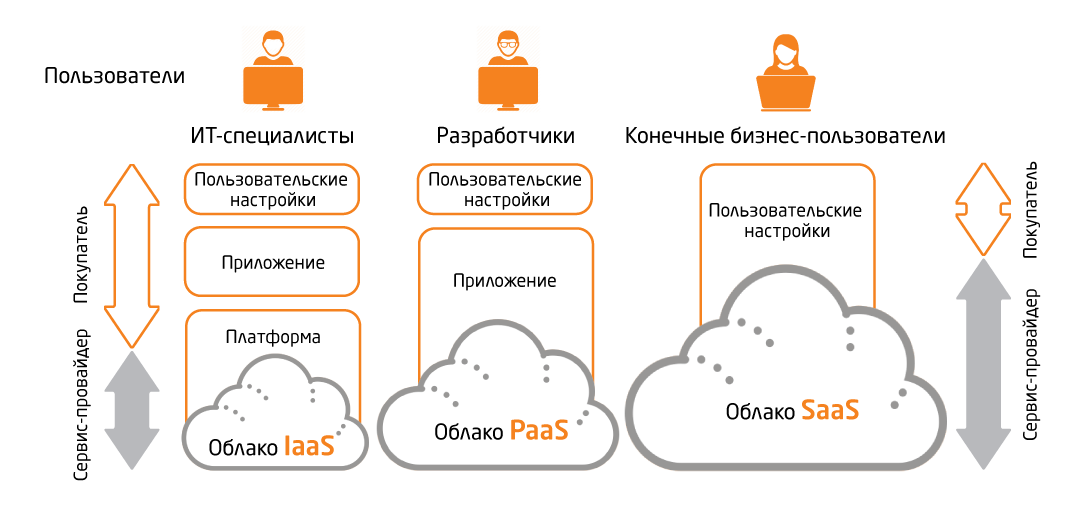
Преимущества использования бессерверных вычислений
Эффективность событийной архитектуры (event-driven architecture, EDA), которая лежит в основе бессерверных вычислений, не вызывает сомнений у профессионалов IT-индустрии. Эта архитектура дает следующие ценные преимущества:
-
Изначальная поддержка автоматического масштабирования. Характерной особенностью решения является его высокая гибкость, позволяющая масштабировать вычислительные ресурсы и функциональные возможности именно тогда, когда в этом есть потребность. И наоборот, при пониженных (внепиковых) нагрузках рабочая среда сворачивается.
-
Более удобная среда развертывания. В бессерверных инфраструктурах программистам проще и удобнее разрабатывать и развертывать свои приложения. Теперь им не нужно заботиться о второстепенных вещах, например о том, как обслуживать инфраструктуру или добиваться своевременной синхронизации данных. Изначальная гибкость бессерверной архитектуры гарантирует простоту автоматизации для большинства технологических процессов.
-
Стабильность. Бессерверная архитектура позволяет переложить львиную долю обязанностей по управлению данными и инфраструктурой на плечи поставщика облачных услуг. Таким образом, возможность не заботиться об инфраструктурном обеспечении, оркестрировании и распределении данных кода, а также о решении проблем с простоем ресурсов — обо всем том, что было огромной головной болью при работе на локальных программных платформах предыдущего поколения, — сохранит вашей команде огромный пул рабочего времени.
-
Экономическая эффективность. Минимизация затрат — это, пожалуй, самый важный фактор, который ярко выделяет бессерверные инфраструктуры на фоне бесчисленного множества других облачных решений. Именно оплата за фактический объем использованных ресурсов помогает избежать неоправданных затрат при разработке и развертывании приложений. Вы платите только за те периоды работы сервера, когда некие запланированные события инициируют соответствующие действия в облаке.
-
Сокращение задержек. Используя для развертывания инфраструктур облачные сервера, компании получают возможность разместить свои ресурсы на ближайших для конечных пользователей доступных серверах. Таким образом обеспечивается легкость подключения и совместимость форматов данных в отсутствие критичных по времени сбоев и простоев системы.
В конечном счете вам решать, что выбрать: микросервисы или бессерверные фреймворки. Более того, вы можете легко «заточить» обе эти технологии под свои бизнес-потребности. Компания ByteAnt, в свою очередь, всегда готова помочь вам найти наиболее эффективное интеграционное решение. Напишите нам — и мы в индивидуальном порядке рассмотрим вашу проблему и поделимся своим практическим опытом.
Сервисная шина предприятия (ESB)
Сервисная шина предприятия использовала веб-сервисы уже в 1990-х, когда они только развивались (быть может, некоторые реализации сначала использовали CORBA?).
ESB возникла во времена, когда в компаниях были отдельные приложения. Например, одно для работы с финансами, другое для учёта персонала, третье для управления складом, и т. д., и их нужно было как-то связывать друг с другом, как-то интегрировать. Но все эти приложения создавались без учёта интеграции, не было стандартного языка для взаимодействия приложений (как и сегодня). Поэтому разработчики приложений предусматривали конечные точки для отправки и приёма данных в определённом формате. Компании-клиенты потом интегрировали приложения, налаживая между ними каналы связи и преобразуя сообщения с одного языка приложения в другой.
Очередь сообщений может упростить взаимодействие приложений, но она не способна решить проблему разных форматов языков. Впрочем, была сделана попытка превратить очередь сообщений из простого канала связи в посредника, доставляющего сообщения и преобразующего их в нужные форматы/языки. ESB стал следующей ступенью в естественной эволюции простой очереди сообщений.
В этой архитектуре используется модульное приложение (composite application), обычно ориентированное на пользователей, которое общается с веб-сервисами для выполнения каких-то операций. В свою очередь, эти веб-сервисы тоже могут общаться с другими веб-сервисами, впоследствии возвращая приложению какие-то данные. Но ни приложение, ни бэкенд-сервисы ничего друг о друге не знают, включая расположение и протоколы связи. Они знают лишь, с каким сервисом хотят связаться и где находится сервисная шина.
Клиент (сервис или модульное приложение) отправляет запрос на сервисную шину, которая преобразует сообщение в формат, поддерживаемый в точке назначения, и перенаправляет туда запрос. Всё взаимодействие идёт через сервисную шину, так что если она падает, то с ней падают и все остальные системы. То есть ESB — ключевой посредник, очень сложный компонент системы.
Это очень упрощённое описание архитектуры ESB. Более того, хотя ESB является главным компонентом архитектуры, в системе могут использоваться и другие компоненты вроде доменных брокеров (Domain Broker), сервисов данных (Data Service), сервисов процессной оркестровки (Process Orchestration Service) и обработчиков правил (Rules Engine). Тот же паттерн может использовать интегрированная архитектура (federated design): система разделена на бизнес-домены со своими ESB, и все ESB соединены друг с другом. У такой схемы выше производительность и нет единой точки отказа: если какая-то ESB упадёт, то пострадает лишь её бизнес-домен.
Главные обязанности ESB:
- Отслеживать и маршрутизировать обмен сообщениями между сервисами.
- Преобразовывать сообщения между общающимися сервисными компонентами.
- Управлять развёртыванием и версионированием сервисов.
- Управлять использованием избыточных сервисов.
- Предоставлять стандартные сервисы обработки событий, преобразования и сопоставления данных, сервисы очередей сообщений и событий, сервисы обеспечения безопасности или обработки исключений, сервисы преобразования протоколов и обеспечения необходимого качества связи.
У этого архитектурного паттерна есть положительные стороны. Однако я считаю его особенно полезным в случаях, когда мы не «владеем» веб-сервисами и нам нужен посредник для трансляции сообщений между сервисами, для оркестрирования бизнес-процессами, использующими несколько веб-сервисов, и прочих задач.
