
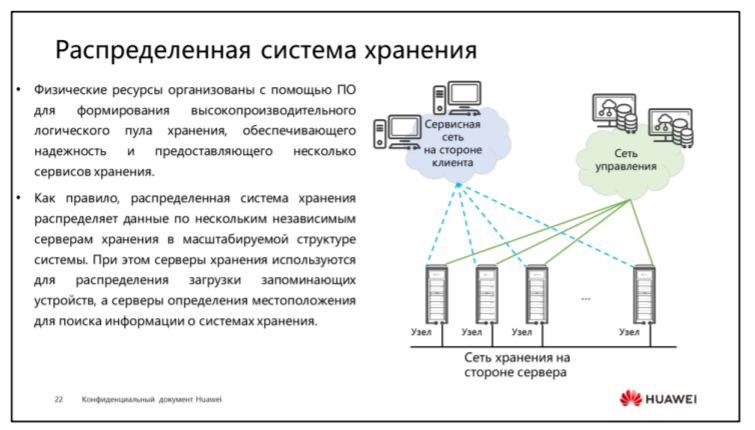
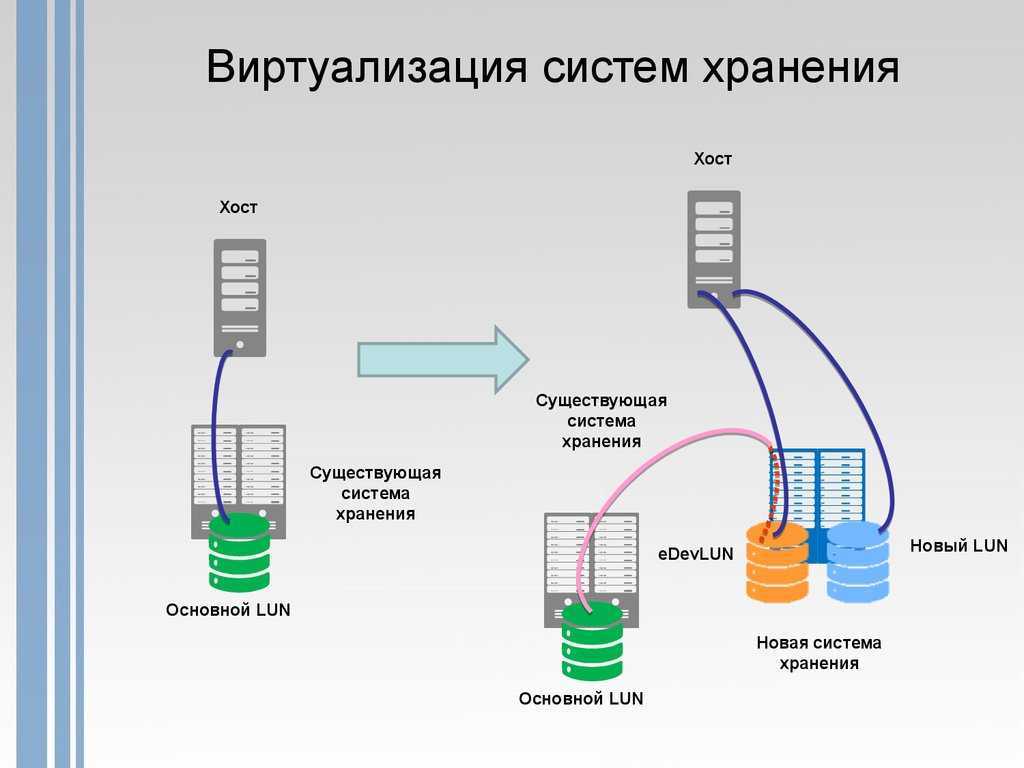
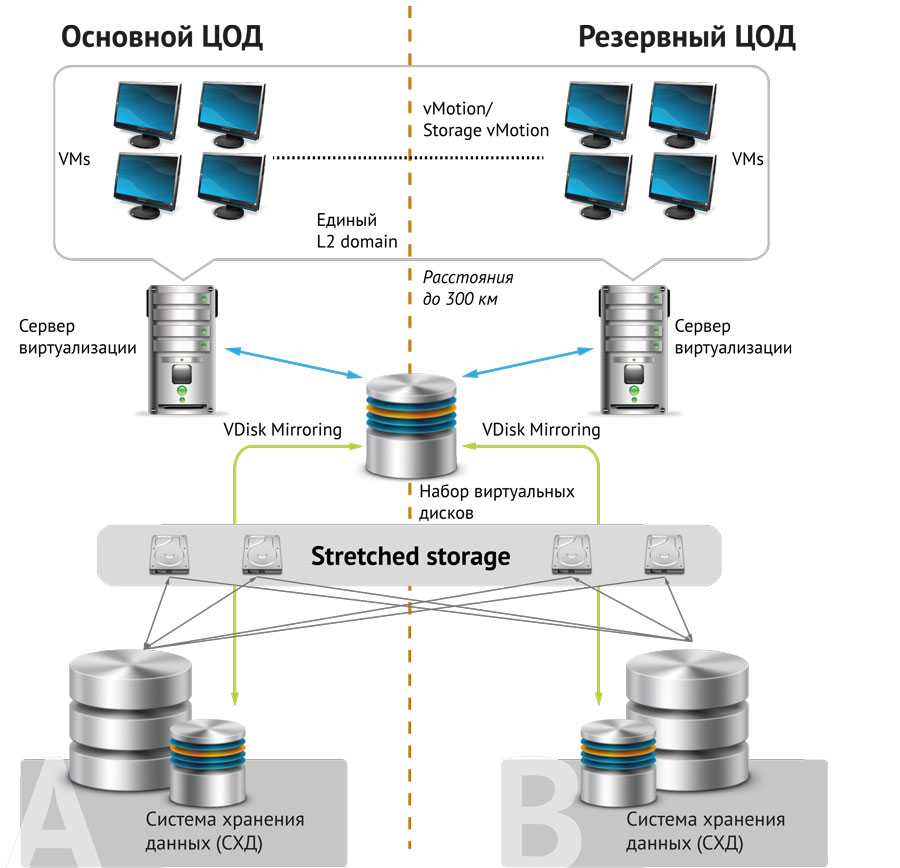
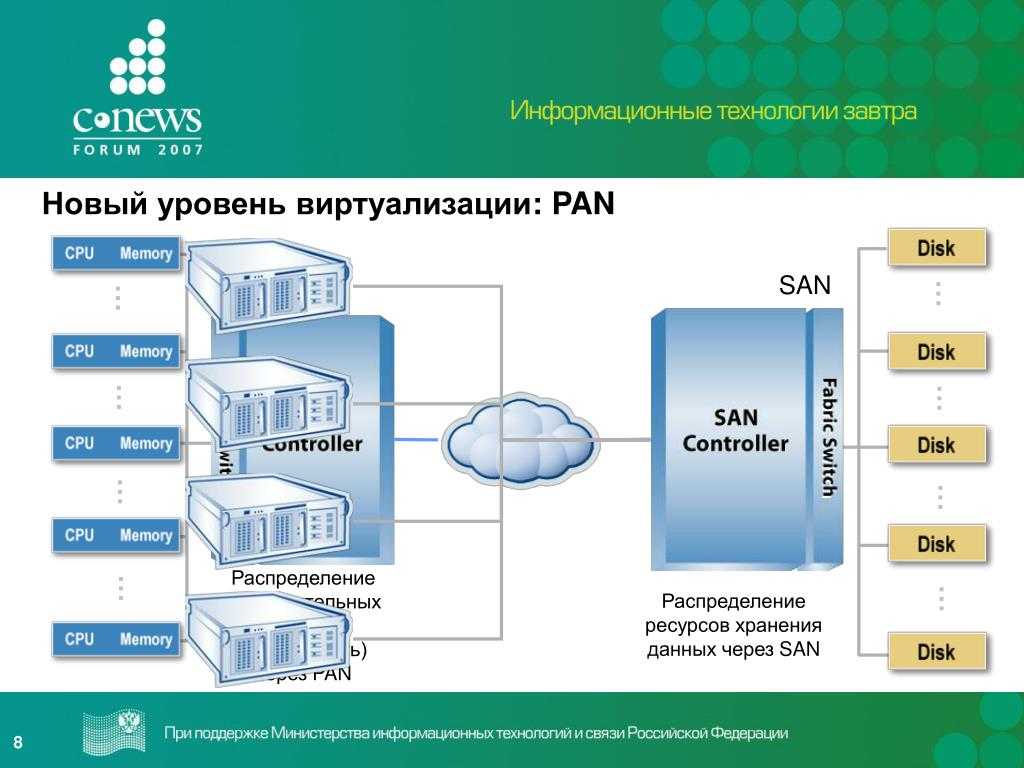
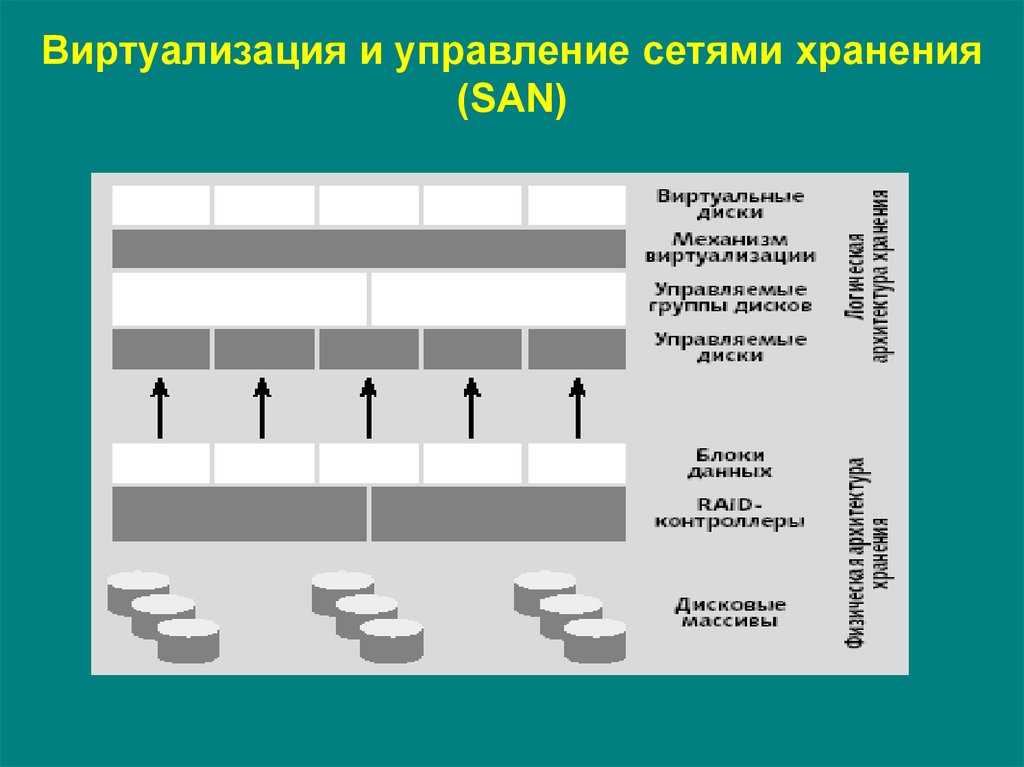
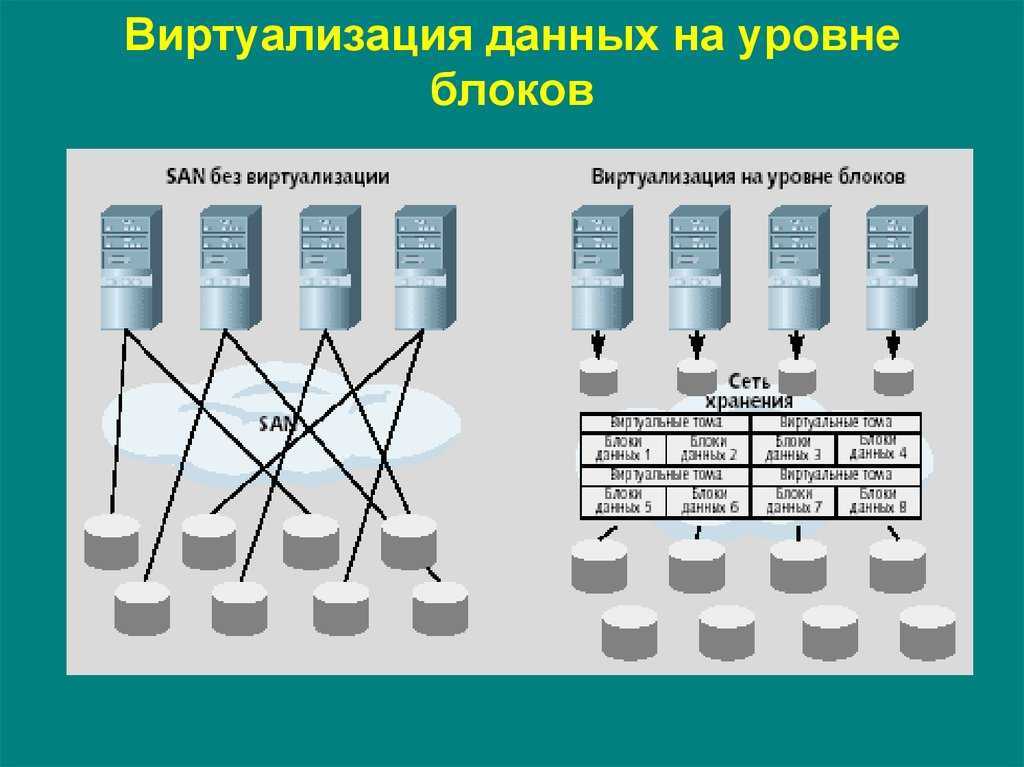
Здесь смотрим, а там считаем
Хотелось бы отметить еще одно немаловажное преимущество VDI. Оно заключается в том, что абсолютно все вычисления производятся непосредственно на стороне сервера
Именно эти операции и носят название «облачные вычисления». Так как вычисления осуществляются в самом «облаке», которое находится в ЦОД, само по себе пользовательское устройство (в любом варианте исполнения), по сути, является просто терминалом, отображающим картинку виртуальной машины. Абсолютно никакие данные организации не обрабатываются и не хранятся на клиентском устройстве. Естественно, при подобном распределении нагрузки используемое совсем не обязательно использовать сверхмощное клиентское устройство. Вполне достаточно, чтобы его технические показатели позволяли устанавливать сетевое соединение, а также отображать некий удаленный рабочий стол. А есть определенный ряд аппаратных реализаций, которые подразумевают полное отсутствие системного блока у пользователя. В этом случае абсолютно все необходимое для работы оборудование размещено прямо в мониторе. В качестве ОС прошивают специальный Linux (или настраиваю Windows). Именно с его помощью и будет осуществляться в последующем подключение к соответствующему виртуальному рабочему месту. Также сэкономить неплохие деньги на ИТ — инфраструктуре дает возможность использование тонких клиентов.
Средства повышения надёжности данных в АСУ ТП
Технологии поддержки «горячего» резервирования ICONICS для серверов, клиентов и других компонентов АСУ ТП реализованы и в новом пакете Hyper Historian версии 10.6. Конфигурирование узлов для «горячего» резервирования даёт возможность построения универсальных многоуровневых систем с целью минимизации избыточности данных. С Hyper Historian достаточно легко создать распределённые многоуровневые системы. Система верхнего уровня может служить хранилищем данных для основной и резервной копий критической информации. Многочисленные системы верхнего уровня могут выполнять репликацию всех исторических данных. Также резервируемые системы нижнего уровня могут передавать либо весь информационный поток данных, либо только сводные агрегированные данные в одну или несколько систем верхнего уровня. Многоуровневые архитектуры обеспечивают защиту от возможных потерь данных, вызванных остановкой той или иной информационной системы, простоями в сети и т.п. В многоуровневых системах архивации данные не хранятся непосредственно в таблицах Microsoft SQL Server, вместо этого используется высокооптимизированная файловая система, независимая от реляционной базы данных.
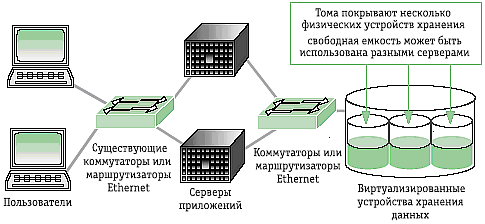
Рис. 3. Архитектура систем хранения DAS для Hyper Historian
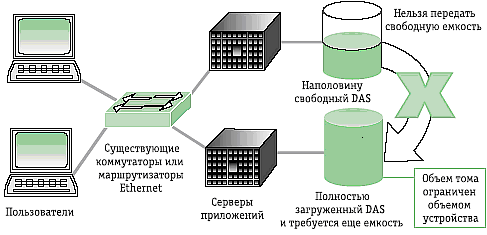
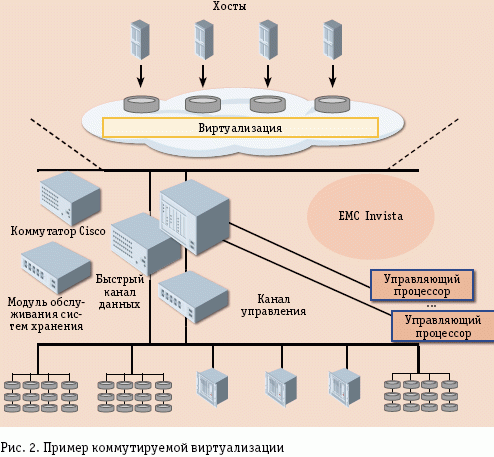
Одним из вариантов реализации передовых технологий хранения Hyper Historian являются устройства DAS (Direct Attached Storage). В основе решения DAS лежит технологическая схема, в которой устройство для хранения данных подключено непосредственно к серверу или к рабочей станции, как правило, через внешний интерфейс SAS. На рис. 3 схематично показано, как на любом уровне с одинаково высокой надёжностью полностью интегрируются данные, тревоги и события, сводная информация и другие производственные данные, а также информация о конфигурации базы данных. К основным преимуществам DAS-систем можно отнести их низкую стоимость (в сравнении с другими решениями систем хранения данных), простоту развёртывания и администрирования, а также высокую скорость обмена данными между системой хранения и сервером. Благодаря именно этому свойству они завоевали большую популярность в сегментах любого уровня АСУ ТП и многих корпоративных сетей АСУП.
Рис. 4. Базовая архитектура и топология DAS
На рис. 4 приведена базовая топология организации хранилища данных, принятая в большинстве АСУ ТП. В то же время DAS-системы имеют и свои недостатки, к которым можно отнести неоптимальную утилизацию ресурсов, поскольку каждая DAS-система требует подключения выделенного сервера и позволяет подключить максимум два сервера к дисковому массиву в определённой конфигурации. Для создания отказоустойчивого кластера, SQL-сервера и других приложений АСУ ТП описанная модель DAS вполне подойдёт.
Рис. 5. Пример построения отказоустойчивого кластера для системы архивации данных
Пример блок-схемы DAS приведён на рис. 5. Помимо программных технологий организации агрегации, «горячего» резервирования подобная система уже имеет активную логику внутри корпуса и полностью избыточна за счёт использования двух встроенных контроллеров RAID, работающих по схеме «активный – активный» и имеющих зеркалированную копию буферизованных в кэш-памяти данных. Оба контроллера параллельно обрабатывают потоки чтения и записи данных, и в случае неисправности одного из них второй «подхватывает» данные с соседнего контроллера. При этом подключение к низкоуровневому SAS-контроллеру SAS 5E внутри двух серверов (кластеру) может производиться по нескольким интерфейсам (MPIO), что обеспечивает избыточность и балансировку нагрузки в средах Microsoft.
Выход за пределы периметра
При удаленной работе пользователей выгоднее всего использовать инфраструктуру виртуальных рабочих мест. Основные преимущества данного метода мы уже рассмотрели. Теперь остановимся на недостатках.
Серьезное внимание на стороне облака должно уделяться безопасности и настройке сервера. Необходимыми средствами защиты при этом должны стать специальные сканеры уязвимости, средства для предотвращения внешних вторжений, межсетевые экраны, антивирусы и так далее
Естественно, программное обеспечение присутствует и на стороне клиента. Если речь идет о бездисковой станции, то это будет несколько сокращенный дистрибутив Linux. Когда работа осуществляется на планшете или персональном компьютере, используется полноценная операционная система. Как правило, удаленные пользователи используют для подключения именно ПК или планшет. Не сложно понять, что заразить ноутбук, который работает на основе установленной Windows, или планшет, работающий на iOs и Android, вирусом достаточно просто.
