
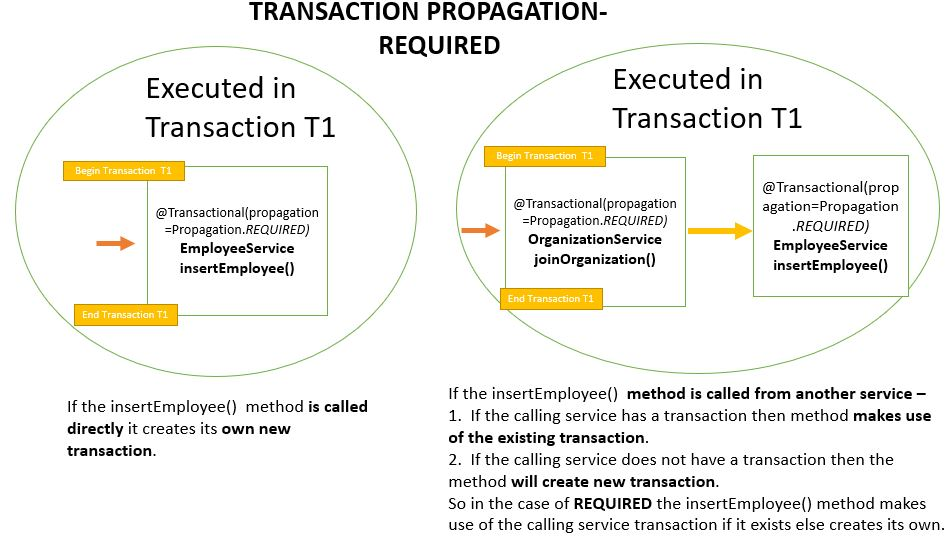
Потоки, процессы, контексты…
Системный вызовРежим ядраРежим пользователяПотокПроцесс
- Регистры процессора.
- Указатель на стек потока/процесса.
- Если ваша задача требует интенсивного распараллеливания, используйте потоки одного процесса, вместо нескольких процессов. Все потому, что переключение контекста процесса происходит гораздо медленнее, чем контекста потока.
- При использовании потока, старайтесь не злоупотреблять средствами синхронизации, которые требуют системных вызовов ядра (например мьютексы). Переключение в редим ядра — дорогостоящая операция!
- Если вы пишете код, исполняемый в ring0 (к примеру драйвер), старайтесь обойтись без использования дополнительных потоков, так как смена контекста потока — дорогостоящая операция.
Волокно
Проблема двойной записи
Единственный индикатор того, что вы столкнулись с проблемой двойной записи, — это необходимость управляемой записи в более чем одну систему. Это требование может быть неочевидным и может выражаться по-разному в процессе проектирования распределенных систем. Например:
-
Вы выбрали лучшие инструменты для каждой задачи, и теперь вам нужно обновить базу данных NoSQL, поисковый индекс и кеш в рамках одной бизнес-транзакции;
-
Созданная вами служба должна обновить свою базу данных, а также отправить уведомление об изменении в другую службу;
-
У вас есть бизнес-операции, которые затрагивают несколько других сервисов;
-
Возможно, вам нужно реализовать идемпотентность для сервиса, потому что конечные пользователи должны повторять неудачные вызовы.
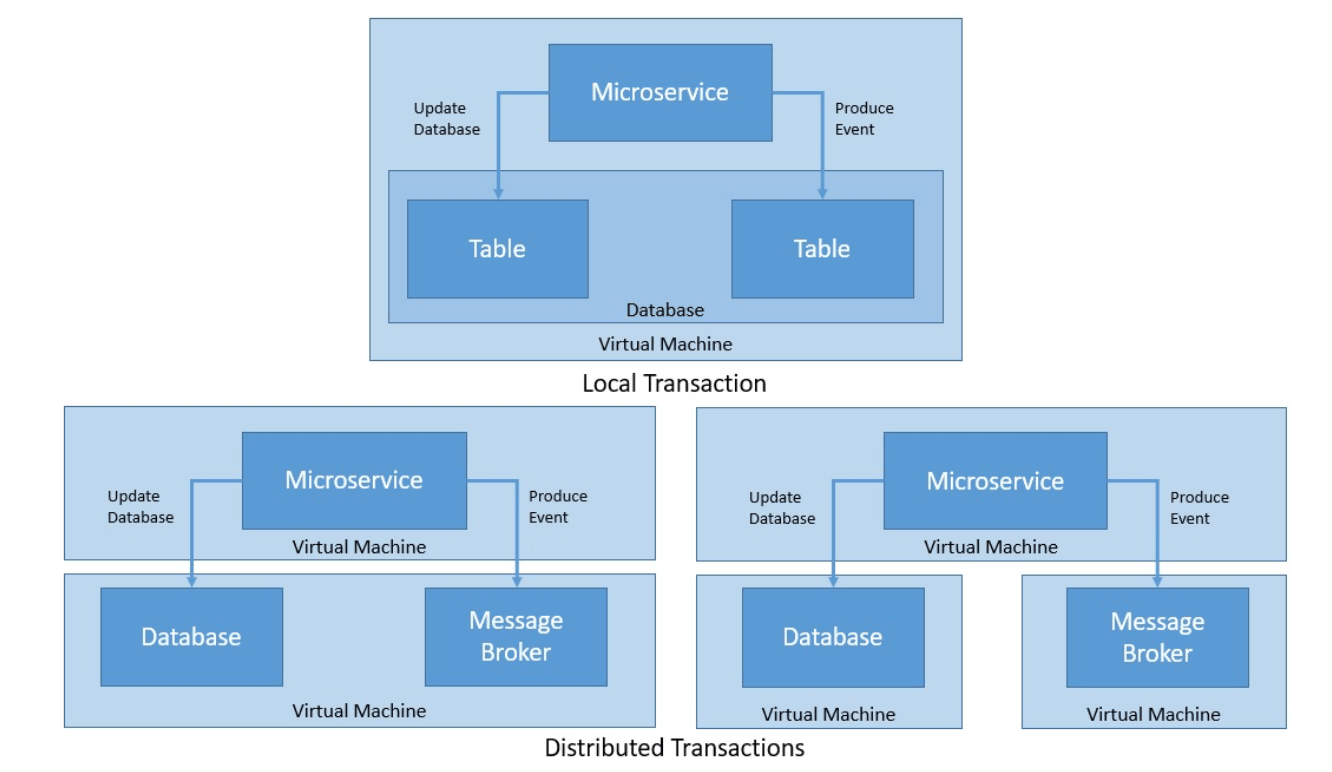
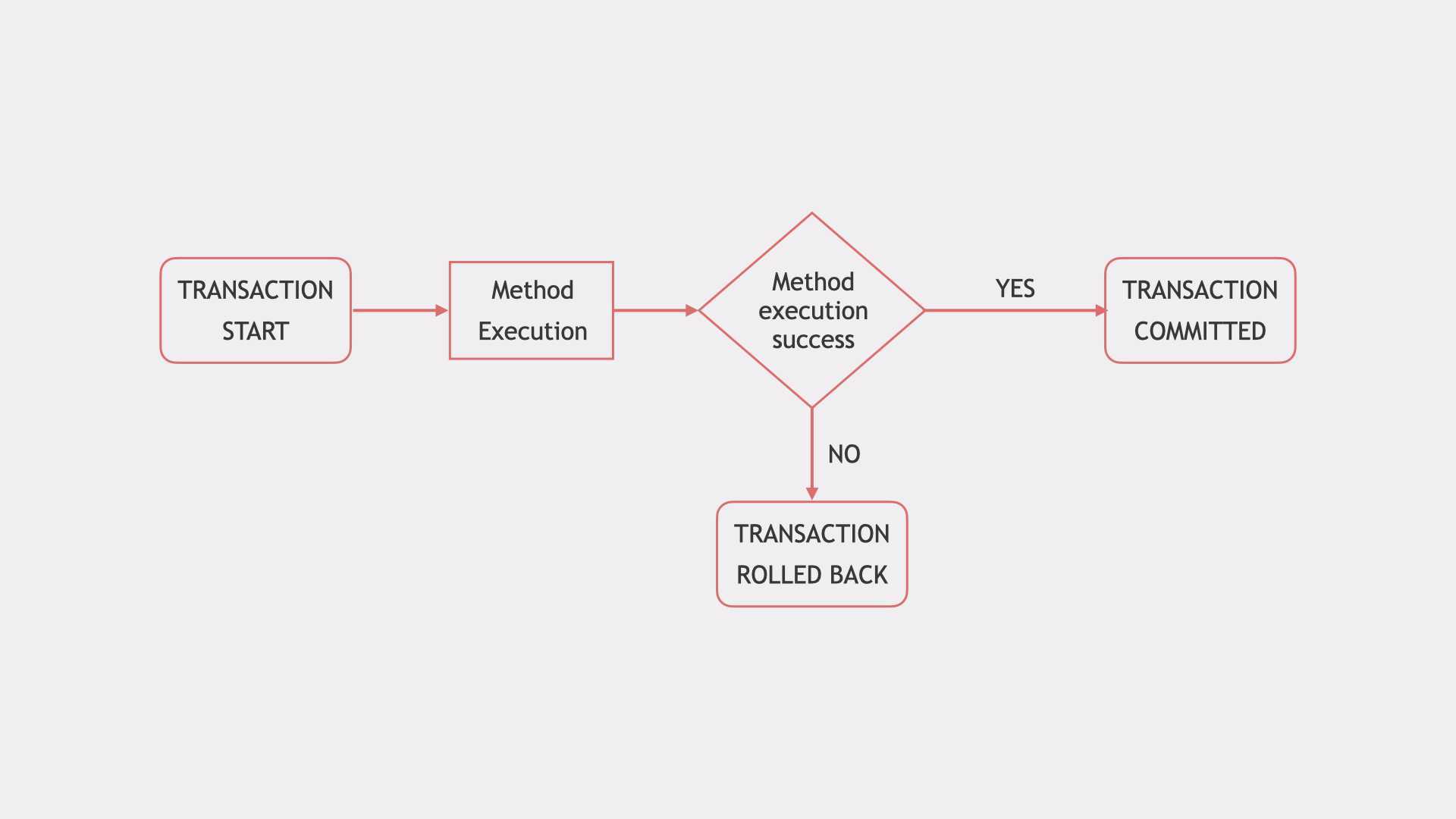
В этой статье мы будем использовать один пример сценария для оценки различных подходов к обработке двойной записи в распределенных транзакциях. Наш сценарий — это клиентское приложение, которое вызывает микросервис для внесения изменений. Служба A (Service A на рисунках) должна обновить свою базу данных A (Database A), но она также должна вызвать службу B (Service B) для операции записи, как показано на рисунке 1. Фактический тип базы данных, как и протокол взаимодействия между службами, не имеет отношения к нашему обсуждению, потому что проблема остается прежней.
Рисунок 1: Проблема двойной записи в микросервисах
Небольшое, но важное уточнение ниже объясняет, почему у этой проблемы нет простых решений. Если служба A записывает данные в свою базу, а затем отправляет уведомление в очередь для службы B (назовем это подходом «локальная фиксация затем публикация»), все равно существует вероятность, что приложение не будет работать надежно
Пока служба A записывает в свою базу данных, а затем отправляет сообщение в очередь, существует небольшая вероятность сбоя приложения после сохранения в базе данных и до второй операции, что оставит систему в несогласованном состоянии. Если сообщение отправляется до записи в базу данных (назовем этот подход «публикация затем локальная фиксация»), существует вероятность сбоя записи в базу данных или проблем с синхронизацией, в результате чего служба B получит событие до того, как служба A зафиксирует изменение в своей база данных. В любом случае этот сценарий включает двойную запись в базу данных и в очередь, что является основной проблемой, которую мы собираемся исследовать. В следующих разделах я расскажу о различных подходах, доступных сегодня для решения этой актуальной проблемы.
О принудительной остановке Thread
В Java 8 отсутствуют методы, при помощи которых можно добиться принудительной остановки. Но можно воспользоваться специальным механизмом, который позволяет вмешаться в потоковые процессы. Достаточно использовать interruption e. Это – механизм потокового оповещения.
У Thread есть булево поле – флаг прерывания. Устанавливается через вызов interrupt(). Проверить факт его задействования можно несколькими методами:
- через bool isInterrupted() потокового объекта;
- используя bool Thread.interruped().
В первом случае происходит возврат флага и его сброс. Во втором вызов осуществляется внутри thread, из которого был вызван метод. Данный прием дает возможность проверки состояния потокового прерывания в Java.
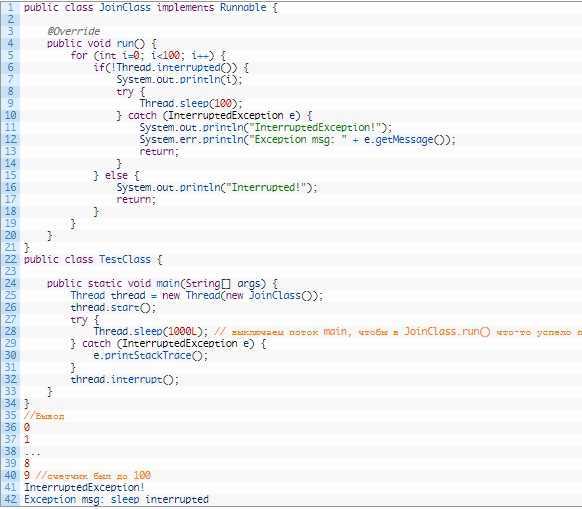
Здесь происходит следующее:
- В методе main() создается объект класса JoinClass, запускаемый через run.
- Происходит проверка на факт завершения. Каждые 100 секунд на экран выводится информация о значении счетчика.
- Главный метод ждет 1 000 мс для того, чтобы счетчик мог произвести расчеты.
- Осуществляется вызов interrupt у JoinClass.
- В цикле обнаруживается исключение.
- В разделе catch активируется return.
По принудительной потоковой остановке тоже много документации, как и по Java Concurrency гайдов на русском.
Выполнение потоков и волокон
В Microsoft Windows используется числовая система приоритетов, распределяющая выполняемые потоки по уровням от 1 до 31. Значение 0 зарезервировано для использования операционной системой. При наличии в очереди на выполнение нескольких потоков Windows сначала обслуживает поток с наивысшим приоритетом.
Каждый экземпляр SQL Server по умолчанию имеет уровень приоритета 7, что соответствует стандартному уровню. Это значение по умолчанию задает потокам SQL Server достаточно высокий уровень приоритета, позволяющий им получать достаточно ресурсов ЦП, не снижая производительности других приложений.
Важно!
В будущей версии Microsoft SQL Server этот компонент будет удален. Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется.
Параметр конфигурации priority boost используется для повышения приоритета потоков экземпляра SQL Server до уровня 13. Это наивысший приоритет. Этот параметр назначает потокам SQL Server более высокий приоритет по отношению к другим приложениям. Таким образом, потоки SQL Server всегда будут обслуживаться в первую очередь, а потоки других приложений не смогут занимать ресурсы системы ранее потоков с более высоким приоритетом. Представленные выше меры могут повысить производительность сервера, на котором выполняются только экземпляры SQL Server. Однако если в приложении SQL Server выполняется ресурсоемкая операция, то не рекомендуется присваивать высокий приоритет другим приложениям, чтобы они не вытесняли поток SQL Server.
Если на компьютере выполняется несколько экземпляров SQL Server, то повышение приоритетов одних может привести к снижению производительности других. Кроме того, включение параметра priority boost может привести к простою других приложений и компонентов, выполняемых на компьютере. Таким образом, данный параметр рекомендуется использовать только в строго определенных условиях.
Concurrency – библиотека для работы со Threads
У Джавы немало документации на русском языке, при помощи которой можно разобраться в принципах работы с языком. И там обязательно рассказывается о многопоточности. В процессе чтения соответствующей информации программеры встречают такое понятие как Concurrency.
Так называют специальную библиотеку Java. В ней собраны спецклассы, предназначенные для работы с несколькими нитями. Они включены в пакет java.util.concurren. Включают в себя различные элементы:
- Concurrent Collections – коллекции, предназначающиеся для работы с многопоточностью. В процессе работа используется принцип блокировки по сегментам информации. Возможна оптимизация параллельного чтения по wait-free алгоритмизации.
- Synchronizers – вспомогательный контент. Задействуется непосредственно при синхронизации потоковой информации. Особо важен для параллельных вычислений.
- Queues – очереди блокирующего и неблокирующего характера для многопоточности. Первый вариант применяет для «тормоза» потоков, если не проходят реализацию те или иные условия. Второй актуален для обеспечения скорости обработки информации. Функционирование в данном случае будет осуществляться без потоковой блокировки.
- Executions – фреймворки, использующиеся для создания потоковых пулов, а также при планировании асинхронных задач, для которых нужно выводить результаты.
- Locks – альтернативные способы синхронизации.
- Atomics – классы, поддерживающие атомарные операции со ссылками/различными примитивами.
Каждый «пакет» имеет собственные классы Java. Они отвечают за те или иные манипуляции при коддинге. Полную информацию о них можно изучить по этой ссылке.
Планирование задач операционной системы
Потоки — это наименьшие единицы обработки, которые могут быть выполнены операционной системой. Они позволяют разделять логику приложения на несколько параллельных путей выполнения. Потоки полезны, когда сложные приложения имеют много задач, которые могут выполняться одновременно.
Когда операционная система выполняет экземпляр приложения, она создает модуль, называемый процессом, для управления экземпляром. Процесс имеет поток выполнения. Это ряд программных команд, выполненных кодом приложения. Например, если простое приложение содержит один набор инструкций, которые можно выполнить последовательно, этот набор инструкций обрабатывается как одна задача и существует только один путь выполнения (или поток) приложения. Более сложные приложения могут иметь несколько задач, которые могут выполняться одновременно, а не последовательно. Для этого приложение может запустить для каждой задачи отдельные процессы, которые являются ресурсоемкими, или запустить отдельные потоки, которые являются относительно менее ресурсоемкими. Кроме этого, каждый поток можно запланировать для выполнения независимо от других потоков, связанных с процессом.
Потоки позволяют сложным приложениям более эффективно использовать ЦП, даже на компьютерах с одним ЦП. С одним ЦП только один поток может выполняться одновременно. Если один поток выполняет длительную операцию, которая не использует ЦП, например считывание с диска или запись на диск, другой поток может выполняться, пока первая операция не завершится. Возможность выполнять потоки, в то время как другие потоки ожидают завершения операции, позволяет приложению увеличить использование ЦП. Это особенно касается многопользовательских приложений, интенсивно использующих операции дискового ввода-вывода, например сервера базы данных. Компьютеры с несколькими ЦП могут одновременно выполнять один поток для каждого ЦП. Например, если компьютер имеет восемь ЦП, он может выполнять одновременно восемь потоков.
