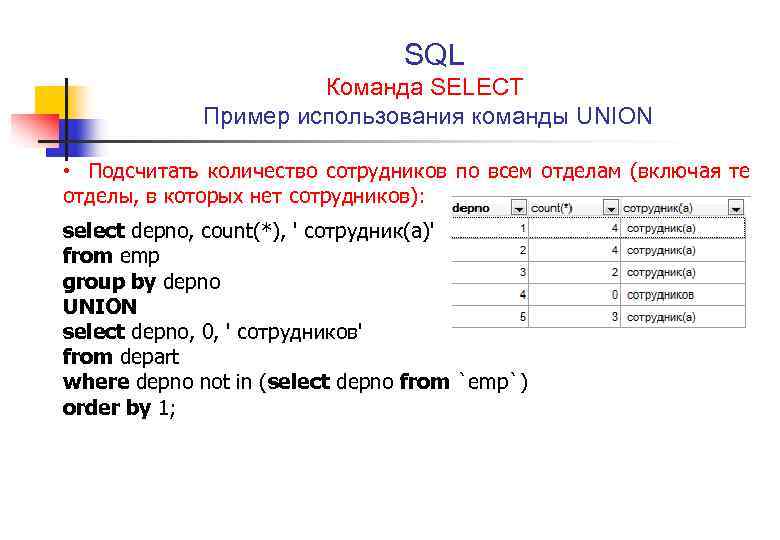
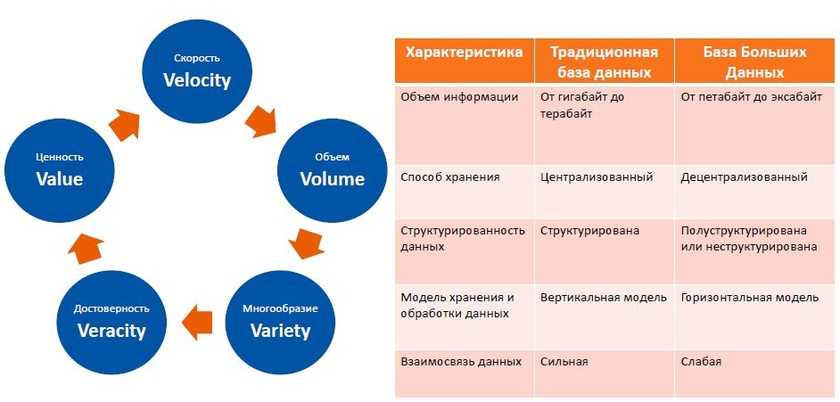
Введение. Почему в сфере работы с данными важно уделять внимание очистке данных и качеству данных?
Независимо от вашего опыта работы с данными и построения отчетности — плохие данные практически всегда приводят к неверным решениям.
На качество данных в первую очередь влияют бизнес-процессы, которые организованы в компании по занесению бизнес-сущностей в информационную систему.
Например, как вводятся накладные, как разносятся накладные по платежкам, как выставляются счета. Все ли взаимосвязано для расчета дебиторской задолженности в автоматическом режиме и т.д.
За все это как раз и отвечают бизнес-процессы. Если компания маленькая, то все можно собрать в ручном режиме и бизнес-процессы (точнее их отсутствие) не оказывают большого влияния на бизнес. Но для среднего и крупного бизнеса бизнес-процессы по занесению и ведению информации — очень критичный вид деятельности.
Для любого специалиста по работе с данными очень важным «параметром деятельности» является авторитет данных, заработать который зачастую не так-то просто, а вот потерять его можно очень быстро.
Если Вы на основе грязных данных разработаете отчеты, а потом скажете своей компании сделать что-то с этими результатами, которые окажутся неверными, то у Вас будет много неприятностей!
Неверные или противоречивые данные приводят к ложным выводам. То, насколько хорошо вы очищаете и понимаете данные, оказывает большое влияние на качество результатов.
Зачастую простой алгоритм может превзойти сложный алгоритм только потому, что ему были предоставлены более качественные данные.
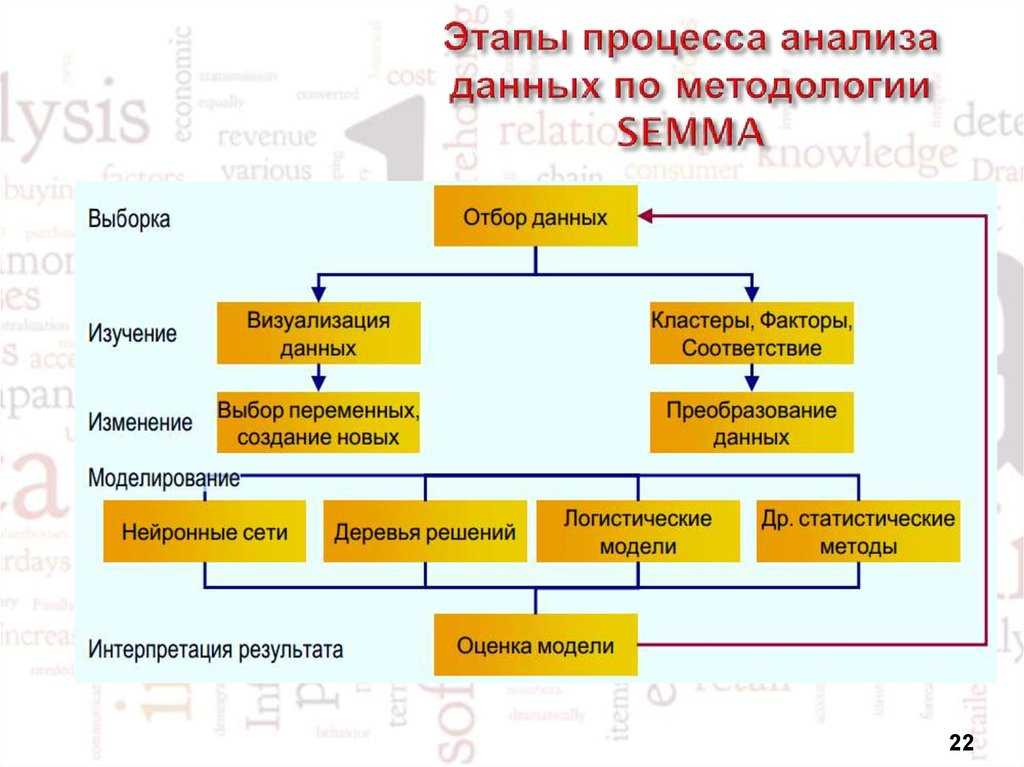
Методы линейного и нелинейного программирования
Для решения экономических задач методом оптимальных решений широко применяются методы линейного и нелинейного программирования. Это одно из прикладных направлений математики, применяющее теорию решения экстремальных задач на множествах, которые задаются системами неравенств и уравнений.
