
Пакеты брать будете?
Что еще из операций ввода-вывода у нас осталось? Правильно, сетевое взаимодействие. Здесь царит та еще чехарда — «официальные» утилиты меняются от релиза к релизу, что, с одной стороны, круто, потому что удобств становится больше, с другой — надо переучиваться каждый раз.
Скажем, какой утилитой смотреть существующие в системе интерфейсы? Кто сказал ? На современных системах ifconfig, как правило, уже вообще отсутствует, ибо есть
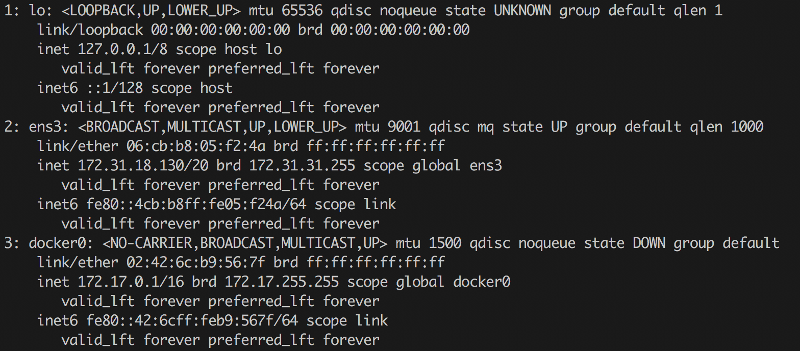
Вроде выглядит немного по-другому, а вроде то же самое. Кстати, для управления сетевыми мостами из консоли часто необходимо ставить пакет bridge-utils. Тогда в консольке появится утилита , с помощью которой можно будет их просматривать (), ну и менять. Но иногда бывает по-другому. Мне встречался случай, когда бриджи были, а brctl их не показывал. Оказалось, что для их создания использовался Open vSwitch и кастомный модуль ядра, для настройки которого надо взять другую утилиту — . Если вдруг у тебя окружение на OpenStack, где эта штука активно используется, — может быть полезно.
Дальше — как насчет таблиц маршрутизации? Как, говоришь, ? Нет, мимо. Сейчас чаще используются и . Ну и самое банальное — как посмотреть открытые порты и процессы, которые их запросили? Например, вот так:

Но думаю, ты уже понял, что банальщиной мы ограничиваться не будем. Давай посмотрим теперь в реальном времени, как пакеты бегают по интерфейсам.
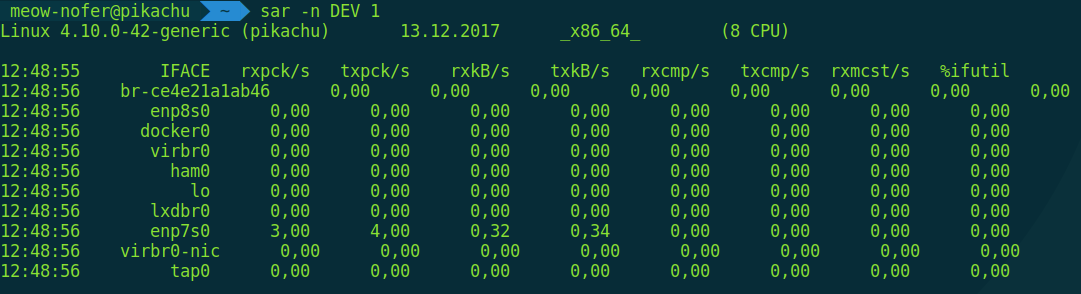
Да, sar — это еще одна отличная утилита для мониторинга. Умеет показывать не только сетевые операции, но и диски и активность процессора. Почитать о ней можешь, например, в статье «Простой мониторинг системы с помощью SAR».
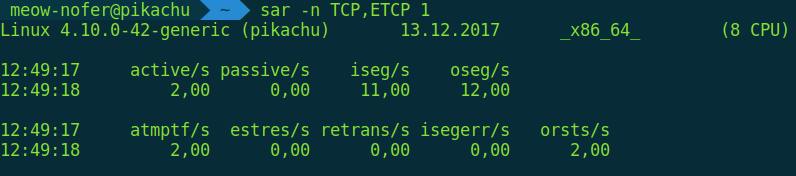
Также sar позволяет мониторить открытие/закрытие соединений и ретрансмиты (это повторные отправки тех же данных, когда сетевое оборудование сбоит или коннект крайне нестабильный, очень помогает траблшутить) в реальном времени.
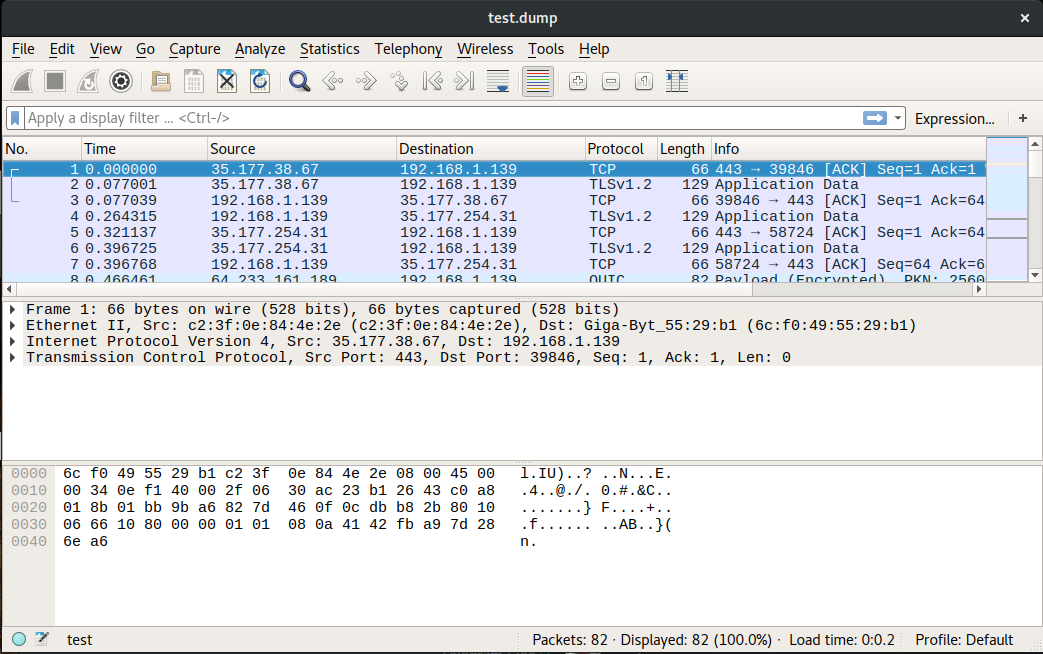
Ну и последнее — конечно, по порядку, а не по значению — это просмотр самого сетевого трафика. Чаще всего для этого используют две утилиты: tcpdump и wireshark. Первая — консольная, ей можно, к примеру, запустить прослушивание на всех интерфейсах и записать трафик в дамп-файл в формате pcap:
Вторая же — графическая. Из нее можно точно так же запустить прослушивание, а можно просто открыть в ней готовый файл дампа, слитый с удаленного сервера. И наслаждаться красотой слоев модели OSI (точнее, TCP/IP).
 Wireshark
Wireshark
Если тебя окружили демоны — логируй их немедленно!
Один из самых простых и банальных способов проверить, что происходит в системе, — это посмотреть системные логи. Вот тут можно почитать о том, какие секреты скрываются в каталоге и откуда они там берутся. До недавнего времени основным механизмом записи логов был syslog, точнее, его относительно современная реализация rsyslog. Она до сих пор активно используется, если интересно почитать, где там что, — можно глянуть, например, сюда.
А что в авангарде? В современных дистрибутивах Linux на основе systemd используется свой механизм логирования, которым можно управлять через утилиту journalctl. Там есть крайне удобная фильтрация по разным параметрам и прочие плюшки. Ссылка на хороший обзор.
Сам же systemd до сих пор остается довольно жарким топиком для обсуждения, поскольку «подминает» под себя многие устоявшиеся инструменты и предоставляет альтернативы к существующим решениям. Например, как запускать какой-то процесс регулярно? Crontab? Вовсе не обязательно, теперь у нас есть systemd timers. А как насчет настройки реакций на системные и «железные» события? В systemd есть поддержка watchdog. А что там со сменой корня — старый добрый chroot? Необязательно, теперь есть новенький systemd-nspawn.
Сам себе Большой Брат
Что вообще такое «мониторинг»? Поскольку я в свое время оканчивал химический университет, у меня это понятие четко ассоциируется с системами управления технологическими производствами. По сути, у нас есть ряд параметров сложной системы, которые мы отслеживаем, а по результатам можем, если необходимо, выполнить управляющее воздействие. Например, понизить давление в реакторе. А еще мы можем отправить уведомление оператору, который уже независимо примет то или иное управляющее решение.
У тех, кто далек от химии, но близок к IT, ассоциация немного другая, но в целом похожая — обычно это экран с кучей графиков, на которых творится какая-то магия, как в голливудских сериалах. Для многих администраторов так оно и выглядит — Graphite/Icinga/Zabbix/Prometheus/Netdata (нужное подчеркнуть) как раз рисуют красивый интерфейс, в который можно задумчиво глядеть, почесывая бороду и гладя свитер.
Большинство этих систем работают одинаково: на конечные ноды, за которыми мы хотим наблюдать, устанавливаются так называемые агенты, или коллекторы, а дальше все происходит по методике push или pull. То есть либо мы указываем этому агенту мастер-ноду, и он начинает периодически отсылать туда отчеты и heartbeat, либо же, наоборот, мы добавляем ноду в список для мониторинга на мастере, а тот уже, в свою очередь, сам ходит и опрашивает агенты о текущей ситуации.
Нет, я не буду рассказывать в подробностях, как настраивать подобные системы. Вместо этого мы голыми руками докопаемся до того, что вообще происходит в системе. Кстати, хороший перечень утилит для сисадмина приведен в статье Евгения Зобнина «Сисадминский must have». Настоятельно советую взглянуть.
Первоначальная настройка lm-sensors
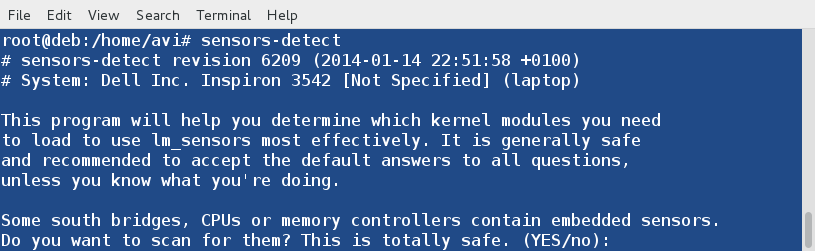
После установки запускаем процесс сканирования датчиков в системе.
После выполнения этой команды, программа начнет спрашивать вас о необходимости сканирования разных сенсоров (как в примере ниже).
Some south bridges, CPUs or memory controllers contain embedded sensors.
Do you want to scan for them? This is totally safe. (YES/no):
Впринципе, во всех случаях достаточно просто нажимать Enter, это будет выбирать значения предложенные программой по умолчанию. Под самый конец программа спросит разрешения добавить в файл модулей необходимые изменения, на что рекоммендуется ответить YES (по умолчанию будет предложено NO).
To load everything that is needed, add this to /etc/modules:
#—-cut here—-
# Chip drivers
coretemp
it87
#—-cut here—-
If you have some drivers built into your kernel, the list above will
contain too many modules. Skip the appropriate ones!Do you want to add these lines automatically to /etc/modules? (yes/NO)
После этого для работы программы нужно перезагрузить компьютер.
30. Linux Dash – Мониторинг производительности сервера Linux
Linux Dash представляет собой веб-панель, которая показывает вам самую важную информацию о ваших системах Linux, к этой информации относится RAM, CPU, файловая система, запущенные процессы, пользователи, использование канала сети в реальном времени, имеется приятный графический интерфейс, программа бесплатна, у неё открытый исходный код.
31. Cacti – Мониторинг сети и системы
Cacti – это веб-интерфейс для RRDtool, он часто используется для контроля использования сети, используя SNMP (Simple Network Management Protocol), также может использоваться для контроля использования центрального процессора.
Особенности Cacti
- Бесплатен, открыт, лицензия GPL.
- Написан на PHP в PL/SQL.
- Инструмент является кроссплатформенным, работает на Windows и Linux.
- Управление пользователями; вы можете создать различные пользовательские аккаунты для Cacti.
Где хранить коллекцию лютневой музыки
Если ты хоть раз размечал диск руками (например, при установке Arch Linux), то наверняка знаешь о существовании утилиты . С ее помощью проще всего посмотреть разделы на этом самом диске:
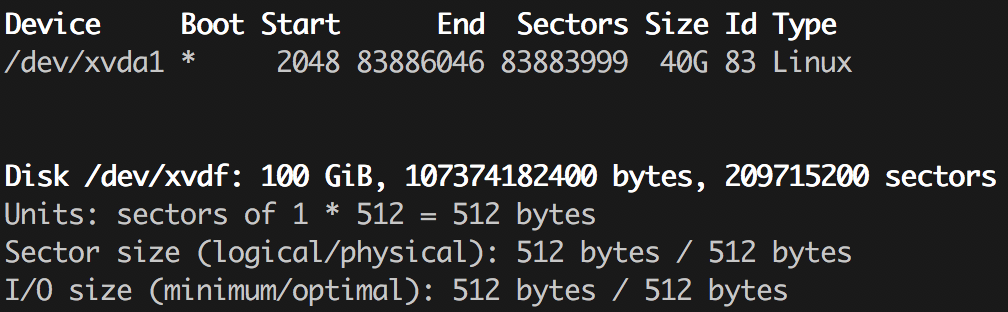
Есть ее более развесистая версия с псевдографическим интерфейсом, называется cfdisk, а также еще пара утилит, которые, на первый взгляд, делают весьма похожие вещи — позволяют управлять разделами на дисках. Это parted (к которому, кстати, есть неплохой GUI на GTK в лице gparted) и gdisk. Наличие такого зоопарка связано с тем, что существует несколько вариантов структурирования разделов на диске, и исторически для разных вариантов использовались разные программы. Наверняка ты уже встречал такие аббревиатуры, как MBR и GPT. Я не буду подробно останавливаться на различиях, но почитать можно, например, в статье «Сравнение структур разделов GPT и MBR». Там оно обсуждается с позиции настройки Windows, но суть от этого не меняется. И да, в современном же мире fdisk уже умеет работать с обоими вариантами, как и parted, поэтому выбирать можно исключительно из личных предпочтений.
Но вернемся к сбору информации. Мы знаем, какие у нас разделы, а теперь давай взглянем на дерево файловой системы, точнее, что куда смонтировано:
Как и раньше, тут отвечает за «человеческий» вывод размеров. Ну и как ты помнишь, размеры файлов у нас можно посмотреть командой :
Наверняка часть читателей сейчас подумала: «Ну что за банальщина, это даже школьники знают, давай чего посвежее». Ладно, давай привнесем реалтайма, как уже делали с оперативкой:
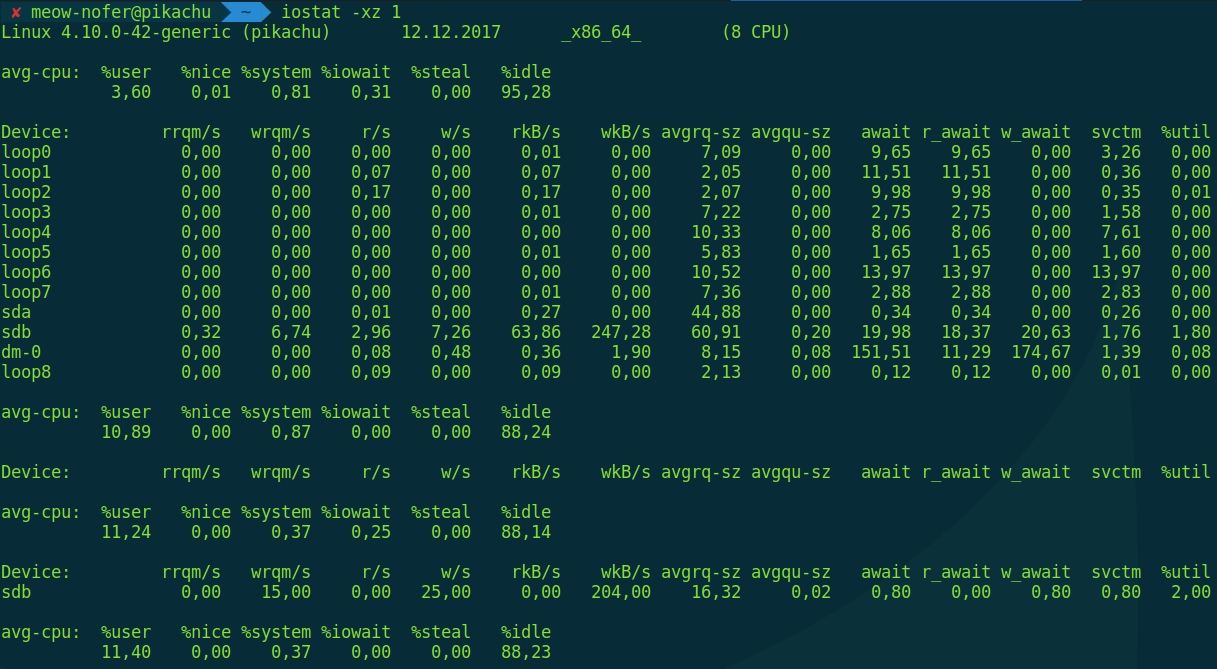
Эта команда выводит средние значения количества операций чтения-записи для всех блочных устройств в системе, обновляя информацию раз в секунду. Это больше «железные» параметры, поэтому есть еще одна команда для просмотра статистики I/O попроцессно, и она, по аналогии, называется iotop.
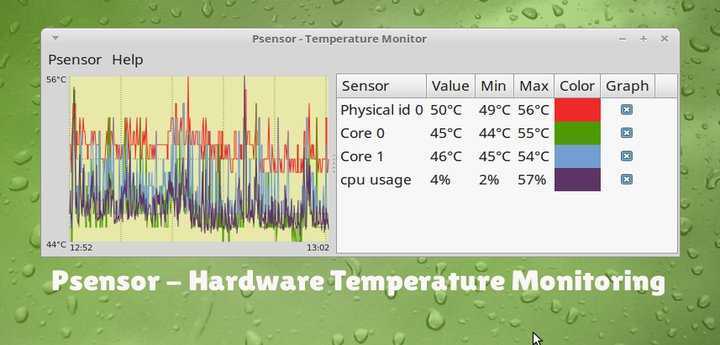
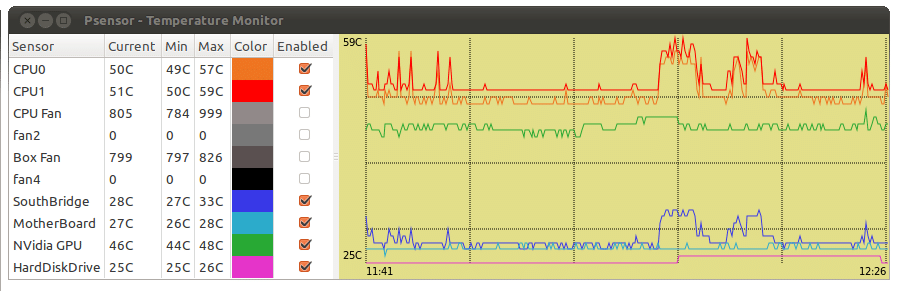
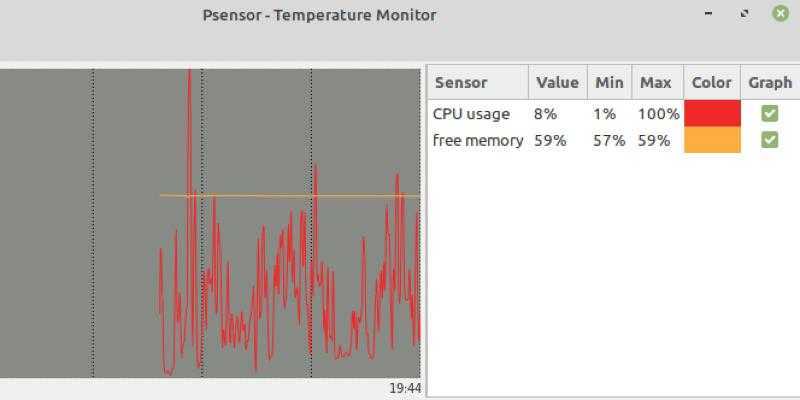
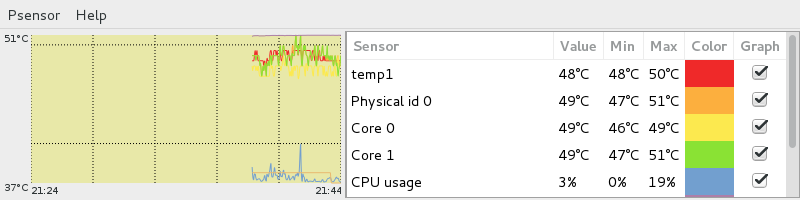
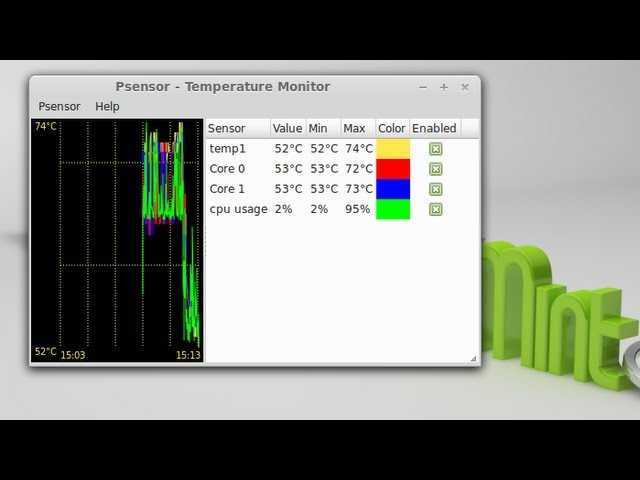
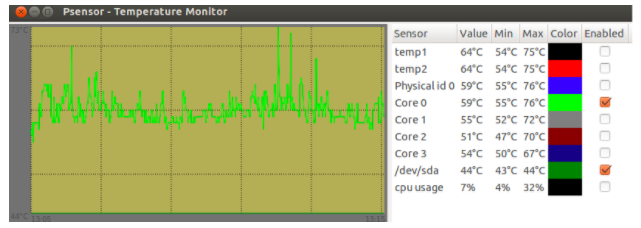
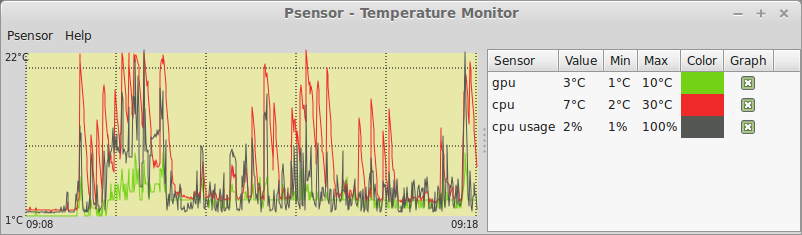
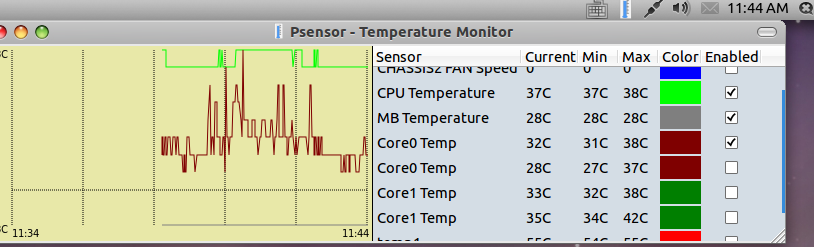
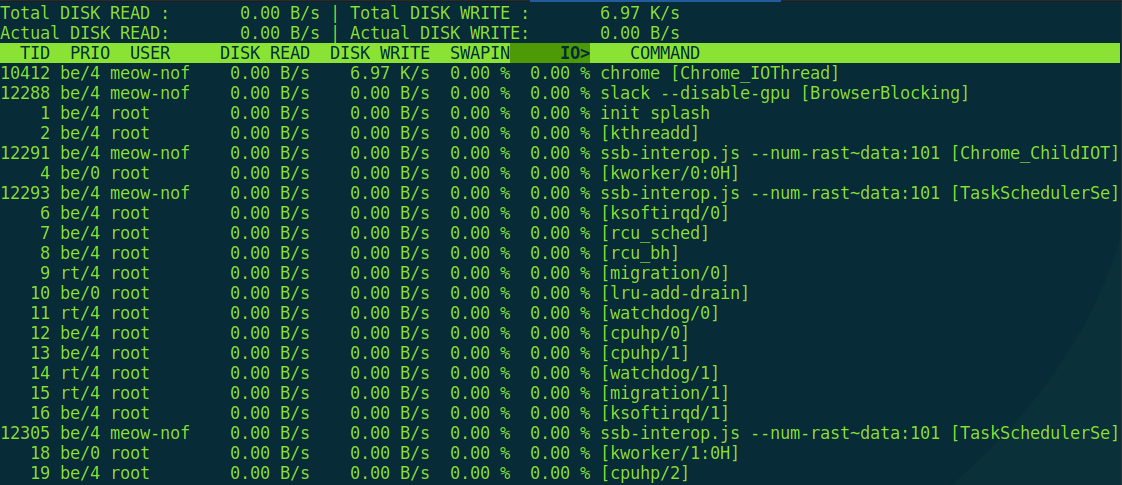
При попытке запуска без прав root она начнет очень мило оправдываться, что, мол, есть один такой баг CVE-2011-2494, который может приводить к утечке потенциально важных данных от одних пользователей другим, «поэтому настрой-ка ты, дружочек, sudo». Оно и верно.
Загрузка …
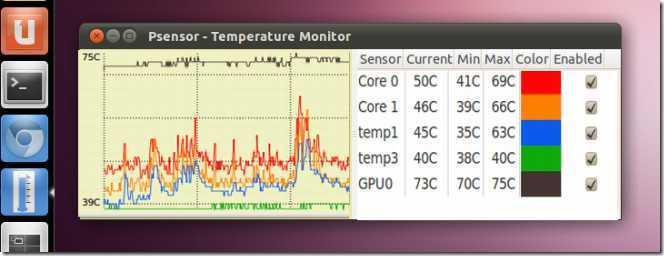
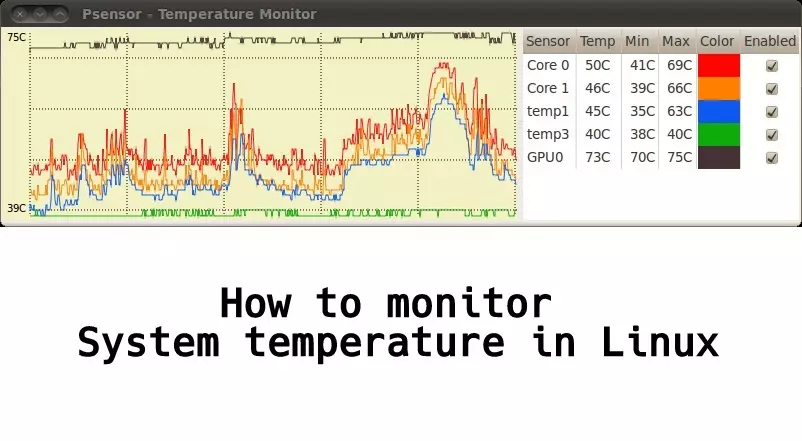
Psensor – GUI-мониторинг температур в Linux
После того, как установлены и настроены все основные инструменты для мониторинга температур. Такие как lm-sensors и hddtemp, можно (и даже нужно) для удобства вывести это в одном приложении с использованием графиков и лог-файлов. Для этого предназначена очень популярная в среде Linux утилита psensor. Она обладает графическим пользовательским интерфейсом и способна агрегировать данные от всех самых популярных утилит-провайдеров всевозможных системных параметров, таких как температуры, обороты вентиляторов, объём RAM и т. д. Пакет для установки также доступен практически в каждом дистрибутиве Linux и обычно называется «psensor».
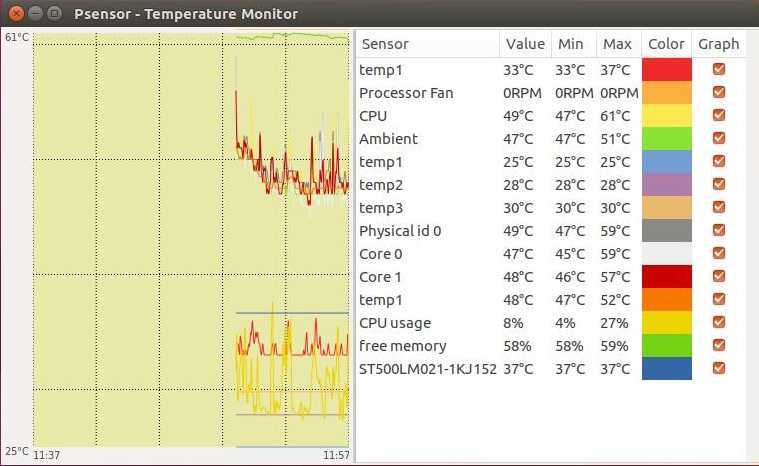
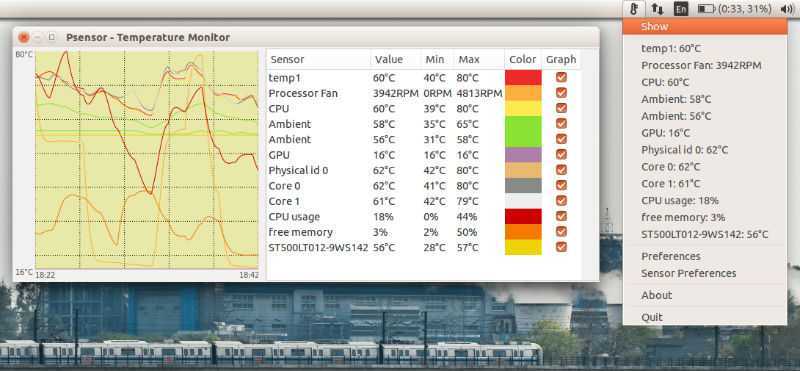
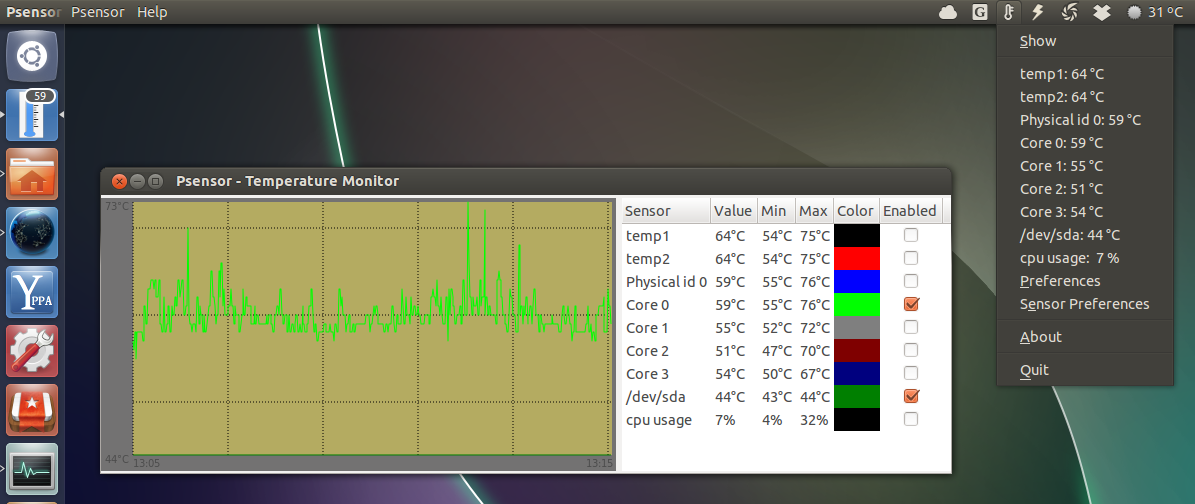
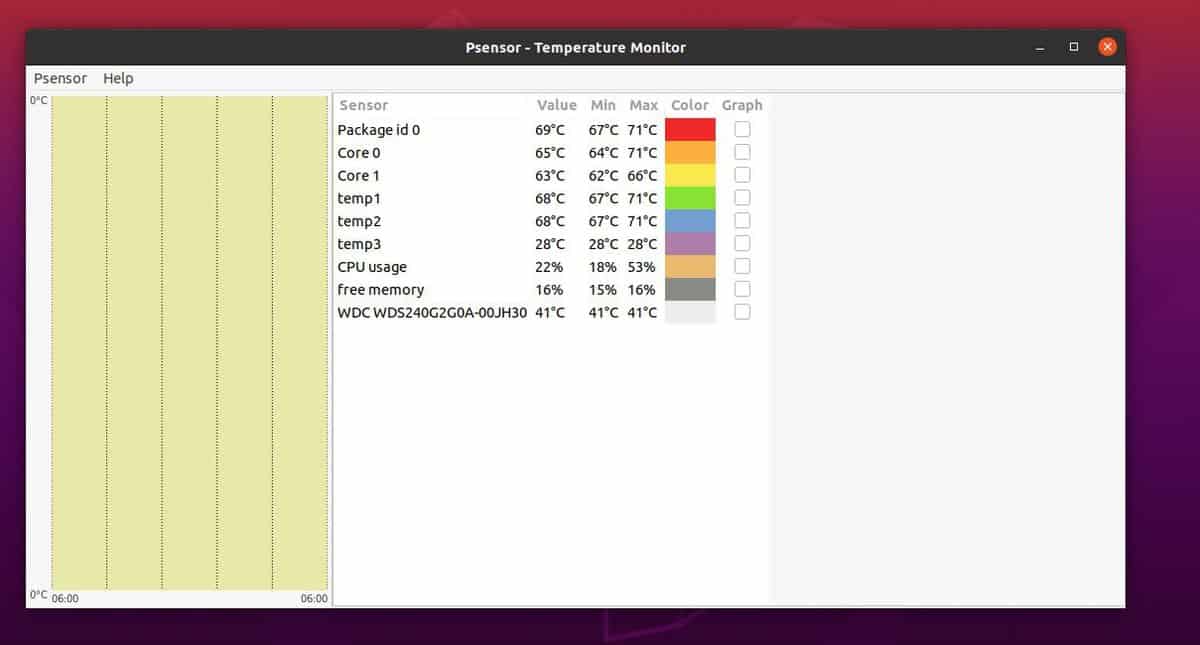
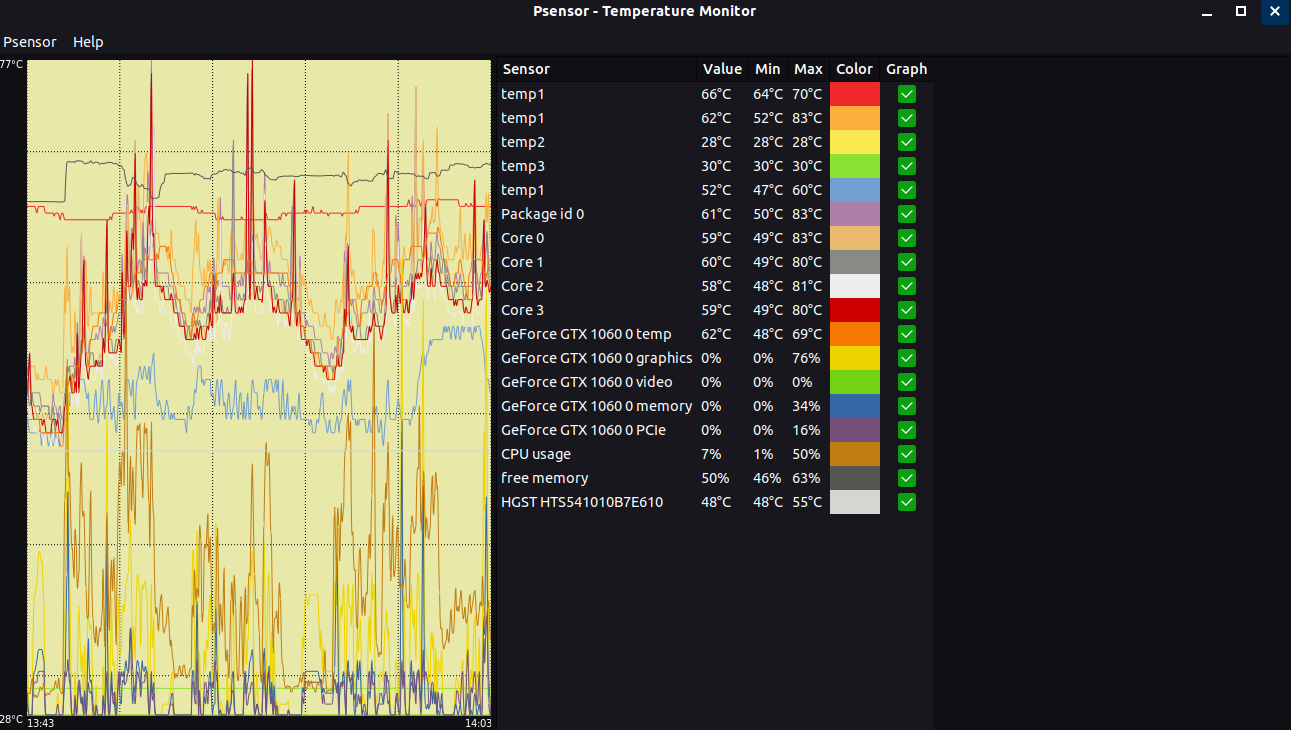
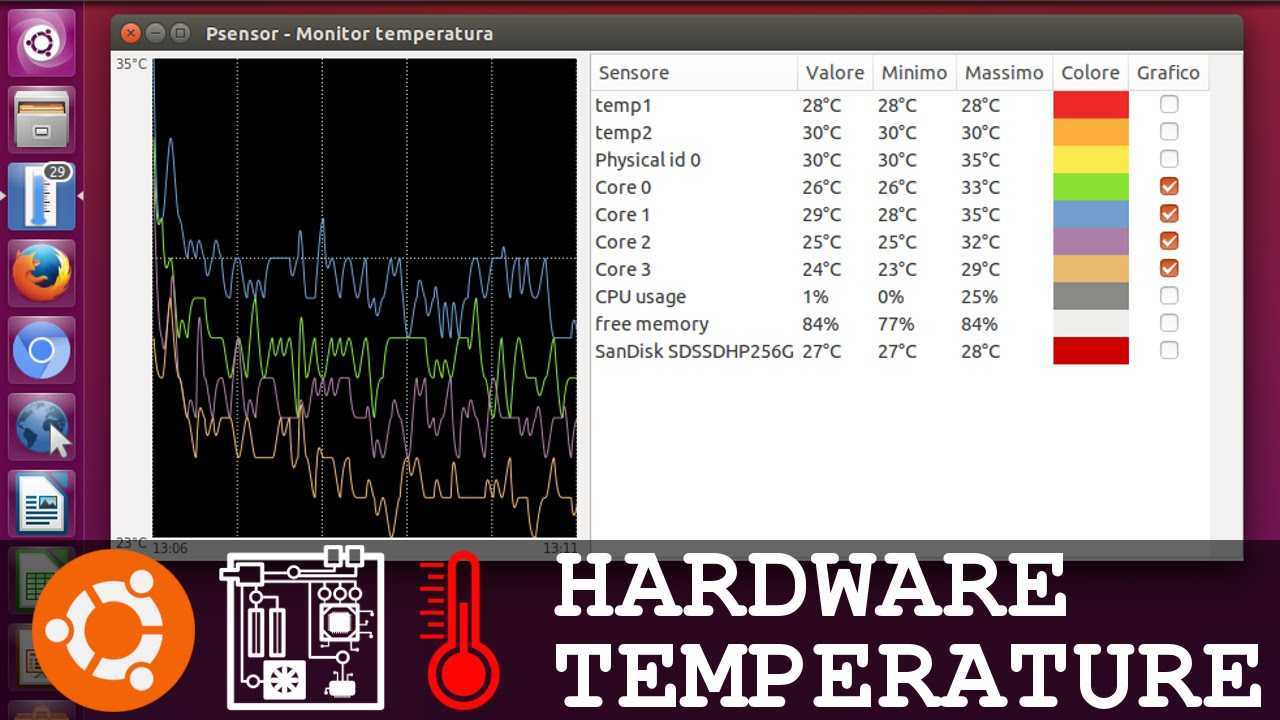
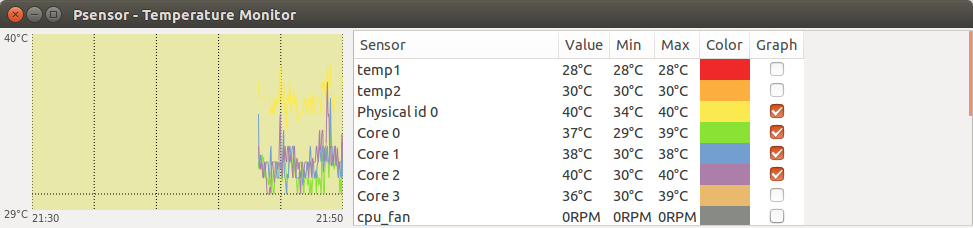
Psensor умеет довольно гибко управлять настройкой и отображением значений датчиков. Разобраться в пользовательском интерфейсе не составляет особого труда, он довольно прост:
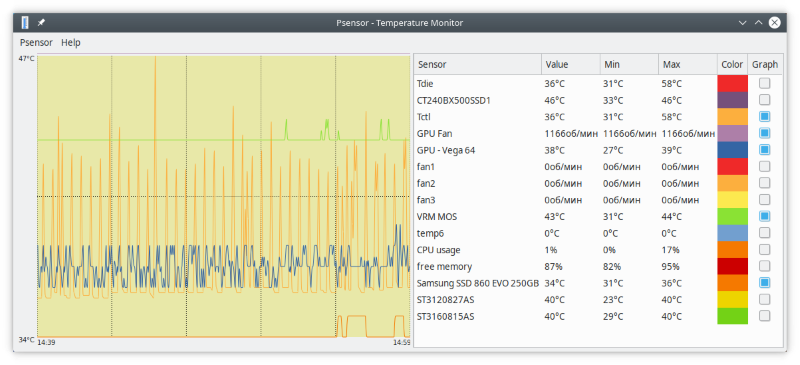 Рис. 1: Графическая утилита psensor — мониторинг температур, оборотов вентиляторов и других системных параметров в Linux .
Рис. 1: Графическая утилита psensor — мониторинг температур, оборотов вентиляторов и других системных параметров в Linux .
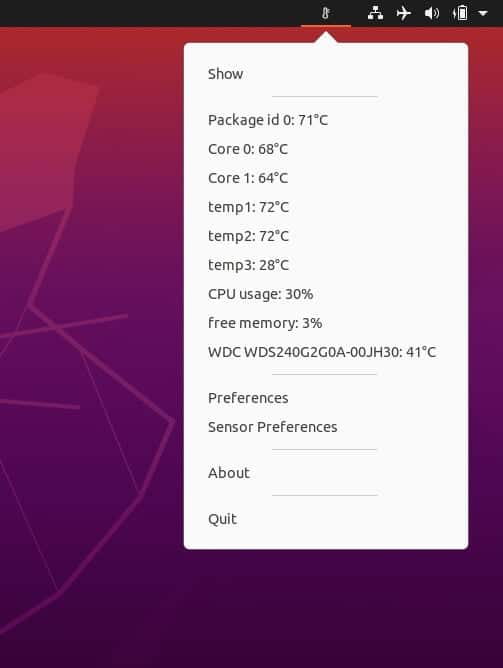
При запуске psensor обычно располагается в системном трее в виде значка термометра. Вызов главного окна psensor осуществляется из контекстного меню значка.
Использование lm-sensors
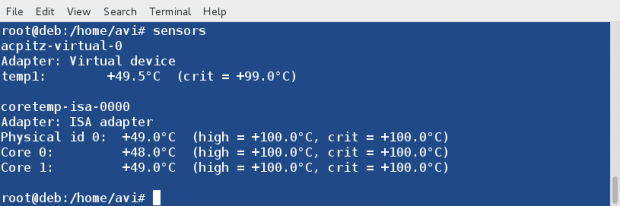
Затем можно будет посмотреть показания датчиков командой (можно выполнять без root привелегий):
В ответ получите примерно следующее:
acpitz-virtual-0
Adapter: Virtual device
temp1: +40.0°C (crit = +75.0°C)coretemp-isa-0000
Adapter: ISA adapter
Core 0: +42.0°C (high = +76.0°C, crit = +100.0°C)
Core 1: +42.0°C (high = +76.0°C, crit = +100.0°C)
Core 2: +46.0°C (high = +76.0°C, crit = +100.0°C)
Core 3: +42.0°C (high = +76.0°C, crit = +100.0°C)
atk0110-acpi-0
Adapter: ACPI interface
Vcore Voltage: +1.14 V (min = +0.85 V, max = +1.60 V)
+12V Voltage: +12.03 V (min = +10.20 V, max = +13.80 V)
+5V Voltage: +5.27 V (min = +4.50 V, max = +5.50 V)
+3.3V Voltage: +3.30 V (min = +2.97 V, max = +3.63 V)
MEMORY: +2.11 V (min = +1.33 V, max = +2.47 V)
+1.2V HT: +1.23 V (min = +1.08 V, max = +1.32 V)
NB: +1.31 V (min = +1.08 V, max = +1.32 V)
SB: +1.50 V (min = +1.35 V, max = +1.65 V)
CPU VTT: +1.10 V (min = +1.08 V, max = +1.32 V)
DDR2 TERM.: +1.06 V (min = +0.63 V, max = +1.17 V)
CPU PLL: +1.52 V (min = +1.35 V, max = +1.65 V)
CPU_FAN FAN Speed: 981 RPM (min = 800 RPM, max = 7200 RPM)
CHA_FAN1 FAN Speed: 518 RPM (min = 800 RPM, max = 7200 RPM)
CHA_FAN2 FAN Speed: 666 RPM (min = 800 RPM, max = 7200 RPM)
CHA_FAN3 FAN Speed: 0 RPM (min = 800 RPM, max = 7200 RPM)
OPT1 FAN FAN Speed: 0 RPM (min = 800 RPM, max = 7200 RPM)
OPT2 FAN FAN Speed: 0 RPM (min = 800 RPM, max = 7200 RPM)
OPT3 FAN FAN Speed: 0 RPM (min = 800 RPM, max = 7200 RPM)
POWER FAN Speed: 0 RPM (min = 800 RPM, max = 7200 RPM)
CPU Temperature: +32.0°C (high = +60.0°C, crit = +95.0°C)
MB Temperature: +39.0°C (high = +45.0°C, crit = +95.0°C)
OPT1: +0.0°C (high = +45.0°C, crit = +95.0°C)
OPT2: +0.0°C (high = +45.0°C, crit = +95.0°C)
OPT3: +0.0°C (high = +45.0°C, crit = +95.0°C)
Зачем следить за температурой оборудования?
Обычных пользователей этот вопрос, конечно, может совсем и не волновать. За температурами следят администраторы, геймеры, тестеры и оверклокеры. Представитель из каждой из обозначенных категорий деятельности делает это в целях, непосредственно связанных с родом деятельности
Так, например, для администратора критически важно не допустить перегрева, иначе велик риск завалить систему. Для тестеров важно выявить стабильные характеристики режимов работы оборудования в различных режимах использования. В том числе и температурных
Практически во всех случаях, когда речь идёт о комнатном использовании оборудования, в частности, компьютерного железа, важно не допускать именно высоких температур. Ведь вся современная электроника построена на полупроводниках. Для которых «комфортным» для рабочих температур является диапазон от -40 до +60 градусов по Цельсию. По этой причине все геймеры и оверклокеры так стремятся оснастить свои системы максимально эффективными системами охлаждения. Подобный подход позволяет существенно компенсировать температурный нагрев в самых требовательных приложениях и играх. А также при разгоне тех же процессоров и графических чипов
В том числе и температурных
Практически во всех случаях, когда речь идёт о комнатном использовании оборудования, в частности, компьютерного железа, важно не допускать именно высоких температур. Ведь вся современная электроника построена на полупроводниках
Для которых «комфортным» для рабочих температур является диапазон от -40 до +60 градусов по Цельсию. По этой причине все геймеры и оверклокеры так стремятся оснастить свои системы максимально эффективными системами охлаждения. Подобный подход позволяет существенно компенсировать температурный нагрев в самых требовательных приложениях и играх. А также при разгоне тех же процессоров и графических чипов.
5. Netstat – Статистика сети
Netstat – это инструмент командной строки для мониторинга статистики входящих исходящих сетевых пакетов, а также статистики интерфейсов. Это весьма полезный инструмент для каждого системного администратора для контроля производительности сети и решения проблем, связанных с сетью.
netstat -a | more Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 localhost.local:privoxy 0.0.0.0:* LISTEN tcp 0 0 localhost.localdom:9475 0.0.0.0:* LISTEN tcp6 0 0 :ssh :* LISTEN tcp6 0 0 :https :* LISTEN tcp6 0 0 :mysql :* LISTEN tcp6 0 0 :www-http :* LISTEN udp 0 0 HackWare:bootpc 0.0.0.0:* raw6 0 0 :ipv6-icmp :* 7 Active UNIX domain sockets (servers and established) Proto RefCnt Flags Type State I-Node Path unix 2 STREAM LISTENING 13574 /tmp/.X11-unix/X0 unix 2 STREAM LISTENING 13573 @/tmp/.X11-unix/X0 unix 2 DGRAM 11811 /run/user/120/systemd/notify unix 2 STREAM LISTENING 14509 @/tmp/dbus-l6VTvQ0c unix 2 STREAM LISTENING 11815 /run/user/120/systemd/private unix 2 STREAM LISTENING 11820 /run/user/120/bus unix 2 STREAM LISTENING 11822 /run/user/120/pulse/native
Command Line Tools
It’s a difficult task for every network or system administrator to monitor, analyze and debug Linux system performance problems frequently. This command line tools come handy when you keep an eye and want to know what’s going on inside your Linux system.
Top – Linux Process Monitor
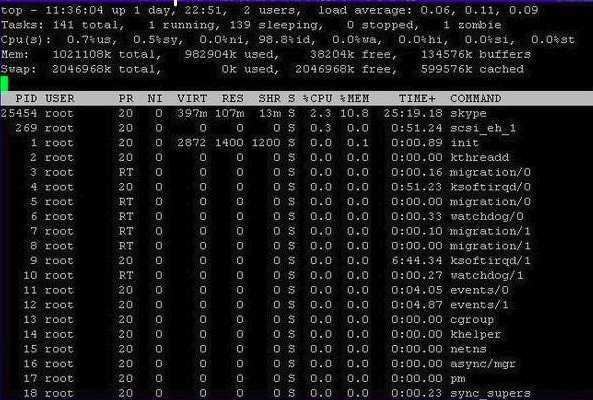
“Top” command is a Linux performance monitoring tool which comes pre-installed in many Linux or Unix system. “Top” command comes handy when you need to have an overview of all the threads or process running in the system.
It displays various system information including Memory usage, CPU usage, Swap Memory, Buffer Size, Cache Size, Process PID, etc. It also shows the excessive use of memory and CPU of a system running process.
Mytop
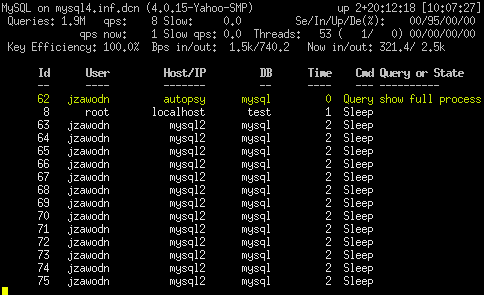
Mytop is a MySQL thread and performance monitoring tool which let you have a close look into the database and queries that’s processing in the real times.
Htop – Linux Process Monitor
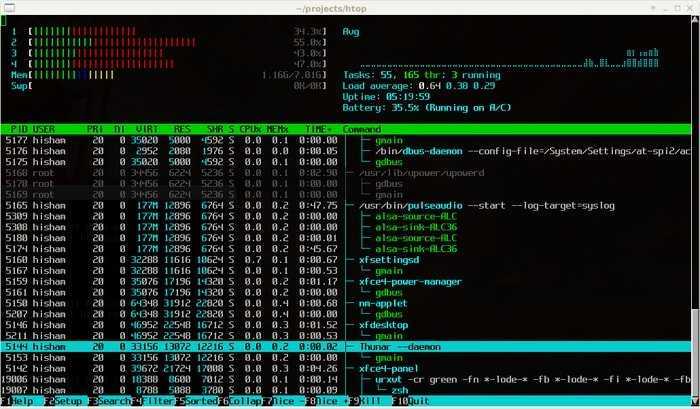
Htop is an advanced Linux process monitoring tool which is similar to “Top” but offers some rich features like interactive process viewer, vertical and horizontal process viewer, shortcut keys, etc. It’s a third-party Linux monitoring tool that doesn’t come pre-installed in Linux or Unix system. You need to download and install it in the system.
Atop – Performance Monitor for Linux
Atop is a Linux performance monitoring tool which provides reporting of all system threads or process, daily system logging, process activity for long-term data analysis, overloaded system resources, etc. It also shows the system activity on CPU, memory, swap, disks (including LVM) and network layers.
PowerTOP
If you want a simple tool that diagnoses issues with Linux systems power consumption and power management, then PowerTOP is the right tool. Moreover, it has an interactive mode where you can run the experiment with the various system-wide setting to get the best power management setting for the server.
iotop – Monitor Linux Disk I/O
Like “Top” command and “Htop” program, iotop is a python program to show you I/O usages data through “Top” like interface. This tool lets you monitor real-time disk I/O and process. Moreover, you can also check the high used disk read and write time for the threads or process.
Инструмент мониторинга Perf в Linux
В Linux инструмент Perf может анализировать ядро, приложения, системные библиотеки, события программного обеспечения с помощью команд и подкоманд. Его также можно использовать как PMU (блок мониторинга производительности) в Linux. Инструмент Perf написан на языке программирования C и построен под лицензией GNU GL. В этом посте мы увидим, как установить инструмент Perf в системе Linux и как его запустить.
1. Установите Perf в Ubuntu/Debian Linux
Системный мониторинг Perf и инструмент анализа поставляются с общими для Linux пакетами. Установить Perf в дистрибутивы Ubuntu или Debian Linux довольно просто. Во-первых, вы можете начать с обновления системного репозитория.
sudo apt update
Затем выполните следующую команду aptitude, приведенную ниже, чтобы установить общие инструменты Linux на свой компьютер. Следующая команда требует привилегий root; убедитесь, что вы являетесь пользователем root. Когда установка завершится, вы можете найти пакеты Perf в каталоге /usr/bin/perf.
sudo apt install linux-tools-common
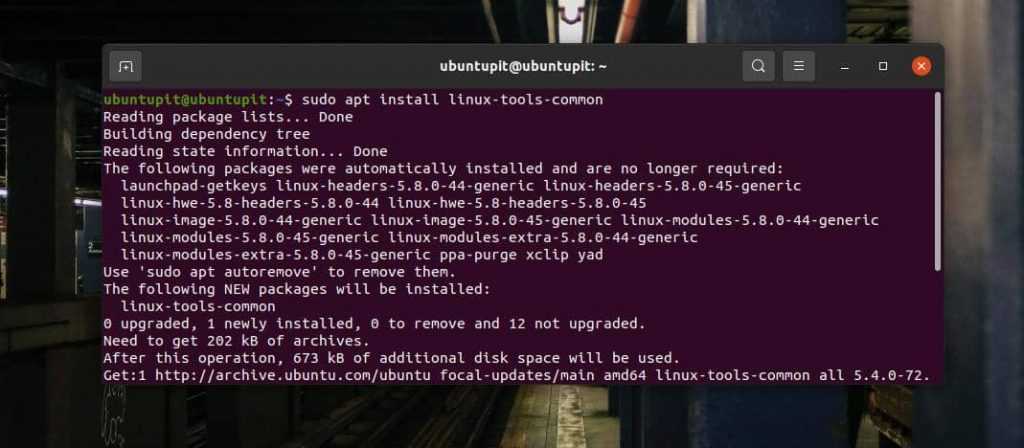
Поскольку Perf — это общий пакет Linux, убедитесь, что Perf совместим с вашим ядром Linux. Чтобы проверить ядро вашей системы, выполните следующую команду. Взамен вы получите версию своего ядра.
uname -r
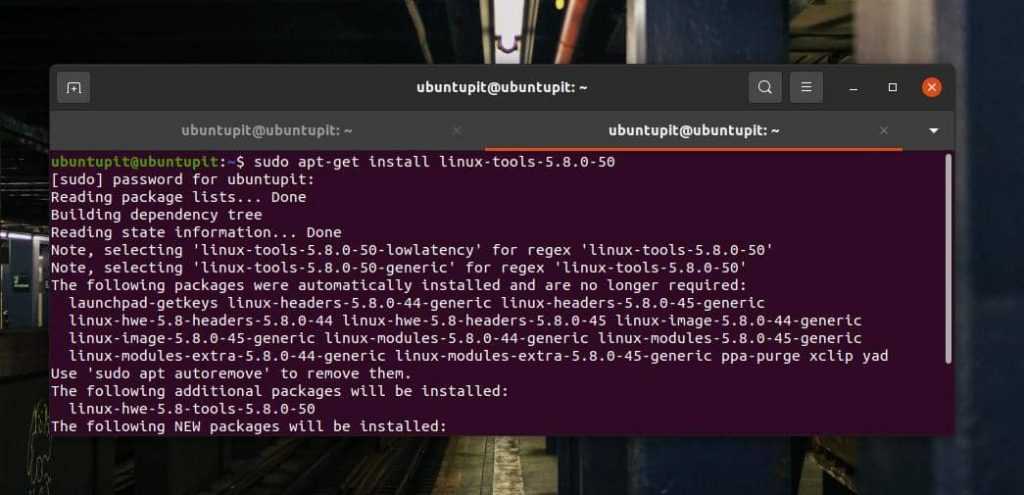
Теперь запишите версию своего ядра и напишите команду терминала, показанную ниже, для установки общих инструментов Linux, подходящих для вашего ядра.
sudo apt-get install linux-tools-5.8.0-50
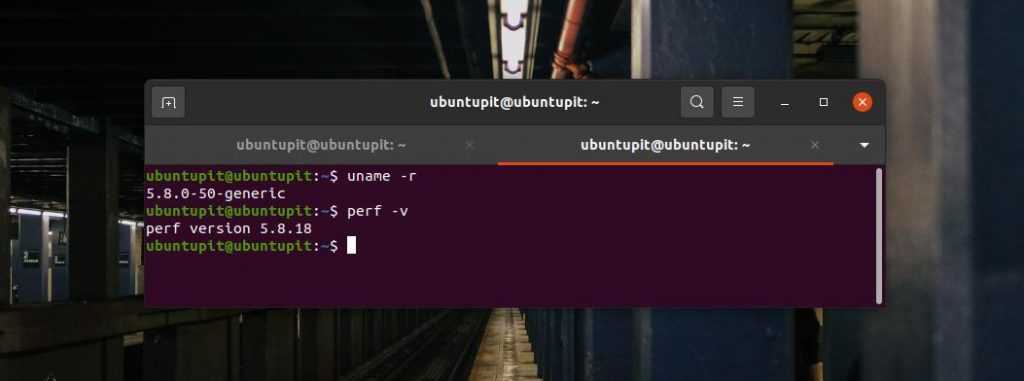
Теперь вы можете, наконец, запустить следующую команду, чтобы проверить версию Perf на вашем компьютере. В свою очередь, вы увидите, что Perf имеет ту же версию, что и ядро.
perf -v
2. Установка Perf в Fedora/Red Hat
Установить инструмент мониторинга системы Perf на Red Hat Linux или рабочую станцию Fedora проще, чем на Debian/Ubuntu. Вы можете запустить следующие команды YUM в оболочке терминала на вашем компьютере, установив инструмент Perf. Следующие команды требуют привилегий root; убедитесь, что он у вас есть.
yum update yum install perf
Если вы используете машину Red Hat на основе DNF, вы можете попробовать выполнить следующие команды в Perf установки оболочки.
dnf update dnf install perf
Когда установка завершится, не забудьте запустить команду проверки версии, чтобы узнать, работает инструмент или нет.
perf -v
3. Начните с Perf
До сих пор мы видели, как установить Perf в Ubuntu и в системе Red Hat/Fedora. Пора начать с этого. Вначале вы можете запустить команду , чтобы познакомиться с синтаксисами Perf.

perf --help
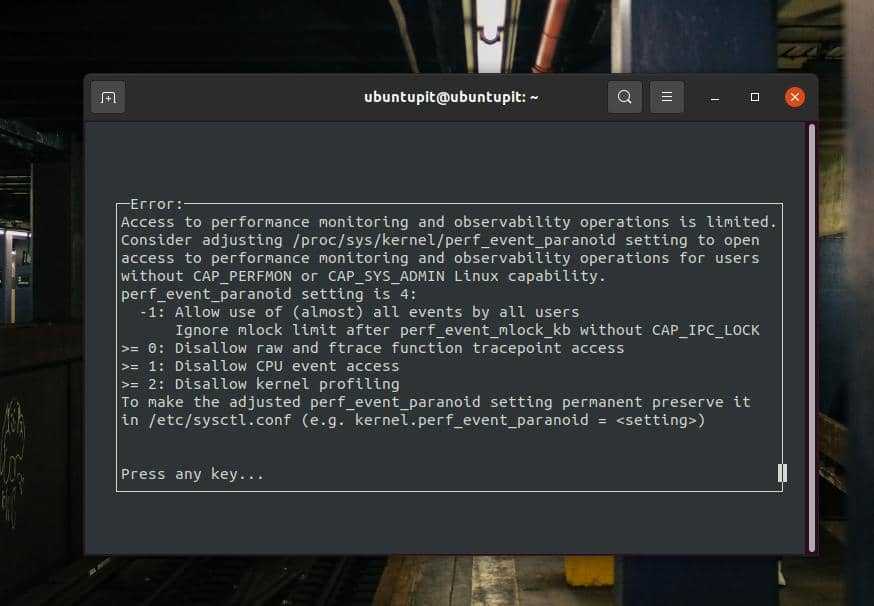
Здесь я покажу несколько важных и повседневных команд Perf. Для всех команд требуются привилегии root, и они выполняются во всех дистрибутивах Linux. Если вы видите сообщение об ошибке, как показано ниже, нет причин для беспокойства. Вам просто нужно вернуться в командную оболочку и повторно запустить команду с правами root.
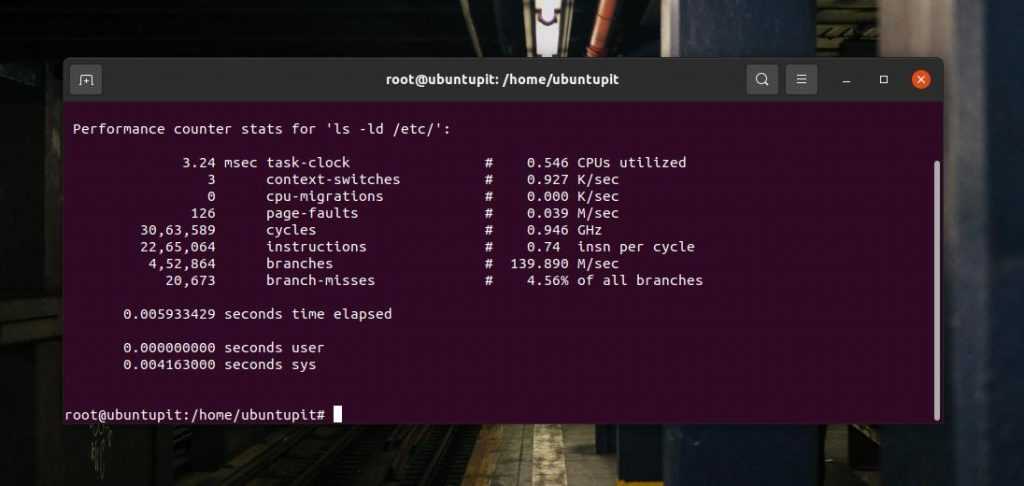
1. ls -ld
Команды могут выводить на печать состояние использования ЦП, циклы ЦП и другую статистику счетчиков производительности, связанных с ЦП.
perf stat ls -ld /etc/
2. list
В Linux инструмент Perf может распечатать все события ядра с помощью команды list. Он может создавать как подробные, так и статистические отчеты о событиях ядра.
perf list perf list stat
3. top
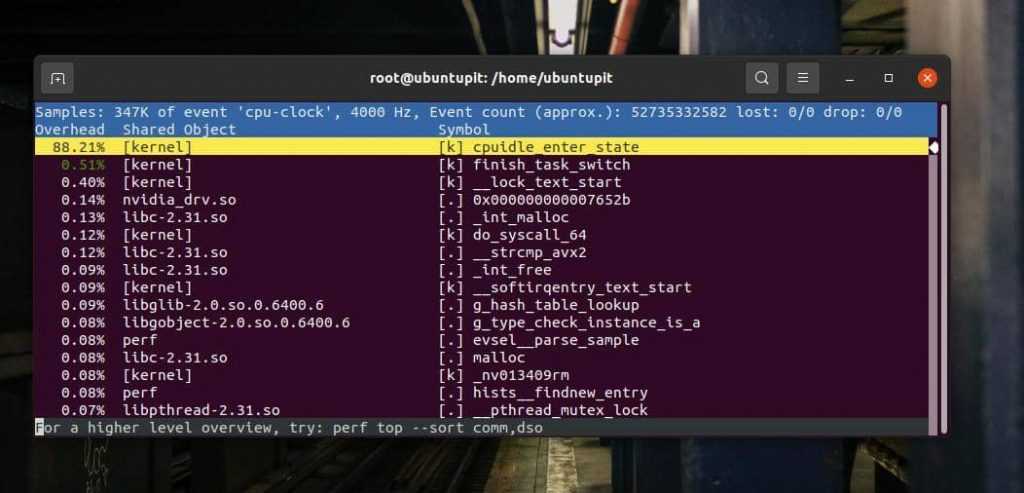
Следующая команда top может очень точно распечатать события тактовой частоты процессора и события ядра. Он также показывает процент использования ядра и процессора.
perf top -e cpu-clock
4. record
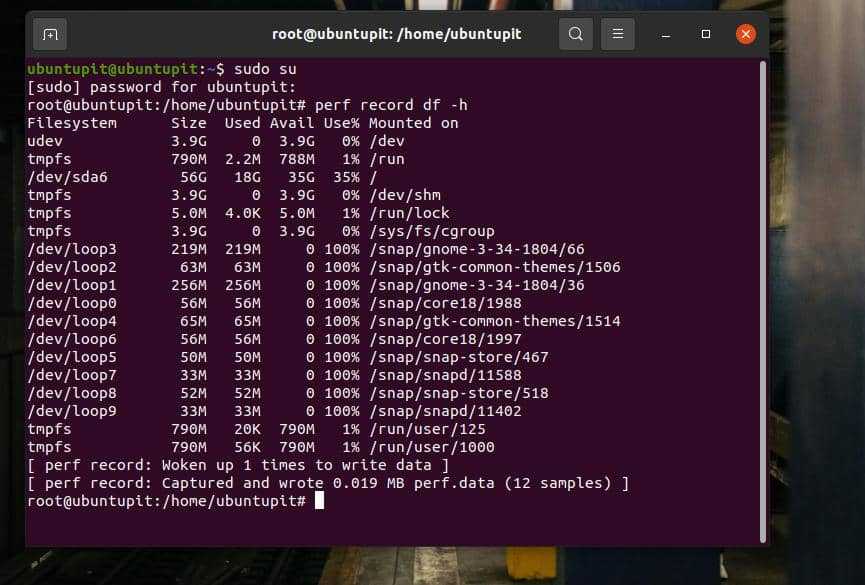
Следующая команда запишет данные любой команды Perf, которую вы хотите сохранить для использования в будущем.
perf record df -h
Чтобы просмотреть или отобразить записанные данные, вы можете запустить следующую команду в оболочке.
perf report -i <perf file>
5. bench
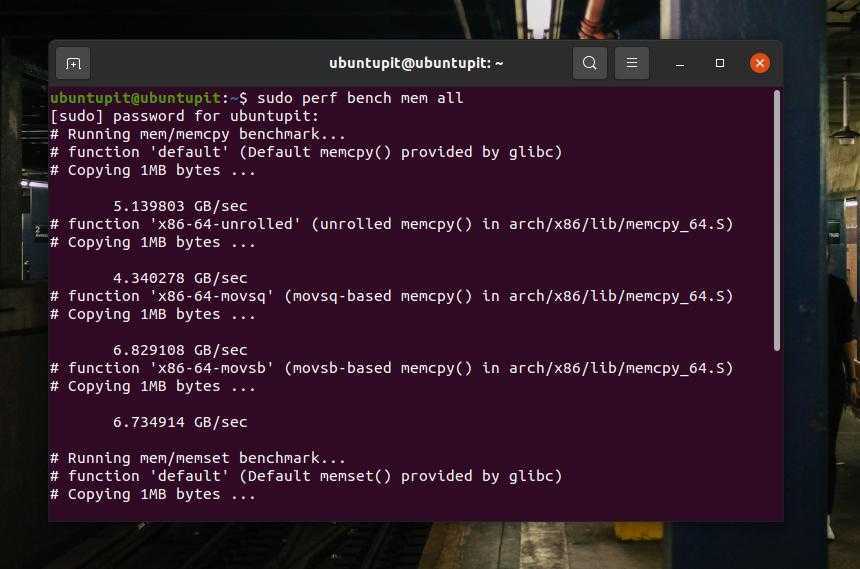
Чтобы запустить быстрый тест производительности вашей системы, вы можете выполнить следующую команду, чтобы получить отчеты о тестировании производительности системы, тактовой частоты процессора и других параметров.
perf bench mem all
Использование данных датчиков
Графические фронтэнды
Существует множество разнообразных фронтэндов для отображения данных датчиков.
psensor — GTK приложение для отслеживания аппаратных датчиков, включая температуры и скорости вентиляторов. Отслеживает материнскую плату и центральный процессор (используя lm-sensors), Nvidia GPUs (используя XNVCtrl), и жёсткие диски (используя hddtemp или libatasmart).
xsensors — X11 интерфейс к lm_sensors.
