Введение
Сегодня расскажем как построить максимально отказоустойчивую сетевую инфраструктуру предприятия, с минимальной привязкой к конкретному вендору, преимущественно на открытых протоколах и стандартах.
Условно говоря, сетевую инфраструктуру можно разделить на ряд компонентов:
-
ЛВС (локальная вычислительная сеть) — IT-инфраструктура на основе группы стандартов IEEE 802.3.
-
БЛВС (беспроводная локальная вычислительная сеть) — IT-инфраструктура на основе группы стандартов IEEE 802.11, так или иначе интегрированная с ЛВС.
-
Вспомогательные системы (система управления IP пространством, инвентарная система, система описания сетевых сервисов, системы мониторинга).
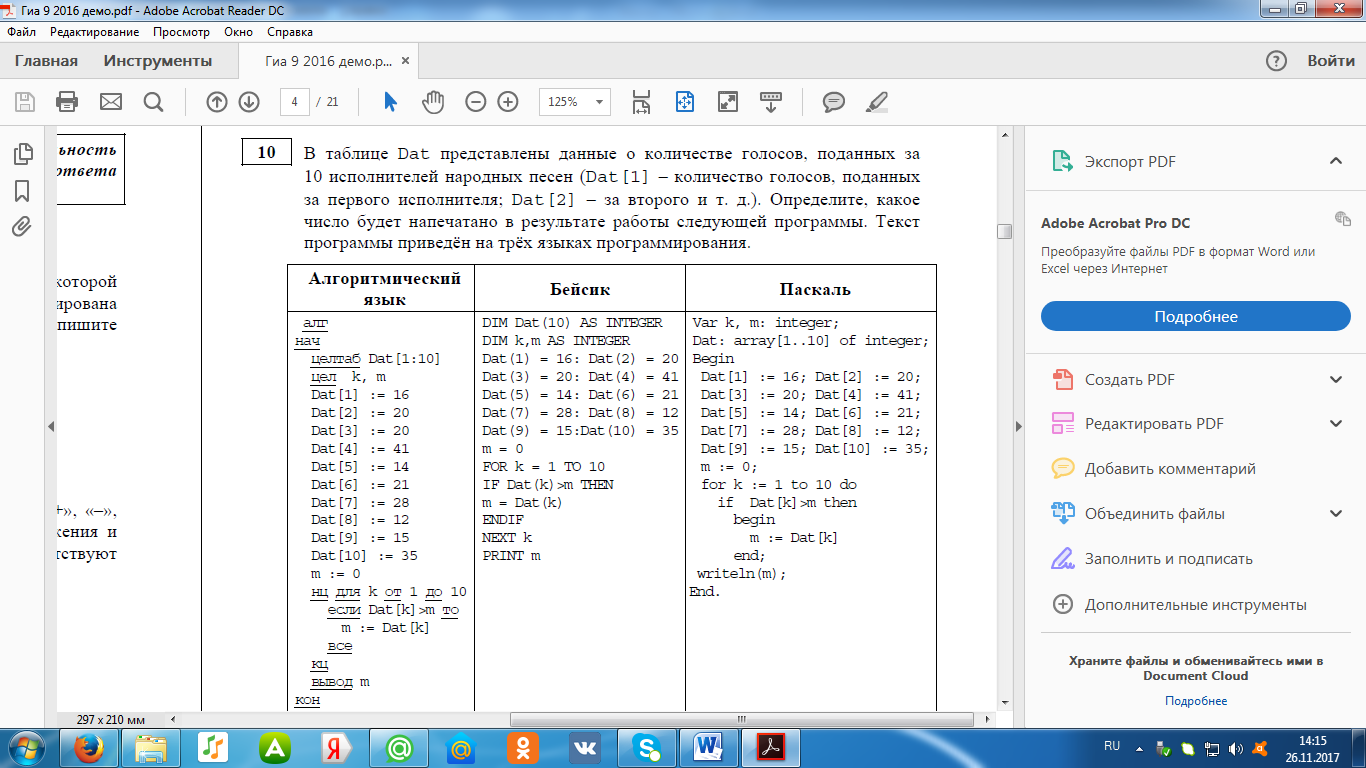
Сегодня начнем с ЛВС.
Отказоустойчивость (больше линков, больше железа, меньше технологий)
Active-passive vs active-active
Выбор схемы active-active не является оптимальным из-за того, что данные мониторинга загрузки оборудования в режиме active-active не будут достаточно информативными, чтобы гарантировать работу сети в случае выхода из строя одного из компонентов.
Пример построения сети на L2:
Три кита отказоустойчивости:
-
Резервирование линков. Каждый логический канал между активным сетевым оборудованием должен состоять как минимум из двух физических каналов;
-
Резервирование оборудования. Каждый логический модуль уровня ядра и распределения должен состоять из двух физических устройств;
-
Грамотная настройка оборудования.
Резервирование линков и оборудования
Потребуются две серверные для построения территориально-распределенных компонентов ЛВС, чтобы минимизировать влияние аварии в одной из серверных на работу всей сети. Под авариями подразумеваются такие события, как продолжительное отключение электропитания, физическое повреждение каналов связи, пожар, поломки оборудования и пр;
Потребуется два провайдера Интернета (или других сервисов) до каждой серверной (оптика)
Оптические трассы могут быть перекопаны техникой, поэтому важно еще иметь дополнительный линк провайдера по радио.
Три источника проблем
-
Неправильная настройка оборудования. Все может отлично работать, и даже продолжительное время, но какой-то внешний фактор может нарушить работу сети;
-
Человеческий фактор. Настройка и администрирование оборудования человеком рано или поздно приведет к ошибкам. Человек не может выдавать одинаковый результат втечение продолжительного времени. Например, если администратор вот уже Х лет не делал ни одной ошибки, не факт что завтра он не спутает консоль коммутатора доступа с консолью коммутатора ядра;
-
Поломки оборудования.
Откажитесь от проприетарных решений
Проприетарное программное обеспечение — это программный продукт, владельцем и собственником которого является его разработчик или другой обладатель авторского права. Оно не соответствует принципам свободного и полусвободного программного обеспечения. При этом владелец авторского права имеет монопольное право на модификацию, копирование, распространение и использование этого программного обеспечения
Важно понимать, что коммерческое ПО может быть свободным, но не стоит путать с ним проприетарные программы
Каждый производитель активного сетевого оборудования предлагает свои проприетарные решения для упрощения настройки администрирования сети, для построения высоконадежных и отказоустойчивых систем. И эти решения могут быть вполне себе эффективными и полезными. Но у проприетарных решений есть и недостатки:
- зависимость от конкретного производителя. В случае необходимости замены оборудования или масштабирования сети перейти на другого не так просто;
- повышение и сужение требований к персоналу. Инженер должен знать конкретные решения конкретного производителя;
- усложнение процесса поиска и устранения неисправностей. При этом усиливается необходимость контракта на техническую поддержку производителя.
Лучше строить вендор-независимую отказоустойчивую сеть, для этого необходимо минимизировать использование проприетарных протоколов и отдать предпочтение открытым стандартам.
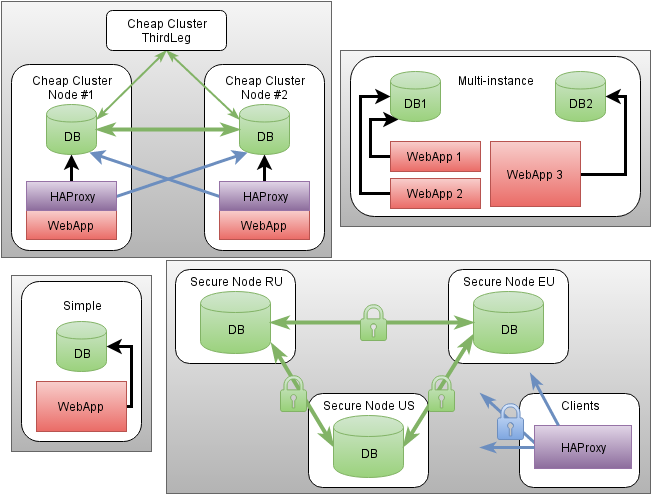
Резервирование серверов (кластеры)
В подобных случаях применяется резервирование сервера целиком. C помощью специального программного обеспечения несколько серверов объединяются в единую систему. В случае аварии на одном из них, его нагрузка перекладывается на другие, входящие в систему. Такая организация называется кластером высокой доступности (high availability cluster, HA-кластер).
В простейшем и самом распространённом случае система состоит из двух серверов (так называемый двухузловой кластер), один из которых является основным, а другой —дублирующим, резервным (конфигурация active/passive). Все вычисления производятся на основном сервере, а дублирующий сервер включается в работу в случае аварии на основном. Такая конфигурация является затратной, так как каждый узел дублируется. На схеме ниже показана конфигурация active/passive, состоящая из нескольких (N) серверов.
Конфигурация Active/Passive
В другом варианте построения кластера серверы (два или больше) могут иметь равноценный статус, то есть работать одновременно (конфигурация active/active). В такой конфигурации нагрузка вышедшего из строя сервера распределяется по остальным серверам кластера. Если серверов в кластере немного, то скорее всего произойдёт снижение производительности, так как нагрузка на оставшиеся в кластере серверы возрастёт.
Конфигурация Active/Active
Здесь стоит заметить, что в конфигурации active/passive (которая имеет полное резервирование каждого узла) такого снижения не будет. Однако этот вариант стоит дороже, так как каждый узел дублируется. Фактически, за отказоустойчивость и отсутствие потери производительности всегда приходится платить двойную цену.
Третьим, альтернативным вариантом, который позволяет избежать как высоких расходов, так и потери производительности кластера при отказе одного из узлов, является конфигурация N+1. В этой конфигурации кластер имеет один полноценный резервный сервер, который при работе в обычном режиме не несёт на себе никакой нагрузки, а включается в работу только в случае отказа одного из активных серверов.
Конфигурация N+1
Краткое сравнение конфигураций сведено в таблицу ниже. Стоит отметить, что кроме описанных трех, бывают и другие, более сложные конфигурации отказоустойчивых кластеров. Например, N+M – когда для обеспечения более высокого уровня отказоустойчивости в состав кластера включается не один, а несколько резервных серверов.
|
Active/Active |
Active/Passive |
N+1 |
|
|
Стоимость решения |
Нормальная (суммарная стоимость всех узлов; все узлы кластера работают) |
Высокая (фактически – двойная, т.к. дублируются все узлы кластера) |
Нормальная + 1 (суммарная стоимость всех узлов + 1 резервный узел) |
|
Производи-тельность при отказе |
Снижение производительности |
Нет снижения производительности |
Нет снижения производительности |
Требования к отказоустойчивому кластеру
В текущей реализации VMmanager вы можете создать отказоустойчивый кластер при следующих условиях:
- тип лицензии — VMmanager-infrastructure;
- тип виртуализации — KVM;
- тип хранилища — Ceph или SAN;
-
на узлах кластера установлены ОС AlmaLinux 8, CentOS 7, РЕД ОС 7.2 или РЕД ОС 7.3;
- в кластере не менее трёх и не более 24 узлов;
- к кластеру подключено ровно одно хранилище;
- системное время на всех узлах должно быть синхронизировано.
Обратите внимание!
Функциональность HA-кластера с типом настройки сети IP-fabric имеет ряд ограничений. Например, сервер с платформой нельзя перенести на ВМ в таком кластере.
Создание отказоустойчивого кластера
Чтобы создать отказоустойчивый кластер:
-
Настройте сетевое хранилище.
Если вы используете Ceph
- Настройте узлы хранилища Ceph. Подробнее см. в статье Предварительная настройка Ceph.
-
Настройте в хранилище файловую систему CephFS. Пример настройки:
-
Создайте сервер метаданных (MDS) на узле Ceph:
CODE
Пояснения к команде
<node> — имя узла Ceph
-
Создайте пулы CephFS для данных и метаданных:
CODE
CODE
-
Создайте файловую систему CephFS:
CODE
Пояснения к команде
cephfs_name — имя файловой системы
-
Если вы используете SAN
Выполните предварительную настройку iSCSI. Подробнее см. в статье Предварительная настройка SAN.
- Подключите хранилище к кластеру. Подробнее см. в статье Управление хранилищами кластера.
- Задайте настройки отказоустойчивости. Подробнее см. в статье Настройка отказоустойчивости.
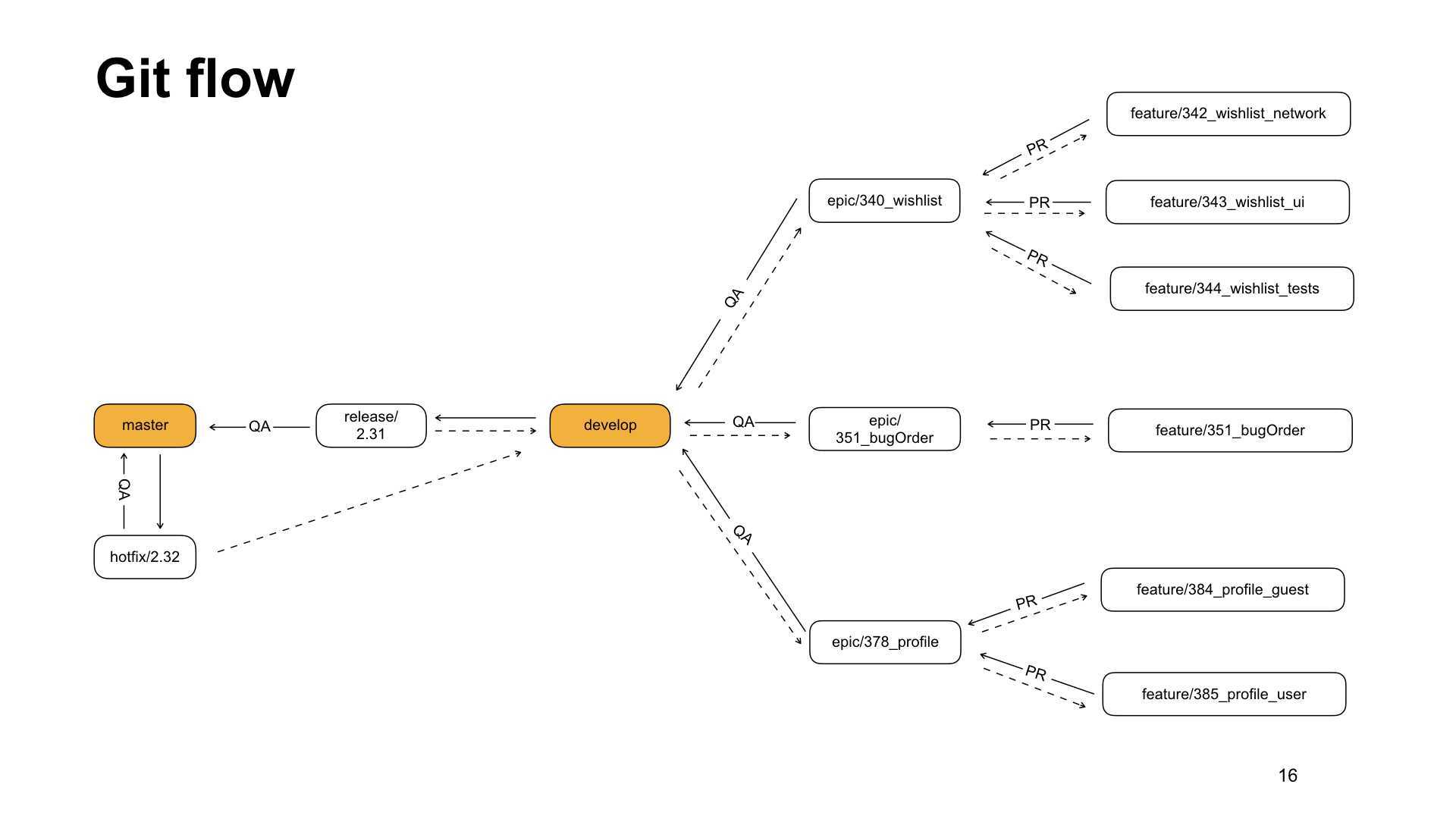
Долой проприетарное рабство!
Каждый производитель активного сетевого оборудования предлагает свои проприетарные решения для упрощения настройки администрирования сети, для построения высоко надежных и отказоустойчивых систем. И эти решения могут быть вполне себе эффективными и полезными. Но у проприетарных решений есть недостатки:
-
Появляется зависимость от конкретного производителя, в случае необходимости замены оборудования или масштабирования сети не так просто перейти на другого производителя;
-
Повышаются и сужаются требования к персоналу (инженер должен знать конкретные решения конкретного производителя);
-
Усложняется процесс поиска и устранения неисправностей и усиливается необходимость контракта на техническую поддержку производителя.
Поэтому мы строим вендор-независимую отказоустойчивую сеть, для этого необходимо минимизировать использование проприетарных протоколов — отдаем предпочтение открытым стандартам. Плюсы отказа от объединения физических коммутаторов в кластер или стек:
-
Минимизация масштабов простоя сервиса в случае сбоя в ПО на одном из физических коммутаторов — это не приведет к сбою всего виртуального коммутатора или стека, и, как следствие, простою сервиса;
-
Унификация настроек коммутаторов (первый порт это всегда Gi1/0/1, а не Gi3/0/1);
-
Минимизация использования проприетарных технологий и минимизации зависимости от вендора;
-
Минимизация масштабов простоя сервиса в случае обновления ПО и перезагрузки. Несомненно, производители предлагают механизмы обновления ПО без простоя, но это на данный момент не все производители умеют, и не все инженеры будут изучать мануал, а если и будут, то все равно попросят maintenance window у бизнеса для перестраховки;
-
Минимизация простоя сервиса в случае ошибки по причине человеческого фактора. Например, если администратор случайно перезагрузит коммутатор доступа, то перезагрузится только 1 устройство, а не стек из Х коммутаторов. А если инженер случайно перезагрузит коммутатор распределения или ядра, то простой сервисов ограничится только временем сходимости сети;
-
Простота замены оборудования: достаточно скопировать бэкапный конфиг и подключить устройство в сеть, без сложных и рискованных процедур по объединению оборудования в стек или кластер; никогда не знаешь наверняка, все ли пройдет без сбоев и перезагрузок.
Минусы отказа от объединения физических коммутаторов в кластер или стек:
-
Потребуется увеличение количества физических линков (удорожание СКС). Отказоустойчивость или дешевизна, нужно выбрать одно;
-
Усложнится (сделается не loop free) L2 домен (этим пугают производители, предлагая проприетарные решения). Решается грамотной настройкой выбранного протокола группы STP;
-
Усложнится процесс администрирования, так как будет больше логических устройств. Решается применением автоматизации, которая не предусматривает подключение к оборудованию инженерами “руками” для решения рутинных задач;
-
Замедлится сходимость сети — это явный минус. Если стоит задача максимально ускорить сходимость сети и если сходимость сети в 1 минуту уже очень долго для бизнеса, лучше присмотреться к проприетарным решениям, так как любой протокол группы STP в этом случае будет проигрывать.
-

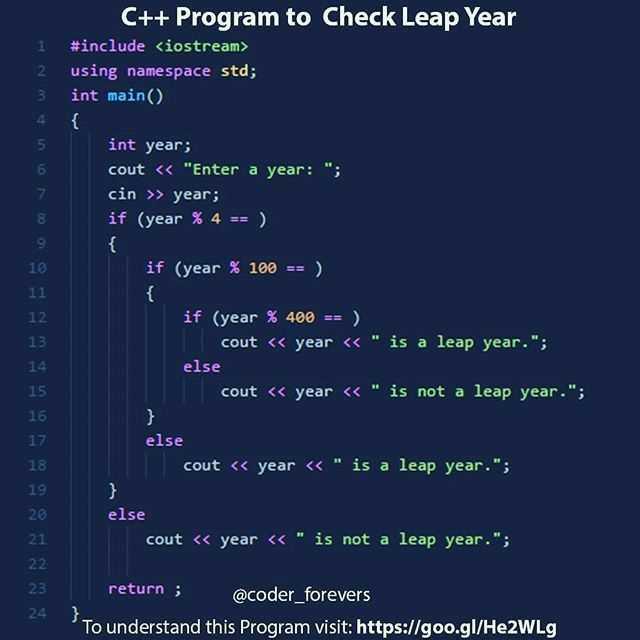
Модульность (занудно, но важно)
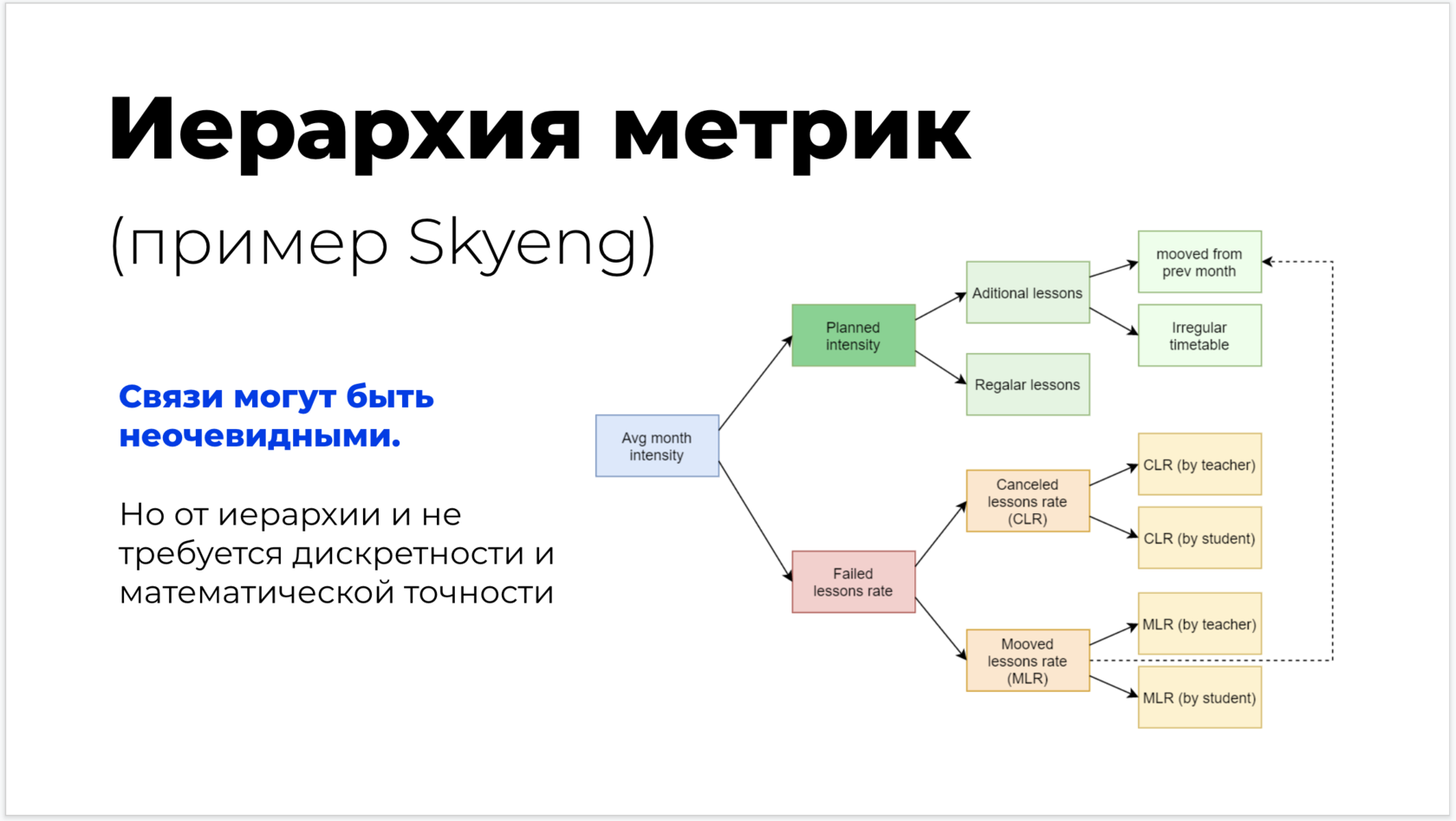
В зависимости от требований бизнеса, сетевую инфраструктуру удобно разделить на несколько логических компонентов (модулей), например:
-
Модуль ядра сети (коммутаторы ядра сети) предназначен для быстрой коммутации и маршрутизации, объединения других модулей в единую систему. Чаще всего это будут два коммутатора, которые производители позиционируют как “Core Switch”. Лучше территориально разнести по разным серверным;
-
Модуль кампусной сети (коммутаторы уровней распределения и доступа). Каждый логический коммутатор уровня распределения должен состоять из двух физических коммутаторов, лучше территориально разнести по разным серверным. Коммутаторы уровня доступа должны состоять из одного физического коммутатора. В случае надобности подключения оконечных сетевых устройств, требующих питание по active PoE, необходимо предусмотреть коммутаторы доступа с поддержкой active PoE. При этом должен быть отражен расчет бюджета PoE;
-
Модуль подключения серверного оборудования. Как правило, модуль представляет собой набор из межсетевых экранов, высокопроизводительных коммутаторов и модулей расширения фабрики с поддержкой IEEE 802.1BR, предназначенных для центров обработки данных. Тут все сильно зависит от масштабов бизнеса;
-
Модуль подключения к сети Интернет. Представляет собой набор коммутаторов, межсетевых экранов, с поддержкой подключения к удаленным объектам (IPSec VPN) и подключения удаленных рабочих мест (SSL/IPsec VPN) в случае надобности;
-
Модуль вспомогательных систем управления может включать в себя следующие компоненты: система управления IP-пространством IPAM (IP Address Management), инвентарная система, система описания сетевых сервисов или управления конфигурацией, системы мониторинга, система контроля доступа NAC (Network Admission Control), NTP, FTP, TFTP и пр.
Любой выбор — это всегда баланс между плюсами и минусами того или иного решения. Предлагаемый вариант подхода к построению сети призван удовлетворить трем главным для нас критериям: отказоустойчивость, простота, независимость от модели и производителя.
Продолжение следует во второй части
Сетевые принтеры
Управление сетевыми принтерами — дело весьма хлопотное: стоит выйти из строя
одному, как админы вынуждены будут разбираться с недовольными менеджерами и
другими представителями офисной фауны. Часто упростить себе жизнь можно,
сгруппировав несколько идентичных принтеров (имеется в виду, что принтеры должны
иметь одного производителя, одинаковые модели, одинаковое количество памяти и
использовать одинаковые драйвера, — Прим.ред.) в пул. В этом случае клиентские
системы отсылают задания на одно логическое устройство печати, а сервер уже
самостоятельно перенаправляет их первому доступному физическому принтеру. Такой
подход позволит не только повысить доступность, но и равномернее распределить
нагрузку на принтеры, увеличить отклик, а значит, и производительность (пулинг
не допустит ситуации, когда один принтер простаивает, а второй завален
заданиями). Хотя не следует бездумно включать эту опцию, необходимо учитывать и
физическое расположение принтеров. Вряд ли пользователи будут в восторге, что
нужно бегать по этажам в поисках своих распечаток. Кроме того, весьма
нежелательно, чтобы ценные документы попадали на глаза тем лицам, для которых
они не предназначены.
Сгруппировать принтеры в пул достаточно просто. Для этого следует перейти во
вкладку «Устройства и Принтеры» (Devices and Printers), расположенную в «Панели
управления» (Control Center), вызвать окно свойств одного из принтеров, которые
будут добавлены в пул, и перейти во вкладку «Ports». Здесь требуется установить
флажок «Enable printer pooling» и отметить устройства, которые будут завязаны в
пул.
Еще одна ремарка от редактора: пулинг обеспечивает высокую доступность и
отказоустойчивость для принтеров, но не для сервера печати, поэтому при
необходимости можно настроить кластер печати по аналогии с тем, что
рассказывается в упомянутой выше статье «Безотказный файлообменник».
Логика работы
Используемые сервисы
Для управления отказоустойчивым кластером VMmanager использует:
- собственный сервис ha-agent;
- cобственный микросервис hawatch.
Платформа запускает сервис ha-agent на каждом узле кластера. Сервисы ha-agent взаимодействуют между собой с помощью ПО Corosync. Алгоритмы Corosync назначают один из сервисов ha-agent мастером. В дальнейшем платформа взаимодействует только с этим сервисом с помощью hawatch.
Процедура выбора мастера
мастера происходит в следующих ситуациях:
- при включении системы отказоустойчивости в кластере;
- при выходе из строя действующего мастера;
- при изменении конфигурации HA-кластера;
- при обновлении версии HA-кластера.
Чтобы прошёл успешно, в нём должно участвовать (N/2 + 1) узлов, где N — общее число узлов кластера. Значение (N/2 + 1) нужно округлить до целого числа в меньшую сторону. Например, в кластере с двумя узлами должны участвовать оба узла, в кластере с 17 узлами — 9. Если исправных узлов в кластере меньшеем необходимо, процедура не . Если узлов будет больше, чем необходимо, то в примут участие только те узлы, которые были готовы к процедуре раньше. Алгоритмы Corosync гарантируют, что информация о времени готовности узлов к одинакова для всех участников кластера.
При выборе мастера каждый из узлов-выборщиков с помощью специального алгоритма рассчитывает свой приоритет и сообщает его остальным участникам кластера. Мастером назначается узел с самым большим приоритетом. После назначения мастера кластер начнёт работу в режиме отказоустойчивости.
Узлы, которые были не готовы к началу , присоединяются к кластеру после завершения процедуры . При добавлении новых узлов в отказоустойчивый кластер
Обычно процедура занимает около 15 секунд.
Статусы узлов кластера
В отказоустойчивом кластере узлы могут принимать следующие статусы:
-
рабочие:
- мастер — узел в рабочем состоянии и выбран мастером;
- участник — узел в рабочем состоянии;
-
нерабочие:
- изоляция по сети — узел недоступен по сети, но у узла есть доступ к хранилищу;
- изоляция по хранилищу — у узла нет доступа к хранилищу, но узел доступен по сети;
- полный отказ — узел недоступен по сети и у него нет доступа к хранилищу;
-
специальные:
- выход из HA-кластера — узел недоступен по сети, но узлу доступен проверочный IP-адрес;
- сеть нестабильна — сеть регулярно теряется на срок менее 15 секунд.
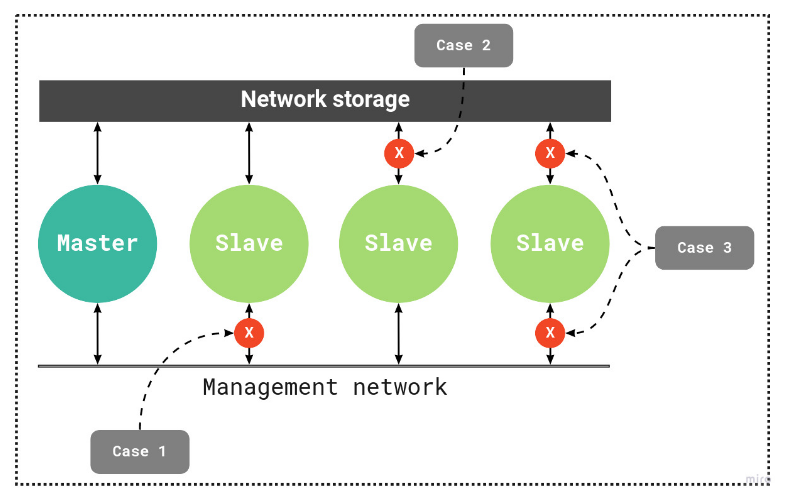
Схема работы HA-кластера
Примечания к схеме
Master — узел-мастер
Slave — узлы-участники
Network storage — сетевое хранилище кластера
Management network — сеть управления узлами кластера
Case1 — пример статуса «изоляция по сети»
Case2 — пример статуса «изоляция по хранилищу»
Case3 — пример статуса «полный отказ»
Определение статуса узла
Сервис ha-agent считает узел повреждённым, если узел потерял связь с другими узлами кластера и/или подключённым хранилищем. Проверка связи проводится с помощью алгоритмов Corosync. Дополнительно узлы кластера записывают информацию о своём статусе в файл на сервере хранилища. Обновление статуса происходит один раз в три секунды. Если информация о статусе не обновлена, мастер определит узел как повреждённый.
Среднее время определения нерабочего статуса — от 15 до 60 секунд.
В настройках отказоустойчивости можно указать проверочный IP-адрес. При потере связи с кластером узел проверит доступность этого IP-адреса с помощью утилиты ping:
- если IP-адрес недоступен, узел будет изолирован и запустится процесс релокации ВМ;
- если IP-адрес доступен, узел будет исключён из отказоустойчивого кластера. ВМ на этом узле продолжат работу.
Если узел регулярно теряет связь по сети на срок менее 15 секунд, он получает статус «сеть нестабильна». Процедура релокации в этом случае не проводится.
Процедура аварийного восстановления
Когда узел кластера определяется как отказавший, сервис ha-agent на узле:
- Останавливает все ВМ. Если ВМ не удалось остановить, перезагружает узел.
- Изолирует узел.
- Передаёт информацию о статусе узла мастеру.
Когда мастер получает информацию об отказе узла или самостоятельно определяет узел как отказавший, запускается процедура релокации ВМ. Порядок релокации ВМ зависит от значений приоритетов запуска — чем выше у ВМ значение приоритета, тем раньше она будет перенесена. Процедура релокации запускается только для тех ВМ, которые были выбраны в настройках отказоустойчивости.
После перезагрузки узла его ВМ запустятся, только если узел имеет один из рабочих статусов — «мастер» или «участник» . Запущены будут только ВМ, которые принадлежат этому узлу согласно метаданным кластера. Такой подход позволяет избежать случаев «split brain», когда к одному диску подключаются одновременно две ВМ.


Учтите особенности своего предприятия
В первую очередь необходимо разработать техническую документацию проекта внедрения локально-вычислительных сетей. На начальном этапе лучше воспользоваться IT-консалтингом, чтобы профильная компания могла учесть особенности и реальные потребности именно вашего предприятия. Не имея опыта, можно легко выбрать неподходящее программное или аппаратное обеспечение, поэтому не стоит рисковать финансами и временем.
Стоит также подумать о сетевом дизайне, ведь именно с него начинается создание собственной сетевой инфраструктуры. В ходе этого процесса решается, какие устройства будет необходимо использовать, сколько модулей потребуется и какие функции они должны выполнять. При этом учитывается размер компании, ведь для построения корпоративной сети малого бизнеса подойдут более доступные и менее сложные языки моделирования. Многопрофильность фирмы предполагает использование сравнительно мощных инструментов. В любом случае необходимо учитывать потенциал роста компании: грамотно настроенные локально-вычислительные сети легко масштабировать и расширить их возможности.
Отказоустойчивость на уровне инфраструктуры
Как было показано выше, основным способом повышения отказоустойчивости является дублирование узлов. Рассмотрим этот процесс на нескольких примерах. Для начала возьмём простую (и довольно часто встречающуюся) топологию инфраструктуры небольшой компании:
В конфигурации на этом рисунке мы защищены от потери данных на СХД (т.к. СХД имеет два контроллера), но не защищены от простоя в случае, если выйдет из строя коммутатор. Поэтому для повышения отказоустойчивости нам нужно добавить второй коммутатор, и подключить к нему остальное оборудование:
Теперь мы защищены от неполадок как со стороны СХД, так и со стороны коммутатора. Но что будет, если выйдет из строя сетевой адаптер сервера? Этот сервер потеряет доступ к сети и СХД. Поэтому нужно задублировать также и сетевые адаптеры:
Кажется, теперь мы задублировали всё, что можно. Остаются только сами серверы. Их можно объединить в отказоустойчивый кластер, как было описано ранее: