
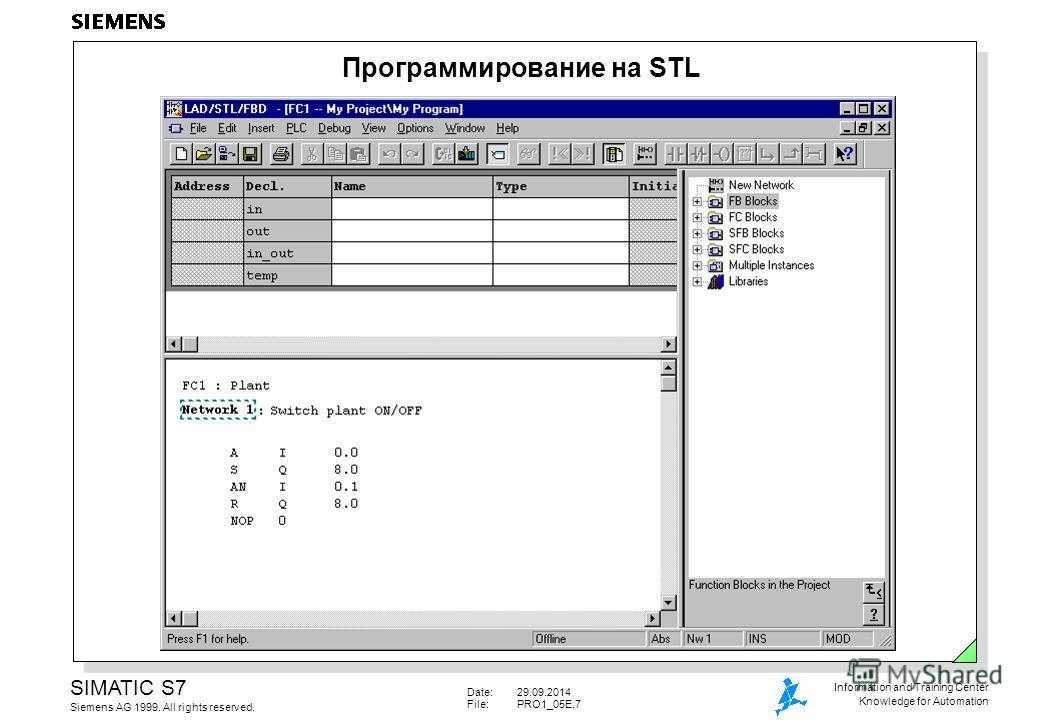
STL-интерфейс
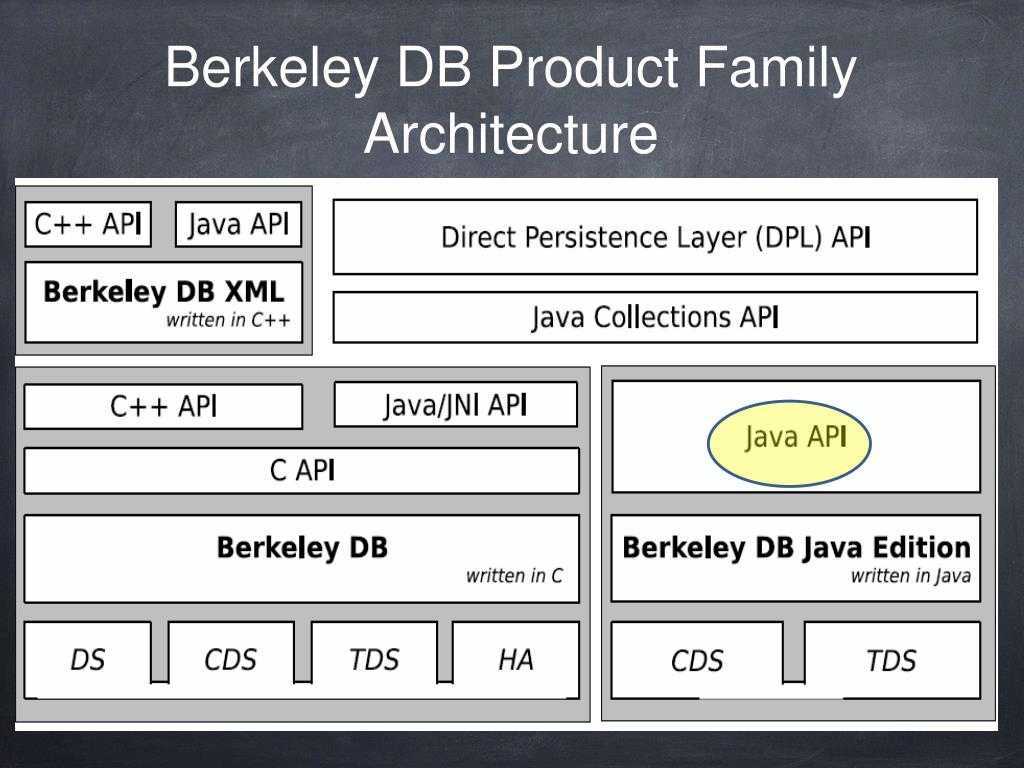
Berkeley DB представляет из себя библиотеку, написанную на С. Она имеет биндинги к таким языкам, как Perl, Java, PHP и другие. Интерфейс для С++ представляет из себя оболочку над С кодом с объектами и наследованием. Для того, чтобы сделать возможным доступ к базе данных аналогично операциям с STL-контейнерами, имеется STL-интерфейс, как надстройка над С++. В графическом виде слои интерфейсов выглядят так:
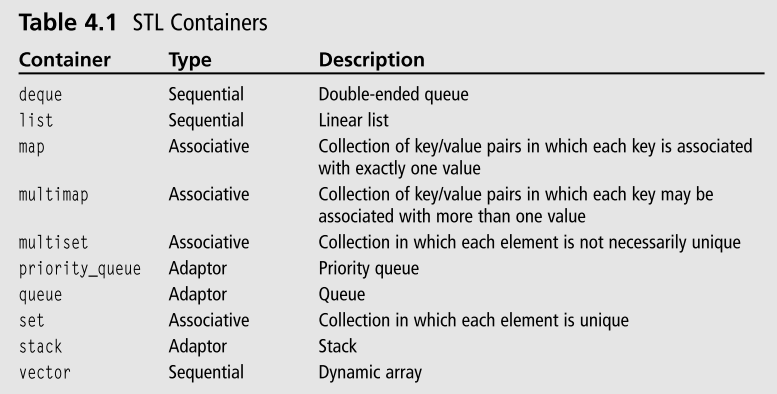
Так, STL-интерфейс позволяет получить элемент из базы данных по ключу (для Btree или Hash) или по индексу (для Recno) аналогично контейнерам или , найти элемент в БД через стандартный алгоритм , проитерировать по всей базе через цикл . Все классы и функции STL-интерфейса Berkeley DB находятся в пространстве имен dbstl, для сокращения, под dbstl будет подразумеваться так же и STL-интерфейс.
Архитектура Berkeley DB
Berkeley DB примечательна своей простой архитектурой в сравнении с другими системами баз данных, такими как, например Microsoft SQL Server и Oracle Database. Например, в ней отсутствует сетевой доступ — программы используют базу данных через вызовы внутрипроцессного API. Она поддерживает SQL в качестве одного из интерфейсов, начиная с версии 5.0, хотя и не поддерживает столбцы в таблицах в традиционном понимании на уровне внутренней архитектуры. Berkeley DB предполагает работу с парами ключ-значение, где ключ и значение могут иметь фиксированную или переменную длину, а функция сравнения ключей может быть написана и назначена прикладным программистом. Программа, которая использует БД, сама решает, как данные сохраняются в записи; БД не налагает ограничений на данные, хранимые в записях. Запись и её ключ оба могут иметь размер до четырёх гигабайт.
Berkeley DB поддерживает необходимые возможности баз данных, такие как ACID-транзакции, детальные блокировки, интерфейс распределённых транзакций XA, горячее резервное копирование и репликацию. Berkeley DB может использоваться как средство для построения хранимых индексов, так и в качестве хранилища данных.
Oracle предлагает BDB в трёх вариантах:
- Berkeley DB — собственно библиотека на языке “C”;
- Berkeley DB Java — библиотека, переписанная на Java (поддержка Google Android, Apache Maven);
- Berkeley DB XML — библиотека на Си, реализующая XML-СУБД на основе Berkeley DB со средствами работы с XML (Xerces, XPath, XQuery, XQilla).
Berkeley DB входит в состав большинства дистрибутивов Linux. Существуют интерфейсные средства для работы с Berkeley DB на Perl, Python и других языках.