Для конкретной Desktop environments:
Freon (расширение GNOME Shell) — Расширение выводит на экран температуры ЦП, дисков, видеокарты, напряжения и оборотов вентилятора в GNOME Shell.
GNOME Sensors Applet — Апплет панели GNOME для отображения значений аппаратных датчиков, включая температуру ЦП, скорость вращения вентиляторов и вольтаж.
lm-sensors (LXPanel plugin) — Отслеживает температуру/вольтаж/скорости вентиляторов in LXDE с помощью lm-sensors.
MATE Sensors Applet — Отображает считанные значения аппаратных датчиков на вашей панели MATE.
Sensors (Xfce4 panel plugin) — Hardware sensors плагин для панели Xfce.
Thermal Monitor (Plasma 5 applet) — Апплет KDE Plasma для мониторинга CPU, GPU и других доступных датчиков температуры.
sensord
Существует дополнительный демон sensord (включен в пакет ), позволяющий журналировать данные с сенсоров в кольцевые базы данных (rrd) для последующей визуализации. Смотрите ман для уточнения деталей.
25. Sysstat – Система контроля производительности всё-в-одном
Ещё один инструмент мониторинга для вашей системы Linux. На самом деле Sysstat – это не команда, это название проекта. В действительности Sysstat – это пакет, который включает много инструментов слежения за производительностью, к ним относятся iostat, sadf, pidstat и много других инструментов, которые показывают вам множество статистической информации о вашей ОС Linux.
Особенности Sysstat
- Доступна во многих стандартных репозиториях дистрибутивов Linux.
- Может собирать статистику об использовании RAM, CPU, SWAP. Помимо этого, способность мониторить активность ядра Linux, NFS сервера, сокетов, TTY и файловых систем.
- Способность мониторить статистику ввода и вывода для устройств, задач и т.п.
- Способность выводить отчёты о сетевых интерфейсах и устройствах, в том числе с поддержкой IPv6.
- Sysstat может показать вам также статистику энергопотребления (использование, устройства, скорость вентиляторов и т.д.).
- Многие другие функции.
Настройка мониторинга температуры Linux
Сначала нужно настроить низкоуровневые инструменты для считывания данных о температуре компонентов lm_sensors и hddtemp. Начнем с lm_sensors. После этого вы уже сможете посмотреть температуру linux.
1. Настройка lm_sensors
Для запуска мастера настройки ls_sensors выполните команду:
Отвечайте Y на все вопросы. Утилита попытается обнаружить все доступные в системе встроенные аппаратные датчики (для процессора, видеокарты, памяти и других микросхем), а также автоматически определить подходящие драйвера для них.
Когда сканирование датчиков завершится вам будет предложено добавить обнаруженные модули ядра в автозагрузку:
В Ubuntu или Debian модули будут добавлены в /etc/modeuls. А в Fedora будет создан файл /etc/sysconfig/lm_sensors. Для автоматической загрузки нужных модулей достаточно добавить lm_sensors в автозагрузку:
sudo systemctl enable lm-sensors
Теперь вы можете посмотреть температуру процессора Linux и других аппаратных компонентов с помощью команды sensors:
Измерение и мониторинг температуры
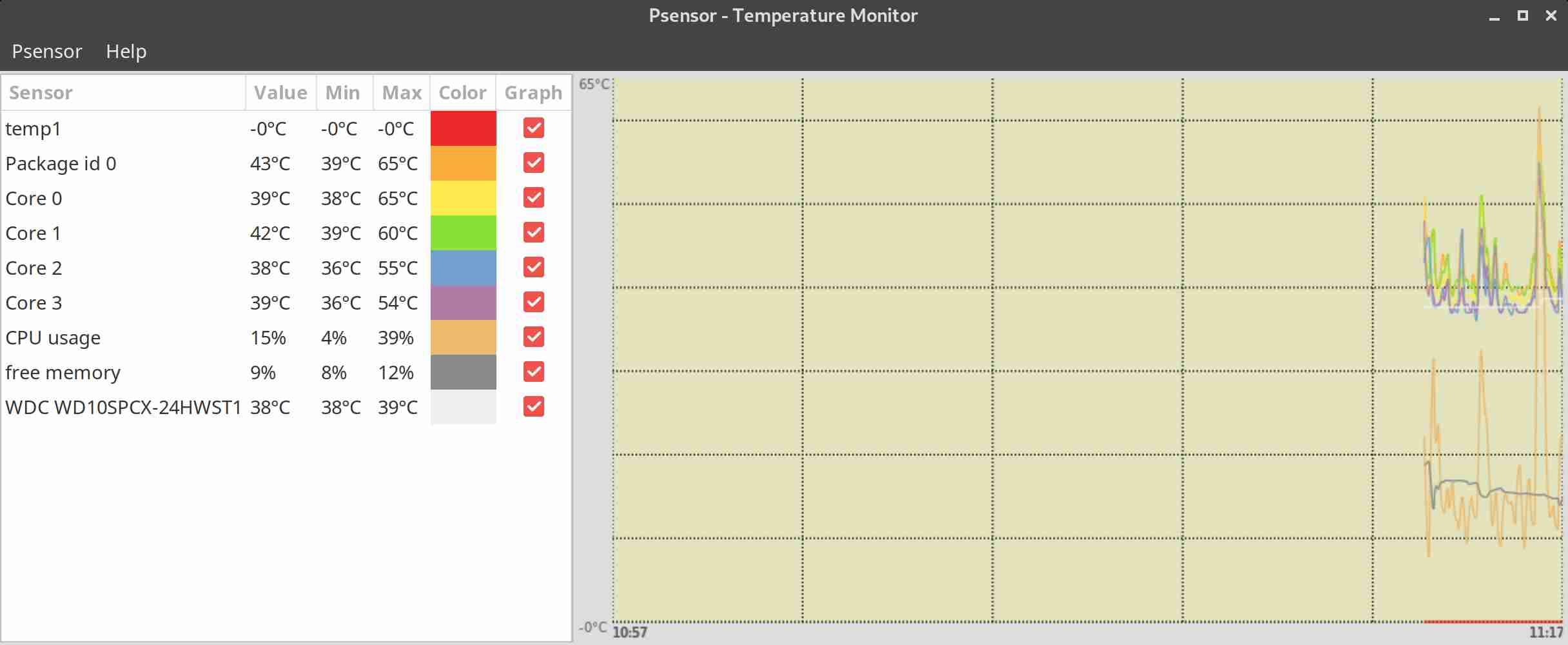
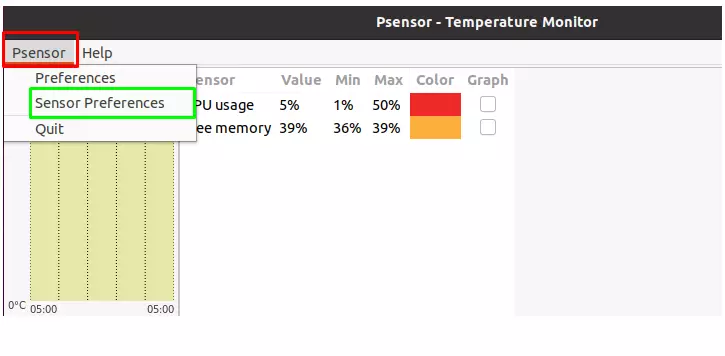
Теперь можно начать мониторинг температуры linux с помощью psensor. Для этого просто запустите программу. Вы можете сделать это с помощью главного меню или же выполнив команду:
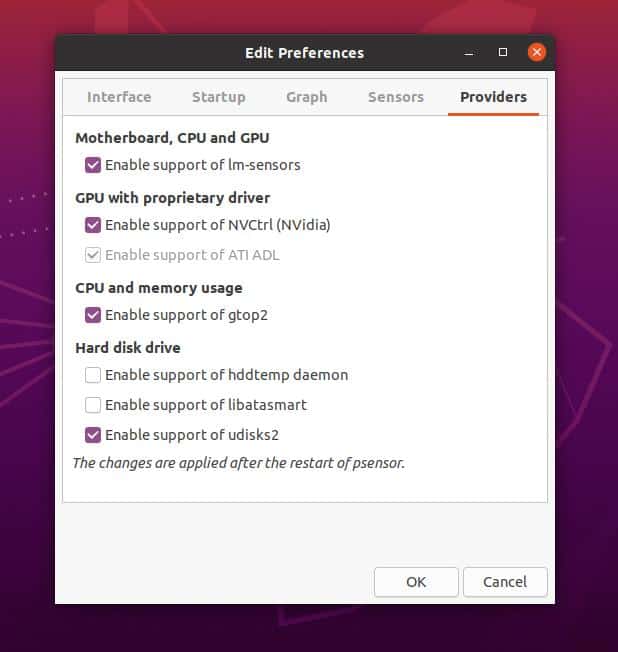
Вызовите контекстное меню в главном окне программы и выберите Параметры. Здесь вы увидите список доступных датчиков. Вы можете выбрать за какими датчиками нужно наблюдать.
Еще можно установить уровень тревоги для каждого датчика на вкладке Alarm. Когда температура Linux превысит заданную вы получите уведомление.
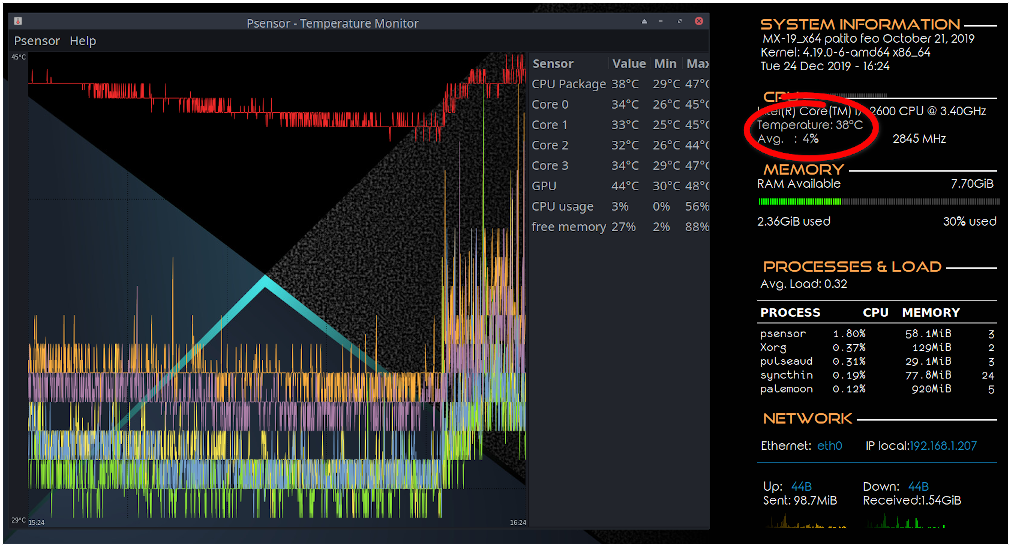
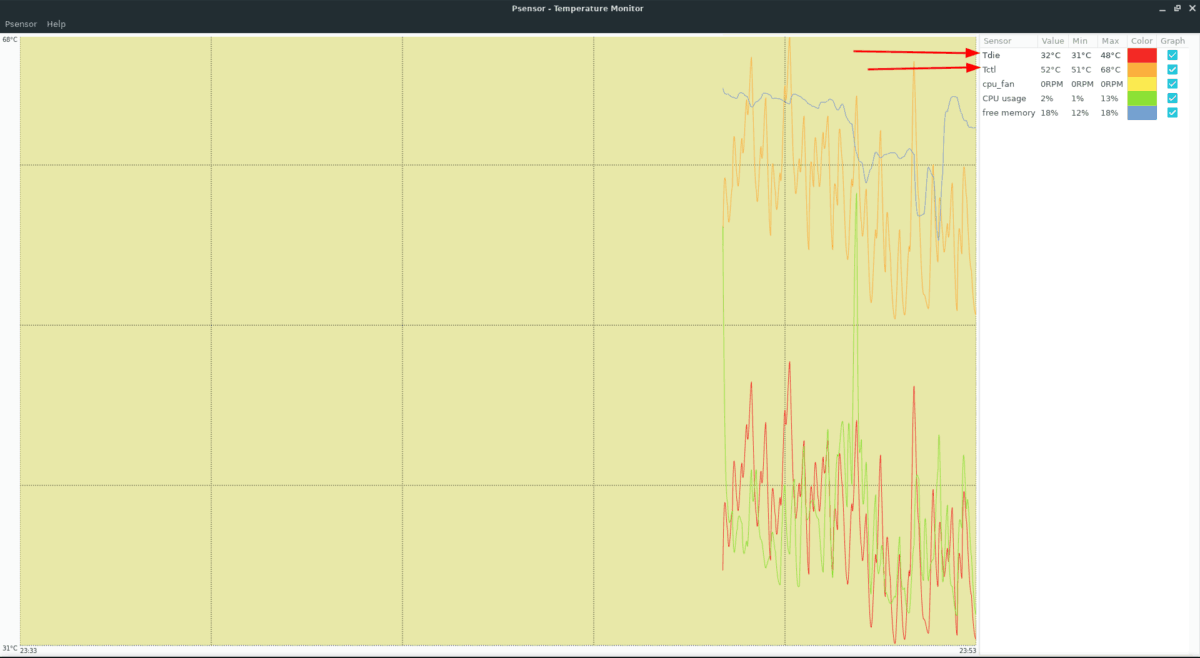
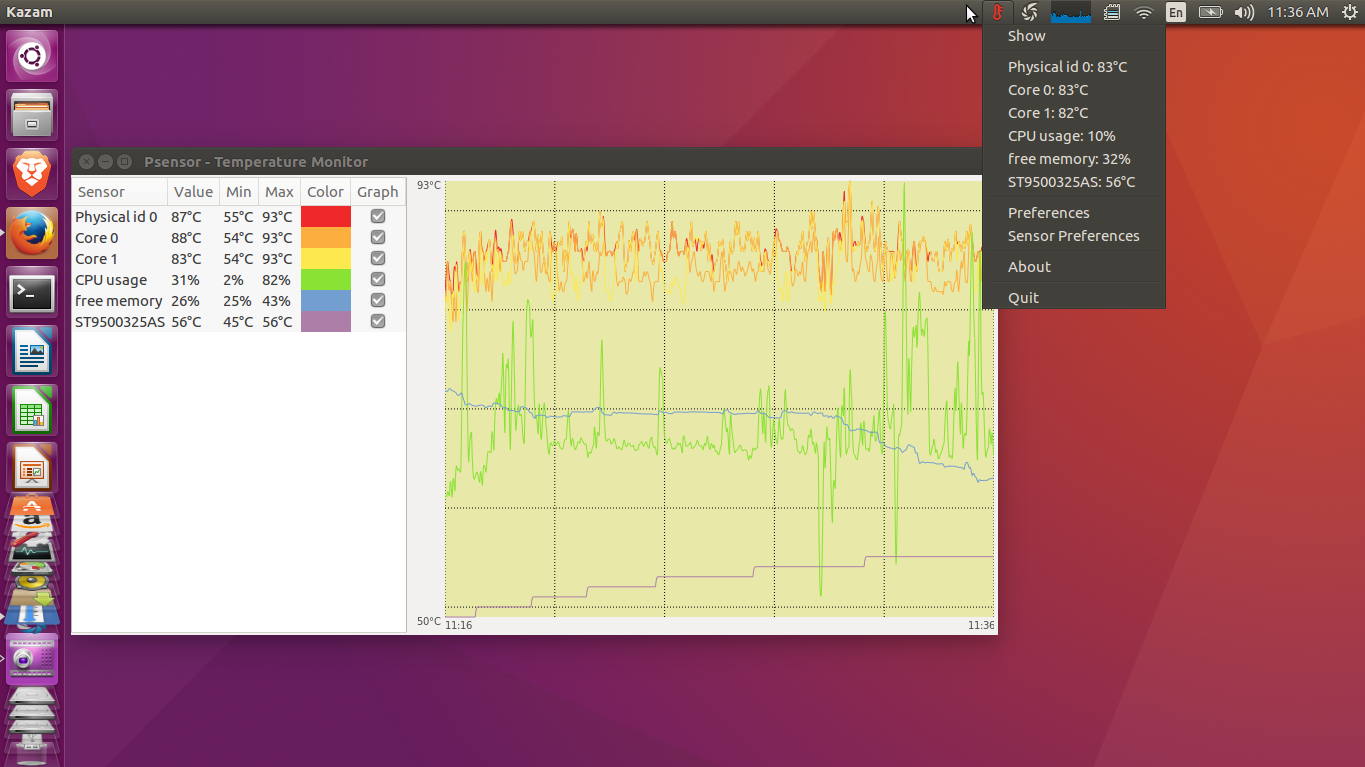
По умолчанию температура в psensor измеряется в градусах Цельсия. В последних версиях также есть поддержка конвертации в градусы по Фаренгейту.
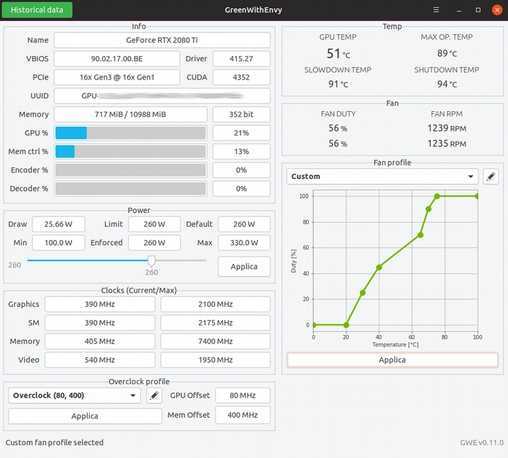
Работа с программой GreenWithEnvy для видеокарт nvidia
Работа с программой GreenWithEnvy проста и интуитивно понятна. Для ее установки инсталлируют библиотеки:
sudo apt install git meson python3-pip python3-setuptools libcairo2-dev libgirepository1.0-dev libglib2.0-dev libdazzle-1.0-dev gir1.2-gtksource-3.0 gir1.2-appindicator3-0.1 python3-gi-cairo appstream-util
а потом выполняют команды:
flatpak --user remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo flatpak --user install flathub com.leinardi.gwe flatpak update
Запуск GreenWithEnvy производится командой:
flatpak run com.leinardi.gwe
или просто:
gwe
Скриншот утилиты GreenWithEnvy:
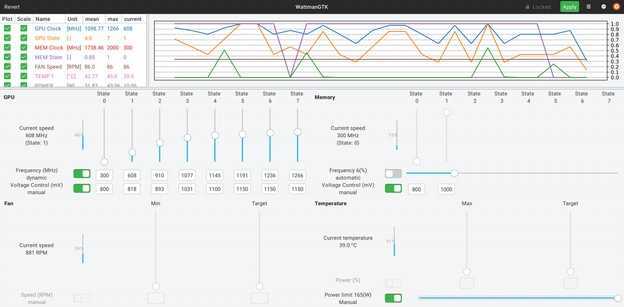
Установка и работа с утилитой Wattmangtk для мониторинга и разгона видеокарт AMD в Ubuntu
Программа WattmanGTK — это эмулятор Wattman (для Windows), работающий в linux с ядром 4.8+ (Ubuntu 16.10 и выше). Программа работает с AMDGPU kernel driver, имеет следующие возможности:
- показывает состояние памяти, GPU P-states, включая вольтаж;
- может мониторить сигналы сенсоров видеокарт;
- поддерживает работу со скриптами разгона, а также позволяет изменять параметры работы GPU прямо из графического интерфейса;
- поддерживает риги с несколькими видеокартами.
К сожалению, пока WattmanGTK не поддерживает управление вентиляторами кулеров видеокарт.
Для работы WattmanGTK нужно установить необходимые пакеты окружения командой (вводят сразу все строки):
Установка производится из терминала, запущенного в папке со скачанной программой WattmanGTK командами:
git clone https://github.com/BoukeHaarsma23/WattmanGTK cd WattmanGTK sudo python3 setup.py install
Для корректной работы WattmanGTK с видеокартами АМД также нужно скорректировать файл /etc/default/grub, а именно:
строку GRUB_CMDLINE_LINUX_DEFAULT=»quiet splash»
нужно привести к виду:
GRUB_CMDLINE_LINUX_DEFAULT="quiet amdgpu.ppfeaturemask=0xffffffff"
и обновить grub командой:
sudo update-grub
и перезагрузить компьютер.
Скриншот WattmanGTK:
Заключение
В своем материале я рассмотрел два различных способа, с помощью которых можно мониторить любой удаленный сервис по протоколу tcp, либо локальную службу на сервере linux. Конкретно в моих примерах можно было воспользоваться вторым способом в обоих случаях. Я этого не сделал, потому что первым способом я не просто проверяю, что служба запущена, я еще и обращаюсь к ней по сети и проверяю ее корректную работу для удаленного пользователя.
Разница тут получается вот в чем. Допустим, сервер squid у вас запущен и работает на сервере. Проверка работы локальной службы показывает, что сервис работает и возвращает значение 1. Но к примеру, вы настраивали firewall и где-то ошиблись. Сервис стал недоступен по сети, пользователи не могут им пользоваться. При этом мониторинг будет показывать, что все в порядке, служба запущена, хотя реально она не может обслужить запросы пользователей. В таком случай только удаленная проверка покажет, что с доступностью сервиса проблемы и надо что-то делать.
Из этого можно сделать вывод, что система мониторинга zabbix предоставляет огромные возможности по мониторингу. Какой тип наблюдения и сбора данных подойдет в конкретном случае нужно решать на месте, исходя из сути сервиса, за которым вы наблюдаете.