В случае, если исследуемое явление экономики можно выразить линейной функцией и многочленами первой степени, то используются методы линейного программирования. Задачи этой области знания решаются достаточно быстро и легко. Методы нелинейного программирования применяются тогда, когда в задаче есть какие-либо ограничения.
Примером задач линейного программирования могут быть различного рода производственные задачи. В них рассчитываются объемы закупок, выпуска и их соотношение для получения прибыли. Наиболее часто пользуются графическим методом решения данных задач. С помощью графиков строится область допустимых решений. Сопоставление графиков позволит найти оптимальное соотношение доходов и расходов предприятия.
Применение симплекс-метода требует приведения элементов задачи к равенству. Затем он используется для поступательного приведения решений к оптимальному варианту для задачных условий. Основой метода является итерация или повторение некоторого набора действий несколько раз.
Часто решение задач требует составления большого числа таблиц. Развитие высоких технологий позволяет оптимизировать работу по поиску оптимальных решений с помощью программ, работающих с таблицами.
Нелинейное программирование позволяет расширить пространство вариантов оптимальных решений для задачи. Это необходимо, ибо решение может лежать вне области, определенной ограничениями.
Проверка модели
Проверка (валидация) модели, то есть фаза тестирования, — это важный этап. Он позволяет проверить модель, построенную на основе начальных данных. Он важен, потому что позволяет узнать достоверность данных, созданных моделью, сравнив их с реальной системой. Но в этот раз вы берете за основу начальные данные, которые использовались для анализа.
Как правило, при использовании данных для построения модели вы будете воспринимать их как тренировочный набор данных (датасет), а для проверки — как валидационный набор данных.
Таким образом сравнивая данные, созданные моделью и созданные системой, вы сможете оценивать ошибки. С помощью разных наборов данных оценивать пределы достоверности созданной модели. Правильно предсказанные значения могут быть достоверны только в определенном диапазоне или иметь разные уровни соответствия в зависимости от диапазона учитываемых значений.
Этот процесс позволяет не только в числовом виде оценивать эффективность модели, но также сравнивать ее с другими. Есть несколько подобных техник; самая известная — перекрестная проверка (кросс-валидация). Она основана на разделении учебного набора на разные части. Каждая из них, в свою очередь, будет использоваться в качестве валидационного набора. Все остальные — как тренировочного. Так вы получите модель, которая постепенно совершенствуется.
Связанные задачи
| Раздел | Описание |
|---|---|
| Определение алгоритма, используемого моделью интеллектуального анализа данных | запросить параметры, используемые для создания модели интеллектуального анализа данных |
| Создание пользовательского подключаемого алгоритма | Подключаемые алгоритмы |
| Исследование модели с помощью средства просмотра конкретного алгоритма | Средства просмотра моделей интеллектуального анализа данных |
| Просмотр содержимого модели с помощью общего формата таблицы | Просмотр модели в средстве просмотра деревьев содержимого общего вида (Майкрософт) |
| Сведения о настройке данных и использовании алгоритмов для создания моделей | Структуры интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных)Модели интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных) |
Клиенты, договоры, продукты
В плохой MDM-системе всегда жестко зашиты все виды обрабатываемых сущностей. Более того, MDM обычно и внедряется ради этих сущностей, среди которых, как правило, клиенты и продукты. Но завтра обязательно появятся и другие важные сущности, которыми надо управлять.
Начнется все с сотрудников, домохозяйств и связанных корпоративных групп, потом появятся сложноустроенные сущности для описания активов и риск-профилей, затем добавятся какие-нибудь FATCA-эккаунты и профили соцсетей. И каждый раз вам придется переписывать вашу MDM-систему, тратя на это огромные деньги и теряя драгоценное время.
На самом же деле MDM должен уметь без доработок хранить любые сущности. В правильной MDM-системе вообще нет табличек с названиями customers, employees, accounts, assets и прочими подобными.
Как извлечь значения, игнорируя пустые ячейки
Если исходный список содержит пустые ячейки, формула, которую мы только что обсудили, вернет ноль для каждой пустой строки, что может быть проблемой. Это вы и наблюдаете на скриншоте чуть выше. Чтобы исправить это, сделаем несколько небольших корректировок.
Формула массива для извлечения различных значений, исключая пустые ячейки:
Аналогичным образом вы можете получить список различных значений, исключая пустые ячейки и ячейки с числами:
Напоминаем, что в приведенных выше формулах A2: A13 – это исходный список, а B1 – ячейка прямо над первой позицией формируемого списка.