При заражении неким вредоносным кодом есть шанс перехвата. Причем, «перехвачены» могут быть также и учетные данные, которые применяются при подключении к VDI.
Помимо всего прочего операционные системы, а также приложения в себе содержат некоторые уязвимости, которые смогут использовать злоумышленники с целью получения свободного доступа к устройству, а далее и к самому удаленному рабочему столу. Достаточно неплохим решением при борьбе с угрозами подобного характера, может стать применение одноразовых паролей. И даже если злоумышленники перехватят учетные данные, все равно не удастся использовать их для установки соединения с VDI и виртуализированными серверами.
Еще к средствам защиты следует отнести запрет на передачу информации в облако с клиентского устройства. В процессе отправки на сервер файлов существует некоторая вероятность проникновения внутрь вредоносного кода. Однако его не пропустит установленный в облаке антивирус. А если требуется работа с файлами, необходимо выделить специальную карантинную зону, когда будут заканчиваться и проверяться на вирусы файлы.
Но все равно самым идеальным вариантом станет закрытие любых возможностей обмена информацией между клиентским устройством и виртуальной машиной. Только в этом единственном случае вся конфиденциальная информация будет реально максимально защищена, так как она не будет покидать периметр дата-центра, виртуализации серверов.
Дисковый контроллер и бэкплейн
Дисковый контроллер (HBA)
В системах хранения данных дисковый контроллер является устройством, через которое подключенные накопители передаются вычислительным ресурсам системы. Физически дисковый контроллер обычно представлен отдельной картой расширения, но также может быть в виде чипа, интегрированного в непосредственно в материнскую плату. Если говорить простым языком, то дисковый контроллер позволяет видеть и работать с дисками всем следующим уровням СХД.
HBA (Host Bus Adapter, адаптер главной шины) — разновидность дискового контроллера, которая позволяет системе видеть подключенные накопители по отдельности.

Рисунок 5. Дисковый контроллер от Broadcom (9400-8i Tri-Mode Storage Adapter).

Triple-mode
