Введение
С каждым годом различные журналы и издательства по проектированию встраиваемых систем все чаще говорят о программируемых логических интегральных схемах (ПЛИС). Технология FPGA часто рассматривается как одна из самых мощных, но и одна из самых разочаровывающих этапов для разработчика встраиваемых систем.
С каждым новым поколением FPGA становятся быстрее, имеют меньшую геометрию и меньшее потребление, увеличивается количество логических элементов, улучшается показатель стоимость/количество операций, возможности кажутся бесконечными. Однако с большой мощностью (и реконфигурируемостью) приходят, по крайней мере, с ПЛИС, некоторые серьезные проблемы обучения и разочаровывающие дни (недели) в офисе. Давайте поговорим о том, где сегодня находятся ПЛИС, где они были всего несколько лет назад, и о некоторых болевых точках, которые все еще существуют.
Altera + OpenCL: программируем под FPGA без знания VHDL/Verilog +18
- 08.11.15 10:17
•
ishevchuk
•
#269009
•
Хабрахабр
•
•
Высокая производительность, Параллельное программирование, Блог компании НТЦ Метротек
Рекомендация: подборка платных и бесплатных курсов DevOps — https://katalog-kursov.ru/
Всем привет!Altera SDK for OpenCL — это набор библиотек и приложений, который позволяет компилировать код, написанный на OpenCL, в прошивку для ПЛИС фирмы Altera. Это даёт возможность программисту использовать FPGA как ускоритель высокопроизводительных вычислений без знания HDL-языков, а писать на том, что он привык, когда это делает под GPU.
Я поигрался с этим инструментом на простом примере и хочу об этом вам рассказать.
План:
Осторожно
Концепция магазина образов FPGA
Создание эффективно работающего FPGA-образа для определенной прикладной задачи — достаточно трудоемкая и длительная по времени задача. У хорошо слаженной команды на программирование образа может уйти до пары месяцев, а менее опытные клиенты потратят гораздо больше времени, а то и не справятся с этой задачей вообще.
Поэтому сама собой напрашивается концепция магазина образов, — по аналогии с существующими магазинами приложений для таких платформ как MacOS, Windows или Android. Разработчики могли бы передавать туда работоспособные образы, созданные ими для различных задач, а клиенты — приобретать их для загрузки на свои серверы с FPGA-ускорителями, если эти образы соответствует вычислительным задачам в их проектах.
В компании Selectel в 2018 году начата работа над созданием подобного магазина образов FPGA, которые можно было использовать на арендованных серверах Selectel с этой технологией. Тем самым, для клиентов значительно ускорился бы цикл разработки для новых проектов, а сами программисты (авторские коллективы) получили бы определенный доход от ранее проделанной работы, плюс были бы защищены от пиратского распространения образов по рынку без их согласия.
Полезная ссылка:
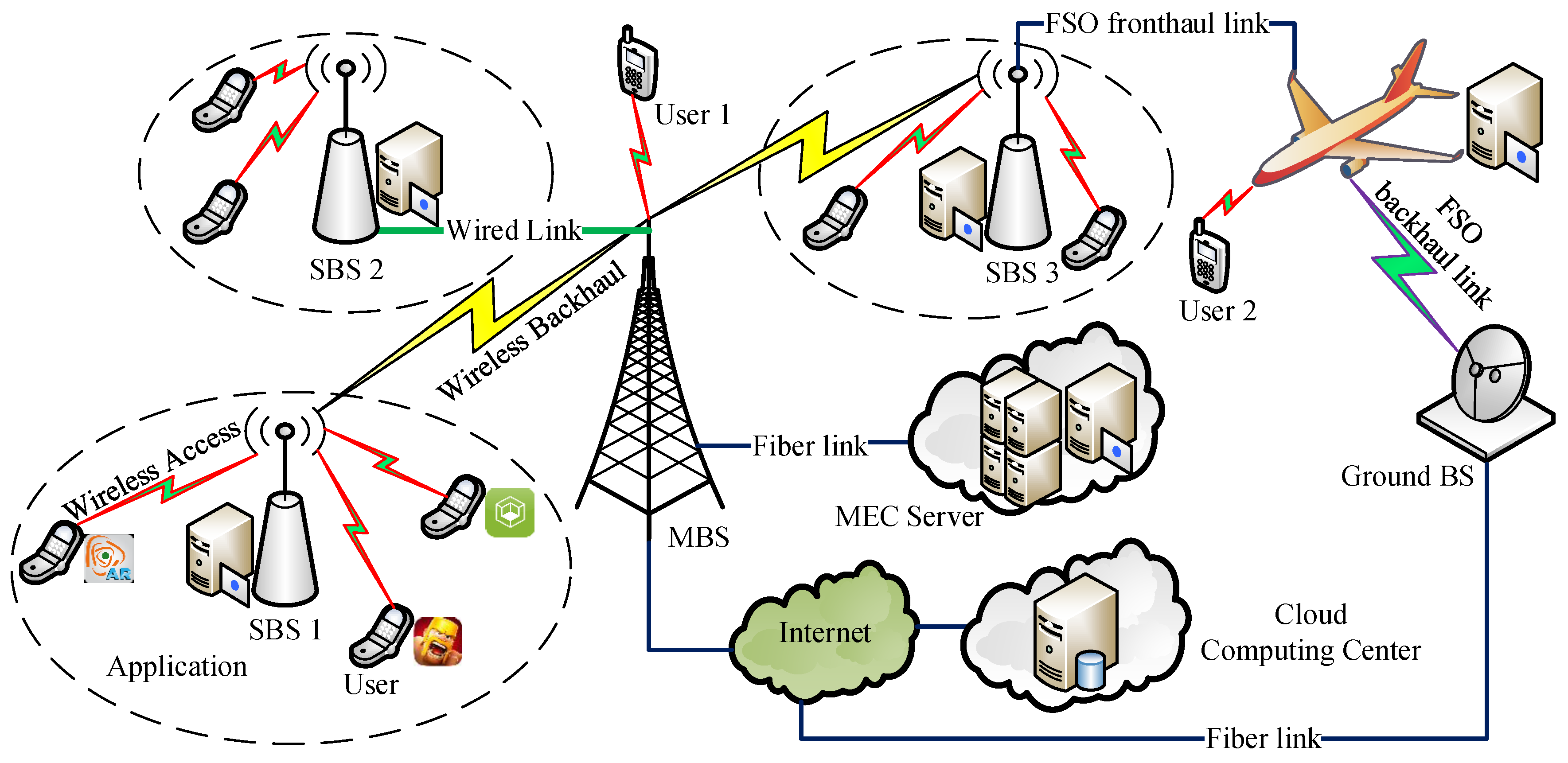
Совместимость ножек (DIP-8)
Конфигураторы AT17 и Altera EPC1064/EPC1213 в корпусе DIP-8 совместимы по цоколевке. Конфигураторы Atmel могут использоваться для конфигурирования FPGA путем установки прямо в панельку EPC1064/EPC1213 без какого-либо изменения схемы. Табл. 5 показывает соответствие названия ножки конфигуратора Atmel названию ножки Altera.
