
Введение
Файловые системы определяют способ хранения данных. От них зависит, с какими ограничениями столкнется пользователь, насколько быстрыми будут операции чтения и записи и как долго накопитель проработает без сбоев. Особенно это касается бюджетных SSD и их младших братьев — флешек. Зная эти особенности, можно выжать из любой системы максимум и оптимизировать ее использование для конкретных задач.
Выбирать тип и параметры файловой системы приходится всякий раз, когда надо сделать что-то нетривиальное. Например, требуется ускорить наиболее частые файловые операции. На уровне файловой системы этого можно достичь разными способами: индексирование обеспечит быстрый поиск, а предварительное резервирование свободных блоков позволит упростить перезапись часто изменяющихся файлов. Предварительная оптимизация данных в оперативной памяти снизит количество требуемых операций ввода-вывода.
Увеличить срок безотказной эксплуатации помогают такие свойства современных файловых систем, как отложенная запись, дедупликация и другие продвинутые алгоритмы. Особенно актуальны они для дешевых SSD с чипами памяти TLC, флешек и карт памяти.
Отдельные оптимизации существуют для дисковых массивов разных уровней: например, файловая система может поддерживать упрощенное зеркалирование тома, мгновенное создание снимков или динамическое масштабирование без отключения тома.
Практическое применение
Масштабируемые файловые серверы идеально подходят для хранилища серверных приложений. Ниже перечислены некоторые примеры серверных приложений, которые могут хранить свои данные в масштабируемом файловом ресурсе.
- Веб-сервер IIS может хранить конфигурацию и данные для веб-сайтов в масштабируемом файловом ресурсе. Дополнительные сведения см. в разделе Общая конфигурация.
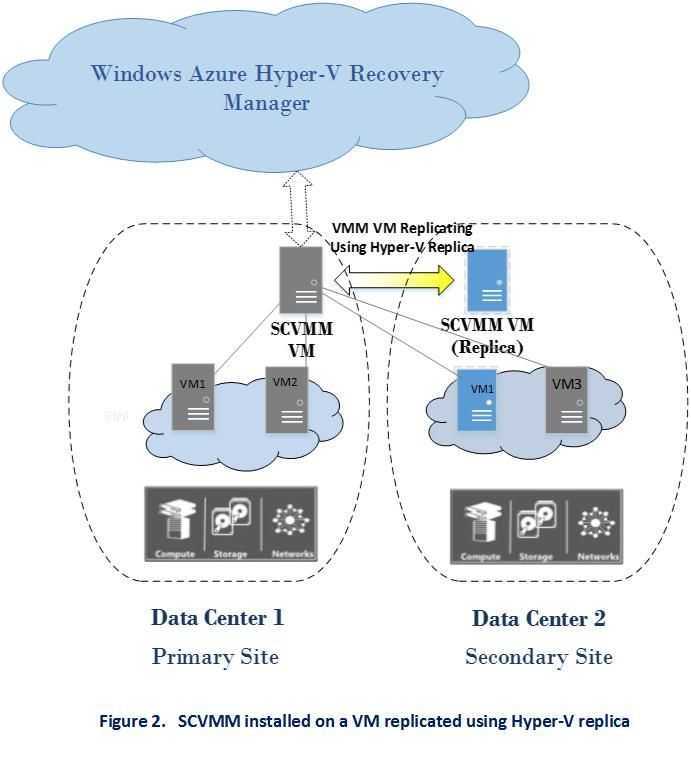
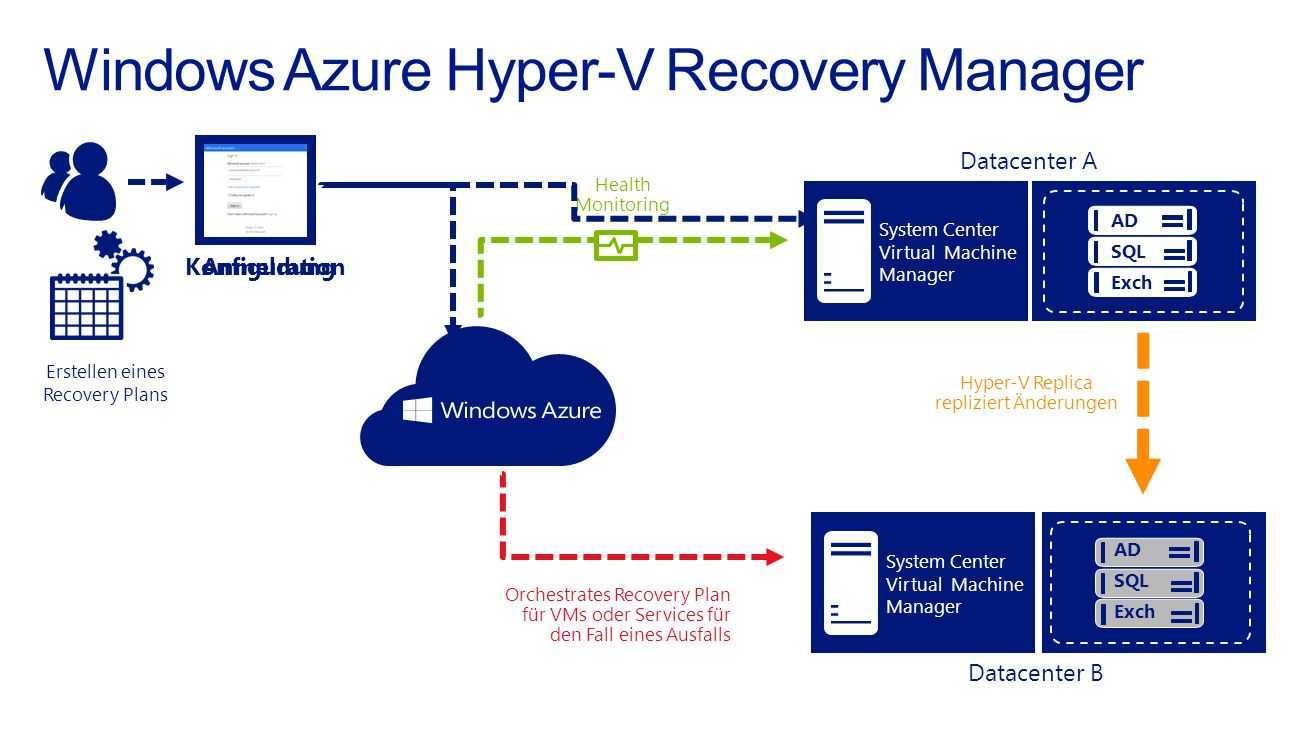
- Hyper-V может хранить конфигурацию и динамические виртуальные диски в масштабируемом файловом ресурсе. Дополнительные сведения см. в разделе Развертывание Hyper-V через SMB.
- SQL Server может хранить динамические файлы базы данных в масштабируемом файловом ресурсе. Дополнительные сведения см. в разделе Установка SQL Server с файловым ресурсом SMB в качестве хранилища.
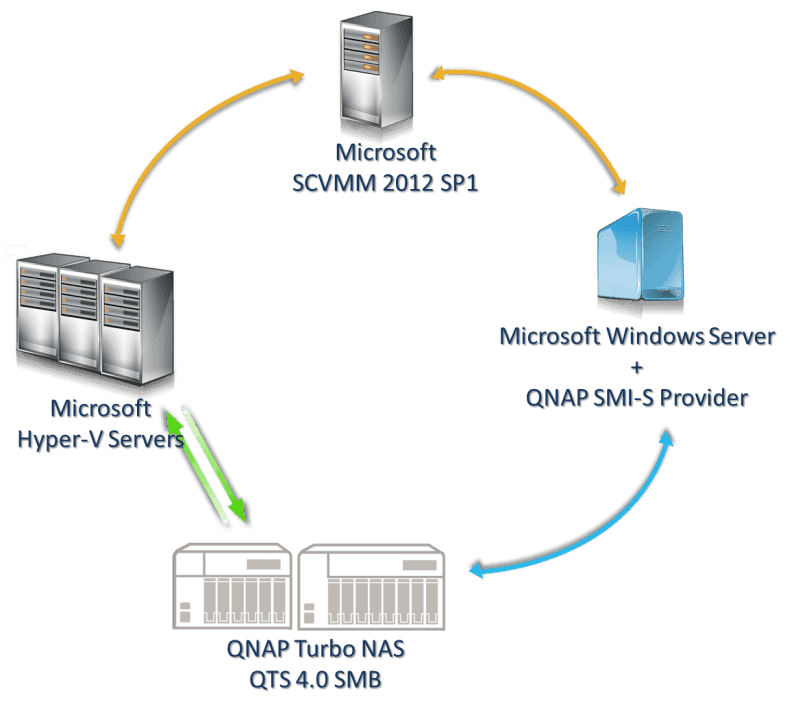
- Диспетчер виртуальных машин (VMM) может хранить общую папку библиотеки (содержащую шаблоны виртуальных машин и связанные файлы) в масштабируемом файловом ресурсе. Однако сам сервер библиотеки не может быть Scale-Out файловым сервером. Он должен находиться на автономном сервере или отказоустойчивом кластере, который не использует роль кластера файлового сервера Scale-Out.
При использовании масштабируемого файлового ресурса в качестве общей папки библиотеки можно применять только те технологии, которые совместимы с масштабируемым файловым сервером. Например, репликацию DFS нельзя использовать для репликации общей папки библиотеки, размещенной в масштабируемом файловом ресурсе
Также важно, чтобы на масштабируемом файловом сервере установлены последние обновления программного обеспечения
Чтобы использовать масштабируемый файловый ресурс в качестве общей папки библиотеки, сначала добавьте сервер библиотеки (скорее всего, это виртуальная машина) с локальной общей папкой или вообще без общих папок. Затем при добавлении общей папки библиотеки выберите общую папку, размещенную на масштабируемом файловом сервере. Этот ресурс должен быть управляемым VMM и созданным исключительно для использования сервером библиотеки. Также не забудьте установить последние обновления на масштабируемом файловом сервере. Дополнительные сведения о добавлении серверов библиотеки VMM и общих папок библиотек см. в разделе «Добавление профилей в библиотеку VMM». Список доступных в настоящее время исправлений для файловых служб и служб хранилища см. в статье базы знаний Майкрософт 2899011.
Примечание
Некоторые пользователи, например информационные работники, имеют рабочие нагрузки, которые значительно влияют на производительность. Например, если такие операции, как открытие и закрытие файлов, создание новых файлов и переименование существующих файлов, выполняются несколькими пользователями, они оказывают влияние на производительность. Если файловый ресурс включен с непрерывной доступностью, он обеспечивает целостность данных, но также влияет на общую производительность. Для постоянной доступности требуется сквозная запись данных на диск, чтобы обеспечить целостность в случае сбоя узла кластера на масштабируемом файловом сервере. Таким образом, пользователь, который копирует несколько больших файлов на файловый сервер, может ожидать значительно более низкую производительность на постоянно доступном файловом ресурсе.
Хаб открытых данных – это …[править]
Основной независимый ресурс наборов открытых государственных данных, на котором собраны и структурированы существующие на сегодня в России наборы данных.+
Открытый ресурс, в который выгружают персональные данные граждан с целью продажи и передачи третьим лицам
В терминологии специалистов – историческое событие, после которого было открыто, что можно использовать данные в управлении процессами (продажи, менеджмент и т.д.)
Аналитическая панель, наглядное представление информации о бизнес-процессах, трендах, зависимостях и других метриках в компактном виде, которое позволяет увидеть значения конкретных показателей и динамику их изменений
Способ защиты данных с помощью визуальных решений
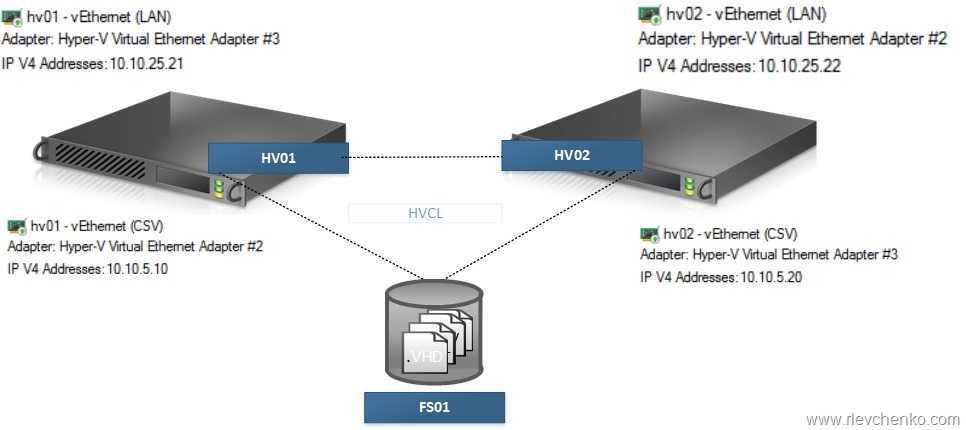
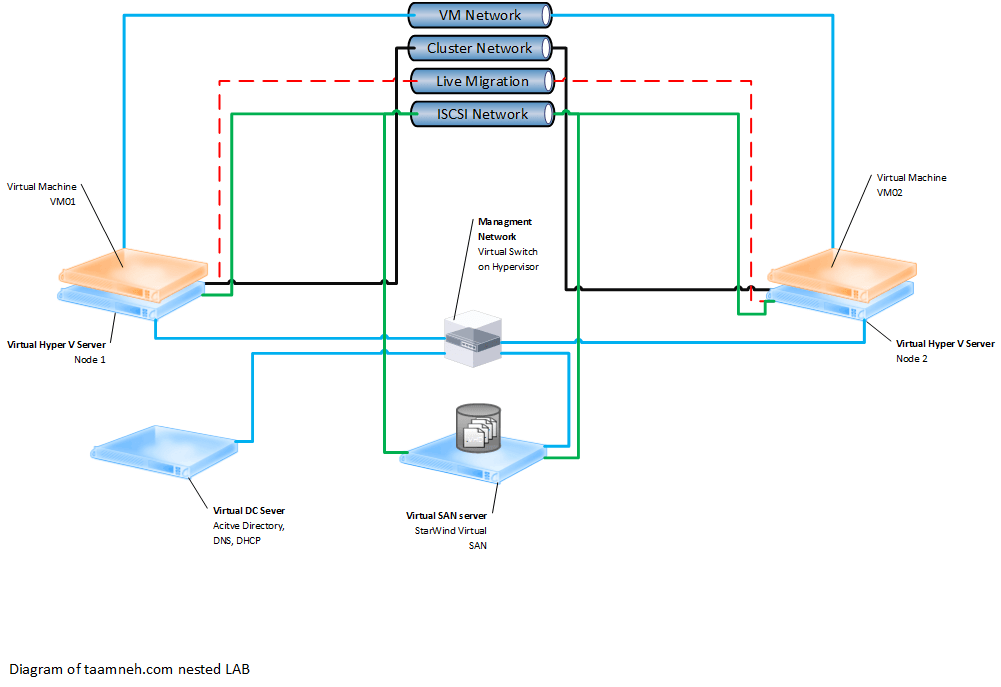
Шаг 2. Настройка сети
Если вы развертываете Локальные дисковые пространства на виртуальных машинах, пропустите этот раздел.