Существуют дисковые контроллеры, которые совмещают в себе возможность одновременной работы сразу с тремя протоколами (SATA, SAS, NVMe). Этот подход удобен и обеспечивает гибкость при проектировании системы хранения, так как позволяет подключать как традиционные SATA-диски, так и сверхбыстрые NVMe накопители.
Бэкплейн и экспандер
В большинстве случаев накопители в СХД подключаются непосредственно через бэкплейн (backplane) — специальную плату в дисковой полке или сервере с разъемами для SAS, SATA, NVMe накопителей, которая соединяется с дисковым контроллером. Сам дисковый контроллер, как правило, поддерживает прямое подключение ограниченного числа накопителей. Для увеличения числа подключаемых дисков используют экспандер. В большинстве случаев он представляет собой чип, который устанавливается на бэкплейн.

Рисунок 6. Бэкплейн Supermicro BPN-SAS-826TQ.
Рисунок 7. SAS-экспандер Broadcom в виде чипа.
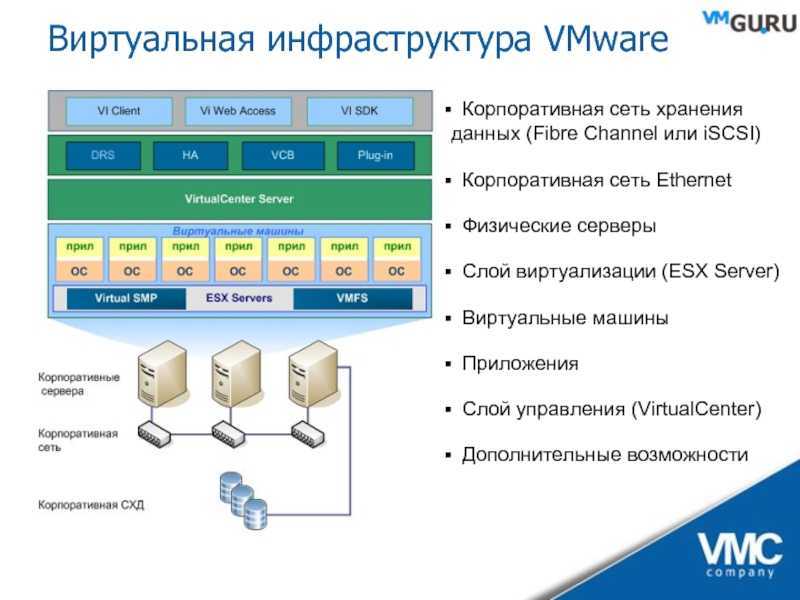
Платформы виртуализации
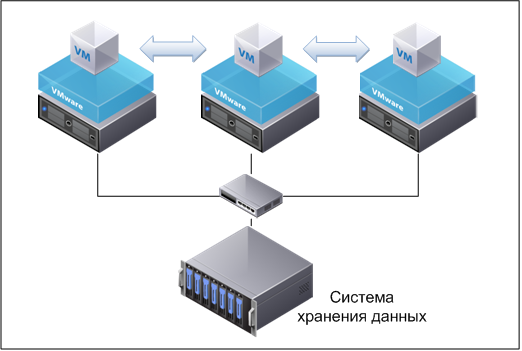
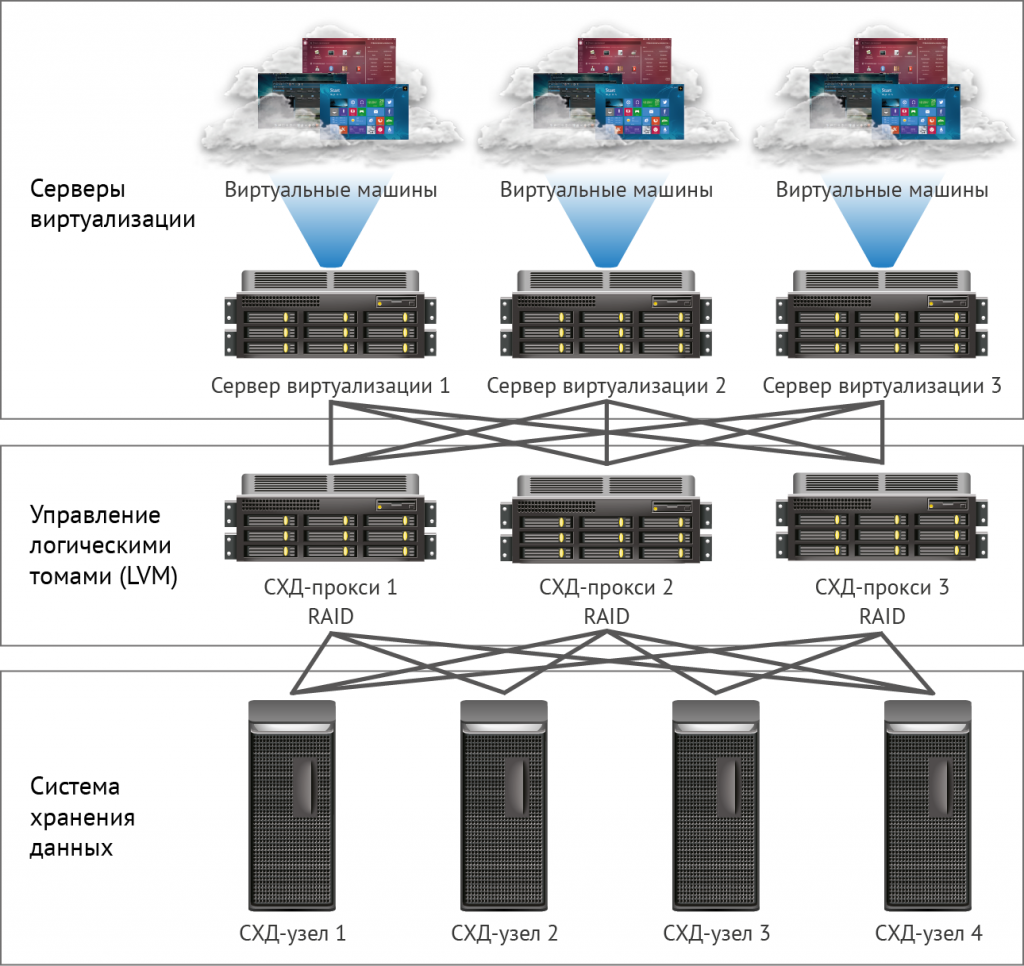
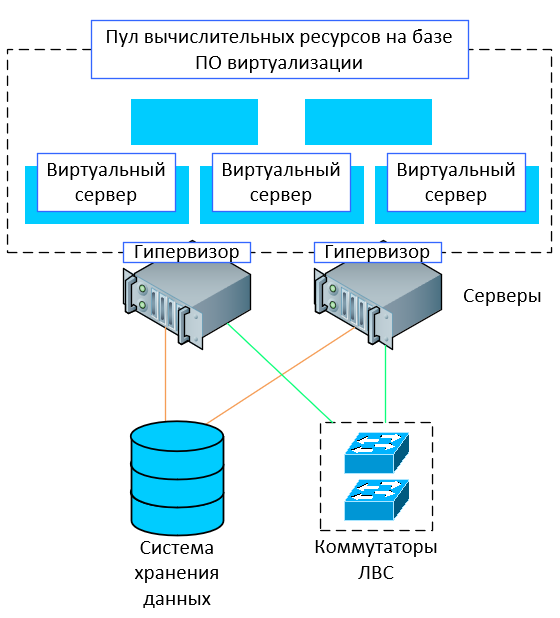
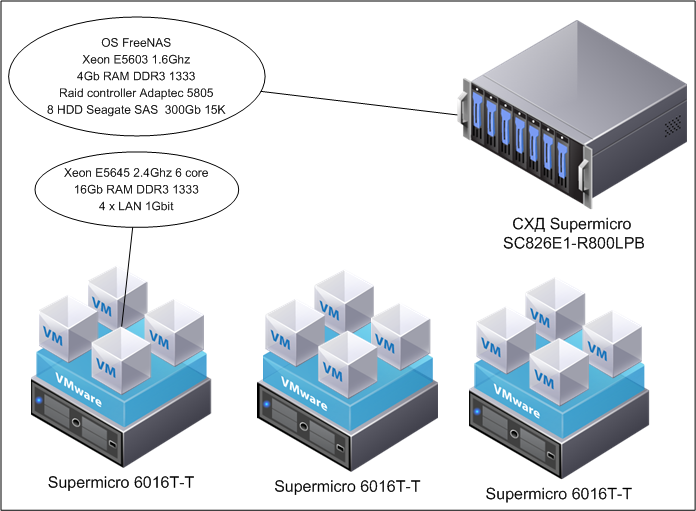
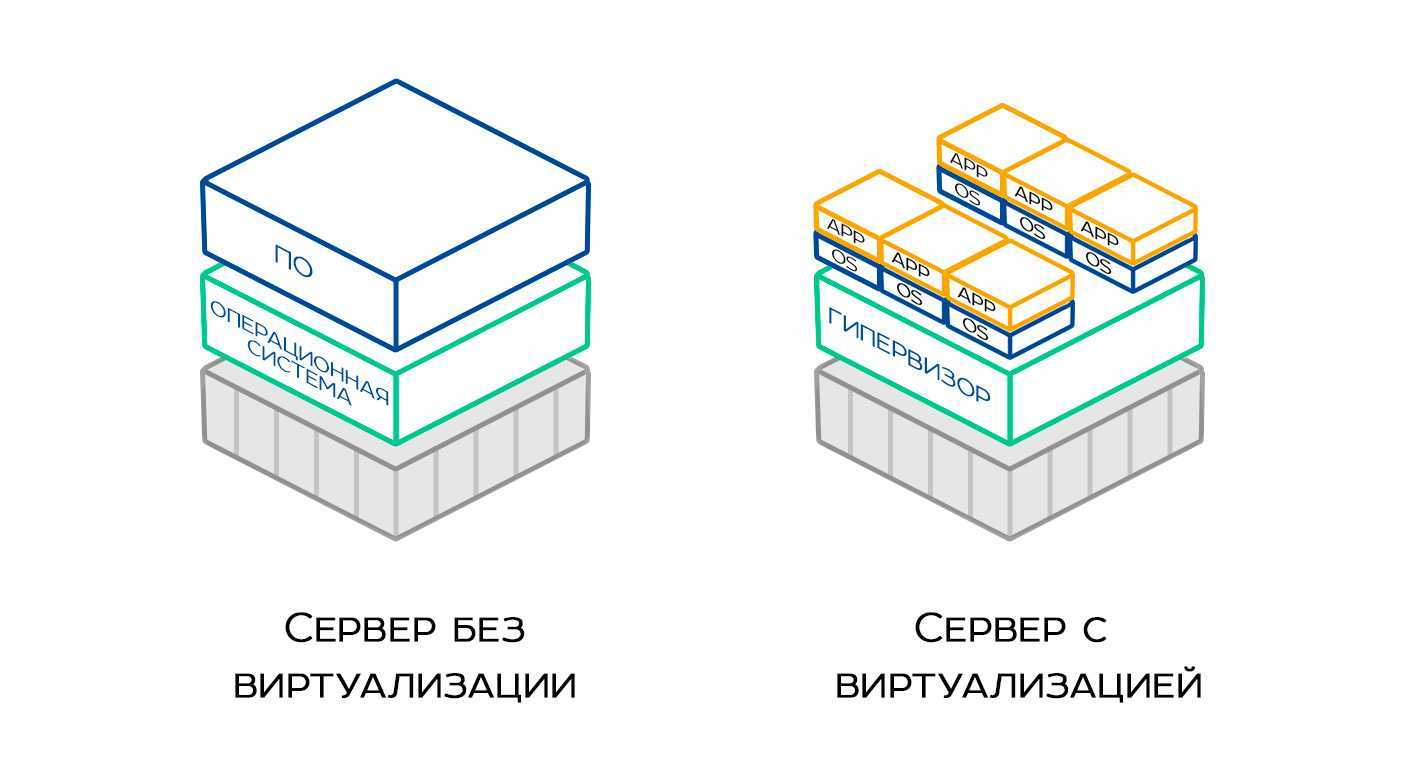
Для того, чтобы выделить вам необходимые ресурсы, используется такой процесс как виртуализация, которая помогает на одном физическом сервере создать несколько виртуальных. Сама возможность запуска нескольких изолированных друг от друга виртуальных серверов используется для оптимизации энергопотребления. Гораздо проще и дешевле иметь схему «один сервер — множество ОС — множество информационных систем», чем «Один сервер — одна ОС — одна информационная система». Виртуализация делается с помощью специального программного обеспечения — гипервизоров или платформ для виртуализации. Одни из самых популярных — Vmware ESXi и KVM (встроена в ядро Linux). Оба не требуют установки ОС на сервер, могут работать «из-под железа»
Какие бывают системы хранения данных
Существует классификация СХД: они делятся на файловые, блочные и объектные. Каждый вид СХД определяет в каком виде хранятся данные, способ доступа к ним, и, как результат, простоту управления и скорость доступа к данным.