На этом скриншоте показан результат отбора:
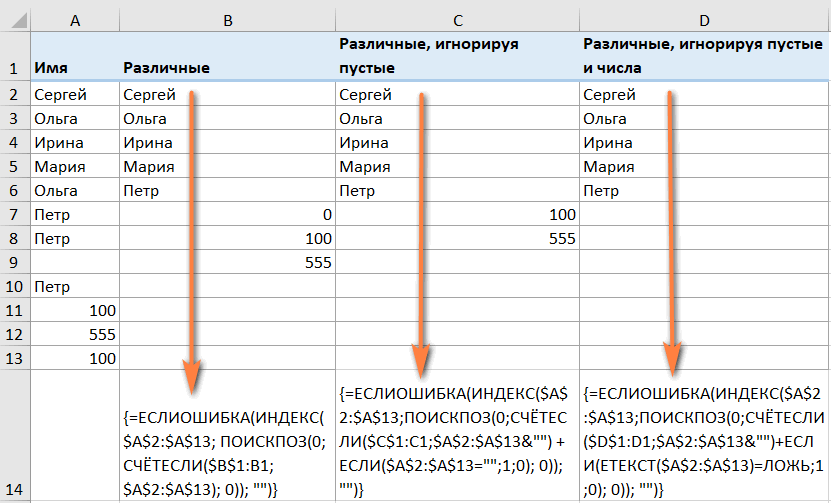
Быть может, кому-то будет полезна еще одна формула –
Она работает с числами и текстом, игнорирует пустые ячейки.
Профилирование данных в Python 3 с помощью Pandas
Любой, кто работает с данными в Python, знаком с пакетом pandas. Если это не так, pandas — это пакет для большинства данных, отформатированных по строкам и столбцам. Если у вас еще нет библиотеки Pandas, обязательно установите ее, используя pip install в предпочитаемом вами терминале:
pip install pandas
Теперь давайте посмотрим, что может сделать для нас реализация pandas по умолчанию:
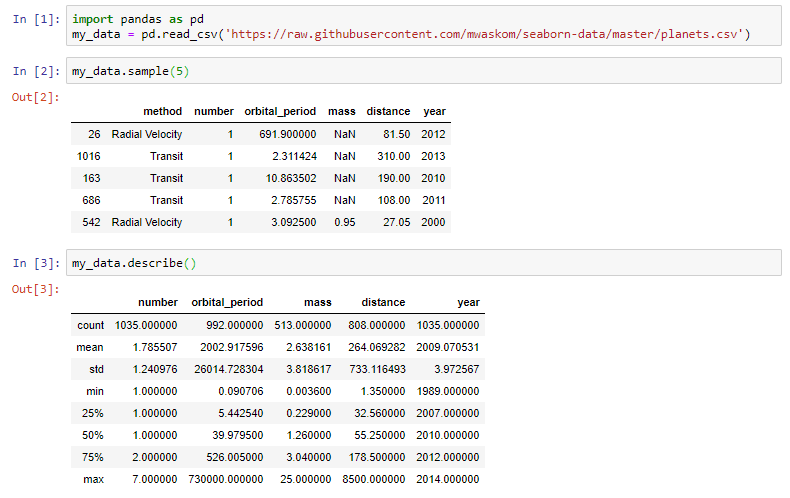
Любой ‘DataFrame’ в Pandas имеет метод .describe(), который возвращает приведенную выше сводку
Однако обратите внимание, что в выходных данных этого метода категориальные переменные отсутствуют. В приведенном выше примере столбец «method» полностью исключен из вывода!
Pandas Data Profiling
В этом разделе будет описана библиотека «Pandas Profiling». Эта библиотека формирует многостраничный отчет (на картинке ниже только небольшая часть этого отчета).



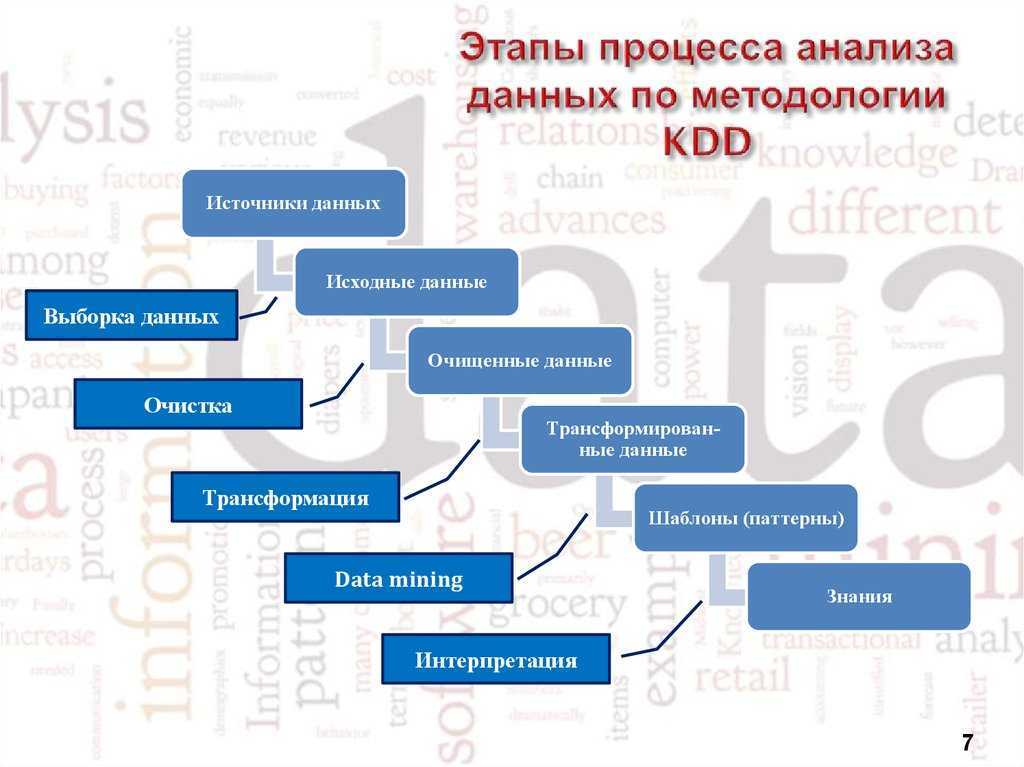
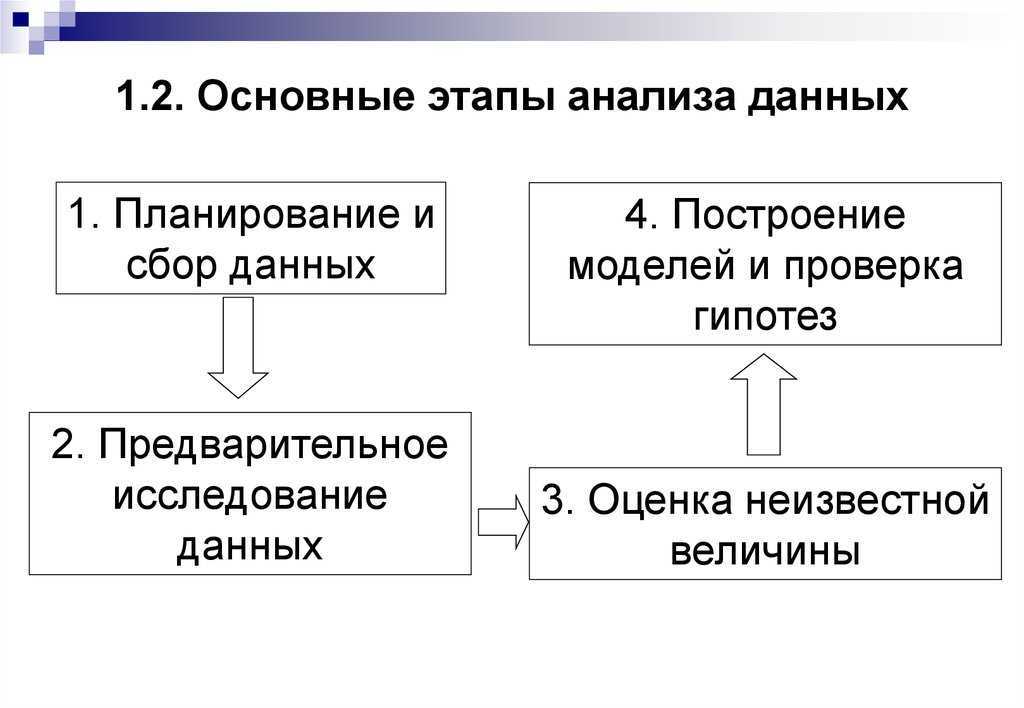
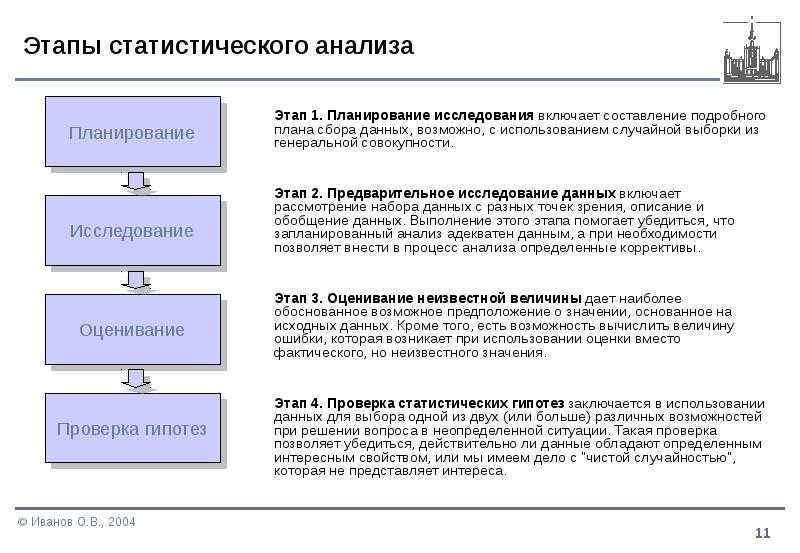



- Основы : тип, уникальные значения, пропущенные значения
- Квантильная статистика, такая как минимальное значение, Q1, медиана, Q3, максимум, диапазон, межквартильный диапазон
- Описательные статистические данные, такие как среднее значение, мода, стандартное отклонение, сумма, среднее абсолютное отклонение, коэффициент вариации, эксцесс, асимметрия
- Наиболее частые значения
- Гистограмма
- Выделение корреляций высококоррелированных переменных, матрицы Спирмена, Пирсона и Кендалла
- Матрица отсутствующих значений , счетчик, тепловая карта и дендрограмма отсутствующих значений
(Список функций прямо из GitHub для профилирования Pandas )
Используя пакет Pandas Profiling!Чтобы установить пакет Pandas Profiling, просто используйте pip install в своем терминале:
pip install pandas_profiling
Опытные аналитики данных на первый взгляд могут посмеяться над тем, что они пушистые и кричащие, но это, безусловно, может быть полезно для быстрого получения непосредственного представления о ваших данных:

Первое, что вы увидите, это обзор (см. Рисунок выше), который дает вам очень высокую статистику ваших данных и переменных, а также предупреждения, такие как высокая корреляция между переменными, высокая асимметрия и многое другое.
