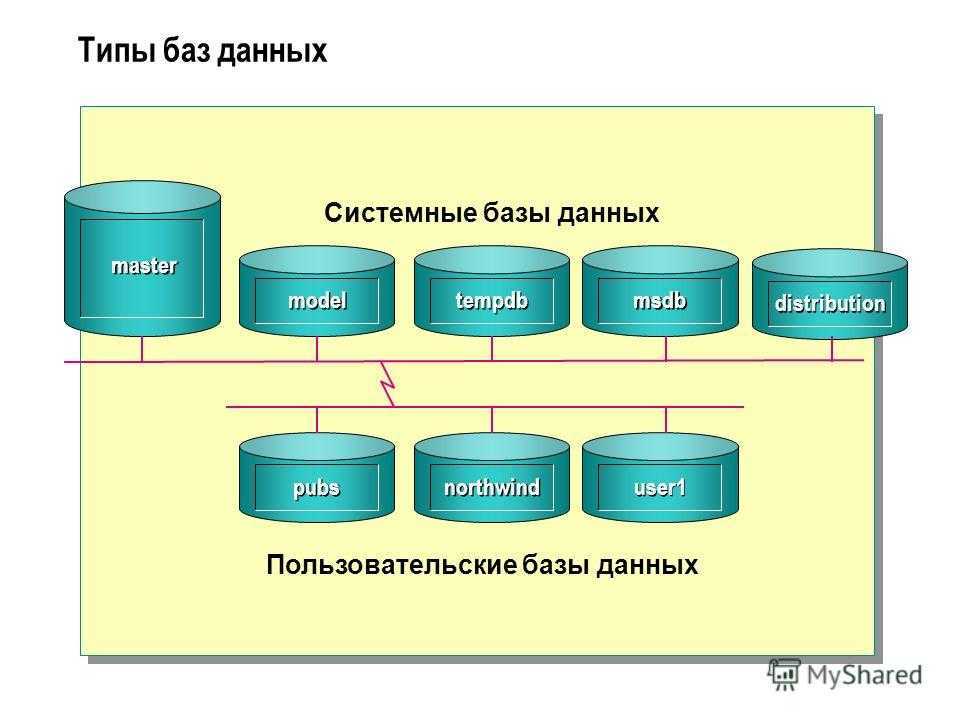
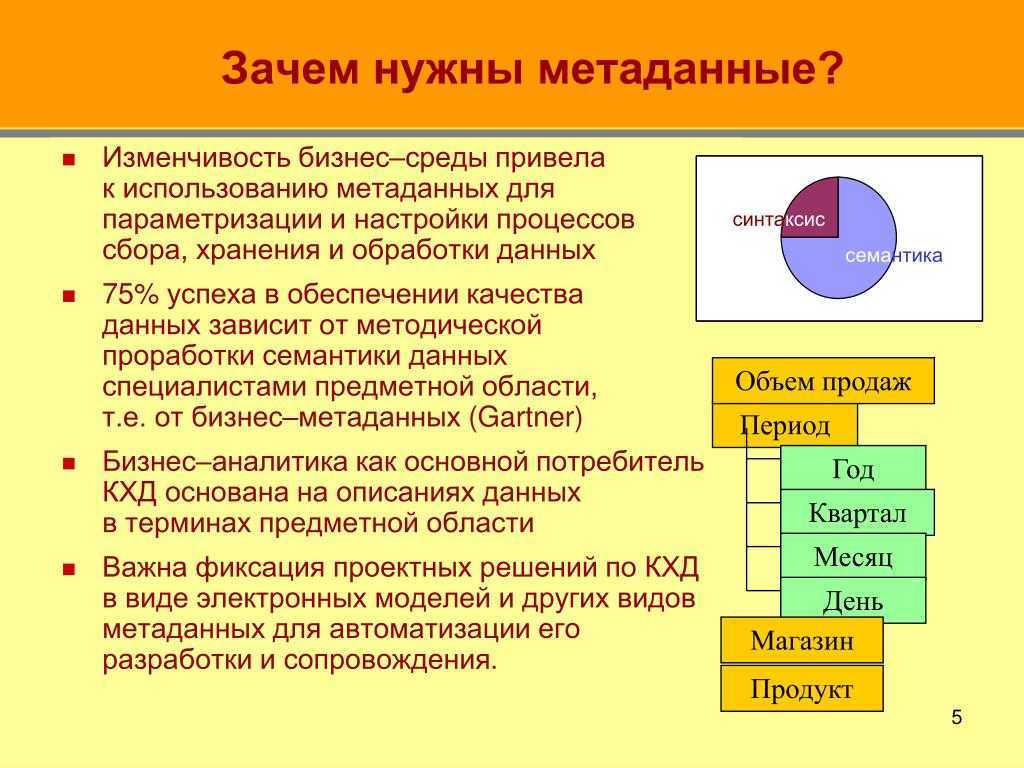
Качество данных
Отсутствие качественных данных (приведенных к единому формату, недублирующихся, согласованных между собой, без “мусорных” записей) в информационных системах многих компаний является данностью, с которой приходится работать. Зачастую этот факт при внедрении новых ИС не учитывается, и в конце реализации проекта компания получает еще одну систему со своим набором данных, слабо согласующимися с данными других систем. В таких случаях при попытке настройки взаимодействия несогласованность данных приводит к тому, что интеграция систем есть, а интеграции данных нет. Может даже получиться несколько наборов данных в одной системе идентичных по сути, но разных по представлению (например, “юр. лицо” и “Юридические лица”).
Решать задачу согласованности данных призваны системы управления мастер-данными (Master Data Management, MDM). Но сегодня эти системы в российских компаниях являются больше экзотикой, чем нормой (об этом свидетельствует список референсов основных поставщиков MDM-решений). В отсутствии единой MDM-системы в компании задачи согласования данных и обеспечения их качества ложатся на процессы интеграции. Для этого разрабатываются бизнес-правила преобразования данных, создаются таблицы соответствия и т.п. решения, что по сути своей представляет систему MDM для одного или группы интеграционных процессов.
Конечно, не рекомендуется решать задачи интеграции, миграции данных и задачи улучшения качества данных, дедубликации в рамках одного проекта. Но если выхода нет, то прежде чем начинать разрабатывать бизнес-правила и таблицы соответствия, необходимо изучить данные, провести их предварительный анализа путем профилирования (Data Profiling). Проведение профилирования позволяет получить информацию о содержании, качестве и структуре данных. Этот важный этап, предшествующий этапу проектирования процессов интеграции, очень часто игнорируется, что приводит в итоге к несогласованности данных в интегрируемых системах
Еще одной важной задачей профилирования данных является сужение множества передаваемых данных, ведь в процессе анализа можно выявить “мусорные”, дублирующиеся или ненужные вообще для передачи данные
Итак, к типичным проблемам интеграции, связанным с качеством данных, можно отнести:
несогласованность интегрируемых данных, в следствие отсутствия в компании единой системы управления мастер-данными;
непридание важности профилированию, анализу и очистки данных перед реализацией процессов интеграции
KG против подходов RDB
В случае интеграции дополнительного источника данных,
KG ( граф знаний ) формально представляет значение, связанное с информацией, путем описания понятий, отношений между вещами и категориями вещей. Эта встроенная семантика с данными предлагает значительные преимущества, такие как анализ данных и работа с разнородными источниками данных. Правила могут быть применены к KG более эффективно с помощью графического запроса. Например, запрос графа делает вывод данных через связанные отношения вместо повторного полного поиска таблиц в реляционной базе данных. KG облегчает интеграцию новых разнородных данных, просто добавляя новые отношения между существующей информацией и новыми объектами
Это упрощение особенно важно для интеграции с существующими популярными открытыми источниками данных, такими как Wikidata.org.
SQL -запрос тесно связан и жестко ограничен типом данных в конкретной базе данных и может объединять таблицы и извлекать данные из таблиц, и результатом обычно является таблица, а запрос может объединять таблицы по любым столбцам, которые совпадают по типу данных. СПАРКЛзапрос является стандартным языком запросов и протоколом для связанных открытых данных в Интернете и слабо связан с базой данных, что облегчает повторное использование и может извлекать данные через отношения, свободные от типа данных, и не только извлекать, но и генерировать дополнительный граф знаний с более сложные операции (логика: транзитивная/симметричная/обратная/функциональная)
Запрос на основе логического вывода (запрос на основе существующих утвержденных фактов без создания новых фактов с помощью логики) может быть быстрым по сравнению с запросом на основе рассуждений (запрос на основе существующих плюс сгенерированных/обнаруженных фактов на основе логики).
Информационная интеграция разнородных источников данных в традиционную базу данных сложна, что требует перепроектирования таблицы базы данных, например, изменения структуры и/или добавления новых данных. В случае семантического запроса запрос SPARQL отражает отношения между сущностями таким образом, который соответствует человеческому пониманию предметной области, поэтому семантическое намерение запроса можно увидеть в самом запросе. В отличие от SPARQL, SQL-запрос, отражающий специфическую структуру базы данных и полученный путем сопоставления соответствующих первичных и внешних ключей таблиц, теряет семантику запроса, упуская связи между сущностями. Ниже приведен пример, в котором сравниваются запросы SPARQL и SQL для лекарств, лечащих «туберкулез позвоночника».
Технические трудности
Процесс организации интеграции сводится к следующим действиям:
- определение источника/приемника данных;
- анализ данных источника;
- выбор инструмента интеграции;
- согласование форматов, способа и периодичности обмена данными (согласование регламента интеграции);
- проектирование и разработка процессов интеграции;
- тестирование;
- промышленная эксплуатация.
При этом почти всегда основные трудности возникают на этапах разработки и тестирования. Но причины для их появления закладываются раньше.
Выбор платформы интеграции данных является крайне важным этапом. Нет смысла покупать дорогие решения для организации простого переноса данных из одной системы в другую (хотя подобные решения и позволят решить эту задачу). Можно воспользоваться и бесплатным продуктом или написать собственное приложение. Но в тоже время следует понимать, что для решения задач очистки данных, организации сложных бизнес-процессов их передачи, работы с большим объемом данных нужно иметь хорошую интеграционную платформу.
Еще одной ошибкой, связанной с интеграционной платформой, является её неправильное использование. Нет смысла покупать Informatica PowerCenter для того, чтобы всю логику преобразования данных реализовать на языке PL/SQL базы данных Oracle.
Стремление разработчиков к универсальности и применению передовых технологий, форматов, шаблонов и т.п. может излишне усложнить решение по интеграции. Организация обмена данными через web-сервисы порой приводит к задержкам передачи и обработки большого объема данных, усложнению выявления ошибок в данных в огромных xml-файлах и т.д. Все стремится к простоте. При организации процессов интеграции не следует их усложнять без необходимости протоколами с шифрованием, web-сервисами, гарантированной доставкой и т.п.
Подводя итог под техническими трудностями, можно сказать, что к ним относятся:
- выбор неподходящей платформы интеграции;
- неверное использование платформы интеграции;
- излишнее усложнение решения.
Конечно, список является неполным, и его можно и нужно расширять. К чему и призываю.
Ситуации семантической интеграции
Из примера использования в отрасли было замечено, что семантические отображения выполнялись только в рамках класса онтологии или свойства типа данных. Эти идентифицированные семантические интеграции представляют собой (1) интеграцию экземпляров класса онтологии в другой класс онтологии без каких-либо ограничений, (2) интеграцию выбранных экземпляров в одном классе онтологии в другой класс онтологии с помощью ограничения диапазона значения свойства и (3) интеграцию экземпляров класса онтологии. экземпляров класса онтологии в другой класс онтологии с преобразованием значения свойства экземпляра. Каждое из них требует определенного отношения отображения, которое соответственно: (1) отношение отображения эквивалентности или подчинения, (2) отношение условного отображения, которое ограничивает значение свойства (диапазон данных), и (3) отношение отображения преобразования, которое преобразует значение свойства (единичное преобразование). Каждое идентифицированное отношение отображения может быть определено как (1) тип прямого отображения, (2) тип отображения диапазона данных или (3) тип отображения преобразования единиц.





Нужные и важные навыки аналитика
-
Понимание, что такое API
-
Понимание основных требований к сервисам
-
Понимание видов интеграционного взаимодействия (синхронно или асинхронно)
-
Понимание работы очередей сообщений
-
Понимание работы шины данных
Хочу успокоить, аналитику не обязательно уметь проектировать все это, но обязательно понимать основные принципы их работы и для чего они необходимы и какие документы что описывают. Эти знания позволяют быстро ориентироваться в информации и находить необходимые сведения.
Что же такое API?
Для начала нужно определить на какие вопросы нам отвечает API:
-
Как ко мне и к моей системе можно обратиться?
-
«Ко мне можно обращаться так и так, я обязуюсь делать то и это»
API внешней системы сообщает нам каким образом обратиться к этой системе. При каких случаях на стороне смежной системы запустятся те или иные алгоритмы или процессы, которые зависят от набора переданных параметров. Какие данные смежная система готова возвращать в ответ, в каких случаях от них поступит запрос, и в каком виде необходимо направлять ответ.
Основные требования к описанию сервиса
Сохранение единой структуры сообщения При описании веб-сервиса необходимо сохранять структуру иерархии его объектов. (разработчики опираются на нее при формировании сообщения)
Полнота описания данных по каждому значению будущего сообщения
Идентификатор – системное наименование;
Название – бизнес название
Поле таблицы – источник хранения значения в БД. Записывается через точку (значение.таблица)
Тип данных – числовой, текстовый, справочник, дата и т.д.
Размерность – ограничение по количеству символов
Например, если поле представляет собой «чек-бокс», то его размерность будет единицей для обозначения да/нет/пусто
Обязательность может пониматься, как важность наличия тега даже с пустым значением, или как важность заполнения тега в сообщении
Блок может быть разделен на два значения:
Обязательность для системы 1 (отправителя)
Обязательность для Системы 2 (получателя)
Комментарий – для указания дополнительной информации, при необходимости
Обычно используется два типа сообщений:
Запрос (Request) – исходящее сообщение от Системы 1 в Систему 2
Ответ (Response) – входящее сообщение от Системы 2 в Систему 1 в результате полученного запроса (Request).
Организационные трудности
Так как процессы интеграции находятся на стыке нескольких информационных систем, то вопросы ответственности за обеспечение работоспособности процессов интеграции и обеспечение качества данных являются всегда спорными и должны решаться в первую очередь. Для решения этих вопросов можно использовать следующее правило: сторона, заинтересованная в данных, должна выполнять всю основную работу по организации интеграции и ее дальнейшему сопровождению.
Если заинтересованных сторон в интеграции нет (а бывает и такое), то следует применять административный ресурс — назначать ответственного сверху. Конечно, наилучшего результата можно достичь только при коллективной работе. Бросаться в крайности и назначать одного ответственного за всё без предоставления ему соответствующих полномочий не нужно. При назначении ответственных следует помнить, что за качество данных должны отвечать все же бизнес-специалисты Заказчика и специалисты службы сопровождения тех информационных систем, в которых эти данных хранятся.
Еще одной сложностью, с которой приходится сталкиваться — это закрытость служб сопровождения и разработчиков информационных систем компании Заказчика. Например, при построении хранилища данных необходимо проводить анализ данных и их структуры, хранящихся в системах-источниках. Но зачастую изучить их не получается по причине того, что не предоставляется документация, запрещается доступ к системе-источнику, отсутствуют примеры данных и т.д. В таком случае специалистами Заказчика применяется следующий подход при взаимодействии с Разработчиком: “Скажите, что Вам нужно, а мы дадим только то, что из этого есть в системе”. Это приводит к тому, что у бизнес-аналитиков и специалиста по модели данных складывается неполная картина о имеющихся данных в компании. Как результат, неполное хранилище данных. Избежать этого можно только путем правильной ориентацией специалистов Заказчика на взаимодействие с консультантами Разработчика.
Другим немаловажным моментом является необходимость привлечения к анализу данных и последующей разработке бизнес-правил преобразования данных предметных экспертов Заказчика. Какими бы опытными не являлись бизнес-аналитики Разработчика, все особенности и детали могут знать только специалисты Заказчика, имеющие практический опыт работы с данными компании.
