
DNS SRV
Это метод, призванный быть универсальным. Более того, он описан стандартом RFC.
Суть заключается в создании SRV-записей в DNS. Данная запись создается по следующему синтаксису:
_<имя службы>._<протокол> <приоритет> <вес> <порт> <хост>
* где:
- <имя службы> — имя сервиса (например, imap).
- <протокол> — сетевой протокол (TCP, UDP, TLS).
- <приоритет> — порядок, в котором идет учет строки.
- <вес> — если приоритеты совпадают у служб, порядок определяется по их весу.
- <порт> — порт, на котором слушает служба.
- <хост> — имя сервера, на который будет вести запись.
Пример записей для настройки почты:
| Запись | Приоритет | Вес | Порт | Хост | Описание |
| _smtp._tcp | 10 | 10 | 25 | smtp.dmosk.ru. | Протокол для отправки почты на другие серверы. |
| _pop3._tcp | 10 | 10 | 110 | pop.dmosk.ru. | Загрузка почты с сервера. |
| _imap._tcp | 10 | 10 | 143 | imap.dmosk.ru. | Работа с почтой на удаленном сервере. |
| _smtps._tcp | 30 | 10 | 465 | smtp.dmosk.ru. | Отправки почты с защитой соединения. |
| _submission._tcp | 20 | 10 | 587 | smtp.dmosk.ru. | Отправки почты с защитой соединения. |
| _imaps._tcp | 20 | 10 | 993 | imap.dmosk.ru. | Работа с почтой с защитой соединения. |
| _pop3s._tcp | 20 | 10 | 995 | pop.dmosk.ru. | Загрузка почты с защитой соединения. |
* в данном примере мы отдаем приоритет более защищенным средствам подключения (smtps, imaps, pop3s).
Пример записей в DNS Bind:
_smtp._tcp IN SRV 10 0 25 smtp.dmosk.ru.
_pop3._tcp IN SRV 20 0 110 pop.dmosk.ru.
_imap._tcp IN SRV 10 0 143 imap.dmosk.ru.
_smtps._tcp IN SRV 0 0 465 smtp.dmosk.ru.
_submission._tcp IN SRV 0 0 587 smtp.dmosk.ru.
_imaps._tcp IN SRV 0 0 993 imap.dmosk.ru.
_pop3s._tcp IN SRV 10 0 995 pop.dmosk.ru.
Обход XML-контента
При включении в конвейер модуля сопоставления XML во время обхода выполняется сопоставление всех элементов, которые являются XML-документами. Убедитесь, что выполняется обход только известного XML-контента. При обходе неизвестного контента или нескольких источников могут быть непреднамеренно сопоставлены элементы XML, использующие сопоставленные элементы XML для других целей. Это может привести к включению в индекс неправильных метаданных.
Существуют два основных способа обхода XML-контента для FAST Search Server 2010 for SharePoint.
Обход XML-документов с помощью соединителя FAST Search (Content SSA). Позволяет загружать XML-документы с веб-серверов, общих папок и библиотек документов SharePoint.
Примечание
Элемент, обход которого выполнен, может состоять из нескольких частей, как, например, элемент списка SharePoint или сообщение электронной почты с несколькими вложениями. Модуль сопоставления XML сопоставляет XML-контент только в первой (основной) части элемента, но не во вложениях.
Для загрузки XML-контента из столбца таблицы базы данных используется соединитель базы данных FAST Search (дополнительные сведения см. в статье Обход контента базы данных с помощью соединителя базы данных FAST Search (Возможно, на английском языке) на сайте Microsoft TechNet). В правиле обхода на основе SQL можно указать, что данный столбец в таблице базы данных сопоставлен предопределенному внутреннему свойству data
В этом же внутреннем свойстве содержится основной контент документ при передаче от соединителя индексации конвейеру обработки элементов.
В приведенном ниже примере показано простое правило обхода, предназначенное для загрузки формального описания продукта на языке XML из таблицы Product во внутреннее свойство data.
Важно!
Свойство data нельзя сопоставить в качестве свойства для обхода, однако в данном случае его можно рассматривать как контент XML-документа. Рекомендации по типам контента, приведенные в разделе Определение формата и анализ элементов, также применимы и к этим типам элементов.