Программы, в которых используется Berkeley DB
Berkeley DB является хранилищем данных для серверов LDAP, СУБД и множества других проприентарных и свободных программ. Ниже приведён список программ, в которых для хранения данных используется Berkeley DB:
- Bogofilter — свободный спам-фильтр который хранит свои списки ключевых слов в Berkeley DB;
- Caravel CMS — свободный web-движок изначально разработанный для использования в более чем 2000 организаций Меннонитской церкви;
- Citadel — свободная платформа совместной работы, в которой все данные, включая базу сообщений, хранятся в Berkeley DB;
- Fedora Directory Server — сервер каталогов уровня предприятия c открытым исходным кодом. Изначально именно под нужды FDS (тогда сервер назывался Netscape Directory Server) была адаптирована академическая версия BerkeleyDB;
- Jabberd2 — сервер сети Jabber;
- KDevelop — интегрированная среда разработки для Linux и других Unix-подобных операционных систем;
- KLibido — свободный клиент новостных групп USENET, ориентированный на скачивание бинарных файлов;
- MemcacheDB — Распределённое постоянное хранилище данных, реализующее интерфейс Memcached;
- Movable Type — проприетарная система публикации блогов, разработанная калифорнийской компанией Six Apart;
- MySQL — поддержка таблиц BDB включена в дистрибутив исходного кода MySQL начиная с версии 3.23.34 и в бинарную версию MySQL-Max. BerkeleyDB обеспечивает транзакционный обработчик таблиц для MySQL. Использование BerkeleyDB повышает для таблиц шансы уцелеть после сбоев, а также предоставляет возможность осуществлять операции COMMIT и ROLLBACK для транзакций. Дистрибутив исходного кода MySQL поставляется с дистрибутивом BDB, содержащим несколько небольших исправлений, которые позволяют устранить определённые проблемы при работе с MySQL. Начиная с версии 5.1 таблицы BDB более не поддерживаются;
- OpenLDAP — свободная реализация “Облегчённого протокола доступа к каталогам” (LDAP);
- Redland — прикладной каркас для RDF. Может использовать BDB для постоянного хранения данных (троек);
- RPM — Менеджер пакетов RedHat;
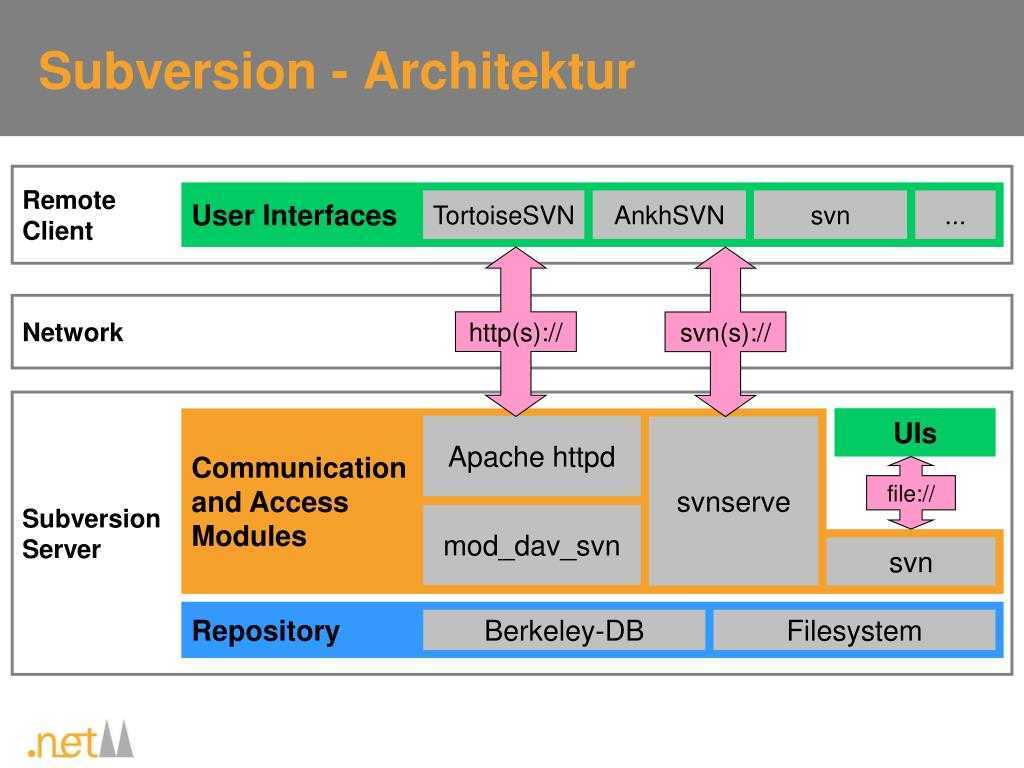
- Subversion — Система управления версиями, разработанная чтобы заменить CVS;
- Sun Grid Engine — Свободная система управления распределёнными ресурсами. Самый популярный планировщик пакетных очередей задач для вычислительных ферм;
- Spamassassin — Антиспамовое приложение;
- Wialon — система спутникового мониторинга транспорта, работающая через Web-интерфейс.
