
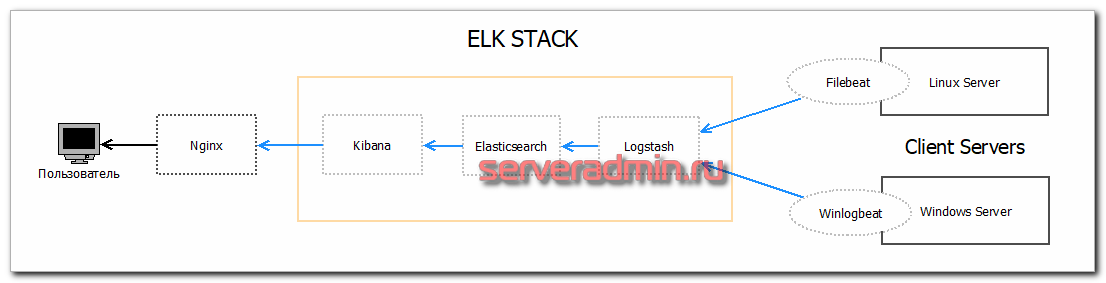
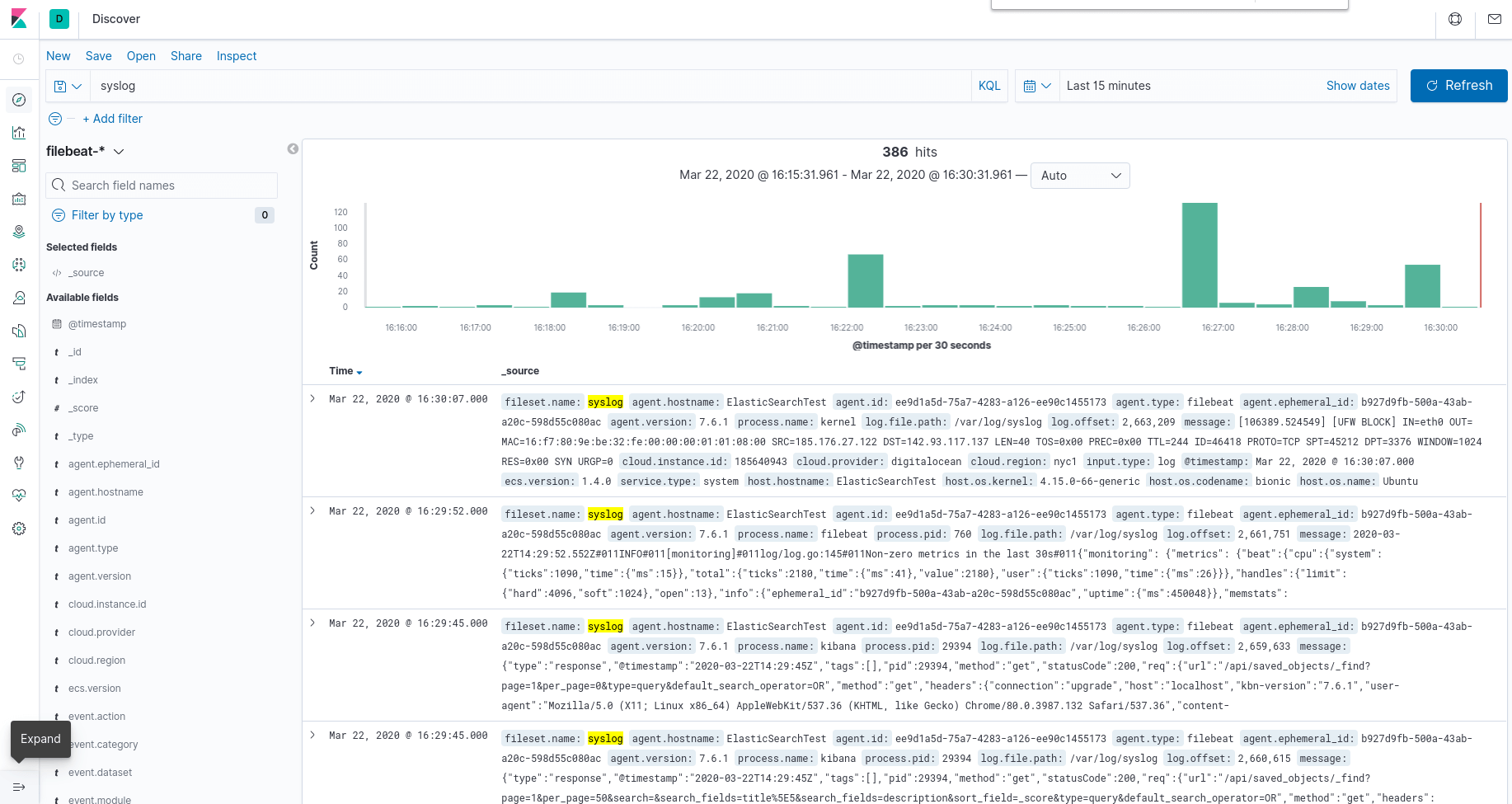
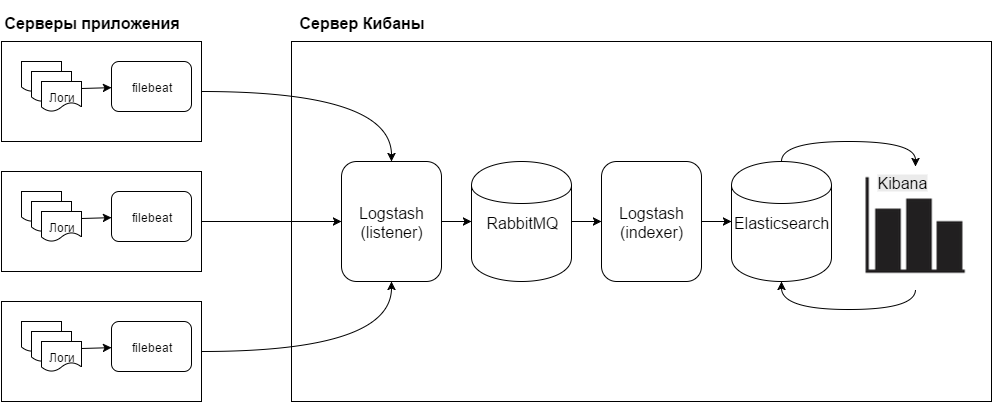
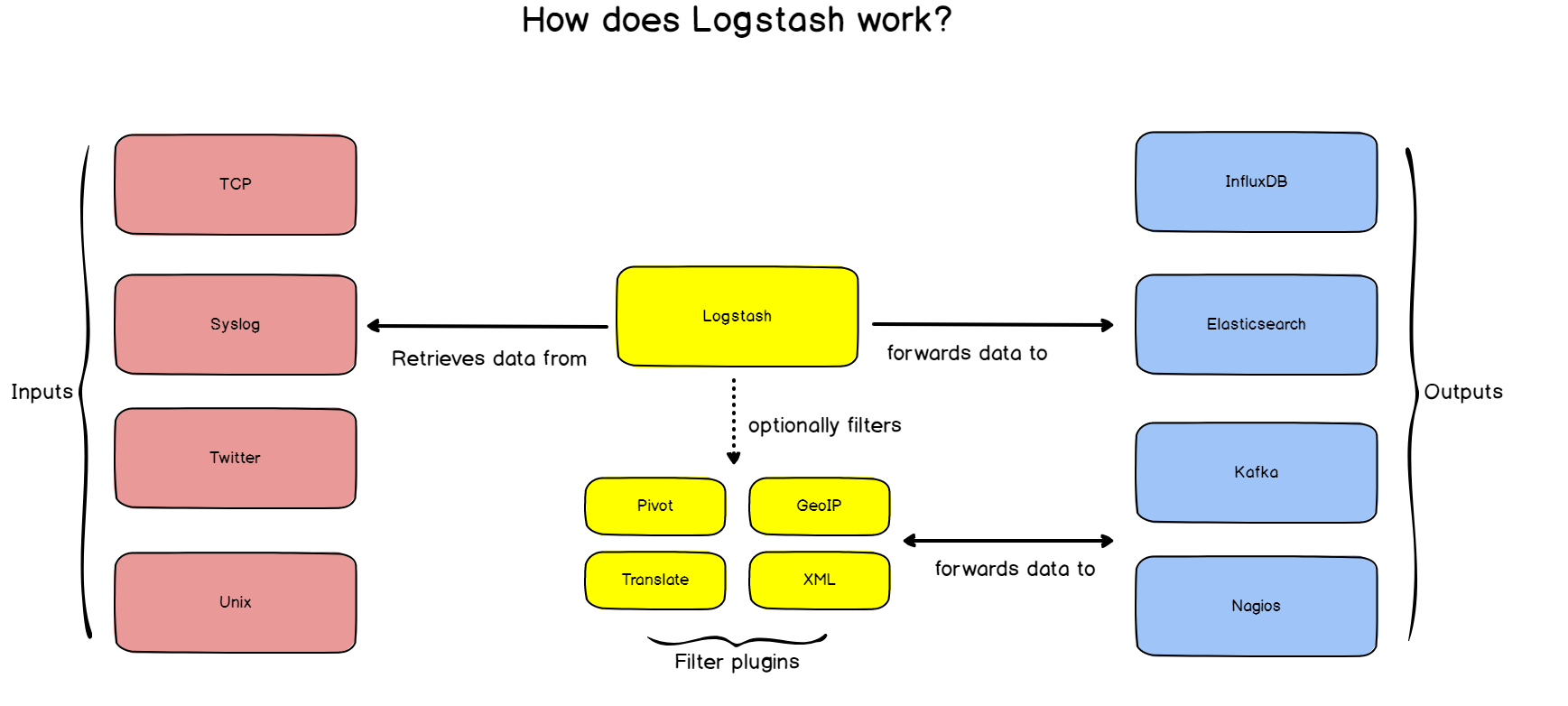
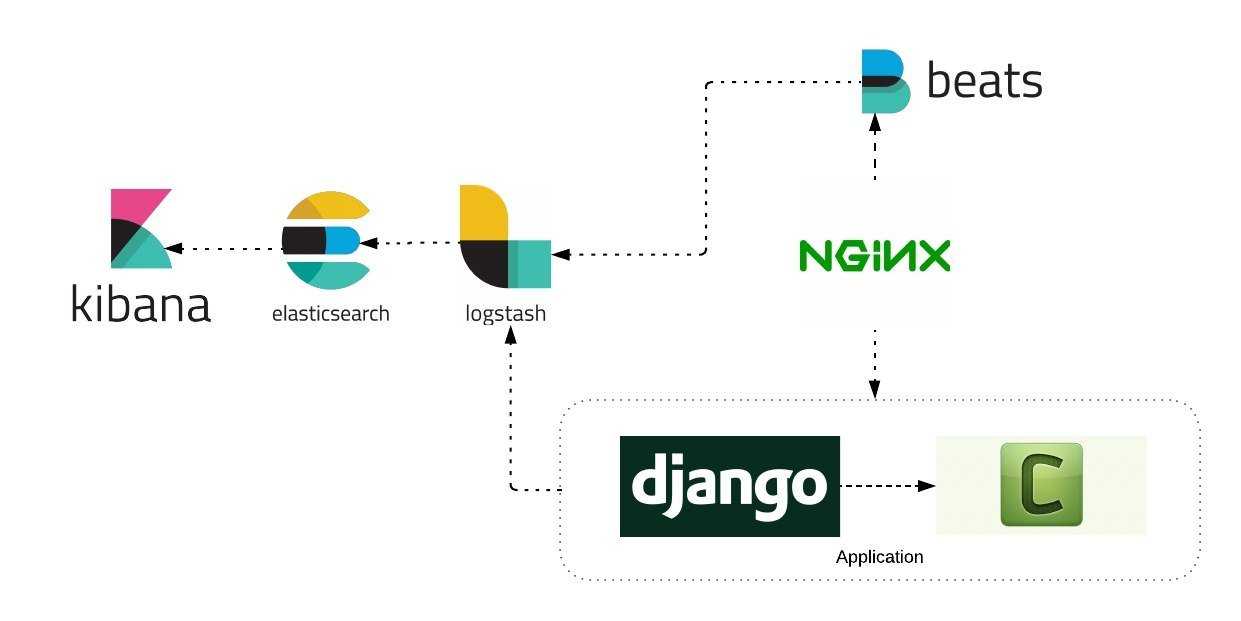
Пример сбора логов для NGINX
Рассмотрим реальный пример сбора логов с конкретного приложения. Мы настроим два варианта:
- NGINX -> Filebeat-> Logstash -> Elastic.
- NGINX -> Logstash -> Elastic.
Первый вариант похож на тот, что мы уже рассмотрели, а вот второй позволит нам напрямую отправить лог из nginx в logstash.
С использованием Filebeat
Открываем конфигурационный файл Filebeat:
vi /etc/filebeat/filebeat.yml
В раздел paths добавим путь для сбора логов nginx:
paths:
…
— /var/log/nginx/*.log