Также рекомендую не забывать, что реализации ESB уже достаточно развиты и в большинстве случаев позволяют использовать для своего конфигурирования пользовательский интерфейс с поддержкой drag & drop.
Достоинства
- Независимость набора технологий, развёртывания и масштабируемости сервисов.
- Стандартный, простой и надёжный канал связи (передача текста по HTTP через порт 80).
- Оптимизированный обмен сообщениями.
- Стабильная спецификация обмена сообщениями.
- Изолированность контекстов домена (Domain contexts).
- Простота подключения и отключения сервисов.
- Асинхронность обмена сообщениями помогает управлять нагрузкой на систему.
- Единая точка для управления версионированием и преобразованием.
Недостатки
- Ниже скорость связи, особенно между уже совместимыми сервисами.
- Централизованная логика:
- Единая точка отказа, способная обрушить системы связи всей компании.
- Большая сложность конфигурирования и поддержки.
- Со временем можно прийти к хранению в ESB бизнес-правил.
- Шина так сложна, что для её управления вам потребуется целая команда.
- Высокая зависимость сервисов от ESB.
Архитектура следующего поколения платформы данных
Рисунок 6: Сдвиг парадигмы построения платформы данных следующего поколения.
Данные и распределённая domain driven архитектура
Рисунок 8: Распределённые конвейеры обработки данных, реализованные внутри своих доменов
Данные и продуктовое мышление
Кросс функциональная data-команда бизнес-домена
Рисунок 10: Кросс функциональная доменная data-команда
- Масштабируемое хранения данных в разных форматах
- Шифрование данных (тут же хэширование, обезличивание и т.д.)
- Версионирование data-продуктов
- Хранение схемы данных data-продукта
- Контроль доступа к данным
- Журналирование
- Оркестровка потоков/процессов по обработке данных
- Кэширование данных в памяти
- Хранение метаданных и data lineage
- Мониторинг, оповещения, логгирование
- Расчёт метрик качества data-продуктов
- Ведение каталога данных
- Стандартизация и политики, возможность контроля соответствия
- Адресация data-продуктов
- CI/CD pipelines для data-продуктов
Поиск по никнейму
WhatsMyName — это не просто сервис, а целый комбайн, который ищет по 280 сервисам!
WhatsMyName
Здесь можно сортировать сервисы по категориям, а еще есть возможность экспортировать результат поиска (URL найденных профилей) в нескольких форматах.
Сервис Usersearch.org предоставляет поиск не только по популярным соцсетям, но и по тематическим форумам и сайтам знакомств.
USERSEARCH.ORG
SuIP.biz — постоянно обновляемая и обширная база сервисов с удобной выдачей. Время проверки — где‑то одна‑две минуты. Минус — деления на категории нет.
suIP.biz
По завершении поиска можно скачать отчет в формате PDF.
— сервис с быстрой проверкой по популярным и не очень сервисам. У него в базе встречаются интересные тематические сайты, вроде MyAnimeList и Last.fm.
InstantUsernameSearch
Checkuser ищет по небольшому списку сайтов, а кроме того, позволяет проверять занятость доменного имени.
На сам поиск уходит примерно минута. Единый список ссылок из результатов получить нельзя.
Namechekup использует обширный список сервисов для проверки, которая, кстати, не занимает много времени.
Получить все ссылки разом здесь тоже нельзя.
Список веб‑сервисов у Namecheckr небольшой, но и проверка очень быстрая. Сами сервисы по большей части популярные и не очень соцсети. Проверяет и некоторые домены.
Отдельно существует сервис‑двойник под незамысловатым названием Namech_k. Он проверят упоминание конкретного юзернейма по десяткам сайтов. К тому же у сервиса есть свой API, чтобы можно было вызывать из скриптов.
Namech_k
В репозитории нашего соотечественника (и автора статьи в «Хакере») Soxoj есть большой список проверок, которые могут быть полезны для интернет‑розыска, и сервисов поиска по никнейму — спасибо ему! Здесь собраны такие утилиты, как Sherlock, Maigret, Snoop, sherlock-go и Investigo, каждая из которых зарекомендовала себя как неплохой инструмент для поиска и сбора открытых данных.
Чек‑лист Soxoj
Отдельно хотелось бы выделить и упомянуть утилиту Maigret.
Maigret
Она позволяет собирать досье на человека по имени пользователя, проверяя наличие учетных записей на огромном количестве сайтов (более 2300) и собирая всю информацию с доступных страниц. Не использует никаких ключей API. Это, кстати, форк другой OSINT-утилиты — Sherlock. Обрати внимание, что по умолчанию поиск запускается не по всем сайтам, а только по 500 самых популярных.
info
Читай также: «Пробей меня полностью! Кто, как и за сколько пробивает персональные данные в России», «Боты атакуют. Тестируем телеграм‑боты для поиска персональных данных»
Mикросервисная архитектура
Микросервисная архитектура систем программирования основывается на разработке приложений как набора сервисов. Каждый из небольших сервисов обособлен в собственном процессе и связывается с несложными легковесными механизмами. Зачастую это API для HTTP-ресурса.
Основа таких сервисов – бизнес-возможности. Они имеют отдельный автоматизированный механизм и работают отдельно друг от друга.
Административное управление между сервисами сводится к минимуму. Они могут использовать разные технологии хранения данных и иметь отличные друг от друга языки написания.
Создание микросервисной архитектуры систем основывается на компонентизации сервисов, которая делит программное обеспечение на различные компоненты (сервисы) изолированные друг от друга. Каждый из таких сервисов несёт свою ответственность. Изменение одних компонентов не должны влиять на другие.
Архитектура работает по принципу компонентизации сервисов. Она разделяет программное обеспечение на различные изолированные компоненты (сервисы) каждый из которых несет единую ответственность. Изменения в одной сервисе не должны затрагивать другие.