Но это даже не близко ко всему. Прокручивая вниз, мы обнаруживаем, что этот отчет состоит из нескольких частей. Просто показывать результат этого 1-линейного с картинками не будет справедливо, поэтому я вместо этого сделал GIF:
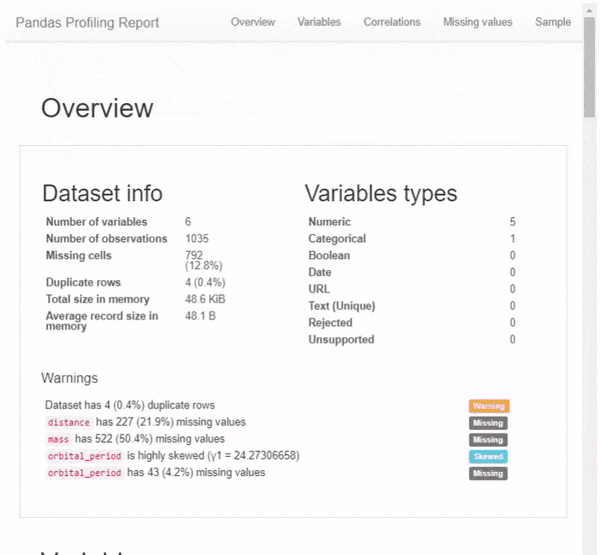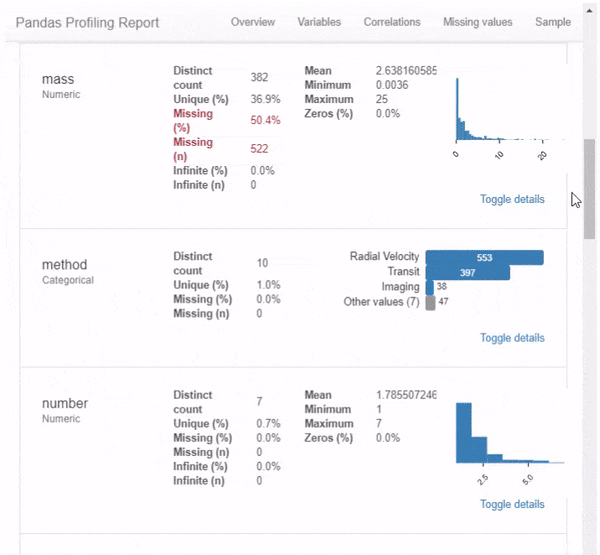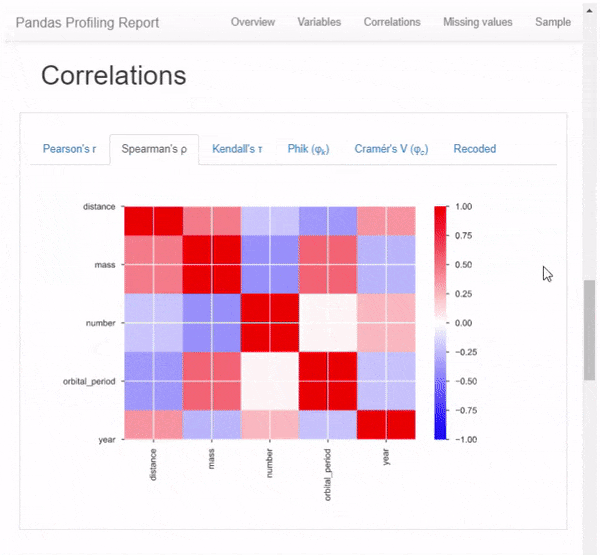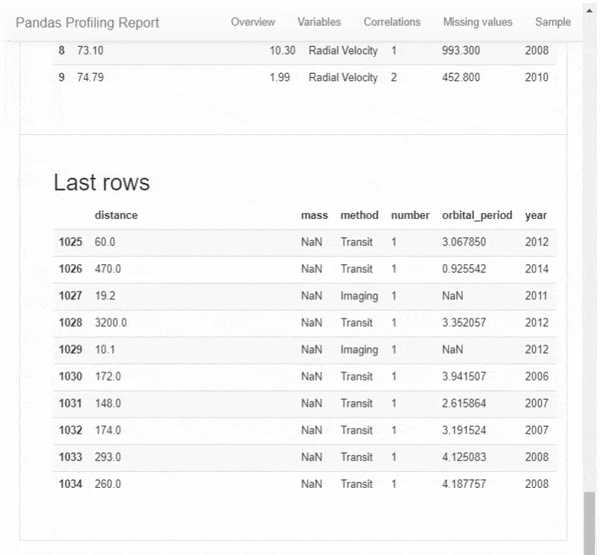
Я настоятельно рекомендую вам изучить возможности этого пакета самостоятельно — в конце концов — это всего лишь одна строка кода, и вы можете найти ее полезной для дальнейшего анализа данных.
import pandas as pd
import pandas_profiling
pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/planets.csv').profile_report()
На что еще обратить внимание?
Если вы чего-то не можете рассмотреть, не стесняйтесь и попросите у продавца увеличительное стекло, оно поможет вам увидеть детали. Особенно это касается украшений с тонким, ажурным плетением. Конечно, все детали рассмотреть не удастся, но какие-то значимые дефекты можно увидеть
А также обратите внимание на то, как продавец обращается с изделиями, есть ли у него перчатки, условия хранения украшений. Выбрав украшение, поинтересуйтесь наличием документов в магазине и сертификатов на ювелирную деятельность
 Выбор золотой цепочки
Выбор золотой цепочки
Далее посмотрите на бирку изделия, иногда ее называют паспортом. На ней должна значится вся информация об этом украшении. В правильно оформленной бирке имеется:
- фирма, которая изготовила изделие;
- адрес производства и контактная информация;
- полное название украшения, металл и торговое название;
- вес изделия;
- проба изделия;
- стоимость украшения.
Если в изделии есть вставки камней или другого металла, они также указываются на бирке. Иногда можно встретить информацию о размере изделия или его длине.