Знаете ли Вы, что электромагнитное и другие поля есть различные типы колебаний, деформаций и вариаций давления в эфире.
Понятие же «физического вакуума» в релятивистской квантовой теории поля подразумевает, что во-первых, он не имеет физической природы, в нем лишь виртуальные частицы у которых нет физической системы отсчета, это «фантомы», во-вторых, «физический вакуум» — это наинизшее состояние поля, «нуль-точка», что противоречит реальным фактам, так как, на самом деле, вся энергия материи содержится в эфире и нет иной энергии и иного носителя полей и вещества кроме самого эфира.
В отличие от лукавого понятия «физический вакуум», как бы совместимого с релятивизмом, понятие «эфир» подразумевает наличие базового уровня всей физической материи, имеющего как собственную систему отсчета (обнаруживаемую экспериментально, например, через фоновое космичекое излучение, — тепловое излучение самого эфира), так и являющимся носителем 100% энергии вселенной, а не «нуль-точкой» или «остаточными», «нулевыми колебаниями пространства». Подробнее читайте в FAQ по эфирной физике.
НОВОСТИ ФОРУМАРыцари теории эфира |
10.11.2021 — 12:37: ПЕРСОНАЛИИ — Personalias -> — Карим_Хайдаров.10.11.2021 — 12:36: СОВЕСТЬ — Conscience -> — Карим_Хайдаров.10.11.2021 — 12:36: ВОСПИТАНИЕ, ПРОСВЕЩЕНИЕ, ОБРАЗОВАНИЕ — Upbringing, Inlightening, Education -> — Карим_Хайдаров.10.11.2021 — 12:35: ЭКОЛОГИЯ — Ecology -> — Карим_Хайдаров.10.11.2021 — 12:34: ВОЙНА, ПОЛИТИКА И НАУКА — War, Politics and Science -> — Карим_Хайдаров.10.11.2021 — 12:34: ВОЙНА, ПОЛИТИКА И НАУКА — War, Politics and Science -> — Карим_Хайдаров.10.11.2021 — 12:34: ВОСПИТАНИЕ, ПРОСВЕЩЕНИЕ, ОБРАЗОВАНИЕ — Upbringing, Inlightening, Education -> — Карим_Хайдаров.10.11.2021 — 09:18: НОВЫЕ ТЕХНОЛОГИИ — New Technologies -> — Карим_Хайдаров.10.11.2021 — 09:18: ЭКОЛОГИЯ — Ecology -> — Карим_Хайдаров.10.11.2021 — 09:16: ЭКОЛОГИЯ — Ecology -> — Карим_Хайдаров.10.11.2021 — 09:15: ВОСПИТАНИЕ, ПРОСВЕЩЕНИЕ, ОБРАЗОВАНИЕ — Upbringing, Inlightening, Education -> — Карим_Хайдаров.10.11.2021 — 09:13: ВОСПИТАНИЕ, ПРОСВЕЩЕНИЕ, ОБРАЗОВАНИЕ — Upbringing, Inlightening, Education -> — Карим_Хайдаров. |
Berkeley DB overview
C interfaces, supplied with Berkeley DB, allow to realize the management of database records in the dbm-style and provide access to the extension of the set, including the mechanism of elegant solution of processing tasks identical records, as well as multi-user support system access and transactions. The last extension allows simultaneously complete several transactions (with permanent data modification) or roll back them (with database recovery to the state before the transaction).
