Сжатие изображений с потерями
Сжатие изображений с потерями напрямую связано с качеством визуализации. Как правило, этот процесс в высшей степени субъективен. Обычно его решают 5-6-ю экспертами по 4-6 балльным шкалам. Это так называемый ROC анализ, который приемлем для оценки изображений общей визуализации. Интересно отметить, что улучшение качества изображения, например с применением контурной подрезки, воспринимается ROC экспертами как нежелательное, т.е. не соответствующее оригиналу. Можно привести примеры автоматической оценки качества образа изображения по метрикам ошибок, например по наиболее массово применяемому методу PSNR (пиковое отношение сигнал/шум) или SQNR (сигнал\шум квантования). Однако эти метрики чисто синтаксические. Например, они бессильны перед муаром или другими площадными артефактами. Для простоты восприятия укажем на разницу между реально падающим снегом и снегоподобными шумам, которые возникают на мониторе при наличии внешних (грозовые разряды, электромагнитный резонанс, плохо отсканированное изображение и т.п.) воздействий. Просто в этих метриках отсутствует семантика.
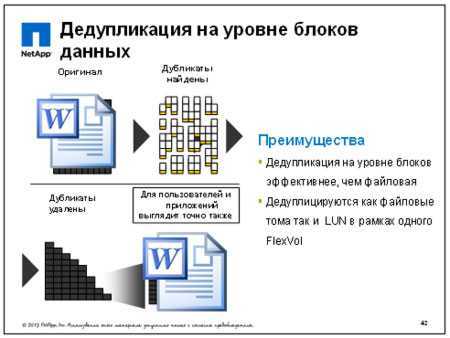
Здесь и далее приведено сравнение по объему V хранения: для полутонового изображения ( рис.8.1a- яркостная составляющая Y для рис.8,) или: рис.8.1a – оригинал, V = 64 Кб; рис.8.1b – предельное (по FAS-технологии) сжатие для распознавания с точки зрения процессора V = 0.76 Кб; рис.8.1c – продукт визуализации рис.8.1b, т. е. размер рис.8.1c также равен 0.76 Kб. На рис.8.1d – предельное сжатие по .jpg, его объём V = 2,38 Кб. Назовем представления типа рис.8.1b канальными образами.
Алгоритмы сжатия без потерь
Есть два основных варианта: алгоритм Хаффмана или LZW. LZW используется повсеместно, но объяснить его довольно сложно, он неинтуитивный и требует целой лекции. Гораздо приятнее объяснить алгоритм Хаффмана.
Алгоритм Хаффмана берёт файл, разбивает его на фрагменты, с которыми ему удобно работать, а потом смотрит, насколько часто встречается каждый фрагмент. Самые частые слова этот алгоритм обозначает коротким кодом, а самые редкие — кодом подлиннее. Так как самые частые слова занимают теперь гораздо меньше места, то и готовый файл становится меньше.
Но есть и минус: иногда нужно хранить эту таблицу соответствий слов и кода прямо в этом же файле, а она может сама по себе получиться большой. Чаще всего алгоритм Хаффмана применяется для сжатия текстовых файлов и видео без потерь.
Вот пример: берём песню Beyonce — All The Single Ladies. Там есть два таких пассажа:
All the single ladies
All the single ladies
All the single ladies
Now put your hands up
…
If you like it then you shoulda put a ring on it
If you like it then you shoulda put a ring on it
Don’t be mad once you see that he want it
If you like it then you shoulda put a ring on it
Здесь 281 знак. Мы видим, что некоторые строчки повторяются. Закодируем их:
ТАБЛИЦА СЖАТИЯ
\a\ All the single ladies
\b\ Now put your hands up
\c\ If you like it then you shoulda put a ring on it
\d\ Don’t be mad once you see that he want it
ТЕКСТ ПЕСНИ
\a\ \a\ \a\ \b\
…
\c\ \c\ \d\ \c\
Вместе таблицей сжатия этот текст теперь занимает 187 знаков — мы сжали текст почти на треть благодаря тому, что он довольно монотонный.
Настройка томов дедупликации
Давайте рассмотрим, насколько большими должны быть тома, чтобы они могли поддерживать дедуплицированные VHDX-файлы, содержащие данные DPM. В CPS мы создали тома по 7,2 ТБ каждый. Оптимальный объем зависит главным образом от того, насколько много и насколько часто меняются данные в томе, а также от скорости передачи данных в подсистеме дискового хранилища
Важно отметить, что если обработка дедупликации не соответствует скорости ежедневных изменений данных (отток), скорость экономии будет снижаться, пока обработка не будет завершена. Дополнительные сведения см
в разделе Определение размера томов для дедупликации данных. Для дедупликации томов рекомендуется использовать следующие общие рекомендации.
-
Использовать дисковые пространства с контролем четности с контролем наличия корпуса для увеличения гибкости и улучшения использования дискового пространства.
-
Формат NTFS с единицами выделения 64 КБ и большими сегментами записей файлов, чтобы лучше работать с дедупликации разреженных файлов.
-
В конфигурации оборудования, превышающей рекомендуемый размер тома 7,2 ТБ, тома будут настроены следующим образом:
-
С поддержкой двойной четности 7,2 ТБ + 1 ГБ кэш обратной записи
-
ResiliencySettingName == Parity
-
PhysicalDiskRedundancy == 2
-
NumberOfColumns == 7
-
Interleave == 256 КБ (производительность двойной четности при чередовии 64 КБ гораздо ниже, чем при чередовстве по умолчанию 256 КБ)
-
IsEnclosureAware == $true
-
AllocationUnitSize=64 КБ
-
Large FRS
Настройте новый виртуальный диск в указанном пуле носителей следующим образом.
-
-
Каждый из этих томов необходимо затем отформатировать в:
В развертывании CPS они затем настраиваются как CSV.
-
В этих томах DPM будет хранить ряд VHDX-файлов для хранения данных резервной копии. Включите дедупликацию на томе после его форматирования следующим образом:
Эта команда также изменяет следующие параметры дедупликации на уровне тома:
-
Задайте для параметра UsageType значение Hyper-V: обеспечивает выполнение дедупликации открытых файлов, которая необходима, поскольку VHDX-файлы, используемые DPM для хранения резервных копий, остаются открытыми в случае запуска DPM в своей виртуальной машине.
-
Отключить PartialFileOptimization. Это приводит к оптимизации всех разделов открытого файла, а не к просмотру измененных разделов с минимальным возрастом.
-
-
Задайте для параметра MinFileAgeDays значение 0: с отключенным параметром PartialFileOptimization параметр MinFileAgeDays определяет такой режим, при котором дедупликация выполняется только для тех файлов, которые не были изменены в течение этого количества дней. Поскольку мы хотим начать дедупликацию данных резервного копирования во всех файлах DPM VHDX без задержки, нам нужно указать для параметра MinFileAgeDays значение 0.
-
-

Дополнительные сведения о настройке дедупликации см. в разделе Установка и настройка дублирования данных.
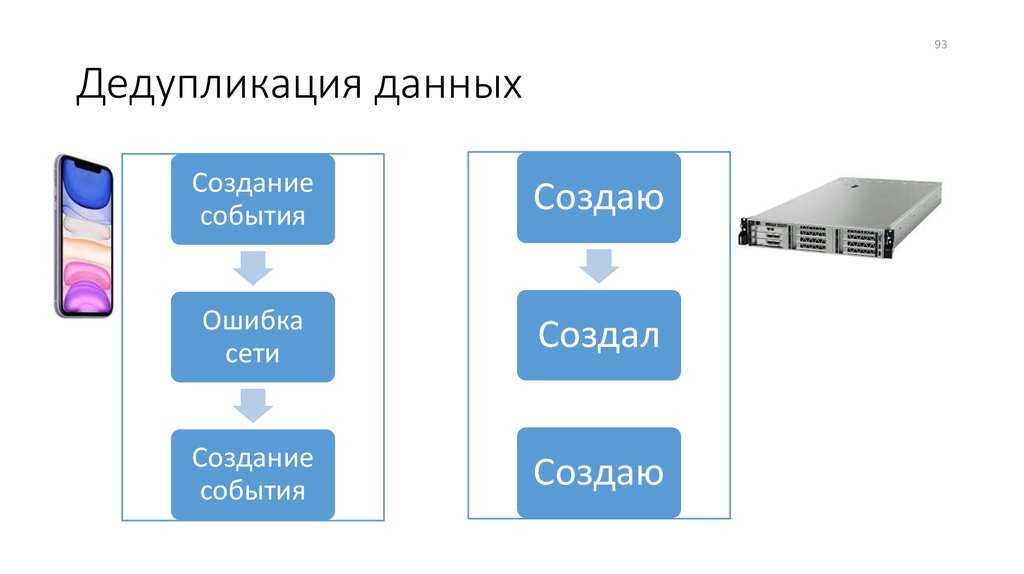
Дедупликация данных и резервное копирование
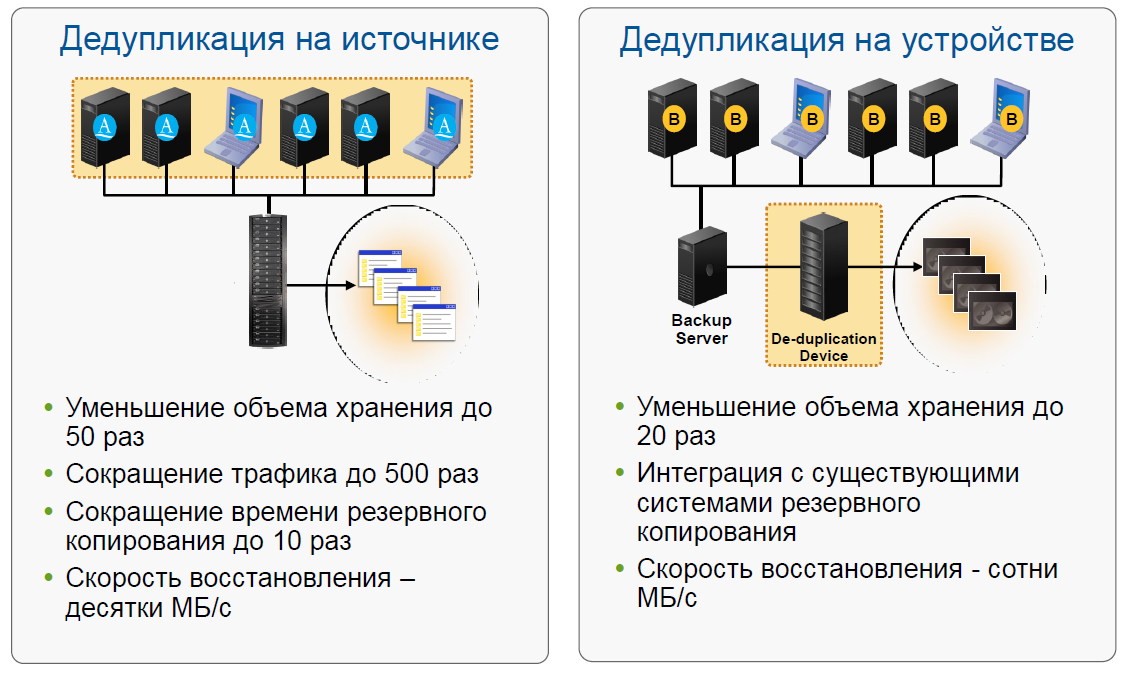
Кроме всего вышеописанного, в процессе создания резервной копии данных дедупликация может выполняться разными методами по:
- месту выполнения;
- источнику данных (клиенту);
- стороне хранения (серверу).
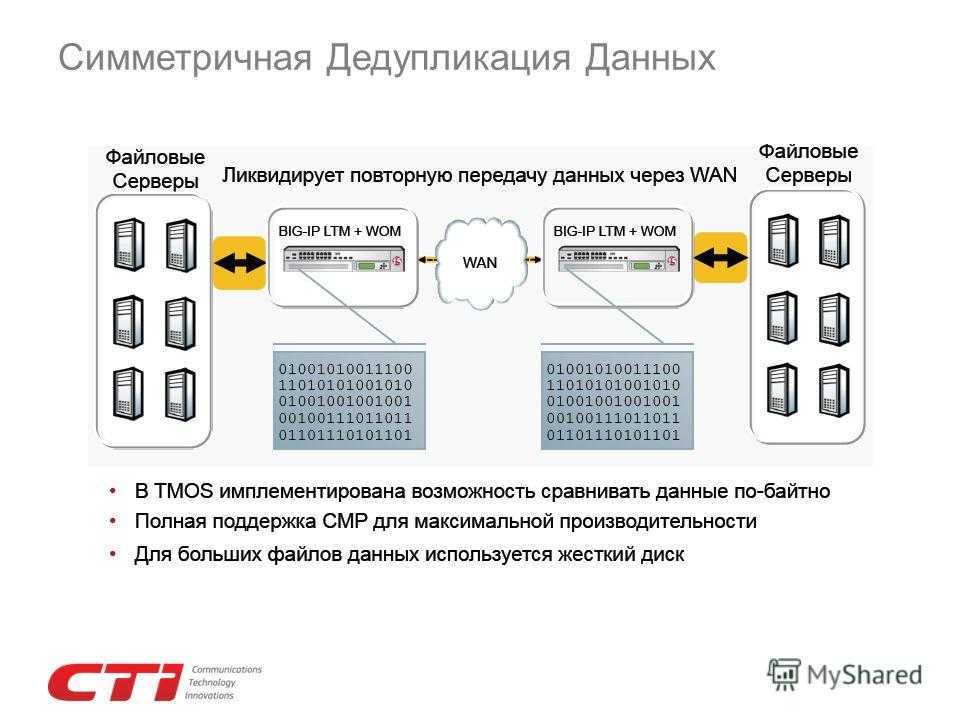
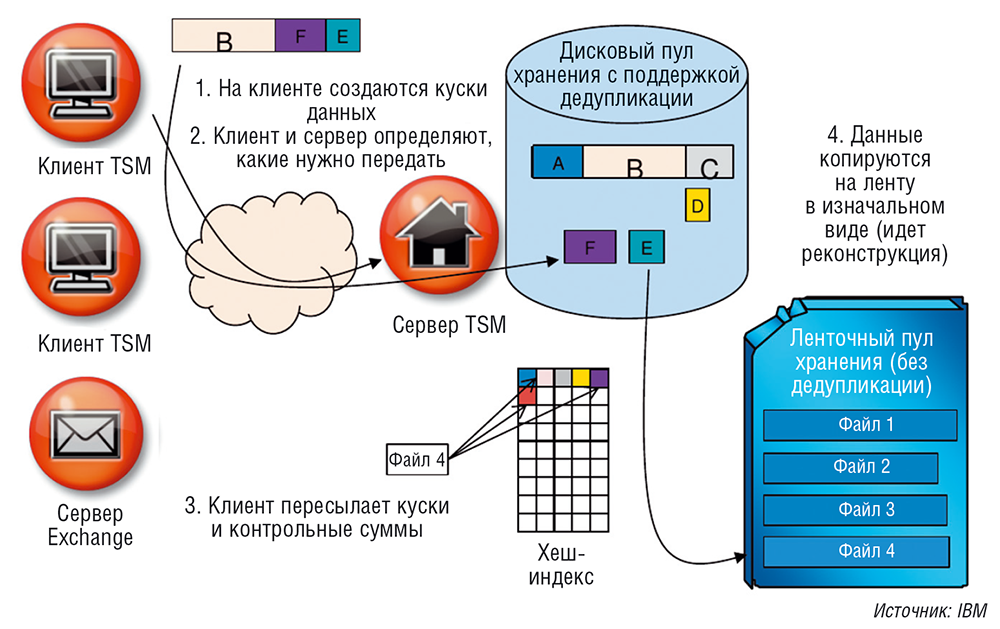
Дедупликация клиент-сервер
Совмещенный метод дедупликации данных, при котором необходимые процессы могут запускаться как на сервере, так и на клиенте. Прежде, чем отправить данные с клиента на сервер, программное обеспечение вначале пытается «понять», какие данные уже записаны.
Для такой дедупликации изначально необходимо вычислить хеш у каждого блока данных, после чего отправить их на сервер в виде файла-списка различных хеш-ключей. На сервере же производится сравнение списка этих ключей, а затем клиенту отправляются блоки с данными.
Этот способ существенно снижает нагрузку на сеть, т. к. передаются исключительно уникальные данные.
Дедупликация на клиенте
Подразумевает выполнение операции непосредственно на источнике данных. Поэтому, при такой дедупликации будут задействованы вычислительные мощности именно клиента. После завершения процесса данные будут отправлены на устройства хранения информации.
Такой вид дедупликации всегда реализуется при помощи программного обеспечения. А главный минус описанного метода заключается в высокой нагрузке на ОЗУ и процессор клиента. Ключевое преимущество же кроется в возможности передачи данных по сети с низкой пропускной способностью.
Дедупликация на сервере
Используется в случае, когда данные поступают на сервер в полностью необработанном виде — без кодирования и сжатия. Такой вид дедупликации подразделяется на программный и аппаратный.
Аппаратный тип
Реализовывается на базе устройства дедупликации, которое предоставляется в виде определенного аппаратного решения, объединяющем логику дедупликации и процедуру восстановления данных.
Преимущество такого метода заключается в возможности передавать нагрузку с серверных мощностей на определенную аппаратную единицу. Сам процесс дедупликации при этом получает максимальную прозрачность.
Программный тип
Подразумевает использование специального программного обеспечения, которое, собственно, и выполняет все необходимые процессы дедупликации. Но, при таком подходе всегда необходимо учитывать нагрузку на сервер, которая будет возникать в процессе дедупликации.
Тяни за ярлык:
about windows 7;ca and outlook;dns and ca;ESX или ESXi?;Exchange 2010exchange 2019forest exchangeinfo about firewalls 2009install DHCP в win2008linux and unix serversms project;Office2010;Outlook and RPC/HTTP;PGP;public_mail on isa2004;RPC/HTTP-прокси на Exchange;setup exchange 2007;setup exchange 2010;setup isa2004;SMTP на Exchange;symantec and exchange;trendmicroUpgrade Esxi 3.5 до Esxi 4.0;vmware 6.7VMWare Vsphere 4;win 2008windows 8windows 2016Ваш первый Exchange;Корпоративный файл-сервер;Мое первое знакомство с VMWare;Настройка IIS 6.0;Настройка коннектора;Ручная установка Win 2008Установка DC;Установка Exchange 2003 sp2как я отдыхал…синематограф
Дедупликация при резервном копировании
 Процедура удаления дубликатов нередко выполняется в процессе сохранения резервной копии. Причем процесс может различаться по месту исполнения, источнику информации (клиенту) и способу хранения (используемому серверу).
Процедура удаления дубликатов нередко выполняется в процессе сохранения резервной копии. Причем процесс может различаться по месту исполнения, источнику информации (клиенту) и способу хранения (используемому серверу).
Клиент-сервер. Это совмещенный вариант, при котором мероприятие может выполняться как на клиенте, так и на самом сервере. Прежде чем отправлять сведения на сервер, специальное ПО пытается определить, какие сведения уже были записаны. Как правило, применяется дедупликация блочного типа. Для отдельного блока сведений вычисляется хеш, а перечень хеш-ключей отправляется на сервер. На серверном уровне выполняется сравнение ключей, после чего клиент получает необходимые блоки данных. При использовании такого решения снижается общая нагрузка на сеть, так как осуществляется передача только уникальных файлов.
Дедубликация на сервере. Теперь поговорим о том, как делать дедупликацию данных на сервере. Такой вариант применяется в тех случаях, когда сведения передаются на устройство без обработки. Может выполняться программная или аппаратная процедура проверки данных. Программная дедубликация подразумевает применение специального ПО, которое и запускает требуемые процессы
При подобном подходе важно учитывать нагрузку на систему, так как она может быть слишком высокой. Аппаратный тип совмещает специальные решения на основе дедубликации и процедуры бэкапа.
Дедубликация на клиенте
При создании бэкапа возможна репликация данных на самом источнике. Такой способ позволяет задействовать только мощности самого клиента. После проверки данных все файлы отправляются на сервер. Data deduplication на клиенте требует особого программного обеспечения. Недостаток решения в том, что оно приводит к повышенной загрузке оперативной памяти.
Сжатие с потерями и без потерь
Есть два принципиальных вида сжатия — с потерями и без.
Сжатие с потерями означает, что в процессе мы лишились части информации. Алгоритмы сжатия с потерями стараются сделать так, чтобы мы потеряли только те данные, которые нам не слишком важны.
Представьте, что сжатие с потерями — это краткий пересказ произведения из школьной программы: школьнику не так важны описания природы и авторский стиль, ему главное сюжет
Краткий пересказ сохранил только важное, но передал это намного быстрее
Сжатие без потерь — это когда мы уменьшаем размер файла, при этом не теряя в качестве. Для этого используются интересные математические приёмы и кодирование. Главная мысль — чтобы при раскодировании все данные остались на месте.
Преимущества дедупликации данных
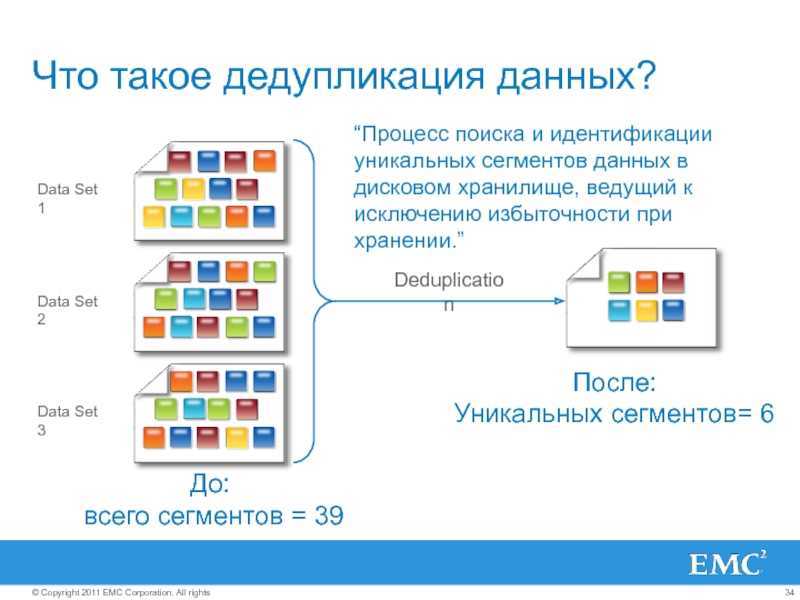
Дедупликация данных помогает администраторам хранилища снизить затраты, связанные с дублирующимися данными. Большие наборы данных часто имеют большое количество дублирования, что повышает затраты на хранение данных. Пример:
- Файловые ресурсы пользователей могут содержать множество копий одних и тех же или похожих файлов.
- Гостевые службы виртуализации могут практически не отличаться от служб на виртуальных машинах.
- Моментальные снимки резервных копий могут иметь минимальные отличия от ежедневных.
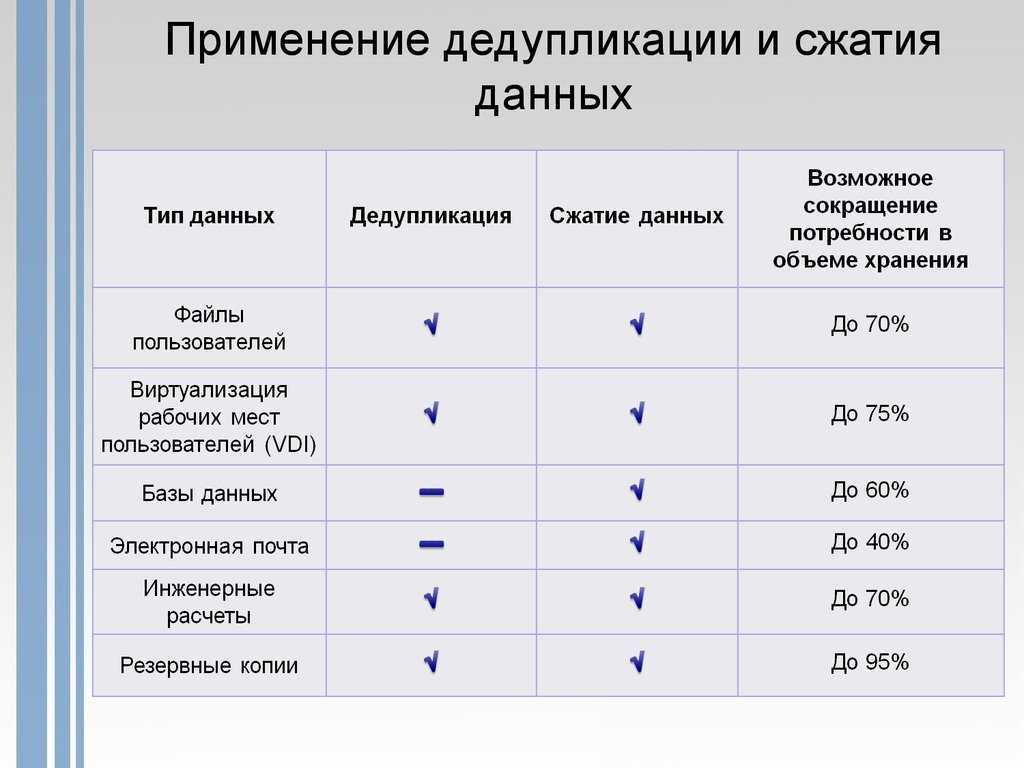
Экономия места, которую может обеспечить дедупликация данных, зависит от набора данных или рабочей нагрузки в томе. В наборах данных с высоким уровнем дупликации скорость оптимизации достигает 95 %, а объем использования службы хранилища может уменьшаться в 20 раз. В следующей таблице представлены типичные значения экономии за счет дедупликации для разных типов содержимого.
| Сценарий | Содержимое | Обычная экономия пространства |
|---|---|---|
| Документы пользователя | Документы Office, фотографии, музыка, видео и т. д. | 30-50 % |
| Общие ресурсы развертывания | Двоичные файлы программного обеспечения, CAB-файлы, символы и т. д. | 70–80 % |
| Библиотеки виртуализации | Образы ISO, файлы виртуальных жестких дисков и т. д. | 80–95 % |
| Файловый ресурс общего доступа | Все вышеперечисленное | 50–60 % |
Примечание
Если вы просто хотите освободить место на томе, рассмотрите возможность использования Синхронизация файлов Azure с включенным распределением по уровням в облаке. Благодаря этому вы сможете кэшировать часто используемые файлы локально и распределять редко используемые файлы по уровням облака, сохраняя пространство в локальном хранилище и поддерживая производительность. Дополнительные сведения см. в статье Планирование развертывания Синхронизации файлов Azure.
Настройка роли
Возможность управлять ролью находится на вкладе «Файловые службы»:
Во вкладке по работе с разделов выберем один из них и нажмем правой кнопкой мыши. В выплывающей меню мы увидим «Настройка дедупликации данных»:
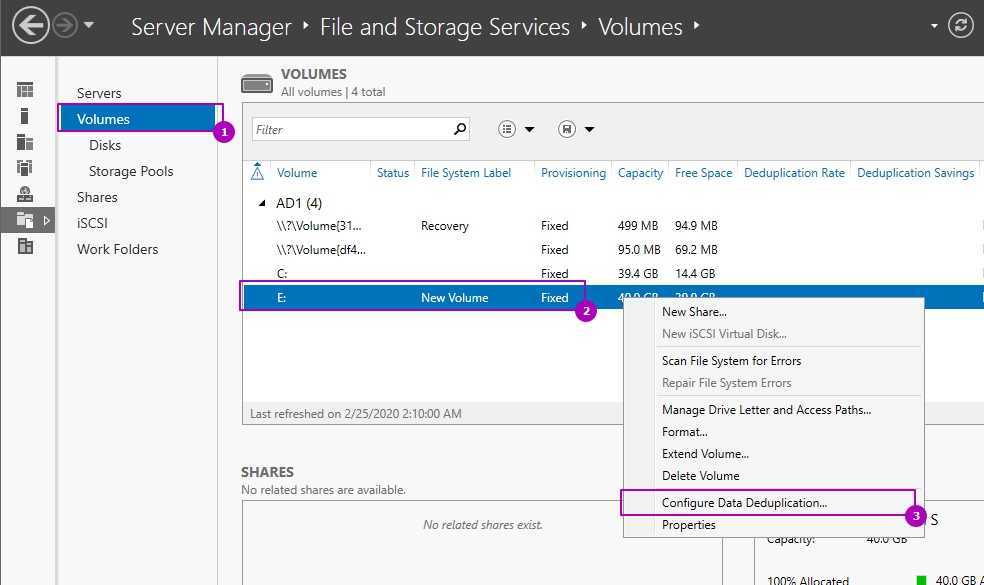
По умолчанию дедупликация отключена. У нас есть выбор из трех вариантов:
- Файловый сервер общего назначения;
- Сервер инфраструктуры виртуальных рабочих столов (VDI);
- Виртуализированный резервный сервер.
Каждый из этих режимов устанавливается с рекомендуемыми настройками и дальнейшие изменения можно пропустить:
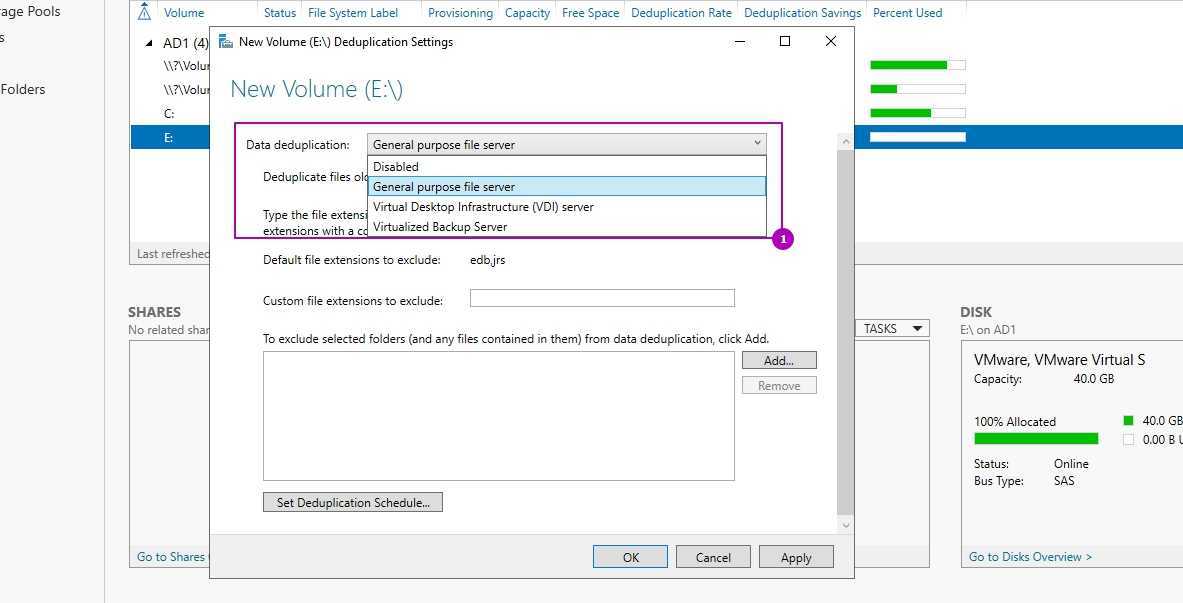
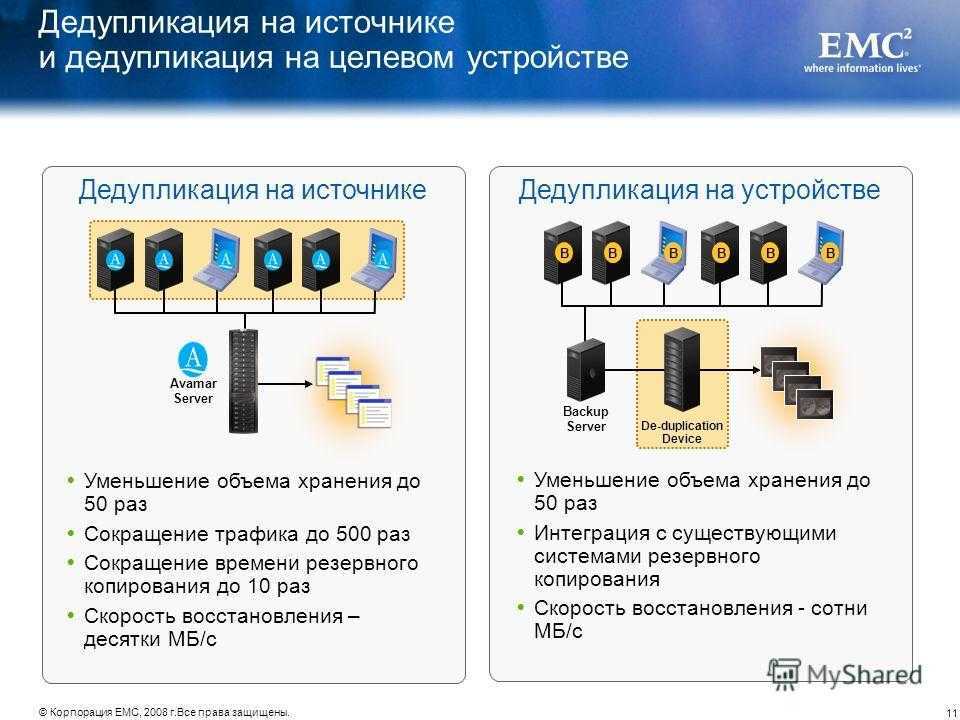
Важной настройкой является установка возраста файла (область 1), который будет проходить процесс оптимизации. Новые файлы пользователей могут активно меняться в течение нескольких дней, что в пустую увеличит нагрузку на сервер при дедупликации, а затем не открываться вовсе
Если установить значение 0, то дедупликация не будет учитывать возраст файла вовсе.
В области 2 указываются расширения файлов для исключения из процессов дедупликации. Рекомендую установить несколько расширений, которые не несут значительную роль. Затем, через недели две, оценить нагрузку на сервер и, если она будет удовлетворительной, убрать исключение. Вы можете сделать и обратную операцию, добавив в исключения расширения уже после оценки нагрузки, но этот вариант не настолько очевиден как первый. Проблема будет в том, что исключенные файлы не раздедуплицируются автоматически (только с Powershell) и они все так же будут нуждаться в поддержке и ресурсах. В области 3 исключаются папки.

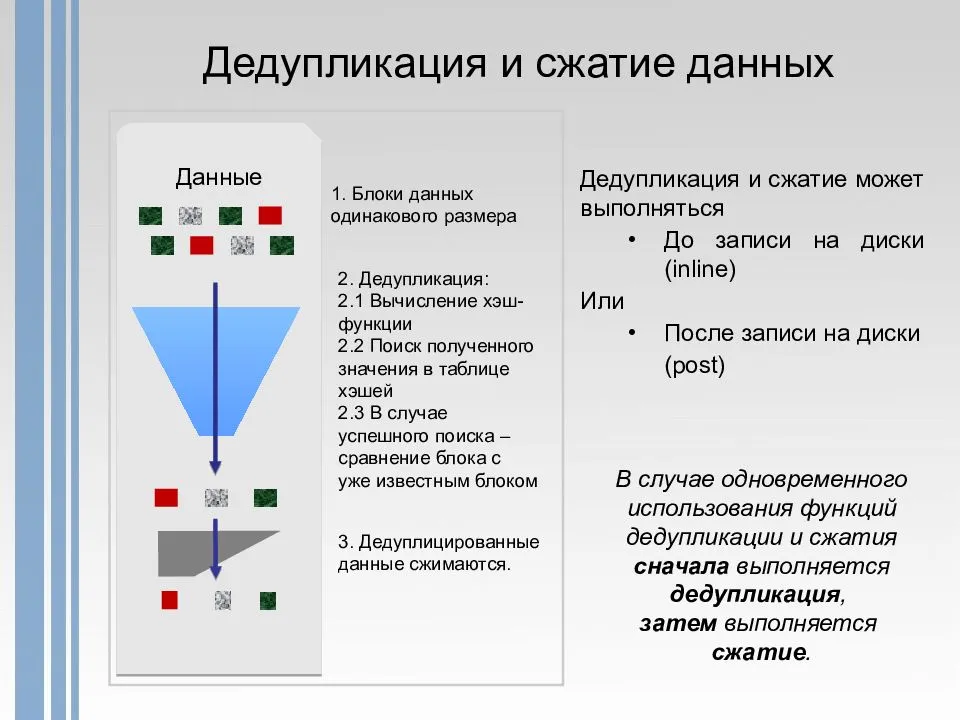


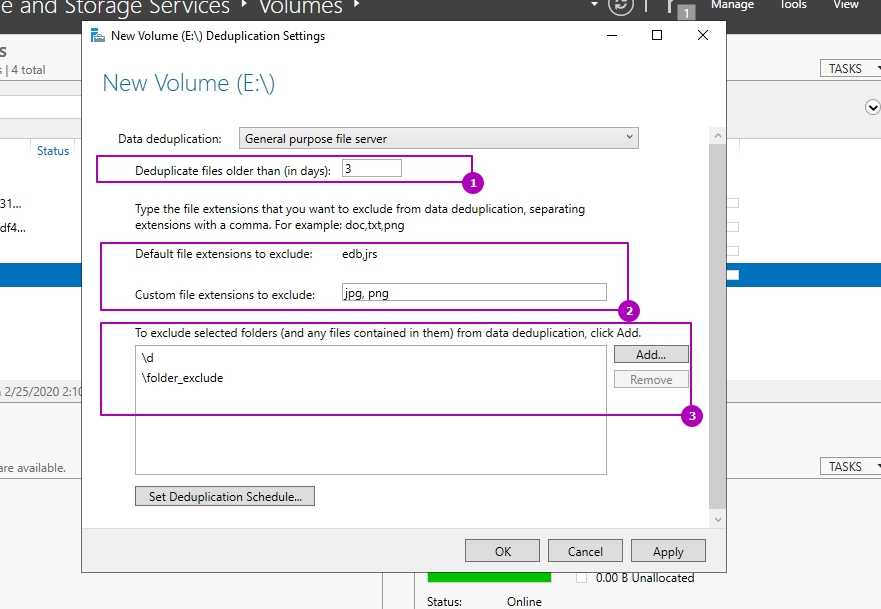
В окне расписания мы можем настроить следующее:
- Фоновая оптимизация (Enable background optimization) — включена по умолчанию. Работает с низким приоритетом не мешая основным процессам. При высокой нагрузке останавливается автоматически. Срабатывает один раз в час;
- Включить оптимизацию пропускной способности (Enable throughput optimization) — расписание, когда дедупликация может выполнятся без ограничения в ресурсах. Можно настроить на выходные дни например;
- Создать второе расписание оптимизации пропускной способности (Create a second schedule for throughput optimization) — расписание аналогично предыдущему. Можно настроить на вечернее время.
На этом настройки, которые выполняются через интерфейс заканчиваются. Если снять галочку, которая включает дедупликацию, все процессы поиска и дедупликации остановятся, но файлы не вернуться в исходное положение. Для обратного преобразования файлов нужно запускать процесс Unoptimization, который выполняется в Powershell и описан ниже.
Как работает сжатие файлов: сжатие с потерями
Сжатие с потерями уменьшает размер файла, удаляя ненужные биты информации. Это наиболее распространенный формат изображений, видео и аудио, где нет необходимости в идеальном представлении исходного мультимедиа. Многие распространенные форматы для этих типов носителей используют сжатие с потерями; MP3 и JPEG — два популярных примера.
MP3 не содержит всей аудиоинформации из оригинальной записи — вместо этого он выбрасывает некоторые звуки, которые люди не могут слышать. В любом случае вы не заметите, что они отсутствуют, поэтому удаление этой информации приведет к меньшему размеру файла, практически без недостатков.
Аналогично, файлы JPEG удаляют ненужные части изображений. Например, в изображении, содержащем голубое небо, сжатие JPEG может изменить все пиксели неба на один или два оттенка синего вместо использования десятков различных оттенков.
Однако чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, испытали это с грязными файлами MP3, загруженными на YouTube. Например, сравните этот высококачественный музыкальный трек:
С этой сильно сжатой версией той же песни:
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, допустим, у вас есть огромный файл изображения RAW. Хотя вы, вероятно, хотите сохранить это качество при печати изображения на большом баннере, бессмысленно загружать файл RAW в Facebook.
Изображение содержит так много данных, что не заметно при просмотре на сайтах социальных сетей. Сжатие изображения в высококачественный JPEG выбрасывает некоторую информацию, но изображение выглядит почти невооруженным глазом. Смотрите наше сравнение популярных форматов изображений
JPEG, GIF или PNG? Типы файлов изображений объяснены и протестированы
JPEG, GIF или PNG? Типы файлов изображений объяснены и протестированыЗнаете ли вы различия между JPEG, GIF, PNG и другими типами файлов изображений? Знаете ли вы, когда следует использовать один вместо другого? Не бойся, MakeUseOf все объясняет!
Прочитайте больше
для более глубокого взгляда на это.
Сжатие с потерями в общем использовании
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства видов носителей
В связи с этим жизненно важно, чтобы такие компании, как Spotify и Netflix, постоянно передавали огромные объемы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной
Можете ли вы представить, было ли каждое видео YouTube храниться и передаваться в оригинальном несжатом формате?
Но сжатие с потерями не очень хорошо работает с файлами, для которых важна вся информация. Например, использование сжатия с потерями в текстовом файле или электронной таблице приведет к искаженному выводу. Вы действительно не можете ничего выбросить без серьезного вреда для конечного продукта.
При сохранении в формате с потерями, вы часто можете установить уровень качества. Например, многие графические редакторы имеют ползунок для выбора качества JPEG от 0 до 100.
Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла, с небольшой разницей в глазах. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Ниже вы можете увидеть пример этого (нажмите, чтобы увидеть увеличенные изображения). Слева оригинальное изображение, загруженное с Pixabay в формате JPEG. Среднее изображение является результатом сохранения его в формате JPEG с 50-процентным качеством. И самое правое изображение показывает исходное изображение, сохраненное вместо этого в формате JPEG с 10-процентным качеством.
На первый взгляд среднее изображение выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. Конечно, самое правое изображение сразу выглядит ужасно.
Перед кадрированием для загрузки размеры файлов составляли 874 КБ, 310 КБ и 100 КБ соответственно.
С потерями
В конце 80-х годов прошлого века цифровые изображения стали более распространенными, появились стандарты сжатия изображений без потерь . В начале 1990-х годов стали широко используются методы сжатия с потерями. В этих схемах можно сэкономить некоторая потеря информации, как несущественных деталей. Существует соответствующий компромисс между сохранением информации и уменьшением размера. Схемы сжатия данных с потерями разработаны на основе исследования того, как люди воспринимают данные, о которых идет речь. Например, человеческий глаз более чувствителен к незначительным изменениям яркости, чем к изменениям цвета. JPEG загрузка изображений частично работает путем округления несущественных битов информации. Ряд популярных форматов сжатия используют эти особенности в восприятии, в том числе психоакустика для звука и психовизуализация для изображений и видео.
Большинство форм сжатия с потерями основаны на кодировании с преобразованием, особенно на дискретном косинусном преобразовании (DCT). Впервые он был предложен в 1972 году Насиром Ахмедом, который разработал рабочий с алгоритмом Т. Натараджаном и К. Р. Рао в 1973 году, прежде чем представить его в январе 1974 года. DCT является наиболее широко используемым методом сжатия в мультимедийных форматах для изображений (таких как JPEG и HEIF ), видео ( например, MPEG, AVC и HEVC ) и аудио (например, MP3, AAC и Ворбис ).
Lossy сжатие изображения используется в цифровые камерах для увеличения емкости памяти. Точно так же DVD, Blu-ray и потоковое видео используют форматы кодирования видео с потерями . Сжатие с потерями широко используется в видео.
При сжатии звука с потерями используются методы психоакустики для удаления неслышимых (или менее слышимых) компонентов аудиосигнала. Сжатие речи часто выполняется с помощью даже более предлагаемых методов; кодирование речи выделяется как отдельная дисциплина от сжатия звука общего назначения. Кодирование речи используется в интернет-телефонии, например, взятие звука используется для копирования аудиокомпакт-дисков и декодируетсяопроигрывателями.
Сжатие с потерями может вызвать потерю генерации.
Миф4. Все данные одинаковы
- Тип данных — данные, прошедшие программное сжатие, метаданные, медиа-потоки и зашифрованные данные всегда имеют очень невысокий коэффициент дедупликации или не сжимаются вовсе.
- Степень изменяемости данных — чем выше объем дневных изменений данных на блочном или файловом уровне, тем ниже коэффициент дедупликации. Это особенно актуально для систем резервного копирования.
- Срок хранения — чем больше копий данных вы имеете, тем выше коэффициент дедупликации.
- Политика резервного копирования — политика создания дневных полных копий, в противовес политике с инкрементными или дифференциальными бэкапами, даст больший коэффициент дедупликации (см. исследование ниже).
Рис. 5 Оценка коэффициента дедупликации в зависимости от типов данных и политики резервного копирования
Преимущества
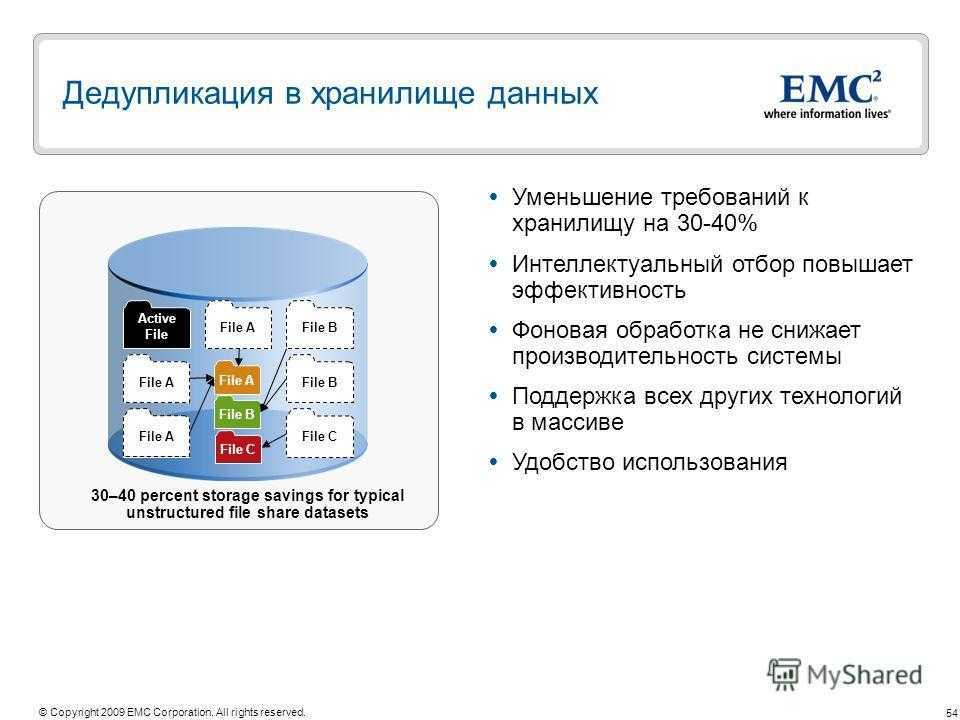
Хранилище дедупликация данных уменьшает объем хранилища, необходимый для данного набора файлов. Он наиболее эффективен в приложениях, где на одном диске хранится много копий очень похожих или даже идентичных данных — удивительно распространенный сценарий. В случае резервного копирования данных, которое обычно выполняется для защиты от потери данных, большая часть данных в данной резервной копии остается неизменной по сравнению с предыдущей резервной копией. Обычные системы резервного копирования пытаются использовать это, опуская (или жестко связывая ) файлы, которые не изменились, или сохраняя различия между файлами. Однако ни один из подходов не учитывает всех избыточностей. Жесткое связывание не помогает с большими файлами, которые изменились лишь незначительно, например, с базой данных электронной почты; различия обнаруживают дублирование только в соседних версиях одного файла (рассмотрим раздел, который был удален, а затем снова добавлен, или изображение логотипа, включенное во многие документы). Оперативная дедупликация сетевых данных используется для уменьшения количества байтов, которые должны быть переданы между конечными точками, что может уменьшить требуемую полосу пропускания. См. Оптимизация WAN для получения дополнительной информации. Виртуальные серверы и виртуальные рабочие столы выигрывают от дедупликации, поскольку она позволяет объединить номинально отдельные системные файлы для каждой виртуальной машины в единое пространство хранения. В то же время, если данная виртуальная машина настраивает файл, дедупликация не изменит файлы на других виртуальных машинах — чего нет в таких альтернативах, как жесткие ссылки или общие диски. Аналогичным образом улучшено резервное копирование или создание дубликатов виртуальных сред.
