контексте означает — с точки зрения математических пейперов по алгоритмам. А в статьях и рабочей документации, как правило, во всех случаях используют «Большое „О“».
Если хотите подробнее узнать об остальных нотациях, посмотрите интересный видос на эту тему. Также полезно понимать, как сильно отличаются скорости возрастания различных функций. Вот хороший cheat sheet по сложности алгоритмов и наглядная картинка с графиками оттуда:
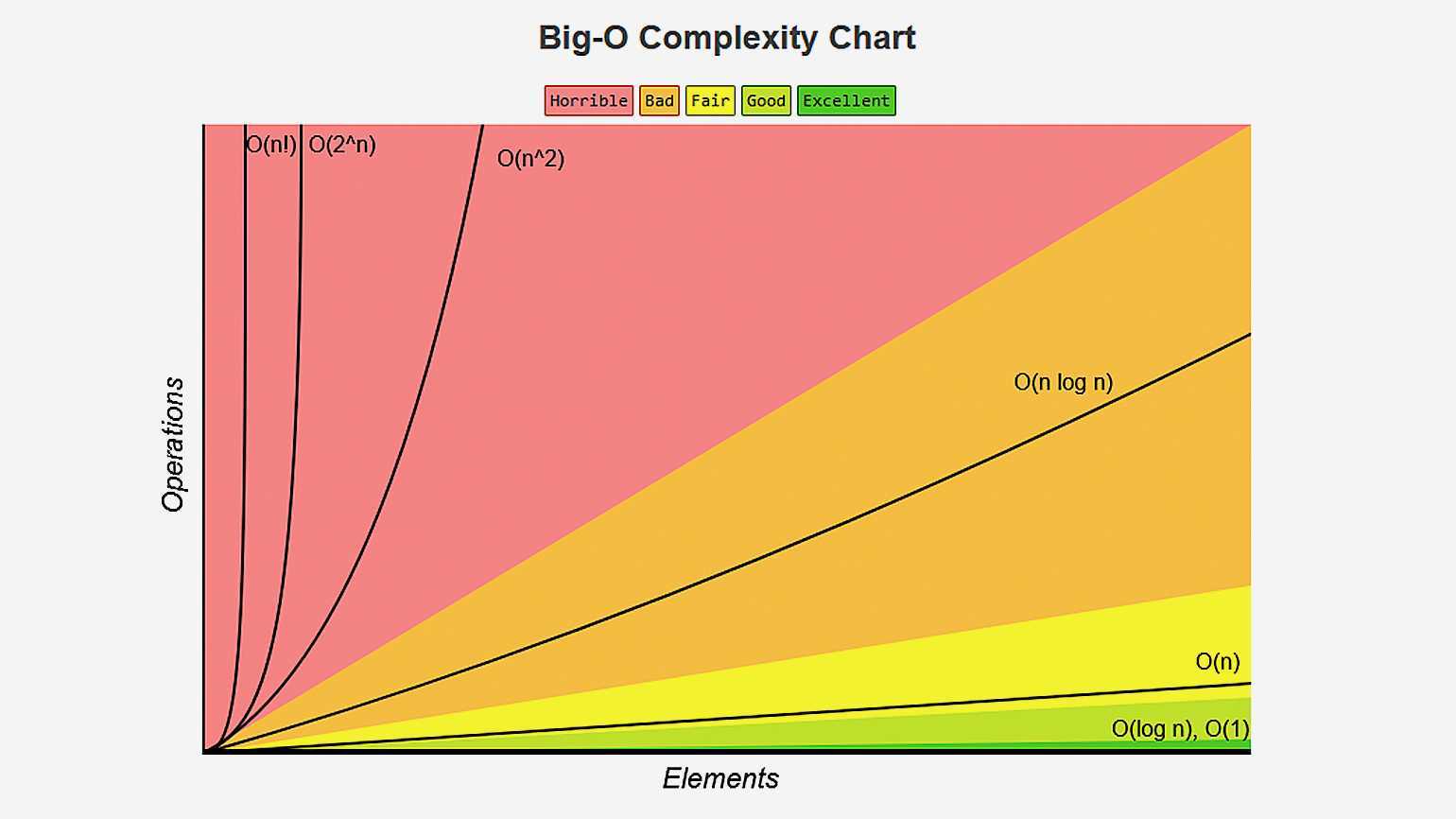
Сравнение сложности алгоритмов. Скриншот: Валерий Жила для Skillbox Media
Хоть картинка и наглядная, она плохо передаёт всю бездну, лежащую между функциями. Поэтому я склепал таблицу со значениями времени для разных функций и N. За время одной операции взял 1 наносекунду:
Все ошибки в Genshin Impact
Ошибки в Genshin Impact будут появляться у некоторых игроков вне зависимости от платформы, на которой они будут играть. Мы предлагаем вам рассмотреть основные ошибки, с которыми вы можете столкнуться на самых разных этапах игры.
Ошибка 0xc000007b Genshin Impact
- убедитесь, что у вас на ПК стоит актуальная версия DirectX, при необходимости обновитесь
- запустите файл GenshinImpact.exe в папке с Геншином от имени администратора
- обновите библиотеки DLL (скорее всего у вас возникли проблемы с xinput1_3.dll);
- если ничего из этого не помогло, то можно удалить лаунчер и Геншин, после чего установить их заново с нуля
- если и это не решило проблему, свяжитесь с техподдержкой Геншина
Ошибка 9910 Геншин Импакт
В Геншин Импакт ошибка 9910 может возникнуть из-за проблем с загрузкой ресурсов или других игровых файлов. Мы рекомендуем вам:



