
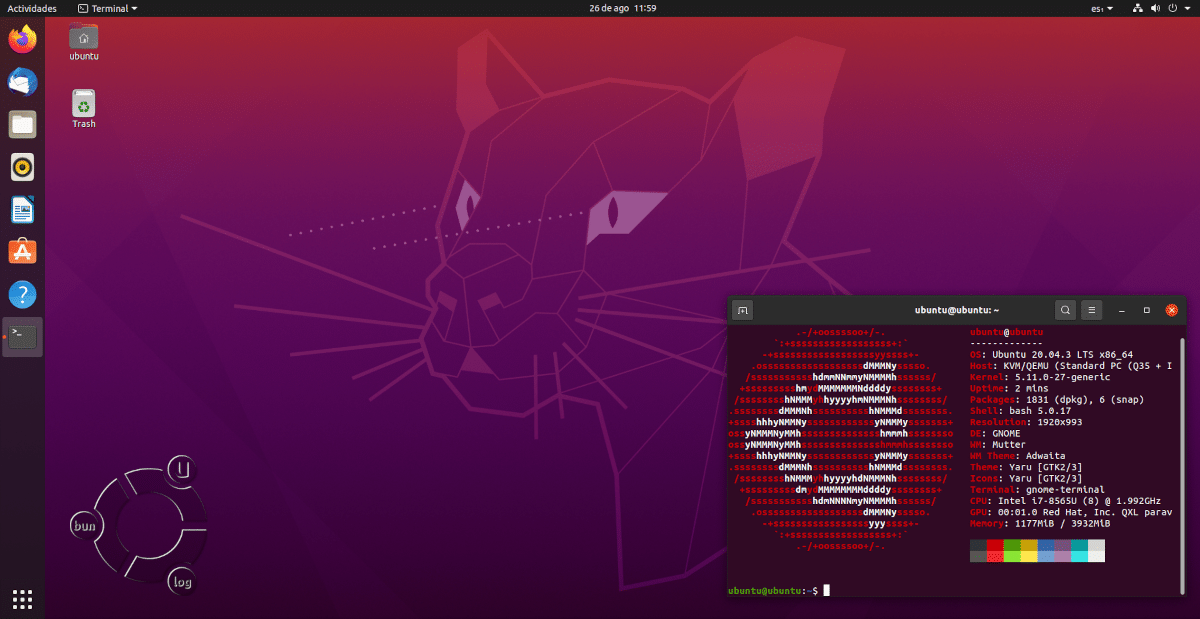
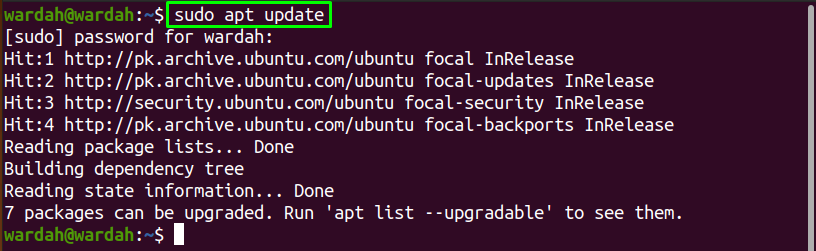
Basic Command Line Interface Usage
To create a database, run the command:
Where ‘database’ is the name of your database. If the file already exists, Sqlite will open a connection to it; if it does not exist, it will be created. You should see output similar to:
Now let’s create a table and insert some data. This table named “wines” has four columns: for an ID, the wine’s producer, the wine’s kind, and country of the wine’s origin. As it’s not Friday yet, we’ll insert only three wines into our database:
We’ve created the database, a table, and some entries. Now press to exit Sqlite and type the following (again substituting your database’s name for ‘database’), which will reconnect to the database we just created:
Now type:
And you should see the entries we’ve just made:
Great. That’s it for creating and reading. Let’s do an update and delete:
Which will update the database so all wines which are listed as coming from France will instead be listed as coming from South Africa. Check the result with:
And you should see:
Now all our wines come from South Africa. Let’s drink the KWV in celebration, and delete it from our database:
And we should see one fewer wine listed in our cellar:
And that covers all of the basic database operations. Before we finish, let’s try one more (slightly) less trivial example, which uses two tables and a basic join.
Exit from Sqlite with the command and reconnect to a new database with .
We’ll be creating a very similar table, but also a table, which stores the country’s name and its current president. Let’s create the countries table first and insert South Africa and France into it with (note that you can copy-paste several lines of sqlite code at once):
And then we can recreate our wines table with:
Now let’s see what kinds of wine there are in South Africa with:
And you should see:
And that covers a basic Join. Notice that Sqlite does a lot for you. In the join statement above, it defaults to , although we just use the keyword . Also we don’t have to specify as it’s unambiguous. On the other hand, if we try the command:
We’ll get the error message . Which is fair enough as both of our tables have an column. But generally Sqlite is fairly forgiving. Its error messages tend to make it fairly trivial to locate and fix any issues, and this helps speed up the development process.