Резюмируя перечень организационных трудностей, можно сказать, что к ним относятся:
- отсутствие ответственных за интеграционные процессы;
- недостаточный административный ресурс или несвоевременное его применение;
- отсутствие ответственных за качество данных;
- закрытость служб сопровождения и разработчиков информационных систем компании Заказчика;
- непривлечение к анализу данных и последующей разработке бизнес-правил преобразования предметных экспертов Заказчика.
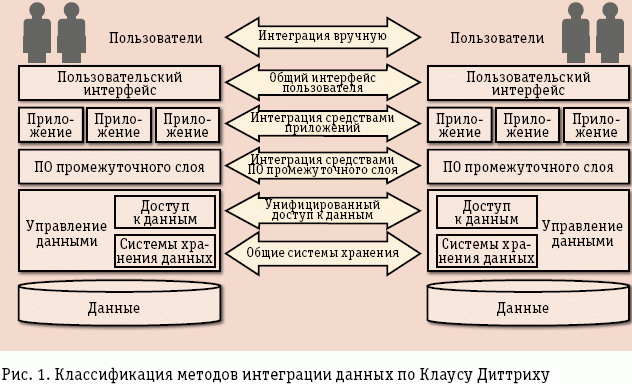
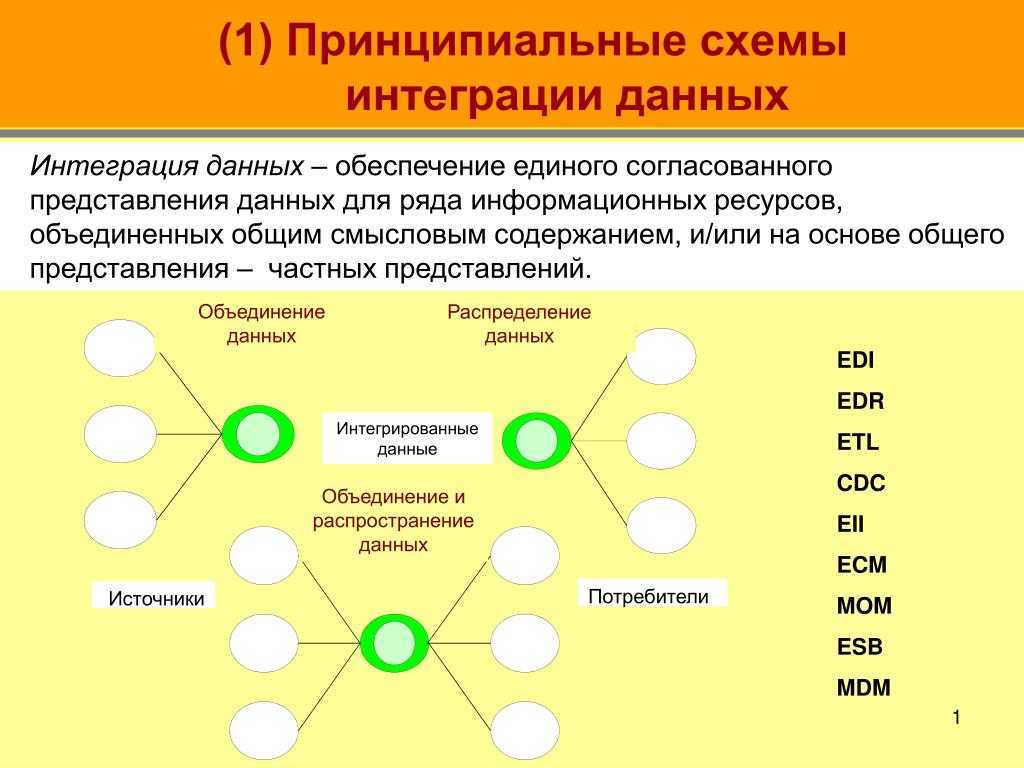
В чем сложность интеграции?
-
С точки зрения аналитики проектирование каждого нового процесса будет отличаться от предыдущего, но во всем всегда есть нюансы. Для разработчиков и архитекторов существуют некие паттерны, которые в определенной степени их выручают. Для анализа таких шаблонов нет.
-
При реинжнириге процессов часто выясняется, что старые системы дают качественные показатели надежности, но с позиции аналитика, совершенно не упрощают интеграцию.
-
Данные с которыми необходимо работать беспорядочны и не сразу поддаются формализации, не говоря уже о структурировании. Сюда можно сразу отнести форматы данных.
-
-
Изменчивость требований «на ходу». Особенно если в интеграции участвует более двух систем.
-
Требования информационной безопасности. Интеграция, в первую очередь история про обмен данными и часто это персональная информация как клиента, так и компании, требующая соблюдения правил для ее защиты\







Эти и многие иные аспекты способны усложнить задачу по проектированию интеграционных процессов
Важно помнить, что в каждом из кейсов будут свои особенности и каждый из них имеет способ решения
Стандартизация
Основные органы, публикующие стандарты: существуют различные органы по стандартизации, роль которых заключается в проверке стандартов или рекомендаций, которые отрасли, в частности, будут использовать в качестве поддержки для обеспечения взаимодействия своих услуг и продуктов, а тем более совместимости:
- ISO : Международная организация по стандартизации (издает международно применимые стандарты)
- ITU : Международный союз электросвязи (комитет ITU-T издает только технические рекомендации, которые затем утверждаются как международные стандарты ISO или как стандарты на межправительственном или национальном уровне).