* обратите внимание, что путь до логов nginx (/var/log/nginx), которые вы захотите собирать, может быть другим, но данный путь является стандартным. Перезапускаем filebeat:
Перезапускаем filebeat:
systemctl restart filebeat
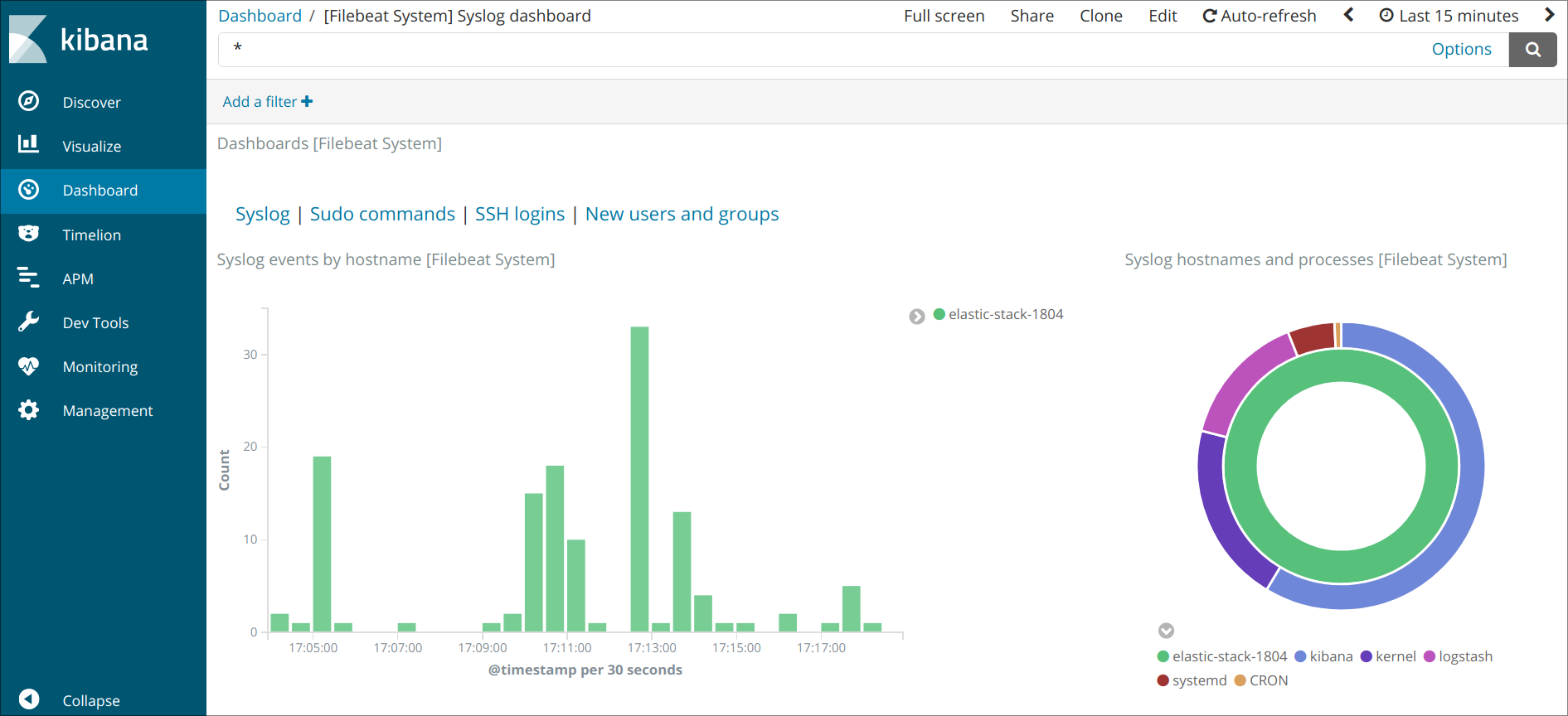
Делаем несколько запросов к веб-серверу, открываем kibana и вводим в фильтр «nginx»:
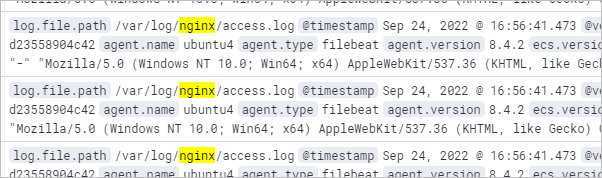
Отправка логов напрямую в Logstash
Для отправки логов из nginx в logstash мы будем использовать стандарт syslog. Для этого добавим прослушавание в сам logstash:
vi /etc/logstash/conf.d/input.conf
Допишем:
…
syslog {
port => 5140
}
…
* в нашем примере logstash будет принимать логи стандарта syslog на порту 5140.
