
Tarantool в Docker на Windows
Мне кажется, с точки зрения инфраструктуры Docker — самое лучшее, что случилось в индустрии за последнее десятилетие. Теперь можно попробовать практически любой продукт без длительной настройки с помощью простой команды . И Tarantool тут не исключение. Поэтому установите Docker для Windows, если он у вас не установлен, зайдите в консоль и введите следующую команду:
Если образ Tarantool 1.7 ещё не скачан, то он автоматически скачается, и новый контейнер, созданный из этого образа, будет запущен. Всё. Мы запустили Tarantool! Параметр (detached) говорит о том, что контейнер необходимо запустить в фоне. Поэтому всё, что вы увидите в консоли после выполнения команды, — это ID контейнера.
Теперь самое время подключиться к нашему новому экземпляру Tarantool через его собственную консоль:
Мы подключаемся к контейнеру с именем и выполняем в нём команду в интерактивном режиме. После этого откроется консоль Tarantool, и вы сможете выполнять в ней любые команды.
Как видите, после установки Docker для запуска Tarantool потребовалось выполнить одно действие, ещё одна команда нужна, чтобы подключиться к Tarantool. Это даже проще, чем в предыдущем примере с Windows Subsystem for Linux. Именно поэтому мне гораздо больше нравится вариант с Docker. Ну и кроме того, Tarantool в Docker работает в той же среде, в которой он будет работать в production.
Сейчас экземпляр Tarantool запущен и работает в Docker. И он даже где-то хранит данные, что уже неплохо. Проблема только в том, что мы не знаем, где именно данные хранятся. Нужно указать место на Windows-хосте, где Tarantool сохранял бы логи и snaphot’ы. Также надо сделать Tarantool доступным из Windows по определённому порту, например 3301. Всё это требуется, чтобы к нему можно было подключиться из нашего .NET-приложения по .
Но перед тем как это сделать, остановим и удалим наш существующий контейнер:
Создадим папку , в которой будут размещаться логи и snaphot’ы нашего экземпляра Tarantool. Имя и месторасположение папки выбрано произвольно. Не забудьте только сделать диск, на котором находится папка, доступным для Docker: кликните на иконку Docker в системном трее и выберите в контекстном меню пункт В открывшемся диалоговом окне в разделе необходимо указать нужные диски.
Теперь запустим новый Docker-контейнер с Tarantool:
Мы связали папку на Windows с контейнера — местом, где (согласно настройкам контейнера) хранятся данные. После запуска контейнера можно увидеть, что в папке появились файл логов и snapshot.
Теперь Tarantool доступен из Windows по адресу . Мы можем обратиться к нему из нашего .NET-приложения (или любого другого). Единственная проблема — Tarantool на данный момент пуст. Создадим space’ы и при необходимости добавим в них какие-то данные. Также создадим пользователей и назначим им права. Вручную делать это в консоли — не самая лучшая идея, поэтому давайте напишем для этих целей скрипт инициализации на Lua. Детально создание полноценного Lua-скрипта инициализации мы рассмотрим в следующем разделе, а пока давайте сделаем минимальный скрипт, который дальше будем улучшать. Для этого создадим папку и в ней файл . Детали конфигурации сейчас не очень важны. Вот минимальный Lua-скрипт, который нужно создать:
app.init.lua
Также для запуска Docker-контейнера не хочется каждый раз вводить сложные команды. Поэтому давайте воспользуемся Docker Compose и пропишем всю конфигурацию в YAML файле , который поместим в .
docker-compose.yml
Здесь мы создаём сервис с именем из образа . При этом в качестве аргумента при запуске передаём наш конфигурационный файл , а также делаем Tarantool доступным из Windows на порту 3301. Кроме того, мы связываем Windows-папки и c Docker-контейнером.
Теперь можно запустить Tarantool с помощью Docker Compose одной простой командой:
Остановить и удалить контейнер с Tarantool можно командой:
Если вы уже находитесь в папке с файлом , то путь к файлу можно не указывать:
Ну что же. Мы настроили запуск Tarantool с помощью одной команды и создали простой скрипт инициализации. Сейчас структура папок выглядит следующим образом:
Пришло время написать более продвинутый скрипт инициализации, который создаст пользователя, space и загрузит тестовые данные.