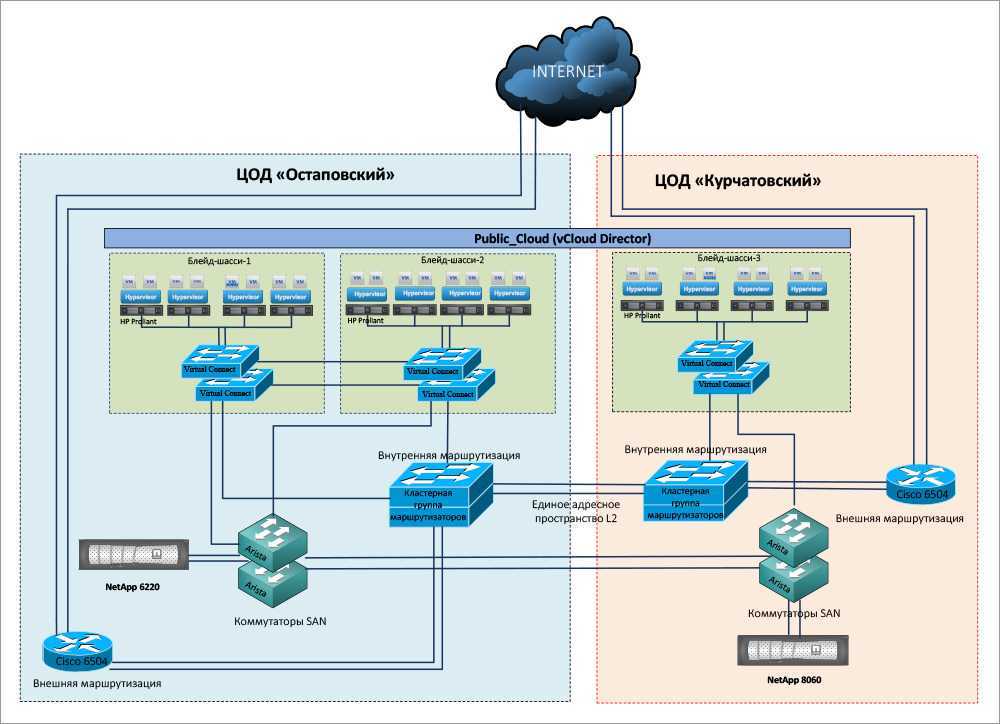
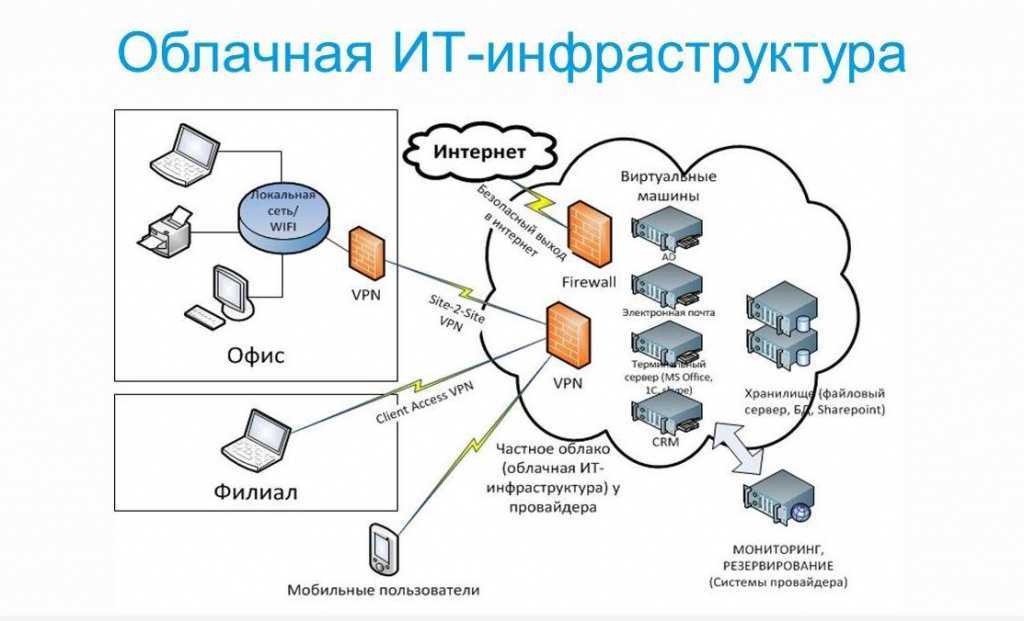
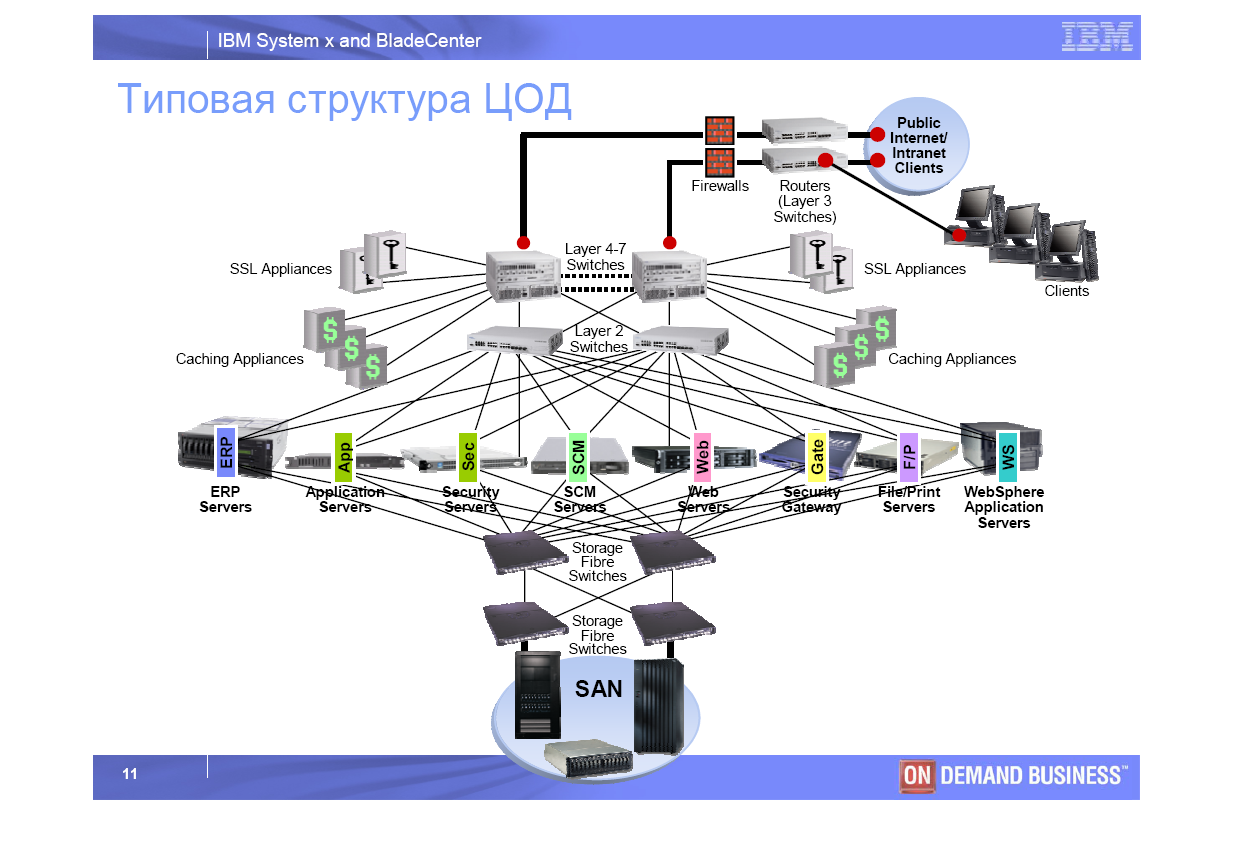
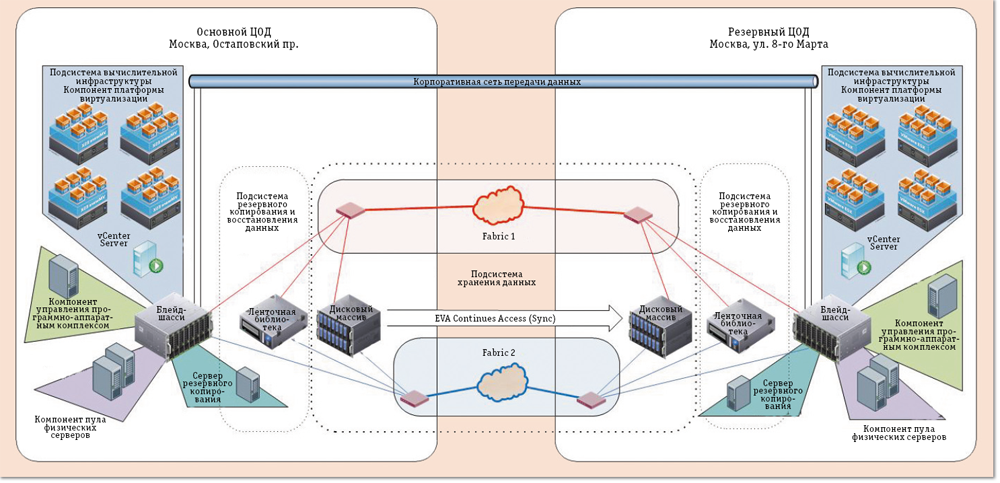

Mикросервисная архитектура
Архитектура включает в себя отдельные компактные микросервисы. Они способны расширяться обособленно и не зависят друг от друга. Вот 5 основных компонентов такой архитектуры:
- сервисы (Services);
- сервисная шина (Service Bus);
- внешняя конфигурация (External configuration);
- шлюз API (API Gateway);
- контейнеры (Containers).