Таблица 5
| Номер ножки | Altera DIP-8 | Atmel DIP-8 | Замечания |
| 1 | DATA | DATA | Cовместимы |
| 2 | DCLK | CLK | Cовместимы |
| 3 | (WP)OE | (WP)RESET/OE | Совместимы, если в приборе Atmel полярность Reset — активный низкий (ОЕ — акт. высокий) |
| 4 | NCE | CE | Cовместимы |
| 5 | GND | GND | Cовместимы |
| 6 | NCASC | CEO(A2) | Cовместимы |
| 7 | Vpp | SER_N | Ножка OTP EPROM фирмы Altera используется для ISP в АТ17А фирмы Atmel |
| 8 | Vcc | Vcc | Cовместимы |
Таблица 6
| Номер ножки | Altera PLCC—20 | Atmel PLCC—20 | Замечания |
| 1 | TDO | — | Особенность ЕРС2 |
| 2 | DATA | DATA | Совместимы |
| 3 | ТСК | — | Особенность ЕРС2 |
| 4 | DCLK | DCLK | Совместимы |
| 5 | — | WP1 | Особенность АТ17с512А/010A |
| 5 | VccSEL | — | Особенность ЕРС2 |
| 8 | OE | OE | Совместимы, когда полярность Reset — акт. низкий (ОЕ — высокий) в приборах Atmel |
| 9 | nCS | nCs | Совместимы |
| 10 | GND | GND | Совместимы |
| 11 | TDI | — | Особенность ЕРС2 |
| 12 | NCASC | NCASC(A2) | Совместимы |
| 13 | NINIT_CONFIG | — | Особенность ЕРС2 |
| 14 | VppSEL | — | Особенность ЕРС2 |
| 15 | — | READY | Особенность приборов Atmel |
| 18 | Vpp(программирующая ножка) | SER_EN | Ножка OTP EPROM фирмы Altera используется для ISP в АТ17А фирмы Atmel |
| 19 | TMS | — | Особенность ЕРС2 |
| 20 | Vcc | Vcc | Cовместимы |
Как реализован eFPGA?
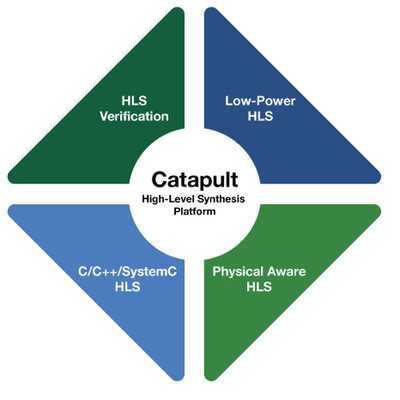
Эта концепция называется eFPGA или встроенной FPGA. Он состоит из интеграции ПЛИС как части SoC, а, следовательно, не как отдельного чипа, что открывает возможность принятия этого типа устройств на общем рынке.
Как и во встроенном графическом процессоре, внешнее кольцо, которое связывает выделенную FPGA с внешней стороной, потеряно, поскольку это является общим для всей SoC. Это уменьшает размер SoC на 25% по сравнению с его специальной версией.
Преимущество eFPGA заключается в том, что, используя ту же скорость передачи данных, что и остальные элементы SoC, он увеличивает скорость при обмене данными. EFPGA, находящаяся на том же процессоре и использующая те же кабели для связи, будет работать намного быстрее, чем стандартная FPGA, отделенная от ЦП, что представляет собой повышение производительности по сравнению с eFPGA, а не с выделенной FPGA, это позволяет нам делать то, что невозможно со стандартной ПЛИС, но в то же время мы ограничены в том, что можно сделать в eFPGA, поскольку там не так много места, как в ПЛИС.
Это означает, что на данный момент для реализации FPGA как неотъемлемой части системы существует два сценария. Первый — это eFPGA, второй — FPGA в виде чиплета, это отдельная тема, охватывающая очень разные рынки. Например, вы можете рассмотреть возможность создания нейронной сети для ИИ с невстроенной ПЛИС, чего нельзя сделать в eFPGA.
eFPGA для ввода-вывода на процессорах и графических процессорах ПК.
Наиболее очевидное применение — это интерфейсы ввода-вывода, например, мы можем реализовать интерфейс USB с FPGA и SerDES и перенастроить их для работы в качестве интерфейса SATA. Мы также можем сделать то же самое с FPGA и подключенным к нему радио, например, чтобы преобразовать Wi-Fi Прямой интерфейс в Bluetooth в зависимости от необходимости конфигурации. Идея заключается не в том, что конечный пользователь вносит эти изменения, а в том, что эти изменения вносит ассемблер или производитель аппаратного компонента.
Также возможно реализовать это в графическом процессоре, например, могут появиться экраны с поддержкой DP 2.0, а ваш графический процессор поддерживает только DP 1.4, но благодаря тому, что видеодрайвер был реализован в FPGA, это может быть перепрограммированным и получить поддержку нового видеовыхода. Также может случиться так, что вы приобрели графический процессор для майнинга и не заинтересованы в отображении графики, в этом случае вы можете перенастроить FPGA вывода на экран в криптографическом процессоре или даже небольшом ASIC для ускорения добычи.
Как правило, eFPGA могут использоваться для замены внешних интерфейсов процессора и часто используются на периферии без необходимости переделывать чип. Не только интерфейсы ввода и вывода, но и Оперативная память, например, переход от интерфейса DDR4 к LPDDR4 без необходимости изготовления двух разных микросхем.
eFPGA интегрирован в ядро ЦП
Один из способов повышения производительности процессоров в будущем — это сосредоточение внимания на общих и повторяющихся частях кода. Другое решение — ускорение тяжелых частей кода, которые будут выполняться специализированными модулями.
Практически одновременно с покупкой Xilinx AMD опубликовала патент, в котором говорилось об использовании ПЛИС для ускорения определенных инструкций, которые перейдут на более высокий уровень интеграции. Это FPGA уже внутри процессора, а не как дополнительный элемент SoC.
- ЦП может включать в себя один или несколько программируемых исполнительных модулей, которые можно переконфигурировать для выполнения всех видов инструкций.
- Упомянутые исполнительные блоки представляют собой eFPGA, часть ЦП, отвечающая за этапы сбора и декодирования данных, является общей для всех ЦП и отвечает за распределение инструкций, которые должны быть выполнены, в eFPGA, который действует как исполнительный блок.
- Когда процессор загружает поток, он также загружает типы исполнительных модулей, которые требуются для его выполнения, поэтому eFPGA настраиваются как такие модули благодаря внутренним файлам конфигурации.
- Модули eFPGA можно перепрограммировать на лету, и каждый из них выполняет свою функцию.