Создание скрипта инициализации
Наш скрипт инициализации будет делать следующее. Во-первых, создавать пользователя с паролем . Этому пользователю предоставляются права на чтение, запись и выполнение. Во-вторых, создавать space . А также три индекса: уникальный индекс на первое поле (поля считаются с единицы, а не с нуля), где будет храниться ID пользователя в виде GUID-строки, уникальный индекс на третье поле, где будет храниться логин, и неуникальный индекс на пятое поле, где будет храниться рейтинг пользователя в виде числа. Создание пользователей, space’а и индексов происходит в функции . А в функции мы добавим три записи в space’е users. Функция позволяет выполнить функцию один раз для текущей базы данных, что мне кажется очень полезной возможностью. Далее приведён полный код :
app.init.lua
Внесите изменения в файл и перезапустите Docker-контейнер с Tarantool-командой:
Теперь у нас есть полноценно работающий Tarantool с данными, с которыми мы можем работать из .NET-приложения.


Настройка базы данных
Обсудим инициализацию игры. В методе нам нужно заполнить спейсы Tarantool’а данными о покемонах. Почему бы не хранить все игровые данные в памяти? Зачем нужна база данных? Ответ на это: . Без базы данных мы рискуем потерять данные при отключении электроэнергии, например. Но если мы храним данные в in-memory базе данных, Tarantool позаботится о том, чтобы обеспечить постоянное хранение данных при их изменении. Это дает дополнительное преимущество: быстрая загрузка в случае отказа. Tarantool’а быстро загружает все данные с диска в память при начале работы, так что подготовка к работе не займет много времени.
Мы будем использовать функции из встроенного модуля Tarantool’а :
- для создания спейса под названием (покемон), чтобы хранить информацию о покемонах (мы не создаем аналогичный спейс по игрокам, потому что планируем только отправлять и получать информацию об игроках с помощью вызовов API, так что нет необходимости хранить ее);
- для создания первичного HASH-индекса по ID покемона;
- для создания вторичного TREE-индекса по статусу покемона.
Обратите внимание на аргумент в спецификации индекса. ID покемона – это первое поле в кортеже Tarantool’а, потому что это первый элемент соответствующего типа Avro
То же относится к статусу покемона. В самом JSON-файле поля ID или статуса могут быть в любом положении на JSON-карте.
Реализация метода выглядит следующим образом:
Сортировка
Когда Tarantool сравнивает строки, по умолчанию он использует двоичные параметры сортировки (binary collation). При этом он учитывает только числовое значение каждого байта в строке. Например, код символа (раньше называлась «значение ASCII») — число 65, код — число 66, а код – число 98. Поэтому , если строка закодирована в ASCII или UTF-8.
Двоичная сортировка — лучший выбор для быстрого детерминированного простого обслуживания и поиска с использованием индексов Tarantool.
Но если вы хотите такое упорядочение, как в телефонных справочниках и словарях, то вам нужна одна из дополнительных сортировок Tarantool: или . Они обеспечивают и соответственно.
Дополнительные виды сортировки unicode и unicode_ci обеспечивают упорядочение в соответствии с и правилами, указанными в Техническом стандарте Юникода №10 – Алгоритм сортировки по Юникоду (Unicode Technical Standard #10 Unicode Collation Algorithm (UTS #10 UCA)). Единственное отличие между двумя видами сортировки — :
сортировка принимает во внимание уровни веса L1, L2 и L3 (уровень = „tertiary“, третичный);
сортировка принимает во внимание только вес L1 (уровень = „primary“, первичный), поэтому, например, .
Для примера возьмем некоторые русские слова:
'ЕЛЕ' 'елейный' 'ёлка' 'еловый' 'елозить' 'Ёлочка' 'ёлочный' 'ЕЛь' 'ель'
…и покажем разницу в упорядочении и выборке по индексу:
-
с сортировкой по :
tarantool> box.space.Tcreate_index('I', {parts = {{field = 1, type = 'str', collation='unicode'}}}) ... tarantool> box.space.T.index.Iselect() --- --'ЕЛЕ' -'елейный' -'ёлка' -'еловый' -'елозить' -'Ёлочка' -'ёлочный' -'ель' -'ЕЛь' ... tarantool> box.space.T.index.Iselect{'ЁлКа'} --- -[] ... -
с сортировкой по :
tarantool> box.space.Tcreate_index('I', {parts = {{field = 1, type ='str', collation='unicode_ci'}}}) ... tarantool> box.space.T.index.Iselect() --- --'ЕЛЕ' -'елейный' -'ёлка' -'еловый' -'елозить' -'Ёлочка' -'ёлочный' -'ЕЛь' ... tarantool> box.space.T.index.Iselect{'ЁлКа'} --- --'ёлка' ...
Сортировка включает в себя ещё множество аспектов, кроме показанного в этом примере сопоставления букв верхнего и нижнего регистра, с диакритическими знаками и без них, и с учётом алфавита. Учитываются также вариации одного и того же символа, системы неалфавитного письма и применяются специальные правила для комбинаций символов.
Для английского, русского и большинства других языков используйте «unicode» и «unicode_ci». Если вам нужно, чтобы у кириллических букв „Е“ и „Ё“ веса 1 уровня были одинаковыми, попробуйте киргизскую сортировку.
Специализированные дополнительные виды сортировки: Для других языков Tarantool предлагает специализированные виды сортировки для любого современного языка, на котором говорят более миллиона человек. Кроме того, специализированные дополнительные виды сортировки возможны для особых случаев, когда слова в словаре упорядочиваются не так, как в телефонном справочнике. Чтобы увидеть полный список, выполните команду .
Вездесущий Tarantool: от email до IIoT
В отличие от всех вышеперечисленных IMDB, Tarantool является отечественным продуктом, разработанным в Mail.ru Group еще в 2008 году для внутреннего пользования. В частности, эта Big Data система применяется в Почте, Облаке, myTarget и других сервисах Mail.ru. В апреле 2016 года компания опубликовала исходный код Tarantool в открытом доступе под лицензией BSD. Вообще эта СУБД широко применяется в российских Big Data проектах. Например, ее используют соцсети Badoo и Одноклассники , мобильные операторы Билайн, Yota и Мегафон, Avito, Qiwi, Аэрофлот и Альфа-банк. Практическое признание Тарантул получил за способность эффективно работать при высоких нагрузках и с большими объемами данных, обеспечивая производительность на уровне миллион транзакций в секунду на одном ядре простейшего сервера. Таким образом, Tarantool позволяет снизить расходы на hardware в распределенном кластере Big Data .
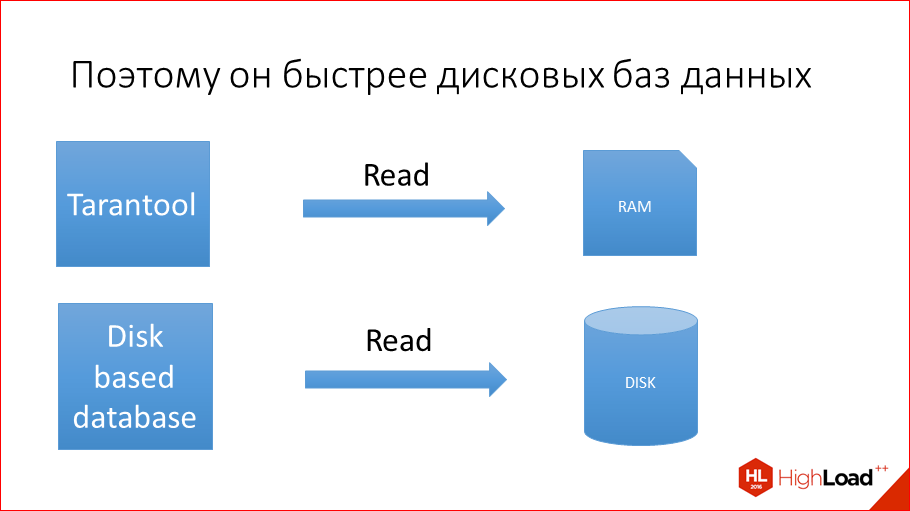
Подобное быстродействие обеспечивается тем, что данные в Tarantool хранятся в оперативной памяти. Благодаря этому запросы на чтение выполняются очень быстро. Запросы на запись также проходят оперативно за счет синхронизации обновлений и последовательного добавления в конец журнала транзакций (Write Ahead Log, WAL), который расположен на жестком диске. Таким образом, данные на диске и в памяти всегда синхронизированы. Последовательная WAL-запись позволяет Tarantool заполнять журнал со скоростью 100 Мбайт/с, соблюдая требования ACID (atomicity, consistency, isolation, durability — «атомарность, согласованность, изоляция и долговечность») .