Популярные статьи
Высокооплачиваемые профессии сегодня и в ближайшем будущем
Дополнительный заработок в Интернете: варианты для новичков и специалистов
Востребованные удаленные профессии: зарабатывайте, не выходя из дома
Разработчик игр: чем занимается, сколько зарабатывает и где учится
Как выбрать профессию по душе: детальное руководство + ценные советы
Основными характеристиками микросервисной архитектуры являются:
- сервисная компонентизация;
- организация отталкивается от бизнес-возможностей;
- ориентация на продукты, а не на проекты;
- умные конечные точки и глупые каналы (Smart endpoints and dumb pipes);
- децентрализованное управление;
- децентрализованное управление данными;
- автоматизированная инфраструктура;
- защита от сбоев;
- эволюционное проектирование.
Отдельное развитие каждого микросервиса под управлением различных команд наиболее оптимально в таком подходе. Передача данных осуществляется по стандартному протоколу и формату данных, поэтому структура одного сервиса не повлияет на функциональность смежных.
Плюсы:
- Высокий уровень изоляции со слабой связанностью.
- Повышенная модульность.
- Изолированные системы предотвращают влияние сбоя в одном сервисе на другой.
- Гибкость и масштабируемость на высоком уровне.
- Ускоренные итерации, благодаря простой модификации.
- Улучшенная система обработки ошибок.
- В отличие от многослойной архитектуры, решает проблемы с потоками данных.
Недостатки:
- При обмене данных между сервисами есть повышенный риск сбоя.
- Затрудненное управление из-за большого количества сервисов.
- Распределительная архитектура обязывает искать пути решения ряда проблем: задержка в сети, удержание гармоничного баланса нагрузки.
- Требует обязательного тестирования в распределительной среде.
- Долгое время реализации.
Мы рассмотрели все виды архитектуры систем. Отражение взаимодействия бизнеса и ИТ является основной задачей при создании архитектуры. С одной стороны, это документирование и стандартизация бизнес-процессов. С другой – описание составляющих архитектуры веб-систем на логическом уровне с учетом связей с бизнес-процессами.
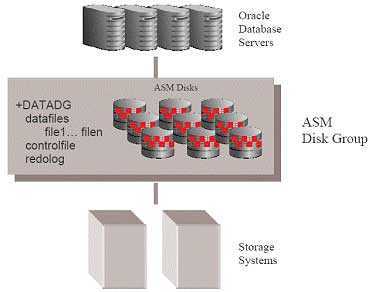
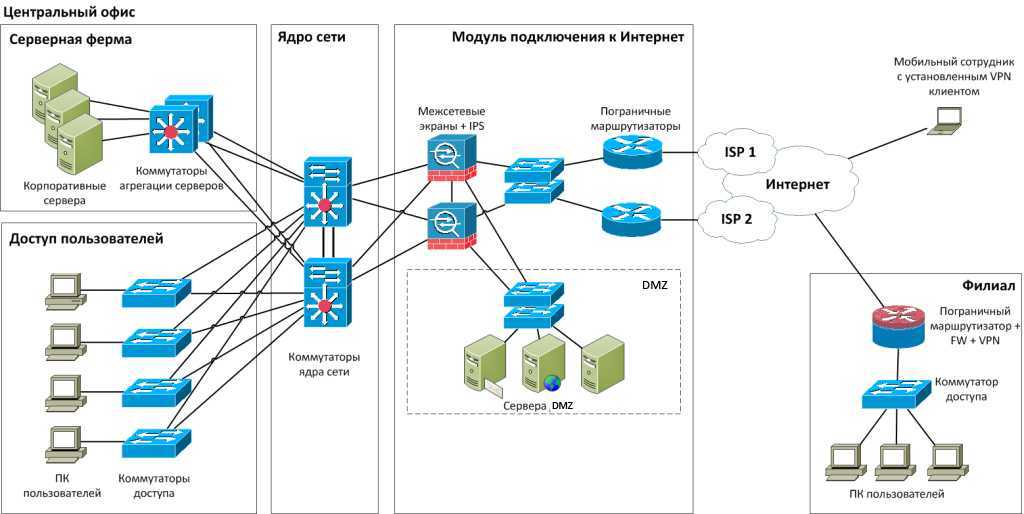
Текущая архитектура платформы данных в крупной компании
- Первое поколение: проприетарные корпоративные хранилища данных и платформы бизнес-аналитики. Это решения за большие суммы денег, которые оставили компаниям столь же большие объёмы технического долга. Технический долг в тысячах неподдерживаемых ETL джобов, таблиц и отчетов, которые понимает только небольшая группа специалистов, что приводит к недооценке положительного влияния этого функционала на бизнес.
- Второе поколение: экосистемы больших данных (Big Data) с Data Lake в качестве серебряной пули. Сложная экосистема больших данных и долго отрабатывающие batch джобы, поддерживаемые центральной командой узко-специализированных data-инженеров. В лучшем случае используется для R&D аналитики.
- использования облачных сервисов для хранения и обработки данных и облачных Machine Learning платформ.
Рисунок 1: Три поколения платформ данных
Централизованное и монолитное
Рисунок 2: Вид с высоты 10 000 метров на монолитную платформу данных
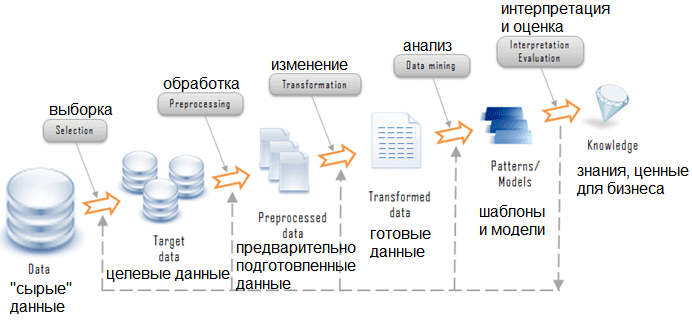
- Сбор (to ingest) данных со всей организации от транзакционных систем, отвечающих за операционную поддержку бизнеса, до данных от внешних поставщиков. Например, в сфере потокового мультимедиа платформа данных обеспечивает загрузку таких данных, как: производительность медиа плееров; особенности пользовательского взаимодействия с плеерами; прослушиваемые песни; артисты, на которых пользователи подписаны; финансовые транзакции с поставщиками контента и данные исследования рынка внешними компаниями (демографическая информация о клиентах и т.п.).
- Очистка, обогащение и преобразование данных, загруженных из источников в тот формат достоверных данных, которые могут использовать различные группы потребителей. В нашем примере, одним из таких процессов трансформации данных могло бы быть преобразование отдельных кликов пользовательского взаимодействия в пользовательские сессии, обогащённые данными о пользователях — чтобы представить пользовательский опыт в виде агрегированных представлений.
- Предоставление доступа (to serve) к наборам данным конечным пользователям. Реализация пользовательских потребностей в интервале от аналитики и machine learning до BI отчетов. В нашем примере потокового мультимедиа, это может быть предоставление доступа в режиме реального времени к информации о дефектах и качестве работы медиа плееров по всему миру. Работать такой доступ может через распределённые интерфейсы, такие как Kafka.
Рисунок 3: Централизованная платформа данных без чётких границ между данными разных бизнес-доменов. И без владения соответствующими данными со стороны бизнес-домена
- Большое количество источников и большие объёмы данных. Чем больше данных становятся доступными повсеместно, тем меньше наши способности собирать, согласовывать и контролировать их в рамках одной платформы. К примеру, касательно клиентской информации появляется всё больше источников внутри и за пределами организаций. Они предоставляют разнообразную информацию о существующих и потенциальных клиентах. Подход, при котором нам нужно собирать и хранить данные в одном месте, чтобы получить ценность из интеграции различных источников, ограничит нашу способность реагировать на появление новых источников данных. Поймите меня правильно, я осознаю потребность аналитиков и data scientists обрабатывать разнообразные наборы данных с минимальными издержками и с возможностью интеграции их. Также понятно, что данные наших информационных систем (обслуживающие операционные потребности бизнеса) следует отделять от данных, используемых в аналитических целях. Но я предполагаю, что существующие решения централизованных хранилищ данных – не самый оптимальных вариант для крупных предприятий с большим количеством бизнес-доменов и постоянно появляющимися новыми источниками данных.
- Потребности организаций в инновациях. Необходимость в быстрой проверке гипотез и частых экспериментах ведёт к большому количеству вариантов использования данных. Это подразумевает постоянно растущее количество трансформаций в данных, которые необходимо реализовывать на наших централизованных платформах данных. Долгое время реализации потребностей пользователей исторически являлось точкой организационных трений и остаётся таковым при текущей архитектуре платформы данных.
Заблуждения
1. Это легче
После прочитанного вы вряд ли посчитаете микросервисную архитектуру лёгким делом, но это распространённое заблуждение. Сложность создания микросервиса наглядно показывает график:
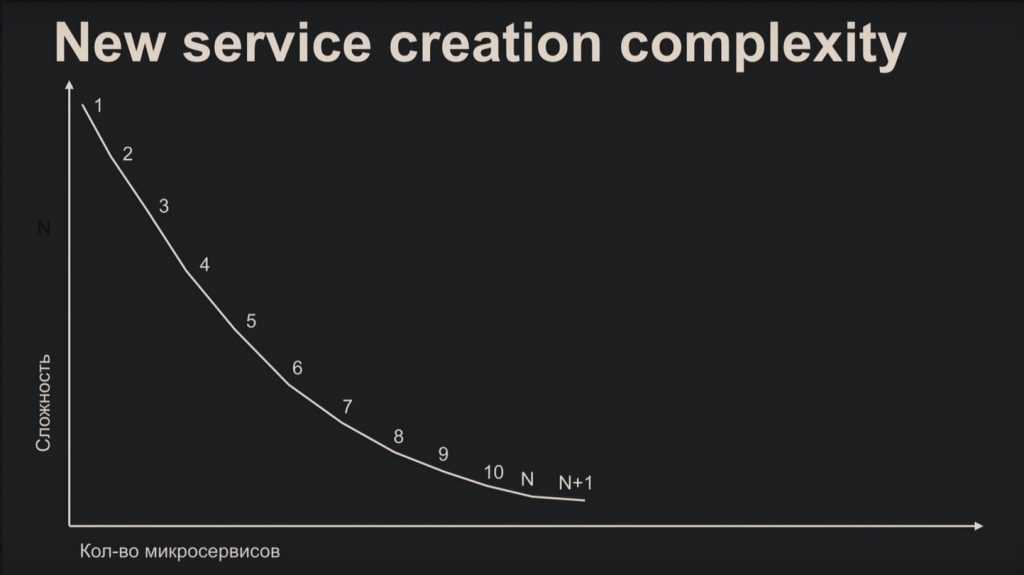
С самого начала вы медленно и печально разбираетесь с документацией, бесконечно подбираете протоколы и другие компоненты. К энному микросервису вы нарабатываете стандартные шаблоны, что в несколько раз облегчает процесс.
С точки зрения поддержки – наоборот, потому что увеличивается количество микросервисов. Новый разработчик вынужден будет часами сидеть за изучением диаграмм, чтобы понять глобальную картину и принцип работы системы.
2. Лучше производительность
Представьте, сколько придётся ждать отправителю комплексного запроса, пока он сходит в кучу разных микросервисов. Поэтому ради производительности переезжать на эту архитектуру не всегда целесообразно. В качестве альтернативы перепишите куски проекта на более эффективном языке, или добавьте профилирование к монолиту.
Infogram
Infogram
Сильные стороны бесплатной версии
- Infogram, в отличие от других инструментов, поддерживает анимации, позволяющие изменять масштаб объектов, организовывать их перемещение, отражение, появление и исчезновение, прокрутку.
- В визуализации можно добавлять собственные элементы, изображения и фигуры.
Слабые стороны бесплатной версии
- В бесплатной версии можно создать не более 10 проектов, в каждом из которых может содержаться до 5 страниц.
- Infogram поддерживает более 550 типов карт. Но в бесплатной версии доступно лишь 13 типов.
- В бесплатной версии нельзя создавать проекты, закрытые от посторонних.
- Нельзя организовывать подключение к источникам данных и работать с данными, изменяющимися в режиме реального времени.
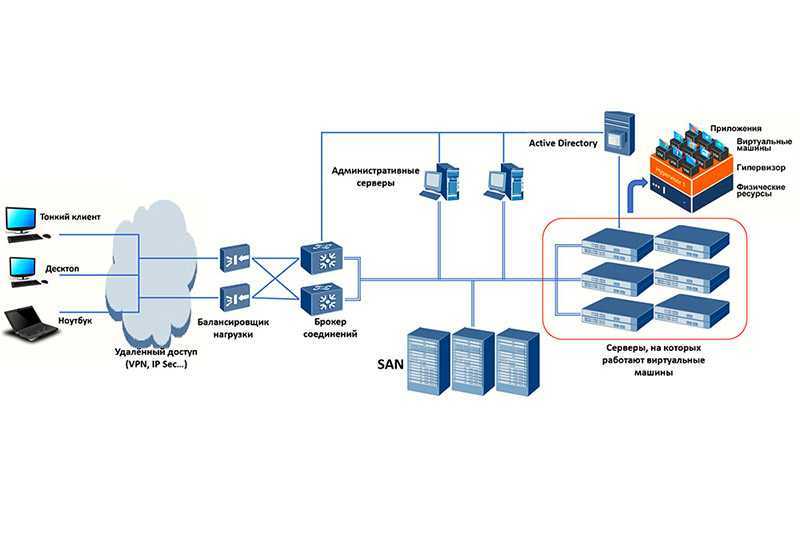
Принцип 1. Клиент-серверная архитектура
Сама концепция клиент-серверной архитектуры заключается в разделении некоторых зон ответственности: в разделении функций клиента и сервера. Что это означает?
Например, мы разделяем нашу систему так, что клиент (допустим, это мобильное приложение) реализует только функциональное взаимодействие с сервером. При этом сервер реализует в себе логику хранения данных, сложные взаимодействия со смежными системами и т.д.
Что мы этим добиваемся и как могло бы быть иначе? Давайте представим, что клиент и сервер у нас объединены. Тогда, если мы говорим о мобильном приложении, каждое мобильное приложение каждого клиента должно было бы быть абсолютно самодостаточной единицей. И тогда, поскольку у нас единого сервера нет для получения/отправки информации, у нас получилась бы какая-то сеть единообразных компонентов – например, мобильные приложения общались бы друг с другом – такая распределённая сеть равноценных узлов.