Именно эта информация дает ответ на вопрос, как правильно выбрать золото. Ее можно отчасти использовать и для серебряных изделий. Если на украшении присутствуют драгоценные камни, не забудьте проверить и их на подлинность и наличие дефектов. Такие проверки нужно проводить в магазине возле витрин, чтоб доказать несоответствия в изделии.
Проверяя качество товара, не забудьте о таких критериях, как размер изделия, стиль и то, насколько оно вам подходит. Примеряйте украшения на себя, а если покупаете подарок, лучше заранее узнать размер или не срывать пломбу до того, как украшение не примеряют. Для того, чтоб выглядеть стильно, лучше подобрать золотые украшения одной пробы и цвета.
Советами стоит воспользоваться для того, чтоб не только не переплатить за изделие, но и чтоб получить долговечный и красивый товар. При условии грамотной эксплуатации качественный товар будет долго обходиться без ремонта и не поменяет свои характеристики и дизайн.
https://youtube.com/watch?v=r9Upe2SVvEM
Что такое master-данные?
Мастер-данные («основные данные» или «нормативно-справочная информация») — это данные, записывающие справочную информацию, то есть значения, которые могут использоваться для указания, к чему какие данные относятся. Самый простой пример применения мастер-данных – разного рода справочники или классификаторы.
MDM-системы — это решения для управления справочной информацией. Их главная цель — обеспечить единство представления массивов данных во всех информационных системах. Кроме того, такой тип решений позволяет решить проблемы несоответствия, дублирования и несопоставимости данных.
Для того, чтобы разобраться в том, как MDM-система должна функционировать, важно понять, как устроены процессы по работе с данными. Процессы можно поделить на несколько видов
Процессы можно поделить на несколько видов.
- Reference Data Management — это простые линейные справочники, в которых не требуется какая-либо сложная логика, например, справочники стран или валют. Cамый многочисленный набор справочных данных, с которыми приходится работать.
- MDM— это данные линейных или иерархических справочников с идентичной структурой хранения, где одна запись по своему составу и атрибутам похожа на другую. Пример таких справочников —клиенты, контрагенты, абоненты, организационная структура (например, сотрудники и все, что с ними связано).
Такие данные чаще всего подвергаются обязательной функции дедубликации (выявление и слияние дубликатов данных), поскольку работа с дублированными справочными данными может приводить к несоответствию отчетности, неверным решениям в части работы с клиентами и т.д.. Так, если для многих справочников (продуктовых/материальных ценностей) характерно централизованное ведение, то для клиентских справочников, где присутствуют физические лица, используют другую схему работы, которая называется консолидацией данных или гармонизацией мастер-данных.
Процесс консолидации начинается с появления данных во фронтальных системах, например, на интернет-порталах, после чего происходит их расшифровка и перемещение в систему управления нормативно-справочной информацией для поиска дубликатов, далее начинается разработка единой записи на основе всех, которые были найдены ранее. Затем данные направляются в хранилища, озера данных и другие системы как единая версия правды.
- Сложные иерархические справочники, часто зависящие от других справочников. Самый частый пример — продукты, товары, услуги, работы.
Исходя из потребностей работы с мастер-данными, промышленные системы MDM в своем составе имеют возможность:
- моделирования справочников;
- выполнения интеграционных процессов по наполнению и последующему предоставлению мастер-данных;
- слияния записей, которые были найдены как потенциальные дубликаты, или их разделения. Поскольку система может принять неверное решение, специалист должен иметь возможность вручную разделить записи и указать, что они уникальны. Для оптимизации этого процесса можно настроить систему так, чтобы она позволяла найти способ создать золотую запись или мастер-запись, которая соберет несколько дубликатов с различными полями и значениями;
- установки вертикальных и горизонтальных связей между используемыми значениями. Так, если справочники иерархические, — например, справочник холдингов, — специалистам необходимо управлять составными частями холдингов и их частями, например, дочерними организациями, и «привязывать» туда людей. При этом между справочниками должны быть и горизонтальные связи. Например, есть клиент, у которого есть продукт, который он приобрел в конкретной торговой точке. Горизонтальная связь здесь формируется между этими тремя объектами.
Как с ними бороться
Большинство негативных последствий можно избежать, если «причесать» информацию, настроить и внедрить систему дедупликации данных.
Наиболее эффективный подход, используемый в решении Loginom Data Quality для устранения проблемы дублей, состоит из следующих шагов:
- Предварительная очистка и обогащение данных о клиентах.
- Подготовка стратегии поиска дублей — задание условий, при выполнении которых записи будут считаться совпадающими.
- Тестирование стратегии на реальных данных и ее корректировка при необходимости.
- Задание правил формирования «золотой» записи — записи о клиенте с максимально заполненными и актуальными атрибутами, такими как ФИО, телефоны, документы, дата рождения и т.д.
Расскажем подробнее о каждом шаге поиска дублированных записей.
Страница статьи
ПРОБЛЕМЫ АНАЛИЗА ДАННЫХ МЕДИЦИНСКОЙ СТАТИСТИКИ
Шахгельдян Карина Иосифовна, Гельцер Б.И., Гмарь Д.В., Кривелевич Е.Б., Теук К.А., Транковская Л.В.







DOI:
Аннотация
Представлены результаты оценки пригодности данных медицинской статистики для комплексного автоматизированного анализа. Показано, что автоматизированная обработка больших объемов данных необходима не только на этапе анализа, но и в процедурах их предварительной обработки. В работе систематизированы и классифицированы проблемы, которые ограничивают качество комплексного анализа данных медицинской статистики, и предложен алгоритм, состоящий из последовательно проведенных процедур, обеспечивающий корректную подготовку показателей для дальнейшего анализа. Алгоритм разработан и применен к данным 1,5 млн записей медицинской статистики, собранных в Медицинском информационно-аналитическом центре Департамента здравоохранения Приморского края за 2004-2014 гг.