Файловые
Хранят информацию в виде файлов, собранных в каталоги (папки). Файлы организуются и извлекаются благодаря метаданным, которые сообщают, где находится тот или иной файл. Условно такую систему можно представить в виде каталога.
Блочные
Данные хранятся независимо друг от друга. Каждому такому блоку присваивается идентификатор, который позволяет системе размещать каждый блок, где ей удобно. Блочные хранилища не полагаются на единственный путь к данным (в отличии от файловых хранилищ).
Объектные
Расщепляют файлы на «объекты», которые находятся в одном, общем хранилище. Оно может быть поделено на тома, каждый из которых может иметь уникальный идентификатор и подробные метаданные, которые позволяют быстро находить объекты. Подобный подход — это распределённая система.
Накопители в СХД
СХД может работать с разными носителями данных: магнитная лента, оптические диски, жесткие диски (HDD) и твердотельные накопители (SSD/NVMe). Мы рассмотрим только два последних типа, так как именно они распространены в качестве универсальных носителей в большинстве систем.
Надо понимать, что накопители в СХД задают аппаратный предел производительности: система не может работать быстрее, чем сумма производительности ее накопителей. Медленнее — может.
Накопители имеют много важных параметров и характеристик, которые следует учитывать при построении СХД, но базовыми атрибутами, пожалуй, можно назвать тип интерфейса и форм-фактор.
Интерфейсы современных HDD и SSD
Интерфейс представляет собой протокол взаимодействия накопителя и вычислительных ресурсов системы. Интерфейс является важным фактором, влияющим на параметры накопителя: от него зависит пропускная способность, время задержки, расширяемость, возможность горячей замены и, конечно же, стоимость.
Интерфейсы SATA и SAS изначально появились на HDD-дисках, но затем стали стандартом и для SSD. Однако SATA и SAS не могут раскрыть весь потенциал производительности SSD, поэтому для подключения твердотельных накопителей все чаще используется интерфейс PCIe и протокол NVMe. Также стоит отметить NL-SAS диски, которые по сути являются гибридом SAS-интерфейса и SATA накопителя.
Таблица 1. Общее сравнение характеристик HDD и SSD накопителей
| Класс | HDD | SSD | ||||
| Интерфейс | SATA | SAS | SATA | SAS | PCIe | |
| Накопитель | SATA | NL-SAS | SAS | SATA | SAS | NVMe |
| Надежность | Низкая | Средняя | Высокая | Средняя | Высокая | Высокая |
| Производительность | Низкая | Низкая | Средняя | Высокая | Высокая | Очень высокая |
| Стоимость | Низкая | Низкая | Средняя | Средняя | Высокая | Очень высокая |
Форм-фактор
Все HDD имеют схожую конструкцию подвижных элементов, поэтому их внешний корпус — это прямоугольный кейс типа SFF (Small Form Factor, 2.5″) или LFF (Large Form Factor, 3.5″). Каждый из этих типов корпуса может иметь различные разъемы интерфейса.

Рисунок 2. Western Digital Ultrastar SN640 в форм-факторе SFF 2.5″ (слева) и Seagate Exos X12 в форм-факторе LFF 3.5″ (справа).
Flash-накопители не имеют движущихся деталей и поэтому реализованы в более разнообразных формах. Дополнительным импульсом для разнообразия форм-факторов SSD стало развитие PCIe-интерфейса, который добавил варианты прямого размещения накопителей на серверной платформе.
Таблица 2. Форм-факторы HDD и SSD накопителей
| Форм-фактор | HDD | SSD |
| 3.5″ (LFF) | SATA, NL-SAS, SAS | — |
| 2.5″ (SFF) | SATA, NL-SAS, SAS | SATA, SAS, NVMe |
| M.2* | — | SATA, NVMe |
| Add-In Card (AIC) | — | NVMe |
| EDSFF | — | NVMe |
*используются в качестве системных дисков

Рисунок 3. Intel Optane SSD в форм-факторе Add-In-Card HHHL (Half-Height Half-Length).
Форм-фактор является достаточно динамичным параметром, который постоянно меняется и совершенствуется в зависимости как от изменения интерфейсов, так и от изменения подходов к построению СХД. Более подробно про актуальные форм-факторы можно прочитать на сайте SNIA.
JBOD
В современных СХД накопители могут размещаться как в основном корпусе СХД, так и в дисковых корзинах — JBOD (Just a Bunch Of Drives). Физически такие корзины представляют собой корпус для монтажа в стойку, заполненный накопителями. Для NVMe накопителей сейчас активно используются JBOF (Just a Bunch Of Flash), специализированные дисковые корзины для флеш-накопителей. Например, OpenFlex Data24 от компании Western Digital.

Рисунок 4. Дисковая корзина WD Ultrastar Data102.