Interfaces for C ++ and Java implement a small set of classes for working with databases. The root class in both languages is called Db — it contains methods that encapsulate the dbm-style interfaces mentioned above.
There are also interfaces to work with Berkeley DB using scripting languages Perl, Python, and Tcl.
Berkeley DB could be connected to the application code dynamically or statically.
History
Berkeley DB was born as a new implementation of hash access method, created instead of hsearch and various dbm options (namely, dbm AT & T Corporation, the ndbm from Berkeley, and gdbm, developed under the GNU Project). The product was developed and released under the name Hash in 1990 by programmers Seltzer and Yigit.
In the first major version of Berkeley DB, published in 1991, some changes were made to the user interface and added a new access method, B + tree. Around the same time, Seltzer and Olson developed a prototype transaction system based on the Berkeley DB called LIBTP, which code is not published.
In 1992 year Berkeley DB 1.85 was incorporated into the 4.4BSD UNIX operating system. In the early ’90s Seltzer and Bostic accompanied the code in Berkeley and Massachusetts. While it is widespread among users.
By mid-1996 there were users who needed the support of the commercial product. Taking into account their wishes, Bostic and Seltzer formed Sleepycat Software company. It develops, distributes and supports Berkeley DB, as well as the accompanying software and documentation. In mid-1997, Sleepycat released Berkeley DB 2.1, containing a number of important innovations, including the ability to multi-user access to databases. The company produces about three commercial versions of the product per year. Last released her version of Berkeley DB has the number 3.1.
Using Berkeley DB
Library Berkeley DB supports multi-user access to databases. It can be connected to the code of stand-alone applications, to a set of co-operating applications or servers that handle client requests and performs them in accordance with the operation of the database.
Berkeley DB is easier to understand and use than stand-alone database. It stores and retrieves records that consist of key-value pairs. Keys are used to locate items and may be any type of data or structure supported by the programming language.
The programmer can specify Berkeley DB to use his own written functions to perform operations with keys. For example, the access method B + tree can use an arbitrary comparison function, and Hash — arbitrary function. If the user-defined functions are not specified, Berkeley DB uses its own. Otherwise, the system generally does not review or interpret keys and values. Values can be of any length.
It is important to understand what Berkeley DB is not. Berkeley DB — is not a database server that handles requests from the network. It is also not SQL-core executes a query. Also Berkeley DB is not a relational or object-oriented database.
All these systems could be built on top of the Berkeley DB, which in itself is only an embedded database engine. The developers tried to make it a portable, compact, fast and reliable.
Добавление в cmake-проект
Для иллюстрации примеров с Berkeley DB используется проект BerkeleyDBSamples.
Структура проекта выглядит следующим образом:
Корневой CMakeLists.txt описывает общие параметры проекта. Исходные файлы с примерами находятся в sample-usage. sample-usage/CMakeLists.txt выполняет поиск библиотек, определяет сборку примеров.
Для подключения библиотеки в проект cmake в примерах применяется FindBerkeleyDB. Он добавлен как подмодуль git в submodules/cmake. При сборке может потребоваться указать . Например, для библиотеки выше, установленной из исходников, необходимо указать флаг cmake .
В корневом файле CMakeLists.txt необходимо добавить в путь к модулю FindBerkeleyDB:
После этого в sample-usage/CMakeLists.txt выполняется поиск библиотеки стандартным образом:
Далее, добавляем исполняемый файл и линкуем его с библиотекой Oracle::BerkeleyDB:
Berkeley DB
Berkeley DB — это встраиваемая масштабируемая высокопроизводительная БД с открытым исходным кодом. Она доступна бесплатно для использования в open source проектах, но для проприетарных есть существенные ограничения. Поддерживаемые возможности:
- транзакции
- лог с упреждающей записью для восстановления после отказов
- шифрование данных алгоритмом AES
- репликация
- индексы
- средства синхронизации для многопоточных приложений
- политика доступа — один писатель, множество читателей
- кеширование
А так же многие другие.
При инициализации системы пользователь может указать, какие подсистемы использовать. Это позволяет исключить трату ресурсов на такие операции, как транзакции, логирование, блокировки, когда они не нужны.
Доступен выбор структуры хранения и доступа к данным:
- Btree — реализация отсортированного сбалансированного дерева
- Hash — имплементация линейного хеша
- Heap — для хранения использует heap file, логически разбитый на страницы. Каждая запись идентифицируется страницей и смещением внутри нее. Хранилище организовано таким образом, что удаление записи не требует уплотнения. Это позволяет использовать его при недостатке физического места.