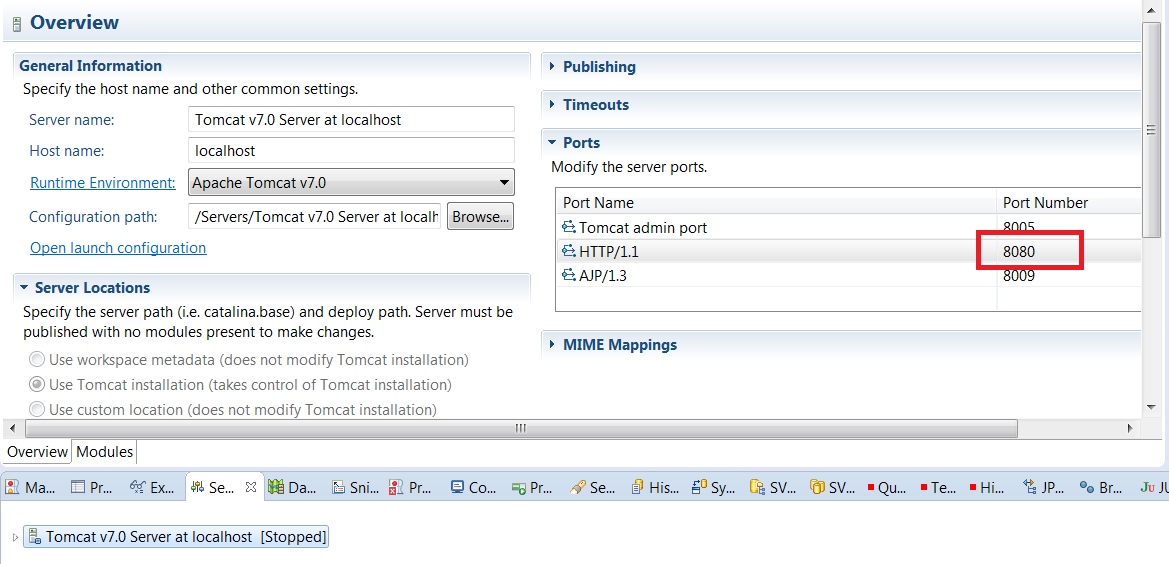
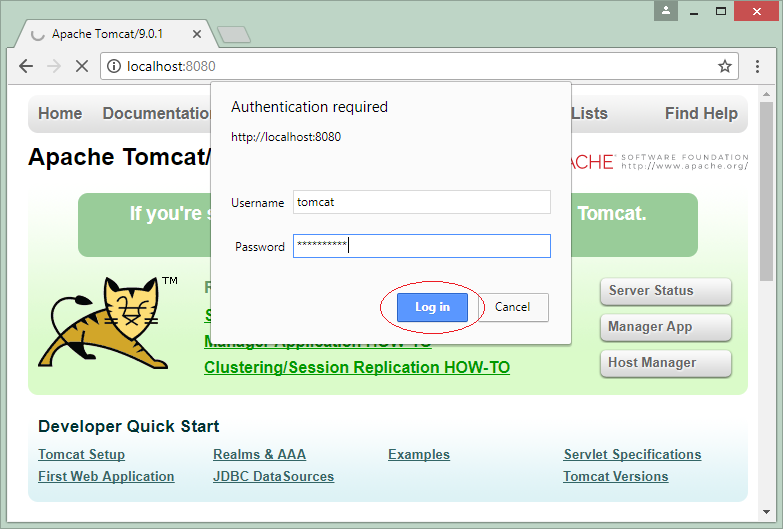
Добавление телеканала
Разворачиваем меню «IPTV Каналы», открываем страницу «Каналы». В списке уже будет предустановленный телеканал «Test channel», удалите его и давайте добавим свой канал (кнопка «Add a channel»).
Заполняем основные поля: «Номер канала», «Название канала», загрузим логотип, поставим галочку «Базовый канал».
Нажимаем на кнопку «Добавить ссылку», появляется всплывающее окно с формой добавления URL канала и дополнительными опциями. Как мы видим из подсказки, в эту строку нужно ввести «solution+URL». Solution — это подсказка для плеера приставки, какую библиотеку использовать для воспроизведения. В большинстве случаем достаточно указать «auto» (например, «auto udp://239.255.1.1:5500»). Для HLS рекомендуемый Инфомиром solution — ffmpeg.