For further help with syntax, the official documentation is full of diagrams like this one, which can be helpful, but if you prefer concrete examples, here is a link to a tutorial with a nice overview of most of the join types.
Finally, Sqlite has wrappers and drivers in all the major languages, and can run on most systems. (http://www.sqlite.org/cvstrac/wiki?p=SqliteWrappers» target=»_blank).
Основы работы с SQLite3
Для начала работы с SQLite3 в Питоне нужно провести импорт соответствующего модуля, а затем создать объект коннектинга к базе. Сделать это можно так:

Cursor в SQLite3
Cursor – это элемент, без которого невозможно продолжить работу. Представляет собой метод соединения. Сначала устанавливается коннектинг, после чего происходит создание cursor с применением объекта соединения.
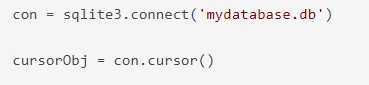
Выше – наглядный пример контактирования с cursor.
Создание
После того, как с cursor стало все ясно, третьей важной операцией выступает создание «табличного хранилища»:

Здесь будет происходить следующее:
- Импортируется модуль SQLite3.
- Осуществляется определение функции с именем sql_connection.
- Внутри оной будет установлен блок try, в котором метод connect() вернет объект соединения после коннектинга.
- Определяется блок исключений. При наличии оных осуществляется вывод на печать сообщения об ошибке.
- Когда неполадки отсутствуют, соединение устанавливается. Скрипт сообщит об успешном подключении к памяти.
Теперь соединение блока finally будет закрыто. Это не обязательный шаг. Он просто помогает освобождать память устройства.
Здесь можно увидеть, как на SQLite происходит создание базы в Питоне.
Useful commands
| Command | Description |
|---|---|
| .databases | List names and files of attached databases |
| .dump | Dump the database or a specific table in an SQL text format |
| .exit / .quit | Exit the SQLite shell |
| .headers | Turn display of headers on or off, when displaying output of SQLstatements |
| .help | Show available commands |
| .import | Import data from a file into a table |
| .mode | Set output mode |
| .open | Open a database from a file |
| .output | Redirect the output to a file |
| .read | Execute SQL statements from a file |
| .save | Write in-memory database into a file |
| .schema | Show the CREATE statements used for the whole database or for a specific table |
| .show | Show current values for various settings |
| .show | List names of tables |
Установка SQLite
Установка SQLite на WSL (т. е. Ubuntu):
- Откройте терминал WSL (т. е. Ubuntu).
- Обновите пакеты Ubuntu:
- После обновления пакетов установите SQLite3 со следующими параметрами:
- Подтвердите установку и получите номер версии:
Чтобы создать тестовую базу данных с именем example.db, введите:
Чтобы просмотреть список баз данных SQLite, введите:
Чтобы просмотреть состояние базы данных, введите:
База данных будет пуста после создания. Вы можете создать новую таблицу для базы данных с помощью .
Теперь введет созданную базу данных.
Чтобы выйти из командной строки SQLite, введите:
Дополнительные сведения о работе с базой данных SQLite см. в документации по SQLite.
Чтобы работать с базами данных SQLite в VS Code, попробуйте использовать расширение SQLite.
Создаём таблицу с товарами
У нас есть база, в которой можно создавать таблицы для хранения данных. Создадим первую таблицу для товаров:
Если посмотреть внимательно на код, можно заметить, что текст внутри кавычек полностью повторяет обычный SQL-запрос, который мы уже использовали в прошлой статье. Единственное отличие — в SQLite используется INTEGER вместо INT:
Теперь соберём код вместе и запустим его ещё раз:
Но после второго запуска компьютер почему-то выдаёт ошибку:
sqlite3.OperationalError: table goods already exists
Дело в том, что при повторном запуске программа пытается создать таблицу с товарами, которая уже есть в базе. Так как имена таблиц совпадают, а двух одинаковых имён быть не может, отсюда и возникает ошибка.
Чтобы не попадать в такую ситуацию, добавим проверку: посмотрим, есть ли в базе нужная нам таблица или нет. Если нет — создаём, если есть — двигаемся дальше:
Точно так же мы потом сделаем и с остальными таблицами — сразу встроим проверку, и если нужных таблиц не будет, то программа создаст их автоматически.