- Queue — очередь, хранит записи фиксированной длины с логическим номером в качестве ключа. Она спроектирована для быстрой вставки в конец, и поддерживает специальную операцию, которая удаляет и возвращает запись из головы очереди за один вызов.
- Recno — позволяет сохранить записи как фиксированной, так и переменной длины с логическим номером в качестве ключа. Обеспечивает доступ к элементу по его индексу.
Чтобы избежать неоднозначности, необходимо определить несколько понятий, которые используются при описании работы Berkeley DB.
База данных — хранилище данных в виде ключ-значение. Аналогом базы данных Berkeley DB в других СУБД может служить таблица.
Среда баз данных — оболочка для одной или нескольких баз данных. Определяет общие настройки для всех баз данных, такие как размер кеша, пути хранения файлов, использование и конфигурацию подсистем блокировки, транзакций, логирования.
В типичном случае использования создается и настраивается среда, а в ней одна или несколько баз данных.
Applications that use Berkeley DB
Berkeley DB system is integrated into a number of products, open source and commercial. Here are some types of them.
- Directory servers, which store and retrieve data using the LDAP directory protocol, as well as implement a naming and directory lookup service for local networks. The basis of this service — checking and updating of the database, but using a simple protocol rather than SQL or ODBC. Berkeley DB serves as a built-in data manager in most existing directory servers, including LDAP-servers by Netscape, MessagingDirect and others.
- Furthermore, Berkeley DB is embedded in a variety of other products. The system is used to manage access control lists; storing user keys in environments that use public key encryption; for table entries corresponding vehicle and the network address in the server address; to store configuration and device information in video editing programs.
- Berkeley DB is also part of many open source software released at the Internet. In particular, the system is integrated into the Apache Web-server and graphical environment Gnome. All commercial Linux distributions and lots of BSD variants contain Berkeley DB.
Access Methods
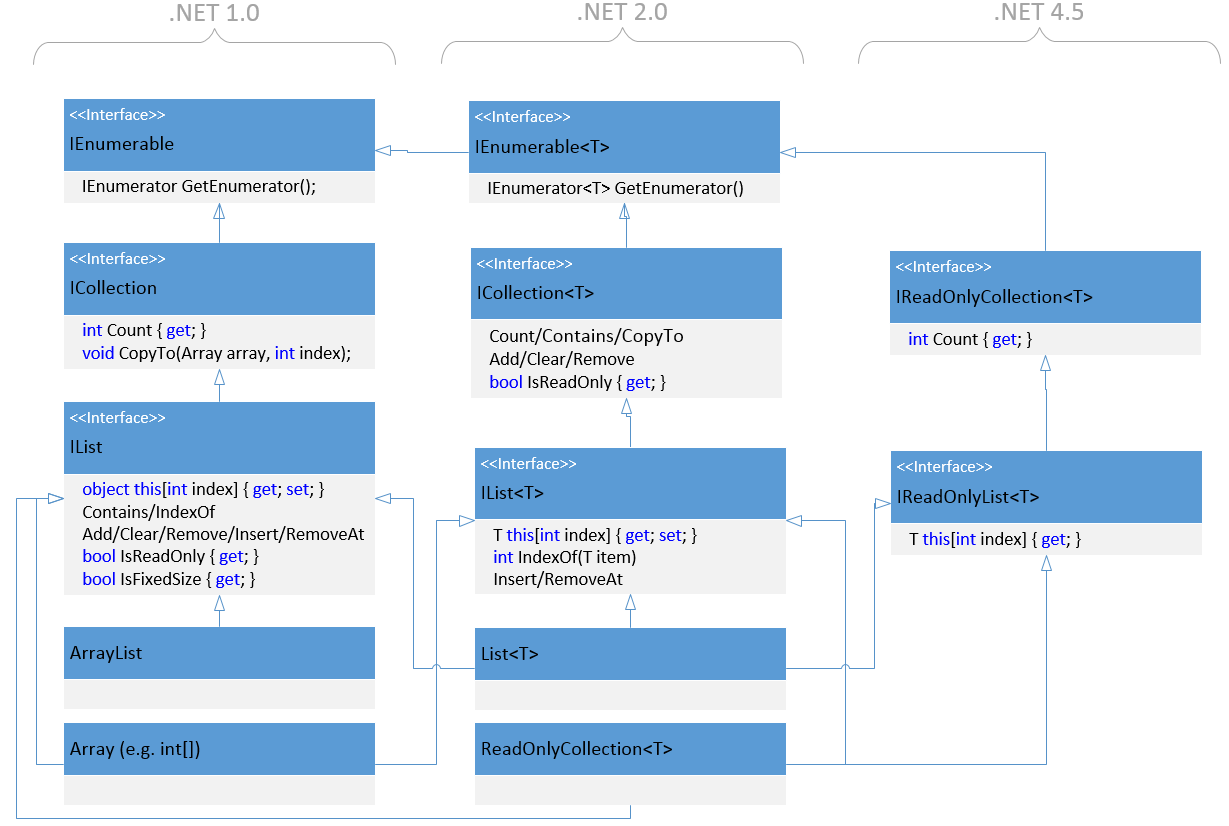
In database terminology, database access method is a set placed on the disk structure used to store data and operations on this structure. For example, many database systems support access method B + tree. It allows you to search by exact match ( «find keys, equal to some constant»), the search interval ( «find the keys that fall in between the two constants interval»), as well as insert and delete records.
Berkeley DB supports four access methods: B + tree, Persistent Queues (Queue), Extended Linear Hashing (Hash), and Fixed- or Variable-length Records (Recno). In the methods of B + tree and Hash keys may have an arbitrary structure. The Queue access methods and Recno each a number is assigned to each record , which performs key’s function. In all methods of access value can have an arbitrary structure. If the programmer inserts its own compare function or hash, Berkeley DB stores and retrieves values without interpreting them.
As the main repositories all access methods use the OS file system.
Hash