Так как у меня видеосервер Flussonic, я сразу включаю поддержку временных ссылок. Они нужны, чтобы защитить контент от несанкционированного просмотра.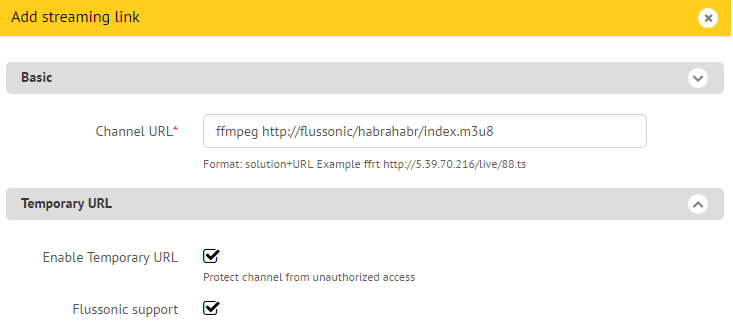
В результате должно получится: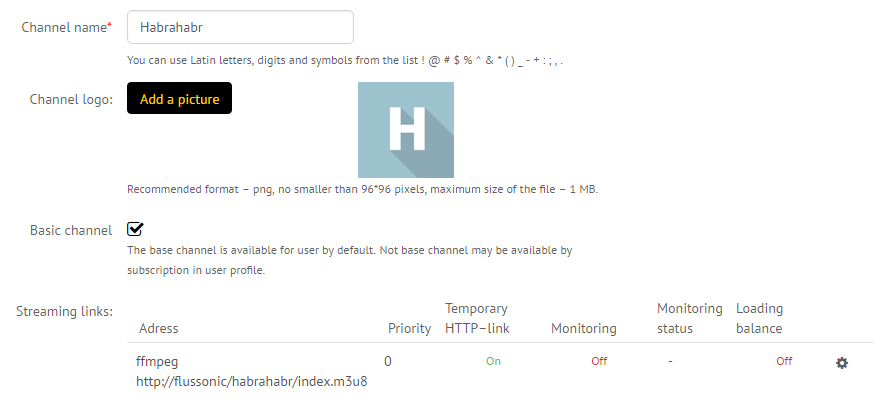
Пропустим пока настройку программы передач (EPG) и ТВ-архива (DVR). Сохраняем.
Пример конфигурации модуля сопоставления XML
В данном примере в качестве входа контента рассматривается следующий XML-элемент.
Ниже приведен пример конфигурации модуля сопоставления XML, предназначенного для извлечения информации из такого элемента.
В данном примере модуль сопоставления XML применяет сопоставление из таблицы 1.
Таблица 1. Сопоставления модуля сопоставления XML
|
Элемент |
Сопоставление |
|---|---|
|
//Title |
mytitle в наборе свойств «d6ee4933-09c4-46e3-a5e4-b3787cb4a090» с типом варианта «31». |
|
//Size |
mysize в наборе свойств «d6ee4933-09c4-46e3-a5e4-b3787cb4a090» с типом варианта «3». |
|
//Date |
mydate в наборе свойств «38c35ad5-69ee-4776-886f-95961a73d52d» с типом варианта «64». |
|
//Tag |
mytags в наборе свойств «d6ee4933-09c4-46e3-a5e4-b3787cb4a090» с типом варианта «31». Для разделения нескольких сопоставлений элементов используется точка с запятой. |
|
/Document/Tutti |
mymulti в наборе свойств «d6ee4933-09c4-46e3-a5e4-b3787cb4a090» с типом варианта «31». select=»first» означает, что выполняется сопоставление только первого подходящего элемента. В данном случае это означает, что извлекается текст «Hello». |
Клиент (обращение к web-сервису)
Тут просто приведу примеры обращения к веб-сервисам. Откуда берутся правила обмена , правила выгрузки, значения параметров и т.п. – это уже вопрос вашей прикладной задачи и её реализации.