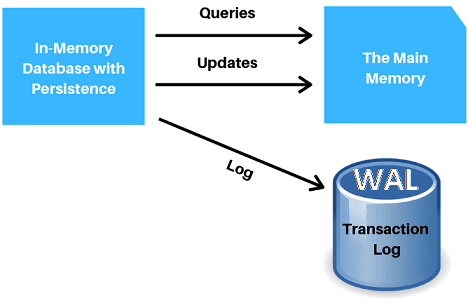
Принцип работы In-Memory Database
Важно, что Тарантул может работать как на мощных серверах с сотнями гигабайт оперативной памяти, так и на виртуальных машинах от облачных провайдеров, а также на устройствах интернета вещей (Internet of Things, IoT), в т.ч. промышленного (Industrial IoT, IIoT)
Tarantool IIoT поддерживает MQTT- и MRAA-протоколы работы с датчиками, генерирующими большие объемы данных для обработке в режиме real time. Еще средства Tarantool IIoT позволяют создавать скрипты для описания процессов сбора технологических показателей с конечных устройств, их обработки и сохранения, обеспечивают репликацию и отправку в облачные ЦОД. Эти возможности делают Tarantool отличным инструментом для разработки IIoT-решений .
Обратной стороной всех этих достоинств являются специфические недоставки, характерные как для всех IMDB-систем вообще, так и для Тарантул в частности. Об этом мы поговорим в следующей статье, а сейчас разберем, как связаны Tarantool и Arenadata – отечественный разработчик Big Data решений.
Поскольку Tarantool является open-source решением, исходный код этой системы используется для создания новых Big Data продуктов. В частности, российская компания «Аренадата Софтвер», которая разработала первый отечественный дистрибутив Apache Hadoop (Arenadata Hadoop), массивно-параллельную СУБД Arenadata DB на базе Greenplum и Arenadata QuickMarts – кластерную колоночную СУБД для генерации аналитических отчетов по большим данным в реальном времени, на базе Tarantool создала собственную платформу резидентных вычислений — Arenadata Grid . Чем эта Big Data система отличается от оригинала и как она интегрирована с другими компонентами экосистемы Apache Hadoop, мы рассмотрим завтра.
А обучиться работе с продуктами компании Arenadata и получить сертификат специалиста можно в нашем лицензированном учебном центре повышения квалификации «Школа Больших Данных» в Москве:
- Администрирование кластера Arenadata Hadoop
- Основы Arenadata Hadoop
- Эксплуатация Arenadata DB
- Администрирование кластера Arenadata Streaming Kafka
- Администрирование Arenadata Streaming NiFi
Смотреть расписание
Записаться на курс
Источники
- https://www.gartner.com/en/documents/3955768/hype-cycle-for-data-management-2019
- https://ru.wikipedia.org/wiki/Резидентная_база_данных
- https://www.information-management.com/news/gartners-19-leading-in-memory-databases-for-big-data-analytics
- https://en.wikipedia.org/wiki/List_of_in-memory_databases
- https://ru.wikipedia.org/wiki/Tarantool
- https://www.cnews.ru/news/top/2019-09-09_iz_mailru_ushel_sozdatel_samogo
- https://www.osp.ru/os/2017/02/13052224/
- https://arenadata.tech/products/adg/
Как устроен Tarantool: архитектура и принципы работы
Прежде всего отметим наиболее важные концепции Tarantool с точки зрения разработчика Big Data приложений :
- поддержка SQL и документо-ориентированных запросов на скриптовом мультипарадигмальном языке Lua;
- поддержка ACID-транзакций (Atomicity, Consistency, Isolation, Durability – атомарность, согласованность, изоляция, стойкость);
- индексация по первичным ключам, с поддержкой неограниченного числа вторичных ключей и составными ключами в индексах;
- разделение доступа на основе ACL-модели (Access Control List);
- единый механизм упреждающей записив журнал (WAL, Write Ahead Log), который обеспечивает согласованность и сохранность данных в случае сбоя – изменения не считаются завершенными, пока не проходит запись в WAL;
- синхронная и асинхронная репликация локально и на удаленных серверах, когда сразу несколько узлов могут обрабатывать входящие данные и получать информацию от других узлов.
Основными программными компонентами Tarantool являются следующие :
- JIT (Just In Time) Lua-компилятор – LuaJIT;
- Lua-библиотеки для самых распространенных приложений;
- сервер документоориентированной NoSQL-СУБД Tarantool с 2-мя движками – резидентным (In-memory, memtx), который хранит все данные в оперативной памяти, и дисковый (vinyl), который эффективно сохраняет данные на жесткий диск, используя разделение на диапазоны, журнально-структурированные деревья со слиянием (log-structured merge trees) и классические B-деревья.
