
Свежие новости и статьи

Статьи
10 ноября 2022
Как мы на Яндекс Почту мигрировали: кейс ALP ITSM
ALP ITSM обеспечивает IT-поддержку компаниям разного масштаба — от небольших офисов с 20 сотрудниками до международных фастфуд-гигантов. Мы помогаем нашим клиентам находить выгодные IT-решения, подбираем и устанавливаем оптимальные сервисы. Но недавно мы сами оказались в ситуации, когда нужно было отказываться от привычных решений и искать новые варианты. Рассказываем, как наша компания численностью 120 сотрудников переходила на отечественный почтовый продукт и что из этого вышло.
Статьи
5 сентября 2022
Импортозамещение и локализация ИТ-инфраструктуры. Что общего? И в чем отличия?
В чем разница между импортозамещением и локализацией ИТ? Для каких компаний подходят эти две стратегии? Значит ли их реализация, что от иностранного софта и оборудования нужно будет отказаться полностью? Разобраться в теме помог Сергей Идиятов, руководитель направления консалтинга ALP ITSM.

Статьи
22 августа 2022
Топ-5 рекомендаций для CEO: как локализовать IT-инфраструктуру?
Для компаний с центральным офисом в зарубежных странах санкционный кризис стал серьезным испытанием. При сохранении бизнеса в России нужно выделить IT-инфраструктуру локального офиса и сделать ее независимой и автономной от глобальной компании, объявившей об уходе из РФ. Этот «развод по-итальянски» требует четкого плана, ресурсов и крепких нервов. Как минимизировать риски, рассказывает Сергей Идиятов, руководитель направления консалтинга ALP ITSM, сервисной IT-компании холдинга ALP Group.

Статьи
11 мая 2022
Не можно, а нужно: рассказываем, как безболезненно перенести IT-инфраструктуру компании в российское облако. Кейс ALP ITSM
За последние два месяца российские компании столкнулись с различными сложностями, в том числе по части IT. Среди них — остановка продажи нового ПО, невозможность оплаты услуг западных сервисов, повышение цен на оборудование и всевозможные блокировки. ALP ITSM помогает клиентам найти решения, чтобы обезопасить IT-инфраструктуру в нынешних условиях. Делимся опытом миграции из зарубежных облаков в российские.
Статьи
1 апреля 2022
Автоматизируй это! Четыре бизнес-процесса, где нельзя обойтись без Service Desk.
Когда компания растет, увеличивается и количество запросов от пользователей. Однажды это превращается в «снежный ком»: техподдержка не справляется с потоком, заявки теряются, время обработки обращений все дольше, пользователи недовольны. Знакомая ситуация? Тогда нужно срочно внедрять ServiceDesk. Разбираемся, чем может помочь эта система, и какие направления стоит автоматизировать в первую очередь.
Интегратор НЕ сделает за вас всей работы
свойопределить проблемы
- неравномерное распределение нагрузки на виртуальную инфраструктуру;
- высокое количество аварий в ИТ-инфраструктуре;
- высокая степень загрузки высококвалифицированных специалистов выполнением простых задач;
- низкий уровень доступности корпоративных сервисов;
- большое количество звонков на первую линию;
- длительное время с момента возникновения аварии до ее обнаружения;
- необходимость оптимизации работы системных администраторов;
- низкая производительность ИТ-инфраструктуры;
- отсутствие достоверных данных о ресурсах ИТ-инфраструктуры;
- отсутствие инструментов предупреждения аварий.
зафиксировать метрики
- среднее количество инцидентов, зафиксированное за отчетный период;
- среднее время простоя ключевых сервисов;
- средний % доступности ИТ-инфраструктуры;
- средний % утилизации инфраструктуры;
- количество обращений на первую линию за отчетный период;
- среднее время с момента возникновения инцидента до его обнаружения;
Какие решения для мониторинга есть на рынке
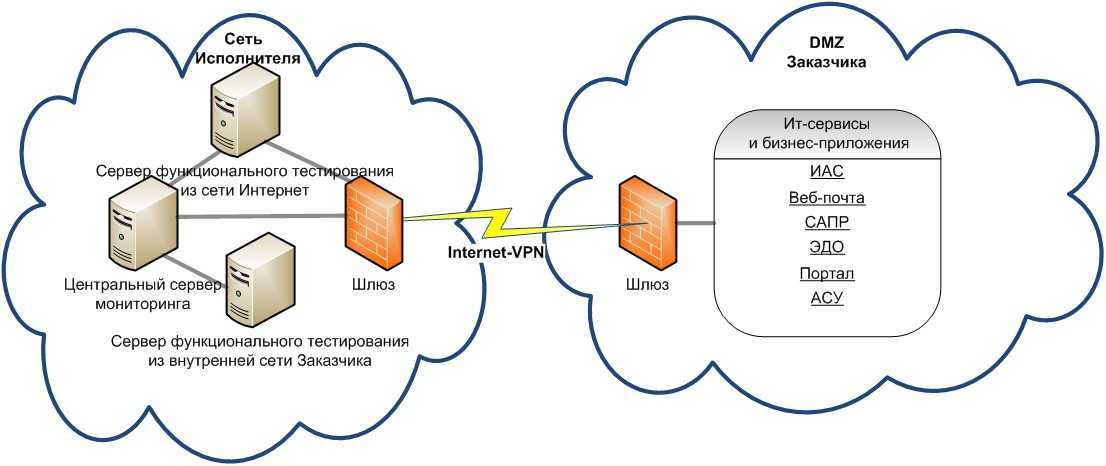
Решения для мониторинга сети можно разделить условно на три класса. Первый — это различные open source-программы, которые можно скачать и использовать бесплатно. Но, как и многие бесплатные продукты, они поставляются не в «коробочном» виде и требуют тонкой настройки под конкретные задачи, что, в свою очередь, требует наличия в штате квалифицированных специалистов. При этом специалисту не стоит забывать, что вся ответственность за работу решения в данном случае лежит на нем, а компании — что специалист может сменить место работы и разобраться в его настройках будет очень непросто.
«Использование open source-программ вполне оправдано при решении базовых задач мониторинга, к примеру — состояния конкретного порта коммутатора, мониторинга не бизнес критичных сервисов, или в том случае, когда нужен какой-то кастомизированный подход», — объясняет Иван Орлов, эксперт по мониторингу сетевой инфраструктуры ИТ-компании КРОК.
Второй класс решений — это инструменты мониторинга, включенные в состав продуктов других производителей. К примеру, компании-поставщики средств виртуализации, а также оборудования сетевой инфраструктуры, предлагают уже готовые системы мониторинга под их решения.
«Это профессиональный продукт, за разработку и поддержку которого отвечает производитель, опираясь на лучшие мировые практики. Нет явной необходимости что-то дописывать или изобретать — включил и работает. Но нужно понимать, что функциональность такого решения может быть ограничена работой только с определенным набором оборудования или систем», — говорит Иван Орлов.
Третий класс — это специализированные NPMD-решения (network performance monitoring and diagnostic) enterprise уровня. Их производители сфокусированы и специализируются на разработке продуктов для глубокого анализа производительности сетевой инфраструктуры и предлагают наиболее функциональные решения на рынке.
«NPMD уровня enterprise — это не просто анализ состояния сети с точки зрения ее скорости или задержек, это инструмент мониторинга качества работы бизнес-приложений с точки зрения сетевого взаимодействия ее участников. Сети будущего — это сети, ориентированные на приложения. А мониторинг сети, ориентированный на приложения, — это уже настоящее», — объясняет Иван Орлов.
Задачи зонтичного мониторинга
Зонтичный мониторинг помогает решить сразу несколько важных задач компании.
1. Оценка влияния события или инцидента в инфраструктуре на бизнес-процессы.
Оценивается влияние не на КЕ, сервер или коммутатор, а именно на бизнес-процессы и информационные системы, которые важны для бизнеса. Комплексный мониторинг ИТ и ИБ дает возможность связать событие с определенными рисками с точки зрения безопасности, расставить приоритеты и понять, какой реакции требует происходящее.
При этом исключаются ситуации, при которых с процессами что-то происходит, но об этом никто не знает.
2. Сокращение времени на расследование и реагирование на инциденты ИТ и ИБ, благодаря их оперативному выявлению и представлению информации о них ответственным сотрудникам.
Сотрудник, который будет заниматься решением инцидента, получает весь необходимый контекст. Он видит информацию о нагрузке, об использовании ресурсов, о параллельно происходящих ИТ- и ИБ-инцидентах. Например, если произошло резкое повышение нагрузки в какой-то части ИТ-инфраструктуры, это может быть техническая проблема, а может — DDoS-атака, которая направлена на ресурсы компании. В таком случае это будет уже инцидентом информационной безопасности, что повлияет на расследование и устранение проблемы.
3. Обеспечение контроля расследования и реагирования на инциденты ИБ.
Процессное решение в комплексном мониторинге обеспечивает для каждого инцидента прозрачную схему ответственности. Событие отслеживается на всех этапах жизненного цикла, информация о нем передается определенным сотрудникам для принятия решения, выполнения каких-то действий или согласований, сроки обработки контролируются. При этом время на реакцию устанавливается в соответствии с приоритетом инцидента, который рассчитывается на основании ресурсно-сервисной модели, модели рисков, влияния на бизнес и на конечных пользователей ИТ-услуг.
4. Применение предиктивной аналитики для проактивного предупреждения инцидентов.