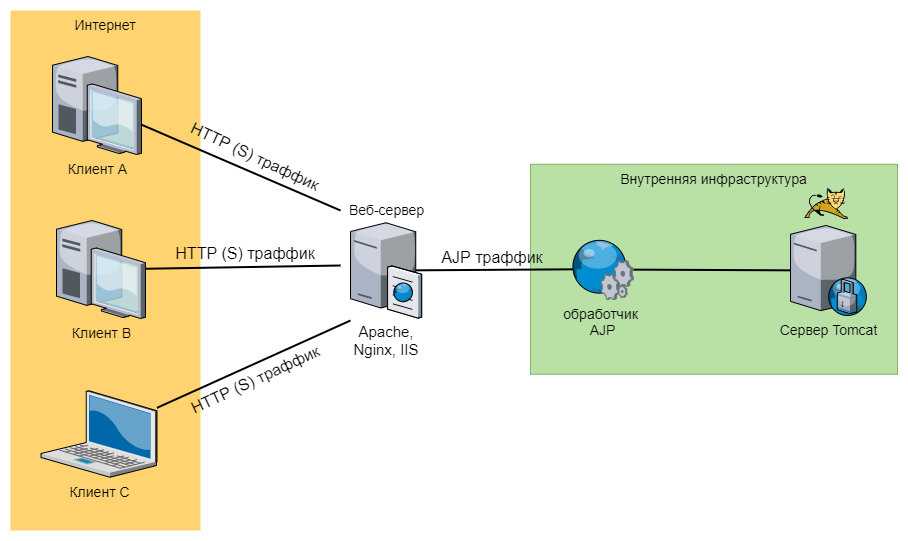



Передача данных в базу-приемник
Пример передачи xml-данных в базу-приемник, на стороне которой работает вышеописанный web-сервис:
Функция ПередатьНаСервере(СтрокаXML)
Данные = Новый ХранилищеЗначения(СтрокаXML, Новый СжатиеДанных(9));
// Подкдючение
Определения = Новый WSОпределения("http://server1c8/db_buh/ws/xml-exchange.1cws?wsdl", "WebServices", "12345");
Прокси = Новый WSПрокси(Определения, "http://your-domain.ru/", "ОбменДаннымиXML", "ОбменДаннымиXMLSoap");
Прокси.Пользователь = "WebServices";
Прокси.Пароль = "12345";
// Передача
ТекстОшибки = "";
ЗагруженоОбъектов = Прокси.ПринятьДанные(Данные, ТекстОшибки);
Если НЕ ПустаяСтрока(ТекстОшибки) Тогда
Сообщить(ТекстОшибки);
КонецЕсли;
Возврат ЗагруженоОбъектов;
КонецФункции // ПередатьНСервере()
Данные перед этим получены из этой базы-источника функцией:
Функция ВыгрузитьКонтрагента(Организация, Контрагент)
ПравилаОбмена = ПолучитьПравилаОбмена();
// Инициализация
Обмен = Обработки.УниверсальныйОбменДаннымиXML.Создать();
Обмен.РежимОбмена = "Выгрузка";
ИмяФайлаДанных = ПолучитьИмяВременногоФайла("xml");
Обмен.ИмяФайлаОбмена = ИмяФайлаДанных;
// Загрузка правил
ИмяФайлаПравилОбмена = ПолучитьИмяВременногоФайла("xml");
ЗаписьТекста = Новый ЗаписьТекста(ИмяФайлаПравилОбмена);
ЗаписьТекста.Записать(ПравилаОбмена);
ЗаписьТекста.Закрыть();
Обмен.ИмяФайлаПравилОбмена = ИмяФайлаПравилОбмена;
Обмен.ЗагрузитьПравилаОбмена();
// Параметры
Обмен.УстановитьЗначениеПараметраВТаблице("Организация", Организация);
// Правила выгрузки данных
// Сначала все отключаем
Для Каждого Строка из Обмен.ТаблицаПравилВыгрузки.Строки Цикл
Строка.Включить = ;
Обмен.УстановитьПометкиПодчиненных(Строка, "Включить");
КонецЦикла;
// Включаем нужное правило
СтрПравил = Обмен.ТаблицаПравилВыгрузки.Строки.Найти("Контрагенты", "Имя", Истина);
Если СтрПравил = Неопределено Тогда
ВызватьИсключение "ПередатьНСервере(): не удалось найти правило выгрузки ""Контрагенты"" в правилах обмена.";
КонецЕсли;
СтрПравил.Включить = 1;
Обмен.УстановитьПометкиРодителей(СтрПравил, "Включить");
// Отбор
Постр = Новый ПостроительОтчета("ВЫБРАТЬ ПЕРВЫЕ 1 _.* ИЗ Справочник.Контрагенты КАК _
|{ГДЕ _.Ссылка.* КАК Справочник_Контрагенты}");
Постр.Отбор.Добавить("Справочник_Контрагенты").Установить(Контрагент);
СтрПравил.ИспользоватьОтбор = Истина;
СтрПравил.НастройкиПостроителя = Постр.ПолучитьНастройки();
// Выгрузка
Обмен.ВыполнитьВыгрузку();
ЧтениеТекста = Новый ЧтениеТекста;
ЧтениеТекста.Открыть(ИмяФайлаДанных, КодировкаТекста.UTF8);
СтрокаXML = ЧтениеТекста.Прочитать();
ЧтениеТекста.Закрыть();
УдалитьФайлы(ИмяФайлаДанных);
УдалитьФайлы(ИмяФайлаПравилОбмена);
Возврат СтрокаXML;
КонецФункции // ВыгрузитьКонтрагента()
Получение данных от web-сервиса
Пример получения данных от web-сервиса:
Функция ПолучитьДанныеОтВебСервиса(ПравилаСтрокой)
// Подкдючение
Определения = Новый WSОпределения("http://server1c8/db_buh/ws/xml-exchange.1cws?wsdl", "WebServices", "12345");
Прокси = Новый WSПрокси(Определения, "http://your-domain.ru/", "ОбменДаннымиXML", "ОбменДаннымиXMLSoap");
Прокси.Пользователь = "WebServices";