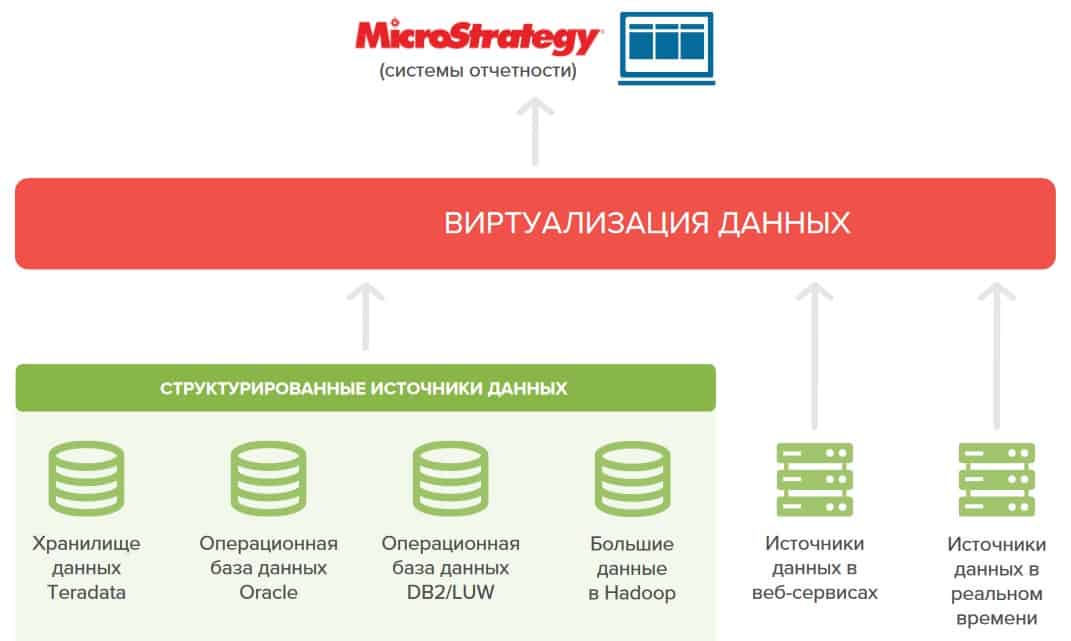
Data Lake и корпоративное хранилище данных: как работать с Big Data
В 2010-х годах, с наступлением эпохи Big Data, фокус внимания от традиционных DWH сместился озерам данных (Data Lake). Однако, считать озеро данных новым поколением КХД не совсем корректно по следующим причинам:
разное целевое назначение – DWH используется менеджерами, аналитиками и другими конечными бизнес-пользователями, тогда как озеро данных – в основном Data Scientist’ами. Напомним, в Data Lake хранится неструктурированная, т.н. сырая информация: видеозаписи с беспилотников и камер наружного наблюдения, транспортная телеметрия, графические изображения, логи пользовательского поведения, метрики сайтов и информационных систем, а также прочие данные с разными форматами хранения (схемами представления). Они пока непригодны для ежедневной аналитики в BI-системах, но могут использоваться Data Scientist’ами для быстрой отработки новых бизнес-гипотез с помощью алгоритмов машинного обучения ;
разные подходы к проектированию. Дизайн DWH основан на реляционной логике работы с данными – третья нормальная форма для нормализованных хранилищ, схемы звезды или снежинки для хранилищ с измерениями
При проектировании озера данных архитектор Big Data и Data Engineer большее внимание уделяют ETL-процессам с учетом многообразия источников и приемников разноформатной информации. А вопрос ее непосредственного хранения решается достаточно просто – требуется лишь масштабируемая, отказоустойчивая и относительно дешевая файловая система, например, HDFS или Amazon S3 ;
наконец, цена – обычно Data Lake строится на базе бюджетных серверов с Apache Hadoop, без дорогостоящих лицензий и мощного оборудования, в отличие от больших затрат на проектирование и покупку специализированных платформ класса Data Warehouse, таких как SAP, Oracle, Teradata и пр.
Таким образом, озеро данных существенно отличается от КХД. Тем не менее, архитектурный подход LSA может использоваться и при построении Data Lake. Например, именно такая слоенная структура была принята за основу озера данных в Тинькоф-банке :
- на уровне RAW хранятся сырые данные различных форматов (tsv, csv, xml, syslog, json и т.д.);
- на операционном уровне (ODD, Operational Data Definition) сырые данные преобразуются в приближенный к реляционному формат;
- на уровне детализации (DDS, Detail Data Store) собирается консолидированная модель детальных данных;
- наконец, уровень MART выполняет роль прикладных витрин данных для бизнес-пользователей и моделей машинного обучения.
В данном примере для структурированных запросов к большим данным используется Apache Hive – популярное средство класса SQL-on-Hadoop. Само файловое хранилище организовано в кластере Hadoop на основе коммерческого дистрибутива от Cloudera (CDH). Традиционное DWH банка реализовано на массивно-параллельной СУБД Greenplum . От себя добавим, что альтернативой Apache Hive могла выступить Cloudera Impala, которая также, как Greenplum, Arenadata DB и Teradata, основана на массивно-параллельной архитектуре. Впрочем, выбор Hive обоснован, если требовалась высокая отказоустойчивость и большая пропускная способность. Подробнее о сходствах и различиях Apache Hive и Cloudera Impala мы рассказывали здесь. Возвращаясь к кейсу Тинькофф-банка, отметим, что BI-инструменты считывают данные из озера и классического DWH, обогащая типичные OLAP-отчеты информацией из хранилища Big Data. Это используется для анализа интересов, прогнозирования поведения, а также выявления текущих и будущих потребностей, которые возникают у посетителей сайта банка .
LSA-архитектура корпоративного Data Lake в Тинькоф-банке
В следующей статье мы продолжим разговор про архитектурные особенности современных DWH с учетом потребности работы с Big Data и рассмотрим еще несколько примеров таких гибридных подходов. А технические подробности реализации КХД и другие актуальные вопросы управления бизнес-данными вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Модели Данных
- Hadoop для инженеров данных
- Cloudera Impala Data Analytics
- Hadoop SQL администратор Hive
Смотреть расписание
Записаться на курс
Источники
- https://ru.wikipedia.org/wiki/Хранилище_данных
- https://habr.com/ru/post/269727/
- https://habr.com/ru/post/281553/
- https://habr.com/ru/post/495670/
- https://chernobrovov.ru/articles/kuda-slit-big-data-ili-zachem-vam-ozero-dannyh.html
- https://habr.com/ru/company/tinkoff/blog/259173/
3.2 Norton Ghost 12.0
Ghost 12.0 предоставляет широкие возможности для
резервирования и восстановления, включая возможность создания скрытого раздела
на вашем системном диске, где можно хранить (а затем запустить) загрузочный
образ и образ вашего диска для быстрого и лёгкого последующего восстановления.
Мы используем этот способ на наших тестовых машинах, чтобы облегчить процесс их
восстановления до первоначального состояния. Большинство продавцов ноутбуков
поступают также, чтобы упростить и ускорить покупателям возврат к «заводскому»
образу диска.
При запуске программы Ghost появляется окно, в котором на
панели задач предлагаются различные опции резервирования и восстановления.
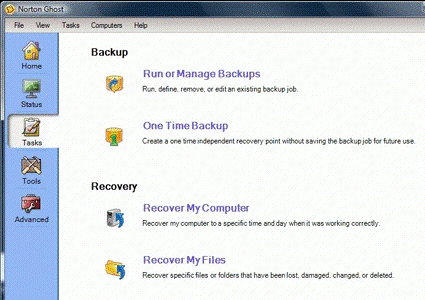
После первого запуска программы вы увидите набор базовых
опций резервирования и восстановления.