В перспективе инциденты можно будет предсказывать еще до того, как они возникнут, окажут реальное влияние на бизнес или пользователей и принесут материальный ущерб. Как показывает практика, до 30% ИТ-инцидентов могут быть предсказаны заранее, и предотвратить их проще, чем потом устранять последствия.
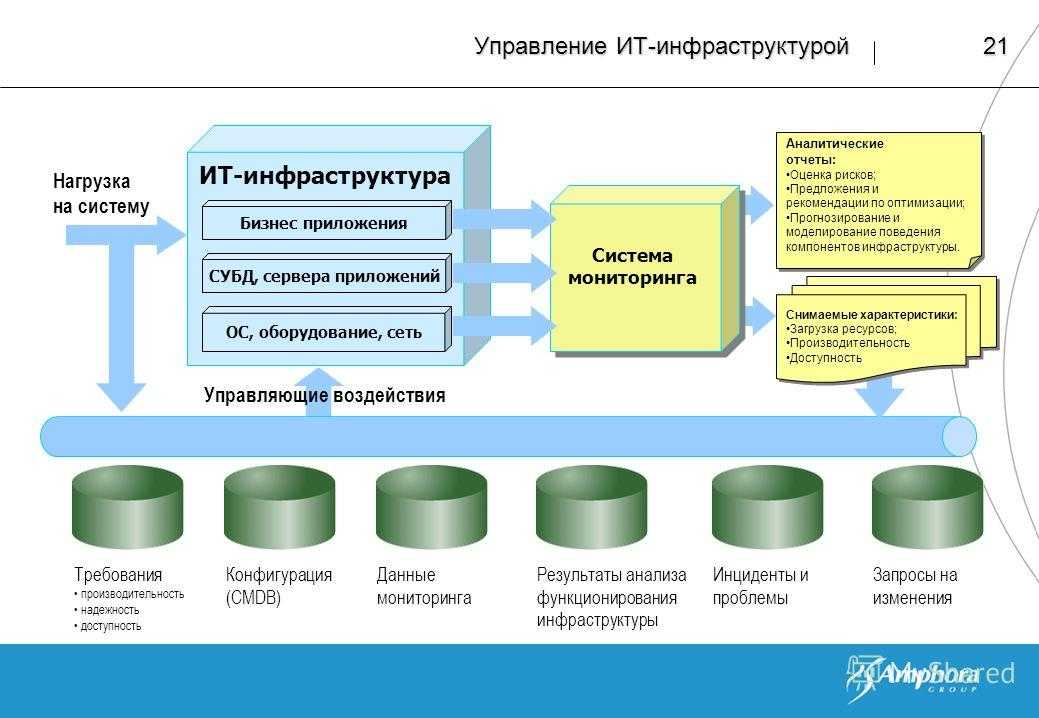
Особенности управления ИТ инфраструктурой
Развитая инфраструктура ИТ современного предприятия включает в себя большое число аппаратных и программных составляющих, количество которых постоянно растет. Одновременно взаимосвязи между различными компонентами структуры неуклонно усложняются на фоне растущей интеграции ИТ в бизнес-процессы. В итоге все это определяет необходимость перехода задачи управления инфраструктурой ИТ с поддерживающего (технического) уровня на уровень стратегический.
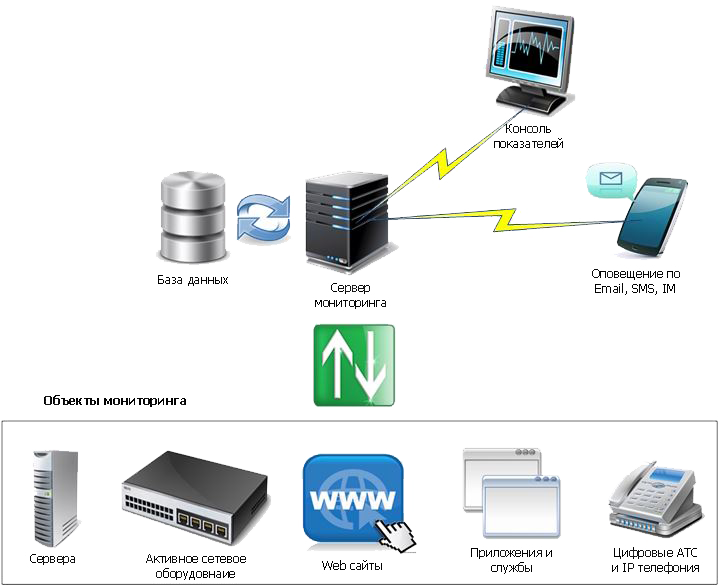
Итак, системы мониторинга и управления предоставляют ИТ специалистам возможность управлять информационной системой из единого центра. Решение о внедрении таких систем является практически для каждой компании на сегодняшний день стратегически правильным, поскольку позволяет значительно уменьшить нагрузку на системных администраторов, оперативно выявлять проблемы и быстро определять причины их возникновения и устранять, формировать статистику по отказам, чтобы на ее основании принимать решения о модернизации или внедрении новых составляющих ИТ инфраструктуры.
Современные центры обработки данных состоят из сотен единиц серверного, сетевого оборудования, а также мощных систем хранения данных, территориально расположенных в нескольких ЦОД. Чтобы эффективно управлять столь большим количеством техники и программ, требуется много временных и трудовых ресурсов. Многие предприятиям просто не по силам справиться со столь сложной и масштабной задачей. Поэтому наилучшим выходом станет обращение в специализированную аутсорсинговую компанию.
Помимо предоставления технического облуживания ИТ сервисов, специалисты компании-аутсорсера смогут предложить решение, позволяющее максимально эффективно автоматизировать управление инфраструктурой, а именно: базами данных и приложениями, серверами, сетевыми устройствами и системами хранения информации. Использование современных систем управления ИТ инфраструктурой дает возможность выполнять автоматизацию полного цикла управления, интегрируя их с системами мониторинга и службы поддержки с помощью общей консоли управления.
Управление печатью
На сегодня в крупных компаниях задействованы тысячи печатающих устройств. Иногда топ-менеджмент предприятия даже не представляет, сколько устройств используется, каков объем печати и сколько стоит техническое обслуживание оборудования. Негативными последствиями этого становятся недостаточно контролируемые затраты на печать, трудности с поддержкой техники и нарушение ключевых бизнес-процессов предприятия. Чтобы этого избежать, следует воспользоваться эффективным решением управления печатью.
Управление активами ПО (Asset management)
На данный момент все большую популярность приобретают решения, предназначенные для оптимизации процессов управления активами программных приложений и их защиту. Функции такого решения включают в себя ведение учета программного обеспечения и его использования, срока действия лицензий и остальных документов, свидетельствующих о праве на использование программ, разработку и внедрение регламентов и политик приобретения необходимых программ, отслеживание ввода их в эксплуатацию, вывод из эксплуатации и другие действия.

Другие решения управления ИТ инфраструктурой предприятия:
- общий мониторинг;
- управление виртуальными средами;
- управление контентом;
- провижининг и активация услуг;
- управление инфраструктурой ЦОД (DCIM);
- управление инженерной инфраструктурой;
- мониторинг приложений;
- контроль соблюдения Соглашения об уровне сервиса – SLA.
Концепция зонтичного мониторинга ИТ+ИБ
В зонтичном, или комплексном, мониторинге данные из всех систем мониторинга и управления ИТ-инфраструктурой, которые используются в компании, собираются в едином центре. Информация анализируется, очищается от незначительных и некорректных событий и привязывается к ресурсно-сервисной модели ИТ-систем и услуг. Данные SIEM обогащаются информацией о состоянии ИТ-инфраструктуры и релевантных ИТ-событиях, поступивших в зонтичный мониторинг, и собираются в единой системе управления бизнес-процессами. Это помогает однозначно идентифицировать любое событие с конкретным учетным объектом и с определенной информационной системой, в рамках которой этот объект используется. В результате сотрудники ИТ- и ИБ-подразделений получают оперативную аналитику в виде дашбордов, а также площадку для взаимодействия в решении или расследовании инцидента.