Такие системы в реальной жизни есть и можно найти их примеры. Например, в блокчейне. Тем не менее, в случае с REST мы говорим о том, что разделяем ответственность. Например, отображение информации, её обработку и хранение.
Клиент-серверная архитектура
Также сервер может иметь базу данных (см. рисунок ниже). В данном случае надо понимать, что пара «сервер и БД» тоже будет парой «клиент-сервер». Только в данном случае сервером будет БД, а сам сервер — клиентом.
Трёхзвенная архитектура
Что дает клиент-серверная архитектура и зачем она нужна?
Во-первых, клиент-серверная архитектура дает нам определённую масштабируемость: есть сервер, есть единая точка обработки запросов. При необходимости выдерживать большую нагрузку мы можем поставить несколько серверов. Также к нему можно подключать достаточно большое количество клиентов (сколько сможет выдержать). Таким образом, клиент-серверная архитектура позволяет добиться масштабируемости.
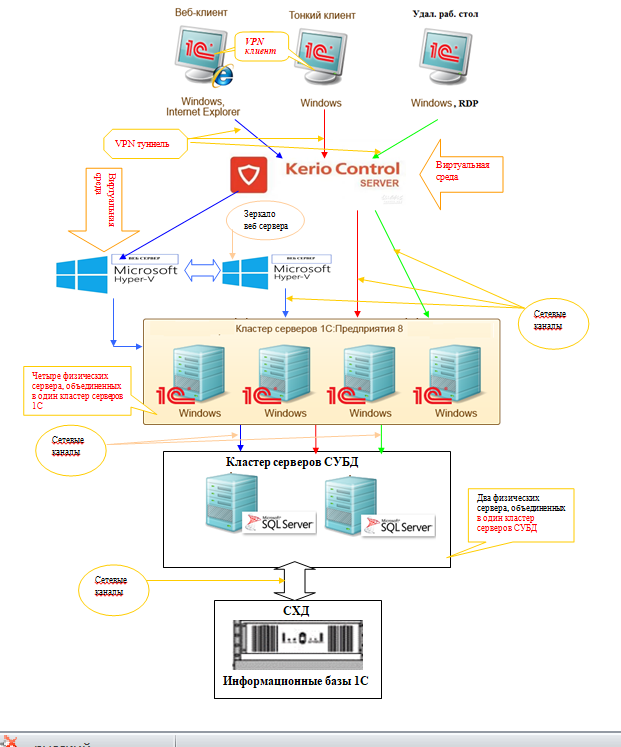
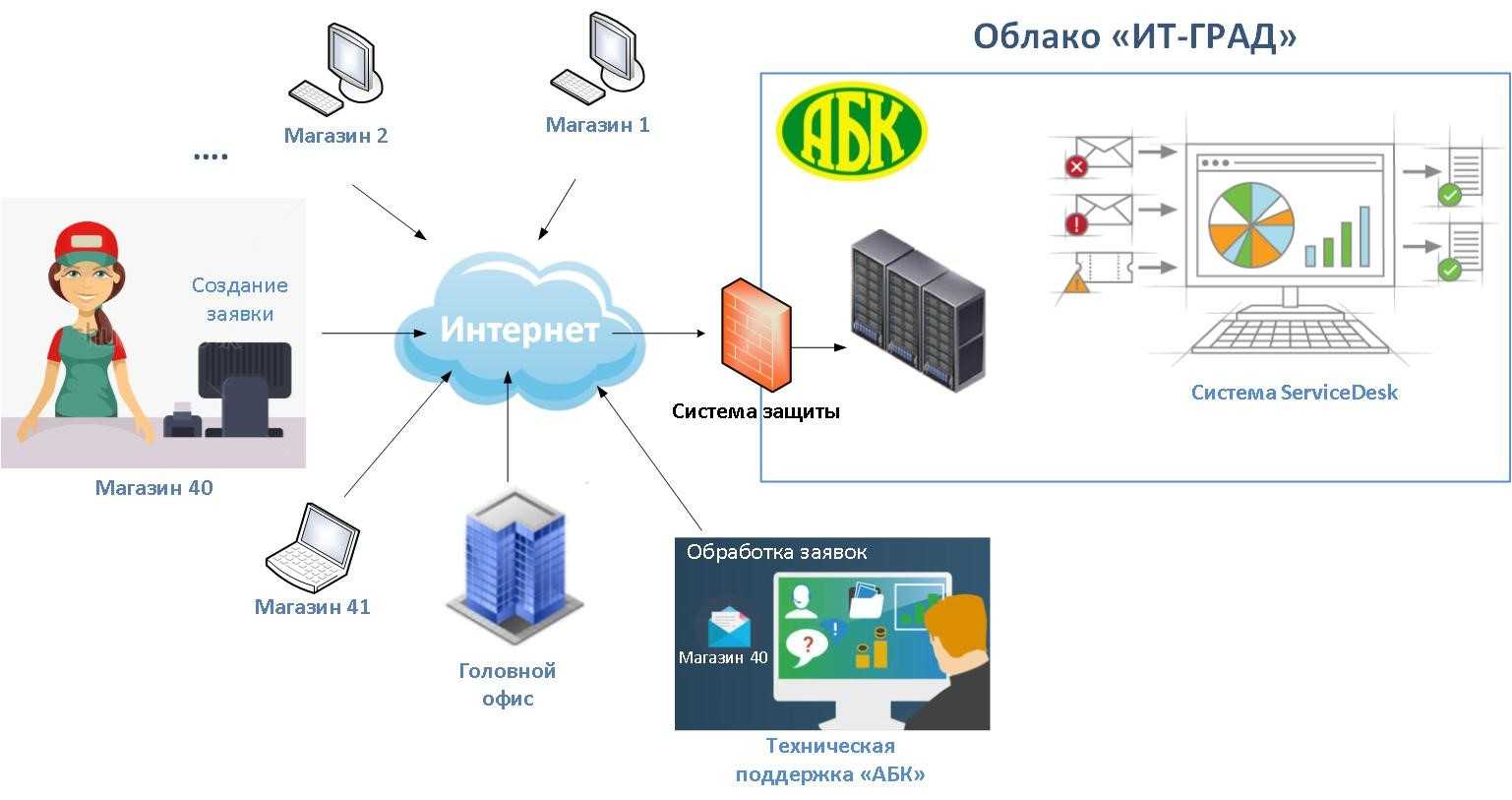
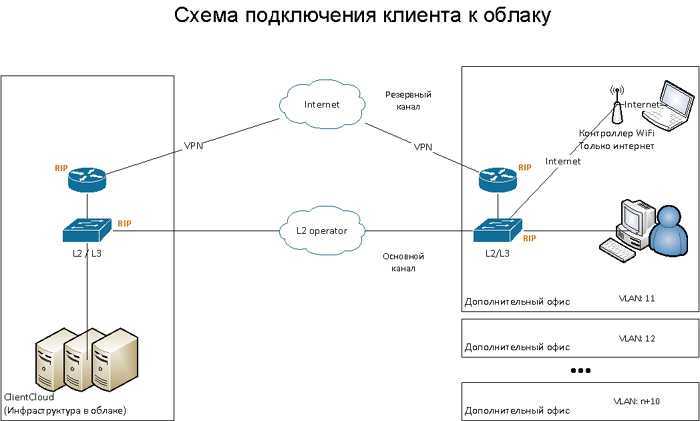
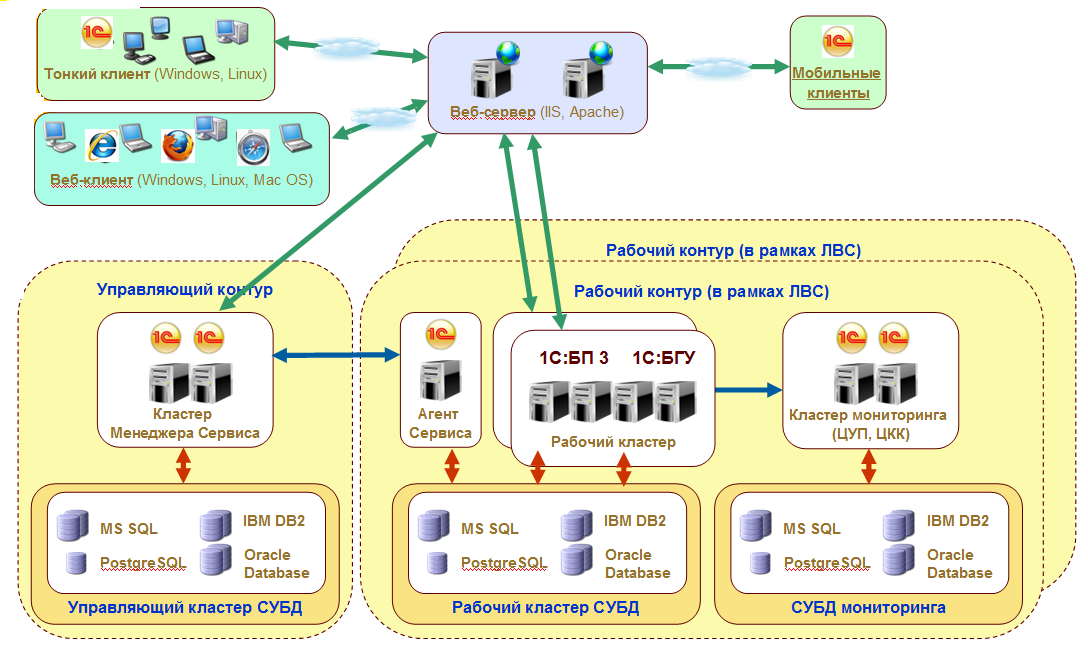
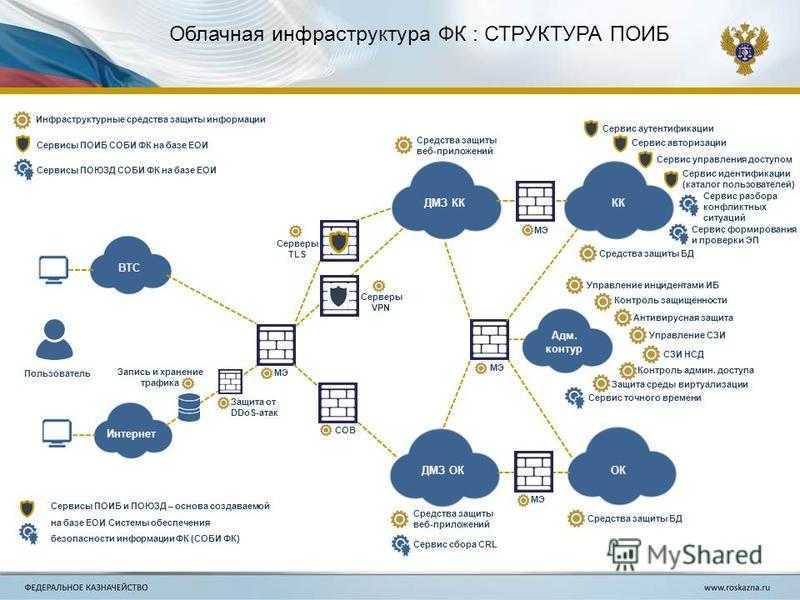
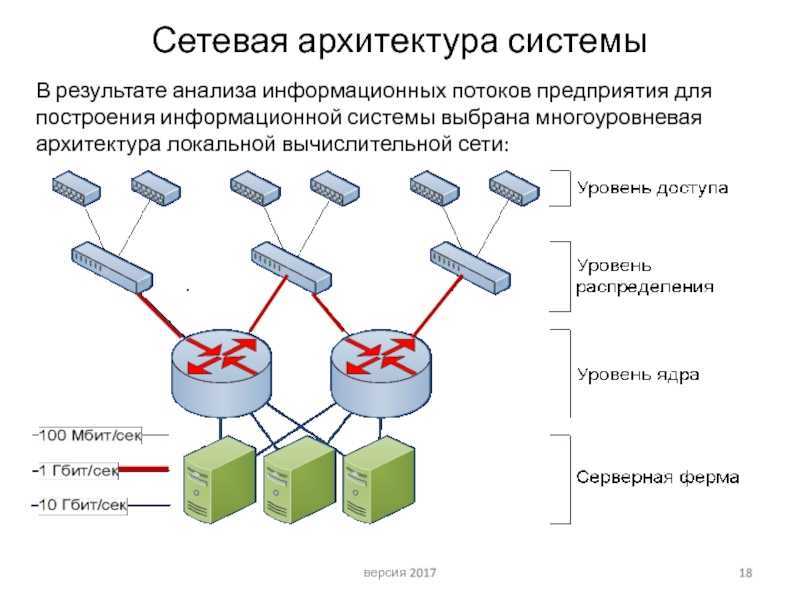
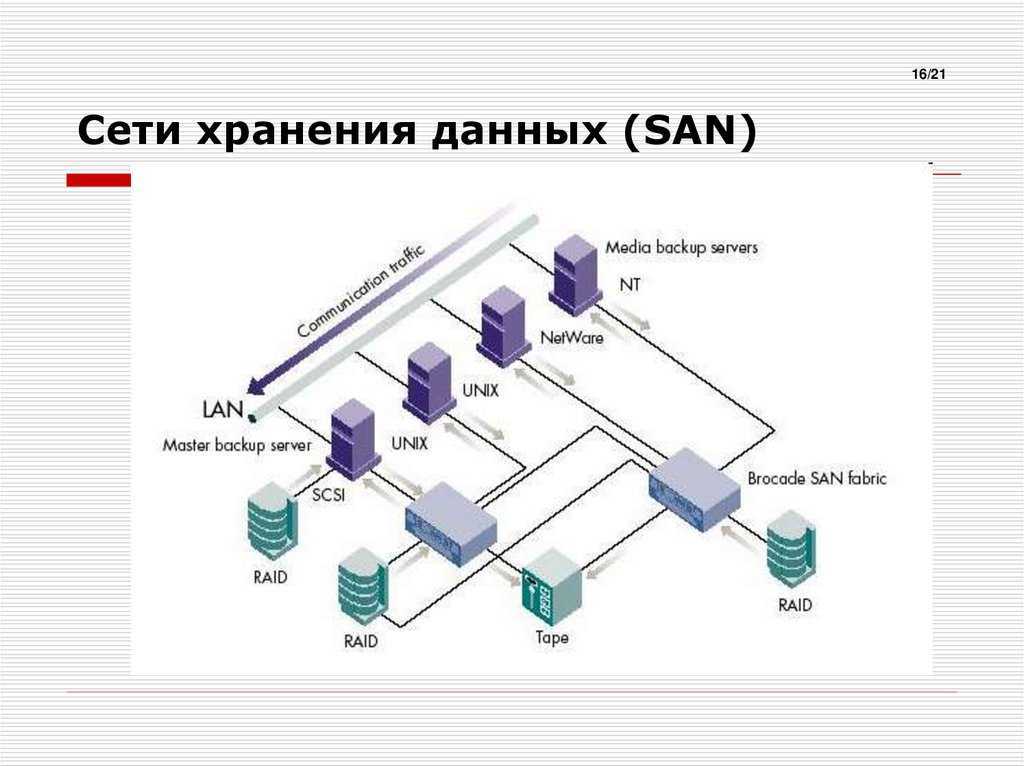
Во-вторых, REST даёт определённую простоту поддержки. Если мы хотим изменить логику обработки информации на сервере, то выполним эти изменения на сервере. В данном случае мы можем и не менять каждого клиента, как если бы они были абсолютно равноценной сетью.