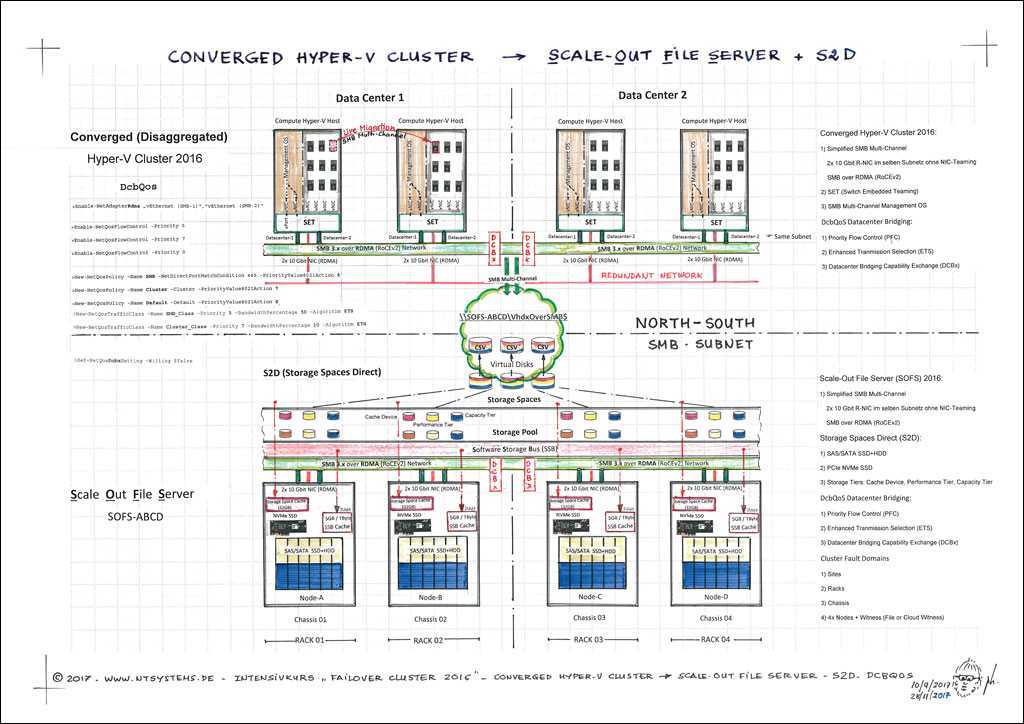
Локальные дисковые пространства требуется сеть с высокой пропускной способностью и низкой задержкой между серверами в кластере. Требуется по крайней мере 10 ГбE сети и рекомендуется удаленный прямой доступ к памяти (RDMA). Вы можете использовать iWARP или RoCE, если он имеет логотип Windows Server, соответствующий вашей версии операционной системы, но iWARP обычно проще настроить.
Важно!
В зависимости от сетевого оборудования, особенно с RoCE версии 2, может потребоваться некоторая конфигурация коммутатора верхнего уровня. Правильная конфигурация коммутатора важна для обеспечения надежности и производительности Локальные дисковые пространства.
Windows Server 2016 появилось объединение встроенных коммутаторов (SET) в виртуальном коммутаторе Hyper-V. Это позволяет использовать одни и те же физические порты сетевого адаптера для всего сетевого трафика при использовании RDMA, уменьшая количество необходимых физических портов сетевого адаптера. Для Локальные дисковые пространства рекомендуется использовать встроенную командную группу коммутаторов.
Переключение или переключение между узлами
- Переключение: сетевые коммутаторы должны быть правильно настроены для обработки пропускной способности и типа сети. При использовании RDMA, реализующего протокол RoCE, настройка сетевого устройства и коммутатора еще более важна.
- Без переключения: узлы могут быть соединены с помощью прямых подключений, избегая использования коммутатора. Для каждого узла требуется прямое подключение к каждому другому узлу кластера.
Инструкции по настройке сети для Локальные дисковые пространства см. в руководстве по развертыванию Windows Server 2016 и 2019 RDMA.
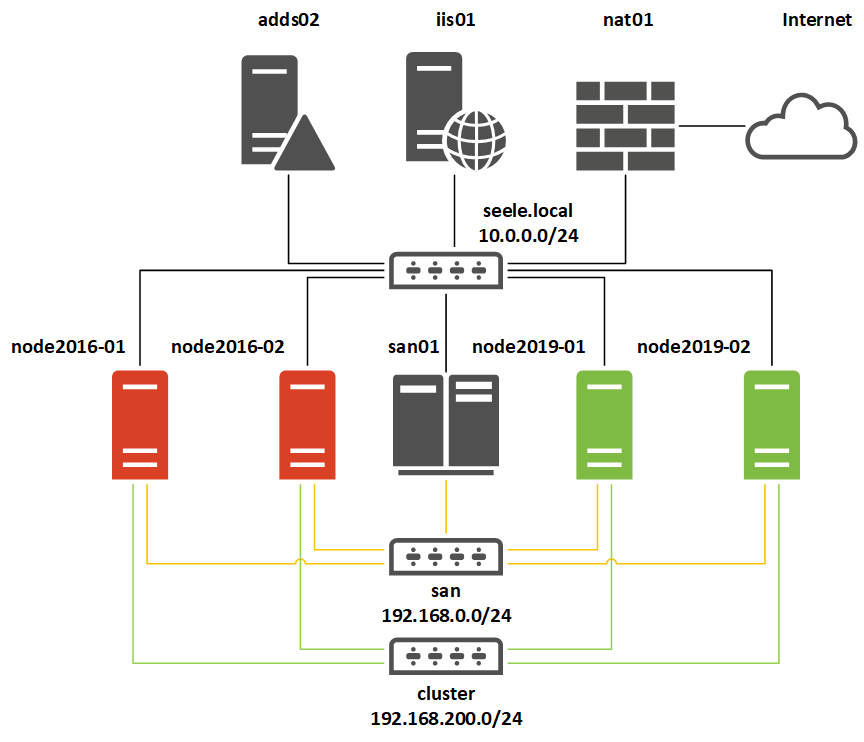
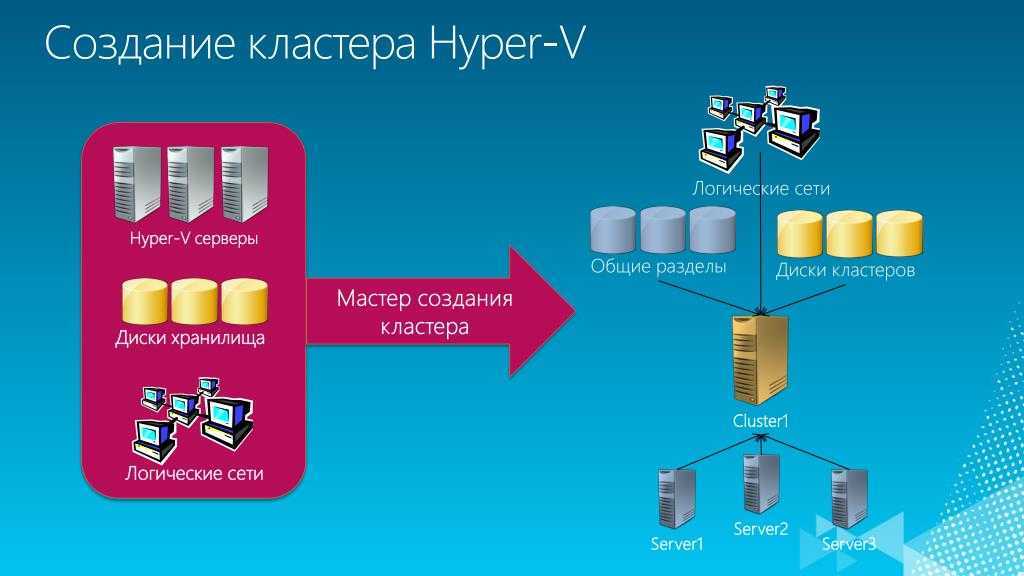
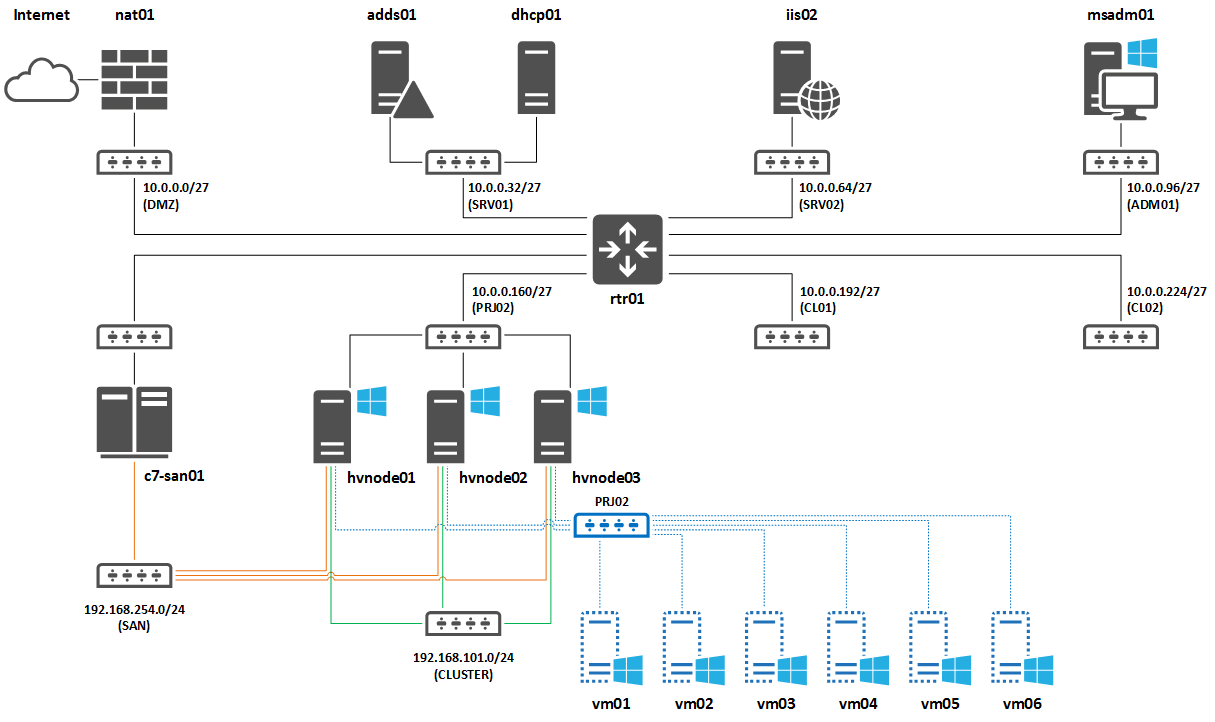
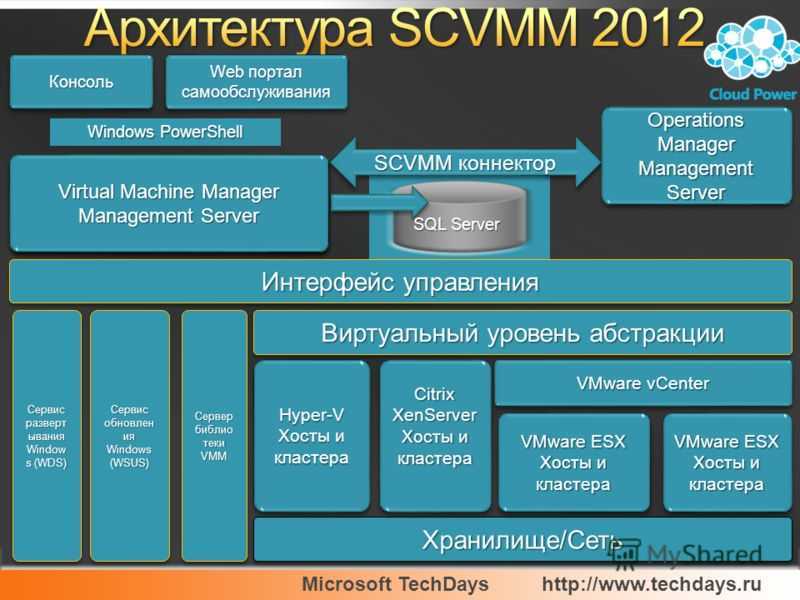
Общие корни
Различных файловых систем создано свыше сотни, но актуальными можно назвать чуть больше десятка. Хотя все они разрабатывались для своих специфических применений, многие в итоге оказались родственными на концептуальном уровне. Они похожи, поскольку используют однотипную структуру представления (мета)данных — B-деревья («би-деревья»).
Как и любая иерархическая система, B-дерево начинается с корневой записи и далее ветвится вплоть до конечных элементов — отдельных записей о файлах и их атрибутах, или «листьев». Основной смысл создания такой логической структуры был в том, чтобы ускорить поиск объектов файловой системы на больших динамических массивах — вроде жестких дисков объемом в несколько терабайт или еще более внушительных RAID-массивов.
B-деревья требуют гораздо меньше обращений к диску, чем другие типы сбалансированных деревьев, при выполнении тех же операций. Достигается это за счет того, что конечные объекты в B-деревьях иерархически расположены на одной высоте, а скорость всех операций как раз пропорциональна высоте дерева.
Как и другие сбалансированные деревья, B-trees имеют одинаковую длину путей от корня до любого листа. Вместо роста ввысь они сильнее ветвятся и больше растут в ширину: все точки ветвления у B-дерева хранят множество ссылок на дочерние объекты, благодаря чему их легко отыскать за меньшее число обращений. Большое число указателей снижает количество самых длительных дисковых операций — позиционирования головок при чтении произвольных блоков.
Концепция B-деревьев была сформулирована еще в семидесятых годах и с тех пор подвергалась различным улучшениям. В том или ином виде она реализована в NTFS, BFS, XFS, JFS, ReiserFS и множестве СУБД. Все они — родственники с точки зрения базовых принципов организации данных. Отличия касаются деталей, зачастую довольно важных. Недостаток у родственных файловых систем тоже общий: все они создавались для работы именно с дисками еще до появления SSD.