Например, программа может часто использовать целочисленные блоки, но не SIMD-блок, потому что, если исполнительные блоки реализованы как eFPGA, мы можем перенастроить тот, который был как SIMD-блок, чтобы он действовал как дополнительный целочисленный блок.
Процесс разработки (workflow)
- Код кернела описывается в файле *.cl.
- Готовится хостовое приложение на С/C++, которое будет производить выделение необходимых объемов памяти и «загрузку» значений в кернел.
- С помощью утилиты aoc, которая входит в Altera OpenCL SDK, «компилируется» ядро в aocx файл. С помощью gcc собирается хостовое приложение.
- При запуске host_app произойдет загрузка прошивки FPGA, в ядро загрузятся подготовленные данные и начнется их обработка.
- Счетчики для профилирования собирают данные, которые поместятся в файл profile.mon.
- С помощью утилиты aocl можно посмотреть этот отчет и сделать вывод: удовлетворяет ли по времени выполнения/производительности эта реализация.
- Если удовлетворяет, то можно перекомпилировать ядро без —profile, т.к. профилирующие счетчики отнимают ресурсы в FPGA. С другой стороны, если дополнительных ядер не планируется добавлять, то можно и не пересобирать.
- Если не удовлетворяет, то надо оптимизировать/писать ручками/взять другой чип или смириться.
aocxнескольких часовaoc kernel.cl
Сборка aocx
- kernel.cl скармливается clang, который переводит описание в IR, а так же проводит различные оптимизации.
- Генерируется RTL-ное Verilog IP-ядро. Сгенеренные файлы доступны для чтения (незашифрованы) и могут быть просимулировать в обычном симуляторе (например, ModelSim). Однако, там не весь код автосгенеренный: есть модули, которые явно писал человек.
- Полученное IP «присоединяется» к дефолтому проекту для платы и получается обычный проект для Quartus’a.
- Проходит сборка проекта (Analysis & Synthesis, Fitter, Assembler). Именно этот пункт занимает наибольшее время (от десяти минут до нескольких часов): поиск оптимальных мест расположения примитивов требует много вычислений.
- Результат сборки, информация о борде и прочее размещают в aocx, который является просто ELF-файлом.
aocx
ХОРОШАЯ
Большие, реконфигурируемые, море логических ресурсов
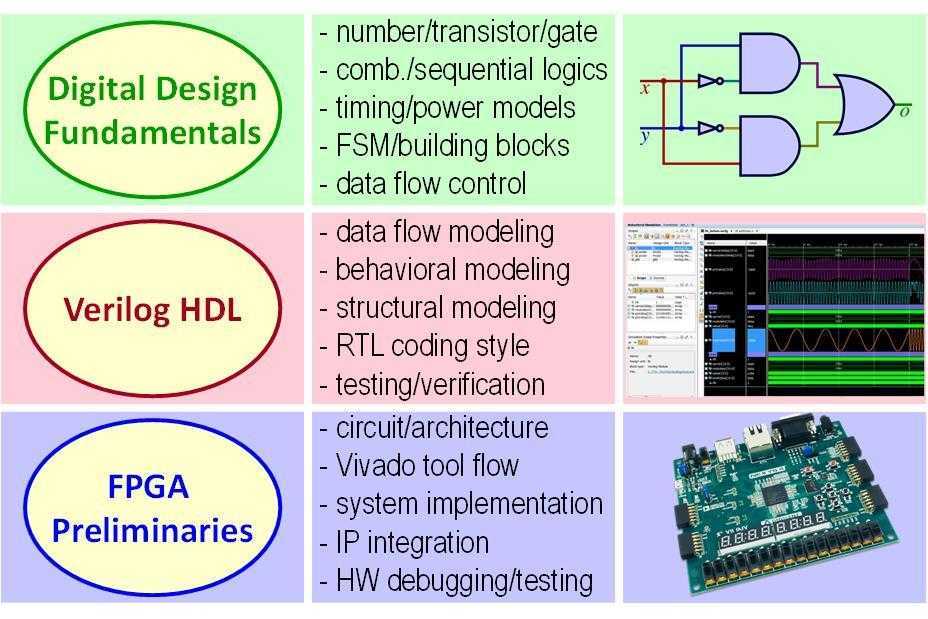
Технология FPGA позволяет разработчику реализовать практически любой алгоритм и/или управление, которые ему требуются. Современная ПЛИС состоит из десятков, а то и миллионов логических элементов и триггеров, которые могут быть объединены вместе, чтобы реализовать всё: начиная от антидребезга для кнопки (denounce circuit) и заканчивая хост-контроллером x16 PCIe gen-3. Использование ПЛИС в вашем проекте дает вам почти бесконечную свободу для реализации любой необходимой вам функциональности.

Уровень абстракции
Представьте себе, что вы хотите спроектировать систему на логических микросхемах 74-ой серии, и люди, которые работали с первыми ПЛИС, должны были сделать почти то же самое. К счастью, сегодня нам не приходится думать на таком низком уровне. Существуют языки, называемые языками описания аппаратного обеспечения (HDL – Hardware Description Language), которые помогают разработчикам описать их алгоритм и передать его синтезатору, который затем создает список соединений логических выражений и регистров (нетлист). Кроме того, существует широкий спектр технологий и языков абстракции более высокого уровня. Xilinx предоставляет инструмент под названием Vivado HLS (HLS расшифровывается как high-level synthesis – высокоуровневый синтез), который позволяет разработчику писать на C, C++ или System C и затем из этого описания генерировать HDL код на языках VHDL или Verilog. Здесь, в Viewpoint Systems, мы часто используем технологию LabVIEW FPGA, которая позволяет описывать проект на ПЛИС с помощью графической среды программирования, использующей парадигмы потока данных.
Ресурсы и экосистема
Коммерчески доступные ПЛИС существуют с середины 1980-х гг. это долгий срок для развития технологии и её экосистемы. Существует множество ресурсов, доступных для всего: от понимания того, как устроен кремний, до того, как синтезатор генерирует нетлист, до лучших методологий описания HDL-кода для генерации логических структур, необходимых вам. Вы можете зайти на Amazon и поискать книги по ключевому слову FPGA и найдёте сотни доступных книг. Если вы загуглите слово FPGA, вы сможете найти десятки тысяч ответов на вопросы. Поскольку HDL является текстовым описанием, эти вопросы и ответы индексируются поисковыми системами, что делает поиск информации простым и быстрым.


Кроме того, за последние несколько лет появилось больше ресурсов об инструментах синтеза более высокого уровня, таких как Vivado HLS, Calypto/Catapult и LabVIEW FPGA.
Скорость и размеры
Современные ПЛИС могут работать очень быстро – например, с частотой в сотни мегагерц. Вы можете подумать: «но, мой процессор Intel работает на гигагерцовой частоте!” Это правда! Однако ваш процессор Intel является «процессором общего назначения» – он делает большое количество вещей довольно хорошо, а не небольшое количество вещей действительно хорошо. ПЛИС позволяют писать массово параллельные реализации алгоритмов, при этом пропускная способность может быть в 10 раз, 100 раз или 1000 раз выше, чем любого процессора на современном рынке.