Перезапускаем logstash:
systemctl restart logstash
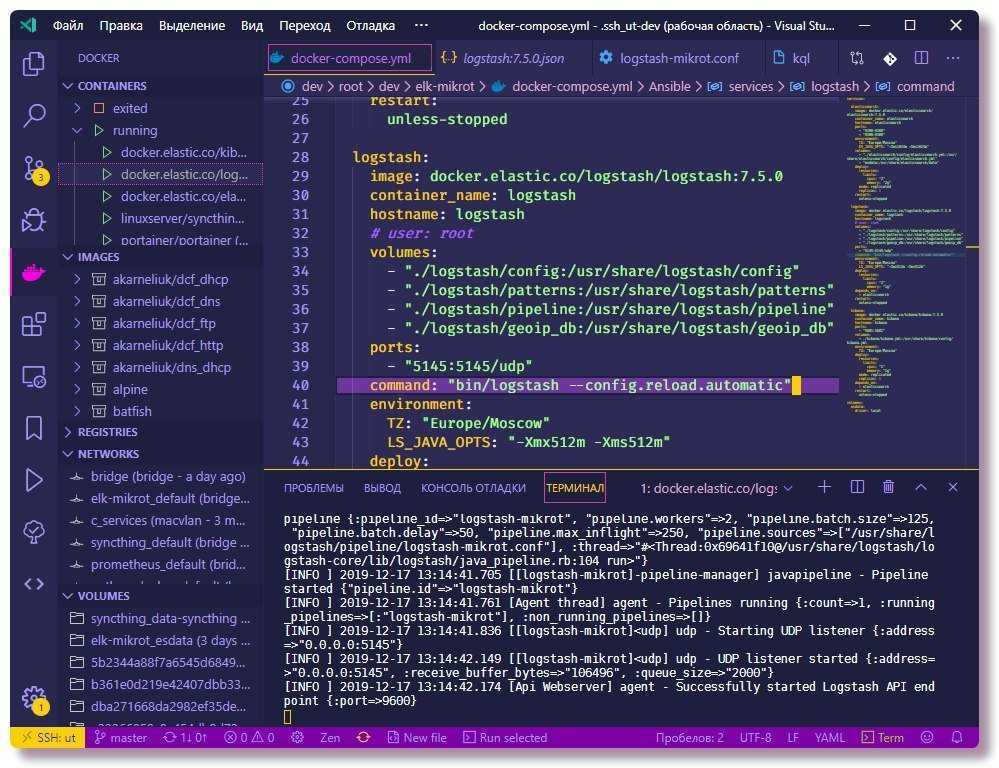
Откроем конфигурационный файл nginx:
vi /etc/nginx/nginx.conf
* обратите внимание, что в вашем случае для настройки виртуальных доменов может использоваться несколько разных конфигурационных файлов. Формат логов приводим к виду:
Формат логов приводим к виду:
log_format logstash ‘$remote_addr — $remote_user «$host» ‘
‘»$request» $status $body_bytes_sent ‘
‘»$http_referer» «$http_user_agent»‘;
А настройку логов приводим к виду:
access_log syslog:server=localhost:5140,tag=nginx_access logstash;
error_log syslog:server=localhost:5140,tag=nginx_error notice;
* в данном примере мы отправим логи на сервер localhost (локальный, но если настройка выполняется удаленно, то необходимо указать имя сервера или IP-адрес) и порт 5140, который мы настроили на logstash.
Перезапускаем nginx:
nginx -t && nginx -s reload
Проверяем логи.
Создание правил
- -l — вывести список имеющихся правил;
- -а — добавить новое правило;
- -d — удалить правило из списка;
- -D — удалить все имеющиеся правила.
$ auditctl -a <список>, <действие> -S <имя системного вызова> -F <фильтры>
- task — события, связанные с созданием новых процессов;
- entry — события, которые имеют место при входе в системный вызов;
- exit — события, которые имеют место при выходе из системного вызова;
- user — события, использующие параметры пользовательского пространства;
- exclude — используется для исключения событий.
$ auditctl -a exit,always -S open -F path =/etc/
$ auditctl -a exit,always -S open -F path =/etc/ -F perm = aw
$ auditctl -a exit,always -F path =/etc/ -F perm = aw
Шаг 3 — Установка MariaDB
Теперь добавьте MariaDB в стек сервера. Для надлежащей работы ERPNext 12 требуется MariaDB 10.2+. Поскольку Ubuntu 20.04 включает MariaDB 10.3 в свои официальные репозитории, вы можете установить эту версию с помощью команды :
Также, если вы предпочитаете более новую версию MariaDB, можно следовать . Он проведет вас по шагам мастера онлайн-репозитория MariaDB, который поможет установить новейшую версию — MariaDB 10.5.
После установки установите следующие пакеты:
ERPNext 12 — это приложение Python, поэтому для управления базой данных требуется библиотека . требуется для доступа к определенным функциям разработчика MariaDB.
Затем добавьте дополнительный слой безопасности на сервер MariaDB, запустив скрипт :
Скрипт будет давать подсказки с помощью вопросов:
- В первом диалоговом окне вам будет предложено ввести пароль root, но так как пароль еще не задан, нажмите .
- Затем при запросе изменить пароль root MariaDB ответьте . Использование пароля по умолчанию и аутентификации Unix — это рекомендуемая настройка для систем на базе Ubuntu, поскольку учетная запись root тесно связана с задачами автоматизированного обслуживания системы.
- Оставшиеся вопросы будут связаны с удалением анонимного пользователя базы данных для ограничения возможности входа в учетную запись root дистанционно на localhost, удалением тестовой базы данных и перезагрузкой таблиц привилегий. На эти вопросы можно спокойно ответить .
После завершения выполнения скрипта MariaDB начнет запуск с использованием настройки по умолчанию. Для стандартной установки ERPNext используется пользователь root для всех операций базы данных. Хотя этот подход может быть удобен для настроек одного сервера, он не является оптимальным с точки зрения безопасности. Поэтому в следующем разделе вы узнаете, как избежать этой проблемы путем создания нового пользователя со специальными привилегиями.
Создание пользователя-суперадминистратора MariaDB
ERPNext будет использовать пользователя root MariaDB для управления подключениями базы данных, но это не всегда идеальное решение. Чтобы преодолеть это ограничение и разрешить пользователю без привилегий root управлять MariaDB, вы вручную создадите базу данных с именем вашего пользователя. Затем вы сможете присвоить специальные привилегии новому пользователю для управления операциями базы данных ERPNext.
Откройте командную строку MariaDB:
Теперь создайте новую базу данных с именем пользователя, которое вы хотите назначить для подключений MariaDB. В этом обучающем руководстве будет использоваться , но вы можете выбрать другое имя:
Убедитесь, что база данных была создана с помощью этого оператора SQL:
Вы увидите примерно следующий вывод:
Теперь создайте пользователя MariaDB с привилегиями, аналогичными root, а затем задайте пользователю надежный пароль на свой выбор. Сохраните пароль в надежном месте, он понадобится вам позже:
Теперь подтвердите создание пользователя и новые привилегии пользователя:
Результат должен будет выглядеть следующим образом:
Теперь очистите привилегии, чтобы вступили в силу все изменения:
После этого закройте сеанс:
Теперь, после создания пользователя базы данных, необходимо только сделать отладку MariaDB для обеспечения надлежащей работы ERPNext 12. К счастью, команда ERPNext предоставляет превосходный шаблон настроек, который вы будете использовать в качестве отправной точки для внедрения. В следующем разделе вы узнаете, как правильно настроить базу данных MariaDB.
Шаг 5 — Настройка ERPNext 12
Теперь, после подготовки серверной части вашей базы данных, можно продолжить настройку вашего веб-приложения ERPNext. В этом разделе вы узнаете, как установить и выполнить настройку всех компонентов, необходимых для ERPNext 12 и затем установить непосредственно приложение.
Начните с подготовки сервера с помощью всех системных пакетов, необходимых для ERPNext 12. Установите общесистемные зависимости с помощью следующей команды:
Переменная была передана в команду установки для отключения подсказок Postfix. Для получения подробной информации о настройке Postfix ознакомьтесь с нашим руководством Установка и настройка Postfix в Ubuntu 20.04
Затем обновите , стандартный диспетчер пакетов Python, и установите последние версии трех дополнительных модулей Python:
упрощает установку и обновление пакетов Python, добавляет возможности шифрования, а помогает системе выполнять мониторинг. Теперь, после установки всех необходимых глобальных зависимостей, вы установите все службы и библиотеки, необходимые для ERPNext 12.
Настройка Node.js и Yarn
ERPNext 12 может работать с версией 8+ среды сервера Node.js. На самом деле на момент составления этого обучающего модуля официальный скрипт ERPNext использует Node 8. Но с точки зрения безопасности рекомендуется установить новую версию, так как срок использования Node 8 закончился в 2020 г., и поэтому он больше не будет получать обновления безопасности. На момент составления этого обучающего модуля Ubuntu 20.04 содержит версию 10.19 Node.js. Хотя эта версия все еще поддерживается, по тем же причинам (окончание срока использования) настоятельно рекомендуется не использовать ее. Для этого руководства версия 12 LTS Node.js будет установлена вместе с соответствующими диспетчерами пакетов и
Обратите внимание, что в каркасе Frappe используется для установки зависимостей. Если вы решите использовать другой метод установки, убедитесь, что в вашей системе работает конечная версия 1.12+
Добавьте в вашу систему репозиторий NodeSource:
Теперь вы можете проверить содержание загруженного скрипта:
Если вы удовлетворены содержанием скрипта, можно запустить скрипт:
Этот скрипт автоматически обновит список . Теперь вы можете установить на вашем сервере:
Затем установите на глобальном уровне с помощью диспетчера пакетов :
Теперь, после установки Node, можно продолжить настройку для вашей платформы.
ERPNext использует инструмент с открытым исходным кодом для конвертации содержимого HTML в PDF с помощью механизма исполнения Qt WebKit. Эта функция используется главным образом для печати счетов-фактур, ценовых предложений и других отчетов. В случае ERPNext 12 требуется определенная версия с обновленным Qt.
Для установки начните с перехода в подходящий каталог для загрузки пакета, в данном случае :
Загрузите соответствующую версию и пакет для Ubuntu 20.04 со страницы проекта:
Теперь установите пакет с помощью инструмента :
Затем скопируйте все относящиеся исполняемые файлы в каталог :
Когда файлы будут на месте, измените их разрешения, чтобы они стали исполняемыми:
Теперь, после надлежащей установки , мы добавим Redis в стек нашей базы данных.
Установка Redis
ERPNext 12 использует Redis для повышения производительности MariaDB. В частности, Redis помогает с кешированием.
Сначала установите Redis из официального репозитория Ubuntu 20.04:
Затем активируйте Redis при запуске:
Теперь, после добавления Redis в ваш стек, давайте обобщим, что уже выполнено. На данный момент вы установили основные компоненты, необходимые для ERPNext 12, среди которых:
- Серверная часть базы данных MariaDB
- Среда сервера Node.js JavaScript
- Диспетчер пакетов Yarn
- Кэш базы данных Redis
- Генератор документов PDF
Независимо от того, устанавливаете ли вы систему ERP для разработки или производства, вы готовы к следующему шагу, а именно к установке каркаса комплексной разработки Frappe и фактического веб-приложения ERPNext 12.