Теперь наполняем нашу таблицу товарами, используя стандартный SQL-запрос. Например, можно добавить два стола, которые стоят по 3000 ₽:
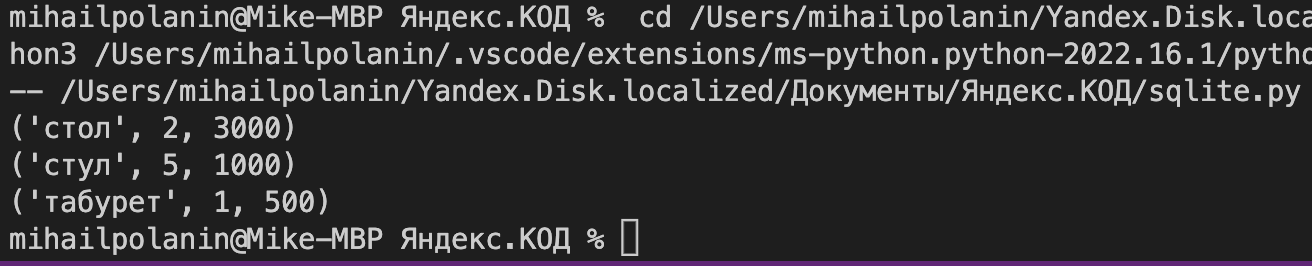
Но добавлять записи по одному товару за раз — это долго и неэффективно. Проще сразу в одном запросе добавить все нужные товары: стол, стул и табурет:
В конце мы добавили вывод таблицы — так можно убедиться, что запрос сработал и данные отправились в базу в нужное место.
Изменение записей в таблице
С помощью запроса ALTER TABLE и дополнительных команд можно изменять таблицу следующим образом:
- переименовать таблицу — RENAME TABLE,
- добавить колонку — ADD COLUMN,
- переименовать колонку — RENAME COLUMN,
- удалить колонку — DROP COLUMN.
К примеру, добавим в нашу таблицу колонку с высотой собаки в холке:
Чтобы изменить значения в существующих записях таблицы понадобится запрос в SQLite – Update. В этом случае возможно как изменение значений ячейки в группе строк, так и изменение значения ячейки отдельной строки.
В качестве примера, внесем значения высоты собак в холке в нашу таблицу:
Наша итоговая таблица будет выглядеть так:
Подключение из Windows
Инструменты SQL Server в Windows подключаются к экземплярам SQL Server в Linux так же, как они подключались бы к любому удаленному экземпляру SQL Server.
Если у вас компьютер с ОС Windows, который может подключаться к компьютеру с ОС Linux, попробуйте выполнить те же действия этого раздела в командной строке Windows, запустив sqlcmd. Необходимо использовать имя или IP-адрес целевого компьютера на Linux, а не , и открыть TCP-порт 1433 на компьютере с SQL Server. Если у вас возникли проблемы с подключением из Windows, см. .
Другие инструменты, которые запускаются в Windows, но подключаются к SQL Server на Linux:
- SQL Server Management Studio (SSMS)
- Windows PowerShell
- SQL Server Data Tools (SSDT)
Installing SQLite3
All FEUP computers have sqlite3 already installed, so you should not need to carry out this step in those machines. If you want to install it in your personal laptop for home work or study, read on.
Manual Installation (portable)
- Download the precompiled binaries for from the website
For Windows, I recommend you unzip the download into C:\sqlite3. For other OS’s you should use your home folder, like ~/sqlite3.
and unzip them to a folder in your computer. Please choose the appropriate file depending on your operating system (Windows, Linux or macOS).
- Navigate to the folder where you extracted your download
- You should see 3 files:
Установка SQL Server
Чтобы настроить SQL Server в Ubuntu, выполните следующие команды в терминале для установки пакета mssql-server:
-
Импортируйте открытые ключи GPG из репозитория:
-
Зарегистрируйте репозиторий Ubuntu для SQL Server:
Совет
Если вы хотите установить другую версию SQL Server, ознакомьтесь с версиями этой статьи для или .
-
Выполните следующие команды для установки SQL Server:
-
Когда установка пакета завершится, выполните команду и следуйте указаниям, чтобы задать пароль системного администратора и выбрать выпуск. Напоминаем, что следующие выпуски SQL Server имеют бесплатные лицензии: Evaluation, Developer и Express.
Не забудьте указать надежный пароль для учетной записи системного администратора. Его минимальная длина должна составлять 8 символов, он должен содержать строчные и прописные буквы, десятичные цифры и (или) специальные символы.
-
По завершении настройки убедитесь в том, что служба работает.
-
Если вы планируете подключаться удаленно, может потребоваться открыть в брандмауэре TCP-порт SQL Server (по умолчанию 1433).
-
Импортируйте открытые ключи GPG из репозитория:
-
Зарегистрируйте репозиторий Ubuntu для SQL Server:
Совет
Если вы хотите установить другую версию SQL Server, ознакомьтесь с версиями этой статьи для или .
-
Выполните следующие команды для установки SQL Server:
-
Когда установка пакета завершится, выполните команду и следуйте указаниям, чтобы задать пароль системного администратора и выбрать выпуск. Напоминаем, что следующие выпуски SQL Server имеют бесплатные лицензии: Evaluation, Developer и Express.
Не забудьте указать надежный пароль для учетной записи системного администратора. Его минимальная длина должна составлять 8 символов, он должен содержать строчные и прописные буквы, десятичные цифры и (или) специальные символы.
-
По завершении настройки убедитесь в том, что служба работает.
-
Если вы планируете подключаться удаленно, может потребоваться открыть в брандмауэре TCP-порт SQL Server (по умолчанию 1433).
-
Импортируйте открытые ключи GPG из репозитория:
-
Зарегистрируйте репозиторий Ubuntu для SQL Server:
Совет
Если вы хотите установить другую версию SQL Server, ознакомьтесь с версиями этой статьи или .
-
Выполните следующие команды для установки SQL Server:
-
Когда установка пакета завершится, выполните команду и следуйте указаниям, чтобы задать пароль системного администратора и выбрать выпуск. Напоминаем, что следующие выпуски SQL Server имеют бесплатные лицензии: Evaluation, Developer и Express.
Не забудьте указать надежный пароль для учетной записи системного администратора. Его минимальная длина должна составлять 8 символов, он должен содержать строчные и прописные буквы, десятичные цифры и (или) специальные символы.
-
-
По завершении настройки убедитесь в том, что служба работает.
-
Если вы планируете подключаться удаленно, может потребоваться открыть в брандмауэре TCP-порт SQL Server (по умолчанию 1433).
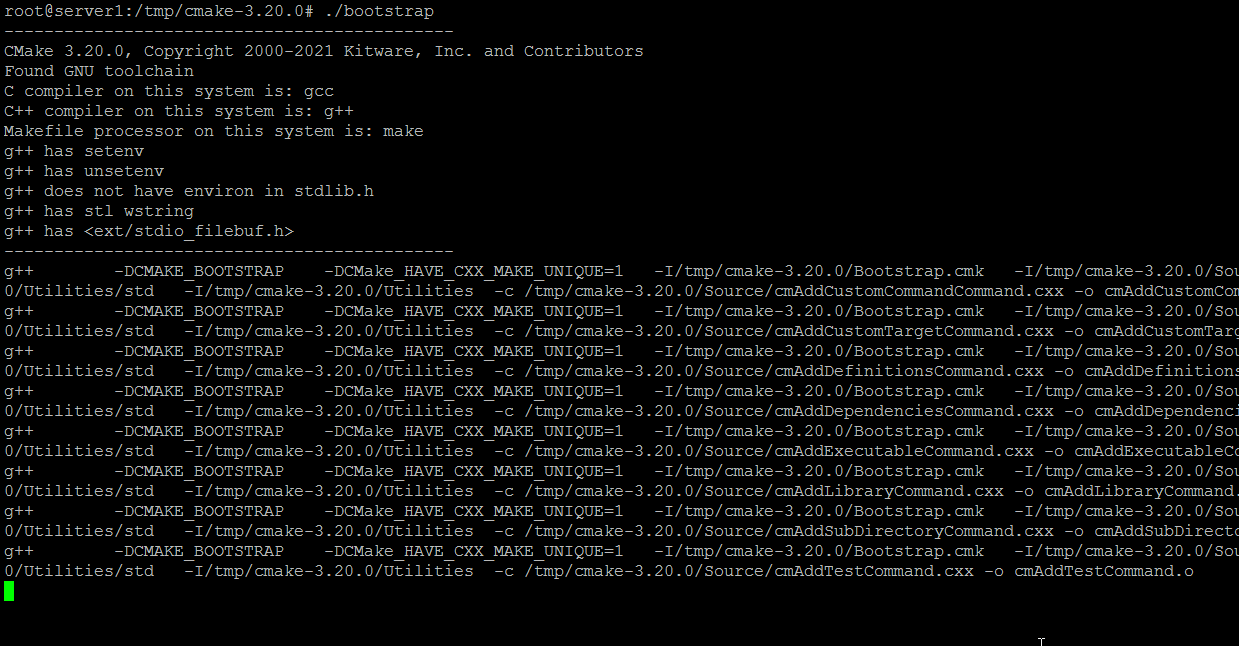
В результате сервер SQL Server будет запущен на компьютере Ubuntu и готов к использованию!
Стандартные команды
Теперь давайте пройдёмся по списку стандартных команд sqlite3, которые предназначены для взаимодействия с базой данных. Стандартные команды могут быть классифицированы по трём группам:
- Язык описания данных DDL: команды для создания таблицы, изменения и удаления баз данных, таблиц и прочего.
-
- CREATE
- ALTER
- DROP
- Язык управления данными DML: позволяют пользователю манипулировать данными (добавлять/изменять/удалять).
-
- INSERT
- UPDATE
- DELETE
- Язык запросов DQL: позволяет осуществлять выборку данных.
Заметка: SQLite так же поддерживает и множество других команд, список которых можно найти тут. Поскольку данный урок предназначен для начинающих, мы ограничимся перечисленным набором команд.
Файлы баз данных SQLite являются кроссплатформенными. Они могут располагаться на различного рода устройствах.
Далее знакомство с sqlite3 будет осуществляться на базе данных, предназначенной для хранения комментариев. Для публикации комментария пользователю необходимо будет добавить следующие данные:
- Имя
- Сайт
- Комментарий
Из всех этих полей только адрес сайта может быть пустым. Так же можем ввести колонку для нумерации комментриев. Назовём её .
Теперь давайте определимся с типами данных для каждой из колонок:
| Атрибут | Тип данных |
| post_id | INTEGER |
| name | TEXT |
| TEXT | |
| website_url | TEXT |
| comment | TEXT |
Тут вы сможете найти все типы данных, поддерживаемые в SQLite3.
Так же следует отметить, в SQLite3 данные, вставляемые в колонку могут отличаться от указанного типа. В MySQL такое не пройдёт.
Теперь давайте создадим базу данных. Если вы ещё находитесь в интерфейсе sqlite3, то наберите команду для выхода. Теперь вводим:
В результате, в текущем каталоге у нас появится файл comment_section.db.
Заметка: если не указать название файла, sqlite3 создаст временную базу данных.
Создание таблицы
Для хранения комментариев нам необходимо создать таблицу. Назовём её . Выполняем команду:
CREATE TABLE comments (
post_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
email TEXT NOT NULL,
website_url TEXT NULL,
comment TEXT NOT NULL );
обеспечит уверенность, что ячейка не будет содержать пустое значение. и расширяют возможности поля post_id.
Чтобы убедиться в том, что таблица была создана, выполняем мета команду . В результате видим нашу таблицу .
Заметка: Для получения структуры таблицы наберите
Теперь можем внести данные в таблицу.
ВСТАВКА СТРОК
Предположим, что нам необходим внести следующую запись:
Name : Shivam Mamgain Email : xyz@gmail.com Website : shivammg.blogspot.com Comment : Great tutorial for beginners.
Для вставки воспользуемся командой INSERT.
INSERT INTO comments ( name, email, website_url, comment ) VALUES ( 'Shivam Mamgain', 'xyz@gmail.com', 'shivammg.blogspot.com', 'Great tutorial for beginners.' );
Указывать значение для не нужно т.к. оно сформируется автоматически благодаря настройке .
Чтобы набить руку можете вставить ещё несколько строк.
ВЫБОРКА
Для выборки данных воспользуемся командой SELECT.
SELECT post_id, name, email, website_url, comment FROM comments;
Этот же запрос может выглядеть так:
SELECT * FROM comments;
В результате из таблицы будут извлечены все строки. Результат может выглядеть без разграничения по колонкам и без заголовка. Чтобы это исправить выполняем:
Для отображения шапки введите .
Для отображения колонок выполните команду .
Выполняем SELECT запрос ещё раз.
Заметка: вид отображения можно изменить, воспользовавшись мета командой .
UPDATE comments SET email = 'zyx@email.com' WHERE name = 'Shivam Mamgain';
В результате запись будет изменена.
Для выполнения команды DELETE нужно так же указать условие.
К примеру нам необходимо удалить комментарий с post_id = 9. Выполняем команду:
DELETE FROM comments WHERE post_id = 9;
Для удаления комментариев пользователей ‘Bart Simpson’ и ‘Homer Simpson’ выполним:
DELETE FROM comments WHERE name = 'Bart Simpson' OR name = 'Homer Simpson';
ИЗМЕНЕНИ СТРУКТУРЫ
Для добавления новой колонки следует использовать команду ALTER. К примеру введём поле username. Выполняем команду:
ALTER TABLE comments ADD COLUMN username TEXT;
Данная команда создаст новое текстовое поле в таблице . Для всех сток в качестве значения будет выставлено NULL.
Так же мы можем использовать команду ALTER для переименования таблицы на .
ALTER TABLE comments RENAME TO Coms;
About
SQLite is a lightweight Database Management System (DBMS) which allows its users to implement a relational schema and run SQL queries over it, without the need for a standalone database server. This is convenient because the setup is minimal and the database can be easily bundled with application files.
SQlite is portable, which means that you can install it on any computer, even when you do not have Administration privileges. It is also quite interesting for mobile development in platforms such as Android or iOS.
SQLite implements ACID (Atomic, Consistent, Isolated, and Durable) transactions. This makes it possible to rollback all changes made during transactions in the event of a system crash or power loss.
SQLite does not, however, implement the .
For our classes we will be using SQLite3.
Step 5 — Updating Tables in SQLite
In the following two sections you will first add a new column into your existing table and then update existing values in the table.
Adding Columns to SQLite Tables
SQLite allows you to change your table using the command. This means that you can create new rows and columns, or modify existing rows and columns.
Use to create a new column. This new column will track each shark’s age in years:
You now have a fifth column, .
Updating Values in SQLite Tables
Using the command, add new values for each of your sharks:
In this step you altered your table’s composition and then updated values inside the table. In the next step you will delete information from a table.
Как создать базу данных в SQLite
Существует несколько способов, чтобы сделать create database в sqlite:
1. Как отмечалось выше, при запуске sqlite3 можно указать имя базы данных:
Если база my_first_db.db существует, то она откроется, если нет — она будет создана и автоматически удалится при выходе из sqlite3, если к базе не было совершено ни одного запроса. Поэтому, чтобы убедиться, что база записана на диск, можно запустить пустой запрос, введя ; и нажав Enter:
После работы изменения в базе можно сохранить с помощью специальной команды SQLite «.save» с указанием имени базы:
или полного пути до базы:
При использовании команды «.save» стоит проявлять осторожность, так как эта команда перезапишет все ранее существовавшие файлы с таким же именем не запрашивая подтверждения. 2
В SQLite создать базу данных можно с помощью команды «.open»:
2. В SQLite создать базу данных можно с помощью команды «.open»:
Как и в первом случае, если база с указанным именем существует, то она откроется, если же не существует — то будет создана. При таком способе создания новаябаза данных SQLite не исчезнет при закрытии sqlite3, но все изменения перед выходом из программы нужно сохранить с помощью команды «.save», как показано выше.