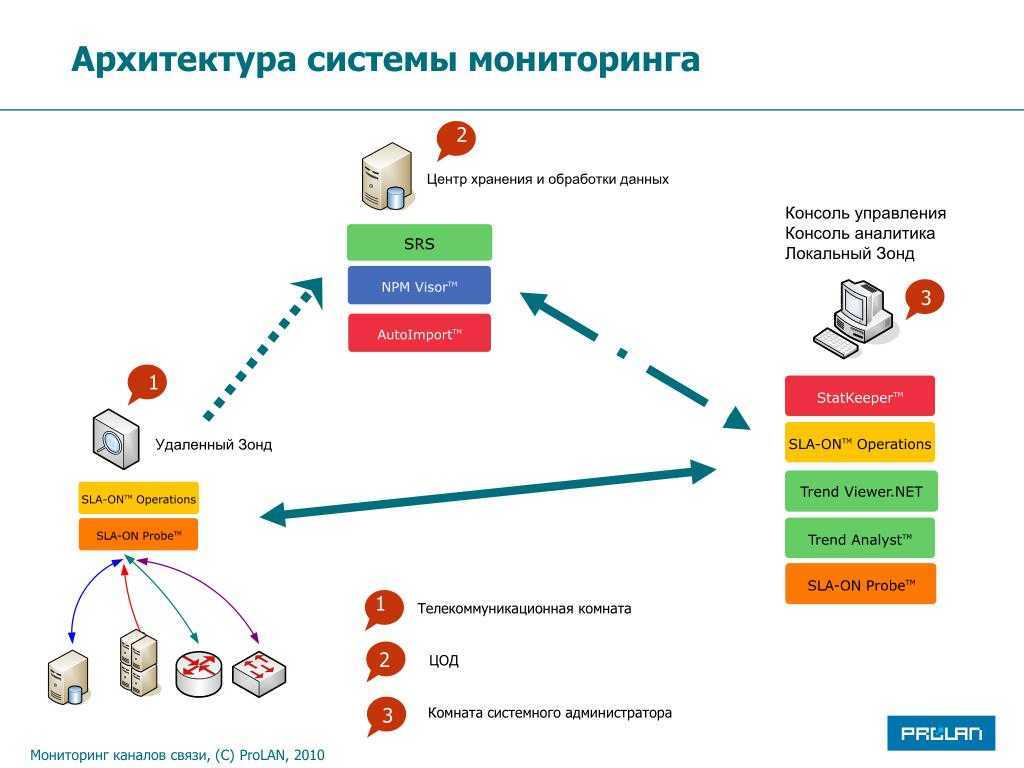
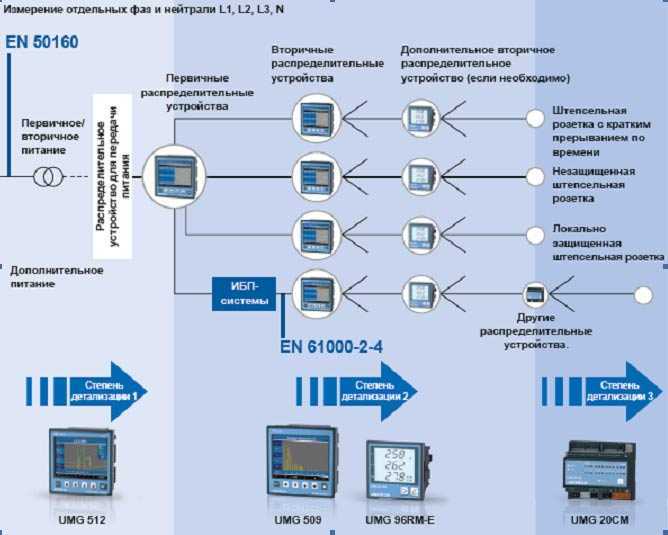
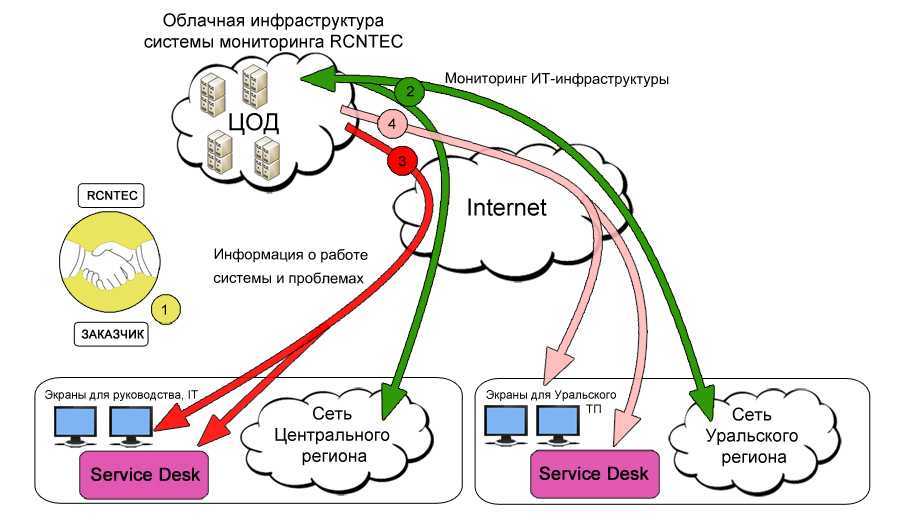
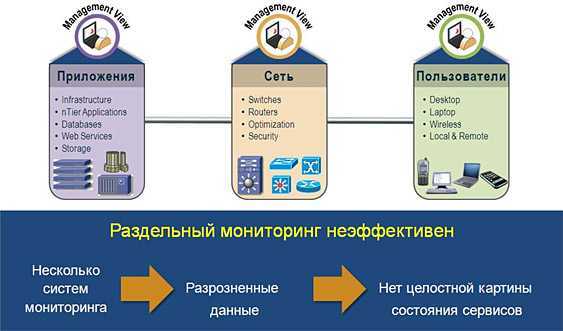
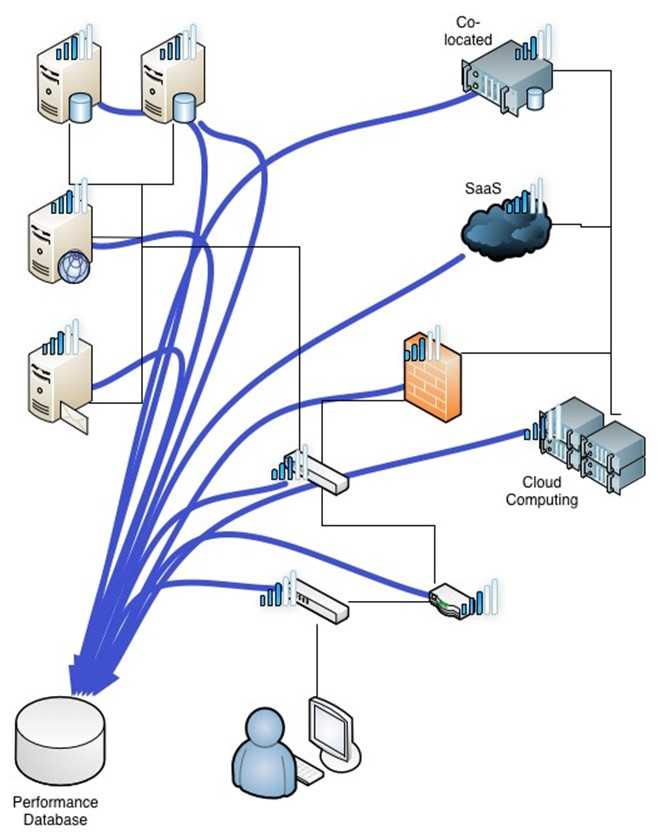
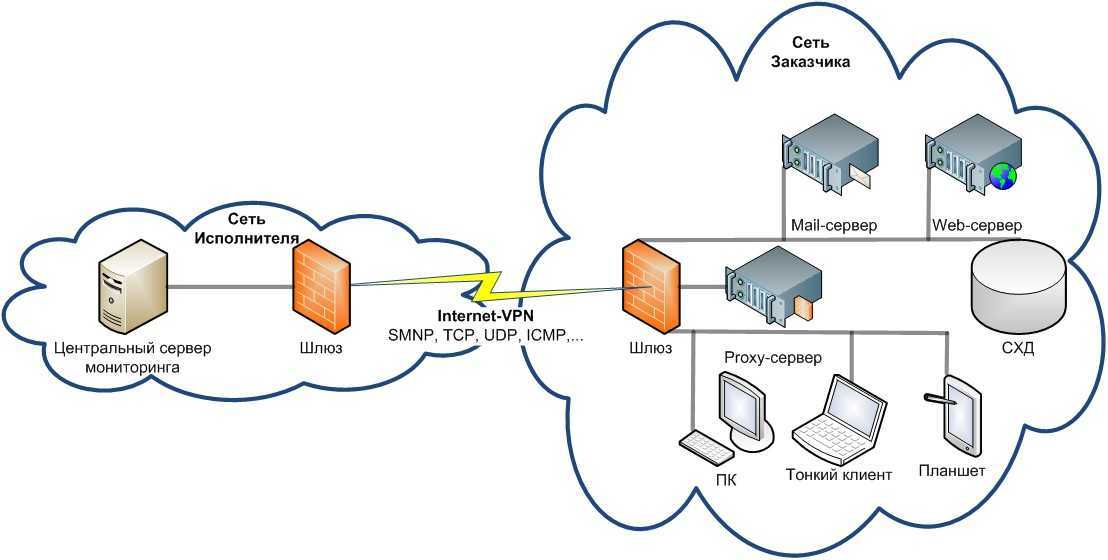
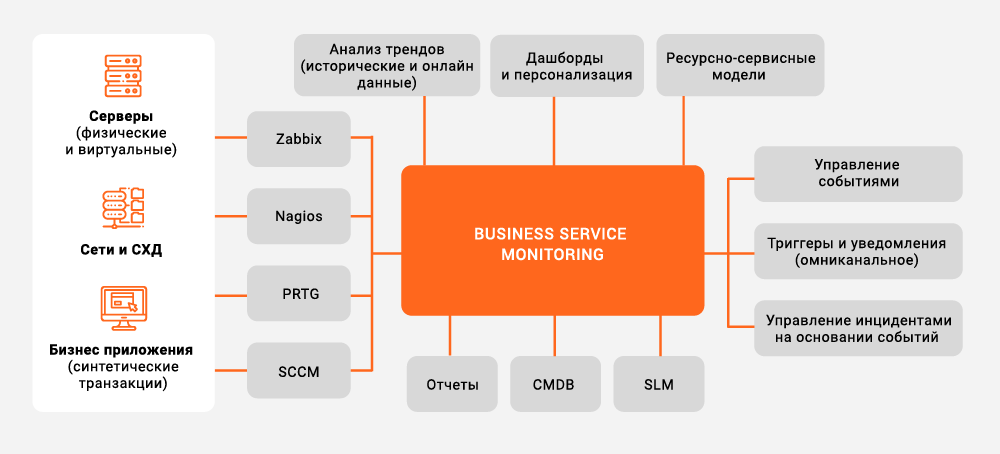 Реализация зонтичного мониторинга на примере Naumen Business Service Monitoring
Реализация зонтичного мониторинга на примере Naumen Business Service Monitoring
Таким образом, связь данных технологических систем мониторинга и управления, систем управления информационной безопасностью, SIEM-систем и процессных систем управления ИТ-подразделениями помогает создать некий единый центр мониторинга. С его помощью можно наблюдать инфраструктуру с технологической и бизнес-стороны, со стороны безопасности и управления.