Прокси.Пароль = "12345";
// Параметры
ПравилаВыгрузки = Новый Массив;
ПравилаВыгрузки.Добавить("ИерархияКонтрагентов");
ПравилаВыгрузкиXDTO = СериализаторXDTO.ЗаписатьXDTO(ПравилаВыгрузки);
ЗначенияПараметров = Новый Структура("КодБазыИсточника", "00001");
ЗначенияПараметровXDTO = СериализаторXDTO.ЗаписатьXDTO(ЗначенияПараметров);
// Получение данных
Правила = Новый ХранилищеЗначения(ПравилаСтрокой, Новый СжатиеДанных(9));
Данные = Прокси.ОтдатьДанные(Правила, ПравилаВыгрузкиXDTO, ЗначенияПараметровXDTO);
// Возвращаем строку XML
Возврат Данные.Получить();
КонецФункции // ПолучитьДанныеОтВебСервиса()
Отношение расширения
Нужно сказать, что в диаграммах вариантов использования применяется ещё один вид связи – отношение расширения. На мой взгляд, применение отношение расширения несколько специфично, поскольку неправильное его использование может запутать читателя диаграммы. Тем не менее, для полноты картины мы всё равно рассмотрим применение этого отношения на практике. В последний раз модифицируем нашу диаграмму!
Во время дистанционного обучения школьникам необходимо выполнять домашние задания и присылать их в виде архива или фотографий учителям. Получается, нужно добавить возможность прикреплять файл к сообщению в нашей системе. Чтобы отобразить это на диаграмме мы будем использовать отношение расширения. Отношение расширения обозначается пунктирной линией с V-образной стрелкой на конце (похоже на отношение включения), над стрелкой добавляется надпись “extend ”.
Чтобы лучше понять этот тип отношений рассмотрим пример. Допустим, вы делаете заказ в сети быстрого питания. Вы хотите заказать бургер. Вам, скорее всего, вам предложат расширить ваш заказ картошкой фри или соусом. Давайте изобразим процесс заказа на диаграмме вариантов использования.
На диаграмме предполагается, что к заказу МОЖЕТ БЫТЬ
добавлена картошка фри или соус (необязательно)
Два нижних варианта использования описывают возможные «расширения» для базового варианта использования
Исходя из этого примера, мы можем сделать важное замечание
Вернёмся к нашему основному примеру. Мы хотим, чтобы действие «прикрепить файл к сообщению» расширяло действие «отправить сообщение». На диаграмме это изображается следующим образом:
Расширяем функционал отправки сообщений
с помощью функции прикрепления файлов к сообщению
(Необязательно прикреплять файл к каждому сообщению)
Как итог, получим такую диаграмму:
Четвёртая версия диаграммы
Вот и всё. Я постарался рассказать вам про все моменты построения диаграммы вариантов использования при проектировании программных систем. В следующем вашем проекте обязательно попробуйте построить данную диаграмму на стадии проектирования. Ваши усилия обязательно окупятся!
Общие рекомендации:
-
Диаграммы очень просто изменять. Не нужно пугаться того, что требования к программе могут измениться или что вы что-то забыли отобразить на диаграмме. Вы можете добавить элементы к диаграмме, когда вам угодно.
-
Не нужно засорять диаграмму слишком мелкими действиями. Объедините все общие действия в одну группу под общим названием, чтобы было просто читать диаграмму.