Что такое цифровая экономика?[править]
Хозяйственная деятельность, в которой ключевым фактором являются данные в цифровом виде +
Стадия развития технологий интернет, концепция вычислительной сети физических предметов («вещей»), оснащенных встроенными технологиями для взаимодействия друг с другом или с внешней средой и объединяющая целый стек технологий
Общий подход к цифровой трансформации и внедрению управления на основе данных на промышленном предприятии
Подход к цифровой трансформации компании, основанный на решении использовать современные технологии и практики проектной работы
Направление, в котором стартапы, инновационные компании и само государство оцифровывают государственные продукты и услуги, используя новые технологии
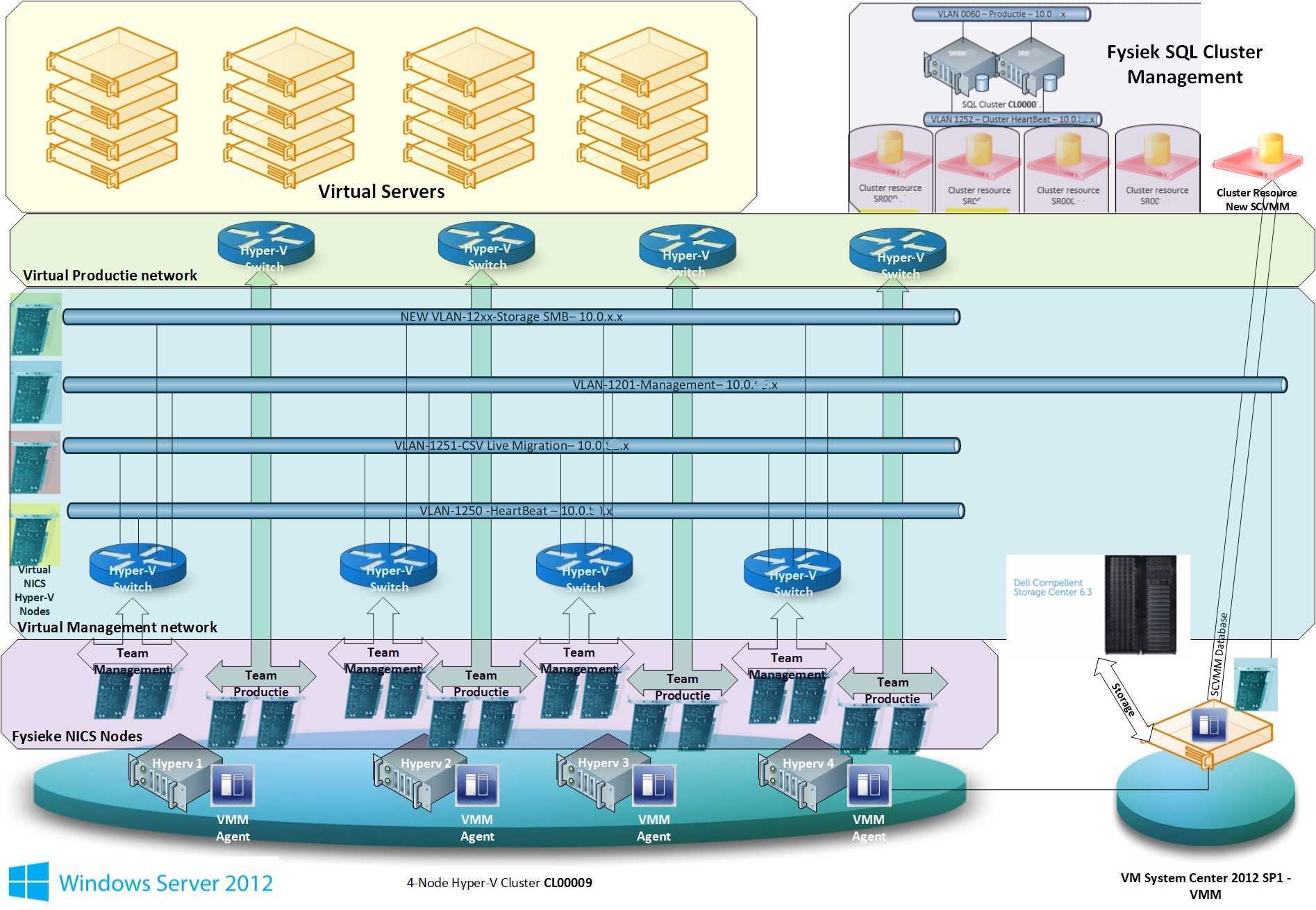
Запуск обновления
- Щелкните СтруктураХранилищеФайловые серверы. Щелкните правой кнопкой мыши SOFS и выберите >.
- В разделе > мастера обновления щелкните узлы, которые требуется обновить, или нажмите кнопку Выбрать все. Затем щелкните Профиль физического компьютера и выберите профиль для узлов.
- В разделе Конфигурация BMC выберите учетную запись запуска от имени с разрешениями на доступ к BMC или создайте новую. В списке Протокол внешнего управления выберите протокол, который используют контроллеры BMC. Чтобы использовать интерфейс DCMI, щелкните IPMI. DCMI поддерживается, даже если не отображается в списке. Убедитесь в том, что указан правильный порт.
- В разделе Настройка развертывания просмотрите узлы для обновления. Если мастеру не удалось определить все параметры, для узла отображается оповещение Отсутствующие параметры. Например, если узел не был подготовлен на компьютере без операционной системы, параметры BMC могут быть неполными. Укажите недостающие данные.
- При необходимости введите IP-адрес контроллера BMC. Можно также изменить имя узла. Не снимайте флажок Пропустить проверку Active Directory для этого имени компьютера, если только вы не изменяете имя узла и вам не требуется гарантировать, что новое имя не используется.
- В конфигурации сетевого адаптера можно указать MAC-адрес. Это необходимо сделать в том случае, если вы настраиваете адаптер управления для кластера, и вам требуется настроить его как виртуальный сетевой адаптер. Это не MAC-адрес контроллера BMC. Если вам требуется указать параметры статического IP-адреса для адаптера, выберите логическую сеть и IP-подсеть (при необходимости). Если подсеть включает пул адресов, можно установить флажок Получить IP-адрес, соответствующий выбранной подсети. В противном случае введите IP-адрес, находящийся в логической сети.
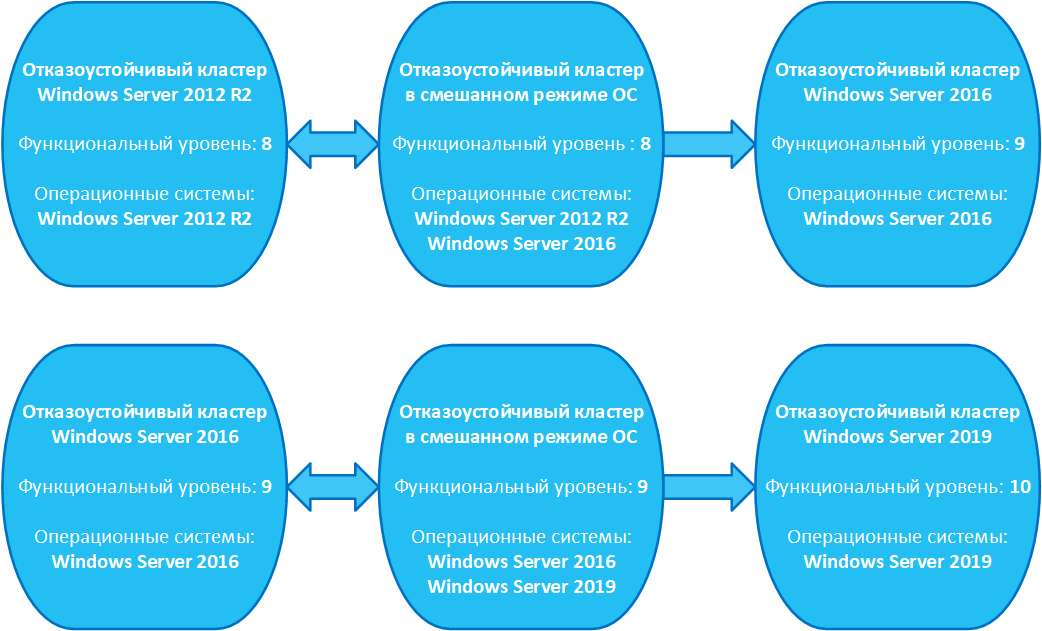
- В разделе Сводка нажмите кнопку Готово, чтобы начать обновление. Если мастер успешно завершает работу, значит, узел успешно обновлен и все узлы SOFS работают под управлением Windows Server 2016 или более поздней версии. Мастер обновляет функциональный уровень кластера до Windows Server 2016.
При необходимости можно обновить функциональный уровень масштабируемого файлового сервера, который был обновлен вне VMM. Для этого щелкните правой кнопкой мыши Файловые серверы укажите имя SOFS >и выберите пункт >. Это может потребоваться, если узлы SOFS были обновлены перед их добавлением в структуру VMM, однако масштабируемый файловый сервер по-прежнему работает в качестве кластера Windows Server 2012 R2 или более поздней версии.
Обзор методологии
1. Собираем требования
В качестве источника могут выступать результаты опросов стейк-холдеров, анализ бизнес-целей проекта и историй использования
При этом важно конкретизировать, что имеет в виду клиент. Например, не просто «безотказная работа сайта», а «допустимый период простоя – 30 минут в месяц».
Далее мы оцениваем важность требований по двум критериям:
- ценность для бизнеса;
- степень влияния на архитектуру.
Уровни важности оцениваем по шкале HML (high, medium, low — высокий, средний, низкий). Таким образом, каждое требование будет иметь двухбуквенное сочетание
Архитектурно значимые пункты имеют обозначения HH, HM, HL, MH, MM. Стоит отметить, что большое число требований HH означает высокие риски на проекте.
2. Проектируем архитектуру
Мы проектируем архитектуру ПО, исходя из наиболее значимых атрибутов качества.
Это рекурсивный процесс, в ходе которого система декомпозируется на более мелкие подсистемы.
ADD — первый метод, который концентрируется на атрибутах качества и способах их достижения. Важным вкладом ADD было признание того, что анализ и документация являются неотъемлемой частью процесса проектирования. Этот метод успешно применяется более 15 лет.
Сейчас актуальная версия ADD — 3.0, итеративная. Согласно ей, проектирование выполняется поэтапно в течение всего времени разработки системы, в каждом спринте. В ней по шагам описано руководство по тем задачам, которые необходимо выполнить в рамках каждой итерации.
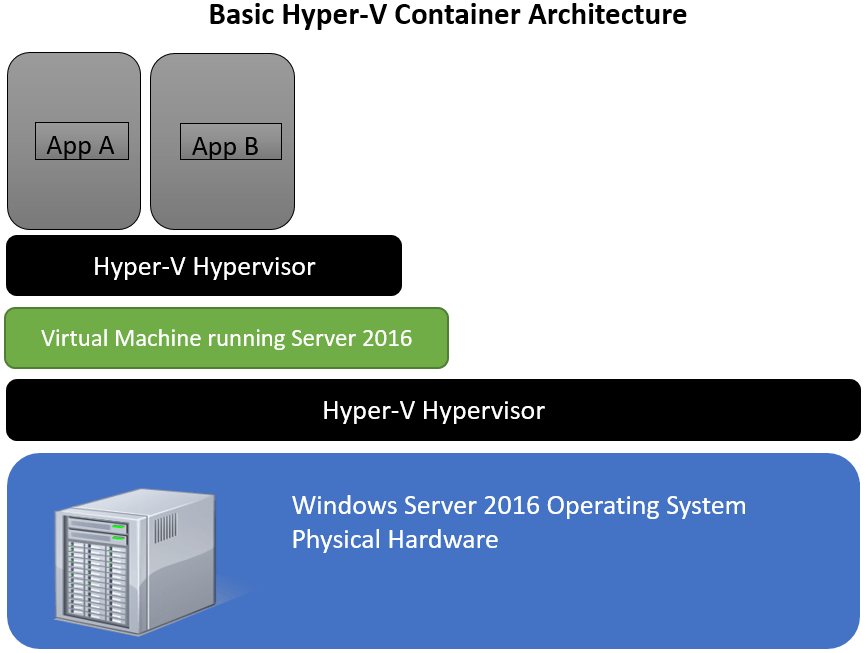
Флеш-память как двигатель прогресса
Твердотельные накопители постепенно вытесняют дисковые, но пока вынуждены использовать чуждые им файловые системы, переданные по наследству. Они построены на массивах флеш-памяти, принципы работы которой отличаются от таковых у дисковых устройств. В частности, флеш-память должна стираться перед записью, а эта операция в чипах NAND не может выполняться на уровне отдельных ячеек. Она возможна только для крупных блоков целиком.

Связано это ограничение с тем, что в NAND-памяти все ячейки объединены в блоки, каждый из которых имеет только одно общее подключение к управляющей шине. Не будем вдаваться в детали страничной организации и расписывать полную иерархию. Важен сам принцип групповых операций с ячейками и тот факт, что размеры блоков флеш-памяти обычно больше, чем блоки, адресуемые в любой файловой системе. Поэтому все адреса и команды для накопителей с NAND flash надо транслировать через слой абстрагирования FTL (Flash Translation Layer).
Совместимость с логикой дисковых устройств и поддержку команд их нативных интерфейсов обеспечивают контроллеры флеш-памяти. Обычно FTL реализуется именно в их прошивке, но может (частично) выполняться и на хосте — например, компания Plextor пишет для своих SSD драйверы, ускоряющие запись.
Совсем без FTL не обойтись, поскольку даже запись одного бита в конкретную ячейку приводит к запуску целой серии операций: контроллер отыскивает блок, содержащий нужную ячейку; блок считывается полностью, записывается в кеш или на свободное место, затем стирается целиком, после чего перезаписывается обратно уже с необходимыми изменениями.
Такой подход напоминает армейские будни: чтобы отдать приказ одному солдату, сержант делает общее построение, вызывает бедолагу из строя и командует остальным разойтись. В редкой ныне NOR-памяти организация была спецназовская: каждая ячейка управлялась независимо (у каждого транзистора был индивидуальный контакт).
Задач у контроллеров все прибавляется, поскольку с каждым поколением флеш-памяти техпроцесс ее изготовления уменьшается ради повышения плотности и удешевления стоимости хранения данных. Вместе с технологическими нормами уменьшается и расчетный срок эксплуатации чипов.
Модули с одноуровневыми ячейками SLC имели заявленный ресурс в 100 тысяч циклов перезаписи и даже больше. Многие из них до сих пор работают в старых флешках и карточках CF. У MLC корпоративного класса (eMLC) ресурс заявлялся в пределах от 10 до 20 тысяч, в то время как у обычной MLC потребительского уровня он оценивается в 3–5 тысяч. Память этого типа активно теснит еще более дешевая TLC, у которой ресурс едва дотягивает до тысячи циклов. Удерживать срок жизни флеш-памяти на приемлемом уровне приходится за счет программных ухищрений, и новые файловые системы становятся одним из них.
Изначально производители предполагали, что файловая система неважна. Контроллер сам должен обслуживать недолговечный массив ячеек памяти любого типа, распределяя между ними нагрузку оптимальным образом. Для драйвера файловой системы он имитирует обычный диск, а сам выполняет низкоуровневые оптимизации при любом обращении. Однако на практике оптимизация у разных устройств разнится от волшебной до фиктивной.
В корпоративных SSD встроенный контроллер — это маленький компьютер. У него есть огромный буфер памяти (полгига и больше), и он поддерживает множество методов повышения эффективности работы с данными, что позволяет избегать лишних циклов перезаписи. Чип упорядочивает все блоки в кеше, выполняет отложенную запись, производит дедупликацию на лету, резервирует одни блоки и очищает в фоне другие. Все это волшебство происходит абсолютно незаметно для ОС, программ и пользователя. С таким SSD действительно непринципиально, какая файловая система используется. Внутренние оптимизации оказывают гораздо большее влияние на производительность и ресурс, чем внешние.
В бюджетные SSD (и тем более — флешки) ставят куда менее умные контроллеры. Кеш в них урезан или отсутствует, а продвинутые серверные технологии не применяются вовсе. В картах памяти контроллеры настолько примитивные, что часто утверждается, будто их нет вовсе. Поэтому для дешевых устройств с флеш-памятью остаются актуальными внешние методы балансировки нагрузки — в первую очередь при помощи специализированных файловых систем.
Практический пример использования файловых систем
Владельцы мобильных гаджетов для хранения большого объема информации используют дополнительные твердотельные накопители microSD (HC), по умолчанию отформатированные в стандарте FAT32. Это является основным препятствием для установки на них приложений и переноса данных из внутренней памяти. Чтобы решить эту проблему, необходимо создать на карточке раздел с ext3 или ext4. На него можно перенести все файловые атрибуты (включая владельца и права доступа), чтобы любое приложение могло работать так, словно запустилось из внутренней памяти.