3. Как уже упоминалось, при запуске sqlite3 без аргументов, будет использоваться временная база данных, которая будет удалена при завершении сеанса. Однако эту базу можно сохранить на диск с помощью команды «.save»
Step 2 — Creating a SQLite Database
In this step you will create a database containing different sharks and their attributes. To create the database, open your terminal and run this command:
This will create a new database named . If the file already exists, SQLite will open a connection to it; if it does not exist, SQLite will create it.
You will receive an output like this:
Following this, your prompt will change. A new prefix, , now appears:
If the file does not already exist and if you exit the promote without running any queries the file will not be created. To make sure that the file gets created, you could run an empty query by typing and then pressing “Enter”. That way you will make sure that the database file was actually created.
With your Shark database created, you will now create a new table and populate it with data.
Быстродействие
SQLite спокойно работает с десятками миллионов записей (с сотнями тоже — я проверял). Обычные дают на моем ноуте около 240 тысяч записей в секунду. А если подключить исходный CSV как виртуальную таблицу (такая специальная фича) — еще в 2 раза быстрее.
Среди разработчиков распространено мнение, что SQLite не подходит для веба, потому что поддерживает только одного клиента. Это миф. В режиме write-ahead log (стандартная фича современных СУБД) читателей может быть сколько угодно. Писатель — один, но часто больше и не надо.
SQLite отлично подходит для небольших сайтов и приложений. Например, sqlite.org использует SQLite в качестве базы, не заморачиваясь с оптимизацией (~200 запросов на страницу). При этом у него 700К визитов в месяц, а работает быстрее 95% сайтов.
Плюсы, минусы — SQLite и MySQL
Давайте быстро суммируем существенные различия между двумя вариантами:
Преимущества SQLite:
- На основе файлов и прост в настройке и использовании
- Подходит для базовой разработки и тестирования
- Легко переносимый
- Использует стандартный синтаксис SQL с небольшими изменениями
- Легко использовать
Недостатки SQLite:
- Отсутствует управление пользователями и функции безопасности
- Трудно масштабируется
- Не подходит для больших баз данных
Преимущества MySQL:
- Легко использовать
- Предоставляет большой функционал
- Хорошие функции безопасности
- Легко масштабируется и подходит для больших баз данных.
- Обеспечивает хорошую скорость и производительность
- Обеспечивает хорошее управление пользователями и множественный контроль доступа
Недостатки MySQL:
- Требуются некоторые технические знания для настройки
- Немного другой синтаксис по сравнению с обычным SQL
Step 4 — Reading Tables in SQLite
In this step, we will focus on the most basic methods of reading data from a table. Recognize that SQLite provides more specific methods for viewing data in tables.
To view your table with all of the inserted values, use :
You will see the previously inserted entries:
To view an entry based on its (the values we set manually), add the command to your query:
This will return the shark whose equals :
Let’s take a closer look at this command.
- First, we all () values from our database, .
- Then we look at all values.
- Then we return all table entries where is equal to .
So far you have created a table, inserted data into it, and queried that saved data. Now you will update the existing table.
PostgreSQL
Обзор и особенности
PostgreSQL — это СУБД с открытым исходным кодом, в которой особое внимание уделяется масштабируемости и совместимости стандартов. Как и MySQL, PostgreSQL использует модель базы данных клиент / сервер и серверный процесс, который обрабатывает взаимодействие с клиентом и управляет файлами базы данных и операциями, которые называются процессами
PostgreSQL обрабатывает параллельные клиентские сессии, создавая («разветвляя») новые процессы для каждого соединения. Этот процесс отделен от основного процесса и создается и уничтожается в течение жизненного цикла клиентского соединения. Postgres написан на C и соответствует стандарту ACID, поддерживает функции и хранимые процедуры. В отличие от MySQL, PostgreSQL поддерживает материализованные представления (кэшированные представления) для частого и быстрого доступа к большим и активным таблицам.
Как и MySQL, PostgreSQL также обладает некоторыми расширенными функциями, такими как безопасность и репликация. PostgreSQL использует синхронную репликацию между первичной и вторичной базами данных. В дополнение к обеспечению контроля доступа пользователя, контроля доступа на основе хоста и аутентификации пользователя, сам PostgreSQL также обеспечивает функцию шифрования связи клиент-сервер с использованием SSL. Полное соответствие ACID присуще PostgreSQL и существует в программах NDB Cluster InnoDB и MySQL.