Способы запуска потоков
Приложение, создающее экземпляр класса Thread, должно предоставить код, который будет работать в этом потоке. Существует два способа, чтобы добиться этого:
Предоставить реализацию объекта Runnable. Интерфейс Runnable определяет единственный метод — run, который должен содержать код, выполняющийся в потоке. Объект Runnable передается конструктору Thread. Например:
public class HelloRunnable implements Runnable {
public void run() {
System.out.println("Hello from a thread!");
}
public static void main(String args[]) {
(new Thread(new HelloRunnable())).start();
}
}
Использовать подкласс Thread. Класс Thread сам реализует Runnable, хотя его метод run не делает ничего. Можно объявить класс Thread подклассом, предоставляя собственную реализацию метода run, как в примере:
public class HelloThread extends Thread {
public void run() {
System.out.println("Hello from a thread!");
}
public static void main(String args[]) {
(new HelloThread()).start();
}
}
Обратите внимание, что оба примера вызывают Thread.start, чтобы запустить новый поток. Какой из способов выбрать? Первый — с использованием объекта Runnable — более общий, потому что этот объект может превратить отличный от Thread класс в подкласс
Этот способ более гибкий и может использоваться для высокоуровневых API управления потоками
Какой из способов выбрать? Первый — с использованием объекта Runnable — более общий, потому что этот объект может превратить отличный от Thread класс в подкласс. Этот способ более гибкий и может использоваться для высокоуровневых API управления потоками.
Второй способ больше подходит для простых приложений, но есть условие: класс задачи должен быть потомком Thread.
Определение многопоточности
Многопоточность Java – это поддержка одновременной работы более одного потока. В процессе выполнения приложения некоторые «операции» осуществляются параллельно друг другу, да еще и в «фоновом» режиме. Наглядные примеры:

- сигнальная обработка;
- операции с памятью;
- управление системой устройства/софта.
Приложение примет только первый поток. За счет многопоточности осуществляется одновременный прием и обработка нескольких потоков в рамках одной и той же утилиты.
Важно: многопоточность не имеет места с процессорами одноядерного типа. Там время процессорного характера делится между несколькими процессами и «открытыми» потоками
Состояния потоков
Потоки могут пребывать в нескольких состояниях:
- New – когда создается экземпляр класса Thread, поток находится в состоянии new. Он пока еще не работает.
- Running — поток запущен и процессор начинает его выполнение. Во время выполнения состояние потока также может измениться на Runnable, Dead или Blocked.
- Suspended — запущенный поток приостанавливает свою работу, затем можно возобновить его выполнение. Поток начнет работать с того места, где его остановили.
- Blocked — поток ожидает высвобождения ресурсов или завершение операции ввода-вывода. Находясь в этом состоянии поток не потребляет процессорное время.
- Terminated — поток немедленно завершает свое выполнение. Его работу нельзя возобновить. Причинами завершения потока могут быть ситуации, когда код потока полностью выполнен или во время выполнения потока произошла ошибка (например, ошибка сегментации или необработанного исключения).
- Dead — после того, как поток завершил свое выполнение, его состояние меняется на dead, то есть он завершает свой жизненный цикл.
Как создавать потоки: способы реализации
Пока не рассмотрены примеры многопоточности в языке Java, стоит уяснить, каким образом создаются threads. Существуют различные варианты развития событий. Все зависит от того, какие задачи предстоит реализовывать.
Создание потоковых «элементов» возможно через:
- класс, реализующий Runnable;
- классы, расширяющие Thread;
- реализацию java.util.concurrent.Callable.
Первый вариант встречается на практике чаще всего. Связано это с тем, что Java реализует интерфейс не в единственном количестве. Это дает возможность наследования классов.
Метод Runnable
На практике все перечисленные способы создания threads не слишком трудно реализовать. В случае с Runnable потребуется:
- создать объект класса thread;
- сделать class object, который реализовывает интерфейс Runnable;
- вызвать метод start() у объекта thread.
Все это поможет сделать new thread, а затем использовать его.
Метод Thread
Еще один вариант – наследование. Для этого предстоит:
- сделать class object ClassName extends Thread;
- обеспечить предопределение run() в соответствующем классе.
Позже будет приведен пример, в котором осуществляется передача имени потока «Second»
Через Concurrent
В этом случае потребуется:
- сделать объект класса, работающего с интерфейсом Callable;
- обеспечить создание ExecutorService, в котором пользователь указывает пул потокового характера;
- создать Future object.
Последний шаг осуществляется путем внедрения метода submit.
Процессы
Процессы являются контейнерами. Их основная задача – изолировать программы друг от друга, чтобы одна не могла получить доступ к памяти другой.
В контексте Python каждому процессу выделен свой интерпретатор. Когда мы запускаем несколько процессов из кода, то мы обнаруживаем такое же количество процессов в мониторинге системы.
Небольшой пример создания процессов:
Процессы представлены как экземпляр класса Process из встроенной библиотеки multiprocessing.
У нас есть функция, которая принимает 1 параметр и печатает приветствие с переданным параметром. Внутри конструкции if мы создаем два процесса p1 и p2 в качестве параметров, то есть мы передаем:
target – с названием выполняемой функции,
args – параметры для функции, которую мы будем вызывать,
daemon – с флагом True, который говорит нам, что процесс будет являться «демоном» – об этом чуть позже.
Для того чтобы процесс стартовал, мы вызываем у каждого метод .start().
Но ниже мы вызываем еще и метод .join().
Для чего нужен join() и что такое daemon? Или основные и фоновые процессы
У нас есть основной (главный) процесс, который содержит весь код нашей программы, и два дополнительных (фоновых) p1, p2. Их мы создаем, когда мы прописываем параметр daemon=True. Так мы как раз и указываем, что эти два процесса будут второстепенными. Если мы не вызовем метод join у фонового процесса, то наша программа завершит свое выполнение, не дожидаясь выполнения p1 и p2.
Немного теории о процессах
Процессы не могут работать параллельно на одноядерной машине.
Параллельное вычисление – выполнение двух и более задач одновременно, когда каждое ядро процессора берет задачу и выполняет ее. На многоядерной машине параллельное вычисление – нормальная практика. Однако количество ядер у нас ограничено, причем весьма сильно, а процессов в системе работает много.
Познакомимся с еще одним термином — вытесняющая многозадачность.
Вытесняющая многозадачность — это такой способ управления задачами, при котором решение о переключении процессора с выполнения одного процесса на выполнение другого принимается планировщиком операционной системы.
Предположим, что у нас одноядерный процессор и ему приходится выполнять работу множества программ одновременно. Как он это делает?
В этом случае каждой программе выделяется небольшой промежуток времени, то есть программы конкурируют за доступ к ядру. Процессор сам переключает контекст выполнения, и таким образом создается впечатление, что программы работают одновременно. Но это не совсем так.
Проще говоря, одна программа поработала какое-то время, и процессор переключает контекст на другую, чтобы она выполнила запланированные действия, передала обратно и так далее.
Когда количество процессов превышает количество ядер, на помощь приходит конкурентное вычисление.
Потоки – что это и с чем их едят
В Java поток – это единица реализации программного кода. Последовательность данных, которая могут работать параллельно с другими своими «аналогами».