Перейдем к архитектуре: распределенный кластер Tarantool состоит из подкластеров, которые называются шарды (shard). Каждый шард хранит некоторую часть данных и представляет собой набор реплик, одна из которых является ведущим узлом, обрабатывающим все запросы на чтение и запись. При разделении (шардинге) данных они распределяются на заданное количество виртуальных сегментов с уникальными номерами. Рекомендуется задавать количество сегментов в 100-1000 раз больше, чем потенциальное число кластерных узлов с учетом масштабирования кластера в перспективе. Однако, слишком большое число сегментов может потребовать дополнительную память для хранения информации о маршрутизации, а слишком маленькое – привести к снижению степени детализации балансировки.
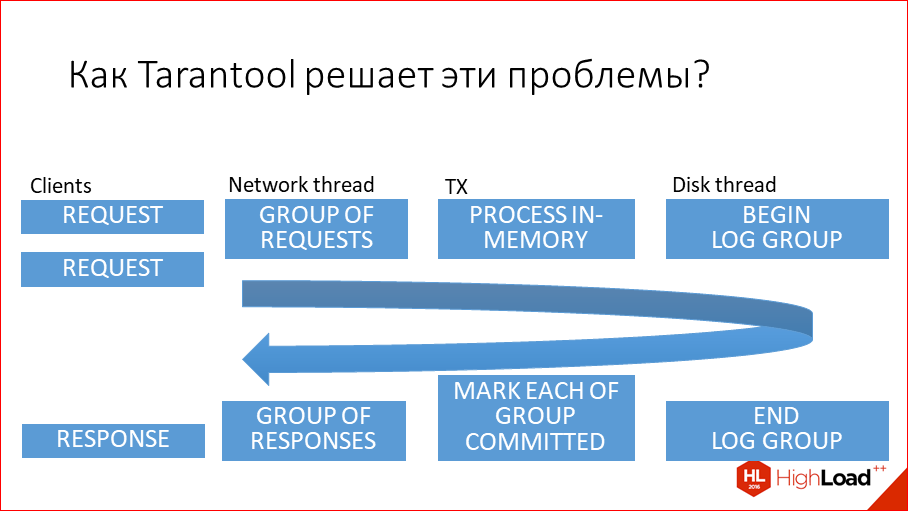

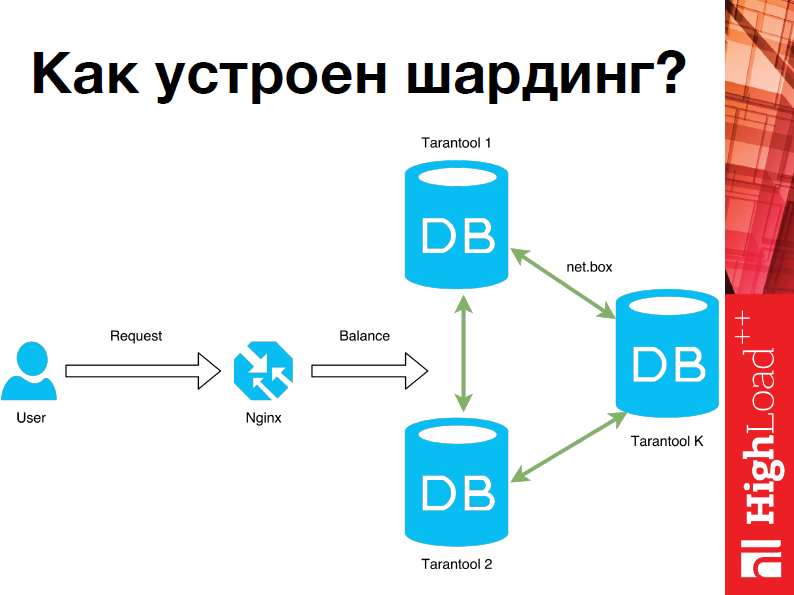
Итак, каждый шард хранит уникальное подмножество сегментов, причем один сегмент не может относиться к нескольким шардам одновременно. Таким образом, с архитектурной точки зрения сегментированный кластер Tarantool включает следующие компоненты :
- хранилище (storage) – узел, который хранит подмножество набора данных. Несколько реплицируемых хранилищ составляют набор реплик (шард, shard). У каждого хранилища в наборе реплик есть роль: мастер или реплика. Мастер обрабатывает запросы на чтение и запись. Реплика обрабатывает запросы только на чтение.
- Роутер (router) – автономный компонент, который обеспечивает маршрутизацию запросов чтения и записи от клиентского приложения к шардам. В зависимости от функций приложения, роутер работает на его уровне или на уровне хранилища. Он сохраняет топологию сегментированного кластера прозрачной для приложения, скрывая такие детали, как номер и местоположение шардов, процесс балансировки данных, отказы реплики и восстановление после них. Роутер может сам идентифицировать сегмент, если приложение четко определяет правила вычисления идентификатора сегмента на основе запроса. Для этого роутеру необходимо знать схему данных. У роутера нет постоянного статуса, он не хранит топологию кластера и не выполняет балансировку данных. Роутер поддерживает постоянный пул соединений со всеми хранилищами, созданными при запуске, что помогает избежать ошибок конфигурации.