PostgreSQL использует технику, называемую многоверсионным управлением параллелизмом или MVCC, для обеспечения согласованности данных при одновременном доступе к данным. Этот метод лучше, чем использование только блокировок для параллелизма, поскольку он минимизирует конфликт блокировок в многопользовательской среде, что значительно повышает производительность. Для обратной совместимости или приложений, требующих классической технологии блокировки, PostgreSQL также позволяет использовать технологию блокировки таблиц и строк для обеспечения параллелизма. Напротив, MySQL поддерживает MVCC только в экземплярах InnoDB.
Недостатки
Во время частых обновлений вы можете увидеть еще один большой недостаток: поскольку кластерные индексы не поддерживаются, PostgreSQL окажет огромное негативное влияние на производительность по сравнению с базами данных MySQL.
Владение, поддержка и основные клиенты
PostgreSQL является открытым исходным кодом, и исходный код публикуется и поддерживается глобальной командой разработчиков PostgreSQL. PostgreSQL имеет два варианта поддержки сообщества и коммерции. Сообщество поддерживает принятиесписок рассылкиФорма, вы также можете найти список поставщиков коммерческой поддержки. Хотя PostgreSQL имеет меньшую долю рынка по сравнению с MySQL, у него впечатляющий список клиентов, таких как AWS RedShift, Instagram, ViaSat и Cloudera.
MySQL
Обзор и особенности
MySQL этоСамый популярныйОдна из открытых и масштабных систем СУБД. В отличие от SQLite, он использует архитектуру сервер / клиент, состоящую из многопоточного сервера SQL. Эта многопоточная функция MySQL обеспечивает более высокую производительность, поскольку потоки ядра могут легко использовать несколько процессоров. База данных написана на C и C ++ и поддерживаетРазличные платформы,Такие как операционная система Windows Server и дистрибутивы Linux, такие как RHEL 7 и Ubuntu. Он также следует системе ACID для обеспечения согласованности транзакций и предоставляет различные коннекторы и API, такие как C, C ++, Java, PHP и т. Д.
Масштабируемость, безопасность и репликация — вот некоторые ключевые функции, которые делают MySQL одним из самых популярных решений в корпоративных приложениях:
- Функции безопасности включают MySQL Access Privilege System, которая обеспечивает аутентификацию пользователя,Система управления учетными записями пользователейИ зашифрованное соединение с использованием SSL.
- MySQL обеспечивает репликацию с главного сервера на подчиненный сервер и с главного сервера на главный сервер. Это очень полезно при расширении операций чтения. Его можно использовать в качестве решения для резервного копирования и даже при сбое в случае сбоя. MySQL также имеет больше функцийКоммерческие продукты。
- Например, MySQL Enterprise Edition имеет дополнительные функции, такие как MySQL Transparent Data Encryption (TDE), MySQL Enterprise Backup и MySQL Document Storage.
- MySQL также предоставляет встроенную многопоточную библиотеку, чтобы обеспечить меньшую площадь для встраиваемых и IoT-систем.
Преимущества и варианты использования
В дополнение к наличию нескольких корпоративных функций, еще одним важным отличием MySQL от SQLite является поддержка многопользовательскими функциями MySQL. Вместе с функциональностью и масштабируемостью предприятия это делает его идеальным выбором для распределенных приложений.
С точки зрения пропускной способности и производительности, MySQL имеет преимущества перед PostgreSQL и может использоваться для простых операций чтения. По сравнению с PostgreSQL, он также проще в установке и использовании и имеет более широкое сообщество.
Недостатки
Когда MySQL перемещает старые данные в отдельную область, называемую сегментом отката, массовая INSERT отрицательно влияет на производительность. Это основной момент PostgreSQL. Он также не очень хорошо работает для длительных SELECT и наиболее подходит для небольших SELECT, особенно тех, которые охватывают кластерные индексы. Некоторые другие недостатки включают в себя отсутствие полнотекстового поиска и медленное одновременное чтение и запись.
Владение, поддержка и основные клиенты
MySQL принадлежит и поддерживается Oracle. Поддерживать поддержку сообщества через форумы и черезпокупкаКоммерческие продукты получили важную поддержку. Некоторые из основных клиентов MySQL — это Facebook, GitHub и YouTube.
Выясняем, как лучше всего поступить
Итак, теперь у нас есть абстрактное синтаксическое дерево, на основе которого заказывается состав сэндвичей, и мы планируем переходить к приготовлению нашего первого сэндвича, верно? Не совсем.
Абстрактное синтаксическое дерево представляет то, что вы хотите – то есть, пару сэндвичей. Оно не сообщает, как их сделать. Прежде, чем перейти к плану, мы должны определиться, какой путь изготовления сэндвичей оптимален.
При помощи нашей сэндвичеделки можно собрать целое множество разных сэндвичей, так что мы запасёмся всевозможными ингредиентами. Если мы хотим сделать сэндвичище, который сдобрим всеми имеющимися у нас топпингами, то машине стоило бы, ориентируясь на абстрактное синтаксическое дерево, посетить местоположение каждого ингредиента и решить, пойдёт он в ход или нет.