-
Старайтесь не допускать пересечений соединительных линий. Это может затруднить чтение диаграммы для вас и для ваших коллег.
-
Не дублируйте варианты использования на диаграмме. Если приходится дублировать варианты использования, то элементы диаграммы надо постараться расставить по-другому.
-
Пользуйтесь специальными компьютерными программами для построения диаграмм. Это существенно упростит весь процесс моделирования.
Общие сведения о модуле сопоставления XML
Модуль сопоставления XML используется для обхода в Интернете и общих папках XML-документов, для которых требуется настраиваемое извлечение и преобразование. При включении в конвейер модуля сопоставления XML во время обхода выполняется сопоставление всех элементов, которые являются XML-документами. Модуль сопоставления XML не следует использовать для обхода неизвестного контента или нескольких источников, поскольку при этом может быть выполнено сопоставление XML-элементов, не представляющих интереса.
Для указания элементов XML-контента для сопоставления используется XPath 1.0, а также собственно файл конфигурации. Например, можно обрабатывать несколько выражений, добавлять разделители строк, разбивать строки и удалять пробелы.
Для каждой инструкции сопоставления указываются свойства для обхода, которым сопоставляется извлеченный XML-контент. Дополнительные сведения о свойствах для обхода см. в статьях Планирование схемы индексации (FAST Search Server 2010 для SharePoint) (Возможно, на английском языке) и Справочник по схеме индексации.
Программа передач (EPG)
Без программы передач строить сервис нельзя, людям уже давно не интересно просто щелкать каналы. EPG нужна не только для того, чтобы пользователь мог посмотреть как называется текущая передача и что будет сегодня вечером, а еще для организации видеоархива! Позволяя пользователям смотреть передачи, которые уже прошли (т.н. Catch UP).
Stalker умеет импортировать EPG из формата XMLTV.
XMLTV — популярный формат описания программы передач основанный на XML, поддерживается всеми поставщиками EPG. Содержит подробное описание: название, время начала, время окончания, жанр, описание, картинку, список актеров, возрастной рейтинг и прочую информацию.
Для продолжения настройки, нам надо добыть поставщика EPG. Они бывают платные, бывают бесплатные. Отличаются количеством телеканалов, количеством информации (например, картинки для каждой передачи и список актеров есть далеко не у всех). Рекламировать никакие сервисы не буду, найдите в Google программу передач в формате XMLTV и продолжим.
Открываем меню «IPTV каналы» → «EPG». Кнопка «Добавить EPG».
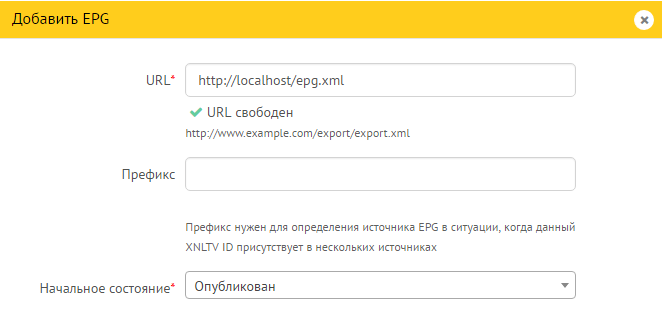
Нам потребуется вставить ссылку на веб-сервер, где лежит xml файл. Из собственного опыта добавлю, что поставщики чаще всего выкладывают на закрытый паролем ftp-сервер, и вдобавок еще архивируют, поэтому в Stalker вставляем ссылку на localhost, а в crontab добавляем скрипт, который будет скачивать и распаковывать XMLTV в нужную папку.
После добавления ссылки, нажмите «обновить». Если все сделали правильно, получится:
Теперь переходим в настройки телеканала. Меню «IPTV каналы» → «Каналы», нажимаем редактировать наш телеканал. Нас интересует раздел «EPG», указываем ID нашего телеканала и, при необходимости, корректируем время под наш часовой пояс.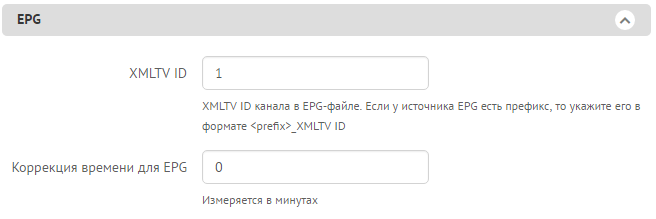
Как узнать XMLTV ID телеканала
Открываем текстовым редактором XMLTV файл и смотрим. В данном примере: «Первый канал» — 1, «Россия 1» — 2, «ТВЦ» — 3.