Свежие новости и статьи
Статьи
10 ноября 2022
Как мы на Яндекс Почту мигрировали: кейс ALP ITSM
ALP ITSM обеспечивает IT-поддержку компаниям разного масштаба — от небольших офисов с 20 сотрудниками до международных фастфуд-гигантов. Мы помогаем нашим клиентам находить выгодные IT-решения, подбираем и устанавливаем оптимальные сервисы. Но недавно мы сами оказались в ситуации, когда нужно было отказываться от привычных решений и искать новые варианты. Рассказываем, как наша компания численностью 120 сотрудников переходила на отечественный почтовый продукт и что из этого вышло.
Статьи
5 сентября 2022
Импортозамещение и локализация ИТ-инфраструктуры. Что общего? И в чем отличия?
В чем разница между импортозамещением и локализацией ИТ? Для каких компаний подходят эти две стратегии? Значит ли их реализация, что от иностранного софта и оборудования нужно будет отказаться полностью? Разобраться в теме помог Сергей Идиятов, руководитель направления консалтинга ALP ITSM.
Статьи
22 августа 2022
Топ-5 рекомендаций для CEO: как локализовать IT-инфраструктуру?
Для компаний с центральным офисом в зарубежных странах санкционный кризис стал серьезным испытанием. При сохранении бизнеса в России нужно выделить IT-инфраструктуру локального офиса и сделать ее независимой и автономной от глобальной компании, объявившей об уходе из РФ. Этот «развод по-итальянски» требует четкого плана, ресурсов и крепких нервов. Как минимизировать риски, рассказывает Сергей Идиятов, руководитель направления консалтинга ALP ITSM, сервисной IT-компании холдинга ALP Group.
Статьи
11 мая 2022
Не можно, а нужно: рассказываем, как безболезненно перенести IT-инфраструктуру компании в российское облако. Кейс ALP ITSM
За последние два месяца российские компании столкнулись с различными сложностями, в том числе по части IT. Среди них — остановка продажи нового ПО, невозможность оплаты услуг западных сервисов, повышение цен на оборудование и всевозможные блокировки. ALP ITSM помогает клиентам найти решения, чтобы обезопасить IT-инфраструктуру в нынешних условиях. Делимся опытом миграции из зарубежных облаков в российские.
Статьи
1 апреля 2022
Автоматизируй это! Четыре бизнес-процесса, где нельзя обойтись без Service Desk.
Когда компания растет, увеличивается и количество запросов от пользователей. Однажды это превращается в «снежный ком»: техподдержка не справляется с потоком, заявки теряются, время обработки обращений все дольше, пользователи недовольны. Знакомая ситуация? Тогда нужно срочно внедрять ServiceDesk. Разбираемся, чем может помочь эта система, и какие направления стоит автоматизировать в первую очередь.
SIEM
Переход от LM к системам класса Security Information and Event Management требуется в двух случаях:
-
Необходимо оповещение операторов о подозрениях на инциденты (далее — инциденты) в режиме близком к реальному времени. К этой опции должны прилагаться сотрудники, работающие в том же режиме — 24х7.
-
Необходимо выявление последовательностей разнородных событий. Это уже не просто фильтрация и агрегация, как в LM или Sigma (на текущий момент).
Дополнительно вы получите:
-
Правила «из коробки», которые хороши в качестве примеров или отправной точки. Или после глубокой доработки и настройки.
-
Историческую корреляцию, совмещающую преимущества SIEM (структура корреляционного запроса) и LM (работа с данными на всю глубину). Быстрое тестирование нового правила на исторических данных, проверка только что пришедшего IOC, который обнаружен две недели назад, запуск правил с большими временными окнами в неурочное время – всё это применения данной функции. Она может быть частью базового решения, требовать отдельных лицензий или вовсе отсутствовать.
-
Второстепенные для одних, но критичные для других функции. Иное представление данных на дашбордах, отправка отчётов в мессенджер, гибкое управление хранением событий и т.д. Производитель стремится оправдать скачок цены от LM к SIEM.
Задачи на этом этапе следующие:
Создание логики детектирования всех интересных вам инцидентов. Без автоматизации вам приходилось выбирать только самые критичные
Сейчас можно учесть всё действительно важное. Главный вопрос – как на таком потоке выстроить реагирование.
Уменьшение ЛПС и ЛОС путём обогащения данных – добавления информации из внешних справочников, изменения пороговых значений, дробления правил по сегментам, группам пользователей и т.д
Возросший объём статистики по работе сценариев улучшает качество их анализа.
Обе задачи решаем итерационно. Хороший показатель – 15 инцидентов на смену аналитика. Достигли его – закручиваем гайки дальше.
Начинаем оценивать эффективность расследования – время на приём в работу инцидента, время на реагирование, время на устранение последствий и т.д. И пытаться этой эффективностью управлять – что мешает работать быстрее, где основные задержки?
Результаты использования SIEM:
Выявление инцидентов происходит в автоматическом режиме, возможно обнаружение и корреляция цепочек разнородных событий.
Рост числа типов инцидентов
Аналитик переключает внимание с обнаружения на расследование и реагирование. При этом не стоит забывать про Threat Hunting – этот метод остаётся лучшим для определения новых для вас угроз.
Какой шаг сделать дальше? Тут лучших практик нет. Следующие этапы могут идти последовательно в любом порядке, параллельно или вовсе отсутствовать.
Интегратор НЕ сделает за вас всей работы
свойопределить проблемы
- неравномерное распределение нагрузки на виртуальную инфраструктуру;
- высокое количество аварий в ИТ-инфраструктуре;
- высокая степень загрузки высококвалифицированных специалистов выполнением простых задач;
- низкий уровень доступности корпоративных сервисов;
- большое количество звонков на первую линию;
- длительное время с момента возникновения аварии до ее обнаружения;
- необходимость оптимизации работы системных администраторов;
- низкая производительность ИТ-инфраструктуры;
- отсутствие достоверных данных о ресурсах ИТ-инфраструктуры;
- отсутствие инструментов предупреждения аварий.
зафиксировать метрики
- среднее количество инцидентов, зафиксированное за отчетный период;
- среднее время простоя ключевых сервисов;
- средний % доступности ИТ-инфраструктуры;
- средний % утилизации инфраструктуры;
- количество обращений на первую линию за отчетный период;
- среднее время с момента возникновения инцидента до его обнаружения;
IDS или IPS
Этот класс решений скорее всего уже внедрён вами как отдельное средство защиты. Он позволяет анализировать копию трафика (Detection в Intrusion Detection Systems) или блокировать вредоносную активность (Prevention). Современные решения работают в гибридном режиме. Это аналог антивируса для сети. Основным методом обнаружения угроз являются сигнатуры, от обновления которых производителем или сообществом (в случае opensource решения) зависит эффективность работы системы. Специалисту или даже отделу сложно угнаться за скоростью обновления такой низкоуровневой логики при самостоятельной разработке. При этом основных сетевых протоколов несколько десятков, что делает решение «из коробки» довольно эффективным. По крайней мере, не так сильно зависящим от инфраструктуры, как хостовые средства защиты.
Пользовательские сигнатуры позволяют часть логики корреляции, относящейся к сети, вынести во внешнее относительно SIEM устройство. Это отлично дополняет SIEM, даже если он анализирует копию трафика.
Результат использования IDS/IPS:
-
Угрозы на уровне сети выявляются в автоматическом режиме с высоким качеством. Нетиповые атаки закрываются пользовательским контентом или несигнатурными модулями – поведенческий анализ, выявление IOC и т.д.
-
SIEM получает готовые подозрения на инциденты. Если корреляция и требуется, то это корреляция второго и выше уровней.