Но для сэндвича BLT нам требуются только бекон, латук и томаты. Работа пошла бы быстрее, если бы мы задали машине посетить только три этих местоположения (по индексу) и переходить только между ними.
SQLite приходится принимать подобные решения, когда она планирует, как выполнить запрос. Для этого она опирается на статистические данные о содержимом своих таблиц.
Ускоряем запросы, руководствуясь статистикой
Когда SQLite рассматривает абстрактное синтаксическое дерево, могут найтись сотни способов доступа к данным, позволяющие выполнить запрос. Самый тривиальный подход – просто считать всю таблицу, проверяя каждую строку, годится ли она нам. Именно такой подход называют «полное сканирование таблицы» — он страшно медленный, если вам нужно выбрать из большой таблицы всего несколько строк.
Другой подход — пользуясь индексом, быстро переходить к интересующим вас строкам. Индекс — это список идентификаторов строк, которые отсортированы в один или несколько столбцов. В данном случае у нас получится вот такой индекс:
В таком случае идентификаторы для строк со всеми людьми, которым нравится «мальвовый» цвет, окажутся у нас в индексе сгруппированными вместе. Используя индекс при запросе, мы должны сначала считывать позицию в индексе, а затем перейти к строке в таблице. В результате стоимость каждой такой операции (на строку) возрастает, поскольку приходится проводить две операции поиска – но «мальвовый» не нравится почти никому, поэтому и строк в нашей результирующей выборке будет мало.
А что произойдёт, если искать популярный цвет, например, «голубой»? Если сначала выполнить поиск по индексу, а потом переходить в таблице к такому множеству строк, то операция окажется даже медленнее, чем простой полнотабличный поиск.
Поэтому SQLite проделывает с нашими данными некоторый статистический анализ, чтобы выработать (пожалуй) оптимальный рецепт для каждого запроса.
Статистка SQLite хранится в нескольких таблицах «sqlite_stat». Эти таблицы развивались годами, и теперь в них ведётся статистика сразу четырёх видов. Но в новейших версиях SQLite остались в ходу лишь две из них: и .
Формат таблицы прост. В ней хранится приблизительное число строк для каждого индекса, а также количество дублирующихся значений для столбцов индекса. Эта грубая статистика эквивалентна отслеживанию простейших средних значений для датасета: они не слишком точны, но их быстро вычислять и обновлять.
Таблица несколько более продвинутая. В ней хранится несколько десятков значений, выборочно взятых со всего индекса. Поскольку SQLite может делать такую значительно более тонкую выборку, очевидно, что эта база данных в принципе понимает, насколько уникальны различные значения в масштабах всего пространства ключей.
Подключение к БД
Использоваться сведения из БД смогут только после непосредственного подключения «таблицы с информацией» к приложению Питона. Перед тем, как устанавливать соединение, требуется убедиться в то, что:
- была создана подходящая база данных – Test DB;
- есть таблица Employee в оной;
- присутствуют поля first_name, last_name, age, income, sex;
- для доступа к БД установлено имя testuser, а также пароль test123;
- на устройстве есть PyMySQL.
Далее будут рассмотрены примеры работ, базирующиеся на БД Test. Чтобы грамотно управлять информацией в приложении, предстоит предварительно разобраться с основами MySQL.
Вот пример соединения:
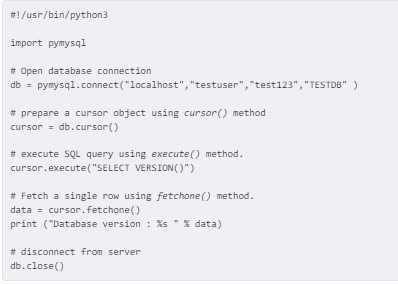
Он при запуске выдаст надпись с версией БД. Если соединение с источником провелось успешно, объект коннектинга вернется и будет сохранен в БД. Его можно задействовать позже. В противном случае для базы данных устанавливается значение НЕТ. Объект db применяется для создания объекта курсора (cursor). Последний позволяет выполнять запросы SQL. Перед выходом cursor будет гарантировать закрытость соединения с «хранилищем», а также освобождение ресурсов устройства.
Create Table отвечает за создание таблички.
Step 3 — Creating a SQLite Table
SQLite databases are organized into tables. Tables store information. To better visualize a table, one can imagine rows and columns.
The rest of this tutorial will follow a common convention for entering SQLite commands. SQLite commands are uppercase and user information is lowercase. Lines must end with a semicolon.
Now let’s create a table and some columns for various data:
- An ID
- The shark’s name
- The shark’s type
- The shark’s average length (in centimeters)
Use the following command to create the table:
Using makes that field required. We will discuss in greater detail in the next section.
After creating the table, an empty prompt will return. Now let’s insert some values into it.
Inserting Values into Tables
In SQLite, the command for inserting values into a table follows this general form:
Where is the name of your table, and go inside parentheses.
Now insert three rows of into your table:
Because you earlier specified for each of the variables in your table, you must enter a value for each.
For example, try adding another shark without setting its length:
You will receive this error:
In this step you created a table and inserted values into it. In the next step you will read from your database table.



