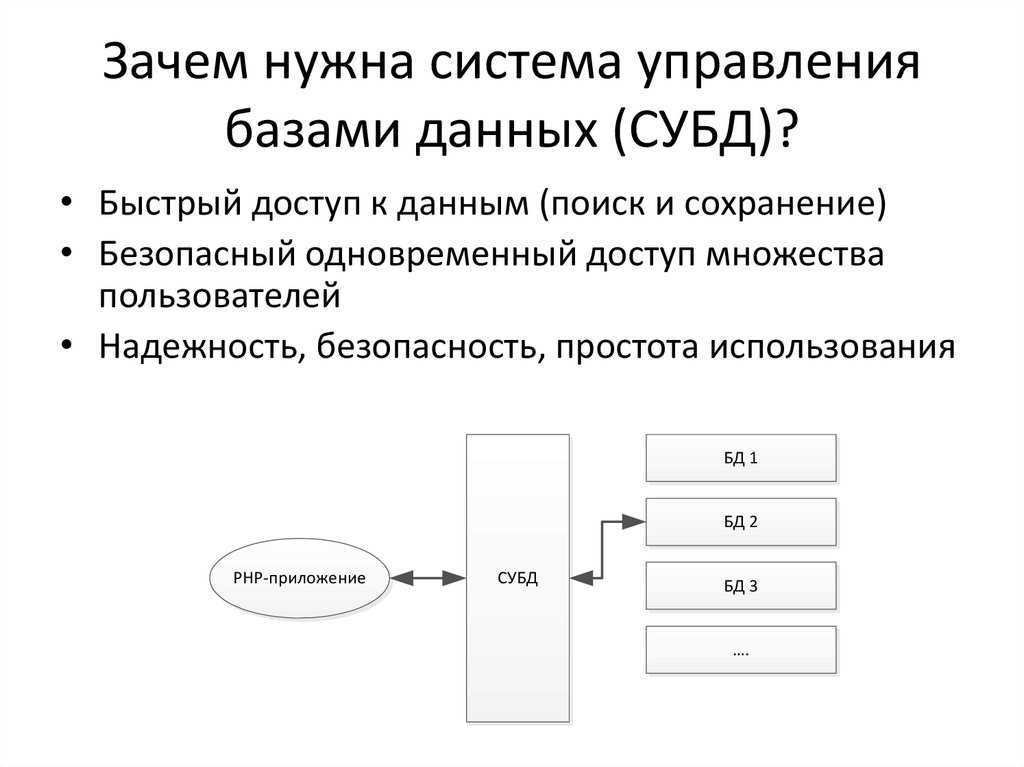
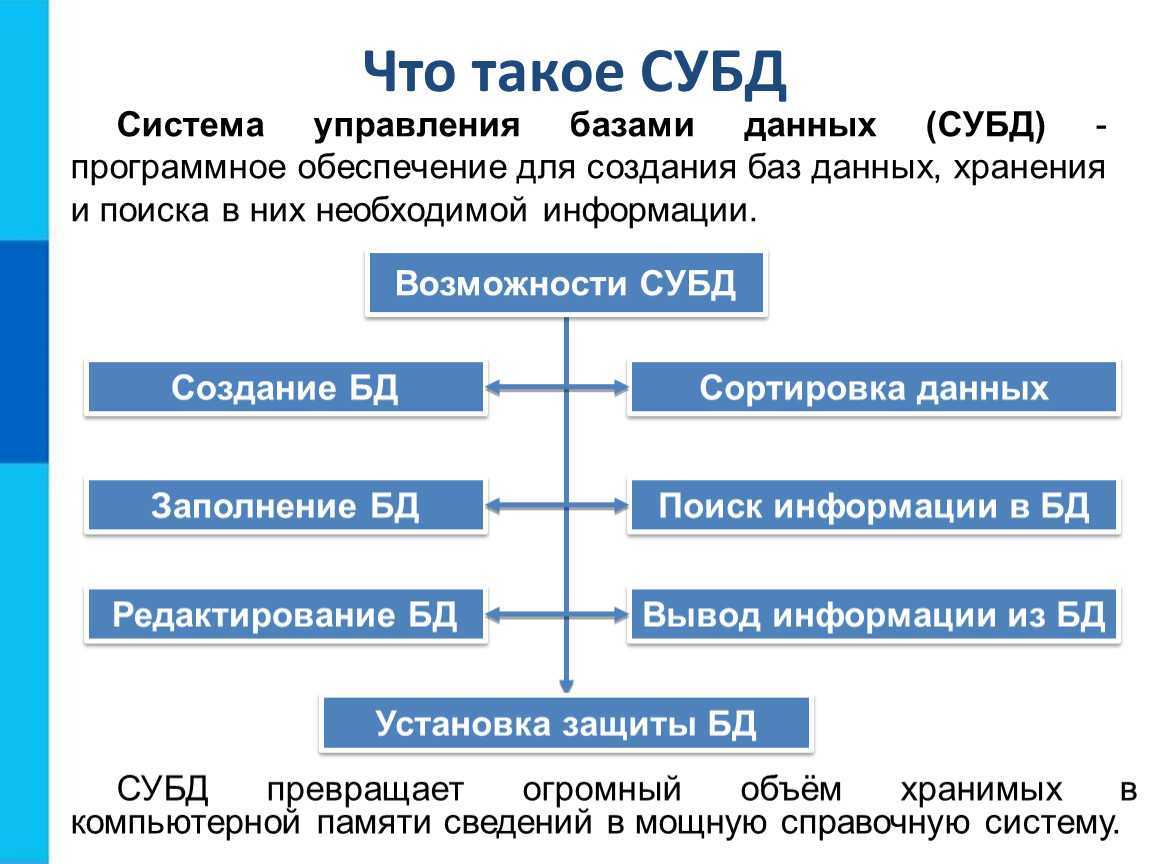
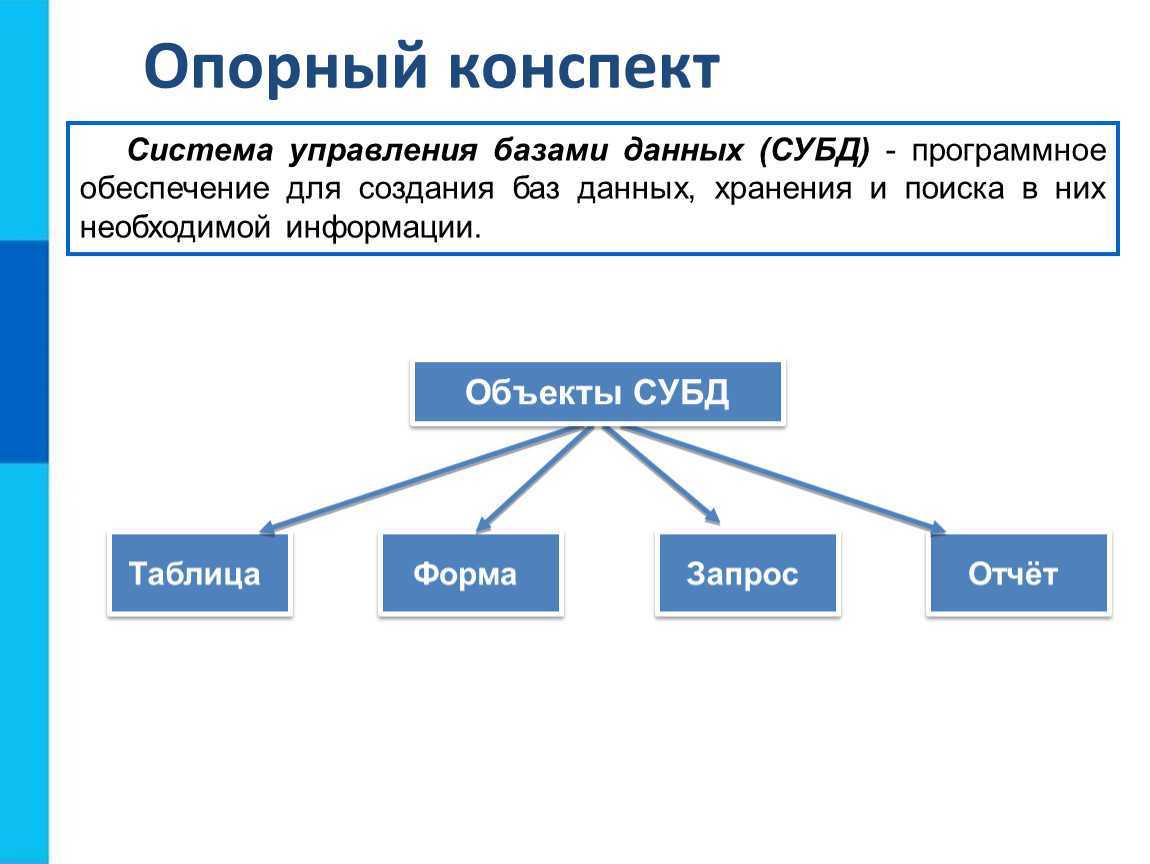
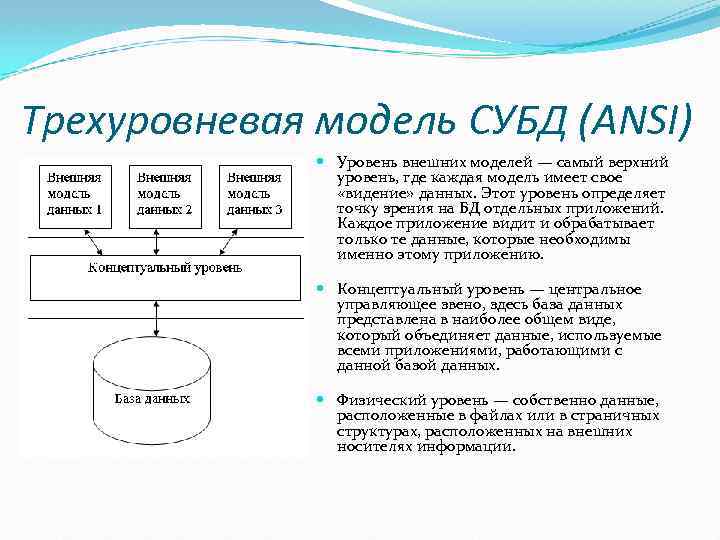
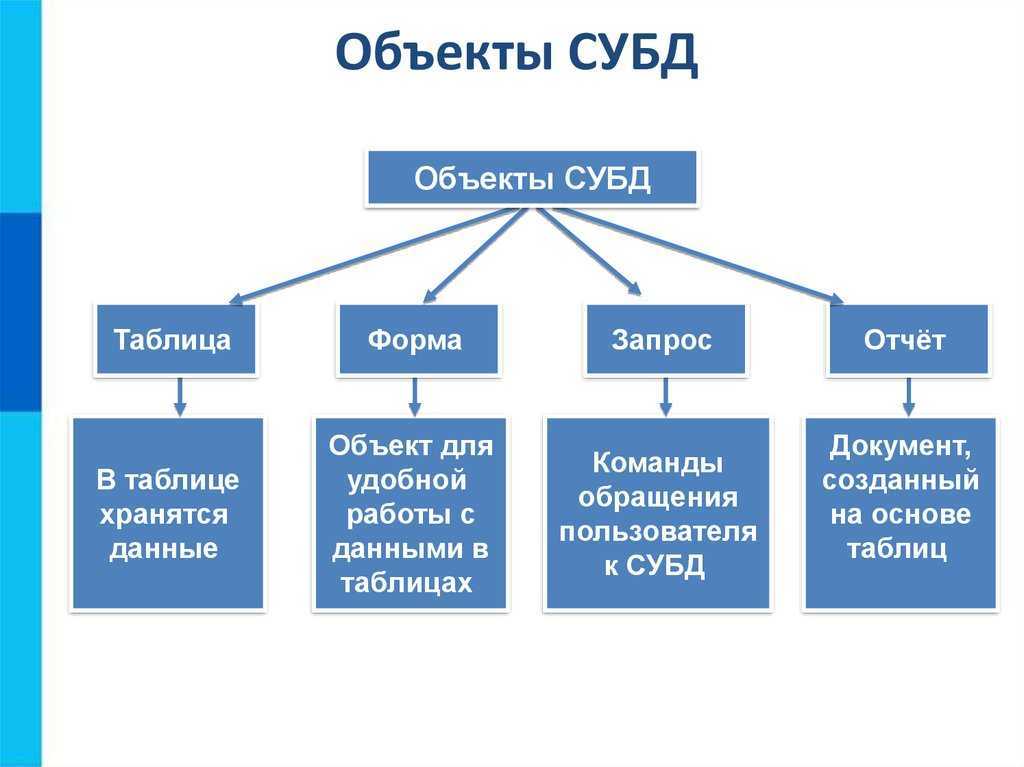
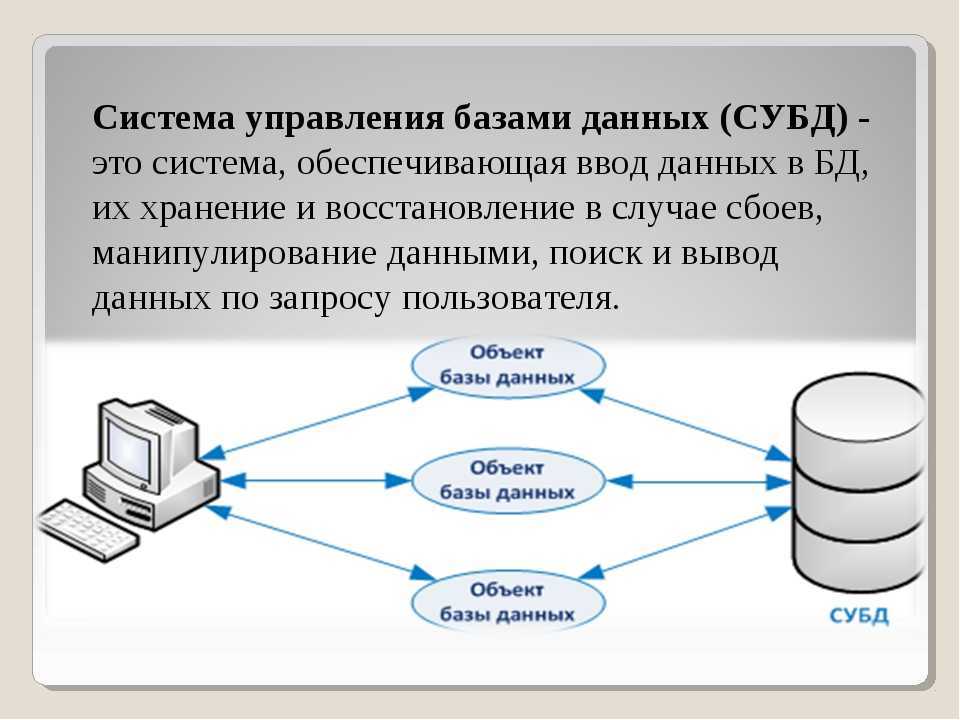
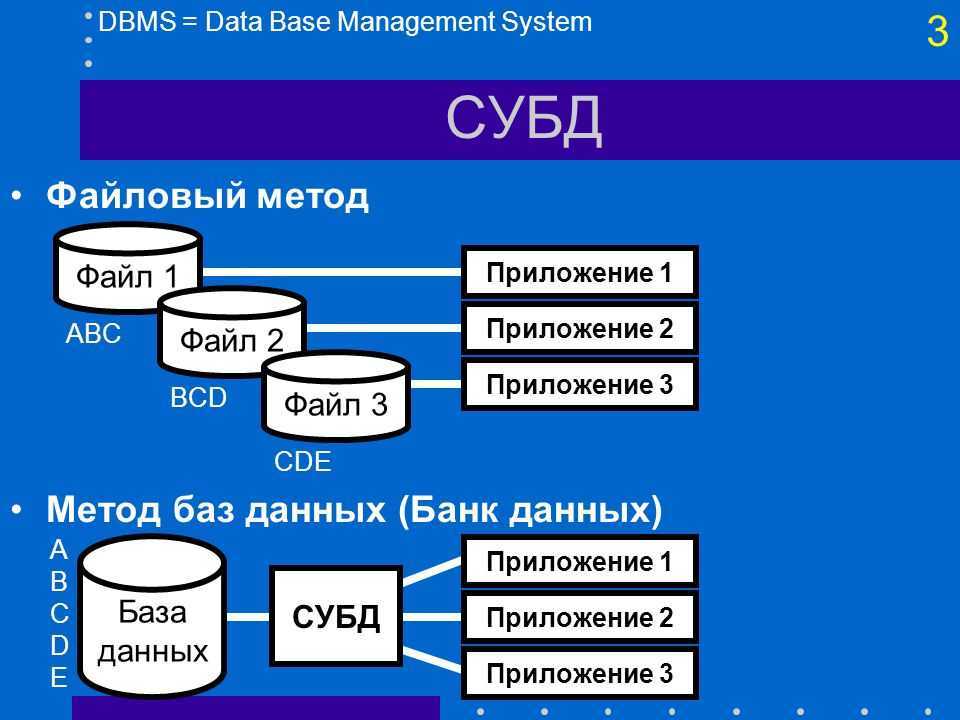
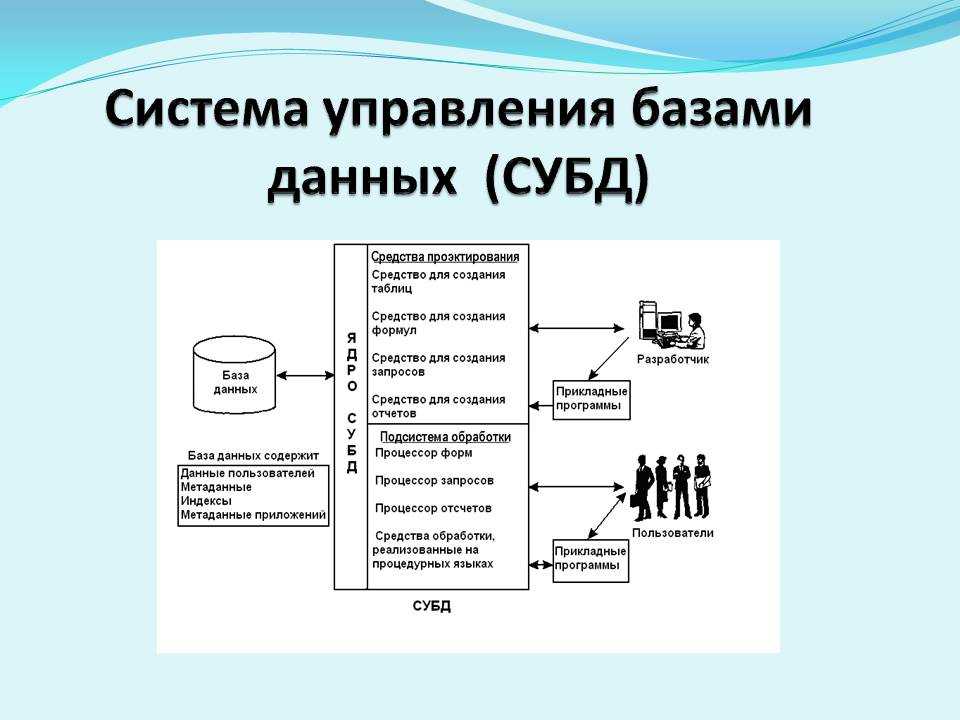
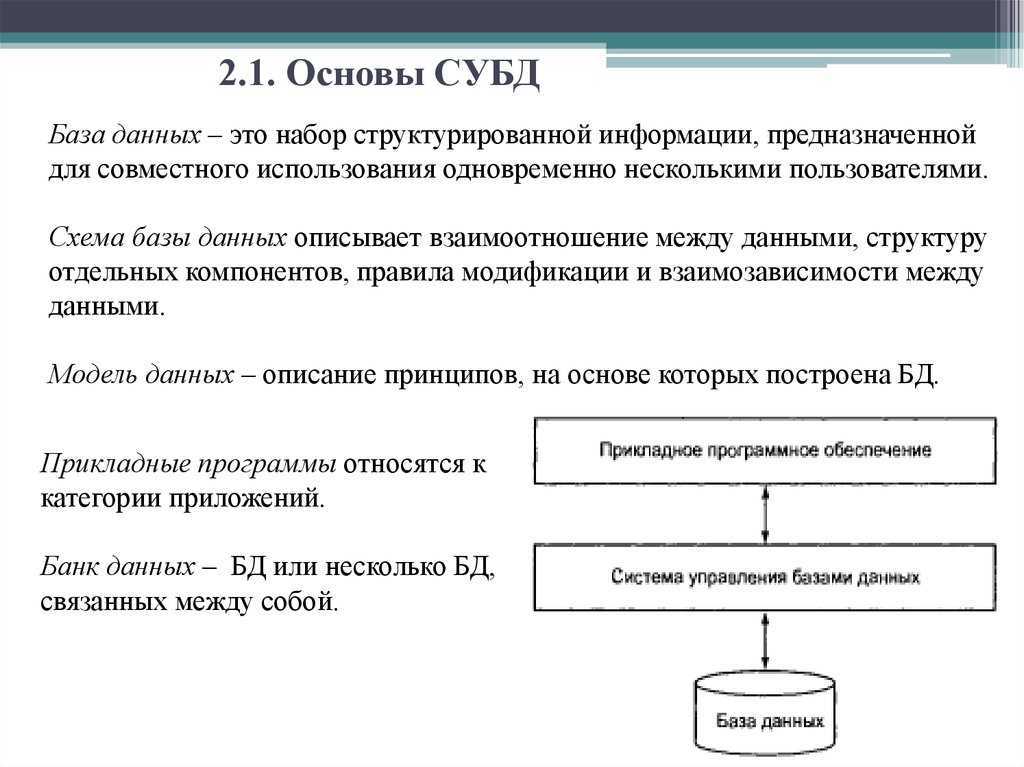
Описание иерархических наборов данных
В описанном в первой части статьи примере иерархия строилась для иерархического справочника. Для иерархических справочников система компоновки данных автоматически создает специальные наборы данных, при помощи которых и достраивается иерархия. Однако встречаются ситуации, в которых нужно построить иерархию самостоятельно.
Рассмотрим пример.
Допустим, у нас есть справочник Сотрудники, в котором есть реквизит Руководитель, содержащий ссылку на сотрудника, являющегося непосредственным руководителем сотрудника. В документе РасходнаяНакладная имеется реквизит Ответственный, в котором указывается сотрудник, ответственный за документ.
Требуется выдать отчет, в котором документы будут сгруппированы по ответственным за документы сотрудникам, с выводом иерархии по сотрудникам.
Для создания такого отчета:
Создадим набор данных «Документы», получающий список документов при помощи запроса:
ВЫБРАТЬ РасходнаяНакладная.Ссылка КАК Документ, РасходнаяНакладная.Номер, РасходнаяНакладная.Дата, РасходнаяНакладная.Контрагент, РасходнаяНакладная.Ответственный КАК СотрудникИЗ Документ.РасходнаяНакладная КАК РасходнаяНакладная
Данный запрос выдаст нам документы с сотрудниками за них ответственных.
Для построения иерархии создадим набор данных «ИерархияСотрудников». Его запрос будет выглядеть так:
ВЫБРАТЬ Сотрудники.Ссылка КАК Сотрудник, Сотрудники.РуководительИЗ Справочник.Сотрудники КАК СотрудникиГДЕ Сотрудники.Ссылка В (&Сотрудник)
Как видно, данный запрос будет возвращать сотрудников, перечисленных в параметре запроса Сотрудник.
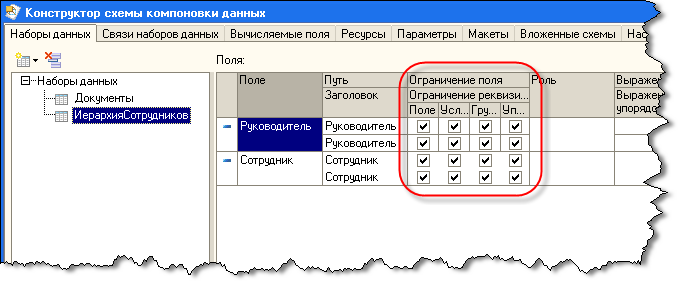
Для того чтобы данный набор данных получал по иерархии всех руководителей, опишем связь. В конструкторе схемы компоновки данных это делается на закладке «Связи».
В связи укажем, что связываем набор данных ИерархияСотрудников сам с собой. В качестве выражения источника будет выступать выражение «Руководитель», а в качестве выражения — приемника «Сотрудник». Таким образом, из каждой записи набора данных будет получено значение поля Руководитель и будет осуществлен поиск полученного значения в поле Сотрудник в этом же наборе данных и система рекурсивно получит все записи по иерархии. Т.к. в запросе записи получаются только для сотрудников, переданных в параметре Сотрудник, то в связи укажем, что следует использовать этот параметр, и т.к. параметр может принимать список значений, обозначаем это в связи, установив соответствующий флажок.

Теперь в схеме следует создать еще одну связь, которая будет указывать, что поле Сотрудник набора данных Документы следует связать с полем иерархического набора данных.

ВАЖНО!При выводе иерархических записей система компоновки данных выводит в результат поля с теми же именами, какие были у полей, для которых достраивалась иерархия. Поэтому, в иерархическом наборе данных поле, с которым осуществляется связь основного набора должно называться так же, как и в основном наборе
Так, в приведенном выше примере, в иерархическом наборе данных связуемое поле должно иметь имя Сотрудник.
После описания связей, результат отчета с иерархической группировкой будет выглядеть приблизительно так:
| Ответственный | ||
| Документ | Дата | Контрагент |
| 0000001 | 28.06.2006 14:19:00 | Эльбрус |
| 0000002 | 28.06.2006 14:30:32 | Эльбрус |
| 0000004 | 28.06.2006 14:32:06 | Большаков Андрей |
| Тарасов | ||
| Степанов | ||
| Иванов | ||
| 0000003 | 28.06.2006 14:30:49 | Алекс-2002 |
| 0000006 | 28.06.2006 14:32:47 | Филипенко |
| 0000007 | 28.06.2006 14:34:04 | Центр детского творчества |
| 0000010 | 28.06.2006 14:36:36 | Никитин Юрий |
| 0000013 | 28.06.2006 14:45:29 | Алекс-2002 |
| 0000014 | 28.06.2006 14:47:20 | Эльбрус |
| 0000019 | 28.06.2006 14:58:16 | Магазин на ул. Алексеева |
| Петров | ||
| 0000016 | 28.06.2006 14:49:47 | Алекс-2002 |
| 0000017 | 28.06.2006 14:50:23 | Турмасов Марат Сергеевич |
| 0000018 | 28.06.2006 14:51:36 | Завод РТИ |
| Степанов | ||
| 0000005 | 28.06.2006 14:32:32 | Завод РТИ |
| 0000008 | 28.06.2006 14:35:37 | Алекс-2002 |
| 0000015 | 28.06.2006 14:48:09 | Русская одежда |
| Федоров | ||
| 0000009 | 28.06.2006 14:36:05 | Магазин на ул. Алексеева |
| 0000011 | 28.06.2006 14:37:04 | Магазин на ул. Алексеева |
| 0000012 | 28.06.2006 14:38:18 | Автохозяйство №34 |
|
СОВЕТДля того чтобы поля иерархического набора данных не отображались пользователю, следует отключить у этих полей доступность настройки. Делается это на закладке «Наборы данных» конструктора схемы компоновки данных.
|
Будни автоматизации или «мне нужна программка для 3D упаковки» Промо
Автоматизация отечественных предприятий, которой приходиться заниматься, это нужная и высокооплачиваемая, но довольно нервная работа. Выручает юмор. Например, при общении с требовательным клиентом можно вспомнить анекдот: «Держась руками за стену, на ногах еле стоит мужик. К нему пристает ребенок: «Ну, папа, пожалуйста, сделай мне кораблик!», папа отвечает: «Ага! — Сейчас все брошу и пойду делать тебе кораблик!». Про один такой сделанный для клиента «кораблик» и хочется рассказать. Надеюсь, совместное погружение в теплое ламповое (то есть клиентоориентированное) программирование доставит Вам положительные эмоции, да и задача попалась интересная. Поплыли?
Операции над данными
Добавление в базу данных новой записи. Корневая запись обязательно должна содержать значение ключа.
Изменение значения данных записи. Ключевые данные не должны изменяться.
Удаление некоторой записи и всех подчиненных ей записей.
Извлечение:
- корневой записи по ключевому значению, допускается также последовательный просмотр корневых записей;
- следующей записи (следующая запись извлекают в порядке левостороннего обхода дерева).
Операция извлечения допускает задать условия выборки (например, извлечение сотрудников с окладом менее 10 тысяч рублей).
Определение 5
Все операции изменения могут применяться лишь к одной «текущей» записи, предварительно извлеченной из базы данных. Такой подход к работе с данными называется навигационным.
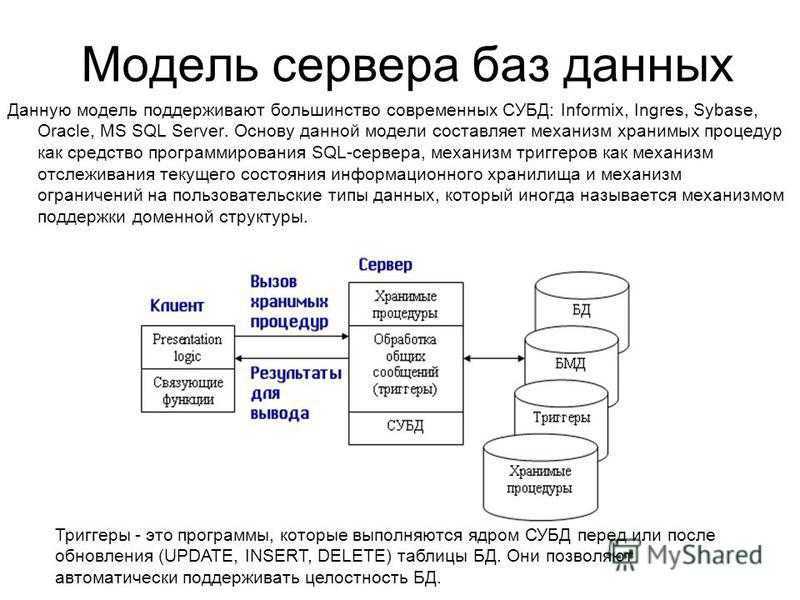
Управляющая часть иерархической модели
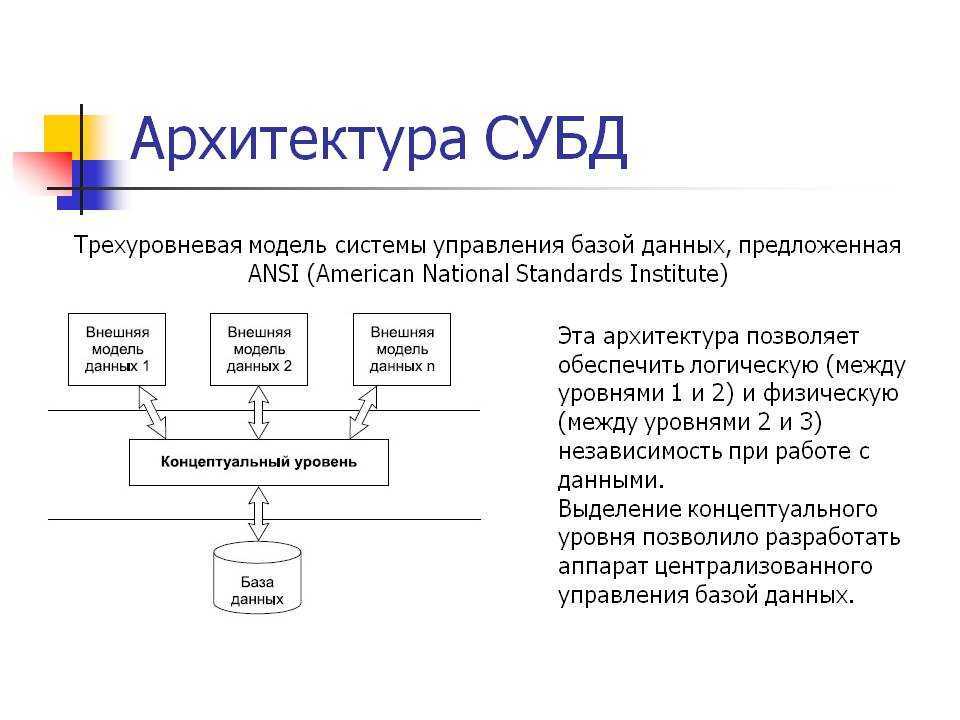
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как ее логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Как всё начиналось
В 60-х годах прошлого столетия появилась необходимость в надежной модели хранения и обработки данных. В первую очередь эти данные генерировались банками и финансовыми организациями. В то время не существовало единых стандартов работы с данными и моделями, да и работа как таковая заключалась в ручном упорядочении и организации хранящейся информации.
У банков худо-бедно получалось записывать информацию о транзакциях в виде файлов в заранее подготовленную структуру. У каждой организации было собственное понимание того, как все это должно выглядеть и работать. Не было таких понятий, как консистентность (англ. data consistency), целостности данных (англ. data integrity). В файлах часто встречались дубликаты данных клиентов и их транзакций, которые необходимо было каким-то образом уточнять и приводить в порядок, делалось это в основном вручную. В целом все проблемы того времени в отношении работы с данными можно разделить на несколько основных видов:
-
Представление структуры в каждом файле было различным.
-
Необходимо было согласовывать данные в разных файлах, чтобы обеспечить непротиворечивость информации.
-
Сложность разработки и поддержки приложений, работающих с конкретными данными, и их обновления при изменении структуры файла.
По сути, здесь мы видим антипаттерн «чистой архитектуры», который был описан Робертом Мартином (Robert C. Martin).
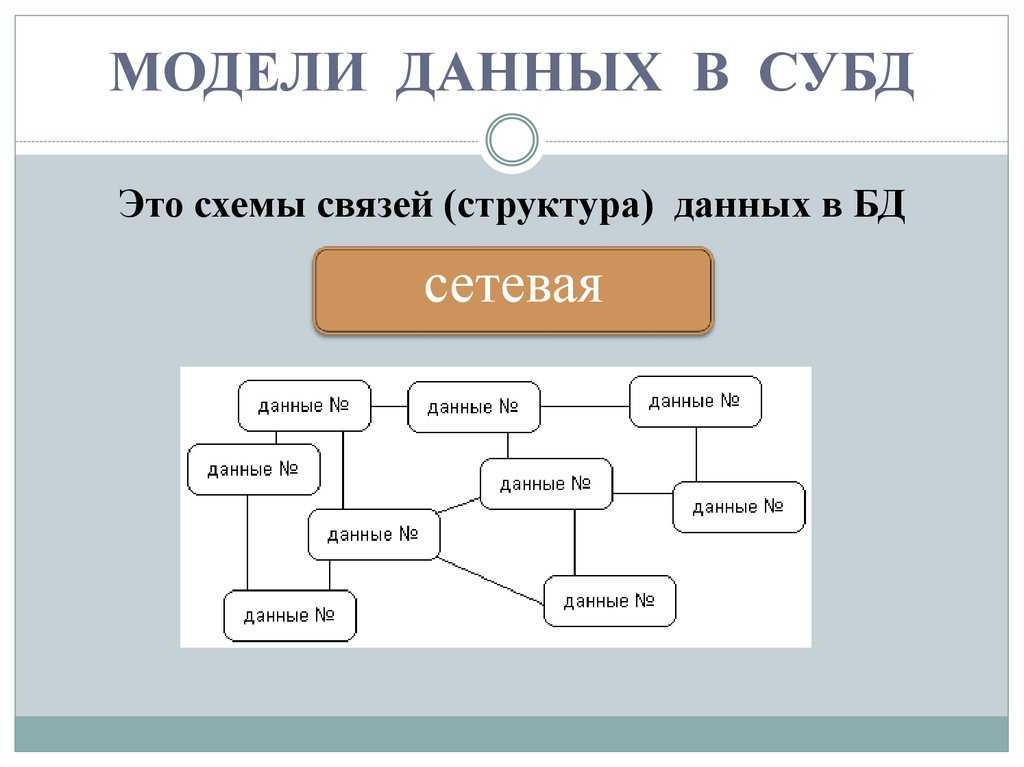
Следует отметить, что были попытки создания моделей, позволяющих навести порядок в данных и их обработке. Одна из таких попыток — иерархическая модель, в которой данные были организованы в виде древовидной структуры. Иерархическая модель была востребованной, но не гибкой. В ней каждая запись могла иметь только одного «предка», даже если отдельные записи могли иметь несколько «потомков». Из-за этого базы данных представляли только отношения «один к одному» или «один ко многим». Невозможность реализации отношения «многие ко многим» могла привести к проблемам при работе с данными и усложняла модель. Более того, вопросы консистентности данных и отсутствия дублирования информации здесь вообще не стояли. Первая иерархическая СУБД называлась IMS от IBM.
На помощь иерархической пришла сетевая модель данных, и уже новая концепция реализовала отношение «многие ко многим». Данный подход был предложен как спецификация модели CODASYL в рамках рабочей группы DBTG (Data Base Task Group).
Но всё это модели, которые сложно было поддерживать. Упростить задачу сбора и обработки данных смог Франк Кодд (Edgar F. Codd). Его фундаментальная работа привела к появлению реляционных баз данных, которые нужны практически всем отраслям. Кодд предложил язык Alpha для управления реляционными данными. Коллеги Кодда из IBM — Дональд Чемберлен (Donald Chamberlin) и Рэймонд Бойс (Raymond Boyce) — создали один из языков под влиянием работы Кодда. Они назвали свой язык SEQUEL (Structured English Query Language), но изменили название на SQL из-за существующего товарного знака.
Создание запросов к иерархической таблице с помощью иерархических методов
После того как таблица HumanResources.EmployeeOrg будет заполнена, эта задача продемонстрирует, как можно проводить запросы к иерархии с помощью некоторых иерархических методов.
Поиск подчиненных узлов
-
Sariya имеет одного подчиненного. Чтобы запросить подчиненных Sariya, выполните следующий запрос, в котором используется метод IsDescendantOf :
Результатами будут Sariya и Wanida. Sariya перечисляется, поскольку она является потомком на нулевом уровне. Wanida является потомком на первом уровне.
-
Запросить эту информацию можно также с помощью метода GetAncestor . принимает аргумент уровня, попытка вернуть который выполняется. Поскольку Wanida находится одним уровнем ниже Sariya, следует использовать метод так, как показано в следующем коде:
В этот раз результатом будет только Wanida.
-
Теперь измените значение на David (EmployeeID 6), а уровень на 2. Выполнение следующей инструкции также вернет значение Wanida:
В этот раз в результате также будет возвращена Mary, являющаяся подчиненной David, и находящаяся на два уровня ниже.
Управление иерархическими данными
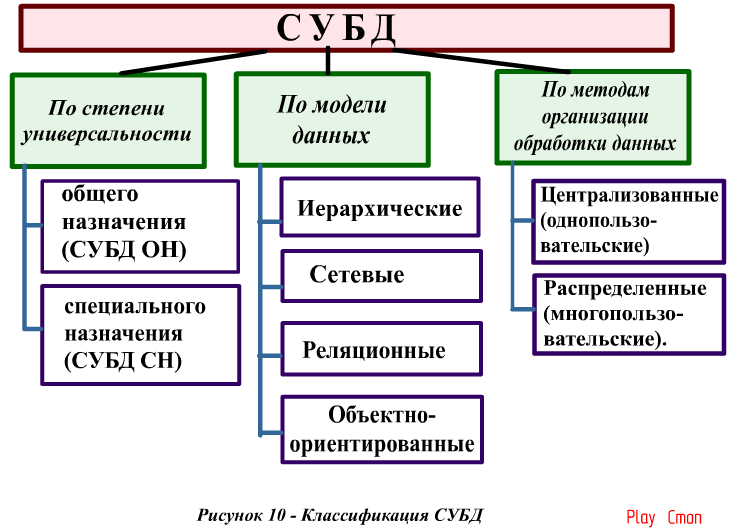
Иерархическая модель базы данных имеет 2 средства управления ими:
- языковые средства их описания (ЯОД);
- языковые средства манипулирования ими (ЯМД).
Физическая структура иерархической БД описывает, во-первых, логическую структуру рассматриваемой модели, а во-вторых, собственно структуру хранения БД. Способ доступа при этом определяет способ организации отношений физических записей.
Способ доступа может быть:
- индексным;
- иерархически прямым;
- иерархически последовательным:
- иерархически индексно-прямым;
- иерархически индексно-последовательным.
Помимо обязательного установления имени иерархической БД, а также способа доступа к любому из элементов, которые концентрирует в себе иерархическая модель данных, описание первой обязательно должно включать определение типов всех сегментов данных, вошедших в БД, согласно выстроенной иерархии.
Так, при описании типов сегментов рекомендуется начинать с главного корня рассматриваемой модели. Иерархическая модель данных имеет особенность: всякая физическая БД может включать лишь 1 корень. Однако в 1-й иерархической системе может быть расположено несколько физических БД.
Иерархическая модель данных среди всех своих операторов манипулирования последними выделяет операторов просто поиска данных (поиск указанного дерева БД, переход от 1-го дерева к другому, поиск экземпляра сегмента, который удовлетворяет условию, прочее) с возможностью их модификации (поиск и удержание в целях последующей модификации единственного экземпляра сегмента, который удовлетворяет условию и т. д.) и, соответственно, операторы модификации данных (помещение нового экземпляра сегмента в заданную позицию, удаление либо обновление текущего экземпляра соответствующего сегмента).
Здесь автоматически сохраняется единство ссылок между потомками и предками. Как уже было упомянуто ранее, существует правило касательно того, что потомок не может существовать без родителя.
Ограничения типа данных hierarchyid
Тип данных hierarchyid имеет следующие ограничения.
-
Столбец типа hierarchyid не представляет дерево автоматически. Приложение должно создать и назначить значения hierarchyid таким образом, чтобы они отражали требуемые связи между строками. Некоторые приложения могут содержать столбец типа hierarchyid , указывающий местоположение в иерархии, определенной в другой таблице.
-
Параллельными процессами создания и присвоения значений hierarchyid управляет само приложение. Нет никакой гарантии, что значения hierarchyid уникальны, если приложение не использует ограничение уникального ключа или не обеспечивает уникальность своей логикой.
-
Иерархические связи, представленные значениями hierarchyid , не применяются как отношения внешнего ключа. Можно, а иногда и удобно иметь иерархическую связь, в которой у A есть потомок B и когда A удаляется, у B остается связь с несуществующей записью. Если это неприемлемо, приложение должно запросить потомков, прежде чем удалять родителей.
Заполнение таблицы существующими иерархическими данными
В этой задаче таблица создается и заполняется данными из таблицы EmployeeDemo. Эта задача включает следующие шаги.
- Создание таблицы, содержащей столбец типа hierarchyid . Этот столбец может заменить существующие столбцы EmployeeID и ManagerID . Однако эти столбцы нужно сохранить. Это нужно для того, чтобы существующие приложения могли ссылаться на эти столбцы, а также для помощи при распознавании данных после передачи. Определение таблицы задает столбец OrgNode как первичный ключ, следовательно, этот столбец должен содержать уникальные значения. В кластеризованном индексе на основе столбца OrgNode будут храниться данные в последовательности ключа OrgNode .
- Создание временной таблицы, которая будет использована для слежения за тем, сколько сотрудников напрямую подчиняются каждому менеджеру.
- Заполнение новой таблицы данными из таблицы EmployeeDemo .
Создание новой таблицы с именем NewOrg
В окне редактора запросов запустите приведенный ниже код, чтобы создать таблицу с именем HumanResources.NewOrg.
CREATE TABLE HumanResources.NewOrg
(
OrgNode hierarchyid,
EmployeeID int,
LoginID nvarchar(50),
ManagerID int
CONSTRAINT PK_NewOrg_OrgNode
PRIMARY KEY CLUSTERED (OrgNode)
);
GO
Создание временной таблицы с именем #Children
-
Создайте временную таблицу с именем #Children . В ней должен быть столбец Num , который должен содержать количество потомков каждого узла:
-
Добавьте индекс, который значительно ускорит работу запроса, заполняющего таблицу NewOrg :
Заполнение таблицы NewOrg
Рекурсивные запросы запрещают использование вложенных запросов со статистическими выражениями. Вместо этого заполните таблицу #Children с помощью следующего кода, который использует метод ROW_NUMBER() для заполнения столбца Num :
Просмотрите таблицу #Children
Обратите внимание, что в столбце Num содержатся последовательные номера для каждого менеджера.
Результирующий набор:
Заполнение таблицы NewOrg. Используйте методы GetRoot и ToString, чтобы объединить значения столбца Num в формат hierarchyid ; затем обновите столбец OrgNode результирующими иерархическими значениями:
Столбец типа данных hierarchyid становится более понятным, если его преобразовать в символьный формат
Просмотрите данные в таблице NewOrg , выполнив следующий код, содержащий два представления столбца OrgNode :
Столбец LogicalNode содержит данные столбца типа данных hierarchyid , преобразованные в более доступную текстовую форму, представляющую иерархию. В оставшихся задачах для представления логического формата столбцов типа hierarchyid также следует использовать метод .
Удалите временную таблицу, она больше не понадобится:
Ниже описаны подходы к индексированию иерархических данных:
Есть два подхода к индексированию иерархических данных:
-
В глубину
В индексе преимущественно в глубину строки поддерева хранятся рядом друг с другом. Например, записи всех сотрудников, в цепи подчиненности которых есть данный руководитель, хранятся рядом с записью руководителя.
В индексе преимущественно в глубину все узлы поддерева узла хранятся вместе. Поэтому индекс преимущественно в глубину эффективен для обработки запросов по поддеревьям. Например, «найти все файлы в этой папке и ее подкаталогах».
-
-
В ширину
Если используется индексирование в ширину, строки одного уровня иерархии хранятся вместе. Например, записи всех сотрудников, напрямую подчиненных одному и тому же руководителю, хранятся рядом друг с другом.