-
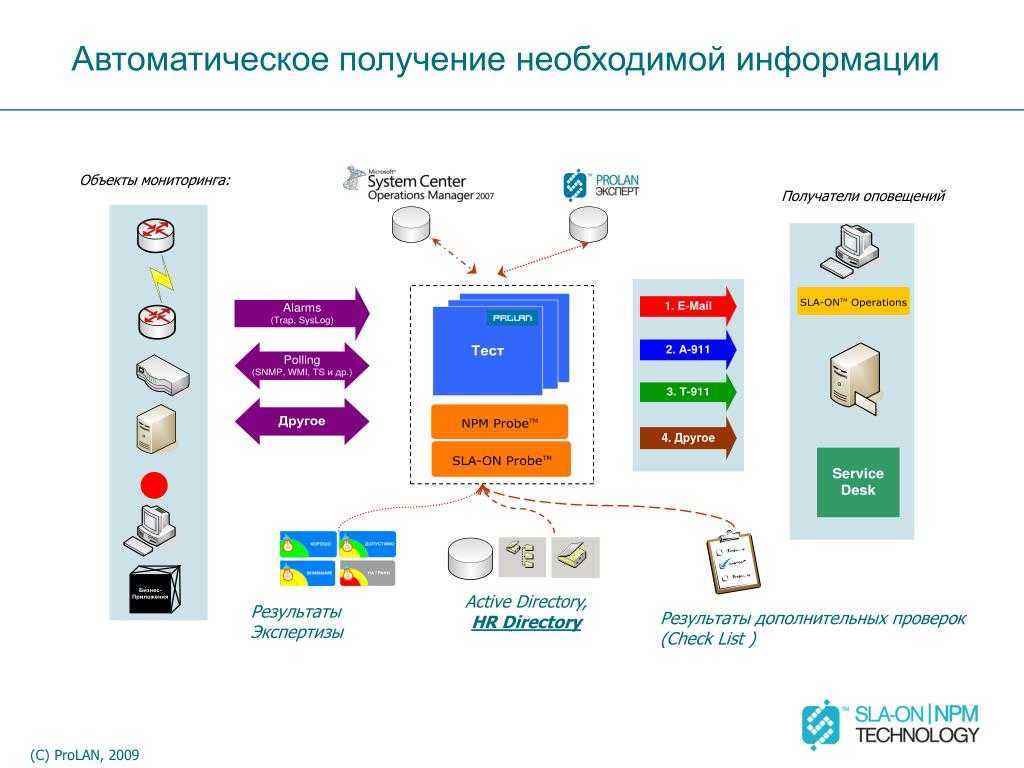
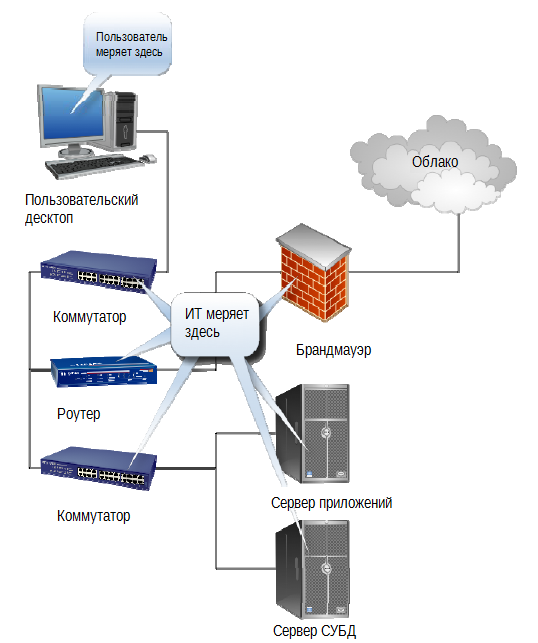
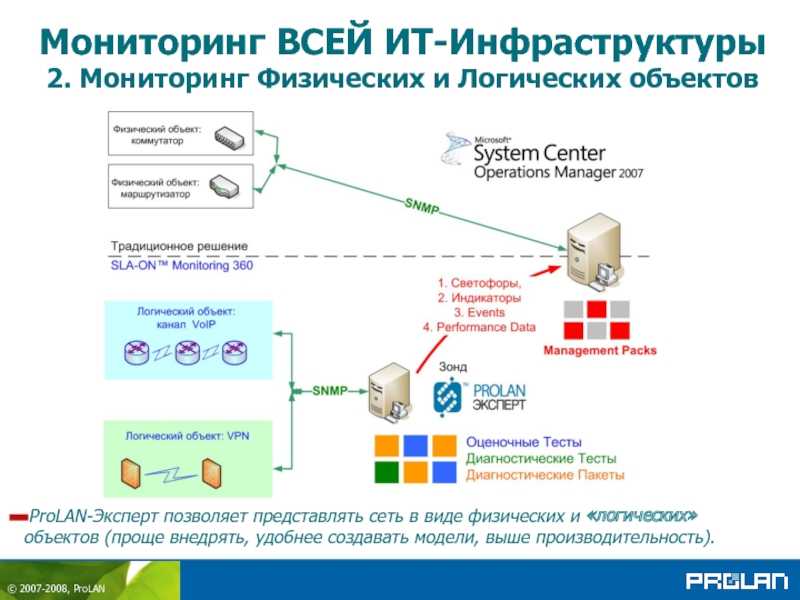
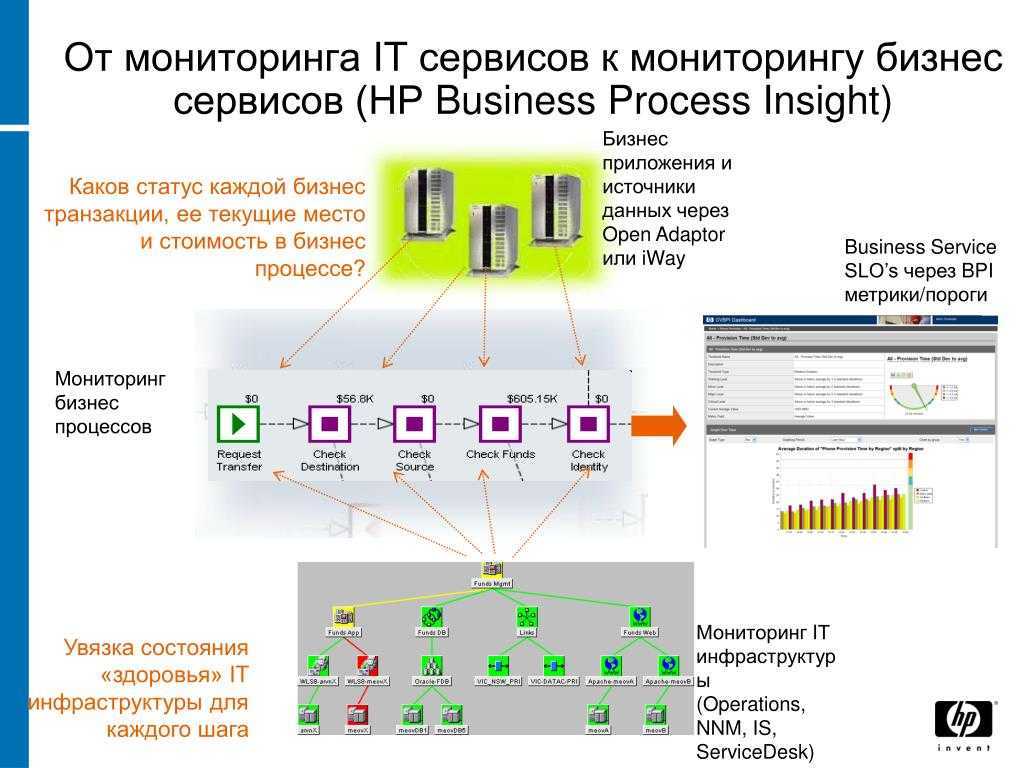


Мониторинг НЕ начнет приносить пользу, пока вы не начнете работать с ним и адаптировать его под свои потребности
- кто и как будет работать с системой;
- кто несет ответственность за поддержание системы в актуальном состоянии;
- кто имеет право корректировки пороговых значений метрик;
- каким образом происходит создание новых метрик;
- в каких случаях должны создаваться новые метрики;
- в какой срок происходит создание новых метрик;
- что должно происходить в случае, если система мониторинга зафиксировала аварию;
- кто и как на эту аварию должен реагировать;
- кто несет ответственность за функционирование системы мониторинга;
- как будут разрешаться конфликты, связанные с появлением ложных или с отсутствием верных сигналов.
UBA или UEBA
Некоторые решения данного класса являются самостоятельными продуктами. Но многие вендоры SIEM предоставляют его в виде модуля. Кто-то говорит, что он заменяется набором правил (а кто-то даже заменяет). Какие возможности даёт это техническое средство?
Если в двух словах – это антифрод, только более универсальный. Идеи в основе схожи. Если подробнее – каждое подозрительное действие, совершенное пользователем (User в User Behavior Analysis) или и пользователем, и сущностью (Entity в UEBA; чаще всего это хост), приводит к добавлению баллов. После достижения определённой суммы создаётся подозрение на инцидент или аналитик сам следит за ТОП10-20-50 подозрительных пользователей. «Репутация» обеляется со временем. Например, сумма баллов уменьшается на фиксированную величину или процент каждый час. Работа с такими данными не отличается от стандартных подозрений на инциденты.
Такой подход полезен в двух случаях:
Индикаторы, считающиеся подозрительными, не могут в одиночку свидетельствовать о возникновении инцидента.
Использование статистики или машинного обучения (такими границами производители обозначают алгоритмы в составе решений) над вашими данными выдвигает и проверяет гипотезы, которые сложно тестировать вручную или с помощью корреляции. Например, сравнение сущности с остальными представителями ее группы. Почему сотрудник маркетинга ходит на какой-то ресурс, если его коллеги этого не делают? Ему нужны такие полномочия? На AD DC в 2 раза больше попыток аутентификации, чем на других
Это ИТ или ИБ проблема? Важно сформировать вводные для алгоритмов – от пороговых значений, до групп сущностей.
Результат использования U(E)BA – выявление угроз методами с высоким ЛПС или методами, для которых невозможно создать и поддерживать простой алгоритм без ущерба для качества обнаружения инцидентов.
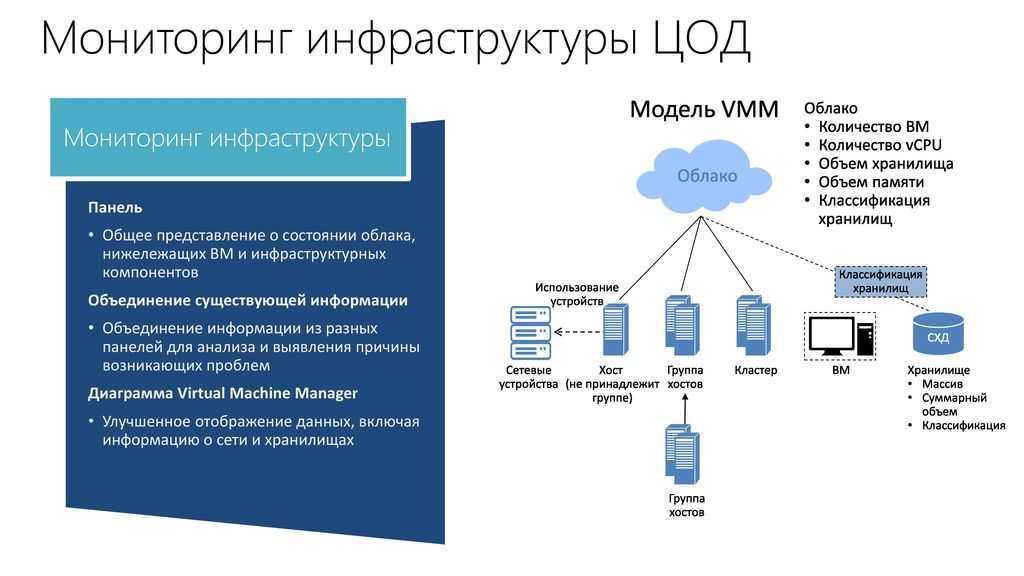
Как работает NPMD уровня enterprise
Зачастую в компаниях нет единой точки сетевого мониторинга, которая могла бы показать, где конкретно произошел или может произойти сбой. И если такая ситуация
случается, на поиск первопричины тратится критично много времени. Основное преимущество NPMD-решений в том, что они позволяют собирать и анализировать не только потоки данных (как встроенные вендорские и open source-решения), но и пакетные данные приложений внутри компании. Благодаря пакетному анализу сети мы можем увидеть не только показатели состояния инфраструктуры, но и метрики качества работы приложений с точки зрения каждой пользовательской операции, сессии, времени отклика баз данных, серверов приложения, a также времени прохождения запроса по сети, детали пользовательского запроса и ответа и т.д. Это дает точное понимание, какое влияние ИТ-инфраструктура оказывает на работу бизнес-приложений. Если у компании есть такой инструментарий, обнаружение и предотвращение аварийных ситуаций становится гораздо проще и не оказывает драматического влияния на бизнес-процессы.
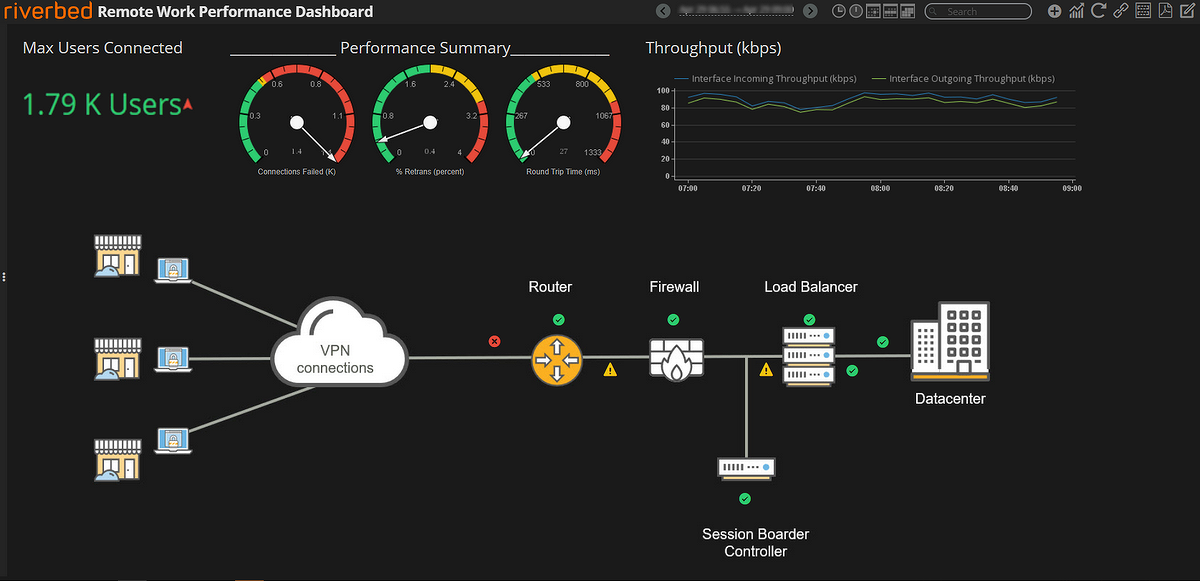
Дашборд с текущей верхнеуровневой информацией о работе бизнес-приложения
«Возьмем ERP систему, которая состоит из нескольких основных компонентов — базы данных, веб-портала, приложения для пользователей. И если приложение для пользователей начинает работать медленно, то с помощью стандартных средств мониторинга невозможно будет увидеть, на каком участке системы есть проблема. Базовое решение покажет лишь то, что приложение запущено, осуществляется обмен информацией и все работает. Система класса NPMD анализирует информацию обо всех сетевых взаимодействиях и может показать на каком участке произошел сбой — на уровне конкретного пользователя, конкретной сессии с конкретным компонентом приложения. После этого проблемой сразу займется профильный ИТ-отдел, что в несколько раз ускорит ее решение», — приводит пример Иван Орлов.
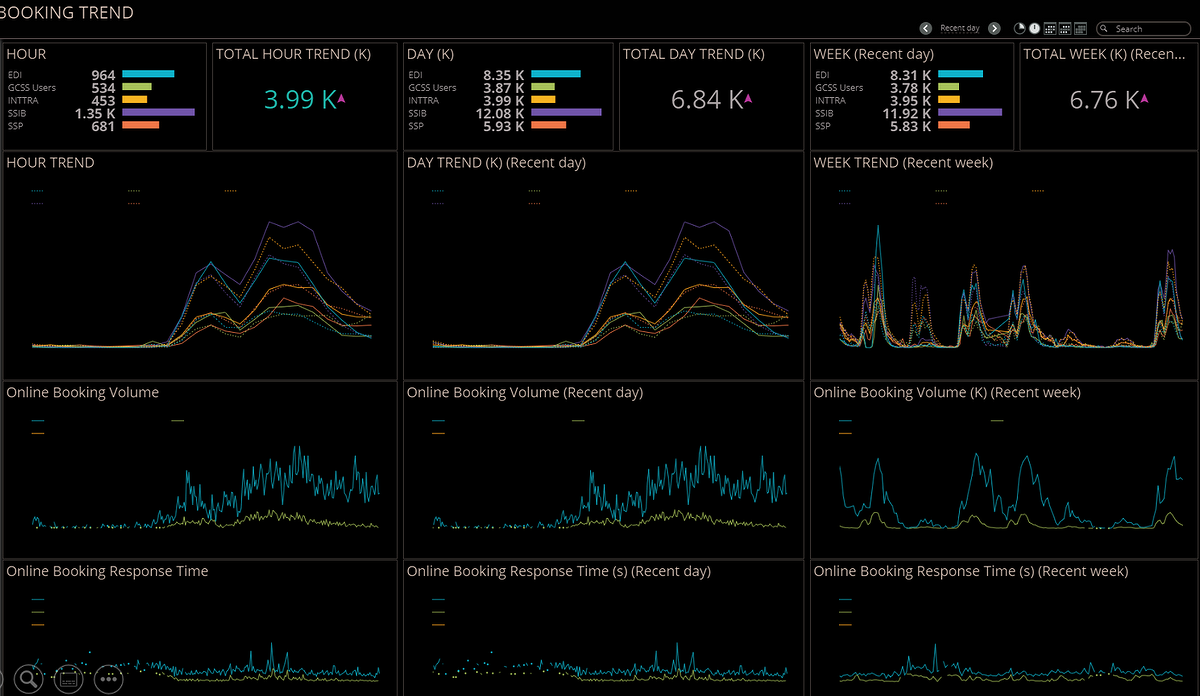
Дашборд с информацией о количестве активных пользователей бизнес-приложения за последний час/день/неделю и время отклика сервиса
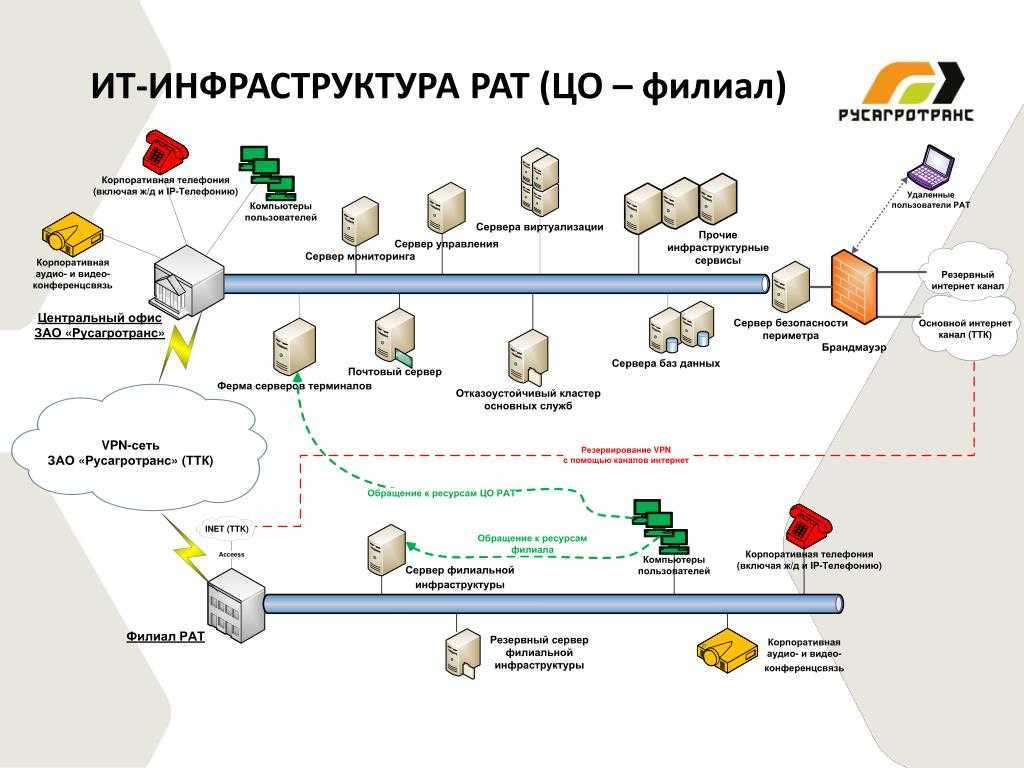
Состав ИТ-инфраструктуры
Сервер — это персональный компьютер, задача которого заключается в сервисном программном обеспечении без прямого участия сотрудника.