Хотя высокоуровневая абстракция отлично подходит для более быстрого вывода продукта на рынок (time-to-market ) вы просто никогда не сможете заставить свой проект работать так же быстро, как при написании кода вручную в традиционном HDL, таком как VHDL или Verilog. Языки абстракции и технологии высокоуровнего синтеза могут быть великолепны для быстрого создания прототипа; однако неизбежные накладные расходы всегда будут делать ваш проект более ресурсозатратным и, следовательно, более медленным (более низкая максимальная тактовая частота).
Принцип работы
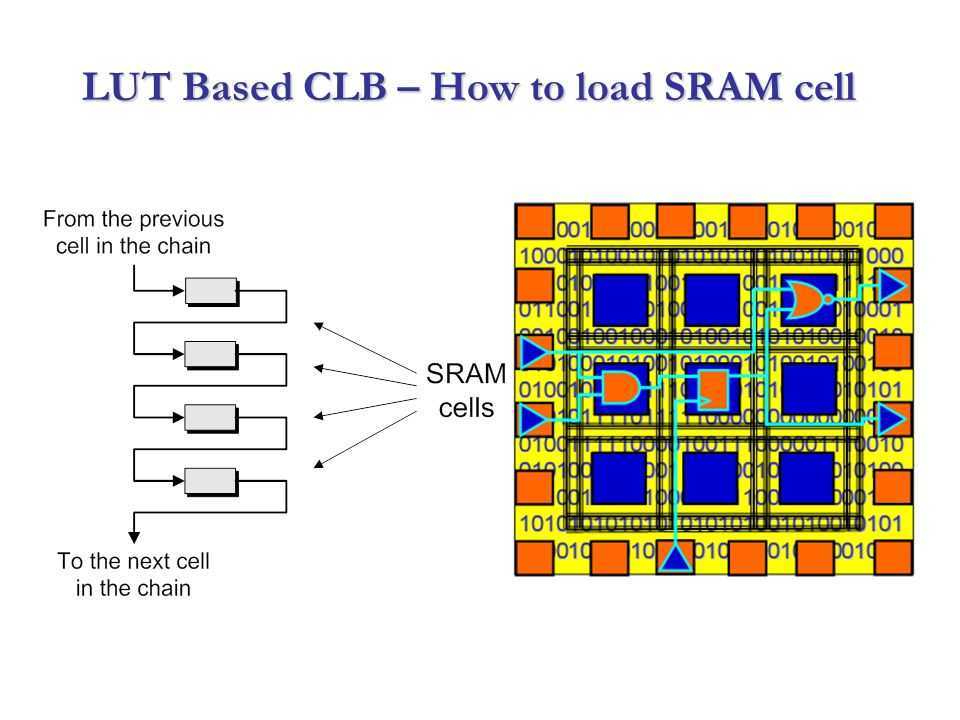
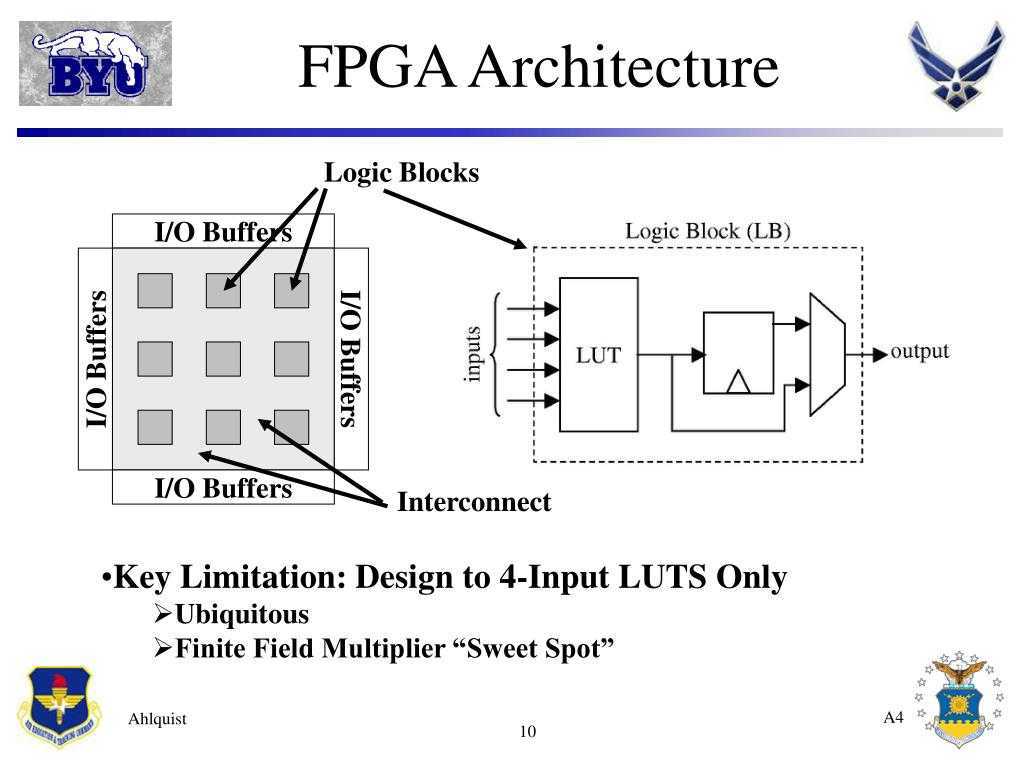
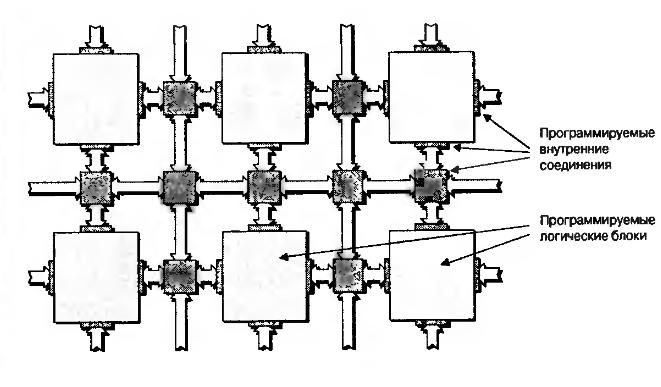
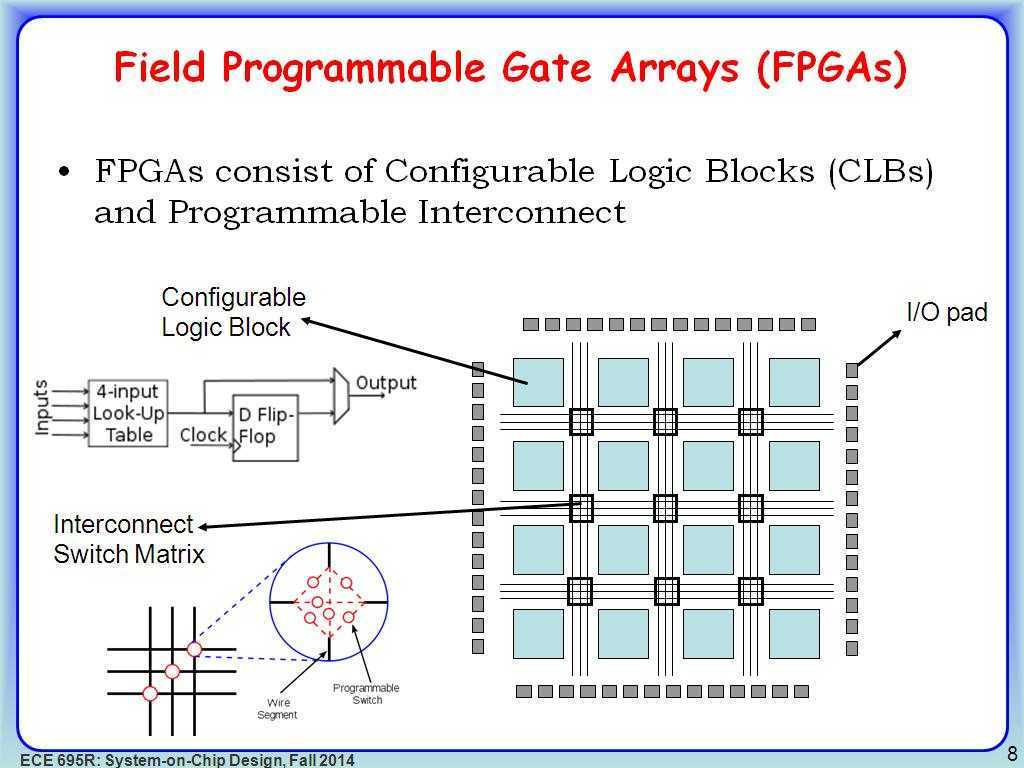
Микросхема FPGA — это та же заказная микросхема ASIC, состоящая из таких же транзисторов, из которых собираются триггеры, регистры, мультиплексоры и другие логические элементы для обычных схем. Изменить порядок соединения этих транзисторов, конечно, нельзя. Но архитектурно микросхема построена таким хитрым образом, что можно изменять коммутацию сигналов между более крупными блоками: их называют CLB — программируемые логические блоки.