В индексе преимущественно в ширину все прямые потомки узла хранятся в одном месте. Поэтому индекс преимущественно в ширину эффективен для запросов по прямым потомкам. Например: «найти всех прямых подчиненных этого начальника».

![Иерархическая база данных [реферат №9693]](https://robotrackkursk.ru/wp-content/uploads/c/f/d/cfdbe4d82b9aabd1f665210d29f42d45.jpeg)
Выбор стратегии индексирования (в глубину, в ширину или обе) и ключа кластеризации зависит от того, какие из вышеуказанных типов запросов обрабатываются чаще и какие операции более важны (SELECT или DML). Пример использования стратегий индексирования см. в разделе Tutorial: Using the hierarchyid Data Type.
Создание индексов
Для организации данных в ширину можно использовать метод GetLevel(). В следующем примере создаются оба типа индекса: преимущественно в глубину и преимущественно в ширину.
Справочник по TableAdapterManager
По умолчанию класс создается при создании набора данных, содержащего связанные таблицы. Чтобы предотвратить создание класса, измените значение свойства набора данных на false. При перетаскивании таблицы, которая имеет отношение к области конструктора страницы Windows Формы или WPF, Visual Studio объявляет переменную-член класса. Если привязка данных не используется, необходимо вручную объявить переменную.
Класс не является типом .NET. Поэтому его невозможно найти в документации. Он создается во время разработки в рамках процесса создания набора данных.
Ниже приведены часто используемые методы и свойства класса:
| Член | Описание |
|---|---|
| Метод | Сохраняет все данные из всех таблиц данных. |
| Свойство | Определяет, следует ли создать резервную копию набора данных перед выполнением метода. Логических. |
| Tablename Свойство | Представляет объект . Созданный объект содержит свойство для каждого управляемого объекта. Например, набор данных с таблицей Customers и Orders создается с помощью набора данных, содержащего и свойства. |
| Свойство | Управляет порядком отдельных команд вставки, обновления и удаления. Присвойте этому параметру одно из значений в перечислении . По умолчанию устанавливается значение InsertUpdateDelete. Это означает, что операции вставки, обновления, а затем удаления выполняются для всех таблиц в наборе данных. |
Перемещение узла с потомком
-- Перемещаем узел с по меньшей мере одним потомком
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- старый родитель для head waiter
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- гарантирует
-- получение нового идентификатора на случай,
-- если имеется потомок
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error 0 GOTO START -- При ошибке повторить
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;
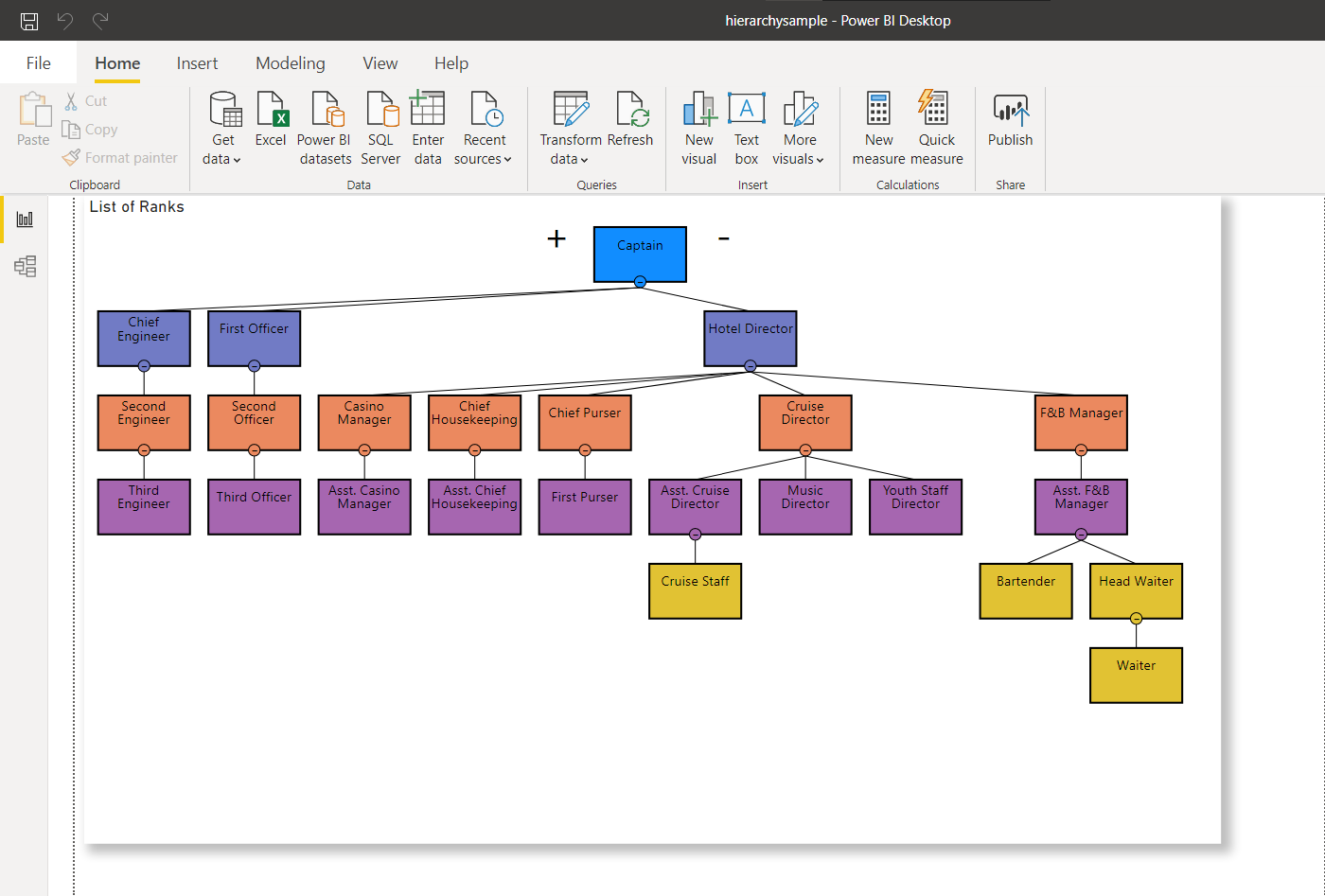 Рис.9: Все дочерние узлы Asst. F&B Manager исправлены
Рис.9: Все дочерние узлы Asst. F&B Manager исправлены
Основные свойства типа hierarchyid
Значение типа данных hierarchyid представляет позицию в древовидной иерархии. Значения hierarchyid обладают следующими свойствами.
-
Исключительная компактность
Среднее число бит, необходимое для представления узла в древовидной структуре с n узлами, зависит от среднего количества потомков у узла. Для небольших уровней ветвления (0 — 7) этот размер равен 6*logAn бит, где A — средний уровень ветвления. Для представления узла в иерархии организации, насчитывающей 100 000 человек со средним уровнем ветвления 6, необходимо около 38 бит. Эта величина округляется до 40 бит (5 байт), которые необходимы для хранения.
-
Сравнение проводится в порядке приоритета глубины
Если заданы два значения hierarchyid — a и b, a<b означает, что значение a появляется раньше значения b, если проходить по дереву с приоритетным направлением в глубину. Индексы для типов данных hierarchyid располагаются в порядке приоритета глубины, а узлы, встречающиеся рядом при проходе по дереву с приоритетным направлением глубины, хранятся рядом друг с другом. Например, потомки некоторой записи хранятся рядом с этой записью.
-
Поддержка произвольных вставок и удалений
С помощью метода GetDescendant можно в любой момент создать одноуровневый элемент, расположенный справа от заданного узла, слева от заданного узла или между любыми двумя другими одноуровневыми элементами. Свойство сравнения сохраняется, если произвольное число узлов вставляется в иерархию или удаляется из нее. Большинство операций вставки и удаления сохраняют свойство компактности. Однако операции вставки между двумя узлами приводят к созданию значений hierarchyid, обладающих менее компактным представлением.
Основные понятия иерархической модели
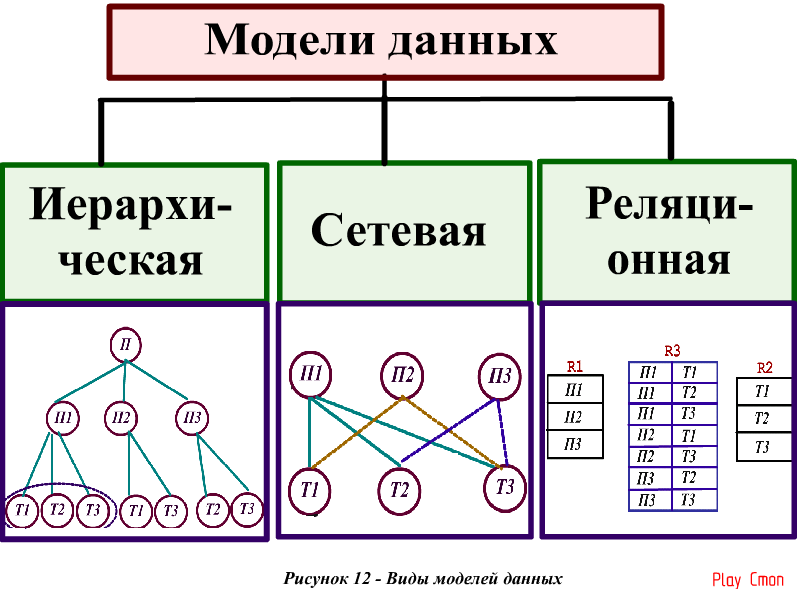
Иерархическая модель является самой ранней моделью баз данных. Для понимания иерархической модели необходимо запомнить следующие термины:
- Атрибут (или поле)– минимальный элемент данных. Атрибут имеет уникальное имя, по которому к нему можно обратиться из программного кода.
- Запись – логически связанная совокупность атрибутов. Запись имеет уникальное имя, которое позволяет обращаться к ней из программного кода. Записи можно добавлять, изменять, удалять.
- Экземпляр записи – конкретная запись с конкретными значениями атрибутов.
- Групповое отношение — иерархическое отношение между записями двух разных типов. Запись, которая, находится выше по иерархии, называется родительской. Записи, которые, расположены ниже по иерархии называются дочерними.
Модель графически можно представить в виде перевернутого дерева, которое состоит из записей различных уровней. Вверху дерева находится одна запись, которая называется корневой записью. Корневая запись содержит ключ — атрибут с уникальным значением. Некорневые записи тоже имеют ключи, но эти ключи должны быть уникальными только в рамках группового отношения. Каждая запись однозначно идентифицируется полным ключом. Полным ключом записи называется совокупность ключей всех записей, начиная с корневой и заканчивая данной записью.
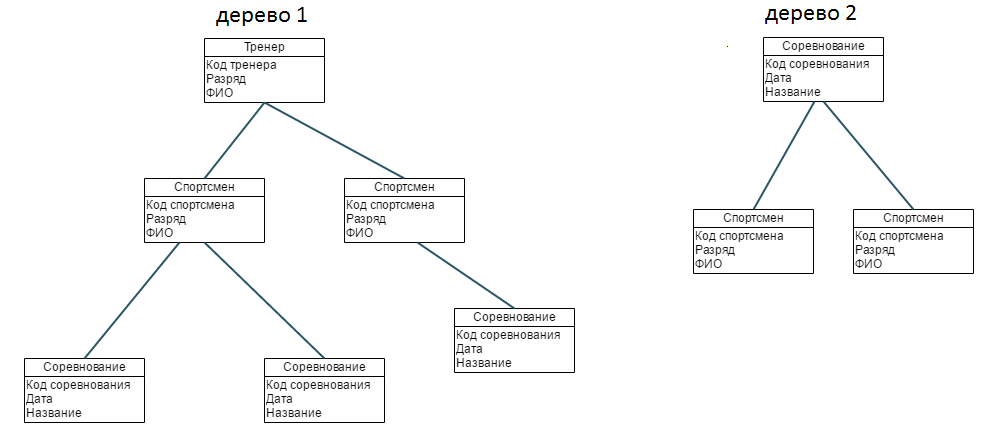
Пример 1
Имеется спортивный клуб, где у каждого спортсмена есть свой тренер. У тренера может быть несколько спортсменов. Спортсмены участвуют в соревнованиях. Каждый спортсмен может участвовать во многих соревнованиях. Для автоматизации учета в спортивном клубе потребуются следующие записи:
- Спортсмен (код спортсмена, разряд, ФИО);
- Тренер (код тренера, разряд, ФИО);
- Соревнование (код соревнования, дата, название).
Отношения между записями соответствуют связям между объектами реального мира. Например, отношение между объектом «тренер» и объектом «спортсмен» моделируется связью типа «один-ко-многим». Поэтому в записи «спортсмен» являются дочерними по отношению к записи «тренер». А вот между объектами «спортсмен» и «соревнование» в реальной жизни присутствует связь «много-ко-многим», потому что спортсмен может участвовать во многих соревнованиях, а в одном соревновании участвует много спортсменов. Отношения типа «много-ко-многим» в иерархической модели данных не существует. Единственный способ смоделировать его — это дублирование информации путем создания дополнительного дерева 2.
Ограничения типа данных hierarchyid
Тип данных hierarchyid имеет следующие ограничения.
-
Столбец типа hierarchyid не представляет дерево автоматически. Приложение должно создать и назначить значения hierarchyid таким образом, чтобы они отражали требуемые связи между строками. Некоторые приложения могут содержать столбец типа hierarchyid , указывающий местоположение в иерархии, определенной в другой таблице.
-
Параллельными процессами создания и присвоения значений hierarchyid управляет само приложение. Нет никакой гарантии, что значения hierarchyid уникальны, если приложение не использует ограничение уникального ключа или не обеспечивает уникальность своей логикой.
-
Иерархические связи, представленные значениями hierarchyid , не применяются как отношения внешнего ключа. Можно, а иногда и удобно иметь иерархическую связь, в которой у A есть потомок B и когда A удаляется, у B остается связь с несуществующей записью. Если это неприемлемо, приложение должно запросить потомков, прежде чем удалять родителей.
Изучение текущей структуры таблицы сотрудников
Образец базы данных Adventureworks2017 (или более поздней версии) содержит таблицу Employee в схеме HumanResources. Чтобы не изменять исходную таблицу, на этом шаге создается копия таблицы Employee , называющаяся EmployeeDemo. Для упрощения этого примера копируется только пять столбцов из исходной таблицы. Затем выполняется запрос к таблице HumanResources.EmployeeDemo , позволяющий просмотреть структуру данных в таблице без использования типа данных hierarchyid .
Копирование таблицы Employee
- Запустите следующий код в окне редактора запросов, чтобы скопировать структуру и данные таблицы Employee в новую таблицу EmployeeDemo. Поскольку в исходной таблице уже используется hierarchyid, этот запрос фактически преобразует иерархию в плоскую структуру, чтобы получить записи руководителя и сотрудника. В следующих частях этого занятия мы будем реконструировать эту иерархию.
Изучение структуры и данных таблицы EmployeeDemo
Новая таблица EmployeeDemo представляет собой типичный пример таблицы в существующей базе данных, которую можно подвергнуть миграции в новую структуру. Запустите следующий код в окне редактора запросов, чтобы увидеть, как таблица использует самосоединение для отображения связей сотрудник-менеджер.
SELECT
Mgr.EmployeeID AS MgrID, Mgr.LoginID AS Manager,
Emp.EmployeeID AS E_ID, Emp.LoginID, Emp.JobTitle
FROM HumanResources.EmployeeDemo AS Emp
LEFT JOIN HumanResources.EmployeeDemo AS Mgr
ON Emp.ManagerID = Mgr.EmployeeID
ORDER BY MgrID, E_ID
Результирующий набор:
MgrID Manager E_ID LoginID JobTitle
NULL NULL 1 adventure-works\ken0 Chief Executive Officer
1 adventure-works\ken0 2 adventure-works\terri0 Vice President of Engineering
1 adventure-works\ken0 16 adventure-works\david0 Marketing Manager
1 adventure-works\ken0 25 adventure-works\james1 Vice President of Production
1 adventure-works\ken0 234 adventure-works\laura1 Chief Financial Officer
1 adventure-works\ken0 263 adventure-works\jean0 Information Services Manager
1 adventure-works\ken0 273 adventure-works\brian3 Vice President of Sales
2 adventure-works\terri0 3 adventure-works\roberto0 Engineering Manager
3 adventure-works\roberto0 4 adventure-works\rob0 Senior Tool Designer
…
Получаемый в результате набор содержит 290 строк.
Обратите внимание, что использование предложения ORDER BY приводит к тому, что прямые подчиненные каждого уровня управления будут находиться вместе. Например, все семь прямых подчиненных уровня MgrID 1 (ken0) перечисляются вместе
Сгруппировать всех косвенных подчиненных уровня MgrID 1 тоже возможно, хотя это гораздо сложнее.
Примеры
Простой пример
Следующий пример намеренно упрощен, чтобы легче было приступить к работе. Сначала создайте таблицу для хранения определенных географических данных.
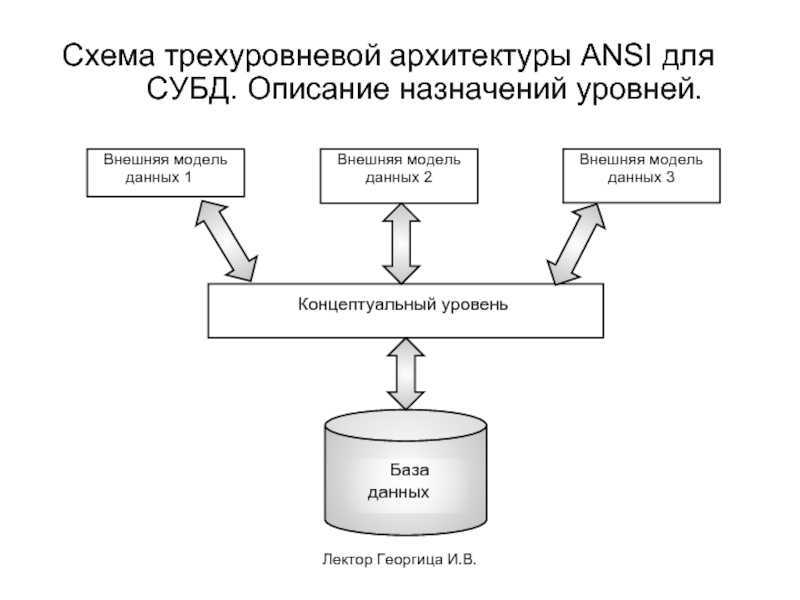
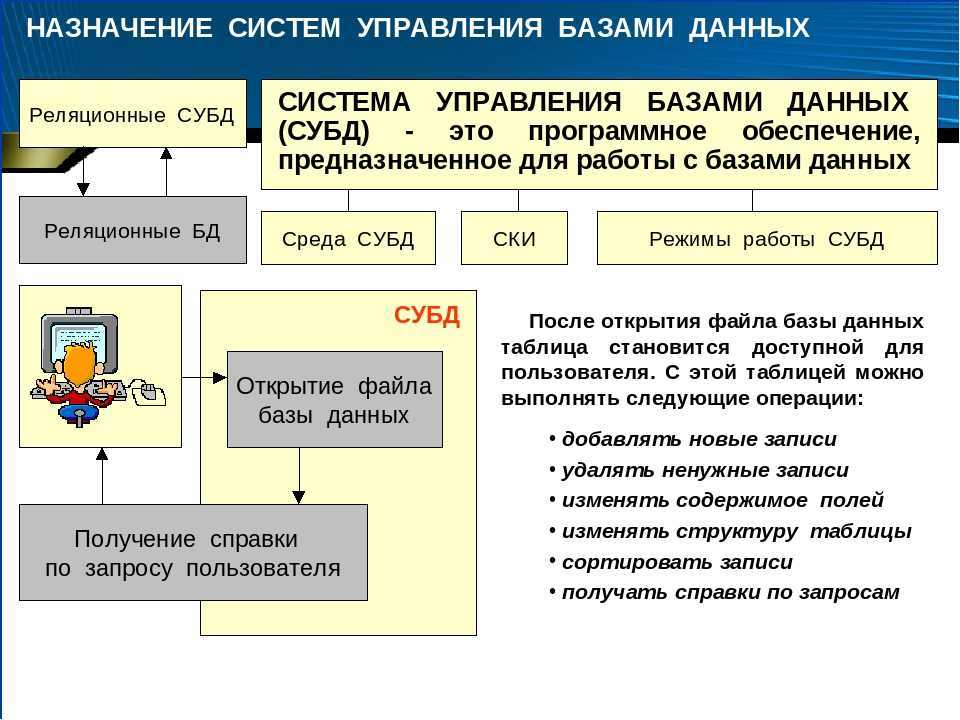
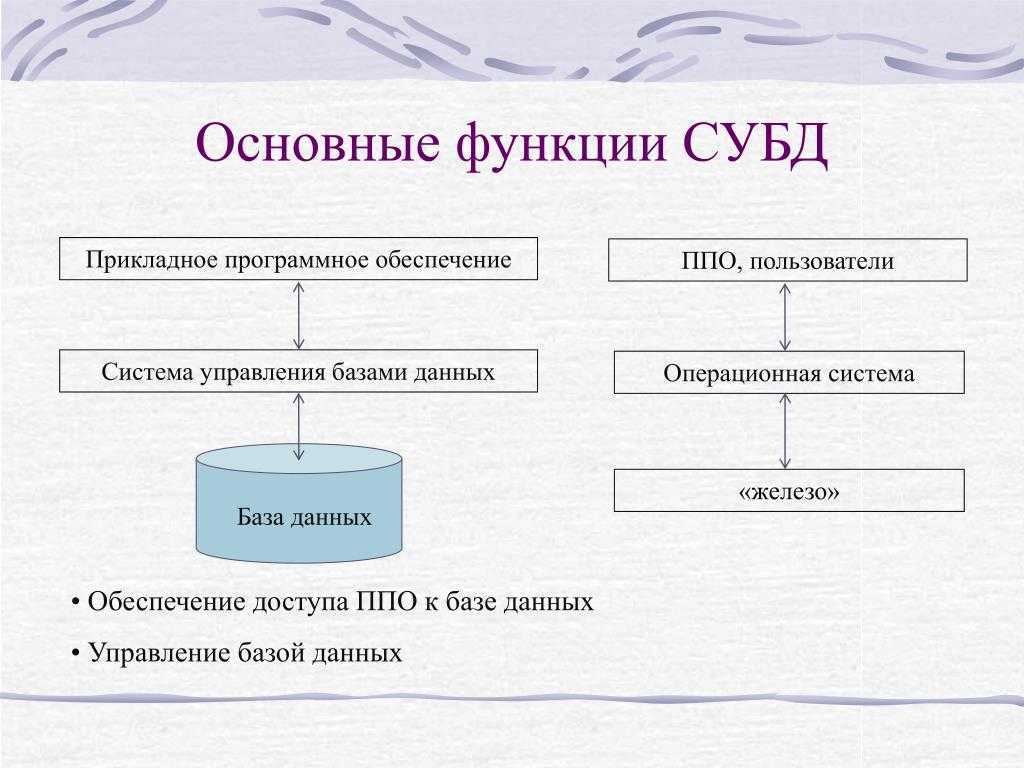
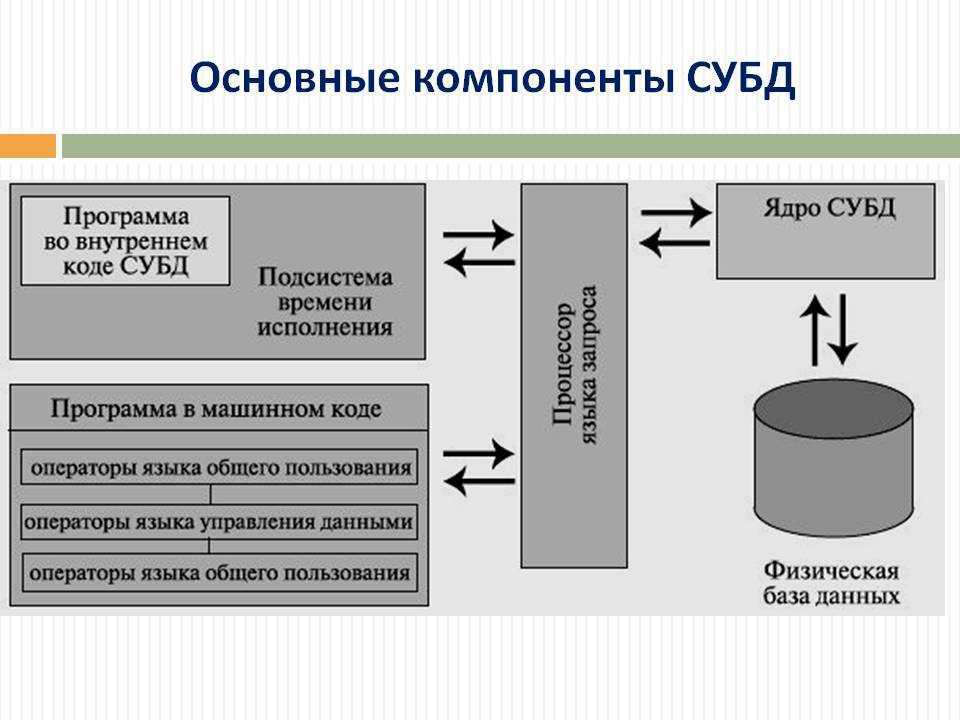
Теперь вставьте данные для некоторых континентов, стран или регионов, штатов и городов.
Выберите данные, добавляя столбец, который преобразовывает данные уровня в текстовое значение, удобное для восприятия. Этот запрос также отсортирует результат по типу данных hierarchyid .
Результирующий набор:
Обратите внимание, что иерархия имеет допустимую структуру, даже если она не является внутренне согласованной. Байя — единственный штат
Он отображается в иерархии как одноранговый по отношению к городу Бразилиа. Аналогичным образом, у станции Мак-Мердо нет родительской страны или региона. Необходимо решить, подходит ли этот тип иерархии для использования.
Добавьте еще одну строку и выберите результаты.
Это демонстрирует наличие других возможных проблем. Киото можно ввести в качестве уровня даже при отсутствии родительского уровня . И Лондон и Киото имеют одинаковое значение свойства hierarchyid. Опять-таки пользователи должны решить, подходит ли этот тип иерархии для использования, и заблокировать значения, недопустимые для использования.
Кроме того, в этой таблице не используется верхняя часть иерархии . Она была опущена, потому что общий родительский объект для всех континентов отсутствует. Его можно добавить путем добавления всей планеты.
Создание запросов к иерархической таблице с помощью иерархических методов
После того как таблица HumanResources.EmployeeOrg будет заполнена, эта задача продемонстрирует, как можно проводить запросы к иерархии с помощью некоторых иерархических методов.
Поиск подчиненных узлов
-
Sariya имеет одного подчиненного. Чтобы запросить подчиненных Sariya, выполните следующий запрос, в котором используется метод IsDescendantOf :
Результатами будут Sariya и Wanida. Sariya перечисляется, поскольку она является потомком на нулевом уровне. Wanida является потомком на первом уровне.
-
Запросить эту информацию можно также с помощью метода GetAncestor . принимает аргумент уровня, попытка вернуть который выполняется. Поскольку Wanida находится одним уровнем ниже Sariya, следует использовать метод так, как показано в следующем коде:
В этот раз результатом будет только Wanida.
-
Теперь измените значение на David (EmployeeID 6), а уровень на 2. Выполнение следующей инструкции также вернет значение Wanida:
В этот раз в результате также будет возвращена Mary, являющаяся подчиненной David, и находящаяся на два уровня ниже.