Шаг 1 — Настройка брандмауэра
Хотя настройка брандмауэра для разработки опциональна, для производства она является обязательной с точки зрения безопасности.
Вам потребуется открыть следующие порты на вашем сервере ERPNext:
- и для HTTP и HTTPS соответственно
- для подключения MariaDB (рекомендуется только при необходимости удаленного доступа к базе данных)
- и для IMAP и STMP соответственно
- для SSH (если вы еще не включили в настройках UFW)
- для тестирования платформы перед развертыванием в производство
Чтобы сразу открыть несколько портов можно использовать следующую команду:
Также можно разрешить подключения с определенных IP-адресов на конкретных портах с помощью этой команды:
После открытия всех необходимых портов активируйте брандмауэр:
Затем подтвердите статус брандмауэра:
UFW выведет список ваших включенных правил. Убедитесь, что открыты необходимые порты ERPNext:
Дополнительную информацию о настройке UFW можно найти в нашем руководстве по настройке брандмауэра с UFW в Ubuntu 20.04.
Настройка соответствующего брандмауэра — это первый из двух предварительных шагов. Теперь мы настроим раскладку клавиатуры и кодирование символов на вашем сервере.
Что такое LAMP-стек?
LAMP — это акроним, который традиционно означает «Linux, Apache, MySQL и PHP», что является популярным набором программного обеспечения многих веб-приложений или веб-сайтов. Стек LAMP является достаточно мощным, и при этом он сравнительно прост и удобен в использовании.
В последние годы набирают популярность разные вариации LAMP-стека, например, вместо языка программирования PHP используют Python или Perl, а вместо СУБД MySQL используют PostgreSQL.
На виртуальных серверах ServerSpace операционная система семейства Linux, а именно Ubuntu 18.04, уже установлена, поэтому в инструкции будет описана установка остальных компонентов.
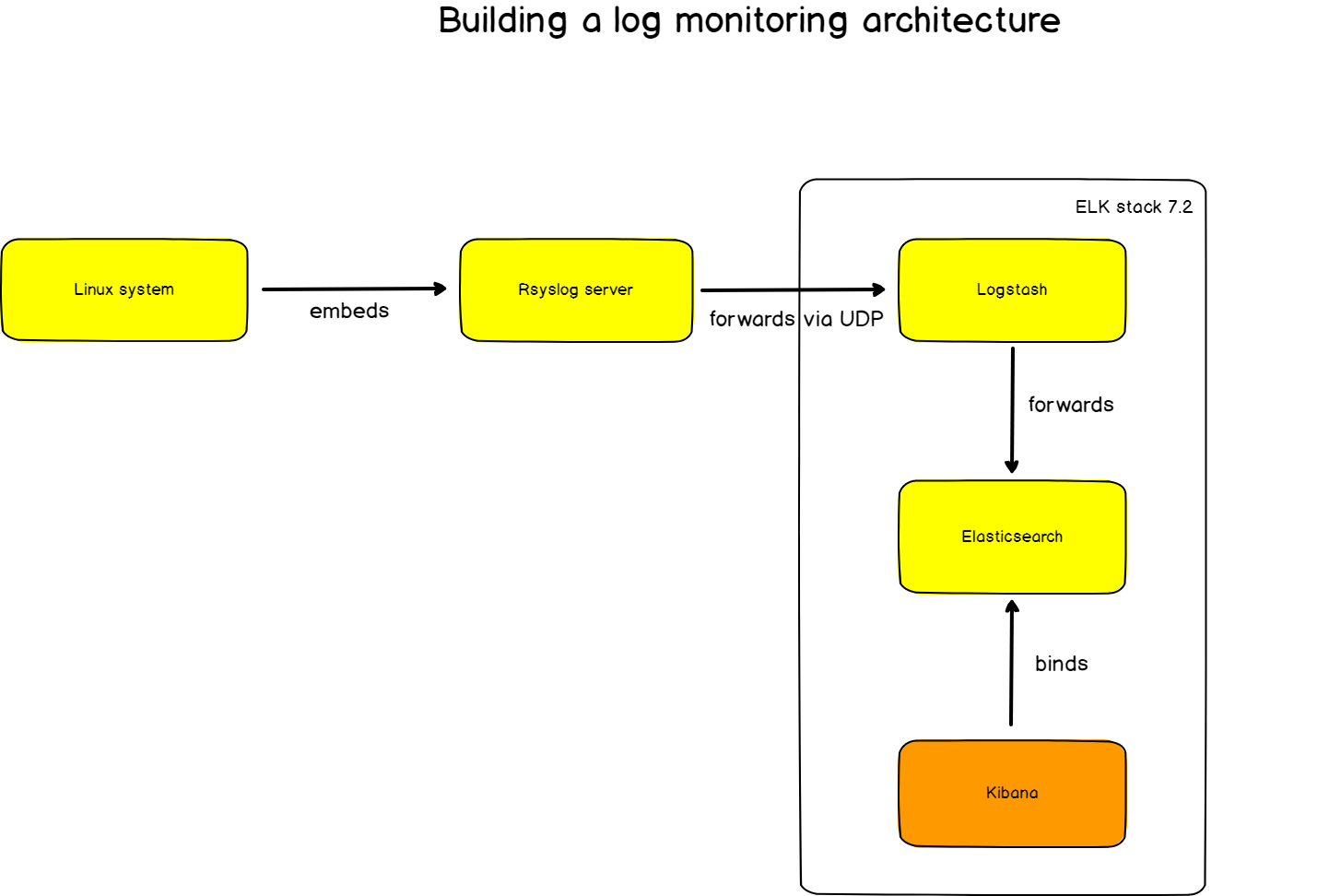
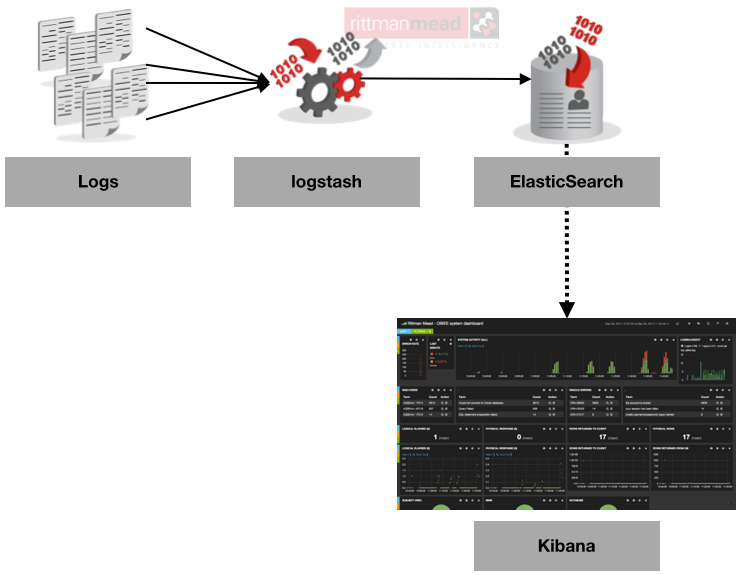
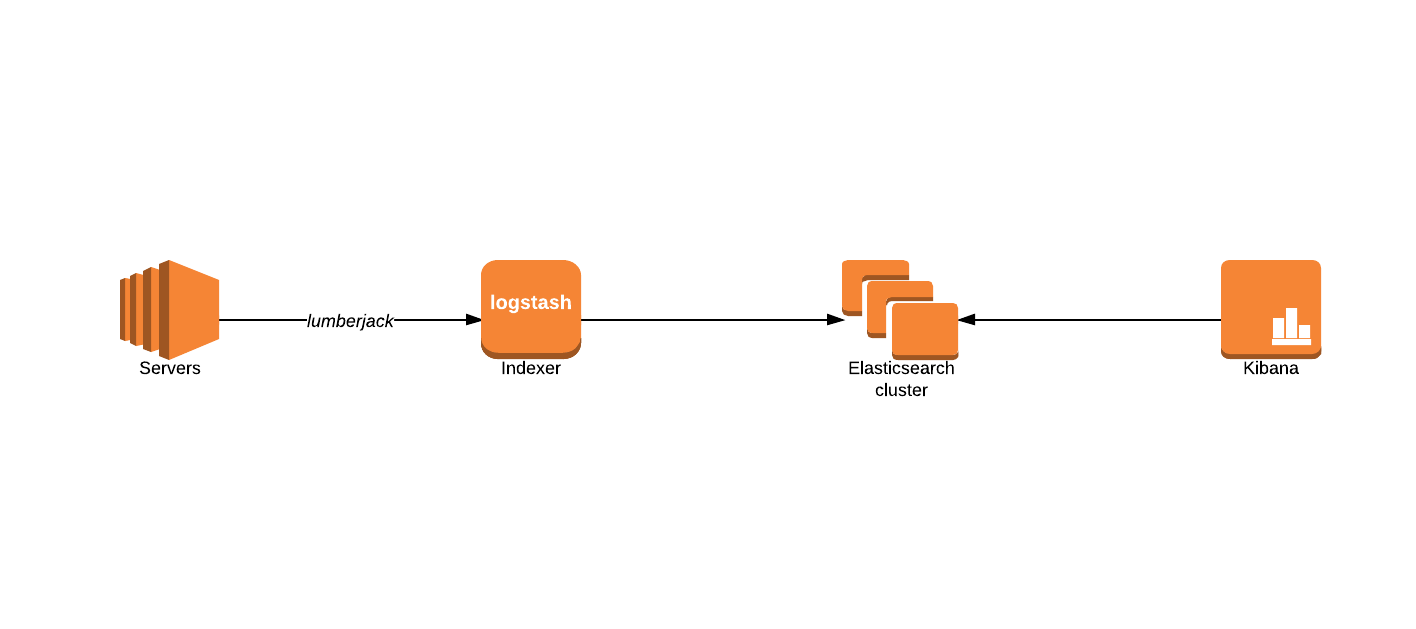
Установка Filebeat
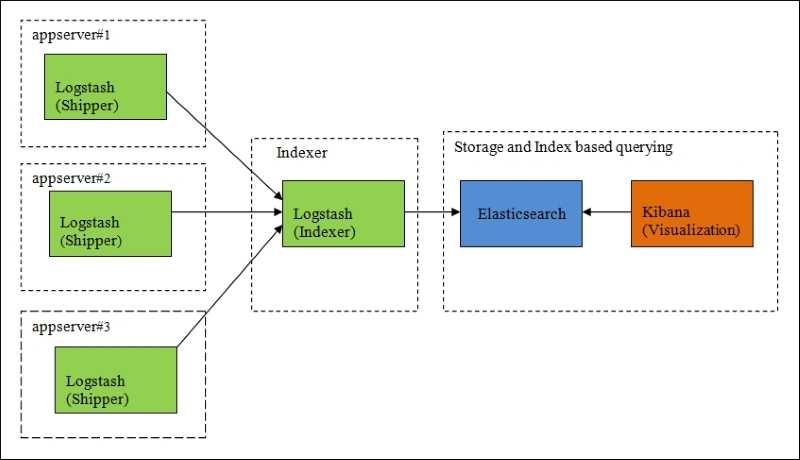
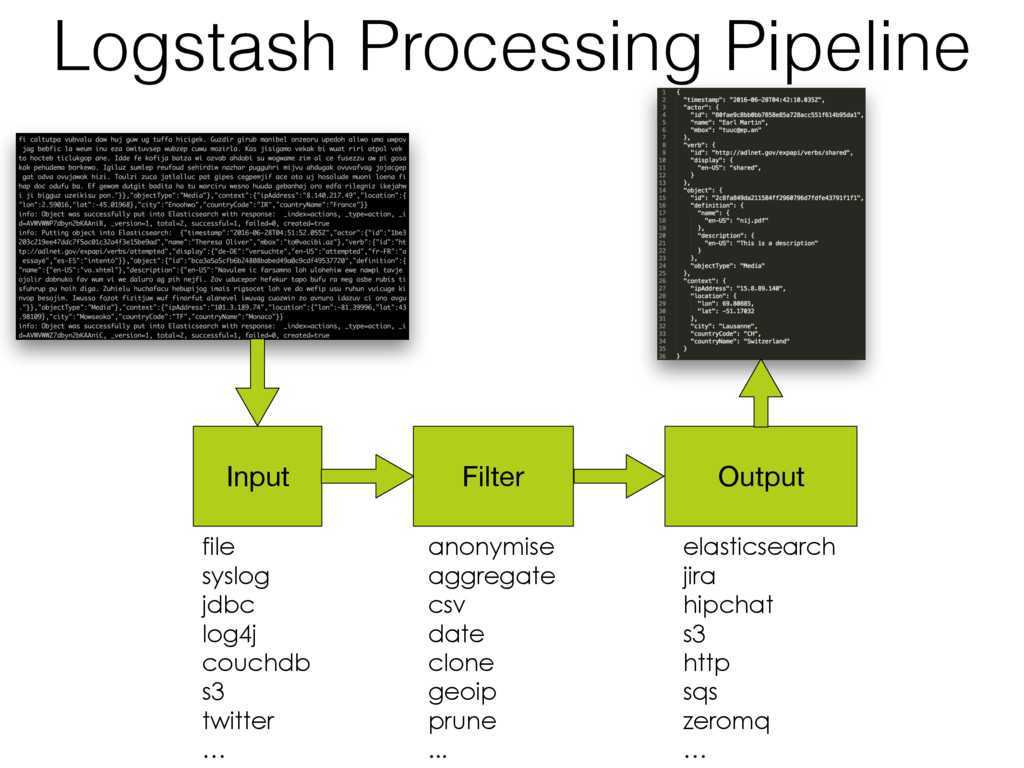
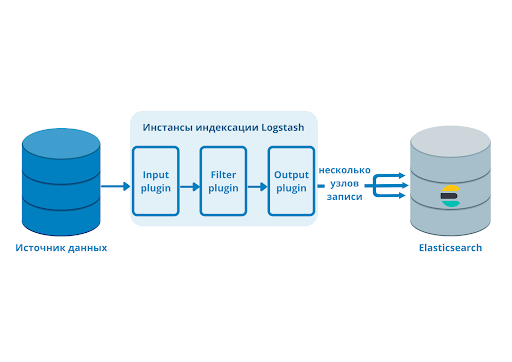
Для установки предлагаются apt- и yum-репозитории, deb- и rpm-файлы. Метод установки зависит от задач и версий. Актуальная версия — 5.х. Если все ставится с нуля, то проблем нет. Но бывает, например, что уже используется Elasticsearch ранних версий и обновление до последней нежелательно. Поэтому установку компонентов ELK + Filebeat приходится выполнять персонально, что-то ставя и обновляя из пакетов, что-то при помощи репозитория. Для удобства лучше все шаги занести в плейбук Ansible, тем более что в Сети уже есть готовые решения. Мы же усложнять не будем и рассмотрим самый простой вариант.
Подключаем репозиторий и ставим пакеты:
В Ubuntu 16.04 с Systemd периодически всплывает небольшая проблема: некоторые сервисы, помеченные мейнтейнером пакета как enable при старте, на самом деле не включаются и при перезагрузке не стартуют. Вот как раз для продуктов Elasticsearch это актуально.
Все настройки производятся в конфигурационном файле /etc/filebeat/filebeat.yml, после установки уже есть шаблон с минимальными настройками. В этом же каталоге лежит файл filebeat.full.yml, в котором прописаны все возможные установки. Если чего-то не хватает, то можно взять за основу его. Файл filebeat.template.json представляет собой шаблон для вывода, используемый по умолчанию. Его при необходимости можно переопределить или изменить.
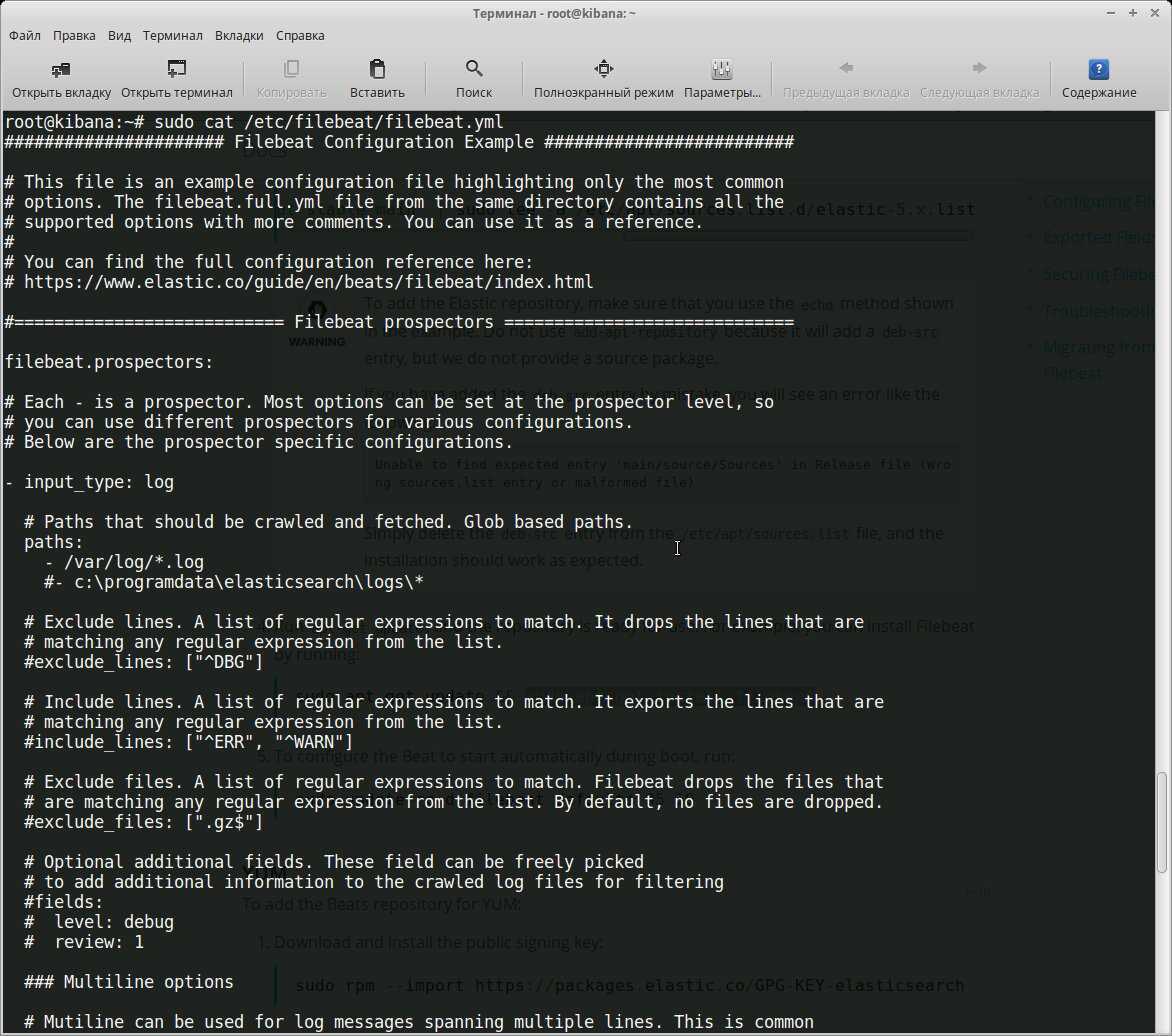 Конфигурационный файл Filebeat
Конфигурационный файл Filebeat
Другие статьи в выпуске:
Xakep #218. Смотри во все глаза
- Содержание выпуска
- Подписка на «Хакер»-60%
Нам нужно, по сути, выполнить две основные задачи: указать, какие файлы брать и куда отправлять результат. В установках по умолчанию Filebeat собирает все файлы в пути , это означает, что Filebeat соберет все файлы в каталоге , заканчивающиеся на .