Также можно изменять логическую функцию, которую выполняет CLB. Достигается это за счет того, что вся микросхема пронизана ячейками конфигурационной памяти Static RAM. Каждый бит этой памяти либо управляет каким-то ключом коммутации сигналов, либо является частью таблицы истинности логической функции, которую реализует CLB.
Так как конфигурационная память построена по технологии Static RAM, то, во-первых, при включении питания FPGA микросхему обязательно надо сконфигурировать, а во-вторых, микросхему можно реконфигурировать практически бесконечное количество раз.
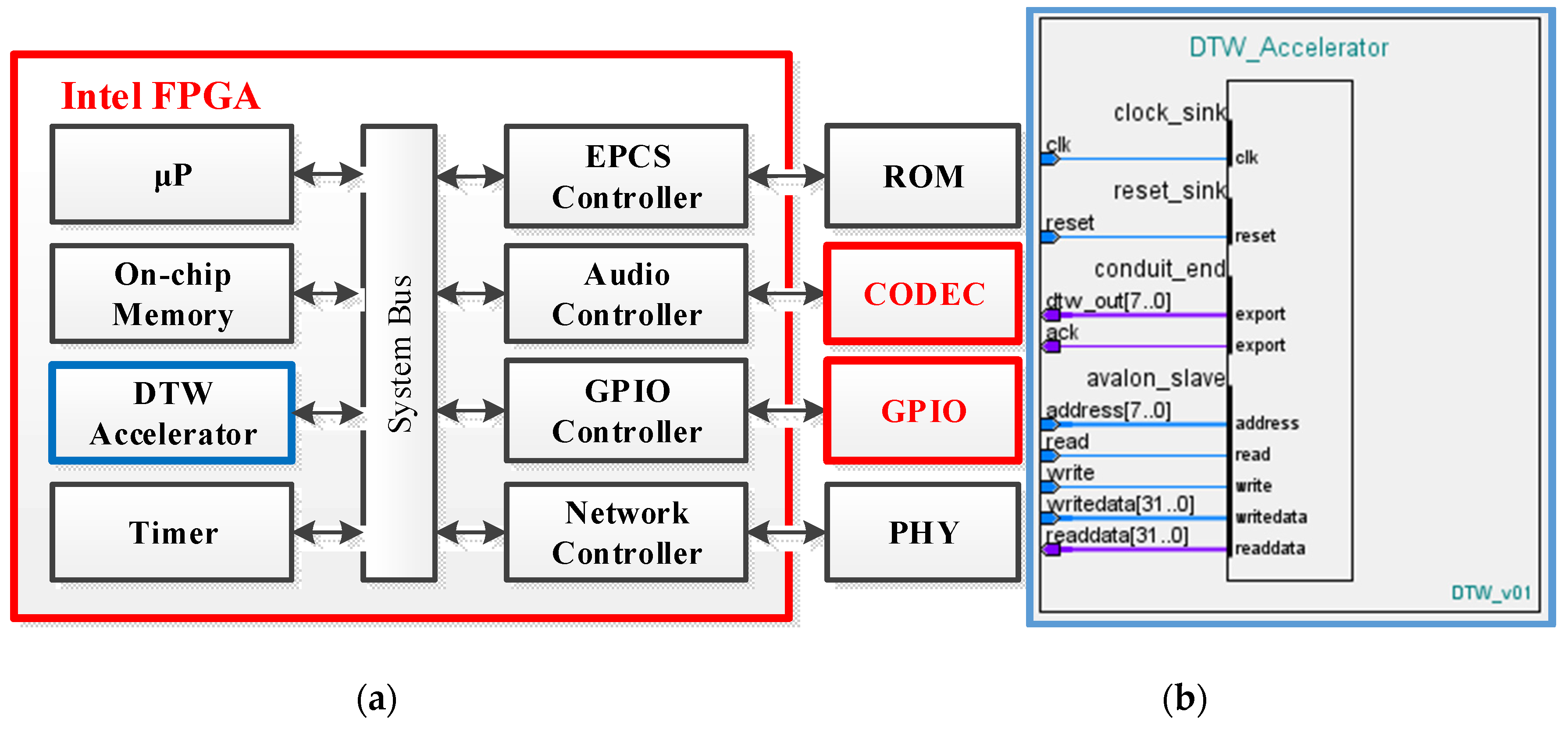
 Очень упрощенная 2D-структура микросхемы без конфигурационной памяти
Очень упрощенная 2D-структура микросхемы без конфигурационной памяти
Другие статьи в выпуске:
Xakep #236. FPGA
- Содержание выпуска
- Подписка на «Хакер»-60%
Блоки CLB находятся в коммутационной матрице, которая задает соединения входов и выходов блоков CLB.