- Балансировщик – фоновый процесс равномерного распределения сегментов по шардам, во время которого выполняется миграция сегментов по наборам реплик. Балансировщик запускает периодически, перераспределяя данные из наиболее загруженных узлов в менее загруженные, когда предел дисбаланса в наборе реплик превышает показатель, указанный в конфигурации.
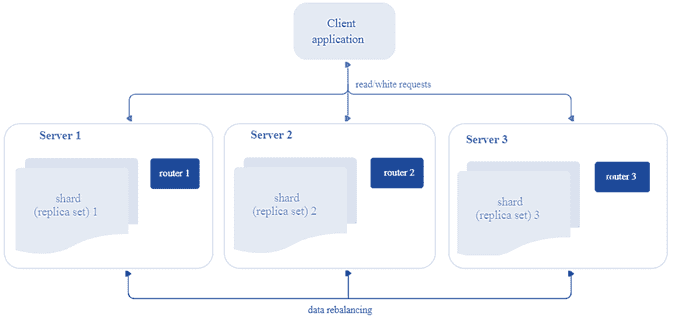
Архитектура СУБД Tarantool
Пример для MySQL
В данном примере предполагается, что установлены MySQL 5.5, MySQL 5.6 или MySQL 5.7. Последние версии MariaDB также подойдут, используется коннектор к MariaDB для C. Самым важным пакетом будет пакет для разработчиков клиента MySQL, который обычно называется libmysqlclient-dev. Наиболее важным файлом из этого пакета будет файл libmysqlclient.so или с похожим названием. Можно использовать « find« или « whereis«, чтобы узнать, в каких директориях установлены эти файлы.
Также нужно будет установить библиотеку общего пользования Tarantool с драйвером для MySQL, загрузить ее и использовать для подключения к экземпляру MySQL-сервера. После этого можно передавать любой оператор MySQL на экземпляр сервера и получать результаты, включая наборы результатов.
Установка
Проверьте инструкции по загрузке и установке бинарного пакета, которые применимы к среде, где установлен Tarantool. Помимо установки , установите . Например, в Ubuntu добавьте строку:
$ sudo apt-get install tarantool-dev
Что касается библиотеки общего пользования с драйвером для MySQL, ее можно установить двумя способами:
Из LuaRocks
Begin by installing luarocks and making sure that tarantool is among the
upstream servers, as in the instructions on rocks.tarantool.org, the
Tarantool luarocks page. Now execute this:
luarocks install mysql
Пример:
$ luarocks install mysql MYSQL_LIBDIR=/usr/local/mysql/lib
Из GitHub
Go the site github.com/tarantool/mysql. Follow the instructions there, saying:
$ git clone https://github.com/tarantool/mysql.git $ cd mysql && cmake . -DCMAKE_BUILD_TYPE=RelWithDebInfo $ make $ make install
На данном этапе желательно проверить, что после установки появился файл под названием , а также проверить, что этот файл находится в директории, которую можно найти по запросу .
Подключение
Начните с выполнения запроса для драйвера mysql. В дальнейших примерах у него будет имя .
mysql = require('mysql')
Теперь выполните:
*имя_подключения* = mysql.connect(*параметры подключения*)
Параметры подключения включены в таблицу. Доступные параметры:
- – строка, значение по умолчанию = „localhost“
- – число, значение по умолчанию = 3306
- – строка, значение по умолчанию – имя пользователя в операционной системе
- – строка, по умолчанию пустая
- – строка, по умолчанию пустая
- – логическое значение, по умолчанию, false (ложь)
The option names, except for , are similar to the names that MySQL’s
mysql client uses, for details see the MySQL manual at
dev.mysql.com/doc/refman/5.6/en/connecting.html.
The option should be set to true if errors should be
raised when encountered. To connect with a Unix socket rather than with TCP,
specify and .
Пример с использованием таблицы, заключенной в {фигурные скобки}:
conn = mysql.connect({
host = '127.0.0.1',
port = 3306,
user = 'p',
password = 'p',
db = 'test',
raise = true
})
-- ИЛИ
conn = mysql.connect({
host = 'unix/',
port = '/var/run/mysqld/mysqld.sock'
})
Пример с созданием функции, которая определяет параметры в отдельных строках:
tarantool> -- Функция подключения. Использование: conn = mysql_connect()
tarantool> function mysql_connection()
> local p = {}
> p.host = 'widgets.com'
> p.db = 'test'
> conn = mysql.connect(p)
> return conn
> end
---
...
tarantool> conn = mysql_connect()
---
...