СКС (структурированные кабельные системы) являются фундаментом ИТ-инфраструктуры предприятия. Объединяют в одну цепь ПК и оборудование, а также передают данные.
ЛВС (локальная вычислительная сеть) — это система, состоящая из аппаратного, программного обеспечения и охватывающая относительно небольшую площадь (например, внутри школы, развитой структуры офисов предприятия, т.п.).
ИБП (источник бесперебойного питания) защищает от аварии рабочие процессы, устройства компании при кратковременном отключении основного источника.
АТС (автоматическая телефонная станция) представляет собой совокупность устройств, способных в автоматическом режиме передавать сигнал вызова от абонента к абоненту.
Сетевое оборудование — это устройства, обеспечивающие работоспособность сети.
Сетевой коммутатор — прибор, объединяющий узлы в рамках выбранной сети или сразу нескольких сетей. Данные доставляются исключительно получателю. Это увеличивает надежность, производительность сети за счет снятия с других сегментов не адресованные им задачи по обработке данных.
Сетевой концентратор или “хаб” — это контроллер, который соединяет несколько устройств Ethernet в один сегмент (передает трафик от устройства А к устройству Б).
Маршрутизатор — прибор, который пересылает данные между сегментами сети и выполняет действия, основываясь на правилах и таблицах маршрутизации.
Рабочая станция — комплекс средств, включающий оборудование для ввода и вывода данных, программное обеспечение, возможные дополнительные устройства: принтер, сканер, прочее.
Программное обеспечение — совокупность программ, позволяющая пользователю использовать ресурс персонального компьютера.
Свежие новости и статьи
Статьи
10 ноября 2022
Как мы на Яндекс Почту мигрировали: кейс ALP ITSM
ALP ITSM обеспечивает IT-поддержку компаниям разного масштаба — от небольших офисов с 20 сотрудниками до международных фастфуд-гигантов. Мы помогаем нашим клиентам находить выгодные IT-решения, подбираем и устанавливаем оптимальные сервисы. Но недавно мы сами оказались в ситуации, когда нужно было отказываться от привычных решений и искать новые варианты. Рассказываем, как наша компания численностью 120 сотрудников переходила на отечественный почтовый продукт и что из этого вышло.
Статьи
5 сентября 2022
Импортозамещение и локализация ИТ-инфраструктуры. Что общего? И в чем отличия?
В чем разница между импортозамещением и локализацией ИТ? Для каких компаний подходят эти две стратегии? Значит ли их реализация, что от иностранного софта и оборудования нужно будет отказаться полностью? Разобраться в теме помог Сергей Идиятов, руководитель направления консалтинга ALP ITSM.
Статьи
22 августа 2022
Топ-5 рекомендаций для CEO: как локализовать IT-инфраструктуру?
Для компаний с центральным офисом в зарубежных странах санкционный кризис стал серьезным испытанием. При сохранении бизнеса в России нужно выделить IT-инфраструктуру локального офиса и сделать ее независимой и автономной от глобальной компании, объявившей об уходе из РФ. Этот «развод по-итальянски» требует четкого плана, ресурсов и крепких нервов. Как минимизировать риски, рассказывает Сергей Идиятов, руководитель направления консалтинга ALP ITSM, сервисной IT-компании холдинга ALP Group.
Статьи
11 мая 2022
Не можно, а нужно: рассказываем, как безболезненно перенести IT-инфраструктуру компании в российское облако. Кейс ALP ITSM
За последние два месяца российские компании столкнулись с различными сложностями, в том числе по части IT. Среди них — остановка продажи нового ПО, невозможность оплаты услуг западных сервисов, повышение цен на оборудование и всевозможные блокировки. ALP ITSM помогает клиентам найти решения, чтобы обезопасить IT-инфраструктуру в нынешних условиях. Делимся опытом миграции из зарубежных облаков в российские.
Статьи
1 апреля 2022
Автоматизируй это! Четыре бизнес-процесса, где нельзя обойтись без Service Desk.