Ключ. слова
данные медицинской статистики, анализ больших данных, проблема качества данных, data
Об авторах
Шахгельдян Карина ИосифовнаФГБОУ ВО Владивостокский государственный университет экономики и сервиса; ФГАОУ ВО НИУ Московский институт электронной техники 690014, г. Владивосток; 124498, г. Москва, г. Зеленоград д-р техн. наук, доц., директор института Информационных технологий, Владивостокский государственный университет экономики и сервиса carinash@vvsu.ru
Гельцер Б.И.ГАОУ ВО Дальневосточный федеральный университет; ФГБОУ ВО Тихоокеанский государственный медицинский университет 690950, г. Владивосток; 690002, г. Владивосток, Россия
Гмарь Д.В.ФГБОУ ВО Владивостокский государственный университет экономики и сервиса 690014, г. Владивосток
Кривелевич Е.Б.ГБОУ ВПО Тихоокеанский государственный медицинский университет 690002, г. Владивосток
Теук К.А.ФГБОУ ВО Владивостокский государственный университет экономики и сервиса 690014, г. Владивосток
Транковская Л.В.ФГБОУ ВО Тихоокеанский государственный медицинский университет 690002, г. Владивосток, Россия
Список литературы
Provost F., Fawcett T. Data Science for Business. O’Reilly Media; 2013.
Raghupathi W., Raghupathi V. Big data analytics in healthcare: promise and potential. Health Information Science and Systems. 2014; 2.
Drowning in Big Data? Reducing Information Technology Complexities and Costs For Healthcare Organizations. Frost & Sullivan White Paper. Available at: http://www.emc.com/collateral/analyst-reports/frost-sullivan-reducing-information-technology-complexities-ar.pdf.
Александрова А.Л., Колесник А.Ю., Якимович М.В. Методика мониторинга результативности услуг здравоохранения на муниципальном уровне. Available at: http://www.urbaneconomics.ru/download.php?dl_id=1633 (доступ 7 марта 2016)
Крашенинникова Ю.А. Медицинская статистика как способ легитимации распределения ресурсов в российской системе здравоохранения. Вопросы государственного и муниципального управления. 2011; 4: 28-42.
Какорина Е.П., Огрызко Е.В. Некоторые проблемы медицинской статистики в Российской Федерации. Менеджер здравоохранения. 2012; 6: 40-46.
Семенова В.Г., Гаврилова Н.С., Евдокушина Г.Н., Гаврилов Л.А. Качество медико-статистических данных как проблема современного российского здравоохранения. Общественное здоровье и профилактика заболеваний. 2004; 2: 11-18.
Шахгельдян К.И. Проблемы качества данных и информации в корпоративной информационной среде вуза. Информационные технологии. 2007; 6: 71-80.
Общие сведения о службах Data Quality Services. Available at: https://msdn.microsoft.com/ru-ru/library/ff877917(v=sql.120).aspx (доступ 7 марта 2016)
Elastic. We’re About Data. Available at: https://www.elastic.co.
RStudio. Available at: https://www.rstudio.com.
Здоровье населения и здравоохранение Приморского края в 2014 г. Информационно-аналитический сборник (под ред. М.В. Волковой). 2015; Владивосток; 64 C.
Здоровье населения и здравоохранение Приморского края в 2006 г. Информационно-аналитический сборник (под ред. Е.Б. Кривелевича). 2007; Владивосток; 73 С.
Вертидо Дж. Качество данных: новый метод выбора «золотой записи». Windows IT Pro. 2015; 7. Available at: http://www.osp.ru/win2000/2015/07/13046427.
Stop words. Available at: https://en.wikipedia.org/wiki/Stop_words
Для цитирования:
For citation:
Контент доступен под лицензией Creative Commons Attribution 3.0 License.
ISSN: (Print)ISSN: (Online)
Этап 4. 1 клиент = 1 сегмент
На этом этапе применяются классические модели для формирования персонального рекомендованного списка продуктов. В их основе – данные о действиях клиента. К таким моделям относятся:
-
Content-based, который основан на поиске однородности товарных и/или клиентских характеристик без привязки к покупкам. Метод может быть использован при дефиците транзакционных данных (например, «короткий чек»), поскольку основан в большей степени на экспертной расстановке приоритетов в атрибутах товаров.
-
Transaction-based основан на том же поиске однородности товарных атрибутов, с той лишь разницей, что они должны принадлежать одной и той же покупке. Метод может быть применен при условии значимых транзакционных связей между атрибутами товаров или клиентов.
Для персонализации на данном этапе используются различные подходы построения моделей:
-
Collaborating Filtering User-based, или предложение товаров, приобретаемых «похожими» клиентами. Для каждого покупателя формируется вектор покупок, в котором все товары имеют свой приоритет на основании истории покупок аналогичных клиентов. В качестве метрик близости или корреляции клиентов может применяться косинус угла между векторами покупок. Данный метод применяется при недостаточной истории транзакций клиента и «неоднородности» поведения одних потребителей относительно других. В этом случае имеет смысл «переносить» вектор покупок одних клиентов на других, схожих по потребительскому поведению. Подобной «неоднородностью» потребления обладают клиенты, например, категорий beauty или household.
-
Collaborating Filtering Item-based, или предложение товаров, похожих на уже приобретенные конкретным клиентом, где в отличие от User-based подхода каждому товару проставляется вектор клиента, в котором покупатель имеет свой приоритет на основании его покупок. Метрикой может служить косинус угла между векторами клиентов.
-
Метод ассоциативных правил, позволяющий интерактивно вычислить перечень товаров, которые продаются совместно. Алгоритм делит наборы на «характерную» (это предпосылка) и «менее характерную» (цель) части, далее ищет закономерности между ними на основе расчета показателей: support (частота набора товаров), confidence (вероятности «характерной» и «нехарактерной» частей в наборе) и lift (вероятность покупки «нехарактерной» части набора при приобретении «характерной»).