Поток отвечает за выполнение инструкций запущенного процесса, к которому он относится. Все это происходит параллельно с иными потоками этого же process. Является легковесным. Может «общаться» с другими потоками. Для реализации поставленной задачи требуется применение специальных методов.
Какими могут быть потоки – классификация
Собеседование по Java и многопоточности обязательно предусматривает вопросы по «обычным» потокам в программировании. Стоит классифицировать оные. Это помогает разобраться, за что отвечает тот или иной «вариант».
Существует разделение потоков по типу движения информации:
- вводные – информация поступает в утилиту, после чего считывается;
- выводные – программа передает те или иные сведения, осуществляется запись в потоки.
Присутствует разделение по типу передаваемых электронных материалов. Не во всех случаях программисты используют байты. В Java и других языках может использоваться текст. На основании этого выделяют следующие потоки:
- символьные;
- байтовые.
У каждого приведенного примера существуют собственные абстрактные классы.
Принципы работы потоков
Перед использованием в Java многопоточности, нужно понимать, как будет работать каждая такая «операция». Многое зависит от того, какие манипуляции реализовываются. Чаще всего имеет место чтение и запись.
В Java потоки будут обладать примерно таким алгоритмом:
- Создается экземпляр необходимого потока.
- Последний открывается для дальнейшего считывания. При необходимости – для записи новой информации.
- Пользователь проводит задуманные изначально действия. В предложенном примере – чтение и запись информации.
- Осуществляется закрытие потока.
Создание и открытие экземпляра – это единый шаг. Остальные действия не реализовываются одновременно. Они воплощаются в жизнь последовательно.
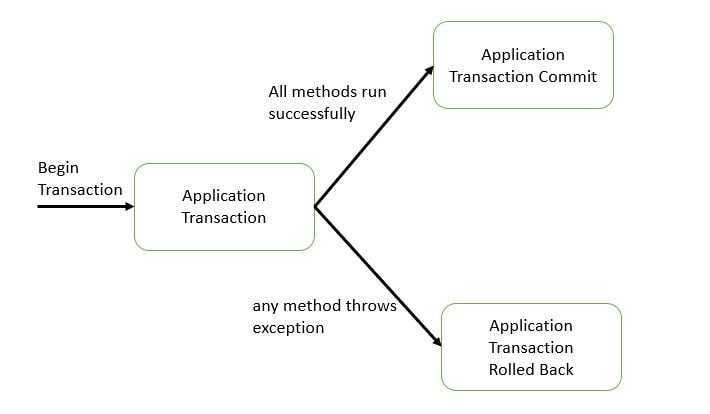
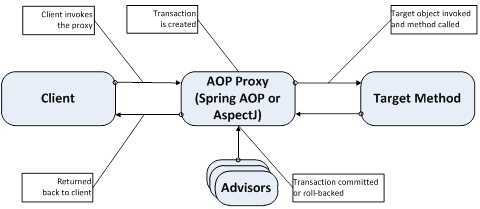
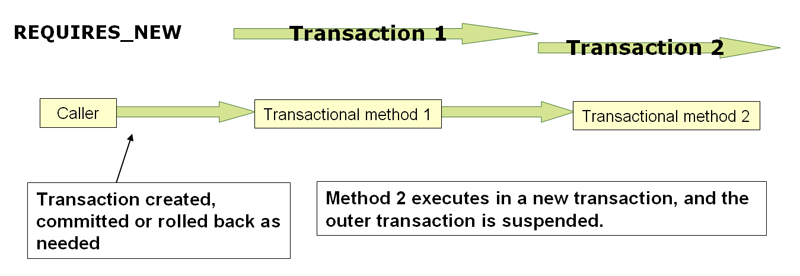
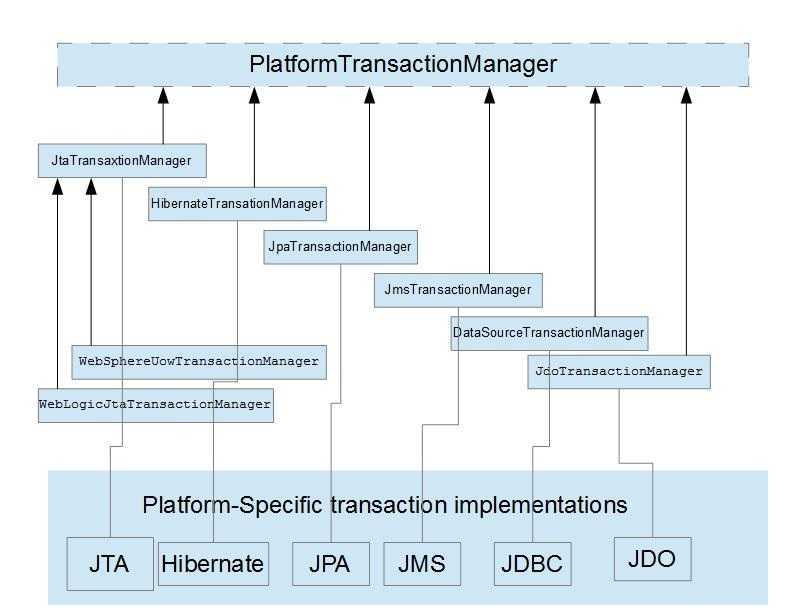
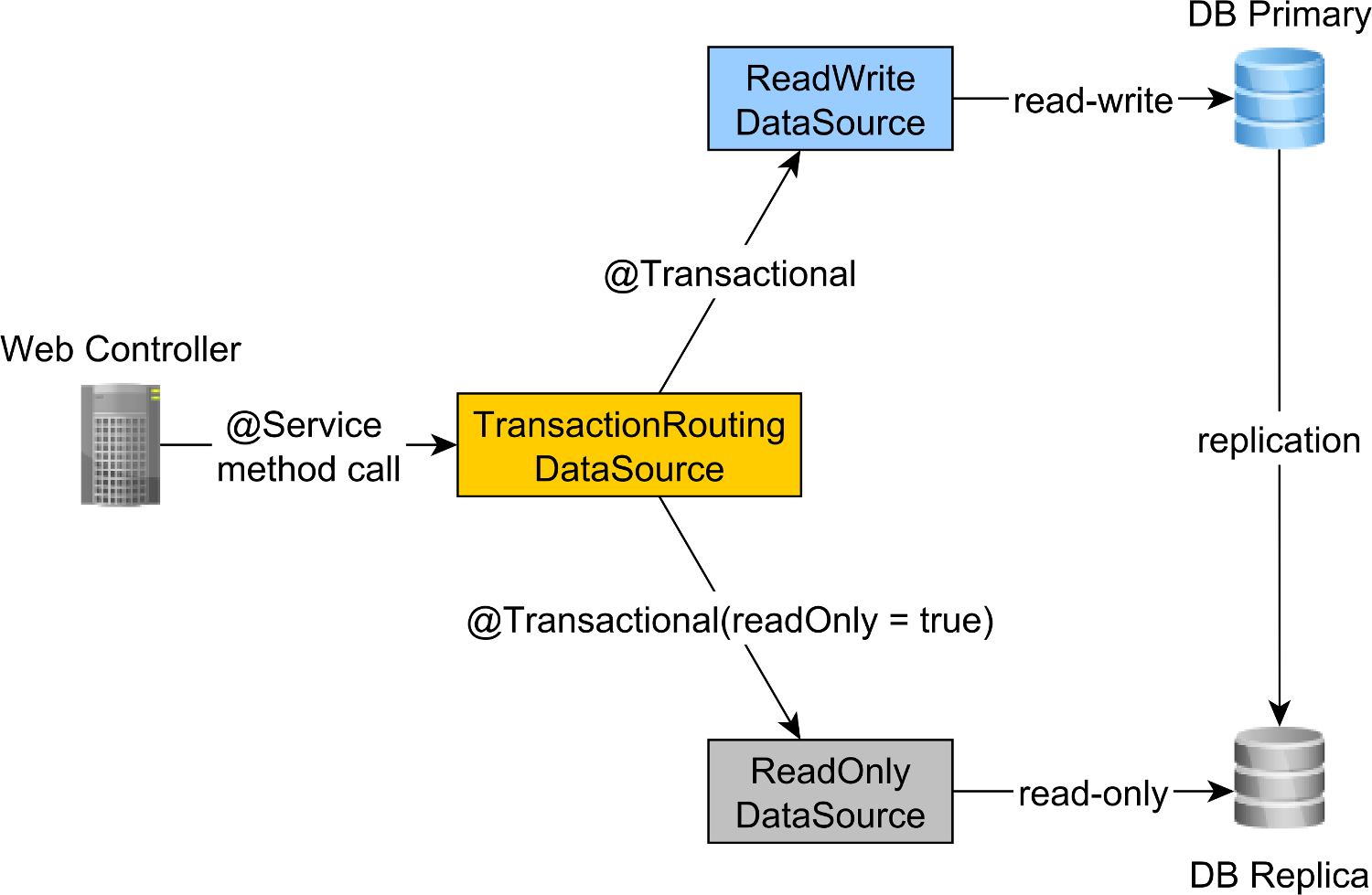
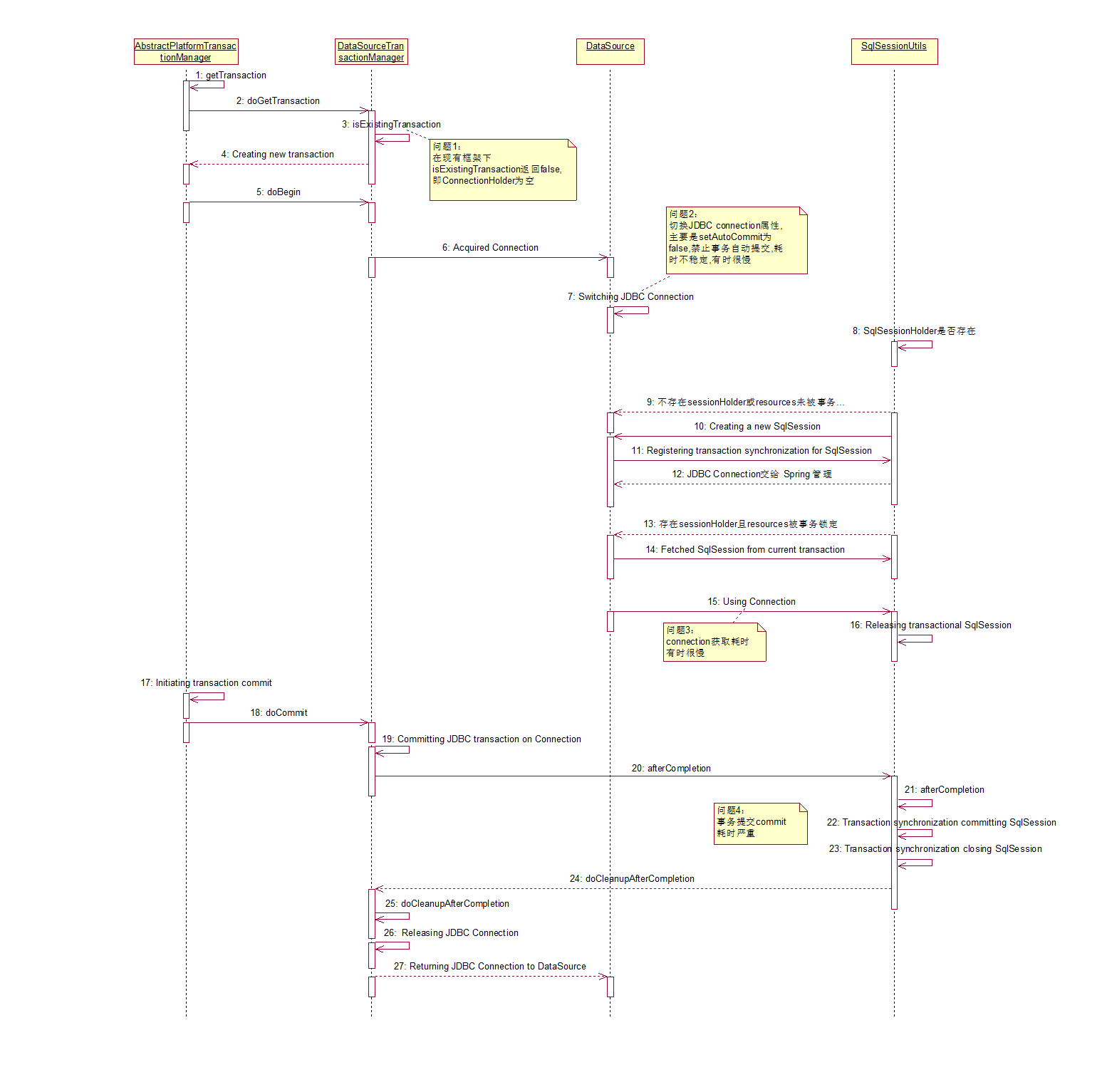
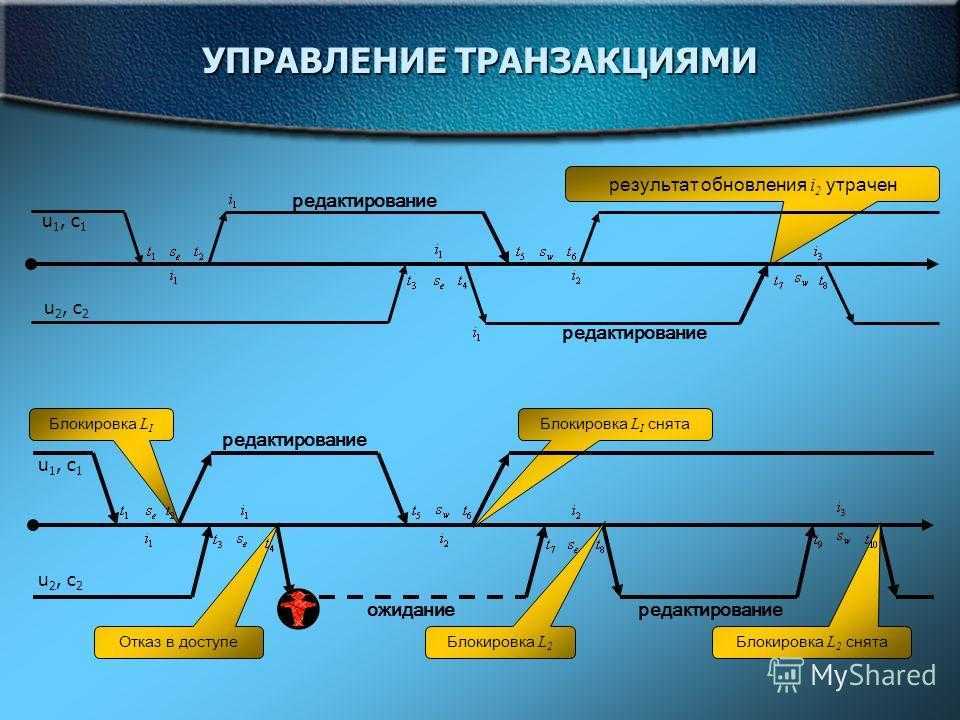
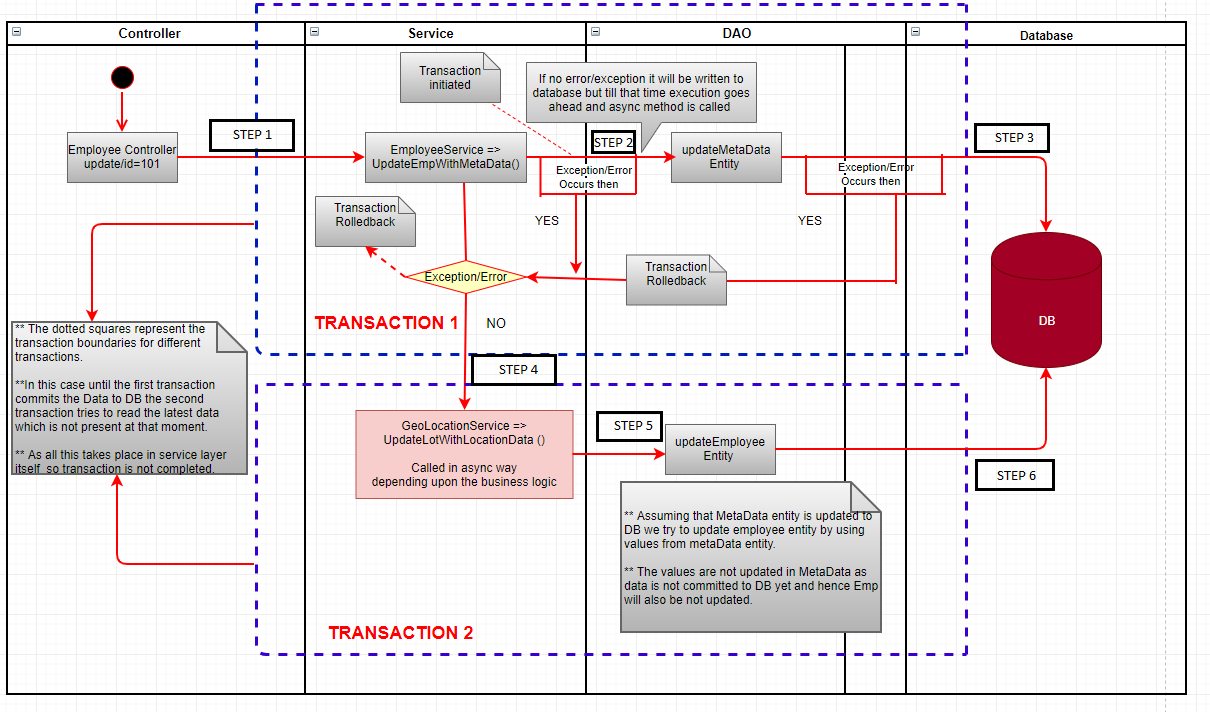
Чем хороши потоки
В процессе программирования можно использовать различные элементы и операции. Потоки в Java имеют ряд преимуществ. К ним относят:
- Относительную легкость по сравнению с процессами. Это позволяет минимизировать ресурсные затраты для функционирования приложения.
- Быстрое переключение софта.
- Упрощенную схему взаимодействия процессов между собой.
У мелких утилит есть всего одна «нить». Это – главная нить (main thread). Дополнительно могут запускаться иные потоки. Они будут носить название дочерних. Главный thread отвечает за выполнение метода main, после чего завершается.
Как выбрать стратегию распределенных транзакций
Как вы, возможно, уже догадались из этой статьи, не существует правильного или неправильного шаблона для обработки распределенных транзакций в архитектуре микросервисов. У каждого шаблона есть свои плюсы и минусы. Каждый шаблон решает одни проблемы, в свою очередь порождая другие. Таблица нг представляет собой краткое изложение основных характеристик для рассмотренных мною схем двойной записи.
Рисунок 12: Характеристики шаблонов двойной записи
Какой бы подход вы ни выбрали, вам необходимо будет объяснить и задокументировать мотивы выбора этого решения и долгосрочные архитектурные последствия вашего выбора. Вам также понадобится заручиться поддержкой команд, которые будут внедрять и поддерживать систему в долгосрочной перспективе.
Мне нравится организовывать и оценивать подходы, описанные в этой статье, на основе их атрибутов согласованности данных и масштабируемости, как показано на рисунке 13.
Рисунок 13: Характеристики относительной согласованности данных и масштабируемости шаблонов двойной записи
В качестве хорошей отправной точки мы могли бы оценить различные подходы — от наиболее масштабируемых и высокодоступных до наименее масштабируемых и доступных.
Высокий уровень масштабирования и доступности: параллельные конвейеры и хореография.
Если ваши шаги временно изолированы, тогда имеет смысл запустить их в методе параллельных конвейеров. Скорее всего, вы можете применить этот шаблон к определенным частям системы, но не ко всем. Далее, предполагая, что между этапами обработки существует временная связь, и определенные операции и службы должны выполняться раньше других, вы можете рассмотреть подход “хореография”. Используя хореографию сервисов, можно создать масштабируемую, управляемую событиями архитектуру, в которой сообщения перетекают от сервиса к сервису через децентрализованный процесс оркестровки. В этом контексте реализации шаблона “Исходящие” с Debezium и Apache Kafka (например, Red Hat OpenShift Streams для Apache Kafka ) особенно интересны и набирают обороты.
Средний уровень масштабирования и доступности: оркестровка и двухфазная фиксация
Если хореография не подходит, и вам нужна центральная точка, отвечающая за координацию и принятие решений, тогда вы можете подумать об оркестровке. Это популярная архитектура с доступными стандартными и пользовательскими реализациями с открытым исходным кодом. В то время как стандартная реализация может вынудить вас использовать определенную семантику транзакций, собственная реализация оркестровки позволит вам найти компромисс между желаемой согласованностью данных и масштабируемостью.
Низкий уровень масштабирования и доступности: модульный монолит
Если вы идете дальше влево, скорее всего, вам очень нужна согласованность данных, и вы готовы к большим компромиссам во всем остальном. В этом случае распределенные транзакции посредством двухэтапных фиксаций будут работать с определенными источниками данных, но их сложно надежно реализовать в динамических облачных средах, предназначенных для масштабируемости и высокой доступности. В этом случае вы можете полностью перейти к старому доброму модульному монолитному подходу, дополненному практиками, заимствованными из микросервисов. Такой подход обеспечивает высочайшую согласованность данных, но за счет связи среды выполнения и источника данных.
Параллельные конвейеры
В шаблоне хореография нет централизованного места для запроса состояния системы, но есть последовательность сервисов, которые распространяют состояние через распределенную систему. Хореография создает последовательный конвейер сервисов обработки, поэтому мы знаем, что когда сообщение достигает определенного шага бизнес-процесса, оно уже прошло все предыдущие шаги. Но что, если бы мы могли ослабить это ограничение и обработать все шаги независимо? В этом сценарии служба B может обработать запрос независимо от того, обработала его служба A или нет.
В подходе с параллельными конвейерами мы добавляем службу маршрутизатора, которая принимает запросы и перенаправляет их в службу A и службу B через брокера сообщений в одной локальной транзакции. Начиная с этого шага, как показано на рисунке 10, обе службы могут обрабатывать запросы независимо и параллельно.
Рисунок 10: Обработка через параллельные конвейеры
Хотя этот шаблон очень просто реализовать, он применим только в ситуациях, когда между службами нет временной привязки. Например, служба B должна иметь возможность обрабатывать запрос независимо от того, обработала ли служба A тот же запрос. Кроме того, этот подход требует дополнительной службы маршрутизатора или наличия у клиента информации об услугах A и B для отправки сообщений.
Слушай себя
Существует более легкая альтернатива этому подходу, известная как шаблон «Слушай себя» , в котором одна из служб также действует как маршрутизатор. При этом альтернативном подходе, когда служба A получает запрос, она не будет записывать изменения в свою базу данных, а вместо этого опубликует запрос в системе обмена сообщениями, где конечными потребителями являются служба B, и сам сервис А. Рисунок 11 иллюстрирует этот подход.
Рисунок 11: Шаблон «Слушай себя»
Причина отказа от записи в базу данных состоит в том, чтобы избежать двойной записи. Как только сообщение попадает в систему обмена сообщениями, оно отправляется в службу B, а также возвращается в службу A в совершенно отдельном контексте транзакции. Благодаря такому развороту потока обработки служба A и служба B могут независимо обрабатывать запрос и писать в свои соответствующие базы данных.
Преимущества и недостатки параллельных конвейеров
В таблице 5 приведены преимущества и недостатки использования параллельных конвейеров.
|
Преимущества |
Простая масштабируемая архитектура для параллельной обработки. |
|
Недостатки |
Требуется временный демонтаж на независимые события; трудно понять глобальное состояние системы. |
|
Примеры |
Многоадресная рассылка и разделитель Apache Camel с параллельной обработкой. |
Итого
Отдельные процессы
Плюсы:
+ Работают параллельно.
+ Используют все ресурсы ядра процессора.
+ Можно загрузить все ядра процессора.
+ Изолированная память.
+ Независимые системные процессы.
+ Подходит для CPU bound операций.
Минусы:
-
Если необходимо использовать общую память, то необходимо синхронизировать, так как нет общих переменных.
-
Требуют больших ресурсов, так как запускают отдельный интерпретатор.
Используем там, где обрабатываемые данные не зависят от других процессов и данных. Например:
+ Расчет нейронных сетей.
+ Обработка изолированных фотографий.
+ Архивирование изолированных файлов.
+ Конвертация форматов файлов.
Отдельные потоки
Плюсы:
+ Работают параллельно.
+ Используют немного памяти.
+ Общая память.
Минусы:
-
Одновременный доступ к памяти может приводить к конфликтам.
-
Сложный код.
Используем там, где код много раз ожидает, пока выполнится задача. Например:
+ Работа с сетью.
Асинхронность
Плюсы:
+ Работает в одном процессе и в одном потоке.
+ Экономное использование памяти.
+ Подходит для I/O bound операций.
+ Работает конкурентно.
Минусы:
-
Сложность отладки.
-
CPU bound операции блокируют все задачи.
Используем там, где код много раз ожидает. Например:
+ Работа с сетью.
+ Работа с файловой системой.
Основываясь на конкретных плюсах и минусах, нам становится легче выбирать подход и грамотно использовать процессорное время и память. Хотя Python является мультипарадигменным языком общего назначения, на нем можно писать практически любые программы, используя любой подход. Но особенно приятно, когда ваш веб-сервис может держать в сотню раз больше соединений или отрабатывать запросы в 8 раз быстрее, обходясь меньшим количеством памяти.
Спасибо за внимание! Надеемся, что этот материал был полезен для вас.
Авторские материалы для разработчиков мы также публикуем в наших соцсетях – ВК и Telegram.