- ANSI : Американский национальный институт стандартов: Национальный комитет по стандартам США.
- CEN : Европейский комитет по стандартизации: межправительственный комитет по стандартизации в Европейском Союзе.
- CENELEC : Европейский комитет по стандартизации в области электротехники: подкомитет
- AFNOR : Французская ассоциация стандартизации: национальный комитет по стандартизации Франции, выпускает стандарты NF в серии Z для ИТ.
Стандарт: ISO 16100-1: 2002 Часть 1 ISO 16100 определяет структуру для взаимодействия набора программных продуктов, используемых в области производства, и для облегчения их интеграции в производственное приложение. Эта структура охватывает модели обмена информацией, программные объектные модели, интерфейсы, сервисы, протоколы, профили возможностей и методы тестирования на соответствие.
Секретариат ISO / TC 184 / SC 5 занимается вопросами взаимодействия, интеграции и архитектуры для корпоративных систем и приложений автоматизации. Этот секретариат опубликовал 46 статей в этом контексте, в том числе:
- ISO 16100-1: 2009: Системы промышленной автоматизации и интеграция — Профиль квалификации производственного программного обеспечения для взаимодействия — Часть 1: Структура.
- ISO 16100-3: 2005: Системы промышленной автоматизации и интеграция — Профиль квалификации производственного программного обеспечения для взаимодействия — Часть 3: Интерфейсные услуги, протоколы и шаблоны возможностей.
- ISO 15745-4: 2003: Системы промышленной автоматизации и интеграция — Структуры интеграции приложений для открытых систем — Часть 4: Справочное описание систем управления на базе Ethernet.