Для каждого телеканала придется вручную указывать ID. Способа автоматизировать это я пока не знаю.
Атрибуты
XML-элементы
могут включать в себя не только метки, но и другую информацию. У элементов есть
атрибуты, т.е. дополнительная информация о каждом элементе. Например, элемент
глава (Chapter) дополнительно может иметь атрибут автор (Author) и университет, к которому
относится автор (University). Эти атрибуты позволяют найти все работы
определенного автора или университета. Далее приведен пример XML-разметки, где
показаны атрибуты Author
и University.

Имея возможность классифицировать информацию из атрибутов,
можно из исходного контента создавать новые информационные продукты.
Авторы документации давно пользуются преимуществами
включения атрибутов в элементы формируемого контента, что дает читателям
возможность изучать справочные материалы и инструкции с большим пониманием.
Атрибуты помогают определить, в каком информационном продукте и на каких языках
должен появиться элемент. Например, некоторые элементы следует использовать на
веб-сайтах, но они не годятся для печатных справочников; другие должны
появиться в испанской, а не португальской версии документа.
Задумайтесь об этом на минуту. Благодаря атрибутам, контент
получает возможность саморазвиваться. Например, элементы и атрибуты можно
использовать для создания динамического контента для сетевых информационных
продуктов, в основе которого лежат личные предпочтения ваших пользователей.
Почему Stalker?
В первую очередь Stalker интересен тем, что он бесплатный. Правда бесплатный, без пробных периодов и ограничения функционала. Исходный код можно скачать на GitHub.
Это очень важное преимущество Stalker перед решениями других производителей. Я работаю много лет в сфере IPTV и не знаю других бесплатных решений
Я спрашивал у коллег и даже разработчиков Инфомира, они тоже не знают.
Не каждый оператор готов вкладывать деньги в покупку Middleware, потому что сразу не понятно зачем она вообще нужна. Вот спутниковые приемники принимают телеканалы, CAS-система защищает контент, приставки показывают видео, биллинг деньги считает. А что делает Middleware? Список каналов и погоду показывает?
Конечно же нет, но этого уже достаточно чтобы заинтересоваться бесплатным решением и установить Stalker на тестовый сервер чтобы познакомиться поближе.
DTD-спецификации и схемы
Структура информационного продукта описывается в определении
типа документа (DTD) или в схеме. Схема, в отличие от DTD, представляет собой действительный
XML-документ, однако оба способа нашли широкое распространение в описании
информационных моделей (DTD-спецификации несколько чаще используются в
публикациях, схемы — в разработке), оба имеют большую моделирующую способность
и содействуют многократному применению контента.
Проще сначала рассмотреть DTD-спецификации. Ниже показано, как DTD определяет элемент «резюме
главы».

Снова отметим, что XML-контент по большей части удобочитаем
для человека. В вышеприведенном примере первая строка DTD используется для
объявления элемента-главы («Chapter»). Заголовок вводится по желанию («Title?» говорит о том, что
заголовка может и не быть), далее следует один или несколько
элементов-параграфов (seсtion), при этом «Section», «Section+»
говорит о том, что имеется 2 или более параграфа. Следует помнить, что правила
задаете вы, DTD – лишь их воплощение.
DTD-спецификации
и схемы – как и информационные модели, которые они призваны представлять –
могут быть простыми и очень сложными. Если у вас есть интерес к управлению
структурированным контентом и многократному использованию информации, то нужно
найти время для изучения принципов работы XML и DTD/схем. Информацию можно
найти самостоятельно, перечень сетевых ресурсов приведен ниже. Однако, прежде
чем приступать к очень сложным проектам, следует обратиться к консультанту,
специализирующемуся на создании структурированного контента.
Количество стыков с операторами связи
Этот параметр очень важен (выше уже было сказано, почему). Одновременно этот параметр оказался чуть ли не самым сложным для анализа: очень сложно найти подходящую информацию. Но при желании найти её можно. Во-первых, можно (и нужно) обращаться к официальным сайтам компаний: там, например, опубликована информация о количестве партнёров по пирингу.
По количеству партнёров лидируют Akamai, CloudFlare, Cloudfront и G-Core Labs. У каждой из этих компаний — более 5000 партнёров. У остальных участников обзора — от 1000 до 2000.