При выборе резервирования запускается «Мастер» (Define Backup
Wizard), который помогает пройти все необходимые шаги. В следующем окне
выбираем создание образа всего диска, потому что это пригодится для
восстановления «с нуля».
Первый шаг, который предлагает «Мастер» резервирования, — это
выбор типа резервирования: полное (всей системы) или выборочное (отдельных
файлов и папок).
Далее из списка дисков нужно выбрать диск или диски, для
которых будут сделаны резервные копии.
В данном окне выберите один или несколько дисков для создания
образов.
После этого нужно указать тип точки восстановления: будет ли
она потенциально принадлежать к обновляемой, когда инкрементные образы могут
добавляться хоть до бесконечности, или это будет одиночный образ диска.
При создании нового образа нужно указать, будет ли это
независимая отдельная копия, или же впоследствии к ней могут добавляться инкрементные
копии.
Далее нужно выбрать целевой диск для создания образа. В нашем
случае это второй внутренний диск нашей тестовой системы.


Выберите целевой диск для образа вашего диска (как правило,
этот диск отличается от того диска, образ которого создаётся).
Сейчас можно выбрать опции точки восстановления: имя, схема
сжатия, контроль считыванием после записи, максимальное число наборов точек
доступа (по умолчанию три), возможен ли будет поиск резервной копии, и включать
ли в поиск системные и временные файлы.
Рабочее место «в облаке»
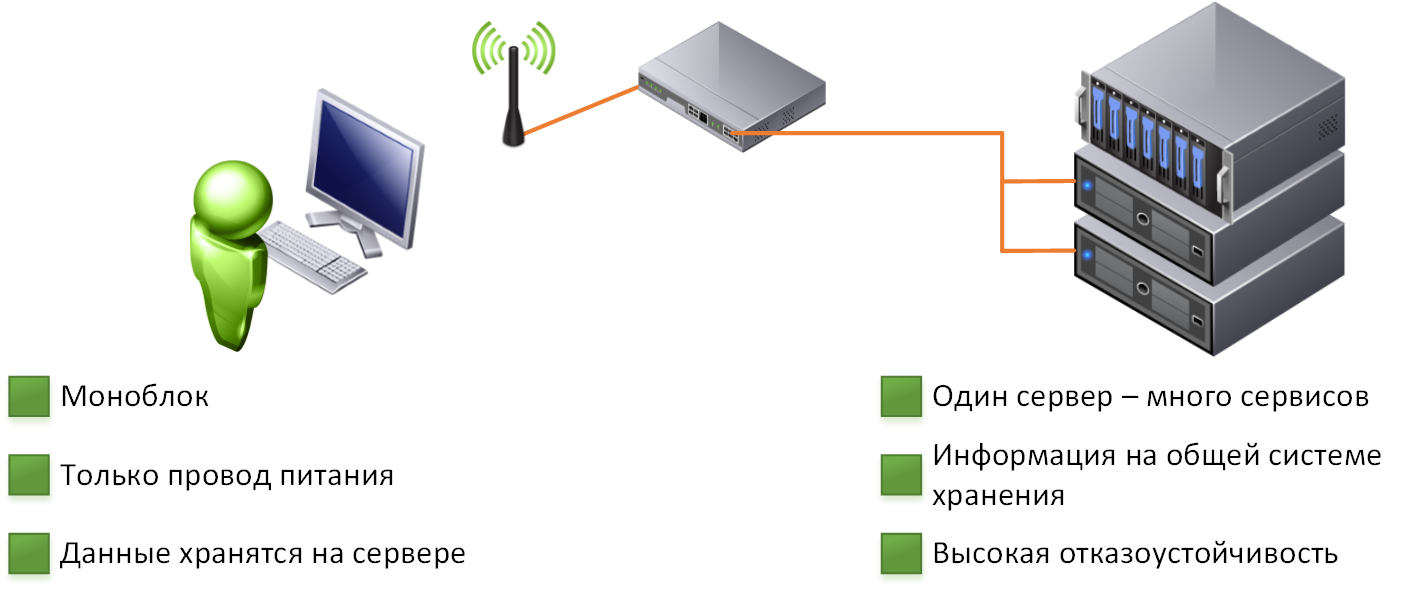
Так, сама по себе VDI — это инфраструктура так называемых виртуальных рабочих станций (виртуальных машин). Суть данной технологии заключается в полном замещении физических ЭВМ массивом виртуальных компьютеров (установкой виртуальных машин), которые развернуты в ЦОД. При необходимости доступ к ним может быть осуществлен с любого клиентского устройства, подходящего для подобных целей. В качестве рабочей консоли при этом вполне может использоваться, как тонкий клиент или самый обычный компьютер, так и компьютер мобильный, который дает возможность доступа к виртуальной РС не только непосредственно в офисе, но и абсолютно из любой точки мира, где есть возможность выйти в сеть Интернет.
Уточним, что любой персональный компьютер — это цельная и неделимая система, состоящая из таких компонентов, как пользовательские приложения, данные, а также операционная система и аппаратные средства. Для осуществления квалифицированной поддержки всех этих систем в офисе требуется целый штат квалифицированных специалистов с достаточно высокой оплатой труда. Причем, речь идет именно о грамотных работниках, а не об аникейщиках. Ведь далеко не всегда решение проблемы заключается в банальном извлечении листа бумаги, застрявшего в принтере либо замене вышедшей из строя мышки.
Все бизнес — приложения современного образца, в том числе и те, которые используют интерфейс, требуют обязательного наличия целого ряда специальных приложений, а также определенных настроек на клиентском компьютере. В качестве удачного примера такой системы вполне можно привести всем известную СХД DocsVision.
Разумеется, поддержка любых клиентских рабочих мест (настройка Windows) требует материальных затрат от руководства компании. А как быть, если пользователи осуществляют свою рабочую деятельность удаленно? В подобной ситуации значительно усложняется процесс настройки ПО, ведь все работы необходимо выполнить пользователю самостоятельно (удаленное администрирование может быть не применимо). Но как показывает практика, далеко не все владеют такими навыками. А говорить о решении более глобальных проблем, возникающих при удаленной работе, и вовсе бессмысленно. Также телефонные и Интернет — консультации очень редко помогают справиться с возникшими сложностями. Виртуализация серверов поможет упростить задачу.
Применение VDI дает уникальную возможность действительно существенно сократить материальные затраты на сопровождение и обслуживание клиентских рабочих мест. Экономия достигается благодаря тому, что в администрировании нуждается только лишь серверная часть. И достаточно просто написать несложную пошаговую инструкцию по подключению для удаленных пользователей, которая будет состоять буквально из четырех пунктов. И вся необходимая поддержка при этом автоматически будет сведена к осуществлению контроля за правильностью действий, выполняемых на основании инструкции.