Существует также секретариат ISO / TC 46 / SC 4 ISO, который занимается вопросами технической совместимости. В рамках этого проекта опубликовано 24 статьи в этом контексте, в том числе:
- ISO 10160: 2015: Информация и документация — Взаимодействие открытых систем (OSI) — Определение прикладной службы для межбиблиотечного абонемента.
- ISO / CD 20614: Протокол обмена данными для взаимодействия и сохранения.
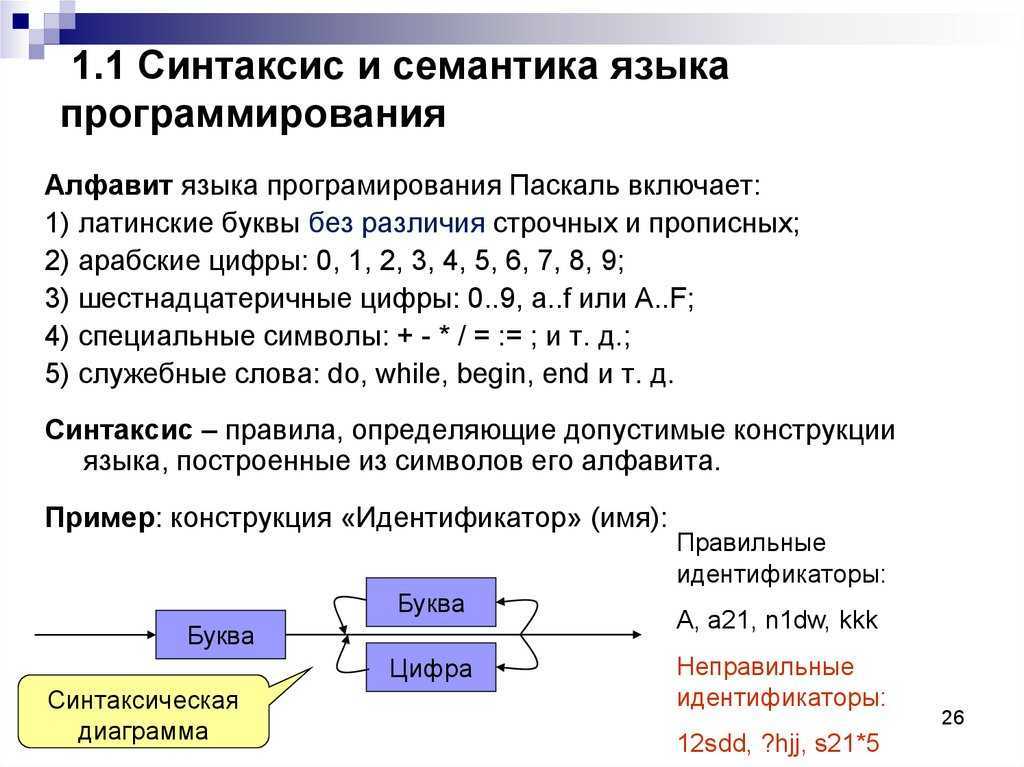
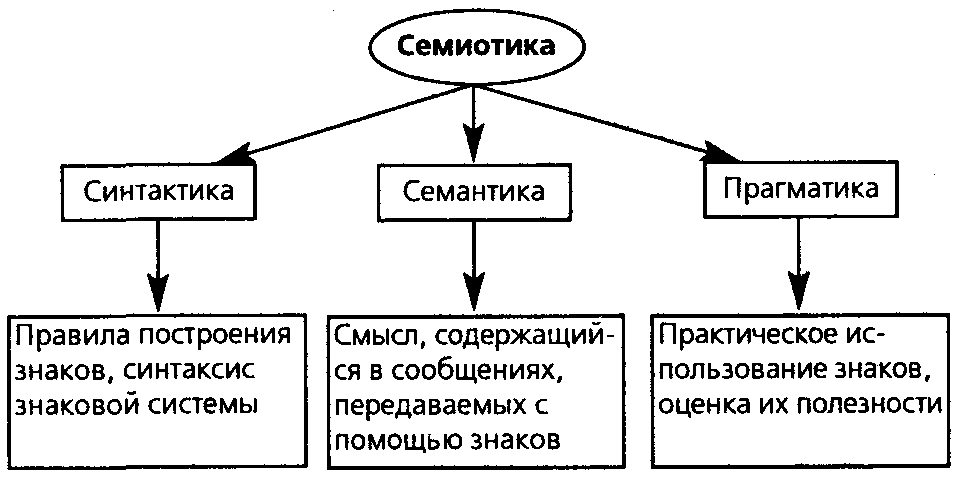
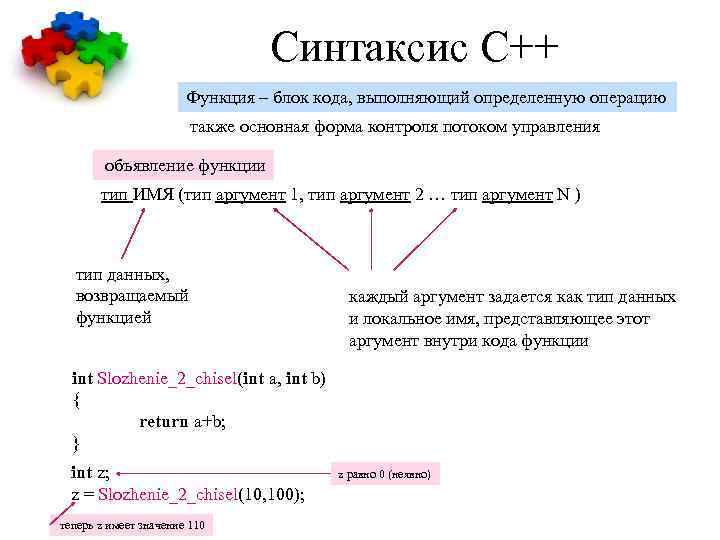
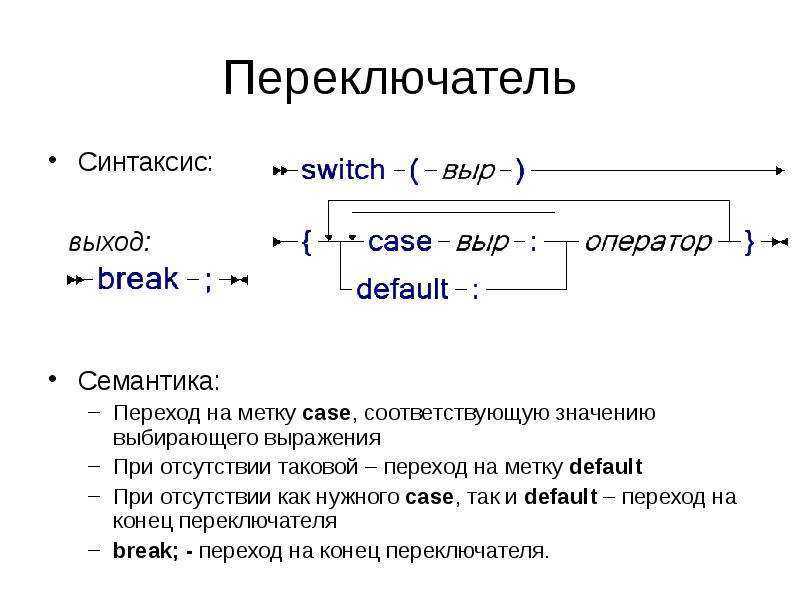
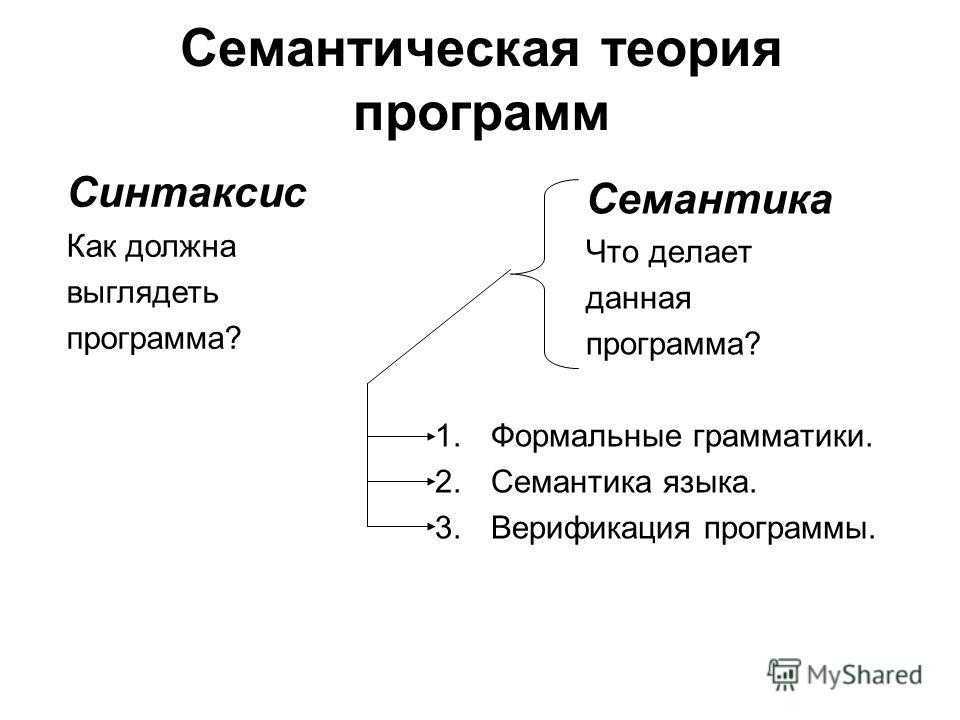
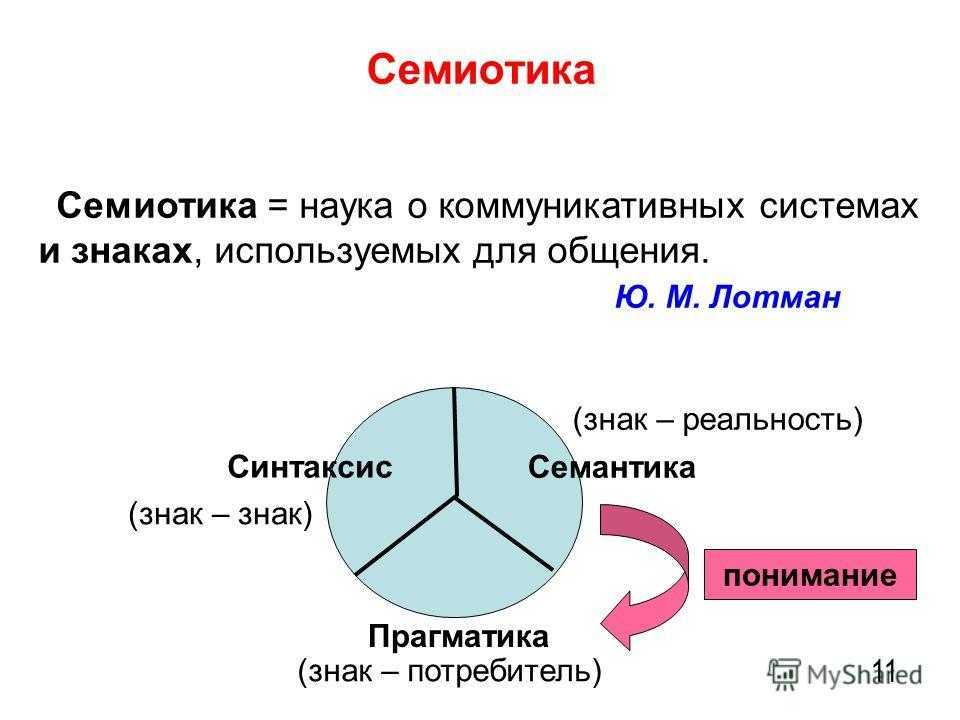
1.2.2 Синтаксис и семантика языка
синтаксиссемантикупрагматику
Всякий язык программирования, в частности, Zonnon, можно определить
как множество предложений — т.е. некоторое множество цепочек или
конечных последовательностей элементарных единиц из некоторого непустого
конечного множества символов, называемого словарем (или алфавитом) языка.
Понятно, что при таком рассмотрении языка программирования мы только фиксируем
множество символов, которые можно использовать для записи программ, а также
класс допустимых (или, как принято говорить, синтаксически правильных)
программ, не сопоставляя никакого смысла этим синтаксически правильным
программам.
Ясно, что задавать множество допустимых программ исчерпывающим их перечислением
нежелательно и даже невозможно. Мы хотим, чтобы описание языка было обозримым
(заведомо конечным), хотя описываемый язык может быть и бесконечным. Обычный
подход, удовлетворяющий этому требованию, состоит в том, что предложения