Во-вторых, все компании, отобранные нами для обзора, вполне можно «пробить» с помощью сервиса PeeringDB. Там можно найти, к каким точкам обмена трафиком подключена та или иная компания и где установлено её пиринговое оборудование.
Информация о количестве точек обмена трафиком, к которым подключены участники нашего обзора, приведена в следующей таблице:
| Провайдер | Число IXP | Число партнёров по пирингу |
|---|---|---|
| Akamai | 333 | 1700 |
| G-Core Labs | 157 | >5000 |
| CloudFront | 343 | нет данных |
| Cloudflare | 411 | >5000 |
| Ngenix | 25 | >1000 |
| CDNVideo | 40 | >1000 |
| KeyCDN | не найдено | нет данных |
| Fastly | 245 | >1000 |
| CDN77 | 56 | нет |
Постановка задачи и её анализ
Представьте, что мы хотим разработать программу для построения графиков функций. Давайте кратко изобразим основной функционал такой программы на диаграмме вариантов использования UML:
Разумеется, мы хотим, чтобы наше приложение обладало графическим интерфейсом. На данном этапе разумно будет разбить задачу построения диаграммы на две части:
-
Построить диаграмму для классов, ответственных за работу с пользовательскими математическими функциями.
-
Построить диаграмму для классов, ответственных за корректное отображение графических элементов в программе.
Классы, ответственные за работу с математическими функциями будут предоставлять возможность создавать объекты математических функций и подсчитывать таблицу значений.
Давайте определимся с тем, как мы собираемся работать с функциями. Во-первых, договоримся, что мы будем работать не напрямую с функциями, а только с их телами.
Именно поэтому в этой статье мы будем оперировать термином математическое выражение, а не термином функция.
Компьютер не может оперировать напрямую математическими выражениями, записанными в строке так же просто, как и обычными числами, записанными в коде программы.
Поэтому мы создадим набор классов, которые будут «знать», как работать с такими данными. Упрощённая схема создания математических выражений представлена на рисунке ниже.
Для того чтобы мы могли работать с телом функции, записанным в виде строки, необходимо разбить эту строку на элементарные части. Их чаще всего называют лексемами (от англ. «lexeme») или токенами (от англ. «token»). В данной статье мы будем использовать термин токен. Получить список токенов математического выражения можно, используя алгоритм сортировочной станции.


Затем из полученного списка токенов мы будем строить постфиксную запись выражения.
На этом этапе математическое выражение мы будем считать обработанным и готовым к работе. Чтобы вычислить значение этого выражения, мы будем подставлять вместе переменной какое-либо действительное значение.
Для удобства работы с нашим приложением нужно добавить возможность определения и использования именованных констант. Например, использование распространённых математических констант, таких как π = 3,141592.. или e = 2,71828.. будет очень удобным для пользователей.
В заключение, хочется отметить, что каждое серьёзной программе необходим механизм обработки ошибок. Наша программа не будет исключением. Пользовательские выражения будут проверяться на корректность математической записи.
Давайте подведём итог и выясним, какие классы нам будут нужны для решения поставленной задачи:
-
Класс для хранения математического выражения. Назовём его MathExpression.
-
Класс для разбиения строкового представления выражения на список токенов — MathParser.
-
Класс для построения постфиксной формы выражения из списка токенов — MathFormConverter.
-
Класс для работы с именованными константами — MathConstantManager.
-
Класс для проверки корректности пользовательского математического выражения — MathChecker.
-
Класс для подсчёта таблицы значений математического выражения — MathCalculator.
Составление правил иерархии контента
Самое главное отличие структурированных документов от
неструктурированных заключается в существовании «правил». Эти правила
формализуют порядок ввода в документ текста, графических объектов и таблиц.
Например, у абзаца неструктурированного документа есть форматирование – шрифт,
размер и интервалы. У того же абзаца структурированного документа есть
«обертка», которая определяет, какие элементы могут идти в тексте до и после
него. Правила оформления элементов задаются в определении типа документа (DTD)
или в схеме – далее будет сказано об этом более подробно.
Управление структурированным контентом предполагает уход от меток
форматирования и переход к работе с правилами представления информации. Отсюда
следует укрепление информационной модели, но при этом возникают сложности с
внедрением новой системы управления, так как создатели контента привыкли
работать в системах, управляющих внешним видом документа.
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.