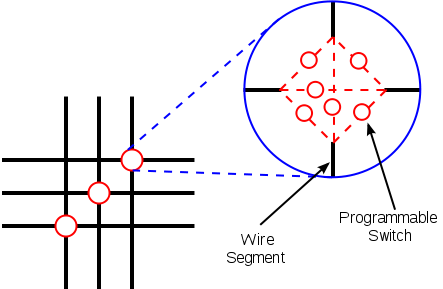 Схема коммутационной матрицы
Схема коммутационной матрицы
На каждом пересечении проводников находится шесть переключающих ключей, управляемых своими ячейками конфигурационной памяти. Открывая одни и закрывая другие, можно обеспечить разную коммутацию сигналов между CLB.
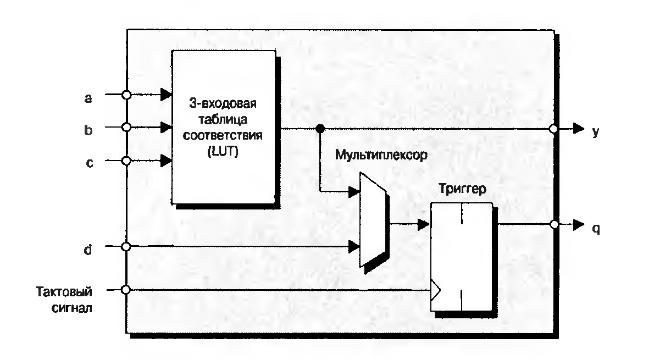 CLB
CLB
CLB очень упрощенно состоит из блока, задающего булеву функцию от нескольких аргументов (она называется таблицей соответствия — Look Up Table, LUT) и триггера (flip-flop, FF). В современных FPGA LUT имеет шесть входов, но на рисунке для простоты показаны три. Выход LUT подается на выход CLB либо асинхронно (напрямую), либо синхронно (через триггер FF, работающий на системной тактовой частоте).
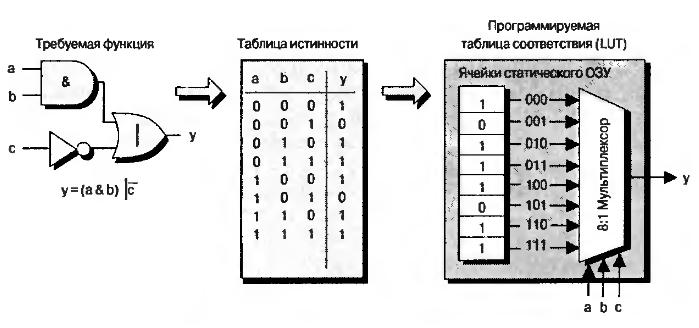 Принцип реализации LUT
Принцип реализации LUT
Интересно посмотреть на принцип реализации LUT. Пусть у нас есть некоторая булева функция . Ее схемотехническое представление и таблица истинности показаны на рисунке. У функции три аргумента, поэтому она принимает 2^3 = 8 значений. Каждое из них соответствует своей комбинации входных сигналов. Эти значения вычисляются программой для разработки прошивки ПЛИС и записываются в специальные ячейки конфигурационной памяти.
Значение каждой из ячеек подается на свой вход выходного мультиплексора LUT, а входные аргументы булевой функции используются для выбора того или иного значения функции. CLB — важнейший аппаратный ресурс FPGA. Количество CLB в современных кристаллах FPGA может быть разным и зависит от типа и емкости кристалла. У Xilinx есть кристаллы с количеством CLB в пределах примерно от четырех тысяч до трех миллионов.
Помимо CLB, внутри FPGA есть еще ряд важных аппаратных ресурсов. Например, аппаратные блоки умножения с накоплением или блоки DSP. Каждый из них может делать операции умножения и сложения 18-битных чисел каждый такт. В топовых кристаллах количество блоков DSP может превышать 6000.
Другой ресурс — это блоки внутренней памяти (Block RAM, BRAM). Каждый блок может хранить 2 Кбайт. Полная емкость такой памяти в зависимости от кристалла может достигать от 20 Кбайт до 20 Мбайт. Как и CLB, BRAM и DSP-блоки связаны коммутационной матрицей и пронизывают весь кристалл. Связывая блоки CLB, DSP и BRAM, можно получать весьма эффективные схемы обработки данных.
Замена однократно программируемых приборов фирмы Altera на перепрограммируемые приборы серии AT17A фирмы Atmel
В выборе устройства и разработке схемы для любого FPGA ключевыми вопросами являются:
соответствие числа битов программы FPGA объему памяти конфигуратора;
совместимость цоколевки и применимость конструктивного исполнения;
конфигуратор ведущий или ведомый ( важно только для 512A/010A/020A/002A);
существование слабого внутреннего подтягивающего или опускающего резисторов на ножках FPGA или конфигуратора;
предупреждение столкновений для тактовых сигналов в течение ISP;
предупреждение столкновений на линиях сигналов RESET/OE и CE (nCS) в течение ISP (только для 65/128/256).
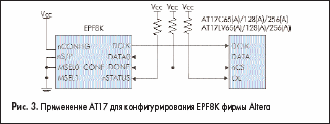
Приборы ЕРС фирмы Altera могут замещаться конфигурационными перепрограммируемыми приборами фирмы Atmel серии АТ17А путем трансляции программных файлов из формата Altera в формат Atmel. Для облегчения этого процесса Atmel предлагает программную утилиту CPS, которую можно свободно получить на сайте Atmel. Она работает под операционными системами Windows’95/98/NT. Эта программа выдает Intel (MCS-86) Нех-файл, который может быть прочитан любыми стандартными программаторами. При работе с программатором ATDH2200E фирмы Atmel и этой программой, данные могут загружаться непосредственно в конфигураторы Atmel (см. рис. 9).
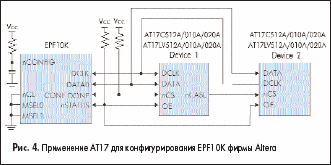
Серия конфигураторов АТ17А может непосредственно применяться в устройствах с FPGA фирмы Altera, предоставляя пользователю возможность перепрограммирования.
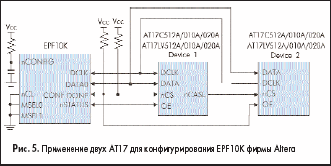
Применение конфигураторов показанное на рис. 3–5 аналогично соответствующим рекомендациям по применению ОТР EPROM Altera. Отличие существует лишь на рис. 4 и 5, где рекомендуется использование RC-цепочки на входе nCONFIG для того, чтобы ввести задержку в 100–200 мс, обычно устанавливаемую приборами ОТР EPROM Altera. Эта задержка позволяет источнику питания установить нормальный уровень напряжения на плате до того, как будет выполнен сеанс конфигурированния FPGA.