-
Customer Decision Tree (CDT) для моделирования процесса принятия иерархических решений клиента.
-
Цепи Mаркова для моделирования череды событий, в которой каждое последующее событие зависит от предыдущего (например, категория рынка DIY).
-
Similarities – подбор похожего товара на основании векторизации изображения. Такой подход – идеальное решение в построении рекомендаций для fashion- и beauty-сегментов.
-

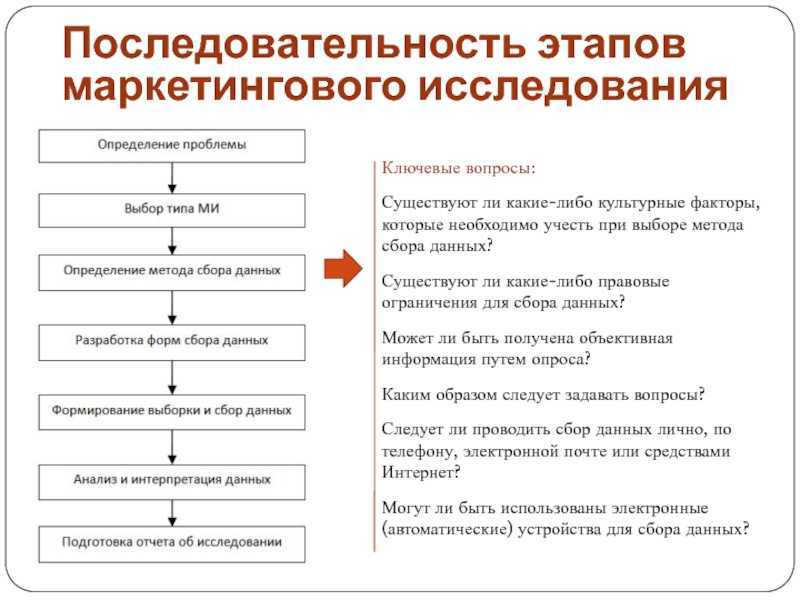
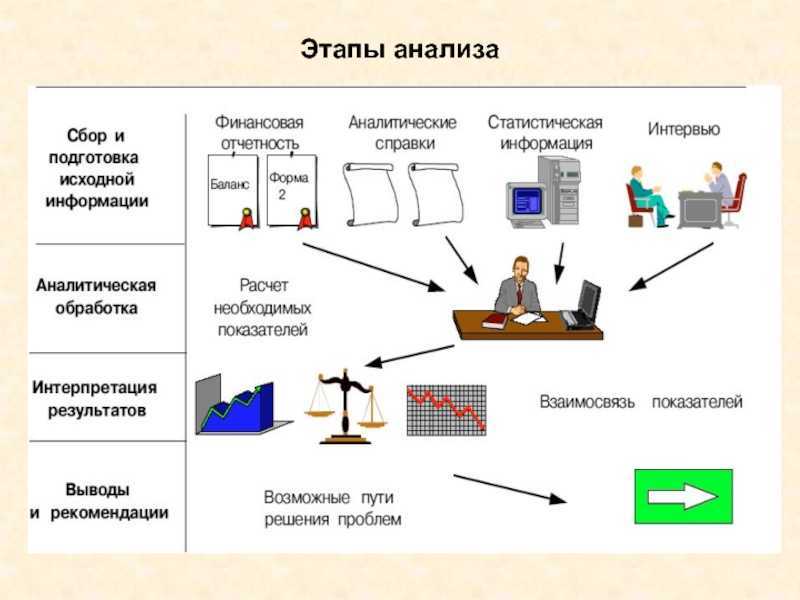
Примеры управления качеством данных в разных отраслях
- Финансы. Предприятия, предлагающие финансовые услуги, выполняют управление качеством данных для выявления и защиты конфиденциальных данных, мониторинга и обеспечения соблюдения нормативных требований, а также автоматизации отчетности.
- Производство: производители делают это, чтобы вести точные записи о своих поставщиках и клиентах и периодически обновлять их. Они также нуждаются в этом, чтобы вовремя узнавать о проблемах с качеством и исправлять и оптимизировать свои стратегии.

- Медицинские учреждения: необходимо управление качеством данных для ведения точных и полных записей о пациентах. Это помогает им предоставлять надлежащий уход за пациентами и планы лечения, а также обеспечивает более быстрое и правильное выставление счетов и управление рисками.
- Государственный сектор. Организациям государственного сектора необходимо управление качеством данных, чтобы поддерживать полные, точные и непротиворечивые данные об их текущих проектах, сотрудниках, подрядчиках и других участниках, чтобы гарантировать, что они достигают своих целей.
Вывод
Качество данных жизненно важно для бизнеса. Следовательно, собранные вами данные должны быть высокого качества с точки зрения точности, полноты, актуальности, достоверности и согласованности, среди прочих характеристик
Это поможет вам принимать правильные бизнес-решения, хорошо обслуживать клиентов и эффективно управлять организацией.
Подводя итог
Прежде чем внедрять MDM-систему, убедитесь, что она не станет вашей большой проблемой и не принесет вам огромные расходы. Правильная MDM-система должна уметь без доработок:
• сохранять любые сущности;
• легко менять набор атрибутов для каждой сущности;
• гибко управлять содержанием атрибутов, защищая вас от дублирования данных и создания лишних и бессмысленных для бизнеса атрибутов типа «Моб. тел. только VIP»;
• избавить вас от многочисленных и бесполезных, по сути, справочников;
• формировать «золотую запись» в режиме онлайн на основе гибких бизнес-правил.
Правильная и полезная MDM-система — это не так сложно, как кажется. Зато она будет заметно удобнее и дешевле в эксплуатации.