Berkeley DB supports the Hash access method that implements an extensible linear hash table. The peculiarity of this hash is a function that adapts to table height, and all the hash of the basket in a stable state stay not completely filled as far as possible.
Hash access method supports insertion and deletion of records, as well as search, but only the exact match. It allowes the repetition of all the records stored in the table, but the order of their return is not defined.
B + tree
Berkeley DB access method supports B + tree. B + tree stores key-value pairs in the leaf pages, and a pair of «key child page address» — on internal nodes. The keys are stored in the tree in sorted order specified by a comparison function which is in it’s own turn specified when creating the database. To simplify the page tree traversal problem at the leaf level pointers to the neighbors are contained. B + tree supports searching by exact match (equality) or interval (permissible only interval «greater than or equal to»). As well as the hash table, B + trees support the insertion, deletion and repetition of all the entries in the tree.
As the recordings fill the pages they are divided — roughly half of the keys goes to a new page, located at the same level of the tree. Most implementations of B + tree is left after dividing both nodes half filled. In general, this leads to a decrease in performance when caller inserts keys in order. But Berkeley DB remembers the order of insertion and page breaks are not equal, and so that they are filled by more than half. This reduces the size of the tree and the overall size of the database and the search performance is increased.
By deleting blank pages are reunited through a reverse partitioning. This access method does not take any additional action to balance the page when you delete or insert. Keys with each update do not move from page to page. The implementation of such a possibility could, in some cases, reduce the search time, but the additional complexity of the code would lead to slower updates and frequent deadlock.
Queue
Berkeley DB implements a queue access method, managing high-performance long-term bursts. It is based on the method of access B + tree, but uses the logging and locking mechanisms needed to work in the conditions of intensive multi-user access to the head and tail of the queue. The process of updating the head or tail of the queue block other threads not throughout the entire transaction, but only at the time of its execution. By this way quality support of parallel execution of transactions is significantly improved.
Recno
Berkeley DB comprises a method of accessing entries fixed or variable length called Recno. It assigns each record logical number, which can be searched and updated. Recno may, for example, download a text file in a database by treating each row as an entry. Using this feature, in a text editor, a quick search by line number could be made.
Recno is based on access method in B+tree and provides a simple interface for storing values, ordered by number. Recno generates record numbers on their own. From a programmer’s perspective values are numbered consecutively, starting with one. A developer can tell the system whether the entries are automatically renumbered after deleting records with lower numbers. If so, new keys ccould be inserted between the existing ones.