Где и когда применять
Связи с причинами описанными выше есть рекомендации, где имеет смысл использовать роль:
- Файловые сервера
- VDI
- Архивы с бэкапом
Фактически вы не сможете использовать эту роль со следующими условиями (без учета разницы в версиях):
- файлы зашифрованные (EFS);
- файлы с расширенными атрибутами;
- размер файлов меньше чем 32 Кб;
- том является системным или загрузочным;
- тома не являющиеся дисками (сетевые папки, USB носители).
В теории вы можете работать с любыми остальными типами файлов и серверов, но дедупликация очень ресурсозатратный процесс и лучше следовать объемам, указанным выше. Допустим у вас на сервере много файлов формата mp4 и вы предполагаете, что существенная их часть разная — вы можете попробовать исключить их из анализа. Если сервер будет успевать обрабатывать остальные типы файлов, то вы включите файлы mp4 в анализ позже.
Так же не стоит использовать дедупликацию на базах данных и любых других данных с высоким I/O, так как они содержат мало дублирующих данных и часто меняются. Из-за этого процесс поиска уникальных данных, а следовательно и нагрузка на сервер, может проходить в пустую.
Дедупликация работает по расписанию и может использовать минимум и максимум мощностей. В зависимости от общего объема и мощности сервера разный процесс дедупликации (их 4) может занять как час, так и дни. Microsoft рекомендует использовать 10 Gb оперативной памяти на 10 Тb тома. Часть операций нужно делать после работы, какие-то в выходные — все индивидуально.
На некоторых программах бэкапа, например Veeam, тоже присутствует дедупликация архивов. Если вы храните такой бэкап на томе Windows, с такой же функцией, вам нужно выполнить дополнительные настройки. Игнорирование этого может привести к критическим ошибкам.
При копировании файлов между двумя серверами, с установленной ролью, они будут перенесены в дедуплицированном виде. При переносе на том, где этой роли нет — они будут сохранены в исходном состоянии.
Microsoft не рекомендует использовать robocopy, так как это может привести к повреждению файлов.
В клиентских версиях, например Windows 10, официально такой роли нет, но способ установки существует. Люди, которые выполняли такую процедуру, сообщали о проблемах с программами подразумевающие синхронизацию с внешними базами данных.




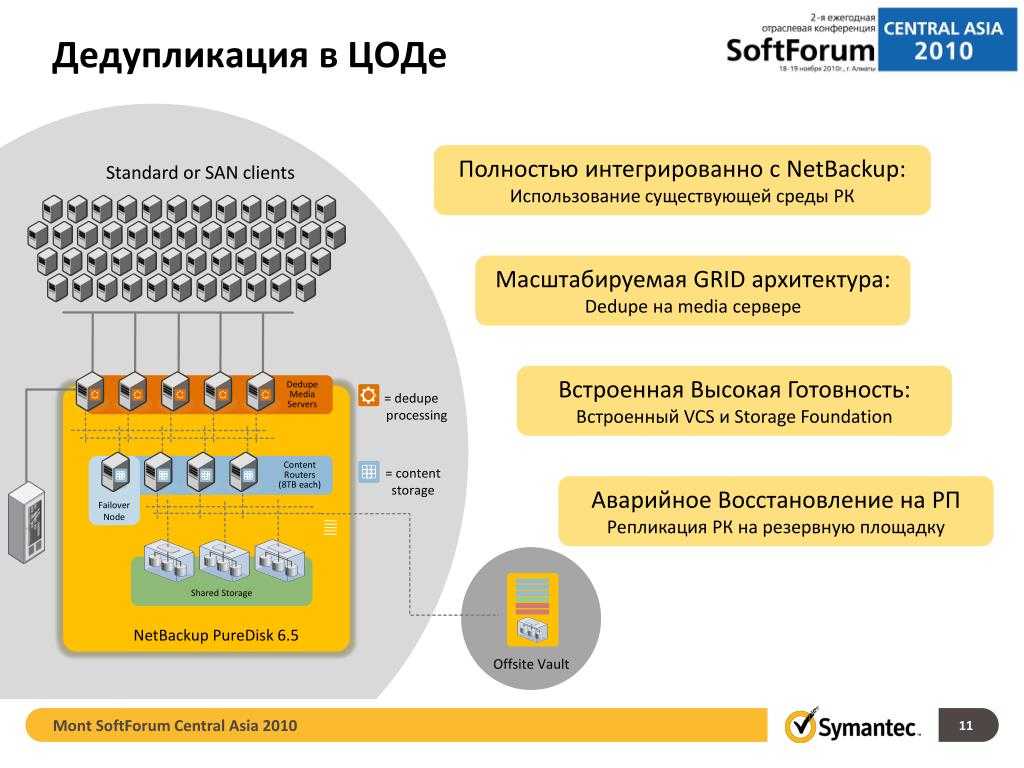
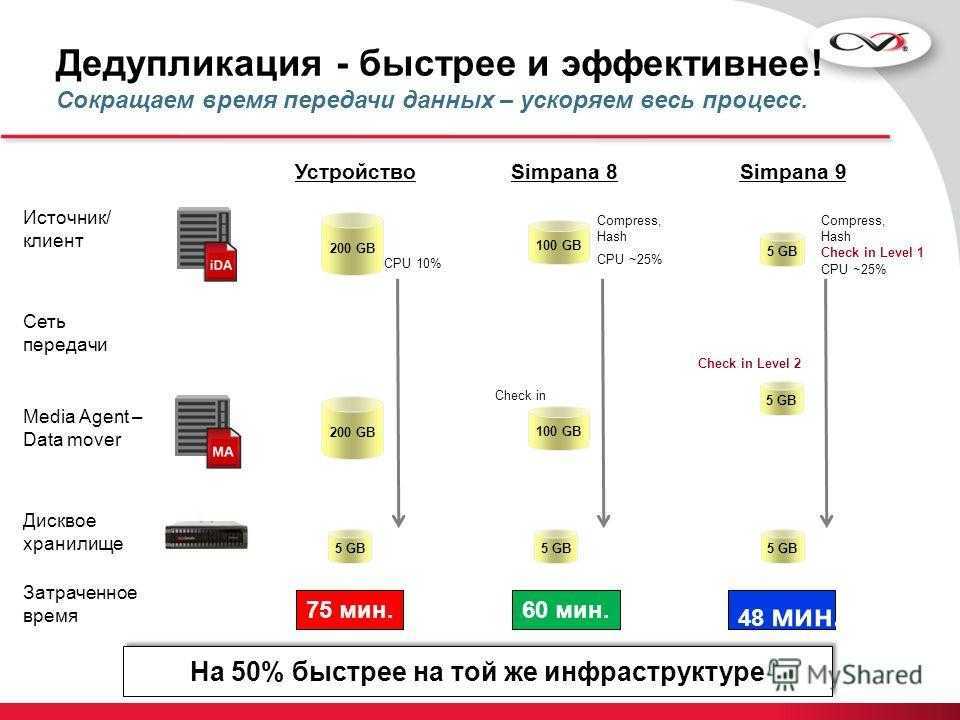

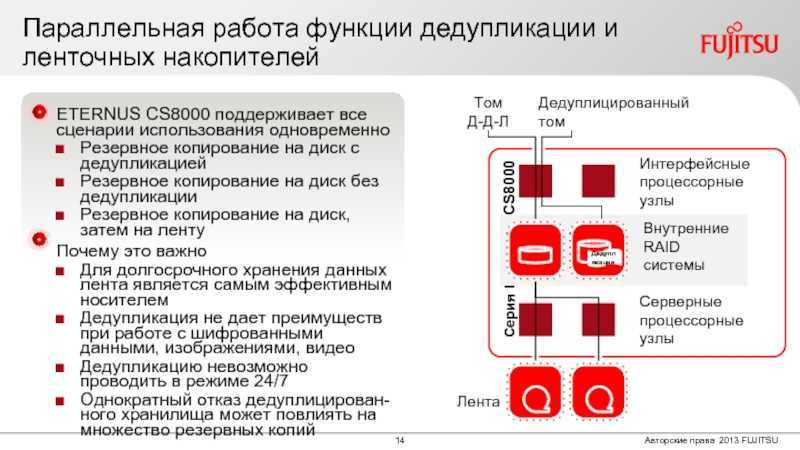
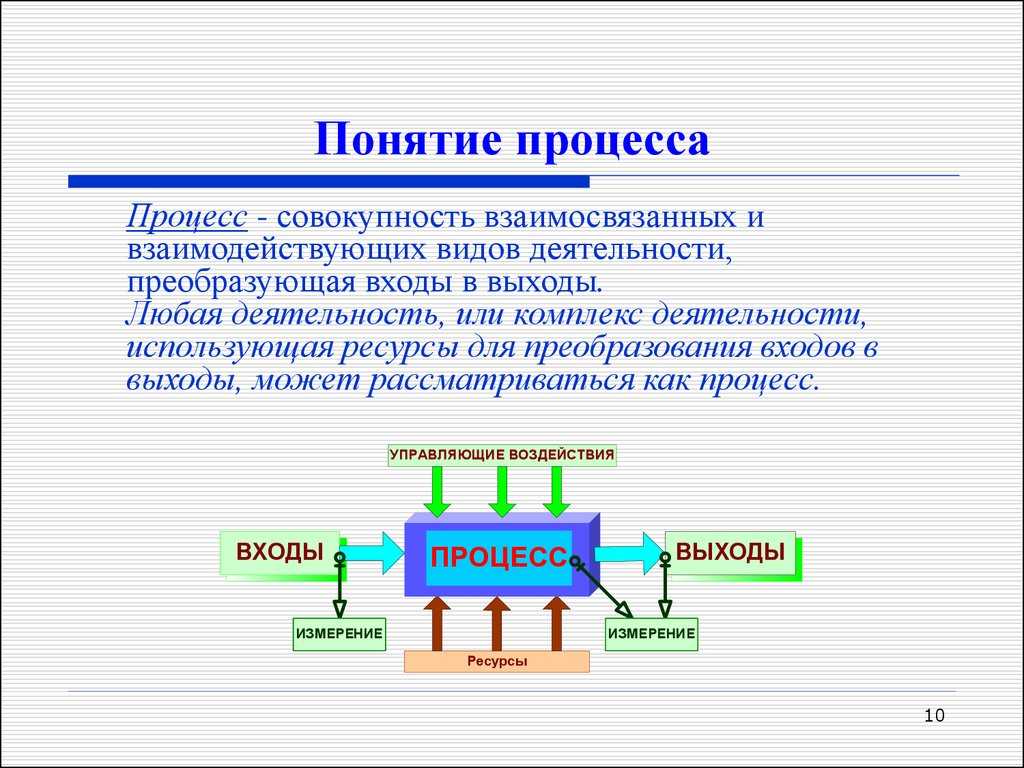
Область применения
Наверняка у многих возникает закономерный вопрос, зачем нужна дедупликация данных и можно ли обойтись без нее. Как показывает практика, рано или поздно все равно приходится прибегать к data deduplication. Со временем копии и дубликаты файлов могут заниматься в 2–3 раза больше места, чем оригинальные файлы, поэтому требуется удаление ненужных данных. Особенно часто процесс дедубликации используют разработчики на рынке резервного копирования.
Кроме этого, технология нередко применяется на серверах продуктивной системы. В этом случае процедура может выполняться средствами ОС или дополнительным программным обеспечением.
Популярные услуги
Аренда выделенного сервера в России
Аренда сервера и СХД необходимой производительности.
Все оборудование размещаются в собственном отказоустойчивом ЦОДе с зарезервированными системами энергоснабжения, охлаждения и каналами связи.
Аренда хостинга для сайта
Хостинг сайтов в спб приходится приобретать любой уважающей себя компании. Это нужно для создания и дальнейшей раскрутки сайта. В компании Xelent клиентам на выбор доступна аренда виртуального или vps-сервера.