Учитывая, что большинство демонов хранят логи в своих подкаталогах, их тоже следует прописать индивидуально или используя общий шаблон:
Источники с одинаковым input_type, log_type и document_type можно указывать по одному в строке. Если они отличаются, то создается отдельная запись.
Поддерживаются все типы, о которых знает Elasticsearch.
Дополнительные опции позволяют отобрать только определенные файлы и события. Например, нам не нужно смотреть архивы внутри каталогов:
По умолчанию экспортируются все строки. Но при помощи регулярных выражений можно включить и исключить вывод определенных данных в Filebeat. Их можно указывать для каждого paths.
Если определены оба варианта, Filebeat сначала выполняет , а затем . Порядок, в котором они прописаны, значения не имеет. Кроме этого, в описании можно использовать теги, поля, кодировку и так далее.
Теперь переходим к разделу Outputs. Прописываем, куда будем отдавать данные. В шаблоне уже есть установки для Elasticsearch и Logstash. Нам нужен второй.
Здесь самый простой случай. Если отдаем на другой узел, то желательно использовать авторизацию по ключу. В файле есть шаблон.
Чтобы посмотреть результат, можно выводить его в файл:
Нелишними будут настройки ротации:
Это минимум. На самом деле параметров можно указать больше. Все они есть в full-файле. Проверяем настройки:
Применяем:
Сервис может работать, но это не значит, что все правильно. Лучше посмотреть в журнал и убедиться, что там нет ошибок. Проверим:
Еще важный момент. Не всегда журналы по умолчанию содержат нужную информацию, поэтому, вероятно, следует пересмотреть и изменить формат, если есть такая возможность. В анализе работы nginx неплохо помогает статистика по времени запроса.
Расположение логов по умолчанию
Большинство файлов логов Linux находятся в папке /var/log/ вы можете список файлов логов для вашей системы с помощью команды ls:
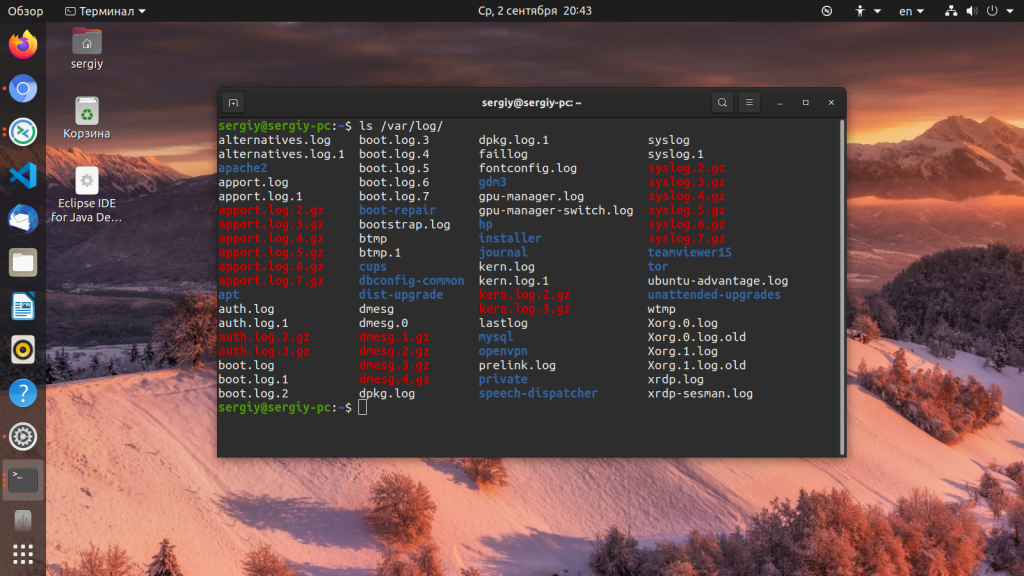
Ниже мы рассмотрим 20 различных файлов логов Linux, размещенных в каталоге /var/log/. Некоторые из этих логов встречаются только в определенных дистрибутивах, например, dpkg.log встречается только в системах, основанных на Debian.
- /var/log/messages — содержит глобальные системные логи Linux, в том числе те, которые регистрируются при запуске системы. В этот лог записываются несколько типов сообщений: это почта, cron, различные сервисы, ядро, аутентификация и другие.
- /var/log/dmesg — содержит сообщения, полученные от ядра. Регистрирует много сообщений еще на этапе загрузки, в них отображается информация об аппаратных устройствах, которые инициализируются в процессе загрузки. Можно сказать это еще один лог системы Linux. Количество сообщений в логе ограничено, и когда файл будет переполнен, с каждым новым сообщением старые будут перезаписаны. Вы также можете посмотреть сообщения из этого лога с помощью команды dmseg.
- /var/log/auth.log — содержит информацию об авторизации пользователей в системе, включая пользовательские логины и механизмы аутентификации, которые были использованы.
- /var/log/boot.log — Содержит информацию, которая регистрируется при загрузке системы.
- /var/log/daemon.log — Включает сообщения от различных фоновых демонов
- /var/log/kern.log — Тоже содержит сообщения от ядра, полезны при устранении ошибок пользовательских модулей, встроенных в ядро.
- /var/log/lastlog — Отображает информацию о последней сессии всех пользователей. Это нетекстовый файл, для его просмотра необходимо использовать команду lastlog.
- /var/log/maillog /var/log/mail.log — журналы сервера электронной почты, запущенного в системе.
- /var/log/user.log — Информация из всех журналов на уровне пользователей.
- /var/log/Xorg.x.log — Лог сообщений Х сервера.
- /var/log/alternatives.log — Информация о работе программы update-alternatives. Это символические ссылки на команды или библиотеки по умолчанию.
- /var/log/btmp — лог файл Linux содержит информацию о неудачных попытках входа. Для просмотра файла удобно использовать команду last -f /var/log/btmp
- /var/log/cups — Все сообщения, связанные с печатью и принтерами.
- /var/log/anaconda.log — все сообщения, зарегистрированные при установке сохраняются в этом файле
- /var/log/yum.log — регистрирует всю информацию об установке пакетов с помощью Yum.
- /var/log/cron — Всякий раз когда демон Cron запускает выполнения программы, он записывает отчет и сообщения самой программы в этом файле.
- /var/log/secure — содержит информацию, относящуюся к аутентификации и авторизации. Например, SSHd регистрирует здесь все, в том числе неудачные попытки входа в систему.
- /var/log/wtmp или /var/log/utmp — системные логи Linux, содержат журнал входов пользователей в систему. С помощью команды wtmp вы можете узнать кто и когда вошел в систему.
- /var/log/faillog — лог системы linux, содержит неудачные попытки входа в систему. Используйте команду faillog, чтобы отобразить содержимое этого файла.
- /var/log/mysqld.log — файлы логов Linux от сервера баз данных MySQL.
- /var/log/httpd/ или /var/log/apache2 — лог файлы linux11 веб-сервера Apache. Логи доступа находятся в файле access_log, а ошибок в error_log
- /var/log/lighttpd/ — логи linux веб-сервера lighttpd
- /var/log/conman/ — файлы логов клиента ConMan,
- /var/log/mail/ — в этом каталоге содержатся дополнительные логи почтового сервера
- /var/log/prelink/ — Программа Prelink связывает библиотеки и исполняемые файлы, чтобы ускорить процесс их загрузки. /var/log/prelink/prelink.log содержит информацию о .so файлах, которые были изменены программой.
- /var/log/audit/- Содержит информацию, созданную демоном аудита auditd.
- /var/log/setroubleshoot/ — SE Linux использует демон setroubleshootd (SE Trouble Shoot Daemon) для уведомления о проблемах с безопасностью. В этом журнале находятся сообщения этой программы.
- /var/log/samba/ — содержит информацию и журналы файлового сервера Samba, который используется для подключения к общим папкам Windows.
- /var/log/sa/ — Содержит .cap файлы, собранные пакетом Sysstat.
- /var/log/sssd/ — Используется системным демоном безопасности, который управляет удаленным доступом к каталогам и механизмами аутентификации.
Как установить Clang 9 на Ubuntu
Если вам нужно заставить Clang 9 работать с Ubuntu, вы будете рады узнать, что в большинстве выпусков Ubuntu, даже в последней версии Ubuntu 21.04, он есть в репозитории программного обеспечения. Чтобы начать работу с Clang 9, начните с открытия окна терминала.