Установка полярности RESET
Все конфигураторы в ряде AT17 и AT17A имеют способность изменять полярность RESET/OE. Это требуется, чтобы позволить устройствам должным образом конфигурировать различные семейства FPGA. Заданное по умолчанию состояние — активный низкий OE и активный высокий RESET.
Конфигураторы 65/128/256 используют различные алгоритмы с конфигураторами 512/010/020/002.
Программирование полярности RESET/OE конфигураторов 65/128/256
Установка полярности активный высокий OE (активный низкий RESET): Запишите байт данных FF по адресу 3FFFH. С двумя дополнительными ножками, используемыми при программировании поступите следующим образом:
Установка полярности активный низкий OE (активный высокий RESET): Запишите байт FF по адресу 3FFFH. С двумя дополнительными ножками, используемыми при программировании, поступите следующим образом:
Подтверждение (проверка) полярности RESET:
Включите устройство, должно наблюдаться следующее:
Если при этом ножка ДАННЫЕ находится в третьем состоянии, то RESET/OE запрограммирован как активный высокий OE (активный низкий RESET); если вывод ДАННЫЕ читает «0» или «1», то RESET/OE — активный низкий OE (активный высокий RESET).
Программирование полярности RESET/OE для конфигураторов 512/010/020
Установка полярности активный высокий OE (активный низкий RESET): Запишите четыре байта FF FF FF FF по адресам 20000–20003.
Установка полярности активный низкий OE (активный высокий RESET): Запишите четыре байта 00 00 00 00 по адресам 20000-20003.
Подтверждение полярности RESET/OE 512/010/020 конфигураторов: выполните чтение четырех байтов данных по адресам 20000–20003. Если данные — 00 00 00 00, тогда RESET запрограммирован для активный низкий OE (активный высокий — RESET); если данные — FF FF FF FF, тогда RESET запрограммирован как активный высокий OE (активный низкий — RESET).

Программирование полярности RESET/OE для конфигуратора 002
Установка полярности активный высокий OE (активный низкий RESET): Запишите четыре байта FF FF FF FF по адресам 400000–400003.
Установка полярности активный низкий OE (активный высокий RESET): Запишите четыре байта 00 00 00 00 по адресам 400000–400003.
Проверка полярности RESET/OE конфигуратора 002: выполните чтение четырех байтов данных по адресам 400000–400003. Если читаются данные 00 00 00 00, тогда запрограммировано активный низкий OE (активный высокий — RESET); если данные — FF FF FF FF, тогда запрограммирован активный низкий RESET.
Замечания: при программировании полярности RESET на конфигураторах AT17 и AT17A
- Состояния упомянутых выше ножек должно поддерживаться в течение полного цикла записи.
- После того как полярность RESET изменена, питание конфигуратора должно быть выключено.
Что такое ПЛИС?
FPGA — это матрица программируемых логических вентилей, которую можно настроить любым способом, чтобы указанная матрица работала как конкретный чип. Они используются в средах, где требуется специальное оборудование, но они настолько специализированы, что массовое производство невыгодно, а также для создания прототипов новых функций будущих процессоров.
ПЛИС состоят из нескольких блоков настраиваемой логики, которые связаны между собой. Они отличаются от других процессоров тем, что в остальном логику их схемотехники изменить нельзя. Вы не можете превратить CPU в GPU после его изготовления, но это можно сделать с помощью FPGA, загрузив файл конфигурации, который перепрограммирует его логические вентили.
Очевидно, что у этой программной емкости есть несколько аналогов, первая заключается в том, что она не может достичь тактовых частот микросхем, которые являются ПЛИС, вторая заключается в том, что избыток схемотехники из-за уровня их конфигурации приводит к увеличению необходимого количества транзисторов. и таким образом площадь.
Конфигураторы фирмы Atmel
Конфигурационная ЕЕРRОМ (конфигуратор) для устройств FPGA является последовательной памятью, которая используется для загрузки образа FPGA.
Серия конфигурационных приборов фирмы Atmel обладает следующими особенностями:
- совместимость с AT6000, ATT3000 (Atmel), EPF6K, EPF8К, FLEX10K, ACEX (Altera), XC2000, XC3000,XC4000, XC5000 (Xilinx), Lucent ORCA FPGA, MPA1000;
- прямая замена для OTP EPROM фирм-производителей FPGA;
- конкурентоспособность с OTP EPROM по стоимости;
- широкий выбор объемов: от 64 К до 1 M;
- программируемая полярность сигнала Reset позволяет адаптироваться к любым FPGA;
- различные виды конструктивного исполнения: DIP, PLCC или SOIC;
- простой интерфейс к FPGA требующий только одной ножки ввода-вывода;
- программируемость «в системе» через 2-проводную шину;
- серия поддерживается стандартными промышленными программматорами;
- высокая скорость конфигурации FPGA (15 МГц);
- время программирования — 2 секунды;
- каскадное соединение для программирования больших FPGA;
- сигнал «Готов» гарантирует достоверность включения питания системы;
- свойство защиты записи позволяет использовать незанятую часть памяти для хранения данных в энергонезависимой памяти;
- малая потребляемая мощность;
- 3,3-вольтовая версия;
- эмуляция последовательных программируемых ПЗУ 24CXX.
В качестве примера в табл. 1 приведено сравнение перепрограммируемых конфигураторов фирмы Atmel с OTP EPROM фирмы Altera.
Таблица 1
| Atmel AT17A | Altera EPC1 | |
| ISP (программируемость в системе) | Да | Нет3 |
| Перепрограммируемость | Да | Нет3 |
| Наличие питания 3,3 В | Да | Да |
| ISP (программируемость в системе) при питании 3,3 В | Да | Нет3 |
| Корпус 8 ножек DIP | Да5 | Да4 |
| Корпус 20 ножек PLCC | Да2 | Да |
| Каскадируемость | Да | Да |
| Прибор 128К х 1 | Да | Нет |
Примечания:
Как видно из таблицы, конфигураторы фирмы Atmel обладают рядом преимуществ в сравнении с OTP EPROM фирмы Altera.
Примерно такая же картина вырисовывается при сравнении их с OTP EPROM фирмы Xilinx.
Наличие такого качества, как программируемость в системе, позволяет выполнять изменения в проектах без опасения увеличить стоимость устройства на стоимость OTP EPROM, заменяемого после каждой модификации. Это, в свою очередь, отражается на легкости внесения изменений в схему и сокращении времени разработки, что сказывается на снижении стоимости проекта и повышении его конкурентоспособности.
Концепция магазина образов FPGA
Создание эффективно работающего FPGA-образа для определенной прикладной задачи — достаточно трудоемкая и длительная по времени задача. У хорошо слаженной команды на программирование образа может уйти до пары месяцев, а менее опытные клиенты потратят гораздо больше времени, а то и не справятся с этой задачей вообще.