Конечно, есть и минусы. В случае с клиент-серверной архитектурой мы понимаем, что у нас есть единая точка отказа в виде сервера. Если отказал сервер и у нас нет дополнительных инстансов, то для нас это будет означать неработоспособность системы.
Также потенциально может увеличиться нагрузка, поскольку часть логики мы вынесли с клиента на сервер. Клиент будет совершать меньше каких-либо действий самостоятельно, соответственно, у нас возрастёт количество запросов между клиентом и сервером.
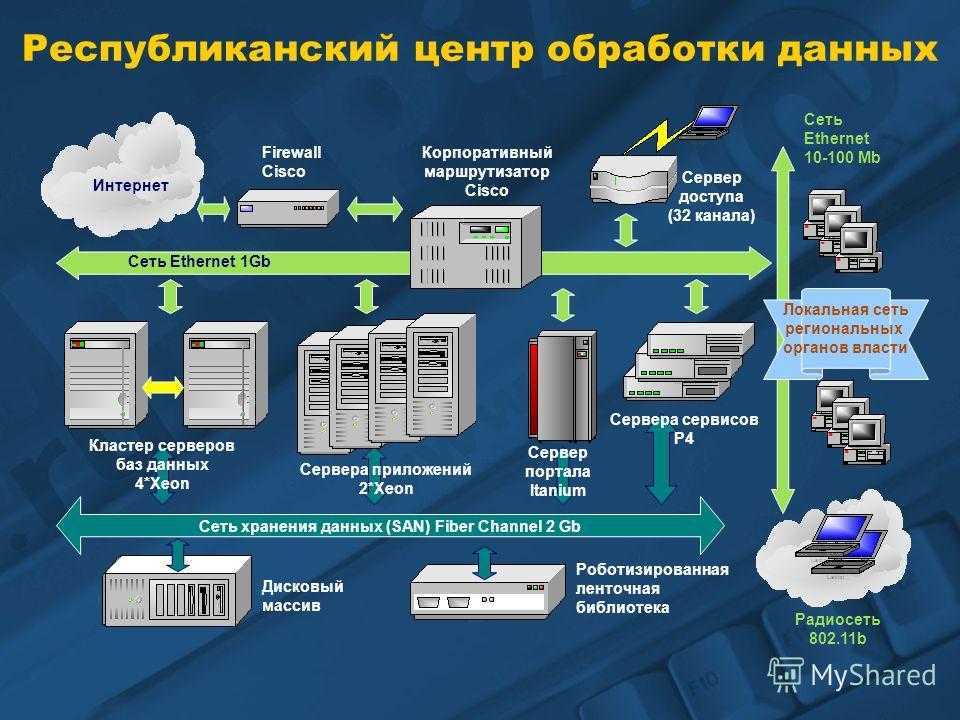
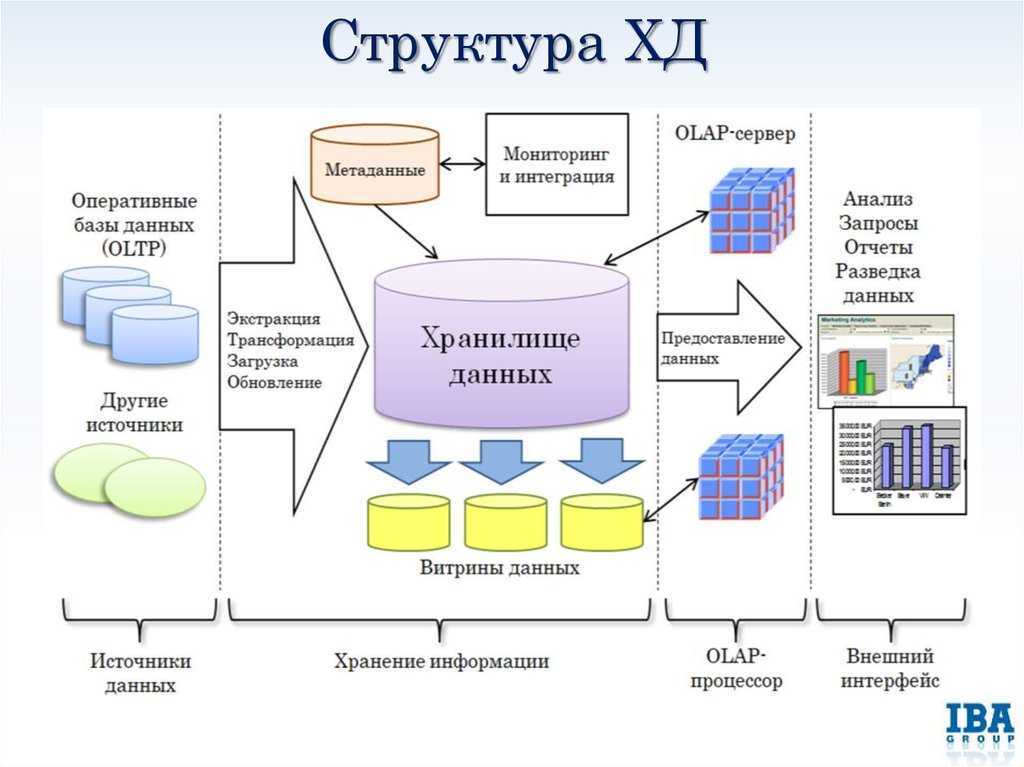
Где хранить корпоративные данные: краткий ликбез по Data Warehouse
Потребность в КХД сформировалась примерно в 90-х годах прошлого века, когда в секторе enterprise стали активно использоваться разные информационные системы для учета множества бизнес-показателей. Каждое такое приложение успешно решало задачу автоматизации локального производственного процесса, например, выполнение бухгалтерских расчетов, проведение транзакций, HR-аналитика и т.д.
При этом схемы представления (модели) справочных и транзакционных данных в одной системе могут кардинально отличаться от другой, что влечет расхождение информации. Частично этот вопрос Data Governance мы затрагивали в контексте управления НСИ. Кроме того, большое разнообразие моделей данных затрудняет получение консолидированной отчетности, когда нужна целостная картина из всех прикладных систем. Поэтому возникли корпоративные хранилища данных (Data Warehouse, DWH) – предметно-ориентированные базы данных для консолидированной подготовки отчётов, интегрированного бизнес-анализа и оптимального принятия управленческих решений на основе полной информационной картины .
Заключение
В последние десятилетия SOA сильно эволюционировала. Благодаря неэффективности прежних решений и развитию технологий сегодня мы пришли к микросервисной архитектуре.
Эволюция шла по классическому пути: сложные проблемы разбивались на более мелкие, простые в решении.
Проблему сложности кода можно решать так же, как мы разбиваем монолитное приложение на отдельные доменные компоненты (разграниченные контексты). Но с разрастанием команд и кодовой базы увеличивается потребность в независимом развитии, масштабировании и развёртывании. SOA помогает добиться такой независимости, упрочняя границы контекстов.
Повторюсь, что всё дело в слабой взаимозависимости и высокой связности, причём размер компонентов должен быть больше прежнего. Необходимо прагматично оценить свои потребности: используйте SOA, лишь когда это необходимо, поскольку она сильно увеличивает сложность. И если на самом деле вы можете обойтись без SOA, то лучше выберите микросервисы подходящего размера и количества, не больше и не меньше.