языка строятся по определенным правилам, в совокупности составляющим то,
что называют грамматикой языка. Эти грамматические правила приписывают
предложениям языка некоторую синтаксическую структуру, которая используется
в дальнейшем при определении смысла предложений.
Грамматику языка можно описывать различными способами. Например, ее
можно задавать в виде порождающей системы, т.е. набора правил, применением
которых можно породить все предложения языка и только их. Этот способ задания
языка программирования ориентируется на человека, поскольку человек использует
язык программирования именно для создания (порождения) программ, решающих
поставленные задачи. Поэтому нами в дальнейшем будет использоваться именно
этот способ.
Семантика языка программирования — это правила придания смысла синтаксически
правильным программам. В конечном счете эти правила определяют ту последовательность
действий вычислительной машины, которую она должна выполнить, работая по
данной программе. Например, семантика языка команд компьютера определяется
самим компьютером: машинная программа означает в точности то, что осуществляет
вычислительная машина при работе по данной программе. Аналогично семантика
языка высокого уровня может быть определена через описание правил выполнения
соответствующей виртуальной машины. Для описания семантики языка Zonnon
мы будем использовать виртуальную Zonnon-машину (сокращенно ВМ), не забывая
о том, что для исполнения Zonnon-программ на реальных компьтерах требуются
трансляторы — например, мы будем ориентироваться на использование транслятора
для языка Zonnon для платформы .NET.