Операционная система Windows не умеет делать на флешках больше одного раздела. С этой задачей легко справится Linux, который можно запустить, например, в виртуальной среде. Второй вариант — использование специальной утилиты для работы с логической разметкой, такой как MiniTool Partition Wizard Free. Обнаружив на карточке дополнительный первичный раздел с ext3/ext4, приложение Андроид Link2SD и аналогичные ему предложат куда больше вариантов.
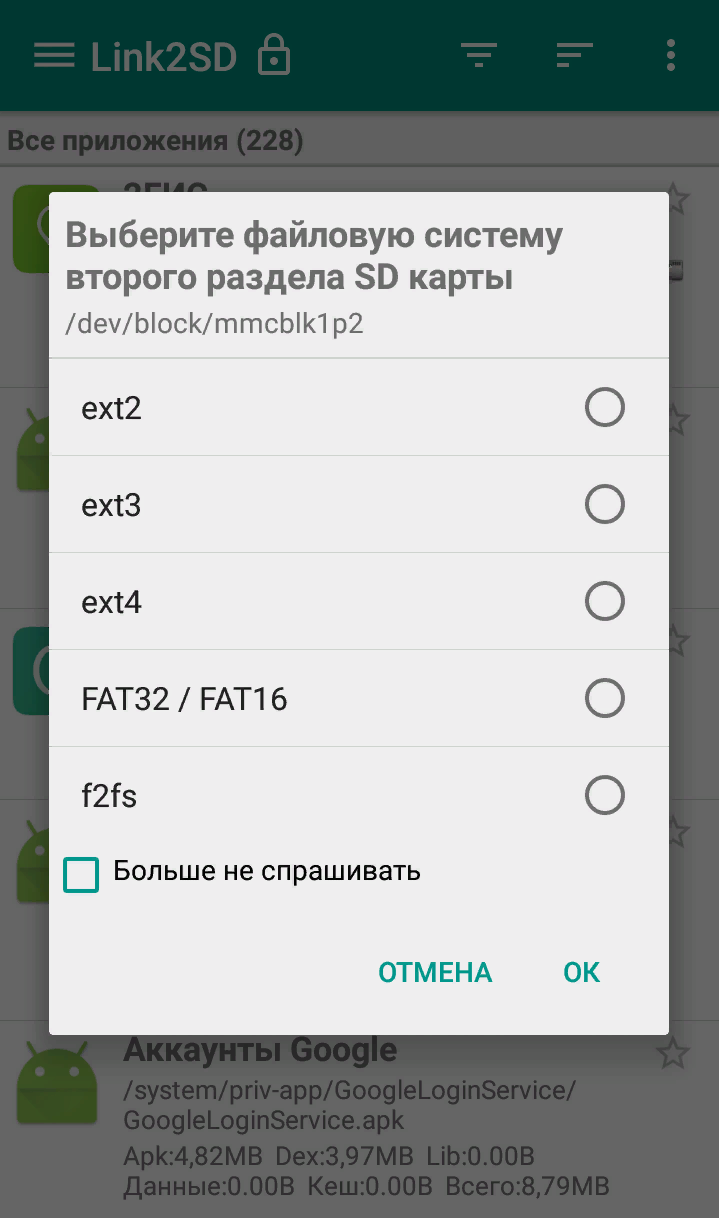
Флешки и карты памяти быстро умирают как раз из-за того, что любое изменение в FAT32 вызывает перезапись одних и тех же секторов. Гораздо лучше использовать на флеш-картах NTFS с ее устойчивой к сбоям таблицей $MFT. Небольшие файлы могут храниться прямо в главной файловой таблице, а расширения и копии записываются в разные области флеш-памяти. Благодаря индексации на NTFS поиск выполняется быстрее. Аналогичных примеров оптимизации работы с различными накопителями за счет правильного использования возможностей файловых систем существует множество.
Надеюсь, краткий обзор основных ФС поможет решить практические задачи в части правильного выбора и настройки ваших компьютерных устройств в повседневной практике.
Как освободить флеш-память смартфона
Карточки microSD(HC), используемые в смартфонах, по умолчанию отформатированы в FAT32. Это основное препятствие для установки на них приложений и переноса данных из внутренней памяти. Чтобы его преодолеть, нужно создать на карточке раздел с ext3 или ext4. На него можно перенести все файловые атрибуты (включая владельца и права доступа), поэтому любое приложение сможет работать так, словно запустилось из внутренней памяти.
Windows не умеет делать на флешках больше одного раздела, но для этого можно запустить Linux (хотя бы в виртуалке) или продвинутую утилиту для работы с логической разметкой — например, MiniTool Partition Wizard Free. Обнаружив на карточке дополнительный первичный раздел с ext3/ext4, приложение Link2SD и аналогичные ему предложат куда больше вариантов, чем в случае с одним разделом FAT32.
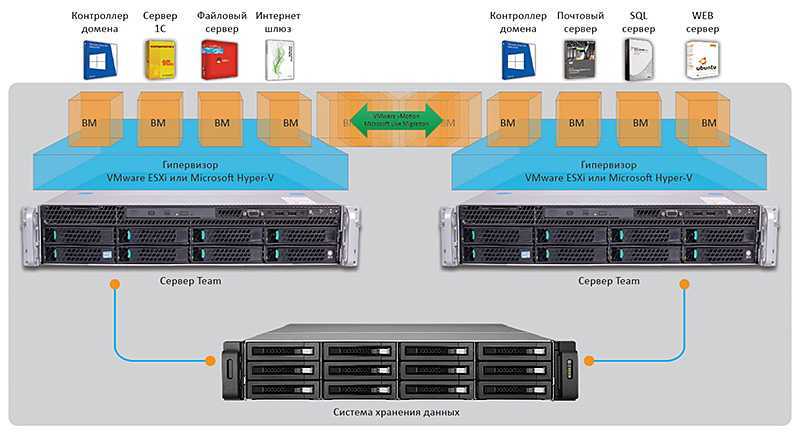
Архитектура решения
Гиперконвергентный вариант развертывания
Рис. 2. Гиперконвергентный вариант развертывания
- Консолидация вычислительных ресурсов и ресурсов хранения (не нужно внедрять и сопровождать выделенную внешнюю СХД).
- Совместное горизонтальное блочное масштабирование вычислительных ресурсов и ресурсов хранения.
- Простота внедрения и сопровождения.
- Централизованное управление.
- Экономия стоечной ёмкости и энергопотребления.
- All-flash — узлы кластера снабжаются только flash-носителями (NVMe, SSD);
- HDD — узлы кластера снабжаются только HDD-носителями;
- Гибридная — два независимых уровня хранения на HDD и SSD.
Архитектура Ceph
Давайте теперь изучим самый верхний уровень архитектуры Ceph и ее основные компоненты. Затем перейдем на следующий уровень, на котором познакомимся с некоторыми ключевыми аспектами Ceph и продолжим более подробное изучение системы.
Экосистему Ceph можно грубо поделить на четыре части (см. рис.1): клиенты (пользователи данных), сервера метаданных (которые кэшируют и синхронизируют распределенные метаданные), кластер хранения объектов (в котором в виде объектов хранятся как данные,так и метаданные, и в котором реализованы другие ключевые особенности), и, наконец, кластерные мониторы (с помощью которых реализованы функции мониторинга).
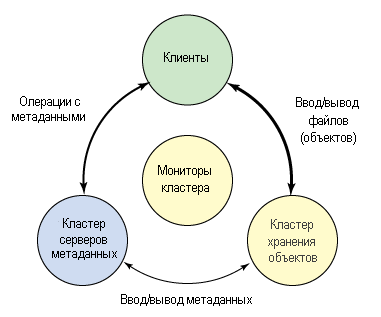
Рис.1. Концептуальный взгляд на экосистему Ceph
Как видно на рис.1, клиенты с помощью серверов метаданных выполняют операции с метаданными (для определения местонахождения данных). Сервера метаданных управляют размещением данных, а также указывают, куда помещать новые данные
Обратите внимание, что метаданные хранятся в кластере хранения данных (отмечено как «Metadata I/O» — ввод / вывод метаданных). Фактический файловый ввод/вывод происходит между клиентом и кластером хранения объектов
Таким образом, управление высокоуровневыми функциями POSIX (такими, как открытие, закрытие и переименование) осуществляется с помощью серверов метаданных, тогда как управление обычными функциями POSIX (такими, как чтение и запись) осуществляется непосредственно через кластер хранения объектов.
Другой взгляд на архитектуру системы показан на рис.2. Набор серверов получает доступ к экосистеме Ceph через клиентский интерфейс, в котором реализована взаимосвязь между серверами метаданных и хранилищем объектов данных. Распределенную систему хранения данных можно рассматривать в виде нескольких слоев, среди которых есть слой устройств хранения данных (Extent and B-tree-based Object File System — объектная файловая система с масштабированием и использованием двоичных деревьев или альтернативная) и выше его управляющий слой, предназначенным для управления репликацией данных, обнаружения отказов и восстановления данных с последующей их миграцией, который называется RADOS (Reliable Autonomic Distributed Object Storage- надежное автономное распределенное хранилище объектов данных). И наконец, для выявления отказов компонентов и последующего уведомления об этом используются мониторы.
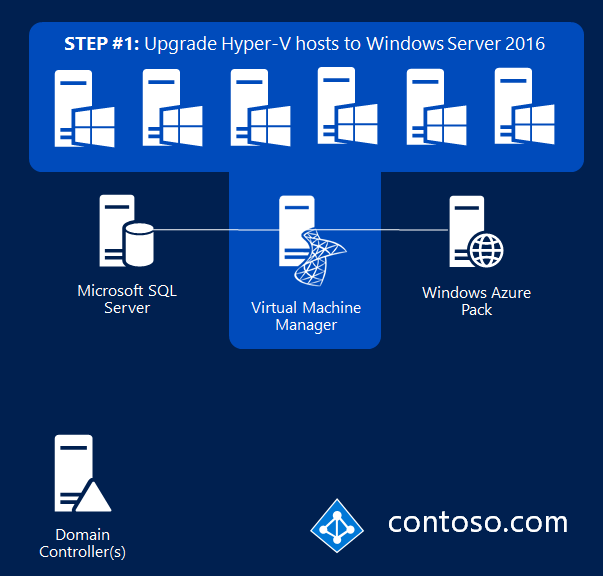

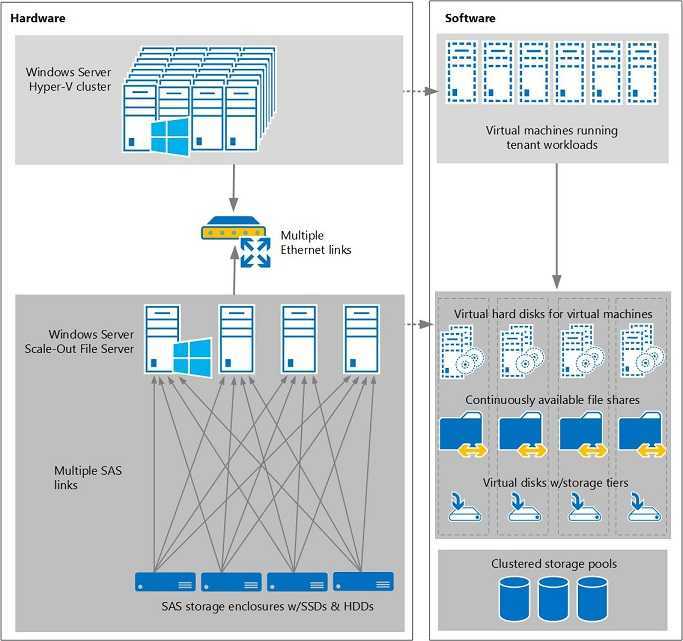
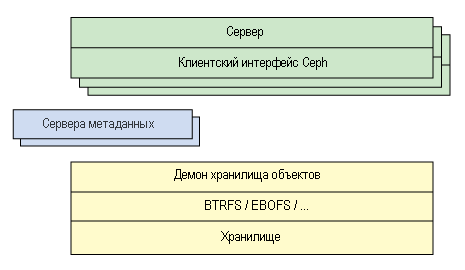
Рис.2. Упрощенная схема слоев экосистемы Ceph
Фаза 4: Mo’sh
В этой фазе будем реализовывать команды , , и для нашей интерактивной строки. Работа ведётся в файлике .
Вероятно вы уже знакомы с понятием рабочего каталога. Текущий рабочий каталог ( от current working directory) — это такой каталог, от которого рассчитываются относительные пути к файлам. Например если равно , то если обратиться к файлу этот самый файл будет искаться под именем . Если переключить на , то доступ к файлу будет аналогичен доступу к файлу . Символ может быть добавлен к началу любого пути и в таком случае оный будет считаться абсолютным, а не относительным. Другими словами не будет использовать текущий рабочий каталог. Таким образом обращение к всегда будет ссылаться на файл с именем в корневом каталоге вне зависимости от текущего рабочего каталога.
В нашей оболочке текущий рабочий каталог можно будет изменить при помощи команды . Например ежели запустить команду , то станет равным . Если после этого запустить , то станет равным .
Большинство операционных систем предоставляют специальный системный вызов для изменения рабочего каталога процесса. Поскольку наша ОС ещё не имеет процессов и системных вызовов, мы будем следить за изменениями непосредсвенно силами нашей интерактивной оболочки.
Команды
Вы реализуете четыре команды, которые позволяют взаимодействовать с файловой системой посредством интерактивной оболочки: , , и . В контексте этого задания они определяются следующим образом:
- (print the working directory). Распечатывает полный путь к текущему рабочему каталогу.
- (change (working) directory). Изменяет текущий рабочий каталог на . Требует аргумента .
- (list the files in a directory). Перечисляет все файлы в каталоге. и являются необязательными аргументами. Если передан флаг , то должны отображаться скрытые файлы. В противном случае такие файлы отображаться не должны. Если не передан, то отображаются записи из текущего рабочего каталога. В противном случае отображаются записи из каталога . Эти аргументы могут быть использованы вместе. Однако должен стоять перед . Недопустимые аргументы должны приводить к ошибкам. Кроме того должна выводиться ошибка, если каталог не сущесвует.
- (concatenate files). Выводит содержимое файлов по указанным путям один за другим. Требуется по меньшей мере один такой аргумент. Если путь не указывает на реально сущесвующий файл — выводить ошибку. Если файл содержит недопустимый контент в контексте кодировки UTF-8, то также выводить ошибку.
Все не абсолютные пути должны быть обработаны относительно текущего рабочего каталога. Все абсолютные пути должны обрабатываться от корня. Пример действия команд можно посмотреть в гифке выше. Когда вы будете реализовывать эти команды — можете выводить ошибки или содержимое каталогов любым способом, каким сочтёте нужным. Главное, чтоб вся необходимая информация присутствовала.
Реализация
Расширьте реализацией этих четырёх команд. Используйте мутабельный для того, чтоб отслеживать текущий рабочий каталог. Этот самый должен изменяться каждым вызовом . Будет полезно создать функции с общей сигнатурой для каждой из ваших команд. Для дополнительного уровня типобезопасности можете выделить трейт, как абстракцию для команд и реализовывать этот трейт для каждой команды.
После того, как вы реализовали, протестировали и проверили все четыре команды с учётом указанных спецификаций — задача этой лабы решена. Поздравляем!
Такие дела.