BDB JE Backup/Recovery and Tuning
Backup and Recovery
We can simply backup the BDB databases by creating an operating system level copy of all jdb files. When required we can put the archived files back into the environment directory to get a database back to the state it was at. The best option is to make sure all transactions and the write process are finished to have a consistent backup of the database.
The BDB JE provides a helper class located at com.sleepycat. je.util.DbBackup to perform the backup process from within a Java application. This utility class can create an incremental backup of a database and later on can restore from that backup. The helper class ideally freezes the BDB JE activities during the backup to ensure that the created backup exactly represents the database state when the backup process started.
Tuning
Berkeley DB JE has 3 daemon threads and configuring these threads affects the overall application performance and behavior. These 3 threads are as follow:
| Cleaner Thread | Responsible for cleaning and deleting unused log files. This thread is run only if the environment is opened for write access. |
| Checkpointer Thread | Basically keeps the BTree shape consistent. Checkpointer thread is triggered when environment opens, environment closes, and database log file grows by some certain amount. |
| Compressor Thread | For cleaning the BTree structure from unused nodes. |
These threads can be configured through a properties file named je.properties or by using the EnvironmentConfig and EnvironmentMutableConfig objects. The je.properties file, which is a simple key-value file, should be placed inside the environment directory and override any further configuration which we may make using the EnvironmentConfig and EnvironmentMutableConfig in the Java code.
The other performance effective factor is cache size. For ondisk instances cache size determines how often the application needs to refer to permanent storage in order to retrieve some data bucket. When we use in-memory instances cache size determines whether our database information will be paged into swap space or it will stay in the main memory.
| je.cleaner.minUtilization | Ensures that a minimum amount of space is occupied by live records by removing obsolete records. Default occupied percentage is 50%. |
| je.cleaner.expunge | Determines the cleaner behavior in the event that it is able to remove an entire log file. If “true” the log file will be deleted, otherwise it will be renamed to nnnnnnnn.del |
| je.checkpointer.bytesInterval | Determines how often the Checkpointer should check the BTree structure. If it performs the checks little by little it will ensure a faster application startup but will consume more resources specially IO. |
| je.maxMemory Percent | Determines what percentage of JVM maximum memory size can be used for BDB JE cache. To determine the ideal cache size we should put the application in the production environment and monitor its behavior. |
A complete list of all configurable properties, with explanations, is available in EnvironmentConfig Javadoc. The list is comprehensive and allows us to configure the BDB JE at granular level.
All of these parameters can be set from Java code using the EnvironmentConfig object. The properties file overrides the values set by using EnvironmentConfig object.
Helper Utilities
Three command line utilities are provided to facilitate dumping the databases from one environment, verifying the database structure, and loading the dump into another environment.
| DbDump | Dumps a database to a user-readable format. |
| DbLoad | Loads a database from the DbDump output. |
| DbVerify | Verifies the structure of a database. |
To run each of these utilities, switch to BDB JE directory, switch to lib directory and execute as shown in the following command:
The JAR file name may differ depending on your version of BDB JE. These commands can also be used to port a BDB JE database to BDB Core Edition.
A very good set of tutorials for different set of BDB JE APIs are available inside the docs folder of BDB JE package. Several examples for different set of functionalities are provided inside the examples directory of the BDB JE package.
Практический пример
Для демонстрации применения dbstl разберем простой пример из файла sample-map-usage.cpp. Это приложение демонстрирует работу с контейнером в однопоточной программе. Сам контейнер аналогичен и хранит данные в виде пары ключ/значение. В качестве нижележащей структуры БД может использоваться Btree или Hash. В отличии от , для контейнера фактическим типом значения является . Этот тип возвращается, например, для . Он определяет методы для сохранения объекта типа в БД. Одним из таких методов является .
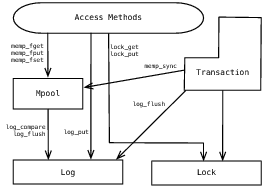
В примере работа с базой происходит следующим образом:
- приложение вызывает методы Berkeley DB для доступа к данным
- эти методы обращаются к кешу для чтения или записи
- при необходимости идет обращение непосредственно к файлу с данными
Графически этот процесс показан на рисунке:
Для уменьшения сложности примера, в нем не используется обработка исключений. Некоторые методы контейнеров dbstl могут выбрасывать исключения при возникновении ошибок.