Предполагаем, что в дальнейших примерах будет использоваться имя „conn“.
Как проверить связь
Чтобы убедиться, что подключение работает, следует использовать запрос:
*имя-соединение*ping()
Пример:
tarantool> connping() --- -true ...
Исполнение оператора
Для всех операторов MySQL запрос будет:
*имя-соединения*execute(*sql-оператор* )
где – это строка, а необязательные параметры – это дополнительные значения, которыми можно заменить любые знаки вопроса («?») в SQL-операторе.
Пример:
tarantool> connexecute('select table_name from information_schema.tables')
---
--table_nameALL_PLUGINS
-table_nameAPPLICABLE_ROLES
-table_nameCHARACTER_SETS
<...>
-78
...
Закрытие соединения
Чтобы закрыть сессию, которую открыли с помощью , используется следующий запрос:
*имя-соединения*close()
Пример:
tarantool> connclose() --- ...
For further information, including examples of rarely-used requests, see the
README.md file at github.com/tarantool/mysql.
А что вообще такое IIoT?
Сначала я напомню, что IIoT — это industrial internet of things (промышленный интернет вещей). Это такая концепция, когда у объектов промышленности появляется доступ в интернет как в сеть и доступ к интернет-сервисам (которые работают в центрах обработки данных — ЦОДах). Давайте посмотрим на рисунок:
Что мы тут видим? Рисунок поделен на две части — «центр» и «на местах».
«Центр» — это ЦОД или облако, т. е. любой облачный IaaS-сервис, в котором можно разворачивать IT-инфраструктуру: Amazon, Azure и т. д.

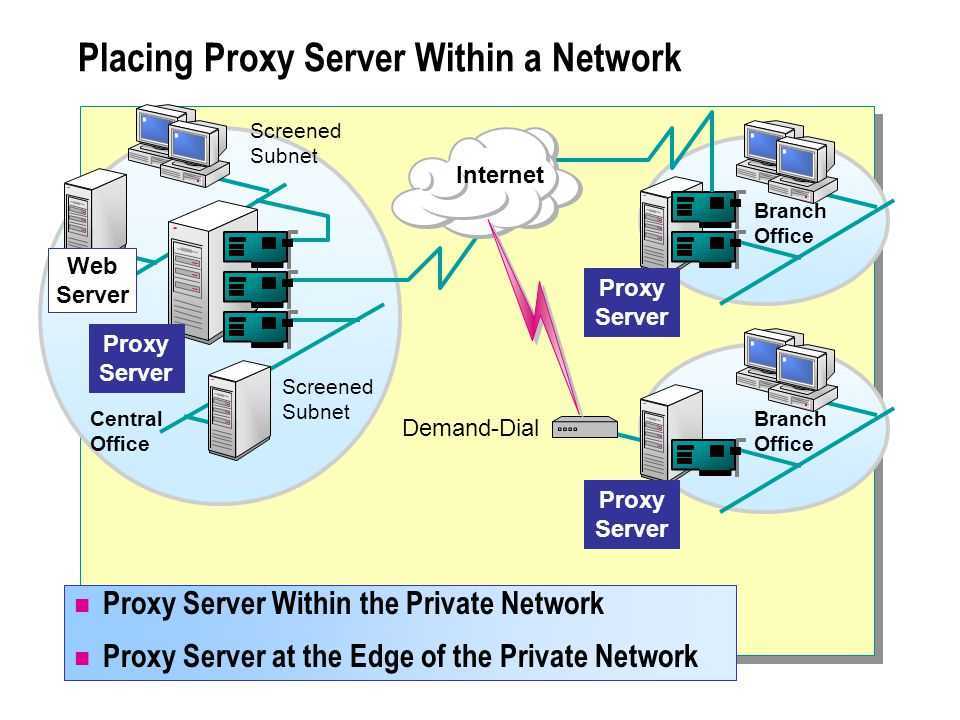
«На местах» — я, если честно, не знаю, какой правильный термин тут использовать. Уверен, читатели меня поправят и предложат красивое определение. Я лучше расскажу, что имею в виду под «на местах»: в поле (в прямом смысле слова — на агрокультурном поле), на производственной площадке (на заводе, фабрике, металлообрабатывающих, горнодобывающих и нефтегазовых объектах), на ремонтной площадке, на транспорте (в автомобиле, грузовике, ж/д вагоне, локомотиве), на объектах городской инфраструктуры (в местах сбора информации о потреблении электричества и воды, в канализации, вдоль улиц, в объектах освещения), на объектах междугородной инфраструктуры (вдоль шоссе, железных дорог, возможно, линий электропередач). В общем, «на местах» — это везде, куда рука интернета только начинает добираться. Еще можно сказать «в поле», но тогда появляется риск сузить круг промышленного интернета вещей только до агрокультурного поля.
Версионирование образа для докера tarantool/tarantool
Допустим, версия образа 1.7.3. А какая версия Tarantool внутри? Мы знаем, что 1.7.3, но номер сборки неизвестен. Единственный вариант — посмотреть исходники. Допустим, нужна версия Tarantool 1.7.3-115, потому что в 114 ещё была проблема, которая нас больно бьет, а в 116 — мы не знаем, есть она или нет. Какую версию образа взять?
Мы решили задачу просто: сами собираем свой образ, указываем конкретный номер сборки — и всё прекрасно работает. Но в целом это небольшая проблема. Образ по умолчанию прекрасно работает и покроет бо́льшую часть запросов, туда включены все основные модули, которые нужны для работы с Tarantool: мониторинг, очереди и т. д. Можно брать и пользоваться.
Как устроено ядро?
всегда
- Тапл = строка
- Спейс = таблица
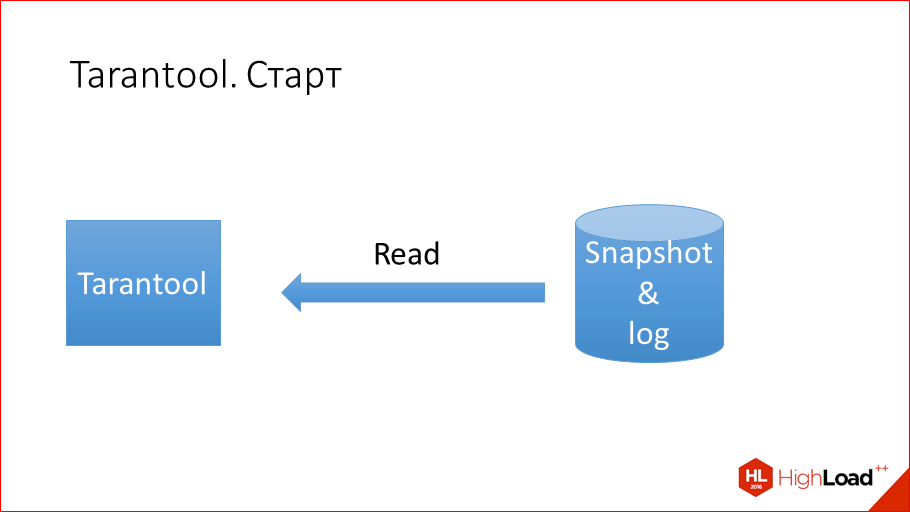
- Tarantool находит последний snapshot и начинает его читать.
- Прочитывает и смотрит, какие есть xlog после этого snapshot. Читает их.
- По завершению чтения snapshot и xlog имеем снимок данных, который был на момент рестарта.
- Дальше Tarantool достраивает индексы. В момент чтения snapshot строятся только primary индексы.
- Когда все данные подняты в память, мы можем построить вторичные индексы.
- Tarantool запускает приложение.
Устройство ядра в шесть строк:
- Данные находятся в памяти
- Доступ к данным из одного треда
- Изменения пишутся во Write Ahead Log
- К данным построены индексы
- Периодически сохранятся Snapshot
- WAL реплицируется.
Выводы
.NET — это далеко не только Windows: .NET Core работает на всех платформах. У нас в production есть .NET-приложение, которое прекрасно функционирует на Linux. Наши opensource-проекты без проблем собираются и работают на Windows, Mac OS и Linux (тестируются только Windows 10, Max OS X, Ubuntu 16.04). При этом вполне возможно для разработки и отладки использовать весь богатый инструментарий, доступный в мире .NET и зачастую бесплатный даже для коммерческой разработки.
Благодаря кроссплатформенности новых .NET-решений, появляется возможность использовать недоступные ранее инструменты, например, Tarantool. Если вам важна скорость работы, вторичные индексы, возможность использования СУБД в качестве сервера приложений или очереди задач, то Tarantool — очень хороший выбор на сегодняшний день.