Next:1.2.3
Алфавит и словарь
Up:1.2
Как можно определить
Previous:1.2.1
Два примера простых
Приложения и методы
В интеграции корпоративных приложений (EAI) семантическая интеграция может облегчить или даже автоматизировать связь между компьютерными системами с помощью публикации метаданных . Публикация метаданных потенциально дает возможность автоматически связывать онтологии . Один из подходов к (полу)автоматическому отображению онтологий требует определения семантического расстояния или его обратного семантического подобия и соответствующих правил. Другие подходы включают так называемые лексические методы , а также методологии, основанные на использовании структур онтологий. Для явного указания сходства/равенства в большинстве языков онтологии существуют специальные свойства или отношения. СОВА, например, имеет «owl:equivalentClass», «owl:equivalentProperty» и «owl:sameAs».
Со временем в системных проектах могут появиться компонуемые архитектуры, в которых опубликованные семантические интерфейсы объединяются, чтобы обеспечить новые и значимые возможности . В основном они могут быть описаны с помощью декларативных спецификаций времени разработки, которые в конечном итоге могут быть отображены и выполнены во время выполнения .
Семантическая интеграция также может использоваться для облегчения действий по проектированию и отображению интерфейса во время разработки. В этой модели семантика явно применяется только к дизайну, а системы времени выполнения работают на уровне синтаксиса . Этот подход «раннего семантического связывания» может улучшить общую производительность системы, сохраняя при этом преимущества дизайна , управляемого семантикой .
На что было бы важно обратить внимание?
Цель Важно понимать в чем заключается основная цель интеграции – какую задачу предстоит решить в конечном итоге.
Описание бизнес-процесса Детальное описание возможных сценариев интеграционного бизнес-процесса. Важно избегать любых разночтений в требованиях
Способ интеграционного взаимодействия
Выбор способа передачи данных зависит от множества требований, предъявляемых не только бизнес-заказчиком, но и информационной безопасностью (ИБ), архитекторами и т.д.
ДанныеПри описании документации важно понимать, какие данные необходима передавать или подучать, их обязательность, формат и т.д. Если это не описать, то в будущем точно придется потратить ресурсы на дополнительную проработку и анализ.
Проектная документация смежной системы. При описании взаимодействия необходимо ознакомиться с документацией смежной системы. Это позволяет снизить риски внезапного выявления важных особенностей смежной системы. Если даже вам говорят, что подобной документации нет — это не повод сдаваться. Кто-то же создал смежную систему, а значит без документации ее не могли допустить до запуска на «продуктиве». Понимание смежной системы качественно упростит вам задачу
Тестирование. Никогда не поздно начать смотреть в сторону планирования тестирования. Уже на стадии проектирования аналитик должен создавать «юз-кейсы», которые и лягут в основу ТЗ и сценариев тестирования.




Будьте убедительны и идите до конца. Всегда есть тот, кто ответит на ваши вопросы. Даже если это вы сами.
Примечания и ссылки
- Гилки, Герберт Т. (1960), «Новые методы обогрева воздуха», Новые методы обогрева зданий: конференция по корреляции исследований, проводимая Институтом строительных исследований, Отделом инженерных и промышленных исследований, как одна из программ осенних конференций BRI., Ноябрь 1959 г., Вашингтон: Национальный исследовательский совет (США). Строительный научно-исследовательский институт, п. 60, OCLC 184031,
- CIS 8020 — Системная интеграция, Государственный университет Джорджии, ОЭСР
- Корпоративная интеграция: Основное руководство по интеграционным решениям Бет Голд-Бернштейн (автор), Уильям Рух. ( ISBN 978-0321223906 ) ( ISBN 032122390X )
- Willium y Arms 2000 (афифа икбал)
- ISO / IEC 2382: 2015
- ↑ и
- На пути к взаимодействию разнородных информационных систем, e-TI,
- ↑ и
- Системы промышленной автоматизации и интеграция — Профилирование производственных возможностей программного обеспечения для обеспечения взаимодействия — Часть 1: Структура, ISO 2002
Заключение
В процессе проектирования информационных систем широкое применение нашла новая парадигма – “разработка управляемая моделями” MDD, в основе которой лежит способ организации и управления архитектурой проектируемой системы MDA.
Наиболее полную поддержку MDD обеспечивает современная интегрированная среда разработки Rational Software Architect – результат эволюцииRational Rose и Rational Rose XDE.
Разработка на основе моделей с помощью Rational Software Architect при полном использовании ресурсов этого продукта позволяет создавать информационные системы любой сложности на профессиональном уровне. Простое описание технологии из нашей статьи показывает как можно использовать Rational Software Architect в MDD.
Главной особенностью Rational Software Architect является то, что этот продукт обеспечивает полную поддержку современной парадигмы управляемой моделями разработки (MDD). Интерфейс и инфраструктура разработки на основе ресурсов в Rational Software Architect дополняет MDD, позволяя повторное использование моделей, а также их трансформацию.
Связанные материалы
 BPMN и UML диаграммы при проектировании информационных систем BPMN и UML диаграммы при проектировании информационных систем
|
 Программы для построенияUML диаграмм Программы для построенияUML диаграмм
|
 Как построить диаграмму деятельности в StarUML Как построить диаграмму деятельности в StarUML
|
 Визуальное моделированиепредметной области Визуальное моделированиепредметной области |
 Rational Rose и техническое проектирование информационных систем Rational Rose и техническое проектирование информационных систем |
 Rational Rose и рабочее проектирование информационных систем Rational Rose и рабочее проектирование информационных систем |
Смотри также…
- Методологии проектирования информационных систем
- Методы проектирования информационных систем
- Инструментальные средства проектирования информационных систем
- Статистический индекс производительности информационной системы
Вот пока и все. Удачи в совершенствовании знаний и умений в использовании MDD при проектировании информационных систем с помощью RSA.