Виртуальный сервер (VDS/VPS)
Оптимальные тарифы для облачных решений!
Полный аналог «железного» сервера в виртуальной среде.
Часто задаваемые вопросы
Чем отличается дедупликация данных от других средств оптимизации?
Есть несколько важных различий между дедупликацией данных и другими распространенными решениями для оптимизации хранения.
-
Чем отличается дедупликация данных от хранилища единственных копий?
Хранилище единственных копий (SIS) является предшественником технологии дедупликации данных и впервые было представлено в выпуске Windows Storage Server 2008 R2. Для оптимизации тома хранилище единственных копий выявляло в нем полностью идентичные файлы и заменяло их логическими ссылками на одну копию такого файла, размещенную в общем хранилище SIS. В отличие от хранилища единственных копий, дедупликация данных способна уменьшить пространство, занимаемое файлами, которые не полностью идентичны, но имеют некоторые одинаковые элементы, а также файлами, в которых встречается много повторяющихся элементов. Хранилище единственных копий считается устаревшим начиная с выпуска Windows Server 2012 R2, а в Windows Server 2016 его полностью заменила дедупликация данных. -
Чем отличается дедупликация данных от сжатия NTFS?
Сжатие NTFS используется файловой системой NTFS на уровне тома. Эта необязательная функция NTFS оптимизирует каждый файл по отдельности, сжимая его во время записи. В отличие от сжатия NTFS, дедупликация данных использует для экономии места одновременно все файлы на томе. Это гораздо эффективнее, чем сжатие NTFS, ведь файл может одновременно иметь как внутреннее дублирование данных (которое устраняется сжатием NTFS), так и сходство с другими файлами в томе (которое не устраняется сжатием NTFS). Кроме того, дедупликация данных использует модель постобработки. Это означает, что новые или измененные файлы записываются на диск в неоптимизированном виде, и лишь затем дедупликация данных оптимизирует их. -
Чем отличается дедупликация данных от форматов архивации файлов, таких как ZIP, RAR, 7Z, CAB и т. д.?
Форматы ZIP, RAR, 7Z, CAB и другие выполняют сжатие для определенного набора файлов. Как и в случае с дедупликацией данных, оптимизируются повторяющиеся фрагменты внутри файлов и в разных файлах. Однако вам необходимо выбрать файлы, которые должны быть включены в архив. Семантика доступа также отличается. Чтобы получить доступ к определенному файлу в архиве, необходимо открыть архив, выбрать файл, а затем распаковать его для использования. Дедупликация данных работает незаметно для пользователей и администраторов, не требуя никаких ручных операций. Кроме того, дедупликация данных сохраняет семантику доступа — оптимизированные файлы выглядят для пользователя точно так же, как и раньше.
Можно ли изменить параметры дедупликации данных для выбранного типа использования?
Да. Хотя дедупликация данных обеспечивает рациональные значения по умолчанию для рекомендуемых рабочих нагрузок, вам может потребоваться настроить параметры для наиболее эффективного использования хранилища. И не забывайте, что в некоторых случаях .
Можно ли вручную запускать задания дедупликации данных?
Да, . Это удобно, если запланированное задание не было выполнено из-за недостатка системных ресурсов или ошибки. Кроме того, есть специальное задание отмены оптимизации, которое запускается только вручную.
Можно ли просмотреть историю запусков заданий дедупликации данных?
Да, .