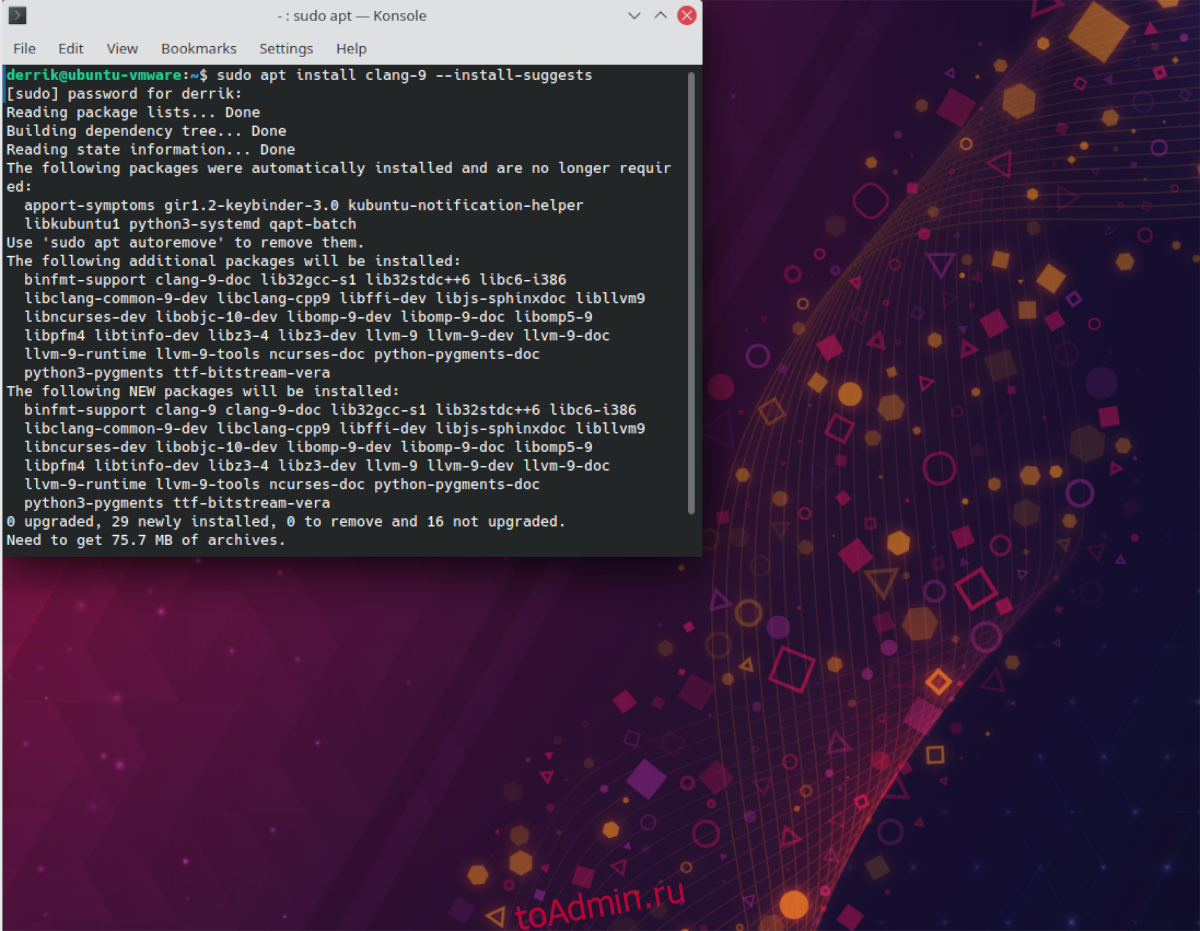
Чтобы открыть окно терминала на рабочем столе Ubuntu, нажмите Ctrl + Alt + T на клавиатуре. Когда он откроется, используйте команду apt install ниже, чтобы установить пакет Clang 9. Обязательно используйте параметр командной строки –install-sizes, так как он скажет Ubuntu получить все необходимое для использования Clang 9.
sudo apt install clang-9 --install-suggests
После ввода этой команды в окне терминала Ubuntu предложит вам ввести пароль. Сделай так. Когда вы это сделаете, он соберет все предложенные пакеты для установки на ваш компьютер.
После того, как Ubuntu соберет все пакеты для установки, вам будет предложено нажать клавишу Y на клавиатуре. Нажмите клавишу Y на клавиатуре, чтобы подтвердить, что вы хотите продолжить установку.
После нажатия Y Ubuntu установит Clang 9 в вашу систему. Когда закончите, закройте окно терминала или начните использовать Clang 9 в командной строке.
Установка PHP и дополнительных расширений
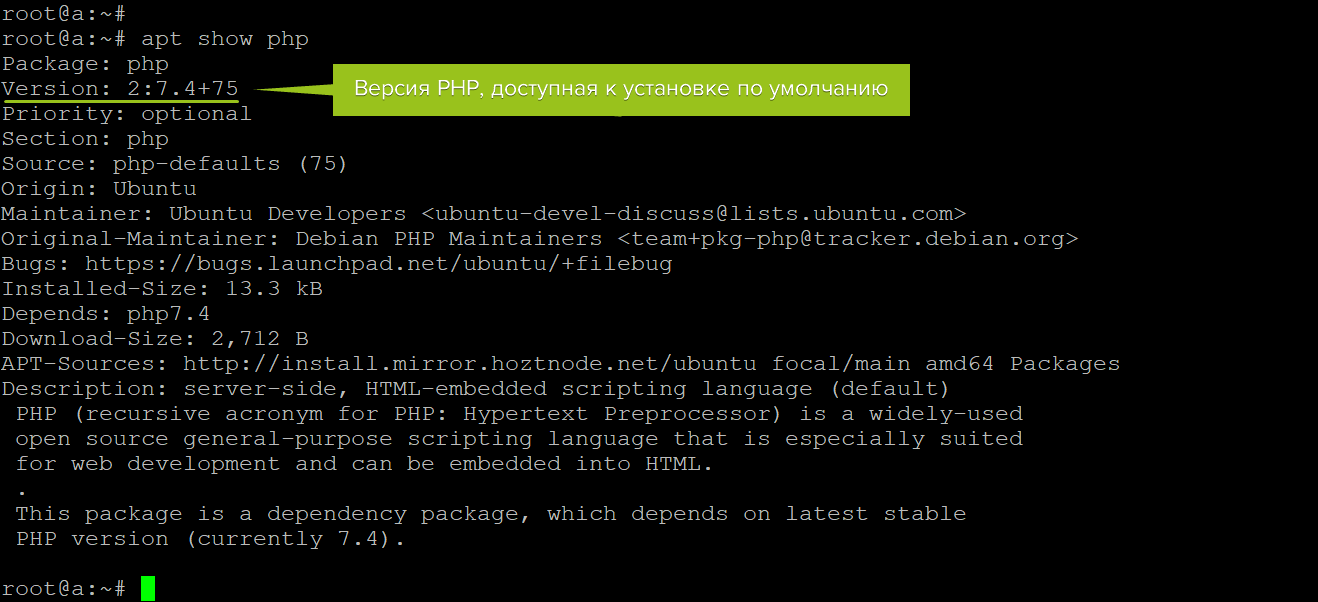
Проверить доступную для установки версию PHP можно командой:
-
Ubuntu и Debian:
apt show php
-
CentOS:
yum info php
Знать её нужно для корректной установки нужных компонентов на следующем шаге (для Ubuntu и Debian). В примере версия PHP — 7.4. Вам при установке нужно заменить её в команде на ту, которая доступна для вашей операционной системы.
Если версия вам подходит, после этого можно перейти к установке:
-
Ubuntu и Debian:
apt -y install php7.4 php7.4-fpm php7.4-mysql php-common php7.4-cli php7.4-common php7.4-json php7.4-opcache php7.4-readline php7.4-mbstring php7.4-xml php7.4-gd php7.4-curl php7.4-zip
-
-
CentOS:
yum -y install php-fpm php-mysqlnd php-cli php-json php-mbstring php-xml php-gd php-curl php-zip
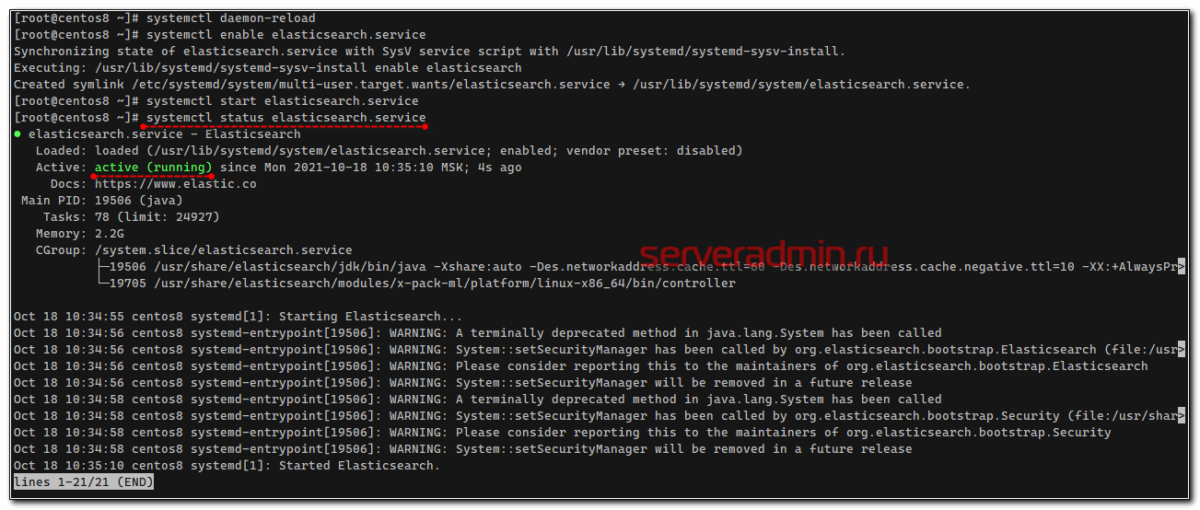
Дополнительные расширения PHP, доступные для установки, можно посмотреть командой:
-
Ubuntu и Debian:
Для конкретной версии:
apt-cache search php | egrep ‘7.4’ | grep module
Версии по умолчанию:
apt-cache search php | egrep ‘module’ | grep default
-
CentOS:
yum search php | grep module
Установить выбранный модуль можно командой:
-
Ubuntu и Debian:
apt -y install php7.4-soap
-
CentOS:
yum -y install php-soap
После установки PHP запускаем менеджер процессов php-fpm и добавляем его в автозагрузку:
-
Ubuntu и Debian:
systemctl start php7.4-fpm && systemctl enable php7.4-fpm
-
CentOS:
systemctl start php-fpm && systemctl enable php-fpm
Проверим установленную версию PHP:
php -v
После установки PHP нужно отредактировать настройки php-fpm по умолчанию, предназначенные для веб-сервера Apache:
-
Ubuntu и Debian:
nano /etc/php/7.4/fpm/pool.d/www.conf
-
CentOS:
vim /etc/php-fpm.d/www.conf
В файле ищем блок кода Unix user/group of processes и меняем apache на www-data для Debian и Ubuntu и nginx для CentOS.