Поэтому сама собой напрашивается концепция магазина образов, — по аналогии с существующими магазинами приложений для таких платформ как MacOS, Windows или Android. Разработчики могли бы передавать туда работоспособные образы, созданные ими для различных задач, а клиенты — приобретать их для загрузки на свои серверы с FPGA-ускорителями, если эти образы соответствует вычислительным задачам в их проектах.
В компании Selectel в 2018 году начата работа над созданием подобного магазина образов FPGA, которые можно было использовать на арендованных серверах Selectel с этой технологией. Тем самым, для клиентов значительно ускорился бы цикл разработки для новых проектов, а сами программисты (авторские коллективы) получили бы определенный доход от ранее проделанной работы, плюс были бы защищены от пиратского распространения образов по рынку без их согласия.
Полезная ссылка:
Области применения FPGA
С момента своего изобретения и вплоть до сегодняшних дней одним из базовых направлений применения FPGA было и остается прототипирование микросхем для мелко- и среднесерийных изделий, когда изготовление микросхем ASIC экономически нецелесообразно.
На начало 2018 года, по сведениям российской компании Алмаз-СП, сферы применения FPGA –ускорителей выглядели следующим образом:
- 50% — спецприменения в военной электронике,
- 20% — телекоммуникации (оборудование базовых станций GSM и др.),
- 10% — обработка видеопотоков (видеостудии, видеоаналитика),
- 10% — промышленное применение,
- 10% — прототипирование и прочее (включая научные расчеты).
Однако, несмотря на преимущественно военное применение в прошлом, сфера гражданского использования FPGA –ускорителей растет сейчас гораздо быстрее. В 2015 году Intel приобрела одного из крупнейших производителей FPGA — компанию Altera. Разработки Altera теперь воплощаются в кремний уже под брендом Intel. И новая линейка FPGA-чипов, известная как Intel Cyclone 10 не заставила себя ждать. Модели чипа Cyclone 10 GX показывают очень высокую производительность (до 134 GFLOP) и имеют расширенные возможности ввода-вывода. Подключение к другим устройствам выполняется через сетевой порт 10GE или по шине PCI Express x4. Эти FPGA-чипы предназначены для систем машинного зрения, наблюдения, видео трансляций, а также робототехники. Младшая модель чипа Cyclone 10 LP реализована как вычислительное ядро для инженерных систем — управления комплексами датчиков, контроллерами двигателей и так далее.
Кроме линейки Cyclone, в производственной программе Intel присутствуют и другие серии FPGA-чипов, унаследованные от Altera: MAX, Arria и Startix. Последние две серии — самые мощные чипы FPGA из существующих на рынке, в 2018 году ожидается их обновление до уровня Arria 10 и Startix 10. Startix 10 будет построена на гиперфлекс-архитектуре и обладать производительностью 10 терафлопс (т.е. почти на 3 порядка мощнее Cyclone 10).
Серии Cyclone, MAX, Arria и Startix частично перекрывают друг-друга по производительности, но Intel позиционирует каждую серию отдельно. Для Arria это сигнальные процессоры для приборостроения, для Startix — высокопроизводительные вычисления в дата-центрах, телекоммуникациях. Про области применения для серии Cyclone, которая единственная получила обновления в 2017 году, мы уже говорили. Но еще одну такую область применения для Cyclone стоит упомянуть обязательно — это «Интернет вещей», IoT.
В заключение несколько чаще всего встречающихся типовых вопросов и ответов по этой теме
Ответ: В будущей версии CPS будет включена опция, позволяющая объединить два pof-файла и затем конвертировать этот файл в один bst-файл или один hex-файл.
Пока же мы рекомендовали бы проделать следующее: вы можете использовать опцию /B в программе Atmel CPS, чтобы преобразовать файлы *.pof и *_1.pof в два bst-файла. (Один файл преобразуется за один раз.) Теперь вы сможете открыть оба bst-файла текстовым редактором. Вставьте содержимое второго bst-файла в конец первого и сохраните в одном-единственном bst-файле
Пожалуйста обратите внимание, что порядок для копирования содержания файла очень важен. Наконец, вы можете программировать объединенный bst-файл в AT17LVXXXA СППЗУ, используя процедуру /P с установкой параметра «Семейство FPGA» в «Другие AT6K»
Если вы используете программатор иного вида, чем программатор Atmel ATDH2200, вы можете послать два pof-файла в группу Atmel «Приложения конфигураторов» по адресу Они будут использовать программное обеспечение CPS с вышеупомянутой процедурой, чтобы запрограммировать преобразованный и объединенный bst файл в Atmel AT17 ряд СППЗУ. Затем они будут использовать какой-либо иной программатор, чтобы прочитать данные от устройства и сохранят результат в hex (шестнадцатеричный объектный файл Intel MSC), который является популярным форматом и который будет принят любыми программаторами.
Замечание: CPS — бесплатное программное обеспечение, которое может быть загружено с сайта Atmel по адресу:
http://www.atmel.com/atmel/products/prod185.htm или с российского сайта:
http://www.atmel.ru/Binary/spcinstall.exe.
Вопрос: Если я конфигурирую только одно устройство FLEX 10K, APEX, ACEX или Mercury, что я должен делать с конфигурационным выводом nCEO?
Ответ: В схеме конфигурации только с одним устройством FLEX 10K, APEX, ACEX или Mercury вывод nCEO не используется, поскольку он работает так, как работал бы в цепочке конфигурационных устройств. Поэтому оставьте вывод nCEO свободным и работайте с ним как с зарезервированным выводом.



Как заявлено в файле отчета, ножка nCEO — специализированный конфигурационный вывод, который не может использоваться после конфигурации как ножка ввода-вывода. Ножка nCEO устанавливается на высоком уровне перед конфигурированием устройства и переходит в низкое состояние после того, как устройство успешно конфигурировано. Вы можете использовать ножку nCEO, чтобы воздействовать на вывод nCE другого FLEX 10K, APEX, ACEX или Mercury в цепочке устройств.
Вопрос: Какое напряжение я должен подключить к ножкам Vcc устройств конфигурации EPC1, EPC2 или EPC1441 при конфигурировании устройства FLEX с различными напряжениями VCCIO и VCCINT?
Ответ: В устройствах конфигурации EPC1, EPC2, или EPC1441 ножка VCC может быть связана с напряжением питания 3,3 или 5 В, поскольку все устройства FLEX 10K и АРЕХ имеют вводы с допуском 5 В.
Когда ножки VCC у EPC1 или EPC1441 связаны с 3,3 В, вы должны включить опцию «Использование низковольтовой конфигурации EPROM» в диалоговом окне Global Project Device Options (меню Назначения) перед генерацией файла программирования для конфигурирующего ПЗУ.
Напряжение питания EPC2 устанавливается подключениями VCCSEL и VPPSEL, а не через программное обеспечение.