Когда компания растет, увеличивается и количество запросов от пользователей. Однажды это превращается в «снежный ком»: техподдержка не справляется с потоком, заявки теряются, время обработки обращений все дольше, пользователи недовольны. Знакомая ситуация? Тогда нужно срочно внедрять ServiceDesk. Разбираемся, чем может помочь эта система, и какие направления стоит автоматизировать в первую очередь.
Шаги к достижению целевой зрелости
Реализацию комплексного мониторинга можно разбить на 3 основных этапа.
 Достижение целевой зрелости процессов возможно только поэтапно
Достижение целевой зрелости процессов возможно только поэтапно
Первично реализуется процесс управления событиями ИБ. Уже произошедшие в инфраструктуре события запускаются в процессную платформу, управляются с точки зрения выделения ресурсов, контроля сроков, жизненного цикла, своевременного информирования и отчетности. Параллельно выстраиваются процессы управления ИТ-подразделением: инцидентами, изменениями и конфигурациями.
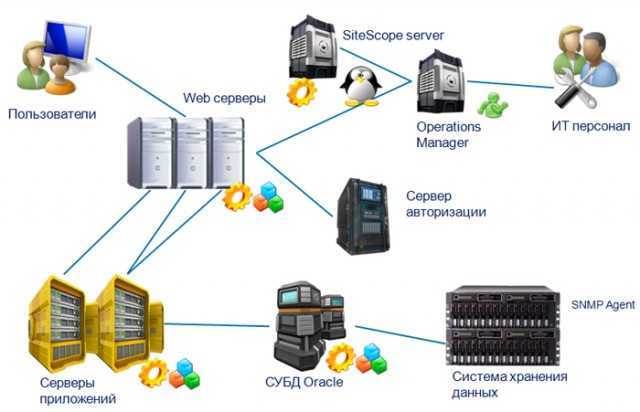
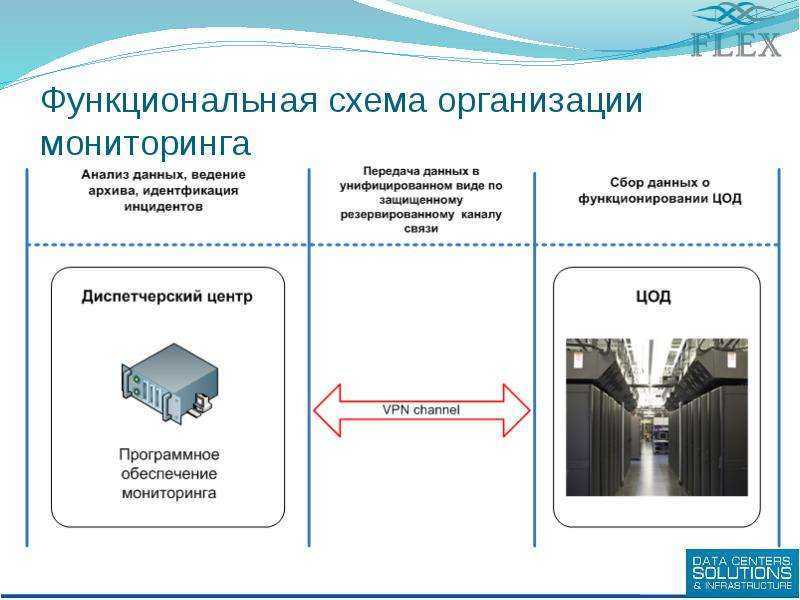
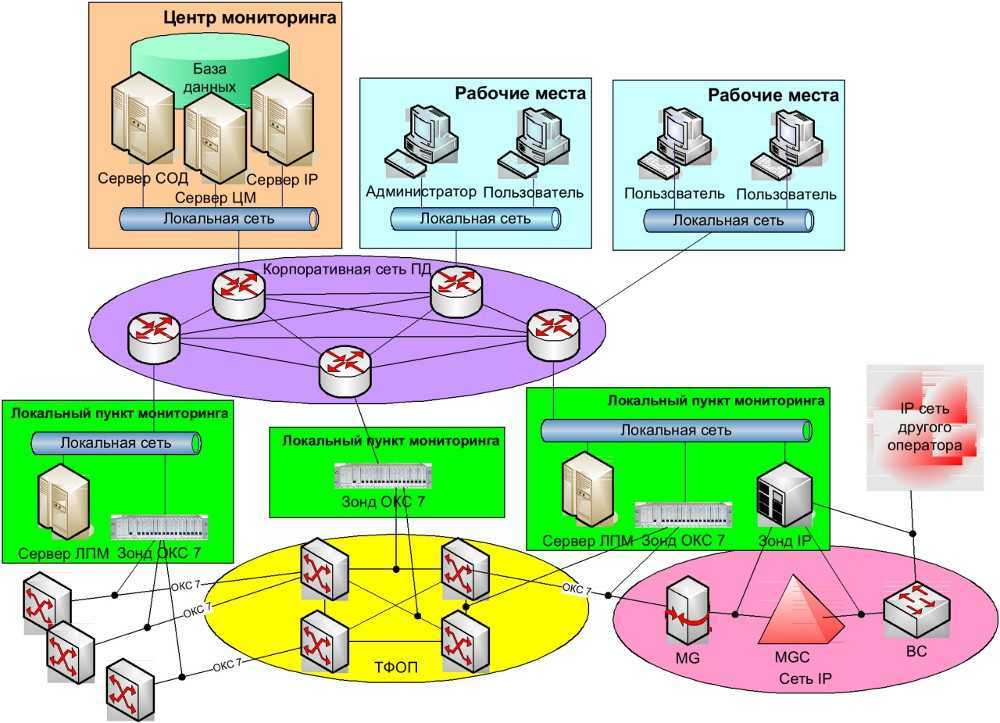
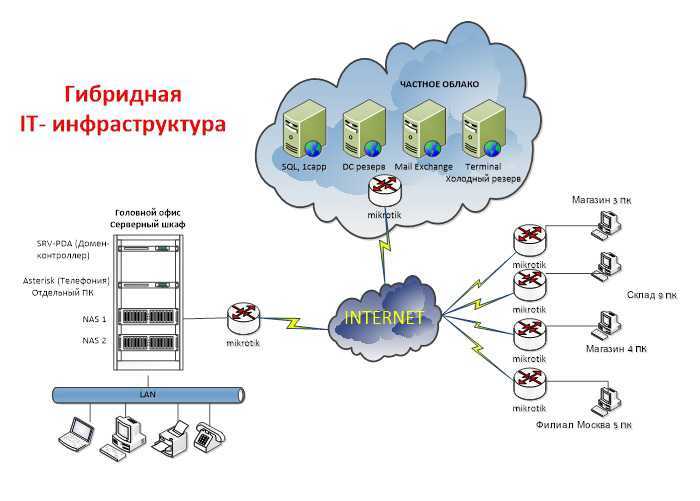
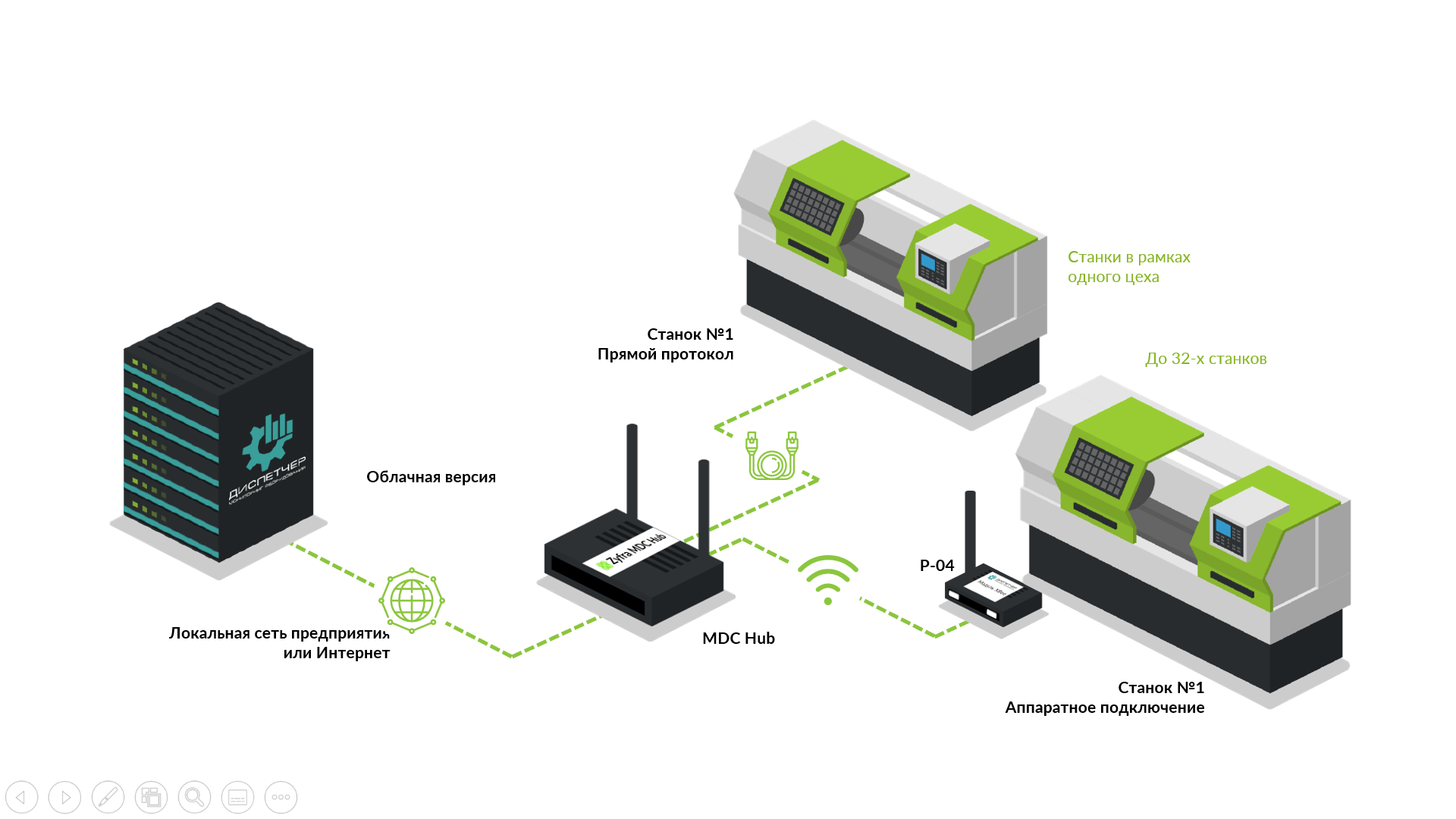

После эти события обогащаются информацией из ИТ-инфраструктуры, дополняются данными из реальных систем управления, таких как система управления виртуализацией. Выстраивается весь процесс работы и реакции ответственных сотрудников.
Далее строится процесс управления инцидентами ИБ, который предполагает уже проведение расследований, реакцию ответственных сотрудников на события или комплексы событий, которые в конечном итоге представляют собой инцидент.
Реализовать зонтичный мониторинг помогают инновационные процессные, мониторинговые и управленческие платформы. Такие как Naumen Business Services Monitoring, Ankey SIEM и Naumen Service Desk. При этом источником данных для комплексного мониторинга может быть потенциально любая система, которая связана с ИТ или с ИБ и способна передать информацию в систему зонтичного мониторинга для дальнейшего накопления и анализа.
Внедрение ИТ-мониторинга
Процесс внедрения мониторинга IT инфраструктуры весьма сложен и часто предполагает длительную настройку, но и результат налицо.
Поэтому мы включили данную услугу в абонентское обслуживание клиентов, сделав услугу еще более проактивной — 82% инцидентов, связанных с функционированием серверной группировки, решаются еще на этапе возникновения.
Внедрение ИТ-мониторинга предполагает полноценную интеграцию с рабочей базой и средствами оповещения, включая:
- Сбор и хранение сведений о ряде значимых параметров ИТ-систем;
- Проверку качества ИТ-услуг;
- Прогнозирование и предотвращение сбоев;
- Постоянный анализ показателей оборудования;
- Интеграцию с системой HelpDesk, что увеличивает скорость подачи заявок и анализа сведений;
- Автоматическую подачу заявок при появлении нестабильной работы систем;
- Комфортный метод получения оповещений.
Система IT-мониторинга помогает эффективно устранять системные сбои еще отказов оборудования. Это обязательная практика для организаций, чья работа напрямую зависит от информационных технологий.
Функции ИТ-мониторинга:
Интеллектуальное управление
Управление всеми процессами и оптимизация ресурсов. Система создает отчеты о специфике работы всех сценариев вашей корпоративной системы, что позволяет ей функционировать более эффективно.
Детализация
Система не просто указывает на определенные недочеты, но и вносит конкретику. К примеру, пора заменить коммутатор — но их много, так какой выбрать?
С мониторингом все просто — программа выведет конкретное устройство, что существенно упростит задачу и сделает реагирование более оперативным.
Визуализация «узких мест»
Чтобы найти источник неприятностей, достаточно открыть карту системы — никаких сотен папок и меню, все наглядно продемонстрировано. Данная функция увеличивает скорость реагирования.
Планирование
Данный процесс предполагает моделирование тех или иных ситуаций, вызванных внесением изменений в ИТ-инфраструктуру вашей компании. Автоматизация на основании внедренной политики подразумевает ввод критичных показателей. Эти мероприятия способствуют предотвращению масштабных сбоев.