Остался последний штрих. Открываем для редактирования конфигурационный файл PHP:
-
Ubuntu и Debian:
nano /etc/php/7.4/fpm/php.ini
-
CentOS:
vim /etc/php.ini
В файле ищем раздел Paths and Directories (он почти в самом конце файла), внутри находим параметр cgi.fix_pathinfo. Нужно раскомментировать его (удалить «;» в начале строки) и изменить значение с «1» на «0».

После этого сохраняем файл и перезапускаем веб-сервер, чтобы новые настройки применились:
-
Ubuntu и Debian:
systemctl reload nginx && systemctl reload php7.4-fpm
-
CentOS:
systemctl reload nginx && systemctl reload php-fpm
Настройка базового конфигурационного файла для сайта
Чтобы веб-сервер мог корректно обрабатывать запросы к сайтам, осталось добавить базовый конфигурационный файл вместо установленного по умолчанию. Для этого:
-
Удаляем конфигурационный файл default, использующийся по умолчанию, и создаём его замену, default.conf:
-
Ubuntu и Debian:
unlink /etc/nginx/sites-enabled/default touch /etc/nginx/sites-available/default.conf ln /etc/nginx/sites-available/default.conf /etc/nginx/sites-enabled/default.conf
-
CentOS:
touch /etc/nginx/conf.d/default.conf
-
-
Откроем новый файл в консольном текстовом редакторе и добавим туда содержимое:
-
Ubuntu и Debian:
nano /etc/nginx/sites-available/default.conf
-
CentOS:
vim /etc/nginx/conf.d/default.conf
Скопируйте в файл следующий блок настроек:
-
Ubuntu и Debian:
server { listen 80; listen :80; server_name _; root /usr/share/nginx/html/; index index.php index.html index.htm index.nginx-debian.html; location / { try_files $uri $uri/ =404; } location ~ .php$ { fastcgi_pass unix:/run/php/php7.4-fpm.sock; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; include snippets/fastcgi-php.conf; } location ~ /.ht { access_log off; log_not_found off; deny all; } }
-
CentOS:
server { listen 80; listen :80; server_name _; root /usr/share/nginx/html/; index index.php index.html index.htm index.nginx-debian.html; location / { try_files $uri $uri/ =404; } location ~ .php$ { fastcgi_pass unix:/var/run/php-fpm/php-fpm.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } location ~ /.ht { access_log off; log_not_found off; deny all; } }
-
Осталось проверить, что в конфигурационном файле отсутствуют ошибки, и перезапустить nginx для применения настроек:
nginx -t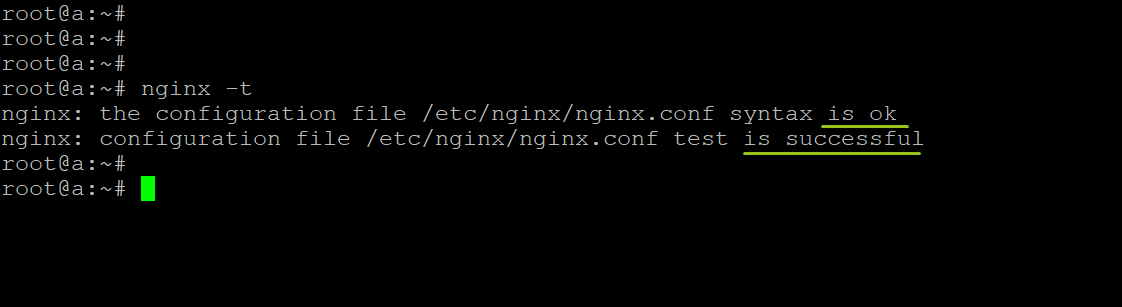
8 Logwatch
Я уверен, что среди нас есть те, кто не хочет, чтобы вся церемония была связана с «единой», «централизованной» системой ведения журналов.
Их бизнес базируется на отдельных серверах, и они ищут что-то быстрое и эффективное для просмотра своих файлов журналов.
Ну тогда, скажи привет Logwatch.
После установки LogWatch может сканировать системные журналы и создавать отчеты нужного вам типа.
Это несколько устаревшее программное обеспечение (читай «надежное»), хотя оно было написано на Perl.
Итак, вам понадобится Perl 5.6+ на вашем сервере для его запуска.


У меня нет скриншотов, которыми можно поделиться, потому что это чисто командная строка, демонизированный процесс.
Если вы наркоман CLI и любите стиль старой школы, вам понравится Logwatch!
Etc
Society
Quotes
Bulletin:
History:
Classic books:
Most popular humor pages:
The Last but not Least Technology is dominated by
two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt.
Ph.D
Copyright 1996-2021 by Softpanorama Society. www.softpanorama.org
was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP)
without any remuneration. This document is an industrial compilation designed and created exclusively
for educational use and is distributed under the Softpanorama Content License.
Original materials copyright belong
to respective owners. Quotes are made for educational purposes only
in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains
copyrighted material the use of which has not always been specifically
authorized by the copyright owner. We are making such material available
to advance understanding of computer science, IT technology, economic, scientific, and social
issues. We believe this constitutes a ‘fair use’ of any such
copyrighted material as provided by section 107 of the US Copyright Law according to which
such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free)
site written by people for whom English is not a native language. Grammar and spelling errors should
be expected. The site contain some broken links as it develops like a living tree…
| You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or
referenced source) and are
not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness
of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be
tracked by Google please disable Javascript for this site. This site is perfectly usable without
Javascript.
Last modified:
January 09, 2020
Правила аудита
Для создания, удаления и модификации правил аудита предназначена утилита auditctl. Есть три основных опции, которые принимает эта команда:
- -a – добавить правило в список;
- -d – удалить правило из списка;
- -D – удалить все правила;
- -l – вывести список заданных правил.
Если ты сейчас выполнишь команду «auditctl -l» от имени администратора, то, скорее всего, увидишь «No rules», а это значит, что ни одного правила аудита еще не существует. Для добавления правил используется следующая форма записи команды auditctl:
Здесь список – это список событий, в который следует добавить правило. Всего существует пять списков:
- task – события, связанные с созданием процессов;
- entry – события, происходящие при входе в системный вызов;
- exit – события, происходящие во время выхода из системного вызова;
- user – события, использующие параметры пользовательского пространства, такие как uid, pid и gid;
- exclude – используется для исключения событий.
Не беспокойся, если смысл списков кажется тебе непонятным. По сути, это всего лишь фильтры, которые позволяют сделать правила более точными. На деле из них используются только entry и exit, которые позволяют зарегистрировать либо сам факт обращения к системному вызову, либо его успешную отработку.
Второй параметр опции – ‘-a’ – это действие, которое должно произойти в ответ на возникшее событие. Их всего два: never и always. В первом случае события не записываются в журнал событий, во втором – записываются.
Далее указывается опция ‘-S’, которая задает имя системного вызова, при обращении к которому должен срабатывать триггер (например, open, close, exit, и т.д.). Вместо имени может быть использовано числовое значение.
Необязательная опция ‘-F’ используется для указания дополнительных параметров фильтрации события. Например, если мы хотим вести журнал событий, связанных с использованием системного вызова open(), но при этом желаем регистрировать только обращения к файлам каталога /etc, то должны использовать следующее правило:
Чтобы еще более сузить круг поисков, сделаем так, чтобы регистрировались только те события, при которых файл открывается только на запись и изменение атрибутов:
Здесь ‘a’ – изменение атрибута (то есть attribute change), а ‘w’ – запись (то есть write). Также можно использовать ‘r’ – чтение (read) и ‘x’ – исполнение (execute). Другие полезные фильтры включают в себя: pid – события, порождаемые указанным процессом, apid – события, порождаемые указанным пользователем, success – проверка на то, был ли системный вызов успешным, a1, a2, a3, a4 – первые четыре аргумента системного вызова. Фильтр key используется для указания так называемого ключа поиска, который может быть использован для поиска всех событий, связанных с этим ключом. Количество возможных фильтров достаточно велико, их полный список можно найти в man-странице auditctl.
Вообще, для слежения за файлами в auditctl предусмотрен специальный синтаксис, при котором опцию ‘-S’ можно опустить. Например, описанное выше правило может быть задано следующим образом (здесь опция ‘-p’ – это эквивалент фильтра perm):
Или используя более короткую форму (здесь оцпия ‘-p’ – это эквивалент фильтра perm, а ‘-k’ – фильтра key):
Таким же образом может быть установлена «слежка» за любым индивидуальным файлом:



